
Abstract
This article reports on four experiments aiming to examine immediate post-sentential recall of core sentence information (conveyed by direct objects), and optional/additional information (conveyed by temporal or locative adjuncts). Participants read simple and unambiguous Czech sentences such as Starší důchodce velmi pečlivě pročetl noviny v neděli v knihovně: “An older retiree read the newspaper very carefully on Sunday in the library.” Sentences always appeared as a whole after pressing a space bar. Immediately after the sentence disappeared, an open-ended (free response) question was presented targeting either the direct object (e.g., newspaper), temporal adjunct (e.g., on Sunday), or locative adjunct (e.g., in the library). Altogether, it was found that the core information (conveyed by the direct object) was recalled almost perfectly, whereas additional information, conveyed by temporal and locative adjuncts, was recalled with significantly lower accuracy rates. Information structure also played a role: if the temporal or locative adjunct was focused, it was recalled better than if it was unfocused. The present article thus shows systematic differences in recall success for different pieces of information. These findings suggest the presence of selective attention mechanisms during early stages of sentence processing. Factors such as syntactic function or information structure influence the degree of attention to different pieces of information conveyed by a sentence. In turn, certain pieces of information may not be consciously accessible already after the sentence is processed.
Introduction
Imagine that a friend tells you something you do not know: “Hey, did you hear that Paul twisted his ankle on Friday evening in the park while he was jogging with Susan?” You would probably be sorry for Paul, you might think about how it happened, whether it hurt a lot, whether it has already healed, and so on. But perhaps, you would be less inclined to think about the day it happened, about the location or about the person accompanying Paul. The sentence above contained several pieces of information and all of them could be important to you. However, some might seem more important (such as what happened) than others (such as where and when it happened). Perhaps, you would remember that Paul twisted his ankle for some time, but straight after hearing the sentence, you might not be entirely certain when exactly it happened.
The aim of this article is to examine immediate recall of various pieces of information after reading a sentence. Specifically, we were interested in differences in recall between core information (conveyed through arguments, i.e., direct objects) and additional or optional information (conveyed by temporal or locative prepositional phrases). We also examined whether these differences are influenced by information structure (word order position).
Sentence information recall
There is a long tradition of research on sentence recall (e.g., Baddeley et al., 2009; Bransford & Franks, 1972; Brener, 1940; Miller & Selfridge, 1950; Tremblay et al., 2011; Tulving & Patkau, 1962), but such studies typically focused on general recall rate (i.e., number of recalled words in the correct order) and rather overlooked the differences in recall between various types of information conveyed by the sentence.
Most findings on sentence information recall (or recognition/accessibility more precisely) thus come from the study of information structure, which has been mainly concerned with the effects of linguistic focus. For example, McKoon et al. (1993) showed that syntactically prominent positions enhanced the accessibility of various concepts. Using a probe recognition task, they showed that the information contained in a predicate (His critical boss is demanding at times.) was more easily accessible than the same information contained in a prenominal modifier (His
Such findings led Ferreira and Lowder (2016) to claim that sentence processing is driven by information structure and that the given information is processed rather superficially (or in a “good-enough fashion”), whereas the new information is the target of processing effort (see also Ferreira & Chantavarin, 2018).
Studies which would examine other aspects of sentence information recall (such as the effects of syntactic function) are rather sparse. For example, Clark (1966) analysed recall of subjects (actors), their modifiers, verbs, and objects in simple active sentences such as The bored student sharpened the pencil. He found that actors were recalled the most accurately, verbs the least accurately, and objects and modifiers in between. However, James (1972) showed that the rate of subject and object recall in sentences (such as The explanation satisfied the photographer) was influenced by the imageability of these sentence parts and that the recall rate was similar if the imageability was controlled. Similar findings were presented also in James et al. (1973) for sentences such as The burglar was startled by the incident. Nevertheless, James (1972) and James et al. (1973) also showed a lower recall rate for verbs (in comparison to subjects and objects) for which no explanation is offered.
Interestingly, Holmes and Forster (1972) conducted a rapid serial visual presentation (RSVP) experiment in which they presented sentences with varying complexity and after each sentence, they asked the participants to report as many words as they could remember in the correct order. Among other things, they documented a generally low rate of reporting adjectives and adverbs (e.g., after reading sentences such as Alan left a large pile of books in the library, the adjective was reported only in 67% of cases). In a related study conducted in French, Mehler et al. (1978) found that adjectives were reported to a rather low extent if they modified a noun (but to the same extent as other parts of the sentence if they stood in the predicate).
In sum, the above-mentioned studies show that the rate of accessibility of certain pieces of information contained in a sentence may differ. However, most of the studies used recognition tasks (or other measures of RTs or eye movements, see Filik et al., 2011) and targeted the core information (such as focused information or information conveyed by the syntactically obligatory elements such as subjects, objects, or verbs). The predominant focus on online measures (i.e., RTs) in these studies is well-founded, because the overall error rate in the recognition tasks was typically very low and did not yield any significant effects. Thus, one might expect that the use of comprehension questions like Was the boss demanding? after reading sentences such as those examined by McKoon et al. (1993), would not yield any interesting findings (the success rate would be probably approaching 100%). Nevertheless, from the two studies using the RSVP task (Holmes & Forster, 1972; Mehler et al., 1978), it seems that optional sentence parts, (such as adjectives or adverbs) are accessible to a relatively low degree immediately after reading a sentence.
More recently, the ability to recall certain pieces of information from a sentence has been extensively tested under the Good-Enough Processing Framework (Christianson, 2016; Ferreira & Yang, 2019). The main claim of this framework is that sentence processing is often shallow and imprecise and that comprehenders employ simple heuristics which allow them to arrive at reasonably accurate representations of the sentence content without expending too much processing effort (Karimi & Ferreira, 2016). Studies under this framework employed question answering accuracy to show the systematic nature of misinterpretation—they have mostly been concerned with locally ambiguous, garden-path sentences (e.g., Christianson et al., 2001; Christianson & Luke, 2011; Christianson et al., 2006; Chromý, 2022; Malyutina & den Ouden, 2016) or noncanonical sentences (e.g., Christianson et al., 2010; Ferreira, 2003). Interestingly, even these studies do not inform us about what factors influence readers’ recall accuracy immediately after reading uncomplicated, plausible, and unambiguous sentences.
Current study
The key question we ask in this article, is whether there are differences in information encoding already in the early stages of sentence processing. In case there are, some pieces of information may be consciously accessible more likely than others already immediately after the sentences was processed. Thus, we focus on the differences in immediate recall of various information contained in a sentence using open-ended (free response) comprehension questions. More specifically, we compare recall of core information (conveyed by direct objects) to additional or syntactically optional information (conveyed by temporal and locative adjuncts).
Direct objects versus adjuncts
A direct object presents an obligatory part of a transitive sentence (together with other arguments such as a subject), whereas temporal and locative adjuncts are optional in the sense that their presence is not necessary for the sentence to be grammatical. An object, together with a predicate and a subject, may thus be seen as conveying the core information of the sentence (such as what happened or who did it), whereas adjuncts as conveying additional or optional information (such as where or when did it happen).
In grammatical theory and also in psycholinguistics, the distinction between arguments (such as subjects and objects) and adjuncts has played an important role (see Tutunjian & Boland, 2008). For example, it has been shown that arguments tend to be processed faster than adjuncts (e.g., Clifton et al., 1991; Schütze & Gibson, 1999; Speer & Clifton, 1998). However, some studies have shown that this tendency can be overridden by other factors, such as preceding context (Liversedge et al., 1998) or verb intransitivity (Kennison, 2002). To our knowledge, no study aimed to examine the differences in recall rates of information conveyed by objects (or any other arguments) and adjuncts.
We are fully aware that the distinction between arguments and adjuncts is not straightforward and that sometimes, it is even disputed (Koenig et al., 2003). Although the purpose of the present article is not to examine the distinction between arguments and adjuncts in general, we want to show that the opposition between direct objects and temporal/locative adjuncts affects recall of the pieces of information conveyed by these structurally different sentence constituents.
Structure of Czech
The experiments presented in this article use unambiguous sentences in Czech. Czech enables scrambling (Ross, 1986), that is, using different word orders without changing the meaning of a sentence. Importantly, scrambling may be used for manipulating the topic–focus opposition, since it is assumed that the given element must precede a new one (Kučerová, 2012). Scrambling allows getting the new information to the latest sentential position or to peak it in a contrastive way; see Examples (1)–(3).
(1) Herečk-a v divadl-e přijal-a kytic-i. female-actor-nom.sg in theater-loc.sg accept-pst.sg bouquet-acc.sg “A female actor accepted a bouquet in the theater” (2) Herečka přijal-a kytic-i v divadl-e. female-actor-nom.sg accept-pst.sg bouquet-acc.sg in theater-loc.sg ‘A female actor accepted a bouquet in the theater’ (3) Kytic-i herečka přijal-a v divadl-e. bouquet-acc.sg female-actor-nom.sg accept-pst.sg in theater-loc.sg “A female actor accepted a bouquet in the theater”
These three examples present well-formed sentences in Czech, all meaning “A female actor accepted a bouquet in the theater.” However, word order used in Example (1) focalizes the object (the bouquet), whereas word order in Example (2) focalizes the locative adjunct (in the theater). In Example (3) the object (the bouquet) is topicalized (it is a contrastive topic).
In the spoken modality, recent psycholinguistic research has shown that prosody may interact with scrambling more than it was previously thought. The results of several experiments (Šimík & Wierzba, 2017; Šimík et al., 2014) have shown that scrambling possibly exists as a secondary factor which only assists in placing the chosen element closer to the area of larger prosodic prominence and, logically, preventing contextually less important elements from being stressed. Nevertheless, since the experiments reported here are being conducted using written (not auditory) stimuli and there are no overt prosodic cues, we believe that what information is focused (or the most prominent) can be effectively manipulated through scrambling (word-order manipulations).
Since Czech word order is flexible, objects and adjuncts may occur in various parts of a sentence. Based on a corpus of approximately 30,000 clauses, Siewierska and Uhlířová (1998) claim that the most typical word order in Czech is SVO (63.1% of cases), meaning that the object is quite typically focused in Czech. The typical adjunct position is far from clear, since various adjunct types seem to behave differently. Importantly, Uhlířová (1974) shows that temporal adjuncts tend to be focused in 38% of cases, whereas locative adjuncts are in about 65% of cases.
