
Abstract
Background
The motivations to share anonymised datasets from clinical trials within the scientific community are increasing. Many anonymised datasets are now publicly available for secondary research. However, it is uncertain whether they pose a privacy risk to the involved participants.
Methods
We located a broad sample of publicly available, de-identified/anonymised randomised clinical trial datasets from human participants and contacted their owners to request access, following their local procedures. We classified personal data within these datasets, including unique direct identifiers such as date of birth and other personal data that, on their own, does not identify an individual but may do so when combined with each other, such as sex, age and race (indirect identifiers). Combining indirect identifiers forms strata, and adding more identifiers increases granularity by dividing the data into a larger number of smaller strata. The re-identification risk score equations evaluate membership in these strata in three ways: first, by measuring the proportions of participants in strata above predetermined risk threshold levels (Ra); second, by locating the smallest stratum (Rb); third, by estimating the average membership across all strata in a dataset (Rc). The risk scores range from 0 (lowest risk) to 1 (highest risk); they do not aim to re-identify individuals in the datasets and are used for routinely collected health records. If a dataset contained a direct identifier, it automatically scored 1 in all metrics. Conversely, if a dataset contained no direct or up to one indirect identifier, it automatically scored 0 in all metrics. Finally, we explored which characteristics of the datasets were associated with the risk scores and compared the risk scores and their usability.
Results
Seventy datasets from 14 data sources were analysed. Thirty-one datasets were shared with minimal restrictions (open access), while 39 were shared with varying levels of restrictions before access was granted (controlled access). Datasets had, on average, four identifiers and mean risk scores ranging from 0.47 to 0.91. The most common pieces of information present in the datasets that, when combined, may indirectly identify a participant were sex (80%) and age (72.9%).
Conclusions
This study confirms that clinical trial datasets are rich in personal details and that using re-identification risk scores as a measure of this richness is feasible. These scores could inform the anonymisation process of clinical trials datasets regarding their level of granularity prior to releasing them for secondary research. We propose a strategy for employing these scores in the decision-making process for releasing clinical trials datasets.
Keywords
Background
There is a strong drive, particularly from publishers and funders, to encourage the release of anonymised trial datasets. 1 New grant applications with funding from the National Institutes of Health, 2 Cancer Research UK 3 and the UK Medical Research Council 4 must contain a concrete data-sharing plan. The International Committee of Medical Journal Editors (ICMJE) requires all clinical trials enrolling participants on or after January 1, 2019, to have a data-sharing plan in their registration. 5 Also, the ICMJE encourages editors to prioritise publishing work from authors who have shared their data. 6 Data sharing has become essential in clinical trials for disseminating research, enhancing knowledge through meta-analysis, enabling new investigations on existing datasets and maximising the efforts invested in data collection.7,8
Many anonymised datasets are currently available for secondary research via clinical data repositories 9 or directly from researchers, using either open or controlled access models. Controlled access requires some form of approval before obtaining datasets, whereas open access imposes minimal restrictions. 10 Anonymisation of data is complex, 10 and complete anonymisation could result in a loss of detail necessary for appropriate analysis. Therefore, balancing the reduction of re-identification risk while retaining sufficient detail for valid research is crucial. The lack of a gold-standard anonymisation method within the clinical trial community 11 along with limited resources and training, 12 complicates this further, leading to uncertainty about the privacy risks posed by available datasets13,14 to the involved participants.
We aimed to evaluate some publicly available datasets by calculating their re-identification risk scores using El Emam’s methods. 15 These scores numerically estimate the potential of re-identifying individuals from anonymised data, helping to assess the effectiveness of anonymisation techniques in preserving privacy. Commonly used for routinely collected health records,16,17 these scores theoretically indicate higher re-identification risks with higher values, without aiming to re-identify individuals. We calculated and described these scores, investigated dataset characteristics associated with increased or decreased scores and compared the scores to assess their usability. To our knowledge, no studies have directly used the proposed methods of calculating re-identification risk scores across various publicly available clinical trial datasets.
Methods
A full protocol (Appendix 1 in the supplementary materials) 18 was finalised on 1 December 2020.
We collected a sample of publicly available, de-identified/anonymised clinical trials datasets to estimate their re-identification risk scores, using three equations designed for this purpose. 19
Datasets sources
We identified 18 data sources through previous research, 18 web searches and word of mouth. These included 16 repositories and two journals with established data-sharing policies (BMJ and PLOS One). Datasets were requested from repositories between 7 May 2021, and 23 September 2022. We also searched for randomised controlled trials (RCTs) published in the two journals from January 2013 (BMJ) and March 2014 (PLOS One) (when their data-sharing policies were introduced), up until 30 April 2022 (details in Supplementary Appendix 2).
Types of datasets
Our inclusion criteria consisted of datasets from RCTs on human participants, deemed anonymised and/or de-identified by data holders and suitable for secondary research. We excluded datasets described as containing identifiable information protected solely by controlled access or data-sharing arrangements. We limited our selection to studies with materials available in English or Spanish due to the language skills within the writing team.
Data collection and analysis
Selection and request of datasets
One investigator (AR) searched the sources (repositories or journals) and screened titles and descriptions of datasets to determine eligibility and identify duplicates. For sources with five or fewer eligible datasets, all datasets were requested. For sources with more than five eligible datasets, five were selected at random using SAS 20 by assigning a random number to each dataset, ordering them based on these random numbers and requesting the first five. If a dataset was unavailable, it was replaced with the next on the ordered list. This exploratory sample ensured a fair representation from all sources and maximised the information we could obtain given our limited resources.
Due to the following factors, we revised this sampling strategy for some sources:
Project Data Sphere 21 : has two levels of controlled access (researcher vetoing and researcher vetoing plus data-sharing agreements (DSAs)). Initially, five datasets were requested. The signed DSA covered four datasets, while one did not require a DSA. Additional datasets were accessible without a DSA, so we randomly chose another four, totalling nine datasets.
Large Repositories: Requesting more than five datasets was more efficient, as some owners were unwilling to share certain datasets or the datasets were listed but not yet prepared. Oversampling helped us achieve our target of five datasets and mitigated the inflexibility of DSAs tailored to specific datasets. For instance, at ``The Yale University Open Data Access (YODA) Project’’, 22 we signed a DSA for five datasets, but one study only contained the clinical study report without the individual participant data. Replacing this dataset would have triggered a new DSA, so YODA is represented by only four datasets.
