
Abstract
Lexico-semantic effects in lexical decision and semantic categorisation tasks have been investigated using the megastudy approach, but not with other traditional spoken word recognition tasks. To address this gap, this megastudy examined the single-word shadowing task, where 96 native English speakers repeated aloud each word they heard as quickly and as accurately as possible. Item-level hierarchical regression and linear mixed-effects analyses produced identical results: Words with longer token duration were associated with slower response times while high-frequency and phonologically distinctive words were repeated faster. These findings were consistent with previous studies and other tasks, which suggests that lexical effects are task-general in spoken word recognition. However, after controlling for lexical variables, six semantic variables did not account for any additional unique variance in response times. These results suggest that the single-word shadowing task is heavily dependent on lexical processing and can be completed without activating semantics. Cross-task comparisons with another megastudy’s data on auditory lexical decision and semantic categorisation tasks further suggest that lexical effects are task-general, while semantic richness effects are task-specific in spoken word recognition.
The past decade has seen a number of studies applying the megastudy approach to spoken word recognition (Ernestus & Cutler, 2015; Ferrand et al., 2018; Goh et al., 2020; Goh et al., 2016; Tucker et al., 2019; Winsler et al., 2018). In a megastudy, a large corpus of words maintains original and continuous lexico-semantic property values in regression models, instead of bivariate splits into groups in traditional factorial designs (see Balota et al., 2012 for a review). This allows a broader selection of words without the strict matching between groups and a simultaneous examination of a wider array of linguistic variables.
Except for the studies by Goh et al. (2016) and Winsler et al. (2018) that included a semantic categorisation task (SCT), where participants categorise a word as concrete or abstract, all extant megastudies in the auditory domain employed the lexical decision task (LDT), where participants discriminate words from nonwords. LDT is widely used in megastudies, because it is easy to understand for normal participants and to administer, allowing for quick and mass data collection sessions. Current insights on the influence of linguistic properties on spoken word recognition processes from the megastudy approach are, therefore, limited primarily to effects on the LDT. SCT offers similar advantages and is particularly suited for investigating semantic processing and abstract–concrete word comparisons, as it requires explicit semantic decisions. However, the additional lexical or semantic decision components in both LDT and SCT are uncommon in natural communication, potentially confounding spoken word processing. These decision-making components also make the tasks challenging for individuals with language impairments. Furthermore, researchers must carefully control materials, such as matching words and nonwords in LDT or balancing concrete and abstract words in SCT.
In contrast, the single-word shadowing task, also known as auditory repetition or auditory naming (Bates & Liu, 1996), is simpler and represents a more natural form of speech communication compared with the LDT and SCT. This is another conventional spoken word recognition task extensively used in studies of lexical access in speech processing (Luce & Pisoni, 1998; Marslen-Wilson, 1985), where participants are asked to repeat an auditorily presented word as quickly and as accurately as possible. The shadowing task has several advantages over the LDT and SCT: It produces very low error rates and the absence of decision components prevents participants from using strategies during decision-making processes. Due to its simplicity, it can be conducted across a broader age range and with diverse populations (Liu et al., 1997), such as children or clinical populations with language impairments, who lack knowledge of words. In addition, the single-word shadowing task presents only word stimuli without fillers or distractors, eliminating the need for researchers to prepare and match words with nonwords or concrete words with abstract words. However, due to its reliance on verbal responses, this task hampers quick and mass data collection, rendering it more time-consuming and less commonly utilised than the LDT.
While some visual naming megastudies have been conducted, such as the English Lexicon Project (Balota et al., 2007) and the Semantic Priming Project (Hutchison et al., 2013), to date, no such megastudies exist for shadowing. Although both visual naming and shadowing tasks require participants to produce verbal responses, visual naming is a conventional task for visual word recognition, where participants are presented with a visual word on a screen and asked to name it aloud. In contrast, shadowing is a conventional task for exploring spoken word recognition through auditory input. As Marslen-Wilson (1990) explicitly noted, shadowing and visual naming are distinct tasks with different input modalities and should not be conflated. Spoken words in shadowing unfold gradually over time (Mattys, 1997), unlike visual naming, where words are visually presented all at once. Shadowing also requires precise analysis of the phonetic properties of the auditory token to build an articulatory plan for response execution (Luce et al., 1990), a process not involved in visual naming. Empirical evidence further suggests that the cognitive processes underlying shadowing and visual naming differ (Connine et al., 1990; Luce & Pisoni, 1998).
Therefore, this study aims to be the first to extend the exploration of lexico-semantic effects in spoken word recognition from LDT and SCT (Goh et al., 2016) to the single-word shadowing task at the megastudy level, providing insights into the differences and similarities in the effects found across spoken word recognition tasks.
Lexical effects
Existing megastudies on spoken word recognition have primarily focused on examining the effects of various lexical variables on task performance. “Token duration” is measured from the onset to the offset of audio tokens. “Word frequency” indicates how often a particular word appears in a given corpus. “Phonological uniqueness point” refers to the exact point in the input string where only one candidate diverges from the cohort of possible words (Luce, 1986). “Phonological neighbourhood density” is reflected by the number of words formed by a single phoneme change in the target word (Luce & Pisoni, 1998). “Phonological Levenshtein distance” quantifies the distance between a target word and its phonologically similar neighbours (Yarkoni et al., 2008). Due to high correlations among phonological structural variables—such as phonological neighbourhood density, phonological Levenshtein distance, number of phonemes, and number of syllables—researchers have employed principal components analysis (PCA) to consolidate these factors into a single component, termed “phonological distinctiveness” (Goh et al., 2016; Tucker et al., 2019). This component reflects phonological neighbourhood structure and indicates how easily one word can be distinguished from another. Words with higher phonological distinctiveness have more phonemes, more syllables, longer phonological Levenshtein distances, fewer phonological neighbours, and sparser phonological neighbourhoods.
