
Abstract
This study investigates the impact of phonetic realisation and prosodic prominence on visual letter identification, focusing on the letter <e> in German bisyllabic words. Building upon previous research, a computerised letter search task was conducted with 78 skilled adult readers. Words featuring different phonetic realisations of <e > (/eː, ɛ, e, l̩, n̩, ɐ/) in stressed and unstressed first and second syllables were systematically included. Analyses of error rates and response times revealed a graded pattern in the detection of <e>, with the closed long (/eː/) and closed short (/e/) realisations being easiest to detect, open (/ɛ/) and near-open central (/ɐ/) vowels becoming incrementally harder, and silent vowels in syllabic consonants (/n̩/) being the most challenging. Results divided by position and stress of the syllable containing the target letter further indicated influences of prosodic prominence. The findings contribute to understanding the intricate interplay of grapheme–phoneme correspondences and prosodic structure in skilled readers’ visual letter recognition.
Keywords
Introduction
One of the core questions of psycholinguistic reading research has always been how the relationship between orthography and phonology affects the reading process (e.g., Diependaele et al., 2010; Frost, 1998; Halderman et al., 2012). There is consensus now that learning about how letters map onto sounds, that is, grapheme–phoneme correspondences, is at the core of reading acquisition in alphabetic scripts and continues to have an influence on skilled reading (e.g., Castles et al., 2018; Seidenberg, 2017). Moreover, there is abundant evidence that phonology is not only routinely co-activated during silent reading, but even constrains and shapes visual word identification (for a review, see Halderman et al., 2012). In this study, we investigate how the phonetic realisation of a letter in a word affects its detection in skilled adult readers. This topic gained a bit of attention in the early years of psycholinguistic reading research and has then been on and off the radar for half a century. The last decades have brought about methodological and theoretical advancements (e.g., more precisely timed presentation and measurement techniques, more detailed and computationally implemented models of visual word recognition). These warrant reconsideration of the issue and promise to provide updated insights on the role of phonetics in skilled readers’ letter recognition. In particular, we take into account the influence of prosodic prominence on processing, an issue that has received comparably little research interest so far.
In many alphabetic writing systems, a single letter can represent several sounds. For example, in English, the letter <a> can be pronounced as /eɪ/ in <place> or as /æ/ and /ɪ/ in <palace>. The phonetic realisation of the letter is determined by syllabic, suprasyllabic, and lexical factors. At the syllable level, the immediately surrounding letters typically give a hint to the realisation in that context. At the suprasyllabic level, the stress pattern, which in turn is associated with syllable position, can be indicative of the corresponding phoneme. Finally, the realisation of a phoneme can be retrieved from memory (i.e., the mental lexicon) if the whole word is recognised. Moreover, these syllabic, suprasyllabic, and lexical factors may interact with each other. Most of the work on letter–sound relationships, however, has concentrated on monosyllabic words. Only few studies considered the role of suprasyllabic factors for letter–sound relationships in words with more than one syllable, for which prosodic prominence might be an issue.
Drewnowski and Healy (1982) investigated how the same letter is recognised in different contexts, depending on phonetic factors. In a series of experiments, they had participants search for instances of the letter <e> in printed English text and circle these. In Experiment 1, people missed silent <e> more often than pronounced <e> (in line with an earlier similar study by Corcoran, 1966). As voicing in this experiment, though, was confounded with the position of the letter within the word, letter position was controlled for in Experiment 2, in which <e> always appeared as the penultimate letter in an unstressed final syllable. In this setup, no difference in errors was found between silent and pronounced <e>. Due to the position constraints of Experiment 2, however, the pronounced <e> was always schwa, never full /e/. In Experiment 3, then, the authors compared the detection of <e> in unstressed vs. stressed syllables and found that people made more errors in unstressed syllables. It was concluded that syllable stress affects letter detection. In a more recent study, Harris and Perfetti (2016) came to a converging conclusion. In three proof-reading experiments in English, they showed that spelling errors involving vowel letters are detected better in stressed than unstressed syllables, indicating that the prosodic property of lexical stress influences orthographic processing.
Hasenäcker and Domahs (2024) have recently taken up the issue of the stress effect in letter detection to test whether it generalises to (1) response times (RTs) in a computerised task with single-word presentation, (2) all vowel letters (<a, e, i, o, u> instead of just <e>) as well as consonant letters, and (3) the more transparent German orthography. They found the stress effect to generalise to all vowels, though not to the tested consonants. From that, they concluded that vowel detection is especially affected by stress, because vowels carry the most prominent phonetic substrates of stress, i.e., pitch, duration, intensity, and vowel quality.
Although German is typically considered as a rather shallow, transparent orthography with regular and consistent grapheme–phoneme correspondences (at least in the direction of reading), variation in vowel length and quality can be considered less obvious to the point that it can pose a challenge to reading and spelling acquisition (Bredel et al., 2011; Landerl, 2003; Landerl & Reitsma, 2005). In particular, the letter <e> can be regarded as somewhat special, because in comparison to the other vowel letters (<a, i, o, u>) it maps on a greater number of phonemes. Importantly, its correct phonetic realisation can vary vastly depending on the graphemic context within the syllable as well as the syllable’s prosodic prominence, i.e., stress, within the word (cf. Bredel, 2009). For example, in the words “Hering,” “Sesam,” “Kamel,” and “Paket,” <e> appears in stressed syllables and maps to the long closed vowel /eː/. In the word “Nektar” it maps to short open /ɛ/ in a stressed syllable, as it does in an unstressed syllable in “Termin.” In unstressed non-final open syllables, it can also map to short closed /e/, as in “Regal.” Some words, like “Tafel,” have a syllabic consonant (also called vocalic consonant) and no real vowel sound to the extent that the <e> is silent. This is specific to a few letter combinations, in particular <el> and <en>, in unstressed final syllables. Note that the same letter combinations are not reduced when they appear in stressed syllables, as the above example “Kamel” illustrates. The very common letter combination <er> is usually pronounced with a vocalic r, “a-Schwa” /ɐ/, in final unstressed syllables, as in “Pulver” (note that this is not necessarily the case in non-final stressed syllables, as in “Termin” above).
