
Abstract
Jesteadt et al. discovered a remarkable pattern of autocorrelation in log estimates of loudness. Responses to repeated stimuli correlated to about +0.7, but that correlation was much reduced (0.1) following large differences between successive stimuli. The experiment reported here demonstrates the same pattern in absolute identification without feedback; if feedback is supplied, the pattern is much muted. A model is proposed for this pattern of autocorrelation, based on the premise: “There is no absolute judgment of sensory magnitudes; nor is there any absolute judgment of differences/ratios between sensory magnitudes.” Each stimulus in an experiment is compared with its predecessor, greater, less than, or about the same. The variability of that comparison increases with the difference in magnitude between the stimuli, so the assessment of a stimulus far removed from its predecessor is very uncertain. The model provides explanations for the apparent normal variability of sensory stimuli, for the “bow” effect and for the widely reported pattern of sequential effects. It has applications to the effects of stimulus range, to the difficulty of identifying more than five stimuli on a single continuum without error, and to inspection tasks in general, notably medical screening and the marking of examination scripts.
Keywords
In the course of a routine regression analysis of log magnitude estimates of 1 kHz tones on previous stimuli and responses, Jesteadt et al. (1977, Figure 4) discovered a remarkable pattern of autocorrelation. If a stimulus was repeated (to within 4 dB) on successive trials, successive log estimates correlated about +0.7, but that correlation was much reduced (0.1) following large differences between successive stimuli (see Figure 3). This pattern has been replicated by Green et al. (1977), Luce and Green (1978), Baird et al. (1980), and Ward (1979), but only in magnitude estimation, production, and matching tasks. The experiment reported here tests whether a similar pattern of autocorrelation obtains in category judgement. It bears on two separate questions:
Braida and Durlach (1972, Expt. 1) compared magnitude estimation (ME) with absolute identification (AI without feedback), using the same set of stimuli and the same schedule of presentation for both tasks. Their published analysis suggests strongly that ME and AI are essentially the same task, differing only in the mode of expressing the judgements. If that is so, then AI should show the same pattern of autocorrelation as ME; more importantly, if AI fails to show that pattern, then ME and AI are different tasks. The experiment reported here replicates Braida and Durlach’s Experiment 1, with an extra condition, AI with immediate knowledge of results (FB).
Stewart et al. (2005) published a relative judgement model of AI in which judgements are based on the difference (or ratio) between the present and the preceding stimulus. This has proved controversial (e.g., S. D. Brown et al., 2009; S. D. Brown, Marley, & Lacouture, 2007), because the discrimination between two fixed stimuli (e.g., two 0.5-s 1 kHz tones at 60 and 62 dB, Lockhead & Hinson, 1986) is impaired by the inclusion of a more remote stimulus (54 dB) in the identification task. This would appear to involve some absolute assessment of the difference between 54 and 60 dB. In addition, Guest et al. (2016) questioned the role of relative judgement on the basis of a comparison between two tasks: one a conventional AI (of line length) and the second a similar AI of the difference between successive lengths of line (see also Guest et al., 2018).
Anticipating the results of this present experiment, AI (without feedback) shows the same pattern of autocorrelation as ME. Psychologically, they are the same task, differing only in details. Second, the debate (2. above), proposing relative judgement instead of AI, is predicated on an absolute judgement of the difference between successive stimuli. The results below point to a third idea, not previously considered (except Laming, 1984, 1997). Each stimulus in an experiment is compared with its predecessor, greater, less than, or about the same. The variability of that comparison increases with the difference in magnitude between the stimuli, so the assessment of a stimulus far removed from its predecessor is very uncertain. This idea accommodates the pattern of autocorrelation (1. above), which, in turn, proves incompatible with an absolute judgement of the difference between successive stimuli.
Previous authors have proposed a variety of structures in memory to support an AI of the stimulus and those structures have introduced a number of unnecessary problems in the modelling of the “bow” effect (d′ between adjacent stimuli is depressed in the centre of the stimulus range; Luce et al., 1982; Weber et al., 1977) and the widely reported pattern of sequential effects in category judgement (e.g., Ward & Lockhead, 1970, 1971; see Stewart et al., 2005, esp. Table 2, p. 886, for a review). The analyses below relate the bow effect and the sequential effects directly to the pattern of autocorrelation. Structures in memory to support an absolute comparison are not needed.
The experiment
Stimuli
The stimuli were 10, 500-ms bursts of 1,000 Hz tone at levels ranging from 50 to 86 dB, at 4 dB spacing. They were presented at 7-s intervals. The presentation was programmed on a BBC microcomputer, which actuated a Farnell FG1 function generator set to 1 kHz and a Grason–Stadler digital attenuator according to the stimulus level required. The 500-ms tone burst was then passed through a Bruel & Kjoer bandpass filter set to 1/3 octave at 1 kHz, before being delivered to the observer through a Pioneer amplifier and binaural headphones (Radio Spares, 8 Ω impedance). The experiment took place in a sound-proof chamber.
Procedure
ME always came first on the ground that observers should not know that there were only 10 different levels of tone, lest it bias their numerical estimates. AI without feedback always came second on the ground that 3,000 trials with feedback might improve otherwise untrained performance (cf. Mori & Ward, 1995; Tanner et al., 1970). There were 3,000 trials under each condition, administered in five 2-hr sessions on successive days of the week, at the same time each day, Monday–Friday. There were 6 blocks of 100 stimuli in each session. The BBC microcomputer delivered a different random sequence of stimuli for each block of 100 trials, subject to the constraint that each stimulus value followed each other stimulus value (including itself) exactly once. The three different conditions were administered in successive weeks.
In the ME condition, the fifth most intense stimulus (70 dB) was presented 10 times (at 7-s intervals) before each block of 100 trials. The observers were instructed to assign the number 100 to the loudness of this stimulus and to report the numerical loudnesses of subsequent stimuli by using a ratio scale: “Stimuli which appear twice as loud should be reported as 200, while stimuli which appear half as loud should be reported as 50.” In the AI and FB conditions the stimuli were presented once (at 7-s intervals) in order of decreasing intensity before each block of 100 trials. The observers were told to identify the most intense stimulus as 10, the second most intense as 9, and so on, and were instructed to assign these numbers to the stimuli presented on subsequent trials as accurately as possible.
Each trial began with a visual warning “GET READY” for 1 s, followed by the stimulus for 0.5 s. The subject was then instructed “Type response number” and the computer waited until a total of 7 s had passed before presenting the next visual warning. In the FB condition the screen showed “Stimulus was number x” for the last 2 s of that 7-s period.
Instructions
For the ME condition the instructions included: This experiment is about how people judge the loudness of sounds—not the physical energy in the sound, but the loudness as you experience it. In the earphones you will hear a series of tones, all of them of the same pitch, but of various loudnesses. I want you to put a number to each tone in proportion to how loud it seems to you. The first ten tones will all be of the same loudness and you are to call that loudness 100 units. Thereafter, the computer will give you whatever loudness of tone it thinks fit; except that the tone will never be so loud as to hurt your ears, nor so quiet that you are unable to hear it. If one of those tones sounds three times as loud as the standard loudness, you are to call it 300; and if some other tone sounds only one quarter as loud, call it 25. In case this seems an obscure task to you, here are some slips of paper with a line drawn on each. The first line is 100 units long; write a number against each succeeding line to say how long it seems to you in relation to that first line.
1
Remember, it is not the physical length of the line that matters, but how long it seems to you.
For the AI condition the instructions included: There are ten different loudnesses altogether and they will be numbered 1 to 10. I want you to say which loudness you think each tone is. To help you, the first ten tones will be the ten different loudnesses in descending order from 10 to 1, and the correct response to these tones will be 10, 9, 8, etc.
2
Thereafter, the computer will give you any one of those ten loudnesses selected at random, and you are to type in whatever number in the range 1 to 10 you think corresponds to that particular loudness.
For the FB condition the instructions added: When you have typed in your number, the computer will tell you what the correct answer was.
This replication enabled study of all the principal phenomena of AI and ME within the one experiment, thereby excluding the possible involvement of differences in stimuli, instrumentation, and personnel.
Observers
There were four observers, two university students, and two 18-year-old school-leavers, about to go to university. All participated on a voluntary basis, and the experiment was conducted in accordance with the ethical standards of the 1975 Helsinki Declaration. They were each paid £60 on completion of the experiment. 3
Terminology
The experiment presents stimuli from a set of 10, designated Si, i = 1, . . . ., 10, in ascending order of magnitude. The stimulus mean on the scale of 1–10 (5.5) will be designated by
Equation 1 (below) introduces Bn, a random variable, and ε n , an error term of zero mean. The suffix n signifies that the values of these variables are specific to trial n, while their distributions are common to all trials. The mean of Bn will be denoted by β, its variance by σβ2, and the variance of ε n by σε2. Equation 4 introduces a “prior expectation,” which carries weight (1-θ).
Results 4
Comparison of ME, AI, and FB
Figure 1a to c displays the cumulative distributions of responses for each stimulus and all three conditions for Observer 4. 5 For AI and FB the responses are naturally plotted against their numerical values on the abscissa. For ME, where the observer chooses his or her own numerical response, the representation is more complicated. First, the numerical responses are transferred to logarithms base 10, and the average log10 response calculated for each stimulus. These averages are marked on the abscissa of Figure 1a as “Responses, 1, 2....10.” An approximate value on the stimulus scale, 1...10, is then assigned to each log10 estimate by linear interpolation between the stimulus averages. Comparing with AI and FB, the ME data, relative to the stimulus averages, extend below 1 and above 10, whereas AI and FB responses are necessarily constrained. But, setting those extreme responses aside, the ME cumulative distributions are much like AI and FB. Hereafter, log10 magnitude estimates are analysed in exactly the same way as AI and FB responses (cf. Braida & Durlach, 1972).
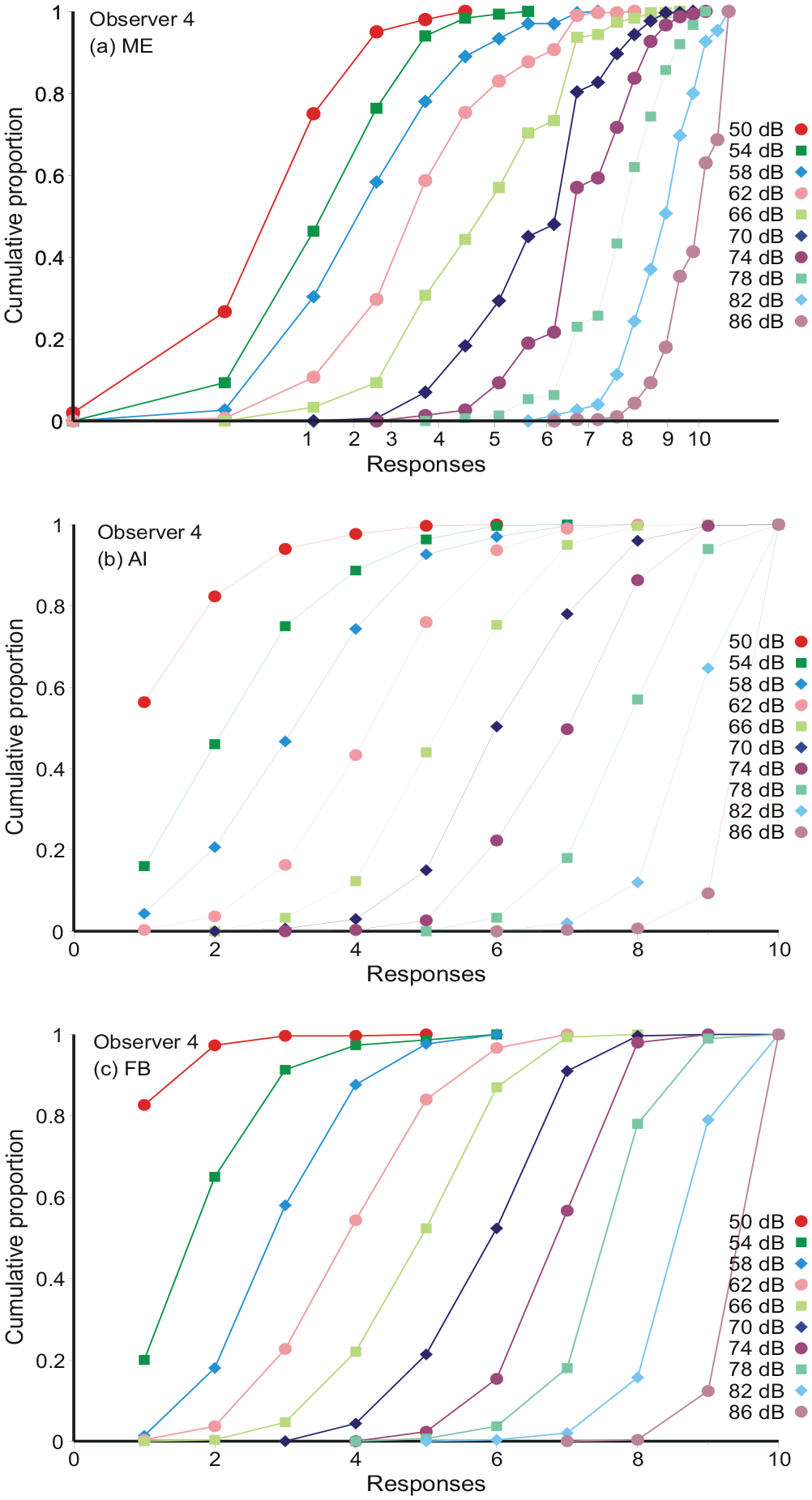
Cumulative distributions of responses from Observer 4. AI and FB responses are plotted against their numerical values on the abscissa. For ME the log10 numerical assignments are plotted against an estimate obtained by linear interpolation between the stimulus averages. These stimulus averages are marked on the abscissa of Figure 1a.