Lexical variables have collectively explained a large amount of response times (RTs) variance in megastudies, ranging from 28.71% (Tucker et al., 2019) to 68% (Goh et al., 2020). Token duration has been demonstrated as the most important variable in the auditory domain, with longer durations associated with longer recognition times (Ferrand et al., 2018). Word frequency and phonological structural variables also play significant roles in spoken word recognition performance (Goh et al., 2016; Tucker et al., 2019). The word frequency effect is reflected as high-frequency words being associated with faster and more accurate responses. However, the impact of phonological distinctiveness varies across megastudies, with some observing that greater distinctiveness leads to faster responses in English (Goh et al., 2016; Tucker et al., 2019), while Ferrand et al. (2018) reported the opposite in French. This discrepancy may be attributed to cross-linguistic differences in phonological neighbourhood density effects. For example, Vitevitch and Rodríguez (2005) demonstrated that words with more neighbours are processed more quickly and accurately in Spanish, whereas in English, they are processed more slowly and less accurately (Luce & Pisoni, 1998; see Vitevitch & Luce, 2016, for a review), possibly due to differences in typical word lengths across languages or in segmentation strategies employed in stress-timed languages like English and syllable-timed languages like French.
Semantic richness effects
Semantic representation is a multidimensional rather than a unitary construct (Pexman et al., 2008). Each dimension captures a specific aspect of semantic information. “Number of features” (NoF) refers to the number of semantic features listed in a subjective semantic features production task (McRae et al., 2005). “Concreteness” 1 reflects the perceptibility of a concept in terms of sensory and motor aspects (Brysbaert et al., 2014). “Emotion” information generally includes “valence,” “arousal,” and “dominance” (Warriner et al., 2013). “Semantic neighbourhood density” (SND) measures the tightness of a word in its semantic neighbourhood based on the co-occurrence information in a corpus (Shaoul & Westbury, 2010). “Semantic diversity” (SemD) indicates the extent to which the meanings of a given word differ across contexts (Hoffman et al., 2013). Semantic richness effects, observed as faster responses and fewer errors for words with higher values on these dimensions (Pexman, 2012), have been found and extended to various visual word recognition tasks, indicating task-generality in the visual domain (Yap et al., 2011, 2012; Zdrazilova & Pexman, 2013).
Our understanding of semantic effects in spoken word recognition primarily derives from factorial experiments. Tyler et al. (2000) found imageability effects in auditory LDT and repetition tasks, where high-imageability words were responded to faster than low-imageability words. Similarly, Sajin and Connine (2014) reported NoF effects in auditory LDT and the visual world paradigm, where words with high NoF were processed faster than those with low NoF. In auditory megastudies, Goh et al. (2016) examined semantic richness effects induced by six properties—concreteness, valence, arousal, NoF, SND, and SemD—on LDT and SCT. After controlling for lexical variables, concreteness, valence, and NoF were found to facilitate task responses. Collectively, these semantic richness variables accounted for additional unique variance in LDT (3%) and SCT (7.5%). Replicated findings from Tucker et al. (2019) and Nenadić et al. (2024) confirmed the reliability of semantic richness effects in auditory LDT.
Shadowing effects
Several lexical and semantic variables have been demonstrated to affect shadowing performance through factorial designs. Word frequency and token duration significantly affected shadowing RTs, with higher frequency and shorter durations associated with faster shadowing (Goldinger, 1998; Tyler et al., 2000). Moreover, the effect of phonological neighbourhood density—words with more similar-sounding neighbours are repeated more slowly and less accurately than those with fewer similar-sounding neighbours—has been reported, due to competition among similar word forms (Luce & Pisoni, 1998; see Vitevitch & Luce, 2016, for a review).
Significant imageability effects have been observed in the study by Tyler et al. (2000), with faster responses to high-imageability words compared to low-imageability words, subsequently confirmed by a negative relationship between imageability and repetition RTs in the study by Savill et al. (2019). Wurm and colleagues found significant effects of some semantic dimensions on the auditory naming RTs, including danger and usefulness (Wurm & Seaman, 2008), evaluation (bad/good), potency (weak/strong), and activity (slow/fast; Wurm et al., 2004). Besides the isolated word shadowing task, Slowiaczek (1994) combined it with the priming paradigm and found that spoken words were repeated more quickly after semantically related primes. Furthermore, semantic effects on shadowing were observed not only in healthy individuals but also in patients with aphasia, who performed better with words with richer semantic information (Chapman & Martin, 2021; Hanley et al., 2002; Tyler & Moss, 1997).
Converging evidence supports the applicability of the shadowing task to examine lexico-semantic effects in spoken word recognition. However, previous studies were restricted to a smaller word set and fewer dimensions in separate examinations.
This study
This study aims to address the existing gap that current auditory megastudies have been limited to the LDT and SCT. To allow comparisons with previous findings, this study extended the study by Goh et al. (2016) on LDT and SCT to the single-word shadowing task. This allowed an examination of the relative contributions of lexical and semantic variables to shadowing, and whether these effects are task-general or task-specific.
Method
Participants
One hundred undergraduate students from the National University of Singapore (NUS), self-reported as native English speakers with no speech or hearing disorders, received partial course credit for participation. After the shadowing task, all participants completed linguistic surveys that were also administered in the Auditory English Lexicon Project (AELP, Goh et al., 2020). This included a language background questionnaire (LBQ) with self-reported ratings of English age of acquisition, listening, reading, speaking, and writing proficiency, a 60-item subset of a vocabulary test drawn from the study by Levy et al. (2017), and a 60-item subset of a spelling test drawn from the study by Burt and Tate (2002). Four participants were dropped from the subsequent analysis (one participant’s audio file was not successfully saved due to technical issues and three non-native English speakers were screened out through the LBQs). The characteristics of the 96 remaining participants are summarised in Table 1. Ethical approval for the protocols was obtained from the ethics review committee and informed consent was obtained from all participants.
