
Abstract
To assist with missing person investigations, the public may be on the lookout during their everyday activities and alert the authorities if the person is encountered. In this Registered Report, participants encoded posters that included an image of a target person along with relevant, irrelevant, or no contextual information about that person. After viewing a poster, participants watched a video that included either the target or a plausible nontarget, using a new experimental paradigm that kept all other conditions of the encounter constant. Previous findings suggest contextual information could affect prospective person memory in several ways. If contextual cues are relevant, they could direct attention to targets and plausible nontargets without improving face recognition and hence have no effect on discriminability (sighting bias hypothesis). Alternatively, any contextual information at encoding (relevant or irrelevant) could encourage deeper processing of each target’s identity and improve sighting discriminability (elaborative encoding hypothesis). A third possibility is that associating a target with relevant contextual information improves both face recognition and attention, resulting in greater sighting discrimination compared with irrelevant or no contextual information (context matching hypothesis). We tested 396 participants and found that associating target faces with contextual information had no significant effect on discriminating between targets and plausible nontargets. The context manipulation also had no significant effect on response bias. Our findings suggest that the previously reported recognition advantage might depend on the kind of contextual information at encoding, on how targets are encountered during testing, as well as on the type of recognition task.
Contextual effects on prospective person memory
Prospectively remembering an unfamiliar person is no easy feat (Lampinen et al., 2009). When recognition is the primary objective, such as in face learning experiments, unfamiliar people can be hard enough to tell apart (Bindemann & Johnston, 2017; Hancock et al., 2000). Asking someone to recognise an unfamiliar person in the future, when their mind is focused elsewhere, creates even further opportunities for error.
Prohibitively difficult as it may sound, remembering someone at an unspecified future time is the cornerstone of a common strategy for locating people who have been reported missing. People are constantly going missing. In the United Kingdom, for instance, someone is recorded missing every 2 or 3 min, and almost two-thirds of the missing people are under 18 years old (National Crime Agency, 2017). To help find missing people, a photograph of the missing person is included in an appeal (e.g., a missing person poster) that is distributed to the public. For these missing person appeals to work, someone would have to (a) learn the missing person’s identity from the appeal, (b) recognise the unfamiliar person and remember the appeal in an unexpected circumstance, and (c) report the sighting to the authorities (Lampinen & Moore, 2016). If even one of these events does not happen, the public will not be able to help authorities find the missing person (Lampinen & Moore, 2016).
Lampinen et al. (2009) emphasise that this alert system relies on two aspects of person memory, retrospective and prospective. Retrospective person memory, the ability to identify a previously seen person (e.g., in a line-up) has been studied extensively. Less attention has been focused on prospective person memory (prospective person memory). Event-based prospective memory is remembering to perform a behaviour, which was previously associated with a target item, whenever the target item is encountered during another ongoing activity (McDaniel & Einstein, 2000). Prospective person memory is when these intentions are associated with, and triggered by, a target individual (e.g., a missing person or a wanted individual; Lampinen et al., 2009).
Retrospective and prospective memory retrieval rely on different processes. During a retrospective memory task, the experimenter directs participants’ attention and puts them in a retrieval mode. Prospective memory, however, requires participants to remember to do something without the experimenter putting them in a retrieval mode (Einstein et al., 2005). Therefore, a prospective memory task is usually considered secondary to other tasks which occur in between the moment the prospective intention is created and when it is executed. In missing person cases, for example, being on the lookout for the missing person is secondary to the public’s everyday activities.
Laboratory and field paradigms have been used to study prospective person memory. Laboratory studies begin with the presentation of several target people (familiarisation phase). Participants are subsequently asked to press a certain key on the keyboard if a target appears during another ongoing activity, such as a team sorting task (Lampinen et al., 2009; Lampinen & Sweeney, 2014). In field-based studies, participants are presented with photographs of targets during a laboratory visit or during a lecture and are asked to email the researchers if they encounter the targets during their everyday life. Then, the targets appear in a place known to be frequented by most participants, such as during another lecture (Lampinen et al., 2009; Moore et al., 2016).
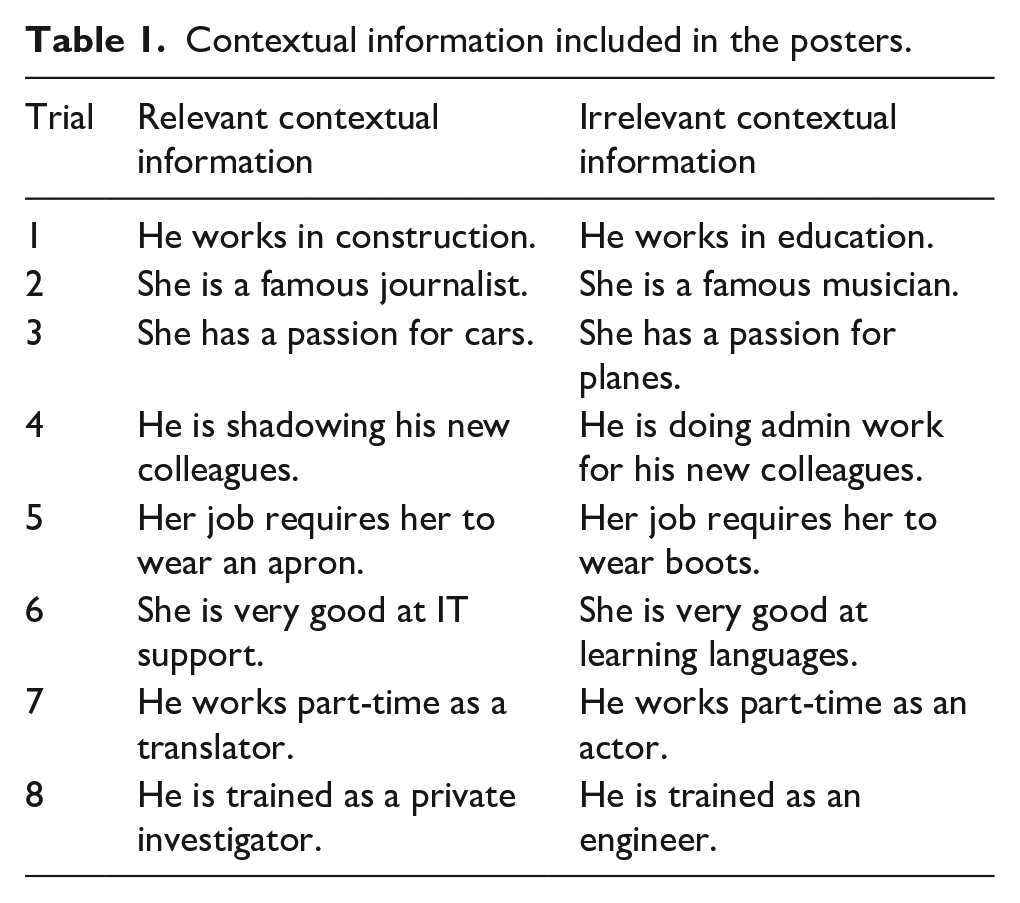
Attempts to improve prospective person memory have drawn attention to the inherent challenges of the task. Researchers have shown that the accuracy of prospective person memory increases when reducing the number of targets (Lampinen, Peters, & Gier, 2012), increasing the number of photos of a single target (Sweeney & Lampinen, 2012), and providing information about the target’s spatial and temporal location (Moore et al., 2016). Despite these improvements, most studies have led to relatively low rates of identification. In the present research, we explore whether including relevant or irrelevant contextual information about a target person in a poster affects how often a target is sighted and how well participants can discriminate between targets and nontargets. The contextual information is considered relevant if it matches the situation in which the targets subsequently appear in the videos.
