
Abstract
Seeing a face in motion can help subsequent face recognition. Several explanations have been proposed for this “motion advantage,” but other factors that might play a role have received less attention. For example, facial movement might enhance recognition by attracting attention to the internal facial features, thereby facilitating identification. However, there is no direct evidence that motion increases attention to regions of the face that facilitate identification (i.e., internal features) compared with static faces. We tested this hypothesis by recording participants’ eye movements while they completed the famous face recognition (Experiment 1, N = 32), and face-learning (Experiment 2, N = 60, Experiment 3, N = 68) tasks, with presentation style manipulated (moving or static). Across all three experiments, a motion advantage was found, and participants directed a higher proportion of fixations to the internal features (i.e., eyes, nose, and mouth) of moving faces versus static. Conversely, the proportion of fixations to the internal non-feature area (i.e., cheeks, forehead, chin) and external area (Experiment 3) was significantly reduced for moving compared with static faces (all ps < .05). Results suggest that during both familiar and unfamiliar face recognition, facial motion is associated with increased attention to internal facial features, but only during familiar face recognition is the magnitude of the motion advantage significantly related functionally to the proportion of fixations directed to the internal features.
Openness, transparency, and reproducibility
While the design, hypotheses, and analysis plan for the experiments reported in this article were not preregistered, efforts were made to comply with the Transparency and Openness Promotion guidelines (Nosek et al., 2015) in the following ways. First, all stimulus materials and analytic methods developed by others have been cited in the text and listed in the “References” section. Second, we report how we determined our sample size, all data exclusions, and manipulations. Third, after deidentification the individual participant data on which study conclusions are based and all the stimulus materials for Experiment 1 have been made publicly available indefinitely at the Open Science Framework (see https://osf.io/xz2hr/). Stimuli used in Experiments 2 and 3 were developed by others, so we do not have permission to share them. Instead, a list of the original stimuli has been made publicly available on the Open Science Framework (see https://osf.io/xz2hr/), including links to the database webpages where the stimuli can be downloaded. Finally, this article has been produced with reference to the APA Style Journal Article Reporting Standards (JARS-Quant Tables 1 and 2, APA, 2020).
Eye movement differences when recognising and learning moving and static faces
Face recognition is the process by which people are identified and distinguished from one another based on the face as a visual stimulus. It is of great importance within applied contexts like person identification at airports and during criminal investigations, but it is also important within our everyday lives to help us navigate social situations. For example, when we identify a person as familiar, perhaps a family member or close friend, we are then able to respond appropriately to them compared with others who are not familiar to us. It is because of this relevance to our everyday lives that several decades of research have sought to understand the complexities of human face recognition and the factors that both impair and enhance it.
Facial movement is one factor that has been found to enhance face recognition (for a review see Xiao et al., 2014). A face can produce two types of motion: rigid and non-rigid. Rigid facial movements are those in which the face maintains its three-dimensional form, while the whole head changes its relative position and/or orientation (e.g., nodding or shaking the head). Non-rigid motions are movements in which individual parts of the face move in relation to one another (e.g., speech movements and expression of emotion). Seeing a face move leads to better learning of previously unfamiliar faces (Butcher et al., 2011; Lander & Bruce, 2003; Pike et al., 1997), more accurate and faster face matching (Thornton & Kourtzi, 2002), and better identification of degraded familiar faces (Butcher & Lander, 2017; Lander et al., 2001). Facial movement has also been found to improve familiar face recognition (Bennetts et al., 2015) and face matching (Longmore & Tree, 2013) in people with developmental prosopagnosia (i.e., individuals with a severe impairment in face recognition), and the facilitative effect of facial movement has been observed in children as young as 3–4 months old (Otsuka et al., 2009). This effect of movement on face recognition is widely referred to as the “motion advantage.”
Behavioural evidence of the impact of facial movement on face recognition has been supported by brain imaging studies that have employed moving stimuli and found that face-specific regions within the superior temporal sulcus (STS) show higher neural activation in response to moving faces relative to static (Fox et al., 2009; Pitcher et al., 2011, 2014). Consequently, Bernstein and Yovel (2015) proposed a dual-route neural model of face processing. According to this model, brain regions within the dorsal face processing pathway (e.g., the face-specific areas in the STS and inferior frontal gyrus) process both changeable facial aspects (e.g., emotional expressions) and facial motion. In contrast, areas within the ventral face processing pathway, including the occipital face area and fusiform face area, process information related to facial form and thus play a role in processing both changeable and invariant facial aspects from static and dynamic faces. The middle temporal visual area sends input to both the dorsal pathway for motion processing and the ventral pathway for structure-from-motion analysis. The dorsal pathway may, therefore, reflect a link between the processing of facial identity and the processing of other aspects of a face (Bernstein et al., 2018).
There are several theories to explain why facial movement might enhance face recognition performance but two theories, first proposed by O’Toole et al. (2002), have dominated the literature. First, the supplemental information hypothesis proposes that we represent characteristic facial motions of individual faces, in addition to the invariant structure of the face. These characteristic facial motions are referred to as “dynamic facial signatures.” This theory has been supported by studies which have shown that it is possible to sort and match shape-normalised facial stimuli based on their motion alone (i.e., faces which only differ in terms of their motion) (Bennetts et al., 2013; Hill & Johnston, 2001). Further evidence for the use of dynamic facial signatures comes from studies that have manipulated the temporal characteristics of facial motion by slowing or speeding clips, or presenting motion in reverse (e.g., Lander & Bruce, 2000; Lander et al., 2006). These manipulations preserve the static (form) information carried in the stimuli but disrupt the characteristic patterns of movement; they also reduce the movement advantage for familiar faces. Importantly, dynamic facial signatures are thought to be learnt over time, providing a more reliable cue to identity the more familiar the face is. This latter prediction was supported by Butcher and Lander (2017), who found that the magnitude of the motion advantage observed for an individual face correlates with how familiar that face is. That is, the more familiar the face was, the more the observer benefitted from seeing it in motion when attempting to identify it.
Second, the representation enhancement hypothesis (O’Toole et al., 2002; O’Toole & Roark, 2010) proposes that facial motion contributes to recognition by facilitating perception of the three-dimensional structure of a face. This hypothesis assumes that motion adds to the quality of the structural information accessible from a human face, and that this benefit transcends the additional views of the face provided from the motion. Notably, unlike the supplemental information hypothesis (which requires movement to be present when faces are learnt and recognised), the mechanism proposed by the representation enhancement hypothesis can facilitate recognition at the point of learning a face and/or recognising it. That is, this theory only requires movement to be present during learning or recognition for motion to influence recognition performance. For example, when learning unfamiliar faces, the motion advantage appears to be driven by differentially encoded mental representations of faces dependent on whether they are learnt moving or static. Pike et al. (1997) found that faces learnt in a rigid motion condition (10-s sequence of the head rotating 360°) were recognised more accurately from static photos, compared with faces learnt from multiple static images. Furthermore, during an old/new recognition task where presentation style (moving or static) was manipulated at both learning and test, Butcher et al. (2011) found no improvement in performance from viewing a moving face at test over and above the advantage provided by seeing the face move at learning. These findings indicate that for unfamiliar face learning the mechanism proposed by the representation enhancement hypothesis influences recognition performance primarily at the learning stage. As predicted by the representation enhancement hypothesis, motion when learning a new face adds to the quality of the face representation making it more likely that face is later recognised.
Although the supplementary information hypothesis and representation enhancement hypothesis (O’Toole et al., 2002) are well supported and offer important contributions to our understanding of the motion advantage, it is possible that other factors play a role in the motion advantage. For instance, eye movements reflect the mental processes underlying cognition and have been found to play a functional role during human face learning (Henderson et al., 2005), but to date no research has investigated whether eye movement patterns differ when learning and recognising moving compared with static faces. Investigating eye movement differences between moving and static faces may therefore help us develop a theoretical understanding of the motion advantage.
There is some research on the motion advantage using eye-tracking, however, much of this research has been concerned with whether motion leads participants to use more part-based processing rather than holistic processing, using composite stimuli (Xiao et al., 2012, 2013) or has investigated eye movements in infants. For instance, Xiao et al. (2015) examined the role of facial movements in face recognition at the ages of 3, 6, and 9 months. They found that across the age groups infants fixated mostly on the centre of static faces but with increased age, they fixated longer on the mouth of moving than of static faces, and less on the eyes of moving than of static faces. These findings are indicative of significant differences in eye movement patterns when processing moving and static faces but cannot be generalised to the eye movement patterns of adults, when engaged in the task of face recognition.
Studies investigating eye movement patterns when viewing static compared with dynamic social interactions also offer some insight to answer the question of whether eye movement patterns differ when processing moving and static faces. For instance, when asked to watch videos of talking faces while trying to understand what was being said, Lansing and McConkie (2003) found that attention was biased towards the eyes when viewing a still image, but gaze shifted to the mouth when the face was seen talking, an effect referred to as the “information source attraction effect.” Võ et al. (2012) similarly observed that gaze follows function. During dynamic face viewing, rather than being predominantly directed towards the eyes, participants rapidly directed attention to different face regions based on “information-seeking control processes in interaction with dynamic events.” That is, when viewing faces in motion during social interactions, attention is allocated dependent on which parts of a face provide the information necessary to pursue the current goal, such as trying to identify the person, understand what is being said, or determine the person’s emotional state. However, these studies were not conducted within the context of face recognition. Võ et al. (2012) asked participants to rate the extent to which they liked each video. It is therefore not clear how eye movements and thus attentional allocation differs when viewing moving compared with static faces when completing a face recognition task.
There are several reasons why eye movements might differ when learning and recognising moving compared with static faces. One possibility is that motion might influence eye movement patterns because low-level movement information captures attention. Motion has been found to capture attention (e.g., Abrams & Christ, 2006) so facial movement might make the features that are moving visually salient. We would therefore expect facial movement to increase attention to the parts of the face that are observed moving in any given stimulus.
Second, the social nature of facial movement might influence how we attend to moving compared with static faces. The facial motion that has been seen in the aforementioned studies to enhance face recognition, the speech movements, the emotional expressions, and the rigid movements of the head, are the same facial movements that communicate a vast array of social information to an observer. In addition to supporting identity processing, facial movement has been found to improve intelligibility of speech sounds in a noisy environment (e.g., MacLeod & Summerfield, 1987, 1990; Munhall et al., 2004), help speech understanding even when the auditory signal is clear (e.g., Arnold & Hill, 2001, Thomas & Jordan, 2004), communicate information about a person’s emotional state (Bassili, 1979; Kamachi et al., 2013), facilitate the differentiation between posed and spontaneous expressions (for a review see Krumhuber et al., 2013), and contain information about a person’s age (Berry, 1990) and gender (Hill & Johnston, 2001). It is therefore important to consider the role that the social nature of facial movement might play in how we attend to moving compared with static faces. Given the discussed findings relating to the “information source attraction effect” (Lansing & McConkie, 2003), it is likely that socially communicative facial movements focus the viewers’ attention on the moving parts of the face that are communicating the social cues (e.g., the mouth when a face is seen speaking).
