
Abstract
Given that learners do not always predict their future memory performance accurately, there is a need to better understand how metamemory accuracy can be improved. Prior research suggests that one way to improve is practice—participants tend to become better at predicting their future memory performance over the course of multi-trial learning experiments. However, it is currently unclear whether such improvements result from participants having practised making metamemory judgements or whether comparable improvements occur even in their absence. This issue was investigated in three multi-trial, cued recall experiments wherein participants either did or did not receive practice making judgements of learning. Metamemory accuracy increased across study blocks but did so equally for the two groups. These results indicate that increased metamemory accuracy with practice is not due to participants having practised explicit metamemory monitoring but instead due to other factors associated with multi-trial learning such as retrieval practice and the availability of prior test performance as a metamemory cue.
Metamemory refers to the processes by which learners monitor and control their memory performance. Because metamemory judgements about the likelihood that one will remember information in the future (i.e., judgements of learning [JOLs]; Rhodes, 2016) predict learning behaviours (e.g., Metcalfe, 2009; Metcalfe & Finn, 2008), understanding such judgements has important implications for learning and cognition. However, metamemory judgements are not always accurate; learners’ predictions sometimes diverge from their actual memory performance in important ways, suggesting that learners are not always able to accurately monitor learning (e.g., Besken & Mulligan, 2014; Koriat & Bjork, 2005; Koriat et al., 2002; Rhodes & Castel, 2008). This divergence between predicted and actual memory may ultimately interfere with learners’ ability to achieve content mastery in so far as inaccurate metacognitive predictions might result in an individual devoting their limited study time to information that is already relatively well-learned at the expense of studying information which would benefit more from further study. As such, the question of how to improve the accuracy of metamemory judgements is of particular importance.
One way that metamemory accuracy might be improved is practice. Generally speaking, as participants try to memorise a set of materials in a multi-trial learning situation, their metamemory accuracy increases with practice (Ariel & Dunlosky, 2011; Finn & Metcalfe, 2007, 2008; Hanczakowski et al., 2013; Koriat, 1997; Koriat et al., 2002, 2006, Experiment 1; Kubik et al., 2022; Scheck & Nelson, 2005; Tauber & Rhodes, 2012; Zawadzka & Higham, 2015). In each learning block of a typical experiment, participants are presented with a study list (e.g., of word pairs) and indicate how likely they are to remember each item (the JOL). This is followed by a memory test (e.g., cued recall), and then the process is repeated through several learning blocks. In the current experiments, we assess whether this metamemory improvement requires practice in making metamemory judgements or if such improvement occurs even in their absence simply as a byproduct of learning. If the former, then introducing overt monitoring judgements might enhance learning via improved metamemory accuracy; if the latter, then the learning situation may be streamlined by omitting such overt judgements (which, under some conditions, may produce ancillary costs, e.g., Mitchum et al., 2016; Norman, 2020). To begin, we consider the effects of practice on two commonly reported measures of metamemory accuracy: calibration and resolution.
Calibration and practice
Calibration refers to the extent to which participants’ average memory performance matches their predicted performance. For example, a participant whose average level of recall aligns with their average JOLs is well-calibrated, whereas a participant whose recall differs substantially from their JOLs is poorly calibrated (i.e., either overconfident or underconfident). Research demonstrates that calibration often improves with practice. For example, Koriat et al. (2006, Experiment 1) found that after being initially overconfident, participants’ predicted and actual memory did not differ following practice. Such findings indicate that predicted and actual memory performance tends to become more closely aligned following practice (Finn & Metcalfe, 2007; Koriat et al., 2006, Experiment 1; Scheck & Nelson, 2005; Zawadzka & Higham, 2015).
Although calibration often improves with practice, this is not always the case. For example, Hanczakowski et al. (2013, Experiment 1) found that participants were well-calibrated during the first block of a cued recall experiment but were significantly underconfident during blocks two and three. Importantly, because participants tend to become increasingly underconfident following practice (Koriat et al., 2002), it may be that whether calibration improves with practice depends on how well-calibrated participants are initially. It may be, e.g., that in situations where participants are sufficiently overconfident to begin with, practice improves calibration by reducing overconfidence. In contrast, in situations where participants are initially well-calibrated or only slightly overconfident, participants may “over-correct” and become underconfident (i.e., poorly calibrated) following practice. In support of this argument, Scheck and Nelson (2005) found that participants’ initial degree of overconfidence was related to their calibration after practice. Specifically, for difficult items, participants were initially overconfident but became well-calibrated with practice. In contrast, for easier items, participants were less overconfident initially but became underconfident (and thus poorly calibrated) with practice. Regardless, the extant literature demonstrates that calibration often improves with practice (Finn & Metcalfe, 2007; Koriat et al., 2006, Experiment 1; Scheck and Nelson, 2005; Zawadzka & Higham, 2015), although there are some exceptions (Hanczakowski et al., 2013, Experiment 1; Koriat, 1997; Koriat et al., 2002; Serra & Dunlosky, 2005). 1 It is important to understand why calibration changes with practice and whether these changes involve improved accuracy or not. To foreshadow, improved calibration was consistently found in the current experiments.
Resolution and practice
Resolution refers to participants’ ability to discriminate between items which they will later remember vs. those which they will later forget. If, e.g., a participant reported higher levels of confidence for subsequently remembered items than for subsequently forgotten items, this participant would have high resolution. Research often demonstrates that participants’ resolution increases with practice (Ariel & Dunlosky, 2011; Finn & Metcalfe, 2007, 2008; Hanczakowski et al., 2013; Koriat, 1997; Koriat et al., 2002, 2006; Kubik et al., 2022; Tauber & Rhodes, 2012), suggesting that practice makes people better at discriminating between items they will and will not remember.
Given that metamemory accuracy often increases with practice, it is important to determine why this increase occurs. Intuitively, it may be that metamemory—like many other cognitive abilities—is a skill which improves with practice. That is, it may be that to increase metamemory accuracy, one must become more skilled at making explicit metamemory judgements. If so, practice with making metamemory judgements may drive, or at least contribute to, improvement rather than, or in addition to, other factors of multi-trial learning, such as repeated learning or retrieval opportunities.
Metamemory theories and the role of practice with metamemory judgements
Indeed, the question is broader than just improvements in metamemory and applies more generally to any change in metamemory occurring with practice. Practice virtually always changes metamemory accuracy; the change is usually positive (improvement) but not always (e.g., some exemplars of underconfidence-with-practice, which produce a net reduction in calibration). Assessing whether making JOLs contributes to this change is important for determining the nature of the underlying metamemory processes, and specifically for determining whether the changes in metamemory are simply a consequence of repeated learning or signal processes that are only carried out when explicit monitoring is evoked. Current theories render conflicting implications regarding this issue, and its resolution is important for further theory development (as discussed in more detail in the General discussion).
Several theories of metamemory suggest that making JOLs contributes to improvements and other changes in metamemory accuracy. For example, with respect to changes in calibration, the anchoring view (England & Serra, 2012; Scheck & Nelson, 2005) argues that making JOLs over multiple trials entails first establishing an anchor point (usually between 30% and 50%, Scheck & Nelson, 2005) and then making adjustments as learning trials unfold. The final JOL represents multiple adjustments from the initial anchor. This implies that if one makes a JOL only after several rounds of learning, one would not arrive at the same point on the JOL scale as one initially formulating an anchor and then adjusting it over multiple preceding trials. 2 Thus, the resulting metamemory performance should be influenced by the rendering of prior JOLs.
Another perspective argues that metacognitive monitoring represents a dual-task challenge, predicated on the idea that overt monitoring judgements (e.g., JOLs) are resource-demanding and thus constitute a dual-task challenge alongside the demands of a primary task (e.g., memory encoding; Griffin et al., 2008; Mitchum et al., 2016). This perspective has been applied to situations in which JOLs interfere with memory encoding (Mitchum et al., 2016; see Rivers et al., 2021, for related discussion) but also implies that the demands of memory encoding impact monitoring processes. A long history of research indicates that practicing dual tasks results in increased accuracy and efficiency for processing both tasks (e.g., Hazeltine et al., 2002; Hirst et al., 1980; Pashler, 1994; Ruthruff et al., 2006), and there is evidence with other monitoring tasks (e.g., metacomprehension judgements for text) that repetition can enhance metacognitive accuracy (specifically, resolution) via reduced processing demands upon repetition (Griffin et al., 2008). Under this view, repeatedly providing JOLs should improve one’s ability to monitor memory and should contribute to improvements in metamemory accuracy with practice.
Consistent with the possibility that overt metamemory judgements contribute to changes in metamemory accuracy is theorising related to JOL reactivity, wherein the information that participants attend to is assumed to be altered as a result of making metacognitive judgements. Specifically, the cue-driven metacognitive framework of reactivity (Double & Birney, 2019) proposes that making metacognitive judgements draws participants’ attention towards cues (e.g., difficulty, task characteristics); this in turn influences subsequent metacognitive judgements. As these cues become salient and are taken into account in metacognitive judgements, metamemory accuracy should be affected. This theorising was prompted by JOL reactivity effects, in which making JOLs affects memory (sometimes positively, sometimes negatively). However, this account explicitly proposes that overt monitoring (e.g., making JOLs) changes the cues that are attended to regardless of the impact on memory performance. Consequently, this account implies that making JOLs plays a role in changes in metamemory accuracy. Finally, although this account is related to the cue-strengthening account of Soderstrom et al. (2015; see also the studies by Myers et al., 2020; Rivers et al., 2021), it differs in some relevant details addressed in the General discussion.
Thus, three perspectives suggest that making JOLs improves or at least changes metamemory accuracy. Specifically, the anchoring account implies that making JOLs affects changes in calibration, the dual-task account implies that making JOLs improves metamemory accuracy (resolution and possibly also calibration), and the cue-driven metacognitive framework proposes that making JOLs contributes to changes in resolution. In contrast, other theoretical perspectives suggest that making metamemory judgements may not be necessary for metamemory accuracy to improve. Instead, these accounts predict that changes in metamemory accuracy are due to the beneficial effects of memory retrieval, and that metamemory accuracy should improve even when participants do not actually make metacognitive judgements. One such account is the Memory for Past Test (MPT; Finn & Metcalfe, 2007, 2008) framework, which suggests that following a memory test, participants use their memory of whether they correctly remembered a given item as a cue to inform subsequent metamemory predictions. Specifically, this framework predicts that participants will give higher JOLs to items they remember getting right previously than to those they remember getting wrong. Relying on prior test performance increases metamemory accuracy because prior retrieval success tends to be diagnostic of future retrieval success. Because participants only have information on prior retrieval after the first memory test, the MPT framework predicts that metamemory accuracy should improve on the second study-test block and onward. Under this view, increases in metamemory accuracy following practice may have less to do with making metamemory judgements and more to do with the fact that participants’ memory for the same material was previously tested.
The possibility that prior retrieval informs metamemory judgements appears to have developed independently in the literature on the testing effect, whereby participants’ memory is improved following testing compared to restudy (Roediger & Karpicke, 2006). In addition to the direct benefits of testing (i.e., enhancing memory performance), researchers have noted indirect benefits as well. Notably, among the benefits of testing listed by Roediger et al. (2011) was greater increases in metamemory accuracy, relative to a restudy condition. Roediger et al. argued that testing may lead to increased metamemory accuracy by allowing learners to discover what they know and what they do not know. Consistent with this argument, King et al. (1980) found that compared to participants who only learned materials using study trials, participants who received study and test trials showed better resolution. Similar evidence supporting the beneficial effects of retrieval practice on metamemory accuracy has been reported by other researchers as well (Barenberg & Dutke, 2019; Chen et al., 2019; Cogliano et al., 2019; England & Serra, 2012; Hughes et al., 2018; Kornell & Rhodes, 2013; Shaughnessy & Zechmeister, 1992; but see Jacoby et al., 2010).
Thus, both the MPT framework and theorising regarding the testing effect suggest that increased metamemory accuracy following practice may result from prior retrieval rather than practice in making metamemory judgements. It should be noted, however, that accounts which emphasise the metamemory benefits of testing do not discount the possibility that making metamemory judgements might benefit metamemory above and beyond retrieval practice. For example, the MPT account predicts that prior memory tests will be taken into account on later trials but does not explicitly predict that prior JOLs will have no effect. For example, it would be consistent with this account if previously making a JOL on an initial trial sensitises the learner to the more useful information available after taking the memory test, such that on a second trial, this information is taken into account to a greater degree than for a learner who had not previously made a JOL. Consequently, the current research is required to help guide theoretical development on the contributions of JOL and retrieval practice on metamemory accuracy, even for the accounts most amenable to a limited role for JOLs in metamemory improvement.
