
Abstract
Word recognition is facilitated by primes containing visually similar letters (dentjst-dentist), suggesting that letter identities are encoded with initial uncertainty. Orthographic knowledge also guides letter identification, as readers are more accurate at identifying letters in words compared with pseudowords. We investigated how high-level orthographic knowledge and low-level visual feature analysis operate in combination during letter identification. We conducted a Reicher–Wheeler task to compare readers’ ability to discriminate between visually similar and dissimilar letters across different orthographic contexts (words, pseudowords, and consonant strings). Orthographic context and visual similarity had independent effects on letter identification, and there was no interaction between these factors. The magnitude of these effects indicated that high-level orthographic information plays a greater role than low-level visual feature information in letter identification. We propose that readers use orthographic knowledge to refine potential letter candidates while visual feature information is accumulated. This combination of high-level knowledge and low-level feature analysis may be essential in permitting the flexibility required to identify visual variations of the same letter (e.g., N-n) while maintaining enough precision to tell visually similar letters apart (e.g., n-h). These results provide new insights on the integration of visual and linguistic information and highlight the need for greater integration between models of reading and visual processing.
Introduction
Understanding the processes that underpin letter identification has been a long-standing goal within experimental psychology. Readers must maintain enough flexibility to recognise that gate and GATE are the same word, but also enough precision to recognise that gate and gale are not. Research shows that readers activate letter representations rapidly despite wide-ranging variability in their visual form (e.g., case and font; Bowers et al., 1998; Hannagan et al., 2012; Kinoshita & Kaplan, 2008). However, existing literature also reveals that this flexibility extends beyond letter identity in the initial moments of visual word recognition. Masked priming paradigms demonstrate that word recognition is facilitated by prior presentation of stimuli that contain visually similar letters (dentjst-DENTIST vs dentgst-DENTIST, Marcet & Perea, 2017; docurnent–DOCUMENT vs docusnent–DOCUMENT; Marcet & Perea, 2018a), numbers (C4BLE-cable vs C9BLE-cable; Kinoshita et al., 2013; Perea et al., 2008), or symbols (C^BLE-CABLE; Perea et al., 2008). Evidence from eye-tracking shows facilitation from visual feature similarities, shown by shorter fixation times for target words in sentences when parafoveal preview contains a pseudoword neighbour with a visually similar letter compared with a visually dissimilar letter (e.g., frjed-fried vs frged-fried; Marcet & Perea, 2018b). Event-related potential data also demonstrate that strings containing letter-like numbers can facilitate lexical access, as such strings evoke similar N400 semantic responses to the words they resemble (4PPL3-APPLE; Lien et al., 2014). Together, these findings suggest that the process of letter identification may consist of an accumulation of information about visual features.
Readers draw upon their knowledge of the writing system to support letter identification processes. For example, readers adjust prioritisation of different visual features as they gain expertise in an unfamiliar alphabet, to discriminate between letters (Wiley et al., 2016). Letter identification is guided by orthographic knowledge, such as knowledge of legal letter combinations or existing words. Consequently, the contexts in which letters appear can significantly alter readers’ ability to discriminate between them. Readers identify letters more accurately when they appear in a real word compared with a pseudoword (Coch & Mitra, 2010; Grainger & Jacobs, 1994; Kezilas et al., 2016; Reicher, 1969; Wheeler, 1970). This word superiority effect is understood as evidence that word representations enrich letter identification processes (Grainger & Jacobs, 1996; McClelland & Rumelhart, 1981; Rumelhart & McClelland, 1982). Letter identification is also more accurate in pronounceable pseudowords (pable) compared with unpronounceable consonant strings (pkwtj) (Baron & Thurston, 1973; Carr et al., 1978). This pseudoword superiority effect suggests that letter identification is also guided by readers’ knowledge of orthotactic constraints (i.e., restrictions on how letters combine within a writing system; Kezilas et al., 2016). Thus, orthographic knowledge appears to play a key role in resolving early uncertainty around letter identity, and may reduce confusability from shared letter features. However, this line of research has not generally tested or controlled for effects of visual feature similarity.