Experiment 1
The aim of the first experiment was to examine the differences in recall accuracy between temporal adjuncts and arguments (sentence objects) in different word order positions. Recall was tested immediately after reading a sentence via simple open-ended comprehension questions. We predicted that the information conveyed by objects will be recalled more accurately than information conveyed by temporal adjuncts and also that the focused information will be recalled more accurately than unfocused information.
The experiment was preregistered on the Open Science Framework: https://osf.io/jq7ua and all the stimuli and data used in the analysis have been made available in the following repository: https://osf.io/zb7r8/
Method
Participants
A total of 144 Charles University undergraduate students (117 female and 27 male; Mage = 22.3 years) participated in Experiment 1. All participants were native speakers of Czech and participated for course credit.
Materials
A total of 24 experimental items were used in Experiment 1 (see https://osf.io/zb7r8/ for the whole list with English translation). Each sentence was transitive and it comprised a subject (modified by an adjective), a verb (modified by an adverb phrase), an object, a temporal adjunct (composed of a preposition and a noun), and a locative adjunct (composed of a preposition and a noun). The sentences were unambiguous (both locally and globally).
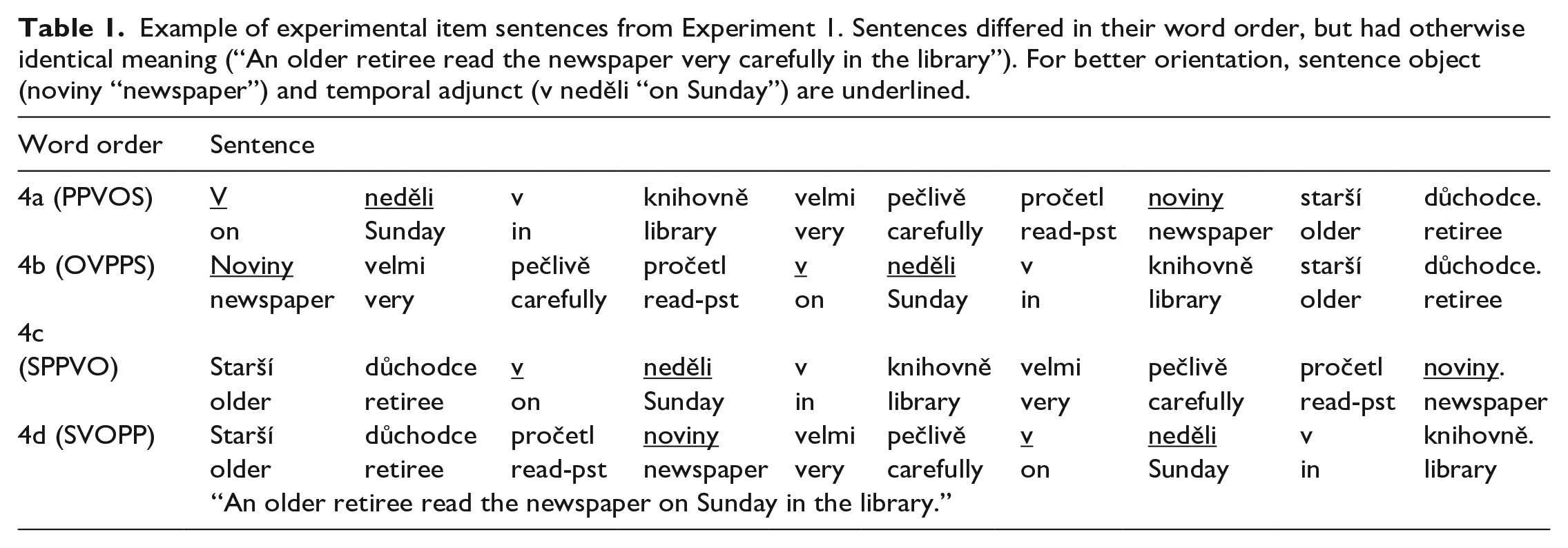
As the previous literature on the topic is very sparse, our aims were rather exploratory and we wanted to test whether the word order position of the object or adjunct plays a role. We constructed sentences where the given element stood either in the sentence initial position, in the sentence medial position, or in the sentence-final (i.e., focused) position. Examples of experimental sentences are shown in Table 1. Altogether, we used four word orders: sentence 4a (PPVOS) 1 contained a temporal adjunct in the initial position and object in the sentence medial position, whereas in sentence 4b (OVPPS), the sentence initial position was occupied by an object and the adjunct was in the sentence medial position. Both these sentences focused the sentence subject. In sentence 4c (SPPVO), an object was in the sentence-final (focused) position and the adjunct was in the sentence medial (i.e., unfocused) position. Finally, in sentence 4d (SVOPP), a temporal adjunct was in the sentence-final position (i.e., it was focused) and the object was in the sentence medial position (unfocused). As Czech has a relatively free word order, all sentences were grammatical and crucially, the syntactic structure was the same (e.g., the adjuncts always modified the verb independently of the word order). However, word order in sentences 4a and 4b was rather marked since VOS and OVS are possible but not common or preferred word orders in Czech (Siewierska & Uhlířová, 1998). These word orders tend not to be expected in out of the blue contexts (such as if the sentence is presented in isolation), but may be used to serve specific purposes such as information structure manipulation, typically to focus the subject (Jasinskaja & Šimík, n.d.).
Example of experimental item sentences from Experiment 1. Sentences differed in their word order, but had otherwise identical meaning (“An older retiree read the newspaper very carefully in the library”). For better orientation, sentence object (noviny “newspaper”) and temporal adjunct (v neděli “on Sunday”) are underlined.
Importantly, the stimuli were constructed according to two main criteria. First, the verbs used were transitive and their only obligatory argument was a direct object (i.e., we did not use verbs which require indirect objects or other modifiers). Second, only those verbs which are not typically modified by temporal or locative adjuncts were used. Information about the verb valency and typicality of modifiers was retrieved from the Valency Lexicon of Czech Verbs VALLEX (Lopatková et al., 2016; Lopatková et al., 2022), which provides a description of valency frames of Czech verbs including the typicality of non-obligatory modifiers. Besides of the two criteria mentioned above, we also used such objects and adjuncts which would be plausible modifiers of the verb of the given sentence. This was based on the intuition of the first author as a native speaker of Czech.
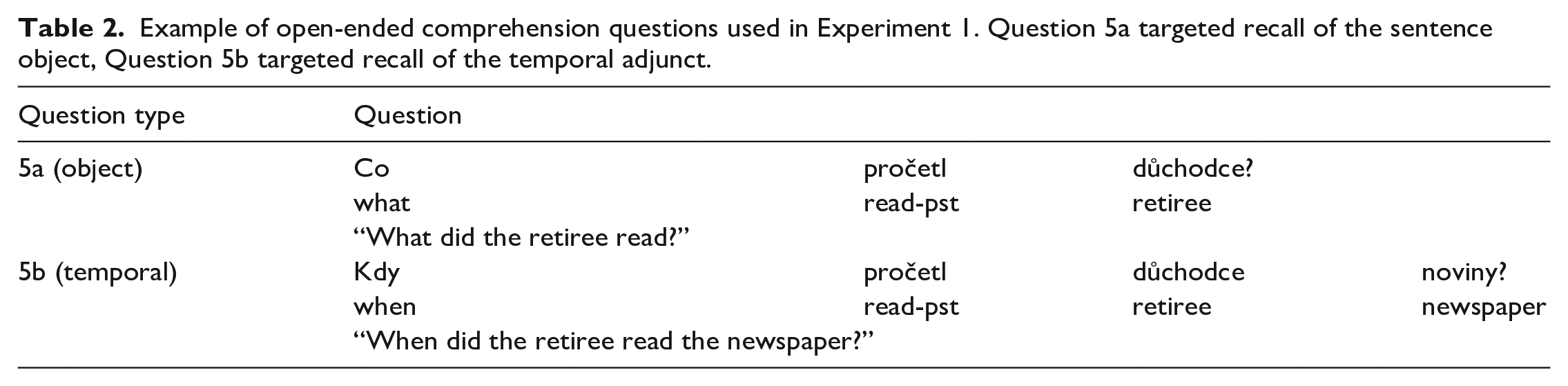
The second independent variable tested was the comprehension question type. After each experimental sentence, participants received an open-ended question targeting either the object, or the temporal adjunct. Examples of the open-ended comprehension questions are shown in Table 2.
Example of open-ended comprehension questions used in Experiment 1. Question 5a targeted recall of the sentence object, Question 5b targeted recall of the temporal adjunct.
In sum, each experimental item consisted of eight conditions (
Another 96 sentences were used as fillers (24 being experimental items from another experiment targeting different phenomena). The comprehension questions in filler items targeted various other parts of the sentence (such as attributes, subjects, etc.), but not temporal adjuncts or objects.
In the beginning, three sentences were presented as practice trials to ensure that participants understood the task correctly. Altogether, participants read 123 sentences which were presented in a randomised order for each participant.
Procedure
The experiment was conducted online using IbexFarm 0.3.9 (http://spellout.net/ibexfarm/). First, participants were informed about the general experimental procedure and they were asked to fill in certain information about themselves, namely sex, age, native language, field of study, and whether they experience any reading problems such as dyslexia. Then, the experiment was begun. First, participants saw a sentence as a series of underscores. Once they pushed the space bar, the whole sentence appeared. Participants’ task was to read the sentence at their normal reading pace and once they were finished, they had to press the space bar again which caused the sentence to disappear and a comprehension question to appear. Participants had to type in the answer and submit it by pressing the Enter key, after which the next sentence appeared as a series of underscores.
The items and filler sentences were presented in fully randomised order. The experiment took about 20–25 min.
Data coding
The response accuracy to the comprehension question was coded manually using simple coding rules. For the correct answers, we counted both verbatim repetitions of the sentence content, and nonverbatim but semantically accurate responses (e.g., use of synonyms, etc.). Also, we ignored whether the answers were orthographically imprecise (i.e., contained typing errors or misspellings). Some answers contained additional information which was not targeted by the question. In these cases, only the targeted information was considered. To illustrate this, using the question What did Mary find? was asked after the presentation of the sentence Mary found the magazine on Monday in the library, we would code as a correct answer the following responses a magazine, but also a periodical, a periodical in the library, a library magazine, I think it was a magazine, or a periodical in the lobby. On the contrary, responses like a book, in the library, on Monday, Mary found, etc., would be coded as incorrect.
