
Abstract
The self-voice plays a fundamental role in communication and identity yet remains a relatively neglected topic in psychological science. As AI-generated and digitally manipulated voices become more common, understanding how individuals perceive and process their own voice is increasingly important. Disruptions in self-voice processing are implicated in several clinical conditions, including psychosis, autism, and personality disorders, highlighting the need for integrative models to explain the self-voice across contexts. However, research faces two major challenges: a methodological one (i.e., replicating the bone-conducted acoustics that shape natural self-voice perception) and a conceptual one (i.e., a persistent bias toward treating the self-voice as purely auditory). To address these gaps, we propose a framework that decomposes the self-voice into five interacting components: auditory, motor control, memory, multisensory integration, and self-concept. We review the functional and neural basis of each component and suggest how they converge within distributed brain networks to support coherent self-voice processing. This integrative framework aims to advance theoretical and translational work by bridging psychology, neuroscience, clinical research, and voice technology in the context of emerging digital voice environments.
Our voice is a uniquely personal signal that manifests our identity in both overt and subtle ways. It reflects a distinctive configuration of auditory-acoustic features that convey physical attributes such as age, sex, and body size, alongside psychological and social traits, including aspects of one’s personality (Sidtis & Zäske, 2021). Like a vocal fingerprint, the self-voice thus serves as a powerful marker of individuality. It is the voice we hear most frequently throughout our lives because we are exposed to it every time we speak. It also functions as a primary vehicle for communication and self-expression, influencing how others perceive us and how we perceive ourselves. Notably, disruptions in self-voice processing have been implicated in clinical conditions such as psychosis (Pinheiro et al., 2017), autism (Chakraborty & Chakrabarti, 2015), and personality disorders (Orepic, Iannotti, et al., 2023), suggesting that self-voice perception plays a broader role in psychological functioning. Despite its relevance, the self-voice has received surprisingly little systematic attention in the cognitive sciences and in clinical research, especially compared with other self-related stimuli such as the self-face or body.
We argue that progress in self-voice research has been limited by two major challenges. The first is methodological: natural self-voice perception involves bone conduction, in which sound vibrations travel through cranial structures, modifying how one’s voice is perceived internally (Reinfeldt et al., 2010). This differs substantially from the air-conducted recordings typically used in experiments, which sound unfamiliar or even aversive to participants (Gur & Sackeim, 1979). Consequently, studies using digital self-voice stimuli may evoke unnatural perceptual and emotional responses, introducing confounds in both behavioral and neuroimaging paradigms. The second challenge is conceptual: people typically perceive their own voice as a purely auditory phenomenon, often unaware of the broader sensory and motor processes that support this perception. This auditory-centric perspective is mirrored in much of the self-voice literature, which has historically emphasized acoustic features over other modalities (see “Historical and Disciplinary Context” section). However, natural self-voice processing is inherently multimodal (Orepic, Kannape, et al., 2023), integrating auditory, motor, proprioceptive, and tactile feedback during speech production. These co-occurring signals likely shape how we identify our voice as our own, distinguishing it from other voices in the environment.
The study of the self-voice is particularly timely because advances in artificial intelligence (AI) increasingly enable seamless and realistic voice modifications. Altering how we hear our own voice can lead to short-term changes in cognition, emotion, and behavior. Similar to the Proteus effect, in which individuals adapt their behavior to align with their digital avatars (Yee & Bailenson, 2007), emerging evidence 1 shows that even brief exposure to a modified self-voice can influence personality traits (Fang et al., 2024), emotional states (Aucouturier et al., 2016; Costa et al., 2018), and social attitudes (Arakawa et al., 2021). For example, making one’s voice sound calmer can reduce anxiety during interpersonal conflict (Costa et al., 2018), whereas aging one’s voice with AI can reduce biases toward older adults (Arakawa et al., 2021). Similar but longer lasting effects are observed in clinical contexts such as gender transition or laryngectomy, in which changes to the self-voice reshape self-perception over time (Bickford et al., 2019; Bultynck et al., 2017). These findings highlight a powerful insight: modifying our voice changes not only how we sound but also how we perceive ourselves. Understanding how the brain integrates these altered signals opens new directions for neuroscience research, clinical intervention, and the design of voice-based technologies.
To address the gaps in self-voice research and guide future studies, we propose a new framework that decomposes self-voice processing into five interacting “building blocks”: auditory, motor control, memory, multisensory integration, and self-concept (see Fig. 1). We first describe the historical and disciplinary context of self-voice research and discuss the special neurocognitive status of the self-voice. We then outline the functional and neural basis of each building block and examine how they may converge to support a unified sense of vocal selfhood. This integrative framework emphasizes translational relevance, particularly in light of emerging technologies—such as AI-generated voice cloning and digital communication platforms—that are reshaping how individuals perceive their own voice. By reframing the self-voice as a multidimensional construct, this article aims to advance a new line of inquiry that bridges theoretical, methodological, and applied domains in an increasingly digital world.
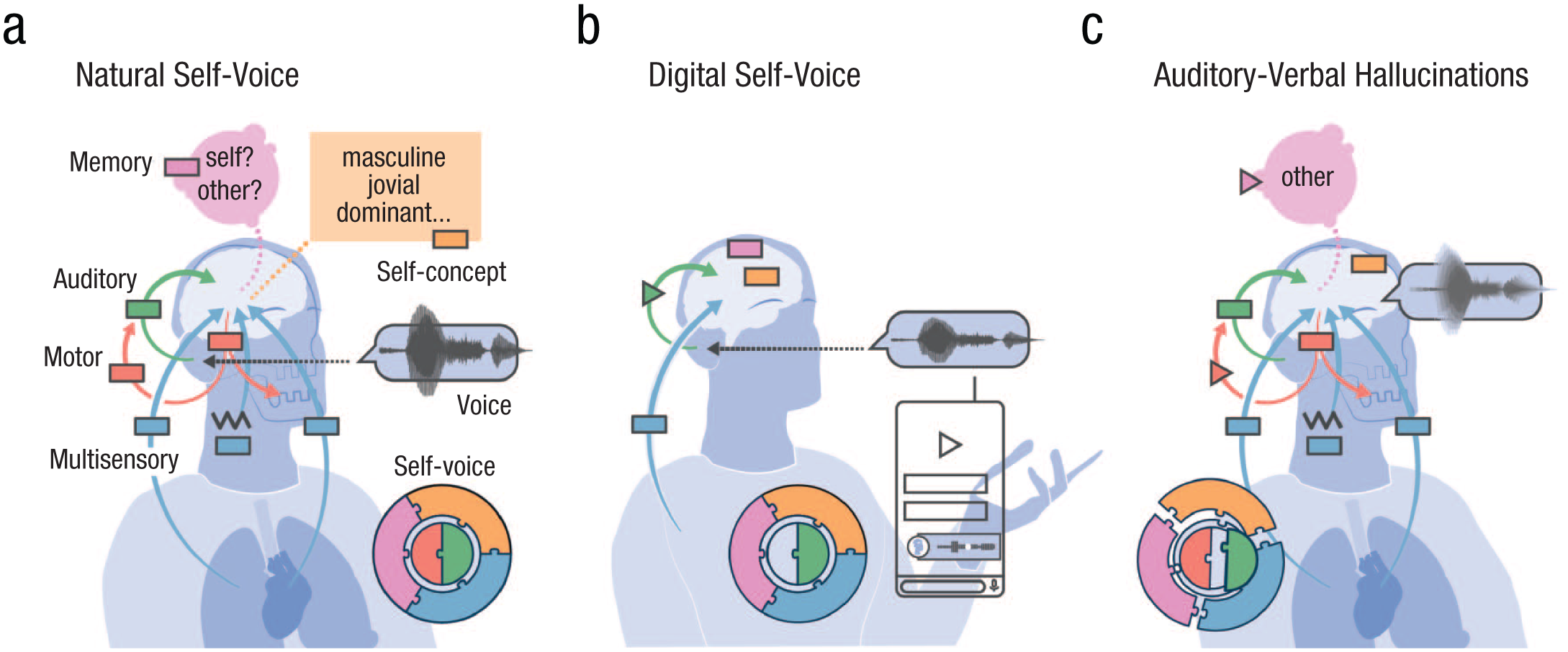
Self-voice building blocks. In (a) natural self-voice perception (during speaking), all five blocks combine to form a complete self-voice representation (puzzle inset). The auditory block (green) processes the acoustic signal (voice waveform). The motor control block (red) generates the voice (downward arrow) and sends sensorimotor predictions to the auditory block (upward arrow) to stabilize perception. The memory block (pink) provides an internal self-voice template for recognizing whether a voice is self-generated or externally generated. The multisensory integration block (blue) incorporates exteroceptive (e.g., bone-conducted vibrations) and interoceptive cues (e.g., respiration). The self-concept block (orange) aligns the perceived voice with personality and social identity. The lack of motor control involvement (incomplete puzzle) and bone-conducted cues in (b) digital self-voices alters perceived voice quality (changed waveform; triangle in the auditory block). In (c) auditory-verbal hallucinations, the blocks fail to integrate properly (distorted puzzle), producing a hallucinated voice (blurry waveform). Disruptions in sensorimotor prediction (triangle in red upward arrow) and in the memory block (pink triangle) contribute to self-other voice confusion.
Historical and Disciplinary Context
The self-voice has received comparatively limited attention in psychology and neuroscience relative to other physical expressions of the self, such as the self-face (for publication count comparisons with the self-face and the bodily self, see the Supplemental Material available online). This imbalance likely reflects both historical and methodological factors. Early theories of perception and identity—spanning psychology, neuroscience, and philosophy—treated the face as the primary, stable, and readily observable marker of personhood, cementing its centrality in the neuroscience of identity (Bruce & Young, 1986; Goffman, 1949; Haxby et al., 2000). By contrast, the voice was considered more variable, technically challenging to measure, and primarily a vehicle for social expression rather than a window into self-identity (Hanley et al., 1998; Kreiman, 2024; Laver, 1980). This asymmetry may have created an early, self-reinforcing bias: research on faces generated influential findings that, in turn, attracted additional researchers and funding.