Other work has explored whether precise visual feature information is less influential on letter identification when top-down orthographic information is available to compensate. Researchers have investigated this question by distorting the visual appearance of letters and measuring readers’ abilities to recognise them in different letter string contexts. Letter distortion is more disruptive in single letters (Fiset et al., 2008) and pseudowords (Rosa et al., 2016) compared with real words. Therefore, existing research indicates that readers use orthographic knowledge to resolve inconsistencies in visual feature information, whether it is distortion from visual noise (Fiset et al., 2008; Rosa et al., 2016) or substitution of a visually similar letter appearing in a word-like string (e.g., dentjst, Marcet & Perea, 2017). However, these scenarios typically involve readers encountering an invalid string and measuring how quickly they recognise the closest word neighbour. Less is known about whether orthographic context reduces ambiguity from visual feature similarity if both letters result in an equally valid string. Readers often encounter this situation, as they must distinguish between word neighbours with similar looking letters (e.g., gate-gale). Based on previous findings, we would expect visually similar neighbours (gate-gale) to be harder to distinguish than visually dissimilar neighbours (gate-game). But how does letter confusability change across orthographic contexts? To our knowledge, researchers are yet to investigate whether orthographic context mediates readers’ ability to discriminate between visually similar letters if they both result in a string with an equivalent word or non-word status.
High-level orthographic knowledge and low-level visual feature analysis both play a key role in letter identification, but less is known about how they interact. The visual forms of letters are highly variable; therefore, readers may use orthographic context to compensate for inconsistencies in visual feature information. Orthographic distributional knowledge provides information on how individual characters relate to each other, as readers can learn from the contexts in which letters co-occur (Schubert et al., 2020). This knowledge can reinforce mappings between variable letter shapes and identities, provide cues on the expected visual form (such as case and font), and assist in refining potential letter candidates while visual feature information is still being accumulated. These context cues not only assist readers in overcoming within-letter visual variability but also reduce the likelihood of confusing visually similar letters. Therefore, cues from orthographic context may play a role in constraining letter candidates to manage the balance of flexibility and precision required during letter identification. If so, letter confusability from visual similarity may be reduced when wider orthographic information is available.
The focus of this work was to examine how high-level orthographic knowledge and low-level visual feature analysis work in tandem during letter identification. We conducted a Reicher–Wheeler task to compare readers’ abilities to discriminate between letters with high and low visual feature similarity across words, pseudowords, and consonant strings. We predicted that readers would be less accurate at discriminating between two letters with high visual feature overlap (m-n) relative to two letters with low visual overlap (m-t). We also predicted that letter identification would be more accurate in words relative to pseudowords, and pseudowords relative to unpronounceable consonant strings, in line with word (Reicher, 1969; Wheeler, 1970) and pseudoword superiority effects (Baron & Thurston, 1973; Carr et al., 1978). Finally, we predicted that letter confusability from visual similarity would be reduced when letter-strings aligned with orthographic and orthotactic knowledge, as we proposed that readers would use their knowledge of words and legal letter combinations to narrow down plausible letter candidates. Therefore, we predicted an interaction where accuracy differences between letters with high and low visual feature similarity would be smaller in words compared with pseudowords, and in pseudowords compared with consonant strings.
Method
Data availability
This study was pre-registered on the Open Science Framework (OSF). Pre-registration, stimuli, instructions, trial-level data, and analysis scripts are openly available (https://osf.io/p4q9u/).
Participants
Seventy-two monolingual English speakers completed the experiment at Royal Holloway University of London, in exchange for £5. All participants were aged 18–35, with normal or corrected-to-normal vision, and no previous history of reading difficulty. The sample size was determined alongside the number of items (24 items per condition) to meet the suggested criterion of 1,600 observations per condition for analyses using linear mixed-effects models (24 × 72 = 1,728 observations per condition, Brysbaert & Stevens, 2018). All participants provided informed consent prior to taking part.