Incorrect answers were further coded for four different types of errors. First, answers in which the participants explicitly stated that they do not know the answer or in which they claimed that the information was not present in the sentence were coded as “I don’t know.” Second, responses which contained a sensible, but incorrect answer to the given question (such as a book in the example above) were coded as “substitution.” Third, responses which seemingly answered a different question (such as “in the library” or “on Monday” in the example above) were coded as “different.” Fourth, the rest of the incorrect answers such as incomplete answers were coded as “other.”
Data analysis
First, reaction times (RTs) were trimmed conservatively and only the data points which were clearly discontinuous (less than 1,300 ms and more than 40,000 ms) were excluded. This represented 0.3% of the data. RTs were not normally distributed and we therefore ran a Box–Cox test (Box & Cox, 1964) to establish the ideal transformation method. The test result was
Second, response accuracy for filler items was checked. The mean accuracy rate was 94.62% and no participant scored under 80%. No participant was thus excluded based on this criterion.
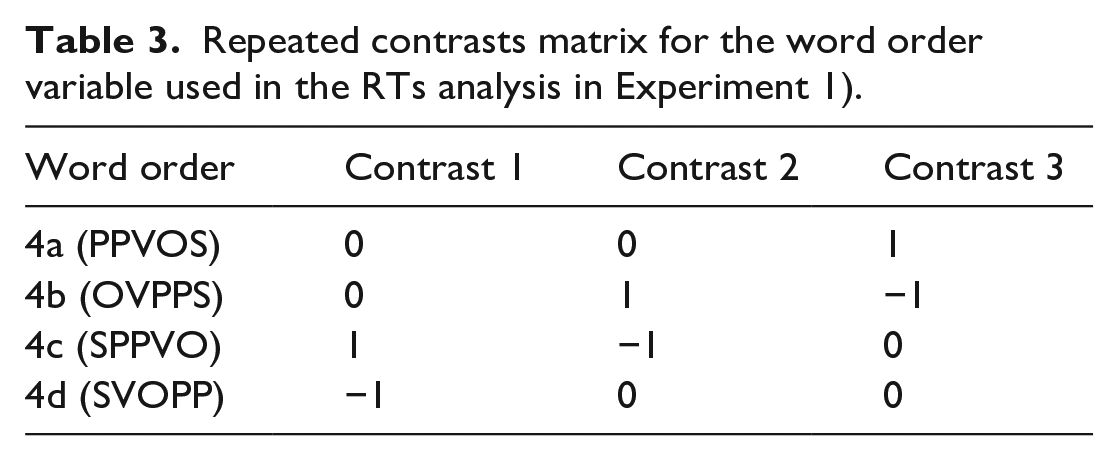
Third, in order to assess differences in RTs based on the different word order conditions, we modelled the data using a linear mixed-effects regression (Bates et al., 2014). The inversely transformed square root RTs served as a dependent variable, the only fixed effect was word order and participant and item were included as random effects. Word order was coded using repeated contrasts (see Schad et al., 2020) based on the word order frequency (see Siewierska & Uhlířová, 1998 and the contrast matrix is shown in Table 3. Contrast 1 contrasted the most common we formula (using lme4 syord orders 4c (SPPVO) and 4d (SVOPP), Contrast 2 contrasted word order 4c (SPPVO) with a less common word order 4b (OVPPS), and Contrast 3 targeted the difference between word order 4b (OVPPS) and the least common word order 4a (PPVOS).
Repeated contrasts matrix for the word order variable used in the RTs analysis in Experiment 1).
Fourth, response accuracy was analysed using logit mixed-effects models (Jaeger, 2008) with question type as a fixed effect, word order as a nested effect within question type, and participant and item as random effects (with question type as a random slope both for items and for participants). Question type was coded using treatment contrasts (with object question as the baseline) and word order was coded using repeated contrasts (as for the RTs analysis).
Fifth, an analysis of the incorrect response types was conducted. This analysis was supplementary to the response accuracy analysis and due to the generally low number of incorrect responses, it is rather descriptive.
Results
RTs
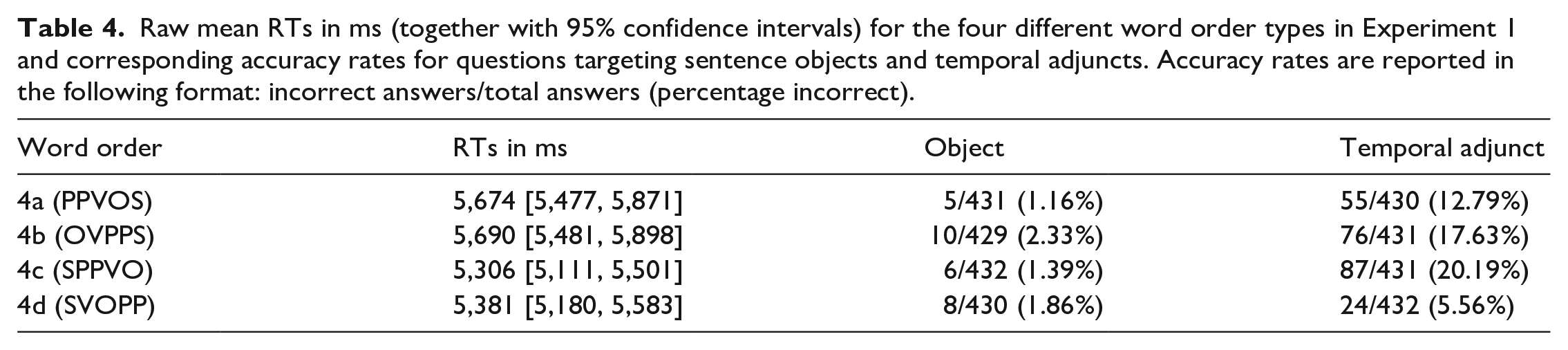
Raw RTs for each condition are presented in Table 4. The linear mixed-effects model (without random slopes due to singularity issues; see Table A1 for the full model in Appendix A) showed a significant effect for Contrast 2 (
Raw mean RTs in ms (together with 95% confidence intervals) for the four different word order types in Experiment 1 and corresponding accuracy rates for questions targeting sentence objects and temporal adjuncts. Accuracy rates are reported in the following format: incorrect answers/total answers (percentage incorrect).
Response accuracy
The overall response accuracy for participants was relatively high. Participants’ mean accuracy was 91.87% (median being 91.67%), the lowest score being 62.5% and the highest score being 100%. The between-item variability was 84.72%–99.3% (median being 91.67%).
The response accuracy for each word order and comprehension question type is reported in Table 4 and it is captured in Figure 1. The linear mixed-effects model (see Table A2 for the full model in Appendix A)
2
yielded two significant effects. First, there was a significant independent effect of question type (β = –3.138, SE = 0.644,
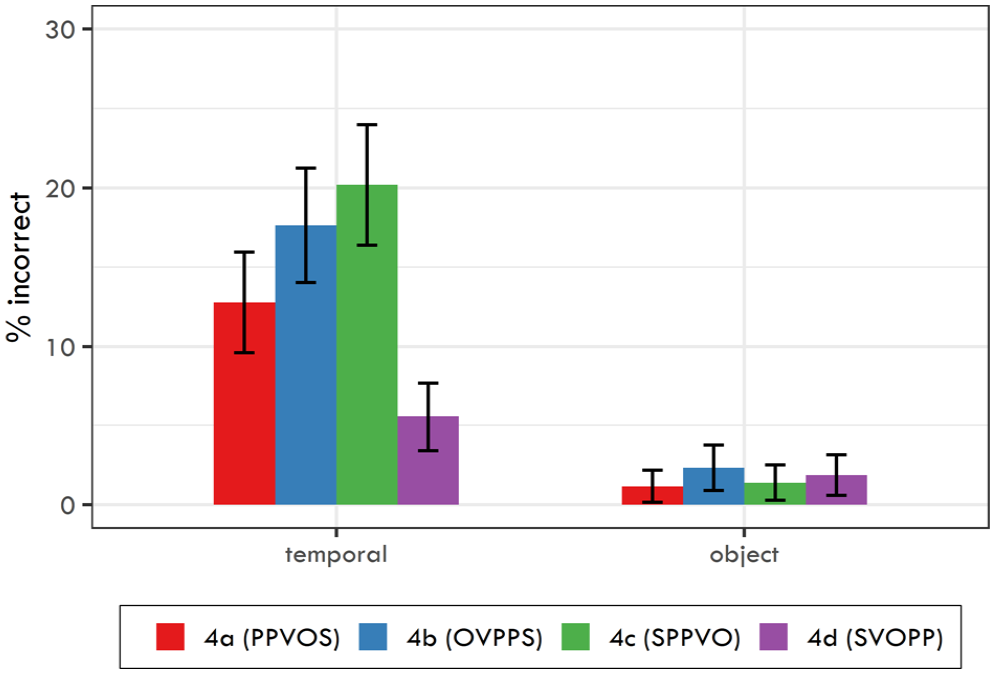
Mean response accuracy together with 95% confidence intervals for the two question types and four word orders used in Experiment 1.
Incorrect responses
The number of incorrect response types for each question is presented in Table 5. We can see that the majority of incorrect answers for both question types was a combination of “I don’t know” answers and “substitutions.” These two incorrect response types account for 93.1% of errors for object questions and 84.3% of errors for temporal adjunct questions.
Number and percentages of incorrect response types for the two question types used in Experiment 1.
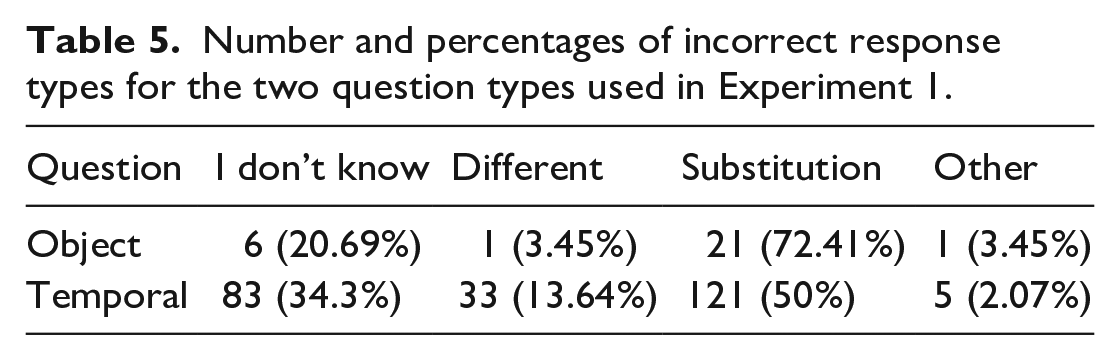
Notably, 13.64% of errors for temporal adjunct questions were answers which seemingly answered a different question (such as answering in the library to the question When did the retiree read the newspaper?).
