
Abstract
Background/Aims:
Multi-arm, multi-stage trials frequently include a standard care to which all interventions are compared. This may increase costs and hinders comparisons among the experimental arms. Furthermore, the standard care may not be evident, particularly when there is a large variation in standard practice. Thus, we aimed to develop an adaptive clinical trial that drops ineffective interventions following an interim analysis before selecting the best intervention at the final stage without requiring a standard care.
Methods:
We used Bayesian methods to develop a multi-arm, two-stage adaptive trial and evaluated two different methods for ranking interventions, the probability that each intervention was optimal (P best ) and using the surface under the cumulative ranking curve (SUCRA), at both the interim and final analysis. The proposed trial design determines the maximum sample size for each intervention using the Average Length Criteria. The interim analysis takes place at approximately half the pre-specified maximum sample size and aims to drop interventions for futility if either P best or the SUCRA is below a pre-specified threshold. The final analysis compares all remaining interventions at the maximum sample size to conclude superiority based on either P best or the SUCRA. The two ranking methods were compared across 12 scenarios that vary the number of interventions and the assumed differences between the interventions. The thresholds for futility and superiority were chosen to control type 1 error, and then the predictive power and expected sample size were evaluated across scenarios. A trial comparing three interventions that aim to reduce anxiety for children undergoing a laceration repair in the emergency department was then designed, known as the Anxiolysis for Laceration Repair in Children Trial (ALICE) trial.
Results:
As the number of interventions increases, the SUCRA results in a higher predictive power compared with P best . Using P best results in a lower expected sample size when there is an effective intervention. Using the Average Length Criterion, the ALICE trial has a maximum sample size for each arm of 100 patients. This sample size results in a 86% and 85% predictive power using P best and the SUCRA, respectively. Thus, we chose P best as the ranking method for the ALICE trial.
Conclusion:
Bayesian ranking methods can be used in multi-arm, multi-stage trials with no clear control intervention. When more interventions are included, the SUCRA results in a higher power than P best . Future work should consider whether other ranking methods may also be relevant for clinical trial design.
Keywords
Introduction
Novel interventions are frequently evaluated in two-arm clinical trials, which compare the intervention against either a placebo or standard of care control. 1 However, head-to-head comparisons of different effective interventions are less frequent, particularly when multiple interventions are developed concurrently. 2 Multi-arm studies, which compare a relatively large number of interventions can be a more efficient method for performing these comparisons, 3 particularly if they stop recruitment to less effective interventions early. 4 This is a type of adaptive trial, where the number of interventions enrolling is based on study data.5,6
Typically, multi-arm adaptive trials perform all analyses in a pairwise fashion against a common control7,8 to determine whether each of the interventions is superior to the control. However, this framework of pairwise comparisons is neither economical nor ethical9–12 and restricts comparisons among experimental interventions, which could be the target of the proposed trial. 13 This is especially crucial when there is no obvious consensus for standard of care intervention, for example, if there is a large variation in practice across institutions or novel interventions have been developed concurrently. 14 In two-arm trials, the designation of a ‘control’ arm between two active comparators is not crucial, but in multi-arm trials, it is not obvious how the multiple arms should be compared. 10
Thus, we aimed to design a multi-arm trial to identify the optimal intervention from a set of active comparators, equivalent to a phase III study. This trial is most relevant to settings where a range of interventions are used, with different interventions favoured by different sites, and there is limited evidence on which intervention offers superior performance. In this setting, we can assume that the investigators are comparing the efficacy of interventions for which safety is well-established and hope to identify less effective interventions early. To achieve this, our proposed trial uses a two-stage design where low-ranked interventions are dropped at the first stage, and the remaining interventions are assessed to determine which, if any, is optimal. We implemented this design in a Bayesian framework and made decisions using the rank of each intervention. 15 The Bayesian framework is well-suited to this design as posterior ranks can be easily computed and it naturally fits within an adaptive design framework.16,17
This study compared two methods to rank the interventions. The first method calculates the probability that an intervention is better than all other interventions
To our knowledge, the proposed ranking methods have only been compared for network-meta-analysis.