Stimuli
Target stimuli consisted of 48 words, 48 pronounceable pseudowords, and 48 unpronounceable consonant strings. These three target stimuli conditions comprised the independent variable of orthographic context. Each target stimulus was assigned a target letter that was present within the stimulus, and two possible foil letters that were not present in the stimulus. Foil letters had either high visual feature overlap or low visual feature overlap with the target letter. This manipulation formed our second independent variable: visual feature similarity (high vs low). The critical target and foil letters included in visual similarity comparisons were the same across each orthographic context condition. Substitution of the target letter with either of the foil letters always resulted in a string with the same orthographic context status as the target (e.g., word: s
Visual feature similarity was quantified using 7-point letter similarity ratings from over 700 people (Simpson et al., 2013). Target letters had a mean similarity rating of 4.19 with foil letters in the high-overlap condition compared with 1.22 with foil letters in the low-overlap condition, t(47) = 24.8, p < .001. This difference between high- and low-overlap conditions was confirmed with a second, objective measure of visual similarity derived from the Hierarchical Model and X (HMAX, Mutch & Lowe, 2008), a biologically motivated computational model that mimics properties of the human ventral visual system through a series of simple (S1, S2) and complex (C1, C2) layers. We used HMAX S1 layer computations to calculate letter similarities, as this layer was modelled upon the earliest instance of feature detection. HMAX calculations revealed that target letters had a mean similarity rating of 0.59 with foil letters in the high-overlap condition compared with 0.50 with foil letters in the low-overlap condition, t(47) = 6.25, p < .001. HMAX and reader ratings were positively correlated, r(323) = .49, p < .001.
Procedure
Participants completed a Reicher–Wheeler task consisting of 144 trials, administered using DMDX (Forster & Forster, 2003). Within each trial, participants viewed a 500 ms fixation cross, followed by a forward mask for 33 ms. A target letter-string (a word, pseudoword, or consonant string) then appeared for a predetermined duration (see below), before a hash symbol (#) backward-masked each letter of the target for 100 ms. During this time, a probe bar (|) appeared above and below one of the hash symbols, which indicated that the participant should identify the letter in the specified position. After 100 ms, a target letter and a foil letter replaced the probe bars above and below one of the hash symbols. The foil letter had either high visual feature similarity or low visual feature similarity to the target letter. Participants then had 5,000 ms to make a button-press response to indicate which of the two letters was present within the string. Targets were counter-balanced to ensure that participants received an equal number of foil letters across high and low visual feature similarity conditions and to ensure that participants saw each target letter-string once.
Target exposure duration was determined for each participant based on performance in an initial staircase-thresholding task (adapted from Davis, 2001), which used the same trial procedure and mask durations as the main task. In the thresholding task, exposure duration began at 33 ms and adjusted after each response. If the participant correctly identified the target letter, exposure duration was reduced by 17 ms. If the participant incorrectly identified the foil letter, exposure duration increased by 17 ms. Exposure duration was held constant after 12 changes in direction, and this value set target exposure duration for each participant in the main task. Exposure during the main experiment was 33 ms for 36 participants, 50 ms for 22 participants, 67 ms for 13 participants, and 83 ms for 1 participant. The exposure durations were similar to previous Reicher–Wheeler studies with skilled adult readers (Chase & Tallal, 1990; Coch & Mitra, 2010; Grainger et al., 2003; Kezilas et al., 2016; Lété & Ducrot, 2008).
Results
Mean accuracy results are visualised in Figure 1. Accuracy data were analysed using logistic generalised linear mixed-effects models with the lme4 package (Version 1.1-12; Bates et al., 2015) in R (Version 4.0.4; R Core Team, 2016). The maximal model was defined as: glmer (Accuracy ~ Exposure Duration + (Visual Feature Similarity × Orthographic Context) + (1|Participant) + (1|Item), family = binomial). Continuous predictors (exposure duration) were centred around the mean. Categorical factor predictors (visual feature similarity and orthographic context) were dummy coded, which resulted in each level of the factor being compared to a specific level acting as a reference. For the fixed effect of visual similarity, accuracy in the high visual similarity condition was compared to accuracy in the low visual similarity condition as the reference. For orthographic context, accuracy performance for words and pseudowords was compared to accuracy performance for consonant strings as the reference. Therefore, the intercept of the model referred to accuracy performance within the two reference conditions (discriminating between low visual similarity letters in consonant strings).