Meanwhile, foundational studies of the self-voice confronted the methodological problem that recorded voices sound different from the voices people hear when speaking, owing to bone-conducted pathways (Gur & Sackeim, 1979; Holzman & Rousey, 1966; Olivos, 1967). This challenge complicated efforts to produce ecologically valid self-voice stimuli and impeded early progress. Moreover, although visual self-recognition could be investigated with static images, studying self-voice processing required dynamic control of auditory feedback and ecologically valid manipulations of vocal identity, technical capacities that have only recently become widely accessible (e.g., Belin & Kawahara, 2025; Kreiman, 2024).
Beyond these historical constraints, research on the self-voice has been fragmented across disciplines. Although much of the empirical foundation comes from cognitive neuroscience, converging evidence from sociophonetics, speech perception, and social psychology highlights the fundamentally interdisciplinary nature of vocal identity. For example, sociophonetics has examined how speakers modulate vocal features to express social identity and group membership (e.g., Bradshaw et al., 2025; Hay, 2018), speech perception research has focused on acoustic and articulatory mechanisms of talker normalization (e.g., Bourguignon et al., 2016), and social psychology has explored how voice cues shape self-presentation and interpersonal perception (e.g., Klofstad et al., 2012). Yet these traditions rarely interact with the cognitive and neural perspectives that dominate contemporary self-voice studies, and the role of self-voice identity remains underexamined within these adjacent disciplines—for instance, how self- versus other-voice markers shape speech perception processes (for a few examples, see Pinheiro, Rezaii, Nestor, et al., 2016; Pinheiro et al., 2023).
Each of the five building blocks of self-voice processing outlined in our framework has, in fact, deep roots in these complementary fields. The auditory block resonates with classic work on speech perception and talker normalization that has examined how listeners accommodate variability in voice acoustics (e.g., Luthra, 2024). The motor control block intersects with phonetics and speech production research, in which articulatory dynamics and feedback control are central (e.g., Parrell & Houde, 2019). The memory block draws on psycholinguistic and associative learning traditions (e.g., Lee & Perrachione, 2022; Perrachione et al., 2011) as well as mean-based coding models of voice identity (e.g., Latinus et al., 2013) that propose that repeated exposure shapes prototypical voice representations centered on a stored “mean” of one’s own or others’ vocal patterns. The multisensory integration block connects to embodied cognition research, emphasizing the convergence of auditory, proprioceptive, tactile, and interoceptive signals in action monitoring (e.g., Orepic et al., 2021, 2022; Orepic, Kannape, et al., 2023). Last, the self-concept block integrates insights from social psychology and sociophonetics research, in which the voice serves as a marker of identity, personality, and group membership, reflecting an interplay between socially informed vocal patterns and the individual’s unique self-expression (Guldner et al., 2024; Ostrand & Chodroff, 2021; Stern et al., 2021). These perspectives complement neuroscientific evidence by showing how self-concept both constrains and is reinforced by vocal self-expression.
Despite these rich disciplinary traditions, they have rarely been synthesized into a unified account. By integrating insights across these domains, the current model aims to reposition the self-voice as a multidisciplinary construct—one that bridges low-level sensorimotor control with high-level representations of social identity and self-concept.
Is the Self-Voice Special?
As the sound we hear most often, a central marker of identity, and a vital tool for communication, the self-voice has a unique cognitive and neural status. This distinctiveness is evident not only when compared with other voices (Graux et al., 2015; Kaplan et al., 2008) but also when contrasted with other self-related stimuli, such as the self-face (Aruffo & Shore, 2012; Hughes & Nicholson, 2010). Crucially, the special processing of the self-voice cannot be fully explained by familiarity alone (Graux et al., 2015; Kaplan et al., 2008; Nakamura et al., 2001), suggesting it engages additional mechanisms beyond those typically involved in processing familiar stimuli.
The self-voice compared with other voices
Behavioral and neuroimaging studies consistently support the idea that the self-voice is functionally distinct from other voices (see Tables 1 and 2 and Fig. 2). The few existing functional neuroimaging studies have shown that listening to recordings of one’s own voice activates specific brain regions more strongly than listening to others. These include the right anterior cingulate cortex and left inferior frontal cortex (self vs. unfamiliar voice; Allen et al., 2005), the right inferior frontal sulcus and parainsular cortex (self vs. familiar voice; Nakamura et al., 2001), and the right inferior frontal gyrus (self vs. familiar voice; Kaplan et al., 2008). These findings suggest a degree of anatomical specialization for self-voice perception, particularly in right-lateralized frontoinsular networks.
Building Blocks of the Self-Voice: Neuroanatomical Correlates
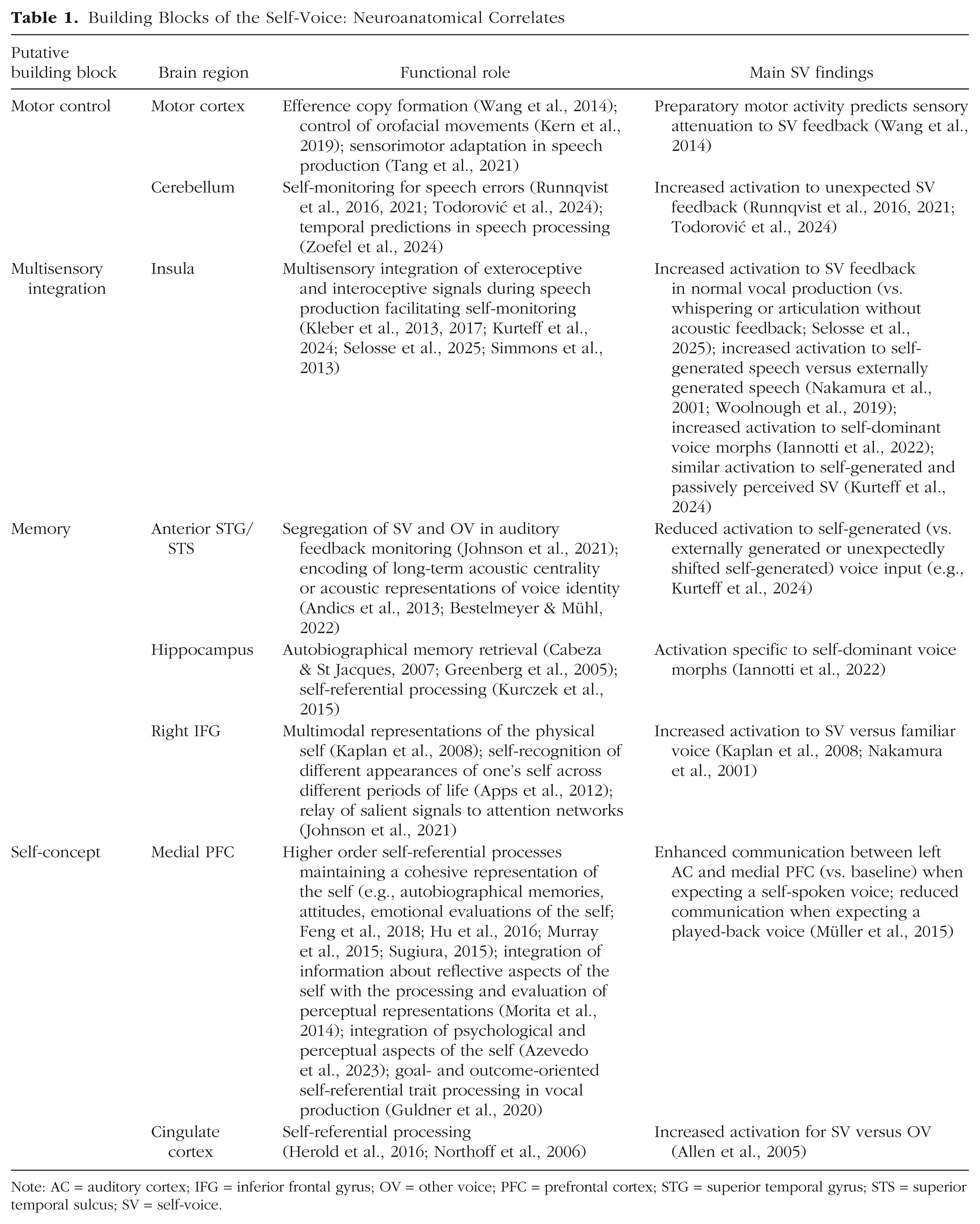
Note: AC = auditory cortex; IFG = inferior frontal gyrus; OV = other voice; PFC = prefrontal cortex; STG = superior temporal gyrus; STS = superior temporal sulcus; SV = self-voice.