BMJ and PLOS One: Studies offering controlled access via DSAs were not pursued due to bottlenecks in our contracts department, and we had already acquired 39 controlled access datasets.
Once a dataset was identified as potentially meeting the inclusion criteria, it was downloaded (if open access), or access was applied for following the data owners’ procedures. The time from request to data access approval was recorded. Some datasets could only be analysed remotely in trusted research environments (TREs).
Data extraction and management
The selected datasets were retrieved and transferred to a secure and password-protected electronic storage area at the University of Edinburgh.23–25 For datasets held in TREs, AR transferred the re-identification risk scores calculation analysis code to those environments and extracted the relevant output.
Datasets were provided in multiple software formats and thoroughly explored to ensure no discrepancies among formats and to check for additional data. Whenever possible, the datasets were compared with their corresponding data dictionary, case report form and/or protocol to verify if they covered all collected data or were partial datasets.
All available metadata, from obtained datasets, was recorded on an MS Excel 26 spreadsheet (attributes collected in Supplementary Appendix 3).
Data synthesis and re-identification risk calculation
We extracted the number of direct and/or indirect identifiers in the datasets as described by Hrynaszkiewicz et al., 27 except for ‘small denominators-population size of <100’ and ‘very small numerators-event counts of <3’ which were already considered within the risk score calculations. The data extraction process involved visual inspection by AR and verification by a second reviewer (SCL, LJW or CJW).
El Emam’s methodology 15 combines all indirect identifiers to create strata within a dataset. For example, combining age, race and sex generate groups like ‘four 18-year-old white males’ or ‘one 79-year-old African American female’. Adding more identifiers further divides data into smaller strata, known as granularity. The goal is to minimise the number of strata while maintaining data utility. Three re-identification risk scores were calculated 15 :
Risk a (Ra): Measures the proportion of participants in a dataset who belong to strata with a re-identification probability higher than seven predefined thresholds (0.01, 0.05, 0.1, 0.2, 0.3, 0.4 and 0.5) 15 (These thresholds were chosen to represent a wide variety of risks). For instance, an Ra of 0.5 at threshold 0.1 indicates that 50% of the participants in the dataset are in strata with 10 or fewer participants.
Risk b (Rb): Identifies the stratum with the smallest membership (regarding all indirect identifiers), representing the worst-case scenario. For example, an Rb of 0.33 indicates that there is at least one stratum with 1 in 3 chances of being re-identified.
Risk c (Rc): Represents the average risk score across the whole strata of the dataset, using all indirect identifiers. A dataset with two strata of 5 and 10 participants would have an Rc of 0.15, calculated as the average of 1/5 and 1/10.
Each risk score ranges from 0 to 1 and was estimated under the prosecutor and journalist scenario.19,28 The prosecutor re-identification risk arises when an adversary knows that a target individual (whose identifiers are known) is in the publicly available dataset. For this scenario, we assessed uniqueness within strata in each dataset. The journalist re-identification risk occurs when an adversary attempts to re-identify any individual in the dataset by matching it with another dataset, solely to prove that re-identification is possible. In this scenario, we used synthetic datasets, scaled to at least 15 times the size of the anonymised datasets, as identification sources for matching. The synthetic datasets were customised to include corresponding indirect identifiers using the algorithm by Bogle and Erickson. 29 Supplementary Appendix 4 shows a worked example for calculating Ra, Rb and Rc.
Several assumptions guided the risk score calculations in both scenarios:
Calculations required at least two indirect identifiers; datasets with fewer were automatically scored 0 30 for all re-identification risks.
Datasets containing at least one direct identifier were automatically scored 1 30 for all re-identification risks.
No recoding or further manipulation of datasets was allowed, except for necessary steps to prepare data for re-identification risks calculation.
Metadata from all included datasets and re-identification risk scores were summarised using descriptive statistics. There were no attempts to re-identify or contact individual participants. This was an exploratory study, so no formal statistical inference was set a priori.
SAS 20 was used for all analysis, except for YODA’s 22 TRE datasets, where STATA 31 was used due to SAS unavailability.
Results
The first dataset was received on the 7 May 2021, and the last on the 26 April 2023. Of the 18 identified data sources, three were excluded: two did not contain relevant RCTs datasets, and one no longer existed when the study protocol was executed. Consequently, 15 data sources were visited, 14,896 datasets preselected and a sample of 86 datasets requested. All data sources offered the data free of charge. The median number of requested datasets per data source was 6 (interquartile range [IQR]: 5–6). We obtained 76 out of 86 (88.4%) requested datasets, faced 9 (10.5%) rejections and received one (1.2%) duplicate. Rejections were due to: five times access was denied as our proposal was not considered a valid reason for data sharing, three datasets were listed but not yet available in their repository and one request received no response from the data owners. The median number of obtained datasets per repository was five (IQR: 5–6). (Supplementary Appendix 5).
We analysed 70 out of 76 (92.1%) datasets (representing 14 data sources) and excluded six datasets (7.9%) because four were not from RCTs, and two were summarised cluster data, instead of individual participant data (flowchart in Supplementary Appendix 6). Supplementary Appendix 5 provides a list of the 70 included studies.
Included datasets’ characteristics
Table 1 summarises the characteristics of the included datasets. Of the 70 datasets, 39 (55.7%) were shared with varying levels of controlled access, while 31 (44.3%) were provided with minimal restrictions (open access). On average, it took 270 days to obtain controlled access datasets and 8 days for open-access datasets. Controlled access sources tended to provide entire datasets (79.5%, 31/39), whereas open access more often supplied only main analysis variables (61.3%, 19/31). This is reflected in the median number of explored variables by type of access: 449(IQR: 217–918) for controlled access vs 92 (IQR: 39–217) for open access. Datasets were provided in multiple software formats (22.9%, 16/70), followed by SAS (21.4%, 15/70) and comma separated values (CSV) (17.1%, 12/70). The most common associated documentation10,32 was the study protocol (78.6%, 55/70) and data dictionary (75.7%, 53/70), with 48.6% (34/70) including additional documentation such as patient information sheets, consent forms and supplementary tables.
Datasets’ characteristics.