Contextual effects
When events are represented in memory, associated contextual information can cue memory retrieval (Tulving & Thomson, 1973). Contextual information can be defined as any stimulus pattern associated with a target stimulus (Davies, 1988), but in the present research we operationalised contextual information as any type of person-related description that could be known about a missing person and included in a missing person appeal, such as “they might be wearing a red shirt” (see Table 1). Prospective person memory relies on attention and face recognition, both of which might be improved by the association of an unfamiliar face with descriptive contextual information at encoding.
Contextual information included in the posters.
Attentional resources
Contrary to retrospective memory, during prospective memory tasks there is no immediate external request to initiate the search for the target at the stage of retrieval. This is difficult because people do not have the attentional resources to closely examine every face they encounter in everyday activities. Another reason why people might avoid attending to strangers’ faces is that staring at or closely examining another person’s face violates social norms (Buchanan et al., 1977; Smith et al., 1977). Accordingly, prospective person memory requires a switch from the current focus of attention (primary ongoing task) to identification of the target (secondary task). For instance, when the primary task requires attention to the target, prospective person memory is significantly better than when it can be completed without attending to the target (Moore, 2017).
Contextual information may improve attention and facilitate identification in prospective person memory tasks through creating different expectations of encounter. Moore and colleagues (2016) found that although more than 60% of participants were able to identify the target from a line-up 24 hr after the experiment (i.e., a retrospective memory task), less than 10% made an accurate sighting during the prospective memory task. The relatively strong line-up accuracy suggests that low performance on the prospective memory task was not due to a failure to remember the target’s face. In the same study, expectations of encountering the targets were manipulated by providing different spatial and temporal information alongside each target’s image (Moore et al., 2016). Participants who were told that the target would be in the same building where the experiment was taking place were significantly more likely to report a sighting than participants who were told that the target would be on campus. Providing temporal information (i.e., they will be on campus in the next 24 hr or the next week) had no significant effect on sightings.
In a more recent study, participants were asked to be on the lookout for four “wanted” individuals while completing a simulated grocery shopping task (Moore et al., 2018). The targets were reported to be wanted for either bank or grocery store robberies, which was designed to manipulate participants’ expectations of a target encounter. Subsequently, all targets appeared in a grocery store. Participants who received accurate contextual information reported more accurate sightings as well as more inaccurate sightings. These studies suggest that depending on the information available during familiarisation with the target, participants could expect to encounter the targets in certain contexts more than in others. In a missing person case, people within the criminal justice system have limited if any control over whether someone interacts with the target or when, but they do have control over the content of the posters they distribute (Wells, 1978). In the present research, we explore whether providing contextual information in a missing person poster helps guide participants’ attention to the target during a subsequent encounter.
Unfamiliar face recognition
Prospective person memory involves face recognition, which raises issues not applicable to other prospective memory tasks. A large body of literature suggests that recognising unfamiliar faces is difficult (Bruce, 1982; Burton & Jenkins, 2011; Roberts & Bruce, 1989). Even judging whether two unfamiliar faces are the same or different, which has minimal demands of memory, yields poor performance. For example, White et al. (2014) found that border control officers accepted 14% of passports that did not match their holders. One reason for this finding might be that unfamiliar face recognition is highly image dependent (Longmore et al., 2017). Prospectively recognising a person is substantially harder because the appearance of a target individual can only be compared with the representation of the target in memory. Fortunately, two lines of research suggest that contextual information can improve unfamiliar face recognition and, therefore, prospective person memory: contextual elaboration during encoding and context reinstatement at test.
Contextual elaboration is theorised to assist retrieval by associating target items with meaningful contexts at encoding (Skinner & Fernandes, 2010). For instance, recognition of unfamiliar faces is improved when faces are combined with descriptive information (e.g., he’s a vegetarian, he smokes cigars, Kerr & Winograd; names or occupations, Schwartz & Yovel, 2016) or judgements of character traits (e.g., honesty or friendliness; Winograd, 1981).
Two explanations for the contextual elaboration effect on face recognition have been suggested. The quantity account posits that providing additional person description information induces a more extensive scan of the face (Bruce & Young, 1986). This type of processing not only maximises the number of features encoded but also increases the likelihood that a distinctive feature of that face will be noticed (Winograd, 1981). Another account suggests that additional conceptual information leads to deeper encoding of unfamiliar faces by creating a richer semantic network of associations for a given face, which in turn results in better recognition accuracy (Bower & Karlin, 1974; Craik & Lockhart, 1972). Consistent with this view, Schwartz and Yovel (2016) suggested that associating a photo of an unfamiliar face with conceptual information (e.g., name) shifts its representation from an image-based percept to a view-invariant concept, providing a complex memory representation of the unfamiliar person (rather than their picture).
Stimuli may also be remembered better if contextual information during encoding and testing are matched. According to the encoding specificity hypothesis (Tulving & Osler, 1968), the likelihood of successful recognition will depend upon whether retrieval processes are sufficiently similar to those engaged at encoding. Thus, unfamiliar face recognition should improve if the testing context matches the information learned during encoding. Applied to prospective person memory, missing people could be more easily recognised if the description on the poster (e.g., had an accident and damaged his foot) is consistent with the way they appear during a later encounter (e.g., wobbly walk).
The susceptibility of memory for unfamiliar faces to contextual influence has been demonstrated empirically using a variety of contextual stimuli, such as other faces (Winograd & Rivers-Bulkeley, 1977), short descriptive phrases (Watkins et al., 1976), clothing (Brutsche et al., 1981), and indoor and outdoor context scenes (Koji, 2013). All of these studies consistently reported better recognition accuracy if the context presented alongside an unfamiliar face during encoding was presented again during the test phase. This is consistent with compound cue models of memory (Gillund & Shiffrin, 1984), which suggest that the probability of retrieval increases if multiple cues (i.e., the unfamiliar face, the personal description, the contextual cues) are associated with the same stimuli (i.e., the initial prospective memory request).
The present research
Here, we introduced a new laboratory paradigm for studying prospective person memory. Participants viewed a target’s photograph and then encountered the target or a plausible nontarget in a video segment from a television series. Target photographs were associated with relevant, irrelevant, or no contextual information. To divert attention away from identification of the target, we incentivised participants to attend to the video content (primary task) rather than to the identity of the actors (secondary task).