Building Blocks of the Self-Voice: Electrophysiological Correlates
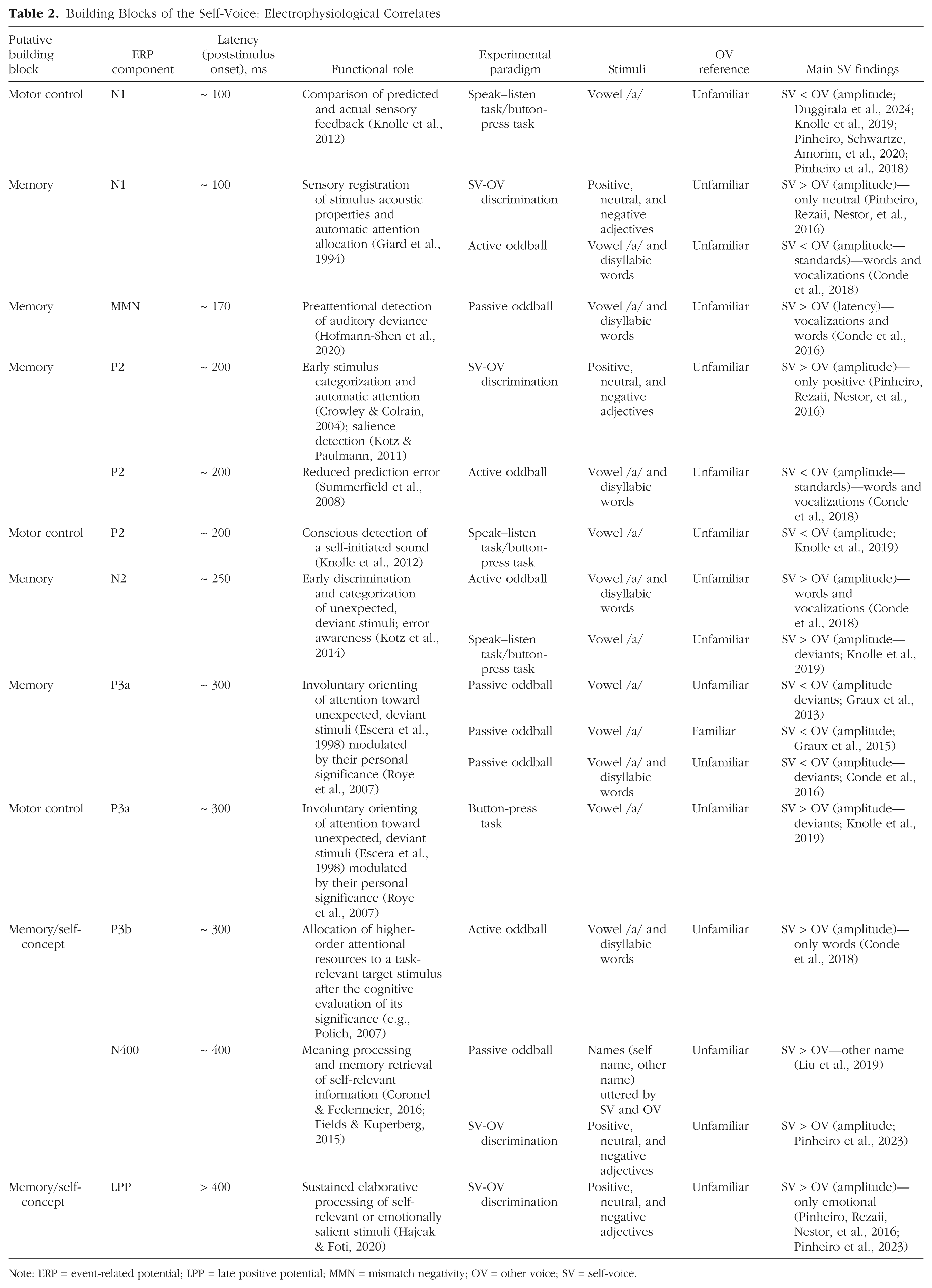
Note: ERP = event-related potential; LPP = late positive potential; MMN = mismatch negativity; OV = other voice; SV = self-voice.
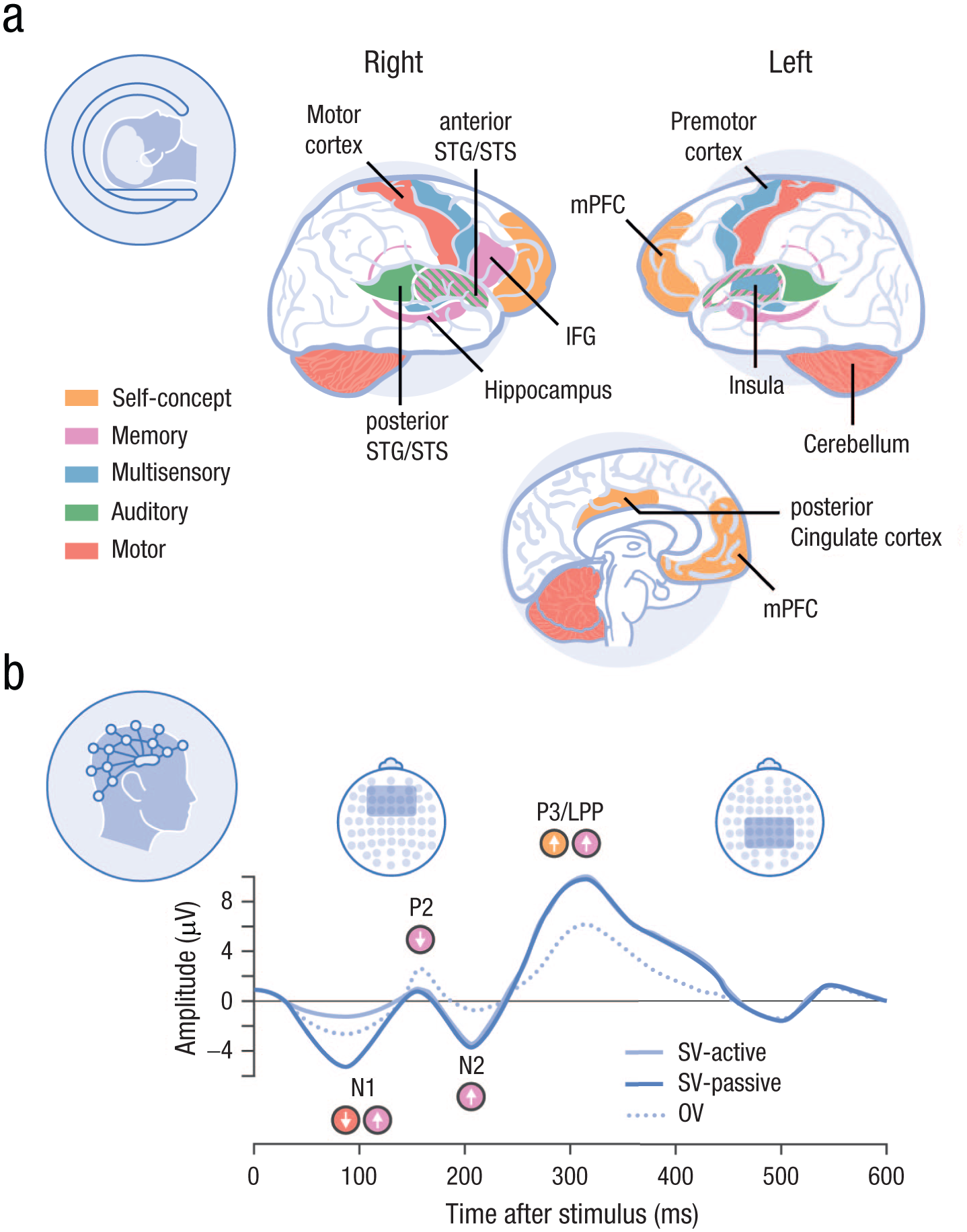
Neural correlates of self-voice processing according to the underlying building blocks. fMRI studies (a) show that listening to one’s own voice (vs. other voices) preferentially activates right-lateralized regions—including the inferior frontal gyrus, anterior cingulate, and superior temporal cortex—reflecting integration of the auditory, motor, and memory signals that underpin self-specific processing. ERP studies (b) show that the self-voice elicits early (N1, P2) and later (P3, LPP) neural responses that are stronger than those to familiar or unfamiliar voices, when there is explicit attention to speaker identity. This indicates automatic attentional capture and sustained processing for self-voice stimuli, supporting its prioritized cognitive and affective status. ERP = event-related potential; fMRI = functional MRI; LPP = late positive potential; SV = self-voice; OV = other voice.
Further evidence for right-hemisphere involvement comes from lesion and lateralization studies. Rosa et al. (2008) found a selective advantage for left-hand responses (right-hemisphere processing) in a self–other voice-discrimination task using voice morphs. Similarly, right-hemisphere lesions were associated with greater deficits in explicit (vs. implicit) self-voice recognition (Candini et al., 2018), underscoring the importance of this hemisphere in consciously accessing vocal self-identity.
Electrophysiological studies also show early and sustained differentiation of the self-voice. Event-related potential (ERP) studies have revealed enhanced amplitudes for the self-voice compared with familiar and unfamiliar voices, beginning within 100 ms of voice onset and extending into later processing stages (Graux et al., 2013; Pinheiro, Rezaii, Nestor, et al., 2016; Pinheiro et al., 2023). These effects are seen in early (e.g., N1) and later (e.g., P3, late positive potential; see Table 2) components, supporting a self-prioritization effect that is modulated by task demands, such as explicit attention to speaker identity (Pinheiro et al., 2023). Differences in task design can yield seemingly contradictory findings across studies (e.g., opposite effects on the same ERP component). Such discrepancies are expected because different tasks engage distinct cognitive processes that modulate auditory regions in different ways (e.g., excitatory vs. inhibitory influences). Importantly, however, a consistent pattern remains: within each study, ERPs reliably differentiate self-voice from other-voice stimuli (for additional discussion, see the Supplemental Material). These ERP findings suggest that the self-voice captures attention automatically and is subject to sustained, elaborative processing, paralleling the prioritization observed for emotionally salient stimuli (Hajcak & Foti, 2020). Psychophysiological data reinforce this idea: studies from as early as the 1960s reported stronger galvanic skin responses to the self-voice compared with other voices, even when participants did not consciously recognize the voice as their own (Olivos, 1967; Rousey & Holzman, 1967).
Behavioral research likewise points to the special status of the self-voice. In voice identity matching tasks, participants more accurately and rapidly identify their own voice compared with other voices (Kirk & Cunningham, 2025), and this effect holds even when stimuli are AI-generated self-voice approximations (Rosi et al., 2025). The self-voice also influences various perceptual and cognitive functions differently than other voices, including word recognition (Cheung & Babel, 2022), distance estimation (Wen et al., 2022), face recognition (Hughes & Nicholson, 2010), and multisensory integration (Aruffo & Shore, 2012). The perception of one’s own voice is also linked to real-world outcomes: in a recent survey, participants reported that how they perceive their speaking voice influences self-expression and social behavior (Chong et al., 2024).
These distinct effects may arise from the self-voice’s ability to capture attention (Conde et al., 2015; Pinheiro et al., 2023), its enhanced affective salience (Conde et al., 2015), or a perceptual bias driven by a sense of ownership (Payne et al., 2024). Interestingly, the self-voice is often rated as more attractive than other voices (Hughes & Harrison, 2013), even when it is not explicitly recognized as self-related (Douglas & Gibbins, 1983).
