
Abstract
The field of psycholinguistics has recently questioned the primacy of word frequency (WF) in influencing word recognition and production, instead focusing on the importance of a word’s contextual diversity (CD). WF is operationalised by counting the number of occurrences of a word in a corpus, while a word’s CD is a count of the number of contexts that a word occurs in, with repetitions within a context being ignored. Numerous studies have converged on the conclusion that CD is a better predictor of word recognition latency and accuracy than frequency. These findings support a cognitive mechanism based on the principle of likely need over the principle of repetition in lexical organisation. In the current study, we trained the semantic distinctiveness model on communication patterns in social media platforms consisting of over 55-billion-word tokens and examined the ability of theoretically distinct models to explain word recognition latency and accuracy data from over 1 million participants from the Mandera et al. English Crowdsourding Project norms, consisting of approximately 59,000 words across six age bands ranging from ages 10 to 60 years. There was a clear quantitative trend across the age bands, where there is a shift from a social environment-based attention mechanism in the “younger” models, to a clear dominance for a discourse-based attention mechanism as models “aged.” This pattern suggests that there is a dynamical interaction between the cognitive mechanisms of lexical organisation and environmental information that emerges across ageing.
Experiential theories of cognition seek to understand the connection between the variance in human experience and the variance in human behaviour (Johns et al., 2019). This connection has been most aptly studied in the domain of language, as it has been repeatedly shown that the frequency of occurrence of words in the natural language environment has a direct and strong impact on lexical processing (Broadbent, 1967; Forster & Chambers, 1973; see Brysbaert et al., 2018 for a review), such that words that occur more often are processed more efficiently. This connection between lexical experience and lexical behaviour suggests that there is a dynamical interaction between the experience that one has with language and the cognitive mechanisms used in the comprehension and production of natural language, where the processes that underlie word retrieval are organised according to the environmental occurrence rate of words.
One area where experiential accounts of cognition are becoming increasingly impactful is in understanding the role of experience on cognition across the ageing spectrum (Ramscar et al., 2014; Wulff et al., 2018; see Ramscar, 2022 for a review). This work capitalises on the simple notion that learning does not end at the onset of young adulthood but rather continues throughout the lifespan. These accounts postulate that behavioural divergence between younger and older adults may be driven by their differential experience with the environment, rather than assuming that changes in older adults’ performance are related to a degradation of the cognitive system (a common assumption in theories of cognitive ageing; for a review, see Salthouse, 2010).
The development of experiential accounts of cognition has been aided by recent advances in computational cognitive modelling. In particular, the rise of corpus-based cognitive models such as Landauer and Dumais’ (1997) classic latent semantic analysis (LSA) model, has demonstrated the systematic connection between the statistics of the natural language environment and lexical semantic behaviour. This model, a member of a class of models referred to as distributional models of lexical semantics (see Günther et al., 2019; Kumar, 2021 for recent reviews), learns the meaning of words through the analysis of how they are used across a large corpus of natural language. While LSA accomplishes this using matrix decomposition, a number of other model types with different learning mechanisms have been proposed, such as those using count-based methods (e.g., Bullinaria & Levy, 2007, 2012), probabilistic inference (Griffiths et al., 2007), neural embedding models (Mikolov et al., 2013), vector-accumulation/noise-cancellation methods (e.g., Jones & Mewhort, 2007), and retrieval-based mechanisms (Jamieson et al., 2018; Johns et al., 2020; Johns & Jones, 2015). The success of distributional models of lexical semantics demonstrates the systematic connection between how words are used in the natural language environment and the meaning that people derive about them. In addition, these models have previously been used to examine differences in lexical semantics across the ageing spectrum (e.g., Taler et al., 2020).
Another area where experience-based cognitive models have been influential in is the development of new lexical strength measures of words. The most prominent measure is the contextual diversity (CD) proposal of Adelman et al. (2006). A CD measure of a word is constructed by counting the number of different contexts in which a word occurs across a corpus, with context typically being defined as a document, paragraph, or moving window within a corpus (see Hollis, 2020 for a recent discussion of issues involving the operationalisation of context), with word repetition within contexts being ignored. When compared with word frequency (WF), CD measures typically provide a small but reliable increase in the amount of variance explained across multiple large behavioural datasets of lexical decision and naming tasks (Adelman & Brown, 2008; Adelman et al., 2006; Brysbaert & New, 2009).
On the surface, WF and CD offer relatively similar explanations for lexical organisation. However, the theoretical interpretations of the measures are quite different (see Jones et al., 2017 for a detailed examination of this issue). WF entails a repetition-based learning mechanism, whereby each time a person processes a word, the strength of that word increases in the lexicon. In contrast, the importance of CD is best explained by the principle of likely need adopted from the rational analysis of memory (Anderson & Milson, 1989; Anderson & Schooler, 1991) as first proposed by Adelman et al. (2006). In this domain, the principle of likely need states that words that occur in the greatest number of different contexts are the words most likely to be needed in a future context, and so should be organised such that they are the strongest within the lexicon.
Recent research has affirmed that CD is an important variable across a number of different domains, such as word learning (Johns, Dye, & Jones, 2016; Mak et al., 2021; Pagán & Nation, 2019; Rosa et al., 2017, 2022; Tapia et al., 2022), sentence processing (Plummer et al., 2014), child language acquisition and processing (Hills et al., 2010; Hsiao et al., 2020; Hsiao & Nation, 2018; Joseph & Nation, 2018), memory processing (Aue et al., 2018; Steyvers & Malmberg, 2003), and bilingualism (Hamrick & Pandža, 2019). In addition, a unique Event-related potential (ERP) signature of CD on word recognition has been found (Vergara-Martínez et al., 2017). This research establishes that measures of CD occupy a central focus in psycholinguistic research.
Jones et al. (2012) offered a refinement of CD measures through the development of their semantic distinctiveness model (SDM). The SDM, a distributional model, produces a graded measure between 0 and 1 using an expectation-congruency mechanism, where contextual occurrences that are completely semantically redundant with past contextual occurrences of a word are given a value of 0, while occurrences in semantically unique contexts provide a strength increase of 1, with most occurrences providing an update strength somewhere in the middle. The proposal of the SDM is that it should be the number of different context types that a word occurs in, not the total number of different contexts. If one knows the types of contexts that a word is likely to occur in, then that word can be predicted when one enters those contexts. However, if a word occurs indiscriminately across different context types, then it cannot be predicted, and should therefore be stored strongly in memory. Thus, the model encodes the semantic diversity (SD) of the contexts that a word appears in. Jones et al. (2012) demonstrated that the SDM produces better fits to large-scale lexical decision and naming time data than CD and WF; they also validated the model’s learning mechanism with an artificial language experiment. Johns et al. (2012) demonstrated that the advantage of the model extends to spoken word recognition data, while Johns et al. (2016) used a unique natural language word learning paradigm to further validate the SDM’s learning mechanism.
As an initial examination into the impact of CD and SD on ageing, Johns, Sheppard, et al. (2016) found that the lexical strength values derived from the SDM provided a larger benefit over WF and CD for older adults as compared with younger adults in a lexical decision paradigm, suggesting that lexical encoding strategies may differ across the lifespan. Similarly, Qiu and Johns (2020), in an experiment based on the previous work of Ramscar et al. (2017), used a paired-associate learning task to examine whether older adults were more impacted than young adults by the large amount of semantic information attached to high SD words. They found that older and younger adults performed equivalently on word pairs involving low SD words, while older adults performed worse than young adults on pairs involving high SD words. This suggests that the greater level of experience that older adults have with language results in SD information being more encoded in the lexical memory of older adults compared with younger adults, impairing their ability to form new associations.
Recently, Johns et al. (2020) and Johns (2021a) have proposed that the real advantage of CD and SD measures lies at much larger levels of contextual scale than previously considered. As a first validation of this finding, Johns et al. (2020) defined CD measures as being at either the single book level (i.e., a word’s strength is updated if it was used in a book, with repetitions within a book being ignored) or at the author level (i.e., a word’s strength is updated if it was used in an author’s collected writings). Both measures provided a substantial improvement in variance accounted for across a variety of lexical decision and naming accuracy data, and when the measures were modified with the SDM, an equivalent finding was found for reaction time (RT) data. The overall best fitting measure used an operationalisation of context at the author level, suggesting that the pattern of individual language usage is important in lexical organisation.
However, using fiction books as sources of contextual information is questionable due to a lack of ecological validity; it is unlikely that people organise their lexicons based upon which books they have read. To overcome these issues, Johns (2021a) used a more communicative source of language to define context, namely large-scale communication patterns on the internet forum Reddit. In Johns (2021a), two new communicatively oriented CD measures were proposed—user contextual diversity (UCD) and discourse contextual diversity (DCD). These measures were computed from examining the communication patterns of over 300,000 users from over 30,000 discourse topics (subreddits), with the total number of words included in the analysis eclipsing 55 billion. These data were obtained from Baumgartner et al. (2020). The UCD measure tallied the number of users who produced a given word, while the DCD measure counted the number of discourses in which the word occurred. These count measures provided a substantial improvement over the classic WF and CD measures for both RT and accuracy data and also the previous models proposed by Johns et al. (2020). These results suggest that the benefit of CD measures lie in socially based operationalisations of context, namely those who produced a set of language and the discourse in which the language was produced.
However, the real benefit of these models was found when the representation of the SDM was changed to reflect socially based information. Johns (2021a) tested two representation types: (1) word representations (WR) and (2) population representations (PR). The WR representation was first used by Johns et al. (2020), and the context representation for this representation type is simply a vector of the count of the number of times each word occurs in a specified contextual unit (either discourse for DCD or user for UCD). Thus, the WR representation is linguistic in nature. In contrast, the PR representation is not directly based in word usage patterns, but instead contains the commenting pattern within a set context.
For the DCD measure, the PR context representation is a count of the number of comments that each user produced within that discourse. Thus, for each discourse studied, the context representation consists of a vector, with the dimensionality of the vector being the total number of users. Each element in the vector corresponds to a single user, and the value of each element is the number of comments that the user produced in that discourse. For the UCD measure, the PR context representation is a count of the number of comments that the user produced in each discourse. For each user studied, the context representation is a vector, with each element being a single discourse. The value of the element is the number of times the user produced a comment in that discourse. Given that there are more users than discourses, the UCD measure receives more updates than the DCD measure. For concrete examples of how these representations are constructed, see Johns (2021a).
It was found that the PR models offered a sizable advantage over their count-based counterparts and the WR models, which suggests that linguistic contexts are not just composed of the words that occurred in a context, but also communicative information about who produced language and in what discourse are also included in a contextual representation. Johns and Jones (2022) provided further analyses examining the success of the PR models in accounting for lexical organisation data.
Similar benefits to the usage of social and commutative linguistic information have been found by Johns (2022), who showed that the PR models provide a similar advantage over WF and CD for item-level episodic recognition rates, and Johns (2021b) who demonstrated that a distributional model of semantics trained on the communication patterns of users provides a unique signal of word meaning. Senaldi et al. (2022) found that the PR models also offer an increased advantage in accounting for idiomatic data, while Antal et al. (2022) showed that it also accounts for unique variance in semantic decision. Combined, these results suggest that communicative and social information is an integral part of language storage and processing.