In their previous study, Hasenäcker and Domahs (2024) focused only on the effect of stress on letter detection without further differentiating between the various phonetic realisations that come with prosodic gradation. Curiously, a post hoc check of the stimuli with the target letter <e> suggested a possible confound between syllable position, stress, and phonemic realisation: six of eight items in the condition “<e> in unstressed second syllable” had the syllabic consonant /l̩/ and one had the syllabic consonant /n̩/, so almost all <e> in this condition were silent. In the eighth item in this condition, the <e> was pronounced as /ɐ/. Hence, it is unclear whether the stress effect for <e> might have been driven by this confound (cf. Exp. 2 by Drewnowski & Healy, 1982). Post hoc cheques of the individual random slopes for Target Letter in the linear mixed-effects models of RTs by Hasenäcker and Domahs (2024) revealed that the slopes were positive for all letters, hence confirming the reported stress effect overall. 1 However, the RT pattern of the target letter <e> stood out, as can be seen in Figure 1, showing the RTs in each condition for each target letter separately. Not only were responses to <e> overall slower than to the other vowel letters, but also was there almost no difference between detection times in stressed compared with unstressed first syllables and, moreover, detection of <e> was particularly slow in unstressed second syllables. This gives further indication to believe that <e> is somewhat special and it warrants circling back to a separate and more nuanced examination of its processing.
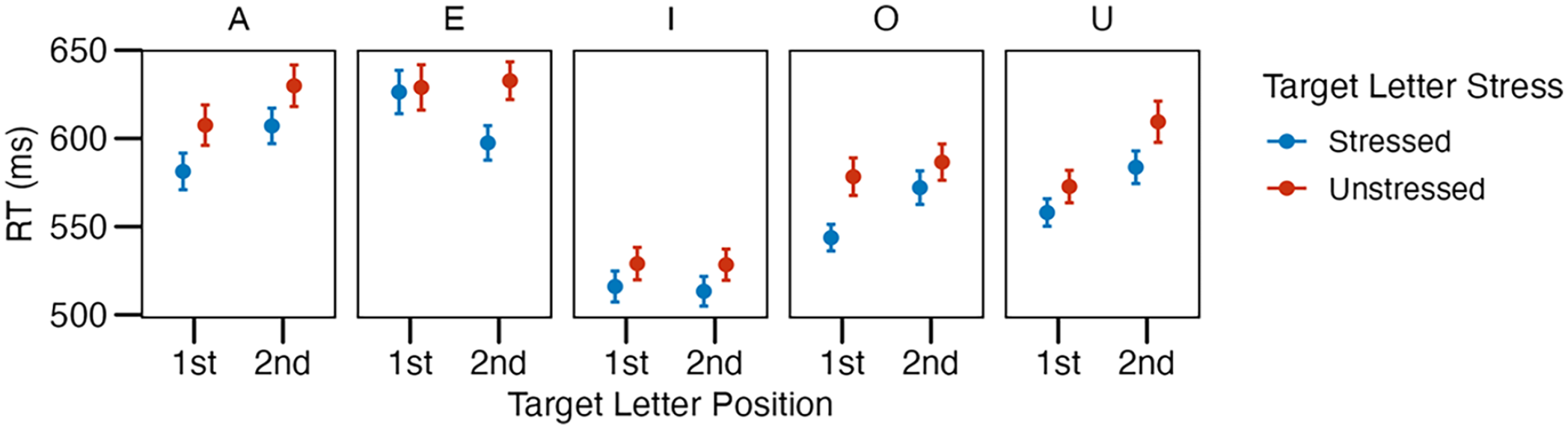
Means and standard errors of response times reanalysis of Experiment 1 from Hasenäcker and Domahs (2024) by target letter position (first vs. second syllable) and target letter stress (stressed vs. unstressed) shown for each target letter (<a, e, i, o, u>) separately.
Several hypotheses can be put forward about the pattern of detecting <e>. The first posits that the grapheme <e> automatically activates all of its possible phonemes and allophones, which then compete with each other (cf. Commissaire & Casalis, 2018, who discussed a similar idea in the context of letter detection in complex graphemes), leading to prolonged search times compared with other vowel graphemes due to the larger degree of grapheme–phoneme ambiguity. This suggests higher RTs for all instances of <e>, regardless of their phonetic realisation.
The second hypothesis proposes a role for lexical stress: <e> is more easily detected in stressed as compared with unstressed syllables (Drewnowski & Healy, 1982; Harris & Perfetti, 2016; Hasenäcker & Domahs, 2024). A variant of this hypothesis assumes not simply a dichotomy between stressed and unstressed syllables but anticipates nuanced effects influenced by the various phonetic realisations associated with graded prosodic prominence (i.e., vowel quality). For example, /eː/ would be particularly easy to detect, because it is prosodically very prominent both in terms of intensity and duration. /ɛ/ might be slightly harder because despite being similarly prominent as /eː/ in terms of intensity when stressed, /ɛ/ is always short and hence less prominent in terms of duration. Also, /ɐ/ might be easier to detect than /l̩/ and /n̩/, because despite all of them occurring only in non-prominent, i.e., unstressed, reduced syllables, they differ in sonority and hence in intensity.
A third hypothesis considers GPC (in)consistencies in an “activation-and-competition” framework: readers are sensitive to the probability of a grapheme mapping to a specific phoneme such as p(<e> being pronounced as /ɐ/), and phonemes with higher probability receive more activation than those with lower probability. Via feedback, then, this would make it easier to identify the letter <e> in its most common realisation. Moreover, this probabilistic sensitivity may be conditional on the graphemic context within the syllable, for example, p(<e> being pronounced as /ɐ/| <e> is followed by <r>). Previous research has shown that context sensitivity plays a role in the spelling of English (Treiman et al., 2002) and German vowels (Domahs et al., 2001). GPC conditional probabilities might even be based on syllable stress, for instance, p(<e> being silent| <e> is in the unstressed syllable) or syllable position, p(<e> being silent| <e> is in the final syllable). Probabilistic sensitivity could also combine graphemic context and syllable stress, i.e., p(<e> being silent| <e> is followed by <l> & is in the unstressed syllable). In fact, a growing body of evidence suggests that grapheme context can serve as a cue to stress (Arciuli et al., 2010; Monaghan et al., 2016; Tomaschek et al., 2023; Treiman et al., 2020).
A fourth hypothesis assumes an effect of letter name similarity: The closer a phonetic realisation of a grapheme is to its corresponding letter name, the easier the letter is to detect. This idea has been put forward several decades ago: Read (1983) reported that in a letter-circling task participants missed the letter <f> more often in the word “of” than in control words, supposedly because of its pronunciation as /v/ in that word. Chetail (2020) also argues for a letter name effect in the context of explaining the effects of letter detection in complex multi-letter graphemes (e.g., detection of A in <beach> vs. A in <place>). Hasenäcker and Domahs (2024), too, raised this issue in their discussion of stress effects, pointing out that possibly participants activated the name of the letter to be searched and held it in their phonological working memory (phonological loop) as a task-solving strategy.
