
Abstract
We argue that ‘topics’ of topic models can be used as a useful proxy for frames if (1) frames are operationalized as connections between concepts; (2) theme-specific data are used; and (3) topics are validated in terms of frame analysis. Demonstrating this, we analyse 12 climate change frames used by NGOs, governments and experts in Indian and US media, gathered by topic modeling. We contribute methodologically to topic modeling in the social sciences and frame analysis of public debates, and empirically to research on climate change media debates.
Keywords
Introduction
Anthropogenic climate change is the most pressing socioecological issue of our time, yet there is little societal consensus on how, even if, it should be addressed (Farrell, 2015, 2016; Nisbet, 2009). This is, to an extent, due to disagreement on the nature of the problem: it is at the same time environmental, cultural and political (Hulme, 2009; Hoffman, 2015; Layzer, 2016). Furthermore, there is significant cross-cultural variation in climate change framing (Broadbent et al., 2016; Kukkonen et al., 2018). Different framings present the problem in different terms and lead to different means of solving it. Struggles over framing often take place in the mass media, one of the most important arenas of interaction and communication for governments, non-governmental organizations (NGOs) and experts, who aim at influencing public opinion and climate policy (Boykoff, 2011; Crow and Boykoff, 2014; Hansen, 2010). Understanding climate framing can help comprehend why common understandings about climate change and its mitigation are so elusive (Anderson, 2009; Billett, 2010; Boykoff, 2011; Boykoff and Boykoff, 2007; Farrell, 2015, 2016; Nisbet, 2009; Schäfer and Schlichting, 2014; Trumbo and Shanahan, 2000).
A thus far under-utilised method in studying environmental debates is a text mining method called topic modeling – specifically, Latent Dirichlet Allocation (LDA) (Blei et al., 2003; see, e.g. DiMaggio et al., 2013; Evans, 2014). Computational approaches such as this have often emphasized induction, in which patterns are expected to arise from the data with as few theoretical preconceptions as possible, while sometimes simultaneously making aggressive claims about causality (Babones, 2016). We attempt to reconcile some of these issues with our approach for employing topic modeling in frame analysis of climate change debates, a theory-rich field which has been argued to be in need of data-mining approaches (Broadbent et al., 2016).
Frame analysis of climate debates could benefit from topic modeling because of certain theoretical compatibilities. If the definition of a frame is that it ‘links two concepts, so that after exposure to this linkage, the intended audience now accepts the concepts’ connection’ (Nisbet, 2009: 17), such linkages should be found by a topic modeling algorithm which detects whether terms ‘tend to occur in documents together more frequently than one would expect by chance’ (DiMaggio et al., 2013: 578). The continued habitual use of particular words together with each other shows that those words have meaning in relation to each other, together forming a cluster of terms, which can be interpreted to represent the presence of a frame, we argue. Thus, LDA topic modeling should be able to assist in discovering frames from texts. 1
Our analysis includes media coverage from two countries that are major players in the global politics of climate change, India and USA, using one newspaper from each of them for three different 6-week time periods around the United Nations Climate Change Conferences between 1997 and 2011. The countries were chosen as hypothetically the most different cases (Pfetsch and Esser, 2004) in an existing dataset collected for a previous research project (Ylä-Anttila and Kukkonen, 2014). How do different speaker groups frame climate change in the debate, as reported by newspapers in India and USA? For the purposes of our analysis, we chose the three most prominent policy actor categories in the media debate in both countries: experts, governments and NGOs. 2
Our methodological contribution is to provide an answer to the debate on whether frames can be operationalized as topics (Bail, 2014; DiMaggio et al., 2013), or, in other words, whether topics can be a reasonable proxy for frames. Our answer is a conditional ‘yes’, only if certain conditions are met. Doing so requires at least: (1) adopting a view of framing as connections between concepts (Entman, 1993, Nisbet, 2009); (2) selecting the input text data to be subject-specific rather than containing multiple thematic topics; and (3) interpretive validation, for which we suggest practical guidelines. Using other more nuanced definitions of frames (such as Goffman, 1974), different qualifications would have to be adopted. Furthermore, rather than claiming that topics found by topic modeling are frames per se (which would be a strong position), we propose that topics can be traces (or proxies) of frames. While this is a weaker claim, it still means topics can be useful for frame analysis, as we will argue. 3
In our empirical analysis, we find that economic concerns seem to be primary in the climate change debate as portrayed by US media, while burden-sharing and environmental risks are emphasized in India. This is understandable considering how many US politicians see climate change mitigation as a threat to their country’s economic competitiveness, whereas the concrete environmental risks of climate change are more acute in India. Speaker groups also differ in the frames they use to interpret global climate change. The top frames we found used by NGOs were ‘citizen participation’ and ‘environmental activism’, the top frames used by experts were ‘climate science’ and ‘economics of energy production’, and the top frames used by governments were ‘Chinese emissions’ and ‘negotiations and treaties’. But the actors also converged in framing climate change through ‘green growth’ and ‘emission cuts’. Such ‘interpretive storylines that can be used to bring diverse audiences together on common ground’ (Nisbet, 2009: 22) are desperately needed and may be found using topic modeling.
Framing climate change
Climate change has become a salient and controversial topic in media all over the globe, peaking in 2009 in both India (MeCCO, 2019) and USA (Schäfer and Schlichting, 2014). Indeed, mass media is an important arena for political debates on climate change, in which the cultural understanding of climate change is constantly shaped by political actors (Boykoff, 2011; Crow and Boykoff, 2014; Hansen, 2010). Consequently, different actors have engaged in very different framings of climate change (Nisbet, 2009). These include the frames of ‘economic competitiveness’, in which climate change is either a threat to economic growth or, perhaps, a driver of it; ‘morality and ethics’, in which climate change and its mitigation are matters of right or wrong; and ‘scientific uncertainty’, in which debates regard whether something is proven or not (Nisbet, 2009: 18). Different framings of the problem lead to different proposed remedies.
In addition to differences between actors, the framing of climate change also varies between political contexts in that frames are culturally specific (Anderson, 2009; Trumbo and Shanahan, 2000). Accounts of US media coverage are numerous, but there are far fewer studies of Indian media coverage. In the US, the media has particularly framed climate change through scientific uncertainty and given disproportionate space to climate sceptics (Boykoff and Boykoff, 2007), partly as a result of the conservative movement systematically disseminating discourses referring to the economic costs of mitigation and the uncertainty of climate science (Hoffman, 2011; McCright and Dunlap, 2003; Oreskes and Conway, 2010), enabled by networks of corporate funding (Farrell, 2015, 2016). While the frames of science and economy have dominated US media discourses, in India, the coverage has focused on the international dimensions of climate policy. Particularly, the North–South divide is salient in Indian debates, as well as the environmental risks global warming poses to India (Billett, 2010; Kukkonen et al., 2018). Contrary to the US, climate scepticism does not carry much weight in India.