One final point warrants emphasis—the theories reviewed in this section provide their clearest implications for how metamemory changes across trials when the same materials are repeatedly learned, rather than the extent to which acquired metamemory accuracy might transfer to new materials. Thus, our experiments focused on this scenario, and it frames our review of the limited prior research.
Prior research of relevance to the current study
Although it is unclear whether making metamemory judgements is necessary to observe improvements in metamemory accuracy, a few studies report data relevant to the current investigation. A first relevant study is that of England and Serra (2012), in which participants made JOLs for some items but not others during the first block of a cued recall experiment. In the second block, with the same list, participants made JOLs for all items. Items for which participants had previously made JOLs did not differ in either calibration or resolution from items for which participants had not previously made JOLs. On the one hand, these results suggest that practicing JOLs may not result in increased metamemory accuracy. However, because of the within-subjects manipulation, all participants received practice in making metamemory judgements for half of the items. Consequently, the improvement in metamemory accuracy may still be a product of practice in making explicit metamemory predictions. By manipulating whether participants made JOLs between subjects over several study-test blocks, we sought to investigate the effects of prior experience in making JOLs on metamemory accuracy more directly.
In another relevant study (Bol et al., 2005), students in a college course were assigned to either a practice or a control group. Participants in the practice group made global metacognitive judgements throughout the course in the form of predictions and postdictions about their average performance on course quizzes, whereas participants in the control group did not. Despite repeatedly making these metacognitive judgements, participants in the practice group did not differ in calibration from the control group during the final exam. Although suggestive, findings of the study by Bol et al. are difficult to interpret given that calibration did not improve with practice throughout the course (see also King et al., 1980). Thus, the current study sought to expand upon such research by determining whether metamemory judgements contribute to increased metamemory accuracy under conditions where metamemory accuracy increases with practice.
The two foregoing studies examined the effect of JOL practice within the same set of materials. Two other studies, of somewhat less importance for current concerns, examined the effect of JOL practice with one set of materials on metamemory for a new set of materials. In an early study by Vesonder and Voss (1985), participants learned a first set of word pairs over multiple trials and then repeated the process with a new set of word pairs. Generally, prior experience with an overt monitoring prediction enhanced resolution but appeared to have little effect on calibration, although these results are not completely clear because there was no direct statistical comparison of the two relevant conditions (see the General discussion for more details). In contrast, Kelemen et al. (2007) found that prior experience with JOLs did not impact resolution although it did produce better calibration (Kelemen et al., 2007, Experiment 2).
These two studies are limited for present purposes for several reasons. First, the two studies only produced conflicting results with regard to resolution, likely because neither study was specifically directed at the current research question. Second, both studies examined the effect of JOL practice with one set of materials on metamemory for a new set of materials. This is an important question that we return to in the General discussion but does not answer the more basic question of how practicing JOLs affects metamemory during the learning of a single set of materials, which, as noted, is the main focus in the present experiments. Finally, in the study by Kelemen et al. (2007), the group that practised JOLs did not show increased (or any change in) resolution over blocks, making the null effect between groups on the final block uninterpretable with respect to the role of JOLs in changes in metamemory accuracy.
Experiment 1
Experiment 1 provides an initial investigation as to whether making metamemory judgements is necessary for observing improved metamemory accuracy. Two groups completed three study-test blocks of cued recall for unrelated word pairs. Participants in the JOL All group made JOLs during the study phase of all three blocks, whereas participants in the JOL Final group made JOLs only during the final block. If either calibration or resolution was better in the JOL All group during the third block, this would provide evidence that making JOLs is necessary to observe improved metamemory accuracy. Alternatively, if no differences in calibration or resolution were observed between groups, this would suggest that practicing making JOLs does not contribute to metamemory accuracy.
Data availability
Data, analysis code, and materials for all three experiments and pre-registrations for Experiments 2 and 3 are available at https://osf.io/4jukt/
Method
Participants
Eighty participants recruited from Amazon Mechanical Turk (MTurk) took part in Experiment 1 in exchange for monetary compensation. 3 We recruited 80 participants so that after anticipated exclusions, we would have approximately 30–35 participants per group, a sample size chosen based on typical sample sizes from studies that exhibited increases in metamemory accuracy in multi-trial learning (e.g., Hanczakowski et al., 2013; Koriat, 1997; Koriat et al., 2002).
Participants in Experiment 1 had to reside within the United States and have an MTurk approval rate greater than or equal to 95%. One participant’s data were lost due to experimenter error. An additional 10 participants were excluded for reasons meant to ensure data quality. Specifically, six participants were excluded for admitting to writing down studied words during the experiment. Two participants were excluded for not being native English speakers. In addition, two participants were excluded for failing at least one of the three attention checks and having at least one block in which they had a recall performance of zero. This left a final sample of 69 participants, with 31 in the JOL All group and 38 in the JOL Final group. In the studies that motivated the current sample size (e.g., Hanczakowski et al., 2013; Koriat, 1997; Koriat et al., 2002), the average effect size for the change in resolution over blocks was
For demographic information for this and subsequent experiments, see Table 1. As seen in Table 1, participants in the JOL All and JOL Final groups did not differ in terms of whether they wrote down words during the study phase of any of the three experiments (see Procedure). For information regarding attrition, see the online Supplementary Material. All procedures in this article were approved by the Office of Human Research Ethics of the University of North Carolina at Chapel Hill.
Participant demographics and exclusions across experiments.
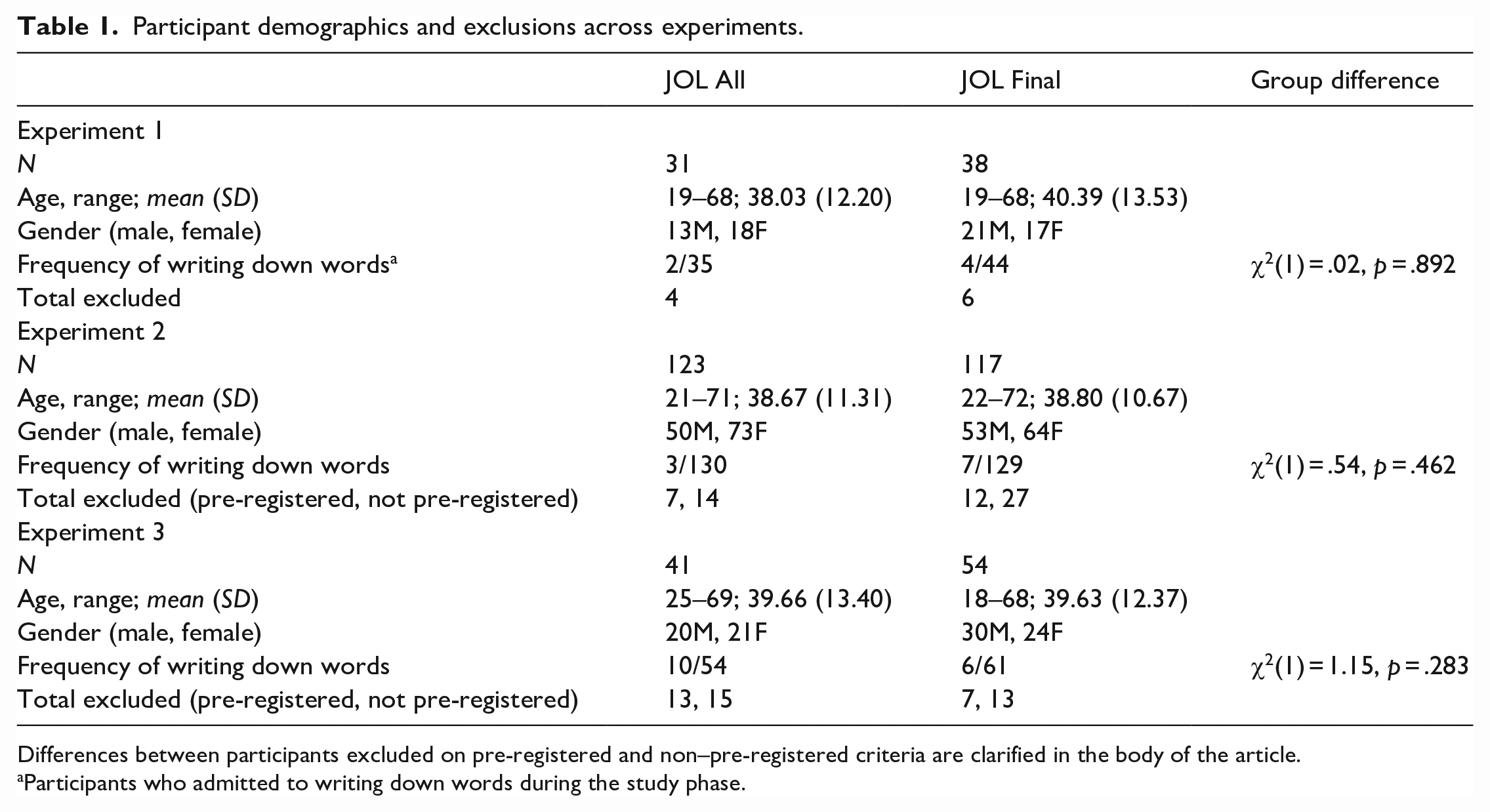
Differences between participants excluded on pre-registered and non–pre-registered criteria are clarified in the body of the article.
Participants who admitted to writing down words during the study phase.
Design and materials
Experiment 1 followed a 2 (group: JOL All vs. JOL Final; between-subjects) × 3 (block; within-subjects) mixed design. Stimuli were 80 nouns drawn from the MRC Psycholinguistic Database (Wilson, 1988). These nouns were between four and six letters in length (M = 4.81, SD = .80), with written frequencies between 100 and 1,000 (M = 231.46, SD = 167.20; Kucera & Francis, 1967) and concreteness ratings between 500 and 700 (M = 567.93, SD = 33.27; Wilson, 1988). Word pairs were formed by randomly selecting 40 words to serve as cues and 40 as targets and then randomly pairing cues with targets. Of the resulting 40-word pairs, two served as primacy buffers, and two as recency buffers, leaving 36 critical pairs. 5
Procedure
Participants began by reading instructions regarding the cued recall task. They were told that their primary task would be to memorise a series of word pairs in preparation for an upcoming memory test. They were told that during the memory test, they would be presented with the first word (the cue) in each pair and would attempt to recall the second word paired with it (the target). Participants assigned to the JOL All group were further instructed that in addition to memorising the word pairs, they would be asked to rate their confidence in remembering each pair. Participants were told that they would rate their confidence on a scale from 0 (not confident at all) to 100 (extremely confident). Participants were encouraged to use the entire scale. Participants in the JOL Final group did not receive these instructions until the final (third) block.
Next, participants were presented with the word pairs, which consisted of the two primacy buffers, the 36 critical pairs presented in a random order for each subject, and the two recency buffers. Each word pair was presented for 4 s. During each JOL trial, the target disappeared after 4 s, and only the cue remained onscreen while participants made a self-paced JOL. After the word pairs were presented, all participants completed 90 s of mental math. Next, participants completed the cued recall test. During this test, participants were shown the cues and were asked to type in the targets that were paired with them previously. Participants were given up to 6 s per trial to enter their answer but could proceed more quickly if an answer was given in under 6 s. No feedback was provided during the test trials.
Participants in the JOL All group completed the aforementioned procedure two additional times, resulting in three blocks of study with JOLs and cued recall. Participants in the JOL Final group had two blocks of study without JOLs followed by cued recall and then made JOLs only during the final block of the experiment. Prior to the study phase of Block 3, participants in the JOL Final group were shown the same JOL instructions as were previously shown to the JOL All group.
Additional steps were taken to ensure data quality. First, each of the three cued recall tests contained a single attention check trial. During this trial, participants saw a prompt that asked them to type a specific word to ensure that they were paying attention. In addition, at the end of the experiment, we asked participants whether they had written any word pairs down during the study phase. Participants were encouraged to be honest and were informed that their answer would not affect their compensation.
Data analysis
Primary outcomes
Cued recall performance was scored correct if the target word was typed accurately as well as for clear typos or misspellings of the target word (e.g., typing “papr” instead of “paper”). The recall measure is percent correct. We took two approaches to operationalizing calibration. Our primary measure of calibration was computed as the absolute difference between average JOLs and average cued recall performance, with lower values indicating better calibration. This measure is similar to how calibration is most typically defined within the metamemory literature, wherein calibration is conceived of as reflecting the difference between average predicted and actual memory performance (e.g., Finn & Metcalfe, 2007; Koriat, 1997; Koriat et al., 2002, 2006; Serra & Dunlosky, 2005). A secondary measure of calibration based on calibration curves was computed using formulas provided by Lichtenstein and Fischhoff (1977). Briefly, this measure operationalises calibration by assigning better calibration scores to participants whose actual memory performance at various levels of predicted performance aligns closely with those predictions. Separate analyses using these two measures of calibration provided highly similar results, supporting the robustness of our results (the single difference between these measures is described in Footnote 11). Because these analyses produced similar results, we report only the primary measure of calibration in the body of the article. Analyses based on the secondary measure of calibration (i.e., curve-based calibration) are included in the Supplementary Material.