Figure 2 shows the mean response for each stimulus on a scale of 1–10, together with linear regression lines. The departures from linearity are small. The gradients are set out in Table 1.
Gradients of linear regression in Figure 2.
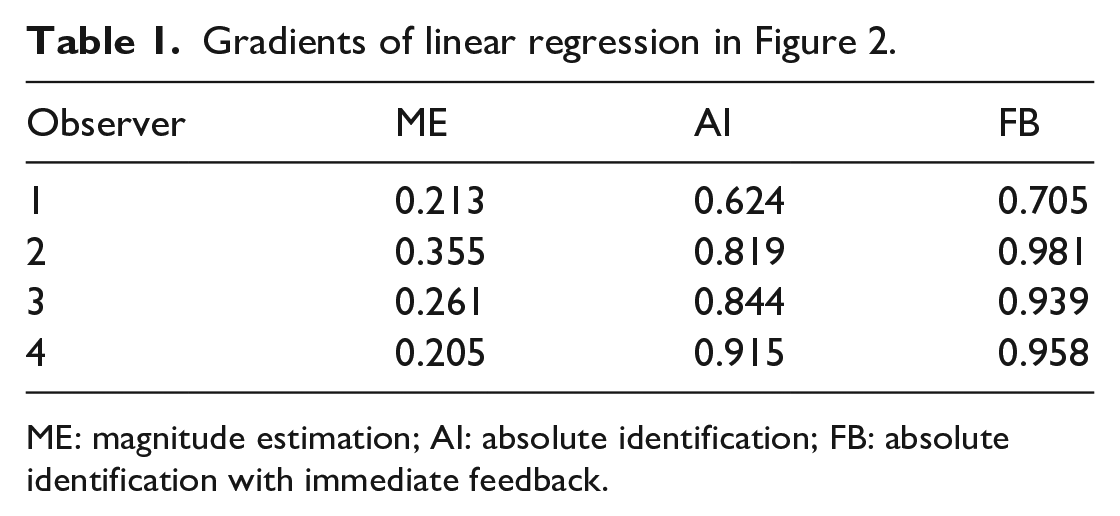
ME: magnitude estimation; AI: absolute identification; FB: absolute identification with immediate feedback.
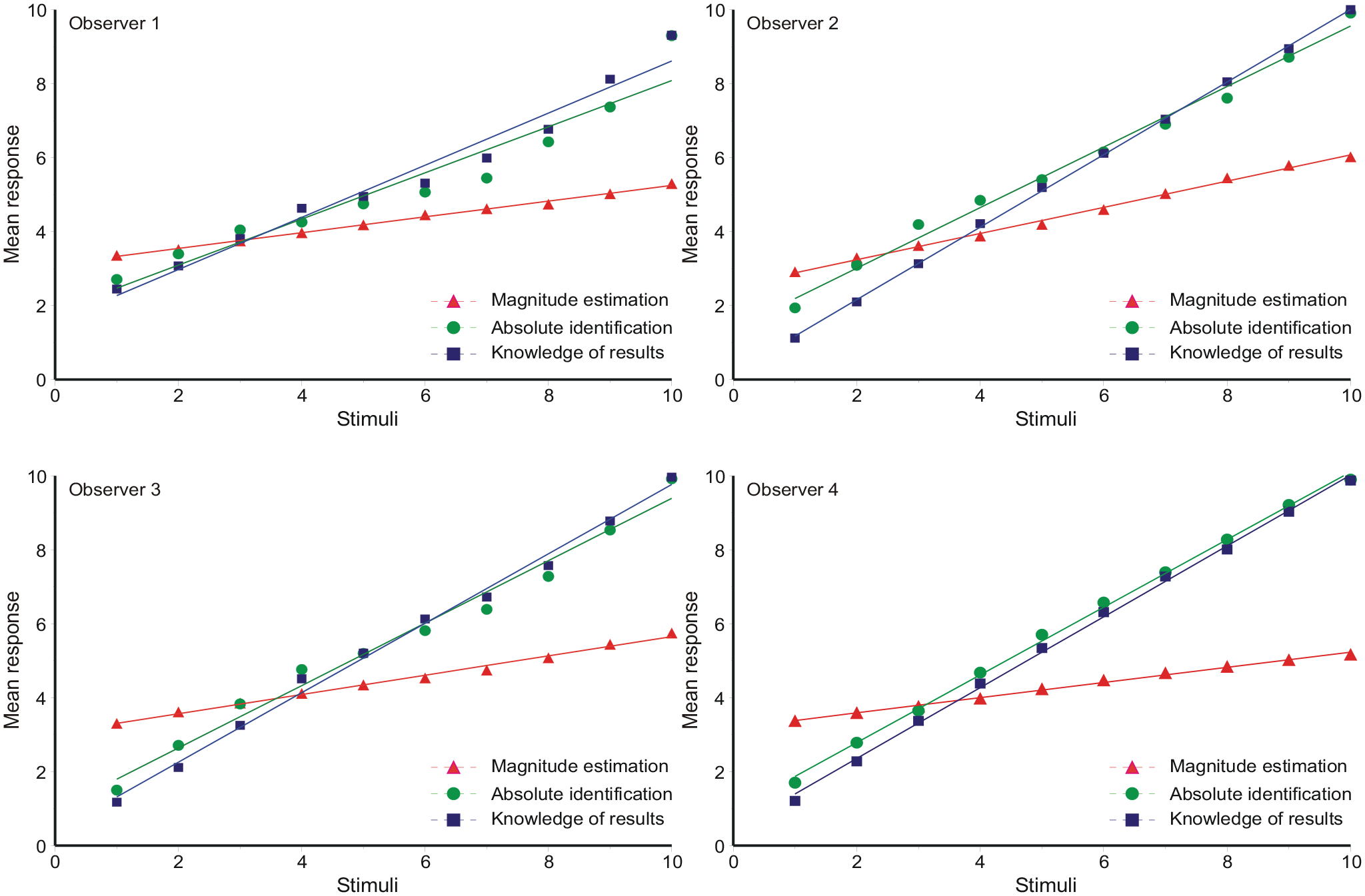
Mean responses as functions of ordinal position, with linear regression lines.
Comparing ME, AI, and FB, the gradients for ME are much reduced because the dependent variable is log N, not N. The gradients for FB are always greater than AI, as one would expect from the provision of knowledge of results. The gradients for these last two are everywhere less than 1, meaning that responses are attracted towards the centre of the stimulus scale. This is the “central tendency of judgment” (Hollingworth, 1909). No similar comparison can be made for ME.
Subsequent analyses
The analyses that follow examine the autocorrelation of responses, the “bow” effect, and the relation of each response to previous stimuli and responses. These analyses are referred to the ordinal scale of stimuli and responses, 1, . . . 10, as metric. It will help understanding if the results are first sketched informally.
The autocorrelation of responses for AI (Figure 3) replicates the pattern already reported for ME by Jesteadt et al. (1977). This identifies AI and ME as psychologically the same task; the difference between them is simply a matter of how the judgements are expressed. The pattern of autocorrelation signifies, first, that there is no absolute judgement—each stimulus is judged relative to the stimulus and response on the preceding trial (Equation 1)—and, second, there is likewise no absolute assessment of differences or ratios in stimulus magnitude—the adjustment of response from one trial to the next is variable. Each judgement is based on a point of reference that varies from trial to trial by the aggregation of independent increments and, by itself, this aggregation would ordinarily exceed all bounds. A prior expected response (Equation 4), derived from the sequence of stimuli (Equation 7) constrains that otherwise increasing variance. Successive points of reference are still the aggregation of independent increments, but the variance is now limited, and the aggregate distribution is approximately normal (cf. Figure 1).
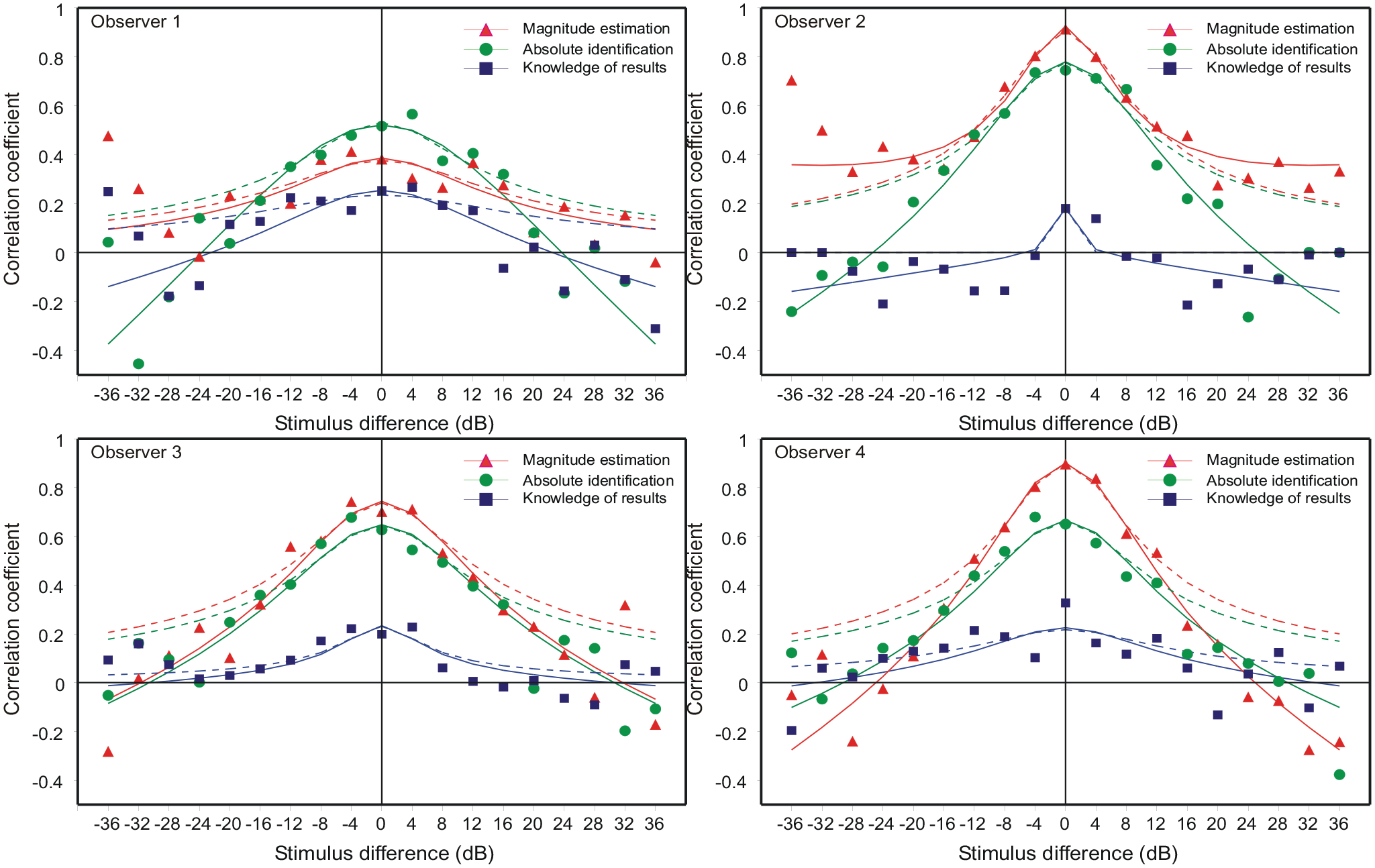
Mean correlation of successive responses as a function of the dB spacing between successive stimuli, Sn – Sn−1. The continuous curves are Equation 3 (A9 in the online Supplementary Material A) with the α-parameter values in Table 2. The dashed curves are the simpler Equation A4 fit to the range –12 to +12 dB only.