Participant characteristics.
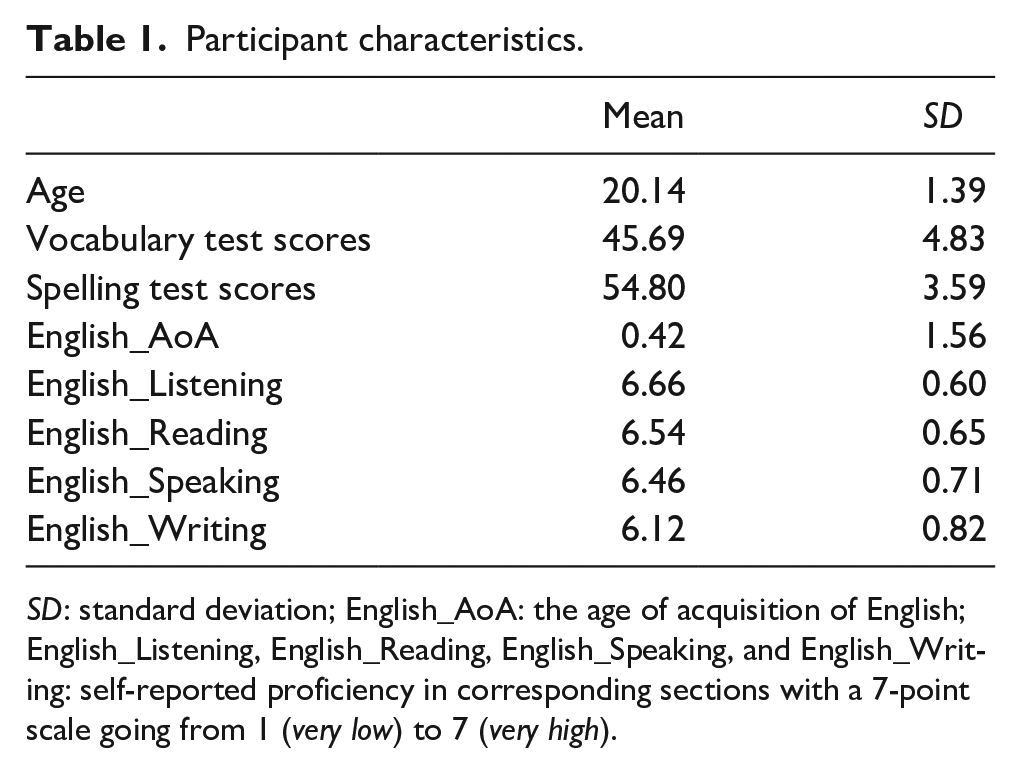
SD: standard deviation; English_AoA: the age of acquisition of English; English_Listening, English_Reading, English_Speaking, and English_Writing: self-reported proficiency in corresponding sections with a 7-point scale going from 1 (very low) to 7 (very high).
Materials
The stimuli pool consisted of 541 concrete words taken from the set in McRae et al. (2005), which was also used by Goh et al. (2016). All auditory tokens in 44.1-kHz, 16-bit, mono WAV files recorded by a female Singaporean English speaker were obtained from the AELP. Tokens of homophone words (e.g., cellar, inn, and jeans), ambiguous words (e.g., bat [baseball], bat [animal]), and tokens that were not correctly identified by at least 80% of listeners in the AELP were excluded. A total of 424 concrete words common to both the McRae norms and the AELP were used in the formal experiment procedure. 2 The average identification rate for these 424 word tokens was 95.63% (SD = 0.06).
To facilitate the comparison between the results of this study and the study by Goh et al. (2016), we employed the same variables of interest, which are grouped into two clusters: lexical variables and semantic variables. Lexical variables included token duration (taken from the AELP), word frequency (Brysbaert & New, 2009), phonological uniqueness point (Luce, 1986), phonological Levenshtein distance (Yarkoni et al., 2008), phonological neighbourhood density, number of phonemes, number of syllables, number of morphemes (all directly taken from the AELP). Six semantic variables of interest were concreteness (Brysbaert et al., 2014), emotional valence and arousal (Warriner et al., 2013), NoF (McRae et al., 2005), SND (Shaoul & Westbury, 2010), and SemD (Hoffman et al., 2013). Table 2 presents descriptive statistics for all word properties and behavioural data.
Descriptive statistics for all word properties and dependent measures (N = 352).