Discussion
In Experiment 1, we found a clear difference in response accuracy between questions targeting objects and temporal adjuncts. Information conveyed by temporal adjuncts was recalled significantly less accurately than information conveyed by objects. Also, there was an effect of word order on response accuracy for temporal adjunct questions. If the temporal adjunct was focused, it was recalled more accurately than if not. This is in accordance with the previous literature on focus effects in sentence comprehension (cf. Kember et al., 2016; Lowder & Gordon, 2015 etc.). A difference in RTs (i.e., in the time it took the participants to process the whole sentence) was also found. The two marked word orders 4a (PPVOS) and 4b (OVPPS) yielded slower RTs than the basic and frequent word order 4c (SPPVO).
Contrary to the results for temporal adjuncts, we did not find any effect of word order on the response accuracy for object questions. However, this may be attributed to a ceiling effect, since the general response accuracy for object questions was extremely high (around 98%).
The experiment also showed that the majority of incorrect answers was a combination of “I don’t know” answers and “substitutions.” However, 13.64% of incorrect answers for temporal adjunct questions were answers categorised as “different.” These answers were predominantly containing locative adjuncts (i.e., in the library as answers to the question When did the retiree read the newspaper?). One possible interpretation is that it might not be entirely nonsensical to answer a temporal question using a locative adjunct (e.g., When did it happen?—When he was in school.). Another explanation may be that such incorrect answers are a result of misread questions (in Czech, the wh-words for temporal and locative questions are formally very close: kdy “when” and kde “where”). A further possibility is that participants prefer to say something in response, even if they know it is false. This possibility is supported by incorrect answers such as responding to a temporal adjunct question using a subject noun phrase (NP). Importantly, the difference in recall between temporal adjuncts and objects would still be pronounced even if we discounted the “different” type of incorrect answers from the results.
Experiment 2
In the first experiment, we found a clear and robust effect of question type on comprehension accuracy. In other words, objects were recalled significantly more accurately than temporal adjuncts. In Experiment 2, we added a third question type which targeted locative adjuncts. We also simplified the design so that we limited the number of word order values to two. This time, we used only the generally more common word orders in Czech, namely SPPVO (4c) and SVOPP (4d). In the previous experiment, these word orders did not differ in their RTs, but they differed in the recall of temporal adjuncts which is presumably because of the position of this element in the sentence: 4d (SVOPP) has temporal adjuncts (and locative adjuncts) in focused position, whereas 4c (SPPVO) has both adjuncts unfocused, in the preverbal position. Thus, Experiment 2 aimed to replicate the findings of Experiment 1 concerning the recall of temporal adjuncts and simultaneously test whether the same pattern also holds for locative adjuncts.
Our prediction was the same as before considering the recall of information conveyed by objects and temporal adjuncts and also considering the recall of focused elements. Moreover, we expected no systematic difference in recall of information conveyed by temporal adjuncts and locative adjuncts (and also a clear difference between objects and locative adjuncts).
The experiment was preregistered on the Open Science Framework: https://osf.io/36n2a and the data are accessible here: https://osf.io/zb7r8/
Method
Participants
A total of 149 undergraduate students of Charles University (104 women, 45 men, Mage = 26.32 years) participated in the experiment for course credit. All were native speakers of Czech and none of them participated in Experiment 1.
Materials
Essentially, the same set of 24 items as in Experiment 1 were used in Experiment 2 (see https://osf.io/zcrfp/ for the full list with English translation). However, only two word order values were used, namely 4c (SPPVO) and 4d (SVOPP) (for example, see Table 1). In 4c (SPPVO), the object was focused, whereas in 4d (SVOPP), temporal and locative adjuncts were focused. In addition to the two question type values used in Experiment 1 (i.e., object-targeting question and temporal adjunct targeting question, see Table 2), a question targeting locative adjunct was included (see Table 6). In sum, Experiment 2 had a
An additional comprehension question used in Experiment 2 which targeted the locative adjunct.

The same set of 96 filler items and three practice items were used as in Experiment 1. In sum, participants read 123 sentences.
Procedure
The experiment was conducted online using IbexFarm 0.3.9 (http://spellout.net/ibexfarm/) and the procedure was identical to Experiment 1.
Data coding
The same coding procedure was used as in Experiment 1.
Data analysis
Data analysis followed the same four steps as in Experiment 1. Clearly discontinuous RTs (i.e., lower than 1,300 ms and higher than 40,000 ms) were trimmed, which represented 1.33% of the data. The Box–Cox test (Box & Cox, 1964) yielded
The mean response accuracy for filler items was 95.85%. No participant scored under 80% and thus, no one was excluded based on this criterion.
RT differences were again analysed using linear mixed-effects models (Bates et al., 2014) with word order as fixed effect (using treatment contrasts with 4c (SPPVO) being coded as a baseline) and participant and item as random effects.
Response accuracy was analysed using logit mixed-effect models (Jaeger, 2008) with question type as a fixed effect, word order as a nested effect within question type, and participant and item as random effects (with question type as a random slope for items and word order as a random slope for participants). 3
Word order was coded the same way as for the RT analysis. Question type was coded using Helmert contrasts (Schad et al., 2020) and the contrast matrix is shown in Table 7. Contrast 1 contrasted the temporal adjunct and locative adjunct questions, and Contrast 2 contrasted the mean for temporal and locative adjunct questions to direct object questions.
Helmert contrasts matrix for the question type variable used in the response accuracy analysis in Experiment 2).

Results
RTs
Raw RTs for each condition are presented in Table 8. The linear mixed-effects model (containing word order as a random slope for participants and no random slope for items; see Table B1 in Appendix B for the full model) did not show any significant effects. Thus, no difference in RTs between word orders 4c (SPPVO) and 4d (SVOPP) was found.
Raw mean RTs (together with 95% confidence intervals) and accuracy rates for the two different word order types in Experiment 2. Accuracy rates are reported in the following format: incorrect answers/total answers (percentage incorrect).

Response accuracy
As in Experiment 1, the overall response accuracy for participants was relatively high. Participants’ mean accuracy was 91.58% (median being 95.83%), the lowest score being 66.67% and the highest score being 100%. The between-item variability was 85.23%–97.99% (median being 92.28%).
The response accuracy for each word order and comprehension question type is reported in Table 8 and it is visualised in Figure 2. The logit mixed-effects model (see full model in Table B2 in Appendix B) yielded two significant effects for the question type: (a) temporal adjunct questions yielded higher rate of incorrect answers than locative adjunct questions (β = 0.786, SE = 0.244,
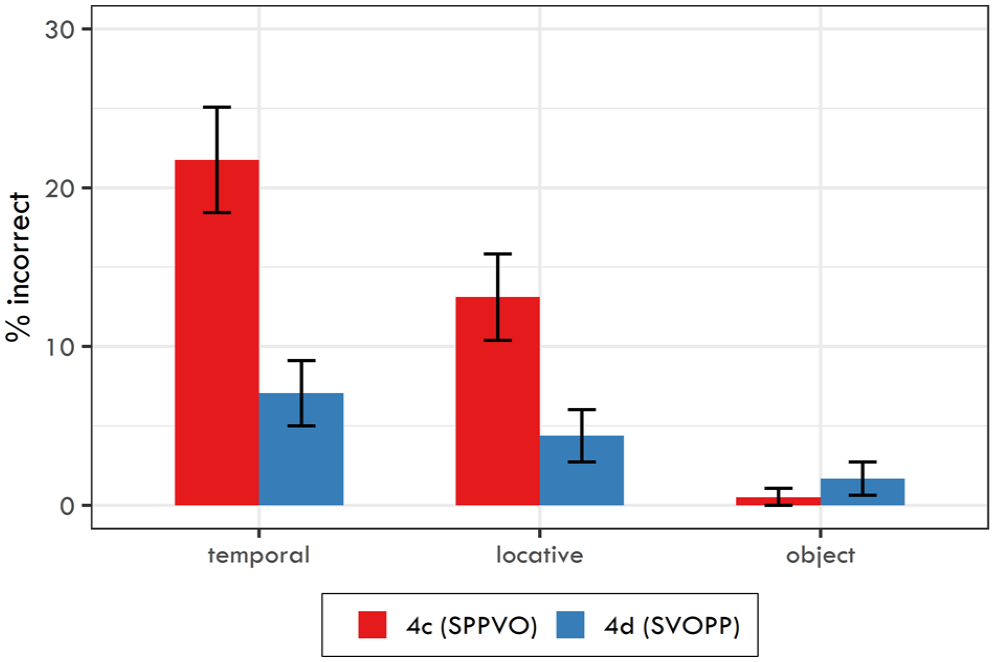
Mean response accuracy for three question types and two word orders used in Experiment 2. Error bars denote 95% confidence intervals.
For temporal adjunct questions, the findings of Experiment 1 were fully replicated. Moreover, the same pattern of results was established also for locative adjunct questions.
Incorrect responses
The number of incorrect response types for each question is presented in Table 9. Again, the majority of incorrect answers for all three question types was a combination of “I don’t know” answers and “substitutions.” These two incorrect response types account for 84.62% of errors for object questions, 73.69% of errors for temporal adjunct questions, and 88.46% of errors for locative adjunct questions.
Number and percentages of incorrect response types for the two question types used in Experiment 2.
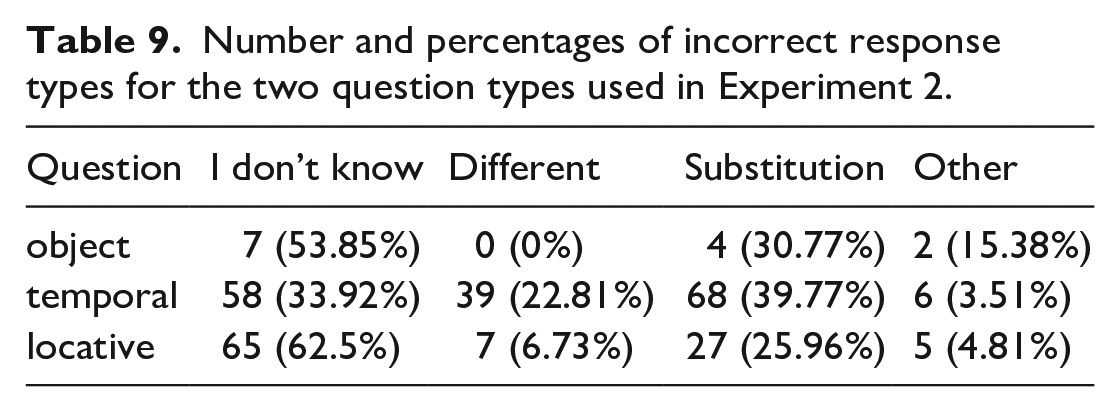
The number of “different” type of incorrect questions was again relatively high for temporal adjunct questions (22.81%). Interestingly, for locative adjunct questions, it was almost negligible (6.73%).
