
Abstract
The Rapid Assessment of Cognitive and Emotional Regulation (RACER) is a tablet-based assessment tool for children that measures executive function (EF) skills. Instructions that are brief and visually presented; game-like tasks are designed to easily engage children regardless of literacy level and variable test administration settings. RACER measures inhibitory control and working memory. This study presents the theoretical rationale and empirical evidence for tablet-based assessments of EF, the process of administering the RACER assessments. The current sample consists of students in Lebanon (N=1900) and Niger (N=850). The results indicate that individual differences in EF can be assessed by the RACER tablet tasks. Specifically, we demonstrate that EF scores are associated in expected ways with age and that tasks function similarly to what has been observed in high-income countries. The feasibility and utility for researchers, practitioners, and clinicians, of this cognitive assessment tool is discussed.
Introduction
A large and growing body of research in Western, educated, industrialized, rich, and democratic (WEIRD; Henrich et al., 2010) societies has linked cognitive function assessed in laboratory settings to real-world behaviors (Blair and Razza, 2007). These studies have demonstrated that, among other capacities, individual differences in executive function (EF) predict school and labor market outcomes (Blair, 2002; Blair and Razza, 2007; Heckman et al., 2006). EF is commonly operationalized by performance on tasks or short games (Miyake and Friedman, 2012). The tasks that are used to assess EF traditionally are computer-administrated cognitive tasks, which are unstandardized but include careful within-person controls resulting in accurate assessments of EF. Importantly, with these kinds of tests, no comparison to standardized “norms” is possible, but these tasks are ideal for within-group associations, linking task performance to individual or group characteristics. This kind of testing is also optimal for non-WEIRD settings such as humanitarian settings in low- and middle-income countries (LMICs) where standardization of tests is difficult or impossible. Here we describe efforts to bring these computerized testing of EF out of the laboratory and into the field in humanitarian settings in LMICs.
EF is understood to refer to three interrelated and intertwined cognitive functions: working memory, the ability to hold in mind and manipulate information for a few seconds when it is no longer present in the environment; inhibitory control, the ability to stop oneself from performing a motoric response that is prepotent; and switching or the ability to rapidly change one goal or action for another (Miyake and Friedman, 2012). Extensive correlational research, primarily in high-income country samples, indicates that EF contributes directly to success. Improvement in EF, in particular working memory through training, results in improvements in standardized math scores (Holmes et al., 2010; Roberts et al., 2011); EF in kindergarten predicts future academic achievement even controlling for current academic competence (Blair and Razza, 2007); and gains in achievement tests are associated with gains in EF (Finn et al., 2014, 2017). Although the barriers to education are generally greater in humanitarian and LMIC settings, the links between education and executive function are less well studied in these settings. Interestingly, initial work has partially replicated findings in high-income countries (McCoy et al., 2015). The links between EF and school achievement are likely in part because EF is a key cognitive mechanism for self-regulation (Blair and Razza, 2007; Hughes and Ensor, 2011; Jacob and Parkinson, 2015; Mazzocco and Kover, 2007; Waber et al., 2006). While EF is not equivalent to self-regulation, self-regulation is, conceptually, more closely linked to EF than other skills because of literature documenting deficits in EF and linked poor self-regulation in patient populations (Barkley, 1997; Barkley et al., 1992; Gruber et al., 2011; Spencer et al., 2007). Recently, self-report measures of impulsivity have been linked with impulsive and rule-breaking behavior in LMIC and humanitarian settings (e.g. Blattman et al., 2017). But again, this is an understudied area and few studies have measured self-reported impulsivity or linked these reports with EF in LMIC settings.
Finally, substantial evidence from high-income country settings indicates that variations in early experiences of childhood are linked with children’s development of EF. Specifically, children’s household disadvantage, such as parental educational attainment and poverty, are strong predictors of children’s EF skills (Blair, 2002; Finch and Obradović, 2017; Hackman et al., 2010; Lawson et al., 2018; Sheridan et al., 2017). Residential mobility is also found to be predictive of EF skills, with moving to a high poverty neighborhood being detrimental to children’s executive function (Roy et al., 2014). One of the mechanisms through which poverty may undermine children’s EF is by reducing the richness and number of learning opportunities children have (Johnson et al., 2016; Sheridan et al., 2012). However, access to formal learning opportunities, presence of stress or trauma, and certainly household disadvantage differ widely around the world and between humanitarian and non-humanitarian settings. Limiting our investigations of the associations among these variables to the narrow range and type of experiences available in high-income countries limits our fundamental understanding of the interplay between early experience, cognitive function, self-regulation, and school success.
In sum, there are many important reasons to extend investigations into EF to humanitarian settings in LMICs. First, as reviewed above, EF is fundamental to education and labor market success, areas that are of central importance to development goals in LMICs. Second, known predictors of EF development in high-income countries (e.g. adversity exposure, poverty, caregiver inputs) are present to a greater degree in humanitarian and LMIC settings. As a result, there have been numerous calls to develop tests appropriate for use in LMIC settings (Fernald et al., 2009; Willoughby et al., 2018; Zuilkowski et al., 2016). These calls have focused on the importance of developing and adapting tests significantly to meet the particular demands of humanitarian and LMIC settings.
Major barriers exist that limit the facility with which cognitive tests administered in high-income laboratory settings can be used in humanitarian LMIC settings. Traditionally, in laboratory settings, EF was assessed using a battery of neuropsychological tests. In this approach, an individual person was administered a number of tests. These would include tests of basic sensory and motor function (e.g. hearing and vision) along with more complex cognitive functions (e.g. long-term memory, linguistic facility, language knowledge and numeracy, logic puzzles, and EF). Each of the tests would be normed by age and gender for a particular population (e.g. individuals in the United States who attend school). The results of each subtest would be interpreted relative to the processing of same age and gendered peers and relative to the entire battery administered. Without these norms and the other subtests in a neuropsychological testing battery, these tests are difficult to interpret accurately. Using these tests in humanitarian and LMIC settings for which they were not adapted or normed is of limited utility (Zuilkowski et al., 2016). While new neuropsychological batteries could be developed for each new country, age group, and setting in which testing was required, iteratively establishing these norms across a large number of country settings would be incredibly difficult and time-consuming. Thus, other approaches may be better suited to the assessment of cognitive function in humanitarian and LMIC settings.