Given the complexity of the videos, manipulating target presence at retrieval could have had unintended and undesirable consequences. For instance, participants’ attention could have been directed towards the actors in one video more than in another, leading to ambiguity about whether responses were affected by the target’s presence or the video’s content. Therefore, target presence was manipulated at encoding: all participants viewed the same video at retrieval, but at encoding half studied a photo of the target who appeared in the video (target-present condition) and the other half viewed a photo of someone who did not appear in the video (target-absent condition).
We were interested in whether contextual information improves prospective person discriminability. Sweeney (2013) found that participants were more likely to identify a target with a tattoo after reading a poster advising that wanted people charged with the same offence as the target are known to have tattoos. This suggested that in prospective person memory tasks relevant context could be used to increase identifications of targets (hits). But it is also possible that relevant context would increase mistaken identifications of a plausible nontarget (false alarms). Thus, whether relevant context increases discriminability remained an empirical question.
Two errors are possible on a prospective person memory task: misses and false alarms. The former occurs when a target is encountered but not noticed or reported. The latter occurs when a nontarget is mistakenly identified as the target (and reported). An efficient way of improving missing person investigations is by enhancing discrimination between targets and nontargets. This can be achieved by increasing correct identifications (hits) or decreasing false alarms. False alarms in a missing person case have the potential to cause delays and waste investigative resources. Nevertheless, such false alarms may not be as harmful as false alarms in other legal contexts (e.g., line-up identifications of innocent suspects), and in some cases law enforcement might prefer to receive any type of information, even of low certainty, to increase the possibility of a good lead. Therefore, increasing the number of sightings (i.e., encouraging a liberal response bias) could be desirable in many cases.
Based on the literature described above, we arrived at competing hypotheses. According to an elaborative encoding hypothesis, contextual information should affect processing of target faces during the familiarisation phase, which should result in better face recognition at the subsequent encounter. This hypothesis would be supported by higher discriminability (d′) in the context conditions compared with the no context condition. However, if valid contextual cues are needed to draw attention to a target during an encounter (i.e., matching context hypothesis), we should observe higher discriminability in the relevant context condition compared with the other two conditions. Alternatively, according to a sighting bias hypothesis, contextual information does not affect face encoding and subsequent recognition but relevant context directs attention towards both targets and plausible nontargets who appear in the expected context. By drawing attention to potential targets without affecting the ability to distinguish between targets and plausible nontargets, relevant contextual information should result in a higher number of both hits and false alarms. This hypothesis would be supported by equivalent discriminability (d′) across conditions and an increase in response bias (c) in the relevant context condition compared with the other two conditions.
Method
Design
This experiment used a 3 (target information: relevant context vs. irrelevant context vs. no context) × 2 (target presence: target absent vs. target present) mixed design. Participants were randomly assigned to encode target photos with a name and a person-related description (additional contextual information), which either matched the context of encounter (i.e., relevant) or not (i.e., irrelevant), or with a name only (no context). Participants were tested over eight trials. Each trial started with a poster showing a photo of a target individual along with relevant, irrelevant, or no contextual information. After 25 s, a video was played. For each participant, half of the trials were target present (i.e., the person from the poster appeared in the video) and half target absent (i.e., the person from the poster did not appear in the video).
Participants had a primary task and a secondary task. The primary task was to pay attention to the video to be able to answer two questions about it, and the secondary task was to spot the target individuals and report a sighting. To encourage participants to prioritise the primary task, performance was rewarded using a points system: each correctly answered video-content question was worth 10 points (primary task), and each correctly identified target was worth 5 points (secondary task). The top 10 participants who collected the most points earned £20 each.
The procedure was divided into two blocks each consisting of four trials. Between the two blocks, participants had a chance to rest and focus on a different type of activity (not including faces) in the middle of the experiment. The order of the blocks, as well as the trial order within each block, were randomised, with the exception that each block contained two target-present and two target-absent trials. Each trial was target absent or target present, based on a computerised random selection from a list of all possible ways of showing half target absent and half target present trials for each block.
Target presence was manipulated by showing photos of someone during the familiarisation phase who did or did not appear in the video during the testing phase. On target absent trials, participants viewed a poster with a photo of someone who did not appear in the subsequent video. If they reported a sighting during those trials, that was classified as a false alarm. Figure 1 shows that for each trial a participant saw either Person A or Person B during the familiarisation phase, but everyone saw Person A during the testing phase. Manipulating target presence during familiarisation minimised the impact of the way targets appear in the video on identification. Target names and contextual information remained consistent across target present and target absent conditions. The only difference was the photographs in the posters.
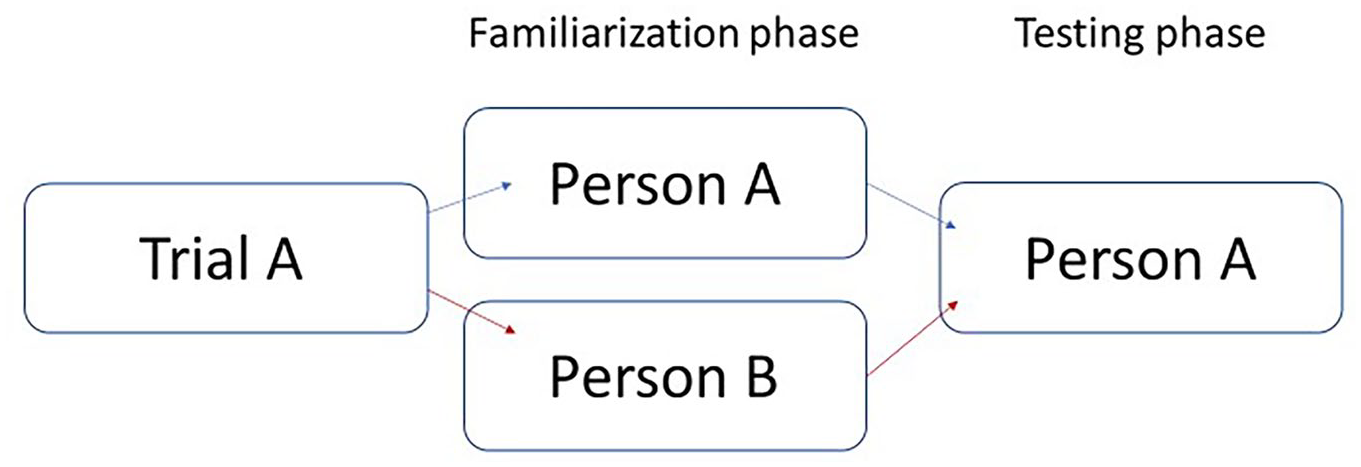
Target presence manipulation.
Participants
We performed sensitivity analyses to estimate a range of possible effect sizes and to determine the required sample size. Previous studies of contextual effects on person identification have resulted in moderate-to-large effect sizes (Koji, 2013: η2 p = 0.33; Lampinen & Sweeney, 2014: η2 p = 0.06, Schwartz & Yovel, 2016: d = 0.75, η2 p = 0.19). Taking into account the possibility that effects in the literature could be inflated by publication bias, we estimated an effect size that was smaller than those we surveyed from the literature: Cohen’s f = 0.18. Power analysis indicated that 396 participants were needed to achieve .90 power for an effect size of f = 0.18 and a two-sided F-test with α = .05. Sensitivity analyses indicated a sample of 396 participants would have power of 99.59% and 99.99% for effect sizes of f = 0.25 and f = 0.4, respectively. Thus, N = 396 gave high power for a range of plausible effect sizes. All sensitivity and power analyses were conducted using the G*Power 3.1 software (Faul et al., 2007).