The goal of this study is to determine if the results from Johns (2021a) hold across the ageing spectrum, through the analysis of large-scale lexical decision data collected by Brysbaert et al. (2019) and Mandera et al. (2020) subdivided by age group. This will be explored by examining and contrasting the performance of the count-based and SD transformed models across the different ageing groups. To preview, the results will show that the usage of different contextual information sources is dynamic across the ageing spectrum, with different lexical organisation principles being deployed for older and younger adults. This suggests that as older adults acquire more lexical information through everyday language experience, the interpretation and use of that information shift as one ages.
Method
Data
The data analysed here were obtained from the recently released data of the English Crowdsourcing Project (ECP; Mandera et al., 2020). This project collected data from more than 1 million participants over the internet using a modified lexical decision task. The resulting dataset includes both RT and accuracy, subdivided by age group. Mandera et al. (2020) demonstrated that these data are highly correlated with more traditional lexical databases, such as the English Lexicon Project (Balota et al., 2007), suggesting that the data are of high quality. Six age groups are examined here: (1) 10–17, (2) 18–23, (3) 24–29, (4) 30–39, (5) 40–49, and (6) 50–59. These age groups were determined based on the splits used by Mandera et al. (2020), with the data available at https://osf.io/rpx87/. The standard mega dataset used to examine lexical organisation is the English Lexicon Project (Balota et al., 2007), which focused on the 18–23 age group. The groups determined by Mandera et al. (2020) allow for a convenient ability to examine how different age groups around this standard group of participants fit to different lexical strength measures, as the 10–17 group corresponds to adolescence, the 18–23 consists of university-aged students, the 24–29 group contains individuals in early adulthood, and the subsequent age groups correspond to different stages of adulthood.
The analyses were conducted at the level of the individual word. For a word to be included in the analyses, we required at least 20 data points for the word for each age group, resulting in a total of 59,368 words (out of 61,854 total words analysed in the ECP). We obtained an average of 47.0 responses per word for the 10–17 group, 107.07 responses for the 18–23 group, 120.47 responses for the 24–29 group, 154.25 responses for the 30–39 group, 108.3 responses for the 40–49 group, and 75.42 responses for the 50–59 group. Thus, there is some variability in the total sample size across words and ageing group, but there is still a large amount of data collected for each individual word across all of the age groups.
Corpora
Johns (2021a) developed new measures of lexical strength using corpora from the internet forum Reddit. These corpora were built using a website entitled pushshift.io (Baumgartner et al., 2020), which assembled all comments from the beginning of the website (June 2005) to now (the corpora used in this article were constructed from all of the comments used on the site up to December 2019). The comments were accessed using the publicly available Reddit API, 1 which makes them available as database files. Two different corpus types were constructed from this data: user and discourse corpora. Each user corpus was composed of the comments that a single user, who had a public username, produced on the forum. For a user corpus to be included in the analysis, the user had to have produced at least 3,000 comments. This criterion resulted in 334,345 user corpora. The discourse corpora mapped onto a single subreddit, which these users commented within. This process resulted in 30,327 discourse (subreddit) corpora. Critically, these corpora contain the equivalent total number of words, but the organisation of the information differs. In total, approximately 55 billion words were analysed.
Vocabulary
The model was trained on the 59,368 words attained from the ECP data.
Count-based models
Four count-based models were tested: (1) WF, (2) CD, (3) UCD, and (4) DCD. WF is the number of times that a word occurred in the corpora. To replicate the traditional CD measure of Adelman et al. (2006), context was considered at the individual comment level, whereby if a word occurred in a comment, the strength of that word was increased by 1, but with repetitions within a comment being ignored. The DCD and UCD are much larger definitions of contexts, with most contexts at these levels typically being in hundreds of thousands or millions of words. The UCD count is the number of users who produced a word, and thus had a maximum value of 334,345 (the number of user corpora). The DCD is the number of subreddits that a word appeared in, and thus had a maximum value of 30,327 (the number of discourse corpora). In all analyses, each variable was reduced with a natural logarithm, mirroring prior work (Adelman & Brown, 2008; Adelman et al., 2006).
The SDM
The SDM has both representational and processing components. The representational components have changed through different implementations of the model, but the processing mechanisms have remained the same. There are two main representation elements: word and context representations. The context representation contains the meaning of the current context that is being processed, while a WR is the sum of all the contexts that a word occurs in. Each word has its own representation in memory. When a word occurs in a context, that word’s lexical strength is increased. The update strength for a contextual occurrence is a transformation of the similarity between a word and the context that the word is occurring in, such that high similarity contexts (redundant with past experience) are transformed into a low update strength, while low similarity contexts (unique compared with past experience) are transformed into a high update strength.
The first implementation of the model was presented in Jones, Johns, and Recchia (2012). In this implementation, the representation that the model utilised was a Word-by-Document matrix, similar to the assumptions of Landauer and Dumais’s (1997) classic LSA model. Each time the model encountered a new context, a new column was added to the matrix. Words that occurred in the context received an update value—entitled a semantic distinctiveness (SD) value—for that context’s column. Words that did not occur in a context, got an encoding strength of 0. The context representation that the model constructed was the sum of the rows of each word that occurred in the context.
This initial implementation had its positive aspects, such as the fact that a word’s strength was directly contained in its memory representation, but it was difficult to use with larger definitions of context, as well as being computationally expensive to scale-up to large corpus sizes. To use the modelling framework with larger context sizes, Johns et al. (2020) switched to defining a context by its WF distribution, namely the frequency of each word that occurred in a book or an author’s collected writings. A word’s representation in this implementation is then the sum of the frequency distributions of the contexts in which a word occurs.
Johns (2021a) further modified this approach by changing the contents of the contextual representation. Specifically, contextual representations were not defined by the words that were used within the context, but rather by communication patterns. Both the UCD and DCD counts were modified with these transformations, with the resulting models entitled the UCD-SD-PR and DCD-SD-PR models. In this article, we will refer to these two models simply as the UCD-SD and DCD-SD models. In these models, the lexical strength of a word is stored in an external counter. The SD models have the same update rules as the UCD and DCD count measures, but instead of getting an update strength of 1 for each context that a word occurs in, the update strength is between 0 and 1. In the SD models, the lexical strength for each word is stored in an external counter.
The PR context representation that the UCD-SD model uses is a count of the number of comments that a user made in each discourse, and thus has a dimensionality of 30,327 (the number of discourse topics). This vector represents the communication pattern of that individual user across all discourse types. The PR representation that the DCD-SD model employs is a count of the number of comments that each user produced in the discourse, and thus has a dimensionality of 334,345 (the total number of users in the dataset). This vector represents the communication patterns of users within that discourse. The UCD-SD model is updated for each user, and thus receives 334,345 updates, while the DCD-SD model is updated for each discourse, and thus receives 30,327 updates. The context representations that the models form are then used to update the words that occurred in that context, by summing the context vector into their memory vector. While the two models are clearly very related, as they are different organisations with the same information, Johns (2021a) did show that they diverge somewhat. Indeed, while Johns (2021a) found that the UCD-SD offers the best fit to a range of lexical organisation data, Johns (2022) found that the DCD-SD offers the best fit to word-level recognition memory rates, suggesting that different datatypes may be more sensitive to different types of lexical information, a primary point of analyses in this article.
We now provide a formal exposition of the mechanisms that the SDM employs. As stated, the update strength that a word receives for a contextual occurrence is based upon a semantic distinctiveness (SD) value. To calculate this value, the similarity between the word’s representation and the current context is used. Similarity is calculated with a vector cosine (normalised dot product), which returns a value between 0 and 1 (as there are no negative values in the representations)
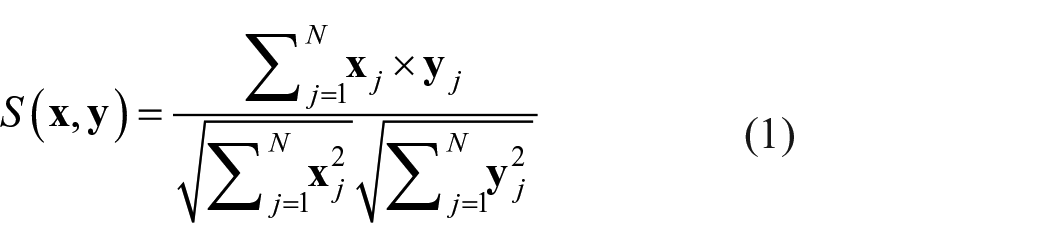
where N is vector dimensionality. An SD value is calculated with an exponential transformation of the similarity between a word and context (based on Shepard’s [1987] law of psychological distance)

where i is the word being processed in context j,
An SD value signals how unique that context was compared with the past contexts that a word occurred in, with a value close to 1 signalling a new type of context, while a value close to 0 signals a completely redundant context. The final step in the model is to update the memory representations of each word that occurred in the context. This is done by summing the context representation into each word’s representation
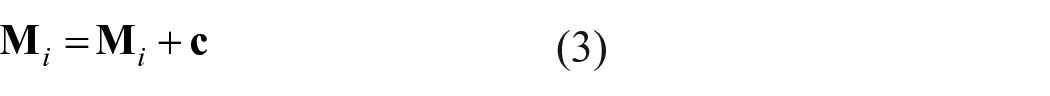
where i goes through each word that occurred in the context.
As stated, the λ parameter is an important component of the SDM architecture that controls the weighting scheme employed by the model. In the initial implementation of the model (e.g., Johns et al., 2012; Jones et al., 2012), a small λ parameter (typically between 1 and 7) was found to provide optimal model performance, which was also found by Johns et al. (2020) when utilising a WF distribution as the model’s representation type. However, Johns (2021a) found that when the model utilised the PR representation, the model was optimised when λ was maximised (set at 400 in that article). It was found that at this λ parameter, the majority of a word’s strength came from a small number of highly distinct contexts. Indeed, Johns and Jones (2022) and Johns (2022) have shown that by constructing a count of the number of highly distinct contexts that a word appears in, a similar level of performance can be achieved compared with the continuous model across both lexical organisation and recognition memory performance. A high λ parameter is explained by the principle of likely need, as very distinct contextual occurrences signal a new type of context that a word could occur in. The λ parameter will be fit independently to the different age groups, and the value of the parameter will help to explain the differences that are found.
Analysis technique
Consistent with past studies, hierarchical linear regression will be used here to determine the unique variance that the lexical strength variables account for when contained in a regression. The end result of this analysis technique is the amount of predictive gain (measured as percent ΔR2 improvement) for one predictor over other competing predictors. The percent ΔR2 is the amount of improvement that one variable causes over other controlled variables. For example, if the inclusion of an additional variable in a regression causes the R2 of the model to be increased to .4 from an initial R2 of .3, this would represent a ΔR2 of 25% (i.e., a .1/.4 improvement, or 25%).
Data availability
The data and associated model values are available at https://osf.io/9mybv/.
