
Abstract
German skilled readers have been found to engage in morphological and syllable-based processing in visual word recognition. However, the relative reliance on syllables and morphemes in reading multi-syllabic complex words is still unresolved. This study aimed to unveil which of these sublexical units are the preferred units of reading by employing eye-tracking technology. Participants silently read sentences while their eye-movements were recorded. Words were visually marked using colour alternation (Experiment 1) or hyphenation (Experiment 2)—at syllable boundary (e.g., Kir-schen), at morpheme boundary (e.g., Kirsch-en), or within the units themselves (e.g., Ki-rschen). A control condition without disruptions was used as a baseline (e.g., Kirschen). The results of Experiment 1 showed that eye-movements were not modulated by colour alternations. The results of Experiment 2 indicated that hyphens disrupting syllables had a larger inhibitory effect on reading times than hyphens disrupting morphemes, suggesting that eye-movements in German skilled readers are more influenced by syllabic than morphological structure.
Many decades of reading research have shown that reading involves more than just processing orthographic whole-word representations. Rather than simply relying on letter-by-letter decoding, expert readers reliably and automatically read words by forming associations in memory between embedded sublexical units (i.e., syllables and morphemes) and their corresponding lexical representations (Ehri, 1995). In fact, this trend is already found in children’s first years of reading instruction (Colé et al., 2012; Häikiö et al., 2011) and spills over to adulthood, with evidence of both syllable and morpheme processing gathered in several languages across tasks (Colé et al., 1999; Conrad et al., 2009; Dawson et al., 2018). The goal of the present eye-tracking study was to shed further light on the mechanisms involved in sublexical reading in a shallow orthography, namely, German. In particular, we sought to directly compare the relative relevance of syllable and morpheme processing by monitoring participants’ eye-movements. Prior research has typically focused either on bi-syllabic, monomorphemic words (Conrad et al., 2011) or on multi-morphemic words (Bertram et al., 2004), but studies that have directly compared morpheme and syllable processing are more scarce (Alvarez et al., 2001; Colé et al., 2012; Domínguez et al., 2006; Häikiö & Vainio, 2018; Hasenäcker & Schroeder, 2017). As such, the interplay between syllable and morpheme processing within multi-syllabic, multi-morphemic words (e.g., formation, a word with three syllables and two morphemes) is not well understood.
Reading multi-syllabic words
Research carried out on different languages suggests that syllables are not only relevant in speech production and comprehension (Cholin et al., 2004) but also represent relevant processing units in visual word recognition (e.g., Conrad & Jacobs, 2004). For example, Ferrand et al. (1996, 1997) found that primes with the same syllabic structure as the target word (cv—CV) produced facilitatory effects in French in a naming task when the prime shared the first syllable with the target, and the syllable had clear boundaries (bal%%%%—BAL.CON), than when preceded by primes containing one letter more (bal%%%%—BA.LADE) or less (ba%%%%—BAL.CON) than the first syllable. Syllable effects have been reported in French (e.g., Chetail & Mathey, 2009a, 2009b), Spanish (e.g., Carreiras & Perea, 2002; Perea & Carreiras, 1998), and German (Conrad & Jacobs, 2004; Stenneken et al., 2007).
Converging evidence of the early involvement of phonological processing in visual word recognition also comes from eye-tracking studies using silent reading tasks (Fitzsimmons & Drieghe, 2011; Inhoff & Topolski, 1994; Pollatsek et al., 1992; Rayner et al., 1998; Sparrow & Miellet, 2002). For example, Pollatsek et al. (1992) found a parafoveal preview benefit for homophones (sent as preview for cent) but not for visually similar words (rent as a preview for cent). Ashby and Rayner (2004) investigated whether syllabically congruent primes could aid visual word recognition during silent English reading. They discovered that when the preview was syllabically congruent (target: de-vice, preview: de_πxw), readers’ first fixation durations on the target word were shorter than when it was incongruent (dev_πx), although the proportion of orthographic overlap between the preview and the target was greater in the incongruent condition. More recently, Hawelka et al. (2013) used eye-tracking to assess whether inhibitory effects of first syllable frequency found in lexical decision tasks are generalisable to natural reading. Using the multi-syllabic items of the German Potsdam Sentence Corpus (Kliegl et al., 2004) as target words, the authors found inhibitory effects that resulted in longer first fixation on multi-syllabic words starting with high-frequent first syllables. This effect was interpreted as evidence of prelexical phonological processing. The authors argued that syllabic representations served as “access units” to the mental lexicon, which also tend to be activated in visual word recognition (see also Stenneken et al., 2007).
The prior evidence for the important role of syllables in silent reading has led to the assumption that syllables are represented as prelexical units of reading at an intermediate stage between letter perception and word recognition. For example, Mathey et al. (2006) extended the interaction activation model (IA model) of McClelland and Rumelhart (1981) by including syllables (the IAS model). As a result, the model accounts for both syllable effects and the influence of orthographic information (see also Ans et al., 1998; Grainger & Ziegler, 2011). Similarly, Conrad et al. (2010) extended the MROM model (MROM-S) by adding syllabic representations units in a separate route, which are connected to both letter and word representations. Syllables activate words that contain them in the initial syllabic position, so that the processing of the target is hampered by lateral inhibition caused by the coactivated syllabic neighbours, with the competition being more severe when the syllable is of high frequency. This way, the model explains the inhibitory effect of syllable frequency on lexical decision reported several languages including German (e.g., Conrad & Jacobs, 2004).
Reading multi-morphemic words
Evidence for morphological processing in skilled reading is abundant (for reviews, see Amenta & Crepaldi, 2012; Rastle & Davis, 2008). For example, in a lexical decision study in English, Ji et al. (2011) reported that transparent and opaque compound words are processed faster than frequency-matched monomorphemic words. The authors argued that morphological decomposition is beneficial because the activation of the individual constituents facilitates the recognition of the whole word. Masked priming studies have also unveiled facilitatory priming effects for truly suffixed primes (player—PLAY) and pseudo-suffixed primes (mother—MOTH), relative to non-morphological controls (cashew-CASH), with prime displays as brief as 42 ms (e.g., Rastle et al., 2004). This shows that at the early stages of visual word recognition, both suffixed (play + er) and pseudo-suffixed (moth + er) words are swiftly decomposed into their morpho-orthographic constituents (Beyersmann et al., 2016; Diependaele et al., 2009; Longtin et al., 2003; Rastle et al., 2004). These results were consistently found in several orthographies, such as French (e.g., Grainger et al., 1991), English (e.g., Beyersmann et al., 2012), and Russian (e.g., Kazanina et al., 2008).
The scope of morphological effects is not only limited to priming studies and lexical decision tasks but also extends to more natural reading settings. Several eye-tracking studies have found that morphemes are recognised and rapidly processed during sentence reading. For instance, Deutsch et al. (2003), using a boundary-contingent paradigm, found a morphological preview benefit effect for Hebrew speakers. When readers parafoveally processed a morphologically related word, target words were processed faster compared with an orthographic control condition, as reflected by early processing measures such as first fixation durations and gaze duration.
Other eye-tracking studies have instead turned to frequency as a diagnostic tool to examine the influence of morphological processing in complex word processing. These studies typically manipulate the frequency of the entire word as well as specific morphological components, and their effects on early and late measures like first, second, or third fixation durations and gaze duration. This methodology is based on the premise that if the frequency of a single morpheme influences fixation durations, then this will demonstrate morphological decomposition in reading complex words (Kuperman et al., 2010; Pollatsek et al., 2000). For instance, Pollatsek et al. (2000), using Finnish compound words, reported a second constituent frequency effect on second fixation duration and gaze duration (as did Juhasz et al., 2003 in English), thus building on Hyönä and Pollatsek’s (1998) findings of first constituent frequency affecting first fixation duration, second fixation duration and gaze duration. In addition, the same group of authors reported a whole-word frequency effect on gaze duration (Experiment 2), indicating that the identification of compound words involves simultaneous processing of morphological constituents and whole-word representations. Further evidence for the important role of constituent frequency on eye-movements comes from a study by Bertram and Hyönä (2003), showing that long Finnish compound words with a high-frequency first constituent elicited shorter gaze durations, shorter first fixation durations, and fewer third fixations than long compounds with a low-frequency first constituent. In addition, the first constituent frequency effect was more pronounced in long compounds than in short ones (Experiment 1), suggesting that short compounds are more likely to be processed as wholes (Experiment 2). This finding was also confirmed by Kuperman et al. (2010) using derived complex words in Dutch. They found that words with shorter suffixes exhibited a stronger whole-word frequency effect on reading times compared with suffix frequency, thus pointing to the important role of suffix length in morphological processing.
An appreciation of the influence of morphological information in reading also comes from eye-tracking studies examining landing positions. Normally, the eyes land in the middle of the word or slightly to the left of it, a phenomenon called optimal viewing position (O’Regan, 1992; Rayner, 1979), from which a word can be processed the fastest. However, it has been demonstrated that when words are morphologically complex, the eye fixations land closer to the beginning of the words (Hyönä et al., 2018; Yan et al., 2014), suggesting that readers are able to pick up words’ morphological structure during parafoveal processing, which helps them adjusting their saccade programming accordingly.
Over the past decades, many morphological processing theories have emerged from the field of visual word recognition (Diependaele et al., 2009; Duñabeitia et al., 2007; Grainger et al., 1991; Grainger & Ziegler, 2011; Longtin et al., 2003; Rastle, 2019; Rastle & Davis, 2008; Rastle et al., 2004). These theories make different assumptions with respect to the time-course of morphological processing during reading, with some predicting that the early stages of morphological processing are semantically “blind” (Beyersmann et al., 2016; Longtin et al., 2003; Rastle et al., 2004), whereas others assume that semantics do already assert an influence on morphological processing during the initial stages of complex word recognition (Feldman et al., 2009, 2015). However, they all agree that skilled readers are experts at rapidly extracting morphological information from print. More recently, it has been proposed that the activation of edge-aligned embedded words posits one of the key ingredients in the analysis of multi-morphemic words as well as in children’s reading acquisition (for more detail, see the word and affix model by Beyersmann & Grainger, 2022 and Grainger & Beyersmann, 2017).