The present study
The purpose of this study was to investigate the role of phonetic realisation and prosodic prominence in the identification of the letter <e>, given its exceptionally inconsistent grapheme–phoneme mapping in German. Following up on our earlier study (Hasenäcker & Domahs, 2024), we conducted a computerised letter search task, but this time focusing exclusively on identification of the letter <e>. Importantly, we included words with <e> in stressed and unstressed first and second syllables of bisyllabic words—as in the previous experiment—but systematically included a variety of phonetic realisations of the letter, namely /eː, ɛ, e, l̩, n̩, ɐ/. Although it is not possible to orthogonally vary the different phonetic realisations across syllable position and stress due to constraints of the German language (i.e., nonreduced <e> never appears in unstressed syllables and vocalic consonants never appear in first syllables of bisyllabic words), we aimed to reflect the range of grapheme–phoneme correspondences of <e> as they typically appear in the language. This investigation not only contributes to our understanding of letter perception but also provides insights into the intricate interplay of phonetic and prosodic influences on orthographic processing.
Method
Participants
A total of 89 participants, recruited via the university’s participant database, completed the study. Participants provided informed consent by button click prior to starting the experiment and received either course credit or monetary compensation after completion of the study. Participants were excluded from data analysis if they had indicated in the questionnaire that their native language was not or not only German (4 participants), they had a diagnosis of dyslexia (3 participants), or they had uncorrected bad vision (2 participants). Furthermore, two participants were excluded because their score on the LexTALE vocabulary test (Lemhöfer & Broersma, 2012) was below 60, suggesting performance close to the chance level. Consequently, data were analysed from the remaining 78 participants (age range: 19–36 years, MAge = 23.9, SDAge = 3.7; 62 female, 15 male, 1 no answer).
Materials
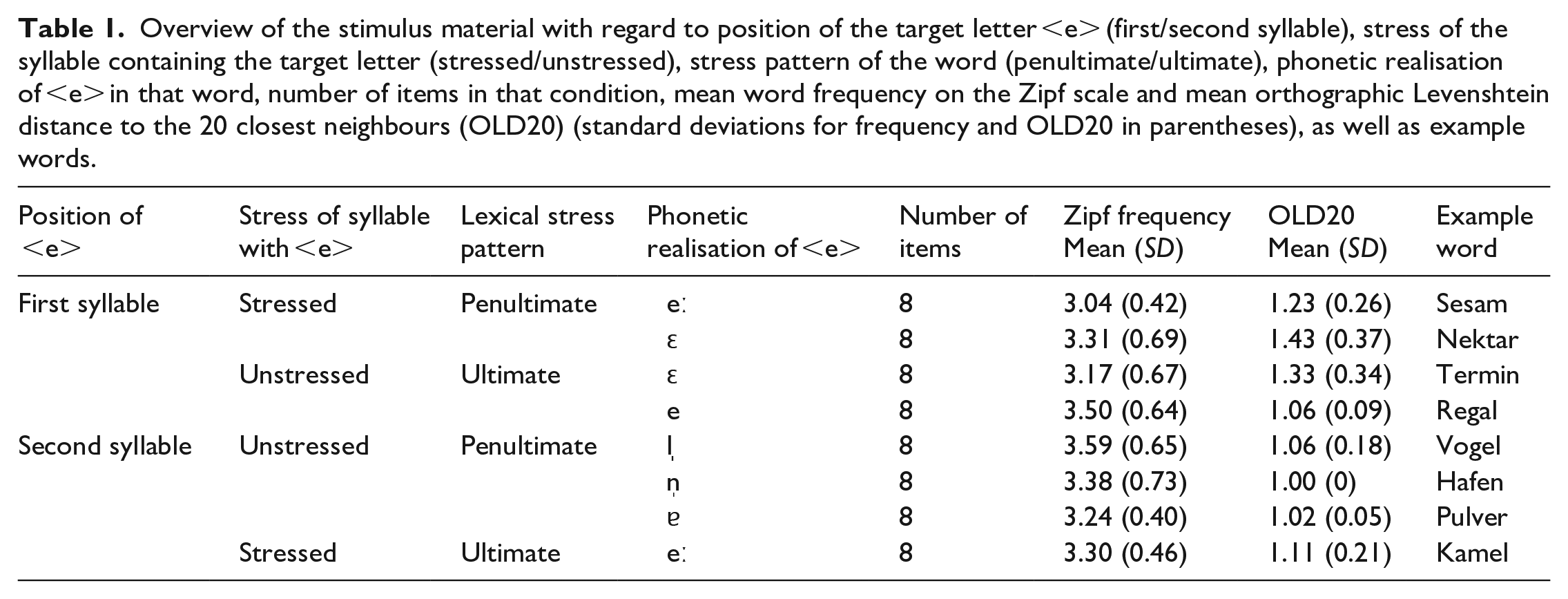
Target stimuli were 64 German bisyllabic nouns that contained the letter <e>—half of the words in the first and half in the second syllable (cf. Table 1). The syllable in which the <e> occurred could be either stressed or unstressed (i.e., the word could have penultimate or ultimate lexical stress). Depending on its position (in a stressed or unstressed first or second syllable) and graphemic context, the <e> is pronounced differently. Overall, in our stimuli, six different realisations of the letter <e> occurred: /eː, ɛ, e, l̩, n̩, ɐ/. Note that in the latter three cases the pronunciation of the <e> merges with that of the following consonant grapheme (<l, n, r>), yielding either the syllabic consonants /l̩/ and /n̩/ or the near-open central vowel /ɐ/. Although most of the realisations of <e> only occur in one specific position-stress combination in bisyllabic words (i.e., /n̩/ only in unstressed second syllables), /eː/ occurs both in stressed first and second syllables and /ɛ/ occurs in both stressed and unstressed first syllables. For each realisation in a specific position-stress combination, our stimulus set contained eight words. Across those groups, frequency of occurrence (on the Zipf scale) and orthographic neighbourhood (operationalised as OLD20), both taken from the DWDS corpus (Heister et al., 2011), were matched. All words were five to six letters in length and had one of the following syllable structures: CV.CVC, CV.CCVC, CVC.CVC, or CCV.CVC. Hence, the letter <e> was always surrounded by consonants and never occurred in the initial or final position of a word.
Overview of the stimulus material with regard to position of the target letter <e> (first/second syllable), stress of the syllable containing the target letter (stressed/unstressed), stress pattern of the word (penultimate/ultimate), phonetic realisation of <e> in that word, number of items in that condition, mean word frequency on the Zipf scale and mean orthographic Levenshtein distance to the 20 closest neighbours (OLD20) (standard deviations for frequency and OLD20 in parentheses), as well as example words.
In addition to the target words, 64 nouns that did not contain the letter <e> were chosen as filler items. Those words were similar to the target words in terms of length, frequency, orthographic neighbourhood, and syllable structure. Half of those words had the lexical stress on the ultimate and half on the penultimate syllable.