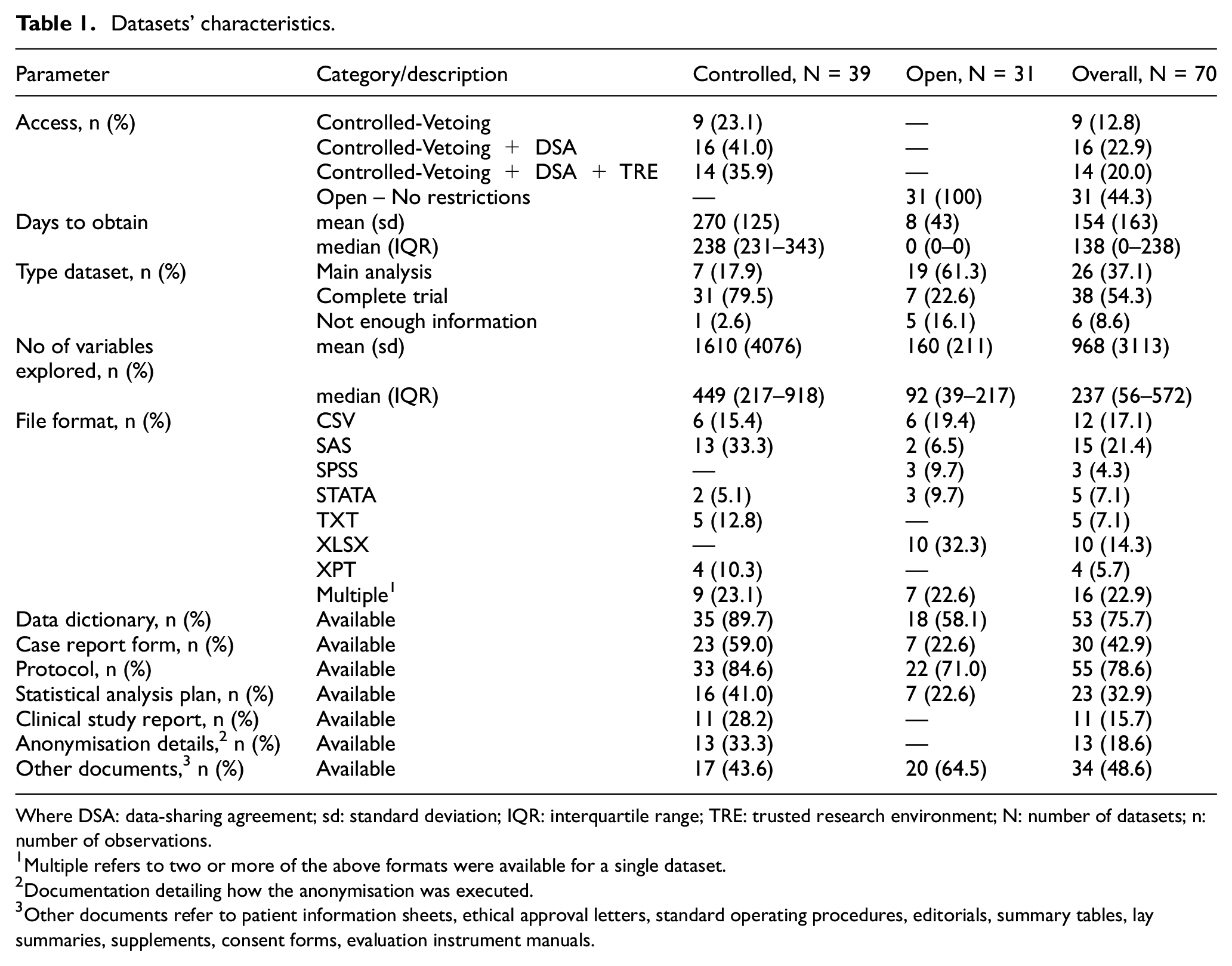
Where DSA: data-sharing agreement; sd: standard deviation; IQR: interquartile range; TRE: trusted research environment; N: number of datasets; n: number of observations.
Multiple refers to two or more of the above formats were available for a single dataset.
Documentation detailing how the anonymisation was executed.
Other documents refer to patient information sheets, ethical approval letters, standard operating procedures, editorials, summary tables, lay summaries, supplements, consent forms, evaluation instrument manuals.
Characteristics of the studies associated to the included datasets
Table 2 presents a summary of the observed characteristics of the studies associated with the included datasets. Clinical trial registrations were found for 92.8% (65/70) of the studies. Most registrations occurred from 2006 to 2015 (54.3%, 38/70), and the studies were primarily published between 2011 and 2020 (70.0%, 49/70). Most studies were multicentred (77.1%, 54/70), and many were multinational (32.9%, 23/70), involved adult participants (80%, 56/70) and utilised a parallel design (82.9%, 58/70). Studies were primarily from clinical trial phase III (38.6%, 27/70) and ‘not applicable’ (35.7%, 25/70). The median number of participants was 355 (IQR: 154–921). We included three studies related to rare diseases (4.3%, 3/70) as defined by Orpha.net. 33
Associated studies characteristics.