Results
To provide an initial understanding of the connection between the different lexical strength variables across the ageing spectrum, Table 1 presents the correlations between the different lexical strength variables and the RT and accuracy data from the ECP for the six age groups. The correlations of the standard SUBTLEX WF values from Brysbaert and New (2009) were also included to provide a comparison for the Reddit data. This table shows that the CD variable has slightly higher correlations than the WF variable for RT and accuracy across all age groups, replicating the initial results of Adelman et al. (2006). The larger-scale DCD and UCD counts provide a very substantial increase in correlation, particularly for the accuracy data. All of the Reddit data substantially outperformed the SUBTLEX norms, suggesting that the Reddit data provides an overall more accurate accounting of lexical organisation data (as well as containing many more word types). In addition, the SD-transformed variables provide a considerable boost over their count-based alternatives, particularly for RT data. Thus, the current results replicate past studies indicating the importance of large-scale measures of contextual occurrence, upon which the DCD and UCD measures capitalise.
Correlations between the RT and accuracy data and lexical strength measures across the six age groups.
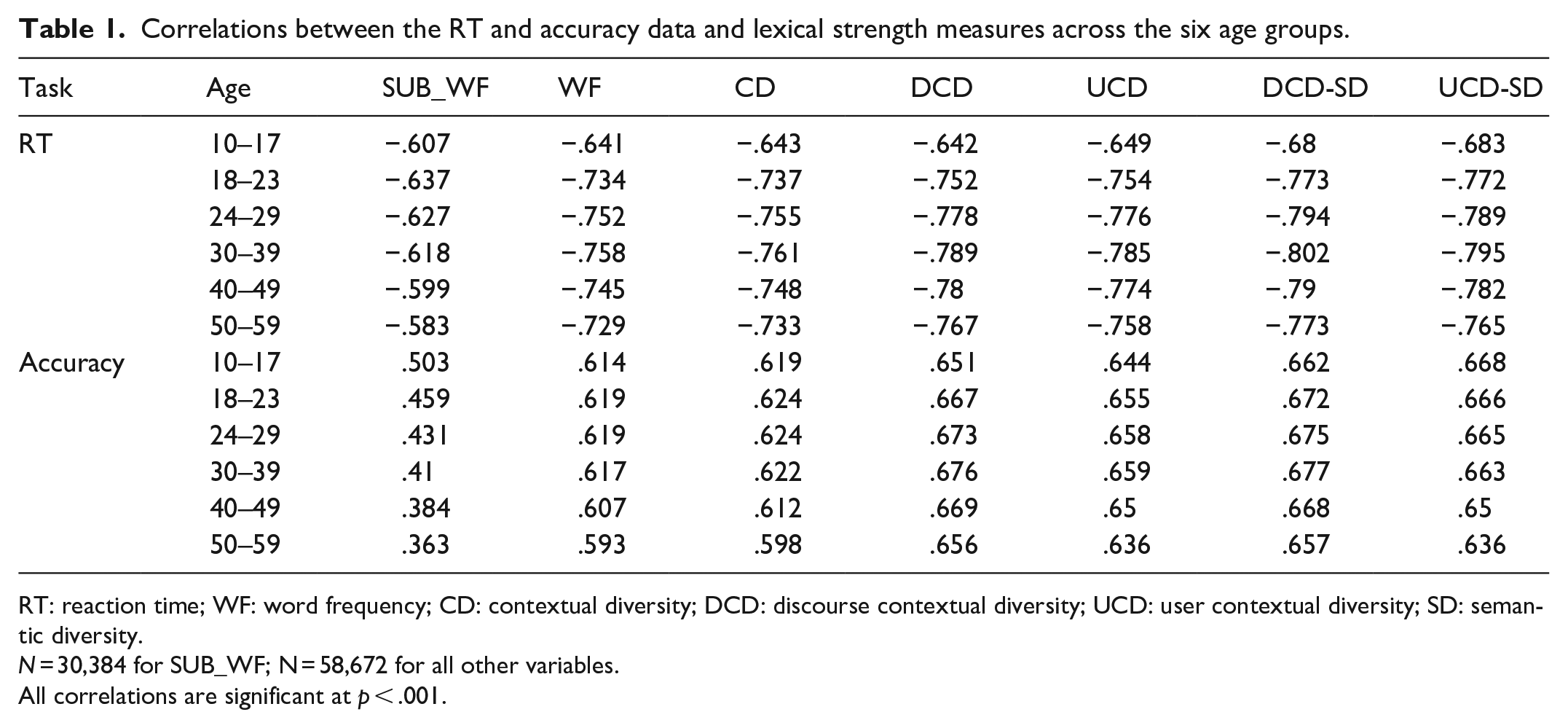
RT: reaction time; WF: word frequency; CD: contextual diversity; DCD: discourse contextual diversity; UCD: user contextual diversity; SD: semantic diversity.
N = 30,384 for SUB_WF; N = 58,672 for all other variables.
All correlations are significant at p < .001.
Recent studies have disagreed about whether older adults show an attenuated frequency effect compared with younger adults. Numerous studies have found a smaller WF effect for older adults (e.g., Brysbaert et al., 2017; Davies et al., 2017; Diependaele et al., 2013), a finding that was corroborated by Mandera et al. (2020) using the ECP data. However, Cohen-Shikora and Balota (2016) did not find a significant difference in the frequency effect across age groups. The results from Table 1 are mixed on the impact of frequency across the different age groups—the SUBTLEX norms show a constant decrease in fit from the 18 to 23 age group onwards, equivalent to the results of Mandera et al. (2020). However, the Reddit WF and CD values show a different pattern, where there is a consistent increase from the 10 to 17 group to the 30–39 group across all variables but decreases for the 40–49 and 50–59 groups. This suggests that there are dynamics in the best fitting corpus for WF values to lexical organisation data across ageing, a result previously suggested by Johns et al. (2019) and Taler et al. (2020). This finding has implications for the usage of WF norms on examining lexical data in different age groups, particularly WF effects. This issue will be discussed in section “General discussion” below.
The goal of the following analyses is to determine how the fits of WF and the various CD measures differ across age groups. This was done using hierarchical linear regression, as detailed previously. The first regression conducted determined the amount of unique variance accounted for by the CD measures and WF when included in a regression. Each CD variable was tested independently and compared directly with WF. Figure 1 shows the results of comparing the three CD count measures (CD, UCD, and DCD) on RT data, Figure 2 shows the results for the accuracy data, while Figure 3 contains a summary of the amount of improvement over WF that the three CD measures provide. Combined, these figures show that the larger scale UCD and DCD account for considerably more variance than the traditional CD measure, while reducing the unique contribution of WF far more than the traditional CD measure does. In addition, Figure 3 shows that the best fitting model shifts across the age groups—for the youngest age groups, the UCD variable accounts for the most variance (especially for the RT data), but eventually the DCD variable accounts for the most unique variance over WF in the older age groups. In addition, the amount of unique variance that the UCD and DCD measures account for increases with increasing age, while the CD variable remains constant, suggesting that the larger-scale measures have a stronger effect on word recognition as people age. This suggests an age-related shift in the type of organisational information that is used for word recognition.
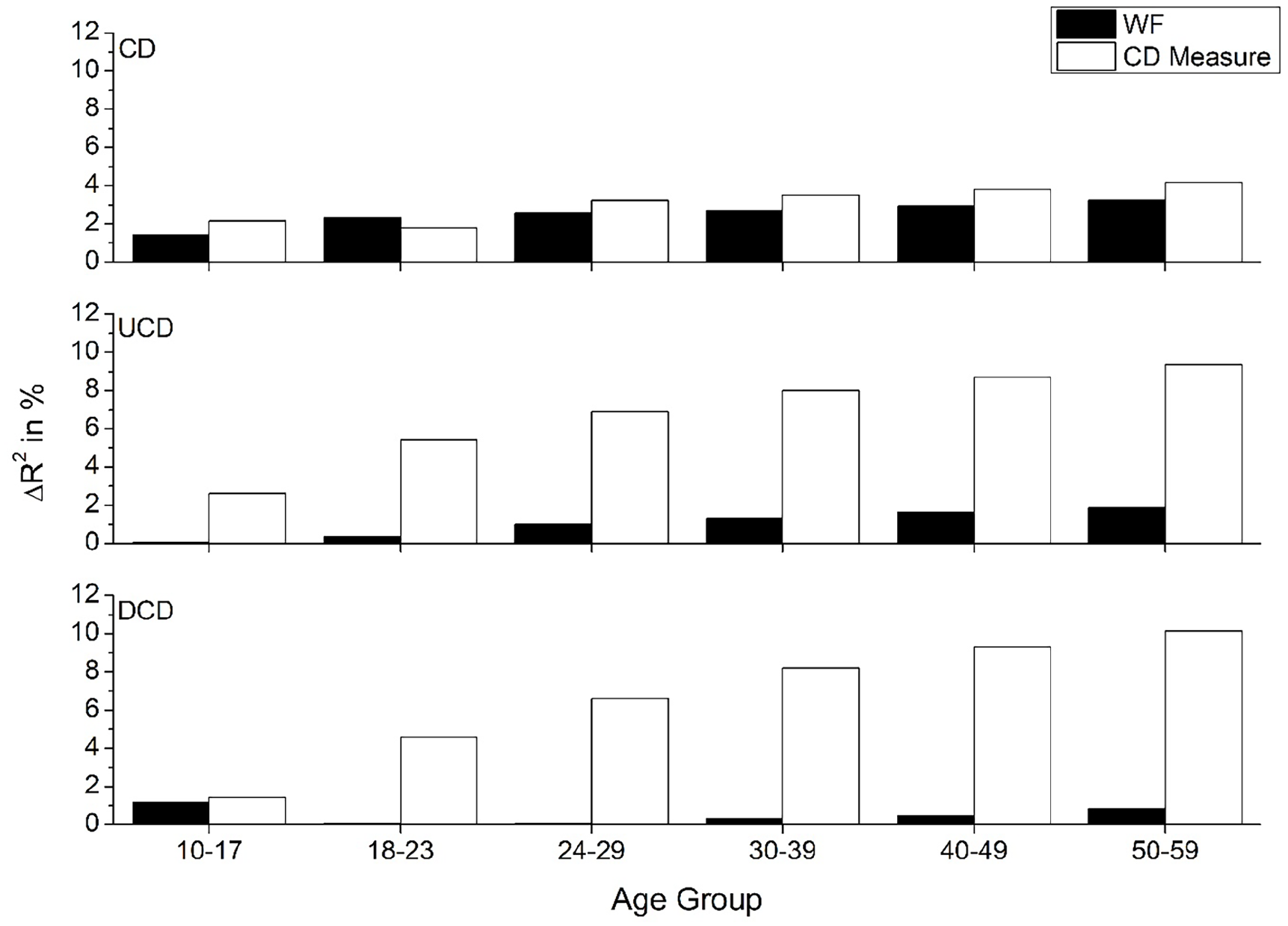
Amount of unique variance that each CD count measure accounts for over WF (and vice versa) for reaction time data across the six age groups.