The model for autocorrelation envisages that sometimes (in AI) an initial assessment may fall outside the range of 1–10. Such an assessment is, of course, forced to “1” or “10,” but that forcing proves essential in accounting for the negative correlations sometimes observed with extreme differences between successive stimuli. This model of autocorrelation is then used to account for the “bow” effect and the sequential effects, which are presented here as consequences of the autocorrelation. The relationships between these different phenomena require some careful calculation; these calculations are placed in the online Supplementary Material.
Autocorrelation of responses
Figure 3 shows the autocorrelation between successive responses as a function of the dB difference between successive stimuli (Sn − Sn−1). For each task there were 3,000 trials organised in blocks of 100. In each block, each stimulus followed each other stimulus (including itself) exactly once. For each combination of successive stimuli (Sn = Si ∩ Sn−1 = Sj), the individual trials were extracted from each block and the subsample of 30 trials analysed separately to deliver a correlation conditional on Sj followed by Si. Figure 3 plots the mean correlation coefficient for each stimulus difference (Si − Sj), −36 to 36 dB. Note that the number of individual correlations averaged in each mean varies: it is 10 for zero difference, reducing to 1 at ±36, so that the central means are more precisely determined.
ME repeats the pattern reported by Jesteadt et al. (1977), Baird et al. (1980), and others. When a stimulus is repeated, the mean correlation ranges from 0.38 (Obs 1) to 0.91 (Obs 2), so the second judgement inherits 14% to 82% of its variance from its predecessor. AI shows the same pattern, slightly muted, where the correlations range from 0.52 (Obs 1) to 0.74 (Obs 2). The correlations are, however, much reduced in FB.
It is plain that when a stimulus is repeated, the stimulus and response on trial n-1 serves as a reference point for the judgement on trial n. Although the correlation is high only for small differences|Si − Sj|, the use of the stimulus and response on trial n-1 as the reference point for trial n must be universal, because the observer cannot know until after the stimulus has been presented how big a stimulus difference is to be judged. On the principle that there is no absolute judgement of stimulus quantities, the response on trial n is approximately (cf. Laming, 1984, Equation 2.8):
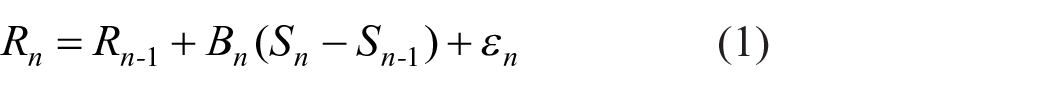
where Bn is a random variable and ε n an error term of zero mean. The suffix n signifies that the values of these variables are specific to trial n, but their distributions are common to all trials. Denote the mean of Bn by β, its variance by σβ2, and the variance of ε n by σε2. Equation 1 selects a response on trial n that will serve as the reference point for the judgement on trial n + 1. 6
For a suitable choice of parameter values [Rn−1, σβ2, σε2], Equation A4 in Supplementary Material A fits the correlations for |Sn − Sn-1| ⩽ 3 well (stimulus difference ⩽12 dB; dashed curves in Figure 3), but for larger stimulus differences the skirts of that equation are all too high. Moreover, the model correlation predicted by Equation A4 is necessarily positive and negative correlations cannot be accommodated at all. This problem occurs at the extreme values of |Sn − Sn−1| and arises because initial assessments, Rn, less than 1 or exceeding 10 are forced to “1” or “10.”
To illustrate this problem, Figure 4 reproduces the data (
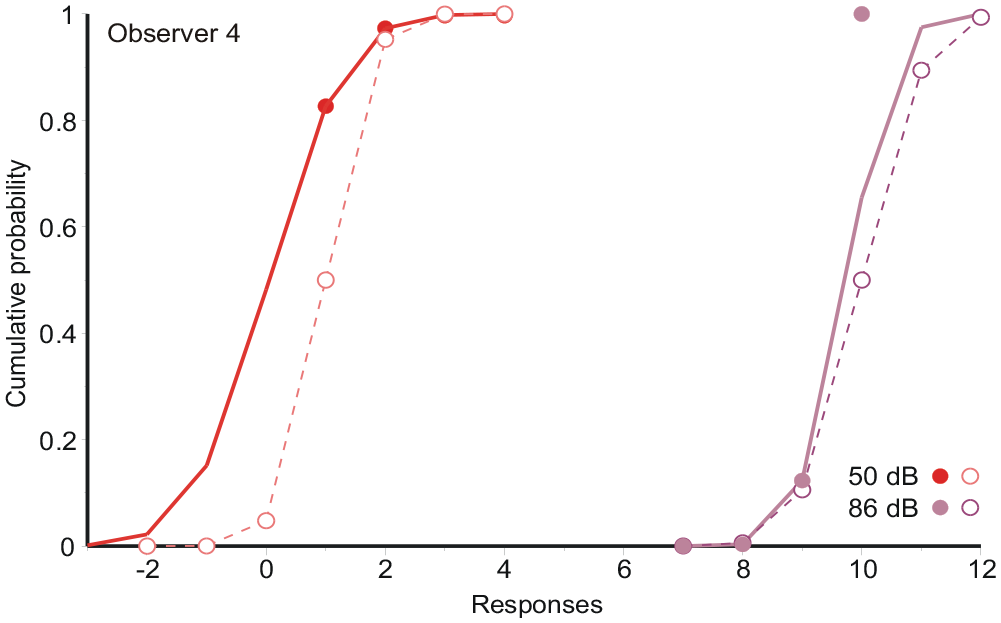
Responses (filled symbols) to the two extreme stimuli in Figure 1c (FB), together with the normal integrals fitted to them, and a conjecture of how the initial assessments (open symbols) might have been distributed. Data from Observer 4.
The recorded distribution of

giving a positive correction when Sn is less than Sn-1, greatest when Sn = S1 (see Figure 4) and a negative correction when Sn is greater than Sn-1, greatest when Sn = S10. This leads (Supplementary Material A, Equation A9) to:
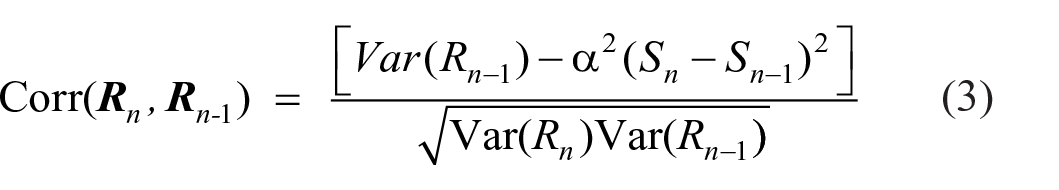
which generates the curved characteristics in Figure 3, with the α-parameter values shown in Table 2.
The formula (Equation A9) depends on the limited range of responses available in AI. In ME there is ostensibly no such limitation; nevertheless, ME shows a similar pattern of correlations, though the estimates of α are smaller.
In FB feedback ostensibly substitutes Sn-1 for
α-parameter values for the model curves in Figure 3.
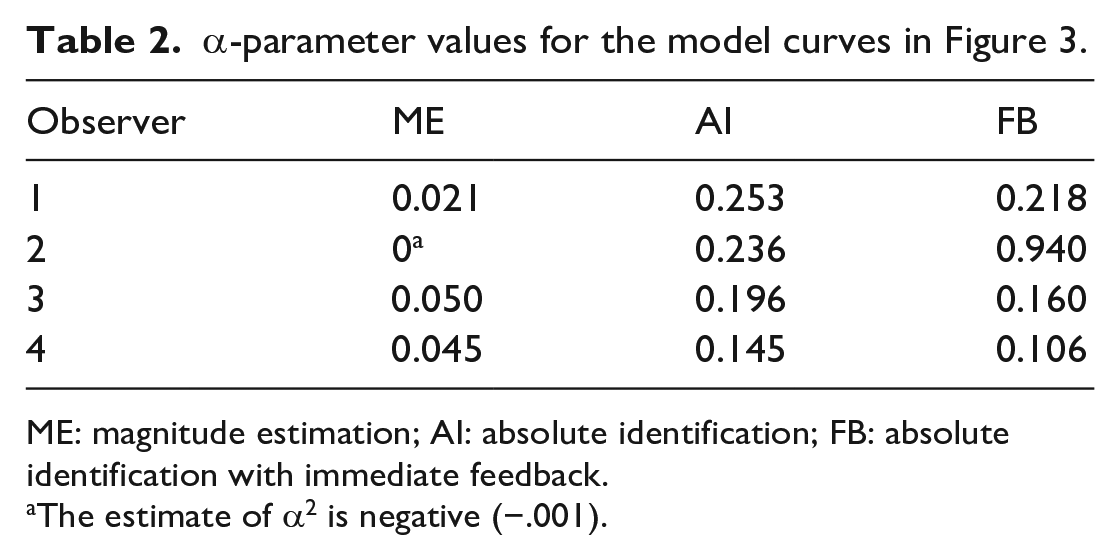
ME: magnitude estimation; AI: absolute identification; FB: absolute identification with immediate feedback.
The estimate of α2 is negative (−.001).
ME: magnitude estimation; AI: absolute identification; FB: absolute identification with immediate feedback.
Prior expectation
Equation 1 generates a sequence of displacements Bn(Sn – Sn−1) +ε n of the point of reference, Rn-1, of which the sum of squares, Σ n (Bn(Sn – Sn−1) +ε n )2 would, without modification, grow beyond all bounds. Suppose that observers have some idea of what kind of response would be appropriate, and let Rπ be that prior expectation. The actual response is then a weighted average (cf. Laming, 1999, Equation 4):
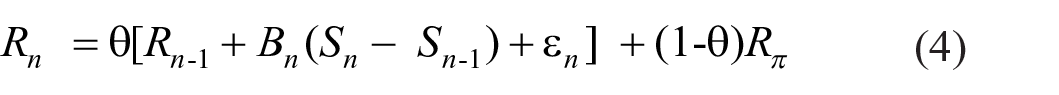
where (1 − θ) is the weight accorded to the prior expectation. The point of reference for trial n is now θRn−1 + (1-θ)Rπ and the cumulative variance becomes Σ n θ2n(Bn(Sn – Sn−1) +ε n )2, which is finite for θ < 1. Rephrasing Equation 4:
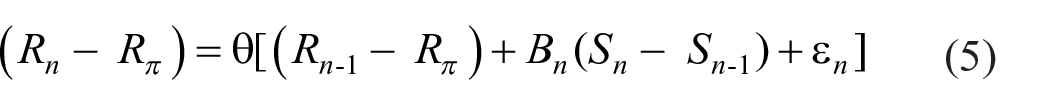
and responses are hereafter referenced to θ(Rn−1 – Rπ).
The prior expectation R π must itself be derived from previous observation of the stimuli. Rewrite Equation 5 as
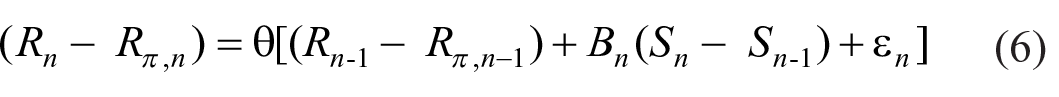
where 8
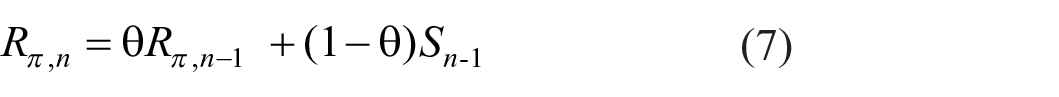
Prior expectation thereby adjusts to the sequence of stimuli.
Equation 6 makes the point of reference for the judgement of Sn the sum of many small adjustments and therefore, at least approximately, normal (cf. Figure 1), but now of finite variance. Herein lies the source of the frequent normal variation in many signal detection and judgement tasks.