18
Thus, our study is the first to compare different ranking methods for decision-making in multi-arm trial designs. We compared the ability of the SUCRA and
Methods
Multi-arm multi-stage trials
Multi-arm multi-stage (MAMS) trials evaluate multiple interventions and use interim analyses to determine whether trial arms should be dropped or continue to the next stage.4,27 Frequentist MAMS have been well-defined and use repeated statistical tests to determine whether interventions should be dropped.4,28,29 In contrast, Bayesian MAMS determine whether interventions should be discontinued or declared superior using predefined decision rules based on estimates from the posterior distribution of the parameters of interest. 4 Some MAMS trials will continue until a conclusion has been reached, 30 while others pre-specify a maximum sample size and number of stages. 4
In our design, we considered two stages and applied different decision rules for the interim and final analyses. During the interim analysis, we decided which interventions were promising enough to proceed to the final analysis stage by determining whether their efficacy exceeded a given stopping boundary. 31 The final analysis aimed to identify the optimal intervention among those that had not been stopped and took place when all participants had been recruited to those interventions. Thus, our proposed trial requires a pre-specified maximum recruitment level for each intervention and the boundaries to (1) stop an intervention at an interim analysis and (2) declare superiority at the final analysis. These key trial design components can then be chosen to minimize the sample size while ensuring that the trial meets its predefined target(s). 31
Our trial is a two-stage
At the interim analysis,
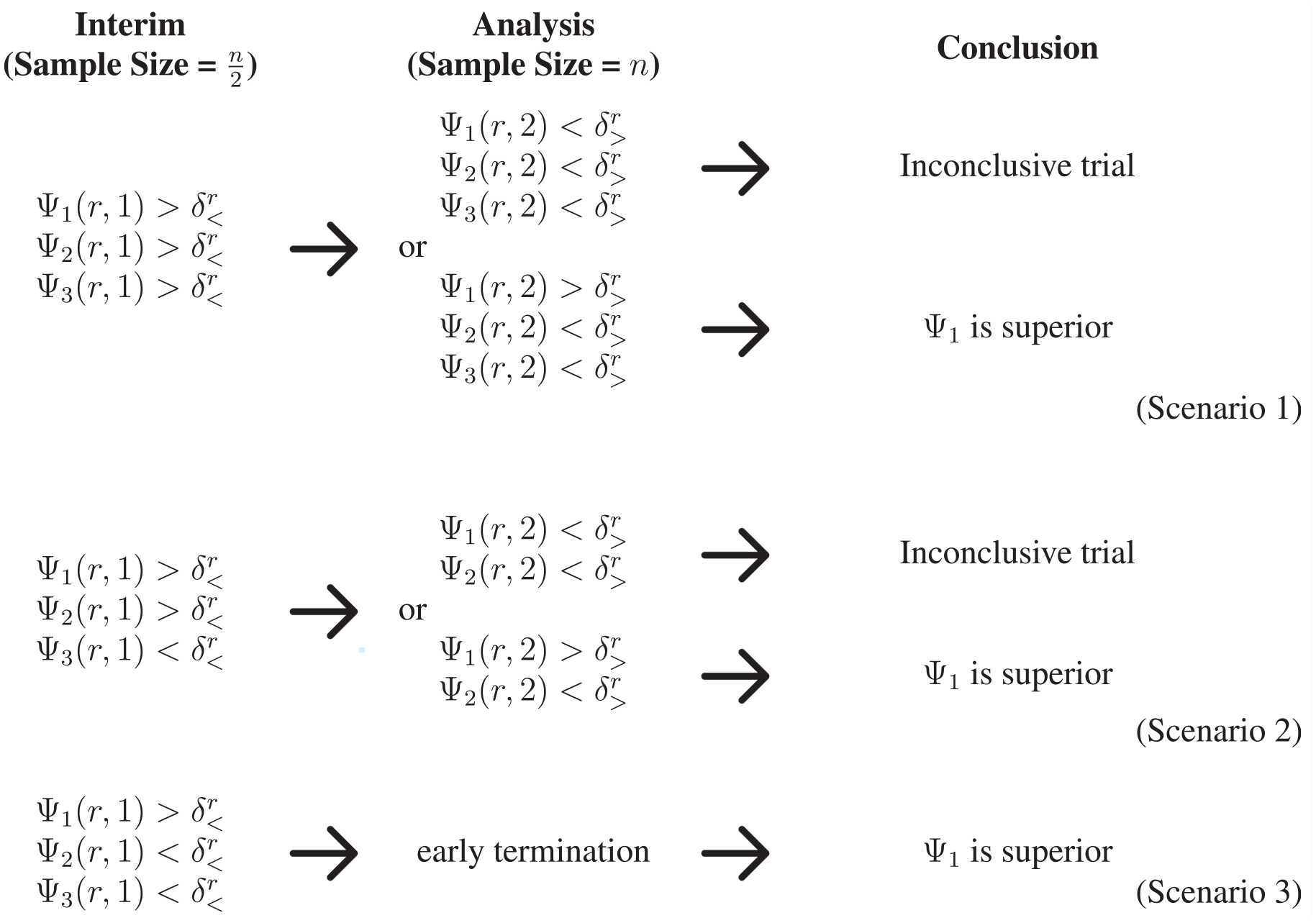