Few studies have analysed media debates via frames used by different kinds of actors (however, see Stoddart et al., 2017; Kukkonen et al., 2020). Some have mainly focused, especially in the US, on the role of the conservative movement and the overall contestation of climate change. Nisbet (2009: 18) notes that ‘trusted sources have framed the nature and implications of climate change for Republicans and Democrats in very different ways’ in the US, but his focus is on specific actors’ specific claims – such as conservative think-tanks’ framing of climate change as scientifically uncertain – rather than painting a broader picture of frames used in the debate. Similarly, Farrell’s (2015, 2016) computational text analysis approach maps out the policy networks and discourses advocated by climate change denialists, but there is still a lack of more general knowledge on variation in framing between speaker groups – particularly whether or not there are frames in which actors converge, creating possibilities for common ground (Broadbent et al., 2016).
Methods and materials
Topic modeling
Text mining methods such as topic modeling find patterns in large datasets. In culturally informed social research, where meaning-making is generally in focus, and close reading of texts is a common method, topic modeling can in contrast be seen as a method of ‘distant reading’ (Moretti, 2013). It reduces the complexity of language to a simplistic assumption, namely that certain words often occur together, and these co-occurrences – word clusters – carry traces of meaning. By observing patterns and variations in the usage of these word clusters, we are able to observe variations in meaning-making habits – a facet of culture. This makes topic modeling suitable for discovering patterns in large datasets, but it should be complemented with close reading to create nuanced knowledge on meaning(s), making social-scientific topic modeling necessarily a mixed-methods endeavour, we argue.
We use MALLET’s (Machine Learning for Language Toolkit) (McCallum, 2002) implementation of Latent Dirichlet Allocation (LDA) (Blei et al., 2003). It is an unsupervised machine learning method: the researcher gives no input as to how the data should be classified. As such, the classifications themselves produced by the software are inductive, grounded in data, and based only on co-occurrences of words, rather than on a preset theoretical framework. Indeed, the typical relationship between data and theory in data mining is similar to that of grounded theory (Glaser and Strauss, 1967), with a strong focus on inductive reasoning, it has been argued (Babones, 2016: 457). However, instead of theory-blind data mining, we argue that theoretical interpretation is just as important in text mining as in ‘ordinary’ qualitative social research. In our approach, the interpretive stage, based on subject-specific researcher knowledge, takes place after the primary, inductive classification is done by machine. As a result, the workflow resembles an abductive rather than an inductive or deductive approach (Timmermans and Tavory, 2012).
Consider a concise description of LDA: ‘[it] assumes that there are a set of topics in a collection (the number is specified in advance) [. . .] Terms that are prominent within a topic are those that tend to occur in documents together more frequently than one would expect by chance [. . .] each document exhibits those topics with different proportions’ (DiMaggio et al., 2013: 577–578). LDA is a probabilistic model, which models the probability of each topic (word cluster) in each document, and the probability of each word in each topic. This is the basis for assigning words into topics, which are essentially probability distributions over a corpus of words (Blei et al., 2003). In simpler terms, and in the case of MALLET, the researcher inputs a dataset consisting of text documents and asks the software to return a particular number of topics, say ten. The outputs are: (1) 10 lists of words that most often occur together in documents; (2) numeric measures for the topics in each document, showing how large a share of that document consists of that topic; and (3) numeric measures for the documents in each topic, representing how large a share of that topic exists in that document. Thus, the typical interpretation of an output is: (1) what ‘topics’ is the dataset about; (2) what topic is each document about and to what extent; and (3) in which documents is a topic discussed, and to what extent. 4
However, the word ‘topic’ in ‘topic modeling’ does not refer to any specific feature of the functioning of the algorithm, which ‘knows’ only co-occurrences of objects (such as words). Calling them ‘topics’ is an interpretation of what the algorithm’s output can be applied to, and what kinds of research settings can be operationalized as clusters formed by co-occurring objects. Finding topics or ‘themes’ in text data is but one possible interpretation. When introducing LDA, Blei et al. (2003) originally stated that they ‘use the language of text collections throughout the paper, referring to entities such as “words”, “documents” and “corpora”’ to ‘guide intuition’ (p. 995), and it has been shown that LDA can be used to model other types of data too, such as numerical coordinates (Schmidt, 2012). We argue that this caveat has gone largely unnoticed and should be acknowledged when thinking about ‘topics’ – this concept has ‘guided intuition’ too much. Even in the case of text data, thematic ‘topics’ are only one thing LDA can be used to model.
From topics to frames
We argue that when modeling texts we already know to be about a particular topic (climate change), LDA outputs are best interpreted as traces of different ways of discussing a topic – that is, frames. If all text is about climate change, the word co-occurrence patterns that emerge from it should represent patterns of using certain words to talk about climate change. Such word use patterns can plausibly be interpreted as an approximation of framing patterns. Most applications of topic modeling emphasize validating the outputs (Evans, 2014; DiMaggio et al., 2013; Grimmer and Stewart, 2013), that is, checking that the word clusters actually represent what we think they do. If our interest lies in frames rather than topics, both internal and external validation should take into account what we already know about frames.
First of all, internally, word clusters must be identifiable as operationalized frames, or ‘schemata of interpretation’ (Goffman, 1974: 21). Thus, a frame ‘allows its user to locate, perceive, identify and label’ (Goffman, 1974: 21) events. After Goffman’s original work, which focused on framing in micro-level face-to-face interaction, the literature on framing has expanded in various directions, and there are now several paradigms of framing used in multiple disciplines. We follow Entman’s (1993) simplified conception of framing: To frame is to select some aspects of a perceived reality and make them more salient in a communicating text, in such a way as to promote a particular problem definition, causal interpretation, moral evaluation, and/or treatment recommendation for the item described. (Entman, 1993: 52, emphasis in original)
Frames, thus, ‘define problems’, ‘diagnose causes’, ‘make moral judgments’ and ‘suggest remedies’ and take place in a ‘communication process’ (Entman, 1993: 52). It is imperative to note that ‘frames as general organizing devices should not be confused with specific policy positions; any frame can include pro, anti and neutral arguments’ (Nisbet, 2009: 18) – indeed, detecting policy positions in texts would require a wholly different approach than presented here. A frame, in this definition, simply ‘links two concepts, so that after exposure to this linkage, the intended audience now accepts the concepts’ connection’ (Nisbet, 2009: 17). Framing ‘endows certain dimensions of the complex issue with greater apparent relevance’ (Nisbet, 2009: 16–17). While the theoretical basis of framing is in Goffman’s (1974) work, this more streamlined definition is better suited for identifying signs of frames in text, since what we observe is linkages between terms, shown by patterns of co-occurrence.