There are therefore clear reasons to believe differences in eye movement patterns will be present when learning and recognising moving compared with static faces. Yet to date there has been no investigation of such differences despite an investigation of that nature offering new insight to our understanding of the motion advantage. Therefore, in addition to replicating the motion advantage effect, the current series of experiments aimed to investigate whether there are eye movement differences between moving and static faces during face learning and recognition.
It is important to consider what the nature of these eye movements differences might be, and how such differences might relate to performance and the motion advantage. Both possibilities propose that viewing a face move will lead to increased attention to the parts of the face that are moving because of attention capture based on low-level movement information/or attention capture based on social relevance. Given the movements of the internal facial features carry a substantial amount of socially important information (e.g., speech, emotional state, and potentially intentions and goals) it seems reasonable to expect that when a face is seen moving, attention will be drawn to these internal regions of the face. This is significant because a large body of research has established that the internal facial features (i.e., eyes, nose, and mouth) are more important for identity processing than external features (i.e., hair, ears, and face shape) (e.g., Ellis et al., 1979; Longmore et al., 2015), and arguably these internal features move more than other facial features. It is only through rigid motion that the hair, ears, and face shape move.
The importance of the internal features has been demonstrated in the eye movement patterns of individuals with developmental prosopagnosia. Individuals with prosopagnosia attend less to the eye region than typical participants, relying instead upon the mouth, face shape, hairstyle, and body (Bobak et al., 2017, de Xivry et al., 2008; Stephan & Caine, 2009). Furthermore, the degree of impairment in prosopagnosia correlates with time spent looking at the inner features of the face, with more severe prosopagnosia associated with less time looking at inner facial features (Bobak et al., 2017). In contrast, individuals with visual object agnosia are not able to adequately process information from the external regions of a face but achieve typical levels of face recognition (Moscovitch et al., 1997). These findings from individuals with visual agnosia indicate that it is possible to achieve “typical” levels of face recognition using predominantly the internal features alone. Taken together with that finding that people with prosopagnosia attend less to the internal features and exhibit poor face recognition, these findings highlight the importance of the internal features in identity processing.
Henderson et al. (2005) demonstrated that eye movements play a functional role during face learning, suggesting that, of the internal facial features, attention to the nose might be of particular importance for optimal identity processing. This claim was supported by Bobak et al. (2017), who found that super-recognisers (i.e., individuals who are exceptionally good at recognising faces) spent more time examining the nose specifically, and that the amount of time spent attending to the nose correlated with face recognition ability in controls. However, Williams and Henderson (2007) found that fixations were largely directed towards the eye region (80%) during both the learning and recognition phases of a face memory task, supporting the notion that that the eyes play a significant role in identity processing (Davies et al., 1977; Haig, 1986; O’Donnell & Bruce, 2001). Birmingham et al. (2008) argue that eyes are fixated not because of their visual salience, but because they are a rich source of social information. However, to date, research that has highlighted the importance of the internal features for identity processing have used static faces (e.g., Ellis et al., 1979; Longmore et al., 2015 but see Xiao et al., 2015, who used moving stimuli but with infant participants). This includes the eye movement studies that have linked greater attention to the internal features of the face with better performance (Bobak et al., 2017; Williams & Henderson, 2007). Therefore, it is not clear whether these findings extend to moving faces.
Nevertheless, taken together these findings suggest that the internal facial region (i.e., eyes, nose, and mouth) is of greatest importance to identity processing. Based on these findings, if facial movement is found to attract attention to the internal facial features because of attention capture based on low-level movement information (e.g., Abrams & Christ, 2006) and/or the processing of social communication information embedded in the movements of these features (Lansing & McConkie, 2003), we should expect to see an improvement in performance when recognising moving compared with static faces; the motion advantage. In addition to the supplemental information and representation enhancement hypotheses (O’Toole et al., 2002), facial movement might facilitate face recognition by focusing our attention on identity-relevant regions of the face. Indeed, this is the proposition presented in the social signals hypothesis (Roark et al., 2003), which posits that the social communication information embedded in facial movement may engage and potentially focus our attention on a person, encouraging identity processing and increasing the likelihood that the face will be remembered. The social signals hypothesis predicts that the motion advantage might be the result of the social relevance of the facial motion drawing attention to these identity-relevant areas of the face, encouraging identity processing.
The current series of experiments used eye tracking to measure the extent to which participants allocate attention to the internal features (eyes, nose, and mouth), internal non-feature area (forehead, chin, and cheeks), and external features (hair, neck, and ears) of a face as a function of presentation style (moving or static). The aim of this was to better understand the mechanisms that underpin the motion advantage by addressing three research questions:
Does seeing a face move enhance face recognition performance (i.e., replication of the motion advantage effect)?
Does facial movement increase attention to areas of the face that might benefit identification (i.e., the internal features)?
If facial movement does increase attention to the internal features, is increased attention to the internal features associated with enhanced recognition performance, and the magnitude of the motion advantage?
These questions were investigated in the context of both familiar (Experiment 1) and unfamiliar (Experiments 2 and 3) face recognition for several reasons. First, the motion advantage is considered more robust during familiar than unfamiliar face recognition. Second, explanations of the motion advantage differ dependent on face familiarity. The two dominant explanations of the motion advantage are thought to play a greater or lesser role in explaining the motion advantage dependent on whether the to-be-recognised face is familiar or unfamiliar. Familiar face recognition benefits from the encoding mechanism of the supplemental information hypothesis, as the observer has familiarity with the face’s characteristic movements, but it also benefits from the perceptual processing mechanism of the representation enhancement hypothesis. In contrast, unfamiliar face recognition is unlikely to benefit from the mechanism proposed in the supplemental information hypothesis as dynamic facial signatures are learnt over time. However, unfamiliar face recognition can benefit from the mechanism proposed in the representation enhancement hypothesis as no prolonged period of learning is required for this perceptual process to enhance recognition performance. Related to this, the stage at which motion benefits face recognition differs for familiar and unfamiliar faces. Facial motion enhances recognition of familiar faces at the point of recognition, but when learning unfamiliar faces, Butcher et al. (2011) and Skelton and Hay (2008) found no improvement in performance from viewing a moving face at test over and above the advantage provided by seeing the face move at learning. This indicates that the motion advantage for unfamiliar faces occurs at the learning stage, not the recognition stage. Consequently, we investigate the effect of facial motion at recognition for familiar faces (Experiment 1), but for unfamiliar faces (Experiments 2 and 3) investigate the effect of facial motion at learning.
Experiment 1
In Experiment 1, participants were presented with a series of famous faces, seen moving or in static form and were tasked with identifying each face while their eye movements were recorded. Based on the previously discussed literature, it was hypothesised that a motion advantage would be observed with participants recognising more of the famous faces when presented in motion than in static form. In addition, it was hypothesised that more attention (indicated by higher proportions of fixations) would be directed to the internal features of moving famous faces when compared with static faces, and conversely less attention to the internal non-feature and external regions of the moving faces than static faces. Finally, it was hypothesised that increased attention to the internal facial features would be associated with better recognition accuracy and a larger motion advantage.
Method
Design
A repeated measures design with one independent variable was used to assess the effect of motion on familiar face recognition. The independent variable was the presentation style (static or moving). The dependent variables (DVs) were recognition accuracy (i.e., the proportion of correctly identified famous faces), dwell time proportion (i.e., proportion of trial time spent on each interest area [IA]), and fixation count proportion (i.e., proportion of all fixations in a trial falling in each IA). The proportion of dwell time and fixations (as opposed to overall dwell time and fixations) was used to ensure that any differences between conditions in the amount of time spent looking at the images were controlled. The two eye movement measures were calculated for three areas of interest: internal features, internal non-feature area, and external facial features, which were treated as separate dependent variables. The internal feature area was a combination of the eyes, nose, and mouth; the internal non-feature area comprised the forehead, chin, and cheeks; and the external feature area comprised the hair, neck, and ears (see Figure 1). Follow-up analyses were conducted on the proportion of dwell time and fixations on each internal feature: eyes, nose, and mouth.

Example stimulus and IAs.
Participants
An opportunity sample of 32 participants (Mage = 26.5 years, SD = 8.33, 13 males), all with normal or corrected to normal vision, completed this experiment within a lab setting at Teesside University. Written informed consent was acquired prior to participation with ethical approval granted by the School of Social Sciences, Humanities and Law Ethics Committee at Teesside University. A priori power analyses were conducted using G*Power (Faul et al., 2007). The effect size used for this analysis was based on Butcher and Lander (2017), which used the same paradigm as the current study and demonstrated a strong effect (d = 1.14). A repeated measures t-test was used as the basis for the assumptions with a significance level of .05 and power of (1 − β) = .80. Following this analysis, the total number of participants required to observe an effect size of d = 1.14 was n = 7. The sample used in the present study was therefore considered sufficient to observe an effect of motion on recognition performance.
Stimuli and apparatus
Moving clips of 60 famous faces (30 men, 30 women) 1 and 10 unknown male Australian celebrities were selected for use in this experiment. Australian celebrities were used as filler trials that all participants would be unfamiliar with. These trials were excluded from all analysis. The famous faces included actors, TV personalities, politicians, and sports men and women. Moving clips were extracted from television interviews, identified using a YouTube search. All stimuli were seen from a frontal viewpoint and showed at least the head and shoulder region of the famous person, with some individuals being shown from the waist upwards. The clips contained predominantly non-rigid motion, including emotional expressions and speech; however, some rigid motion of the head and waist was also present. Using Windows Movie Maker (Microsoft Inc.) clips were edited to be 2 s in duration and greyscale, with a mild blurring effect used to reduce the amount of shape and textural information present. This was done to ensure ceiling effects were not observed. For each famous face, a static stimulus was also produced. For the static stimuli, a single freeze frame was selected from the moving clip, which showed a clear frontal view of the individual’s face that represented a typical image of that person, in that it did not display an unusual facial expression or pose (see Figure 1). Stimuli were 840 × 480 pixels in size although the size of the head and face within the stimuli varied given the nature of the clips used. Head sizes ranged from approximately 5.5 to 13.5 cm in width (M = 8.59 cm, SD = 1.83), reflective of the varying viewing distances from which we recognise a face in everyday life. While variation in head size could influence the spatial frequencies made available and thus the eye movement patterns, facial stimuli were counterbalanced across the moving and static conditions so the impact of head size variation on eye movement patterns did not disproportionately impact on either condition.