The “bow” effect
Estimates of d′ for the discrimination between adjacent stimuli (Si vs. Si + 1) show a depression in the middle of the stimulus set (Luce et al., 1982; Weber et al., 1977). Figure 5 shows d′s calculated from the aggregate data in Figure 1 and the other observers. A normal probability integral was fit to the responses to each stimulus; then d′ for the discrimination between Si and Si + 1 was estimated as
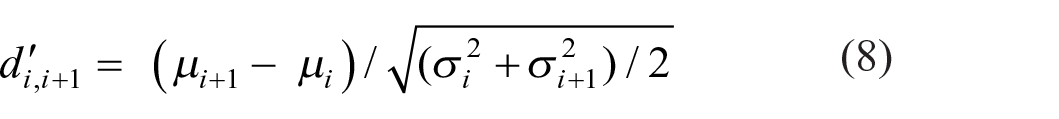
where µ i , µ i + 1 are the adjacent means and σ i 2, σ i + 12 the corresponding variances. Figure 2 shows the mean responses to be approximately linear with respect to the ordinal scale of the stimuli, so that the “bow” effect must result from an increase in response variance in the centre of the stimulus set. This is confirmed in Figure 6, which shows the response variances conditional on each stimulus. An expression for these response variances is derived in Supplementary Material B.
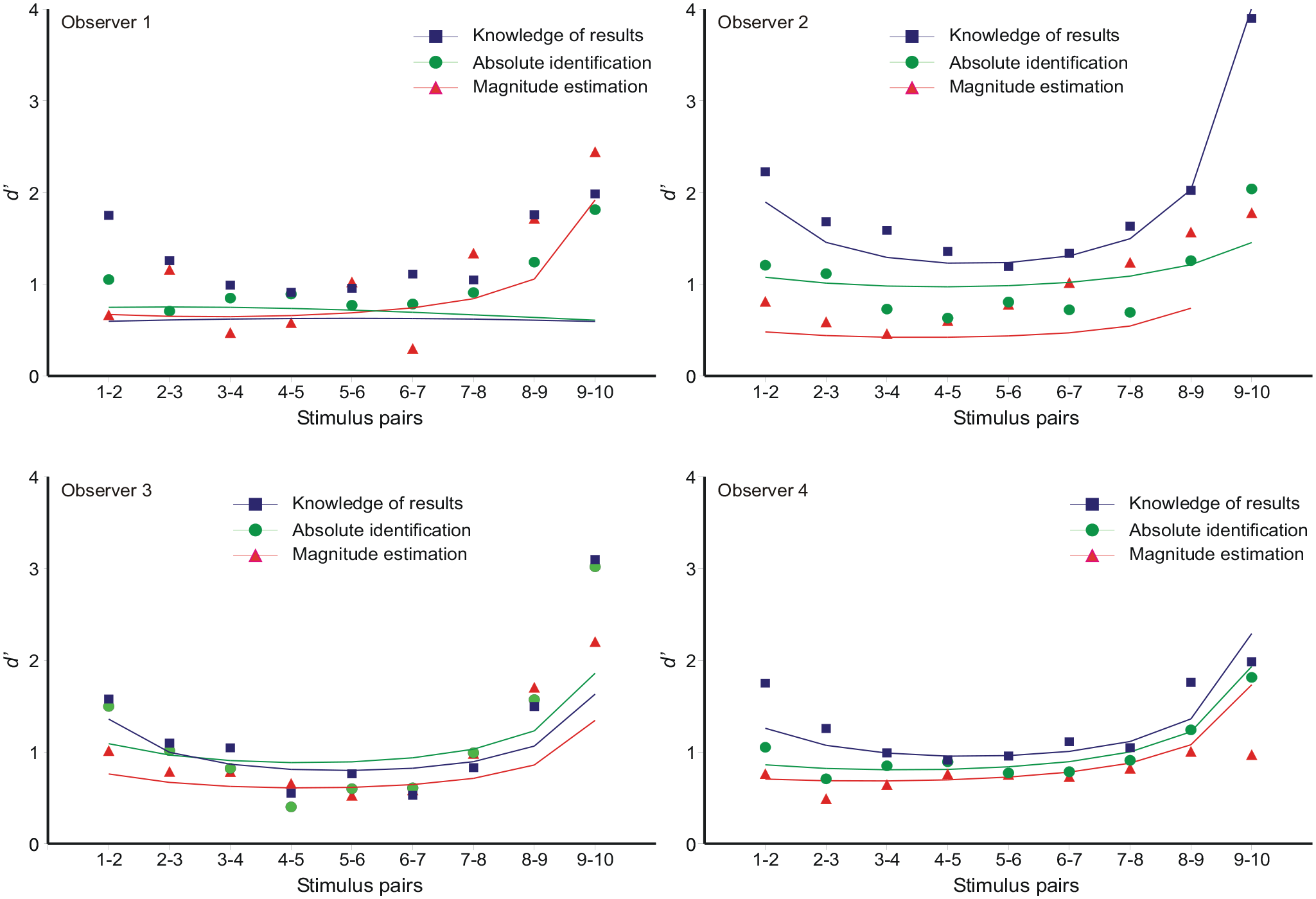
The “bow” effect: estimates of d′ between adjacent stimuli. The model curves are generated by inserting the variances from Equation 9 (cf. Figure 6) into Equation 8.
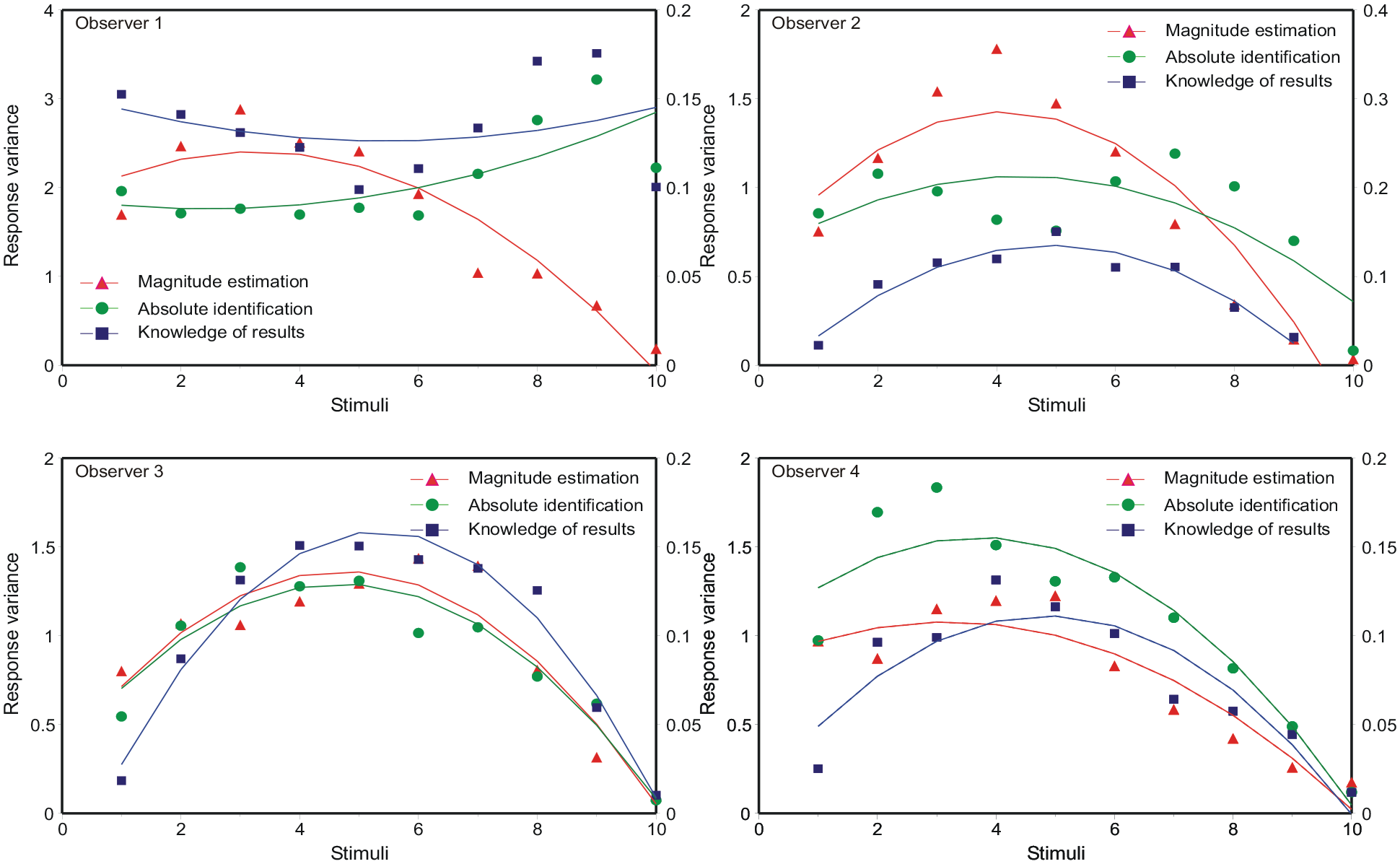
Response variance as a function of ordinal position in the stimulus set. The model curves are Equation 9 (B9 in the online Supplementary Material B), with the parameter values in Tables 6a, b, c in Parameter_estimates.doc.
The data in Figure 6 are asymmetric, while Equation B8 is symmetric about
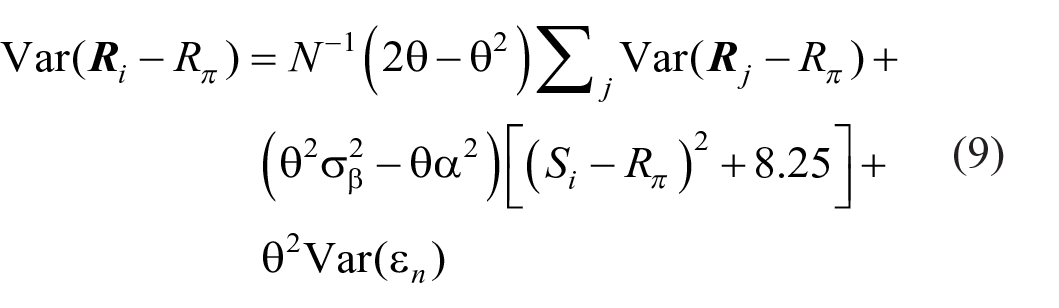
This equation generates the asymmetric curves in Figure 6, with the parameter values in Tables 6a, b, c in Parameter_estimates.doc. Entering the variances calculated from Equation 9 into Equation 8, with unit difference of mean, then generates the predictions for d′ in Figure 5.