Secondly, externally, the frames found should somewhat correspond to previously identified frames in similar data to ensure validity, but there must also be room for discovery in order for topic modeling to be valuable. After all, exploration, finding previously unidentified patterns, is one of the primary reasons for using topic modeling rather than just qualitative reading. This means that the outputs of the model are not very plausible if they directly contradict previous studies carried out using other methodologies. In contrast, findings which somewhat correspond to previous ones are a good indicator that the basic research strategy works and lend credence to new and potentially surprising insights gained from the same model. This is why we selected a case about which there is already a body of empirical research, framing climate change in media discussions (Anderson, 2009; Billett, 2010; Boykoff, 2011; Boykoff and Boykoff, 2007; Broadbent et al., 2016; Farrell, 2015, 2016; Nisbet, 2009, Schäfer and Schlichting, 2014; Trumbo and Shanahan, 2000). Thus, we can assess the validity of the model and pursue novel findings. In other words, if results mostly correspond to previously identified framings of climate change, including at least ‘economic competitiveness’, ‘morality and ethics’ and ‘scientific uncertainty’ (Nisbet, 2009: 18), the model gains credibility. We indeed find these, but in more nuanced forms.
Newspaper materials
The data we use consists of all articles mentioning ‘climate change’ or ‘global warming’ in The New York Times (NYT, USA) and The Hindu (India) for the time spans explained below. While these newspapers are by no means fully representative of national public spheres, both are widely considered relatively liberal, mainstream newspapers, and both have wide circulations within their respective countries. 5 As with all research studying public debates using media data, editorial policies, the national media environment and other factors affect what is published. Nevertheless, the media are one of the primary arenas for public debate, in which actors engage in framing to further their political positions, and through which citizens receive information to understand society around them. Even if the media are biased, it is this biased communication on which public debate is largely based. Thus, studying framing in media debates on climate change is important in itself: it matters for formation of public opinion and possibilities of climate change mitigation (see, e.g. Anderson, 2009; Billett, 2010; Boykoff, 2011; Boykoff and Boykoff, 2007; Nisbet, 2009; Schäfer and Schlichting, 2014; Trumbo and Shanahan, 2000).
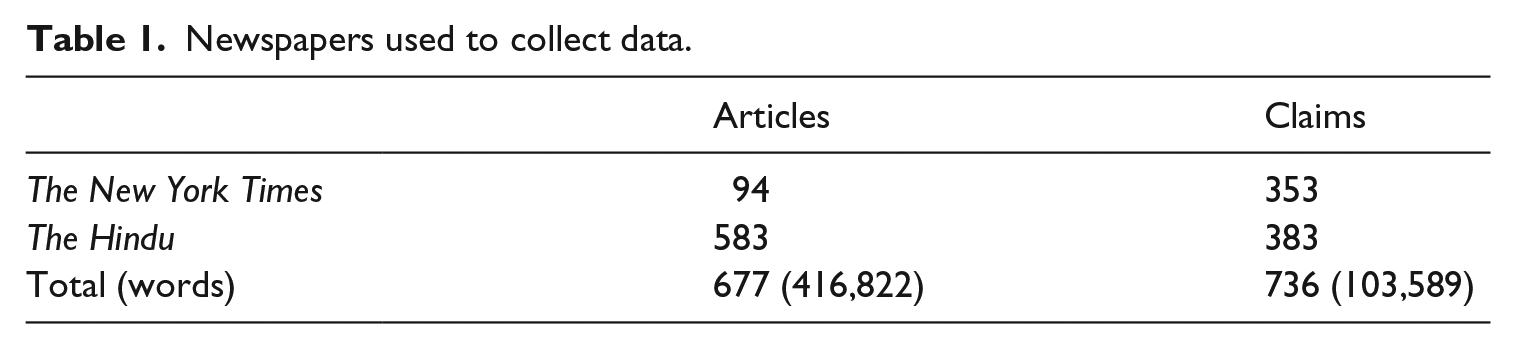
Data was collected around three international climate meetings: Kyoto (1997), Copenhagen (2009) and Durban (2011), 3 weeks before and after each meeting. Altogether, 677 articles were included in the data, shown in Table 1. While the NYT articles are fewer in number, they are longer, which balances the data: both newspapers published a similar number of claims on climate change.
Newspapers used to collect data.
Pre-processing texts
For purposes of previous research, political claims were already marked in the text data, and the speaker category (expert, government or NGO) for each claim was coded (Koopmans and Statham, 1999). A claim is: [A] unit of action in the public sphere. A claim can be a comment in an interview or a public speech, a demonstration or other action whose purpose is to influence public debate. One newspaper article may, therefore, contain several claims by several actors. (Ylä-Anttila and Kukkonen, 2014)
The speaker category was identified not only for direct quotes but also for claims paraphrased by reporters. As an example, the following excerpt from The Hindu was categorized as a government speaker: The developed countries must step up to the plate to come true on their existing commitments to fight climate change, said Jayanthi Natarajan, Indian Environment Minister.
Out of the categories studied, ‘government’ includes officials speaking for governments active in the negotiations, multiple governments giving joint statements and inter-governmental organizations. Since the data consists of reports about climate change conventions, the role of governments was central. The data included 353 claims by government speakers. The speaker was identified as an ‘expert’ if she presented herself with scientific credentials, as coming from scientific institutions, or in other ways clearly positioned as an issue authority. We included 251 claims by expert speakers. ‘Non-governmental organizations’ were the third speaker group included in the analysis. These included civil society actors such as environmental organizations. The data included 132 claims by NGOs.
We only input the previously identified political claims in the model, not the whole text of the newspaper articles, to further specify the data to be about the climate change debate, not just descriptive text on climate change. This was possible because of previous hand-selection, but if no such material is available, other methods should be used to ensure the text data is about a particular topic if one is interested in framing: for example, Levy and Franklin (2013) used comments on regulation of the trucking industry, containing justifications for opinions, which was their object of interest.
The claims were contained in text files named by speaker category, country and an ID. The files were then ‘tokenised’: stripped of all punctuation and empty lines and processed into files that contain one instance of a word (a ‘token’) per line, using simple Python scripts. The tokens were stemmed using the Snowball stemmer in the Python Natural Language Toolkit (Bird and Loper, 2016) to collapse inflected word forms into a single word, for example, ‘changing’, ‘changed’ and ‘changes’ were all converted into ‘chang’, to count them as the same word. MALLET’s standard stopword list was used. We follow Maier et al.’s (2018) guidelines for pre-processing, except for relative pruning, due to the relatively small dataset.