Syllables versus morphemes
The above summary shows that silent reading is clearly modulated by the syllabic and morphemic structure of words; however, only few studies have directly compared the salience of syllables and morphemes in this process. In many Indo-European languages, syllabic and morphemic structure do not always overlap (e.g., far-mer vs. farm-er: see Alvarez et al., 2001; Domínguez et al., 2006), but how do readers solve this challenging conflict between reading units? Are syllables and morphemes equally salient during silent reading?
Fracasso et al. (2016) showed that while phonological and morphological awareness are predictors of reading comprehension in adults, the latter was also a unique predictor of vocabulary skills, as the “ability to break up morphologically complex words into their morphemic constituents enables a reader to use their knowledge of the meanings of the base morpheme and suffix to infer meanings of unfamiliar, morphologically complex words” (Fracasso et al., 2016, p. 147). For example, via access to the individual morphemes in paleo-geo-graph-er, readers may be able to partially derive word meaning, that is, a person (-er) working in the field of ancient (paleo-) geography. Thus, compared with syllable-based reading, morpheme-based reading has the advantage of breaking down the word’s meaning into meaningful chunks (Bhattacharya, 2020; Goodwin et al., 2013; Kearns & Whaley, 2019).
Studies comparing morphological processing in children, adolescents, and adults have suggested that morphological decomposition becomes more important and automatised throughout reading acquisition, such that morphological effects are more pronounced in adults compared with the younger age groups (e.g., Beyersmann et al., 2012; Dawson et al., 2018; Schiff et al., 2012). Although this indicates that skilled readers become increasingly skilled at parsing complex words into morphemes as they become more fluent readers, it does not undermine the possibility that syllable-based parsing is equally important.
Indeed, syllable-based reading has its own advantages of drawing from preexistent oral knowledge (Perfetti et al., 1992) and retaining identified words in the phonological loop of short-term memory (Besner, 1987; Bruck et al., 1995), which is useful for sentence-processing. In this regard, the few studies that directly compared syllable and morpheme processing focused on developing readers. One such study was conducted by Colé et al. (2012) with French second and third graders. The stimuli employed in their naming task (Experiment 2) were segmented using a space at the syllable boundary (den tiste) or morpheme boundary (dent iste), with the assumption that recognition will be faster if the visual manipulation conformed to the units activated during written word identification. Results showed that word recognition times were comparable between the morphemes and syllables-spaced conditions, suggesting that both morpheme and syllable-based reading affected reading fluency to the same degree.
In contrast to Colé et al.’s (2012) findings from French primary schoolers, Häikiö and Vainio (2018) reported differences between syllable and morpheme processing in Finnish first- and second-graders. The authors examined the processing of bimorphemic targets words embedded in sentences using eye-tracking. In half of the target words the last syllable boundary coincided with the (inflectional) morpheme boundary. Using hyphens, words were divided into syllable-congruent and syllable-incongruent (which were also morpheme-congruent in half of the cases) conditions. Second graders spent significantly more time fixating hyphenated than non-hyphenated words, an effect that was less noticeable in first graders. However, when the syllable-incongruent condition overlapped with the morpheme-congruent condition (MCC), neither age group’s gaze durations increased, suggesting that Finnish beginning readers were not slowed down by the broken syllables or the hyphenation, as long as hyphens segmented words into morphemes. The authors interpreted this finding as an indication that participants relied more on morphemes than on syllables in their reading.
A similar paradigm, using lexical decision, was employed by Hasenäcker and Schroeder (2017) in German second and fourth graders, and adults. Multi-syllabic monomorphemic and multi-morphemic words and multi-syllabic pseudo-affixed nonwords were segmented into syllable-congruent and incongruent items using a colon (:). The syllable-incongruent items overlapped with morphemes boundaries. Results showed that second graders were faster in both word identification and pseudoword rejection when the disruption was syllable congruent. However, in fourth graders the syllable-incongruent/morpheme-congruent manipulation impeded the rejection of multi-morphemic pseudowords, suggesting that syllable-based reading was more pronounced in Grade 2, but morpheme-based reading was predominant in Grade 4. Lexical decision responses in adults were not hindered or facilitated by any of the manipulations, which may however have been ascribable to the excessive simplicity of their items (taken from the childLex corpus of Schroeder et al., 2015).
In sum, although the prior evidence shows that both children and adults use syllables and morphemes in their reading, it remains less clear whether the reading system gives preference to the analysis of syllabic or morphemic structure and how potential confounds between syllable- and morpheme-congruency are resolved.
The present study
To address the question of how skilled readers process words with deviating syllable and morpheme-structures, the current eye-tracking study used a method to highlight syllable and morpheme structure in silent reading. The goal was to explore syllable- and morpheme-congruency effects in sentence reading while monitoring participants’ eye-movements, to test if readers find it easier to read text where syllables and morphemes are visually marked. The benefits of eye-tracking are not limited to study online cognitive processes in an ecological reading setting (without the constraint of having participants perform an unfamiliar task; Rayner et al., 1998) but can also be used to tease apart the early versus late processes involved in reading. The goal was to build on prior findings by directly comparing the processing of syllables and morphemes in skilled readers of German, a morphologically rich (Juola, 1998; Kettunen, 2014; Mousikou et al., 2020), syllabically complex (Adsett & Marchand, 2010; Seymour et al., 2003; Stenneken et al., 2007), and orthographically transparent language (Borleffs et al., 2017; De Simone et al., 2021). In the first experiment, syllables and morphemes were highlighted using colours, whereas the second experiment used hyphenation to segment words into their respective reading units.
Experiment 1
In Experiment 1, we presented words in which morphemes or syllables were highlighted using colours, based on a method that is commonly used in German reading instruction (“Silbenmethode” [syllable method], where reading books for children in early school grades mark each alternate syllable in a different colour). The syllable method relies on the assumptions that colour information helps to identify objects and better remember information (Gegenfurtner & Rieger, 2000; Tanaka et al., 2001). Indeed, colour similarities make it easier to aggregate an item formed by many elements, while colour disparities help separate stimuli into multiple things (see Goldfarb & Treisman, 2011). However, only few studies have applied the method to examine the cognitive mechanisms of reading in adults. As a result, the cognitive underpinnings of the “Silbenmethode” are still little understood.
Perhaps, one of the most informative studies in this regard is one by Carreiras et al. (2005), in which the authors examined syllabic effects in Spanish-speaking adults using event-related potentials, while participants performed a lexical decision task. The authors used colours to segment words which varied in frequency, as well as pseudowords such that the colours either did or did not coincide with the syllable structure. In a baseline condition, only one colour was used. No congruency effects were found in the behavioural measures (for related evidence from the transposed letter similarity effect, see Marcet et al., 2019). However, the colour manipulation led to a temporal and spatial dissociation in the ERPs in the P200 time window for pseudowords and low-frequency words, with an amplitude increase for the colour-syllable incongruent condition compared with the colour-syllable congruent and baseline conditions. This suggests that the syllabic structure of low-frequency words and pseudowords is processed during the early stages of visual word recognition (see also Carreiras et al., 2009 for similar conclusions). Crucially, Carreiras et al. (2005) reported no facilitatory effect of syllable colouring (i.e., no differences were found between the baseline and the congruent stimuli in the ERPs or RTs) and therefore does not provide direct support of the hypothesis that the use of syllable colouring supports reading. However, given that Spanish has a simpler syllable structure compared with German (Seymour et al., 2003), it is unclear whether these results are generalisable across languages.
Indeed, preliminary eye-tracking evidence from Chinese (Zhou et al., 2018, 2019), a typically unspaced script, shows that Chinese silent reading is facilitated when words are alternately coloured, such that between-word boundaries are explicitly signalled. Colouring influenced landing position, showing how this method helped L1 Chinese speakers (Zhou et al., 2018) and L2 Chinese learners (Zhou et al., 2019) to optimise their eye fixations. However, colouring segmentation might not have the same impact on reading speed. While alternating colours at word boundaries increased the reading fluency of skilled Chinese readers when reading aloud difficult, technical texts with unfamiliar words (Perea & Wang, 2017), the same effect was not found under normal circumstances, that is, when reading more common texts with familiar words (Perea & Wang, 2017). In fact, it seems that the positive impact of colour segmentation on reading speed decreases with age: in an eye-tracking study, Song et al. (2021) found colour facilitation effects in multi-chromatic compared with mono-chromatic sentence-processing in Grades 2–3 children (as did Perea & Wang, 2017, Experiment 3), but not in Grades 4–5 children.
Similar findings with Grade 2 children have been reported also in alphabetic scripts, with within-word colour segmentation. For example, Lopes and Barrera (2019) investigated syllable colouring in Grade 2 Brazilian-Portuguese speaking children performing an isolated word reading task. They found that highlighting syllables through the use of colours had a positive effect on good readers when reading irregular words, and on poor readers when reading regular and irregular words. Similar findings in French speaking children of the same age were also found by Chetail and Mathey (2009b) using a colour lexical decision task. However, in an eye-tracking study with Finnish beginning readers (Grade 1–2), Häikiö et al. (2015) found no evidence that alternating colours at the syllable boundary affects reading speed, compared with a control condition where no visual cues where given.
Research on using the colouring method with morphemes is scarcer. Ji et al.’s (2011) lexical decision study (Experiment 5) employed a colour contrast (red/black) to encourage the decomposition of English compound words into morphemes, with the assumption that the display manipulation would facilitate morphological parsing, and hence support the retrieval of the compound words’ meaning. However, the colour manipulation did not influence response time or accuracy scores, and if anything inhibited the processing advantage of opaque words compared with monomorphemic words, potentially because in the case of opaque words, this colouring supported a computed meaning that was inconsistent with its stored, conventional meaning.
Other colour segmentation studies have used illusory conjunctions (ICs) first described by Treisman and Schmidt (1982). ICs have been defined as a type of errors that happen in the perceptual binding of proximal elements in a given stimulus, when attention is deviated or diverted (Henderson & McClelland, 2020). In reading research, ICs have been used to “determine the nature of the sublexical units that are automatically perceived at a perceptual level of word processing” (Doignon-Camus & Zagar, 2005), first employed in English by Prinzmetal et al. (1986). The procedure is normally paired with a letter detection task, which serves to divert the participant’s attention. In a stimulus string divided in two colours, participants are asked to (a) detect the target letter; and (b) report in which colour the target letter was presented. For example, participants are asked to determine if the target letter was present in a given word and what colour it was. The target letter (e.g., letter “v” in anvil) is presented either in a unit-congruent condition (syllables, in the example): anvil, or in a unit-incongruent condition: anvil. Prinzmetal et al. (1986) reported syllable preservation errors, where participants reported that a given target letter (v) appeared in the same colour as the rest of its syllable unit (vil), including within the incongruent condition (anvil), suggesting that syllables were automatically activated during visual word processing. The authors reported similar preservation errors in polymorphemic words, indicating that both syllables and morphemes represent functional units in the visual analysis of words (for similar findings from French, see Doignon-Camus et al., 2009; Doignon-Camus & Zagar, 2005).