The experiment was programmed and displayed using SR Research Experiment Builder software (SR Research Ltd., Kanata, ON, Canada), running on a desktop computer using Windows XP (Microsoft, Inc.). Stimuli were displayed in the centre of a 21-in. colour CRT monitor (ViewSonic P227f) with the screen resolution set to 1,024 × 768 pixels at a vertical refresh rate of 160 Hz. Viewing distance was held constant at 65 cm with a chin rest. Eye movements were recorded at a sampling rate of 250 Hz with an EyeLink II head-mounted, video-based eye-tracker (SR Research Ltd., Kanata, ON, Canada), which has an average gaze position error of .5°, a resolution of 1 arcmin, and a linear output over the range of the monitor used. The dominant eye of each participant was tracked, although viewing was binocular.
Procedure
Prior to the start of the main experiment, manual calibration of eye fixations was conducted using a nine-point fixation procedure implemented with EyeLink API software. The calibration was then validated or repeated until the optimal calibration criteria were achieved. The participant then began the main experiment.
The main experiment contained 70 trials, which were split into two blocks of 35 trials, with a different set of 30 famous faces and 5 unknown faces displayed in each block. The blocks differed in presentation style, with one block displaying static faces and the other displaying moving clips. Block order was counterbalanced across participants so that half the participants completed the moving block first followed by the static faces and the rest of the participants completed the static block first followed by the moving faces. Across participants, each famous face was presented equally as often in the moving and static conditions, and trial order within blocks was randomised.
Each trial began with the participant being asked to fixate on a circle presented in the centre of the visual display. This allowed the automated drift-correction procedure to be carried out to rectify any small drifts, which may have occurred in the calculation of gaze position due to participant movement. If the recorded gaze position differed by more than 1° from the central fixation circle, recalibration was performed. If calibration remained good, the experimenter initiated the onset of the face stimulus.
Each face was displayed on the screen for 2 s in both the moving and static conditions. Following the presentation of each face, a screen was presented instructing participants to verbally identify the famous face, either by name or by some other non-ambiguous information. For example, if the participant could only report that the face was that of an actor this would not be deemed a correct identification. However, if the participant said “the actor who played Harry Potter in the film series” for Daniel Radcliffe this would be deemed a correct identification. There was no time limit for participants to make a response, and once they made their response participants were asked to press any key on the keyboard to move on to the next trial.
Following the completion of all 70 trials, a list of the 60 famous face names was presented and participants were asked to rate, using a 5-point Likert-type scale (1 = unfamiliar and 5 = familiar), how familiar they were with each person. Before analysis, data for any faces that were unfamiliar to individual participants (rated 1 or 2) were removed. Between 0 and 42 faces were removed with an average of 11.69 faces removed per participant (SD = 9.52). The remaining faces were rated as familiar.
Results and discussion
Any violation of the sphericity assumption was adjusted for using the Greenhouse–Geisser correction (Greenhouse & Geisser, 1959) and significant main effects were investigated using pairwise comparisons with Bonferroni corrections (Dunn, 1961) applied.
Accuracy
Accuracy was defined as the proportion of correctly identified familiar faces. The overall mean accuracy rate was 75% (SD = 0.16). A Shapiro–Wilk test identified that the accuracy data were not normally distributed, therefore a Wilcoxon signed-rank test was carried out to compare accuracy for moving compared with static faces. Results revealed a significant effect of presentation style, Z = −3.02, p = .003, r = −.53. Participants correctly identified significantly more famous faces when faces were seen moving (M = 0.79, SD = 0.14) compared with static (M = 0.71, SD = 0.18), that is, a motion advantage. This finding supports studies that have observed the motion advantage to be a robust effect when participants are tasked with recognising familiar faces (e.g., Butcher & Lander, 2017; Lander et al., 2001). The existing literature investigating this effect has focused on the role of “dynamic facial signatures,” suggesting that over time the characteristic facial motions of individual faces are learnt and represented in addition to the invariant structure of the face (O’Toole et al., 2002). While this supplemental information hypothesis has gained substantial support (e.g., Bennetts et al., 2013; Hill & Johnston, 2001) other mechanisms through which motion might enhance recognition performance have received less attention, including eye movement differences when recognising moving compared with static faces.
Eye movements
Prior to conducting eye movement analysis, incorrect trials were removed to ensure that eye movement patterns reflected perceptual processing during correct recognition performance. For this experiment, three main IAs were defined: (1) internal features, (2) internal non-feature area, and (3) external features (see Figure 1). Dynamic IAs, adjusted frame by frame, were used for faces presented in the moving condition.
We calculated both the proportion of dwell time and proportion of fixations directed to each IA and these measures were analysed using two one-way repeated measures MANOVA, with presentation style as the independent variable and proportion of time or fixations directed towards the three IAs being the three DVs in each analysis. The dwell time and fixation count findings were found to be highly correlated therefore throughout this article, in the interest of brevity, we report only the fixation proportion results and note in footnotes any instances where the two measures were not consistent.
The MANOVA results revealed a multivariate main effect of presentation style on the proportional fixation count, F(3, 26) = 23.04, p < .001, Wilks Λ = .30, η2 = .70. At the univariate level a significant effect of presentation style was found on the proportion of fixations directed to the internal features, F(1, 31) = 69.46, p < .001, η2 = .69, and internal non-feature area F(1, 31) = 41.65, p < .001, η2 = .57, with a significantly higher proportion of fixations on the internal features of moving faces compared with static, and lower proportion of fixations directed to the internal non-feature area of moving faces compared with static (see Table 1 for M and SDs). There was no effect of presentation style on the proportion of fixations (p = .19) directed towards the external feature area. 2
Mean fixation proportion on each IA (SDs in parentheses) as a function of presentation style and univariate analysis results.
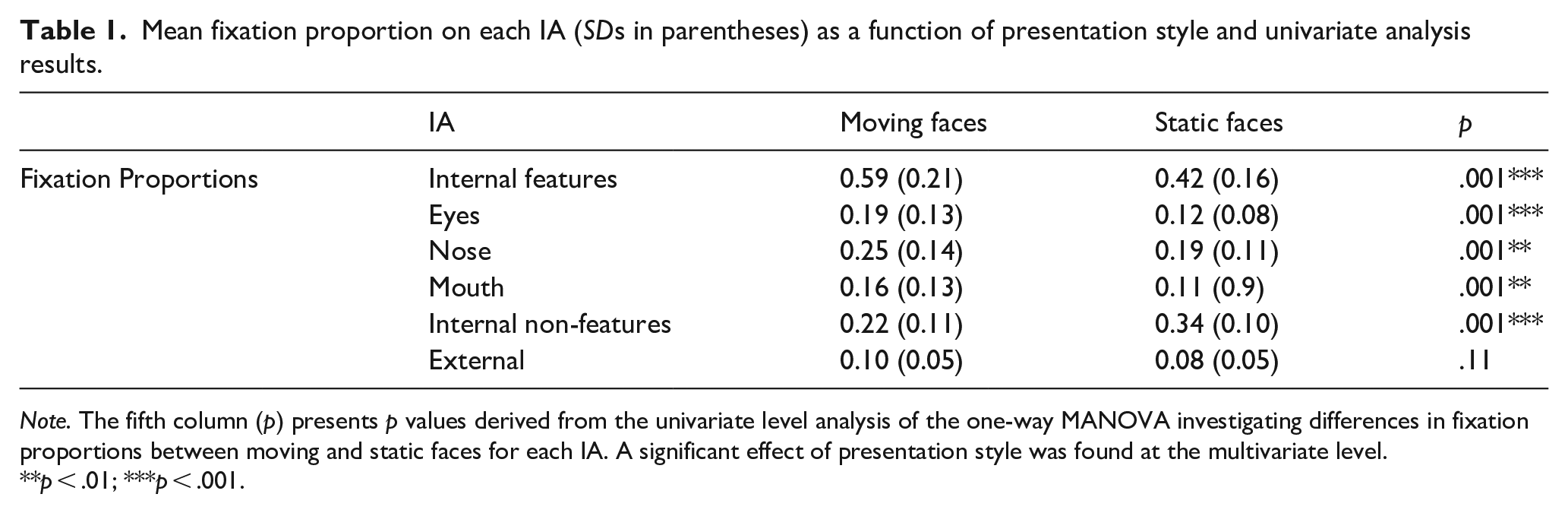
Note. The fifth column (p) presents p values derived from the univariate level analysis of the one-way MANOVA investigating differences in fixation proportions between moving and static faces for each IA. A significant effect of presentation style was found at the multivariate level.
p < .01; ***p < .001.
To assess whether the increased attention to the internal features of moving faces was driven by a particular feature, a follow-up one-way MANOVA was conducted to investigate the effect of presentation style on the proportion of fixations directed to each internal feature: eyes, nose, and mouth. A significant effect of presentation style was found at the multivariate level, F(3, 31) = 30.09 p < .001, Wilks Λ = .24, η2 = .76 (see Table 1 for M and SDs). The univariate analysis was significant for all three areas of interest, revealing that participants directed a higher proportion of fixations to the eyes, F(1, 31) = 26.11, p < .001, η2 = .46, nose, F(1, 31) = 13.34, p = .001, η2 = .30, and mouths, F(1, 31) = 14.51, p = .001, η2 = .32, of moving faces compared with static. 3 Therefore, the increased attention to the internal features of moving faces was not driven by differential attention to one specific internal feature. Instead, participants fixated more on the eyes, nose, and mouths of moving faces, indicating that movement increased attention across the internal features while also reducing the amount of time spent attending to the internal non-feature area of moving faces compared with static. It is worth noting that to avoid ceiling effects, blurred faces were used. Blurring prevents participants from using mid-high spatial frequencies which have been implicated in face processing (Gaspar et al., 2008; Näsänen, 1999; Tardif et al., 2017; Willenbockel et al., 2010). It is therefore possible that blurring might have an impact on the eye movement patterns, especially for dynamic faces, since it has been suggested that facial motion might be processed parafoveally (Plouffe-Demers et al., 2019). As such, future research should endeavour to replicate these eye movements findings using an alternate technique to blur to avoid ceiling effects.