We used sequential analysis as a tool for stopping the experiment if the collected data was sufficient to confirm or disconfirm the specified hypotheses. If conditions would have been met at prespecified interim analysis cheques, an adjustment to α allowed data collection termination before the sample size of the a priori power analysis was reached without inflating the Type I error rate (Lakens, 2014). Using sequential analyses, we tested the hypotheses after collecting data from 132, 264, and 396 participants.
Procedures to perform sequential interim analyses are long established and frequently used in medical trials (e.g., Armitage et al., 1969; Dodge & Romig, 1929). We adopted the Pocock boundary (Pocock, 1977), which lowers α to the same value for each interim analysis and maintains an overall α level of .05. For three analyses (two interim and one final analysis) the Pocock α boundary is set at .022. If the predicted effects were significant (i.e., <.022) at the first (N = 132) or second (N = 264) interim analyses, data collection would have been terminated. We found no support for any of our hypotheses during our two interim analyses and, therefore, data collection continued until the maximum sample size was reached (N = 396). We discuss the scenarios which would have been interpreted as support for a hypothesis and could have resulted in early termination of data collection in the Online Supplemental Materials.
The following exclusion criteria were applied: (a) Participants must not have watched any of the videos or have been familiar with any of the targets from before the experiment; (b) Participants must have performed sufficiently better on the primary task than on the secondary task (otherwise, they were considered to have not followed instructions). Specifically, participants were excluded if they scored more than a standard deviation lower than the group average on the primary task and more than a standard deviation higher than the group average on the secondary task. Finally, participants were excluded if they reported any other issues at the end of the experiment (e.g., technical issues with the video). Excluded participants were replaced by collecting data from additional participants to reach the required sample size.
We collected data from a total of 439 participants. Nineteen participants were excluded because they reported technical issues (most of which were also highlighted by the experimental data, and were related to unstable internet connections), 11 participants because they reported being familiar with the targets and/or videos used, and 13 participants because they performed better on the prospective person memory task than on the primary task. After exclusions we had a final sample size of 396 participants (70% female, 29% male, and 1% preferred not to say; 24% White, 54.5% Asian, 2.5% Black, 5% Mixed, 11.4% Other, and 2.8% preferred not to say). The mean age was 19.67 (SD = 2.25, range 18–37). Participants were undergraduate students from Simon Fraser University (Canada) who participated for partial credit in a psychology course.
Stimuli
Videos
All videos were extracts from the Australian series Rush (2008–2011). This series was chosen because we recruited participants outside of Australia, which minimised the likelihood that participants would be familiar with the actors. Each episode follows a team of police officers conducting an investigation. The first author searched for episodes that included individuals who were not the main characters but whose presence was clear enough for them to be noticeable and recognisable. Clips were also selected to be short, to minimise the risk of distress (i.e., no extreme violence) and to provide enough content to test participants’ memory. The videos were processed using a PremierePro project sequence to facilitate consistent presentation. The videos ranged in length from 54 to 84 s (M = 65.2, SD = 10.2). All videos were in colour, had sound and were presented in full screen. All stimulus materials can be found at https://osf.io/j5hbm/.
The context manipulation was implemented by changing the information presented during the familiarisation phase. Therefore, all participants watched the same eight videos and the variability in target salience during these videos should not have affected any condition more than the others.
Target individuals
Each trial had a video with two associated posters: one containing a target who appeared in the video and one containing a target who did not appear in the video (total eight appearing targets and eight nonappearing targets). Targets who appeared in the video were Rush actors (50% female, varying ages and ethnicities) whose photographs for the encoding task were obtained from Google Images. Appearing target photos were chosen to correspond with each target’s appearance in the videos (e.g., same hair colour, same haircut), but the appearances were not identical (they were not screenshots from the test video). Nonappearing targets were actors or TV presenters chosen to match the description of the appearing target with whom they were paired (i.e., same hair colour, same general face appearance). The purpose of matching pairs of nonappearing and appearing targets was to test whether context improved discrimination between targets and plausible nontargets, rather than simply increasing identifications of anyone who resembled the general look of the target.
Posters
All posters were created using an InDesign template that included a white background, a target’s photo (framed using different colours) on the left, a name on the right, and contextual information (if present) also on the right. All photos were the same size and in the same screen location. See Table 1 for the relevant and irrelevant contextual information used for each poster.
Pilot tests
The suitability of the materials was assessed in several pilot tests. The aim of the first three pilots was to ensure that each target’s appearance in the poster was similar to how they appeared in their respective videos. We first tested whether the targets were recognisable if prospective identification was the primary task. This provided an indication of whether the targets could be plausibly identified from the videos in the absence of another task to distract their attention. We initially tested seven participants using 10 videos and then added 7 more videos and tested a further eight participants. Identification rates for all videos ranged from 35% to 100%. For each trial, participants first saw a picture of a target and then watched for the target during the respective video. Based on these data, we selected the eight videos with the highest identification accuracy rates ranging from .63 to 1.00 (M = 0.70, SD = 0.19). During these pilot tests participants were able to look at the target images during encoding for as long as they wish.
A final five pilot participants were tested using the current experimental procedure where their primary task was to answer specific questions about the videos, and the secondary task was to prospectively recognise the targets. Participants were tested on target-present trials only and were not presented with any contextual information about the targets. During encoding, the pictures were presented for 15 s. This resulted in a mean identification rate of 60%.
Procedure
The experimental task was run online using the Gorilla online experiment builder. 1 The study was framed as a memory game, with the aim of collecting as many points as possible (as described in the Design section). The top 10 participants who collected the most points earned £20 each. First, they watched a video of an experimenter explaining the primary and secondary tasks, the points system and the general structure of the experiment. Participants in the context conditions were also informed that in some cases the presented information might help them spot the targets and in other cases not.
The prospective person memory task was repeated across eight trials. First, participants saw a poster with the target’s name only or the target’s name and contextual information for 10 s. Then the target’s photo was added on the screen alongside that information for an additional 15 s. The posters were presented in the middle of the screen, with the image on the left-hand side and the written text on the right-hand side. Second, participants watched a video which included various people, including the target from the poster or a plausible nontarget. The video started automatically, with no controls to pause, skip, rewind, or replay the clip. If participants recognised the target, they made an identification immediately by pressing the space bar. There was a countdown on the lower side of the screen so participants knew when the video was coming to an end. Therefore, they had until the end of the video to press the spacebar if they were not immediately certain. If they pressed the spacebar again, it was inferred that they decided they were wrong the first time. Therefore, their last sighting was the one that was counted.