Together, these findings highlight the functional uniqueness of the self-voice, reflected in its capacity to engage both low-level sensory and higher-level cognitive processes in ways that differ from the processing of even familiar non-self-voices.
The self-voice compared with the self-face
Both the face and the voice serve as key self-identifiers and follow parallel processing hierarchies (Yovel & Belin, 2013). Like the self-voice, the self-face is processed differently from familiar and unfamiliar faces (Bortolon & Raffard, 2018). However, several lines of evidence suggest that the self-voice may hold an even more distinctive status.
First, the self-voice is arguably the most frequent expression of the self in daily life. Although individuals may see their own face only in mirrors or digital media, they hear their voice every time they speak. Second, the voice plays a more central role in communication than the face: vocal communication is the primary medium of interaction across cultures (Scott, 2019), and the brain may be tuned to prioritize the modality that directly facilitates this function. Third, unlike the self-face, the self-voice inherently engages the motor system, triggering forward model predictions during vocal production. This motor involvement enhances the integration of auditory, somatosensory, and vestibular cues, potentially amplifying self-relevance through multisensory convergence (see “Motor Control” and “Multisensory Integration” sections).
From a clinical standpoint, the self-voice also appears more central. Auditory hallucinations—predominantly in the form of voices—are significantly more common than visual hallucinations (Bauer et al., 2011). Furthermore, difficulties with self–other distinction have been linked to autistic traits in the auditory, but not visual, domain (Chakraborty & Chakrabarti, 2015; see “Translational Implications” section).
When the self-voice and self-face are perceived together, their interaction appears to depend strongly on context. For instance, Hughes and Nicholson (2010) reported that individuals recognize their own face more readily than their own voice and that presenting both simultaneously may impair recognition, perhaps because of the cognitive cost of binding multiple self-related cues. In contrast, Aruffo and Shore (2012) showed that the self-voice—but not the self-face—reduces susceptibility to the McGurk effect, suggesting that the self-voice carries greater perceptual weight during audiovisual speech integration. There is also evidence that auditory and visual self-recognition are partially dissociable. Chakraborty and Chakrabarti (2015) observed no correlation between self-recognition performance across modalities, supporting the view that self-identity processing is modality-specific (Young et al., 2020). Although self-voice recognition may rely on less robust or more ambiguous identity cues than the face (Hughes & Nicholson, 2010), it nonetheless engages distinctive cognitive and neural mechanisms compared with other voices. The “specialness” of the self-voice may therefore manifest in attentional capture, affective salience, or sensorimotor integration rather than in absolute recognition accuracy.
The Building Blocks of the Self-Voice
The perception of one’s own voice is a complex, multicomponent process that integrates sensory, motor, and cognitive systems. We propose that this phenomenon can be comprehensively understood through five foundational components or building blocks: auditory, motor control, memory, multisensory integration, and self-concept (Fig. 1; for a definition of key terms, see Glossary). These components interact dynamically to support the perception and recognition of the self-voice.
The auditory block captures the auditory-acoustic aspects of self-voice processing, which can be influenced by interactions with the other blocks. The motor control block refers to the predictive mechanisms involved in speech production that transform motor intentions into expected sensory outcomes—for example, through efference copies that anticipate the auditory consequences of one’s own speech (Miall & Wolpert, 1996; Wolpert, 1997). The multisensory integration block reflects the convergent processing of incoming feedback from multiple modalities, including auditory, somatosensory, and proprioceptive cues, which are combined to construct a coherent percept of vocal identity. Motor control and multisensory integration blocks are inherently different, even though motor control can involve predictions in modalities other than audition (e.g., somatosensory). Multisensory integration refers to effects in which stimuli across modalities are perceived differently when presented together (e.g., changes in auditory perception during simultaneous somatosensory stimulation), independent of any motor action; motor control, in contrast, refers to effects on sensory processing (potentially across modalities) that are primarily driven by motor-based predictions. The memory block refers to the internal representation of the self-voice—our sense of “what I think I sound like”—which enables the recognition of one’s recorded voice even in the absence of concurrent sensorimotor predictions. Last, the self-concept block encompasses higher-level aspects of the sense of self, such as personality traits or social identities, which shape and are reinforced by vocal behavior (e.g., speaking in ways that align with the norms of one’s social group).
Existing models of speech and voice processing tend to focus primarily on auditory feedback, often underemphasizing the contribution of bone conduction and other bodily signals to natural self-voice perception or addressing only a subset of the relevant processing components. For example, the DIVA (Tourville & Guenther, 2011) and the more recent LaDIVA (Weerathunge et al., 2022) frameworks focus on sensorimotor predictions and incorporate feedforward and feedback loops involving auditory, motor, and somatosensory signals. However, their emphasis remains on externally derived auditory targets rather than on internally generated, multimodal cues that shape the experience of one’s own voice. Leading models of voice perception—such as the hierarchical model of voice processing (Belin et al., 2011) and the prototype-based account of voice identity recognition (Lavner et al., 2001)—similarly focus on acoustic and memory-based mechanisms, largely overlooking the integration of bodily signals during self-generated vocalization. Other models framed within the predictive coding framework highlight the influence of top-down modulations linked to semantic or contextual information (Caucheteux et al., 2023; Friston et al., 2021; Ralph et al., 2017), yet these frameworks tend to focus on speech and linguistic content rather than on the voice as a marker of identity.
In the following sections, we review key empirical findings for each building block, highlight their translational and clinical implications, and outline unresolved questions to guide future research.
Auditory
At its core, each voice has a unique acoustic profile that is shaped by an individual’s vocal apparatus. Although the acoustic parameters that define voice identity remain incompletely understood (Kreiman, 2024), the self-voice introduces additional complexity because of the effects of bone conduction—an internal transmission pathway absent from our experience of most externally generated sounds. Although the term “bone conduction” suggests that sound is transmitted solely through bones, the process is influenced by the combined properties of all tissues and fluids in the head, including skin, cartilage, and inner ear fluids (Adelman et al., 2015; Hosoi et al., 2019; Stenfelt, 2016).
Bone conduction adds low-frequency energy to the perception of one’s own voice, but its acoustic contribution is still not fully characterized (Stenfelt, 2016). Early work (Franke, 1956) and more recent measurements of ear-canal sound pressure (Reinfeldt et al., 2010) have attempted to quantify the frequency ranges at which bone conduction dominates air conduction. These studies show frequency-dependent interactions: bone conduction may dominate between 700 Hz and 1.2 kHz (Pörschmann, 2000) or around 1.5 to 2 kHz (Reinfeldt et al., 2010), with variability across studies. Additionally, speech sounds with greater oral closure (e.g., lip rounding as in /o/) or nasal resonance (e.g., /n/) tend to engage bone conduction more than plosives (e.g., /k/) or open vowels (e.g., /a/; Reinfeldt et al., 2010).
Higher formants (F3–F5) appear to carry a disproportionate weight in self-voice perception. Because these formants are more strongly constrained by stable anatomical properties (e.g., laryngeal cavity shape) and less influenced by speech or transient emotional and physiological states (López et al., 2013; Xu et al., 2013), they have been proposed as relatively invariant markers of self-voice identity. However, evidence for this claim, as well as for the precise contribution of any specific acoustic feature to self-voice perception, remains limited.
Efforts to recreate a more “natural” self-voice in experimental settings have relied on subjective filtering approaches in which participants adjust or rate the spectral profile of their voice until it matches their internal representation. However, these studies have yielded inconsistent results and high interindividual variability (Kimura & Yotsumoto, 2018; Shuster & Durrant, 2003; Vurma, 2014), suggesting no universally valid filter exists (Kimura & Yotsumoto, 2018). Nevertheless, participants often rate filtered self-voices as more natural than unfiltered ones (Shuster & Durrant, 2003), and some neuroimaging studies have even adopted low-pass filtered stimuli to probe brain regions responsive to the self-voice (Kaplan et al., 2008).
A limitation of this spectral filtering approach is its narrow focus on power across frequency bands. A more fruitful strategy may lie in modeling self-voice acoustics using parameters critical for speaker identity, such as fundamental frequency (F0) and formant dispersion—features rooted in the source-filter model of speech (Baumann & Belin, 2010; Chhabra et al., 2012; Kreiman, 2024). These parameters define a low-dimensional voice space in which perceptually similar voices are positioned closer together and acoustic distances correlate with both subjective discriminability (Baumann & Belin, 2010; Chhabra et al., 2012) and neural responses in the voice-selective cortex (Latinus et al., 2013). Recent work shows that self–other voice-discrimination accuracy scales with acoustic distance in this space (Orepic, Kannape, et al., 2023), indicating that the self-voice relies on the same low-level features that support general voice recognition. Although altering these features may not precisely replicate the bone-conduction effect, their perceptual link to voice identity could make them more relevant for approximating the natural perception of one’s own voice. These same acoustic dimensions seem to contribute to cognitive biases favoring self-related stimuli (e.g., self-prioritization effect; Kirk & Cunningham, 2025), highlighting the broader perceptual and cognitive impact of self-voice acoustics.
Seemingly conflicting findings (e.g., reports of stable higher formants vs. unstable spectral filtering) may also stem from methodological differences across studies. For example, some work manipulates self-voice using graphical sliders to approximate bone-conduction acoustics (Kimura & Yotsumoto, 2018; Shuster & Durrant, 2003; Vurma, 2014), whereas other studies assess behavioral responses to preselected acoustic features (Kirk & Cunningham, 2025; Orepic, Kannape, et al., 2023; Xu et al., 2013; for a more detailed discussion, see the Supplemental Material).
Motor control
Unlike static physical features such as the face, the voice must be actively generated (McGettigan, 2015). Its perception is thus intimately tied to motor control. During vocalization, motor signals modulate auditory processing, leading to reduced perceptual salience and attenuated neural responses to self-generated voices compared with external ones (Jennifer & Georgia, 2015; Paraskevoudi & SanMiguel, 2021). This attenuation reflects a core mechanism of voice monitoring, which ensures congruence between intended and produced speech (Pinheiro, Schwartze, & Kotz, 2020).