Validation
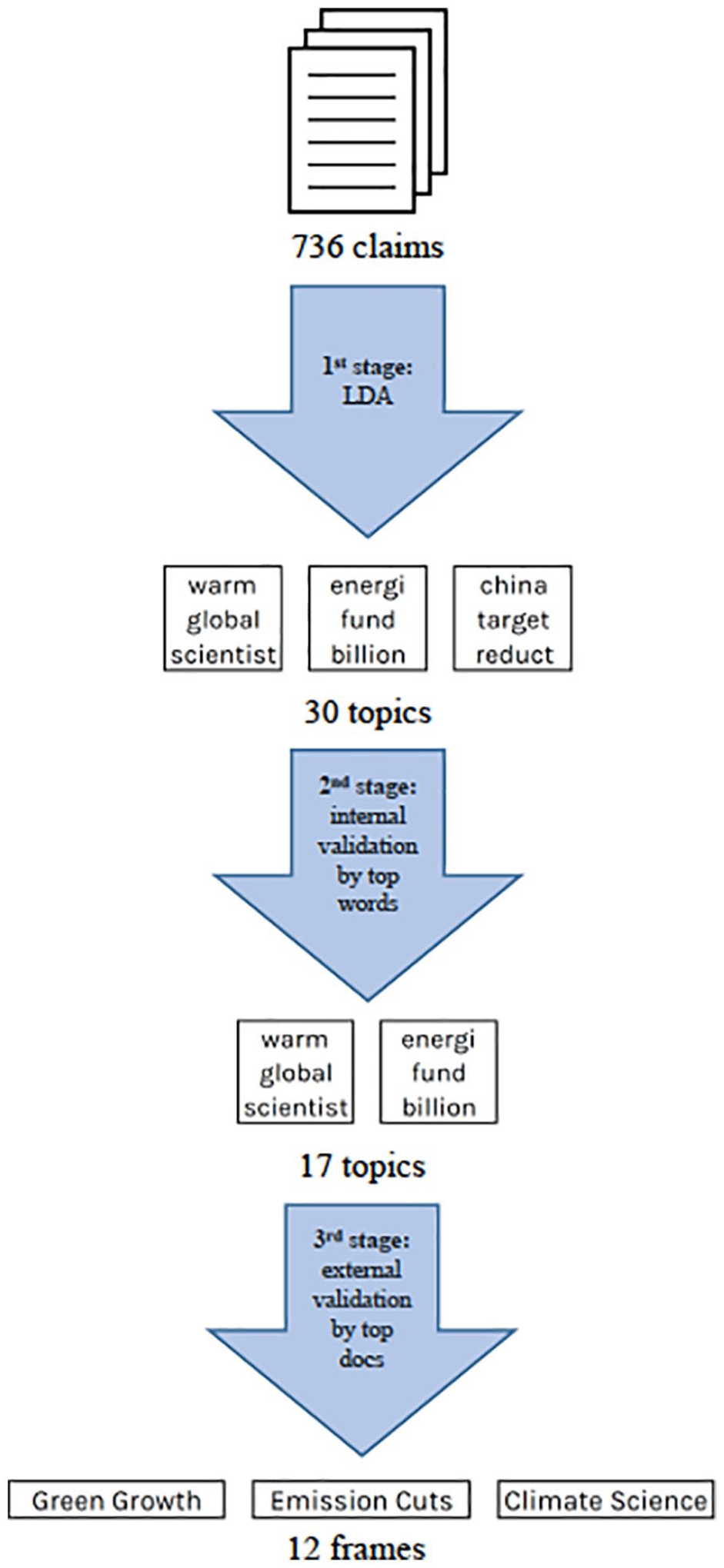
Interpretation and validation of topics has been identified as a crucial point in using topic modeling for analysis of societal phenomena (DiMaggio et al., 2013; Evans, 2014; Grimmer and Stewart, 2013). Since we argue that word clusters output by LDA can be interpreted as traces of frames, we use a three-fold process for ‘frame validation’, presented in Figure 1. The first stage looks at the whole model on the surface, the second inspects the top words of each topic for internal validity (identifying represented frames) and the third inspects the source data itself by looking at the top documents of each topic for external validity (correspondence to identified frame).
Frame validation process.
With LDA, the only input given by the researcher in addition to the data itself is the number of topics. The selection of topic count affects the fit of the model (Evans, 2014: 2), thus, that selection is the first stage (Figure 1) of validating the model. Too many topics result in topics that are too specific, while too few topics results in topics that mix several frames in one. We tested models of 10, 20, 30, 40, 50, 60, 70, 80, 90 and 100 topics, and each output was examined in terms of the top ten words of each topic, to look for word clusters signifying framings of climate change. We ended up with a model of 30 topics, which produced topics that are not too specific and not too general or ‘mixed’. In this first stage, it is better to use too many rather than too few topics, since irrelevant topics will be discarded in the next stages. Useful quantitative measures for model reliability and interpretability have also been proposed recently (see Maier et al., 2018).
In the second stage (Figure 1), we used the top ten words of each topic to qualitatively inspect and discard topics that did not represent internally valid frames, which link climate change to a coherent set of other concepts (Nisbet, 2009). The rationale behind ‘top words’ is that topic models are mixed-membership models: each word can be part of multiple topics but with different probability weights. MALLET outputs a word frequency for words in each topic: the most commonly occurring words matter most in creating the topic, while the rest form a ‘long tail’ of words that are not nearly as significant. Domain-specific research knowledge is important here – as well as familiarity with the data at hand – to make qualitative validation possible. We discarded 13 topics and kept 17, for which we gave a tentative, descriptive frame name (also see Maier et al., 2018). An example of a discarded topic in which we did not find internal coherence is ‘concern’, ‘clear’, ‘don’t’, ‘give’, ‘document’, ‘tax’, ‘accept’, ‘base’, ‘thing’, ‘main’, while an example of a topic deemed coherent is ‘warm’, ‘global’, ‘scientist’, ‘research’, ‘univers(e/al)’, ‘atmospher(e)’, ‘caus(e)’, ‘stud(y/ies)’, ‘effect’ and ‘release’ – this was interpreted as a representation of the ‘climate science’ frame in the model.