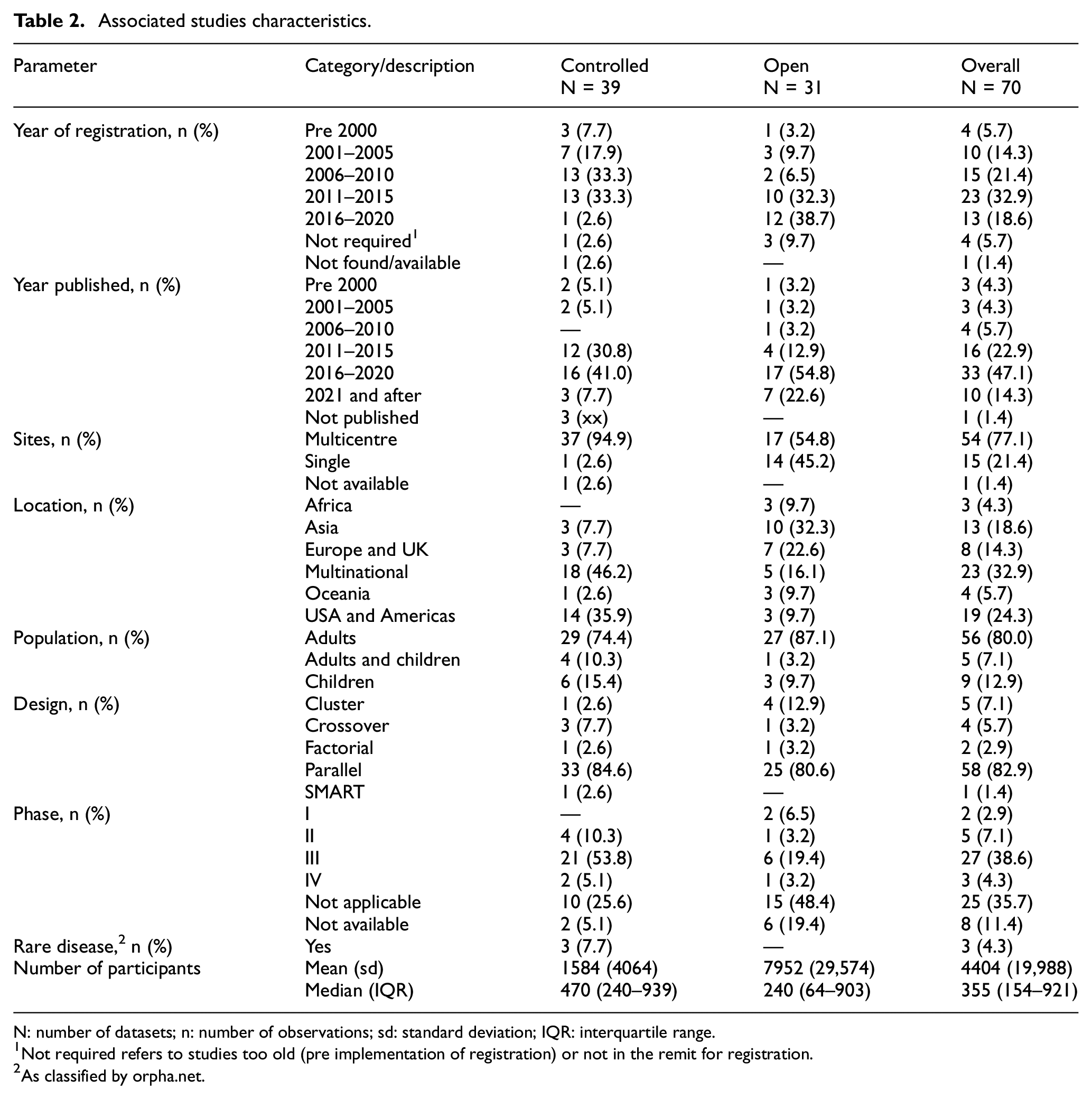
N: number of datasets; n: number of observations; sd: standard deviation; IQR: interquartile range.
Not required refers to studies too old (pre implementation of registration) or not in the remit for registration.
As classified by orpha.net.
Re-identification risk scores results
Table 3 shows that the most common indirect identifiers in the datasets were age (84.3%, 59/70) and sex (80.0%, 56/70), followed by weight (47.1%, 33/70) and height (44.3%, 31/70). Nine (12.9%, 9/70) datasets were automatically risk scored to 0 or 1. Datasets had a median of 4 (IQR: 3–6) identifiers. Mean risk scores ranged from 0.47 to 0.91. Rb was usually higher than Ra (at all thresholds) and Rc. Moreover, the more indirect the identifiers, the higher the risk scores (Supplementary Appendix 6).
Identifiers and re-identification risks scores for included datasets.
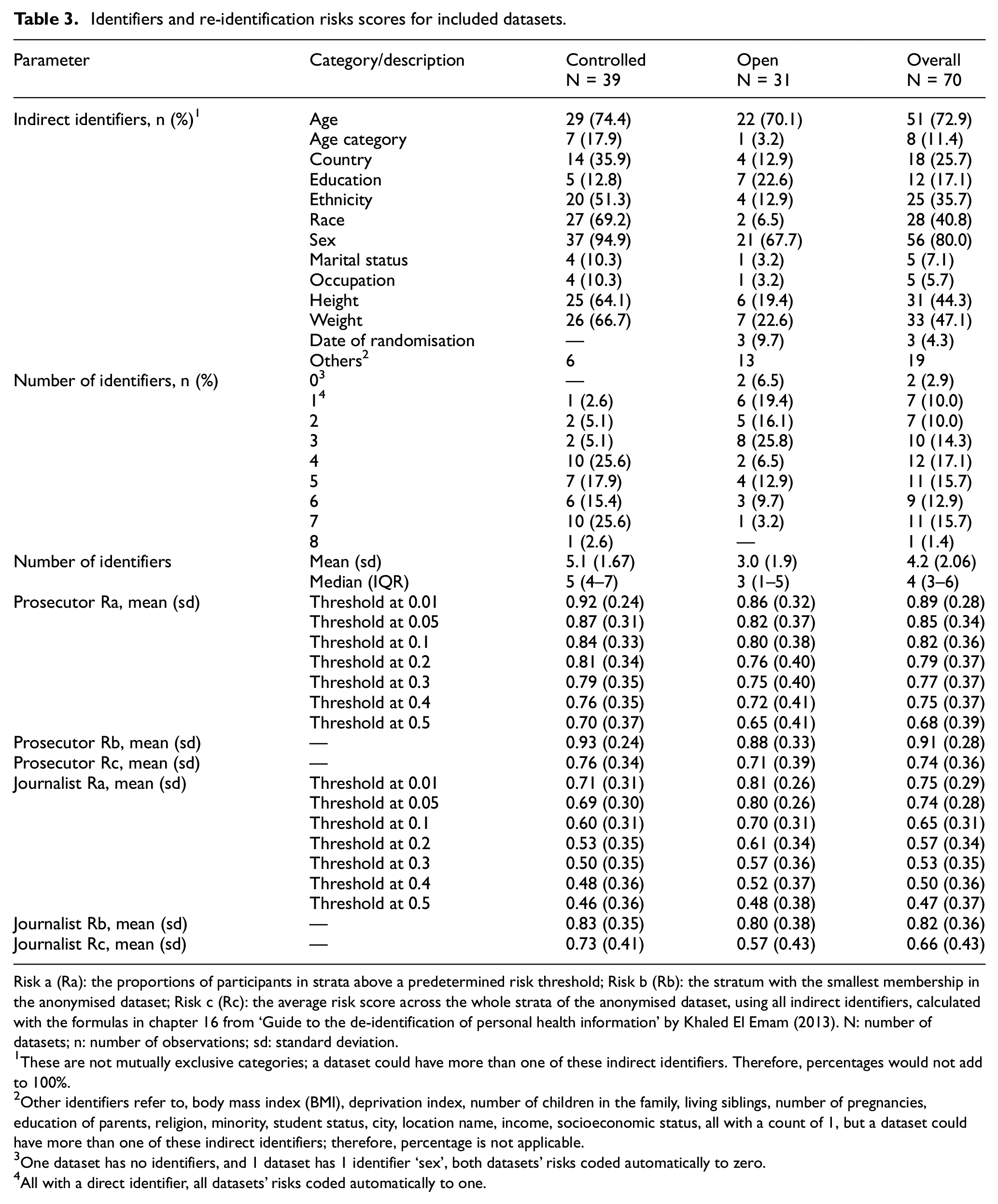
Risk a (Ra): the proportions of participants in strata above a predetermined risk threshold; Risk b (Rb): the stratum with the smallest membership in the anonymised dataset; Risk c (Rc): the average risk score across the whole strata of the anonymised dataset, using all indirect identifiers, calculated with the formulas in chapter 16 from ‘Guide to the de-identification of personal health information’ by Khaled El Emam (2013). N: number of datasets; n: number of observations; sd: standard deviation.