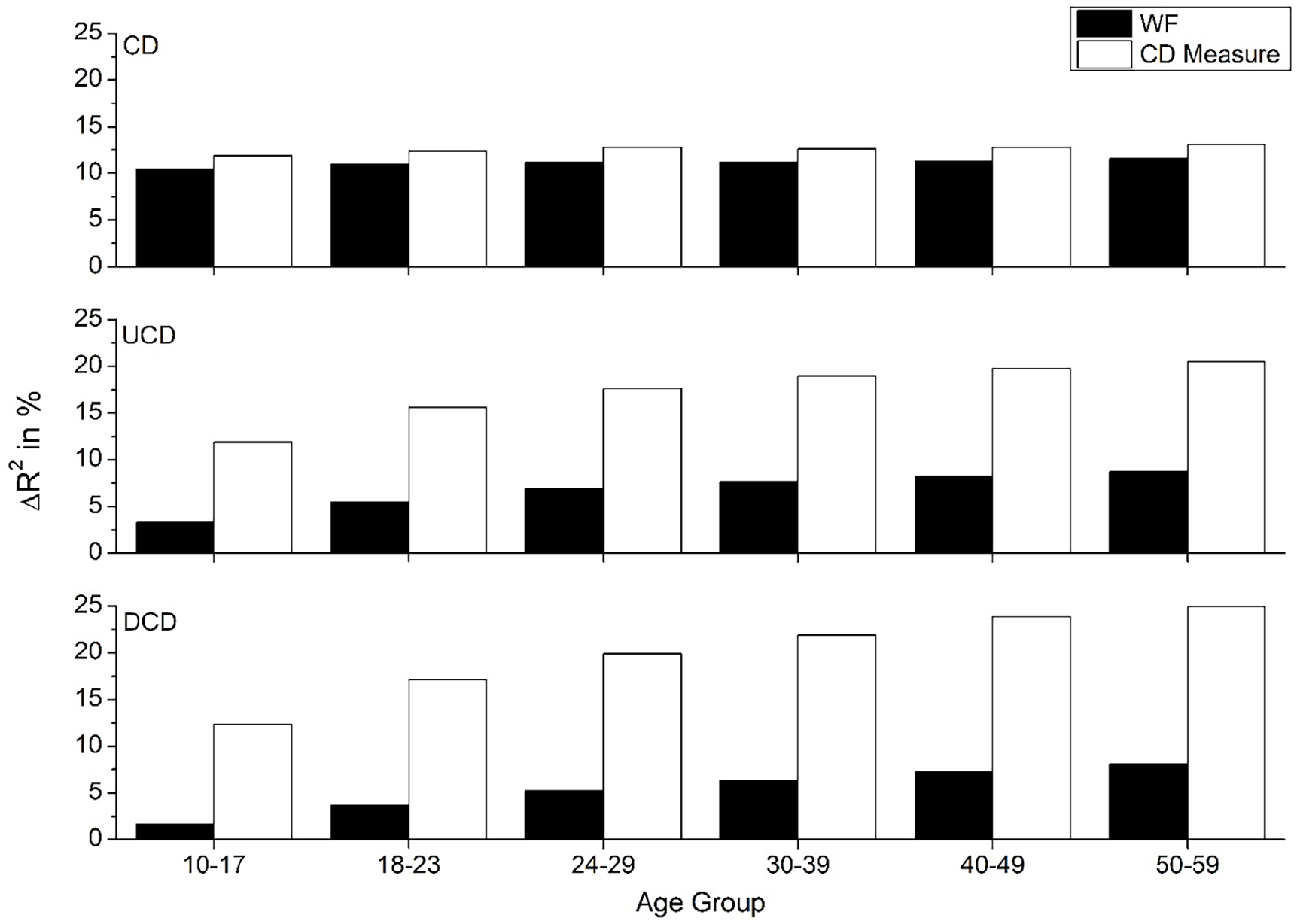
Amount of unique variance that each CD count measure accounts for over WF (and vice versa) for accuracy data across the six age groups.
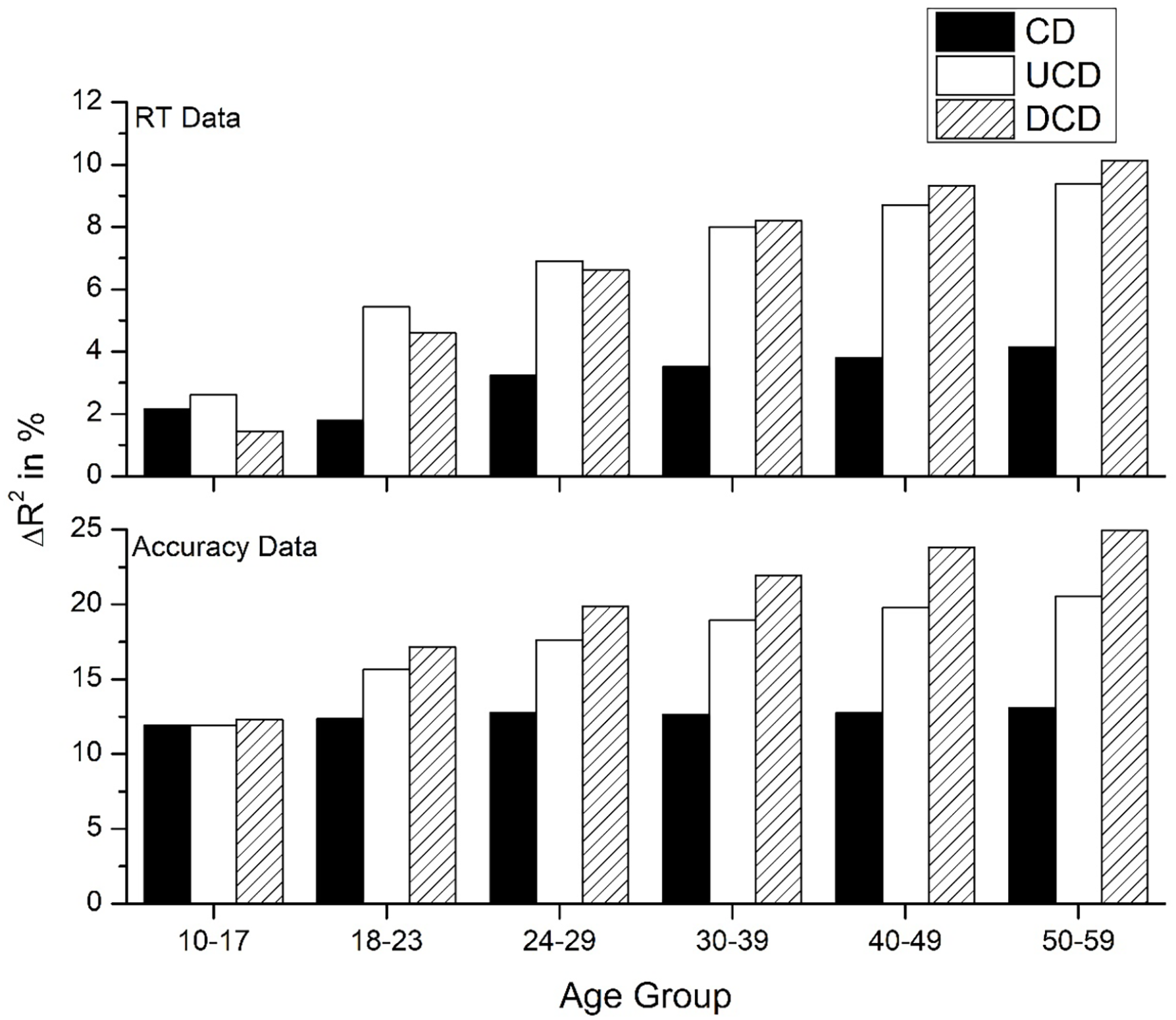
Summary of the improvement that the three CD count measures over WF across all ageing groups.
Next, we examined how much variance the larger-scale UCD and DCD measures account for over and above the standard CD measure, and how this varied in different age groups. Figure 4 shows the amount of unique variance that the UCD and DCD measures account for over CD (and vice versa) for RT data, while Figure 5 shows the results for accuracy data. The bottom panel of each figure shows a direct comparison between the advantage that the DCD and UCD measures provide over CD, allowing us to examine how the advantage differs with age. These figures show that the UCD and DCD measures account for considerably more unique variance over and above CD (as was found for WF), while reducing the unique contribution of CD (although the CD measure still accounts for some variance, especially for accuracy data). In addition, a similar pattern was observed as in Figure 3, whereby the importance of the DCD variable increased for both RT and ageing data as a function of age group, while the UCD variable was relatively more important for the younger groups. This result validates the larger-scale UCD and DCD counts as being superior to the previously proposed CD measure across the ageing spectrum, with the impact of the counts increasing in older age groups.
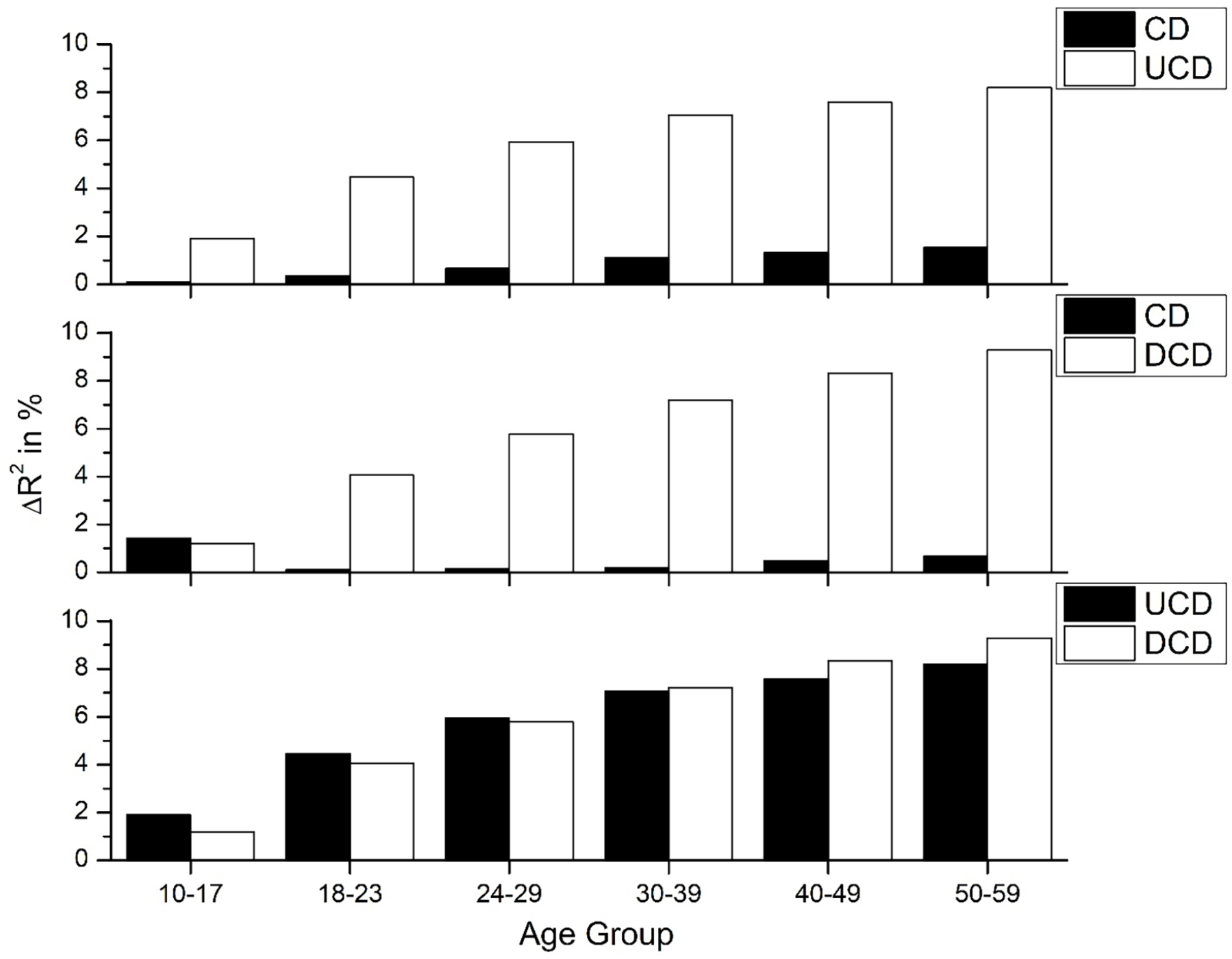
Amount of unique variance that the larger-scale CD values account for over the traditional CD values and each other for the reaction time data from the ECP. The bottom panel of this figure displays a comparison of the amount of unique variance that the UCD and DCD measures account for over CD, taken from the top two panels.