Next, participants answered two multiple-choice questions about the video, which tested their attention during the ongoing task (e.g., What is the colour of the barman’s blouse?). At the end of each trial, a test of attention for the contextual information was administered. Participants saw an incomplete version of the original poster and were instructed to choose the correct context from one of three available options. For example, if the target was described as having a passion for cars in the initial poster, participants saw “She has a passion for _____” in the final poster with the option to choose “cars,” “planes,” or “bicycles.” To keep this step of the procedure consistent across conditions, participants in the no context condition were asked which colour was the frame of the target’s photo in the initial poster.
Between trials participants saw a page reminding them that they could take a break. The programme only proceeded to the next trial if they clicked “next.” After four trials had been completed, participants completed a 2-min filler task (i.e., Where’s Waldo?), during which there was no option to click “Next.”
After the eight prospective memory trials were completed, participants were tested on their retrospective memory of the targets. Using an old/new recognition task, participants saw a sequence of 24 randomly presented individuals. Twelve of the individuals were viewed earlier in the experiment: the eight who appeared in the videos (half of whom also appeared in the posters) and the four who appeared in the poster but not in the video. Twelve were new faces to the participant. The new faces were selected to match the appearance of the people in the videos (including four used as targets in posters for other participants). Prior to the old-new test, participants were instructed that the objective was to identify the eight targets from the posters. On each trial, participants decided whether the person was “old” (previously seen in the posters) or “new” (not seen in the posters). To test memory of the person rather than the picture, the targets’ pictures for this task were different from those used in the prospective memory task and participants were instructed to look for the person and not the picture from the posters. Including all of these faces allowed us to test for possible unconscious transference by looking at false alarms of never-before-seen faces as well as false alarms of familiar faces (i.e., individuals present in the videos but not presented in the posters).
Finally, participants were asked to report their age, gender, ethnicity, whether they prioritised the primary over the secondary task, whether they knew any of the targets or the videos from before the experiment, and whether they experienced any issues during the experiment (open-ended question). On average, the experiment took participants approximately 25 min to complete.
Analyses
For each participant a d′ measure of discriminability and a c measure of response bias were calculated. Face recognition performance was measured by computing d′ calculated by the formula d′ = z(H) – z(FA), with H denoting the proportion of hits and FA denoting the proportion of false alarms. Response bias c was calculated using the formula: c = −0.5 * (z(H) + z(FA)). A hit was scored if the space bar was pressed after the target appeared on a target-present trial, and a false alarm was scored if the space bar was pressed during a target-absent trial (Macmillan & Creelman, 1991).
Equivalence testing (Lakens, 2017; Limentani et al., 2005) was used to test whether any observed effects were too small to be of interest for theoretical or practical purposes. In equivalence testing, the null hypothesis is that there is an effect large enough to be deemed interesting (i.e., outside a specified equivalence bound). The alternative hypothesis is that, if an effect exists, it falls within the equivalence bounds. For this study we used a smallest effect size of interest of Cohen’s d = 0.20. If the equivalence tests indicate that the likelihood of an effect larger than this is below alpha, we would conclude that the conditions were statistically equivalent.
Results
Data are openly available on the project’s OSF page: https://osf.io/j5hbm/
Pre-registered analyses
Attention check
To confirm that participants attended to the contextual information in the poster, responses to the attention check questions were compared with a pre-set minimal level of 75% accuracy (six out of eight trials). Participants were on average 98% (SD = .06) correct on this measure. A one-sided t-test indicated that accuracy on the attention check was significantly higher than 75%, meaning that participants did sufficiently attend to the contextual information presented: t(395) = 70.08, p < .001.
Discriminability
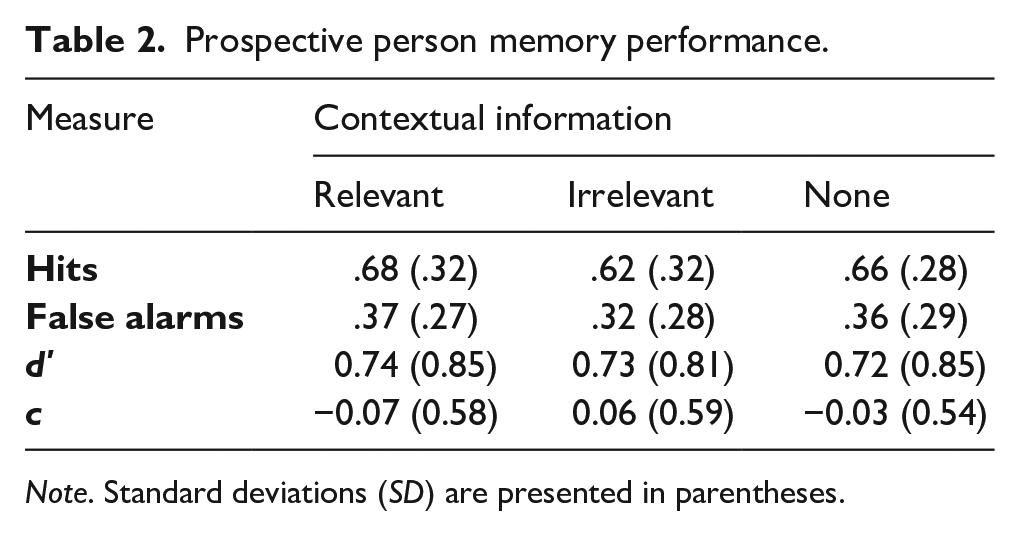
We first ran a one-way ANOVA on discriminability scores, looking at the differences between our three experimental conditions: relevant context, irrelevant context and control (see Table 2). The model revealed no effect of contextual information: F(2, 395) = 0.04, p = .97, η2 p < .01. Our first two hypotheses were, therefore, not supported.
Prospective person memory performance.
Note. Standard deviations (SD) are presented in parentheses.
Following our analyses plan, we then ran two equivalence t-tests to compare d′ scores using a smallest effect size of interest of d = 0.20 and an alpha level of .022. First, we looked at the difference between relevant and irrelevant context conditions. Despite the similar means across these two conditions (see Table 2), the equivalence test was nonsignificant, t(262) = 1.53, p = .06. A second equivalence test comparing the relevant context and no context conditions was also nonsignificant, t(264.87) = 1.44, p = .08. Please see Figure 2 for equivalence bounds and mean differences.