Discussion
Experiment 2 replicated the previous findings of Experiment 1 concerning the difference in recall between information conveyed by objects and temporal adjuncts. Moreover, we found that questions targeting locative adjuncts also had significantly lower response accuracy than object questions. This might be interpreted as an effect of core versus additional information. Objects present core information which is crucial for understanding and for the creation of a situation model (one can say that without them, a transitive sentence does not make sense). On the contrary, adjuncts present additional information, possibly of less importance for accurate sentence comprehension.
We also found that the response accuracy was influenced by the position of the given sentence constituent. For both adjunct types and direct objects, we found an effect of focus position on recall: if the adjunct or object was at the end of the sentence (and thus was focused), it was recalled more accurately than if it was prior to the verb (unfocused position). This can be well explained by the idea of superficial processing of given information which contrasts with more effortful processing of new information (Ferreira & Lowder, 2016).
Contrary to our third hypothesis which expected no difference in recall of the two types of adjuncts, we found that the locative adjuncts were recalled significantly better than temporal adjuncts. This is surprising, because their syntactic status is similar (both are fully optional preposition phrases). There are four possible explanations. First, it may be so that locative adjuncts we used were more imageable than temporal adjuncts and thus are more easily integrated into the situation model. Unfortunately, we did not control for imageability in our experiments. But intuitively, the locative adjuncts used described highly imageable locations such as a library, a classroom, a museum, a market, and so on, whereas our temporal adjuncts were formed mostly using days of the week and months, that is, less imageable words. Second, interference effects might be stronger for our temporal adjuncts than for our locative adjuncts: days of the week and months are both closed categories with few members and they probably compete for activation more than various locations. Third, the locative adjuncts used might be predictable (at least in some sentences) and hence better recalled. In other words, if we would ask a question like Where did Sue buy the vegetables?, there is only a limited set of likely answers (at the market, in the shop/supermarket, perhaps at the farm) if the answer should not be too specific. Thus, it might be possible to answer the locative adjunct questions correctly even if the sentence was processed in a rather shallow fashion. However, there is one more possible explanation for the difference. It might be possible that question wording plays an important role. To clearly distinguish the locative and temporal questions throughout the experiment, we used a rather marked question wording for locative adjunct questions. Instead of asking using a simple wh-word kde (“where”), we used specific construction na jakém místě (“at/in which place”). Perhaps, the specificity of such locative question was the reason for higher rate of correct answers for locative information. Such a possibility is examined in Experiments 3 and 4 and we will return to these issues in the section General discussion.
As in the previous experiment, we found a relatively high rate of “different” type of incorrect questions in Experiment 2. These types of answers were used predominantly for temporal adjunct questions.
Experiment 3
In prior experiments, we observed that direct objects were generally recalled better than temporal and locative references. At the same time, we found that locative references were recalled to a better extent than temporal references. However, these findings may be explicable by a possible confound. In the first two experiments, a question wording has been used which reproduced certain information from the previously read sentence. For example, questions targeting direct objects were formed using the identical verbs and subjects as the previously read sentence. In other words, these questions contained certain cues which could have helped the participants to answer correctly. These cues could have either served as memory cues which partially reactivated the sentence content and thus helped participants to recall the rest of the sentence, or as cues which would delimit the set of possible answers based on participants’ real-world knowledge. For example, certain events can plausibly happen only in a relatively constrained set of locations, but almost any time. Thus, locative questions such as Where did the cook burn the chicken? may yield a lower rate of incorrect responses than temporal adjunct questions such as When did the cook burn the chicken? just because the set of plausible answers is smaller for the locative question.
Importantly, the cues differed between the conditions. Temporal adjunct questions comprised not only the same verb and subject as the previously read sentence, but also the object. And the locative adjunct questions were formed using a more specific type of question beginning (Na jakém místě, literaly meaning “At/in which place,” instead of a general Kde, literally “Where”), whose function was to differentiate it better from the temporal adjunct questions. The aim of the Experiment 3 thus was to test whether we could replicate the previous findings using general, cue-less question wordings such as What happened?, When did it happen?, Where did it happen?.
Our predictions stemmed from the previous findings. We predicted that the information conveyed by objects will be recalled better than information conveyed by adjuncts (both temporal and locative). We also expected the information conveyed by locative adjuncts to be recalled better than information conveyed by temporal adjuncts. And finally, we predicted that the sentence-final position of an information (i.e., focused position) will yield a higher recall success rate.
The experiment was preregistered on the Open Science Framework: https://osf.io/2tzv5 and the data are available there too: https://osf.io/zb7r8/
Method
Participants
A total of 169 participants (148 women, 21 men, Mage = 22.36 years) were recruited from the participants pool of the pregraduate students of Charles University. All students participated for course credit, all were native speakers of Czech, and none had participated in the previous experiments.
Materials
We used the same set of 24 experimental items as in Experiment 2. This time, however, different question wordings were used. Examples of comprehension questions used in Experiment 3 are presented in Table 10 and the full set of experimental items is available here: https://osf.io/96vk7/. The experiment had a 2 ×3 within-subject design, meaning that each participant received four examples of each condition. Together with the set of 96 filler items (also identical to Experiment 2) and 3 practice items, the participants read 123 sentences in Experiment 3.
Example of comprehension questions used in Experiment 3. They targeted either recall of sentence object (6a), temporal adjunct (6b) or locative adjunct (6c).

Procedure
The experiment was conducted online using PC Ibex Farm platform (https://farm.pcibex.net/; Zehr & Schwarz, 2018) and the procedure was identical to Experiments 1 and 2.
Data coding
The identical coding procedure was used as in the three previous experiments. However, an additional specification needed to be done for the What happened? questions, which in principle targeted not only the object, but also the subject and predicate. As a correct response for this question, we accepted not only full responses containing the subject, the verb, and the object, but also occasional partial responses not containing the subject. One of the reasons for this was that Czech as a pro-drop language enables the speakers not to mention the sentence subject under certain circumstances.
Data analysis
Data analysis followed the same four steps as in previous experiments. Clearly discontinuous RTs (i.e., lower than 1,000 ms and higher than 49,000 ms) were first removed (altogether 0.927% of the data). The Box–Cox test (Box & Cox, 1964) yielded
The average response accuracy for filler items was 94.86%. All participants scored above 75% correct answers for fillers and so, no one was excluded based on this criterion.
RT differences were again analysed using linear mixed-effect models (Bates et al., 2014) with word order as fixed effect (using treatment contrasts with 4c (SPPVO) as a baseline) and participant and item as random effects (both with word order as random slope).
Response accuracy was again analysed using logit mixed-effect models (Jaeger, 2008) with question type as a fixed effect with word order as a nested effect within question type and participant and item as random effects (with question type as a random slope both for items and for participants). 4
Word order was coded the same way as for the RT analysis. Question type was coded using Helmert contrasts (Schad et al., 2020), identically as in Experiment 2: Contrast 1 contrasted the temporal adjunct and locative adjunct questions, and Contrast 2 contrasted the mean for temporal and locative adjunct questions to direct object questions.
Results
RTs
Raw RTs for each condition are presented in Table 11. The linear mixed-effects model with word order as a random slope for both participants and for items did not show any significant effects (see the full model specification in Table C1 in Appendix C). Thus, no difference in RTs between word orders 4c (SPPVO) and 4d (SVOPP) was found (as in the previous experiments).
Raw mean RTs (together with 95% confidence intervals) and accuracy rates for the two different word order types in Experiment 3. Accuracy rates are reported in the following format: incorrect answers/total answers (percentage incorrect).

Response accuracy
The overall response accuracy for participants was again very high (M = 91.12%, median = 91.67%, min = 66.67%, max = 100%). The between-item variability was 81.07% to 97.63% (median = 91.42%).
The response accuracy for each word order and comprehension question type is reported in Table 11 and it is visualised in Figure 3. The logit mixed-effects model (for full model see Table C2 in Appendix C) yielded several significant effects: (a) direct object questions had a lower rate of incorrect answers than was the average for temporal and locative adjunct questions (β = –4.747, SE =0.894,
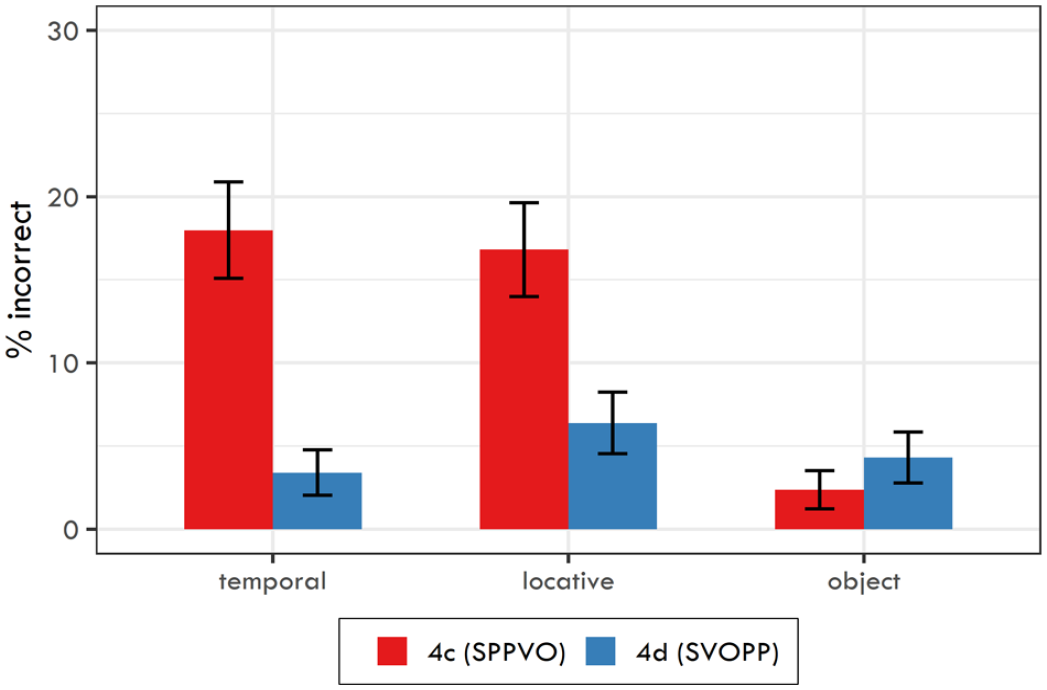
Mean response accuracy for three question types and two word orders used in Experiment 3. Error bars denote 95% confidence intervals.