In sum, the review of the literature shows that it is still unclear whether or not segmentation by colouring does indeed expedite word processing. Although several studies have failed to provide evidence for a facilitatory role of syllable colouring on reading fluency (e.g., Carreiras et al., 2005, 2009; Häikiö et al., 2015), the Silbenmethode still continues to be used extensively in German reading instruction and therefore calls for a more thorough investigation within the German language in particular. This study used eye-tracking to investigate the effectiveness of the colouring method in German by directly comparing syllable and morpheme processing in an ecologically valid way. Participants read sentences where colours were either congruent or incongruent with the embedded syllabic and morphemic structures, relative to a black-coloured control. We hypothesised that if any facilitation effects were to be found (due to highlighting relevant reading units), then the syllable-congruent and the MCCs would be read faster than the control condition. Moreover, if morphological information is more relevant in reading than syllabic information because of its direct link with semantics (as argued by Kearns & Whaley, 2019), participants would spend less time fixating and make fewer regressions to words in the MCC compared with the syllable-congruent condition. As facilitation could also occur through an optimised landing position variability across conditions, we predicted that coloured units may change the landing position of the eye, compared with where no unit is evident (a preregistration of these hypothesis can be found at https://osf.io/csja8).
Method
Participants
The desired sample size (40) was preregistered and determined a priori using the package SimR (Green & MacLeod, 2016) in the R computing environment (R Core Team, 2021) to calculate power for linear mixed model. Using pilot data collected from two volunteers, we ran simulations for each hypothesis. Our simulations predicted that to obtain a power of 80% (d = 0.5), we needed a minimum sample of 30 participants. Based on previous studies in the reading and eye-movements literature (Rayner, 1998), it was decided to increase the calculated sample size to 40 typically reading adults.
In total, 42 native German speakers (35 females, 7 males) participated for monetary reimbursement. Two participants who scored poorly on the Standardised Reading Fluency Test (SLRT) II word reading test (Moll & Landerl, 2010) were excluded (i.e., <16 percentile, corresponding to at least one standard deviation below the mean of the adult population in the standardised reading test), following the German clinical diagnostic guidelines for dyslexia (Galuschka & Schulte-Körne, 2016). The remaining 40 participants were between 20 and 53 years old (M = 29.3; SD = 7.59) and had normal or corrected-to-normal vision. The study was approved by the ethics committee of the Hospital of the Ludwig–Maximilians–University (LMU) and conforms with the ethical principles of the Declaration of Helsinki. Prior to participating in the study, participants provided written, informed consent.
Materials
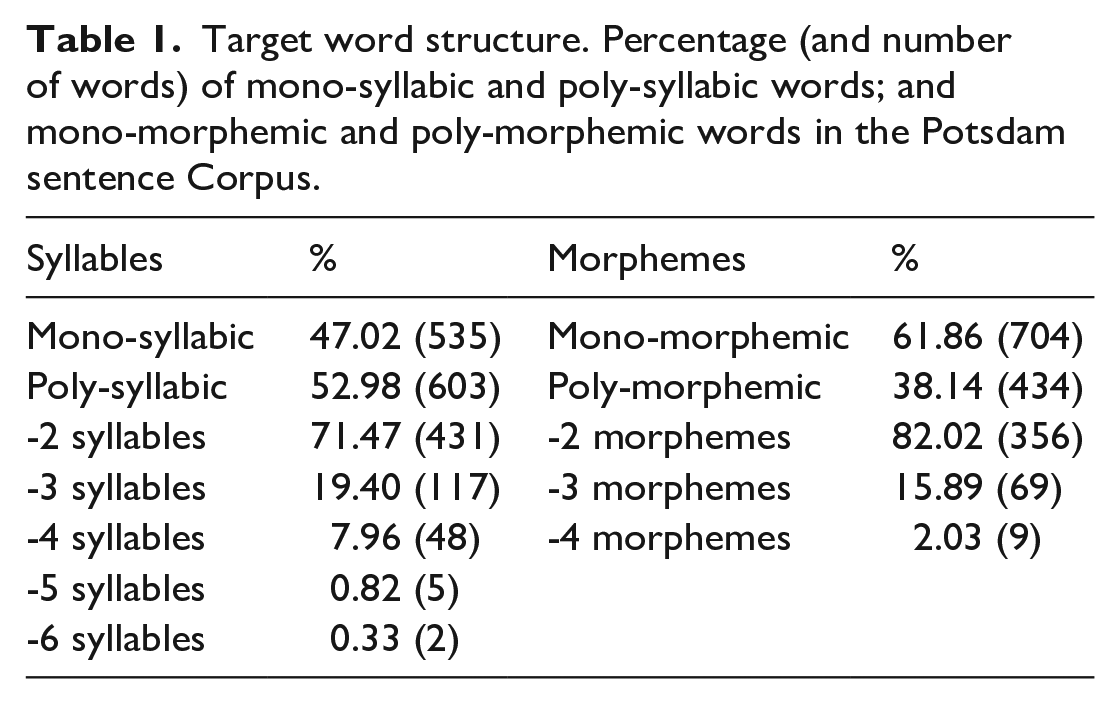
Adults read 140 sentences from the Potsdam Sentence Corpus (Kliegl et al., 2004, 2006). Sentences included 5–11 words (M = 7.9, SD = 1.4), with logarithmic word frequencies averaging to M = 2.1 (SD = 1.3). Overall, there were a total of 1,138 words in the corpus (see Table 1 for words’ statistics).
Target word structure. Percentage (and number of words) of mono-syllabic and poly-syllabic words; and mono-morphemic and poly-morphemic words in the Potsdam sentence Corpus.
The sentences were randomly divided into five conditions of 28 sentences each, which were counterbalanced across participants. Each condition corresponded to a different colour manipulation: syllables-congruent; syllables-incongruent; morphemes-congruent; morphemes-incongruent condition; black-coloured. Moreover, we randomised the stimuli presentation in two additional ways: the order of blocks (conditions were not presented in a fixed order), and the order of sentences.
In the syllables-congruent condition (SCC), syllables were alternately coloured in blue and green, and the colour changed at the syllable boundary or between monosyllabic words. Conversely, in the syllables-incongruent condition (SIC), the syllable was disrupted by moving the colour alternation either to the left or to the right of the syllable boundary. The reason for this manipulation was twofold: (a) to rule out possible facilitation or inhibition effects due to the mere colour alternation and (b) to check whether reading was impaired when the integrity of the unit was broken. The same number of coloured units of the syllable-congruent condition was also kept, to avoid a possible increase in saccades, which could have resulted in higher reading times. Moreover, we made sure not to break any multi-letter graphemes (Schüssel, but not Schüssel, where sch is a multi-letter grapheme in German corresponding to the phoneme /ʃ/).
For the next condition, morphemes were alternately coloured in blue and green (MCC, see Table 2). Affixes and morphemic stem constituents (within both affixed and compound words) were coloured in this condition. We separated inflectional morphemes: past tense (stellte, “put”: verb root + tense and person), gender (eine, “a”: base indefinite article + gender), and number (Kirschen, “cherries”: stem + number). Derivational morphemes were separated from their stems, as in Häuschen (little home) and compound words were divided in their constituents, as in Groβvater (grandfather). Similar to syllables, we created a group of sentences where the morpheme unit was disrupted (morpheme-incongruent condition [MIC]) by moving the morpheme boundary either to the left or the right, without separating multi-letter graphemes. We applied the same principles used in the syllables-incongruent condition.
Experimental design and stimuli examples (Experiment 1).
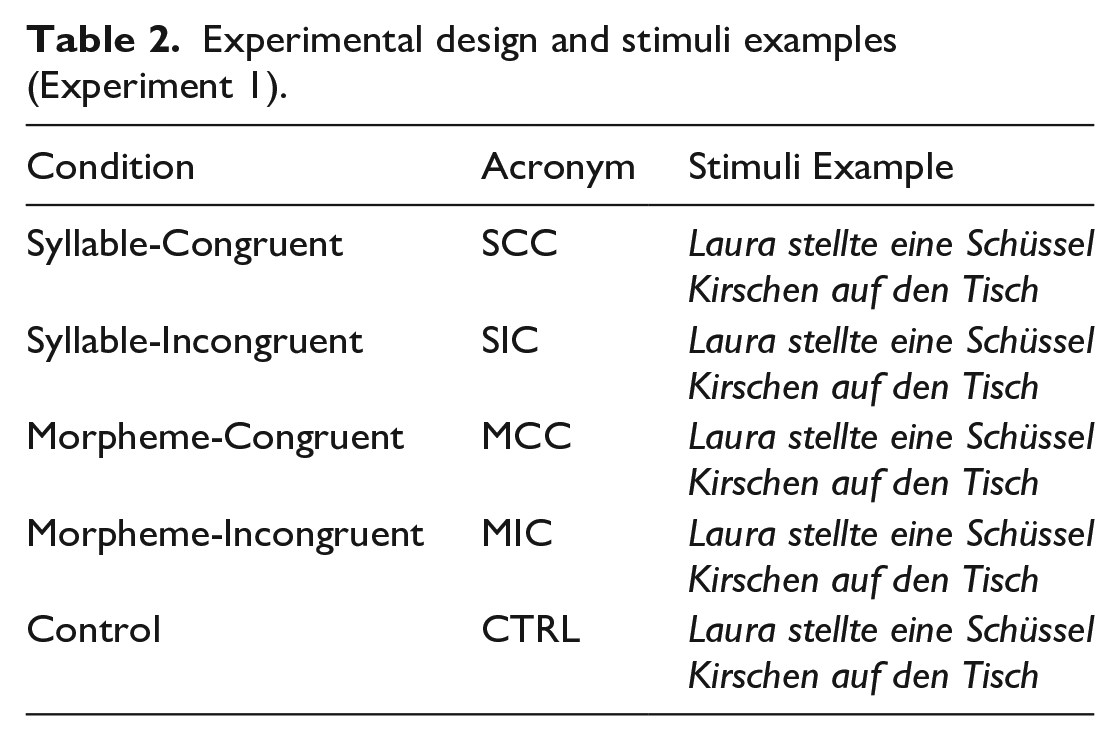
Finally, a fifth group of sentences was composed of black-coloured sentences (CTRL), without any colour alternation. This condition served as a baseline condition. Stimuli examples for each condition are provided in Table 2.