Procedure
The experiment was run as an online study using OSWeb (OpenSesame version 3.3.10; Mathôt et al., 2012) and JATOS (version 3.7.3; Lange et al., 2015). The study was hosted on the MindProbe server (https://mindprobe.eu/). Participants first gave informed consent for their participation. Then they took the German version of the LexTALE vocabulary test (Lemhöfer & Broersma, 2012). This was followed by the experiment itself. The experiment started with the instructions explaining that the task was to search for the occurrence of the letter “e” (presented in lowercase) and indicate via button press whether it was contained in a word or not (F and J on the keyboard for “no” and “yes,” respectively). A practice block of 10 trials was followed by 128 trials organised into four blocks of 32 trials each. We used a similar procedure as Hasenäcker and Domahs (2024), originally adopted by Brand et al. (2007). Everything was presented in white font on a black background. Each trial began with a fixation cross in the middle of the screen for a duration of 1,000 ms, which was then replaced by a word. The word was presented in line with German orthographic rules, that is with an uppercase initial letter, while the other letters were in lowercase. After 50 ms the word was replaced with a blank screen (70 ms) and then a mask of six hash marks, which remained on the screen until participants made a response. An intertrial interval with a blank screen for 1,000 ms was inserted before the next trial started automatically. Participants were shown their average RT and accuracy after each block and were given the opportunity for a self-paced break. The order of items within the experiment was randomised across participants. RT and accuracy for each trial were automatically recorded and saved. After the experiment, participants completed a short demographic questionnaire.
Analysis
Data from the experiment was analysed using R (version 4.2.2, R Core Team, 2022). Total accuracy was quite high (95.23% for all trials, 93.55% for trials of interest), as is typical for a simple letter search task. Accuracy and RTs for trials of interest (i.e., target-present trials) were analysed with (generalised) linear mixed-effects models using the (g)lmer function from the lme4 package (Bates et al., 2015). For the RT analysis, incorrect responses (6.45%) and those with particularly long RTs (>1,500 ms, 1.13%) were excluded before model fitting. Moreover, RTs were inversely transformed to normalise the distribution of the residuals, following inspection of a Box-Cox plot (MASS package; Venables & Ripley, 2002). Outliers were then trimmed by using a random-intercepts-only model and excluding all data points with residuals exceeding 2.5 SD (1.91%; Baayen & Milin, 2010).
In all analyses, accuracy and RT served as the dependent variables. To first parallel the analyses by Hasenäcker and Domahs (2024), we conducted models with a position of <e> (first vs. second syllable) and stress of that syllable (stressed vs. unstressed) as well as their interaction as sum coded fixed effects, including random intercepts for participant and word.
The main analyses of interest had a realisation of <e> (/eː, ɛ, e, l̩, ɐ, n̩/) as a sum coded fixed effect and random intercepts for participant and word. For closer investigation respecting the position and lexical stress of the syllable containing <e>, we conducted follow-up analyses for <e> in the first and second, as well as stressed and unstressed syllables separately. Note that it was not possible to run a single model with phonetic realisation, position, and stress, as well as their interactions, because not all phonetic realisations can occur in both positions and stress conditions in the language and hence in our stimuli (cf. Table 1). For all models, overall effects were tested with Type III sum of squares and chi-square Wald tests and post hoc contrasts were calculated with the emmeans package (Lenth et al., 2023). Data and analysis scripts together with detailed model outputs as supplementary material are provided on OSF: https://osf.io/yw32t/.
Results
Error rates
The analysis of the accuracy data paralleling Hasenäcker and Domahs (2024) revealed no main effect of position (z = −0.76, p = .446), but a significant main effect of stress (z = 3.31, p < .001) as well as an interaction of position and stress (p < .001). Post hoc contrasts indicated that this interaction was driven by a significant stress effect in the second (z = 4.35, p < .001), but not the first syllables (z = −0.42, p = .674).
The main analysis showed a significant effect of realisation of <e> (p < .001). Post hoc contrasts revealed graded effects with the lowest error rates for /eː/ and the highest for /n̩/. In detail, error rates differed significantly between /eː—n̩/ (z = 4.39, p < .001) and also /eː—ɐ/ (z = 3.58, p = .005), as well as between /e—n̩/ (z = 3.36, p = .010), no other contrast was significant (all z < |2.75,| all p > .075). Means and standard errors for each realisation are shown in Figure 2, Panel A.
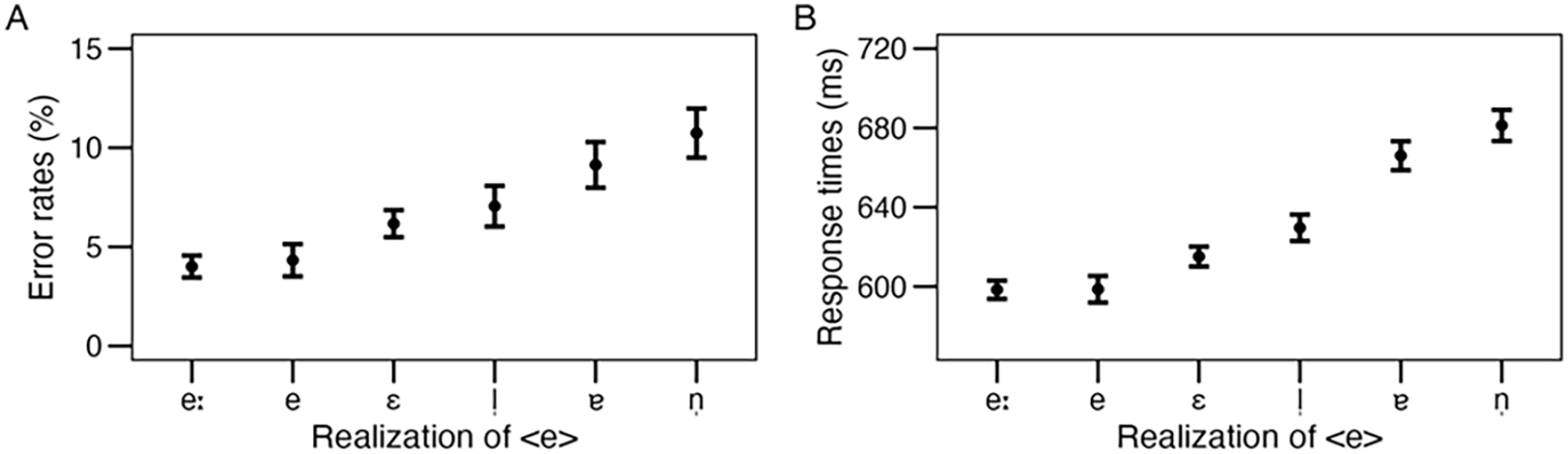
Means and standard errors of error rates (Panel A) and response times (Panel B) for each phonetic realisation of <e>.