Construction of cognitive tasks, common in the field of Cognitive Psychology, is one possible solution. In each cognitive task, a series of trials are administered that assess an individual’s EF; for example, their ability to inhibit themselves from responding or hold information in mind for a short period of time. However, a second series of trials is intermixed with the first. These intermixed trials—in terms of general concentration, visual input, and motor response—are identical to the trials that require EF but lack the specific manipulation which requires a person to employ EF to get the trial correct and are thus termed “baseline trials”. For example, a baseline trial might be asking someone to simply press in the center of a dot within a certain amount of time. Hence, this trial requires speedily interacting with the tablet but doesn’t require EF. In contrast, an EF trial might also present a dot, but would require that participants press away from the dot, on the opposite side of the screen. This requires inhibiting a prepotent response (pressing on the dot) and speedily executing an alternate action, thus it requires EF. However, most of the task demands for these two trials are identical (i.e. remember a rule and speedily execute a motor tablet press). During analysis, EF trials are always compared to baseline trials, and so the within-person difference score is used as an indication of the person’s EF ability specifically, not their general ability to perform cognitive tasks. This way of testing EF allows single, un-normed tasks to be administered outside of a complex and time-consuming battery of tests in a way that allows meaningful interpretation of the results. Specifically, large between-country and setting differences in task performance related to interpreting two-dimensional stimuli or responding by touching a tablet computer should contribute equally to baseline and EF trials. The comparison of these two types of trials should only capture individual differences in EF, not individual differences in general task performance.
Several other aspects of existing neuropsychological batteries and computerized tasks make it difficult to administer them in humanitarian and LMIC settings. First, many of these batteries/tasks rely on facility with representational symbolic knowledge—including, but not limited to, literacy and numeracy. Second, many tasks assume shared knowledge. For example, tasks may show participants pictures of animals (e.g. zebras), weather states (e.g. snow), or buildings (e.g. skyscrapers) which are not equally common throughout the world. Finally, administering paper and pencil versions of these tasks may require substantial skill and intensive training on the part of enumerators. For example, they might require that enumerators time participants’ reactions while also tracking the accuracy of their responses. It may be difficult to find assessors who can quickly pick up such a cognitively-demanding task in LMIC settings, resulting in a choice between poor data quality or lengthy and expensive training.
To overcome these barriers, we designed RACER—Rapid Assessment of Cognitive and Emotional Regulation)—tasks optimized for the widely variable and challenging assessment environments found in humanitarian and LMIC settings. The original set of available tasks included assessments of long-term memory, procedural learning, inhibitory control, working memory, and visual-spatial attention. Here we report on the use of two EF tasks: working memory and inhibitory control.
RACER tasks are designed to be faithfully administered to and by those with no literacy or numeracy knowledge. Linguistic and mathematical proficiency vary dramatically across populations; using letters, words, or numbers as stimuli may primarily capture these differences instead of the intended skills of cognitive control. Second, RACER does not rely on content knowledge. All tasks assess cognitive function using simple shapes, and these shapes are identical across levels of difficulty. This means that variation in knowledge of shapes or colors should not contribute to task performance. Third, we designed short tasks to limit the degree to which distractions could hinder performance. When used in lab settings, cognitive tasks often last from 5 to 15 minutes, which is ample time for respondents to grow bored and distracted. To eliminate the degree to which environmental distractions and individual differences in attention span can influence task performance, each task in RACER lasts 1 to 4 minutes. Fourth, we designed RACER to have relatively low reliance on interviewer training. The most burdensome aspects RACER administration are automated by the application itself, leaving little burden on field personnel. This includes instructional videos, assessments of respondent understanding prior to administration of each game, and all aspects of time-keeping, response recording, and sequencing. Interviewers still have some responsibilities, such as monitoring participant compliance with the rules, but these are limited. Because the role of field personnel is fairly circumscribed, RACER relies minimally on similar facility with a shared language between field personnel and participant. Many countries recognize more than one official language, and most countries have high levels of linguistic diversity. Tests for which administration relies on equal facility with a shared language (e.g. to explain complex rules of game play) are likely to fail in these contexts. Finally, RACER is administered on a tablet computer to reduce reliance on computer literacy. In population-representative samples, particularly outside of high-income countries, computer knowledge is highly variable. Using a traditional keyboard or button box for input may increase barriers to participation and affect task performance. Using a tablet computer allows participants to interact with stimuli on the screen in a more intuitive way. Finally, these tasks are designed so that each task contains baseline trials and EF trials. The outcome measure for each task is EF trials compared to baseline trials. As described above, this comparison should account for between country and setting variance general task performance. Here we test this hypothesis by comparing performance in two humanitarian settings in two different LMICs. Importantly, these tasks are not normed. As described above, the process of norming tasks in each new setting and country is prohibitive. Thus, we can compare the results we observe on RACER observations in high-income countries on similar tasks in general and we can compare performance within our group of participants, but we cannot report an absolute “level” of performance across countries or settings.
