
Abstract
Previous research on event coding has shown that, by default, bindings are binary and elemental, that is, individual objects or single features of these objects can retrieve responses separately and independently. In our study, we applied these findings to the automatic retrieval of former deceptions. Specifically, we investigated whether the person or the question to which one has answered deceptively can retrieve this knowledge independently, or whether there is also evidence for configural retrieval processes that use a combination of person and question information to retrieve the truth status of former episodes. We found evidence for retrieval based on single cues (i.e., person or question), supporting that the elementary retrieval of episodes by independent cues also holds in the context of retrieving knowledge about former lies.
When we are in trouble, we sometimes search for a way out of the situation by telling a lie. If this works fine, we are successful in deceiving someone for the moment, but we still run the risk of being detected on a future occasion. Therefore, we should remember at least some details about our lie, for instance, what we were asked about, or to whom we have lied. Recent research provided first evidence for a retrieval mechanism that helps us to remember the lies we have told in response to certain questions: when re-encountering a question that one has lied to before, the knowledge about having lied is automatically retrieved from memory (Koranyi et al., 2015; Schreckenbach et al., 2020). Similarly, memory retrieval has been found for the conversational partner that one has lied to on a former occasion (Schreckenbach et al., 2019). The aim of the present research was to find out whether these findings can be replicated in a more complex surrounding where different cues are simultaneously available for storage and retrieval.
Specifically, we investigated whether the combination of the question and the person to whom one had lied boosts retrieval effects over and above what question and person information can retrieve when they are presented in isolation. This question is relevant for both theoretical and practical purposes. On a theoretical level, this study informed us whether retrieval processes in the context of lying are organised in an elemental way, allowing independent retrieval for single features or single objects that were part of the respective episode, or whether retrieval can also be organised in a more complex, configural fashion that requires combinations of features or objects for efficient episodic retrieval.
On a more practical level, our study informed us whether retrieval of knowledge about having lied will generalise across different persons (for a certain question) or across different questions (for a certain person), as would be predicted by an elemental perspective on retrieval, or whether and when retrieval of this knowledge is confined to the specific combination of question and person to whom one has lied.
Analysing retrieval of knowledge about lies from an episodic retrieval perspective
The main assumptions of the present approach to memory storage and retrieval of lies are derived from theories of instance-based automatisation of behaviour (Logan, 1988; see also Denkinger & Koutstaal, 2009; Hommel, 1998, 2004; Rothermund et al., 2005). Within these theories, it is assumed that information about the execution of an action together with certain situational cues becomes stored as an episodic unit in memory (alternatively called an event file, Hommel, 1998, 2004; instance, Logan, 1988; or stimulus-response episode, Rothermund et al., 2005; see also Mayr & Buchner, 2006). These episodes are retrieved from memory and become automatically reactivated when one encounters a similar situation again, which then enables the person to act fast and consistently across different situations. Only recently, a broad framework has been provided that aims at explaining a vast range of research findings in the field of action control and automatisation from an episodic retrieval perspective (Frings et al., 2020). However, while we use the structural logic of binding and retrieval theories, there is also an important difference between these accounts and the present study: while binding and retrieval theories mainly focus on transient bindings, we were looking for retrieval effects across larger time intervals spanning minutes rather than seconds that fall within the area of long-term memory. Crucially, we assume that episodes are stored in and can be retrieved from long-term episodic memory (e.g., Schmidt et al., 2016), which differs from what is typically assumed in the event coding literature, namely, that bindings are transient and are dissolved and replaced by new bindings as soon as any element of the binding episode is re-encountered in a new episode (Hommel et al., 2001). Still, in terms of structural similarity, our retrieval effects still can be considered as analogues of typical event coding, in that they capitalise on the retrieval of information that can be either compatible or incompatible with current response requirements.
Applying the perspective of episodic memory retrieval to the field of deception, Koranyi et al. (2015) developed a paradigm in which participants first took part in an oral interview and afterwards were tested for automatic memory retrieval of knowledge about having lied in a priming task. Participants received instructions to tell the truth to half of the questions asked during the interview but to lie to the other half. Afterwards, they had to perform a simple classification task where the probe words honest (in German: ehrlich) and dishonest (in German: gelogen) had to be identified by pressing a corresponding key. Immediately before each probe, a question of the interview was presented as a task-irrelevant prime to test whether responding to a probe word was facilitated by a corresponding prime question. In line with the predictions, the probe word dishonest was identified faster than the probe word honest when preceded by a question that had been answered dishonestly during the interview. This result was interpreted as automatic 1 retrieval of the knowledge of having lied to a question when the same question is encountered again. Similar retrieval mechanisms were observed not only for questions but also for the person to whom one has told a lie versus the truth (Schreckenbach et al., 2019). In the corresponding study, participants performed the same classification task after an interview while being primed with facial pictures of their former interrogators. Again, results revealed a congruency effect indicating that person cues automatically retrieve knowledge about the truth status of one’s former behaviour in former interactions with this person.