Observer 1 in Figure 6 shows response variances that are slightly less in the centre of the stimulus set, except for the extreme stimulus (86 dB) for which the variance is much reduced. Equation B8 in the Supplementary Material delivers response variances peaking in the centre of the stimulus set provided
Sequential effects 9
Category judgements are related to the preceding stimuli and responses. Holland and Lockhead (1968, Figure 3) plotted the “error,”
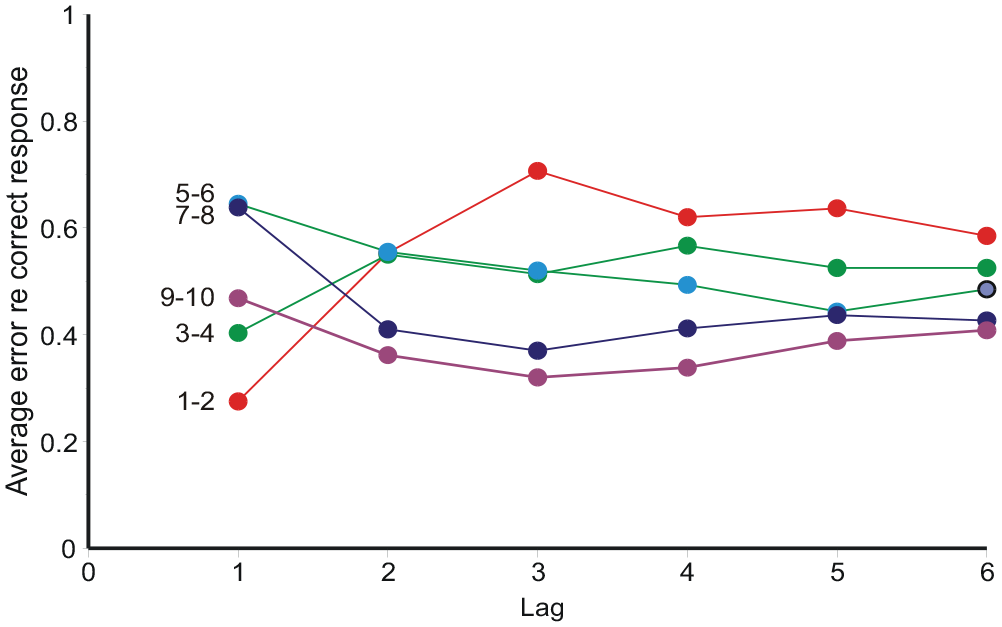
Average “error,”
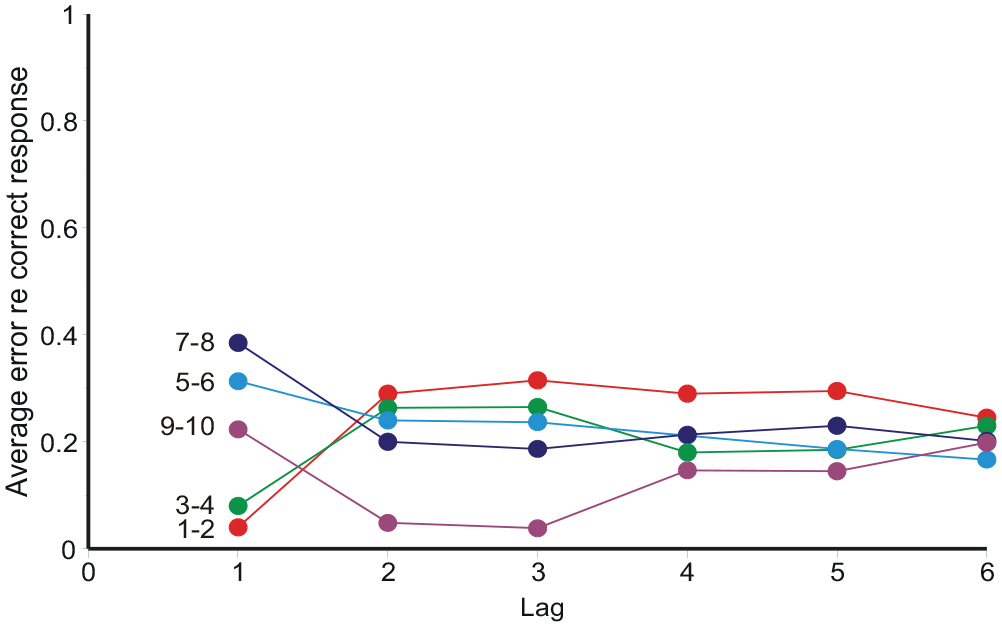
Average “error,”
However, a simple reading of Equation 1 says that
The total regression of
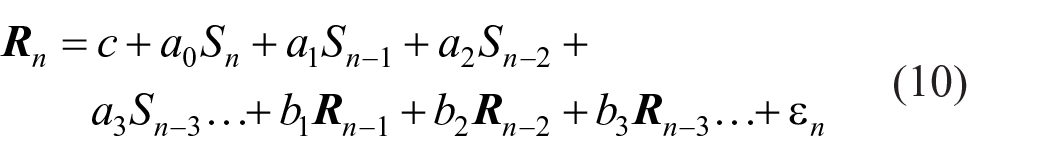
In Equation 10, c is a constant (with the effect of centring all variables to zero mean), ε
n
an error term, and the ak and bj regression coefficients are estimated by minimisation of the sum of squares. The ak estimate Cov(
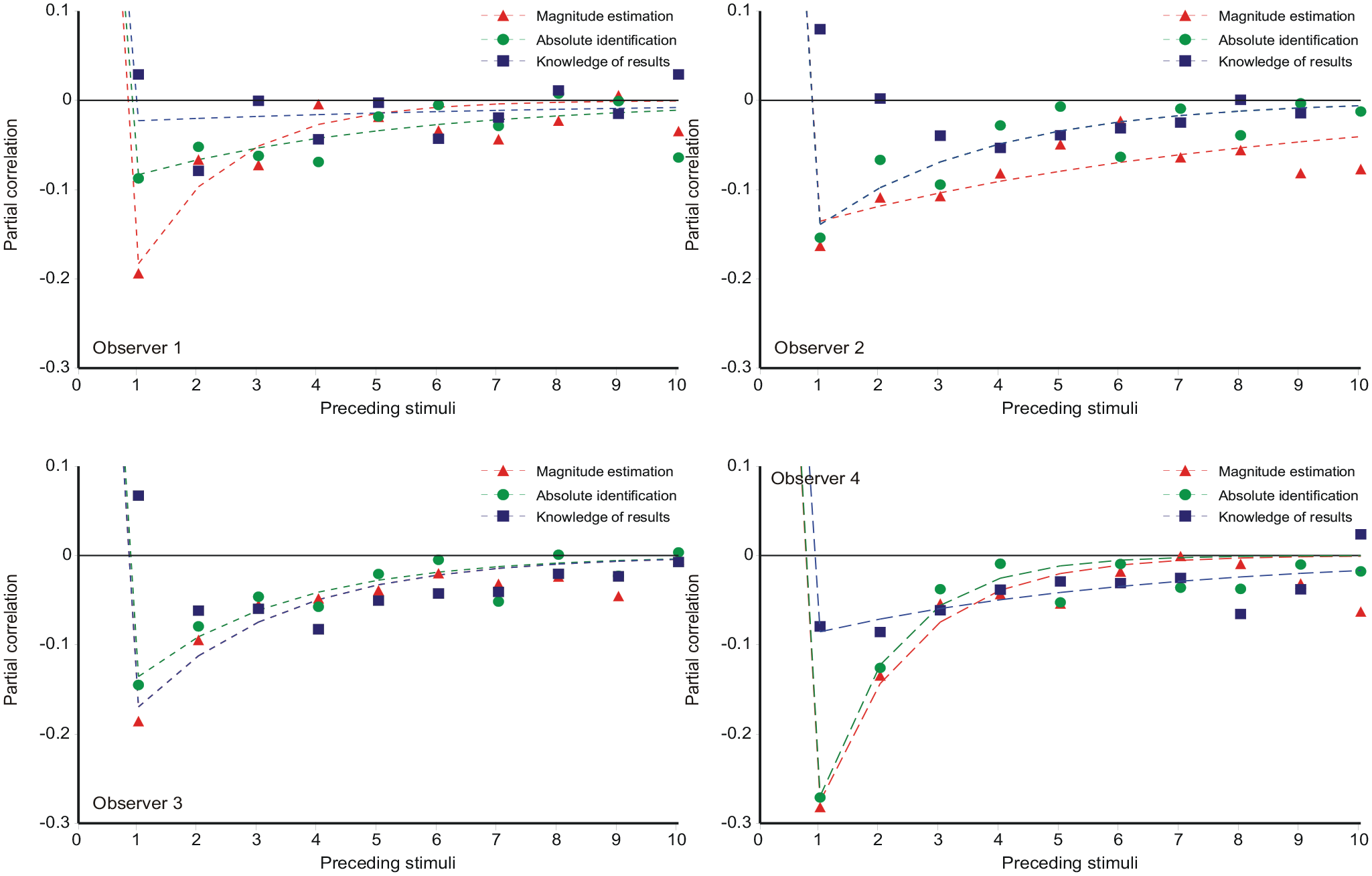
Partial correlation coefficients between
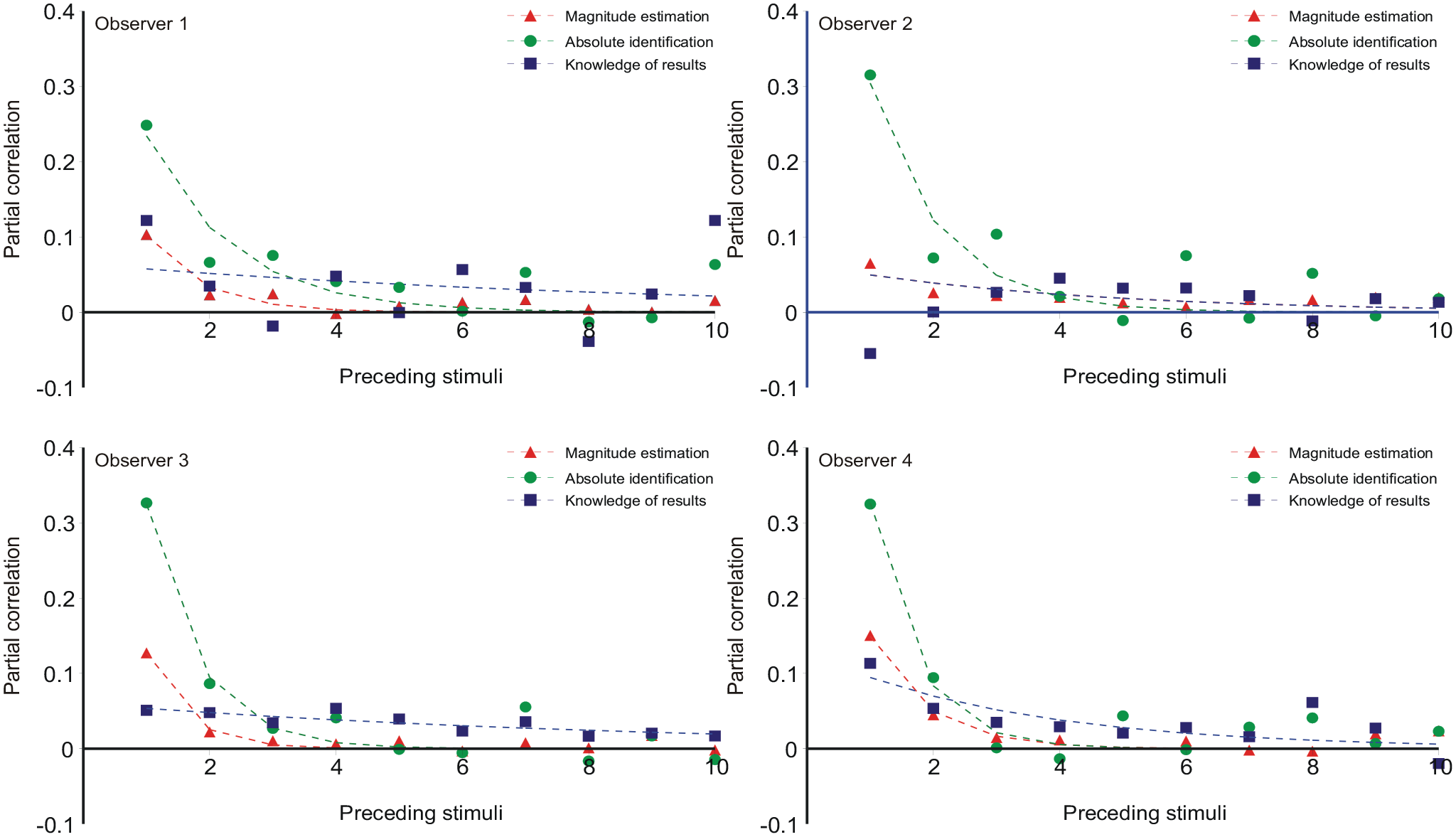
Partial correlation coefficients between
Partial correlations with previous stimuli
The equations
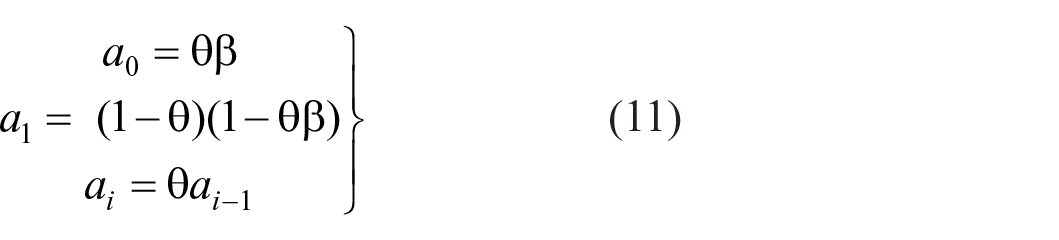
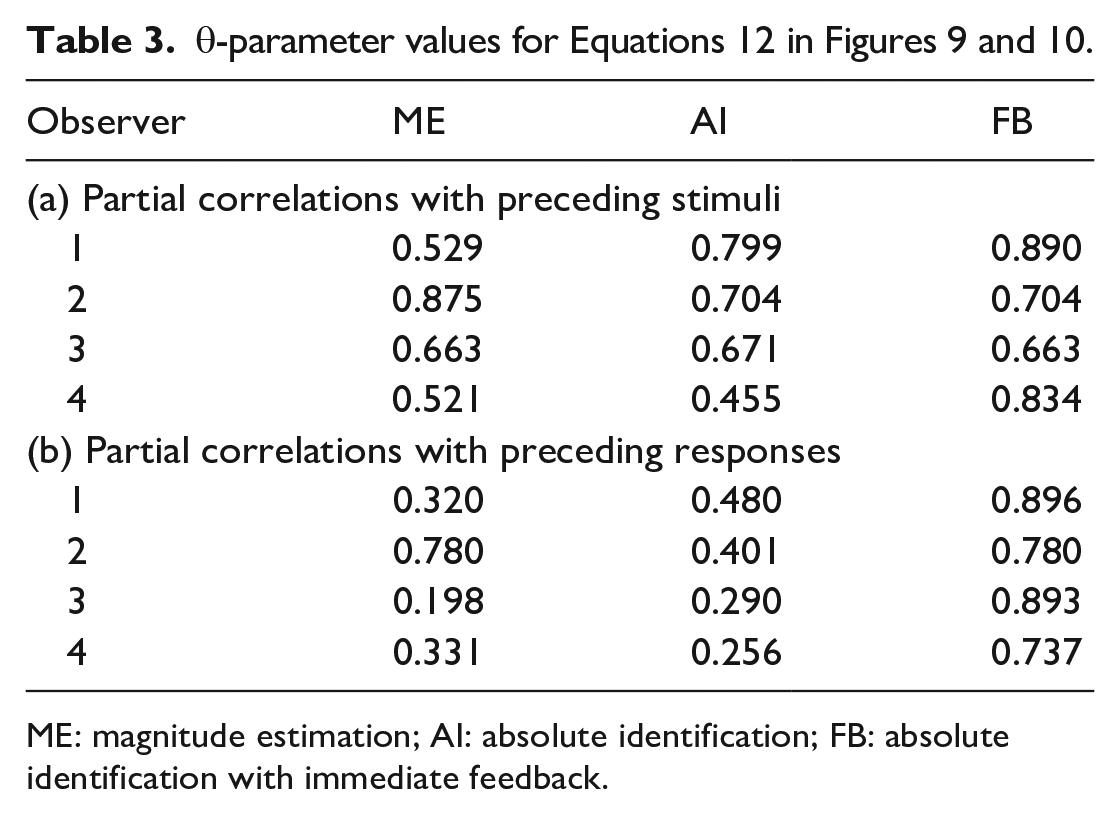
(Supplementary Material C, Equation C5) generate the curves in Figure 9 with the parameter values in Tables 9a, b, c in Parameter_estimates.doc. The θ-parameter (relation of prior expectation to preceding stimuli; Equation 7 is additionally reproduced in Table 3.