In the follow-up analysis with data only for <e> in first syllables (/eː, ɛ, e/), realisation did not reach significance (p = .273) (cf. means and standard errors in Figure 3, Panel A, left side). However, in the analysis for <e> in second syllables (/eː, l̩, n̩, ɐ/), realisation was a significant predictor (p < .001). Post hoc contrasts indicated that differences were significant between /eː—n̩/ (z = 4.33, p < .001), /eː—ɐ/ (z = 3.78, p < .001), and /eː—l̩/ (z = 2.98, p = .015), but not between /l̩—n̩—ɐ/ (all z < |1.56,| all p > .405) (cf. Figure 3, Panel A, right side). With data divided by stress, the model with only stressed <e> (/eː, ɛ/) did not reveal a significant difference between the two realisations (z = 1.65, p = .099) (cf. Figure 3, Panel A, blue colour). The model with unstressed <e> (/ɛ, e, l̩, n̩, ɐ/) did show a significant effect of realisation (p = .007). Post hoc contrasts indicated that this was driven by significant differences between /e—n̩/ (z = 3.42, p = .006) and /e—ɐ/ (z = 2.74, p = .048), whereas none of the other pairs was significantly different (all z <|2.26|, all p > .17) (cf. Figure 3, Panel A, red colour).
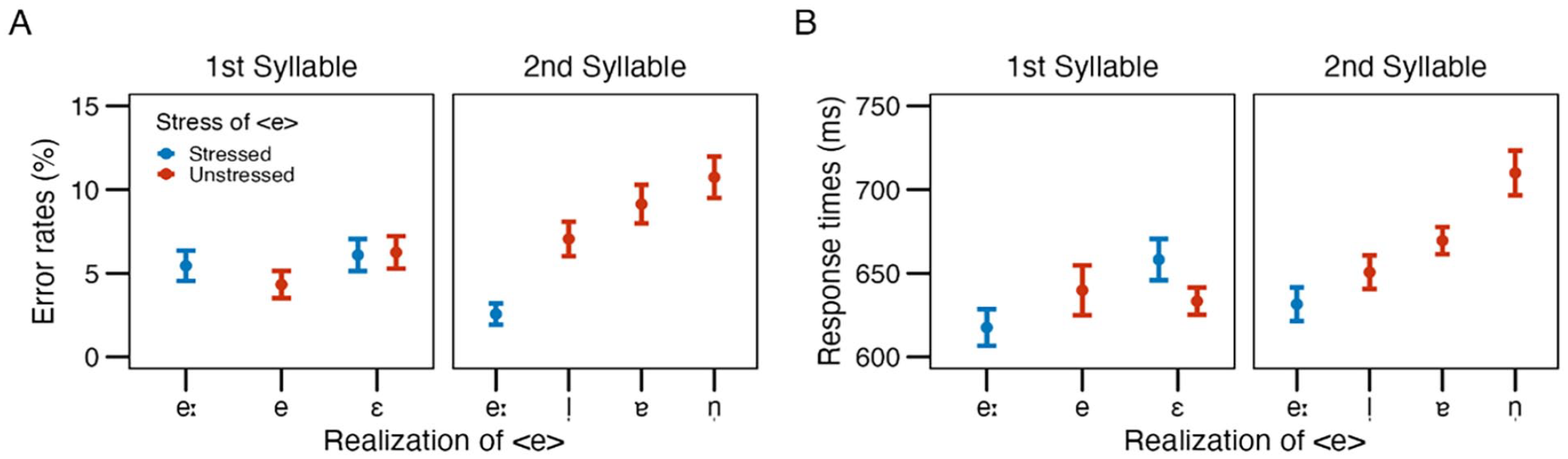
Means and standard errors of error rates (Panel A) and response times (Panel B) for each phonetic realisation of <e> by position (first vs. second syllable) and stress (stressed vs. unstressed).
Response times
The analysis of the response time data paralleling Hasenäcker and Domahs (2024) showed significant effects of position (t = 4.17, p < .001), stress (t = 4.36, p < .001), and their interaction (p = .001). Post hoc contrasts indicated that this interaction was driven by a significant stress effect in the second (z = 5.02, p < .001), but not the first syllables (z = 0.86, p = .381).
The main analysis of the response time data revealed a significant effect of realisation of <e> (p < .001). Post hoc contrasts showed graded effects with response times for /eː/ and /e/ being fastest and /n̩/ being slowest. In detail, response times to /eː/ differed significantly from /l̩, ɐ, n̩/ (all z > 3.65, all p < .005), but not from /e, ɛ/ (all z < 2.20, all p > .250). Also, /e/ differed significantly from /l̩, ɐ, n̩/ (all z > 3.20, all p < .020) but not from /ɛ/ (z = 1.84, p = .436), whereas /ɛ/ differed from /ɐ, n̩/ (both z > 5.29, p < .001) but not from /l̩/ (z = 1.86, p = .426). Finally, /l̩/ differed from /ɐ, n̩ / (both z > 2.90, p < .04), whereas /ɐ—n̩/ did not differ (z = 1.20, p = .839). Means and standard errors for each realisation are shown in Figure 2, Panel B.
The follow-up analysis with data only for <e> in first syllables (/eː, ɛ, e/) showed a significant effect of realisation (p = .002), which was driven by a significant difference between /eː—ɛ/ (z = 3.29, p = .007), as post hoc contrasts indicate, whereas the differences between /eː—e/ and /e—ɛ/ were not significant (z = 0.84, p = .683 and z = −2.32, p = .069, respectively). The model with data for <e> in second syllables also revealed a main effect of realisation (p < .001), with significant differences between /eː—n̩/ (z = 5.79, p < .001), /eː—ɐ/ (z = 4.72, p < .001), and /l̩—n̩/ (z = 3.68, p = .005), but not /eː—l̩/ (z = 2.11, p = .174), /l̩—ɐ/ (z = 2.60, p = .066), and /n̩—ɐ/ (z = −1.08, p = .706). For data divided by stress, the model with only stressed <e> (/eː, ɛ/) did not show a significant difference between the two realisations (z = 1.42, p = .156). The model with unstressed <e> (/ɛ, e, l̩, n̩, ɐ/) did reveal a significant effect of realisation (p < .001). As post hoc contrasts indicated, all pairs were significantly different (all z >|2.91|, all p < |.05|), except for /n̩—ɐ/, /ɛ—l̩/, /e—ɛ/ (all z <|1.89|, all p > |.345|). Means and standard errors for each phonetic realisations by position and stress are shown in Figure 3, Panel B.