While the results of these studies can be taken as first evidence for an automatic memory retrieval of knowledge about former lies, the exact nature of the operation of the retrieval processes is still unclear. Do people retrieve the truth status of their previous statements separately and independently for questions and persons, or do they use combinations of these cues (i.e., a specific person asking a certain question) to guide their retrieval of knowledge of having lied to this person with regard to this question?
Drawing on the large literature on episodic binding and retrieval, there is overwhelming evidence that “bindings are binary,” that is, the situational elements of an episode (objects or features of objects) are typically bound with the co-occurring response in binary stimulus-response (S-R) episodes, enabling each individual object or feature to retrieve the given response separately and on its own (e.g., Giesen & Rothermund, 2014, 2016). Evidence for more complex, configural processes that require combinations of features or objects for retrieval is rare and is confined to situations in which the elements of the initial episode are either not identified in an automatic and independent fashion (Moeller et al., 2016) or when they form contextual backgrounds (Mayr et al., 2018).
The present article aims to transfer these findings into the field of deception, thereby providing a more applied perspective on the memory retrieval mechanisms that are involved in our memory about having lied or told the truth. More specifically, we want to investigate whether different features of the episode in which one has lied (i.e., information regarding the question and the person who asks the question) can retrieve the episode independently, reflecting elemental and independent retrieval, or whether the combination adds something unique to the retrieval process that is not captured by the separate elements, reflecting configural retrieval.
Our former studies suggest that episodic retrieval of lies also follows the principle of elemental retrieval processes: although participants always encountered combinations of relevant cues during the interview situation (e.g., a specific person asking specific questions), single cues in the subsequent priming task were sufficient to produce retrieval effects (Koranyi et al., 2015; Schreckenbach et al., 2019). The ability of single cues to retrieve episodic information supports the claim that each feature of an episode can retrieve the episode independently and on its own. Therefore, the assumption of a configural integration of these cues seems unnecessary, which is why we assume retrieval processes to be elemental and independent by default. However, we have not yet investigated this topic in a systematic fashion in previous studies. Most importantly, we have not compared retrieval effects for single and combined cues, which is why we cannot rule out the possibility that the matching combination of cues might still have a super-additive effect on retrieval, indicating the existence of configural retrieval.
From an applied perspective, recalling one’s former lies across different persons and different questions is typically required to remain fully consistent with one’s lie across different future situations. Often, it is necessary to deceive not just one person with respect to a specific issue; to remain consistent one should tell this lie to a range of different people (e.g., when lying about an exam one failed, this needs to be done consistently to people who know each other [one’s friends, parents, siblings] in order not to be detected). A similar generalisation is also required when it comes to future interactions with the person whom one has told a specific lie: remembering the lie one told before to a specific question will make it easier to respond consistently when interacting again with the same person even when these future interactions centre on a different topic. Answers to other questions may have some thematic overlap with the question to which one lied before, which requires that one adapts the answers to these questions to stay consistent with the original lie. An independent and elemental binding of both person and question information to the knowledge of having lied or told the truth guarantees such generalisation effects, because each of the cues (person or question) on its own suffices to retrieve the knowledge about having lied before, which seems desirable from a functional perspective. Therefore, we predict elemental retrieval when it comes to the knowledge of one’s former statements, as this knowledge usually is of general relevance, either with regard to other people or other questions/topics.
A first pilot study that we conducted to address this question, however, yielded somewhat surprising results (see Supplementary Material 1 for a full description of the methods and results of this experiment): we found the typical retrieval effects for question cues to which one had told the truth or lied when they were combined with a picture of the interviewer who had posed these questions during the previous interview. These effects were eliminated, however, when the questions were combined with a picture of an unknown person. The latter finding may indicate that combinations of the person and the question were used to retrieve information in a configural way, necessitating a joint presentation of the combination to retrieve the truth status of the former response. This conclusion, however, would be in conflict with our former findings where we found reliable retrieval effects for single cues. Alternatively, the findings might be explained if one assumes that combining questions with an unknown face can interrupt retrieval.