To make sure participants read the sentences carefully, we created a comprehension test in the form of multiple-choice questions. Questions would appear after a random interval of sentences, and they would always refer to the previously shown sentence. In total, participants answered 18 questions. All participants scored more than 80% of correct answers in the multiple-choice questions. The full list of materials is available in the following online repository: https://osf.io/w4rsm/.
Apparatus
Eye-movements were recorded using an EyeLink 1000 Plus Desktop Mount eye-tracker (SR Research, Toronto, Canada) in head-stabilised mode. Participants were seated in front of a 15.6-in. monitor (120 Hz refresh rate, 1280 × 960 resolution) at a viewing distance of 65 cm. Stimuli were presented with an uppercase letter height of about 0.62° of visual angle. A 9-point calibration cycle at the beginning and after each break was used to ensure a spatial resolution of less than 0.5° of visual angle.
The experiment was controlled with Experiment Builder software (SR Research, version 1.10.1630). Sentences were presented in Courier New Bold, 30 pt. font, and projected in full window. One sentence was presented per trial, vertically centred on the screen, on a white background.
Procedure
The sessions took place individually in a silent room. Prior to the eye-tracking experiment, an SLRT II (Moll & Landerl, 2010) was administered where participants had to read aloud a list of words and pseudowords as quickly and as accurately as possible in 1-min time.
Participants were then seated in front of a computer. Reading was binocular, but only the movements of the dominant eye were monitored. Eye dominance was determined using a Miles Test (Rice et al., 2008): participants were asked to extend their arms forward and make a triangle-shape like window with their hands. Then, they positioned the window such that a target point hanging on the wall appeared in the centre while both eyes were open. Next, they were told to close one eye at a time and note the position of the target point. The dominant eye was the eye in which the target stayed centred in the frame when the eye was open.
A 9-point calibration procedure was performed, followed by six practice trials, and then the experimental sentences followed. Participants fixated a drift correct target prior to each trial and recalibration was performed as needed. The participant clicked on the mouse to terminate each trial when they had finished reading.
Participants were instructed to read for comprehension at their own pace. It was emphasised that the task was to comprehend the sentences, and not to memorise the content. They were further told that after varying intervals they would get multiple-choice questions about the content of the previously presented sentence.
Results
Data preparation
Practice trials (0.5%), sentences’ first and last words (28.1%), and skipped words (19%) were excluded from the analyses, as is customary in eye-tracking research (Kliegl et al., 2006; Yan et al., 2014; Zhou et al., 2018). To detect outliers, we used Q-Q plots for total reading time, which revealed 12 data points exceeding 2,400 ms, that we excluded (0.04%). We also excluded fixations shorter than 100 ms (3,5%), as it has been argued that they do not reflect cognitive processes, but instead the outcome of micro-saccades performed to adjust eyes’ position (Rayner, 1998) or blinks during the neighbouring fixation (Bertram, 2011). After these exclusions, 25,821 observations were available for analysis.
Subsequently, we divided the data set in three subsets: one for the comparison between syllable-congruent, syllable-incongruent and control conditions (a), one for the comparison between morpheme-congruent, morpheme-incongruent and control conditions (b), and one for the comparison between morpheme-congruent and syllable-congruent conditions. This was done to maximise the number of items in each comparison.
For the comparison between the syllable-congruent, syllable-incongruent, and control conditions (a), we excluded all monosyllabic items (39.8%). Moreover, we excluded words where the morpheme and syllable boundaries fully overlapped (7.45%) to maximise the strength of the manipulation (e.g., in the word Künstler [artist], the colour alternation happens both at the morpheme and at the syllable boundary). 14,378 observations were available for analysis.
For the comparison between the morpheme-congruent, morpheme-incongruent, and control conditions (b), we excluded monomorphemic items (58.6%) and items where the morpheme and syllable boundaries fully overlapped (9.5%). 9,670 observations were available for analysis.
For the comparison between the syllable-congruent and MCCs (c), to ensure comparability, we restricted the data set to items that had only two syllables and two morphemes. Therefore, we excluded monosyllabic and monomorphemic items and items that had more than two syllables/morphemes (76.9%), as well as items where the morpheme and syllable boundaries fully overlapped (14%). 5,134 items were available for analysis.
Linear mixed effect models were run for each of the following dependent variables: first fixation duration (duration of initial fixation on the target during the first pass through the text), gaze duration (sum of all first-pass fixations made on the target), total reading time (sum of all fixations on the target, including any regressions back to it), regressions (probability of making a regression back to the target from a later portion in the sentence), total number of saccades, and landing position. We had preregistered the analyses on total reading time as an indicator of overall ease-of-processing, and performed the additional analyses to explore the time-course of the effects. Data were analysed in the R computing environment (R Core Team, 2021). Linear mixed effects models were constructed using the lme4 package (Bates et al., 2015) with four fixed effects (condition, and centred word length, frequency and predictability), their interactions, and two random effects (participants and items, with correlated random intercepts for both, and random slopes for participants). P values were obtained using the lmerTest package (Kuznetsova et al., 2017). Factor condition was coded using sum-to-zero contrasts to carry out five pair-wise comparisons between the congruent (1), incongruent (–1), and control conditions (0).
Analysis
First fixation duration, gaze duration, total reading time, number of regressions, number of saccades, and landing position were analysed separately. Response time distributions were checked using the Box-Cox system of the powerTransform function in the CAR package (Fox & Weisberg, 2019), showing that response time transformations were not necessary. Moreover, we applied a Holm–Bonferroni correction (Holm, 1979), a sequential approach with the advantage of maintaining the power of the statistical tests (compared with the more common Sidàk/Bonferroni corrections) while controlling for familywise Type 1 errors (Abdi, 2010). The method compares each observed p-value to an adjusted α-threshold. The original p values are listed from the smallest to the largest within each of comparison, across variables. We performed the correction using two different Microsoft Excel tools made available by researchers (Boustani, 2020; Gaetano, 2018) to double-check the correction. For the sake of clarity, we will report adjusted p values (adj. p), instead of adjusted α thresholds, and consider significant any adjusted p value < .05. Observed power calculations indicated that all models had above 80% chance to find an effect.
Reading times
Mean first fixation duration, gaze duration, total reading time, and corresponding standard errors are reported in Table 3. There were no significant differences between any of the conditions, in any of the comparisons (adj. p > .05).
Descriptive statistics of first fixation durations, gaze durations, and total reading times, in milliseconds, for all conditions (Experiment 1).
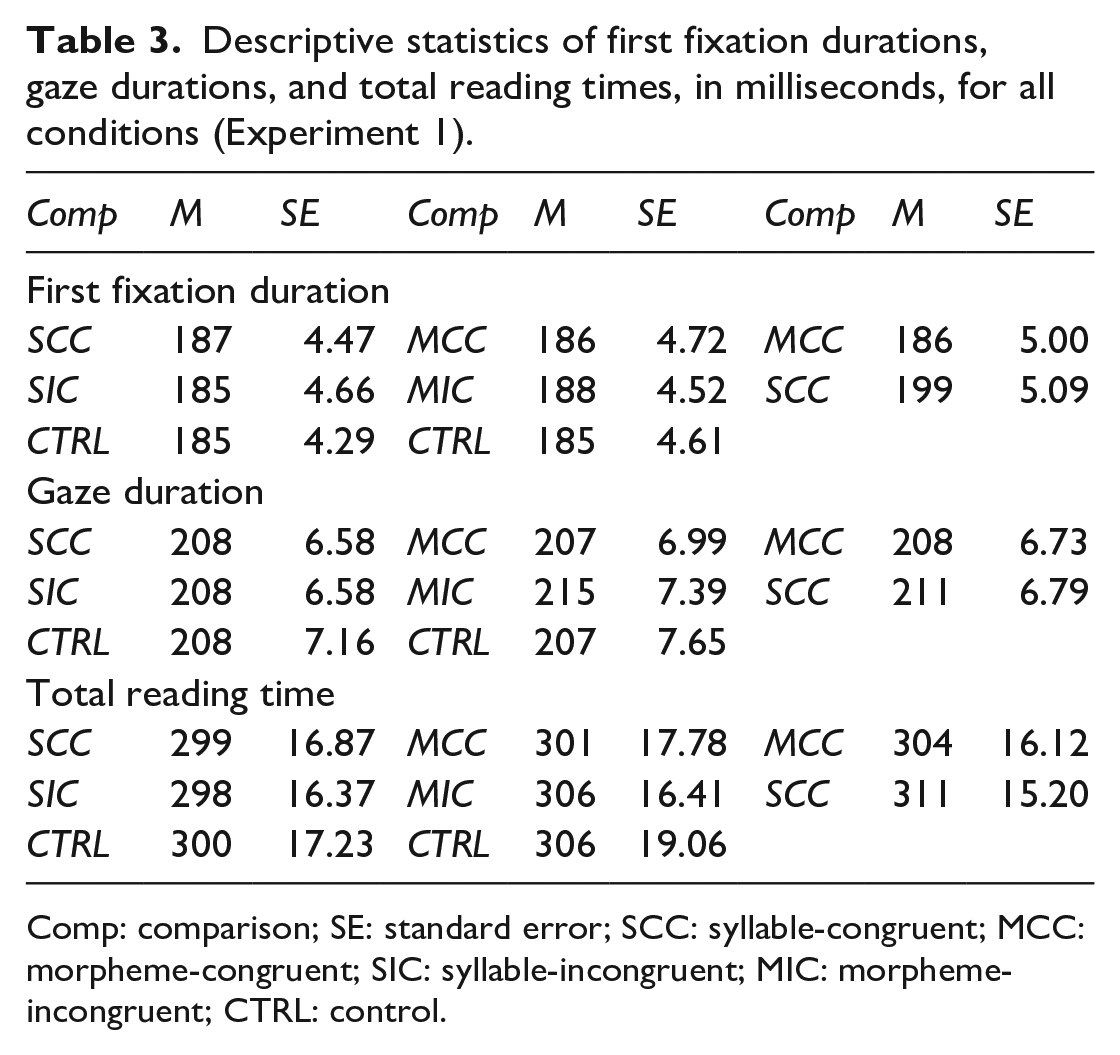
Comp: comparison; SE: standard error; SCC: syllable-congruent; MCC: morpheme-congruent; SIC: syllable-incongruent; MIC: morpheme-incongruent; CTRL: control.