Resolution was operationalised as the within-subject gamma correlation between recall and JOLs (T. O. Nelson, 1984), with 1 indicating perfect resolution and 0 indicating chance-level resolution. Resolution measures the association between JOLs and recall performance during the same block (e.g., the association between JOLs and recall during Block 1, also called forward gamma). In addition to computing resolution, we computed another measure based on within-subject gamma correlations of secondary interest: backward gamma. In contrast to resolution, backward gamma measures the association between JOLs during a given block and recall performance during the preceding block (e.g., the association between JOLs during Block 2 and recall during Block 1, see Finn & Metcalfe, 2008, 2014). In other words, whereas resolution measures one’s ability to discriminate between items that will or will not be remembered in an upcoming memory test, backward gamma measures the extent to which one takes into account prior retrieval success when predicting future memory performance. Backward gamma was computed primarily to test predictions generated by the MPT account and is often greater in magnitude than resolution, indicating that participants do indeed use their prior retrieval success as a cue to predict their future memory (e.g., Finn & Metcalfe, 2008; Kubik et al., 2022).
Analytic strategy
All analyses of variance (ANOVAs) used Greenhouse–Geisser-corrected degrees of freedom to accommodate deviations from sphericity, and post hoc tests used adjusted p-values based on Tukey’s honestly significant difference correction to account for multiple comparisons. For interaction effects, adjustments for multiple comparisons were made for simple effect comparisons of theoretical interest only (e.g., the simple effect of JOL Condition during each block). Independent samples t-tests were conducted as Welch’s t-tests to accommodate unequal variances across groups. All error bars represent 95% confidence intervals. For graphs depicting mean differences as a function of within-subjects variables, error bars represent 95% within-subjects confidence intervals.
Because many of our key statistical tests rely on the interpretation of null effects, we report Bayesian analyses in addition to frequentist analyses. The advantage of doing this is that—unlike frequentist analyses—Bayesian analyses are able to quantify the strength of evidence in favour of the null hypothesis. We report two different Bayes factors: BF10 and BF01. For the majority of analyses, we report BF10, which can be interpreted as the likelihood of the alternative hypothesis relative to the null hypothesis given the observed data. For directional comparisons of final metamemory accuracy, we report BF01, which instead indicates the likelihood of the null hypothesis relative to the alternative hypothesis. For both these, values greater than 10 or less than 1/10 may be interpreted as “strong” evidence for one hypothesis relative to another (e.g., for BF10, values greater than 10 indicate strong evidence for the alternative hypothesis, whereas values less than 1/10 indicate strong evidence for the null hypothesis), values greater than 3 or less than 1/3 as “moderate” evidence, and values between 3 and 1/3 as “anecdotal” or ambiguous evidence (Dienes, 2014).
Bayesian analyses were carried out using the R package BayesFactor (Morey & Rouder, 2018). For Bayesian ANOVAs, Bayes factors for each effect were computed using the anovaBF function, which computes Bayes factors for each fixed effect by comparing the likelihood of the model with and without a given effect. In these analyses, the participant was treated as a random effect. For t-tests and post hoc comparisons, we computed Bayesian t-tests using the ttestBF function, which places a noninformative Jeffreys prior on the variance of the normal population and a Cauchy prior with a width of
Results
Effects of practice on metamemory
See Table 2 for mean recall, JOLs, and calibration and Table 3 for mean resolution and backward gamma for all experiments. To examine the effects of practice on metamemory, we conducted a series of analyses using data from the JOL All group. We began by assessing the effect of practice on calibration using a one-way (block) repeated-measures ANOVA (see Figure 1). There was a significant effect of Block, F(1.73, 51.92) = 5.63, p = .008,
Mean (SD) recall, JOLs, and calibration across experiments.
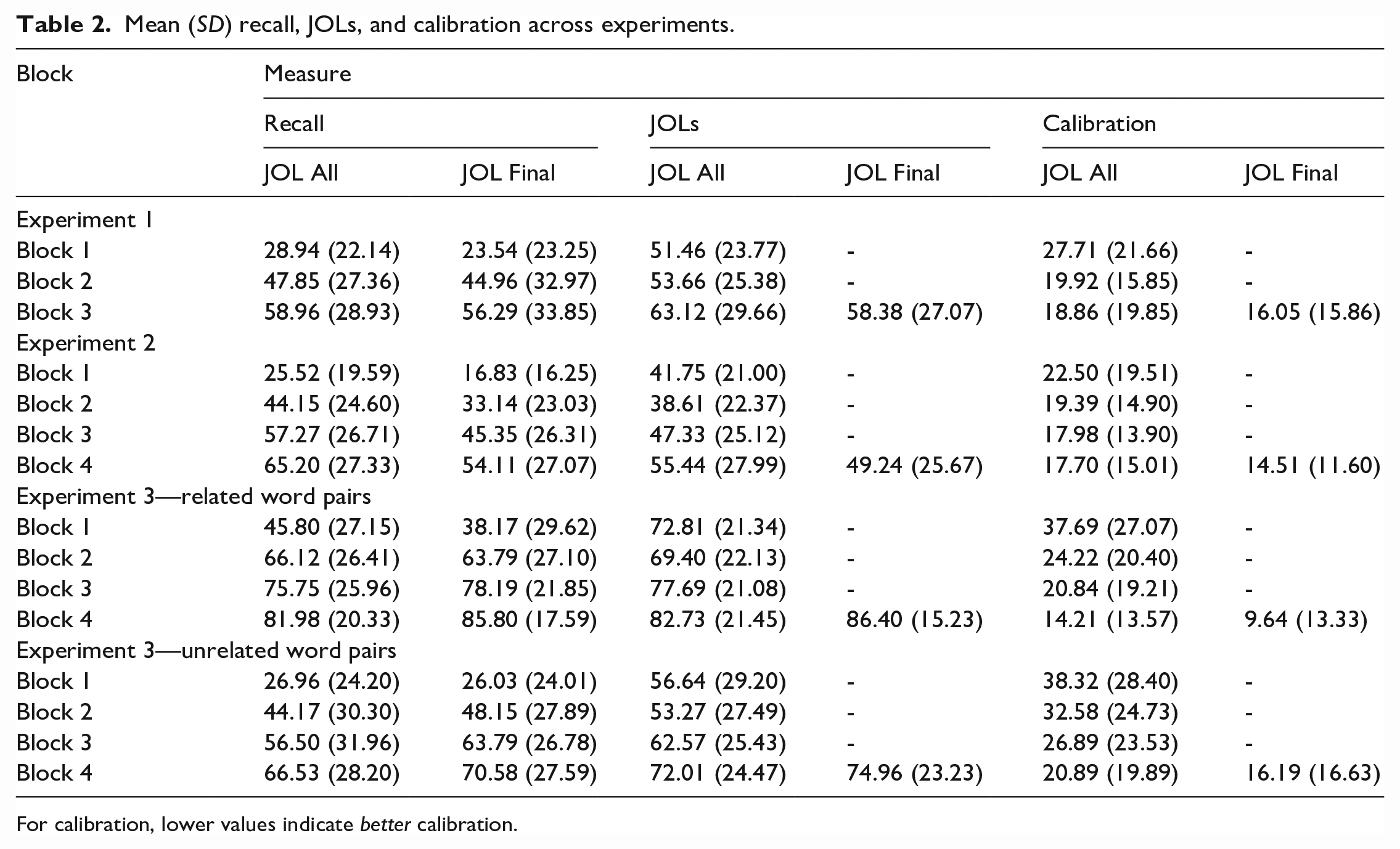
For calibration, lower values indicate better calibration.
Mean (SD) resolution and backward gamma across experiments.
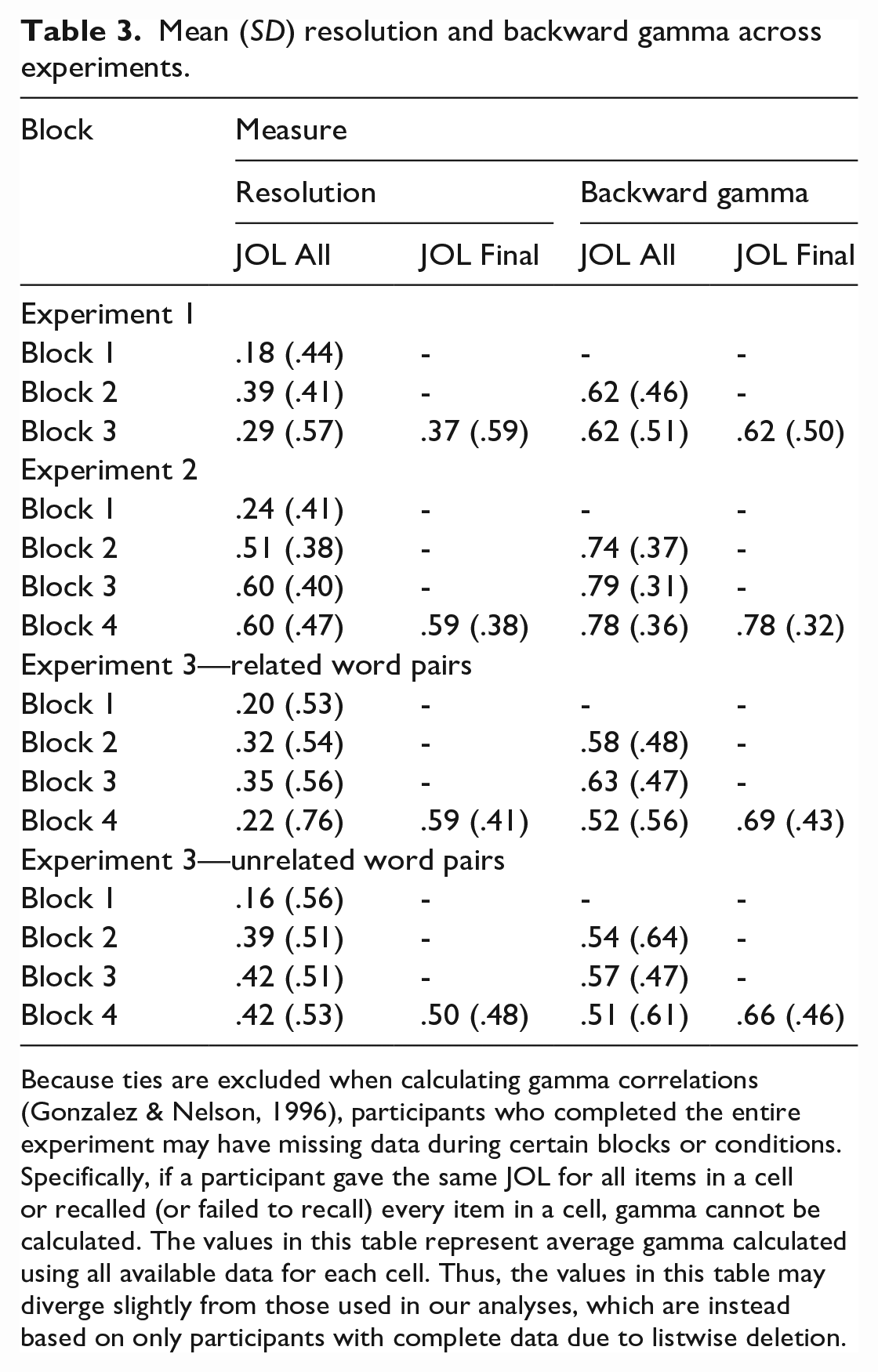
Because ties are excluded when calculating gamma correlations (Gonzalez & Nelson, 1996), participants who completed the entire experiment may have missing data during certain blocks or conditions. Specifically, if a participant gave the same JOL for all items in a cell or recalled (or failed to recall) every item in a cell, gamma cannot be calculated. The values in this table represent average gamma calculated using all available data for each cell. Thus, the values in this table may diverge slightly from those used in our analyses, which are instead based on only participants with complete data due to listwise deletion.