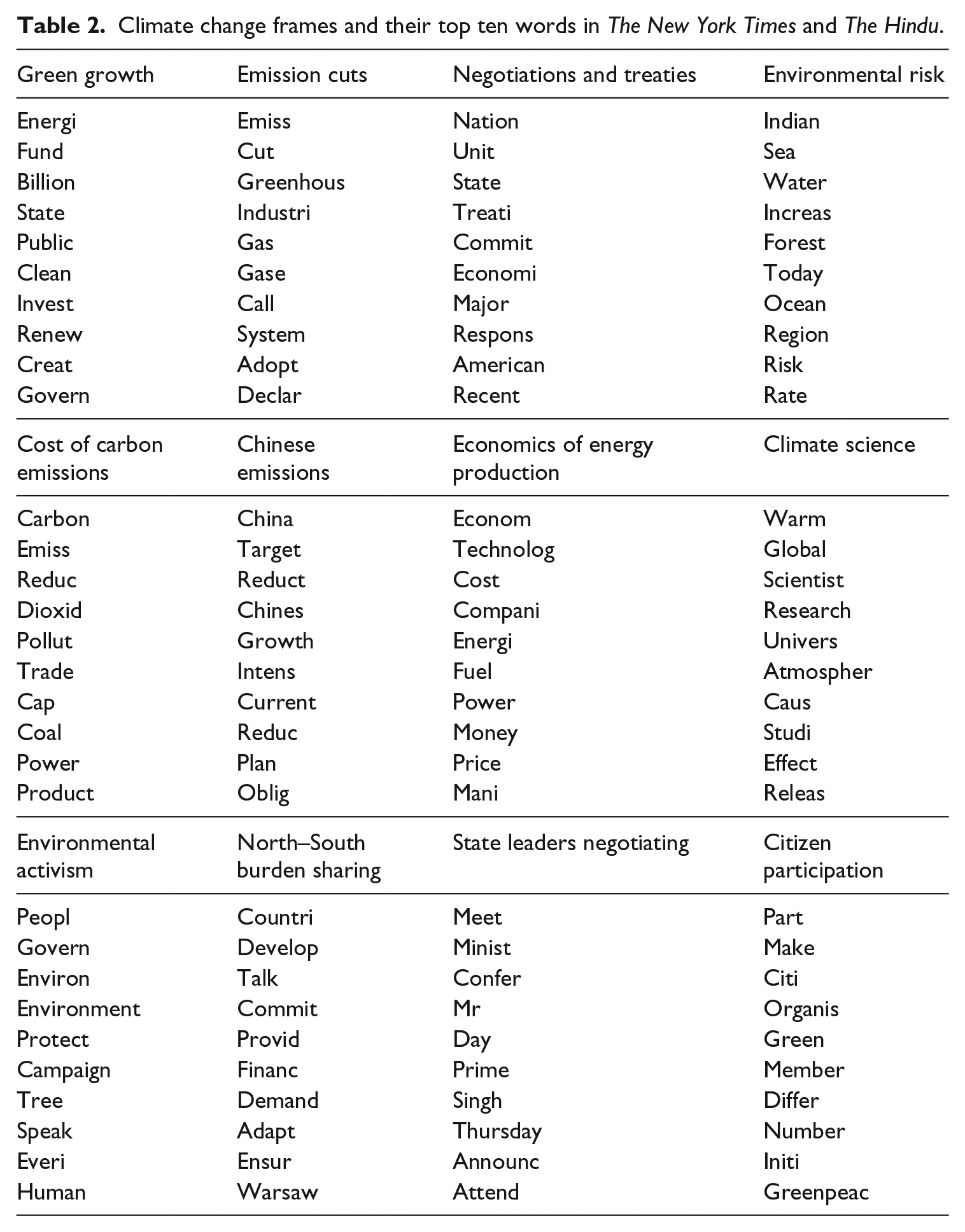
In the third stage (Figure 1), we read the top ten documents in the 17 topics that passed the previous stage to check whether the tentative description fit (also see Maier et al., 2018). Again, using a mixed-membership model like LDA, documents belong to multiple topics but with different weights. This means some of the top documents in the different topics are the same; this is a natural reflection of the fact that a document may contain multiple frames. If the preliminary description fit at least eight of the top ten documents, we kept it. In many cases, the descriptions fit after slight rewording – reading the documents gave a clearer picture of the frame than could be discerned from just the top words. At this stage, we discarded five of the 17 topics on the basis of them not corresponding to a possible frame in the climate debate. Thus, we ended up with 12 ‘topics’ that we considered to be representations of climate change frames, and will refer to as ‘frames’ from now on for the purposes of qualitative analysis. This final set of frames, the top words of which are presented in Table 2, was derived from the data algorithmically, but validated qualitatively, and will next be interpreted qualitatively.
Climate change frames and their top ten words in The New York Times and The Hindu.
Comparisons
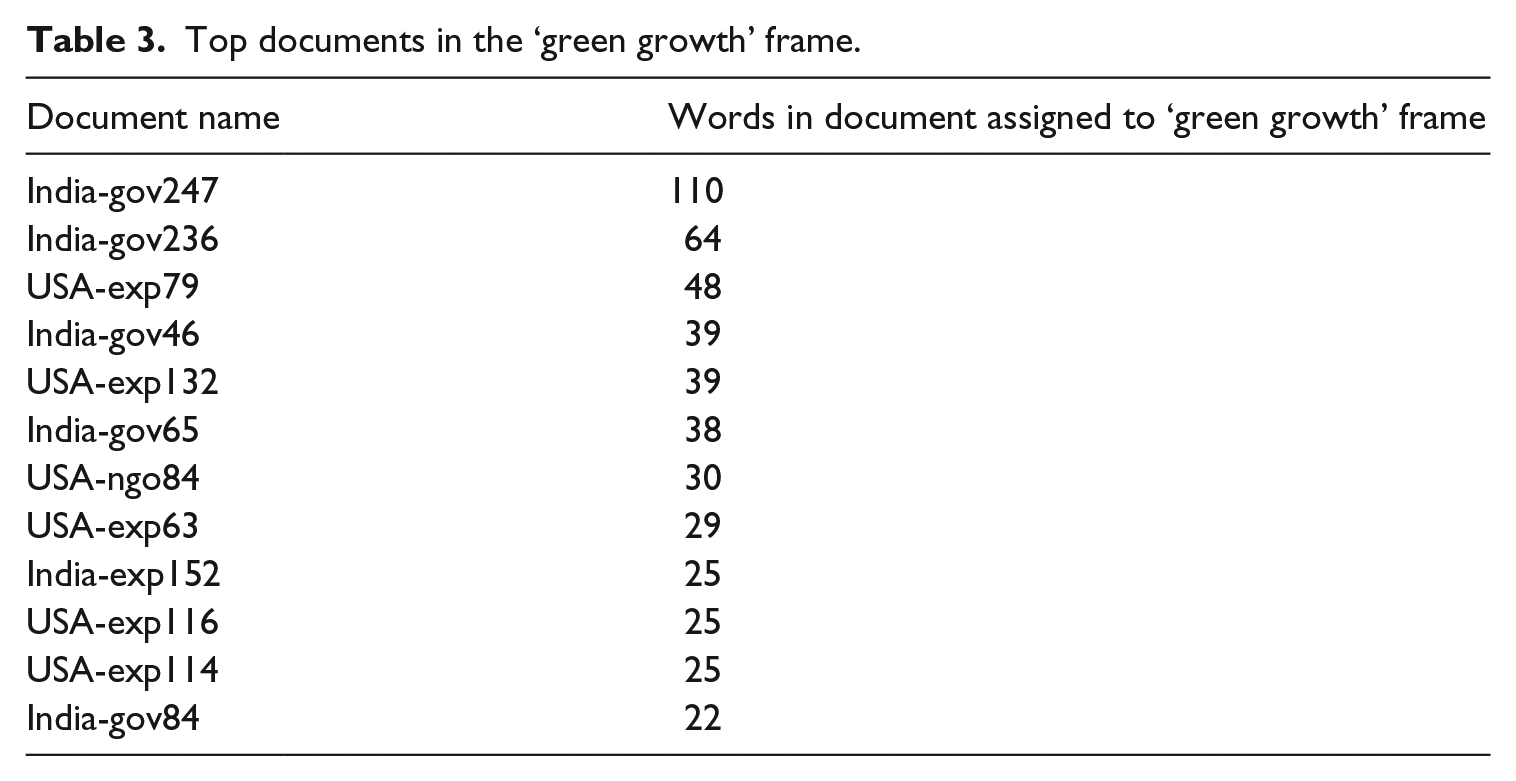
Since MALLET outputs a list of documents for each topic, along with the frequency of words in each document that were assigned to that topic, we can inspect which portion of the top documents in each frame originated from which speaker group and which country. As an example, Table 3 presents the top document list for the ‘green growth’ frame and the number of words in each document that were assigned to this frame by the model. The table only includes documents with 22 or more words assigned to this frame; about 500 documents with less than 22 assigned words are omitted from the table. By comparing the amounts of each speaker group and country in the list of top documents, we can see which speaker groups and which country most contributed to this frame.