Post hoc analyses
To furthermore explore the GPC probability hypothesis and the letter name similarity hypothesis described in the introduction, we conducted two additional post hoc analyses. The first was a small corpus analysis deriving frequencies of the letter <e> mapping to different phonemes in German using the CELEX corpus (Baayen et al., 1995). The second was an analysis of the acoustic similarity between the letter name and different other phonetic realisations of <e>, which we based on an analysis of German vowels from the Kiel Corpus of Read Speech (Pätzold & Simpson, 1997). This allowed us to compare the result patterns from those additional exploratory analyses to the results pattern of the behavioural letter search study, to see whether the patterns align and to evaluate the potential explanatory value of those hypotheses for the observed behaviour.
GPC probability
To explore the GPC probability hypothesis, we conducted a small corpus analysis deriving frequencies of the letter <e> mapping to different phonemes in German. For this, we used the German CELEX corpus (Baayen et al., 1995), which includes word spellings and their phonetic transcriptions. From this corpus, we extracted all bisyllabic nouns containing the letter <e>. We then counted the number of unique words (types) and calculated the cumulative frequencies (token frequencies) for each of the relevant phonetic realisation of the letter <e> (/e, ɛ, l̩, ɐ, n̩/). 2
In the first step, no differentiation by position or stress was made. As Figure 4 shows, the open /ɛ/ is the most often occurring realisation both in terms of word types (Panel A) and token frequencies (Panel B). The pattern of type and token frequencies differs somewhat, especially for the weak realisations. The syllabic consonant /l̩/ and the near-open central vowel /ɐ/ are almost equally frequent as closed /e/ in terms of the number of unique words in which they occur but much less frequent compared with /e/ and /ɛ/ in terms of cumulative word frequencies.
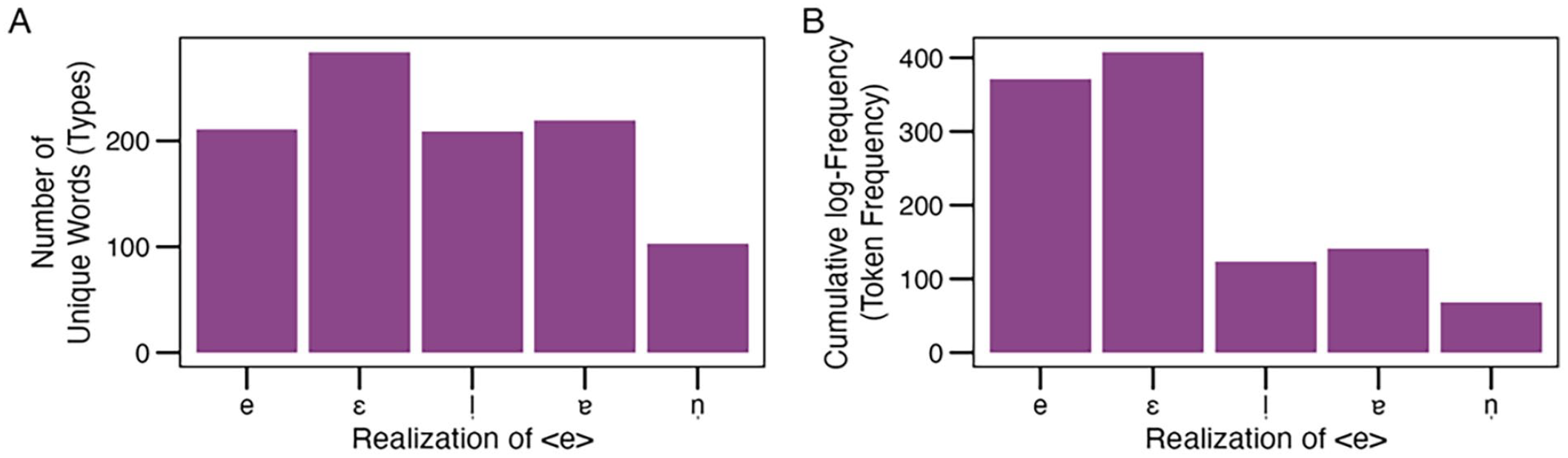
Number of unique bisyllabic nouns containing each realisation (/e, ɛ, l̩, ɐ, n̩/) of the letter <e> (Panel A) and their cumulative logarithmised frequencies (Panel B) as based on CELEX (Baayen et al., 1995).
In the second step, we differentiated by position and stress to reflect the idea of conditional probabilities of <e> being realised a certain way given that it occurs in first or second stressed or unstressed syllables. Note that this allowed us to distinguish between long /eː/ and short /e/. As Figure 5 shows, the differentiation by position and stress provides a more varied picture, clearly illustrating once again that the phonetic realisation, position, and stress tend to be confounded. Interestingly, in this analysis, the pattern between type and token frequencies (Panel A vs. Panel B) diverges even more than in the above analysis. In particular, it becomes evident that there are more unique words with /eː/ in the first syllable than in the second syllable, but for the cumulative frequencies of those words, the pattern switches. Similarly, there are more unique words with stressed than unstressed /ɛ/, but the words with unstressed /ɛ/ have a higher cumulative frequency.
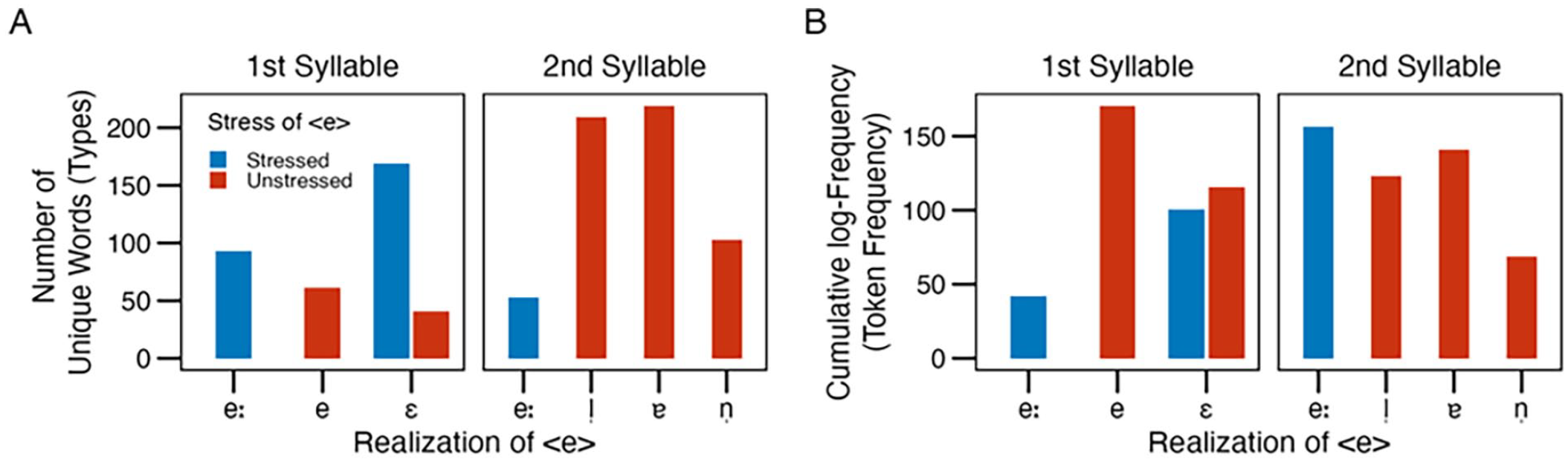
Number of unique bisyllabic nouns with each realisation of <e> by position (first vs. second syllable) and stress (stressed vs. unstressed) (Panel A) and their cumulative logarithmised frequencies (Panel B), all based on CELEX (Baayen et al., 1995).