The dominant theoretical model posits a forward model architecture in which an efference copy of the motor command predicts the sensory consequences of vocalization such that discrepancies between predicted and actual feedback—prediction errors—trigger corrective motor adjustments (Miall & Wolpert, 1996; Wolpert, 1997). These predictions are thought to be relayed via the cerebellum (Knolle et al., 2012; Pinheiro, Schwartze, & Kotz, 2020; Todorović et al., 2024) to the right anterior superior temporal gyrus/sulcus (Johnson et al., 2021). The ventral precentral gyrus is a potential source of motor-related prediction in vocal production (Khalilian-Gourtani et al., 2024). Electrophysiological signatures of this mechanism include the N1 attenuation in EEG (Pinheiro et al., 2018; Pinheiro, Schwartze, Amorim, et al., 2020), M1 attenuation in MEG (Houde et al., 2002; Ventura et al., 2009), and reduced gamma-band activity in electrocorticography (Flinker et al., 2010; Towle et al., 2008). Readiness potentials preceding voluntary speech are linked to efference copy generation and correlated with subsequent sensory attenuation (Ford et al., 2014; Pinheiro, Schwartze, Gutiérrez-Domínguez, & Kotz, 2020; Reznik et al., 2018).
Critically, motor-induced sensory attenuation is not limited to overt vocalization but also occurs when participants trigger self-voice playback via a button press (Johnson et al., 2021; Pinheiro, Schwartze, Amorim, et al., 2020), even in the absence of precise temporal alignment (Orepic et al., 2021). This suggests that self-voice perception recruits broader motor-related prediction systems, not solely speech-specific mechanisms.
Motor control contributions also support self–other voice discrimination. For example, suppression in the right anterior superior temporal cortex occurs only when voice feedback is identified as self-generated (Fu et al., 2006; Johnson et al., 2021). Perturbation studies further show that small, unexpected changes in pitch or intensity elicit compensatory responses, consistent with self-attribution (Burnett et al., 1998; Jones & Munhall, 2002; Natke et al., 2003). In contrast, large deviations often produce following responses, suggesting the voice is attributed to an external source (Burnett et al., 1998; Hain et al., 2000; Larson et al., 2007). Thus, predictive sensorimotor mechanisms help delineate the perceptual boundary between the self-voice and other voices.
The self–other distinction is not only theoretically significant but also clinically relevant. Reduced sensory attenuation is associated with anomalous self-experience in both clinical (Beño-Ruiz-de-la-Sierra et al., 2024; van der Weiden et al., 2015) and nonclinical (Duggirala et al., 2024; Pinheiro et al., 2018; Pinheiro, Schwartze, Amorim, et al., 2020) populations, including hallucination-prone individuals and patients with schizophrenia (see “Translational Implications” section). Such findings underscore the role of sensorimotor prediction in maintaining a coherent sense of vocal self.
Memory
Voice perception research suggests that speaker identity recognition depends on high-level voice identity representations stored in long-term memory (Andics et al., 2013; Latinus et al., 2013). Likewise, self-voice recognition draws on a memory-based template of one’s own voice that is shaped by long-term exposure to self-generated auditory feedback and sensorimotor coupling during speech production (Hickok et al., 2011). This internal self-voice representation supports self-other voice discrimination, even in the absence of efference copy signals, likely via template-matching processes that compare voice input to stored representations. Comparable template-matching mechanisms have also been proposed for other-voice recognition (Lavner et al., 2001; Maguinness et al., 2018), reinforcing the view that identity judgments arise from comparing incoming voice signals to long-term memory traces.
Electrophysiological evidence supports this notion. During self–other voice discrimination tasks, a self-voice-specific topographic EEG map appears around 350 ms postvoice onset, with hippocampal source localization, possibly reflecting the retrieval of the internal self-voice representation (Iannotti et al., 2022). Similarly, late ERPs, such as the P3 (~ 300 ms) and N400 (~ 400 ms), differ reliably between self- and other-voice conditions (Conde et al., 2015, 2016, 2018; Graux et al., 2013, 2015; Liu et al., 2019; see Fig. 2b and Table 2).
Neuroimaging studies contrasting responses to self- versus other-voice stimuli are scarce, yet they indicate greater activation for self-voice in regions implicated in voice identity processing. These include the right (Kaplan et al., 2008; Nakamura et al., 2001) and left (Allen et al., 2005) inferior frontal cortex, the parainsular cortex (Nakamura et al., 2001), and the right anterior cingulate cortex (Allen et al., 2005; see Fig. 2a and Table 1). Studies examining long-term voice representations have identified the right superior temporal cortex as being sensitive to acoustic signal properties related to voice identity (Charest et al., 2013; Latinus et al., 2013). These studies did not directly compare self- with other-voice stimuli but provide complementary evidence for the neural coding of voice identity relevant to self-voice recognition. Consistently, the perceived similarity between a vocal sound and one’s natural voice modulates activity in the bilateral superior and middle temporal gyri (Hosaka et al., 2021). Lesions to the right superior temporal gyrus have also been linked to altered self-voice perception (Andrade-Machado et al., 2023).
These findings suggest a functional hierarchy: the right superior temporal cortex encodes detailed acoustic features of voice identity, whereas the right inferior frontal cortex represents more abstract, cognitive-level voice identity representations (Andics et al., 2013; Bestelmeyer & Mühl, 2022). The latter may constitute a modality-independent self-identity hub because it is activated by both self-voice and self-face stimuli (Kaplan et al., 2008). The right inferior frontal gyrus is also implicated in feedback motor control (as in DIVA; Tourville & Guenther, 2011) and could serve as a convergence node in which sensorimotor predictions both inform and are informed by self-voice identity representations.
However, the mechanisms through which a self-voice representation forms remain unclear. Norm-based coding offers one account, proposing that voice identity is encoded by its deviation from an internal voice prototype (Latinus & Belin, 2011; Latinus et al., 2013). Adaptation studies support this framework: exposure to male voices biases the perception of ambiguous stimuli toward female voices (Schweinberger et al., 2008), and repeated exposure to one identity increases the likelihood of hearing the opposite in morph continua (Latinus & Belin, 2011; Zäske et al., 2010). Voice-selective areas in the superior temporal cortex show greater activation for voices that acoustically deviate from the population average (Latinus et al., 2013). Importantly, the same acoustic features underlying prototype deviation also predict performance in self–other voice-discrimination tasks (Orepic, Kannape, et al., 2023; see “Auditory” section). Thus, individuals may have a central self-voice prototype, formed through long-term experience. Anterior portions of the right superior temporal cortex are particularly responsive to deviations in both acoustic and expected properties of the self-voice (Hosaka et al., 2021), consistent with this possibility. Last, sensory attenuation effects suggest that this self-voice prototype informs forward models in speech production, with prediction errors arising when vocal outputs deviate from the internal template, guiding adjustments and refining self-voice representations. For instance, less prototypical voice outputs elicit reduced sensory attenuation, implying a prediction error from the internal voice template (Niziolek et al., 2013).
Multisensory integration
Under natural speaking conditions, the self-voice is inherently multimodal. In addition to auditory input, self-voice perception is shaped by vibrotactile (Trulsson & Johansson, 2002) and vestibular (Welgampola et al., 2003) signals. Somatosensory feedback from articulator movement is essential for precise vocal control (Tremblay et al., 2003), and somatosensory perturbations can modulate the perception of speech sounds (Ito et al., 2009). Vibrotactile cues, when presented with auditory stimuli, enhance self–other voice-discrimination performance (Orepic, Kannape, et al., 2023) and modulate neural responses to the self-voice (Iannotti et al., 2022). For example, bone conduction—which provides vibrotactile stimulation—improves self–other voice discrimination relative to an air-conduction presentation (Orepic, Kannape, et al., 2023), likely because of added somatosensory cues rather than acoustic differences. However, the integration of sensory modalities during vocalization may vary across individuals. Some speakers rely more on somatosensory than on auditory feedback for articulating certain speech sounds (Lametti et al., 2012).
The multimodal nature of self-voice recognition may be rooted in bodily self-consciousness, the prereflective conscious experience of being a self in a body, which depends on the integration of exteroceptive (e.g., visual, auditory, tactile) and interoceptive (e.g., respiration and heartbeat) cues (Blanke et al., 2015; Park & Blanke, 2019). Multisensory conflict paradigms that disrupt bodily self-consciousness—such as mismatches between visual and tactile or interoceptive signals—can alter self-identification and self-location (Blanke et al., 2015). It is plausible, then, that the brain network underlying bodily self-consciousness also contributes to self-voice perception. This network includes the insula, premotor cortex, and cingulate cortex—regions implicated in both bodily self-consciousness (Blanke et al., 2015; Park & Blanke, 2019) and self-voice processing (Iannotti et al., 2022). These overlaps were observed in a recent study showing that multisensory self-voice cues from vocal-tract vibrations shape emotional prosody production and recruit insular, inferior frontal, and cerebellar regions (Selosse et al., 2025).
Behavioral findings provide additional support for the link between bodily self-consciousness and self-voice perception. Sensorimotor conflicts affecting the torso (a bodily self-consciousness hub) alter the perceived loudness of self-voice stimuli, whereas similar manipulations on peripheral body parts do not (Orepic et al., 2021). Other experiments show that torso-based bodily self-consciousness manipulations bias participants to falsely attribute voices to the self or others in a voice-detection task (Orepic et al., 2024). Interoceptive signals further modulate self-voice perception: self-other voice-discrimination performance improves during inhalation relative to exhalation but is not influenced by cardiac cycle phase (Orepic et al., 2022). This breathing-related modulation is itself amplified by sensorimotor conflicts that disrupt bodily self-consciousness, highlighting a complex interplay between self-voice, interoception, and sensorimotor processing (Orepic et al., 2022).