Number of regressions
This analysis was conducted to test the possibility that participants would make fewer regressions in the MCC compared with the marked syllable condition, since highlighting morphological information could make word recognition faster because of its link with semantics. However, the data did not support this hypothesis (b = 0.001; SE = 0.03; t = 0.05; p = .95).
Number of saccades
There was no difference between the morpheme-congruent and the syllable-congruent conditions (b = –0.29; SE = 0.34; t = –0.84; p = .39).
Landing position
We predicted that highlighting relevant units could change the eyes’ landing position within words if participants early recognised those units. However, using log-transformed data (powerTransform = 0.59; 0.54), we found no evidence that this was the case in any of the conditions (adj. p > .05).
Discussion
We investigated whether highlighting syllables or morphemes with the “Silbenmethode” enhanced reading fluency in German skilled readers, and whether marking morphemes yielded larger facilitation effects compared with marking syllables. The results revealed no such evidence, neither in reading times, number of regressions, number of saccades, nor landing position.
Despite the absence of a syllable or morpheme effect in these data, the results of Experiment 1 do not rule out that German skilled readers rely on syllables and morphemes in their reading. Instead, the findings suggest that the colouring of embedded reading unit, as used in the “Silbenmethode,” does not modulate the eye-movements of German skilled readers.
Earlier ERP results by Carreiras et al. (2005) showed a temporal and spatial dissociation of colour-syllable congruency effects for Spanish low-frequency words and pseudowords, with a larger amplitude for the colour-syllable incongruency condition in the P200 time window compared with the colour-syllable congruency and baseline conditions. However, in the current experiment, we found that the colour congruency effects were not modulated by the difference in word frequency. Cross-linguistically, there might be little reason for assuming differences in syllable processing between German and Spanish, as both languages are orthographically transparent (Seymour et al., 2003). If anything, German is characterised by a higher degree of syllabic complexity than Spanish, with its close CVC syllables and consonant clusters in onset and coda positions (Borleffs et al., 2018; Stenneken et al., 2007). In fact, like us, Carreiras and colleagues did not find any significant differences in the behavioural data. Therefore, it is likely that the ERP signal has a greater sensitivity to reflect changes in the colour of the text compared with eye-tracking.
This might be also the reason why in their eye-tracking study Häikiö et al. (2015) reported an absence of congruency effects using alternated colours (black/red) as syllable boundary cues. However, it is worth noting that the same group of authors conducted a second experiment where they found significant differences in reading speed when colour alternations were replaced with hyphens as segmentation cues. Finnish beginning readers’ gaze durations and sentence reading time were significantly longer when reading hyphenated items compared with nonhyphenated control condition, especially if the hyphen position did not match the syllable boundary. Building on the critical findings by Häikiö and colleagues, we designed a second experiment to test the use of hyphens (-) as an alternative segmentation cue and to directly examine its impact on syllable and morpheme processing in German.
Experiment 2
Results from Experiment 1 provided no evidence that highlighting relevant subword units such as syllables or morphemes via colour alternations modulated eye-movements. Therefore, in Experiment 2 we opted for a more obvious visual disruption using hyphenation while segmenting the stimuli in the same way as in Experiment 1 (e.g., Laura stell-te ein-e Schüssel Kirsch-en auf den Tisch). Hyphenation has been widely used to study syllabic and morphological processing in an orthographically transparent, morphologically rich language such as Finnish (Häikiö et al., 2011, 2015, 2016).
The predictions slightly differed from those of Experiment 1. We theorised that segmenting words in syllables or morphemes would result in longer fixation times in the hyphenated conditions compared with the control conditions. In other words, hyphenation cues were expected to hinder rather than facilitate word processing (Deilen et al., 2022; Häikiö et al., 2011, 2015, 2016; Häikiö & Luotojärvi, 2022). Following the rationale of Experiment 1, we hypothesised that the MCC would result in shorter fixation times than the syllable-congruent condition. Furthermore, if eye-movements are modulated by syllabic and morphemic structure, hyphens placed within units would be expected to disrupt reading, thus resulting in longer fixation times in the incongruent than congruent conditions.
Method
Participants
We recruited 36 participants (27 females, 9 males) with the same characteristics of Experiment 1. Eighteen participants already participated in Experiment 1 and a minimum of 2 months passed from participating in the first experiment. Due to restrictions in COVID-19 mobility at the time of data collection, we terminated recruitment early, thus not reaching the targeted sample size of 40 participants. Furthermore, data of four participants who scored poorly on the SLRT II word reading test (<16 percentile) were not included in the analysis. The remaining 32 participants were between 18 and 52 years old (M = 31.3; SD = 7.7). All had normal or corrected-to-normal vision. All participants provided written, informed consent.
Materials
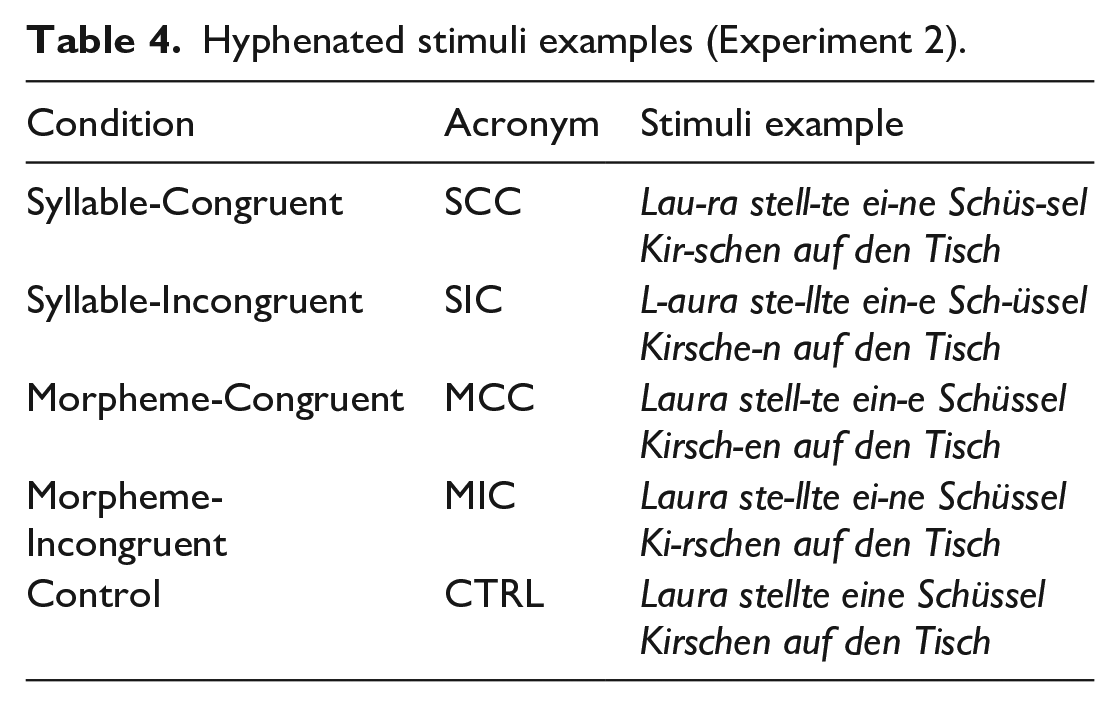
We used the same stimuli as in Experiment 1. In this experiment, syllables and morphemes were separated using a hyphen in the morpheme-congruent, morpheme-incongruent, syllable-congruent, syllable-incongruent conditions (see Table 4). No hyphens were used in the control condition. As inserting hyphens to separate relevant units resulted in longer words, 7.63% of sentences in morpheme conditions, and 11.11% in syllable conditions, did not fit into single lines and fell into double lines. All sentences were presented in black against a white background.
Hyphenated stimuli examples (Experiment 2).
Procedure and apparatus
We used the same procedure and eye-tracker in Experiment 2 as we did in Experiment 1.
Results
Data preparation
Data preparation followed the same principles as in Experiment 1. We excluded practice sentences’ data (0.5%), sentences’ first and last words (27.8%), and skipped words (18.8%). Fixation duration outliers were also excluded if they exceeded 2,400 ms for total reading time (0.03%) or were shorter than 100 ms (3.4%). All participants scored more than 80% of correct answers in the multiple-choice questions.
For the comparison between syllable-congruent, syllable-incongruent, and control conditions (a), we excluded monosyllabic items (39.6%) and items were the morpheme and syllable boundaries fully overlapped (6.3%). In addition, the number of hyphens naturally varied between the syllable-congruent and syllable-incongruent conditions (e.g., Po-li-ti-ker/Polit-iker). Since item length represents an important predictor of eye-movements (Hyönä, 2012), item pairs with varying number of hyphens were excluded (–47.6%). 6,132 observations remained available for analysis.
For the comparison between MCC, morpheme-incongruent and control conditions (b), we excluded monomorphemic items (58.2%) and items where the morpheme and syllable boundaries fully overlapped (9.2%). 7,849 observations were available for analysis.
For the comparison between syllable-congruent versus MCCs (c), we restricted the data set to items that were bi-morphemic and bi-syllabic (excluded items were 76% of the original data set). We also excluded items were the morpheme and syllable boundaries fully overlapped (16%). 4,197 observations were available for analysis.
We extracted first fixation duration, gaze duration, total reading time, and regressions. 1 As in Experiment 1, data were analysed using linear mixed effect models.
Analysis
Similarly to Experiment 1, we corrected p values using the Holm–Bonferroni correction, and response time distributions were checked using the powerTransform. Except for first fixation duration, response time transformations were not necessary. 2 Observed power calculations indicated that all models had above 78% chance to find an effect.
First fixation duration
First fixation durations were log-transformed for the analysis. For clarity, we report raw mean first fixation durations and standard errors in Figures 1 and 4.