Letter name similarity
To test the letter name similarity hypothesis, we made use of the acoustic analysis of German vowels from the Kiel Corpus of Read Speech (Pätzold & Simpson, 1997), from which we took formant frequencies (F1, F2, F3) of different phonetic realisations of the letter <e> (cf. Fig. 5, Panel A). 3 The letter name of <e> in German corresponds in length and quality to the prototypical way it is pronounced in stressed syllables: the closed long /eː/. Hence, this was the baseline of comparison. Notably, in contrast to our experiment, this analysis considers only the long /eː/, but not the short /e/. In addition, it includes the schwa /ə/, which we did not treat separately in our experiment. Pätzold and Simpson (1997) point out that the realisation of weak final syllables varied highly both across and within speakers. For instance, the rhyme of the final unstressed syllable in words like “Vogel” or “Tafel” could be produced by the same speaker either as /ə/ + consonant or as a syllabic consonant /l̩/ with a silent <e> . Hence, we here include /ə/ and additionally assume that /l̩/ and /n̩/ have a silent e, hence corresponding to formant values of 0. For each of the other possible realisations of <e> (/ɛ, ɐ, ə, l̩, n̩/), we then calculated the Euclidean distances to the letter name /eː/. Results are summarised in Figure 6, Panel B. Unsurprisingly, /l̩, n̩/ exhibited the largest distances to the letter name /eː/, whereas /ɛ, ə, ɐ/ showed smaller distances.
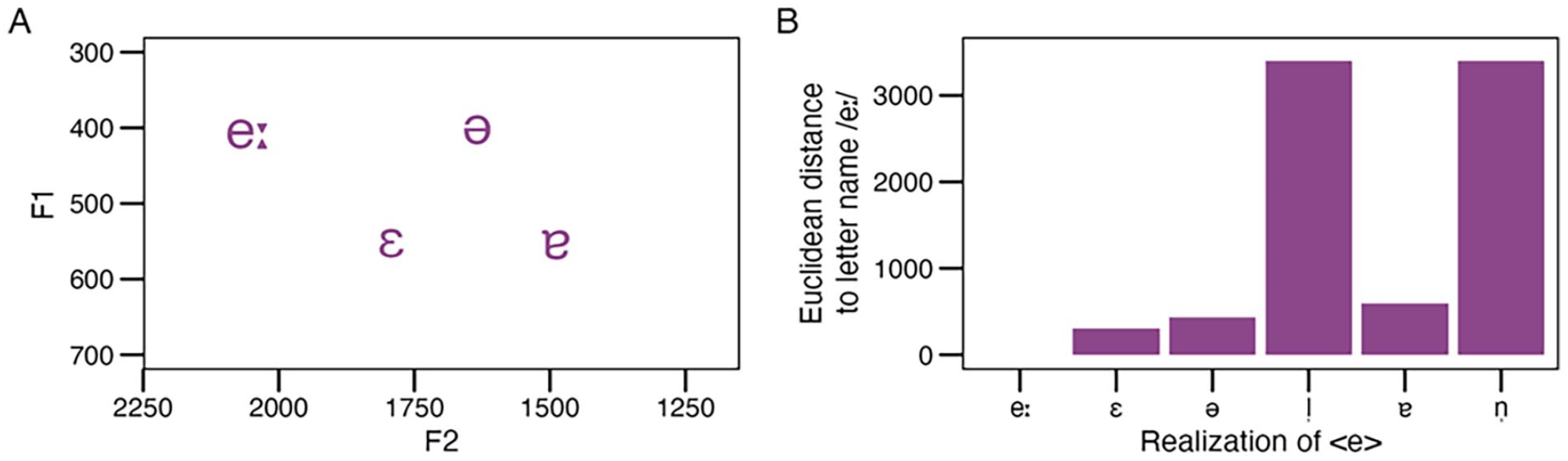
Simplified formant plot of relevant vowels based on values by Pätzold and Simpson (1997) (Panel A) and Euclidean distances between each relevant vowel and the letter name /eː/ (Panel B). Note that while Panel A only displays the first two formants for the sake of simplicity, Euclidean distances plotted in Panel B are based on the first three formants.
Discussion
This study, building upon our prior research (Hasenäcker & Domahs, 2024), examined the impact of phonetic realisation and prosodic prominence on letter identification, addressing the challenges posed by the inconsistent grapheme–phoneme mappings of <e> in different positions of German bisyllabic words. By employing a computerised letter search task with a focus on <e>, encompassing its various phonetic realisations in stressed and unstressed syllables, namely /eː, ɛ, e, l̩, ɐ, n̩/, we aimed to capture the broad spectrum of grapheme–phoneme correspondences.
The study demonstrated a significant influence of stress on the accuracy and speed of detecting the letter <e> in second syllables, though there was no significant stress effect in first syllables. This pattern mirrors not only the accuracy data for <e> detection reported by Drewnowski and Healy (1982) for English but also the response time pattern that we saw in our reanalysis of the results for the letter <e > from Hasenäcker and Domahs (2024, cf. Fig. 1).
One possible explanation for this pattern lies in the time course of visual word processing. As Hasenäcker and Domahs (2024) observed in their analysis of RT distributions, the stress effects increase when processing is slower, suggesting that prosodic influences become more prominent as word processing unfolds. For the first syllable, processing may be too fast for stress effects to fully manifest, especially in the initial rapid stages of letter detection. In contrast, for the second syllable, the word’s stress pattern may have had more time to influence letter detection, which explains the observed stress effect in this position. More importantly, the pattern might also be driven by the different realisations of <e> that constitute the stressed and unstressed categories in different syllable positions, which we will discuss in detail below.