These are not mutually exclusive categories; a dataset could have more than one of these indirect identifiers. Therefore, percentages would not add to 100%.
Other identifiers refer to, body mass index (BMI), deprivation index, number of children in the family, living siblings, number of pregnancies, education of parents, religion, minority, student status, city, location name, income, socioeconomic status, all with a count of 1, but a dataset could have more than one of these indirect identifiers; therefore, percentage is not applicable.
One dataset has no identifiers, and 1 dataset has 1 identifier ‘sex’, both datasets’ risks coded automatically to zero.
All with a direct identifier, all datasets’ risks coded automatically to one.
To further explore these results, pre-specified plots in Supplementary Appendix 6 were used. Ra, Rb and Rc did not seem to be correlated with the number of participants. While the risk scores provided distinct aspects of the dataset’s granularity, a correlation between Ra and Rc was noticed; as the threshold increased, the correlation became stronger (Supplementary Appendix 6). Table 4 shows the re-identifications risk scores from Table 3 categorised.
Re-identification risks scores categorised for included datasets.
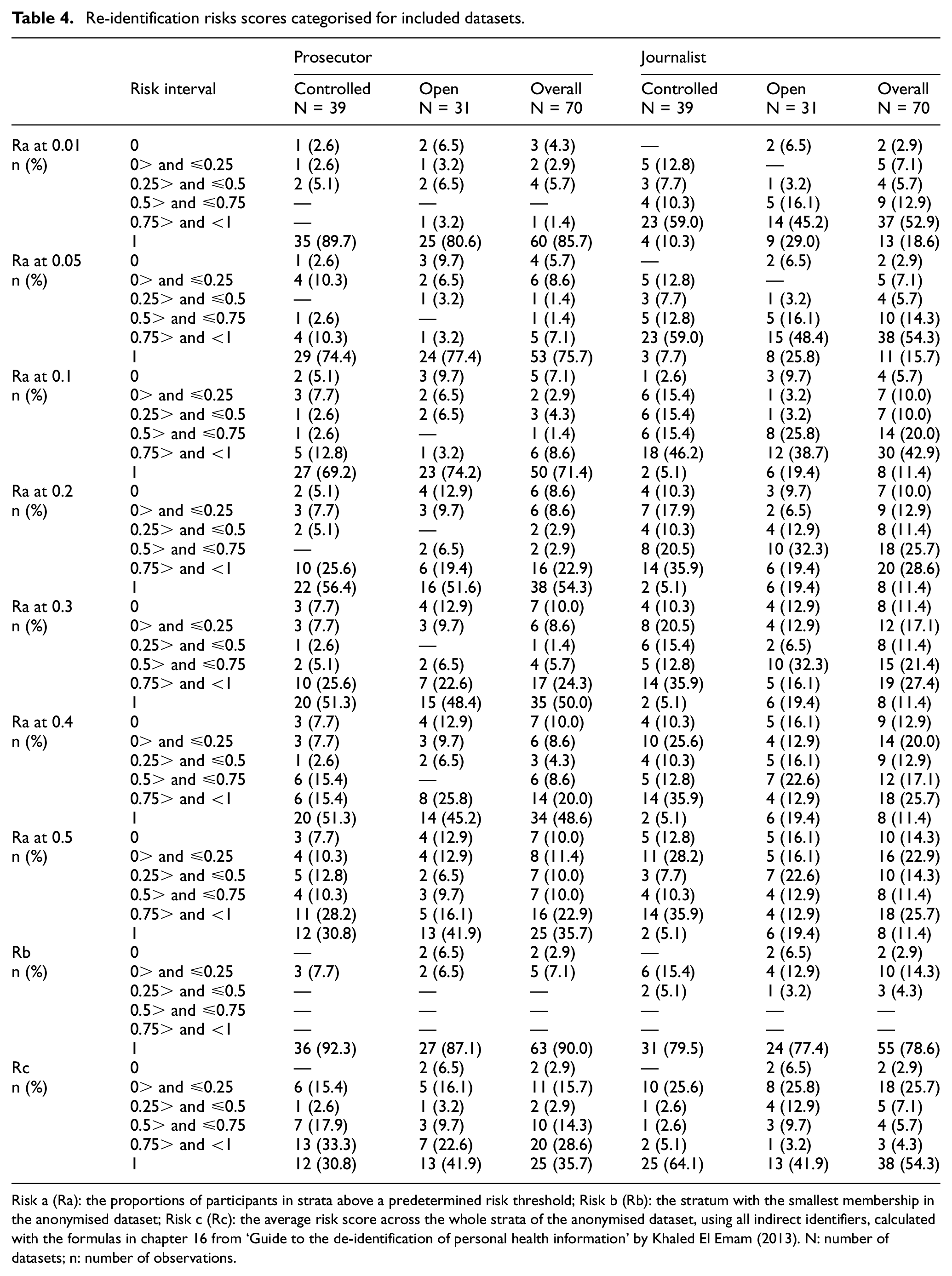
Risk a (Ra): the proportions of participants in strata above a predetermined risk threshold; Risk b (Rb): the stratum with the smallest membership in the anonymised dataset; Risk c (Rc): the average risk score across the whole strata of the anonymised dataset, using all indirect identifiers, calculated with the formulas in chapter 16 from ‘Guide to the de-identification of personal health information’ by Khaled El Emam (2013). N: number of datasets; n: number of observations.