Self-concept
“Self-concept” refers to the cognitive and social representation of the self, which is shaped by development and interpersonal experience (Crone et al., 2022). It comprises both the stability of self-knowledge and the coherence of one’s identity over time (Crone et al., 2022). Remarkably, voices convey cues that listeners rapidly use to form impressions of speakers (Lavan et al., 2024), and vocal feedback may likewise shape the speaker’s own self-representation over time.
Voice production is influenced by the identity one wishes to project. Speakers adjust vocal characteristics to convey attributes such as authority, intelligence, or attractiveness (Guldner et al., 2024; Hughes et al., 2014). Speech patterns are also shaped by social categories and linked to gender roles and sexual identity, as exemplified by pitch modulation in gay men (Gaudio, 1994). When one’s voice does not align with one’s self-concept, emotional distress can result. For instance, transgender individuals frequently experience dissonance between their experienced gender and their perceived voice (Dacakis et al., 2017), which can generate profound discomfort and impact mental health (Haskell, 1987; see “Translational Implications” section).
Conversely, one’s voice can shape one’s self-concept. Auditory feedback from one’s own voice informs self-perception, including inferences about personality traits (Stern et al., 2021). Persistent changes to the voice—such as those following laryngectomy (Bickford et al., 2013, 2019) or vocal fold paralysis (Francis et al., 2018)—can disrupt established self-representations and prompt compensatory adjustments in self-concept. Likewise, hormone therapy during gender transition is often accompanied by shifts in self-perception (Bultynck et al., 2017), suggesting that hormone-driven changes in vocal anatomy may interact with broader social and psychological transformations to reshape the self-voice and, in turn, the sense of self. However, these effects are difficult to disentangle from concurrent contextual and experiential factors inherent to the transition process.
Recent advances in voice-manipulation technologies further underscore the bidirectional link between the acoustic properties of one’s voice and self-representation, revealing how even transient alterations to self-voice feedback can modulate emotional, cognitive, and social dimensions of identity. For example, hearing a calmer version of one’s voice can reduce anxiety, whereas deeper voices may enhance one’s sense of power (Costa et al., 2018). Even impersonating the voice of an older adult can reduce negative social evaluations of older adults (Arakawa et al., 2021). However, it is worth noting that most of these studies—including those using AI-based voice modifications—tested short-term perceptual or behavioral effects in relatively small samples. Their findings should therefore be interpreted with caution.
The medial prefrontal cortex may serve as a neural substrate for the interaction between the self-voice and self-concept. This region is central to self-referential processing (van der Meer et al., 2010) and supports abstract trait-based self-representations (Hu et al., 2016; Levorsen et al., 2023; Marquine et al., 2016). In vocal production, it is more active when speakers express socially relevant information (Guldner et al., 2020) and modulates auditory cortex responses to self-voice feedback (Müller et al., 2015), potentially preparing the auditory system for self-generated stimuli. The medial prefrontal cortex is also more engaged during active vocalization than passive listening, consistent with its role in self-awareness (Jardri et al., 2007) and self-identification (Iannotti et al., 2022).
Dynamic Interactions Among the Building Blocks
Although the five building blocks are presented separately for conceptual clarity, authentic self-voice perception arises from their dynamic interplay (Fig. 3).
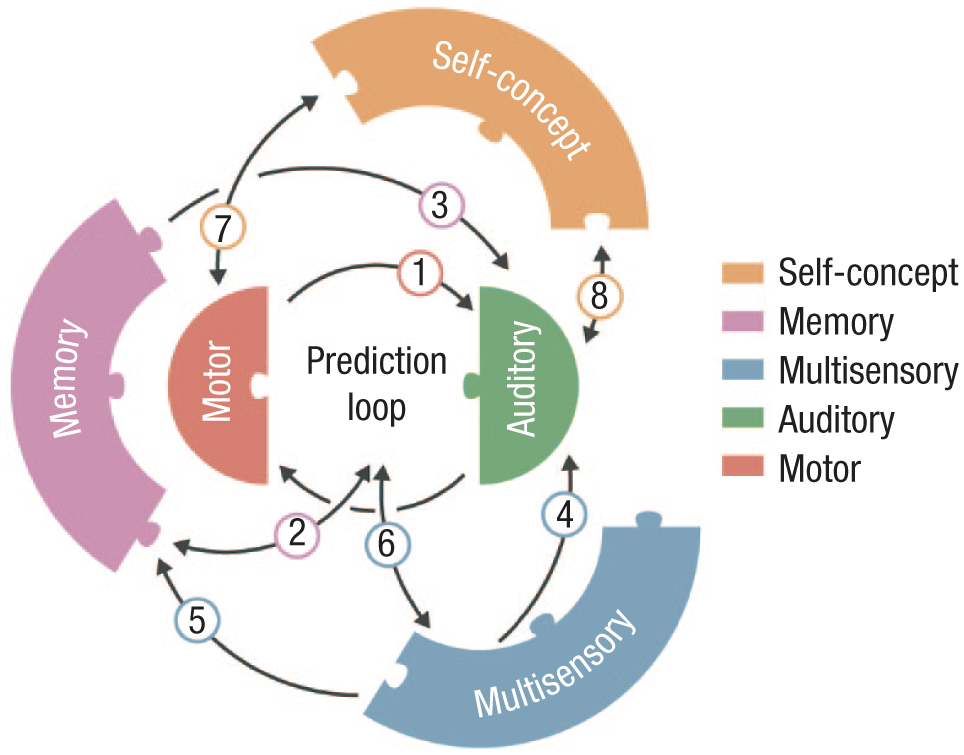
Interactions between the building blocks. Predictions based on motor control regulate auditory self-voice perception during speech (Arrow 1). Motor control predictions draw on the stored self-voice memory template, and persistent prediction-perception mismatches gradually update this template (Arrow 2). The memory template directly shapes auditory self-voice perception (Arrow 3). Multisensory integration influences how auditory signals are combined with other exteroceptive and interoceptive cues, shaping the overall self-voice experience (Arrow 4). Sustained multisensory alterations can reshape the memory template (Arrow 5). Multisensory changes can disrupt the motor control prediction loop, and motor control predictions can also target nonauditory signals (e.g., somatosensory; Arrow 6). Shifts in self-concept can alter speaking style, and these vocal changes can in turn reinforce aspects of the self-concept (Arrow 7). Self-concept influences self-voice perception, and persistent changes in perceived self-voice can gradually modify one’s self-concept (Arrow 8).
The auditory and motor control blocks form a predictive loop that continuously monitors the match between intended and perceived vocal outcomes during real-time speech. When mismatches arise, motor control predictions modulate the auditory block to maintain a stable sensorimotor representation of one’s voice (Fig. 3, Arrow 1). These predictions originate primarily from the motor control block but are also informed by the memory block, which stores a long-term template of the self-voice (Fig. 3, Arrow 2). This relationship is reciprocal: persistent motor control mismatches can gradually update the memory template, leading to revised predictions over time (Fig. 3, Arrow 3).
Multisensory integration mechanisms combine auditory with other exteroceptive and interoceptive feedback to sustain a coherent sense of vocal ownership both during active speech and passive self-voice perception (Fig. 3, Arrow 4). These rapid multisensory interactions also contribute to memory processes that store and update long-term representations of one’s voice (Fig. 3, Arrow 5). In turn, stored representations shape motor control predictions during vocal control, forming a bidirectional recalibration loop (Fig. 3, Arrow 6).
At a higher representational level, the self-concept block constrains and interprets these perceptual-motor signals, aligning them with one’s beliefs about the self, stable identity traits (e.g., personality), and social identity dimensions (e.g., group membership), thereby maintaining coherence between how one sounds and how one believes oneself to be (Fig. 3, Arrows 7 and 8). Accordingly, shifts in self-concept—such as those emerging through developmental or clinical processes—can therefore propagate downward to influence perceptual and motor aspects of self-voice processing. Through its influence on auditory and motor control components, the self-concept also indirectly shapes the memory block, helping maintain a self-voice template aligned with one’s broader identity.
In sum, rather than additive, the five building blocks form a hierarchically organized yet reciprocally connected system that links low-level sensorimotor mechanisms with higher-order self-representations.
Translational Implications of Altered Self-Voice Perception
The self-voice plays a central role in communication, identity, and self-awareness. Disruptions to its perception or processing can therefore have wide-ranging consequences for daily functioning. Given its involvement in a broad spectrum of clinical conditions (see Table 3), a deeper understanding of self-voice perception is of immediate translational relevance. The building-blocks framework introduced in this article offers a structured approach to identifying the specific neurocognitive components affected in these conditions, thereby informing more targeted and effective interventions.