Current study
In the current study, we report on how RACER functions in two humanitarian LMIC settings. First, we examine how RACER performs with displaced Syrian children living in refugee settlements in Lebanon and second with children in Diffa, Niger, affected by Boko Haram attacks near the border with Nigeria. If RACER is accurately assessing EF in these contexts, we expect to confirm the following hypotheses. First, that children will perform better on baseline, non-EF trials compared to either inhibition or working memory trials within each task. We expect this to be true across both settings and for the magnitude of the effects, i.e. the difference between baseline trials and the inhibition or working memory challenge trials to be similar in Lebanon and Niger. We further expect that the magnitude of these effects will be within the range of effects reported in high-income countries on similar tasks. Second, in high-income countries, EF task performance shows strong and reliable associations with age (Best et al., 2009). Thus, we further expect that task performance for EF relative to baseline trials will improve with age. Finally, we hypothesize that while one study site may have higher overall accuracy or faster reaction time (RT), we do not expect that the tasks’ ability to measure EF will differ across locations. Support for these hypotheses would lead to the conclusion that these tasks accurately measure EF in humanitarian and LMIC settings.
Methods
Participants
This study draws on a subset of data from two large cluster randomized control trials evaluating the impact of informal education programs in Lebanon and Niger. In each country, approximately one-half of the child sample within each community or school were randomly selected to take RACER as a part of a larger assessment package.
In Lebanon, 1907 children (50% female, age M = 9.73, SD=2.32, grade M = 2.60, SD =1.71) from 87 communities were assessed at baseline. Of them, 48 children (57% female, age M=9.18, SD=2.42, grade M = 2.11, SD=1.44) were excluded from the final sample due to administration problems. Of the 48 excluded participants, assessors reported that 31 children were not willing to complete the tasks or other field issues; and 17 children stopped playing the first task administered before it reached 50% of the trials. This resulted in a final sample of 1859 participants for study analysis. In addition, 4.2% from the working memory task and 1.6% from the inhibition task were excluded during data processing due to follow-up field notes, duplicate test data, or extremely poor performance; details of these exclusionary criteria are found in the data processing section. Individuals who were excluded due to poor performance were mainly younger (age M=8.28), less likely to be female (47% female), and completed fewer years of education on average (grade M = 1.51).
In Niger, 866 children attending second to fourth grades (53% female, age M = 9.18, SD=1.43, grade M = 2.99, SD =.82) from 30 schools in Diffa and Maine-Soroa districts were assessed at the baseline. All children assessed were eligible for and were attending remedial tutoring support provided for students who were not at or above second grade level in French literacy and math. All assessed children were included in the final sample. However, the working memory game data from 41 children were excluded from the data analysis due to administration issues; 21 of the cases were due to issues reported by field assessors, whereas 20 cases involved poor child performance or more than 50% missing data. In addition, 2.4% of subjects’ working memory task data and 1.6% of subjects’ inhibition task were excluded during data processing due to follow-up field notes, duplicate test data, or extremely poor performance, details of these exclusionary criteria are found in the data processing section. Individuals who were excluded due to poor performance were overall younger (age M=8.86), less likely to be female (43% female), and completed fewer years of education on average (grade M = 2.62).
Measures
RACER
All assessments were administered on Samsung Galaxy Tab A tablets with 9.7” screen, using an android app programmed for RACER assessment. All participants received two tasks, which assessed two different aspects of EF, working memory and inhibitory control.
Working memory was measured using a Spatial Delayed Match to Sample task, a widely-used measure for working memory (Goldman-Rakic, 1996; Thomason et al., 2009). Our version consisted of a total of 52 trials, with 26 working memory trials with 2000-millisecond delay and 26 no-delay trials. In each trial, a respondent is shown a white screen with one, two, or three black dots; each dot can occur in one of nine screen locations (Figure 1). The accuracy of the touch in each trial is measured by the distance from the recorded touch location to each dot. The overall working memory performance is scored by regressing the average distance in the working memory trials on the average distance in the no-delay trials for each respondent. This difference represents the degree to which introducing a short delay, over which participants needed to hold in mind the location of dots, disrupted performance. Because holding in mind stimuli for a short period of time is the definition of working memory, we take the degree to which delay disrupted performance to be an estimate of that child’s working memory ability.
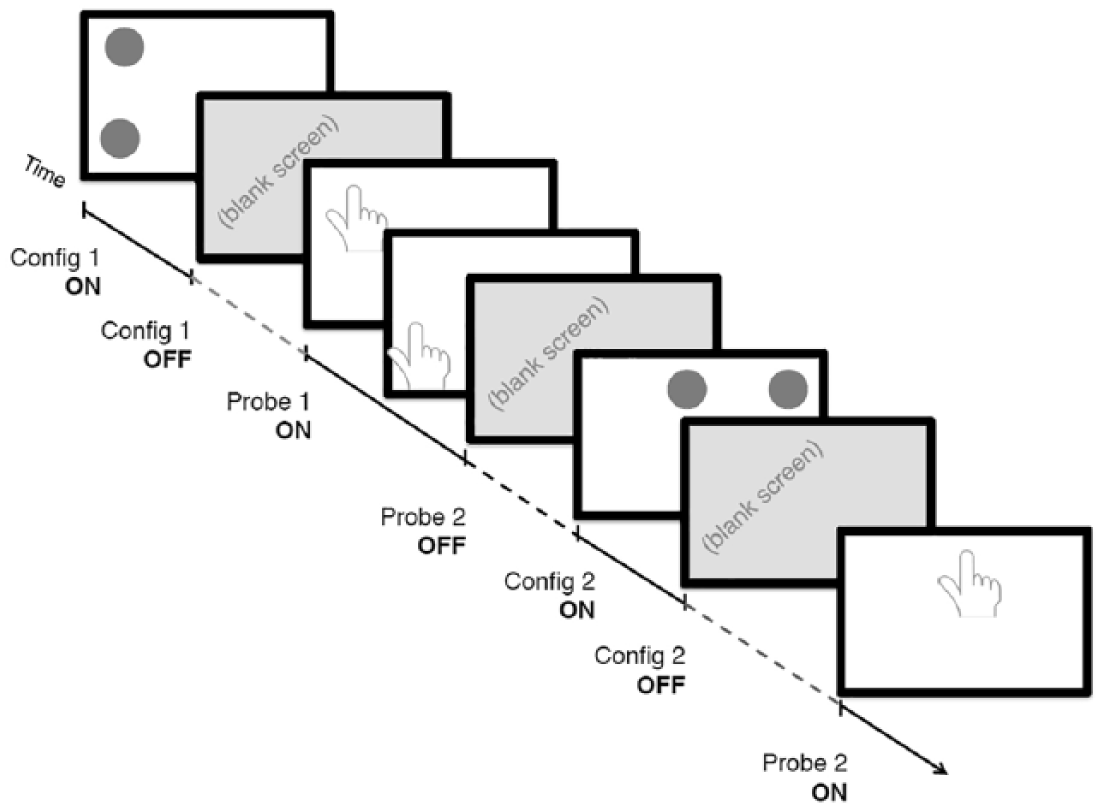
A schematic of the spatial delayed match to sample task used to assess working memory.