Thus, the same trend for the difference between the response accuracy was found for each question type as in Experiment 2 (the accuracy rate was higher if the targeted information was focused, i.e., at the end of the sentence). However, this time, we failed to document a lower response accuracy for temporal adjuncts than for locative adjuncts (in contrast to Experiment 2).
Incorrect responses
Table 12 shows the number of incorrect response types for each question type in Experiment 3. This time, the pattern of results was partially different. Similarly to Experiments 1 and 2, the majority of incorrect answers for direct object and temporal adjunct questions was a combination of “I don’t know” answers and “substitutions.” For object questions, these two response types account for 68.89% of errors and for temporal questions, it is even 88.88%. However, there is a striking difference in the distribution of incorrect error types for locative questions. For this question type, “I don’t know” answers and “substitutions” account only for 35.9% of cases (compared with 88.46% of errors in Experiment 2). This time, the majority of incorrect answers for locative questions were of the “different” type (64.1% compared with only 6.73% of cases in Experiment 2). This means that the participants often responded locative questions using an answer to a seemingly different question type. To illustrate this on an example, the question Kde se to stalo? (“Where did it happen?”) following the sentence Nešikovný stážista v pondělí v jídelně zcela nezáměrně převrhl hrnek. (“A clumsy intern overturned a cup completely unintentionally on Monday in the dining room.”) yielded these “different” answers: v pondělí (“on Monday,” 2
Number and percentages of incorrect response types for the two question types used in Experiment 3.

Discussion
In general, the pattern of results found in Experiment 3 replicated the main findings of the previous two experiments: First, the rate of incorrect answers was significantly higher for the temporal and locative adjunct questions than for the direct object questions. Second, a clear tendency to recall the focused (i.e., sentence-final) information better has been shown for all three question types.
However, we failed to find a difference in recall accuracy for locative and temporal questions in this experiment. This is interesting, because in Experiment 2, temporal questions yielded significantly more errors than locative questions. From the analysis of incorrect response types, it seems that using general, cue-less question wording led to a higher rate of incorrect answers for locative questions than in Experiment 2, but merely because of the much higher rate of “different” type errors (64.1% compared with 6.73% in Experiment 2). If we would consider only the “I don’t know” answers and “substitutions,” temporal questions would have a much higher response inaccuracy (i.e., 128 errors for temporal questions vs. 56 errors for locative questions). The large number of the errors of “different” type for locative questions was unexpected.
The first possibility would be that the participants misread the question (the temporal and locative questions differed only in the wh-word whose form is very similar: kde for where and kdy for when). If this would be the case, however, one should expect the similar pattern also for the temporal adjunct questions and these yielded clearly lower rate of such incorrect answers (only 16 cases compared with 100 for locative questions). Thus, this does not seem to explain the pattern.
The second possibility would be that the participants did not know the answer to the locative question and they at least presented some other part of sentence information to show they really read the sentence.
As one of the anonymous reviewers pointed out, the question What happened? (which we considered as a question targeting the object information) in fact targeted not only the object, but also the subject and the verb. Therefore, it cannot be straightforwardly related to the object-targeting question used in Experiments 1 and 2. However, as we can see, the overall response accuracy was very high for this broad question (97.63% or 95.69%, respectively), which in turn suggests a similarly good object information recall as documented in the previous experiments and a very high recall of verbal information too. Importantly, we have to say that we did not encounter any error which would consist of incorrectly presented verb and correctly presented object or that only the object would be used in the response. This suggests that the response inaccuracy for the what-question should not be elevated due to the inability to recall other information than the object in the data presented here.
Experiment 4
The first three experiments showed a systematic tendency to recall the information conveyed by adjuncts worse than the information conveyed by direct objects. Also, a clear tendency was found that if the targeted information stands in the focused position (i.e., at the end of the sentence), it is recalled better than if it stands in a non-focused position (in the middle of the sentence). The latter finding seems to be very reliable and clear, however, it may be argued that the high success rate in recalling the information which stands at the end of the sentence is in fact not due to the fact that the information is focused, but due to information recency. In the memory literature, such as in the studies on word list recall (e.g., Greene, 1986), it has been demonstrated that the recent information is recalled to a much better extent than information presented before. As the sentences in the present experiments were common, unambiguous and syntactically uncomplicated, we might assume that the most recent information the participants extract while reading would be the sentence-final information. Thus, another experiment was conducted which aimed to distinguish the possible recency effect from the focalization effect.
In Experiment 4, we contrasted the recall of locative and temporal information after it—cleft sentences with the previously examined word orders 4c (SPPVO), which focused the object and 4d (SVOPP) which focused the adjuncts. The it-cleft sentence put the temporal or locative information in focus without positioning it to the sentence-final position. If the previous effects were due to focused position, we should expect the same findings for cleft positions as for the sentence-final positions. However, if the recency accounted for these effects, the cleft structures should yield higher rate of incorrect answers than the SVOPP word order. Our prediction was twofold: (a) temporal and locative information will be recalled to a higher extent in sentence-final (focused) position (SVOPP) than in a non-focused (sentence-medial) position (SPPVO), (b) temporal and locative information will be recalled to the same extent if used in a sentence-final position as if used in a cleft sentence.
We used the same cue-less questions as in Experiment 3. But since we used more sentence types in this experiment, we omitted the direct object questions to reasonably limit the number of conditions per item.
The experiment was preregistered on the Open Science Framework: https://osf.io/wn4uc and the data are available there too: https://osf.io/zb7r8/5
Method
Participants
A total of 239 participants were recruited from the participants pool of the pregraduate students of Charles University. All students participated for course credit, all were native speakers of Czech and none participated in the previous experiments. Two participants were excluded because of their low response accuracy for filler items (i.e., less than 75% correct answers). The resulting sample thus contained 237 participants (197 women, 38 men, 2 unspecified, Mage = 21.65 years).
Materials
As for the experimental sentences, we used again sentences 4c (SPPVO) and 4d (SVOPP) as in previous experiments (see Table 1), but this time, we included two more sentence conditions using temporal and locative clefts (see Table 13). We used comprehension questions targeting temporal (6b) and locative adjuncts (6c) as in Experiment 3 (see Table 10).
Example of two additional sentence types from Experiment 4. Temporal adjuncts (v neděli, “on Sunday”) and locative adjuncts (v knihovně, “in the library”) are underlined. Example 4e represents a temporal-cleft sentence type, whereas Example 4f represents a locative-cleft type.

The full set of experimental stimuli is available here: https://osf.io/a5efx. The experiment had a 4 × 2 within-subject design meaning that each participant received three examples of each condition. The same set of filler items was used as in Experiments 2 and 3. Altogether, participants again read 123 sentences in Experiments 2 and 3.
Procedure
The experiment was conducted online using PC Ibex Farm platform (https://farm.pcibex.net/; Zehr & Schwarz, 2018) and the procedure was identical to all three previous experiments.
Data coding
The identical coding procedure was used as in the previous experiments.
Data analysis
Data analysis followed the same four steps as in previous experiments. Clearly discontinuous RTs (i.e., lower than 1,000 ms and higher than 54,000 ms) were first removed (altogether 0.8% of the data). The Box–Cox test (Box & Cox, 1964) yielded
The average response accuracy for filler items was 94.88% (already not counting the two participants excluded due to lower than 75% response accuracy for fillers).
RT differences were again analysed using linear mixed-effect models (Bates et al., 2014) with word order as fixed effect and participant and item as random effects (with word order as random slope for items). Word order was coded using repeated contrasts and the contrast matrix is shown in Table 14. Contrast 1 contrasted the most common words orders 4c (SPPVO) and 4d (SVOPP), Contrast 2 contrasted word order 4c (SPPVO) with the temporal cleft sentence, and Contrast 3 targeted the difference between the locative-cleft and the temporal-cleft sentences.
Repeated contrasts matrix for the word order variable used in the RTs analysis in Experiment 4).

In the response accuracy analysis, we used a logit mixed-effects model (Jaeger, 2008) with question type as a fixed effect, adjunct position as a nested effect within question type, and participant and item as random effects (with question type as random slope for both). 6 Importantly, we used different contrast coding than in the RTs analysis. As we aimed to test the difference in recall success between the SVOPP sentences and (a) the SPPVO sentences on one hand, and (b) locative- or temporal-cleft sentences on the other hand, we used treatment coding with SVOPP sentence type as the reference value. Question type was also treatment coded (with locative adjunct question as a baseline). The same way to determine the random effect structure was used as for RTs analysis.
Results
RTs
Raw RTs for each condition are presented in Table 15. The linear mixed-effects model with word order random slope for participants yielded several significant effects (see the full model specification in Table D1 in Appendix D): RTs for temporal cleft sentences were slower than for SPPVO sentences (β = 1.028, SE =0.096,
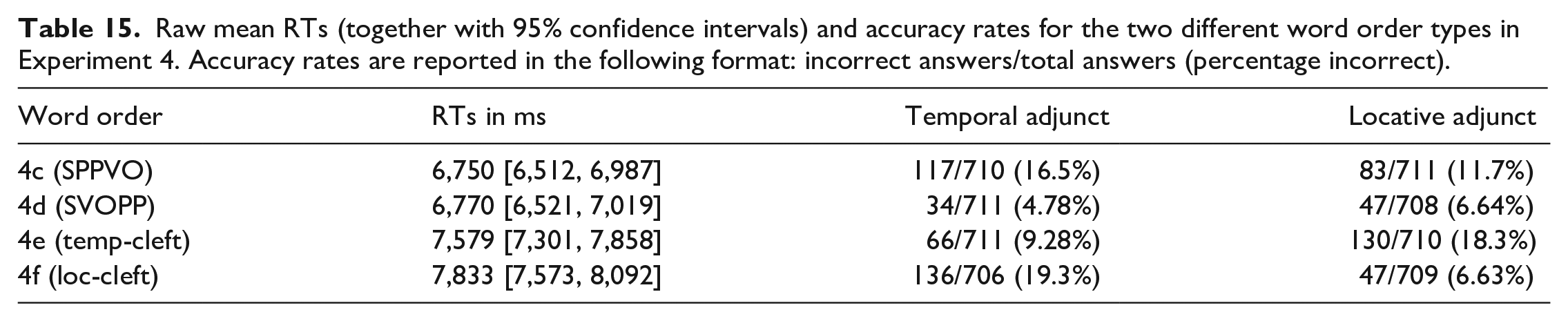
Raw mean RTs (together with 95% confidence intervals) and accuracy rates for the two different word order types in Experiment 4. Accuracy rates are reported in the following format: incorrect answers/total answers (percentage incorrect).