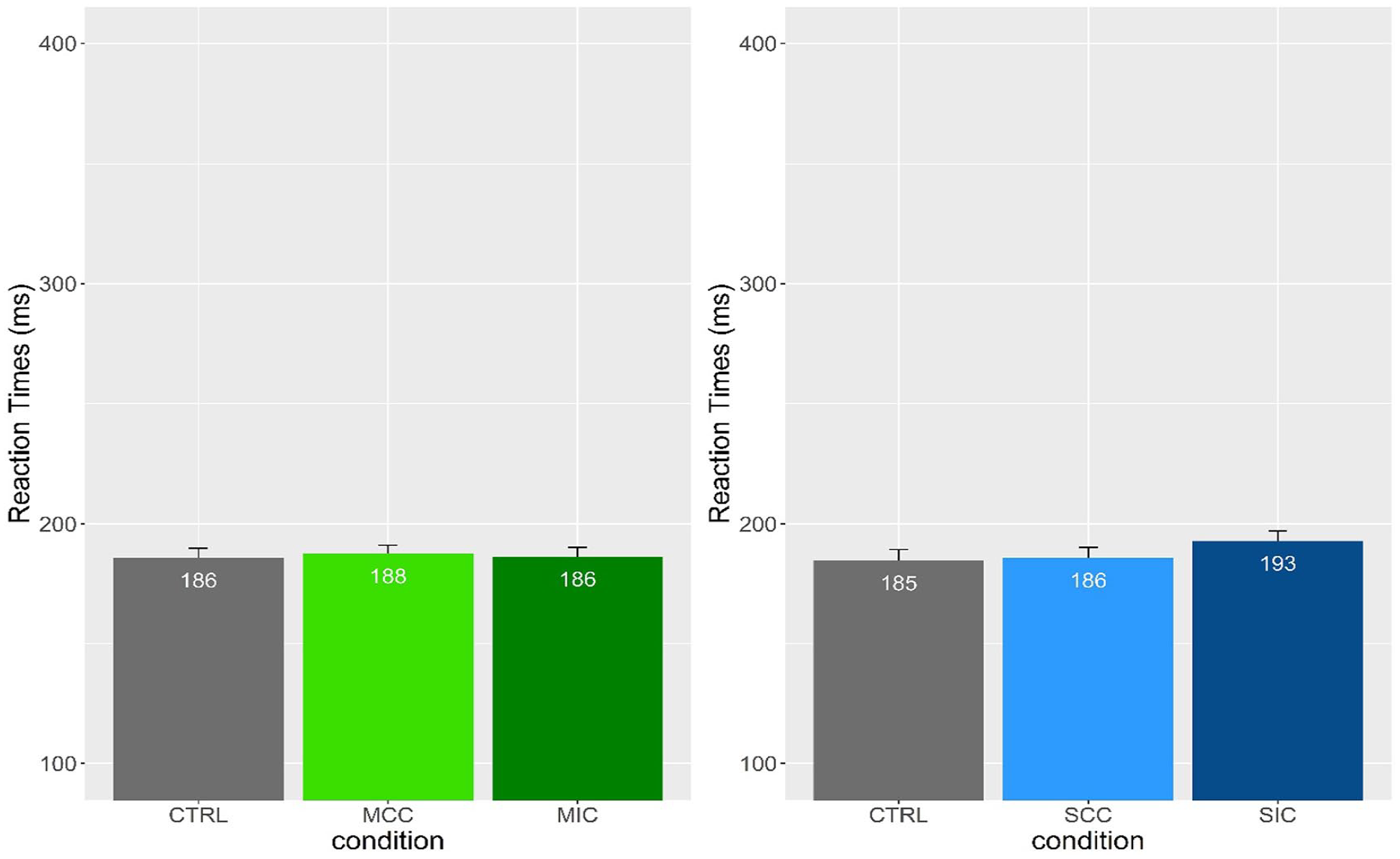
Mean first fixation duration (FFD) and standard errors for the CTRL-MCC-MIC comparison and CTRL-SCC-SIC comparisons.
We found a significant difference in the syllable-congruent versus syllable-incongruent comparison (b = –0.01; SE = 0.007; t = –2.31; p = .02; adj. p = .04), with participants reading the latter condition significantly more slowly than syllable-congruent stimuli. All the other comparisons were not significant (control vs. MCCs, control vs. syllable-congruent conditions, morpheme-congruent vs. morpheme-incongruent conditions, and morpheme-congruent vs. syllable-congruent conditions, adj. p > .05).
Gaze duration
Mean gaze durations and standard errors are reported in Figures 2 and 4. We found significant differences between the control and MCCs (b = –30.06; SE = 5.33; t = –5.63; p < .001; adj. p < .001), and between the control and syllable-congruent conditions (b = –32.47; SE = 5.68; t = –5.70; p < .001; adj. p < .001), with the syllable-congruent and MCCs being read more slowly than the control condition. The difference between the syllable-congruent and MCCs was also significant (b = 28.55; SE = 9.16; t = 3.11; p = .01; adj. p = .03), with morpheme-congruent stimuli being read more slowly. Finally, we found a significant difference between the syllable-congruent and syllable-incongruent conditions (b = –18.17; SE = 6.99; t = –2.59; p = .009; adj. p = .02), with syllable-incongruent stimuli being read more slowly than syllable-congruent stimuli. The comparison between the morpheme-congruent and morpheme-incongruent conditions was not significant (adj. p > .05).
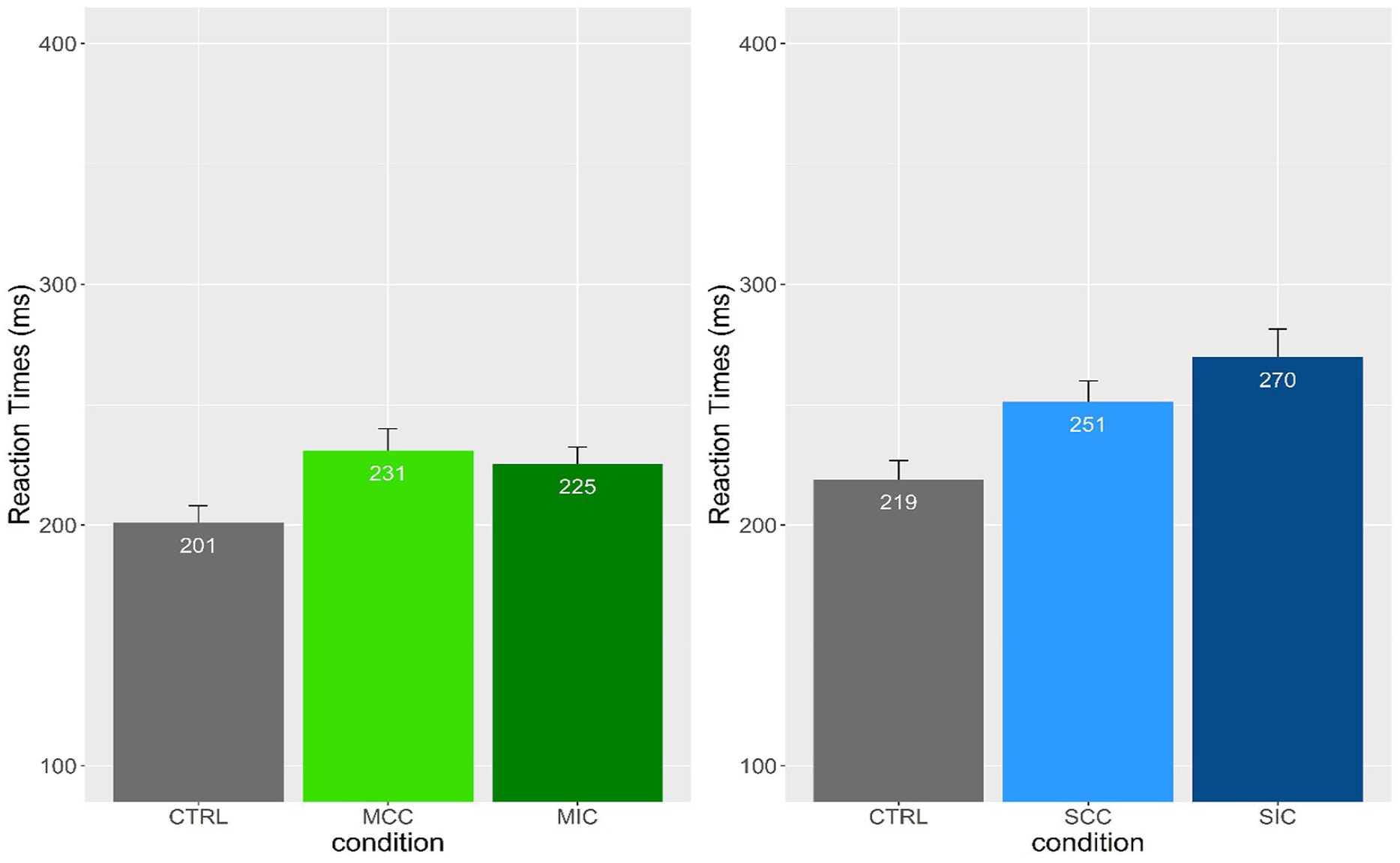
Mean gaze duration (GD) and standard errors for the CTRL-MCC-MIC comparison and CTRL-SCC-SIC comparisons.
Total reading time
Mean gaze durations and standard errors are reported in Figures 3 and 4. We found significant differences between the control and MCCs (b = –56.59; SE = 8.9; t = –6.30; p = < 0.001; adj. p < .001), and between the control and syllable-congruent conditions (b = –52.49; SE = 9.46; t = –5.54; p < .001; adj. p < .001), with the syllable-congruent and MCCs being read more slowly than the control condition. The comparison between the morpheme-congruent and syllable-congruent conditions was also significant (b = 28.5; SE = 9.16; t = 3.11; p = .001; adj. p = .007), with morpheme-congruent stimuli read more slowly than syllable-congruent stimuli. The comparison between the syllable-congruent and syllable-incongruent conditions was significant (b = –24.66; SE = 12.074; t = –2.04; p = .04; adj. p = .04), with syllable-incongruent stimuli read more slowly than syllable-congruent ones. Again, we found no significant difference in the morpheme-congruent and morpheme-incongruent comparison (adj. p > .05).