Top documents in the ‘green growth’ frame.
Results
In this section, we qualitatively interpret the 12 frames, the distribution of speakers in the top documents of each frame, and the distribution of US and Indian claims, shown in Figures 2 and 3.
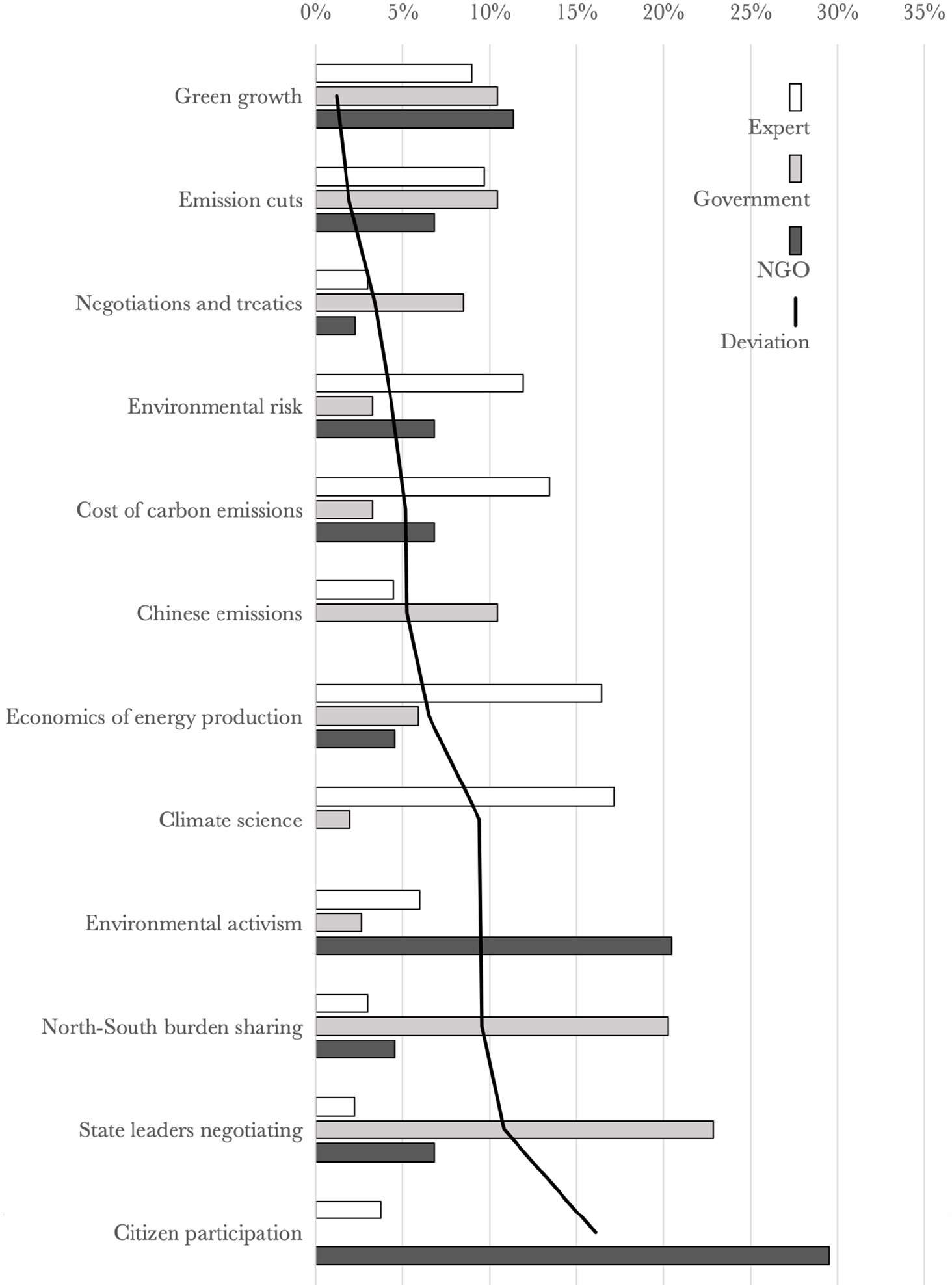
Percentages of frames used by each speaker group – the sum of all ‘expert’ bars is 100 per cent, with standard deviation.
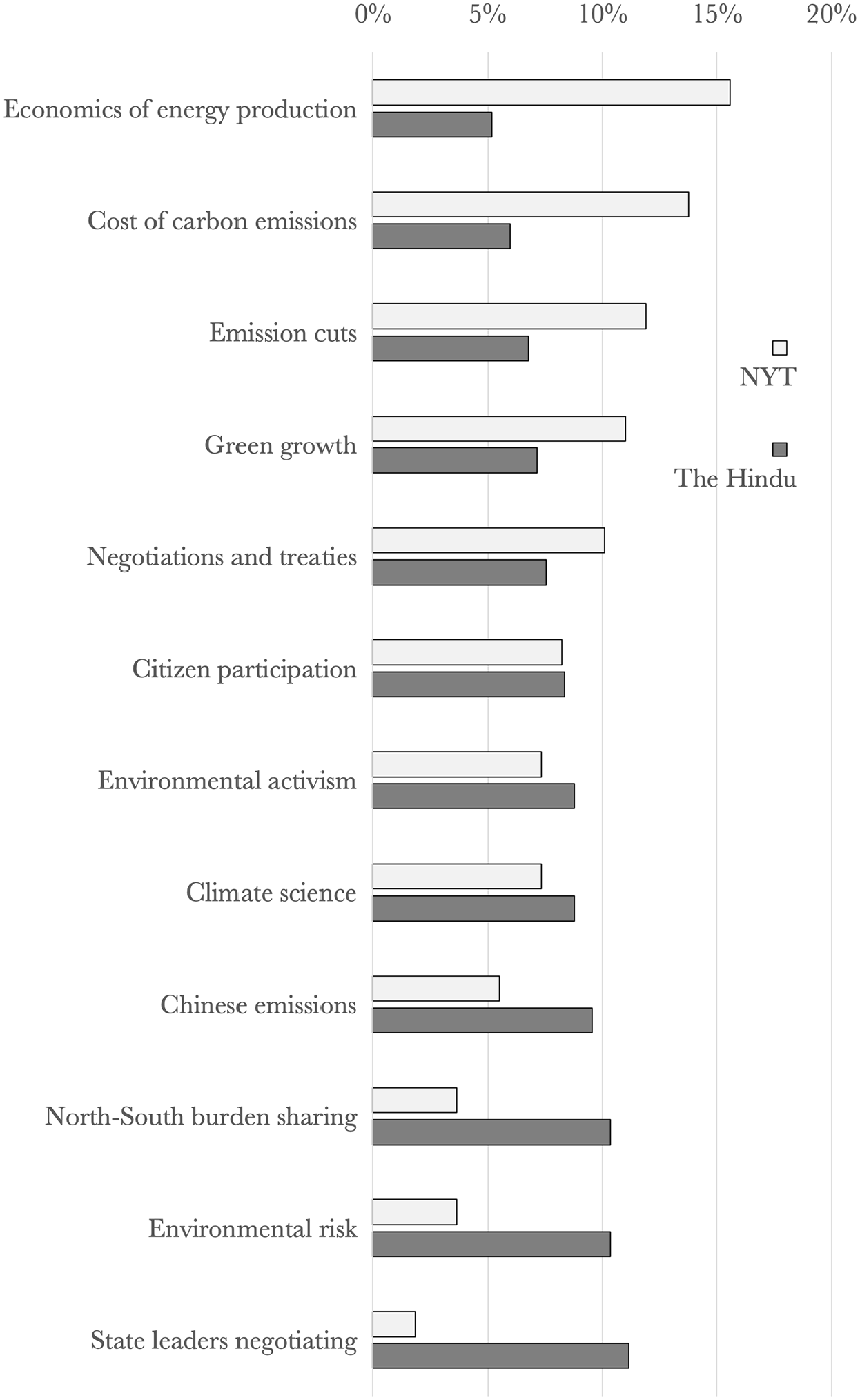
Percentages of frames used in each newspaper – the sum of NYT bars is 100 per cent.