Inhibitory control was measured using a game developed based on the “Simon Task,” a commonly used game in cognitive science (O’Leary and Barber, 1993; Simon and Rudell, 1967). In the same-side trials, a solid pink dot appears and the respondents are instructed to touch the center of the dot, i.e. the same side, as fast as possible. On the opposite-side trials, a yellow-and-black striped dot appears, and respondents are instructed to touch the center of the opposite side of the screen, marked by a cross sign, as fast as possible (Figure 2). Reaction time (RT) is recorded in each of the same-side and opposite-side trials, and an overall inhibitory control score was calculated by regressing the average opposite-side trial RT on the average same-side trial RT. This difference represents the degree to which asking a participant to withhold a prepotent response (pressing on the dot) and to execute a less obvious response (press on the opposite side) disrupts performance on the task. Because suppressing a prepotent response is the definition of inhibition, we take the degree to which opposite-side trials slow performance to be an estimate of that child’s inhibitory control ability.
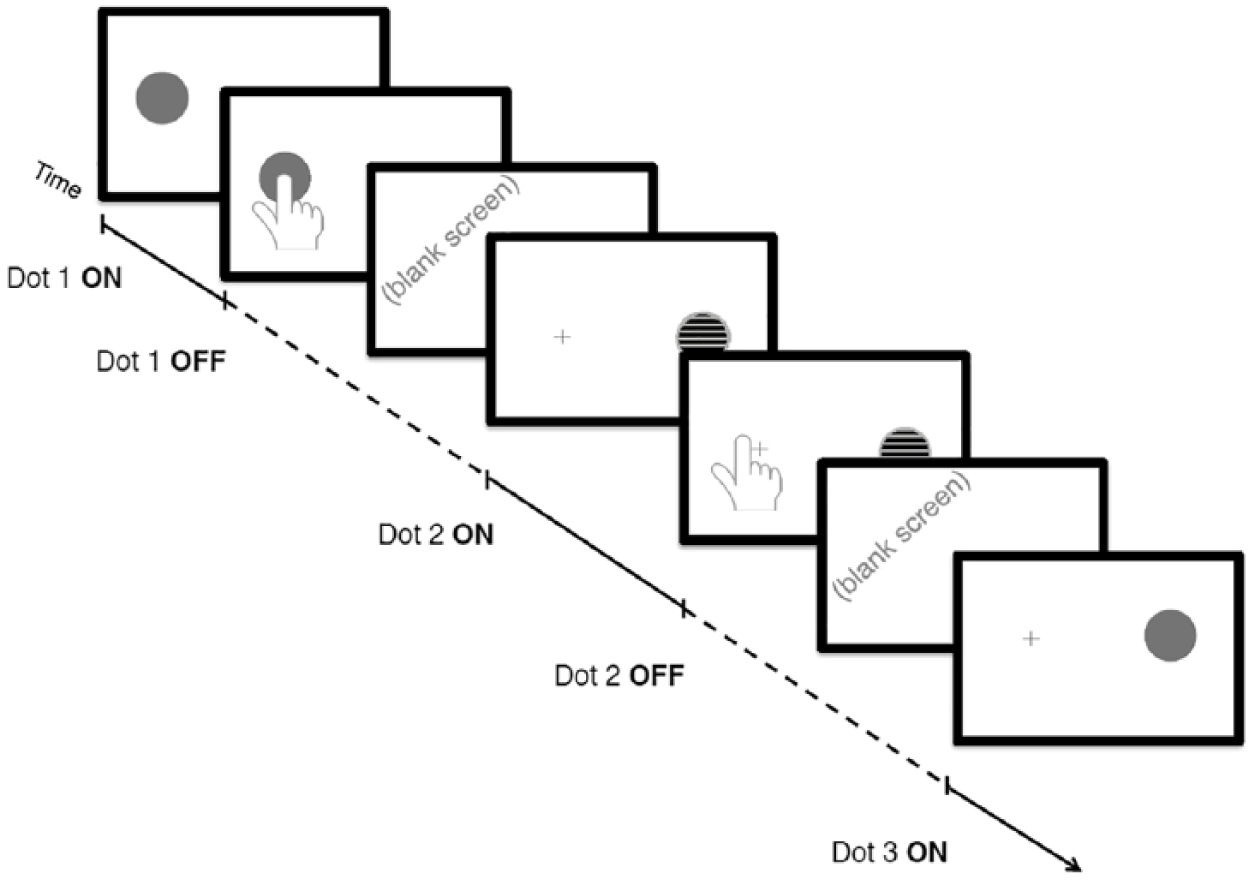
A schematic of the “Simon Task” used to assess inhibitory control.