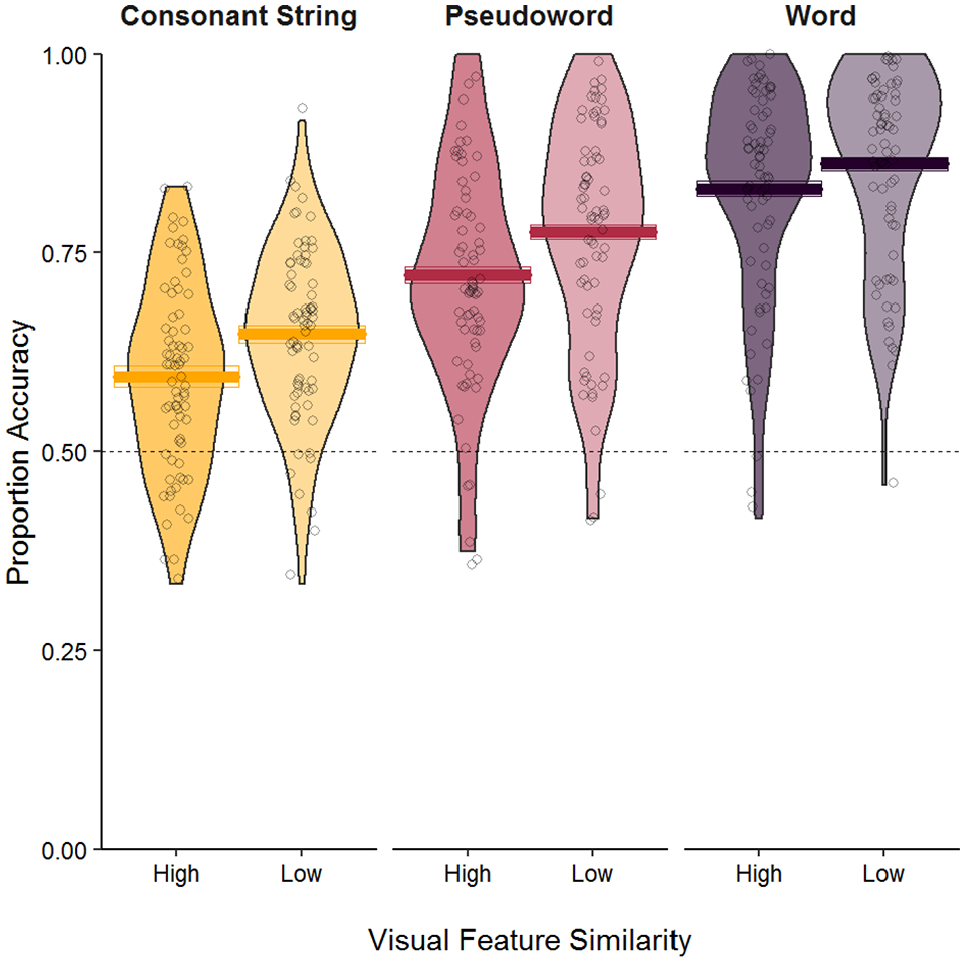
Mean accuracy rates for letter identification in the Reicher–Wheeler task.
We investigated whether each component improved the model fit using pairwise likelihood ratio tests (LRTs), in which random effects, main effects, and the interaction term were systematically added in turn (Matuschek et al., 2017). The model fit was improved by random effects of participant, LRT: χ2(1) = 269.76, p < .001, and item, LRT: χ2(1) = 160.59, p < .001. We then added the fixed effect of exposure duration, which referred to the duration each letter string was presented for based on participant performance in the preliminary thresholding task. The fixed effect of duration exposure continued to improve the fit of the model, LRT: χ2(1) = 16.75, p < .001. Next, we included our fixed effects of interest. The fit of the model significantly improved after including the fixed effects of orthographic context, LRT: χ2(2) = 494.61, p < .001, and visual feature similarity, LRT: χ2(1) = 32.24, p < .001. However, including the interaction term did not significantly improve the model fit, LRT: χ2(2) = 0.36, p = .838. This indicated that there was no significant interaction between visual feature similarity and orthographic context. We opted to preserve the interaction term despite it not improving the fit, as this enabled us to test our pre-established confirmatory hypothesis that orthographic context mediates effects of visual feature similarity (see Roettger, 2019). After establishing the model fit, we ran the model and iteratively redefined the dummy-coded reference level of orthographic context to systematically compare all levels to each other. Fixed and random effects results are reported in Table 1. Beta (β) and odds ratios (ORs) are used to report effect sizes. β is the logit transformed fixed effect coefficient, which refers to the estimated difference between conditions having controlled for random effects. OR (derived from β) measures the difference in odds of being correct (vs incorrect) in one level of a fixed effect compared to another.