Functionality of eye movements
To investigate whether the increased attention to the internal features is functionally related to face recognition performance, and specifically the magnitude of the motion advantage, a series of Spearman’s rank-order correlations were conducted. First, the data were collapsed across moving and static trials to assess the relationship between the proportion of fixations directed to the internal features, overall recognition accuracy (i.e., proportion correct across static and moving trials), and the magnitude of the motion advantage (i.e., the difference between the proportion of correct recognitions in the moving condition compared with the static condition). Overall recognition accuracy was not significantly related to the proportion of fixations on the internal features, rs(30) = −.03, p = .86. The relationship between the magnitude of the motion advantage and proportion of fixations directed to the internal features approached significance, rs(30) = −.33, p = .06. 4
Next, the data were analysed separately for moving and static trials. In the moving condition, the proportion of fixations on the internal features of moving faces was found to be unrelated to both the proportion of correct recognitions, rs(30) = −.01, p = .94, and the magnitude of the motion advantage, rs(30) = −.21, p = .24. In the static condition, there was also no correlation between the proportion of correct recognitions and the proportion of fixations on the internal features of static faces, rs(30) = .15, p = .40. There was, however, a significant negative correlation between the magnitude of the motion advantage and the proportion of fixations directed to the internal features of static faces, rs(30) = −.44, p = .012. The magnitude of the motion advantage was larger for participants who direct less fixations to the internal features of static faces. Taken together, the findings of Experiment 1 support the idea that increased attention to the internal features of moving faces plays a functional role in the motion advantage for familiar faces.
Experiment 2
Experiment 2 aimed to investigate whether differential eye movement patterns for static and moving faces play a role in the motion advantage during unfamiliar face learning too. The motion advantage is not so robust for unfamiliar face recognition, and as discussed earlier the proposed theoretical explanations of the motion advantage (O’Toole et al., 2002) do not equally apply to familiar and unfamiliar faces. Thus, it is important to investigate whether a similar pattern of results emerges during unfamiliar face learning and recognition. In Experiment 2, participants completed an old/new recognition task wherein they learnt a series of faces (seen either as a static image or moving clip) and later had to discriminate these learnt faces from new ones in a recognition test. As mentioned earlier, previous research suggests that the motion advantage for unfamiliar faces occurs at the learning stage and not the recognition stage (e.g., Butcher et al., 2011), therefore faces were always static at test. Despite some studies not observing a motion advantage for unfamiliar face recognition (see Bruce et al., 1999, 2001; Christie & Bruce, 1998), the majority of research has observed improved face recognition when previously unfamiliar faces are learnt in motion (e.g., Butcher et al., 2011; Pike et al., 1997), so it was hypothesised that a motion advantage would be observed—participants would correctly identify more of the faces they learnt in the moving condition than those learnt in the static condition. In addition, we expected to find that during the learning phase there would be greater allocation of attention to the internal features of faces learnt in motion compared with static, and less attention to the internal non-feature and external regions of the moving faces than static faces. Finally, we expected to find that increased attention to the internal facial features would be associated with enhanced recognition performance, and a larger motion advantage.
Method
Design
A repeated measures design with one independent variable (presentation style at learning; moving or static) was used to investigate the effect of facial motion on face learning. The behavioural dependent variables were reaction time (RT) and recognition accuracy, which was measured using both the hit rate (i.e., the proportion of correctly identified targets) and the nonparametric signal detection index A′ (Snodgrass & Corwin, 1988) measuring discriminability. A′ values range from 0 to 1, with A′ = 0.5 representing chance level performance. As in Experiment 1, the eye movement measures were dwell time proportion and fixation count proportion on the three main areas of interest: internal features, internal non-feature area, and external facial features (see Figure 1), which were treated as separate dependent variables and analysed separately for the learning and recognition phases of the experiment. Again, follow-up analyses were conducted on the proportion of dwell time and fixations on each internal feature, eyes, nose, and mouth, where appropriate.
Participants
Sixty participants (Mage = 27.37 years, SD = 9.60.07, 20 males) were recruited to take part in this experiment. All took part at Teesside University within a lab setting. Some participants had previously completed Experiment 1, but none were familiar with the facial stimuli used in this experiment. All participants had normal or corrected to normal vision. Written informed consent was acquired prior to participation and ethical approval was granted by the School of Social Sciences, Humanities and Law Ethics Committee at Teesside University. An initial a priori power analysis using G*Power (Faul et al., 2007) was conducted using the effect size observed in Butcher et al. (2011), which indicated that a sample of n = 9 would be sufficient to observe a motion advantage. However, this power analysis did not account for the eye movement analysis. Due to concerns about statistical power, we reran the power analysis to account for the eye movement analysis based on the eye movement effect sizes found in Experiment 1. The smallest effect size in Experiment 1 was η2 = .17, but the effect of motion is known to be weaker for unfamiliar faces/learning paradigms than familiar face recognition. Therefore, a slightly weaker effect size of a η2 = .05 (f = .23) was used. A repeated measures MANOVA was used as the basis for the assumptions with a significance level of .05 and power of (1 − β) = .90. The total number of participants required to observe an effect size of f = .23 was found to be n = 60. Consequently, we increased the sample to n = 60. The sample used in the present study was therefore considered sufficient to observe an effect of motion on face learning and eye movements. 5
Stimuli and apparatus
The experiment comprised a learning and recognition phase. For the learning phase, 20 faces (12 male, 8 female) were selected from the Amsterdam Dynamic Facial Expressions set (van der Schalk et al., 2011). Each moving clip selected from the database displayed a single person from the shoulders upwards. At the start of each clip the face was seen with a neutral expression before displaying the emotion “joy” from a frontal viewpoint. In addition to the moving clip used in the moving condition, a static stimulus was produced for all 20 faces, for use in the static condition. Using Windows Movie Maker (Microsoft Inc.) the static stimuli were created by isolating the final frame from the moving clips, resulting in a motionless image of each face displaying the apex of the “joy” expression. The apex of the “joy” expression was used in the static condition to ensure that the static stimuli were equally as expressive as the moving stimuli. The duration of the clips was edited to be 4 s long for both the static and moving stimuli, and all stimuli were 720 × 576 pixels in size and displayed in full colour.
As aforementioned, at the recognition phase all faces were presented as a static image. Target stimuli consisted of the same 20 faces shown in the learning phase. However, to ensure that identity recognition was being measured rather than picture recognition, a second static frame was selected from the original moving clip, which showed a neutral expression. An additional 20 faces (12 male, 8 female) displaying a neutral expression were selected from the Radboud Faces Database (Langner et al., 2010; 9 images) and FEI Database (Thomaz & Giraldi, 2010; 11 images) to be used as distractor “new” stimuli. All recognition phase stimuli were edited using GIMP (http://gimp.org) to replace distinctive clothing with a black overlay and standardise the lighting, background, and feature alignment across the faces (see Figure 2). All recognition phase stimuli were 540 × 432 pixels although the size of the head and face within the stimuli varied. Overall head size ranged from approximately 8–11 cm in width (M = 9.1 cm, SD = 0.85) with minimal difference between the target (M = 8.93, SD = 0.78) and distracter stimuli (M = 9.28, SD = 0.90).

Example unfamiliar face stimuli.
The experiment was programmed and displayed using the same software, desktop computer, and apparatus as Experiment 1. Eye movements were recorded in the same way as in Experiment 1.
Procedure
Manual calibration of eye fixations was conducted using the same procedure described in Experiment 1, both prior to the experiment starting and during the experiment where necessary. Once the optimal calibration criteria were achieved the participant began the main experiment. During the learning phase, participants viewed 20 previously unfamiliar target faces (10 static and 10 moving) and were instructed to watch and learn the faces on screen. Each face was presented for 4 s followed by the drift-correction fixation screen which was presented between each face. Faces were presented in a random order and the presentation style of each target face was counterbalanced across participants so that each target was used equally as often in the moving and static conditions. After viewing all 20 faces, participants began the recognition phase.
During the recognition phase, participants viewed 40 faces (20 learnt targets plus 20 distracter stimuli) in a randomised order. Participants were asked to indicate via key press (“a” or “l”) whether each face was “old” or “new,” that is, whether they saw that person during the learning phase or not. The face remained on screen until the participant made their response and no time limit was imposed; however, participants were asked to indicate their choice as quickly and accurately as possible and were aware that RTs were being recorded. After making their response the drift-correction fixation screen was presented before the next trial began.
Results and discussion
Accuracy and RT
In this experiment, only static faces were presented during the recognition phase. Thus, accuracy rates were defined as the proportion of correctly identified faces (hits) that had been learnt in the moving and static conditions. A′ scores were also calculated (Snodgrass & Corwin, 1988) as a measure of recognition sensitivity as well as RTs. RTs were only included for correct trials. Overall, the mean proportion of correctly identified targets was 0.77 (SD = 0.17) with a mean RT of 1,189 ms (SD = 438) and mean A′ score of .88 (SD = 0.06).
Shapiro–Wilk tests identified that the data were not normally distributed for any behavioural measure. Therefore, a series of Wilcoxon signed-rank tests were carried out to compare the accuracy and RTs for faces learnt in motion compared with those learnt as a static image. Results showed a significant effect of presentation style at learning on accuracy, Z = −3.96, p < .001, r = −.51, with performance higher for faces learnt in motion (M = 0.83, SD = 0.16) compared with static (M = 0.71, SD = 0.18). This result was corroborated by a significant effect of presentation style at learning on A′ scores, Z = −3.91, p < .001, r = −.51, with discriminability higher for faces that were learnt moving (M = 0.90, SD = 0.06) compared with faces learnt as static images (M = 0.86, SD = 0.07). Presentation style at learning also had a significant effect on RTs, Z = −3.34, p = .001, r = −.43, with significantly faster RTs for faces learnt in motion (M = 1,136 ms, SD = 430) compared with those learnt as a static image (M = 1,243 ms, SD = 446). Participants were more accurate when recognising faces that they had earlier learnt in motion compared with static, and they were also faster to identify those faces. This result demonstrates that motion can enhance the learning of previously unfamiliar faces, supporting existing research that has observed improved face recognition when previously unfamiliar faces are learnt in motion (e.g., Butcher et al., 2011; Pike et al., 1997).
Eye movements
The same analytic approach and IAs were used here as in Experiment 1 (see Figure 1). Eye movements were analysed separately for the learning and recognition phases, and incorrect trials were removed prior to eye movement analysis. For the learning phase this meant that only faces that were later, in the recognition phase, correctly recognised were included in the analysis.