A pictorial representation of the decision-making in the proposed two-stage trial design. The first and second scenarios proceed to the final analysis stage, where at least two interventions are evaluated at the maximum sample size. Superiority is declared at the interim analysis stage in the final scenario, so the trial is terminated early and no interventions continue to the maximum sample size.
Implementing our proposed design
Before presenting the methods to select the maximum sample size,
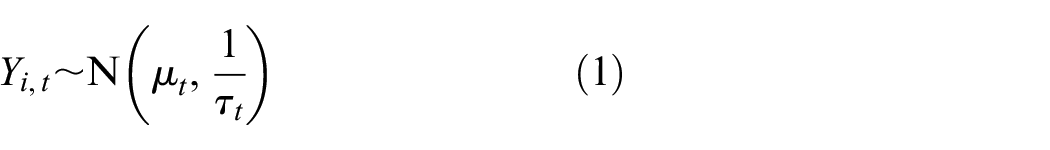
where
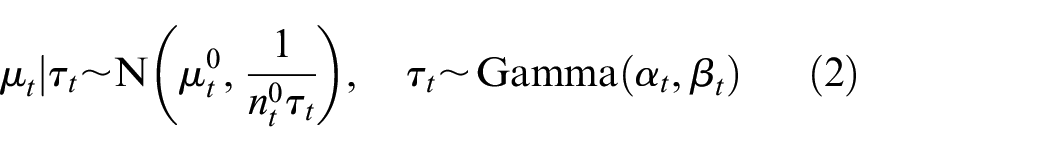
where
Determining the maximum sample size
The proposed trial design required specifying the maximum sample size for each trial arm. We proposed that the maximum sample size is derived using the Average Length Criterion (ALC), a Bayesian method for sample size determination.
25
The ALC controls the average length of the posterior credible interval for parameters of interest, typically the treatment effect but
To adapt the ALC to a multi-arm study, we computed the length of the longest posterior credible interval for
In this study, we selected the maximum sample size as the smallest sample size
Determining the futility and superiority thresholds
We selected the futility and superiority thresholds,
To evaluate type 1 error, we accounted for the prior uncertainty in the parameters
Bayesian predictive power
Once
At the interim analysis, all interventions except one meet the futility criterion;
At the final analysis, a single intervention meets the superiority criterion;
Predictive power can also be computed by evaluating the probability of detecting superiority for a specific intervention, but this power is restricted by the prior probability that the intervention is optimal, whereas our proposed definition can reach 1.
