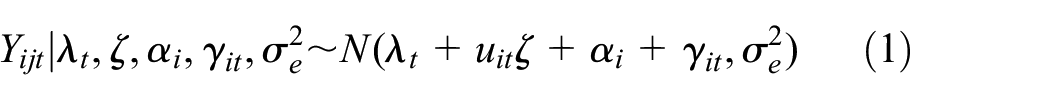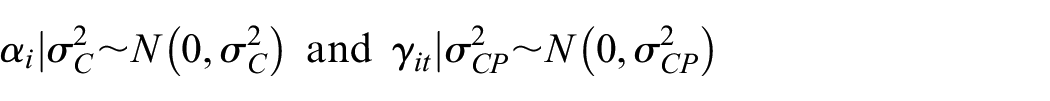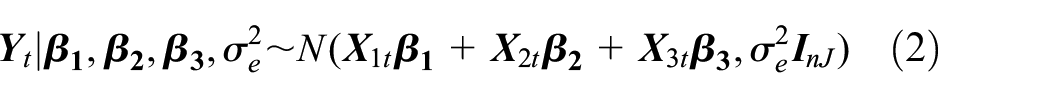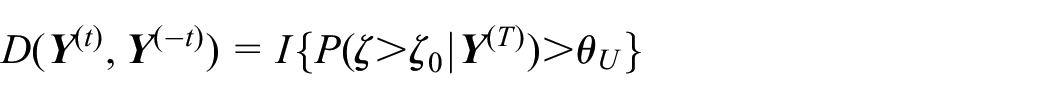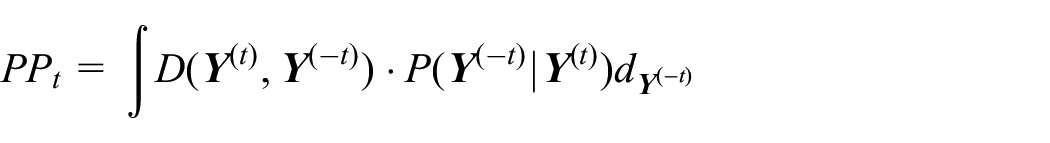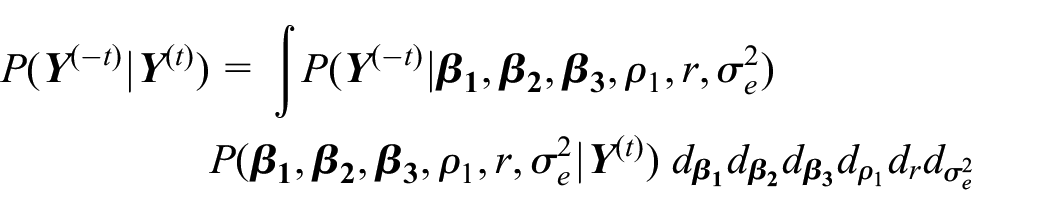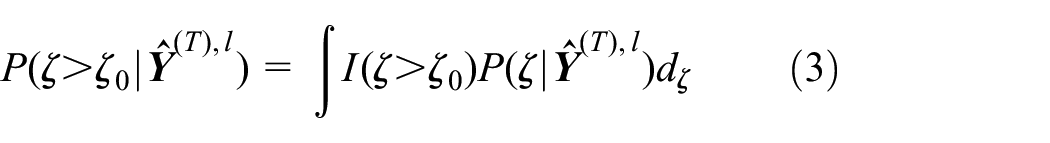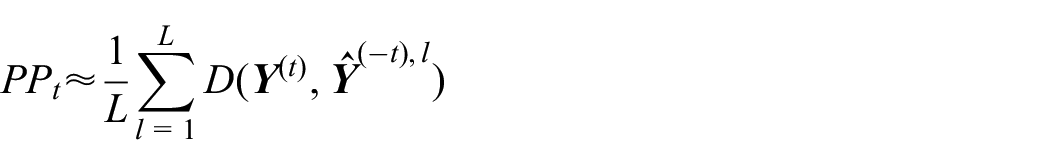The Bayesian group sequential design has been applied widely in clinical studies, especially in Phase II and III studies. It allows early termination based on accumulating interim data. However, to date, there lacks development in its application to stepped-wedge cluster randomized trials, which are gaining popularity in pragmatic trials conducted by clinical and health care delivery researchers.