The current study
We conducted another experiment to investigate the question of elemental versus configural retrieval in the context of truths and lies more systematically, and under more ecologically valid and meaningful conditions. Participants took part in oral interviews and afterwards performed a classification task in which they had to indicate via key press whether a presented probe was the word honest or the word dishonest. As primes, we presented a combination of the different cues that were used in former studies on automatic memory retrieval of deception (i.e., questions—Koranyi et al., 2015; Schreckenbach et al., 2020—and persons—Schreckenbach et al., 2019). With this manipulation, we also increased the complexity of this paradigm, thereby mirroring more lifelike conditions where multiple social interactions with different persons take place in close temporal succession (one estimate being 12 interactions per day; see Zhaoyang et al., 2018), and similar or the same questions can be posed by different people. Combining question and person cues during the test also resembles everyday interactions where multiple cues (i.e., person and question cues) compete for the retrieval of previous episodes.
The experiment was designed to test whether different cues are used for memory retrieval of the knowledge about having lied and whether these cues are used in combination (configural retrieval) or individually (elemental retrieval). We used a similar experimental design as in Schreckenbach et al. (2020) where participants met two different interrogators and had to lie to one of them while telling the truth to the second one. However, this time, participants were asked the same set of questions about the two different topics by each of the interrogators. Their task was then to always be honest to one of the interrogators while lying about one of the two topics to the other one. Thereby, we increased the complexity of the interview situation, while establishing a more realistic proportion of lies and truths with the truth being predominant and lies being told only rarely (cf. DePaulo et al., 1996; DePaulo & Kashy, 1998).
During the subsequent classification task, participants were presented with pictures of either one of their actual interrogators or an unknown person. On top of this picture, a question from the interview appeared, thereby leading to several different combinations of primes: the picture of a person whom participants always told the truth could be combined with (a) a question that they also always answered truthfully or (b) a question that they sometimes had answered deceptively. Similarly, the picture of the deceived person could be combined with (c) a question that was always answered truthfully or (d) the question to which the person had lied. Finally, we also used unfamiliar faces as primes in combination with questions that were either answered (e) truthfully or (f) sometimes deceptively to see whether the recognition of the questions alone led to an observable retrieval effect. In the following, we will describe the two different hypothesised outcomes corresponding to either elemental or configural retrieval (see Figure 1 for a visual presentation of the predicted patterns of results):
H1. Elemental retrieval: According to the elemental account, both kinds of cues retrieve knowledge about the truth status of the response independently of each other. Due to the higher salience and rarity of lies, having lied to a person or question only once suffices to connect this person or question with knowledge about having lied (Koranyi et al., 2015; Schreckenbach et al., 2020), whereas consistent truth-telling will connect the person or question with a “truth” mark. 2 The elemental retrieval account thus predicts compatibility effects of both person and question cues that sum up—or neutralise each other—in an additive fashion (Figure 1a). If person and question primes retrieve the same type of knowledge, strong compatibility effects favouring responses to either true (probe word honest) or false (probe word dishonest) responses are thus expected if both person and question retrieve knowledge about having spoken the truth or having lied, respectively. If person and question primes retrieve opposite information, however, the resulting compatibility effect should be close to zero. If the person prime is neutral (unknown person), the question prime should still retrieve information facilitating either true or false responses for questions to which one has told the truth or lied, respectively, but these effects should be weaker than those in which both person and question retrieve the same information. Statistically, this pattern corresponds to two independent main effects of person and question primes on the resulting compatibility effects (i.e., the difference in responding to honest and dishonest primes).
H2. Configural retrieval: According to a configural account, it is always the specific combination of person and question that retrieves the knowledge about the truth status of the answer that one gave in response to this specific combination (see Figure 1b). In this case, we expect a facilitation of the probe word honest whenever the picture of the person to whom one always told the truth is presented. The effect should not differ between the two types of question primes because all questions were answered truthfully in the presence of this person. That is, even when the person is paired with a question to which one has lied before, but to a different interviewer, the specific combination should retrieve information about the truth of the answer that was given to this specific combination of person and question. For the prime picture of the person to whom one has lied (to some questions), we expect compatibility effects that depend on the type of the question that is presented as a prime. A facilitation of the probe word honest (compared with the probe word dishonest) is expected after the presentation of the question to which participants told the truth, whereas a facilitation of the probe word dishonest (compared with the probe word honest) is expected after the presentation of the question that participants lied to during the interview with this specific interviewer. Finally, no compatibility effects are expected to emerge whenever a prime picture of an unknown person is shown, regardless of whether the questions were always answered truthfully or were lied to during the interview. The reason for this absence of effects is that the specific combinations of person and question had not been encountered before and thus are unable to retrieve any information from memory. Statistically, this hypothesis corresponds to an interaction of person and question primes on the resulting compatibility effects, with different types of questions pushing the compatibility effect into opposite directions when combined with person primes to which one has (sometimes) lied, but having no effect on the resulting compatibility effects when combined with persons who are either unknown or to whom one has always told the truth.