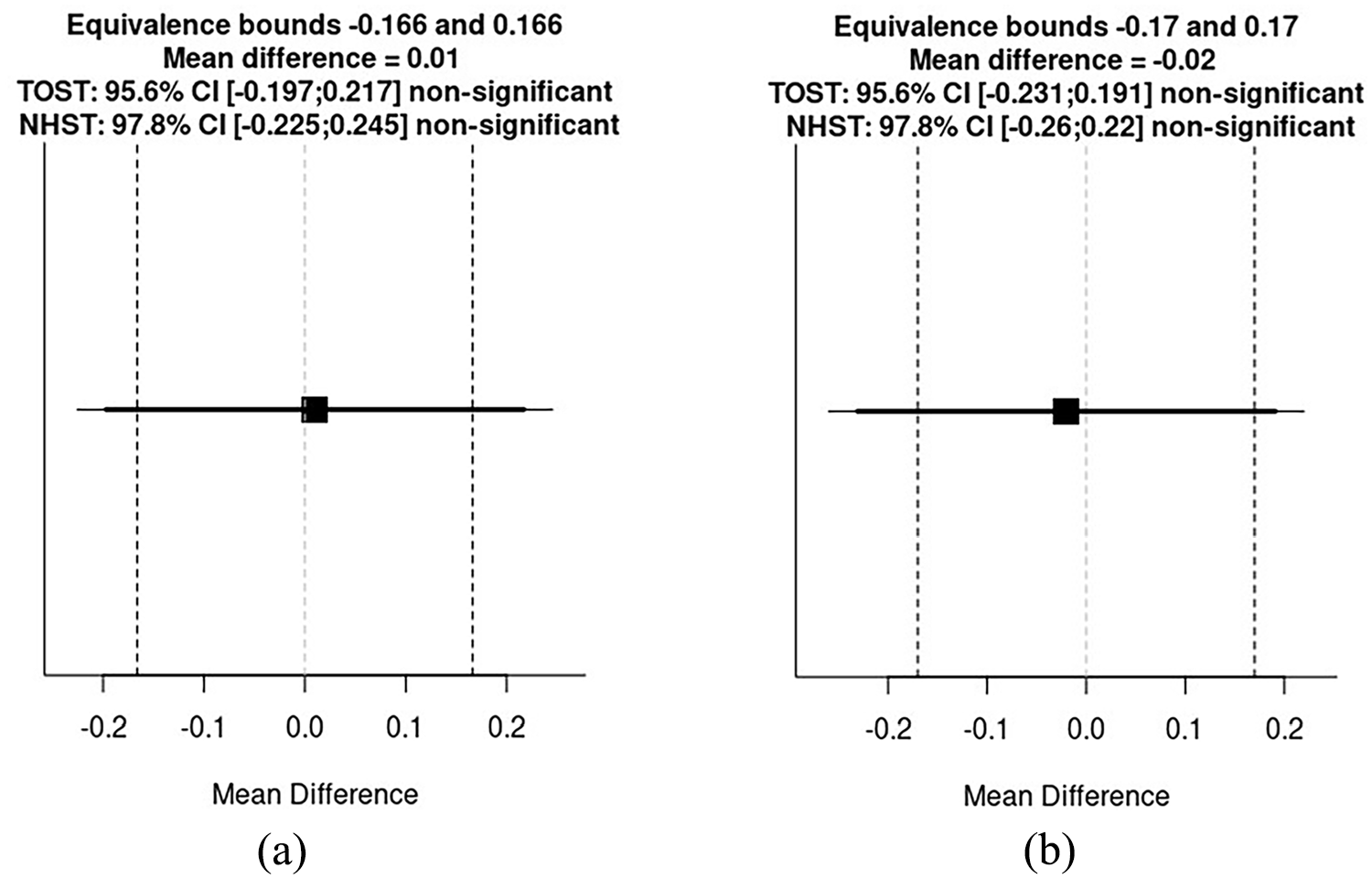
Mean differences between relevant and irrelevant context conditions (a), and relevant and no context conditions (b).
Response bias
We also ran a one-way ANOVA on response bias scores. We found no significant differences between the three context conditions on this measure: F (2, 395) = 1.19, p = .15, η2 p = .01. Two equivalence t-tests on c scores were nonsignificant: one between the relevant and irrelevant context conditions, t(260.97) = 0.18, p = .57, and one between the relevant context and no context conditions, t(264.37) = 1.05, p = .15. Thus, response bias in the relevant context condition was not statistically equivalent to the two other conditions.
Exploratory analyses
Ongoing task performance
To explore the level of participants’ engagement with the ongoing task, we performed exploratory analyses on this measure. When using a prospective person memory task, it is important to assess whether participants were paying attention to both tasks during the experiment. On average, participants were 69% correct (SD = .13) on the questions used as the ongoing task. Ongoing task performance was weakly positively correlated with prospective person memory discriminability: r(396) = .14, p = .004; suggesting that participants who paid more attention during the experiment in general tended to perform better on both tasks. This result could also suggest that some participants have better memory abilities and this improved their performance on both tasks.
Old/New recognition task
Participants also completed an old/new recognition task, using the same targets as for the prospective person memory task (see Table 3). They were asked to say “old” to the eight targets presented in the posters and “new” for everyone else (including four individuals who appeared in the videos but not on the posters, and 12 never-before-seen individuals). We found no significant effect of context condition on either old/new discriminability, F (2, 395) = 1.52, p = .22, η2 p = .01, or response bias, F (2, 395) = 1.87, p = .16, η2 p = .01. We also computed the correlation between prospective memory discriminability and old/new discriminability and found a significant, small to moderate positive correlation between these two measures, r (396) = .23, p < .001, which is expected considering that both tasks rely on face recognition of the same individuals.
Old/new task performance.
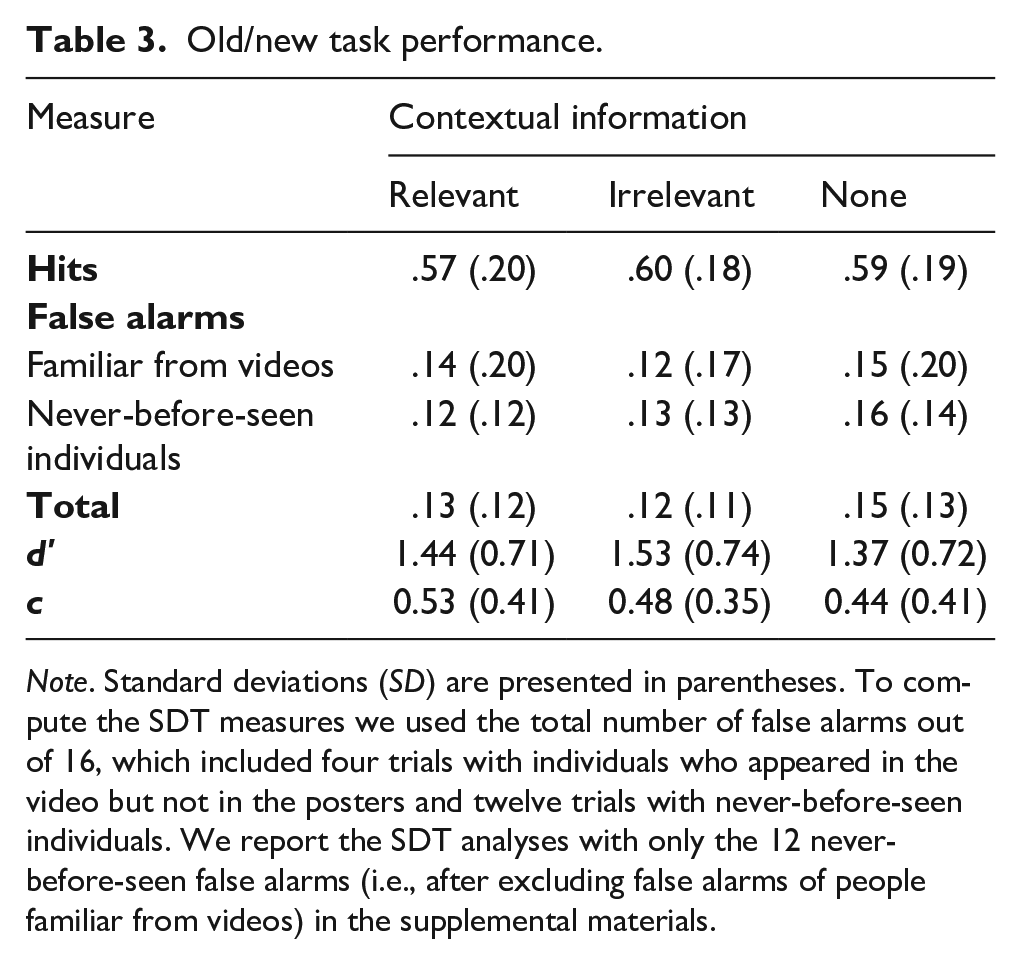
Note. Standard deviations (SD) are presented in parentheses. To compute the SDT measures we used the total number of false alarms out of 16, which included four trials with individuals who appeared in the video but not in the posters and twelve trials with never-before-seen individuals. We report the SDT analyses with only the 12 never-before-seen false alarms (i.e., after excluding false alarms of people familiar from videos) in the supplemental materials.