Age
Age was not measured in the same way across locations. In Lebanon, date of birth was collected, enabling the use of this variable as a continuous measure of age. In Niger, age was self-reported, and children were often uncertain of their ages. In Niger, therefore, age is discrete (e.g. 5, 6, 7, etc.) and unreliable. To assess changes in executive function across ages, we only used the Lebanon sample to avoid introducing measurement error into the analyses. As has been found in previous studies, we predicted that performance in both tasks would be better for older versus younger children (Best et al., 2009).
Training
Locally-recruited assessors were trained to administer RACER and several other cognitive tasks and questionnaire instruments during a five-day training. RACER training and practice took approximately one full training day. Assessors were first introduced to RACER software and principles via a PowerPoint presentation, followed by detailed live modeling of each task. Volunteer trainees then practiced in front of the group with public feedback from the trainers. This was followed by paired practice utilizing scripted instructions for each task; in Niger, this activity was followed by translating the scripted instructions into various local languages. In this study, the same full-day training was repeated for each data collection wave as new assessors were included in each waved of data collection. To perform these tasks, enumerators were trained to instruct participants to use only one finger to respond, to retract their finger in-between tasks, and to play as quickly and accurately as possible. Enumerators monitored participants for compliance and reminded the participants if needed.
Administration setting
RACER was administered in a variety of settings both across and within country contexts. In Lebanon, participants in the control group were most often assessed inside their own or neighbors’ homes in the community, ranging from furnished apartments to tents made from wooden frames and plastic sheeting. In both Lebanon and Niger, children in the treatment group were most often assessed inside or just outside of their remedial or public school structure. These structures also varied considerably, from outdoor space, to a plastic tent, to a classroom building. Level of noise, temperature, light, and distraction were variable as well. For example, when assessment occurred indoors, the setting often lacked electricity. Assessments often took place in close proximity to other children, some of whom were also being assessed or waiting to be assessed. In sum, these were typical field settings for research outside of the laboratory and thus the results of RACER can be considered to reflect what might be expected in typical field settings.
Data processing
Participants’ touches on the screen were recorded for each trial. From this information, we calculated the RT (i.e. the time it took a participant to respond) and the accuracy of their response. All data were processed and analyzed in SAS software, version 9.4 (SAS Institute Inc., Cary, NC).
Several criteria were used to clean the data for analysis. First, four respondents in Lebanon and one respondent in Niger were excluded due to errors administration errors, such as a mislabeled ID, determined by field notes. Second, respondents were excluded due to low accuracy based on the following criteria. For the working memory task, respondents were excluded if they were missing all responses in any of the five trial types: load 1, load 2, load 3, no delay, working memory (short delay). This criteria excluded working memory task data from 79 respondents in Lebanon and 20 respondents in Niger. For the inhibitory control task, respondents were excluded if they did not respond to at least 50% of same or opposite-side trials. This criteria excluded inhibitory control task data from 29 respondents in Lebanon and 4 respondents in Niger. In Lebanon, 12 respondents had both working memory and inhibitory control task data excluded. The final number excluded due to all of the exclusion criteria was 96 (5.2%) respondents in Lebanon and 25 (2.9%) in Niger.
For the working memory task, accuracy was defined as the Euclidean distance from the person’s touch response to the center of the nearest ball presented on the screen in each trial. For example, in a three-item trial, if a respondent touched the screen three times in the exact same location, rather than separate locations close to where the dots had appeared, we calculated three distances for that trial, each subsequently larger as accuracy decreased. We then averaged accuracy for each of the delay conditions (none and long) and each of the load conditions (one-, two-, and three-dot trials). At higher loads (two- and three-dot trials), participants did not always respond to all dots in the allotted time (2 seconds). To handle this missing data, we averaged only the touches made by a participant so as not to penalize them for time-outs. For example, in a three-dot trial, if a respondent only made two touches, the accuracy for that trial was calculated as the average distance for the two touches made, without penalizing the accuracy for the missed third touch. This approach is beneficial for capturing only “true” data, but may artificially inflate accuracies for high-load trials. To examine the effect of load and delay on these missed touches, we also totaled and averaged the number of missed touches for each load condition for each respondent.
Data analysis
To assess working memory capacity, we compared the accuracy of individuals’ responses in a 2 x 3 repeated measures ANOVA with delay (none vs. short) and load (one vs. two vs. three dots) as within-subject factors. We expected participants to perform less accurately on trials where they had to hold in mind the location of dots over a delay relative to the “no-delay” trials and less accurately on trials with more dots. We further expected the decrement in accuracy due to delay to increase as load increased from one to three dots.
For the inhibitory control task, we averaged RT separately for accurate responses to “same-side” and “opposite-side” trials. For the purposes of averaging RT, we considered responses to be “accurate” if they were made anywhere on the correct half of the screen (e.g. same half of the screen as the ball on same-side trials) and inaccurate if they were on the wrong side of the screen. To assess inhibitory control, we compared the RT on the same- versus opposite-side trials using a paired-samples t-test. We expected RT to be significantly faster when participants were able to perform the prepotent response, on “same-side” trials and slower when participants were required to withhold that response in favor of pressing on the opposite side of the screen to where the dot appeared, with the difference in RT reflecting inhibitory control for each participant.
To assess the effect of site location for the inhibitory control task, we submitted RT to 2 x 2 mixed effect ANOVA with location (same vs. opposite) as the within-subject factor and site (Lebanon vs. Niger) as the between-subject factor. For the working memory task, accuracies were submitted to a 2 x 3 x 2 mixed effects ANOVA with delay (none vs. short) and load (one vs. two vs. three dots) as within-subject factors, and site (Lebanon vs. Niger) as the between-subject factor.
Results
Inhibitory control task
Although both accuracy and RT are typically analyzed for tasks of this nature, due to the presence of fixation crosses on both sides of the screen, we found fairly high accuracies for both conditions (see Table 1 for all means and standard deviations). We therefore analyzed the effect of condition on RT rather than accuracy. We predicted slower RT for opposite side compared to same-side trials, because the opposite-side condition required participants to control the urge to press the location where the ball appears and re-direct the attention to the opposite side. As expected, on average, participants responded significantly faster to same-side vs. opposite-side trials in both Lebanon (t1808=12.94, p<0.0001) and Niger (t685=4.15, p<0.0001).