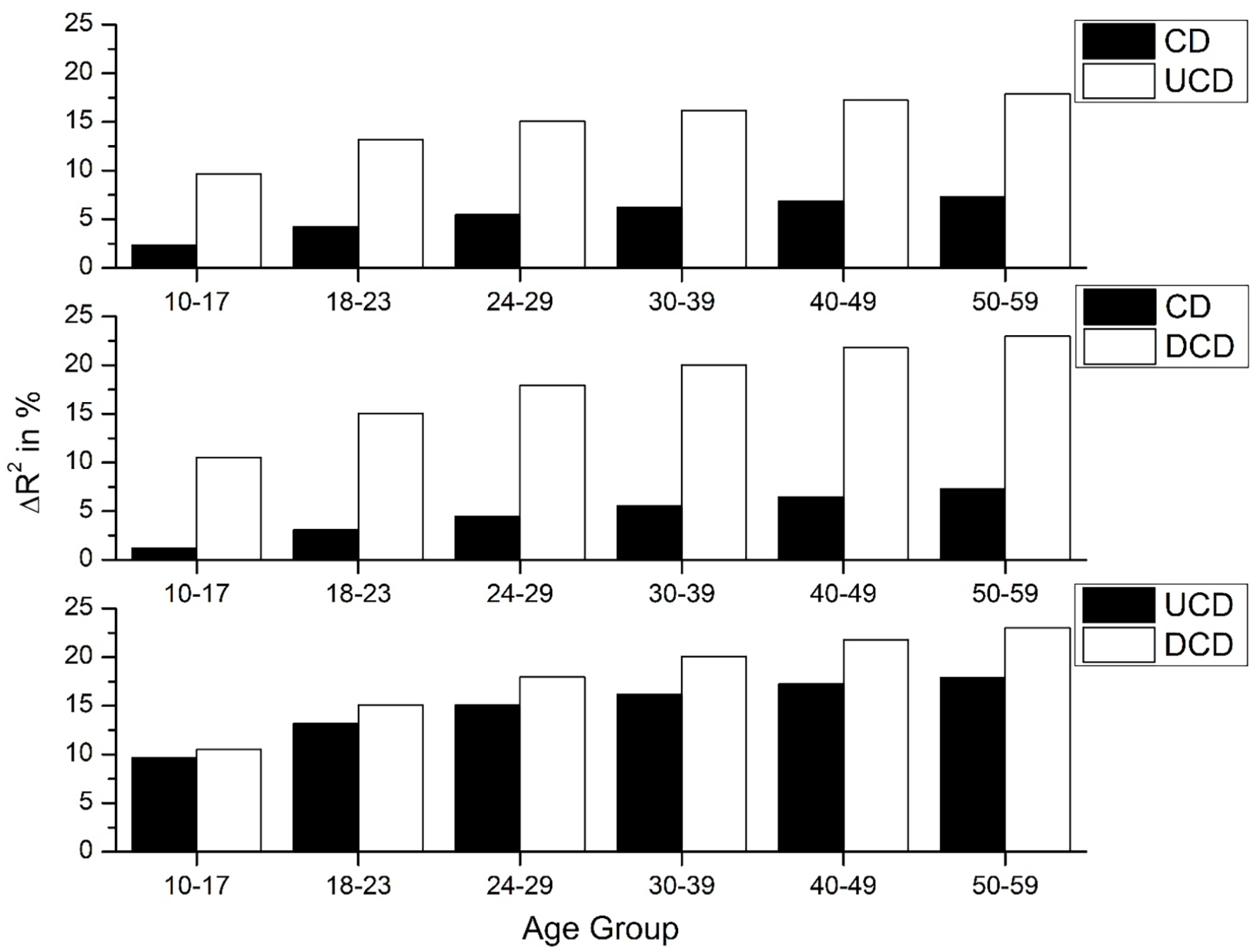
Amount of unique variance that the larger-scale CD values account for over the traditional CD value for accuracy data from the ECP (top: UCD; middle: DCD). The bottom panel of this figure displays a comparison of the amount of unique variance that the UCD and DCD measures account for over CD, taken from the top two panels.
The next analyses involved a direct comparison of the UCD and DCD counts. The result of this regression is depicted in Figure 6 for both the RT (top panel) and accuracy (bottom panel) data. For the RT data, there is a gradual shift from the UCD variable accounting for the most unique variance to the DCD measuring providing the best fit. For the accuracy data, there is a sustained advantage for the DCD count over the UCD count across all age groups but increases in prominence in the older age groups. Taken together, this analysis suggests that there is a sustained shift from the UCD to the DCD count being the superior model with increasing age.
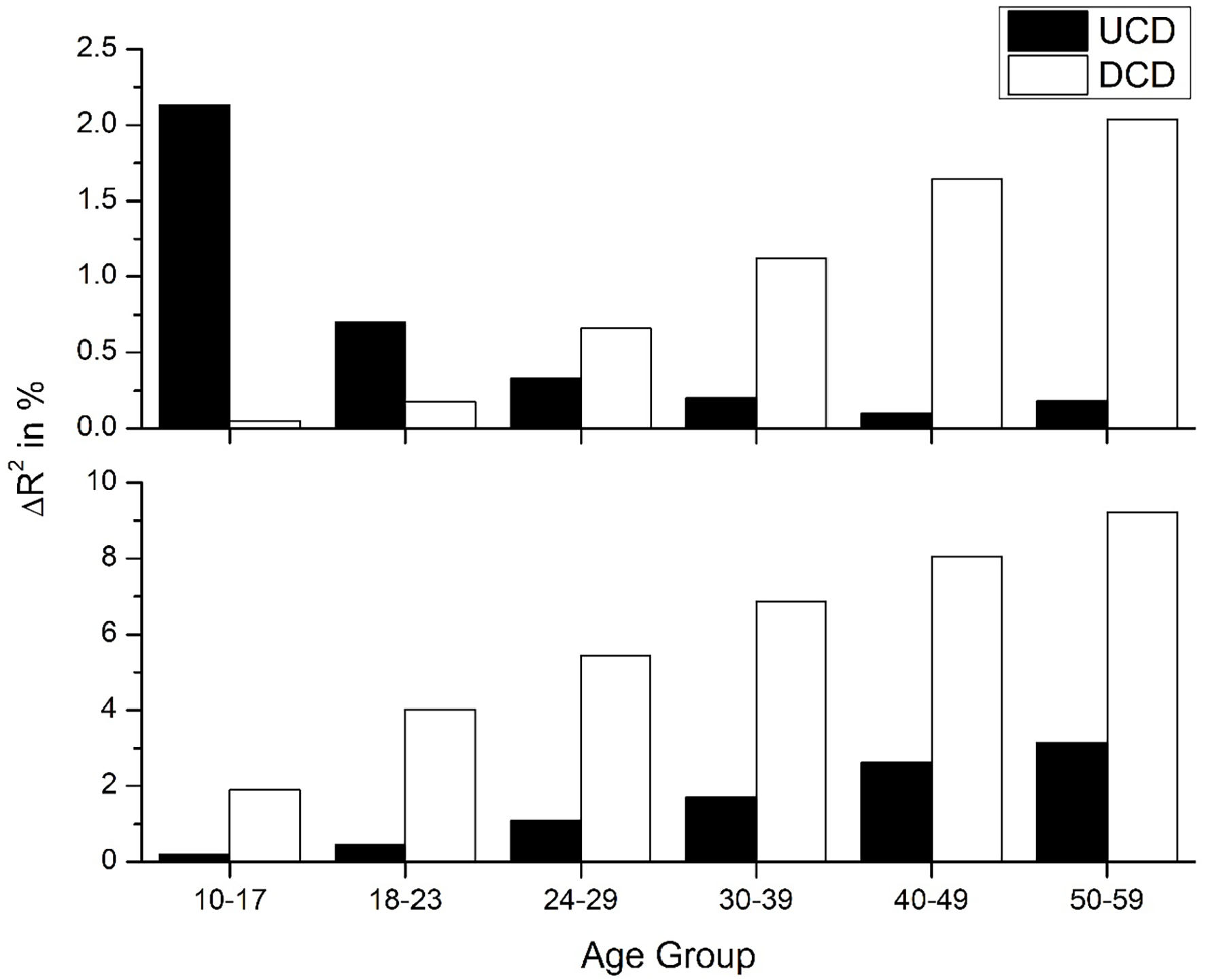
Amount of unique variance that the DCD and UCD measures account for when compared against each other. The top panel contains the results for the reaction time data from the ECP, while the bottom panel examines accuracy data.
The results of Johns (2021a) demonstrated that the DCD and UCD counts transformed with the SDM model accounted for significantly more variance than their count-based alternatives. To first examine the performance of the UCD-SD and DCD-SD models, the amount of variance that these measures account for over WF (equivalent to the analyses contained in Figures 1 and 2) was computed. However, the UCD-SD and DCD-SD models contain a free parameter, λ, which is a weighting parameter that controls the level of discounting given to high similarity contexts and the amount of highlighting given to low similarity contexts. Johns (2021a) found that the optimal value for λ was optimised by maximising the value of the parameter (it was set at 400 in that article). However, the data used in that article were centred around young adult data. Therefore, here we have optimised the λ parameter independently by age group. Optimisation was accomplished by maximising the correlation to the RT and accuracy conjointly for each age group.
The results of this analysis are shown in Figure 7 (RT) and Figure 8 (accuracy), with the top panel in these figures contrasting UCD-SD and WF, the middle panel DCD-SD and WF, and the bottom panel displaying a direct comparison that the two measures provide over WF. These figures paint a somewhat different picture than was seen in Figures 1 and 2, where there was an increase in the amount of unique variance that the UCD and DCD measures accounted for with increasing age. Here, the benefit for the UCD-SD and DCD-SD measures are relatively constant across the different age groups. In addition, the impact of the UCD-SD and DCD-SD-derived variables across the age groups are consistent with the analysis of the count variables, with the UCD-SD measure accounting for more variance for the younger groups, and the DCD-SD variable accounting for more variance in the older groups.