Evaluating the ranking methods
We performed a simulation study to compare two different ranking methods for decision-making in our trial, reported using the aims, data-generating mechanisms, estimands, methods, and performance measures (ADEMP) framework. 35
Aims
We aimed to compare the use of
Data-generating process
The data were simulated from the prior-predictive distribution of the normal-gamma conjugate model (see equations (1) and (2)). The parameters for the normal-gamma conjugate model were chosen to mimic the trial design for Anxiolysis for Laceration Repair in Children Trial (ALICE) (described below) and are set to
Estimands
Depending on the underlying assumptions for the prior mean of the interventions, the key estimand is either the type 1 error, defined as the probability that a trial declares superiority of any interventions when
Methods
We compared two ranking methods for drawing conclusions of superiority and futility during the trial. The rankings are computed using the posterior mean for each intervention;

estimated through simulation from the posterior distributions with 10,000 simulations. The second method was the SUCRA, which numerically summarizes of the entire ranking distribution. To define SUCRA, let
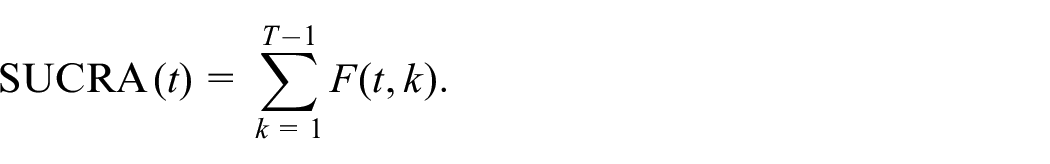
To ensure comparability between the two ranking methods, the thresholds
Performance measures
We used 10,000 simulated trials in each scenario, which guarantees that the estimated quantities have a 95% probability of being with 0.002 of the reported value. We estimate the type 1 error and predictive power as the proportion of simulations in which the relevant criteria are met. We report the chosen thresholds
Designing the ALICE trial
The ALICE trial is a phase III, multi-centre, single-blinded, randomized, three-arm, adaptive trial that aims to compare three anxiolytic agents, intranasal midazolam (INM)
The ALICE trial will enrol children between 1 and 13 years who present to the emergency department with a single laceration requiring simple interrupted sutures alone. The child or caregiver must also desire anxiolysis for the repair. The primary outcome is a weighted mean anxiolysis score, measured using the Observational Scale of Behavioral Distress – Revised (OSBD-R), 39 which ranges from 0 (no distress) to 23.5 (maximal distress).
Determining the priors
The prior information for the ALICE trial was extracted from the published literature and from study undertaken by our team.
24
The prior for the mean of the OSBD-R for INM
The prior parameters used for the ALICE trial.
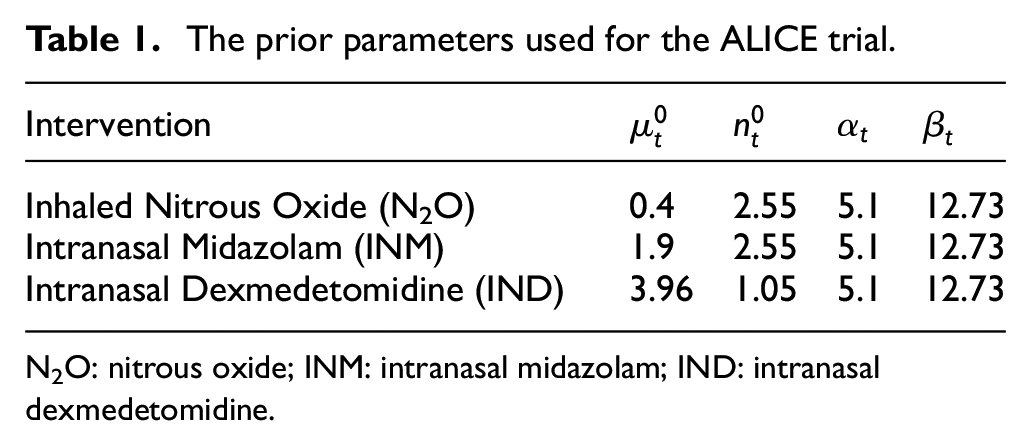
N2O: nitrous oxide; INM: intranasal midazolam; IND: intranasal dexmedetomidine.
Sample size determination
The sample size for the ALICE trial was selected using the ALC, conditional on the priors in Table 1. We simulated 10,000 data sets, conditional on the design prior, for eight different sample sizes from 70 to 140, in increments of 10. For each data set, we obtained the
Designing the ALICE trial
We evaluated both ranking methods to determine the optimal design for the ALICE trial. The optimal thresholds
Results
Evaluating the ranking methods
Tables 2 and 3 display the results of our simulation study of the two ranking methods. We report the results for the optimal threshold
The type 1 error and expected sample size (ESS) under the null hypothesis, obtained for four different scenarios that vary the number of interventions in the adaptive trial.