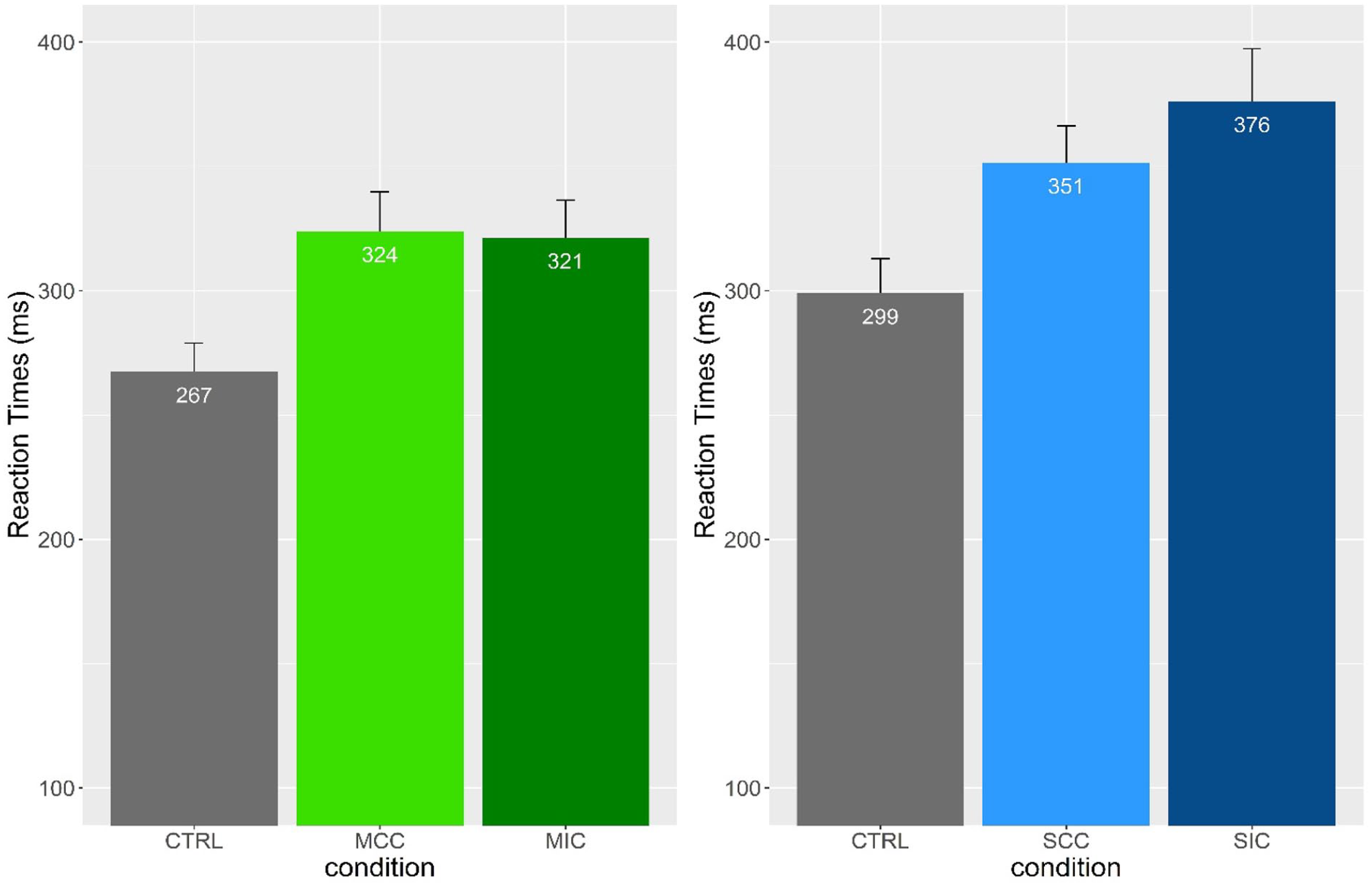
Mean total reading time (TRT) and standard errors for the CTRL-MCC-MIC comparison and CTRL-SCC-SIC comparisons.
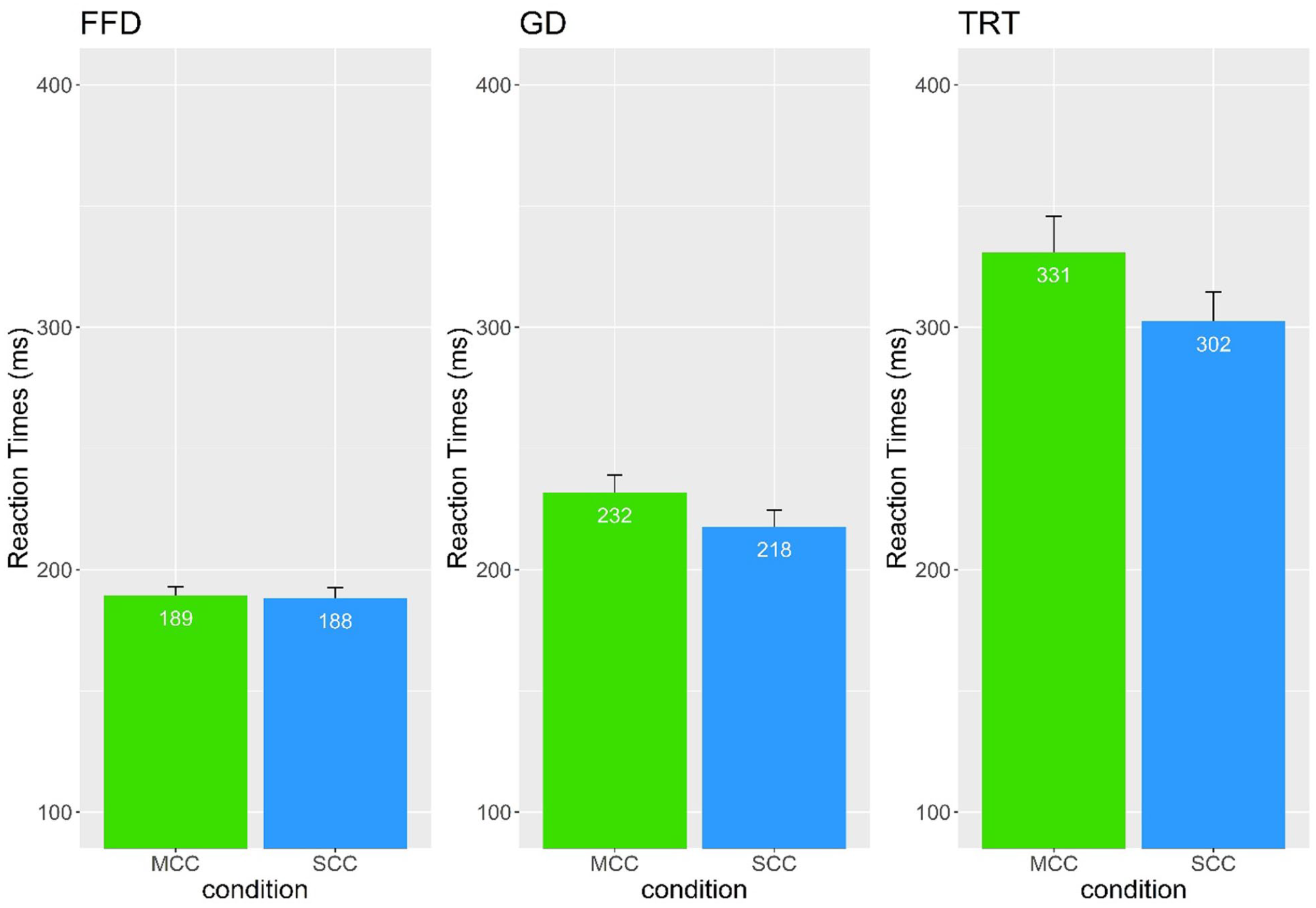
Mean first fixation duration (FFD), gaze duration (GD), and total reading time (TRT) with standard errors for the MCC-SCC comparison.
Number of regressions
As in Experiment 1, we found no evidence that participants made fewer regressions in the MCC compared with the syllable-congruent condition (adj. p > .05).
Discussion
In Experiment 2, we examined the effect of hyphenation as a syllabic / morphemic segmentation cue using eye-tracking. As expected, the use of hyphenation led to longer fixation times compared with the nonhyphenated control condition, even when hyphens segmented words into informative (i.e., congruent) units. Similar results have been previously reported in Finnish developing readers, using hyphens placed between syllables (Häikiö et al., 2015, 2016; Häikiö & Luotojärvi, 2022; but see Häikiö & Vainio, 2018) and between morphemes (Häikiö et al., 2011; Häikiö & Vainio, 2018). The authors found that first and second graders took longer to read words that were hyphenated at syllable and morpheme boundaries compared with the concatenated control, although hyphenation represents a common reading teaching strategy in Finland. This study extends this finding to adults, and to a language which has a more complex syllabic structure (Seymour et al., 2003), with a fairly complex and productive morphological system.
A second, important finding of Experiment 2 is that participants read syllable-incongruent and morpheme-congruent hyphenated words more slowly than syllable-congruent words; that is, the disruption of syllable boundaries significantly impaired reading, whereas participants were less affected by the disruption of morpheme boundaries. These results suggest that in German, syllable structure is more salient than morpheme structure during reading. After all, previous research has demonstrated that phonology plays a central role in silent reading (see Clifton, 2015 for a selective review in English). For example, Ashby and Clifton (2005) showed that participants read multi-syllabic words with two stressed syllables more slowly than those with one stressed syllable. Similarly, Fitzsimmons and Drieghe (2013) found that five-letter monosyllabic words were skipped more often than bi-syllabic words of the same length, even after predictability and frequency were accounted for, suggesting that skilled readers rely on syllabic processing in silent reading. Given that German words are on average longer than English words, the role of syllable structure in silent reading might be more pronounced.
Once again, our results converge with those of Häikiö et al. (2015) who showed that hyphenation that did not coincide with syllable boundaries was more disruptive than hyphenation that matched syllable boundaries. A later study in Finnish (Häikiö & Vainio, 2018) further showed that hyphens that disrupted syllables (SIC) but not morphemes (MCC) did not impair reading, a finding that was not confirmed in the current German data. This difference between the Finnish and the German data might be due to typological considerations. Although both Finnish and German are known to be morphologically productive, German is a highly synthetic, whereas Finnish is a polysynthetic language. In polysynthetic languages, multiple morphemes can be combined into a single continuous word that can even constitute an entire clause at times. In synthetic languages like German, the number of concatenations is more limited and form sentence clauses. As a result, readers of polysynthetic languages like Finnish may be more sensitive to the morphological structure of words, thus leading to more robust morpheme segmentation effects in Finnish than in German. Häikiö and Vainio (2018) reached similar conclusions when comparing their study with the one of Hasenäcker and Schroeder (2017), arguing that the different results might be ascribable to either the fact that Finnish is a more morphologically rich language, or that the difference is to be found in the fact that they used inflectional morphemes, whereas Hasenäcker and Schroeder used derivational ones (Häikiö & Vainio, 2018, p. 1236), while we note that this study used a combination of inflectional and derivational morphemes.