Response accuracy
The overall response accuracy for participants was again very high (M = 88.19%, median = 91.67%, min = 16.67%, max = 100%). The between-item variability was 76.79% to 93.67% (median = 89.45%, M = 88.19%).
The response accuracy for each word order and comprehension question type is reported in Table 15 and it is visualised in Figure 4.
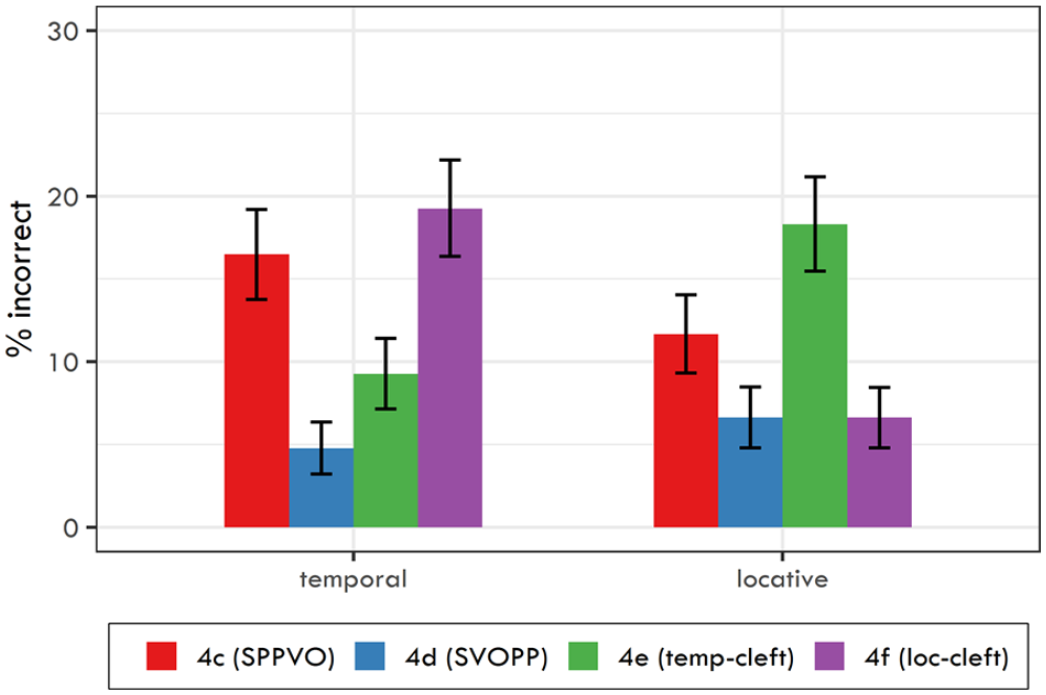
Mean response accuracy for the two question types and four sentence types used in Experiment 4. Error bars denote 95% confidence intervals.
The logit mixed-effects model (see the full specification in Table D2 in Appendix D) yielded several significant effects: (a) for temporal adjunct questions, sentences where the adjuncts were in sentence-final positions (SVOPP) yielded significantly higher response accuracy than for the SPPVO sentences (β = 1.582, SE =0.21,
The results are thus in accordance with our predictions in the sense that we did not see a significant difference between sentence-final and locative-cleft positions for locative adjuncts. However, we documented a difference between the sentence-final and temporal-cleft positions for temporal adjuncts. Therefore, we did a post hoc analysis to see whether the recall for cleft structures differed from the recall for sentence-medial positions. This was done using a similar model which differed only in the reference value for the sentence type variable—this time, sentence-medial position was used as a baseline.
This post hoc model (see Table D3 in Appendix D for a full specification) yielded several significant effects: (a) locative questions had a higher response accuracy than the temporal ones (
To sum up both models, it seems that the cleft position enhances later recallability of the given pieces of information. For the locative questions, we failed to find any difference between sentences when the locative adjunct stood at the sentence end and when the locative adjunct was in the cleft position and we documented a clear difference between the cleft position and sentence medial position. For the temporal questions, it seems that the temporal-cleft information is recalled worse than if this information is focused at the sentence end, but at the same time better than if it is not focused at all.
Interestingly, our analyses documented a rather unexpected difference, namely that the locative adjuncts were recalled worse after temporal-cleft sentences.
Incorrect responses
Table 16 shows the number of incorrect response types for each question type in Experiment 4. As in the three previous experiments, the errors made in answering the temporal adjunct questions are mostly either “I don’t know” answers or “substitutions” (these two error types cover 84.71% of all errors). On the contrary, the majority of incorrect answers to the locative adjunct questions were of the “different” type (52.12%). Thus, an identical pattern can be seen as in Experiment 3, which also employed the cue-less, general questions.
Number and percentages of incorrect response types for the two question types used in Experiment 4.

Discussion
Experiment 4 replicated previous findings that the sentence-final position yields higher recall accuracy than the sentence-medial position for both types of adjuncts. Nevertheless, the main aim of Experiment 4 was to disentangle the unclear difference between recency and focalization effects. It-cleft structures were used to distinguish focused information from information standing at the end of the sentence. For locative adjuncts, the findings were well in accordance with the hypotheses: recall of information standing in the cleft position did not seem to differ from recall of information in the sentence-final position (but both were clearly better than recall of information in the sentence-medial position). For temporal adjuncts, however, the pattern was partially different: for the cleft position, recall was significantly worse than for the sentence-final position, but still significantly better than for the sentence-medial position. Thus, we may argue that the better recall for sentence-final information repeatedly documented in the previous experiments can be explained by recency effects only in part. We do not observe any sings of recency effect for the locative adjuncts. For temporal adjuncts, we may speculate about a possible recency effect. However, the rate of incorrect answers for focused information (i.e., for the cleft position) was still significantly higher than for the non-focused information (i.e., for the sentence-medial position). Thus, the findings of Experiment 4 show that focalization plays its role independently of recency.
The analysis of incorrect answer types found the same pattern of results as in Experiment 3 which employed the same question wordings. This time, however, temporal adjunct questions had a significantly higher rate of incorrect answers than locative adjuncts questions (which is in accordance with the findings of Experiment 2).
General discussion
The aim of this article was to test immediate recall of information after reading a sentence. The main research question was whether there is a difference in recall of core information (conveyed by direct objects) and additional/optional information (conveyed by temporal and/or locative adjuncts). For these purposes, we used open-ended questions following sentences which were visually presented. In Experiment 1, we examined differences in recall between object and temporal adjunct questions and the role of information structure. Experiment 2 also manipulated word order and included locative adjunct questions. Experiment 3 aimed to replicate the results of Experiment 2 using cue-less wording of comprehension questions. And the goal of Experiment 4 was to contrast the effects of information recency and linguistic focus in the recall of temporal and locative adjuncts.
Our findings clearly show that not all pieces of information in a sentence are recalled as easily as each other, when tested immediately after reading a sentence: optional/additional sentence information (conveyed by adjuncts) is recalled less accurately than core information (conveyed by direct objects). Moreover, we found that if the information was focused, recall was facilitated. The differences are striking, especially since the sentences we used were unambiguous, semantically plausible and syntactically simple transitive sentences.
In general, the results presented in this article may be explained by selective attention mechanisms. We argue that during sentence processing, different pieces of information are being attended with varying degrees (and some may be even completely unattended to). In turn, not all pieces of information conveyed in a sentence may be consciously processed (Dehaene et al., 2006) and those which are not, are later not consciously accessible, that is, they are not able to be recalled with relative ease. We argue that attention is driven by factors such as syntactic function and information structure (see also previous studies on focus, i.e., Birch & Garnsey, 1995; Lowder & Gordon, 2015, etc.). Based on our findings, it seems that information coded in adjuncts (and unfocused information) is attended to a lower degree and it therefore often fails to reach readers’ awareness. Nevertheless, it is highly likely that other factors are at play here, such as information predictability (Haeuser & Kray, 2021), a speaker’s experience (Zwaan & Madden, 2005), context (Bransford et al., 1972), imageability (James, 1972), and so on. However, a thorough examination of such factors is already beyond the scope of this article.
The idea of selective attention in language processing has not received much attention, but it is not new. In the field of language education, Gillian Brown (2008) argued that listeners often pay attention only to certain parts of the message and they tend to skim over or ignore other pieces of information (especially when the information load is high). Specifically, she argues that listeners tend to selectively attend more to nouns than to other parts of speech. Moreover, selective attention has also been proposed for explaining learnability of important versus unimportant information from a text (Reynolds, 1992). Crucially, selective attention is a well-studied phenomenon in other cognitive domains, such as in the field of visual processing (e.g., Jensen et al., 2011; Mack, 2003; Neisser, 1979; Simons & Ambinder, 2005, etc.).
As one of the anonymous reviewers pointed out, such an explanation does not directly stem from our results, because it assumes certain online processing mechanisms (i.e., selective attention) and in the present study, we are not testing online processing, but offline recall instead. In principle, we think such a critique has its merit and while interpreting our results, one has to take into account the fact that they are based on recall. However, we firmly believe offline measures may offer important insights into online processing mechanisms and especially sentence comprehension since they target the result of such mechanisms in a way online measures cannot (for a thorough discussion of the advantages of offline measures, see Ferreira & Yang, 2019). This may be illustrated by the fact that various well-known findings in the field of sentence processing which have important implications for online processing mechanisms have been based primarily on offline measures, for example, the lingering misanalysis phenomenon (cf. Christianson et al., 2001), Moses illusion (cf. Erickson & Mattson, 1981), or the inability to correctly comprehend depth-charge sentences (e.g., Wason & Reich, 1979).