Learning phase
The one-way MANOVA results revealed a significant multivariate effect of presentation style on proportional fixation count, F(3, 57) = 4.04, p = .011, Wilks Λ = .83, η2 = .18 (see Table 2 for M and SDs). The univariate level analysis revealed a significant effect of presentation style on the proportion of fixations directed to the internal, F(1, 59) = 11.97, p = .001, η2 = .17, and internal non-feature area at learning, F(1, 59) = 5.04, p = .029, η2 = .08, demonstrating that a significantly higher proportion of fixations was directed to the internal features of moving faces compared with static, alongside a lower proportion of fixations directed to the internal non-feature area of faces presented in motion compared with static. 6 The effect of presentation style was not significant for the proportion of fixations directed to the external area (p = .656).
Mean fixation proportion on each IA during the learning phase (with SDs shown in parentheses) as a function of presentation style.
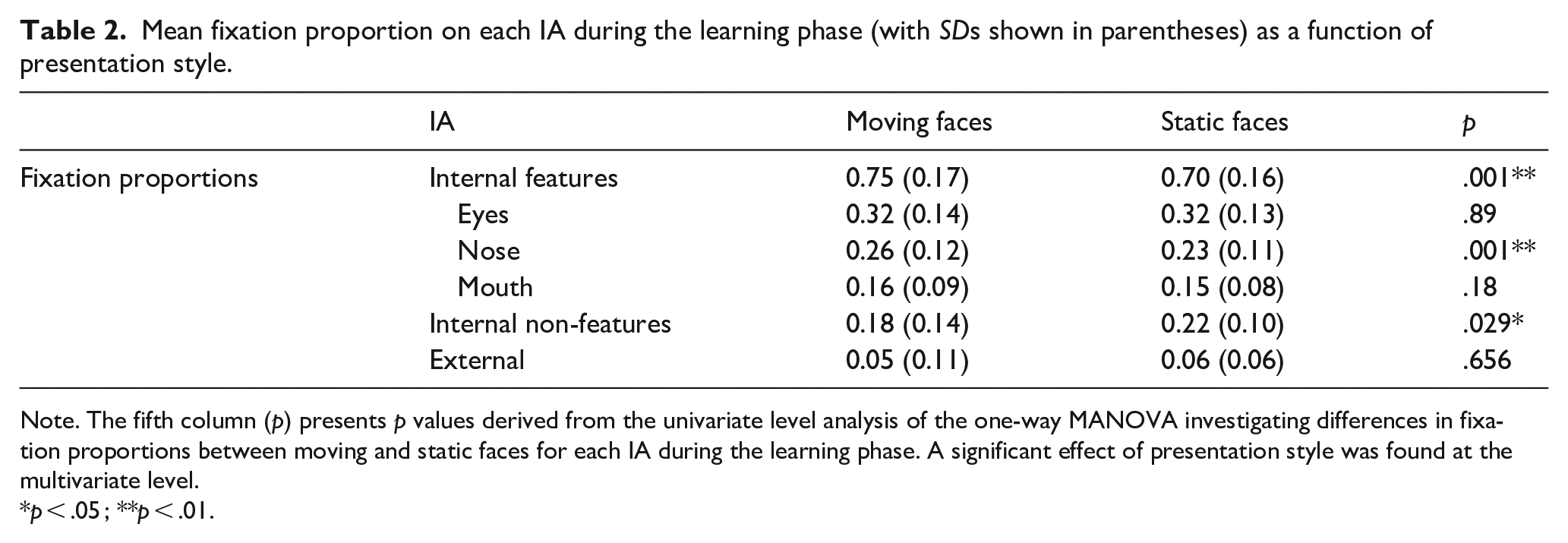
Note. The fifth column (p) presents p values derived from the univariate level analysis of the one-way MANOVA investigating differences in fixation proportions between moving and static faces for each IA during the learning phase. A significant effect of presentation style was found at the multivariate level.
p < .05 ; **p < .01.
A follow-up one-way repeated measures MANOVA was conducted to assess whether the higher proportion of fixations found on the internal features of moving faces was consistent across the individual internal features or driven by one feature. The multivariate analysis revealed a significant effect of presentation style, F(3,57) = 7.22, p < .001, Wilks Λ = .73, η2 = .28. At the univariate level, a significant effect of presentation style was found for the proportion of fixations directed to the nose, F(1,59) = 13.06, p = .001, η2 = .18. Participants directed a higher proportion of fixations to the noses of faces learnt in motion compared with when learning static faces (see Table 2 for M and SDs). The effect was not significant for the proportion of fixations directed to the mouth (p = .18) or eyes (p = .89). The increased attention to the internal features of moving faces was therefore not consistent across the internal features.
Recognition phase
During the recognition phase, all faces were presented in static so here when we investigate the effect of presentation style, we are assessing potential carryover effects on eye movement patterns because of the presentation style at learning–moving versus static. Distracter faces (i.e., those that were not present in the learning phase) were excluded from the analysis. Thus, only hits were included in the analysis (see Table 3 for the descriptive statistics).
Mean fixation proportion on each IA during the recognition phase (with SDs shown in parentheses) as a function of presentation style at learning.
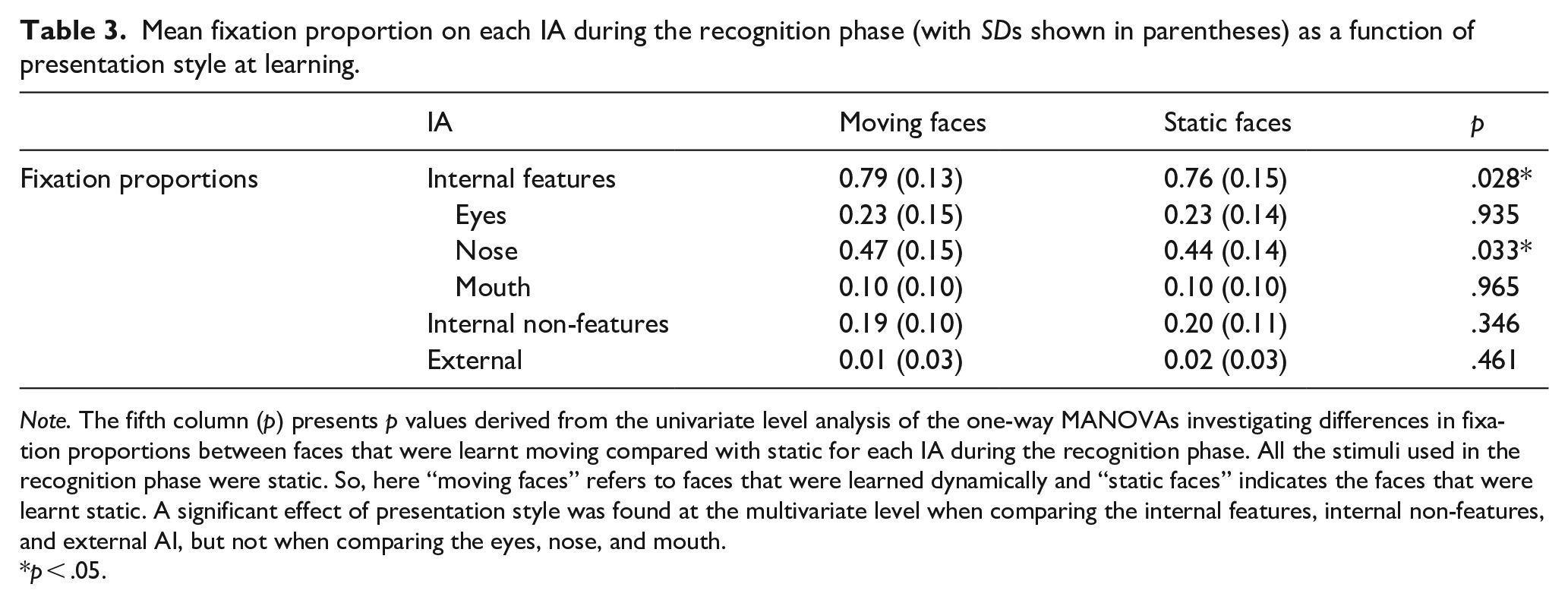
Note. The fifth column (p) presents p values derived from the univariate level analysis of the one-way MANOVAs investigating differences in fixation proportions between faces that were learnt moving compared with static for each IA during the recognition phase. All the stimuli used in the recognition phase were static. So, here “moving faces” refers to faces that were learned dynamically and “static faces” indicates the faces that were learnt static. A significant effect of presentation style was found at the multivariate level when comparing the internal features, internal non-features, and external AI, but not when comparing the eyes, nose, and mouth.
p < .05.
A one-way MANOVA compared the proportion of fixations on the three IAs as a function of whether the face was earlier learnt in the moving or static condition. It revealed a significant multivariate effect of presentation style on the proportional fixation count, F(3, 57) = 3.99, p = .012, Wilks Λ = .83, η2 = .17. At the univariate level a significant effect of presentation style was found on the proportion of fixations directed to the internal features, F(1,59) = 5.09, p = .028, η2 = .08. When completing the recognition task, participants directed a higher proportion of fixations to the internal features of the faces they earlier learnt in the moving condition, compared with those learnt as a static image. All other univariate analyses were not significant indicating that, during the recognition task, there was no difference in the proportion of fixations directed towards the internal non-feature area (p = .346) or the external area (p = .461) as a function of presentation style at learning.
To assess whether the higher proportion of fixations on the internal features of faces learnt in motion compared with static was driven by any one internal feature, a one-way MANOVA was conducted comparing the fixation proportions to each individual internal feature: eyes, nose, and mouth as a function of presentation style at learning. The multivariate analysis was not significant, F(3, 57) = 2.31, p = .086, Wilks Λ = .89, therefore the Benjamini–Hochberg’s correction method (Benjamini & Hochberg, 1995) was used to control false discovery rate (FDR) when assessing the significance of the univariate analyses. The univariate analyses found a statistical difference for the nose, F(1,59) = 4.79, p = .033, η2 = .08. Participants directed a higher proportion of fixations to the noses of faces they earlier learnt in motion compared with static (see Table 3). The effect of presentation style was not significant for the proportion of fixations directed to the eyes (p = .935) or mouth (p = .965).
Despite the fact that all faces were viewed as a static image during the recognition phase, there was some evidence of eye movement differences at the recognition stage dependent on how the face had earlier been viewed at learning. This suggests that perceptual processing differences at encoding, that are manifested in eye movement patterns, may have carryover effects on how the same face is subsequently attended to when seen again. This finding is in line with the “scanpath theory” (Noton & Stark, 1971) that eye movement patterns from learning are often repeated at test, and such repetition represents the matching of the existing feature trace to the current stimulus, which allows for enhanced memory. Indeed, Foulsham et al. (2012) found an individual’s scanpath during recognition to be more similar to that person’s scanpath at encoding than to a different person. Such scanpath routines have also been observed during facial judgements (Kanan et al., 2015). Although it is not clear whether such carryover effects would be found over a longer retention interval than was used here, it remains noteworthy that here participants attended to the nose of moving faces more at learning and subsequently attended to the noses of those same faces more at the recognition stage despite all faces being static at recognition.