Predicted compatibility effects (positive values reflect faster identification of the probe word dishonest, thus indicating retrieval of the knowledge of having lied) for elemental (H1) and configural (H2) retrieval as a function of prime picture (truth vs. lie vs. unknown) and prime question (truth vs. lie).
Based on the clear dominance of elemental retrieval in the event coding literature, and also based on our previous findings of reliable retrieval effects of lies for single cues, we favour the elemental retrieval account. Given that the findings of our pilot study can also be interpreted to suggest configural retrieval, we do not want to rule out the possibility that configural retrieval may emerge under certain conditions. To provide optimal conditions for the occurrence of configural retrieval processes, we let the two experimenters ask the same set of questions in the current study. With these instructions, it is important not to confuse to which interviewer one has lied and told the truth to a particular question. Our experiment was thus designed to provide a strong test for configural retrieval processes—if they exist, they should show up under these conditions.
Method
Participants and design
The study has been conducted in accordance with ethical standards and was approved by the Ethical Commission of the Faculty of Social and Behavioural Sciences of the University of Jena (FSV 19/18). The sample size was determined relying on previous experiments by Koranyi et al. (2015) and Schreckenbach et al. (2019), who found effect sizes between
Materials
The material for the interview comprised eight questions, four of which related to one of two different topics (university and friendship; see Supplementary Material 2 for a complete list). Each question was created to touch a personally important issue but at the same time should not be too intimate to prevent participants from answering untruthfully even if they were instructed to tell the truth. The same set of eight questions was asked by both interviewers during the interview, but the assignment of topic to response instruction was counterbalanced across participants, as was the order of topics during the interview.
As prime pictures, we used facial photos of four interrogators on which they wore the same clothes, hairstyle, and accessories as in the actual interviews. All pictures had a size of 400 × 600 pixel (px), with each person’s eyes placed at the same position in the upper half of the picture (approximately 200 px below the top). Participants were assigned to one of several couples of interrogators, with pictures of this couple serving as familiar and pictures of a different couple serving as unfamiliar prime picture stimuli during the priming task. To avoid confounds, only female interrogators were used.
Procedure
Upon arrival, participants were seated in front of a computer and received instructions on the screen. First, they were informed that they would participate in two successive oral interviews. Then, the picture of a female interrogator was presented on the left side of the screen, while on the right side the interviewer’s name, the topics that participants would be asked about, and the instruction whether to always tell the truth or to lie to one given topic were presented (e.g., “This is Clara. Clara is going to ask you some questions about the topics ‘friendship’ and ‘university.’ Please tell her the truth always.”). After reading and memorising these instructions, participants received complementary instructions about the second female interrogator (e.g., “This is Sophie. Sophie is going to ask you some questions about the topics ‘friendship’ and ‘university.’ Please tell the truth to all questions about friendship but lie to all questions about university.”). In addition, participants were prompted not to reveal their dishonesty to the interrogator and to act so as to convince her of the truthfulness of all of their statements. To achieve this goal, participants were instructed to always wait for some seconds before providing each answer. The order of instructions as well as the assignment of topic or interrogator to response instruction were counterbalanced across participants, as was the order of topics during the subsequent interviews. After the instructions, participants were guided to a separate room where they met the first interrogator. After the first interview, the interrogator left the room and the second interrogator entered to conduct the second interview. During the two interviews, the same set of eight questions was asked by the two interviewers.