The main analyses with realisation of <e> as a predictor revealed a graded pattern: it was easiest (i.e., fastest and least error-prone) for participants to detect the closed, long (/eː/) and short (/e/). Detecting open /ɛ/ was slightly harder. Finding <e> in words with a syllabic consonant, where the <e> itself is basically silent (/l̩, n̩/) was harder. Interestingly, however, it was not equally hard for /l̩/ and /n̩/, but significantly harder for the latter, while the near-open central vowel /ɐ/ ranged in-between the two syllabic consonants (cf. Fig. 2).
Both previous studies (Drewnowski & Healy, 1982; Harris & Perfetti, 2016; Hasenäcker & Domahs, 2024) and this study indicate the effects of positions and stress. However, it was not possible to analyse position, stress, and phonetic realisation as well as their interactions in a single statistical model, because they are intrinsically entangled in the language and hence in our stimuli (cf. Table 1). Hence, instead, we looked at the effect of phonetic realisation for subsets of the data divided by position and stress. These follow-up analyses revealed differences in phonetic realisation of first syllables that are not captured by stress alone. In second syllables, gradation appears even among the unstressed realisations. This pattern of findings confirms that the phonetic realisation of the letter <e> (its vowel quality), influenced by prosodic prominence (e.g., less reduction in prominent syllables) and partially confounded with syllable position, impacts performance in the task. Although the task can be solved purely visually based on the shape of the letter and without recruiting higher levels of word processing, the phonetic realisation and stress affect letter detection: the more prominent the phonetic realisation of <e>, the easier its detection.
We explored two additional hypotheses for the interpretation of our findings: GPC probability and letter name similarity. The first hypothesis considers the GPC (in)consistency. It assumes that the grapheme <e>, when encountered in a word, automatically activates all its possible phonemes and allophones, which then compete with each other (cf. Commissaire & Casalis, 2018). A phonetic realisation with higher probability receives more activation than one with lower probability, predicting graded effects of letter detection based on GPC distributional statistics. Since no database currently exists that quantifies GPC statistics for polysyllabic words of German and hence could be used to test this hypothesis, we conducted a small exploratory corpus analysis based on the German CELEX corpus (Baayen et al., 1995). The frequencies extracted for different phonetic realisations of <e> in bisyllabic nouns are shown in Figures 3 and 4. When compared with the behavioural findings from the letter search task (Fig. 2), the distributional patterns of <e> realisations, especially the cumulative token frequencies, suggest a trend of less frequent phonetic realisations (/l̩, ɐ, n̩/) being more challenging to detect. This is generally in line with the GPC probability hypothesis. However, the exact order does not align perfectly between frequency and detection times (e.g., a mismatch in the order of /e/ and /ɛ/ as well as /ɐ/ and /l̩/). Moreover, there was some variation between the unconditioned analysis (Fig. 3) and the one taking into account position and stress (Fig. 4), as well as between the type (number of unique words, Panel A) and token (cumulative frequencies, Panel B) analyses. Overall, no obvious fit between the behavioural data and the corpus data emerges that could unequivocally explain the graded letter detection effects with the distribution of GPCs.
The second additional hypothesis that we explored considers letter name similarity. It assumes that the closer a phonetic realisation of a grapheme is to its corresponding letter name, the easier the letter is to detect. This idea has been put forward in the context of letter search before (cf. Chetail, 2020; Hasenäcker & Domahs, 2024; Read, 1983) and is further suggested by studies showing that readers use letter information in a number of other reading-related task as well, such as phoneme counting (Treiman & Cassar, 1997) and written word learning (Treiman et al., 2002). In addition, despite that the letter search task can be solved purely visually, we cannot rule out that participants activated the phonological representation of a target word and scanned its acoustic image for the presence of the letter <e>, or rather, the letter name /eː/ (cf. Read, 1983). To test the letter name similarity hypothesis, we calculated acoustic distances between the German letter name /eː/ and the other possible realisations of the letter, based on the acoustic analysis of German vowels from the Kiel Corpus of Read Speech (Pätzold & Simpson, 1997). When comparing the pattern of acoustic distances (Fig. 5, Panel B) to the pattern of behavioural results (Fig. 2), it seems that they overall match relatively well. Hence, letter name similarity fares quite well in explaining the graded letter search results. The order of detection accuracy and times for <e> in unstressed second syllables (/l̩, ɐ, n̩/), however, is still surprising given the calculated distances to the letter name. In both /l̩/ and /n̩/, <e> is predominantly silent. Nonetheless, letter detection was significantly easier for words with /l̩/ than /n̩/, with /ɐ/ surprisingly ranging in between. As Pätzold and Simpson (1997) briefly discuss, there is some variation in the pronunciation of weak syllables. An obvious assumption could be that the <e> in syllabic /l̩/ is on average “less silent” than in syllabic /n̩/, being realised more like /əl/, at least in some variants of German pronunciation and in careful or marked pronunciation. If any of the participants in our letter search task internally realised unstressed second syllable <el> as /əl/, but <en> as the syllabic consonant /n̩/ (silent e), this could explain why the detection accuracy and time are faster for the former than the latter. However, unfortunately, there is no data on the actual (mental) pronunciation of <e> by the participants tested in our experiment.
To summarise, the findings from the additional explorations of GPC probabilities and letter name similarity support that both might have some explanatory value for the behavioural results on letter detection. That said, neither of them seems to obviously explain the pattern of results fully on its own. Future research should aim to investigate these explanations more comprehensively and systematically to provide a more precise picture of the mechanisms underlying syllabic and suprasyllabic factors in letter processing.
Conclusion
Understanding the connection between graphemes and the phonemes they represent is crucial for models of visual word processing, particularly in the context of the GPC component within the sublexical route of dual-route models of reading (Coltheart et al., 2001; Perry et al., 2007). This issue becomes even more demanding when extending these models to address the challenges posed by polysyllabic words. One crucial feature of written German (and other languages) is that the same letter can stand for different phonetic realisations and syllable stress is decisive for this. Because most existing models of visual word processing have solely focused on monosyllabic words (for exceptions, see the CDP++; Perry et al., 2010, 2014a, 2014b), they are limited to GPCs within nonreduced (stressed) syllables. Our study underscores the importance of enhancing models of visual word processing to comprehensively address grapheme–phoneme relationships in stressed and unstressed syllables within polysyllabic words. The detection of letters in polysyllabic words appears to involve top-down influences from prosodic information. Integrating this interactive process into models is crucial for a better understanding of reading beyond monosyllabic words, capturing pronunciation variations across different syllabic contexts, and ensuring accurate reflection of the complexities of real-world linguistic patterns.
In sum, we can conclude that—despite letter search typically being considered a purely visual-perceptual task—the phonetic realisation (vowel quality) of a letter driven by prosodic prominence is pivotal in the identification of the letter <e> by skilled readers of German. Letter detection seems to be influenced by vowel quality and prosodic prominence, highlighting the tight coupling between spoken and written language.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.