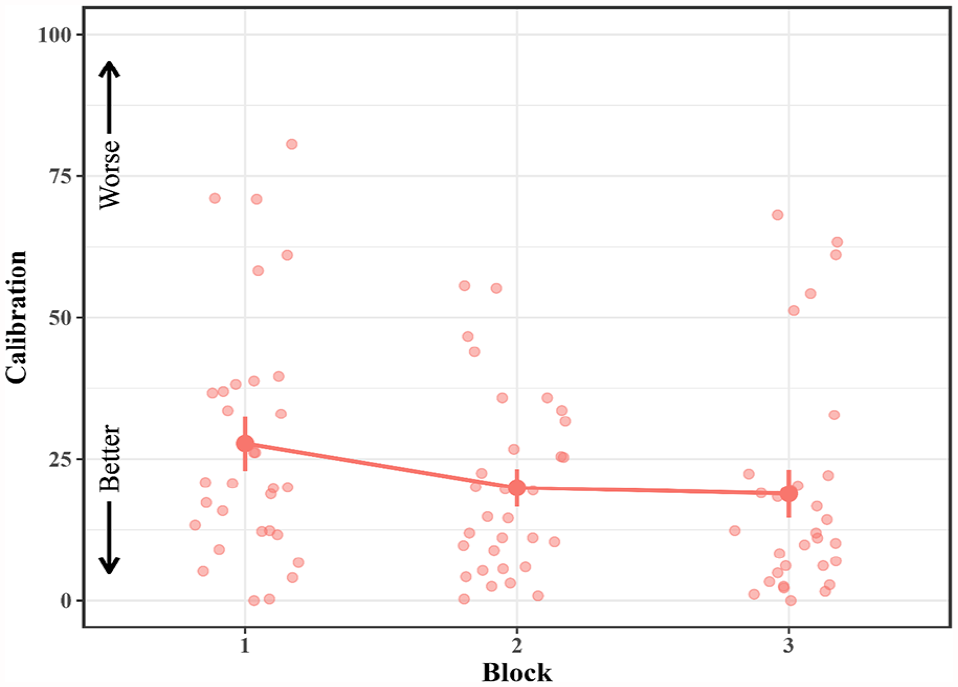
Mean calibration in the JOL All group across blocks in Experiment 1.
Next, we investigated whether resolution increased with practice (see Figure 2). To assess resolution, we conducted a one-way repeated-measures ANOVA with block as a factor. The ANOVA did not reveal a main effect of block, F(1.77, 42.46) = 2.23, p = .126,
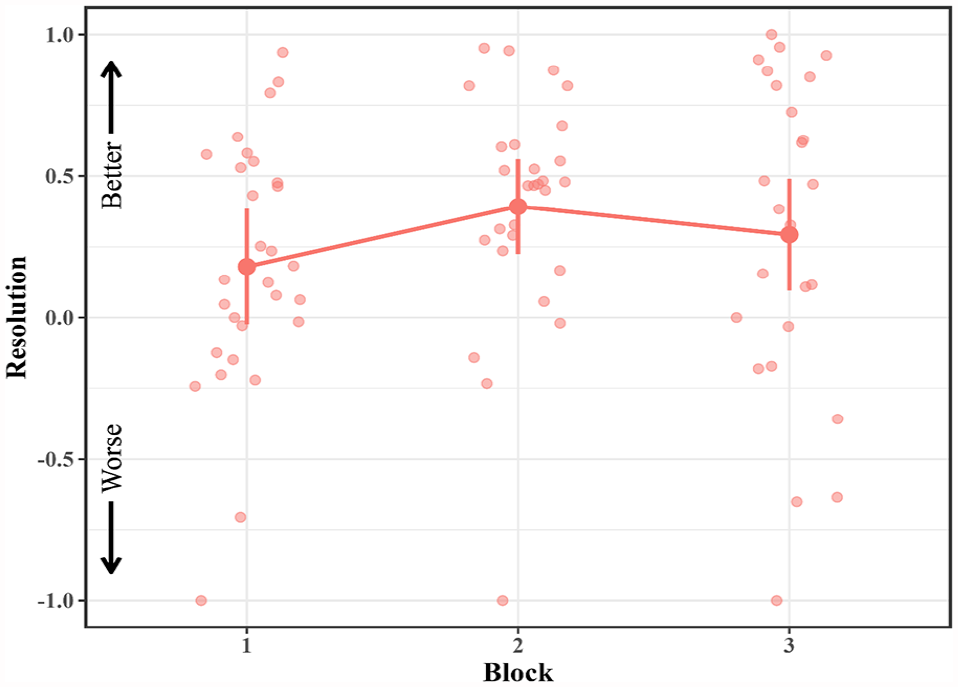
Mean resolution in the JOL All group across blocks in Experiment 1.
Finally, we compared backward gamma and resolution (or forward gamma) during Block 2 using data from the JOL All group and in Block 3 using data from both the JOL All and JOL Final groups. Consistent with prior research (Finn & Metcalfe, 2008; Kubik et al., 2022), backward gamma was found to be greater than resolution during Block 2, t(27) = 3.26, p = .003, dz = .616, BF10 = 12.90, and Block 3, t(58) = 3.98, p < .001, dz = .517, BF10 = 117.26. 7
Group differences in final metamemory accuracy
See Figure 3 for mean group differences in final calibration and Figure 4 for mean group differences in final resolution for all experiments. To test our primary research question of whether making JOLs is necessary to observe increased metamemory accuracy, we compared calibration and resolution between groups during the third block (see Tables 2 and 3). Neither calibration, t(56.88) = .64, p = .527, d = .156, BF10 = .30, nor resolution, t(53.12) = −.54, p = .593, d = .141, BF10 = .30, differed between groups during the final block. 8
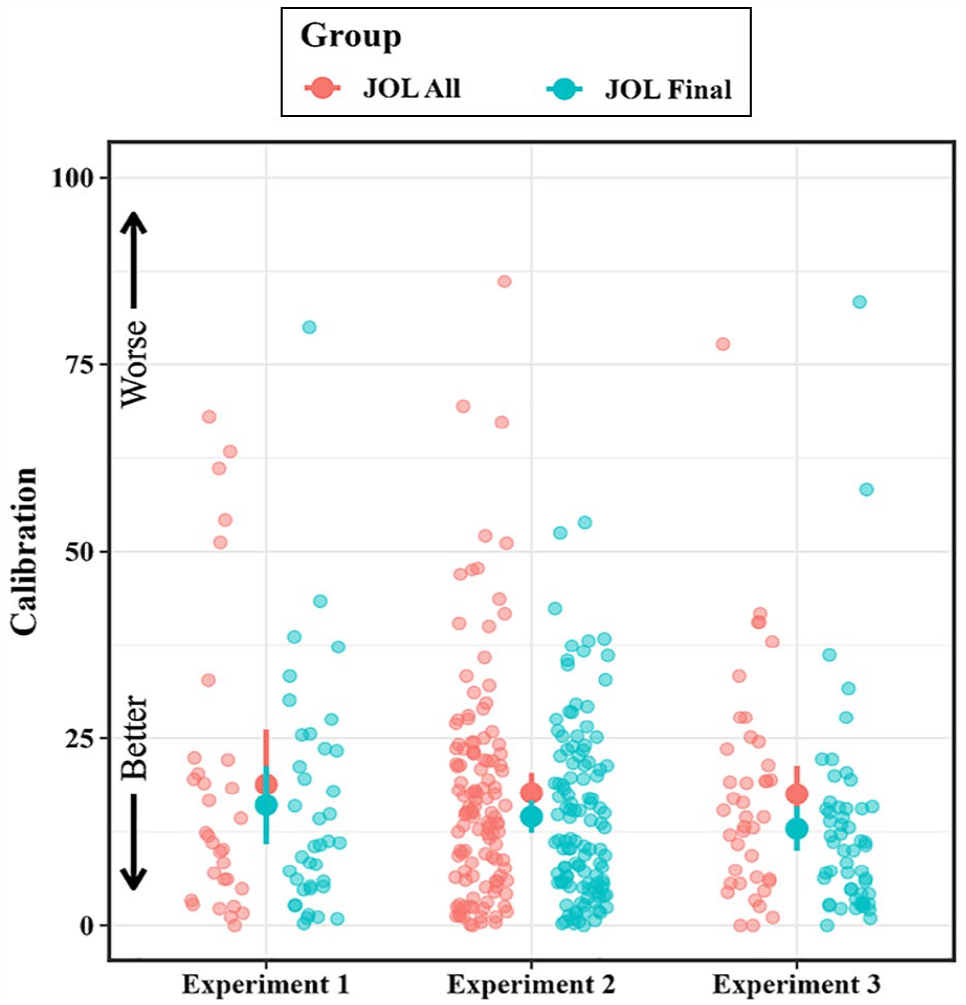
Mean group differences in final calibration across experiments.
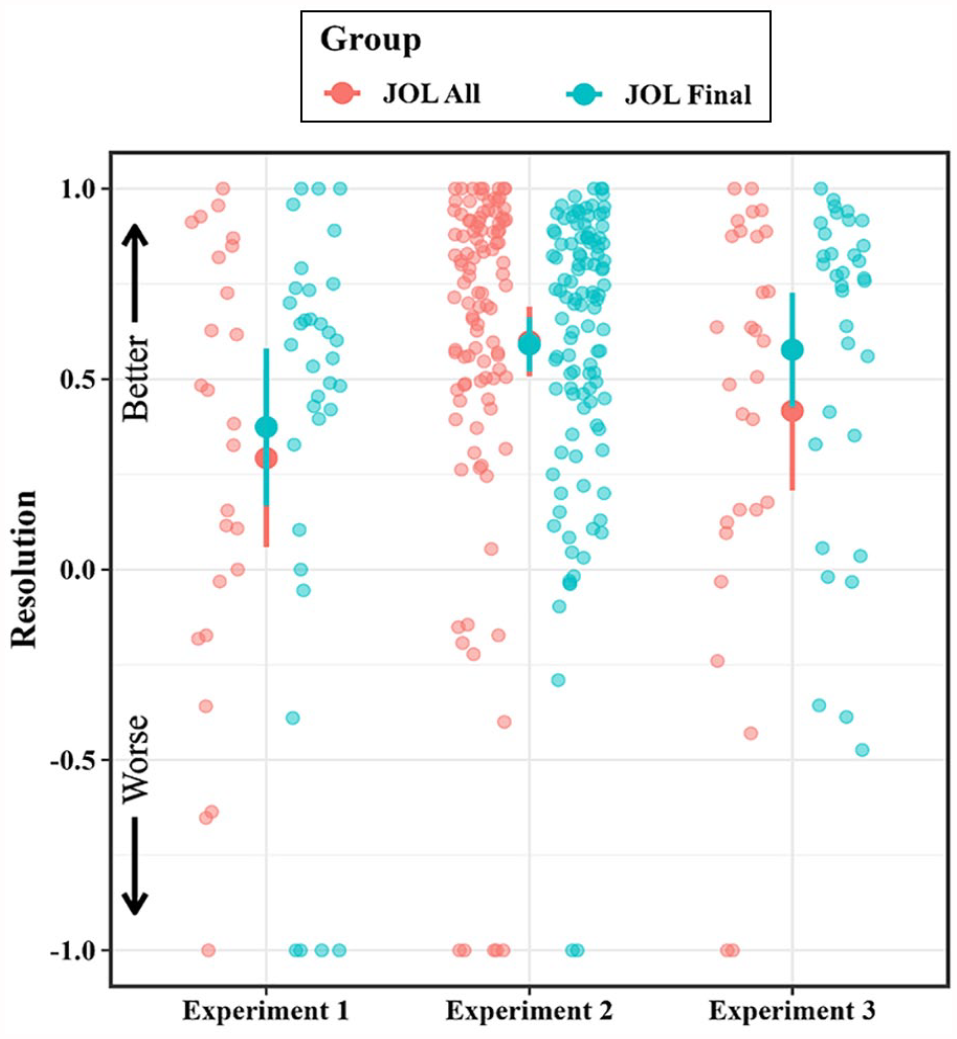
Mean group differences in final resolution across experiments.
Although we computed backward gamma primarily to compare this measure to resolution (see the General discussion of Finn & Metcalfe, 2008, for a more complete discussion of this issue), we assessed whether backward gamma differed between groups during the final block for completeness. As with calibration and resolution, backward gamma, t(53.55) = −.04, p = .969, d = .010, BF10 = .26, did not differ between groups during the final block.
The analyses reported above suggest that final metamemory accuracy did not differ between groups. However, to provide a more complete assessment of these null effects, we also report directional Bayesian t-tests (Morey & Rouder, 2018). These directional tests allowed us to contrast the likelihood of a specific comparison of theoretical interest given our hypotheses: whether the data provided evidence in favour of equivalent accuracy or of greater accuracy in the JOL Final group. For all directional Bayesian t-tests in this article, the null hypothesis was that metamemorial accuracy was equivalent between the JOL All and JOL Final group (H0: MAll − MFinal = 0), whereas the alternative hypothesis was that metamemorial accuracy in the JOL All group exceeded that of the JOL Final group (H1: MAll − MFinal > 0). These analyses indicated support for the null hypothesis as compared to the alternative for both calibration and resolution (Directional Calibration BF01 = 6.11, Directional Resolution BF01 = 5.30). Such results suggest that final metamemory accuracy in the JOL All group did not exceed the accuracy in the JOL Final group.