When testing recall in experimental designs we acknowledge that our results may not necessarily reflect the attentional differences in encoding, but rather memory processes, that is, decay of information in memory (Baddeley, 2000; Wagers & Phillips, 2014). This cannot be excluded completely, but there are several reasons why this argument may not be entirely valid. First, we believe that possible memory decay and the idea of selective attention do not go against each other, but rather go hand in hand. Even if we would think memory decay would influence the presented results, we would need to explain why the information conveyed by adjuncts decays to a much larger extent than the information conveyed by objects. The only likely reasonable explanation would be that these pieces of information were not attended to a similar degree during processing and that their degree of activation has thus differed from the start. Second, we were testing immediate recall of information conveyed by very simple, unambiguous sentences containing 10 words (including two prepositions). It is even relatively easy to repeat such sentences verbatim immediately after hearing them (Baddeley et al., 2009). Third, it has been shown elsewhere that decay effects are actually very small with a mere passage of time, and that the crucial factor causing forgetting is not decay, but interference (Berman et al., 2009). In the experiments presented here, however, no interference should be expected (e.g., there was no intervening temporal adjunct between the targeted temporal adjunct and the question). In sum, we believe there are good reasons not to think solely that memory decay could explain our results.
Another alternative interpretation of our results may lie in the way the conceptual representation of the sentence is formed. It is well documented that during immediate sentence recall, speakers regenerate the sentence from a conceptual representation using recently activated words (cf. Lombardi & Potter, 1992; Potter & Lombardi, 1990). Thus, readers or listeners do not store sentences in a verbatim fashion, but they rather form a conceptual representation, which is partly based on the information communicated by the sentence and partly on the prior contextual knowledge (Bransford et al., 1972). The differences in recall of various pieces of information may thus stem from differences in their integration into the resulting representation, which may be conceptualised as a situation model (Zwaan, 2016; Zwaan & Radvansky, 1998). From this perspective, we might, for example, predict that information conveyed by objects should be recalled better than information conveyed by temporal adjuncts because it is a more dominant part of the situation model and it is represented not only on a causal dimension, but also on temporal or locative dimensions (cf. Zwaan & Radvansky, 1998). Such an interpretation makes intuitive sense, however, it cannot account for the clear differences between focused and unfocused information. Our results demonstrate that if the locative or temporal information is focused, it is recalled significantly better than when it is unfocused. Crucially, the information as such does not change if being focused, the situation model for semantically identical sentences with different information structure should thus not differ. Thus, we believe that such a “reconstructive” explanation does not account for our results fully. In addition, it does not per se contradict the idea of selective attention in processing. It may well be that the degree of integration of certain pieces of information in the situation model differs, but on the contrary, what information actually enters the situation model should be driven by the mechanisms of selective attention which, in turn, is driven by factors such as linguistic focus.
The ability of speakers to consciously recall specific pieces of information, which are conveyed by a sentence was the focal point for this article. However, the inability to consciously recall certain pieces of information does not necessarily mean that such information was not processed at all. It may be part of the conceptual representation of the sentence, but only consciously inaccessible. For example, we may assume that such information may enable priming (as has been shown for consciously inaccessible information in visual processing, e.g., Mack, 2003).
The idea of selective attention during sentence processing may be related to the time spent processing various types of information (e.g., RTs during self-paced reading or fixation times in eye-tracking). We might predict that the more time a reader spends with processing a certain piece of information, the better it will be encoded in the resulting representation. Unfortunately, the experiments reported here were not designed to test this (we employed a whole-sentence-at-once presentation to enable unconstrained reading processes). Nevertheless, such an idea is aligned with findings reported in the previous literature. For example, Haeuser and Kray (2021) recently documented a clear relationship between RTs during processing (in a self-paced reading paradigm) and recognition memory (the longer the RTs, the better the subsequent recognition of the word).
Besides the general evidence for selective attention in sentence processing, there are several partial findings which should be discussed in more detail. First, an obvious argument against the effects of focus in the first three experiments is the possible role of information recency. It might be argued that since the focused information in these experiments stands at the sentence end and these sentences are simple and unambiguous (and readers thus do not need to resort to regressions), the focused information is actually the most recently extracted. Previous studies on recall of word lists (cf. Greene, 1986) have shown that the most recent words tend to be recalled the best. Information recency is thus a serious possible confound for the findings on the role of focus in the first three experiments. Therefore, we aimed to distinguish the effects of information recency and the effects of linguistic focus in Experiment 4, which contrasted cleft constructions (where the focused information stood at the end of the first clause such as Bylo to
Another issue which deserves discussion is the effect of question wording. The first two experiments employed questions which gave participants various cues for their answer. More precisely, the comprehension questions used contained certain bits of information from the targeted sentence. Questions which targeted direct objects always repeated the verb and the subject of the sentence (such as Co pročetl důchodce? “What did the retiree read?”). Questions targeting temporal adjuncts repeated not only the verb and subject, but also the direct object (e.g., Kdy pročetl důchodce noviny? “When did the retiree read the newspaper?”). And questions targeting locative adjuncts were similar to temporal adjunct questions, but they used a rather marked construction Na jakém místě . . . (“At/in which place . . .”) instead of basic Kde (“Where”). One might argue that the nature of these cues could influence recall and that the difference in the given cues could cause the differences in recall rates between the question types. One possibility is that these cues may reactivate the sentence content, which would help the participants to recall the rest of the sentence. Another possibility is that the participants would use such cues to delimit the set of possible answers based on their real-world knowledge. The presence of cues in comprehension questions is a potentially serious confound which we aimed to examine in Experiments 3 and 4. These experiments employed very general, cue-less questions such as Co se stalo? “What happened?,” Kdy se to stalo? “When did it happen?,” and Kde se to stalo? “Where did it happen?” Importantly, this change in question wording did not cause widely differing results. The main effects were still well attested: recall of core information (conveyed by direct objects) was significantly better than recall of additional information (conveyed by temporal and locative adjuncts) and focused information was recalled significantly better than non-focused information.
The only difference related to the different wording of questions lied in the recall of information conveyed by locative adjuncts, more precisely in the pattern of incorrect response types for locative adjunct questions. In Experiment 2, the majority of errors for these questions (88.46%) was a combination of “I don’t know” answers (participants either explicitly stated they did not know the answer, or even claimed that the requested information was not present in the sentence) and “substitutions” (participants answered using a plausible but incorrect phrase, such as in the corridor instead of in the yard). This pattern was identical for temporal adjunct questions in all four experiments (Exp. 1: 84.3%, Exp. 2: 73.69%, Exp. 3: 88.88%, Exp. 4: 84.71%). However, with the cue-less questions, this pattern changed for locative adjunct questions. The majority of incorrect answers was suddenly of the “different” type (i.e., responses which seemingly answered a different question such as on Monday or the intern overturned the cup for Where did it happen?): 64.1% in Experiment 3 and 52.12% in Experiment 4. Such a change in the response pattern is hard to explain. One possibility would be that readers just misread the cue-less questions (especially since the locative question Kde se to stalo? differs only in one letter from the temporal question Kdy se to stalo?). However, such an explanation is rather unconvincing for two reasons. First, if the incorrect answers would be due to question misreading, it should happen equally likely for locative and temporal adjunct questions. However, for temporal adjunct questions such errors are rather infrequent (11.11% in Experiment 3 and 15.01% in Experiment 4). Second, many incorrect responses of the “different” type are not temporal references, but they tend to contain various bits of information from the sentence that are not explicable by misreading (as illustrated in section “Incorrect responses”). Thus, another possibility might be that the readers simply do not know the precise answer and resort to mentioning at least something (however, wrong or irrelevant). However, this is a matter of pure speculation since the present experiments cannot really serve to explain this rather unexpected pattern of results.
In Experiments 2 and 4, temporal adjunct information was recalled to a lesser extent than locative adjunct information. However, we failed to find such differences in Experiment 3. The evidence for a difference between temporal and locative adjuncts is thus rather unreliable. There are many possible reasons for why we would expect recall rates for these two types of information to differ. First, the locative adjuncts used (e.g., in the library, in the museum, in the restaurant, etc.) are intuitively more imageable than the temporal adjuncts (on Monday, in June, etc.). Second, most of the temporal adjuncts used form rather closed categories (days of the week, months) and the members of such categories may interfere during recall, at least to a higher extent than relatively open categories of locative adjuncts (cf. Van Dyke & Johns, 2012). Third, the locative adjuncts used may be predictable, possibly more than the temporal adjuncts. This could play a role especially for questions containing bits of information from the targeted sentence. To illustrate this, consider a sentence A distracted cleaner broke the exhibit on Friday in the museum which we used a Czech equivalent of in our stimuli. If we know that the cleaner broke an exhibit, the locative adjunct in the museum is highly predictable (because exhibits are typically placed in only a few locations, such as museums, galleries, etc.). Presumably, this should help the readers not only to integrate the location information in the conceptual representation, but also to answer a locative adjunct question (such as Where did the cleaner break the exhibit?) correctly. In contrast, knowing that the cleaner broke the exhibit does not cue the reader that a temporal adjunct on Friday will follow and also, it does not help to answer temporal adjunct questions (such as When did the cleaner break the exhibit?). However, the present experiments were not designed to examine these possible effects. Since the evidence for a difference in recall between temporal and locative adjunct questions was rather inconclusive, as such we are not in a strong position to speculate on how these effects may influence the results.
An open question for further research concerns how would pieces of information conveyed by other parts of a sentence be recalled. For example, would direct and indirect objects be recalled similarly or differently? Or to consider the role of attributive information? Also, it would be interesting to examine whether adjunct typicality for the given verb would play a role.
The results of this article support Ferreira and Yang’s (2019) argument that we should employ not only online processing measures (such as RTs) in the study of sentence comprehension. The finding that there are systematic differences in recall success for different pieces of information even in simple, unambiguous sentences such as An older retiree read the newspaper very carefully in the library points out that the mechanisms of processing linguistic input may be systematically selective. As a result, readers or listeners may form a conceptual representation with different levels of acuity—certain aspects of the representation may be very clear and sharp, others relatively blurry, and some even not visible at all. This then influences the ability to recall the pieces of information presented by the sentence.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218231159190 – Supplemental material for When and where did it happen? Systematic differences in recall of core and optional sentence information
Supplemental material, sj-docx-1-qjp-10.1177_17470218231159190 for When and where did it happen? Systematic differences in recall of core and optional sentence information by Jan Chromý and Sonja Vojvodić in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The first author was supported by the Alexander von Humboldt Foundation. Funding was also provided by the Charles University institutional programme Cooperatio.
Supplemental material
The supplementary material is available at qjep.sagepub.com.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.