Trial-level analysis
All participants completed eight trials, each including a target present or a target absent video. Due to the nature of the task, the identity and appearance of each target was correlated with a specific context (see Table 4). Performance, therefore, could be affected by the presence and relevance of the contextual information, the consistency of the target’s appearance at encoding and at test, and the physical similarity between the target and the plausible nontarget. Table 4 shows the percentage of participants who correctly identified each appearing target, and the percentage of participants who incorrectly identified each nonappearing target. Supplemental materials present the results of a linear mixed-effects model examining the effect of Target information (relevant context vs. irrelevant context vs. no context) and Target presence (target absent vs. target present) on sightings, with Participants and Targets as random intercepts. Both participants and targets explained only a small portion of the total variability in sightings.
Prospective person memory performance for each target pair.
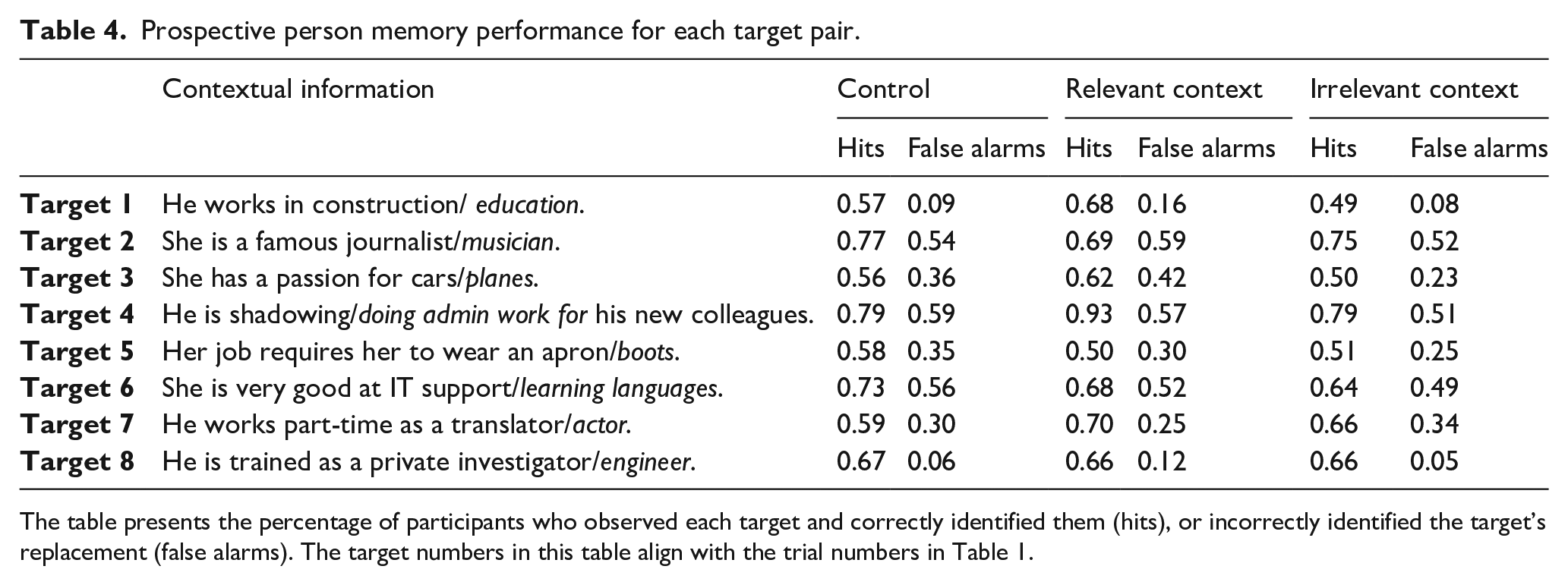
The table presents the percentage of participants who observed each target and correctly identified them (hits), or incorrectly identified the target’s replacement (false alarms). The target numbers in this table align with the trial numbers in Table 1.
Discussion
In this experiment, we associated an unfamiliar face with contextual information during encoding to see if the context would facilitate prospective person memory. We operationalised contextual information as any type of person-related description such as their jobs or clothing (e.g., “He works in construction”). We manipulated the relevance of this contextual information by showing the target during testing in a context that matched the one described during encoding (i.e., relevant context) or in a context that did not match the encoded context (i.e., irrelevant context). We also had a control group in which participants encoded each target face alongside their name only. The results provide no evidence that the additional contextual information affected prospective person memory. The additional information provided in the relevant and irrelevant context conditions did not affect prospective person memory discriminability. While average discriminability scores across the three groups were very similar (i.e., 0.72, 0.73, and 0.74), they were not statistically equivalent when using a smallest effect size of interest of Cohen’s d = 0.20. The contextual information did not have a significant effect on response bias, but response bias was also not statistically equivalent across the three conditions.
We did not detect any significant differences in response bias. Descriptively, the response bias pattern appears similar to what was reported in previous work by Moore et al. (2016). In both studies, participants who were given accurate contextual information reported both more accurate and more inaccurate sightings than participants who were given inaccurate expectations. In line with our results, they also found no significant effect of contextual information on sighting accuracy (which they measured as the proportion of correct sightings/proportion of false sightings). Although we did not find support for any of our hypotheses, the trends in our discriminability data are most aligned with the sighting bias hypothesis. This was based on the premise that contextual information does not affect face encoding and subsequent recognition, but relevant context can direct attention towards both targets and plausible nontargets who appear in the expected context. Response bias, however, was very similar in the relevant and the control conditions which is not in line with this hypothesis.