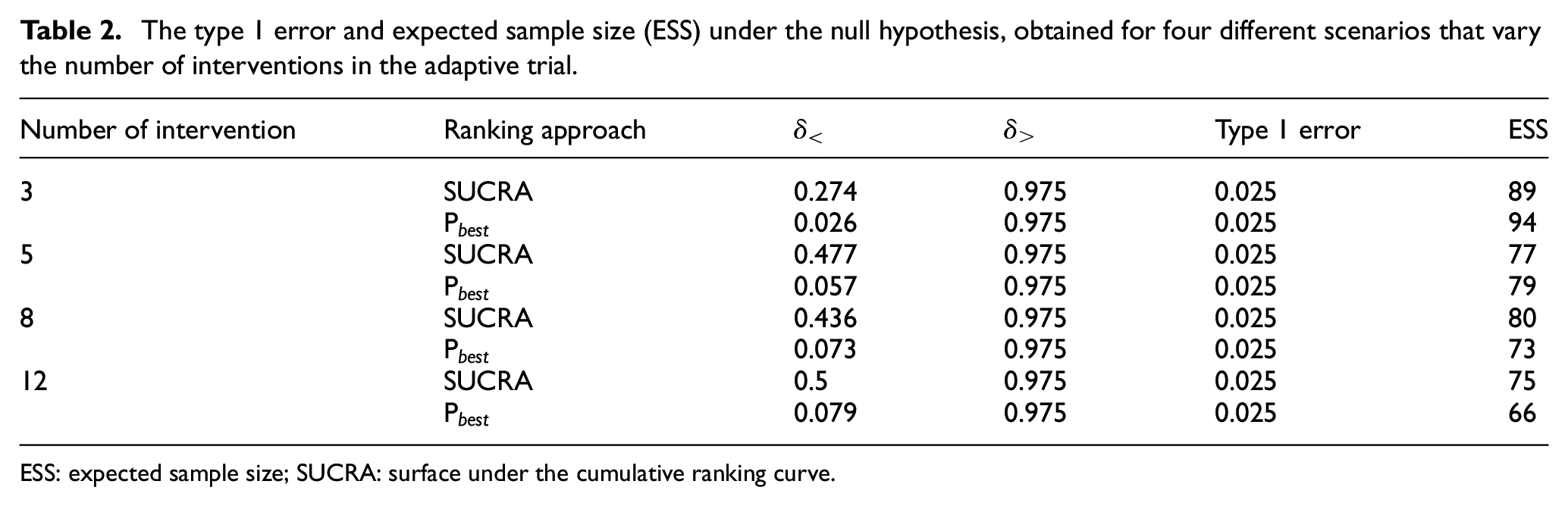
ESS: expected sample size; SUCRA: surface under the cumulative ranking curve.