Conceptual Mapping Between Self-Voice Building Blocks and Clinical Contexts
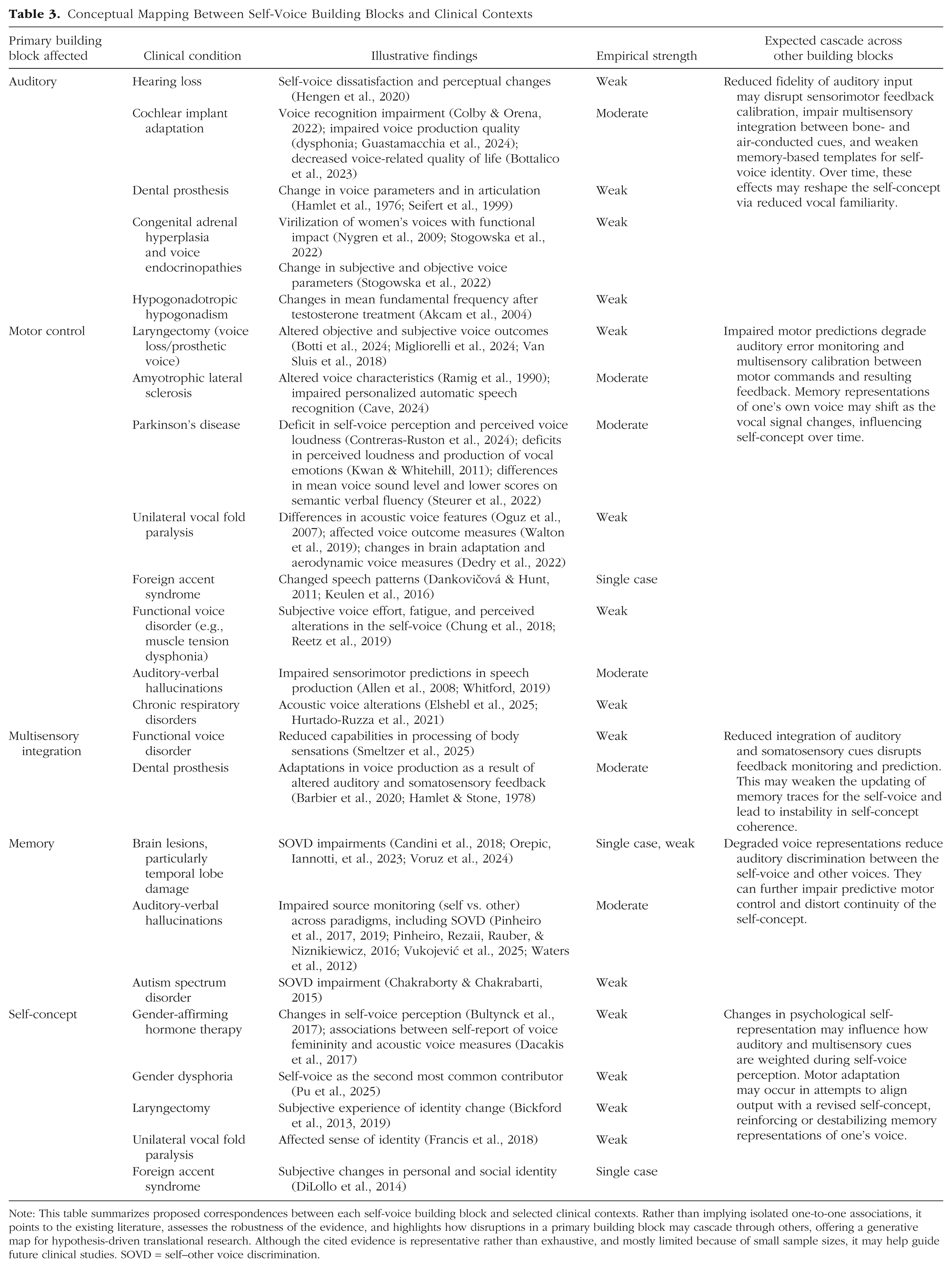
Note: This table summarizes proposed correspondences between each self-voice building block and selected clinical contexts. Rather than implying isolated one-to-one associations, it points to the existing literature, assesses the robustness of the evidence, and highlights how disruptions in a primary building block may cascade through others, offering a generative map for hypothesis-driven translational research. Although the cited evidence is representative rather than exhaustive, and mostly limited because of small sample sizes, it may help guide future clinical studies. SOVD = self–other voice discrimination.
Altered self-voice perception is particularly implicated in auditory verbal hallucinations, the experience of hearing voices in the absence of corresponding external auditory input. A prominent theory suggests that auditory verbal hallucinations arise from disruptions in self-monitoring (Frith et al., 1997), particularly in the feedforward sensorimotor mechanisms associated with self-generated speech (see “Motor Control” section). Supporting evidence includes reduced attenuation of the N1 ERP component during vocalization in individuals who experience auditory verbal hallucinations, relative to passive listening to their own voice (Whitford, 2019), as well as altered frontotemporal connectivity (Allen et al., 2008), both of which may contribute to confusion between self-generated and externally generated voices observed in patients (Pinheiro, Rezaii, Rauber, & Niznikiewicz, 2016; Pinheiro et al., 2017; Vukojević et al., 2025; Waters et al., 2012).
Importantly, auditory verbal hallucinations are not confined to individuals with psychiatric or neurological disorders: they also occur in the general population, ranging from benign, transient experiences to clinically significant episodes (Van Os et al., 2009). Hallucination proneness has been linked to altered self-voice processing, including diminished sensory attenuation during vocalization (Mathalon et al., 2019; Pinheiro et al., 2018; Pinheiro, Schwartze, Amorim, et al., 2020) and a tendency to externalize the self-voice when facing perceptual ambiguity (Asai & Tanno, 2013; Pinheiro et al., 2019). These findings underscore the importance of self-voice research for understanding individual vulnerability to altered perceptual experiences and for developing earlier, more personalized intervention strategies.
Self-voice measures also hold promise in neurosurgical contexts, in which patients often report concerns about feeling “like a different person” after surgery. Recent findings suggest that self–other voice discrimination may serve as a sensitive biomarker for detecting pathological alterations in self-processing (Schaller et al., 2021; Voruz et al., 2024). For example, in one patient who developed borderline personality disorder after the resection of a large meningioma, postoperative assessments revealed a striking inversion in self–other voice discrimination that was present in both behavioral and EEG responses, paralleling the patient’s disturbed self-concept (Orepic, Iannotti, et al., 2023). These methods may similarly shed light on conditions in which the self-voice changes persistently, such as following total laryngectomy (Bickford et al., 2013, 2019), unilateral vocal fold paralysis (Francis et al., 2018), expressive aphasia (Shadden, 2005), foreign accent syndrome (DiLollo et al., 2014), or gender-affirming hormone therapy (Bultynck et al., 2017). Because the self-voice emerges from the interaction of multiple neurocognitive building blocks, these conditions likely involve complex disruptions beyond the auditory modality, affecting sensorimotor integration, memory, and self-concept (see Table 3).
Beyond clinical contexts, the study of the self-voice is increasingly relevant in technology-mediated communication. Emerging technologies now create diverse situations in which the coupling between the natural and digital self-voice is altered—through recorded voices, real-time transformed feedback, and synthetic self-voice clones—each of which engages different components of self-voice processing. Hearing one’s recorded voice involves a purely auditory encounter with the self: it activates stored memory representations of one’s voice but lacks the motor and somatosensory feedback components typically available during speech, often eliciting feelings of estrangement or surprise (Gur & Sackeim, 1979). In contrast, real-time transformed feedback—such as pitch-shifted or AI-converted voice during speaking—preserves the sensorimotor structure of vocal production yet disrupts the alignment between predicted and perceived auditory outcomes. These manipulations selectively perturb motor-based prediction mechanisms that underlie vocal agency. Last, synthetic self-voices, including voice clones and deepfakes, present an additional challenge: they reproduce the acoustic signature of the speaker without any bodily origin or motor involvement, thereby challenging the sense of authenticity and ownership as well as the anchoring of self-concept in one’s own vocal production. Differentiating among these digital self-voice experiences may help isolate differential effects of emerging technologies on the cognitive and affective boundaries of the self in everyday communication.
Together, these clinical and technological contexts highlight the broad relevance of self-voice perception. As our voices increasingly extend into virtual environments, and as health technologies become more personalized, understanding how the self-voice shapes cognition, emotion, and social behavior becomes both timely and essential (Pinheiro, 2025).
Individual, Cultural, and Developmental Modulators
Although the five building blocks provide a useful conceptual structure for understanding self-voice processing, their operation is shaped by contextual, individual, and developmental factors that merit further investigation.
Individual factors such as how self-relevant information is processed (Fenigstein, 1984; Hull et al., 1988) or prior vocal training (Fuchs et al., 2009) may affect the relative weighting and interaction of the components. For example, experienced singers might develop more robust auditory-motor mappings that enhance self-monitoring precision (Jones & Keough, 2008).
Cultural factors are known to affect the sense of self (Chiao et al., 2009, 2010) and likely also shape self-voice processing. In collectivist cultures, in which self-concept is primarily relational (Kashima et al., 1995), individuals may rely more on auditory cues reflecting how one’s voice is perceived by others. In individualistic cultures, in which self-concept emphasizes internal attributes and personal agency (Kashima et al., 1995), memory-based representations of one’s own voice may have a greater influence in maintaining a stable sense of one’s own voice. Such cultural differences would suggest that the relative weighting of the building blocks can shift depending on social and personal factors.
Developmental dynamics provide another important dimension. Sensitivity to self-voice cues and self–other discrimination evolves across the lifespan, with adolescence representing a particularly salient developmental window (Pinheiro et al., 2024). During puberty, rapid anatomical changes in the larynx and vocal folds substantially alter voice pitch, timbre, and resonance (Hollien et al., 1994), requiring the updating of internal self-voice representations. At the same time, motor control processes adapt to produce stable vocal output despite anatomical changes. These acoustic shifts also engage multisensory integration processes because adolescents must reconcile auditory feedback with proprioceptive and bone-conduction signals. Concurrently, heightened social evaluation and identity formation (Crone et al., 2022) amplify the relevance of the self-voice to self-concept. Together, these interactions highlight adolescence as a sensitive period for self-voice processing, in which the auditory, motor control, memory, multisensory integration, and self-concept building blocks are dynamically recalibrated (Pinheiro et al., 2024).
Current empirical constraints nevertheless limit the temporal and causal scope of the existing evidence. Most experimental manipulations of the self-voice—including AI-based voice modifications—measure short-term perceptual or behavioral adjustments. Although clinical case reports (e.g., following laryngectomy or voice therapy) suggest longer term effects, controlled longitudinal data remain scarce. Moreover, disruptions within one building block may cascade across others (see Table 3), yet these interdependencies are rarely tested systematically. Future work should thus examine how individual, cultural, and developmental factors interact to modulate these dynamics, refining the applicability of the proposed framework across contexts and populations. Last, the multifaceted nature of self-voice processing makes selecting an appropriate experimental approach inherently challenging. Apparent discrepancies across studies often arise from differences in task design (see the Supplemental Material). To guide future research, Table 4 summarizes commonly used experimental approaches—with example studies spanning behavioral, EEG, and functional MRI/PET methods—organized around three key contrasts: natural versus digital self-voice, active versus passive processing, and implicit versus explicit tasks.