JOL reactivity
Making JOLs sometimes affects memory performance, a phenomenon dubbed JOL reactivity (for a meta-analysis, see Double et al., 2018). The current experiments were not designed to assess JOL reactivity, but for completeness, we assessed whether the current data showed evidence of JOL reactivity. Because both groups made JOLs in Block 3, we restricted our reactivity analyses to Blocks 1 and 2, during which the JOL All group made JOLs and the JOL Final group did not. As such, reactivity was assessed with a 2 (group: JOL All vs. JOL Final; between-subjects) × 2 (Block 1 vs. 2; within-subjects) mixed ANOVA. This analysis indicated that recall increased between Blocks 1 and 2, F(1, 67) = 97.02, p < .001,
Discussion
The goal of Experiment 1 was to determine whether practicing metamemory judgements is necessary to observe increased metamemory accuracy. To the extent that metamemory is a skill that becomes better with practice, it may be that making metamemory judgements results in subsequent improvements in metamemory accuracy. Alternatively, to the extent that factors associated with multi-trial learning such as retrieval practice drive improvements in metamemory accuracy, increased metamemory accuracy may occur regardless of whether participants make metamemory judgements. Our results are consistent with the latter possibility; in Experiment 1, participants who made JOLs during all three blocks did not differ in either calibration or resolution from participants who only made JOLs during the final block.
Experiment 1 provides preliminary evidence that practicing JOLs is unimportant for changes to metamemory accuracy, but one aspect of our results renders a stronger conclusion premature: Evidence that metamemory accuracy improved with practice was mixed. There is clear evidence that calibration improved, but in contrast to prior research (Ariel & Dunlosky, 2011; Finn & Metcalfe, 2007, 2008; Hanczakowski et al., 2013; Koriat, 1997; Koriat et al., 2002, 2006; Kubik et al., 2022; Tauber & Rhodes, 2012), evidence of improved resolution was less convincing. Although a t-test suggests that resolution improved between Blocks 1 and 2, t(24) = 2.20, p = .038, dz = .440, BF10 = 1.60, the omnibus effect of practice on resolution was not significant. As such, steps were taken in Experiment 2 to increase the likelihood of observing increased metamemory accuracy.
The results of Experiment 1 speak to other issues as well. Consistent with prior research (Koriat et al., 2002), participants in the JOL All group became less overconfident following practice, with significant overconfidence transitioning to well-calibrated predictions in later blocks (see Supplementary Material analysis of Underconfidence with Practice, UWP]). Also consistent with prior research (Finn & Metcalfe, 2008; Kubik et al., 2022), participants in Experiment 1 had greater backward gamma than resolution. This finding suggests that participants’ predictions incorporated prior retrieval success and is consistent with the MPT framework’s assertion that participants use prior memory performance as a cue to inform metamemory judgements (Finn & Metcalfe, 2007, 2008). Broadly speaking, the replication of these effects that are characteristic of multi-trial metamemory reinforces our confidence in the data provided by Experiment 1.
Although the current study is primarily concerned with the effects of making metamemory judgements on metamemory, our results also speak to the effects that such judgements have on memory performance. With regard to JOL reactivity, participants who made JOLs in Experiment 1 did not differ in their cued recall performance compared to participants who did not. This lack of JOL reactivity is consistent with the results of a recent meta-analysis which found that while participants demonstrated moderate JOL reactivity for related word pairs, reactivity was not observed for unrelated word pairs (Double et al., 2018; see also, Soderstrom et al., 2015). Thus, the lack of JOL reactivity in Experiment 1 is consistent with prior research given that Experiment 1 used unrelated word pairs.
Finally, we note that we assessed and interpreted calibration in the traditional way (e.g., Finn & Metcalfe, 2007; Koriat, 1997; Koriat et al., 2002, 2006; Serra & Dunlosky, 2005). However, the traditional interpretation has been critiqued based on the argument that many common forms of JOLs are not directly comparable to recall levels, and so do not allow the computation of absolute calibration (e.g., Hanczakowski et al., 2013; Zawadzka & Higham, 2015). This is an important concern but is not critical for current purposes. Even if the present (traditional) calibration measure cannot be taken as an absolute measure of calibration, the change in JOLs across trials (and their relation to recall) in the JOL All condition is matched by the JOL Final condition. Consequently, regardless of exactly how the change in JOLs and calibration is interpreted, it is the same in the two groups. Whatever changes have occurred to calibration with practice did not depend on repeatedly making JOLs. Furthermore, the alternative calibration analysis (based on calibration curves), described earlier and reported in the Supplementary Material, produces the same conclusions without relying on the same assumptions as the traditional calibration measure.
Experiment 2
The results of Experiment 1 provide preliminary evidence that metamemory judgements are not necessary to observe increased metamemory accuracy. This is somewhat surprising in that it suggests that metamemory may be a skill that does not benefit from overt practice. However, given that Experiment 1 provided an initial demonstration of this result, the goal of Experiment 2 was to further test these preliminary findings.
Two design changes were made to maximise our ability to detect any potential group differences in final metamemory accuracy. First, the sample size in Experiment 2 was increased substantially to provide greater power, an issue of particular importance given that the primary results of Experiment 1 were null differences between the JOL All and JOL Final groups. Second, Experiment 2 had four study-test blocks rather than three. This was done to increase the strength of our practice manipulation, thereby increasing the likelihood of observing group differences in final metamemory accuracy if they are to be found. These changes also carried the added benefit of increasing the likelihood of observing a clearer increase in resolution in the JOL All group. To foreshadow, this increase was indeed found in Experiment 2.
Method
Participants
In total, 300 participants were recruited from MTurk in exchange for monetary compensation. Participants were required to have at least 98% Human Intelligence Task (HIT) Approval Rate and to be located within the United States. The sample sizes of Experiment 1 were chosen based on similar, multi-block studies of metamemory and had very high power for detecting improvement in metamemory accuracy similar to the effects found in those studies (see Participants section for Experiment 1). The sample size of Experiment 2 was chosen to be much larger than that in those studies and far larger than that in typical multi-block studies of metamemory.
We pre-registered that we would exclude participants that wrote down studied word pairs, were non-native English speakers, missed three or more attention checks, and had missing data. With these criteria, 10 were excluded for admitting to writing down the study words, 5 for failing three or more attention checks, and 4 for having missing data. No participants were excluded for being non-native English speakers. We excluded additional participants for meeting criteria that we did not pre-register to ensure data quality: 29 were excluded on the basis of experimenter error, and 12 were excluded because they also participated in Experiment 1. Two participants took part in Experiment 2 twice, and we excluded their second attempt in data analysis. This left a final sample of 240 participants, with 123 in the JOL All group and 117 in the JOL Final group. For the resulting sample size, the power to detect a difference in resolution during the final block is 80% for d = .36 and 95% for d = .47.
Design and materials
Experiment 2 followed a 2 (group: JOL All vs. JOL Final; between-subjects) × 4 (block; within-subjects) mixed design. To increase the generalisability of our results, participants in Experiment 2 studied word pairs drawn from a large pool of items rather than from a single list. Stimuli were 800 nouns drawn from the English Lexicon Project (Balota et al., 2007). These nouns were between four and six letters in length (M = 4.86, SD = .11), with written frequencies between 100 and 1,000 (M = 245.95, SD = 24.00; Kucera & Francis, 1967) and concreteness ratings between 2.86 and 5 (M = 3.83, SD = .13; Brysbaert et al., 2014). Each study list was created by first sampling 36 words from the word pool to serve as the cues. Next, 36 target words were randomly selected from the set of remaining words that were neither forward nor backward associates of the cue words according to the University of South Florida (USF) free association norms (D. L. Nelson et al., 2004). Finally, word pairs were formed by randomly pairing cues with targets.
Participants in Experiment 2 were randomly assigned to 1 of 10 counterbalancing lists. These lists were formed by randomly assigning 36 word pairs to each list. In each list, an additional two pairs were randomly selected to serve as primacy buffers and two as recency buffers. As in Experiment 1, analyses were conducted for the 36 unrelated word pairs of interest in a given list.
Procedure
The procedures of Experiment 2 were identical to those of Experiment 1 except participants in Experiment 2 completed four study-test blocks rather than three. Participants in the JOL All condition again provided JOLs during each block, whereas participants in the JOL Final condition only did so during the final (fourth) block.
Results
Effects of practice on metamemory
To test whether metamemory accuracy increased with practice, we conducted a 4-way (Block) repeated-measures ANOVA of calibration for participants in the JOL All group (see Figure 5). This analysis revealed a significant effect of Block on calibration, F(2.23, 272.61) = 3.72, p = .021,
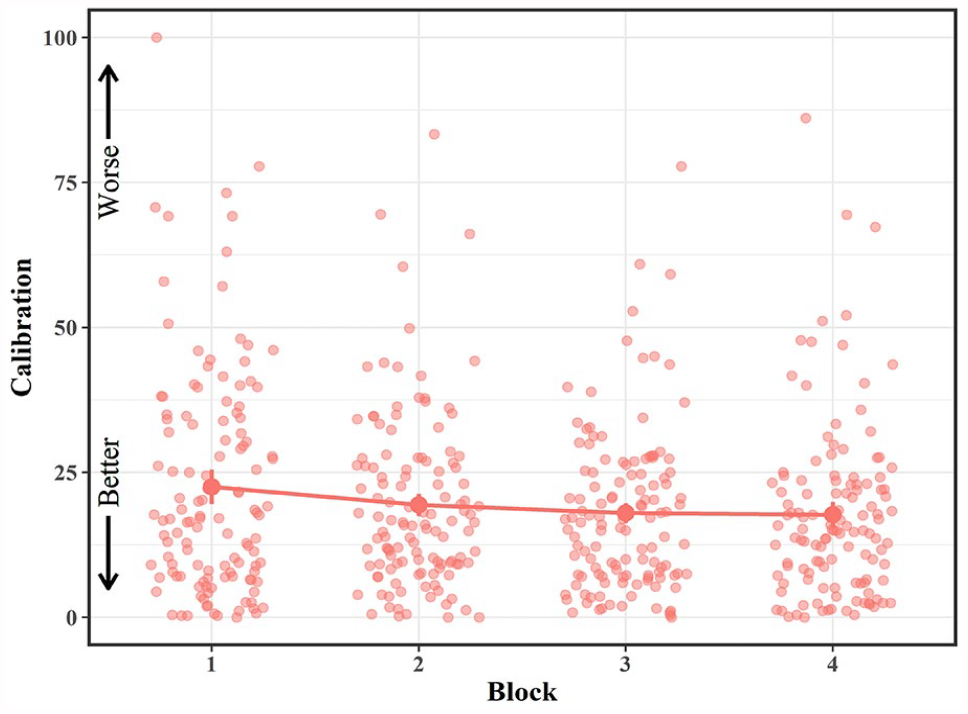
Mean calibration in the JOL All group across blocks in Experiment 2.
A similar analysis of resolution revealed a significant effect of block, F(2.62, 243.68) = 31.69, p < .001,
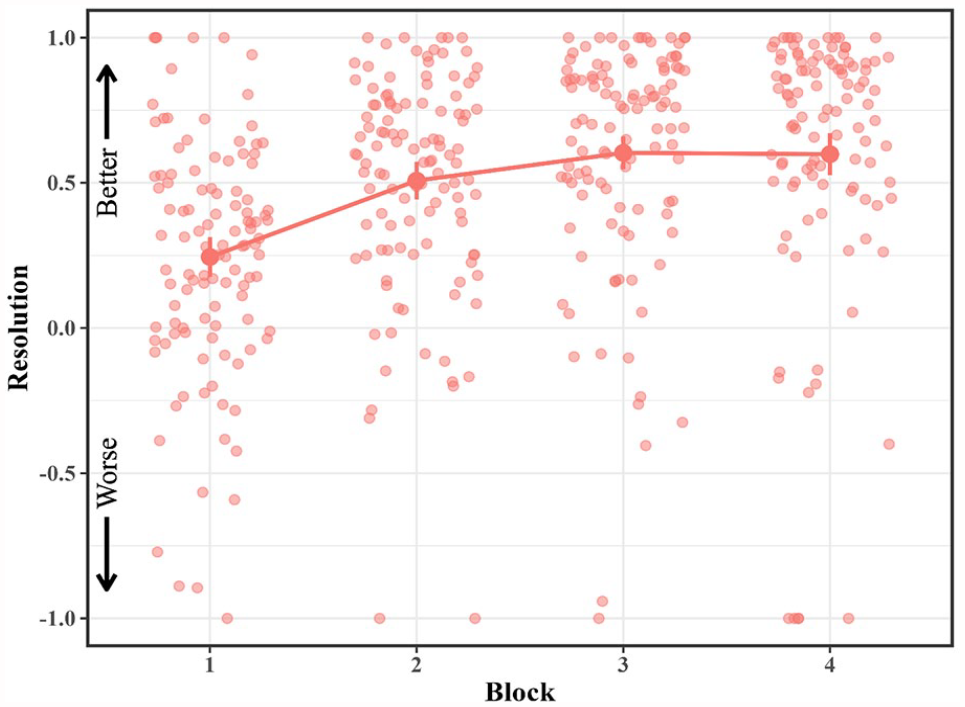
Mean resolution in the JOL All group across blocks in Experiment 2.