We treat the topics in the model as representing frames in which connections are created between different words: they are communicatively represented constructions about which words have to do with climate change. The other words are thus considered, by the speakers, in some way meaningful to climate change. This means that, for example, the ‘emission cuts’ frame contains both statements asserting that emission cuts are necessary and statements asserting they are not – however, they still frame climate change in terms of emission cuts, that is, they posit that emission cuts are relevant with regard to climate change. This is consistent with Entman’s (1993) and Nisbet’s (2009) definition of frames. 6 In the quotes below, occurrences of top ten words of the frame are italicised.
First of all, the ‘green growth frame’ is represented by words such as fund, billion, invest, clean and renew. The claims using this frame refer to sustaining the environment and economic growth simultaneously – by investing in clean energy, for instance – and it is the most uniting frame for speaker groups, as can be seen in Figure 2, providing some hope for common ground in the debate. In the quote below, low-carbon investments are presented as economically viable: Using our national development finance institution and export credit agency, we have channelled hundreds of millions of dollars to strengthen India’s ability to build technical capacity, reduce financial risk, and lower the cost of capital for low-carbon investments. (india-gov247)
With words like emission, cut and greenhouse (gas/effect), ‘emission cuts’ was another fairly unifying frame for all speaker groups, considering Figure 2. All speaker groups agree that emission cuts matter and engage in the discussion about them – whether to argue that they are necessary or that they are not. The quote below discusses emission cuts in the US: The United States could shave as much as 28 percent off the amount of greenhouse gases it emits at fairly modest cost and with only small technology innovations, according to a new report. (usa-expert114)
‘Negotiations and treaties’ is about states taking part in climate negotiations, represented in the top words nation, state, treaty, etc. Naturally, governments engage in this frame the most, as can be seen in Figure 2, but they are very closely followed by experts and NGOs, making this a comparatively uniting topic. Below, The Hindu reports on the effect of US domestic politics on the global negotiations: The US Senate majority leader said on Tuesday that the climate treaty being negotiated in Japan has only ‘bleak prospects’ of ratification by the upper House of the U.S. legislature, even if U.S. negotiators agree to it. (india-gov109)
‘Environmental risk’ is a frame about the imminent consequences of climate change. Speakers, predominantly experts, warn of – or downplay – dangers such as rising sea levels and deforestation, exemplified by words such as sea, water, increase, forest, ocean and risk. This frame was common in The Hindu but rarely utilized in The New York Times, as can be seen in Figure 3, which is in line with previous studies on the Indian climate debate, showing that risks are considered more salient in India than in the US (Billett, 2010). The quote below is from a report on research into environmental risks of climate change: Greenhouse gases are making the world’s oceans hot, sour and breathless, and the way those changes work together is creating a grimmer outlook for global waters, according to a new report from 540 international scientists. (india-expert158)
The ‘cost of carbon emissions’ frame uses words such as carbon, emission, trade, cap, coal, power and product, measuring the effects of emissions in terms of money, primarily discussed by experts in The New York Times, as shown in Figures 2 and 3. As we know, economic framing is exceptionally strong in the American climate debate, largely due to the primacy of economic concerns in the American political culture (Lamont and Thévenot, 2000) and the organized countermovement against climate change legislation (Farrell, 2015, 2016; McCright and Dunlap, 2011). As an example, in the following quote, an expert assesses how carbon emissions should be taxed: But it would be even better, Dr. McKitrick says, to use the temperature readings as the basis for a carbon tax instead of a cap-and-trade system. (usa-expert67)
The ‘Chinese emissions’ frame includes words such as China, target, growth and reduc(e), which correspond to claims that Chinese emissions are crucial for mitigating climate change. It is a frame used mostly by states and experts, and mostly in The Hindu, as seen in Figures 2 and 3, suggesting that China’s role in mitigation is highly relevant for the debate in India. Some claims lay the blame and responsibility for climate change on China, while some praise China for ‘global leadership in renewables’, for example: [T]here is going to have to be much more pressure on China if global emissions are to peak within any reasonable time frame. (usa-expert92)
The ‘economics of energy production’ frame uses words like economy, cost, energy, fuel, power, money and price. Dominated by experts, as shown in Figure 2, discussions in this frame deal with the costs of different methods of producing energy such as renewables and fossils. This was the most strongly US-dominated frame, which comes as no surprise because of the emphasis on economic concerns in American politics (Lamont and Thévenot, 2000). Below, an expert report in NYT assesses possibilities for lowering energy costs: The report said the country was brimming with ‘negative cost opportunities’ – potential changes in the lighting, heating and cooling of buildings, for example, that would reduce carbon dioxide emissions from the burning of fossil fuels even as they save money. (usa-expert114)
The ‘climate science’ frame is defined by words such as scientist, research and study, and consists largely of news articles reporting on climate research. This frame was understandably dominated by experts, as shown in Figure 2, and quite evenly used in the Indian and US data, as shown in Figure 3 – despite the highly contested nature of climate science in the US (Boykoff and Boykoff, 2007; Farrell, 2015, 2016; McCright and Dunlap, 2011) – likely explained by the choice of the liberal New York Times as the data source. The quote below refers to a research report proving anthropogenic climate change: Climate change caused by humans is real and it is happening now [. . .] The recently released report of the Intergovernmental Panel on Climate Change has reconfirmed the basic facts (india-gov247)
‘Environmental activism’ is a frame dominated by NGOs (see Figure 2), employing keywords like people, govern, environment, protect and campaign, connected to local and global activist initiatives to combat climate change, together with broader statements about environmental values and protection. The following quote is from a report on Indian climate activists: [E]co-activist Sunderlal Bahuguna [. . .] said the involvement of people in environmental campaigns was crucial for victory against government moves. Recalling his active participation in the Chipko Movement, he said he had walked from Kohima to Kashmir in 300 days to create awareness among people about the demerits of felling of trees. (india-ngo31)