We did not encounter any reportable critical issues with the analysed datasets; hence, there was no need for us to communicate with any of the data owners or holders.
Re-identification risk scores in action
To understand the behaviour of the risk scores, we conducted two exploratory comparisons on three of the acquired 70 datasets. First, we used the TOPPIC 34 trial anonymised dataset and calculated its risk score according to our protocol. We obtained 240 unique strata, matching its number of participants, and all risk scores were 1. Next, we categorised its continuous indirect identifiers (age, height and weight) in bands of 10 units. This yielded 123 unique strata, with risk scores ranging from 0.27 to 1. We then grouped them into bands of 20 units, resulting in 52 unique strata and risk scores ranging from 0.07 to 1. Then, we collapsed bands with counts less than 5 with their most adjacent band, producing 44 unique levels, with risk scores ranging from 0.05 to 1. From this last categorisation, we also removed age, then reinstated it and subsequently excluded weight. In both cases, the number of strata were 17 and 15 respectively, with risk scores from 0.01 to 1 and 0.004 to 1 (Supplementary Appendix 6).
Second, we compared risk calculations for two datasets (Supplementary Appendix 6). Although both datasets have three indirect identifiers, all risk scores are higher for the IST 35 trial dataset (19435 participants and 2570 unique strata) compared to the RESTART 36 trial dataset risk scores (537 participants – 8 unique levels), as the former is more granular than the latter.
Discussion
The experience of dataset request and extraction
Securing 76 out of 86 (88.4%) requested datasets from 15 data sources indicates a widespread willingness to share data, which is reassuring. However, our affiliation with a reputable academic institution likely improved our chances of securing them. Remarkably, we were not charged any fees by the data holders, which is encouraging given the evolving and increasingly strict regulatory environment for processing personal data.37,38 This situation may change in the future as data holders might start charging for the extra work involved,30,39 especially if this activity is not adequately funded. Conversely, well-funded data-sharing initiatives should generate pre-prepared data packs, helping minimise cost.
The time to obtain most open access datasets was short, 30 datasets received in 0 days, while one outlier taking 241 days, which the owner agreed to provide almost immediately, but it took 241 days to locate and send it. In contrast, procuring controlled access dataset, which required DSAs, was a lengthy and arduous process. Multiple forms needed to be completed before reaching the DSA stage, which often involved extensive negotiations between legal departments. This process should be reviewed, as it should not take nearly 9 months to a year to obtain the datasets.
We observed, as have other researchers 40 before us, that controlled access is not a universal concept but involves a variety of processes. At the simplest end, we only had to fill out a request form, submit our curricula vitae and outline our research question (23.1%, 9/39 datasets). The next level of complexity involved signing DSAs alongside the initial steps (41.0%, 16/39). The most complicated process entailed the additional step of accessing the shared data in a TRE (35.9%, 14/39).
The characteristics of the data packs
Certain characteristics slowed down our analysis: unclear or unavailable data dictionaries, variables repeated multiple times requiring consistency checks and outdated software formats. Conversely, some datasets following the Clinical Data Interchange Standards Consortium (CDISC) Study Data Tabulation Model 41 or Analysis Data Model 42 expedited the analysis. Datasets should be accompanied by clear data dictionaries, avoid duplicated variables and be stored in basic formats like CSV or TXT to avoid compatibility issues, or adhere to recognised standards.
The interpretation of re-identification risk scores
We found that 10% (7/70) of the datasets were labelled as anonymised, yet they contained direct identifiers (personal details), such as date of birth and participants’ initials. These datasets were included in the analysis to highlight this issue, with all their risk scores automatically set to 1, representing the worst-case scenario. Researchers must carefully cross-check their anonymised datasets with the list provided by Hrynaszkiewicz et al. 27 before releasing them. Certain dataset characteristics increased the risk scores, for instance, we encountered exact ages (e.g. measured in days) and dates of randomisation, which could be used to reverse-engineer dates of birth. Some datasets included the ‘Date of Death’ for participants; under the General Data Protection Regulation, personal data protection is not applicable once an individual is deceased. However, Hrynaszkiewicz et al. 27 recommend removing all dates unique to a participant, as this could potentially impact any living relatives. Replacing exact dates with the number of days from randomisation retains analytical value while protecting privacy.
Notably, 2.9% (2/70) of the datasets had no identifiers or only one indirect identifier, resulting in risk scores automatically set to zero. Datasets with no identifiers could be freely shared without privacy implications and are a viable option for researchers. However, even if one (or no) indirect identifier remains, a holistic check must be made. For example, one obtained dataset recorded only age, but its publication indicated that all participants were female and located in a specific region of the UK.
Re-identification risk scores evaluate dataset granularity. As shown in the TOPPIC 34 example, continuous identifiers increase granularity and risk scores more than discrete ones. Since each re-identification risk score assesses different aspects of dataset granularity, we cannot recommend one over the others. Furthermore, we cannot comment on their absolute magnitude as there are no standards or examples for comparison in clinical trials. However, smaller scores generally indicate better privacy protection. 15 Regarding Ra, statistical disclosure control 43 suggests suppressing table cells with counts less than five (i.e. a threshold of 0.2). Releasing datasets at this threshold could be an option, but it might reduce data usability. Researchers need to set a threshold that balances their data utility and privacy risk. More importantly, it is crucial to acknowledge that the threshold cannot ever be zero if indirect identifiers are present. This understanding emphasises that anonymisation is a spectrum, not a binary state, and some risk must be endured. 30 Rb behaved like a discrete variable, often scoring 1 with few exceptions, regardless the number of identifiers. This outcome was expected since most included datasets had at least one stratum represented by only one participant. In the TOPPIC 34 trial dataset comparison, Rb stubbornly remained at 1 despite attempts to reduce granularity. Lowering Rb 30 requires more sophisticated approaches like k-anonymity, 44 where the smallest membership per stratum should be k. Clinical trials researchers might need support in learning new techniques to address this. Finally, Rc showed that datasets not only had a few problematic strata (i.e. with 1 or 2 participants) but also many strata with low participant membership.