Methods:
We propose a Bayesian adaptive design approach for stepped-wedge cluster randomized trials, which makes adaptive decisions based on the predictive probability of declaring the intervention effective at the end of study given interim data. The Bayesian models and the algorithms for posterior inference and trial conduct are presented.
Results:
We present how to determine design parameters through extensive simulations to achieve desired operational characteristics. We further evaluate how various design factors, such as the number of steps, cluster size, random variability in cluster size, and correlation structures, impact trial properties, including power, type I error, and the probability of early stopping. An application example is presented.
Conclusion:
This study presents the incorporation of Bayesian adaptive strategies into stepped-wedge cluster randomized trials design. The proposed approach provides the flexibility to stop the trial early if substantial evidence of efficacy or futility is observed, improving the flexibility and efficiency of stepped-wedge cluster randomized trials.
Adaptive design strategies that make adjustments based on accumulating data have received extensive attention in clinical research due to improved flexibility, efficiency, and ethics.1 They enable researchers to modify design in the middle of a trial based on interim observations, without destroying the validity and integrity of intended studies.2 One of the popular adaptive strategies is the group sequential design, which employs stopping rules that allow researchers to decide whether to stop a trial early in case of overwhelming evidence of efficacy or futility based on interim data.3 This strategy potentially can enhance flexibility and reduce patient exposure, cost, and trial duration.
Within the Bayesian paradigm, the Bayesian group sequential design has been investigated by many researchers.4–6 It can, like traditional group sequential designs, stop the trial early due to efficacy or futility, but with its own advantages: (1) it provides a natural way to use information from previous studies or clinicians’ opinion; (2) it obeys the likelihood principle and does not require the large sample theory for valid inference; (3) it offers results interpretable through a decision theoretical framework.7 Many researchers have advocated that Bayesian trial designs be calibrated to have good frequentist properties.8–11 One important argument is that researchers and regulatory agencies care about the long-run behavior of a trial design, averaged over all therapies evaluated, which is inherently a frequentist outlook. In this spirit, and in adherence to regulatory practice, a Food and Drug Administration12 (FDA) guideline has recommended to assess frequentist operating characteristics, such as type I error and power for Bayesian trial designs. There has been rich development in the design of Bayesian adaptive trials primarily based on frequentist operating characteristics.13–15
Recently, stepped-wedge cluster randomized trials (SW-CRTs) have been increasingly used in large biomedical and health care studies.16–18 In a standard SW-CRT, clusters are randomized to different sequences, which all begin with the control but crossover to the experimental intervention at different steps. At the final step, all clusters receive intervention. Outcome measurements are collected at each step.19,20 SW-CRTs have been preferred in pragmatic studies due to several advantages. It allows stepwise introduction of interventions to all clusters, which mitigates the ethical dilemma of withholding an intervention believed to be superior to the control. It helps reduce logistical challenges, especially when it is difficult to initiate the intervention concurrently to all subjects due to practical or financial constraints. It provides a fair and ethical random process to determine who receive the intervention first as long as all clusters receive the intervention within a reasonable time frame.21 Finally, measurements over multiple steps offer insights into the temporal trend of the intervention effect.
Importantly, the stepwise crossover to intervention and longer study duration motivate the implementation of Bayesian adaptive design strategies. For example, when overwhelming evidence of futility or efficacy is observed at interim analysis, it might be desirable to stop the SW-CRT early to save time and resources.3 Reaching the conclusion early also accelerates adoption by general practice. The Bayesian approach also enables knowledge from previous studies and researchers’ professional opinions to be incorporated into study design through the specification of informative priors. In summary, combining SW-CRTs with Bayesian adaptive strategies has great potential to improve experimental design methodologies and trial practice for pragmatic studies.
Development of adaptive methods for SW-CRTs has been scarce. Grayling et al.3 presented a frequentist group sequential approach for SW-CRTs using the error spending method. There have been some applications of Bayesian models to analyze data generated from SW-CRTs.22,23 Cunanan et al.24 presented a non-adaptive Bayesian SW design for community-based cluster randomized trials. Zhan et al.25 investigated how informative priors specified on time effects in SW-CRTs impact bias and efficiency. To the best of our knowledge, there has been no development of Bayesian adaptive design methods for SW-CRTs.