Finally, we tested whether backward gamma was greater than resolution. Paired t-tests indicated that backward gamma was greater than resolution in Block 2, t(110) = 5.49, p < .001, dz = .522, BF10 = 49,225.28; Block 3, t(107) = 5.84, p < .001, dz = .562, BF10 > 100,000; and Block 4, t(211) = 8.18, p < .001, dz = .535, BF10 > 100,000.
Group differences in final metamemory accuracy
Next, we assessed whether final metamemory accuracy differed between the JOL All and JOL Final groups. As in Experiment 1, calibration did not differ between groups during the final block, t(228.51) = 1.85, p = .066, d = .239, BF10 = .69. Also consistent with the results of Experiment 1, neither resolution, t(198.21) = .13, p = .895, d = .018, BF10 = .15, nor backward gamma, t(214.30) = .06, p = .954, d = .008, BF10 = .15, differed between groups during the final block. As in Experiment 1, directional Bayesian t-tests provided evidence in favour of the null hypothesis for both calibration and resolution (Directional Calibration BF01 = 19.25, Directional Resolution BF01 = 6.06). Thus, the final metamemory accuracy in the JOL All group did not exceed that of the JOL Final group in Experiment 2.
JOL reactivity
Finally, we investigated whether participants in Experiment 2 exhibited positive JOL reactivity, wherein participants who make JOLs perform more accurately than participants who do not (Double et al., 2018). A 2 (group: JOL All vs. JOL Final; between-subjects) × 3 (block; within-subjects) mixed ANOVA of recall performance revealed a main effect of block, F(1.44, 343.01) = 458.82, p < .001,
Discussion
Experiment 1 provided preliminary evidence that actually making JOLs is unnecessary for increased metamemory accuracy. The goal of Experiment 2 was to provide a more powerful replication of the null results of Experiment 1. To this end, Experiment 2 had a larger sample size and a stronger manipulation of practice (i.e., four study-test blocks rather than three). Despite these changes which should maximise our ability to detect group differences, participants in the JOL All and JOL Final groups did not differ in either calibration or resolution during the final block. These results provide additional evidence that practicing metamemory judgements is not necessary to observe improvements in metamemory accuracy.
Crucially, the critical results of Experiment 1 were replicated along with more definitive evidence of increased metamemory accuracy with practice. Experiment 1 demonstrated improved calibration, but the results with resolution were unclear. In Experiment 2, both calibration and resolution improved across blocks. As such, the current results demonstrate with greater clarity that when participants improve in their ability to monitor their learning, such improvements are not explained by participants having practised JOLs per se but are similarly induced in their absence.
In addition to replicating the lack of a group difference in final metamemory accuracy, Experiment 2 replicated results from Experiment 1 regarding the UWP effect and backward gamma. As in Experiment 1, participants tended to become less overconfident with practice (see Supplementary Material). Also consistent with Experiment 1, backward gamma exceeded resolution, providing further support for the MPT framework’s prediction that learners are particularly sensitive to prior retrieval success when predicting their memory performance (Finn & Metcalfe, 2007, 2008).
One way in which the results of Experiments 1 and 2 diverged—however—relates to JOL reactivity. Whereas we did not observe JOL reactivity in Experiment 1, Experiment 2 showed evidence of positive JOL reactivity, with participants in the JOL All group exhibiting higher recall performance than participants in the JOL Final group. Of note, the higher recall of the JOL All group persisted into the final block even though at this point, both groups made JOLs, t(237.61) = 3.16, p = .002, d = .408, BF10 = 14.68. Although this contrasts with the results of Experiment 1 as well as meta-analytic evidence that JOL reactivity is unlikely when participants study unrelated word pairs (Double et al., 2018; see also, Soderstrom et al., 2015), we are not the first to find such results. For example, Dougherty et al. (2005) likewise found that participants who made JOLs had higher recall performance for unrelated word pairs than participants who did not.
Experiment 3
The results of Experiments 1 and 2 provide converging evidence that participants who practice making JOLs are no better at monitoring their learning than those who do not. Although such results suggest that practicing metamemory judgements does not result in increased metamemory accuracy, another possibility warrants consideration. More specifically, it is plausible that practicing metamemory judgements might enhance metamemory accuracy in situations where making such judgements is more likely to draw participants’ attention to between-item differences in memorability. If items are more variable in their memorability, participants who repeatedly make metamemory judgements may be more likely to attend to this variability and increase their metamemory accuracy accordingly. This possibility is consistent with theorising which suggests that practicing metamemory judgements increases metamemory accuracy by drawing participants’ attention to performance-relevant cues (Double & Birney, 2019).
To test this possibility, participants in Experiment 3 studied a mixed list of semantically related and unrelated word pairs. Given that semantically related word pairs are better remembered than unrelated pairs (Connor et al., 1997; Epstein et al., 1975; Mueller et al., 2013), manipulating semantic relatedness within subjects should provide learners with more opportunities to attend to between-item differences in memorability. To the extent that repeatedly making metamemory judgements draws participants’ attention to such differences (Double & Birney, 2019), the potential benefits of practicing making metamemory judgements should be more likely to manifest under such conditions. However, should group differences in final metamemory accuracy not emerge in Experiment 3, this finding would suggest that practicing metamemory judgements does not benefit metamemory accuracy even in situations where such benefits are most likely to occur. Thus, Experiment 3 was intended to serve as an even stronger test of our primary research questions.
Method
Participants
In total, 143 participants recruited from MTurk took part in Experiment 3 in exchange for monetary compensation. We initially planned to collect data on 116 participants before exclusions to achieve sufficient power in the JOL All group to detect an increase in resolution comparable to that observed in Experiment 2. However, because 28 participants participated in prior experiments or in Experiment 3 more than once, these participants were replaced. Of the remaining 115 participants, in accordance with our preregistered exclusion criteria, 16 were excluded for admitting to writing down words during the study phase, one was excluded for being a non-native English speaker, and three were excluded for failing at least three of the four attention checks. This left a final sample of 95 participants, with 41 in the JOL All group and 54 in the JOL Final group. This sample size left sufficient power in the JOL All group to detect the increase in resolution observed in Experiment 2 (
Design and materials
In Experiment 3, participants studied both related and unrelated word pairs. Related pairs were 40 noun-noun pairs taken from a prior study which demonstrated significantly higher cued recall and JOLs for related than unrelated pairs (Connor et al., 1997, Experiment 3; e.g., lamp-desk, nose-ear). These nouns were three to nine letters in length (M = 4.99, SD = 1.35), with an average written frequency of 58.24 (SD = 72.12; Kucera & Francis, 1967) and an average concreteness rating of 4.82 (SD = .20; Brysbaert et al., 2014).
According to USF free association norms (D. L. Nelson et al., 2004), related pairs had an average forward associative strength of .027 (SD = .012, range = .010–.047). To prevent guessing, no target was the primary associate of its corresponding cue. Forty unrelated word pairs were formed by randomly re-pairing related cues and targets. USF associative norms confirmed that these 40 pairs were indeed unrelated.
For the purposes of counterbalancing, two study lists were formed by randomly assigning 20 cues to have related targets in List A and unrelated targets in List B and 20 cues to have unrelated targets in List A and related targets in List B. Within each list, two primacy buffers and two recency buffers were randomly chosen with the constraint that related and unrelated pairs served as buffers equally often. Analyses were conducted on 36 pairs of interest, with 18 being related and 18 being unrelated. The related and unrelated pairs were randomly intermixed in the study list. Related pairs did not differ in their forward associative strength between lists, t(33.05) = .04, p = .968, d = .014, BF01 = .32.
Procedure
The procedures in Experiment 3 were identical to those of Experiment 2.
Results
Effects of practice on metamemory
To assess whether calibration increased with practice, we conducted a 4 (block) × 2 (relatedness: related vs. unrelated; within-subjects) repeated-measures ANOVA of calibration for participants in the JOL All group (see Figure 7). This analysis revealed a main effect of block, F(1.97, 78.71) = 21.47, p < .001,
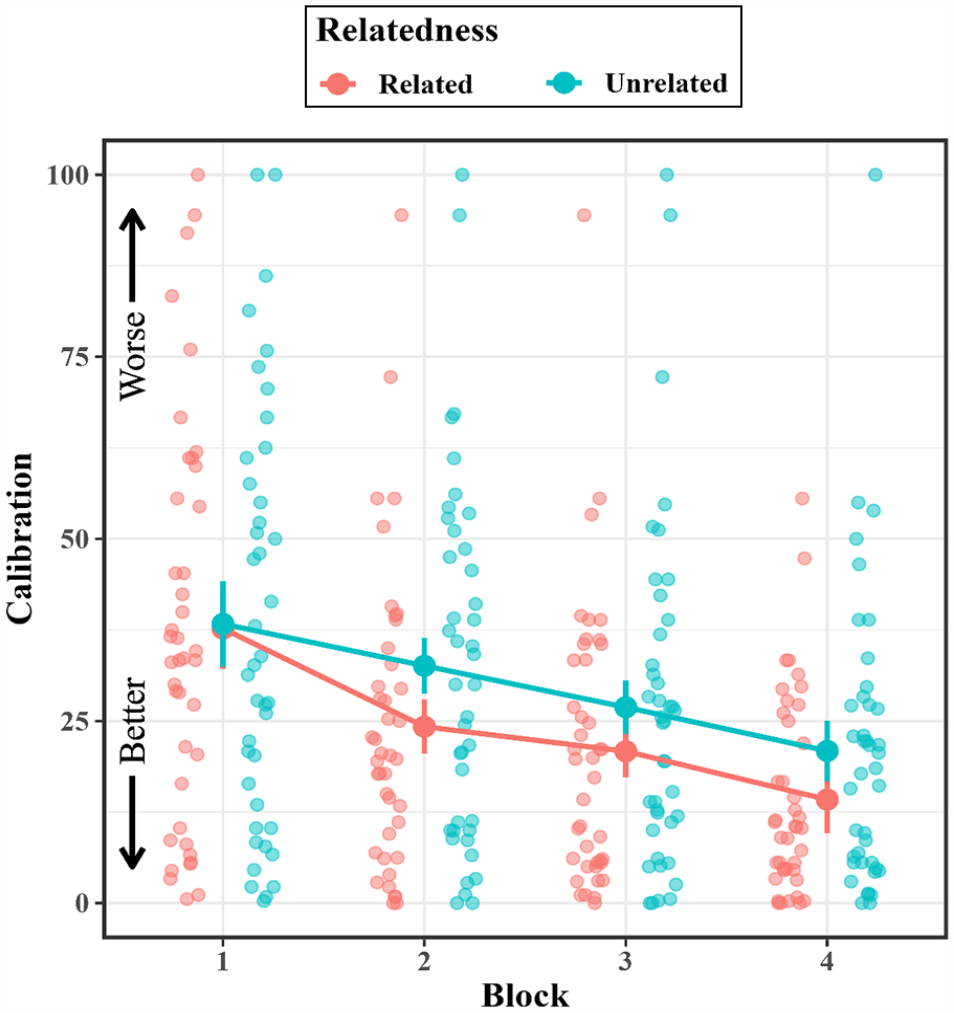
Mean calibration in the JOL All group across blocks in Experiment 3.