Means and standard deviations for task outcomes by site location.
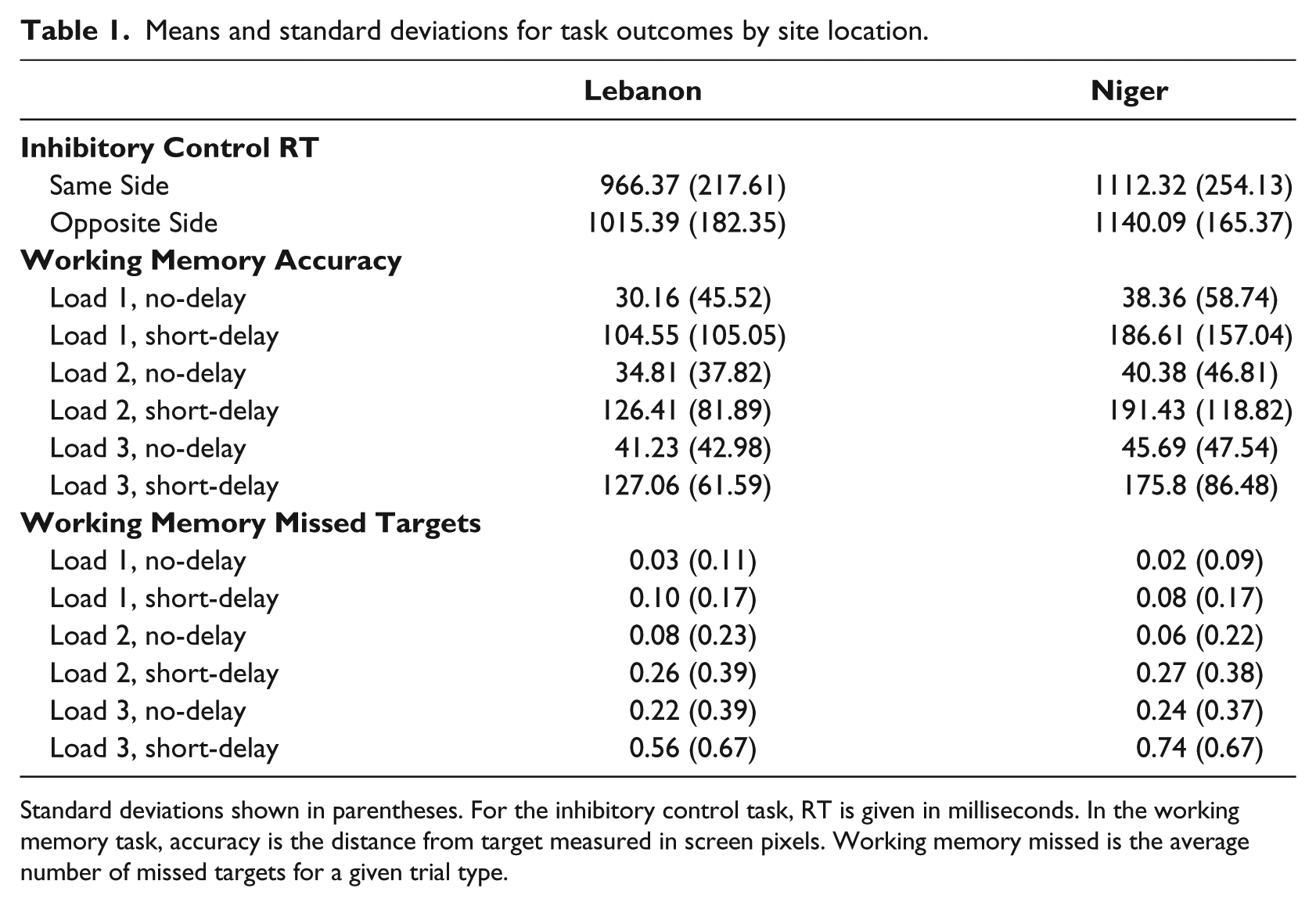
Standard deviations shown in parentheses. For the inhibitory control task, RT is given in milliseconds. In the working memory task, accuracy is the distance from target measured in screen pixels. Working memory missed is the average number of missed targets for a given trial type.
Working memory task
As predicted, we found that when collapsing across loads (one, two and three dots), accuracy was significantly lower in the short-delay condition as compared with the no-delay condition in both locations [Lebanon: F1,1770= 2684.77, p<0.001, partial η2=0.60; Niger F1,669=1240.89, p<0.001, partial η2=0.65]. This main effect of delay suggests that the difference in accuracy between the two conditions can be used as an individual measure of working memory, as it reflects the additional resources recruited in the more taxing memory condition. As expected, we also found a main effect of load with accuracy significantly decreasing as the load increased from one to three dots in both locations [Lebanon: F2,1770= 152.48, p<0.001, partial η2=0.08; Niger F2,669=3.46, p=0.032, partial η2=0.005]. Post-hoc tests, corrected for multiple comparisons (Benjamini and Hochberg, 1995), indicated that accuracy declined parametrically, with two-dot trial worse than one dot trials (t1795=13.87, p<0.001), and three-dot trials worse than two-dot trials (t1795=3.71, p<0.001) in Lebanon. In Niger, a similar decline in accuracy was seen between the one- and two-dot trials (t679=2.38, p=0.17); however, accuracy rebounded when going from two to three-dot trials (t679=4.21, p<0.001). This location effect is explored below in the site-specific effects section. This main effect of load suggests that this accuracy difference can be used as an individual measure of working memory capacity.