In this study, we proposed a Bayesian adaptive approach for SW-CRTs based on posterior predictive probabilities (PPP), which examines accumulating data at interim to determine whether the trial should be stopped early due to overwhelming efficacy/futility or should continue. By constructing decision rules based on PPP, the proposed adaptive design mimics typical clinical decision-making processes. Specifically, conditioning on interim data, the chance (predictive probability) that the trial will demonstrate a conclusive result at the planned end of study is evaluated. The decision to continue or to stop is made according to the strength of this predictive probability, examined against pre-specified thresholds. Extensive simulations are performed to determine various design parameters, so frequentist trial properties (e.g. type I error and power) are preserved.
This article is organized as follows. In “Methods” section, we describe the Bayesian adaptive approach for cross-sectional SW-CRTs and its implementation details. In “Results” section, we conduct extensive simulations to examine how the design parameters and different combinations of thresholds influence the design properties, such as power, type I error, and expected number of subjects. We also illustrate the proposed method with a real example. In “Conclusion” section, we summarize the proposed method and discuss practical issues.
Methods
We describe the Bayesian adaptive approach in the context of a cross-sectional SW-CRT, which could be readily extended to closed-cohort SW-CRTs. A typical SW-CRT involves steps (time points) and clusters. All clusters start from control, and they are randomized to switch to intervention at step and remain on intervention until the end of study, resulting in sequences. Let be the probability of a cluster being randomly assigned to sequence with , where is defined so that its elements for and for . Here, value 0/1 indicates control/intervention. At step , a new panel of subjects is enrolled from Cluster . We assume each subject to contribute one outcome measurement. The total number of subjects enrolled is . Let be the measurement of a continuous outcome obtained at step from subject of the cluster . Under the Bayesian framework, we model the likelihood of by
with
Here are time-specific intercepts, which account for arbitrary temporal trends under control. We use to indicate that cluster receives control/intervention at step and quantifies the intervention effect. Define . By randomization, . This model includes as the cluster random effect and as the cluster-period random effect, which are assumed to be mutually independent. Similar models have been employed by other researchers.26,27 The correlation between measurements from the same cluster within the same period, called the within-period intracluster correlation (wpICC), is . The correlation between measurements from the same cluster but across different periods, called the between-period intracluster correlation (bpICC), is , where has been called the cluster autocorrelation coefficient (CAC).26 Importantly, the within-cluster correlations of are exchangeable across steps under , and block exchangeable (by steps) otherwise.27
At step , the cluster-specific collection of observations is and we define . We use to denote interim observations up to step . Hence, the full set of observations at the end of study is . For , we have
where represents future observations yet to be observed at step .
To facilitate discussion, we rewrite Model (1) in a matrix form
We define , , with for . is an identity matrix. is an design matrix where the row corresponding to is a vector with the element being 1, the element being , and all other elements being 0. is an design matrix for cluster random effects, where the row corresponding to is a vector with the element being 1 and all others being 0. is an design matrix for cluster-period random effects, where the row corresponding to is a vector with the element being 1 and all other elements being 0. Note that are known after randomization. Finally, , , , , , and are defined similarly as and .
Prior distributions for , , , and need to be specified. Model (1) implies that and . Fixed-effect is assumed a non-informative flat prior, which is equivalent to a normal distribution with an infinite variance. It can be shown that there is a deterministic relationship between and . Because variances of random effects are rather abstract concepts, it is often easier to obtain information (from literature or professional opinion) about intracluster correlation and decay of correlation between periods . Hence, we decide to specify priors on instead of . Following Grantham et al.,27 we assume Beta distributions for and , which have a range of 0–1, and a half-Cauchy distribution for . Gelman28 showed that the half-Cauchy prior is superior to the inverse-gamma prior for variance parameters, which can severely distort inference.
The hypotheses of interest are versus , where is the benchmark intervention effect. Under the Bayesian paradigm, hypothesis testing is performed based on the posterior distribution of . At the end of study, we will declare the intervention effective if ; ineffective if ; and the trial is inconclusive if . Here, decision thresholds are design parameters that need to be specified to achieve desired operating characteristics, such as power and type I error. At each step , given interim observations , we will calculate the predictive probability (denoted by ) of declaring the intervention effective at the end of study. We will use to determine whether the trial should be stopped early due to overwhelming evidence of efficacy/futility, based on decision rules:
If , stop the trial and conclude the intervention ineffective;
If , stop the trial and conclude the intervention effective;
Otherwise, continue to step until reaching the end of study.