Using re-identification risk scores
We recommend the process outlined in Figure 1 (adapted from El Emam) 45 to effectively use the risk scores. First, remove all direct identifiers, followed by verifying the presence of indirect identifiers. Next, question the necessity of these indirect identifiers to maintain utility. 46 Note, there is no universally agreed-upon interpretation of data utility, it is context-specific. Researchers must define what utility means for their study. The ability to reproduce the primary outcome analysis with the anonymised dataset can serve as a measure of utility.40,46 The researcher’s definition of utility 47 is pivotal in shaping the anonymised datasets. For example, the TOPPIC 34 trial dataset was designed to allow investigation of new research questions (423 variables, 240 participants, 240 unique levels with four indirect identifiers, Supplementary Appendix 6) while the RESTART 36 trial dataset was designed from primary analysis replication (66 variables, 537 participants, eight unique levels with three indirect identifiers, Supplementary Appendix 6). Once utility is defined, calculate the risk scores, if they are considered high, they could be lowered by manipulating the data through perturbation, recalculation, recoding and suppression 11 and by using privacy models.44,48–50 Finally, use Table 4 to compare the newly anonymised dataset’s re-identification risk scores with those from the datasets included in this research and decide the type of access to be used for release.
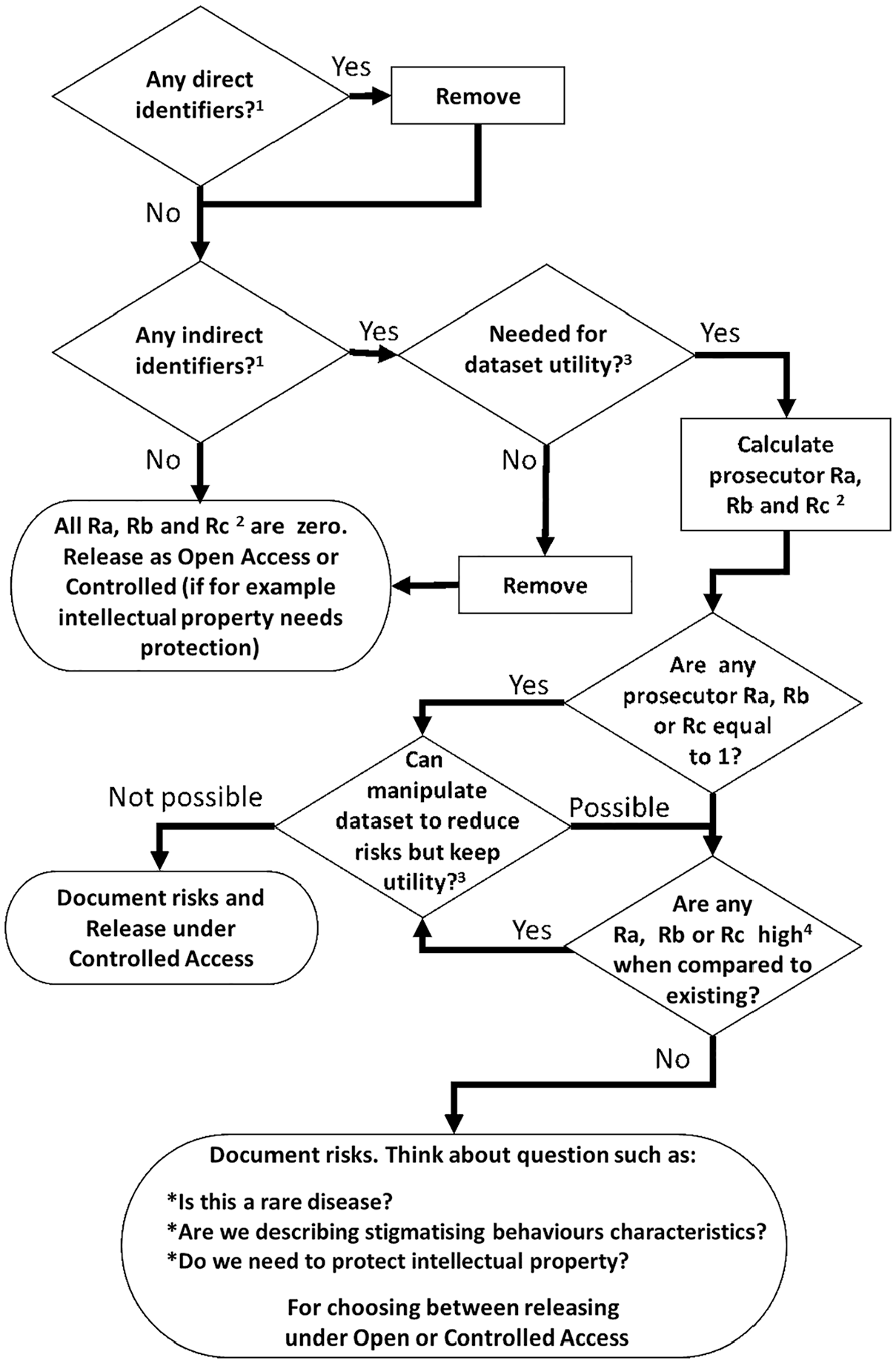
Decision cycle for releasing clinical trials datasets using re-identification risks.
Strengths and limitations
This study covers an emerging area in clinical trials methods research, where even the definition of anonymisation lacks consensus. Therefore, our selection of datasets defined as anonymised or de-identified may have introduced heterogeneity among the characteristics of the requested datasets.
The available datasets currently underrepresent Africa and Oceania, which might limit the applicability of our findings to those continents. There were no restrictions on the age of the selected datasets; however, to enhance the representation of open access datasets, we modified the inclusion criteria for datasets from BMJ and PLOS One. This may have skewed our findings and affected the analysis of publication dates and datasets ages, as our search for these sources was limited to datasets from January 2013 and March 2014 onward, respectively.
We did not find, or actively seek, trials studying risky or stigmatising behaviour, which would require special treatment beyond the scope of this research.51–53 Furthermore, the journalist re-identification risk scores might have been overestimated, as all the matching theoretical datasets were 15 times larger than the original dataset. This scale might not have been sufficient in some cases, especially for small datasets (fewer than 40 participants). Moreover, the probability of a real-life matching dataset existing was not evaluated, as this requires specialised expertise. Given these challenges, using only the prosecutor risk scenario may have been a more appropriate and feasible initial approach.
At least 19 open-access datasets were available when we wrote the protocol for this research, making the project feasible. However, we could not have predicted that controlled-access repositories would be as receptive to our requests as they were. In hindsight, with greater ambition, we could have requested more datasets, thereby increasing our sample size, but given limited resources, it could not have increased significantly.