The predictive power, expected sample size (ESS), and probability of incorrectly identifying a superior treatment under the alternative hypothesis, obtained from 12 simulated cases varying the number of interventions and the incremental difference between the prior means
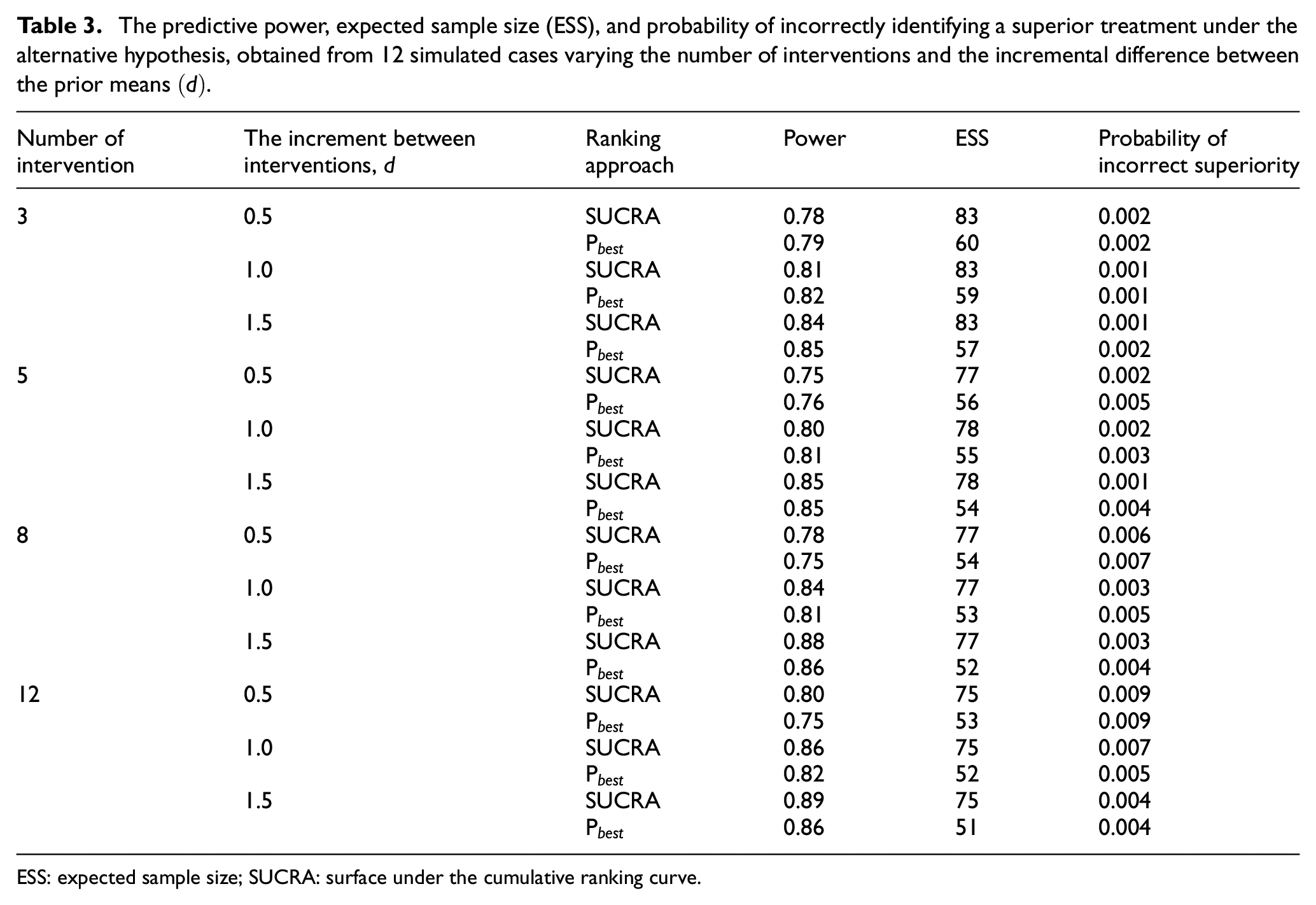
ESS: expected sample size; SUCRA: surface under the cumulative ranking curve.
Ranking interventions using
The expected sample size does not change substantially as the difference between the outcomes increases. We believe this is because the precision of the estimates is the same across the different scenarios and the relatively small sample sizes ensure that interventions are retained in the trial.