‘North-South burden sharing’ includes words like develop(ing), countri(es), finance(e) and commit. It was governments (see Figure 2) who mostly discussed climate change though this frame, which deals with climate justice: whether the Northern countries are more responsible and should finance developing countries in their mitigation actions. Burden-sharing has been recognized as one of the central issues in the Indian debate (Billett, 2010), which was also visible in our comparison: The G77+China group delivered an ultimatum to the developed countries on the issue of Loss and Damage, threatening to walk out of the Warsaw negotiations if the developed countries did not stop blocking it. (india-gov71)
‘State leaders negotiating’ includes words such as meet, (prime) minister, attend and confer(ence). Unsurprisingly, mostly government actors had a voice in this frame (Figure 2). It was the most Indian-dominated of the frames (Figure 3), largely due to The Hindu reporting on Indian delegates’ efforts in the climate meetings, such as in the following quote: Chinese Premier Wen Jiabao on Thursday spoke to Prime Minister Manmohan Singh to exchange views on the climate change conference at Copenhagen. During their 10-minute telephonic conference, the leaders were said to have discussed ways of taking the climate summit forward. (india-gov13)
Finally, ‘citizen participation’ is a frame discussing NGOs and individual citizens taking part in the climate debate process, marked by words such as (take) part, organis(e|ation), member and also names of specific NGOs such as Greenpeace. Not surprisingly, this frame was dominated by NGOs – the most dividing frame measured by deviation of speaker group frequencies (Figure 2). The following quote is from a report in The Hindu: To create public awareness about how climate change is affecting our planet, bicycle enthusiasts took part in a cycle rally on the Capital’s much talked about Bus Rapid Transit (BRT) corridor over the weekend. (india-ngo17)
Discussion
In our newspaper data on climate change media debates in India and the US, we found 12 word-clusters that can be interpreted as modeled representations of frames after a validation process we documented. Studying the distributions of these frames between countries and speaker groups, we noted differences between framing in Indian and US media data, such as the strong position of economic framings in the US, and the emphasis on environmental risks in India. We found frames that were dominated by a particular speaker group, such as experts in the case of climate science, but also frames in which actors converge, such as the green growth frame. These results show that topic modeling outputs can be used as proxies for cultural constructs such as frames, as already argued by some scholars (DiMaggio et al., 2013), but we add certain preconditions that must be met by the research design before and after the actual modeling, summarized below.
We adopted an interpretation of framing in the vein of Entman (1993) and Nisbet (2009). This definition of frames as links between concepts is not as strict as some others (e.g. Benford and Snow, 2000; Goffman, 1974), and we argue LDA is quite suitable for exploring frames understood in this sense, as LDA is based on connections between words detectable by co-occurrence (although certain caveats have been noted by Blei and Lafferty, 2007; Maier et al., 2018; Walter and Ophir, 2019). Secondly, the input data should be thematically defined if frames are to be studied. We used hand-picked data, but another possibility might be ‘distilling data’ by sequential topic models: first using a model to divide data into topics, then running a second model for a thematically-defined subset of data, selected to be topic-specific by the first model, to further classify the data into frames. Thirdly, we suggested a three-stage interpretive validation process, firstly looking at the model as a whole, then checking the internal coherence of topics based on the top words, and finally verifying the external validity of the top documents of each topic.
The frames of economic competitiveness, morality and ethics, and scientific uncertainty had previously been recognized as central frames in the climate change debate (Nisbet, 2009), and the frames we found represent instances of these: ‘cost of carbon emissions’ and ‘economics of energy production’ correspond to the economic competitiveness frame, ‘North–South burden sharing’ corresponds to the morality and ethics frame, and ‘climate science’ to the scientific uncertainty frame. This highlights the necessity of substantive knowledge of the field – LDA does not replace qualitative interpretation, but rather complements it by enabling a degree of automated discovery before the interpretive stage, one which may also highlight unexpected patterns.
Different framings lead to different conceptions of climate change as a societal problem, and how it should be solved. The results of our country comparison are in line with previous accounts of US and Indian media discourses on climate change (Billett, 2010; Kukkonen et al., 2018) – economic concerns are primary in the US, while burden-sharing and environmental risks are emphasized in India. To an extent, these represent differences in the institutionalized habits – that is, culture – of these two national public spheres. 7 But as we argued, using topic modeling to study framing also has an exploratory function: in this case, it reveals a broader set of more specific frames than were previously identified: for example, the differing ‘cost of carbon emissions’ and ‘economics of energy production’ frames laid out above, of which ‘cost of carbon emissions’ is more strongly NGO-dominated.
Indeed, relative to country comparisons, actor category comparisons have thus far been scarce (Broadbent et al., 2016; however, see Kukkonen et al., 2020; Stoddart et al., 2017). Summarizing our results, the top frames used by NGOs were ‘citizen participation’ and ‘environmental activism’; the frames used mostly by experts were ‘climate science’ and ‘economics of energy production’; and the top frames used by governments were ‘state leaders negotiating’ and ‘North–South burden sharing’. We noted that the framings of NGOs and experts were particularly in contrast: NGOs were concerned for the rights of citizens and the environment, while experts framed the problem as an economic and technological one. Governments, in turn, assigned the states a central role, and are mostly engaged in discussion over how climate change can be solved through established international political negotiation processes – which has proved difficult. It is of course probable that factors such as media logics, editorial decisions and sourcing practices have an influence on the types of frames that are linked to different speaker groups. Future studies could examine speaker groups’ framings using other research material, such as interviews and policy documents, to isolate media effects.
We were also able to identify possibilities of common ground in the climate change debate. Despite many differences, the policy actors were able to converge by framing climate change through the frames of ‘negotiations and treaties’, ‘emission cuts’ and ‘green growth’ – the latter of which, especially, may represent some hope for mutual understanding about climate change mitigation (ecological modernization) (Mol et al., 2009).
Footnotes
Authors’ Note
An unreviewed preprint version of this article was previously made available in SocArXiv and an unreviewed research report of this work was previously published in Finnish (Ylä-Anttila, Eranti & Kukkonen 2018).
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Kone Foundation.