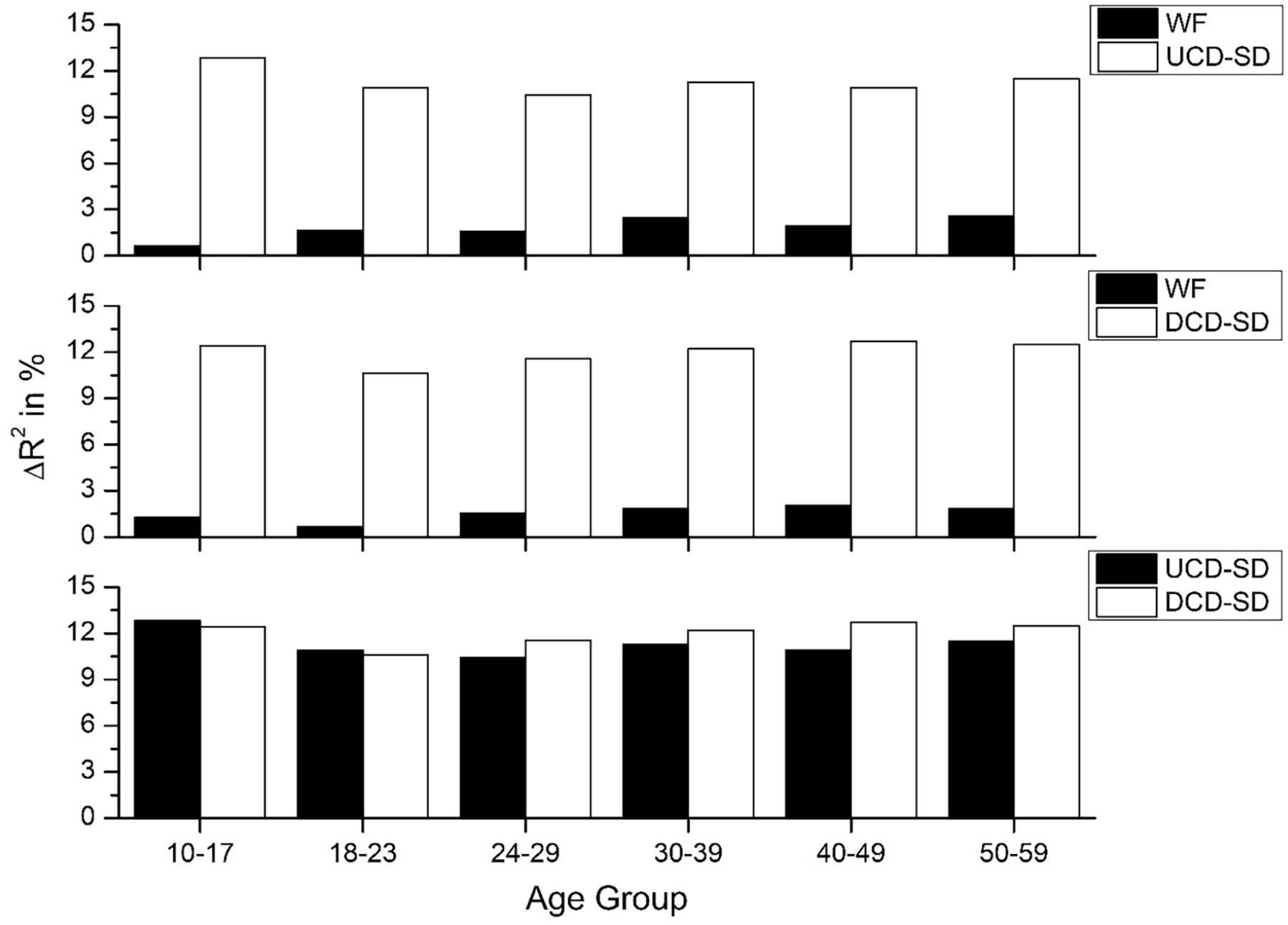
Amount of unique variance that each UCD-SD and DCD-SD measures account for over WF (and vice versa) for reaction time data across the six age groups. The bottom panel of this figure displays a comparison of the amount of unique variance that the UCD-SD and DCD-SD measures account for over WF, taken from the top two panels.
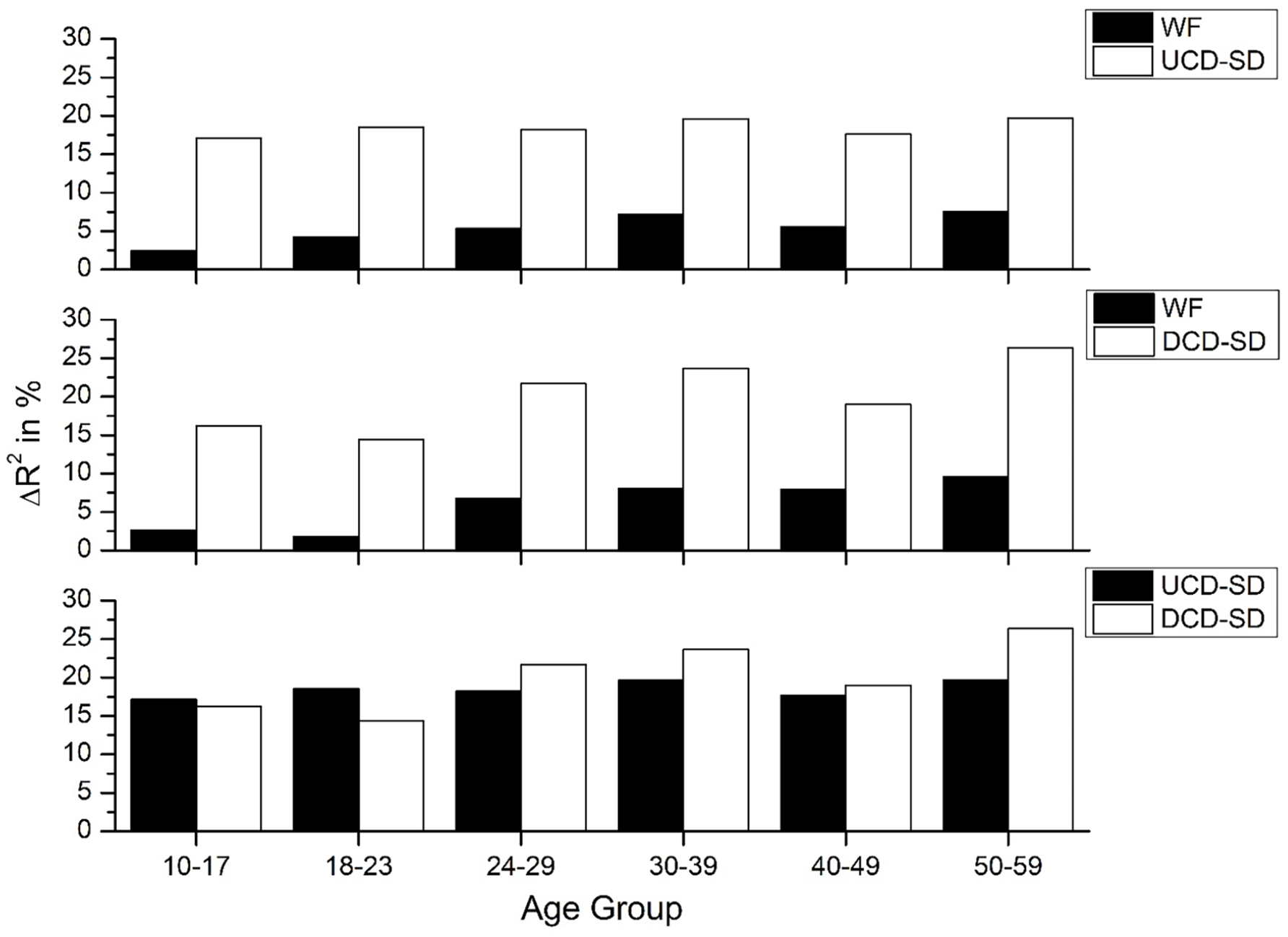
Amount of unique variance that each UCD-SD and DCD-SD measures account for over WF (and vice versa) for accuracy data across the six age groups. The bottom panel of this figure displays a comparison of the amount of unique variance that the UCD and DCD measures account for over CD, taken from the top two panels.
A final question revolves around whether the UCD-SD and DCD-SD variables account for more variance in the datasets when compared with their count-based alternatives and to each other. Such an analysis would allow us to determine why there is a different pattern of fit for the SD models compared with the count models across the aging spectrum, and which of the SD models provides the best fit to the data. The results of this analysis are shown in Figure 9 (RT) and Figure 10 (accuracy), which show two main trends. First, the SD-derived variables provide a considerable advantage over their count-based alternative for the younger age groups, but this advantage dissipates in the older groups. This finding suggests that the impact of the SD transformations mainly occurs with younger participants, with the SD-derived variables only providing a moderate benefit to model fit for the older participants. The second trend replicates previous analyses in this article showing a switch from the UCD-SD model being the best fitting model for the younger groups to the DCD-SD model being the best fitting model for the older groups.