Partial correlations with previous responses
Figure 10 shows the partial correlations of

(Supplementary Material C, Equation C11) with parameter values in Tables 10a, b in Parameter_estimates.doc. The partial correlations for ME and AI in both Figures 9 and 10 show a satisfactory fit to Equations 11 and 12, respectively, which, in turn, describe an exponentially decreasing trend. But FB is different because of the feedback. Ostensibly, this substitutes Sn−1 for
Both Equations 11 and 12 are consistent with an interaction between
Jesteadt et al. (1977) intuited that the entire pattern of sequential interactions was generated by the one interaction between
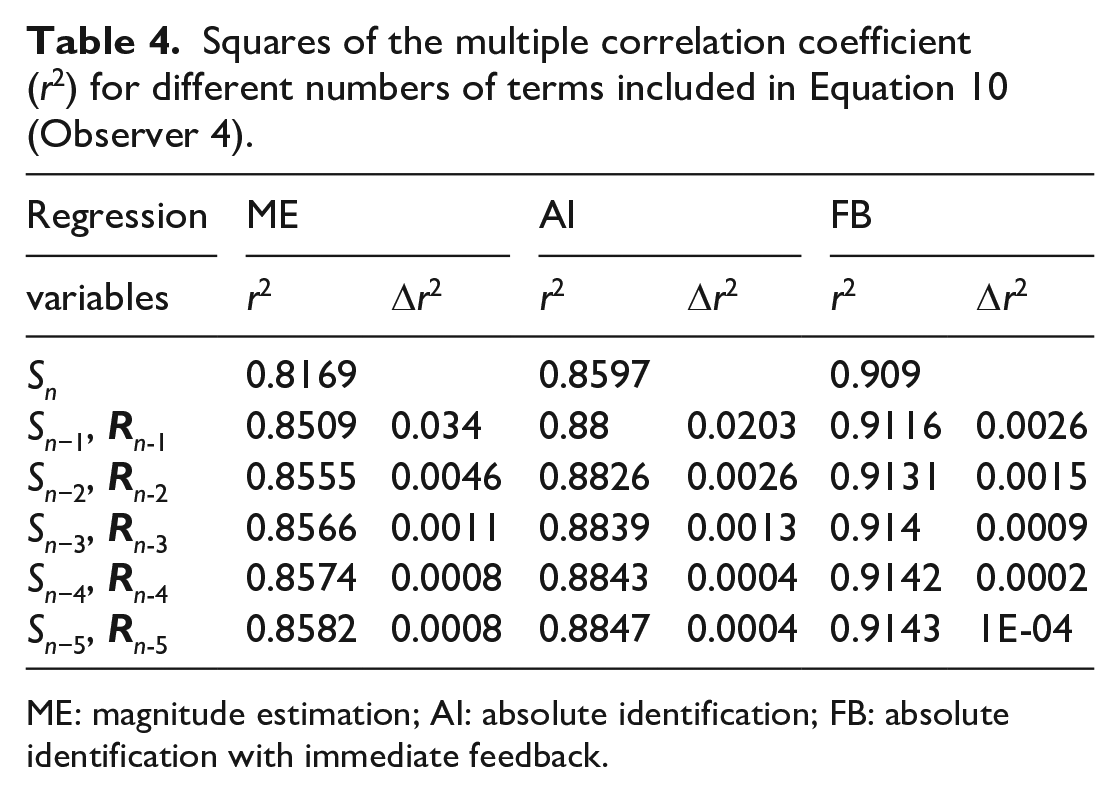
Squares of the multiple correlation coefficient (r2) for different numbers of terms included in Equation 10 (Observer 4).
ME: magnitude estimation; AI: absolute identification; FB: absolute identification with immediate feedback.
So, to a good first approximation, the pattern of sequential relationships is driven by the interaction between
Discussion
Responses to the same stimulus repeated on successive trials correlate about +0.38 (Obs 1) to 0.91 (Obs 2), (AI, Figure 3). It must be that the first of those responses is used as a point of reference for the second—there is no absolute judgement of the second stimulus. This idea was first proposed by Holland and Lockhead (1968, p. 412): In an absolute judgment task with feedback provided, it is proposed that Ss use the remembered magnitude of the stimulus on the preceding trial, and the numeric value of the feedback for that stimulus, as a standard for a comparative judgment of the presented stimulus.
If the stimuli on successive trials differ, the correlation is less, even negative for large differences. But it must still be that the response on one trial is used as a point of reference for the next, because the observer cannot know in advance how that second stimulus will differ from the first. The correlation is less because the extrapolation from one response to the next is variable—there is no absolute judgement of differences or ratios between stimuli. The pattern of autocorrelation in Figure 3 and elsewhere has a profound effect on our understanding of category judgement.
Now, to answer the questions set out in the introduction:
AI without feedback shows the same pattern of autocorrelation as ME. The process of judgement must be the same in both tasks. Minor differences arise because the observer in AI knows that there are (in this experiment) only 10 different stimuli, so that a stimulus that appears to be No. 0 or 11 forces a reappraisal of the framework of judgement.
If AI without feedback is a relative judgement, then so also is AI with feedback. Feedback enters only after a judgement has been output to modify the point of reference for the following trial. It ostensibly substitutes Sn−1 for Rn−1 in Equation 1, and

in Equation 2, because Sn−1 is fixed. The pattern of autocorrelation in Figure 3 is consequently much attenuated. This is important because Stewart et al. (2005) and subsequent contributors to that debate have not ordinarily distinguished between AI with, and without, feedback.
Stewart et al. (2005) proposed a determinate process to link the response on one trial to that on the next—it amounts to an absolute judgement of stimulus differences/ratios (cf. the response–ratio hypothesis, Luce & Green, 1974). Guest et al. (2016) compared conventional AI of 8 lengths of line (Expt 1) with a similar AI of the absolute difference between successive lengths (Expt 2). Their two sets of results are not comparable. In particular, a repeated stimulus gives 65% correct responses in conventional AI (Expt 1), but only 35% in the AI of differences (Expt 2). This may fairly address the particular model proposed by Stewart et al. (2005), with determinate linkage from one trial to the next; but neither of these studies accommodates the pattern of autocorrelation in Figure 3.
The debate, relative judgement versus AI, has coalesced on the specific proposal of an absolute judgement of stimulus differences/ratios by Stewart et al. (2005). The results here point to a third idea, not previously considered (except Laming, 1984, 1997). Each stimulus in an experiment is compared with its predecessor, greater, less than, or about the same. The variability of that comparison increases with the difference in magnitude between the stimuli, so the assessment of a stimulus far removed from its predecessor is very uncertain. This idea accommodates the pattern of autocorrelation in Figure 3, which, in turn, proves incompatible with an absolute judgement of stimulus differences/ratios. It provides a radical new insight into category judgement. The rest of this discussion explores what changes are now needed to present understanding.
Thurstone’s “Law of Comparative Judgment”
Thurstone (1927b) proposed that a stimulus, as perceived by the observer, is intrinsically variable. This would explain why psychophysical judgements, especially discriminations between one stimulus and another, are so variable. Taking that variability to be normally distributed, Thurstone sought to establish a stimulus scale from experimental data. Thurstone (1927a) distinguished five different formulations of this idea, of which “Case V” is much better known these days as the normal, equal variance, signal-detection model.
Torgerson (1958) developed Thurstone’s “Case V” to accommodate a linear array of stimuli. There are N normal distributions of means µ i and common variance σ2,
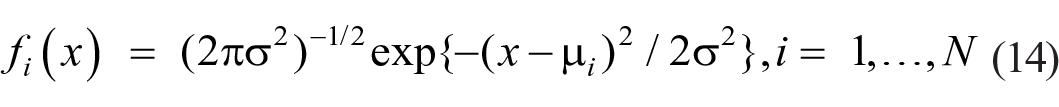
one for each stimulus value, i = 1, . . . ., N, and N-1 criteria, cj, j = 1, . . . . , N-1. The probability of response j given stimulus i, P(Rj|Si), is represented by the proportion of the Si distribution that lies between criteria cj−1 and cj:

The standard deviation is commonly fixed at 1 and the mean of the smallest stimulus at 0; all the other stimulus means and criterion values are then estimated from the data. This implicitly establishes an interval scale of the stimulus continuum in units of the standard deviation and provides a scaffold for the AI of whatever stimulus is presented, subject, of course, to the error σ2 (Braida & Durlach, 1972; Durlach & Braida, 1969; Luce et al., 1976; Treisman, 1985).
Other ideas have been proposed to serve the same function. Some musicians, though not all, can identify an auditory frequency to an accuracy of a quarter tone (about 3%). In general they do not know how they do it, but it appears to be a consequence, rather than a precursor, of their musical training. “Perfect pitch” extends only over the range of the piano keyboard, and Bachem (1954) confesses to making the occasional error of an octave. To my mind, that is absolute judgement. Nosofsky (1986), G. D. A. Brown, Neath, and Chater (2007) and Kent and Lamberts (2005) among others, have proposed exemplar models based on the storage of magnitudes in memory. Stewart et al. (2005, Table 2) have tabulated the principal phenomena of AI and FB that these, and other models, are able to accommodate (though not including autocorrelation).
The present data do not speak of any of those ideas. However, if the judgement of the difference between successive stimuli was absolute, then the correlation between successive responses would be independent of the difference between successive stimuli. The pattern of autocorrelation in Figure 3 tells us that the assessment of the difference between successive stimuli is itself relative (Equation 1; Laming, 1984).
Seeking the simplest account of the present data, the “bow” effect and the sequential interactions are related directly to the pattern of autocorrelation. It is necessary to introduce initial “Off the scale” assessments; it is not possible to identify such assessments in the recorded data, but—try AI for yourself! It is also necessary to diminish the weight of preceding trials exponentially—the judgement process is, at least approximately, Markov. But structures in memory supporting an absolute comparison are not needed.
As Equation 14 stands, there is no autocorrelation, nor sequential effects. So, what needs to change?