The ALICE trial
Table 4 displays the average longest 95% high-density posterior credible interval length for the mean of the OSBD-R score. The maximum sample size of 100 is chosen as the maximum sample size for the ALICE trial as the average longest length of 0.66 close to
The range of sample size and corresponding
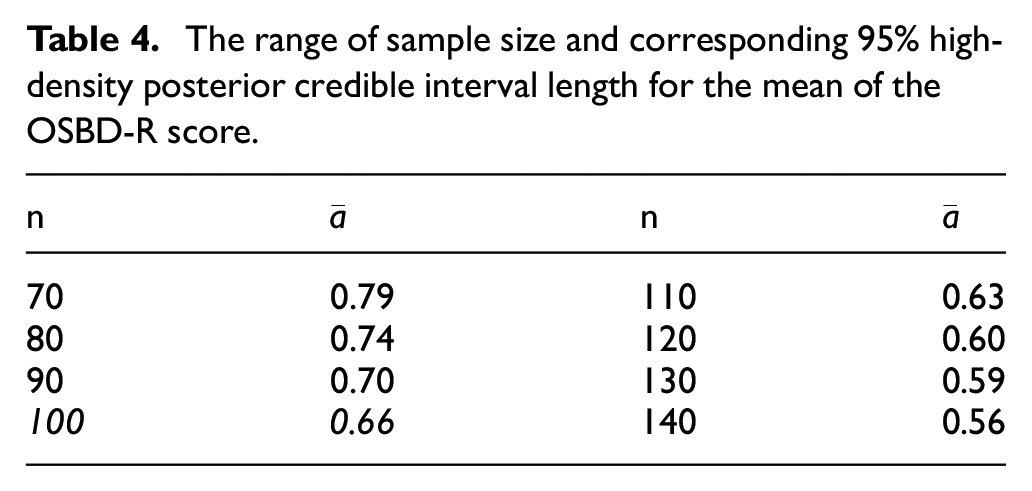
Based on
Discussion
This study evaluated two methods for ranking interventions to make decisions in a Bayesian, multi-arm, two-stage, adaptive trial across 12 scenarios. Broadly, this study showed that
We then used our novel design for the ALICE trial, a randomized trial to determine the optimal anxiolytic agent among three interventions to reduce distress for children undergoing laceration repair. Due to substantial practice variation, it was not obvious which intervention should be considered as the common comparator, necessitating the use of treatment rankings to make trial conclusions. This design is useful for trials where a placebo or clear standard of care is not available and the interventions have previously been shown to be effective. For example, variation in clinical practice where head-to-head trials have not been done, novel interventions developed at the same time by different teams/companies, common off-label use of drugs, for example, in paediatrics where trials are lacking, and the comparison of non-drug related interventions such as different implementation methods. A key challenge of the proposed trial design is choosing the design and analysis priors. We extracted these from previous literature but, in some examples, absolute outcome values may not be available, for example, if only relative treatment effects are reported, which would make this method challenging to implement. Another limitation of the proposed method was the use of conjugate distributions, which limited the models we could consider. For example, we could have considered a pooled precision across the different interventions, but this would have created an infeasible computational burden for our simulation study.
Furthermore, the simulation study could have been expanded to consider additional ranking methods, which is an important avenue for future research. In particular, using only ranking metrics, rather than the absolute effect of interventions, may violate consistency as different metrics may provide different treatment hierarchies. 18 Moreover, the efficacy that we evaluate using the ranking metric may not be clinically significant. A future extension of this design could consider the effect size and a minimum clinically important value in the superiority criteria. This has been suggested in the network meta-analysis 19 and could be extended to our trial design.
Conclusion
In multi-arm clinical trials with no obvious control, Bayesian methods for ranking interventions can be determine the optimal outcome from a set of effective alternatives. In trials with a small number of interventions, the probability that the treatment is superior provides high predictive power, while for larger numbers of interventions, the SUCRA offers increased predictive power. Our results showed both ranking metrics could provide valid, powerful trials with different operating characteristics. Thus, we suggest that investigators carefully consider their trial design and appropriate ranking method before the trial.
Supplemental Material
sj-pdf-1-ctj-10.1177_17407745241251812 – Supplemental material for A comparison of alternative ranking methods in two-stage clinical trials with multiple interventions
Supplemental material, sj-pdf-1-ctj-10.1177_17407745241251812 for A comparison of alternative ranking methods in two-stage clinical trials with multiple interventions by Nam-Anh Tran, Abigail McGrory, Naveen Poonai and Anna Heath in Clinical Trials
Supplemental Material
sj-pdf-2-ctj-10.1177_17407745241251812 – Supplemental material for A comparison of alternative ranking methods in two-stage clinical trials with multiple interventions
Supplemental material, sj-pdf-2-ctj-10.1177_17407745241251812 for A comparison of alternative ranking methods in two-stage clinical trials with multiple interventions by Nam-Anh Tran, Abigail McGrory, Naveen Poonai and Anna Heath in Clinical Trials
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.