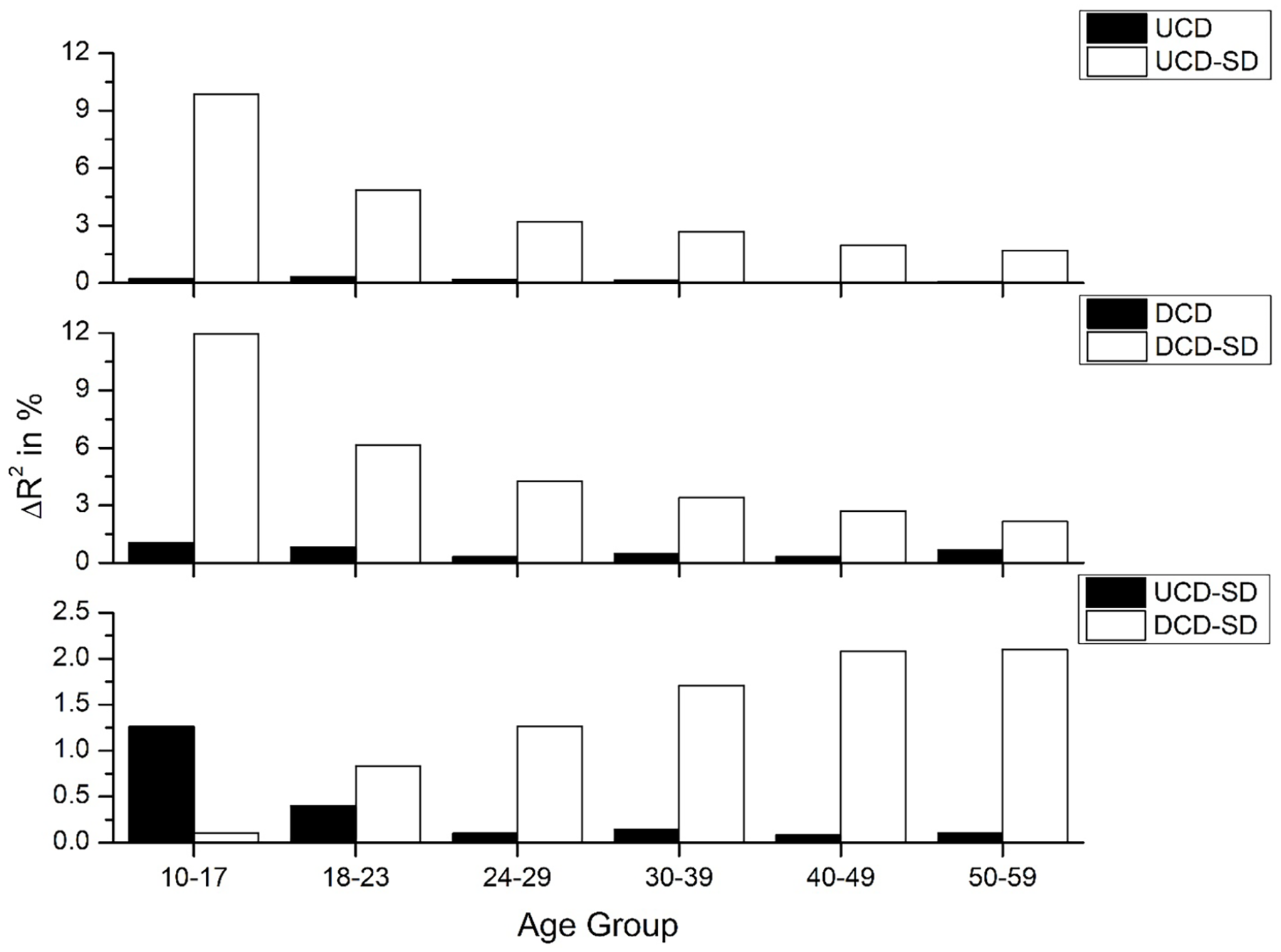
Amount of unique variance that the SD-derived measures account for over their count-based alternatives and each other (bottom panel) for reaction time data.
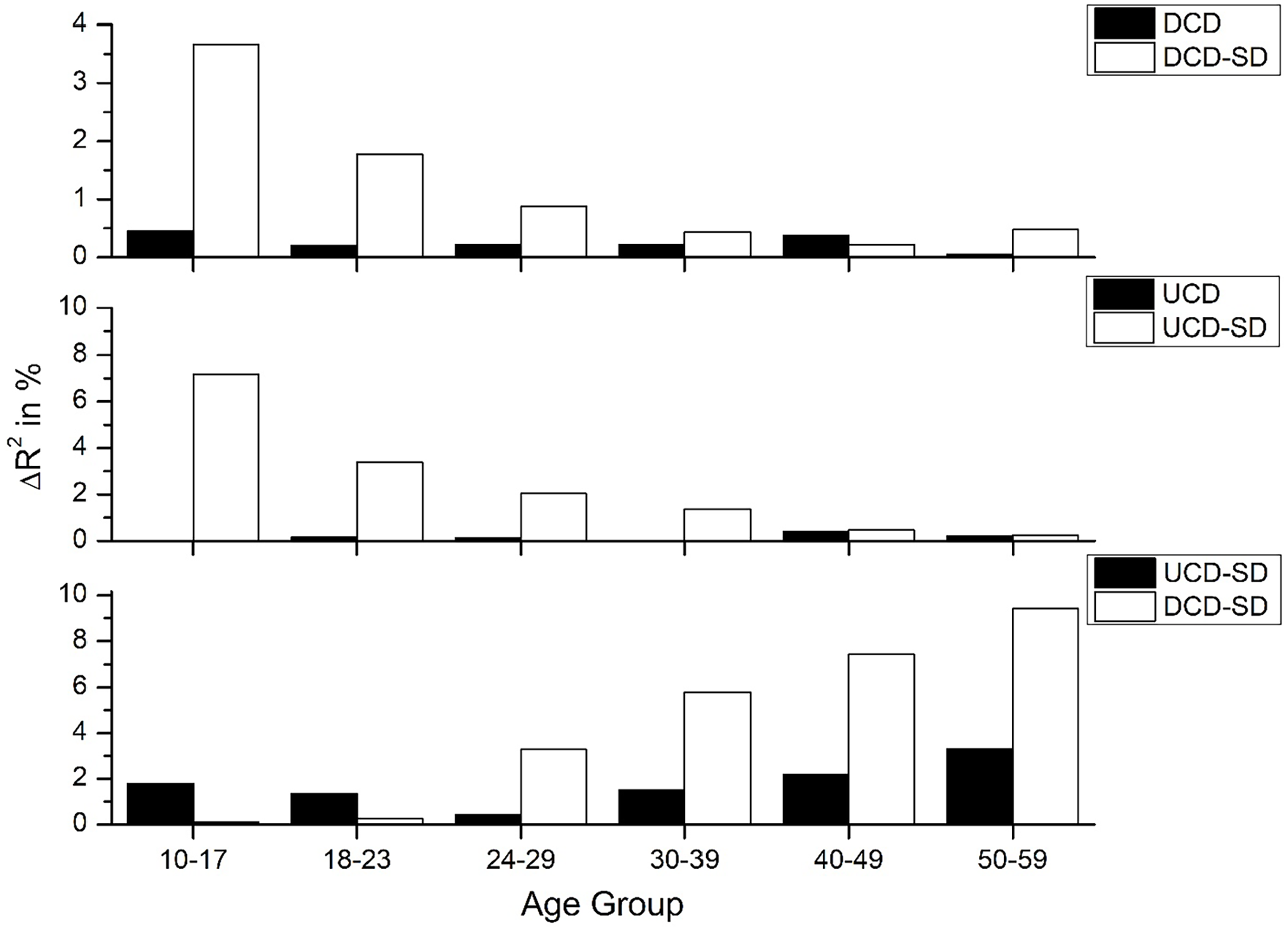
Amount of unique variance that the SD-derived measures account for over their count-based alternatives and each other for accuracy data.
To gain insight into why the SD-transformed models provide a larger advantage to the data for the younger, but not the older, age groups, Figure 11 displays the optimal λ parameter setting for both the UCD-SD and DCD-SD models across the ageing groups. This figure demonstrates that as participant age increases, the optimal λ value decreases, suggesting that there is differential weighting occurring for high versus low similarity contexts occurring for younger versus older people. This result sheds light on the diminishing advantage for the SD-transformed models across for the older age groups, as the count models is a nested model of the SD models (when λ is set at 0, the SD and count models are equivalent). The theoretical implications of this finding will be discussed further below.
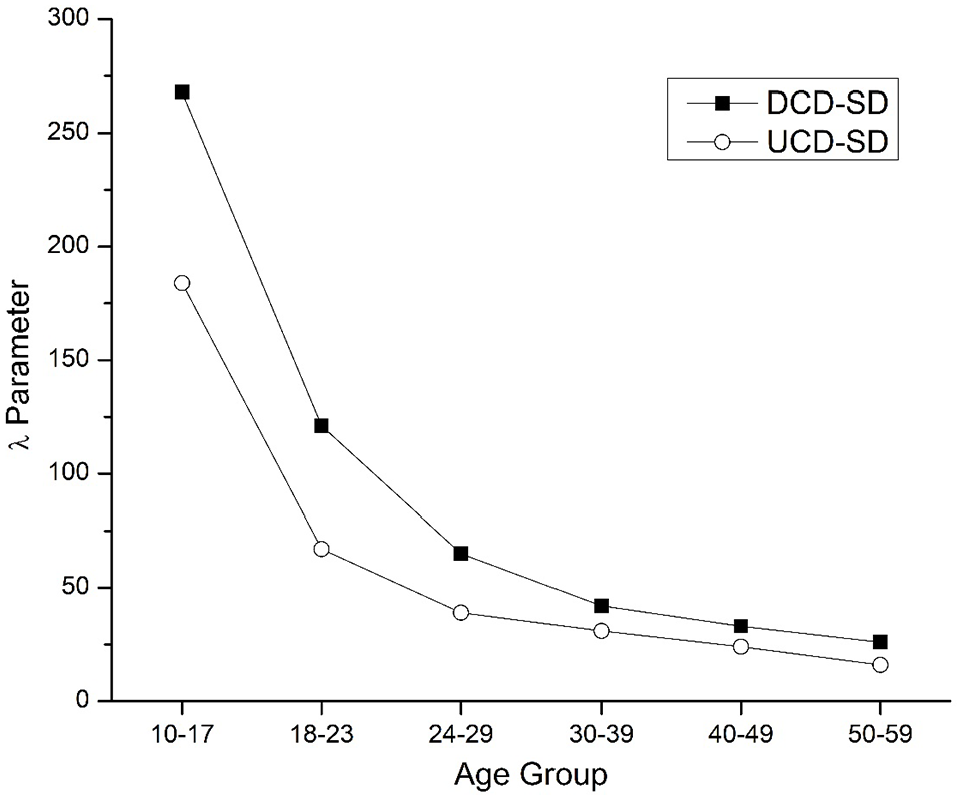
The optimal λ parameter for the SD-transformed CD models across the different ageing groups.
General discussion
The goal of this article was to determine if the advantage of the newly proposed CD measures of Johns (2021a), which are grounded in the communicative and social environment, is consistent across different age groups. We found that the new CD measures, entitled UCD and DCD, account for considerably more variance than WF and the traditional CD measure of Adelman et al. (2006) across all age groups. Consistent with past results (e.g., Johns, 2021a, 2022; Johns & Jones, 2022), the best fits were provided by the UCD and DCD measures transformed with the operations of the SDM (Jones et al., 2012), which weights word occurrences in a new context on a graded scale between 0 and 1.
However, there were differences in the advantages that the count-based and SDM measures provided in different age groups. For the count-based measures, there was a consistent increase in the advantage that the UCD and DCD measures provided over WF and CD (Figures 1 to 5), suggesting that these measures are more integrated into lexical organisation strategies for the older participants (similar to previous results; Johns, Sheppard, et al., 2016). However, the SDM-based measures had a different pattern of fit, where they offered a consistent increase in variance accounted for across all age groups. When the count- and SDM-based measures were directly compared with each other, it was found that the SDM measures provided a very large increase in variance accounted for in the younger subject groups but provided a very small advantage for the older age groups, where the two measure types accounted for similar levels of unique variance. It was found that this advantage was due to a reduction of the λ parameter for the older participant groups, which means that the count-based and optimal SDM measures are more similar for the older age groups.