The roles of the stimuli and criteria need to be interchanged (cf. Lockhead, 2004). There will be N stimuli, µ i , i = 1, . . . ., N, as before, but no directly associated variability. Instead, successive stimuli are categorised against a continually evolving point of reference. Stimulus Si generates response Rj when that momentary point of reference is equivalent to a criterion lying between cj−1 and cj (cf. Equation 15). This interchange of stimuli and criteria leaves the model probabilities calculated from Equation 14 unchanged, but the variability is no longer a property of the stimulus—it is internal to the observer.
If the variability of judgement is no longer intrinsic to the stimulus, it cannot be used to generate a scale of the sensory continuum. Instead, the only metric for analysis is the ordinal scale of the stimulus set and the analyses above have been formulated in this ordinal metric. At the same time, the point of reference evolves by small additive increments from trial to trial (Equation 5) and this explains why experimental data are so well accommodated by normal distributions (Figure 1).
Autocorrelation
The striking pattern of autocorrelation of log magnitude estimates was discovered by Jesteadt et al. (1977) in the course of a routine regression analysis of log Nn on log Sn, log Sn-i, and log Nn-i, intended to test the response–ratio hypothesis of Luce and Green (1974). Green et al. (1977) then showed that the same pattern appeared in magnitude production of loudness (1 kHz tones again) as well as in ME. Luce and Green (1978) showed that the maximum degree of correlation was reduced (to +0.5 to 0.6) in an experiment where the frequency of the tone changed (1 to 4 kHz) from one trial to another. Baird et al. (1980) reported a similar pattern of correlation for the area of random geometric shapes and an attenuated pattern (maximum correlation +0.37) for cross-modality matching of loudness to area. Further correlations have been contributed by Ward (1979) for the separation between two dots on a screen and for the matching of duration to separation. In addition, Siegel (1972) reported that accuracy in the identification of auditory frequency was much increased for a repeated stimulus, a finding that was replicated by Stewart et al. (2005, Fig. 25). But this pattern of autocorrelation has not previously been reported for AI.
“Off-the-scale” assessments
The manner of selecting the next response (Equation 1) means that some initial assessments will be “off the scale,” “0” or “−1” or “10,” “11” or “12.” Although this mostly affects responses to the extreme stimuli (1 and 10), the cumulative data in Figure 1 suggest that it involves other adjacent stimuli as well and, relative to the stimulus averages, the ME data in Figure 1a extend below 1 and above 10. Such responses are, of course, forced in AI to “1” or “10.” That forcing needs to be taken into account, because the pattern of autocorrelation in Figure 3 relates to the responses actually observed, not the (model) responses that constitute the initial assessment. Happily the model of forcing (Equation 2) leads to a simple modification of the model of autocorrelation (Equation A9, A10) and accommodates the negative correlations that sometimes occur following extreme differences of stimulus value. In principle, there should be no “off the scale” responses in ME, but individual negative correlations can be found in the figures published by Green et al. (1977); Jesteadt et al. (1977); Luce and Green (1978) and Baird et al. (1980). In the present experiment, the pattern of autocorrelation for ME is more sharply focused even than for AI and some of the ME correlations are negative.
The “bow” effect
Analyses of the “bow” effect are commonly based on Equation 14, which forces all standard deviations to be the same; the “bow” effect then subsists in a contraction of the estimated means towards the centre of the stimulus scale. But, relative to the ordinal spacing of the stimuli, the response variances are not equal (Figure 6). The relation of mean response to stimulus location is approximately linear (Figure 2), so the “bow” effect must be consequent on that increased response variance in the middle of the stimulus set. The model of autocorrelation generates a model for these variances (Equation B8), which, in turn, generates a model for the “bow” effect (Figure 5) by substitution into Equation 8.
The “bow” effect (Equation B8) is parameter-dependent. If, for example, α, the adjustment for under/overshoot in Equation 2, was 0, the bow would be inverted. Observer 1 in Figure 6 appears to present such an example, except that the variance of responses to the most extreme stimulus (86 dB) is much reduced.
The response variances in Figure 6 are asymmetric—variance is less in the upper half of the scale and this leads to increased values of d′. A similar asymmetry can be found in the data of Luce et al. (1982) and Weber et al. (1977). Several authors have drawn attention to the role of the extreme stimuli, suggesting they serve as “anchors” (Berliner & Durlach, 1973; Durlach & Braida, 1969; Weber et al., 1977). “Off-the-scale” assessments enable those extreme stimuli to be identified with greater accuracy than other stimuli. Stewart et al. (2005) invoke a “limited decision capacity,” which is greatest for the central stimuli; putting that another way, there is less opportunity for error at the ends of the stimulus range.
Sequential effects
Initially sequential effects present a puzzle: responses appear to correlate positively with the preceding stimulus, but negatively with all earlier stimuli. It happens so because Rn correlates positively with Rn−1, and Rn−1 correlates positively with Sn−1. If Rn−1 is left out of the reckoning, there remains a positive correlation between Rn and Sn−1 (Ward & Lockhead, 1970, 1971; Figures 7 and 8 here). Stewart et al. (2005, Equation 8) invoke a confusion of the current stimulus difference (Sn − Sn−1) with representations of other previous differences, whereupon a suitable choice of parameters gives assimilation to Sn−1 and contrast with all previous stimuli. But if sequential relationships are analysed with a regression equation containing both stimulus and response terms (Equation 10), the partial correlation coefficients for ME and AI are all negative (except for the trial stimulus) and show a geometric decreasing trend (Figures 9 and 10), suggesting a Markov process.
Jesteadt et al. (1977) intuited exactly this of their ME data. Table 4 repeats their regression analysis in a slightly modified form to the same effect. Regression on (Sn−1,
Stimulus range
If Thurstone’s Law of Comparative Judgment (Equation 14) applied, then, increasing the range covered by a fixed number of stimuli, the variance σ2 remaining constant, should lead to continually improved resolution; but it does not happen so. Braida and Durlach (1972, Expt. 4) compared AI with feedback for 10 500-ms bursts of 1,000 Hz tones spaced, in different conditions, at 0.25, 0.5, 1, 2, 3, 4, 5, and 6-dB intervals with the highest level always at 86 dB. There were about 1,875 trials per condition for each of three observers. If the variance (σ2) in Equation 14 is estimated from the aggregate data, but separately for each stimulus spacing, it increases in proportion to the square of that spacing, as
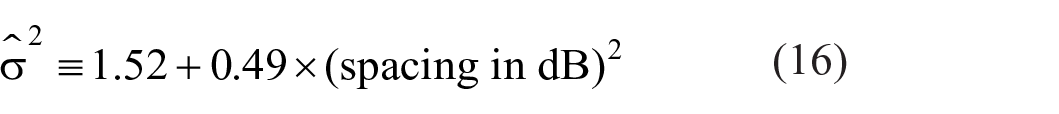
(see Braida & Durlach, 1972, Figure 4c; Laming, 2010, Figure 11, p. 762).
Braida and Durlach (1972, p. 484) proposed a “memory” variance, increasing in proportion to the square of the stimulus range [i.e., 0.49 × (spacing in dB)2], so that the dispersion of identifications increases in proportion to the spacing of the stimuli. For small ranges dispersion is additionally increased (1.52) by intrinsic variability attributed to the stimulus (Equation 14). The analysis here retains the “memory” variance (Equation 4)—dispersion increasing in proportion to stimulus spacing—but abandons Thurstone’s intrinsic variability. Instead, at small ranges dispersion is increased by a presumed variability between different sections of the data (σε2 in Equation 4).
The limit to resolution as a function of stimulus spacing is shown in Figure 11 as information transmitted in bits per trial. It increases to a limit, as spacing increases, of about 2 bits/trial, equivalent to the identification of no more than four stimuli without error. Information transmitted increases as the inverse of the variance relative to the stimulus spacing. Simplifying (Equation B9),
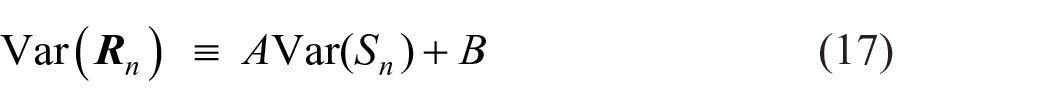
where
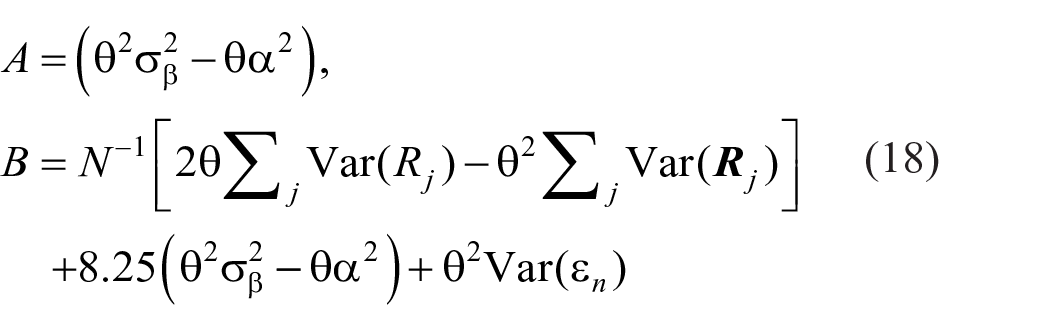
and Var(Sn) (= 8.25) is calculated with respect to the ordinal metric of the stimulus set. Relative to the stimulus spacing in dB, this becomes
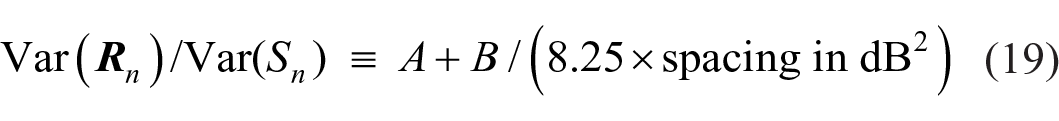
and is the curve fitted in Figure 11 with A = 0.53 and B = 0.25. Figure 11 displays a configuration very similar to Braida and Durlach’s Figure 4d (1972, p. 491), which presents total sensitivity aggregated over the stimulus range (see also Stewart et al., 2005, Figure 11).
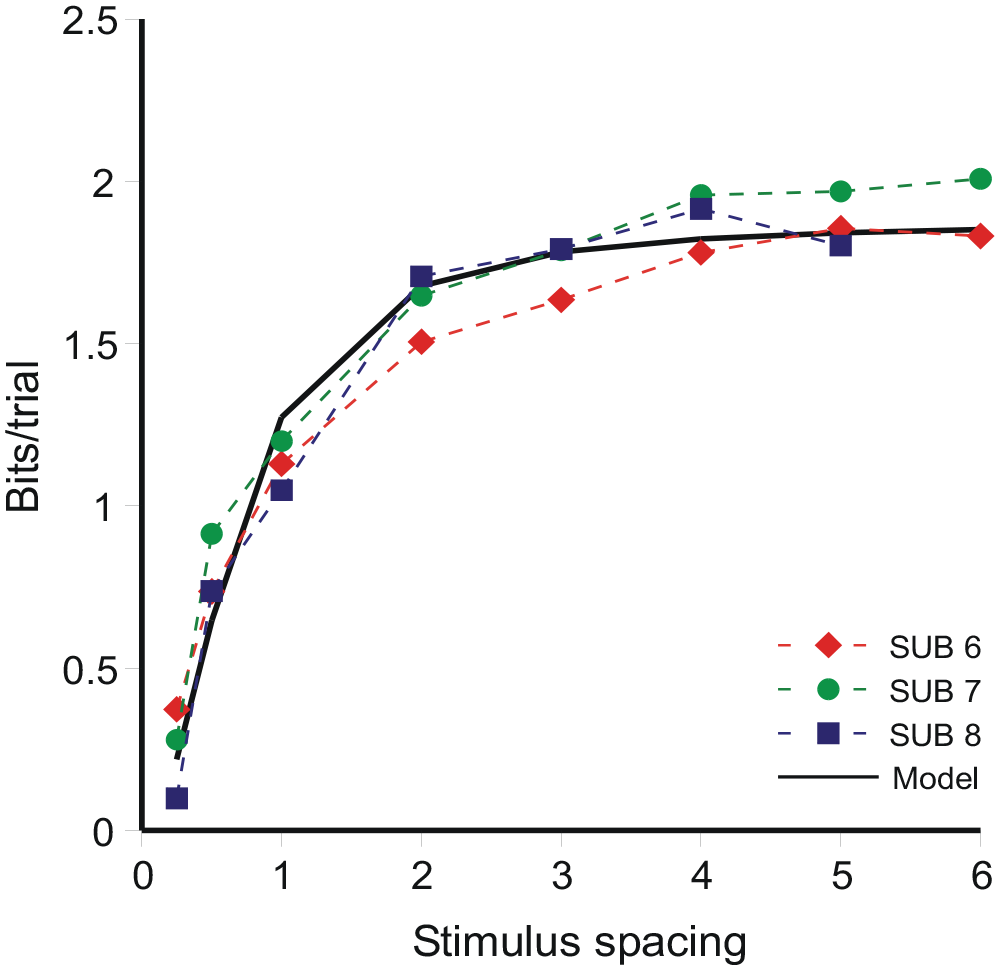
Information transmitted per trial for three observers in Braida and Durlach’s (1972) Expt 4. The model curve is Equation 17.