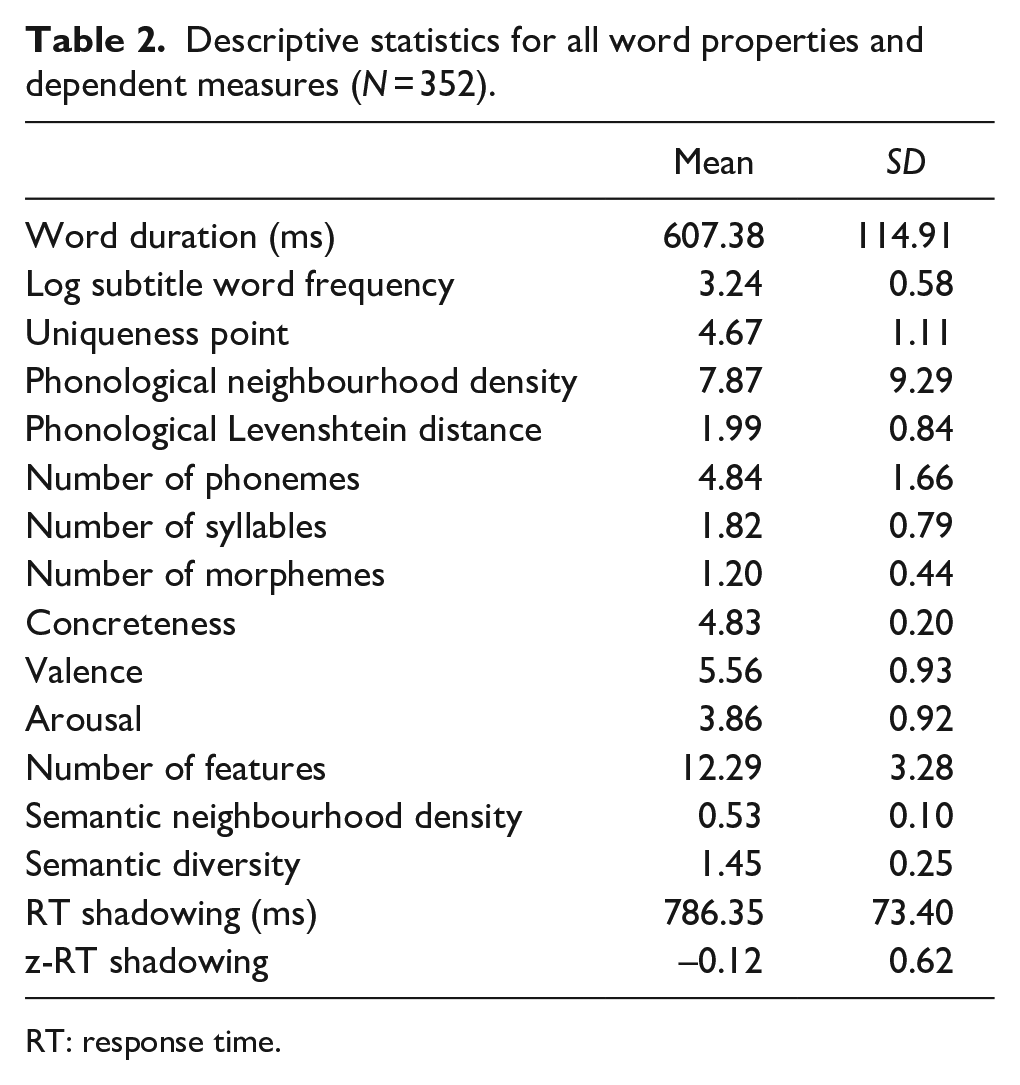
RT: response time.
Procedure
Participants were tested individually in a sound-attenuated lab. They were instructed to complete the single-word shadowing task on a computer running E-prime 3.0. Each trial began with a fixation cross “+” presented in the centre of the screen for 500 ms to indicate the upcoming stimulus. Subsequently, participants were presented with an audio token binaurally through Beyerdynamic DT150 headphones at around 70 dB SPL and were asked to repeat each word aloud into the microphone as quickly and as accurately as possible. The maximum RT allowed was 4,000 ms and the inter-trial interval was 1,000 ms. Shadowing RTs were recorded by an Audio-Technica ATR20 cardioid dynamic vocal microphone connected to a Chronos response box and measured from the onset of each stimulus to the onset of the participant’s verbal response, which was triggered by a digital voice key. In addition, verbal responses were recorded by a digital voice recorder for later offline accuracy analysis.
Beginning with 10 practice trials for task and procedure familiarisation, 424 trials in four blocks of 106 trials each were then run in the formal experiment, with breaks between blocks. The stimuli order was randomised for each participant. The entire experiment, including the single-word shadowing task and linguistic surveys, lasted approximately 40 min.
Results
Following the same data trimming procedures in the study by Goh et al. (2016), we excluded trials in the following order: Words with accuracy rates below 70% (0 items, all words’ accuracies were above 78%), trials with incorrect responses (2.30%), RTs less than 200 ms or more than 3,000 ms (0.02%), and 2.5 standard deviations beyond each participant’s average RT (1.53%) were excluded. Exclusion of words without complete values on lexical and semantic properties resulted in 352 words for analysis. Figure 1 shows the correlation matrix for all variables.
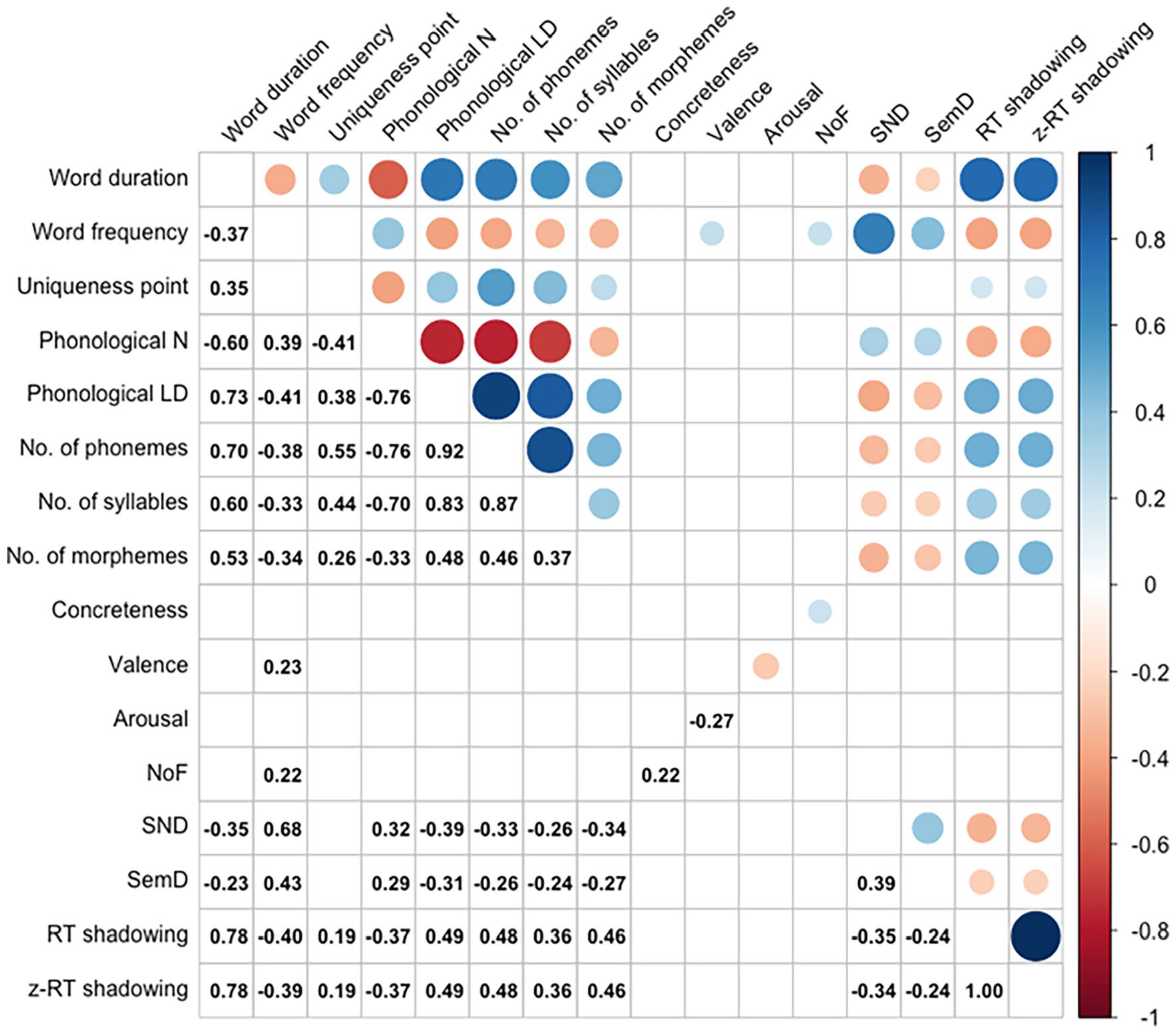
Pearson correlations between all word properties and dependent measures for 352 words.
Figure 1 shows high correlations among number of phonemes, number of syllables, phonological Levenshtein distance, and phonological neighbourhood density (|r|: .70–.92), indicating that they may tap the same construct. Therefore, we conducted a PCA as in the study by Goh et al. (2016) to reduce these four variables to a single component with varimax rotation and Kaiser normalisation. This structural principal component accounted for 85.7% of the variance, with higher values indicating greater phonological distinctiveness. Component loadings are presented in Table 3.
Principal component loadings.