Logistic generalised linear mixed-effects model output for analysis of exposure duration, visual feature similarity, and orthographic context on letter identification.
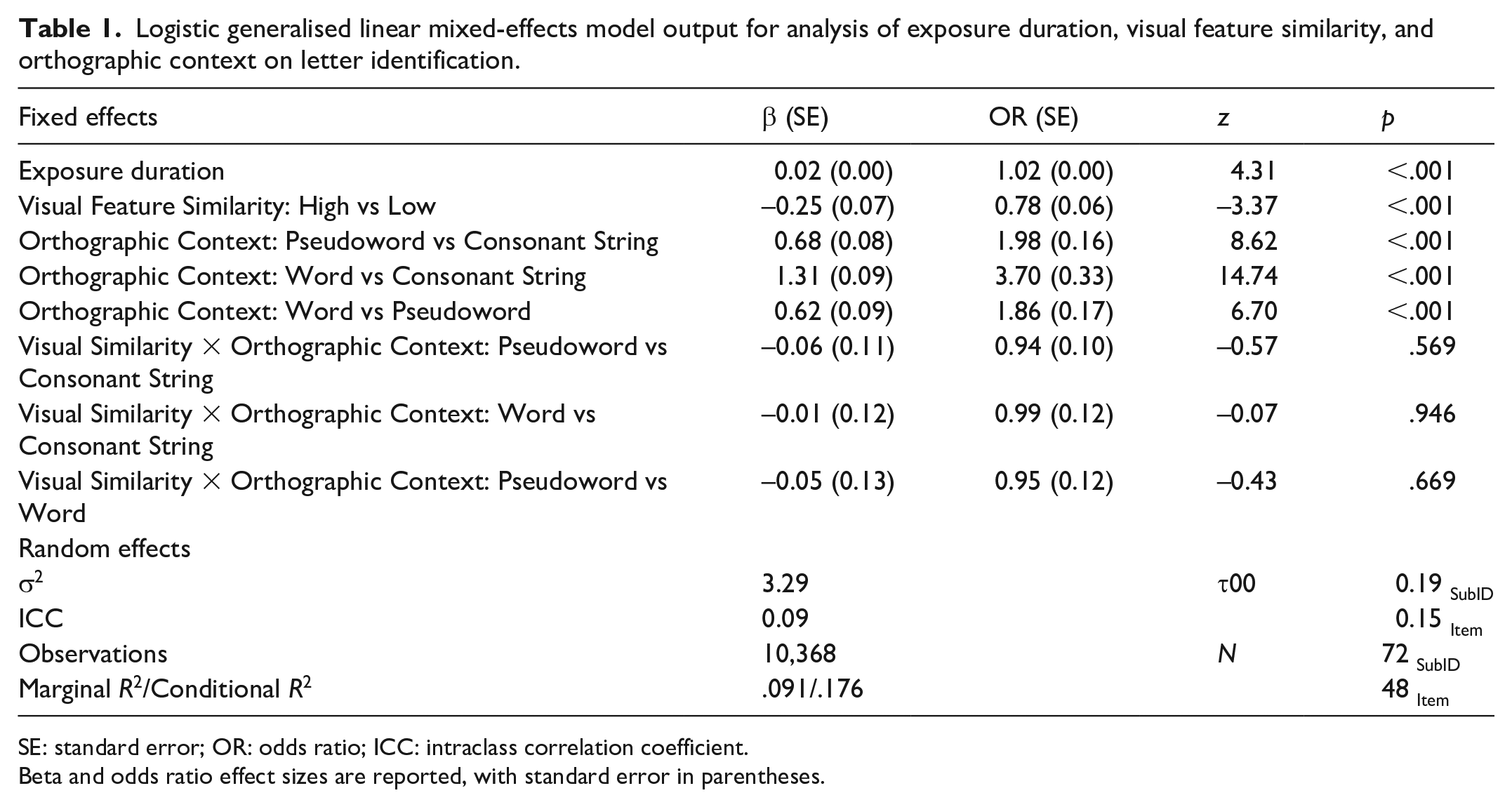
SE: standard error; OR: odds ratio; ICC: intraclass correlation coefficient.