Functionality of eye movements
Like Experiment 1, we observed a motion advantage in face recognition performance coupled with an increase in attention to the internal features of faces learnt in the moving condition. To investigate whether the increased attention to the internal features is related to face recognition performance, and the magnitude of the motion advantage, a series of Spearman’s rank-order correlations were conducted separately for the eye movements during the learning and recognition phases.
Functionality of eye movements at learning
The data were first collapsed across moving and static trials to assess the relationship between the proportion of fixations directed to the internal features at learning, overall RT, overall recognition accuracy (i.e., overall proportion correct), and the magnitude of the motion advantage. None of the behavioural measures were found to be related to the proportion of fixations directed to the internal features at learning (all ps > .05). When the data were analysed separately for the moving and static conditions, there remained no evidence of a correlation between any behavioural measure and the proportion of fixations directed to the internal features at learning (all ps > .05).
Functionality of eye movements at recognition
Again, the data were first collapsed across moving and static trials. Overall RT was significantly negatively correlated with the proportion of fixations directed to the internal features at recognition (i.e., faster RTs associated with more attention to the internal features) rs(58) = −.29, p = .023. Overall recognition accuracy, rs(58) = .24, p = .07, and the magnitude of the motion advantage, rs(58) = .19, p = .137, were unrelated to the proportion of fixations on the internal features at recognition.
When the data were analysed separately for the moving and static conditions there remained no significant correlations between the magnitude of the motion advantage or accuracy and the proportion of fixations directed to the internal features at learning (all ps > .05). The correlation between RTs for faces learnt as a static image and the proportion of fixations directed to the internal features of those faces at recognition did not reach significance within the traditional null hypothesis significance test (p = .055), but there was a significant negative correlation between RTs for faces learnt in motion and the proportion of fixations directed to the internal features of those faces at recognition rs(58) = −.27, p = .034. Taken together, this correlational analysis reveals that faster RTs were associated with a higher proportion of fixations to the internal features. While this finding supports the notion that eye movements are functional in face recognition (Henderson et al., 2005), there was no evidence that increased attention to the internal facial features plays a functional role in the motion advantage for unfamiliar face learning and recognition.
Experiment 3
Experiment 2 found a clear motion advantage in face learning, and presented evidence that eye movements to faces learnt moving differed from eye movements to faces learnt as a static image. This provides good preliminary evidence for differences in eye movements during encoding and recognition as a function of presentation style at learning. However, the stimuli used in Experiment 2 were relatively similar in the encoding and test phases, particularly in the moving condition, where participants viewed the face transitioning from neutral to joyful during the learning phase, and then viewed the face expressing a neutral expression in the test phase. In other words, participants had the advantage of having already seen the moving faces in a neutral expression; this was not the case for the static faces. This raises the possibility that the movement advantage and the eye movement differences observed in Experiment 2 could be attributed to participants in the moving condition matching the faces based on superficial or pictorial cues (which were more similar in the moving than the static conditions), as opposed to more in-depth face representations that generalise across changes in the face. As such, Experiment 3 sought to replicate and extend Experiment 2. We adopted the same old/new recognition task; however, in this experiment the stimuli used in the learning phase showed an entirely different facial expression (joy) to the stimuli used in the test phase (anger).
Method
Design
The experimental design was the same as Experiment 2.
Participants
The same power calculation was applied to Experiment 3 as Experiment 2. Consequently, we recruited a sample of n = 71. Boxplots identified three participants as extreme outliers on several measures, so the final sample consisted of 68 participants (Mage = 24.62 years, SD = 7.44, 18 males); 31 participants took part at Teesside University with the remaining 37 taking part at Brunel University London within a lab setting. All participants took part on a voluntary basis or in return for course credits. None of the participants took part in Experiments 1 or 2 and thus were unfamiliar with the facial stimuli used in the current experiment. All participants had normal or corrected to normal vision. Consent and ethical approval were acquired in the same way as Experiment 2, with additional ethical approval granted by the College of Health Medicine and Life Sciences at Brunel University London.
Stimuli and apparatus
The stimuli for the learning phase of Experiment 3 were identical to those used in the learning phase of Experiment 2.
To create the stimuli for the test phase, the apex of the “anger” expression for the 20 target faces was selected. This ensured there was minimal overlap between the expressions viewed during learning and test for both the moving and static conditions. An additional 20 faces (12 male, 8 female) displaying an angry expression were selected from the Radboud Faces Database (Langner et al., 2010; 12 images), the KDEF Database (Lundqvist et al., 1998; 3 images), and the RADIATE Database (Conley et al., 2018; 5 images) to be used as distractor “new” stimuli. All recognition phase stimuli were edited using Adobe Photoshop to replace distinctive clothing and backgrounds with a standard grey overlay and standardise the lighting and pupil alignment across the faces. All recognition phase stimuli were 720 × 576 pixels although the size of the head and face within the stimuli varied slightly. When presented on screen, overall head size ranged from approximately 8–10.5 cm in width (M = 9.13 cm, SD = 0.54) with minimal difference between the target (M = 8.86, SD = 0.48) and distracter stimuli (M = 9.48, SD = 0.57).
As in Experiment 2, the procedure was programmed and displayed using SR Research Experiment Builder software (SR Research Ltd., Kanata, ON, Canada), running on a desktop computer using Windows XP (Microsoft, Inc.) at Teesside University and Windows 7 (Microsoft, Inc.) at Brunel University London. The apparatus and set-up for participants tested at Teesside University was identical to Experiment 2. For participants tested at Brunel University London, the stimuli were displayed in the centre of a 21-in. colour CRT monitor (Dell P1110) with the screen resolution set to 1,280 × 1,024 pixels at a vertical refresh rate of 100 Hz. Viewing distance was held constant at 60 cm with a chin rest. Eye movements were recorded using an EyeLink 1000 desk-mounted video-based eye-tracker, which recorded eye movements at 1,000 Hz (SR Research Ltd., Kanata, ON, Canada).
Procedure
The procedure for Experiment 3 was identical to that in Experiment 2.
Results and discussion
The analytic approach was the same as Experiment 2.
Accuracy and RT
Overall, the mean proportion of correctly identified targets was 0.72 (SD = 0.15) with a mean RT of 1,380 ms (SD = 561) and mean A′ score of .83 (SD = 0.09). Shapiro–Wilk tests identified that the data were not normally distributed for any behavioural measure, so a series of Wilcoxon signed-rank tests were carried out to compare the accuracy and RTs for faces learnt in motion compared with those learnt as a static image. Results showed a significant effect of presentation style at learning on accuracy, Z = −3.79, p < .001, r = −.46, with performance higher for faces learnt in motion (M = 0.77, SD = 0.14) compared with static (M = 0.67, SD = 0.17). This result was corroborated by a significant effect of presentation style at learning on A′ scores, Z = −3.24, p = .001, r = −.39, with discriminability higher for faces that were learnt moving (M = 0.85, SD = 0.09) compared with faces learnt as static images (M = 0.81, SD = 0.09). Presentation style at learning did not have a significant effect on RTs (p = .99). Nevertheless, these results replicate the motion advantage found in Experiment 2 for accuracy and A′ using stimuli at the learning and recognition phases displaying entirely different expressions. As such, we can be confident that the motion advantage we observed here is an effect of motion per se, rather than any match between facial expression at encoding and test.
Eye movements
The same analytic approach and IAs were used here as in Experiment 2.
Learning phase
The one-way MANOVA results revealed a significant multivariate effect of presentation style on proportional fixation count, F(3, 65) = 4.39, p = .007, Wilks Λ = .83, η2 = .17 (see Table 4 for means and SDs). The univariate level analysis revealed a significant effect of presentation style on the proportion of fixations directed to the internal features, F(1, 67) = 9.06, p = .004, η2 = .12, internal non-feature area, F(1,67) = 7.71, p = .007, η2 = .10, and external area at learning, F(1,67) = 7.55, p = .008, η2 = .10, demonstrating that a significantly higher proportion of fixations was directed to the internal features of moving faces, alongside a lower proportion of fixations directed to the internal non-feature area, and external area of faces presented in motion compared with static.
Mean fixation proportion on each IA during the learning phase (with SDs shown in parentheses) as a function of presentation style.
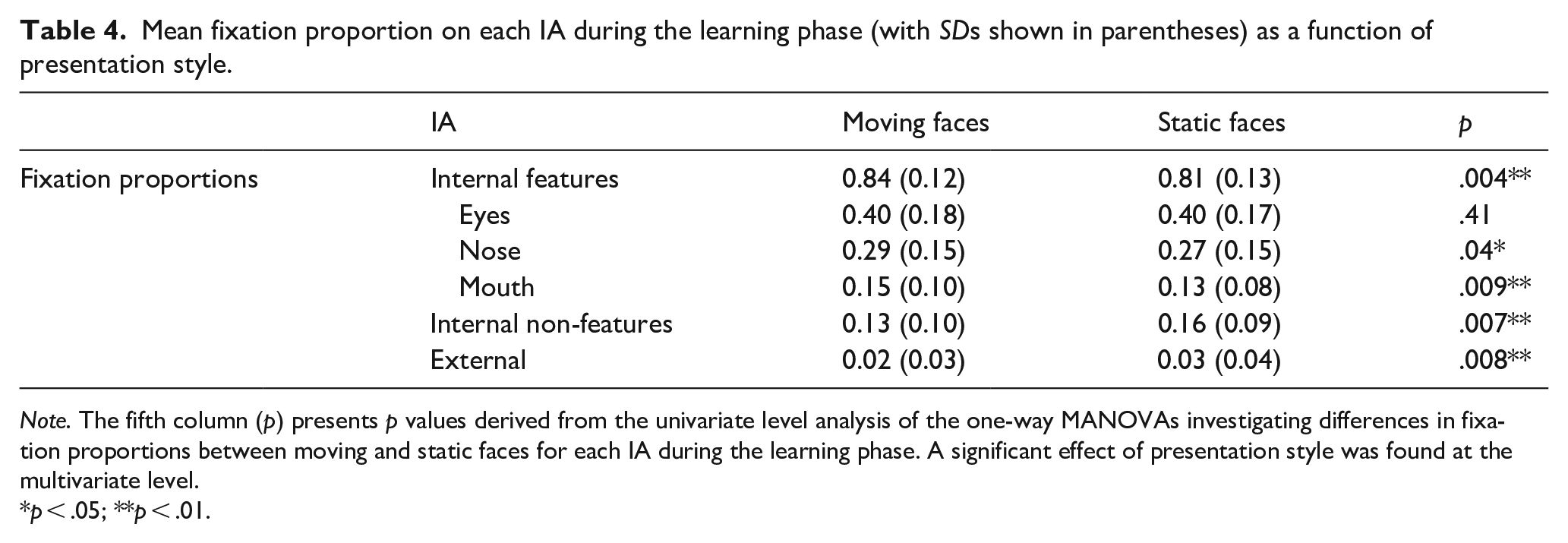
Note. The fifth column (p) presents p values derived from the univariate level analysis of the one-way MANOVAs investigating differences in fixation proportions between moving and static faces for each IA during the learning phase. A significant effect of presentation style was found at the multivariate level.
p < .05; **p < .01.