Item-level hierarchical regression analyses
To allow direct comparison with the findings of Goh et al. (2016), the hierarchical regression analyses were conducted fully in parallel with their studies. To reduce the impact of individual differences in processing speed and variability (Balota et al., 2007; Faust et al., 1999), we utilised z-score transformed RTs as dependent variables for item-level hierarchical regression analyses in R (R Core Team, 2021). The model included five lexical variables in the first step and six semantic variables in the second step, with quadratic valence and the interaction between valence and arousal added in the third and fourth steps, respectively.
The results in Table 4 showed that lexical variables collectively accounted for 64.43% of the variance in shadowing RTs, F(5, 346) = 128.17, p < .001. Word duration, word frequency, and phonological distinctiveness were significant predictors of shadowing latencies. However, none of the semantic variables or their interaction significantly influenced shadowing RTs. Comparisons of the change in R2adjust in Steps 2, 3, and 4 revealed that semantic richness variables did not contribute additional variance in RTs beyond lexical variables, Fchange (6, 340) = 0.57, p = .76; Fchange (1, 339) = 0.34, p = .56; Fchange (2, 337) = 0.55, p = .58. The best-fitting model remained the one that only included lexical predictors.
Standardised regression coefficients for item-level hierarchical regression analyses of single-word shadowing latencies (n = 352).

Coefficients reflect those entered in the corresponding step.
p < .10, *p < .05, **p < .01, ***p < .001.
Linear mixed-effects modelling analyses
Linear mixed-effects modelling was employed to examine the robustness of the item-level hierarchical regression results and to consider the random effects of items and subjects simultaneously, which cannot be addressed in item-level hierarchical regression models (Baayen et al., 2008). Raw RTs 3 were analysed using linear mixed-effects modelling in R with the lme4 package (Bates et al., 2015) and lmerTest package (Kuznetsova et al., 2017).
In the first step 4 , item and subject were treated as random intercepts, and the fixed effect structure was built in a forward-entering approach. Specifically, five lexical variables as fixed effects were entered into the model first, and then six semantic variables were further entered into the model (see Models 1 and 2 in Table 5, respectively). However, adding additional semantic variables did not significantly improve the model fit: χ2(7) = 3.99, p = .781. Thus, we only kept the lexical variables as fixed effects in the model.
Linear mixed-effects model for raw RTs in the single-word shadowing task.