In both locations, there were significant load-by-delay interactions (Lebanon: F2,3540= 40.80, p<0.001, partial η2=0.02; Niger: F2,1338= 17.72, p<0.001, partial η2=0.03). In Lebanon, accuracy decreased as load increased in no-delay trials (p<0.05 for all comparisons with Bonferonni correction; means in Table 1). In the short-delay trials, accuracy decreased going from one-dot to two-dots, but at the highest load (three dots), accuracy plateaued (Mdifference=1.47, p=0.78). In Niger, at the short delay, accuracy decreased going from one to three dots, and two to three dots, but did not differ between one-dot and two-dot trials (Mdifference =1.99, p=0.95). In short-delay trials in Niger, there was an unexpected pattern of accuracy, with an observed, but non-significant decline in accuracy going from one-dot to two-dot trials (Mdifference =4.85, p=0.43), but then a significant improvement in performance comparing two-dot and three-dot trials (Mdifference =15.93, p<0.001). These results contradict the prediction that the biggest drop in accuracy would occur for the hardest condition (three-dots, short-delay). These unexpected results are explored below when we also examined location effects.
Effect of age
As noted previously, age was measured differently across locations. Due to the uncertainty regarding the accuracy of the age variable in Niger, we looked at the effects of age on working memory and inhibitory control only in our Lebanon participants. Age had a large, significant effect on both task outcomes. In the inhibitory control task, a main effect of age (F1,1807= 187.95, p<0.001, partial η2=0.03) suggests that, as expected, participants are faster overall as they get older. The interaction between age and same- vs. opposite-side condition (F1,1807= 32.95, p<0.001) reflects the fact that task performance was better for older participants. In the working memory task, there was again a large and significant main effect of age (F1,1769= 286.88, p<0.001, partial η2=0.14). Age did not interact with load (F2,1769= 2.19, p=0.112), indicating that the decreased accuracy as load increased was consistent across all ages. There were significant interactions between age and delay (F1,1769= 181.58, p<0.001, partial η2=0.09), and a three-way interaction between age, delay and load (F1,1769= 9.29, p<0.001, partial η2=0.005). Visual inspections of age by condition plots indicated that the age by delay interaction reflects an improvement in accuracy as age increased, only at the short delay. The three-way interaction was due to an improvement in accuracy as age increased, only for short-delay trials at the highest load.
Effect of study site
In the inhibitory control task, there was a main effect of study site, due to significantly faster responses in Lebanon (F1,2492= 269.66, p<0.001, partial η2=0.10). Additionally, a significant condition by location interaction reflected the fact that the difference between same and opposite side RTs was larger in Lebanon than Niger (F1,2492= 5.56, p=0.018, partial η2=0.02). We also found a significant effect of location on accuracy, with more accurate responses in Lebanon (F2,2536= 29.68, p<0.001, partial η2=0.012). Again, there was a significant site by location interaction, driven by a different pattern of effects than the response time interaction. There was a larger effect of condition in Niger, driven by equal accuracies in opposite-side trials in both locations, but less accurate responses to same-side trials in Niger (F1,2536= 35.60, p<0.001, partial η2=0.013).
In the working memory task, there was again a significant main effect of study site, with participants responding more accurately (shorter distances from targets) across all conditions in Lebanon (F2,2439= 242.17, p<0.001, partial η2=0.09). A significant delay by location interaction (F1,2439= 273.97, p<0.001, partial η2=0.10), driven by equivalent accuracy in the no-delay condition across both locations, but less accurate responses (larger distances) in the short-delay condition in Niger. A significant load by location interaction (F2,2439= 41.10, p<0.001, partial η2=0.017) reflected differential effects of load on accuracy in the two locations. In Lebanon, there was a parametric effect of load, with accuracy decreasing as the number of dots in a trial increased. In Niger, we found a similar decrement in accuracy when moving from one- to two-dot trials, but an improvement in three-dot trials.
To probe this somewhat unexpected pattern of accuracy in Niger, we ran the same 2 (delay: none v short) x 3 (load: 1 v 2 v 3) x 2 (location: Niger v Lebanon) mixed effect ANOVA, looking at the effects of delay, load and location on the average number of missed targets for a given trial type. A target may have been missed because either no response was made, or a response was made after the allotted time had expired. There were main effects of load (F2,2500= 1697.86, p<0.001, partial η2=0.40), delay (F1,2500= 895.85, p<0.001, partial η2=0.26), and location (F1,2500= 7.26, p=0.007, partial η2=0.003). Participants missed more targets when there were more dots and a delay (Table 1). Across all conditions, participants in Niger missed more targets, although the significant effect of location was particularly small (partial η2=0.003) and should be interpreted with caution. A significant load-by-delay location (F2,2500= 542.62, p<0.001, partial η2=0.18) reflects a different pattern of missed targets across the delay conditions, as load increased. At both delays, increased load resulted in more missed targets; however, during delay trials, there were significantly more missed targets at the highest load. We also found significant load by location (F2,2500= 41.61, p<0.001, partial η2=0.016) and delay by location interactions (F1,2500= 15.25, p<0.001, partial η2=0.006), but in both cases, small effect sizes again suggest that interpretations should be made with caution. The load by location interaction revealed equivalent missed targets at loads 1 and 2, but at the highest load, there were significantly more missed targets in Niger. During highest-load, short-delay trials, participants in Niger missed an average of 0.75 targets, meaning that for many of these trials, only two target responses were used to calculate accuracy. This could help explain the pattern of accuracy observed in Niger across load. With significantly fewer trials contributing to the average accuracy in load 3, it’s possible that participants who would have contributed low accuracy scores to this condition, did not contribute scores at all. Finally, we also found a significant but small three-way load by delay by location interaction on the number of missed targets (F2,2500= 30.98, p<0.001, partial η2=0.012). While the load-by-delay interaction followed the same basic pattern in both locations, the difference in the number of missed targets at the short delay across loads was even greater in Niger, with a large spike in the three-dot condition.