A follow-up one-way repeated measures MANOVA was conducted to assess whether the higher proportion of fixations found on the internal features of moving faces was consistent across the individual internal features. The multivariate analysis revealed a significant effect of presentation style on the proportional fixation count, F(3,65) = 6.02, p = .001, Wilks Λ = .78, η2 = .22. At the univariate level, an effect of presentation style was found for the proportion of fixations directed to the nose, F(1,67) = 4.46, p = .04, η2 = .06, and mouth, F(1,67) = 7.16, p = .009, η2 = .09. Participants directed a higher proportion of fixations to the noses and mouths of faces learnt in motion compared with when learning static faces (see Table 4 for M and SDs). The effect of presentation style was not significant for the proportion of fixations directed to the eyes (p = .41).
Recognition phase
During the recognition phase all faces were presented in static so as in Experiment 2, when we investigate the effect of presentation style, we are assessing potential carryover effects on eye movement patterns because of the presentation style at learning–moving versus static (see Table 5 for the recognition phase descriptive statistics). A one-way MANOVA compared the proportion of fixations on the three IAs as a function of whether the face was earlier learnt in the moving or static condition. The multivariate effect of presentation style on the proportional fixation count was not significant (p = .64). Likewise, at the univariate level the effect of presentation style was not significant for any of the interest areas (all ps > .05). Unlike Experiment 2, during the recognition phase there was no difference in the proportion of fixations directed towards the three areas of interest as a function of presentation style at learning. As such, follow-up analyses on the eyes, nose, and mouth specifically are not reported. This finding has implications for our interpretation of the carryover effect observed in the recognition phase eye movement patterns in Experiment 2. In Experiment 2 the stimuli were relatively similar during the encoding and test phases in the moving condition, resulting in shared identity and pictorial cues, and carryover effects on how the learnt faces were subsequently attended to when seen again. Conversely, in Experiment 3 the learning and test phase stimuli shared only identity cues, not pictorial cues, as entirely different facial expressions were used at learning and recognition. Under these conditions, in Experiment 3 no carryover effect was found. That is, perceptual processing differences manifested in eye movement patterns were seen at encoding as a function of presentation style as in Experiment 2, but these perceptual processing differences did not carry over into the test phase. This suggests that perceptual processing differences at encoding only have carryover effects on how the same face is subsequently attended to when seen again, when stimuli have overlapping pictorial cues as well as identity cues.
Mean fixation proportion on each IA during the recognition phase (with SDs shown in parentheses) as a function of presentation style at learning.
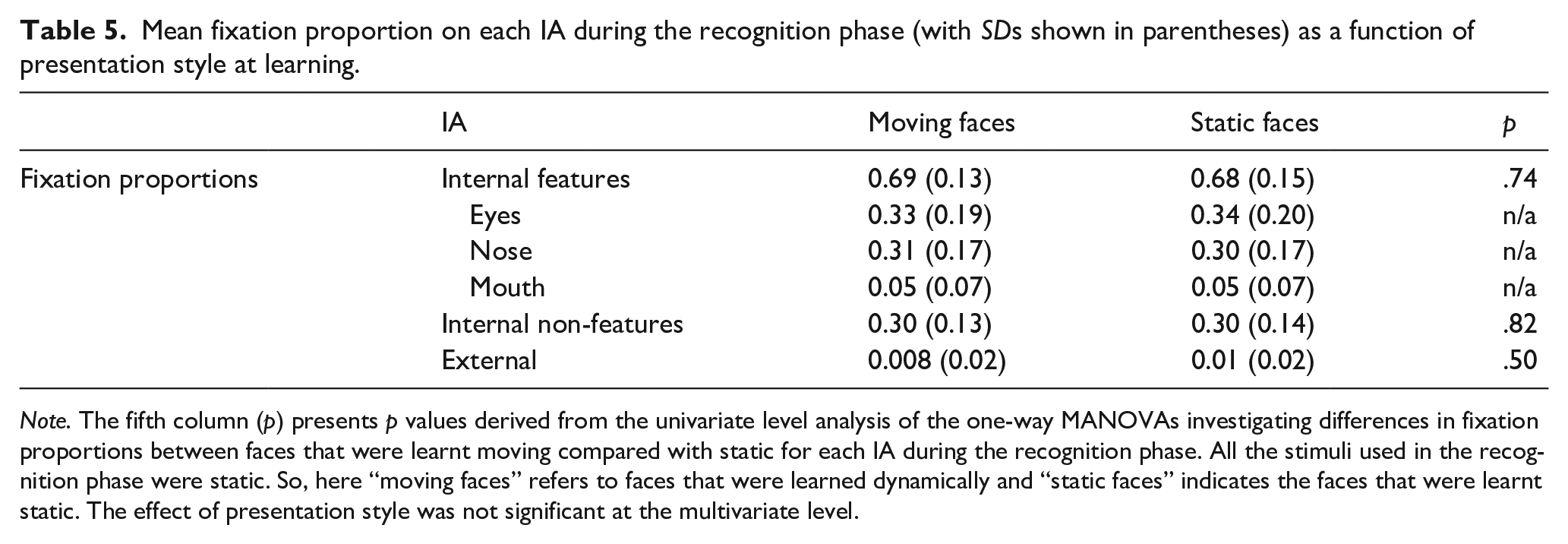
Note. The fifth column (p) presents p values derived from the univariate level analysis of the one-way MANOVAs investigating differences in fixation proportions between faces that were learnt moving compared with static for each IA during the recognition phase. All the stimuli used in the recognition phase were static. So, here “moving faces” refers to faces that were learned dynamically and “static faces” indicates the faces that were learnt static. The effect of presentation style was not significant at the multivariate level.
Functionality of eye movements
To investigate whether the increased attention to the internal features at learning is related to face recognition performance, and specifically the magnitude of the motion advantage, a series of Spearman’s rank-order correlations were conducted for the eye movements during the learning phase. The same analysis is not reported for the recognition phase eye movements as no increase in attention to the internal features was observed at the recognition phase in this experiment.
Functionality of eye movements at learning
The data were first collapsed across moving and static trials to assess the relationship between the proportion of fixations directed to the internal features at learning, overall RT, overall recognition accuracy (i.e., overall proportion correct), and the magnitude of the motion advantage. None of the behavioural measures were found to be related to the proportion of fixations directed to the internal features at learning (all ps > .05). When the data were analysed separately for the moving and static conditions, there remained no evidence of a correlation between any behavioural measure and the proportion of fixations directed to the internal features at learning (all ps > .05). These findings replicate Experiment 2 in demonstrating no evidence that increased attention to the internal facial features plays a functional role in the motion advantage for unfamiliar face learning.
General discussion
The aim of this series of experiments was to better understand the mechanisms that underpin the motion advantage in face recognition. We investigated the prediction that facial movement focuses attention on areas of the face that might benefit identification (i.e., the internal features), encouraging identity processing and increasing the likelihood that the face will be remembered. Across the experiments there were three key findings. First, we found a consistent motion advantage, wherein participants correctly identified famous faces, and learnt unfamiliar faces better in the moving condition compared with static. Second, we found significant differences in eye movement patterns when learning and recognising moving compared with static faces. Overall, facial movement was associated with increased attention to the internal features and less attention to the internal non-feature, and external (Experiment 3 learning phase only) face regions. These differences were consistent during familiar face recognition (Experiment 1) and the learning phase of Experiments 2 and 3. However, the differences were not consistent during the recognition phase of unfamiliar face learning. Eye movement differences as a function of presentation style were found during the recognition phase of Experiment 2, but not 3, and differential attention to the internal non-feature area was not observed when recognising unfamiliar faces, only when learning them. Finally, the magnitude of the motion advantage was significantly functionally related to attention to the internal features, but only during familiar face recognition, not during unfamiliar face learning and recognition. The latter two findings are, to our knowledge, new and thus offer new insight into our understanding of the impact of facial movement on face recognition.
These findings support the existing literature that has found the motion advantage to be a robust effect when recognising familiar faces in non-optimal viewing conditions (e.g., Butcher & Lander, 2017; Lander et al., 2001) and the growing body of literature that has found that facial motion can also facilitate face learning (Butcher et al., 2011; Lander & Bruce, 2003; Pike et al., 1997). In addition to providing the viewer with information about how the face moves, facial movement also provides the viewer with additional static information about the face (e.g., additional face shape information due to seeing the face from multiple angles as it moves). Therefore, it is possible that the motion advantage we observed is a result of additional static information rather than motion per se. However, results have, to date, provided no evidence to support this explanation of the motion advantage as presentation of multiple static images of a face is not seen to produce the same level of recognition performance as moving conditions (Christie & Bruce, 1998; Lander et al., 1999; Pike et al., 1997). A multiple static condition was not used here as it would not have been informative in the context of an eye tracking study because the transition between multiple static images of a face would have driven eye movements. That is, in a multiple static condition attention would be drawn to the area of the face that changed between instances of the face, and thus not reflect typical face processing. As such the additional static information explanation cannot be entirely ruled out but is unlikely given the wealth of past literature opposing it. Instead, the motion advantage we observed can be accounted for by the representation enhancement and supplemental information hypotheses (O’Toole et al., 2002). Both theories are well supported by previous research (Bennetts et al., 2013; Butcher et al., 2011; Hill & Johnston, 2001; Pike et al., 1997) and offer clear explanations as to why viewing a face move might help us to learn or recognise that face.