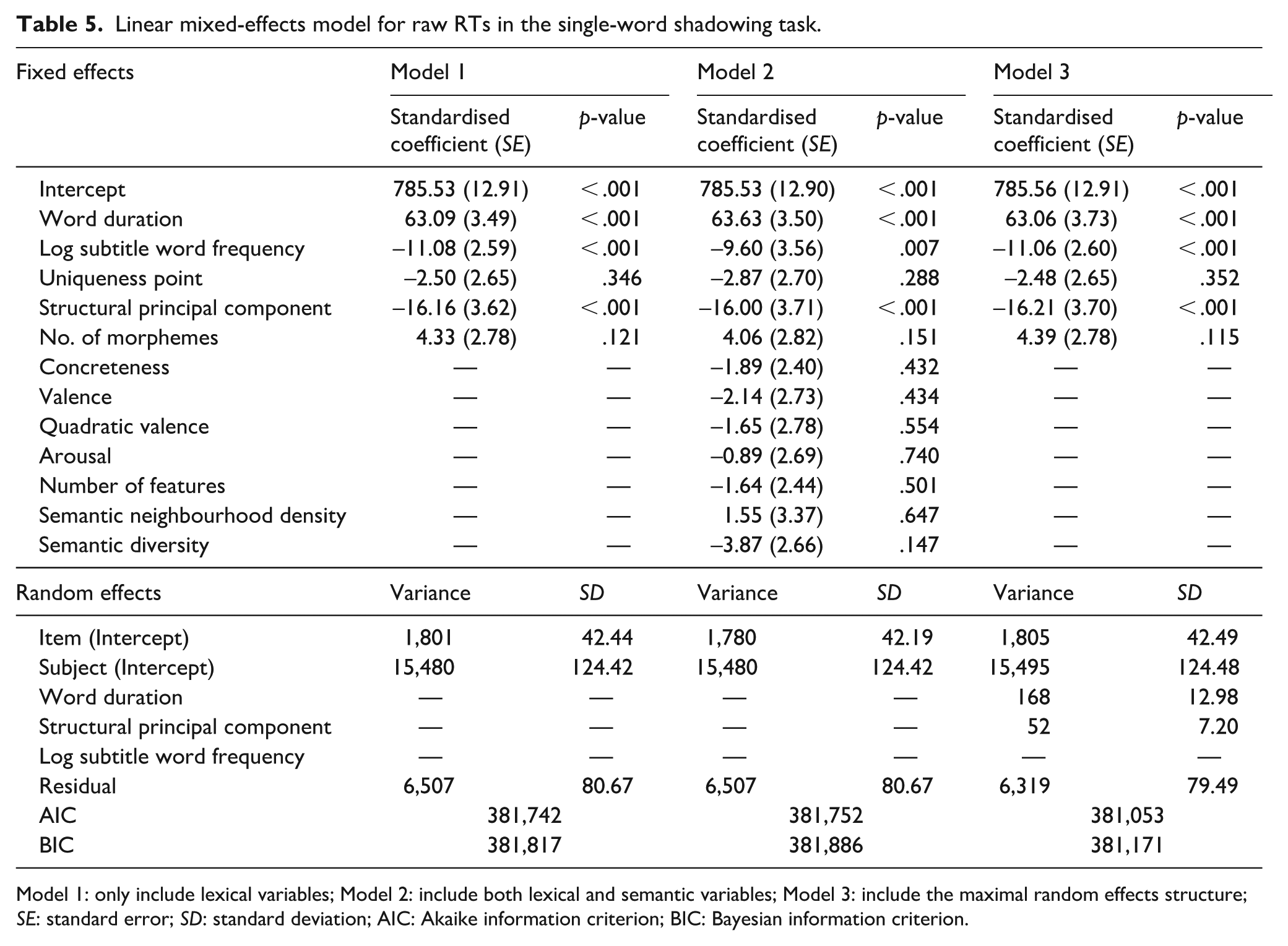
Model 1: only include lexical variables; Model 2: include both lexical and semantic variables; Model 3: include the maximal random effects structure; SE: standard error; SD: standard deviation; AIC: Akaike information criterion; BIC: Bayesian information criterion.
Second, we enriched the random effects structure to improve the model’s fitting. 5 The likelihood ratio tests showed that adding random slopes of the word duration and structural principal component per subject (Model 3) significantly improved the model compared to only including item and subject as random intercepts (Model 1): χ2(5) = 698.06, p < .001. Therefore, the best-fitting model (Model 3) only included lexical variables without any semantic variables.
Together, the results of item-level hierarchical regressions converged with linear mixed-effect models. Only lexical variables significantly affected RTs, without significant relationships between shadowing RTs and any semantic variables. Given the low error rate in the shadowing task (2.30%), we did not analyse the error data.
Discussion
This study is the first to investigate lexico-semantic effects in the single-word shadowing task at the megastudy level with a large set of words. To further compare lexico-semantic effects across tasks, we conducted additional analyses based on words common to this megastudy and the study by Goh et al. (2016). The results in Table 6 showed similar lexical effects but different semantic effects, with varying proportions of variance explained by lexical and semantic properties, across tasks. 6
Comparison of results from item-level hierarchical regression models across different spoken word recognition tasks.
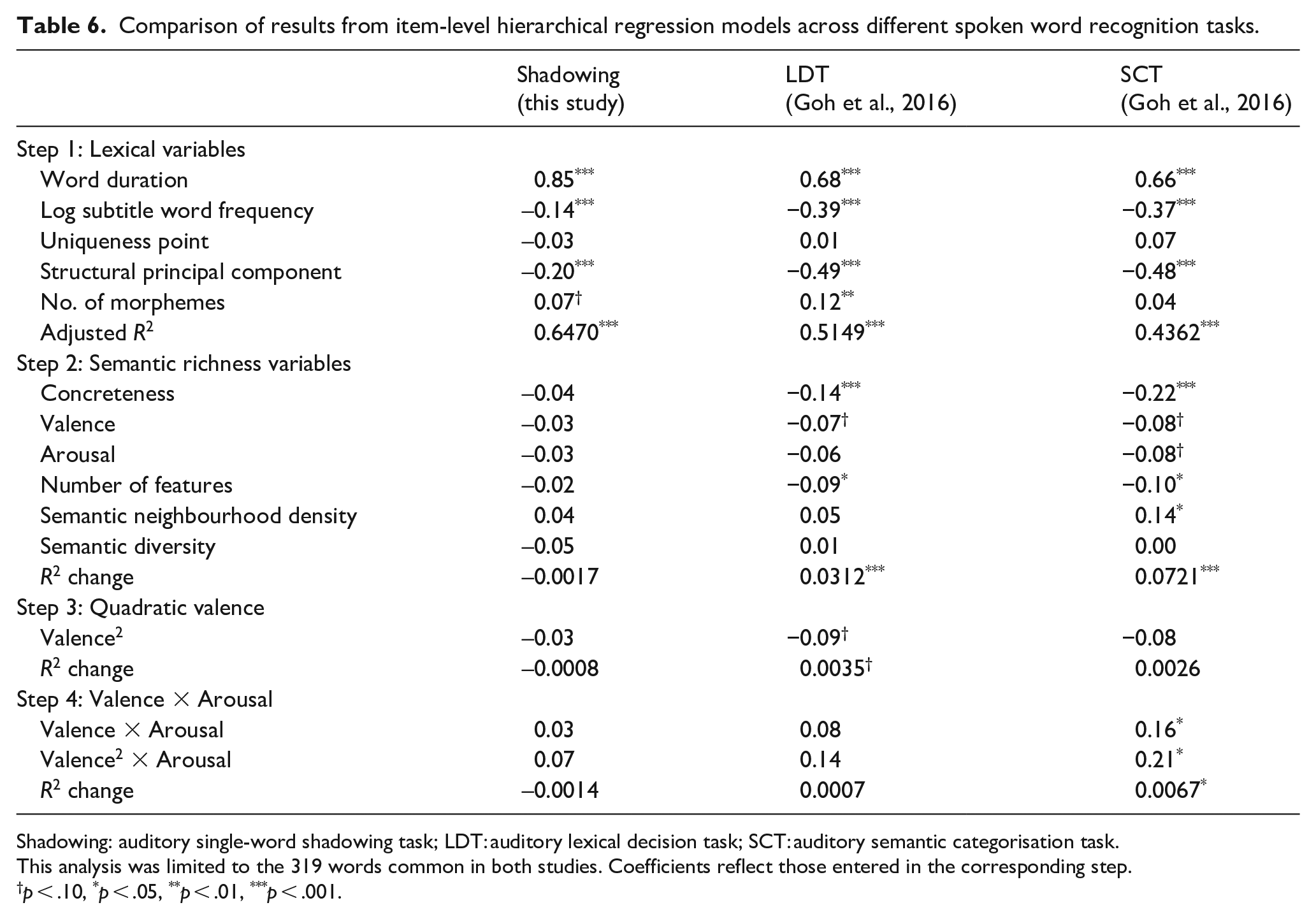
Shadowing: auditory single-word shadowing task; LDT: auditory lexical decision task; SCT: auditory semantic categorisation task.
This analysis was limited to the 319 words common in both studies. Coefficients reflect those entered in the corresponding step.
p < .10, *p < .05, **p < .01, ***p < .001.
Lexical effects in the single-word shadowing task
Significant lexical effects are observed in this study: token duration—longer words are repeated slower; word frequency—common words are repeated faster; and phonological distinctiveness—words with more phonemes, more syllables, longer phonological Levenshtein distance, and fewer neighbours are repeated more quickly. These are in line with previous studies on shadowing (Goldinger, 1998; Marslen-Wilson, 1985; Siew & Vitevitch, 2016; Tyler et al., 2000) and previous megastudies using other spoken word recognition tasks, such as LDT and SCT (Ernestus & Cutler, 2015; Ferrand et al., 2018; Goh et al., 2020; Goh et al., 2016; Tucker et al., 2019). Words with longer token durations take more time to be recognised because speech signals unfold over time (Mattys, 1997) and listeners tend to wait for the sequence of sounds to unfold before responding (Ferrand et al., 2018). High-frequency words are processed faster as they have more easily