Priming task
After the interviews, participants performed a priming task in which primes consisting of a combination of a person and a question were used as retrieval cues for the knowledge about one’s former statements. Each trial had the same temporal structure (see Figure 2): a fixation cross (500 ms) was followed by a prime picture, showing either an interrogator or an unknown person. After 300 ms, the prime question was presented upon the prime picture, approximately at the position where the eyes in the pictures were located (200 px below the top). The question was presented word by word using RSVP (rapid serial visual presentation) with a base duration of 250 ms per word, plus an additional 25 ms per letter. Right after the last word of the prime question, the probe word appeared at the same position of the screen. Participants were asked to decide as fast as possible whether a presented target was the word ehrlich (English: honest) or gelogen (English: dishonest, having lied) by pressing either the D or the K key on the keyboard. The assignment of response keys to probe word was counterbalanced across participants. To ensure that probe words were encoded and identified not only on a perceptual but also on a semantic level, they were degraded by inserting alphanumeric characters between the letters (e.g., §$eh&$r§li#c%h instead of ehrlich). The locations of these additional characters within the probe words were determined randomly for each trial, ensuring a large degree of variability between the probe stimuli. Both stimuli (i.e., the facial photo of the interviewer and the probe word) remained on the screen until the participant responded by pressing one of the assigned keys on the computer keyboard. The next trial was initiated after an inter-trial interval of 750 ms. The priming task comprised 240 experimental trials with order of trials randomised individually. The prime pictures of the interrogators were presented 80 times each, while two different unfamiliar pictures were presented 40 times each. Familiar pictures 10 times preceded each of the 8 questions from the interview while unfamiliar prime pictures did so 5 times. Every combination of primes was half of the times followed by the probe word dishonest and half of the times by the probe word honest. To ensure semantic processing of the prime questions, 24 experimental trials (randomly chosen out of the 240 trials) comprised an additional memory task that had to be performed directly after classifying the probe word (see Wiswede et al., 2013). In the memory task, participants saw a question on the screen which was either the same (50%) or different from the prime question and participants had to answer the question “Is this the question that you’ve just seen?” Participants were not informed in advance whether a trial comprised the additional memory task or not, so they had to process the prime questions in each trial.
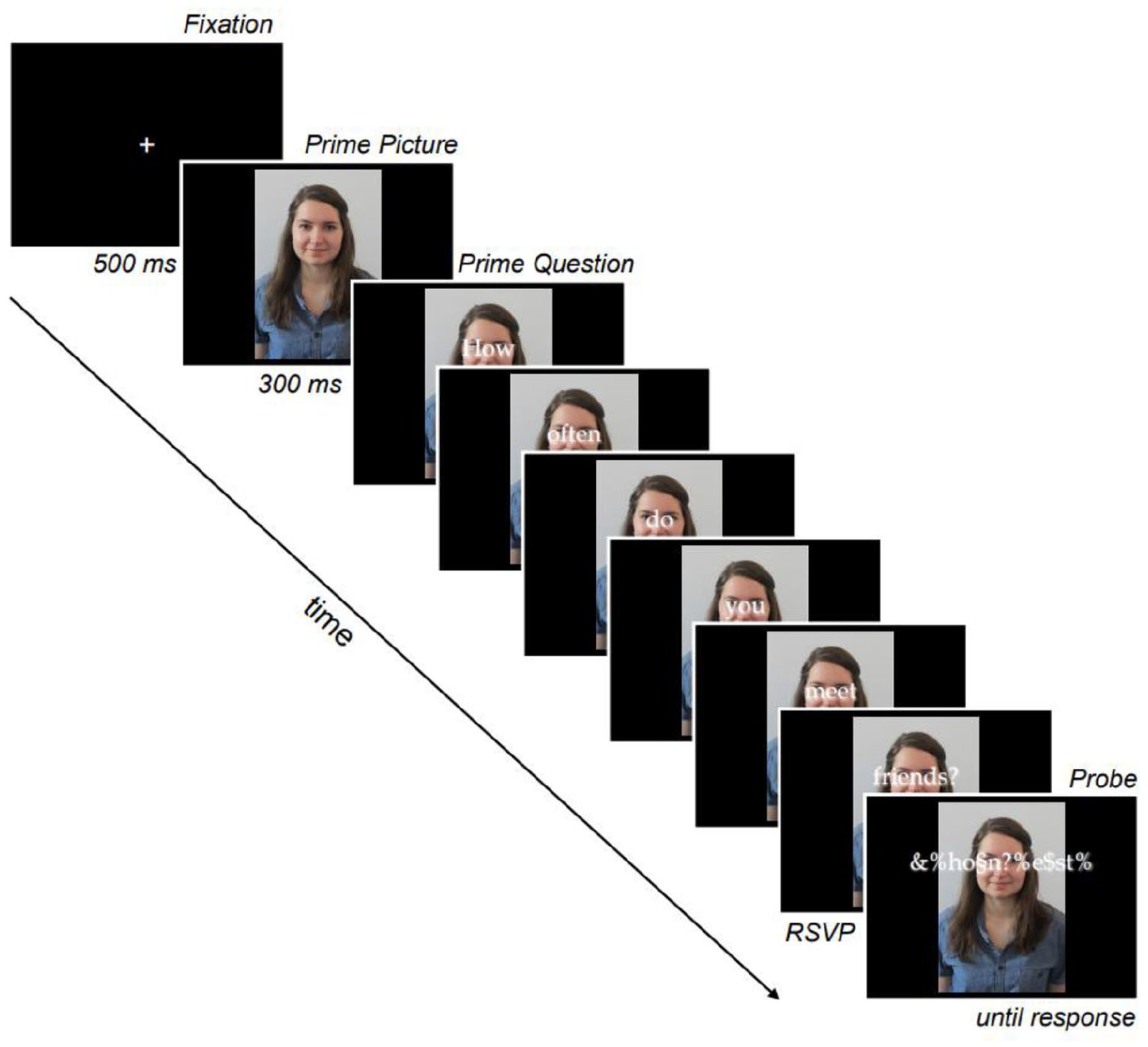
Trial structure of the experiment.