Beta and odds ratio effect sizes are reported, with standard error in parentheses.
There was a significant main effect of visual feature similarity on letter identification accuracy. The odds ratios suggest that participants were 0.78 times as likely (or 22% less likely) to select the correct letter when the foil letter had high visual overlap with the target. There was also a significant main effect of orthographic context on letter identification accuracy. Participants were 1.86 times more likely to correctly identify the target letter in words relative to pseudowords and 3.70 times more likely to correctly identify the letter in words relative to consonant strings. Participants were also 1.98 times more likely to correctly identify the letter in pseudowords relative to consonant strings.
There was no evidence of an interaction between visual feature similarity and orthographic context. The interaction term did not significantly improve the fit of the model and the estimated odds ratios for interaction effects were close to 1 (ORs: 0.94–0.99 or between 1% and 6% less likely), which indicates an equivalent likelihood of high visual similarity reducing letter identification accuracy in either orthographic context. These estimated reductions are unlikely to predict a meaningful difference, as the degree of uncertainty (shown by standard error in Table 1) indicates that each of these estimates could span either side of OR = 1 with sampling error considered. As an additional measure, we conducted exploratory Bayesian analyses to establish whether the absence of an interaction provided evidence for the null hypothesis (i.e., that effects of visual feature similarity are not modulated by orthographic context), or whether there was insufficient evidence to infer a conclusive outcome. Using the motivated maximum approach (Silvey et al., 2021, based on principles of Dienes, 2014), we calculated Bayes factors (BFs) from the interaction estimates produced by our logistic mixed-effects model. BFs were calculated using a half normal distribution (HN). Bayesian results are reported with parentheses expressing the mode of the distribution (first number), and the standard deviation (second number) in convention with Silvey et al. (2021). All BFs were lower than 0.3 (Visual Similarity × Pseudoword vs Consonant String: BFHN(0,0.11) = 0.11, Visual Similarity × Word vs. Consonant String: BFHN(0,0.12) = 0.17, Visual Similarity × Word vs. Pseudoword: BFHN(0,0.13) = 0.05). This indicated moderate evidence for the null hypothesis (Lee & Wagenmakers, 2014; Silvey et al., 2021) that orthographic context does not mediate effects of visual similarity.
Our Bayesian analyses provided evidence that there was no interaction. However, there remains a small possibility that our study was underpowered to detect it (Brysbaert, 2019), despite our relatively large sample size (N = 72) and large number of observations per condition (Brysbaert & Stevens, 2018). Thus, we ran Monte Carlo power analyses on simulated datasets to estimate the interaction effect sizes that could have been reliably detected with our sample size. Power analyses and measures taken to protect against issues of post hoc interpretation are reported in further detail on the OSF. Using the simr package (Version 1.0.5; Green & MacLeod, 2016) in R (Version 4.0.4; R Core Team, 2016), we systematically increased hypothetical interaction effect sizes by β = 0.05 and ran 50 simulations for each increment, beginning at β = 0.1. For each simulation, we modelled a larger effect between words and consonant strings relative to words and pseudowords under our hypothesis that visual similarity effects would have a greater impact on letter identification when less orthographic information is available. Our sample size (N = 72) yielded 80% power to detect an interaction with an effect size of β = 0.3 between visual similarity differences in words and pseudowords, and an effect size of β = 0.4 between visual similarity differences in words and consonant strings. The equivalent odds ratios demonstrate that we had the power to detect an interaction if the benefit of having two visually distinct letters was at least 1.35 times more likely to improve letter discrimination in pseudowords relative to words, and 1.49 times more likely in consonant strings relative to words. These analyses show that, if there was an undetected interaction between visual similarity and orthographic context in our data, it was smaller than the effect sizes stated above.
Discussion
Our results revealed effects of orthographic context and visual feature similarity on letter discrimination accuracy in a Reicher–Wheeler task. Performance improved as letter strings became more word-like (words > pseudowords > consonant strings), replicating the word superiority effect and the pseudoword superiority effect (Baron & Thurston, 1973; Carr et al., 1978; Reicher, 1969; Wheeler, 1970). Performance was also superior when the discrimination involved letters with low visual similarity compared with letters with high visual similarity. There was no interaction between the effects of orthographic context and visual feature similarity; visually similar letters were more confusable irrespective of how closely the target letter string aligned with a real word. Odds ratios indicated that effects of orthographic context were much larger than effects of visual feature similarity, which suggests that top-down orthographic knowledge may be relatively more important than bottom-up feature information in establishing letter identities.