accessible lexical representation from frequency exposure (Marslen-Wilson, 1987). The effect of phonological distinctiveness is consistent with the typical phonological neighbourhood density effect, where words with fewer similar-sounding neighbours are processed more quickly (Luce & Pisoni, 1998; Vitevitch & Luce, 2016). This effect arises from competition among multiple phonologically similar candidates (see Vitevitch & Luce, 2016, for a review). The phonological distinctiveness effect observed in this megastudy, which included words ranging from one to four syllables, demonstrates that its influence extends beyond monosyllabic words. This supports the finding of Vitevitch et al. (2008) that phonological neighbourhood density effects in bisyllabic English words resemble those in monosyllabic words, countering the criticism that the one-phoneme metric for computing neighbourhood density applies only to monosyllabic words and highlighting its broader applicability to multi-syllable words.
Nevertheless, the absence of the uniqueness point effect contradicts previous factorial studies that reported words with an early uniqueness point were repeated more quickly than words with a late uniqueness point (Radeau & Morais, 1990). This discrepancy may be attributed to the application of multiple regression techniques in the megastudy approach, unlike traditional factorial designs that rely on the F- or t-test to assess individual variables without simultaneously considering other variables. In addition, the effect of morphemes on shadowing is not significant, possibly because morphemes represent the smallest meaningful units within words and carry semantic information to some degree.
Despite identical patterns of significant lexical effects across tasks, the proportion of variance accounted for by lexical variables differs, with 64.70% in shadowing RTs, 51.49% in LDT, and 43.62% in SCT. This highlights the critical role of lexical processing in the single-word shadowing task and suggests that while lexical effects are broadly task-general in spoken word recognition, the magnitude of lexical effects is modulated by the task.
Compared with the effects observed in visual naming, a task considered the visual analogue of auditory single-word shadowing, the word frequency effect in this study—common words were processed faster—is consistent with findings from single-word visual naming (Connine et al., 1990; Yap & Balota, 2009; Yap et al., 2011, 2012). However, a notable contrast emerges in the effects of phonological neighbourhood structure. In this study, spoken words with more phonological neighbours are processed more slowly, which stands in contrast with the effects of orthographic neighbourhood structure in visual naming, where visual words with more orthographic neighbours are processed more quickly (see Andrews, 1997, for a review). The latter effect is attributed to the summing of lexical activation across orthographically similar words, which facilitates visual word identification processes (Andrews, 1997).