Under this aspect, our results converge with those of Hasenäcker and Schroeder (2017), although their adult participants were not impaired by the syllable-incongruent condition. It must be noted that Hasenäcker and Schroeder used a lexical decision task, thus investigating single-word recognition. It is possible that the longer fixations on the syllable-incongruent stimuli in our study were due to the additional time needed to integrate the disrupted words in the sentence context: that is, not only word recognition was impaired, but sentence-processing was, too.
General discussion
The aim of this study was to directly compare the processing of syllables and morphemes in a language with a complex syllabic and morphological structure and transparent orthography like German. To address this aim, we employed two different types of segmentation cues: colouring in Experiment 1, hyphenation in Experiment 2. Hyphens and colour alternation positions matched or mismatched syllables boundaries (SCC-SIC) or morpheme boundaries (MCC-MIC). Black-coloured, nonhyphenated sentences served as control condition.
The results of Experiment 1 did not support the hypothesis that highlighting syllabic or morphological information using colours modulates eye-movements or general processing speed. However, Experiment 2 revealed that segmentation by hyphenation leads to longer eye fixations, compared with the non-hyphenated condition, both in the morpheme and the syllable-congruent condition. Critically, the results further showed that the morpheme-congruent and syllable-incongruent conditions were read significantly more slowly than the syllable-congruent condition. The evidence that hyphenation disrupted reading to a greater extent when hyphen position did not match with syllable boundary, can be interpreted as an indication that in silent reading, German skilled readers automatically recognise the underlying syllabic structure of words.
There are several explanations why participants’ reading behaviour may have been affected by syllable structure. In the case of the syllable-congruent condition, participants’ eye-movements may have more easily fallen into a rhythm of syllable-based reading while shifting their eyes through the target sentences, given the important role of syllables in silent reading (e.g., in German, Conrad et al., 2011; Conrad & Jacobs, 2004; Hawelka et al., 2013; Hutzler et al., 2005). Since readers automatically captured the underlying syllable structure, their eye-movements were disrupted when hyphenation did not occur at syllable boundaries. In contrast, the segmentation of words into morphemes would have required a more thorough analysis of letter chunks as units of meaning and therefore may have presented a level of complexity that was not as easily grasped during sentence reading. Of course, there is abundant evidence that German readers engage in morphological processing (e.g., Beyersmann et al., 2020; Smolka et al., 2009), which is not inconsistent with our current findings. In a large web-based study with German third and fourth graders, Görgen et al. (2021) found that morphological awareness is a better predictor for spelling than for reading fluency, suggesting that the use of morphological knowledge is modulated by task-specific requirements. The present data show that within a sentence reading paradigm, highlighting syllable structure via hyphenation has a larger impact on reading behaviour in German compared with highlighting morpheme structure.
An alternative explanation for the prominence of a syllable effect in the current data is that syllable structure is explicitly taught as part of the curriculum of the German schooling system (Bredel et al., 2013). Syllable-based reading instruction has a long tradition in Germany (Reh & Wilde, 2016), with syllable separators dating back to the 16th century (Velten, 2012). As such, skilled readers have a long history of applying syllable-based reading. Duncan et al. (1997) suggested that the style of reading instruction may affect the relative use of different sized units during reading acquisition. Furthermore, in a study looking into the benefits of teaching children orthographic analogies based on onset and rime units, Peterson and Haines (1992) found that the training boosted the children’s phonemic awareness, promoting segmentation skills of these units. Hence, learning to read using syllable-based strategies is likely to boost the syllabic awareness in a similar way, with effects spanning throughout reading development into adulthood.
This would also explain the absence of a morphological effect in the current data, as formal morphological instruction is comparatively less common in the German schooling system. 3 Indeed, recent studies have shown that German readers are proficient at identifying embedded stems (Beyersmann et al., 2020, 2021) perhaps due to the abundant presence of compound words in the German language and have reported to be less reliant on morphological processing than French (Beyersmann et al., 2021) and English readers (Mousikou et al., 2020). Recent longitudinal data involving two large samples of German and French primary schoolers have shown that embedded stem priming effects are more pronounced in German third and fourth graders whereas morphological priming effects are more pronounced in French third and fourth graders (Beyersmann et al., 2021), suggesting that the development of morphological processing mechanisms is influenced by the intrinsic linguistic properties of the language to which children are exposed to. Thus, although German readers clearly process morphemes in their reading (Kempe, 1999), the recognition of syllabic structure appears to predominantly underpin the word processing in our task.
Previous studies argued that syllables, especially the first syllable of polysyllabic words, mediate lexical access (e.g., Carreiras et al., 1993; Prinzmetal et al., 1986; Spoehr & Smith, 1973; Taft & Forster, 1975). In some models of visual word recognition, syllables are represented at an intermediate level situated between the letter and the lexical levels (Jacobs et al., 1998; van Heuven et al., 2001) including the dual-route interactive-activation framework (the IAS model, see Figure 1 of Mathey et al., 2006, p. 389; or the MROM-S model, see Figure 1 of Conrad et al., 2010, p. 872). In these models, two routes allow the reader to access the lexicon, the orthographic (from letters to words) and the phonological (from syllables to words) routes. The latter is equipped with a level of syllabic representations which mediate between the levels of the letter and the word. In the first model (IAS), when letters are activated, this activity spreads to consistent positional syllables. For example, a word’s first bigram, such as “co” in “comix” activates not just the syllable /kom/ but also additional consistent syllables like /kɒr/, /kʌl/, or /kon/. Syllable activation strength is determined not only by the degree of activation at the letter level, but also by the syllable resting level. In the second model (MROM-S), syllabic parsing is modulated both by the frequency of the letter cluster forming the initial syllable and the model’s syllabary, which contains syllabification rules. Further ambiguity is resolved by feedback from the word level. In both models, syllable frequency is proportional to the level of resting activity. As a result, high-frequency syllables are engaged faster than low-frequency syllables. The syllables then activate the corresponding target word, as well as its syllabic neighbours.
Evidence for models implementing syllables at an intermediate level between orthographic input and the lexicon comes from lexical decision and naming tasks (Conrad et al., 2009; Conrad & Jacobs, 2004), showing that reading times in lexical decision and naming tasks tend to be longer if the first syllable of the words is highly frequent (i.e., syllables that are often found in first positions). This suggests that first syllables that are shared among many word candidates lead to lateral inhibition at the level of the orthographic lexicon (Conrad & Jacobs, 2004; Hawelka et al., 2013; Perea & Carreiras, 1998).
The important role of syllables in word processing has also been demonstrated by studies reporting a syllable congruency effect. This effect typically emerges in lexical decision tasks paired with masked priming (Chetail & Mathey, 2009a, 2012). In this paradigm, primes are quickly displayed so that readers can only process them subliminally, and then are replaced by target words to which participants must make a lexical decision. Facilitatory syllabic priming effects are found when the prime and the target share the first syllable as opposed to just the first letters (Chetail & Mathey, 2012). The present eye-tracking study extend these prior findings from single-word psycholinguistics tasks to a more ecologically valid sentence reading paradigm, suggesting that syllables mediate lexical access in a shallow orthography like German.
A further important point to note is that this study was not designed to directly tease apart the independent role of phonology in processing syllabic structures. While phonological and syllabic processing are naturally intertwined (Álvarez et al., 2004; Conrad et al., 2009), orthographic redundancy (i.e., low-frequency bigrams that can be found at the syllable boundary, Seidenberg, 1987) can increase the salience of syllabic units (Conrad et al., 2009; Doignon-Camus & Zagar, 2005). Moreover, participants might segment words in syllable-like orthographic units, which could activate phonological syllables, with orthographic processing preceding phonological processing. Hence, the here observed syllable effect might reflect either an orthographic or a phonological syllable effect, or a combined effect, since readers preprocess orthographic and phonological information already in the parafovea (see Schotter et al., 2012 for a review on parafoveal processing in reading).
As a final point, we do not consider our findings to be automatically generalisable across languages, as reliance on sublexical units may vary depending on morphological and syllabic complexity, orthographic depth, or linguistic typology. Studies specifically designed to reveal readers’ preferred units according to these constructs are needed. Also, while Experiment 1 did not support the idea that colouring segmentation (i.e., the Silbenmethode) modulated sublexical processing in skilled adult readers, it is possible that children who are still in the process of learning to read would differently benefit from colour cues in their reading. An extension of this study to developing readers of German may thus provide fertile grounds for future research, particularly given its importance in German reading instruction.
Conclusion
The present eye-tracking study was designed to directly compare the processing of syllables and morphemes and investigate the use of different segmentation cues including colour highlighting and hyphenation in an orthographically transparent, morphologically rich, and syllabically complex language, namely, German. The results of the first experiment showed that eye-movements were not modulated by colour alternations. Critically, the results of the second experiment revealed that German skilled readers rely more heavily on syllable-based than morpheme-based reading when hyphenation was used as segmentation cue. We speculate that this preference might have either originated from the syllabic awareness boost resulting from the syllable-based reading instruction in the German schooling system; or be the product of an underlying reading mechanism relying on syllables, as has been shown for other transparent orthographies such as French and Spanish.
Footnotes
Acknowledgements
The authors thank Lior Weinreich and Björn Witzel for piloting the experiments, Serje Robidoux for providing statistical advice, and Roland Trouville for trouble-shooting coding scripts.
Data accessibility statement
The data and materials for the experiment are available at https://osf.io/w4rsm/. The preregistration of the first experiment is available at https://osf.io/csja8. Registered project files are available at ![]() .
.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Förderung für Forschung und Lehre grant to X.S. and E.d.S. (REG.NR. 1036), the Deutsche Forschungsgemeinschaft to X.S. (SCHM3460 1-1), and by a Discovery Early Career Researcher Award to E.B. from the Australian Research Council (DE190100850).