We had hypothesised that there would be an interaction between visual similarity and orthographic context, such that effects of visual feature similarity would be stronger where there is less high-level orthographic information available. However, there was no evidence to suggest that the impact of visual similarity on letter confusability varied across word, pseudowords, or consonant strings. Exploratory Bayesian analyses indicated moderate evidence against an interaction, although increased power could provide the benefit of greater certainty. Power simulations revealed that our design was not powered to detect the interaction effect sizes revealed in the model output (Table 1); thus, these estimates of the interaction effect size need to be treated with caution. However, detecting an interaction effect of this size would require a sample of at least 5,000 participants (based on 80% power, calculations available on the OSF). It may be more constructive in future research to determine what an ecologically meaningful interaction effect size would be and calculate power accordingly.
Our findings advance current understanding of letter identification in several ways. First, we believe this work to be one of the first to demonstrate effects of visual feature similarity on letter identification within a Reicher–Wheeler paradigm. This departs from previous work investigating visual feature similarity, which has mostly been restricted to masked priming (although see also Marcet & Perea, 2018b, for parafoveal preview effects). The current work demonstrates that effects of visual feature similarity are not task-specific and have implications for multiple levels of processing. Pre-existing evidence from masked priming demonstrated that visual feature similarity has a discernible influence on low-level perceptual processing (i.e., visual similarity between the prime and the target) and processes that rely upon broad lexical knowledge (i.e., visual similarity between the prime and known word strings), whereas the current findings show that visual feature similarity also impacts processing when readers are required to specifically discriminate between letter candidates.
Second, this study has taken a new approach to investigating visual similarity effects, by investigating the impact of shared featural information across letters that result in equally valid letter strings (i.e., both letters result in a real word, for example). In masked-priming paradigms, researchers have typically compared visual overlap between pseudoword and word neighbours, whereby the pseudoword is the prime and the word neighbour is the target (e.g., dentjst-dentist vs dentgst-dentist; Marcet & Perea, 2017). This has yielded powerful initial evidence that shared featural information can be beneficial for visual word recognition, as readers are faster at overcoming discrepancies between a letter string and the closest known word form if the two are visually similar. When relating to real-life reading experience, this advantage is akin to recovering from a typing or spelling mistake. In contrast, the current work investigates an alternative problem, as it is one of the first to investigate the influence of visual similarity when discriminating between letters that result in equally plausible word forms. In this scenario, readers are not assessing overlap between the visual input and an expected letter form, but instead distinguishing between competing letter identities. This is an alternative but also common challenge during reading, as readers routinely discriminate between word neighbours with similar looking letters (e.g., gate-gale). This critical difference provided a new insight: visual feature similarity may benefit visual word recognition when one letter is more likely to occur than the other, but it can also be disadvantageous if both letters are equally plausible, as it hinders readers’ ability to discriminate between them. This suggests that readers refine potential letter candidates while visual feature information is still being accumulated. Visual feature similarity impedes visual word recognition when both letters are equally viable, as neither competitor has been disregarded as an unsuitable candidate.
This interpretation is further supported by an additional novel conclusion from this work, which relates to how cues are weighted during letter identification. The influence of orthographic context was much larger than the influence of visual feature similarity, which suggests that top-down orthographic knowledge may be prioritised over bottom-up feature information during letter identification. This differential weighting may again occur because orthographic knowledge plays a critical role in filtering letter candidates, enabling readers to maintain the balance of flexibility and precision required for letter identification. Readers must incorporate a certain degree of flexibility when mapping low-level visual features to letter identities, as the visual appearance of letters can be highly variable. However, allowing greater flexibility also increases the risk of letter confusability. We propose that orthographic knowledge mitigates this risk while visual feature information is still being accumulated, by disregarding unlikely letter candidates and prioritising those that would result in a real word or an orthotactically legal letter string.