Next, we examined whether resolution increased across blocks in the JOL All group (see Figure 8). For resolution, we conducted a 4 (block) × 2 (relatedness: related vs. unrelated; within-subjects) repeated-measures ANOVA. Resolution did not increase across blocks, F(2.38, 30.98) = 1.64, p = .206,
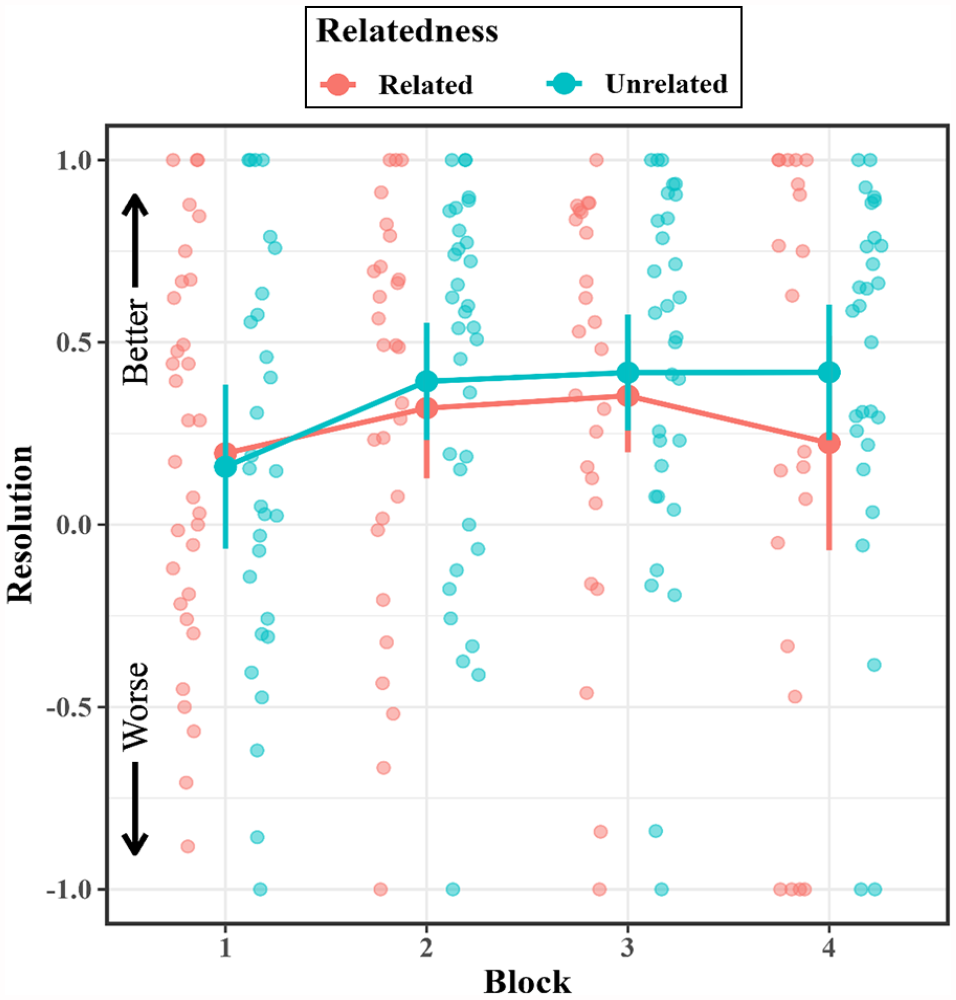
Mean resolution in the JOL All group across blocks in Experiment 3.
Similar results were found with respect to the backward gamma, in which the effects of block (2–4), F(1.87, 28.11) = .21, p = .799,
To test whether backward gamma was greater than resolution, we conducted a series of paired t-tests on the resolution data computed for all items regardless of relatedness. Although backward gamma and resolution did not differ during Block 2, t(34) = .70, p = .488, dz = .119, BF10 = .28, backward gamma was greater than resolution during Block 3, t(30) = 2.72, p = .011, dz = .488, BF10 = 4.14, and Block 4, t(62) = 2.55, p = .013, dz = .321, BF10 = 2.68.
Group differences in final metamemory accuracy
To test whether practicing metamemory judgements impacted metamemory accuracy during the final block, calibration and resolution for the fourth block were each submitted to separate 2 (group: JOL All vs. JOL Final; between-subjects) × 2 (relatedness: related vs. unrelated; within-subjects) mixed ANOVAs. With regard to calibration, the effect of group was insignificant, F(1, 93) = 2.38, p = .126,
With regard to resolution, the effect of group was insignificant, F(1, 46) = 3.00, p = .090,
In terms of backward gamma, the effects of group, F(1, 53) = 1.91, p = .173,
Bayesian t-tests were conducted after computing metamemory accuracy regardless of relatedness. As in prior experiments, directional Bayesian t-tests provided evidence in favour of the null hypothesis (Directional Calibration BF01 = 10.78, Directional Resolution BF01 = 8.06).
JOL reactivity
To examine JOL reactivity, recall during Blocks 1–3 was submitted to a 3 (block; within-subjects) × 2 (group: JOL All vs. JOL Final; between-subjects) × 2 (relatedness: related vs. unrelated; within-subjects) mixed ANOVA. This analysis revealed a significant effect of relatedness, F(1, 93) = 136.27, p < .001,
Discussion
The primary goal of Experiment 3 was to test whether the results of Experiments 1 and 2—which both had unrelated word pairs—would generalise to an experiment in which participants studied both related and unrelated word pairs. If there are circumstances in which practicing metamemory judgements improves metamemory accuracy, these benefits might be most likely when the study list has items that strongly vary in their memorability (Double & Birney, 2019). By this line of reasoning, the use of a mixed list of related and unrelated word pairs in Experiment 3 provided a more sensitive assessment of the potential benefits of metamemory practice on metamemory accuracy.
Even so, the results of Experiment 3 replicated those of Experiments 1 and 2 in showing that participants in the JOL All and JOL Final groups did not differ in their final metamemory accuracy. These findings support the generality of our previous results; rather than being restricted to unrelated word pairs, it appears that the lack of an effect of metamemory practice on metamemory accuracy extends to mixed lists of related and unrelated word pairs as well, even though the relatedness manipulation had substantial effects on recall and JOLs as expected based on prior research (see Mueller et al., 2013, Table 1).
The results of Experiment 3 provided some evidence for increased metamemory accuracy with practice. Consistent with the results of Experiments 1 and 2, Experiment 3 demonstrated a clear increase in calibration. More specifically, participants in the JOL All group became better calibrated during every block of Experiment 3. The results regarding resolution—however—were less clear. Although the omnibus effect of practice on resolution was insignificant, a t-test revealed that—as in Experiment 1—resolution improved between Blocks 1 and 2, t(33) = 2.14, p = .040, dz = .336, BF10 = 1.36. However, given that these analyses are exploratory in nature, these results should be interpreted with caution. The single-paper meta-analyses (SPMs) reported below are intended to provide a more complete picture of the effects of practice on resolution in the current experiments.
The results of Experiment 3 regarding UWP and backward gamma were generally consistent with Experiments 1 and 2. As in prior experiments, participants in Experiment 3 became less overconfident with practice (see Supplementary Material). Analyses of backward gamma indicated that backward gamma exceeded resolution during Blocks 3 and 4, although this difference was not significant during Block 2. Thus, the results of Experiment 3 regarding backward gamma were consistent with prior experiments in so far as they provided evidence that learners used their prior retrieval success as cue to predict their memory performance during the majority of blocks in the experiment.
As a secondary analysis, we assessed whether participants in Experiment 3 exhibited JOL reactivity. Of note, there was a significant interaction effect between block and group on recall performance. Even so, follow-up analyses indicated that the two groups did not differ during any of the first three blocks. Thus, like Experiment 1, Experiment 3 did not show evidence that making JOLs leads to increased recall performance. Although JOL reactivity is more likely with related than unrelated word pairs, there is contradictory evidence about whether this occurs in mixed lists of related and unrelated pairs. Meta-analytic evidence indicates that JOL reactivity is unlikely to manifest when participants study mixed lists with both related and unrelated word pairs (Double et al., 2018), but some subsequent studies show significant JOL reactivity restricted to the related pairs in mixed lists (Jane et al., 2018; Maxwell & Huff, 2023). It is clear that additional research is required to determine when reactivity is likely in mixed lists.
Single-paper meta-analyses
The primary goal of the current study was to determine whether making metamemory judgements is necessary for observing increased metamemory accuracy with practice. To assess this issue, it is important to first demonstrate that metamemory accuracy improves to begin with. Evidence in favour of improved calibration was consistent, as the effect of practice on calibration was significant in every experiment. Evidence in favour of improved resolution—however—is less clear: The effect of practice on resolution was significant in Experiment 2 but not in Experiments 1 and 3. Even so, despite the main effect of block on resolution being insignificant in Experiments 1 and 3, there was evidence of an initial increase in metamemory accuracy: Resolution increased between Blocks 1 and 2 in both Experiment 1, t(24) = 2.20, p = .038, dz = .440, BF10 = 1.60, and Experiment 3, t(33) = 2.14, p = .040, dz = .336, BF10 = 1.36, at least based on frequentist analyses. To investigate this issue further, we conducted an SPM (McShane & Böckenholt, 2017) to investigate changes in resolution across blocks in the JOL All group (see Supplementary Material for the data used in the SPM). Because Experiment 3 was the only experiment to vary semantic relatedness, the data for Experiment 3 were collapsed across this factor. Only participants with complete data were included. The effects of practice on resolution in the JOL All group were analysed using an SPM with block (1–4) as a within-subjects factor. 12 An omnibus Wald test indicated that resolution showed a significant, medium-sized increase across blocks, Wald χ2(3) = 34.38, p < .001, w = .42. We also conducted an SPM to provide a more powerful test of whether the JOL All and JOL Final groups differed in resolution during the final block of each experiment. This analysis indicated that the two groups did not differ in final resolution (SPM Estimate = −.03, SE = .05, 95% CI [−.13, .07]).
In addition to conducting SPMs, we also synthesised results in the current experiments by computing meta-analytic Bayes factors using the BayesFactor R package. Consistent with the SPMs, these Bayesian analyses revealed that participants’ resolution improved between Blocks 1 and 2 (BF10 > 100,000). Resolution did not, however, improve between Blocks 2 and 3 (BF10 = .47) or Blocks 3 and 4 (BF10 = .11). Also consistent with the SPM results, a meta-analytic Bayesian analysis revealed that the JOL All and JOL Final groups did not differ in resolution during the final block (BF10 = .15)
These SPMs and Bayesian analyses indicate that despite significant improvements in resolution with practice, participants who practice making JOLs do not show increased metamemory accuracy compared to those who do not.
General discussion
Increased metamemory accuracy with practice does not require practice with metamemory
Given that predictions about memorability guide study behaviour (e.g., Metcalfe, 2009; Metcalfe & Finn, 2008), and that these predictions are not always accurate (e.g., Besken & Mulligan, 2014; Koriat & Bjork, 2005; Koriat et al., 2002; Rhodes & Castel, 2008), there is a pressing need to understand how metamemory accuracy can be improved. The current study examined the mechanisms underlying one way in which metamemory accuracy can be improved: practice (Ariel & Dunlosky, 2011; Finn & Metcalfe, 2007, 2008; Hanczakowski et al., 2013; Koriat, 1997; Koriat et al., 2002, 2006, 2008, Experiment 1; Kubik et al., 2022; Scheck & Nelson, 2005; Tauber & Rhodes, 2012; Zawadzka & Higham, 2015). Specifically, is making metamemory judgements necessary for improvement, and more generally, change, in metamemory accuracy? To this end, participants in three experiments completed multiple study-test blocks of cued recall, with one group of participants making JOLs throughout the experiment (the JOL All group) and the other making JOLs only during the final block (the JOL Final group). Final metamemory accuracy was compared between groups. In short, our results indicate that increased metamemory accuracy with practice does not require practice with metamemory.
Before interpreting group differences in final metamemory accuracy more fully, it is first important to assess whether metamemory accuracy did indeed improve with practice. Notably, although it is often the case that metamemory accuracy improves, this is not always found (Hanczakowski et al., 2013, Experiment 1; Koriat, 1997; Koriat et al., 2002; Serra & Dunlosky, 2005). Evidence of improved calibration was demonstrated in all three experiments and tended to be most pronounced during earlier blocks (though calibration significantly improved during the later blocks of Experiment 3 as well). This result is consistent with prior research regarding the UWP effect, which often finds that changes in calibration tend to be strongest between the first and second blocks (Koriat et al., 2002). Resolution likewise demonstrated improvements, although this evidence was somewhat less consistent. The positive effect of practice on resolution was significant in Experiment 2, but not in Experiments 1 or 3. Even so, despite differences in the pattern of statistical significance between experiments, an SPM indicated that—in aggregate—participants demonstrated improved resolution. Such results suggest that participants became better able to monitor their learning over blocks in terms of both calibration and resolution.
Having established that participants became more accurate in their metamemory judgements with experience, we now consider our central question: whether practicing metamemory judgements is necessary to observing increased metamemory accuracy. Although one might expect that being deprived of the opportunity to engage in overt practice with JOLs would hinder improvement, our results suggest that—for metamemory—this is not the case; participants who made metamemory judgements were no better able to predict their memory performance than those who did not. More specifically, participants in the JOL All and JOL Final group did not differ in their final calibration or resolution. Note that our calibration measure is the absolute difference between JOLs and actual recall; the average JOLs (see Table 2) make it clear that the groups are equivalent in the direction (over or underconfidence) as well as the degree of calibration. In addition, Bayesian analyses consistently provided evidence in favour of the hypothesis that participants in the JOL All group did not have greater final metamemory accuracy than participants in the JOL Final group. Of note, the lack of group differences in calibration was also replicated in an analysis that used an alternative operationalization of calibration derived from calibration curves, thus demonstrating the robustness of our results (see Supplementary Material).