Overall, our findings suggest that the effect of contextual information on face recognition might be smaller or less general than expected based on prior literature (Bower & Karlin, 1974; Coin & Tiberghien, 1997; Kerr & Winograd, 1982; Winograd, 1981). We tested each participant using two different face recognition tasks: prospective person memory and an old/new recognition task. Previous research showed that contextual elaboration results in a deeper encoding of an individual rather than just their face, which consequently improves memory of that person. Contrary to this, in our study we found no differences in performance between participants who learned targets with names only and participants who also learned the targets with some type of additional contextual information (e.g., their jobs or clothing).
The current study results might, on one hand, suggest that when there already is some conceptual information present such as names, additional contextual information might not further affect face recognition through deeper encoding. In line with the levels of processing framework (Craik & Lockhart, 1972), Schwartz and Yovel (2016) previously suggested that associating a photo of an unfamiliar face with their name is enough to shift its representation from an image-based percept to a view-invariant concept, providing a complex memory representation of the unfamiliar person (rather than their picture) and improving their subsequent recognition accuracy. Using a prospective person memory task, Juncu et al. (2020) found that indeed associating an unfamiliar face with a name improves discriminability in comparison to learning that face from images only. Similarly, Kerr and Winograd (1982) found that although any amount of information improves face recognition in comparison with no conceptual information, increasing the amount of conceptual information did not consistently affect performance. Future studies should focus on manipulating the amount of conceptual information provided during encoding, and test its effect on different types of face recognition.
Another consideration is that the type of contextual information used could be critical for producing an effect on prospective person memory performance. In our study, we were interested in a general effect of contextual information and so we paired the targets with different types of contexts (i.e., jobs, hobbies, and clothing). Learning about a missing person’s clothing might provide important context for recognising them at a chance encounter (e.g., if the missing person usually wears a red jacket, attention might be drawn to anyone wearing a red jacket), but such cues might not encourage the type of processing that improves encoding of the person’s face. Learning about missing person’s job, however, might affect encoding by encouraging viewers of the poster to consider whether the missing person fits their preconceptions of someone performing that job (i.e., elaborative encoding). Hills et al. (2008) found that associating occupation labels with novel faces who are judged to fit that occupation facilitated their encoding in comparison with associating the same labels with nonstereotypical faces. Future studies should focus on specific types of contextual information to distinguish the processes behind potential contextual effects (i.e., abstraction vs. perceptual cues).
In line with Tulving’s encoding specificity theory (Tulving & Osler, 1968; Tulving & Thomson, 1973), we hypothesised that, when provided with relevant contextual information, participants should experience a higher degree of similarity between encoding and testing conditions, which in turn should have increased the number of sightings. Previous empirical studies showed that recognition of unfamiliar faces is improved if faces are presented during testing along with the same partners that accompanied them at encoding (Winograd & Rivers-Bulkeley, 1977), or if they are presented against the same background as during encoding (Beales & Parkin, 1984; Memon & Bruce, 1983). These previous studies, however, used identical encoding and testing contexts to improve recognition. In our experiment, participants were presented with semantic information during encoding and with perceptual information during testing. Therefore, it is possible that the contextual information at encoding was insufficient for the participants to develop accurate expectations of how the targets would appear in the video. For example, in one of our trials, the target was described as a construction worker, and we classified this as relevant because during the video they appeared in a bar wearing a construction uniform. However, it is possible that this context was nonetheless inconsistent with participants’ expectations. For example, the participants might have been expecting to encounter the person at a construction site. Future studies should aim to investigate how participants develop expectations of encounter, and how these expectations relate to the actual testing conditions.
For this experiment, we developed a new experimental paradigm to test prospective person memory in the laboratory. One of the aims in developing this new paradigm was to increase the similarity between how participants’ attention is divided in prospective memory experiments and how their attention is channelled during real-life activities. In most previous laboratory tests of prospective person memory, the images were static; for example, asking participants to look at images of a supermarket to find items on a shopping list (nonfocal task; Lampinen et al., 2009), or images of faces to separate them into different teams (focal task; Lampinen & Sweeney, 2014). Here, we introduced a new paradigm in which participants were asked to watch videos and remember as many details as possible. Thus, our stimuli are more complex and dynamic. Although all videos included a number of people, we did not directly ask participants to pay attention to them. Therefore, this procedure potentially includes both focal and nonfocal processing, which is a better simulation of most real-life activities. Another feature of our paradigm is that we manipulated whether participants would encounter a target or a plausible nontarget, while keeping the conditions of the encounter constant. Performance levels for all tasks were above floor, and the percentage of correct identifications were comparable with previous prospective person memory studies that used images during their ongoing tasks (Juncu et al., 2020; Moore et al., 2016).
It is also possible that our results differ from previous ones because of the nature of the prospective person memory task. Although our participants performed above floor and reported, on average, four sightings, the videos contained many other details that could have drawn their attention away from the targets. Coin and Tiberghien (1997) argued that contextual effects on face encoding are task dependent. They suggested that face description and face reconstruction tasks (i.e., creating composites) are enhanced by facial feature judgements, but face recognition tasks are improved by personality judgements. More work is needed to look at what type of contextual information could improve prospective person memory. Future research could vary the stimulus load, the encoding time, and the time between encoding and testing to further characterise the specific conditions under which face recognition is improved by associated conceptual information.
An important limitation of our study should be considered when interpreting our results, as well as when developing new research. For all participants, the pair of target-nontarget and their associated contextual information were coupled: for each target-nontarget pair we used only one context. This means that each target was always associated with the same type of information. The contextual information used (e.g., “He works in construction”), was therefore confounded with the identity of the target (and their associated nontarget). It is possible that sometimes the videos with the easiest contextual information to remember were also the videos where the targets were harder to identify, and these effects could have cancelled each other out. Future studies should further investigate the effect of contextual information on prospective person memory, using an even wider variety of stimuli and contexts than were used in the present research.
Conclusion
In this registered report, we did not replicate previous findings that associating faces with contextual information improves recognition. Our contextual manipulation was more generic and varied between trials than previously used ones and could be the reason why we found no effect. It is also possible that the way in which the targets appeared in the videos did not match participant expectations enough for them to notice the match in context. Considering the importance of this task for missing people or wanted criminal cases, future studies should further research the effect of different types of information on prospective person memory. Our findings suggest that the previously reported advantage of context on recognition might depend on the nature of the context provided at encoding, on the manner of the encounter with the target at testing, or on the type of memory test. More work needs to be done regarding the potential effects of different types of contextual information on face recognition, and the mechanisms behind these effects.
Supplemental Material
sj-pdf-1-qjp-10.1177_17470218251323820 – Supplemental material for Contextual effects on prospective person memory
Supplemental material, sj-pdf-1-qjp-10.1177_17470218251323820 for Contextual effects on prospective person memory by Stefana Juncu, Ryan J Fitzgerald, Hartmut Blank and James Ost in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by a South Coast Doctoral Partnership grant(ES/P000673/1) from the Economic and Social Research Council to the first author (project reference: 1956663) as a PhD studentship.
Data accessibility statement
Supplementary material
The supplementary material is available at qjep.sagepub.com.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.