Discussion
Across two humanitarian and LMIC settings, we successfully administered RACER, a tablet-based assessment of EF to children ages 5 to 13. Administration of these tasks was tolerated well by participants despite a wide variety of experience with computers, tablets, formal schooling, and testing in general and did not result in undue research burden. With regards to other practical aspects of data collection, we experienced some technical difficulties with using tablets in settings with limited electricity and internet capabilities. However, these difficulties were expected in these settings and did not significantly impede data collection.
The analyses reveal expected effects on tasks assessing inhibitory control and working memory, generally confirming our hypotheses and indicating that using these tasks to assess EF in LMICs is appropriate. Specifically, across settings we observed typical differences between baseline and EF trials, indicating that it is possible to assess EF in these settings in valid and replicable ways. The magnitude of these differences was within the range of what has been observed in high-income countries on similar or identical tasks. In addition, we observed that the magnitude of the difference between EF trials and baseline trials was associated with age in the country for which we had accurate age measurement (Lebanon).
Importantly, we did not fully confirm our hypotheses. We observed unexpected variance across study site. Specifically, in Niger we observed differences in patterns of performance on the working memory task, which indicate that they may have needed more time to respond to the task, particularly on the hardest trials. Extending the time allowed for individuals to respond on these tasks in future versions of RACER would likely decrease these between-country differences.
Does RACER measure EF?
Overall our observations of the impact of variation in task demands on performance were as have been observed in high-income country settings. On the inhibitory control task, participants at both study sites were slower when responding on opposite-side trials, than same-side trials. Opposite-side trials required participants to inhibit a prepotent response, pressing where the ball appeared, and instead choose a less prepotent response, pressing on the opposite side of the screen to where the ball was. On the working memory task, participants at both sites were less accurate when trying to hold in mind the location of a dot they had seen a few seconds earlier than simply pressing the screen where a dot appeared. In addition, the degree to which this delay impaired performance was less for one dot compared to multiple dot trials.
The size of the inhibitory control effect (~30–50ms) is congruent with other studies that used the same task in both children and adults (Bedard et al., 2002; Booth et al., 2003; Davidson et al., 2006). It is difficult to directly compare the size of our working memory task effect with previous studies because in non-tablet tasks, responses are usually made either verbally or with a button press, and therefore accuracy is measured differently. However, our findings of decreased accuracy as both delay and load increase are consistent with spatial working memory task effects found in children (Cowan et al., 2010, 2011; Kharitonova et al., 2015a; Thomason et al., 2008). Additionally, the age effects in our sample (i.e. improved working memory and inhibitory control as children get older) are also consistent with previous findings (Luciana and Nelson, 1998; Riggs et al., 2006; Simmering, 2012).
These findings indicate to us that we can successfully assess working memory and inhibitory control using these tasks across a wide variety of testing environments and with a range of child populations.
Difference in RACER functioning in Lebanon and Niger
In addition to observing robust main effects of task conditions on performance, we observe study site main effects and study site by task condition interactions. In the first case, we observed that in the working memory task, participants in Niger were less accurate across all task conditions as compared to participants in Lebanon. Similarly, in the inhibitory control task, participants in Niger were slower across all conditions than the Lebanon participants. This is likely due to general differences between these countries in educational and development levels (World Bank, n.d.).
In the case of study site-by-condition interactions, we observed that children in Niger had a different pattern of response associated with increasing load on the working memory task. Across both study sites, the largest change in RT was between one- and two-load trials. Compared to remembering one item, all participants appeared to find it more difficult to recall two items. For participants in Lebanon, increasing the load to three items did not appear to further impact performance. This pattern of results is consistent with the idea that two items is the capacity for children in Lebanon; thus, when the load was increased, the children continued to remember about two items, so their performance didn’t change (Kharitonova et al., 2015b; Vogel and Machizawa, 2004). For children in Niger, when the load was increased to three, their performance—as measured by accuracy—appeared to improve. This is an unexpected result, and we hypothesized that it might reflect a strategy change or overall strategy difference whereby children in Niger attempted to recall all items before pressing the tablet computer to indicate where they had seen them previously. If this recall took too long or took longer on trials where their recall was poor, they may have been unable to respond before the time-limit imposed by the task (2 seconds), resulting in a missed trial for that condition. When we examined the number of trials that timed out across load for participants in Lebanon and Niger, our results were consistent with that hypothesis. Children in Niger missed more high-load trials than children in Lebanon. This suggests between-country differences overall speed of response (also as observed by country differences in overall RT) interacted with task demands to predict performance on highest-load trials. Future versions of RACER could increase the time allowable to respond (e.g. to 2.5 seconds) to compensate for this between-country variation in speed of response. Importantly, regardless of this between-country difference, the tasks we used were still able to capture meaningful variation in individual subject performance within each study site consistent with our hypotheses.
Future directions and conclusions
In the current study, we were able to demonstrate that the EF tasks in RACER accurately captured inhibitory control and working memory capacity across a wide age range (5–13 years) and across two vividly different country settings (Niger and Lebanon). However, much is left to do. Future work should compare performance on these tasks to existing normed EF task batteries to document construct validity. In addition, subsequent tests of the reliability of this EF estimate would be central to demonstrating its utility as a dependent measure.
In sum, we present evidence in this study that it is possible to assess working memory and inhibitory control outside of the laboratory in LMIC settings. We obtained valid estimates from children with a wide range of experiences with tablet computers and formal educational settings. These tablet tasks can be used in future research to examine both the correlates of EF and the developmental experiences that positively and negatively impact EF task performance in humanitarian and LMIC settings.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was conducted with the support of Dubai Cares, the Spencer Foundation, the New York University Abu Dhabi Research Institute, the UK Department of International Development’s Economic and Social Research Council, an anonymous donor, and the US Bureau of Population, Refugees, and Migration.