However, other factors that might contribute to the motion advantage, like eye movement differences when processing static and moving faces, have largely been ignored. The current findings demonstrate, for the first time, that eye movement patterns do differ when recognising and learning a moving face compared with static faces. Crucially, as hypothesised, facial motion was associated with more attention to the internal features, and less attention towards the internal non-feature and external feature regions of a face. That is, facial motion was seen to focus attention on the internal facial features that have been found to be of greatest importance for face identification (e.g., Bobak et al., 2017; Ellis et al., 1979; Longmore et al., 2015) and reduce attention to parts of the face that are less reliable cues to identity (e.g., the hairline) (Ellis et al., 1979; Longmore et al., 2015) suggesting that differential eye movement patterns might play a role in the motion advantage.
Increased attention to the internal features of moving faces is likely the result of attention capture based on low-level movement information, or attention capture based on social relevance. A large body of research has established that motion captures visual attention (e.g., Abrams & Christ, 2006). It is therefore likely that facial movement makes the moving features visually salient, increasing attention to those features. A second possible reason attention is drawn to the internal features of moving faces is attention capture based on the social relevance of facial movement. In all three experiments faces were seen displaying social communicative movements, including speech and expressions of emotion. The social signals hypothesis (Roark et al., 2003) predicts that the social communication signals carried by facial motion focus our attention on a person, encouraging processing of identity specific regions of the face and facilitating identification. The current findings demonstrate that facial motion does focus attention on the parts of a face that provide the information necessary to process the social information being conveyed by the face (e.g., what is being said, or the ’person’s emotional state). These social communication signals are often carried in the movements of the internal features, which are considered of greatest importance to identity processing (Bobak et al., 2017; Ellis et al., 1979; Longmore et al., 2015). In sum, the internal features carry many of the social communicative signals conveyed by facial motion, causing facial motion to draw attention to these identity specific regions of the face.
Further research is required to establish why facial movement increases attention to the internal features. While Birmingham et al. (2008) argue that certain facial features are fixated because they are a rich source of social information, attention capture based on low-level movement information cannot be ruled out. Therefore, future research should endeavour to investigate the importance of the social nature of facial movement by comparing attention allocation while viewing facial movements that are social in nature (e.g., emotional expressions and speech movements) to facial movements that are not considered to carry any social communicative information (e.g., chewing, blinking, and sneezing) (Montgomery et al., 2009). In addition, while the current findings cannot be explained by differences in the size of IAs across the moving and static conditions, future research should seek to replicate these findings to ensure they are robust to size and shape variations. As eye movement findings may be influenced by the IAs used in the analysis, one informative approach could be the use of spatially sensitive data-driven analyses such as iMap (Caldara & Miellet, 2011), which can overcome limitations of IA analysis related to priori segmentation of stimuli, as IA analysis is arguably constrained by subjective evaluations. The outcome of this programme of work will provide crucial insights into why there is increased attention to the internal features of moving faces compared with static faces.
Of all the internal features, it is particularly interesting that across all three experiments facial movement was associated with increased fixations to the nose, when arguably the nose moves less than the other internal features (eyes and mouth). That said, this finding supports Bobak et al. (2017), who found that super-recognisers spent more time examining the nose specifically, and that the amount of time spent attending to the nose correlated with face recognition ability in controls. Together with the finding that looking just below the eyes (i.e., the top of the nose) is optimal across face recognition tasks (Peterson & Eckstein, 2012), these findings suggest that where face recognition performance is best (i.e., in the moving condition here and super-recognisers in Bobak et al., 2017) fixations are directed to the nose. This may be because a focus on the upper nose region allows individuals to process information from multiple regions of the face which contribute to identification and social tasks (Peterson & Eckstein, 2012). Indeed, the overlap between gaze position and visual information extraction is not perfect (e.g., Arizpe et al., 2012; Blais et al., 2017). For example, during face processing one may fixate the centre of a face while processing the peripheral information contained in the eyes and/or mouth area (e.g., Blais et al., 2017). Thus, it is possible that participants directly fixated on the nose while utilising other features at the extra-foveal level. In addition, increased attention to the nose has also been associated with increased holistic processing of faces (e.g., Blais et al., 2008; Bobak et al., 2017), suggesting that it is unlikely our participants were resorting to more part-based or analytical processing styles when recognising and learning moving faces (but see Xiao et al., 2012, 2013) who argue facial motion promotes part-based face processing).
While increased attention to the nose, and internal features more generally, was observed across all three experiments there were some noteworthy differences in terms of which internal features were attended more. During familiar face recognition (Experiment 1) the increased attention to the internal features of moving faces was consistent across the internal features (i.e., higher fixation proportions were seen on the eyes, nose, and mouth of moving faces), whereas during unfamiliar face learning the increased attention to the internal features was driven by fixations to the nose and mouth. It is possible that these differences were simply due to perceptual processing differences for familiar and unfamiliar faces, as research has shown that the features attended to do change with increased familiarity (Heisz & Shore, 2008; Stacey et al., 2005).
Alternatively, it is possible that these eye movement differences are a result of the type of facial motion observed. Familiar faces were seen displaying mostly non-rigid speech movements in naturalistic conversation combined with some rigid head movements, wherein the depicted person did not always look at the viewer. It is possible that the nature of the movement and lack of gaze directly at the viewer influenced how the participant attended to the face. For example, when engaged in conversation the mouth of a speaker communicates speech information while the eyes communicate other information, such as gaze direction. To process these different types of information a viewer often fixates the eyes or mouth of a speaker’s face (Gurler et al., 2015; Rennig & Beauchamp, 2018). That is, when viewing a talking face attention allocation tends to be divided between these internal features, which is what was observed here in the famous faces task. On the contrary, unfamiliar faces were seen expressing “joy.” Previous research has found distinct eye movement patterns for different emotions, with joyful faces associated with a focus on the lips and the lower part of the face (Schurgin et al., 2014). This might explain why the increased attention to the internal features of moving unfamiliar faces at encoding was driven by the nose and mouth. It is argued that these distinct eye movement patterns are the result of both stimulus properties but also goal-driven strategies as eye movement patterns reflect attention to the most diagnostic regions of a face to pursue the current goal (e.g., speech, emotion, and/or identity processing).
Another important difference found between familiar face recognition and unfamiliar face learning relates to the relationship between the magnitude of the motion advantage and increased attention to the internal features. We found, for the first time, that the proportion of fixations directed to the internal features of a face is functionally related to the magnitude of the motion advantage when recognising familiar faces (Experiment 1). Individuals who tend to fixate on the internal features of familiar faces regardless of presentation style did not benefit as much from seeing facial motion. Conversely, participants who spent less time attending to the internal features of static faces were seen to benefit most from seeing a face move, perhaps because facial movement encourages processing of the internal features via attention capture based on low-level motion information (Abrams & Christ, 2006) or social relevance (Lansing & McConkie, 2003; Roark et al., 2003). This finding suggests that eye movement differences are functional and play a role in the motion advantage for familiar faces. However, the relationship between attention to the internal features and the magnitude of the motion advantage was not evident during unfamiliar face learning (Experiments 2 and 3) suggesting that the mechanisms that underlie the motion advantage may differ for familiar and unfamiliar faces. This finding might reflect the relative importance of the internal and external features for familiar and unfamiliar face recognition. Face recognition becomes increasingly reliant on the internal features as familiarity with a face increases (Di Oleggio Castello et al., 2017; Ellis et al., 1979), whereas unfamiliar face recognition is characterised by increased reliance on external features (Bonner et al., 2003; Liu et al., 2013; Want et al., 2003). As such, increased attention to the internal features because of facial movement may only be functionally related to the magnitude of the motion advantage for familiar face recognition. This is because during familiar face recognition attention to the internal features facilitates recognition, while for unfamiliar face recognition attention to the external features is beneficial. Alternatively, given the differences in methods used here to investigate familiar and unfamiliar face recognition there was no meaningful between-experiment statistical comparison possible. Therefore, it is not possible to rule out methodological differences as the source of this difference between the familiar and unfamiliar face experiments rather than familiarity per se. For example, this variation may be influenced by differences in the nature of the stimuli rather than by familiarity. Naturalistic stimuli, including more rigid head movements were used in the familiar face experiment. As such it is not possible to determine the actual mechanisms underlying these differences. Further research will be necessary to fully understand the relationship between the motion advantage and attention to internal facial features as the current findings suggest that increased attention to the internal features of moving faces may be functional to the motion advantage, but only significantly related when recognising familiar faces.
In addition to the theoretical importance of this finding, the discovery that attention to the internal features is associated with the magnitude of the motion advantage also has the potential to inform our understanding of developmental prosopagnosia. Previous research has shown that people with developmental prosopagnosia can extract facial movements and use them as a cue to identity (Bennetts et al., 2015; Longmore & Tree, 2013; Steede et al., 2007). However, it is not yet clear whether the mechanisms that underpin the motion advantage are the same for people with developmental prosopagnosia as they are for typically developing individuals. Bobak et al. (2017) found that more severe prosopagnosia is associated with less time looking at inner facial features, but this work was conducted using static faces. Experiment 1 found that the participants who fixated least on the internal facial features of static faces benefitted most from observing facial movement, suggesting that individuals with developmental prosopagnosia, who do not typically attend to the inner facial features as much as typically developing individuals, might benefit from facial movement because it encourages them to attend to the internal features. Future research investigating this hypothesis is necessary.
Surprisingly, although a positive correlation was found between the proportion of fixations to the internal features and RTs (Experiment 2 only), there was no relationship between recognition accuracy and the proportion of fixations directed to the internal facial features. This finding goes against both our hypothesis and previous research that has demonstrated the importance of the internal features for identity processing (e.g., Ellis et al., 1979; Longmore et al., 2015), including eye movement studies that have linked greater attention to the internal features of the face with better performance (Bobak et al., 2017; Williams & Henderson, 2007). However, the previous literature demonstrating the importance of the internal features has exclusively used static faces. So, it is possible that these findings do not extend to the moving faces used here in half the trials. However, given the lack of correlation between recognition accuracy in the static condition and attention to the internal features of static faces, the use of moving faces is unlikely the only contributing factor to this finding. Thus, this finding necessitates further research to understand the importance of the internal features when processing moving faces.
In conclusion, the findings of the present series of experiments show that facial motion can facilitate better familiar face recognition and unfamiliar face learning, and to our knowledge are the first to show that eye movement patterns differ significantly, and in a theoretically important way, when learning and recognising moving compared with static faces. That is, facial movement increased attention to the identity diagnostic internal features, and this increased attention to the internal features appears to play a functional role in the magnitude of the motion advantage for familiar face recognition.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was supported by University Research Funding from Teesside University.