Our findings are consistent with the few studies that have investigated similar issues and shed new light on them. As mentioned previously, in the study by England and Serra (2012), participants made JOLs for some items in a study list but not for others in the first study-test blocks. In the second block, JOLs were made for all items, and metamemory accuracy was equivalent for both types of items. Given that JOL practice was manipulated within subjects, this result could have indicated either: (1) that JOL practice aids metamemory accuracy and transfers to other items that were not subject to JOL practice; or (2) that JOL practice is not needed for improvement. The current results clarify this finding, indicating that JOL practice is not necessary; merely engaging in repeated rounds of study and test enhances metamemory accuracy regardless of JOL practice.
Another study consistent with the current results, reported in the Supplementary Material of Jang et al. (2012), came to our attention after this study was completed. In the experiment by Jang et al., participants studied word pairs under several different practice conditions in a first block, engaging in study only, study with JOLs, study followed by test, or study with JOLs followed by test (in addition, a control group did not engage in the first block). All groups subsequently completed a study-JOL-test block, with half the JOLs performed immediately, and half after a delay. Resolution did not differ across groups for delayed JOLs but did for immediate JOLs. Consistent with our results, participants who first engaged in study-test did not differ in final resolution (for immediate JOLs) from the group who first performed a study-JOL-test block. This converges with the current experiments. However, the current experiments also show that the result holds for improvements in calibration, with a stronger manipulation of practice, with much larger samples (and power), with varying materials (related and unrelated pairs), and when only immediate JOLs are made.
Implications for theories of metamemory
The current results have important implications for theories of metamemory. Several accounts of metamemory imply that practicing JOLs is important for changes in metamemory performance. For example, the anchoring account (Scheck & Nelson, 2005) argues that making JOLs over multiple trials entails first establishing an anchor point and then making a series of adjustments as learning trials unfold. Under this view, the process of making and adjusting JOLs contributes to the end state of metamemory accuracy. The current results indicate, in contrast, that even in the absence of making earlier JOLs, the learner ends up at the same metamemory end state. To cohere with these results, the anchoring account would have to assume that learners develop a JOL anchor and repeatedly adjust it even when not required to make the judgement to begin with and do so to the same degree as when required to explicitly make the judgement.
Another interpretation of the anchoring account might argue that the process of anchoring and adjusting occurs independently on each trial. If so, then the final JOLs entail an equivalent trial-specific process of anchoring and adjusting for both the JOL All and JOL Final groups. Provided the JOL All and JOL Final participants attend to the same cues on the final round (e.g., past test performance), this would result in similar JOLs and similar metacognitive accuracy in the two conditions. However, this interpretation of the anchoring account does not seem viable for two reasons. First, it conflicts with the standard version of the anchoring account which argued that the initial anchor is adjusted across multiple trials (Scheck & Nelson, 2005). Second, the effect of initial (uninformative) anchors persists across multiple trials (Ikeda, 2023), contrary to the notion that JOLs across multiple trials entail independent anchor-and-adjustment procedures.
The claim that explicit metacognitive monitoring (e.g., JOL judgements) is resource-demanding and so represents a dual-task challenge along with the primary task (e.g., memory encoding, Griffin et al., 2008; Mitchum et al., 2016) implies that monitoring should improve with practice because the ability to perform (and co-ordinate) two resource-demanding tasks generally improve with practice (e.g., Hirst et al., 1980; Pashler, 1994; Ruthruff et al., 2006). In contrast, failing to practice both tasks, that is, practicing only memory encoding and not also engaging in explicit monitoring should lead to less or no improvement. This view implies that the JOL All condition should have produced greater metamemory accuracy on the final block, but this was not found.
Likewise, our results contradict implications of the cue-driven metacognitive framework of reactivity which proposes that making JOLs should affect subsequent metamemory accuracy by affecting the mix of cues to which a learner attends (Double & Birney, 2019). The lack of group differences in metamemory accuracy in the current experiments suggests that making JOLs did not generally affect the cues attended to or, more specifically, improve participants’ ability to take performance-relevant cues into account when predicting their memory performance. In terms of specific performance-relevant cues which might have aided metamemory, participants in Experiment 3 studied word pairs which varied in their relatedness, yet despite relatedness impacting memory performance, participants who made JOLs were not better able to account for this effect compared to those who did not. Future research should examine the robustness of our results by examining the effects of making metamemory judgements in the presence of additional performance-relevant cues, such as word frequency and emotionality.
As noted in the introduction, the cue-driven metacognitive framework is related to the cue-strengthening account (Soderstrom et al., 2015), which likewise proposes that under some conditions (e.g., for related word pairs), performance-relevant cues become salient and are used to make metacognitive judgements. This has the effect of enhancing memory of those items, but may also enhance metamemory accuracy with practice. However, this account only renders clear implications under conditions producing JOL reactivity. Thus, this account seems in conflict with Experiment 2, in which JOL reactivity was found along with no effect of JOLs on metamemory accuracy. But Experiments 1 and 3 (which found no JOL reactivity) are less relevant to this account. Additional research focused specifically on JOL reactivity are needed to more fully assess the implications of the cue-strengthening account for metamemory accuracy.
It should be noted that each of the three accounts (anchoring, dual-task, and the cue-driven metacognitive framework) has received support with regard to others of their predictions, so the current results do not broadly impeach these accounts. Rather, the current results indicate that the theories require additional development regarding the role (or lack thereof) of making JOLs in changes in metamemory accuracy. This is especially important because all three accounts embody proposals of how metamemory monitoring changes with practice, and so need to clarify this foundational issue.
Instead, our results agree with accounts that highlight the beneficial effects of prior retrieval on subsequent metamemory accuracy. According to the MPT framework, participants use their memory of prior retrieval success to inform subsequent metamemory judgements (Finn & Metcalfe, 2007, 2008). By doing so, participants should become better able to predict their subsequent memory after being tested. It is important to note that the current experiments provided consistent evidence that participants did indeed use prior retrieval success to guide metamemory predictions, as backward gamma (i.e., the association between prior retrieval success and current JOLs) was consistently greater than resolution (i.e., the association between current JOLs and subsequent retrieval success). These results reinforce the applicability of the MPT framework as a viable explanation for the current data. A similar prediction is made by theorising related to the testing effect in that testing is thought to allow learners to better monitor their learning by showing them what they do and do not know (Roediger et al., 2011). As an aside, this implies that retrieval does not just enhance memory (i.e., the testing effect) but also metamemory, an observation that is well attested in the metamemory literature (as represented by the MPT framework, e.g., Finn & Metcalfe, 2007) but less discussed in the literature on the testing effect itself.
However, as noted in the Introduction, the accounts focusing on retrieval benefits do not deny the possibility that making metamemory judgements might benefit metamemory as well. It would not be contrary to these accounts if overt JOLs enhanced metamemory over and above the contribution of retrieval. However, the lack of group differences in the current experiments argues against this possibility and suggests that prior retrieval is sufficient to explain the increased metamemory accuracy often observed in multi-trial learning experiments. Thus, the current results constrain how these accounts should be interpreted.
On this point, we consider one last account, and a central theory of metamemory, Koriat’s (1997) cue-utilisation account, which implies that both making JOLs and retrieval may contribute to changes in metamemory accuracy with practice. The cue-utilisation account argues that JOLs are inferential, as opposed to reflecting direct access to memory traces, and are driven by various types of cues (intrinsic, extrinsic, and mnemonic), some related to memory outcomes and others less so. The cues used by this inferential process are theorised to change with practice, to wit: “It is proposed that the improved resolution with repeated study of a list of items derives specifically from a change in the basis of JOLs, from a greater reliance on intrinsic cues towards a greater reliance on internal-mnemonic cues” (Koriat, 1997, p. 353), and “With practice learning the same items, JOLs become increasingly more tuned to internal cues” (Koriat, 1997, p. 365). The notion that an inferential process changes with practice suggests that experience with that inferential process (i.e., making JOLs) contributes to its change. Alternatively, Koriat (1997) also noted that JOLs become increasingly related to memory performance on prior tests, implying that an MPT mechanism contributes to changes in metamemory accuracy. In sum, the details of the cue-utilisation account imply that prior JOLs may contribute but are not the whole reason why metamemory accuracy changes with practice. However, it should be noted that this theory is not explicit about the role of prior JOLs in changing metamemory accuracy but leaves the reader to draw inferences from the logic of the account. This indicates the present results are useful for guiding theory development as well as for testing more direct implications of theories.
In this regard, the current results make clear, however, that practicing JOLs is not necessary for improvements in metamemory accuracy. Mere experience with learning the materials is sufficient. This indicates that changes in the basis of the inferential process of making JOLs occurs absent of any overt requirement to make use of this process. The cue utilisation account also emphasises the role of remembering prior test performance as a basis for subsequent JOLs, which makes this aspect of the model similar to the MPT account and consistent with the current results. Importantly, the current results constrain theory and highlights a point on which theories of monitoring are not always clear.
Future directions
We have focused on retrieval practice as the likely basis of increased metamemory accuracy, but we must emphasise that based on the research paradigm used in the current experiments wherein all participants engaged in both restudy and retrieval, we are unable to disentangle effects driven by restudying from those driven by retrieval practice. Even so, because prior research suggests that retrieval practice leads to increases in metamemory accuracy above and beyond restudying (Chen et al., 2019; England & Serra, 2012; Hughes et al., 2018; Jang et al., 2012; King et al., 1980; Kornell & Rhodes, 2013; Shaughnessy & Zechmeister, 1992) and that allowing participants to restudy information does not increase their metamemory accuracy (Jang et al., 2012), we consider it likely that the observed improvements in metamemory accuracy are due to retrieval practice.
Consistent with the bulk of theoretical and empirical work reviewed, the current studies focused on changes in metamemory accuracy when the same material is learned over multiple trials. An important issue for future research is to examine whether practicing JOLs has any impact on subsequent metamemory accuracy when learning new materials. As mentioned in the introduction, two studies speak to this issue and produced conflicting answers both with respect to resolution and calibration. Vesonder and Voss (1985) reported that prior monitoring enhanced resolution for new material, but Kelemen et al. (2007) found that it did not. Likewise, Kelemen et al. (2007, Experiment 2) found some evidence of better calibration, but Vesonder and Voss (1985) did not. Neither of these studies was directly focused on the issues reviewed here, and neither produced definitive results. This is an especially important issue to investigate because metamemory accuracy for new material cannot be impacted by memory for prior test outcomes, which is the leading candidate for the metamemory improvement when the same materials are learned over multiple trials. Consequently, a reason that JOL practice is ineffective (memory for prior tests) will be removed, rendering it possible that JOL practice will be helpful when switching to new material. With regard to resolution, the results of Vesonder and Voss (1985) imply that this will be the case, but the results of Kelemen et al. (2007) argue the opposite. Investigating this issue is an important next step.
When interpreting the current results, it is important to keep in mind that we assessed metamemorial accuracy using immediate JOLs. That is, participants in the current experiments were asked to make JOLs immediately following the initial presentation of studied items as opposed to making JOLs after a delay. To the extent that students may choose to engage in immediate rather than delayed self-reflection more often during learning, the current use of immediate JOLs may be ecologically valid in that it more closely reflects how students make metamemorial judgements if left to their own devices. Nonetheless, because prior research has demonstrated important distinctions between immediate and delayed JOLs, future research should investigate whether the current results generalise to learning situations in which participants are asked to predict their future memory performance after a delay. Given that immediate JOLs tend to be less accurate than delayed JOLs (for a meta-analysis, see Rhodes & Tauber, 2011), it might be predicted that if practice were to improve the accuracy of JOLs, such improvements would be more likely for immediate JOLs, which may have more “room for improvement” compared to delayed JOLs, which should already be relatively accurate. This line of thinking suggests that neither immediate nor delayed JOLs would show improvements in metacognitive accuracy following overt JOL practice. Nonetheless, whether the current results apply to both immediate and delayed JOLs is an open question for future research.
Conclusion
In summary, the current experiments suggest that although metamemory improves with practice, such improvements do not require practice with metamemory. Instead, improvements in metamemory occur regardless of whether participants are asked to monitor their learning and are therefore likely explained by factors associated with multi-trial learning such as retrieval practice. Such results suggest that attempts to improve learners’ metamemory accuracy by giving them practice engaging in such monitoring may prove ineffective.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218241269322 – Supplemental material for Increased metamemory accuracy with practice does not require practice with metamemory
Supplemental material, sj-docx-1-qjp-10.1177_17470218241269322 for Increased metamemory accuracy with practice does not require practice with metamemory by John T West, Jack M Kuhns, Dayna R Touron and Neil W Mulligan in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Preparation of this manuscript was supported by National Institute on Aging, Grant T32 AG049676, to The Pennsylvania State University.
Data accessibility statement
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.