Experimental Approaches to Studying the Self-Voice
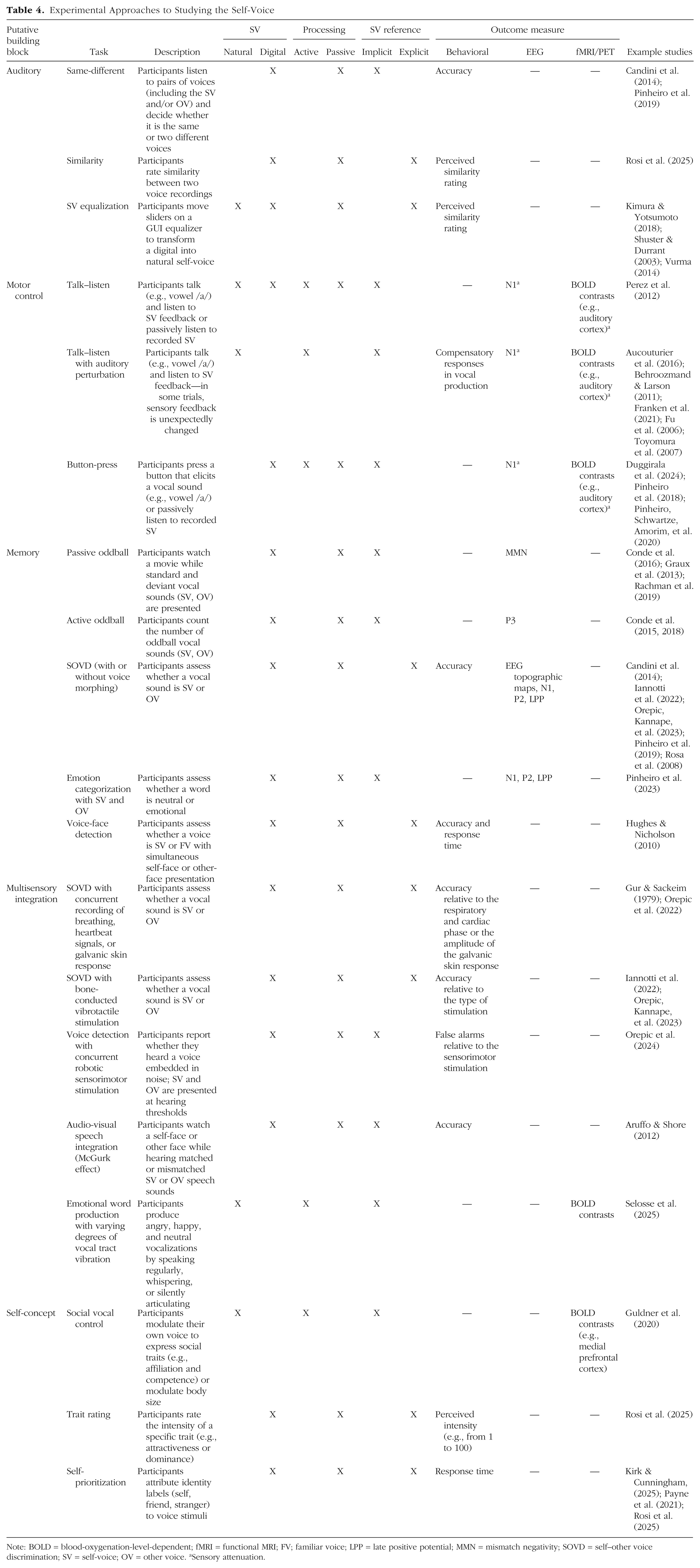
Note: BOLD = blood-oxygenation-level-dependent; fMRI = functional MRI; FV; familiar voice; LPP = late positive potential; MMN = mismatch negativity; SOVD = self–other voice discrimination; SV = self-voice; OV = other voice. aSensory attenuation.
Concluding Remarks
Understanding how individuals develop, represent, and experience a vocal self is central to the broader science of self-consciousness—a topic that has long captivated disciplines ranging from neuroscience and psychology to computational sciences and philosophy. This article proposed a novel framework for deconstructing the building blocks of self-voice perception that encompasses auditory, motor control, memory, multisensory integration, and self-concept components. By integrating these foundational processes, the framework offers a transdisciplinary lens through which to explore the cognitive and neural underpinnings of the auditory self.
Importantly, this approach not only synthesizes fragmented findings across domains but also opens new research avenues at the intersection of psychiatry, developmental science, and AI (see Table 5). For instance, as voice technologies become increasingly pervasive, future studies should investigate how widespread exposure to synthetic, manipulated, or AI-generated voices may shape internal representations of the self-voice. These questions are especially pressing during sensitive developmental windows, such as puberty, when self–other voice distinction may be particularly malleable (Pinheiro et al., 2024).
Outstanding Questions

In addition to addressing risk and resilience in mental health, the framework may inform the design of interventions and technologies that more closely align with individuals’ vocal identity—particularly for those who have lost their natural voice (e.g., because of motor neuron disease; Cave & Bloch, 2021) or who seek voice congruence through gender-affirming therapies.
Ultimately, advancing knowledge of the neurocognitive mechanisms that support the vocal self brings us closer to resolving one of the most intimate paradoxes of human experience: how the voice we produce becomes the voice we hear in the “mind’s ear”. Bridging the gap between the natural and digital self-voice is not only a technological challenge but also a fundamentally cognitive and emotional one, with wide-reaching implications for identity, agency, and self-awareness in today’s digital era.
Glossary
Auditory-verbal hallucinations: Hearing voices or speech that seem real but are not produced by an external source. One of the most common symptoms of schizophrenia, but also present in the general population.
Bodily self-consciousness: The basic sense of owning and controlling one’s body and being located in space. It is supported by multisensory integration of exteroceptive (e.g., vision, touch, sound), interoceptive (e.g., respiration, heartbeat, internal bodily sensations), and proprioceptive signals (information about body position and movement).
BOLD (Blood-Oxygen-Level-Dependent) Signal: The signal measured in fMRI that reflects changes in blood oxygenation linked to neural activity. When a brain region becomes more active, local blood flow increases, producing a change in the BOLD signal.
Bone conduction: Alternative pathway through which the sound of our voice travels to our inner ears. It is based on vibrations of the bones of the skull and other tissues in the head, and it is one of the reasons why we hear our own voice differently from how others hear it.
Corollary discharge: An internal signal the brain sends when starting a movement – such as preparing to speak – to alert sensory areas that a self-generated sound or sensation is about to occur. This helps the brain tell apart sensations caused by oneself from those caused by the outside world.
ECoG (electrocorticography): A brain-recording method that measures electrical activity directly from the surface of the brain.
EEG/MEG (electroencephalography / magnetoencephalography): Techniques that measure the brain’s electrical or magnetic activity from outside the head, offering very fast tracking of neural signals.
Efference copy: An internal copy of the motor command the brain issues when performing an action. This copy allows sensory systems to anticipate the specific feedback the action should produce, such as the expected acoustic consequences of one’s own voice.
Event-related potential (ERP): A brain response measured with EEG or MEG that is time-locked to a specific event, such as hearing a sound.
fMRI (functional magnetic resonance imaging): A brain-imaging method that tracks changes in blood flow to show which brain areas are active during a task.
Formant frequencies (F1-F5): Resonant frequencies in the voice that shape vowel sounds and help identify speakers. Each person has different formant frequencies due to unique anatomies of vocal and nasal cavities. Typically, five different formants are extracted from the speech signals, and the lower ones change more depending on which sound we are articulating.
Forward model: A computational framework that uses internal motor-related signals to predict the sensory outcome of an action. When speaking, the forward model estimates how the voice should sound and feel, allowing the brain to compare expectations with actual feedback and detect mismatches.
Fundamental frequency (F0): The lowest frequency of a voice, often perceived as its pitch. It is lower in males compared to females.
LPP (Late Positive Potential): A late ERP component (beginning around 300-400 ms) that is larger for emotionally or motivationally significant stimuli. It reflects sustained attention and evaluative processing.
MMN (Mismatch Negativity): An ERP response that occurs when an unexpected sound violates a repeating pattern. It appears automatically (without attention) around 100-250 ms and reflects early auditory change detection.
Motor control (vocal control): How the brain directs and coordinates the muscles needed for producing speech.
N1/M1 suppression: Reduction of early (around 100 ms) brain responses (N1 in EEG/MEG, M1 in MEG) when hearing one’s own voice, reflecting the brain’s prediction of self-generated sounds.
Norm-based coding of voices: The idea that the brain represents voices by comparing them to an internal “average voice”, making distinctive voices easier to recognize.
Predictive coding: A theory proposing that the brain constantly generates predictions about incoming sensory information and updates them based on new evidence.
Prediction error: The difference between what the brain expects to perceive and what it actually perceives.
Readiness potential: A slow buildup of brain activity that occurs before a voluntary movement, including speaking.
Self-concept: A person’s understanding of who they are, including their personality traits, abilities, and identity, as well as how they see themselves in relation to others. It reflects both internal self-knowledge and socially shaped aspects of identity, such as roles, group memberships, and how individuals believe they are perceived by others.
Sensory suppression: The brain’s reduction of its own sensory responses to self-generated signals (like the sound of one’s own voice).
Source-filter model of speech: A model describing how the voice is produced: the vocal cords create a sound source, and the vocal tract shapes it into speech.
Supplemental Material
sj-docx-1-pss-10.1177_17456916261422585 – Supplemental material for From Voice to Self: An Integrative Framework on Self-Voice Processing
Supplemental material, sj-docx-1-pss-10.1177_17456916261422585 for From Voice to Self: An Integrative Framework on Self-Voice Processing by Pavo Orepic and Ana P. Pinheiro in Perspectives on Psychological Science
Footnotes
Acknowledgements
The authors thank Carolyn McGettigan and two anonymous reviewers for their insightful and constructive feedback on earlier versions of this manuscript. We also thank Gil Costa for his assistance with figure generation.
Transparency
Action Editor: Zhicheng Lin
Editor: Arturo E. Hernandez