This finding has important theoretical implications, as understanding the weighting attributed to word-level (or “string-level”) cues relative to visual feature cues is essential for understanding the integration of visual and linguistic information. This proposed “mid-level vision stage” of orthographic processing (Grainger, 2018) is often under-specified in cognitive models of reading, as feature-level processes are either assumed a priori or minimally outlined (Marcet & Perea, 2017). There has been greater focus in neuro-biological models of reading. These models propose that mechanisms for visual object identification interact with linguistic processes to facilitate visual word recognition. For example, the local combination detector model (Dehaene et al., 2005) proposes that readers hierarchically encode increasingly large fragments of orthographic information that advance in linguistic complexity (features, letter shapes, abstract letter identities, bigrams, substrings) in the visual ventral stream, with increasing sensitivity to linguistic probabilities within the writing system. The model outlines how feature-level information may be incorporated based on principles of the primate visual system; readers amalgamate oriented bars and local contours to detect letter shapes, which are then used to inform abstract letter representations invariant of font or case. Thus, the local combination detector model is able to explain why visually similar letters are more confusable. However, this model assumes a one-way feed-forward approach, which restricts its ability to explain how orthographic knowledge reduces letter confusability. Without incorporating feedback, it is difficult to align this account with our finding that orthographic status has a much larger influence on letter confusability than low-level visual similarity, particularly as this was observed in a Reicher–Wheeler task with limited exposure to the visual input.
Alternatively, the influence of orthographic knowledge on refining letter candidates can be characterised by principles of cascaded processing, whereby later stages of word processing are implemented before earlier stages are completed (McClelland, 1979). Cascaded processing can explain why effects of visual feature similarity are outweighed by cues from lexical information when available, as word-level feedback plays a greater role in activating letter representations compared to bottom-up activation from feature-level information alone. Recent neural evidence has indicated how cascaded processing may be incorporated into existing neuro-biological models, following detection of feedforward and feedback activity within the ventral stream (Woolnough et al., 2020). Woolnough et al. (2020) found that posterior regions were the earliest to show increased activation in response to orthographic stimuli; however, these regions also demonstrated sensitivity to lexical status later than anterior regions. Differences in early and late selectivity could reflect cascaded processing, as word-likeness recognised in anterior regions may propagate backwards and interact with letter-level processing in posterior regions. Thus, there is potential to inform a cascaded model which could incorporate both the analysis of visual information and feedback from linguistic knowledge.
The greater weighting attributed to high-level orthographic information could otherwise potentially be explained by Bayesian models of reading, which propose that visual word recognition is achieved by readers combining tentative evidence with knowledge of prior probability (Norris, 2006; Norris & Kinoshita, 2012; Norris et al., 2010). Under this interpretation, bottom-up analysis of low-level orthographic features constitutes the tentative evidence and integration of top-down orthographic knowledge shapes the priors of the expected visual word representation. The greater influences of high-level orthographic cues (i.e., word status) relative to low-level visual cues (i.e., feature information) may be due to readers having stronger priors for letter combinations associated with known word representations or phonotactically legal letter combinations, which requires less detailed analysis of the visual evidence. It is less clear how these principles would be ingrained in visual processing, although there is again potential to consider the compatibility of these principles with existing neuro-biological or visual models of reading. For example, previous neuro-imaging work has documented how top-down predictions influence the sensory processing of speech (Davis & Sohoglu, 2020; Sohoglu et al., 2012). Future work could investigate similar principles for reading within the visual domain.
In conclusion, the current study demonstrated that letter identification is supported through a balance of information from visual features and high-level orthographic knowledge. Our results showed that visually similar letters are more confusable than dissimilar letters, indicating that readers encode letter identities with initial uncertainty, based on feature information. Word and pseudoword superiority effects demonstrated that readers also use orthographic knowledge of known words and legal letter combinations to resolve early uncertainty around letter identity. In the absence of an interaction, there is no evidence to suggest that orthographic context mediates effects of visual similarity specifically. Instead, our findings indicate that orthographic knowledge and visual feature similarity have an additive effect on letter identification. This work provides a novel insight that high-level orthographic information plays a greater role than low-level visual feature information in letter identification. We suggest that this is a result of readers using orthographic knowledge to refine potential letter candidates efficiently while visual feature information is still being accumulated. More broadly, this work advances understanding of the integration of visual and linguistic information and highlights the need for greater cross-examination between models of reading and visual processing.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funding from the Economic and Social Research Council (ES/P00072X/1).