To ensure that the honest and dishonest keys maintained their semantic meaning across the experiment, 30 additional filler trials were randomly intermixed into the experimental trials that required a genuine true/false decision (see Eder & Rothermund, 2008; Wiswede et al., 2013). In the filler trials, a true (50%; e.g., “Saturn is a planet”) or false assertion (50%, e.g., “Einstein was a musician”) was presented word by word in the centre of the screen instead of a prime picture. The assertion was followed by the question “honest or dishonest?” that was presented as a response cue instead of a probe word. Participants had to evaluate the truth of the previously presented sentence by pressing the same keys that were also used for the honest/dishonest classification of the experimental trials. The whole experiment had a total duration of approximately 45 min.
Results
All response latencies that were more than one and a half interquartile ranges above the third quartile of an individual’s reaction time distribution were categorised as outliers (Tukey, 1977) and discarded (5.8% of all responses). All response latencies below the threshold of 250 ms were discarded (0.1%), as well as erroneous responses (4.0% of all responses). For each participant, we calculated the difference in response times for honest and dishonest probe words as an indicator of compatibility effects (RThonest – RTdishonest; positive values reflect faster identification of the probe word dishonest, thus indicating retrieval of the knowledge of having lied), separately for each combination of prime person and prime question in the factorial design (see Figure 3 for the pattern of means).
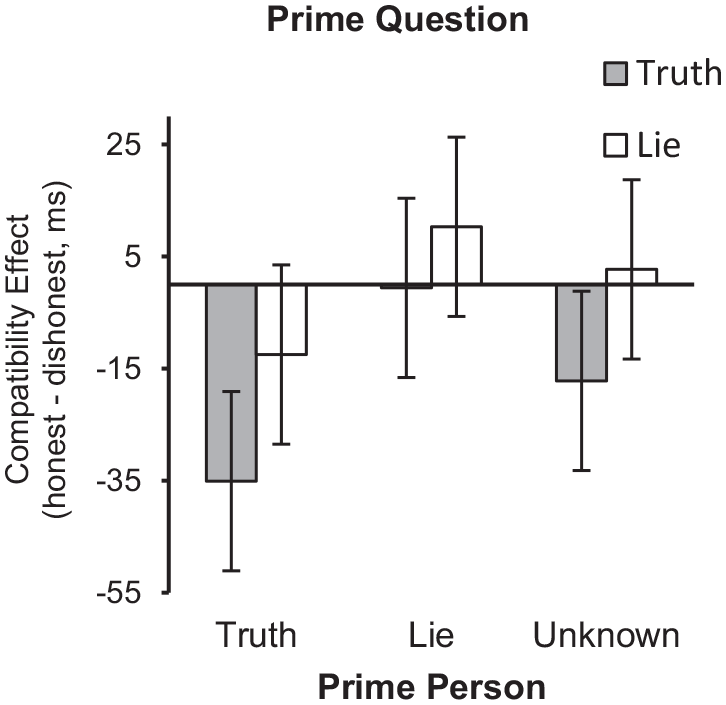
Average compatibility effects (positive values reflect faster identification of the probe word dishonest, thus indicating retrieval of the knowledge of having lied) as a function of prime picture (truth vs. lie vs. unknown) and prime question (truth vs. lie).