Semantic effects in the single-word shadowing task
The absence of significant semantic richness effects in our study primarily contradicts Wurm and colleagues’ findings, potentially due to differences in selected semantic dimensions, methodology for obtaining semantic values, and treatment of variables. Our study explored a broader range of semantic dimensions and utilised multiple well-established large-scale semantic databases with both subjective ratings and objective measures, whereas Wurm and colleagues focused on a limited emotional scope and relied on their small-scale preliminary subjective ratings. In addition, we kept raw semantic values in regression models, while Wurm and colleagues applied log transformations or rescale on semantic values. Intriguingly, Wurm et al. (2004) found that the significant effect of evaluation disappeared after rescaling, indicating the potential instability of results.
Actually, studies reporting semantic effects in shadowing were often restricted to specific conditions. The significant imageability effect reported by Tyler et al. (2000) was limited to words from larger cohorts (i.e., words sharing onsets with more words), implicating that semantic processing facilitates discrimination under greater competition. Similar restricted semantic effects were observed in other spoken word recognition tasks, indicating that semantic processing is dynamically modulated by task demands, particularly being enhanced in high-competition contexts (Zhuang et al., 2011) or less-than-ideal listening environments (Sajin & Connine, 2014).
Comparing semantic effects across tasks reveals a small but existent unique variance explained by semantic variables in auditory LDT and SCT (3.12% and 7.21% in Table 6), but not in shadowing. In addition, Dell et al. (2007) found less than 1% semantic errors in auditory repetition, while 5.7% semantic errors in picture naming. van Paridon et al. (2019) also proposed a direct phoneme-to-phoneme route in shadowing via computational simulations. Healthy individuals can repeat auditorily presented nonsense words, which lack meaning, as quickly and as accurately as possible in studies on shadowing of nonsense words (Vitevitch et al., 1997), providing additional evidence that the completion of shadowing primarily involves phonological processing, independent of semantic knowledge. These findings all suggest that semantic processing is not strictly necessary in the normal single-word shadowing task, unlike auditory LDT and SCT.
Overall, compared with the task-general semantic richness effects in visual word recognition—even observed in visual naming, such as evident effects of imageability, NoF, body–object interactions, and contextual dispersion (Balota et al., 2004; Yap et al., 2011, 2012)—spoken word recognition involves more attenuated and task-specific semantic processing, due to the greater importance of resolving competition among phonologically similar word forms (Luce & Pisoni, 1998).
Specific task demands of the single-word shadowing task
Shadowing is considered a low-demand task (Radeau & Morais, 1990), with the final objective being to produce phonological rather than semantic output. This allows individuals to rapidly repeat words without necessarily activating semantics (Dell et al., 2007; McLeod & Posner, 1984). Besides, phonological codes temporarily stored in the phonological loop can assist task completion (Vitevitch & Luce, 1999). Support for the involvement of the phonological loop in shadowing comes from second language learning studies (Hamada, 2016; Takeuchi et al., 2021) and neuroimaging studies that reported the activation in perisylvian and cerebellum, which related to the phonological loop during shadowing (Peschke et al., 2009; Tommola et al., 2000). Automatic activation of phonemes in one’s native language (Carey, 1971) further simplifies identifying and repeating the same phonemes in shadowing. Thus, semantic access can be circumvented via a direct phoneme-to-phoneme route in the single-word shadowing task (Hanley et al., 2004; Nozari et al., 2010).
Moreover, participants are also highly sensitive to task demands (Hargreaves & Pexman, 2014). Due to the lack of explicit instructions or obvious clues that emphasise word meanings in our study, participants potentially adopted a strategy that minimises attention to semantic content in this immediate task. However, when the shadowing task included explicit semantic relationships in materials, participants were more likely to pay attention to and process semantics. For example, semantic effects were observed in shadowing when combined with the semantic priming paradigm (Slowiaczek, 1994), when materials presented with explicit emotional relationships between word meaning and prosodic cues (Singh & Harrow, 2014), and in a deliberate procedure where words and nonwords were intentionally presented in separate blocks (Savill et al., 2019).
Although shadowing is primarily a phonological task, semantic processing can play a compensatory role for phonological deficits (Savill et al., 2019). Studies on aphasia revealed semantic effects in the shadowing performance of patients with aphasia, particularly those with phonological deficits (Jefferies et al., 2006; Tyler & Moss, 1997). Just like researchers have found a semantic compensation for auditory task performance among healthy participants under competitive phonological conditions, as mentioned earlier.
Conclusion and future directions
Overall, this study extends the exploration of lexico-semantic effects in spoken word recognition from LDT and SCT to the single-word shadowing task at the megastudy level. Our results suggest that the single-word shadowing task is heavily dependent on lexical processing, and semantic processing is not involved, which further suggests the lexical effects are task-general and semantic richness effects are task-specific in spoken word recognition. These findings provide implications for future research by highlighting the suitability of different tasks for addressing distinct research questions. LDT and SCT are well-suited for investigating questions sensitive to high-level semantic processes, such as semantic richness effects on spoken word recognition with different conditions. In contrast, the single-word shadowing task is ideal for studying pure lexical and phonological processing without influence from semantic processing, making it appropriate for further exploring factors such as token duration, word frequency, and phonological neighbourhood structure. Furthermore, the simplicity of the shadowing task and its independence from semantic processing facilitate its application across diverse populations, including clinical assessments of individuals with phonological deficits and studies on lexicon development in young children and in second language learners.
Footnotes
Author contributions
Z.Q. was involved in the conceptualisation, methodology, data collection, formal analysis, writing – original draft, writing – review & editing. W.D.G. was involved in the conceptualisation, writing – review & editing, funding acquisition, supervision.
Declaration of conflicting interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by National University of Singapore Faculty of Arts & Social Sciences Heads and Deanery Research Support Scheme Grants A-8000322-00-00 and A-8001306-00-00, awarded to W.D.G.
Ethical considerations
Ethical approval for the protocols was obtained from the Psychology Departmental Ethics Review Committee of the National University of Singapore (Ethics approval number: 2022-February-02)
Consent to participate
Written informed consent was obtained from all individual participants included in the study.
Consent for publication
Not applicable.