The re-identification risk scores alone do not determine a dataset’s real-world vulnerability to re-identification attacks,54–57 factors such as an attacker’s motivations, resources and potential gains also play a role, which were outside the scope of this research.
Risk score calculations can be rapidly implemented using the freely available R package sdcMicro58–60 or methods outlined in this publication’s appendices. While this research was conducted by experienced clinical trial statisticians, clinical trial researchers with a strong understanding of trial datasets could also perform these calculations. The main strength of this research is its assessment of a variety of datasets using a simple methodology under the same conditions.
Conclusion
This study confirms a strong inclination to share clinical trial datasets, which are rich in personal details. Although re-identification risk scores may appear oversensitive for clinical trial datasets, which are typically smaller than datasets from electronic health records, their high magnitudes do not necessarily translate into real-life re-identification threats for participants. Instead, these scores provide valuable summaries for understanding the granularity of clinical trial datasets, aiding decision-making for dataset release for secondary purposes.
We have demonstrated that calculating re-identification risk scores is simple and feasible. The number and type of identifiers (continuous or discrete) are crucial in controlling risk scores. More identifiers increase granularity, with continuous identifiers adding more granularity than discrete ones. While risk scores alone cannot determine if data is sufficiently anonymised or protected, they can assist in calibrating the anonymisation process of clinical trial datasets.
Researchers can use our findings to compare their anonymised datasets with those we evaluated and should consider employing the process outlined in this research to guide their anonymisation procedures before data release. This includes providing clear data dictionaries and offering datasets in simple formats. The proposed method is a cost-effective and pragmatic solution. While simple, it is highly informative and serves as a useful stopgap, especially when resources are limited.

Supplemental Material
sj-docx-1-ctj-10.1177_17407745251356423 – Supplemental material for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications
Supplemental material, sj-docx-1-ctj-10.1177_17407745251356423 for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications by Aryelly Rodriguez, Linda J Williams, Stephanie C Lewis, Pamela Sinclair, Sandra Eldridge, Tracy Jackson and Christopher J Weir in Clinical Trials
Supplemental Material
sj-docx-2-ctj-10.1177_17407745251356423 – Supplemental material for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications
Supplemental material, sj-docx-2-ctj-10.1177_17407745251356423 for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications by Aryelly Rodriguez, Linda J Williams, Stephanie C Lewis, Pamela Sinclair, Sandra Eldridge, Tracy Jackson and Christopher J Weir in Clinical Trials
Supplemental Material
sj-docx-3-ctj-10.1177_17407745251356423 – Supplemental material for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications
Supplemental material, sj-docx-3-ctj-10.1177_17407745251356423 for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications by Aryelly Rodriguez, Linda J Williams, Stephanie C Lewis, Pamela Sinclair, Sandra Eldridge, Tracy Jackson and Christopher J Weir in Clinical Trials
Supplemental Material
sj-docx-4-ctj-10.1177_17407745251356423 – Supplemental material for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications
Supplemental material, sj-docx-4-ctj-10.1177_17407745251356423 for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications by Aryelly Rodriguez, Linda J Williams, Stephanie C Lewis, Pamela Sinclair, Sandra Eldridge, Tracy Jackson and Christopher J Weir in Clinical Trials
Supplemental Material
sj-docx-5-ctj-10.1177_17407745251356423 – Supplemental material for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications
Supplemental material, sj-docx-5-ctj-10.1177_17407745251356423 for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications by Aryelly Rodriguez, Linda J Williams, Stephanie C Lewis, Pamela Sinclair, Sandra Eldridge, Tracy Jackson and Christopher J Weir in Clinical Trials
Supplemental Material
sj-docx-6-ctj-10.1177_17407745251356423 – Supplemental material for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications
Supplemental material, sj-docx-6-ctj-10.1177_17407745251356423 for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications by Aryelly Rodriguez, Linda J Williams, Stephanie C Lewis, Pamela Sinclair, Sandra Eldridge, Tracy Jackson and Christopher J Weir in Clinical Trials
Supplemental Material
sj-docx-7-ctj-10.1177_17407745251356423 – Supplemental material for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications
Supplemental material, sj-docx-7-ctj-10.1177_17407745251356423 for Evaluating re-identification risks scores in publicly available clinical trial datasets: Insights and implications by Aryelly Rodriguez, Linda J Williams, Stephanie C Lewis, Pamela Sinclair, Sandra Eldridge, Tracy Jackson and Christopher J Weir in Clinical Trials
Footnotes
Acknowledgements
Thanks to all data holder/owners for providing access to the data and to all clinical trial participants who permitted the use of their data for secondary research. Requested acknowledgments statements were:
Author contributions
AR, SCL and CJW conceived the idea for this work supported by SE. AR wrote the first draft and all authors contributed to this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: AR had a scholarship from the University of Edinburgh to undertake a PhD with the support from the Asthma UK Centre for Applied Research (AUKCAR grant no. AUK-AC-2012-01). SCL, LJW, PS and CJW are supported in this work by their employment at the Edinburgh Clinical Trials Unit. TJ is supported by Asthma UK as part of the Asthma UK Centre for Applied Research (grant nos. AUK-AC-2012-01 and AUK-AC-2018-01). SE is supported in this work by her employment at the Pragmatic Clinical Trials Unit. AR, SCL CJW, TJ and SE developed the protocol and all of the authors contributed to manuscript development. Neither sponsor (AUKCAR) nor funder (University of Edinburgh) contributed to protocol or manuscript development. For the purpose of open access, the author has applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising from this submission.
Ethics and dissemination
Prior to commencement, the research was subject to the University of Edinburgh’s Usher Institute ethics/data protection oversight process. The ethics/data protection triage and overview self-audit of ethics/data protection issues, completed on 3 December 2020 (by AR and SL ![]() ), confirmed that the proposed research (being fully anonymous secondary data analysis) posed no reasonably foreseeable ethics/data protection risks. This indicated that there was no requirement for proceeding to full formal ethics/data protection review by the Usher Research Ethics Group.
), confirmed that the proposed research (being fully anonymous secondary data analysis) posed no reasonably foreseeable ethics/data protection risks. This indicated that there was no requirement for proceeding to full formal ethics/data protection review by the Usher Research Ethics Group.
Availability of data and materials
Anonymised raw re-identification risk data and its analysis code may be requested from the corresponding author for further reasonable research.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.