The relative equivalency between the count and SDM measures for the older groups suggests an increased knowledge of context types with increasing age. As has been explored by Johns (2021a, 2022) and Johns and Jones (2022), the unique aspect of the SDM models utilising the socially based PR is that they provide an optimal fit when the λ parameter is maximised. This results in a very discriminative model where unique contextual occurrences, while a small percentage of all contextual occurrences, form most of a word’s lexical strength. From a likely need perspective, this suggests that the model is using the uniqueness of contextual occurrences to discriminate among different context types. However, the change in the importance of the SD models across ageing signals that with increasing age, people store more context types in memory—by reducing the λ parameter, the model interprets each context as being relatively equally important (compared with the model in which a high λ parameter is utilised), a major difference compared with the younger groups. This suggests that as people age and accumulate experience with the linguistic and social world, they develop more refined context-to-word connections. In contrast, younger people do not have the same amount of experience with their surrounding environment, and so have a more limited number of context types to which the current context can be compared with.
To further validate this hypothesis, a simulation was conducted using the count-based version of the SDM (entitled SDM_count) previously used by Johns and Jones (2022) and Johns (2022). In this version of the model, all contextual occurrences of a word where the semantic distinctiveness value (see equation [2]) exceed a set criterion increase a word’s strength by 1, with contextual occurrences that do not exceed that criterion not contributing to a word’s lexical strength. Thus, the SDM_count measure is a count of the number of highly distinct contexts that a word occurs in. If older people have more context types in memory, then they should have a lower criterion when fitting to their data, with the opposite pattern being found for younger people. The value of the criterion set is dependent on the λ parameter (as it controls the distribution of SD values), so the model was fit using a λ parameter of 60, which was kept constant for each age group. The model was optimised by maximising the correlation to each age group’s RT data, testing all criterion values between 0 and 1 in steps of 0.01. The DCD-SD was the model utilised for this simulation.
The results of the simulation are presented in the top panel of Figure 12, which displays the optimal criterion for the different age groups. This figure shows that for the youngest group, there is a very stringent criterion used when maximising the model’s performance, which is systematically reduced as group age increases. To determine the impact that this had on the probability of a contextual occurrence being included in a word’s lexical strength, the bottom panel of Figure 12 contains the percentage of all contextual occurrences that were included with the age groups set criterion. This figure shows that for the 10–17 group, the optimal fit of the model came when including only 6.05% of all contextual occurrences, which rises across the age group, and is at its peak for the 50–59 age group, which includes 75.79% of all contextual occurrences.
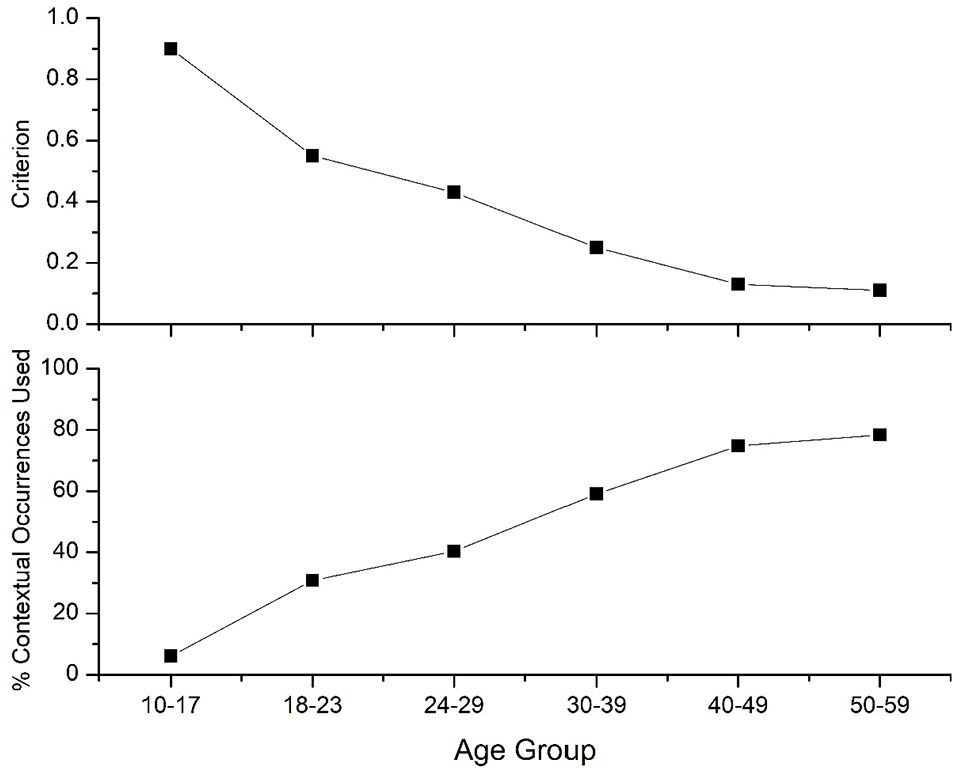
The results of a simulation using the SDM_count model. The top panel displays the optimal criterion set for model performance across the age groups, while the bottom panel displays the percentage of contextual occurrences that were used with the corresponding criterion values.
There are multiple explanations for the results displayed in Figures 11 and 12, which point to a greater number of word-to-context connections for older compared with younger people. The first is that older people, through their increased amount of accumulated experience with the world, have knowledge of a greater number of context types in which a word could occur. This results in the optimal model being more similar to the count-based DCD, rather than the SD models which best account for the younger people’s behaviour, because the older participants have acquired more word-to-context knowledge. This proposal is congruent with the information accumulation perspective of Ramscar et al. (2014). An alternative proposal is that older people have a decreased ability to discriminate between different context types, compared with younger people, resulting in more redundant contextual information being attached to words. This could be due to the decline of various cognitive systems, such as executive function and working memory, which decline with age (e.g., Park & Festini, 2017). It is difficult to discriminate among these possibilities using the methodologies employed here, but should be a topic for future research.
The other consistent finding here was that a shift in the utilisation of the UCD and DCD measures was observed across ageing, whereby the UCD measures offered the best fit for the younger age groups while the DCD measures offered the best fit for the older age groups. As a reminder, UCD operationalises linguistic context as a single individual, while the DCD operationalises linguistic context as a discourse topic. One possible account for this shift is that younger people may organise their lexicon to maximise their communicative effectiveness based on the people that they are likely to communicate with, while older people might organise their lexicon based on the overall discourse context within which they will be communicating. Such an effect may be related to learning—younger people do not have sufficient knowledge of the range of possible discourses where communication could take place but do have a considerable amount of social experience with others, enabling a more individual-focused organisational strategy rather than a discourse-focused one. Validating this hypothesis seems like a promising pathway for targeted behavioural experimentation, for instance, by manipulating user and discourse information within a natural language word learning experiment (see Johns, Dye, & Jones, 2016; Mak et al., 2021; Snefjella et al., 2020 for some possible experimental set-ups).
Recently, there has been a sustained effort to determine the impact of WF on word recognition in ageing populations (e.g., Brysbaert et al., 2017; Cohen-Shikora & Balota, 2016; Davies et al., 2017; Diependaele et al., 2013; Mandera et al., 2020). As can be seen in Table 1, when assessing the SUBTLEX norms of Brysbaert and New (2009) to the data across the ageing groups, there is a reduced fit for both RT and accuracy from the ECP data to SUBTLEX WF across the ageing groups (Mandera et al., 2020 reported a similar finding). However, there is a different pattern for the Reddit data, whereby we observe a consistent increase in the correlation for all lexical strength variables from the 10 to 17 age group to the 30–39 group, with a reduction seen for both the 40–49 and 50–59 groups. This suggests that different corpora can result in different conclusions about the impact of WF on word recognition in ageing, whereby the utilisation of WF from one corpus can result in a different conclusion than WF from a different corpus (see Taler et al., 2020 for a similar result examining differences in corpus construction using verbal fluency data across ageing and corpus types). The issue of variance in different linguistic corpora has been recently examined in detail by Johns and Jamieson (2018, 2019) and Johns et al. (2019, 2020), who demonstrated that the best-fitting WF distributions for a given dataset are based on the demographic characteristics of the participants from whom the data were collected. For example, WF distributions from books with authors born in the United Kingdom account for data collected in the United Kingdom better than WF distributions from books with authors born in the United States (Johns & Jamieson, 2019).
The issue of corpus specificity and ageing presents a fundamental challenge to assessing the impact of language statistics to differences seen in language processing with increasing age. The reason why the impact of WF has been so often studied in psycholinguistics is because it provides insight into the connection between environmental statistics and lexical organisation. However, the type of language experience that any particular individual receives is dependent on many factors, such as the culture they are embedded in, their personal preferences for entertainment, their educational status, and their age, among many other characteristics. Thus, to accurately assess the impact of WF, or any lexical strength variable, there needs to be an understanding of the type of linguistic knowledge that is encoded in a corpus and how it maps onto the population of language users whose behaviour is under study. In the case of the current study, the language statistics contained on Reddit may be more representative of the type of language used by the 10–17 to 30–39 groups, given that these people in these age groups may be more likely to engage in communication on this website, but older adults may not be overly engaged in social interactions on this site.
Among many interesting aspects of the ECP data collected by Mandera et al. (2020) is that they included participants of age 10–17 in their analysis. We have found that the developmental trajectories in this age group, in terms of the usage of different sources of lexical information, is coherent with the patterns found for adult groups. This finding suggests that adolescents may be a promising participant population to examine the impact of lexical experience on language processing, given that this group has a necessarily more limited experience with the language environment, and they may thus serve as a useful counterpoint when examining older adults’ lexical behaviours. A unique component of the adolescent age group is that they likely have much more experience with and consume information from social media at a greater rate than older generations. This increased experience may change the type of contextual information that these individuals pay attention to. Thus, by building lexical organisation models with social media resources may provide an ability to identify how exposure to this type of information changes language processing, an important consideration for future research.
One limitation of the analysis used here is that it only examines a rather limited sample of the ageing spectrum, from 10 to 60 years old. Although it is difficult to run lexical decision experiments on younger individuals who are developing literacy, the finding that the UCD-based measures provide a large advantage over WF and the DCD measures may be a consequence of the learning mechanisms used during the acquisition of language. Specifically, usage-based theories (e.g., Tomasello, 2003) propose that language acquisition is based on the observation of understanding of how others use language within a communicative environment. Thus, paying attention to patterns of individual language usage may be a critical source of information in language acquisition, which leads to a carryover effect that is seen with the adolescent group in this article with the UCD measures being the most important variable to explain their language processing patterns. As individuals age, discourse-based information becomes more important. Given the little change that was found in the superiority of the DCD measures for the older groups, it would be expected that this dominance should be maintained for adults over the age of 60. However, the impact of these variables on individuals who are experiencing cognitive decline is an open question.
The goal of experiential theories of cognition is to understand the connection between the variance in human experience and the variance in human behaviour. The use of WF in models of lexical organisation provides a prototypical quantitative theory of this type, as it demonstrates that words that occur more often in the lexical environment are processed more efficiently. Measures of CD offer a reformulation of classic WF effects in lexical organisation by demonstrating that it is not simply the occurrence of a word that matters to word learning and processing but also that the surrounding context of that occurrence is important. The study of ageing is also a study of the role of experience in cognition, as older adults have necessarily experienced more information than younger adults. The results of this article point to the importance of examining the impacts of different lexical strength measures, such as CD, across the ageing spectrum in the development of experience-based theories of cognition.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Natural Science and Engineering Research Council of Canada (NSERC) Discovery Grant RGPIN-2020-04727 to B.T.J.