Analyses of variance
To test our assumptions, average compatibility effects were submitted to a 3 (prime picture: truth vs. lie vs. unknown) × 2 (prime question: truth vs. lie) analysis of variance (ANOVA) with repeated measures on both factors. We also specified two a priori contrasts for the factor prime picture to test whether retrieval of information occurred for both truthful and untruthful statements or mainly for one of them. The first contrast was specified to compare truth prime pictures with unknown prime pictures, whereas the second contrast compared lie prime pictures with unknown prime pictures. 3
Results revealed significant main effects for both factors. The prime picture significantly influenced compatibility effects, F(2, 60) = 6.52, p = .003,
Bayesian statistics
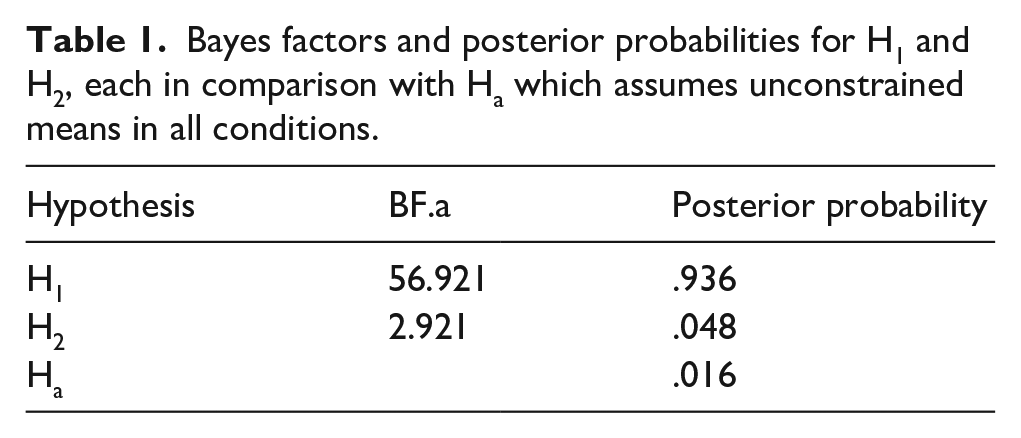
In order to compare probabilities for our hypotheses given the data, we also computed Bayes factors, using the R package Bain (Gu et al., 2018; Hoijtink et al., 2019). Implemented in Bain is the approximate adjusted fractional Bayes factor, which can be used for the evaluation of informative hypotheses (Hoijtink, 2012). The Bayes factors and the posterior probabilities (computed assuming equal prior probabilities) are displayed in Table 1. Constraints for H1 and H2 were defined in a way that they match the described data patterns in Figure 1 as well as our descriptions of the hypotheses. As can be seen, H1 is supported more than H2. A Bayes factor of 56.921 is usually seen as very strong evidence in favour of the H1. The Bayesian error probability associated with preferring H1 equals .064.
Bayes factors and posterior probabilities for H1 and H2, each in comparison with Ha which assumes unconstrained means in all conditions.
Discussion
The aim of our study was to test whether knowledge about having lied to a particular person about a specific question is retrieved by a combination of these cues in a holistic fashion (thereby leading to configural retrieval), or whether both kinds of cues (i.e., the person and the question) can trigger the knowledge about one’s former statements individually (corresponding to elemental retrieval processes). Both types of retrieval have been shown to take place in former studies on event coding, with elemental retrieval processes being the default. Although our experiment investigated long-term retrieval of information that is stored in episodic memory rather than tapping into transient feature-response bindings, we expected these processes to function similarly to binding and retrieval processes in action control (Schmidt et al., 2016). In line with these findings, we observed a pattern of results that closely matches the assumption of an individual retrieval. Specifically, we found independent retrieval effects for person primes and question primes supporting the conclusion that both types of cues can individually trigger the knowledge about having lied before. Another feature of our results that supports this view is the fact that question primes influenced retrieval even in the neutral condition, indicating that they can trigger retrieval of knowledge about having told the truth or a lie even when they were combined with unknown person primes with which they had never been shown before. Importantly, no interaction emerged between the two factors, indicating that the specific combination of person and question cues did not have an additional influence on retrieval effects, which speaks against a configural integration of the cues.
Our current findings correspond to the event coding literature, which also shows a strong predominance of elemental over configural binding and retrieval (e.g., Moeller et al., 2016). A major difference between our study and the event coding literature regards the time interval between the original episode and the test situation that is spanned by the retrieval process, with SR retrieval mechanisms typically investigating retrieval from one trial to the next (for exceptions, see DeSchepper & Treisman, 1996; Giesen et al., 2020; Schmidt et al., 2020; Waszak et al., 2003), whereas retrieval of knowledge about having lied spans much longer time intervals. Another important difference regards the fundamental assumption, which is at the core of the theory of event coding (TEC), that only one event file containing a certain feature can be active at a time, with subsequent encounters of the same stimulus or response code leading to a dissolution of the previous event file (Hommel et al., 2001). In contrast to this assumption, our findings clearly demonstrate that multiple episodes involving the same person and question are stored in and can be retrieved from episodic memory (e.g., the same person asked different questions, and the same questions were asked by different interviewers in our study, and all of these episodes were accessible during the test).
Despite these differences, however, the pattern of effects is highly similar across the two types of paradigms, which raises the question whether it makes sense to differentiate between these two kinds of explanatory accounts. Recent accounts of the episodic retrieval processes in action and cognition thus try to bridge the gap between short-term and long-term retrieval and to combine both phenomena within a single explanatory framework (Frings et al., 2020; Schmidt et al., 2016).