Notwithstanding Braida and Durlach (1972, Expt. 4), it is still sometimes claimed that “measures of discriminability depend on stimulus range” (Gravetter & Lockhead, 1973; Lockhead & Hinson, 1986, p. 53). Lockhead (2004) made the very pertinent point that the intensity of a 1-kHz tone (or the brightness of a light) is but one attribute of a complex stimulus. As a matter of convenience, the intensity of tone or brightness of light is abstracted from the rest of the complex, while the rest is ignored in the analysis of the data. What applies to the physical structure of the stimulus applies also to its temporal structure—specifically the sequence of stimuli and the range of values they span. Lockhead and Hinson compared the three different sets of stimulus magnitudes shown in Table 5 using 0.5-s, 1-kHz tones and both AI and FB.
Levels of 1-kHz tones in the experiment by Lockhead and Hinson (1986).
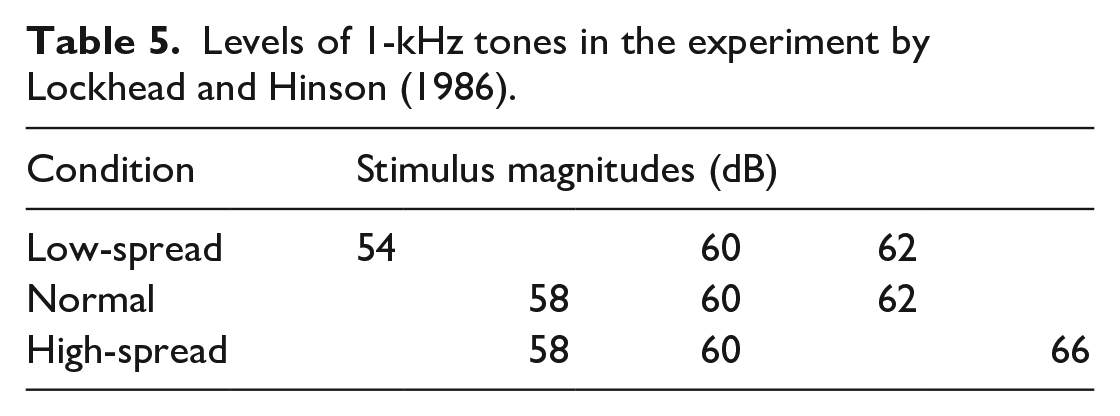
The accuracy of discrimination between 60 and 62 dB was impaired by the 54-dB stimulus in the low-spread condition, compared with the normal; likewise the discrimination between 58 and 60 dB in the high-spread condition. But the assessment of 60 dB, whatever the preceding stimulus, is subject to some variability, and that variability is greater when 54, rather than 58 dB, precedes (Equation 1). This increased variability impairs the resolution of 60 from 62 dB.
Envisage an experiment with seven different tones from 54 to 66 dB at intervals of 2 dB. Identify the (Sn−1, Sn) pairs corresponding to the successive pairs of stimuli in Lockhead and Hinson’s experiment and analyse specifically the responses to those Sn. Reference to Figure 3 shows that the correlation following a 54 or 66 dB Sn−1 will be less, and the variance transmitted from trial n-1 to trial n greater, than with a 58 or 62 dB Sn−1. In short, the impairment of pair-wise discrimination contingent on the remoteness of the preceding stimulus (cf. the “bow” effect in Figure 5) is implicit in the present experiment, which is consistent with Lockhead and Hinson’s findings. S. D. Brown et al. (2009) have replicated Lockhead and Hinson’s experiment with the same outcome.
Response times
S. D. Brown et al. (2009) recorded response latencies and Lacouture (1997) explicitly looked for the “bow” effect and sequential relationships in response time data. In fact, Lacouture replicated Laming (1968, Expt. 6), though with 10 stimuli rather than only 5. Laming presented a series of 800 signals to each of 24 subjects with a 2-min break after every 200 signals. The signals were lengths of line (as Lacouture) at a geometric spacing of 1.41. The signals were mapped in order of length onto five response keys operated with the digits of the right hand. The following observation seems especially relevant: Some subjects showed at times a certain confusion of the signals, which took the form of a transposition of one or more signals to adjacent responses [adjacent on the keypad], up or down the scale. These transpositions were temporary, though they might last for 50 responses and might occur several times during the same experimental session. The transposition of the signals was rarely complete and some correct responses occurred during these periods. In some cases it is known that such correct responses were regarded by the subject as errors [“damn”]. Laming (1968, p. 72)
Limit to information transmitted
It has been known since Hake and Garner (1951) and Garner and Hake (1951) that observers are unable to distinguish more than five stimuli on a single continuum without error. This finding has been replicated with many different stimulus attributes (see Laming, 1984, Table 1; Stewart et al., 2005, Table 1 for tabulation of relevant studies) and the limit of 5 is exceeded only when there is a physical reference enabling the continuum to be, as it were, divided into two independent ranges (Hake & Garner, 1951, is one example), with up to five stimuli identified within each range.
Garner (1953, 1962, Ch. 3), among others, has drawn an analogy between the limited information per trial in category judgements (Figure 11) and the channel capacity that limits the transmission of information through an ideal communications system (Laming, 1968, Ch. 1; Weaver, 1949). This is inappropriate. Channel capacity is measured in bits/unit time, while the quantities in Figure 11 are bits per judgement. The two measures do not match dimensionally. Instead, the limit to information per trial in Figure 11 is a direct consequence of the relativity of judgement.
Calculating the variance of each identification within a set, i = 1, . . . Ν (Supplementary Material B, Equation B3),
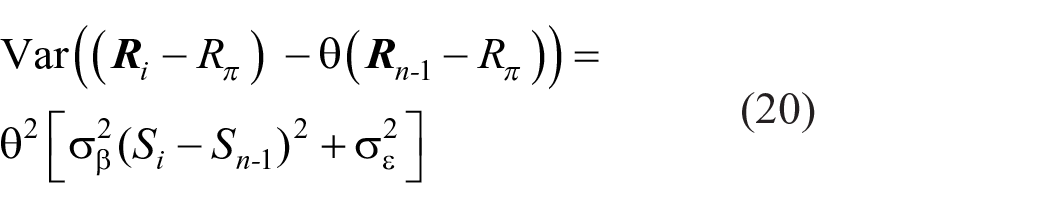
It includes a component θ2σβ2(Si − Sn−1)2, increasing as the square of the difference between successive stimuli. When SN is presented following S1 this component is (N-1)2θ2σβ2, increasing with the size of the set. Identification will begin to fail with end-of-set stimuli, when that variance, increasing in proportion to 1, 4, 9, 16, 25, . . . , becomes excessive. The limit appears to kick in at N = 4 or 5.
The dependence of accuracy on the size of the step between successive stimuli was demonstrated by Luce et al. (1982), who examined category judgements when the sequence of stimuli, of uniform frequency overall, was artificially constrained so that successive stimuli differed by small steps (−1, 0, 1), by slightly larger small steps (−2, −1, 0, 1,2), by large steps (⩾4) and compared these manipulations with a strictly random sequence of stimuli. Although the different stimuli were presented with equal frequency, small steps (−1, 0, 1) yielded much the best resolution and large steps (⩾4) the worst, worse even than strictly random. Values of d′ from these different conditions were modelled by Laming (1984, Table 3) using Equation 1 above.
The implications of relative judgement for a variety of experimental results were first pointed out by Laming (1984), working from Equation 1. That idea was applied to:
Stevens’ Power Law (cf. Laming, 1997, Ch. 11);
ME as implemented by S.S. Stevens and his colleagues, specifically the variance of numerical estimates (J. C. Stevens & Tulving, 1957; and data from S. S. Stevens, 1971, p. 441);
The autocorrelation of log numerical estimates (Baird et al., 1980);
The accuracy of category judgements, specifically the accuracy of resolution (d′ between adjacent stimuli) in the four experimental series studied by Luce et al. (1982);
The information per trial transmitted in category judgements.
However, the models in that paper were complicated by the involvement of Thurstonian scaling (Equation 14), which has here been abandoned. The present analyses are simpler.
Relativity of judgement has practical application to inspection tasks in general, including medical diagnosis (Laming, 2007), the marking of examination scripts (Laming, 1990, 2004a, Ch. 13; 2004b; Kelly et al., 2022), and even peer review (Laming, 1991). Because each judgement uses its predecessor as a point of reference, successive judgements have the propensity to wander. This can be especially important in medical screening, where a clinician makes a succession of judgements of very similar pathologies (Laming, 1995a, 1995b; Laming & Warren, 2000). In addition Laming (2004a) has collected a wide variety of examples of the relativity of judgement in contemporary society.
Conclusion
This present experiment is the latest in a long sequence of studies of estimation/identification of a range of stimuli on a single continuum. Usually there are a small number of observers whose amalgamated results are presented as one. But the four observers in this experiment have each provided a sufficient volume of data to support individual analysis, and large differences can be seen between individual observers (Figures 2, 3, 5, 6, 9, and 10). Caution is needed in drawing conclusions that might apply to observers in general.
The observers in this experiment did not make absolute judgements; instead they referred each stimulus to its predecessor. Neither did they make absolute judgements of the difference/ratio between successive stimuli; although a greater stimulus difference led to a greater difference in successive responses, the extrapolation was variable. It is to be presumed that the observers were unable to accomplish either of these tasks and, to the extent that this experiment replicates the phenomena of similar studies, this presumption must apply to category judgement and ME in general.
The pattern of autocorrelation in Figure 3 has been used to account for the “bow” effect and the pattern of sequential effects and is therefore primary. It has been interpreted to signify that (a) there is no absolute judgement—each stimulus is judged relative to the stimulus and response on the preceding trial—and (b) there is likewise no absolute assessment of differences in stimulus magnitude—the adjustment from one trial to the next is variable.
The point of reference for each judgement therefore varies from trial to trial by the aggregation of independent increments and, by itself, that aggregation would ordinarily exceed all bounds. I have proposed a prior expectation to constrain the otherwise increasing variance, an expectation that is itself derived from the series of stimuli in the experiment. Successive points of reference nevertheless aggregate by small independent increments, and the aggregate distribution should be approximately normal. This provides an alternative explanation for the normal variation seen in ME and AI judgements and, indeed, in sensory judgement generally. Torgerson’s (1958) Case-V model is not needed and is better abandoned. Instead the analysis here has used only the ordinal metric of the stimulus set.
The ideas here contribute directly to an understanding of two other findings, external to the present experiment. Modelling in terms of the ordinal scale of the stimulus set accommodates range effects directly and the variance of judgements within that set provides an immediate explanation why observers are unable to identify more than five stimuli on a single continuum without error. Finally, there are practical applications to inspection tasks in general.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218231159393 – Supplemental material for Autocorrelation in category judgement
Supplemental material, sj-docx-1-qjp-10.1177_17470218231159393 for Autocorrelation in category judgement by Donald Laming in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical approval
The data analysed in this MS are retrospective, dating from 1987 to 1989. As of that time, there was no ethical vetting of projects and therefore no ethical committee approval that can be reported. Nevertheless, all persons in this study participated on a voluntary basis, and the experiment was conducted in accordance with the ethical standards of the 1975 Helsinki Declaration.
Informed consent
This article does not contain clinical studies or patient data.
Data accessibility statement
The original data, and also much part-processed data (aggregate stimulus–response matrices, stimulus–response matrices conditional on the preceding stimulus, matrices (Sn − Sn –1) × (Rn − Rn –1) for AI and FB) for all four participants are available in the file Data.7z on ResearchGate. Likewise, the individual parameter estimates for the model fits in Figures 3, 6, 9, and 10 and the individual ![]() are also available in the file Parameter_estimates.doc on ResearchGate.
are also available in the file Parameter_estimates.doc on ResearchGate.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.