Our findings of elemental retrieval also correspond with our previous studies on the retrieval of knowledge about having lied in which we found evidence for reliable retrieval of single cues (Koranyi et al., 2015; Schreckenbach et al., 2019, 2020). Although we designed our study in a way that should favour configural retrieval for combinations of person and question cues, because the same question had to be answered differently during the interview depending on the interviewer who posed that question, we still did not find any evidence for configural retrieval under these circumstances. Apparently, elemental processing is the default in governing retrieval and also dominates in the retrieving information about having lied or told the truth to persons and questions.
Against this background, the finding of our pilot study still appears to be somewhat enigmatic, because we did not find evidence for effects of question primes on the retrieval of truth status when these questions were combined with pictures of unknown persons. Given that these effects were non-significant also in the current study, but descriptively pointed in the expected direction in both studies, we think it is most likely that the lack of these effects in the pilot study reflects a power problem, rather than being indicative of configural retrieval. We cannot rule out, however, that configural retrieval in the integration of person and question information might emerge under very special circumstances, and that our pilot study was an instance of those conditions.
One might wonder whether our findings actually reflect retrieval processes relating to the episodes that participants encountered during the interview, or whether the compatibility effects reflect a retrieval of the abstract experimental instructions that participants received for the interview. According to the latter, alternative interpretation, the mere instruction of lying/telling the truth to a certain topic or a specific person, is retrieved during the experimental task when the corresponding combination of primes is presented. In our view, however, such an instruction-based explanation of the compatibility effects can be rejected on the following grounds: first, in the current study, a cue-based retrieval of the instructions should lead to a pattern of results that matches the configural hypothesis, because the instructions were framed in a way that combines interviewers and questions (e.g., “Lie to Clara for questions referring to Topic A, but tell the truth to Clara for questions referring to Topic B.”). Our results, however, do not reveal this pattern of findings. For instance, we do not see a retrieval of the information that one should tell (and actually has told) the truth to Person A for questions relating to Topic A, if the person has lied to Person B on the same topic. Similarly, we do not see a retrieval of the information that one should tell (and has actually has told) the truth to Person A for questions relating to Topic A, if one has lied to the same person on the questions relating to Topic B. If anything, our findings could be explained by a partial retrieval of instructions relating to the person and question that are shown in the prime, without integrating this information to derive a specific response that matches the exact instructions that were given. We consider such a partial retrieval to be unlikely because it does not match the format in which instructions were actually presented to participants.
Furthermore, we addressed the question whether retrieval effects are based on a mere memory for instructions in two previous studies. One of these studies investigated questions as primes (Koranyi et al., 2015, Exp. 2) and the other one investigated pictures of interviewers and unknown persons as primes (Schreckenbach et al., 2019, Experiment. 2). In both studies, we found that priming effects indicating an association of a prime with the action plan of lying or telling the truth only occurred for those primes to which an actual lie or truth had been expressed. No such effect occurred for (a) other questions from the same domain, for which a lying instruction had been given, but that had not been presented during the interview, nor (b) for other persons that the same instruction to lie or tell the truth would have applied to.
Thus, although we did not directly address the question of instruction-based retrieval in the current experiment (e.g., we did not present questions relating to the same topics that were not presented during the interviews), we consider an alternative explanation in terms of memory for abstract instructions as being an unlikely explanation for the results of our current study, based on our current and also previous findings.
Conclusion
The present study extends the knowledge about automatic memory retrieval of the knowledge about having lied before by demonstrating that different cues (person and question information) to former lies are typically used for retrieving knowledge about having lied in an elemental way, which matches former findings from the SR binding literature (Giesen & Rothermund, 2014, 2016; Moeller et al., 2016) and also of our previous studies on automatic retrieval of knowledge about having lied (Koranyi et al., 2015; Schreckenbach et al., 2019, 2020). By default, these elemental retrieval processes guarantee that knowledge about having lied generalises across different persons and questions. The presence of just one cue that has been associated to the knowledge of having lied to the current person and/or the current question suffices to retrieve this knowledge from memory, and allows a flexible configuration of current response behaviour in order not to be detected as a liar.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218221085822 – Supplemental material for Feature-specific retrieval of the knowledge of having lied before: Persons and questions independently retrieve truth-related information
Supplemental material, sj-docx-1-qjp-10.1177_17470218221085822 for Feature-specific retrieval of the knowledge of having lied before: Persons and questions independently retrieve truth-related information by Franziska Schreckenbach and Klaus Rothermund in Quarterly Journal of Experimental Psychology
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data accessibility statement
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.