The interim decision thresholds also need to be specified.
In the following, we describe the evaluation of . At the end of study, given fully observed data , the decision function for declaring the intervention effective can be written as
That is, we declare the intervention effective if . At step , however, only is observed, which prevents direct evaluation of . We propose to make interim decisions based on the predictive probability of rejecting given ,
Here is the posterior predictive distribution of future observations given . Specifically,
where is the predictive distribution and is the posterior distribution of model parameters given .
Because distributions such as and do not have a closed form, the evaluation of is accomplished through a series of numerical integration.
First, based on interim observations , we generate random samples from posterior distribution through Markov Chain Monte Carlo (MCMC) simulation.
Second, plug the posterior samples obtained from the first step into and generate future observations (denoted by ) from distribution . Let be samples of generated.
Third, we treat as a “full” dataset. Then, is numerically obtained as the average of over . Importantly, the value of is determined by
Here is the marginal posterior distribution of given , obtained from the joint posterior distribution . In practice, for every sample , the evaluation of equation (3) requires a separate numerical integration based on MCMC simulation from .
The detailed algorithm to conduct a Bayesian adaptive SW-CRT based on the monitoring of is described below. After randomization based on , define , which indicates the treatments received by clusters at step . It has been recommended to start the Bayesian adaptive scheme after enough data have been collected to avoid premature decisions due to spurious results.5,29 We assume that adaptation starts from step .
Algorithm 1
At step , obtain interim observation based on and other design parameters. For the iteration,
(a) Generate a sample of model parameters from posterior distribution , denoted by .
(b) Generate a sample of future observation from , denoted by .
(c) Construct a “full” dataset . Generate samples of from . The samples are denoted by . Here, we use accent ∧ to indicate that the samples are generated using simulated future observations .
(d) Numerically evaluate . Note that is the element of .
(e) Obtain .
The predictive probability of declaring the intervention effective at the end of study is numerically evaluated by
Make adaptive decisions:
(a) If stop the trial early and conclude the intervention ineffective;
(b) If stop the trial early and conclude the intervention effective;
(c) Otherwise, set . If , go to #1. If , go to #4.
Stop the trial. Obtain full observation .
(a) Generate samples of from posterior distribution , denoted by .
(b) Numerically evaluate .
(c) If declare the intervention effective; if , declare the intervention ineffective; otherwise, declare the trial inconclusive.
To simplify notations, we have assumed a constant cluster size . In practice, the numbers of patients enrolled from each cluster are likely to vary randomly across steps. To address this pragmatic issue, we define to be the number of enrolled patients from cluster at step , which is a discrete random variable with mean and variance . The total number of subjects is . Extension of the above models and algorithms to random cluster sizes is straightforward.
Results
Simulation studies
We conduct extensive simulations to illustrate the proposed Bayesian adaptive SW-CRT method and assess the relationship between design parameters (such as decision thresholds, number of clusters, and number of steps) and operating characteristics (such as type I error, power, and the probability of early stop). We assume a cross-sectional SW-CRT with time periods (hence ) and a constant cluster size . We specify time-specific intercepts , an evenly transitioning scheme with for , wpICC with , an exchangeable correlation structure with , and . The benchmark intervention effect is set at . We explore the true values of intervention effect from 0 to 0.3. We implement the Bayesian adaptive strategy from step .
To complete the design of a Bayesian adaptive SW-CRT, the number of clusters and decision thresholds need to be specified. We conduct simulation studies to explore a range of specifications and select the configurations that achieve desired operational characteristics. For illustration, we explore and
We assume diffuse and weak priors for model parameters:27 a non-informative prior for ; a Beta(1.5, 10.5) prior for , with a mode of 0.05; and a half-Cauchy(0,1) prior for . Note that is fixed at 1 under the exchangeable correlation structure; hence, no prior is specified. The R package is used for programming. The target proposal acceptance probability is set at 0.95 to reduce divergences.27 In each MCMC iteration, samples of future observations and samples from posterior distributions given “full” dataset are generated. To minimize imbalance among sequences when the number of clusters is not a multiple of the number of sequences S, we employ a two-step randomization procedure. More details are presented in the Supplemental Material.
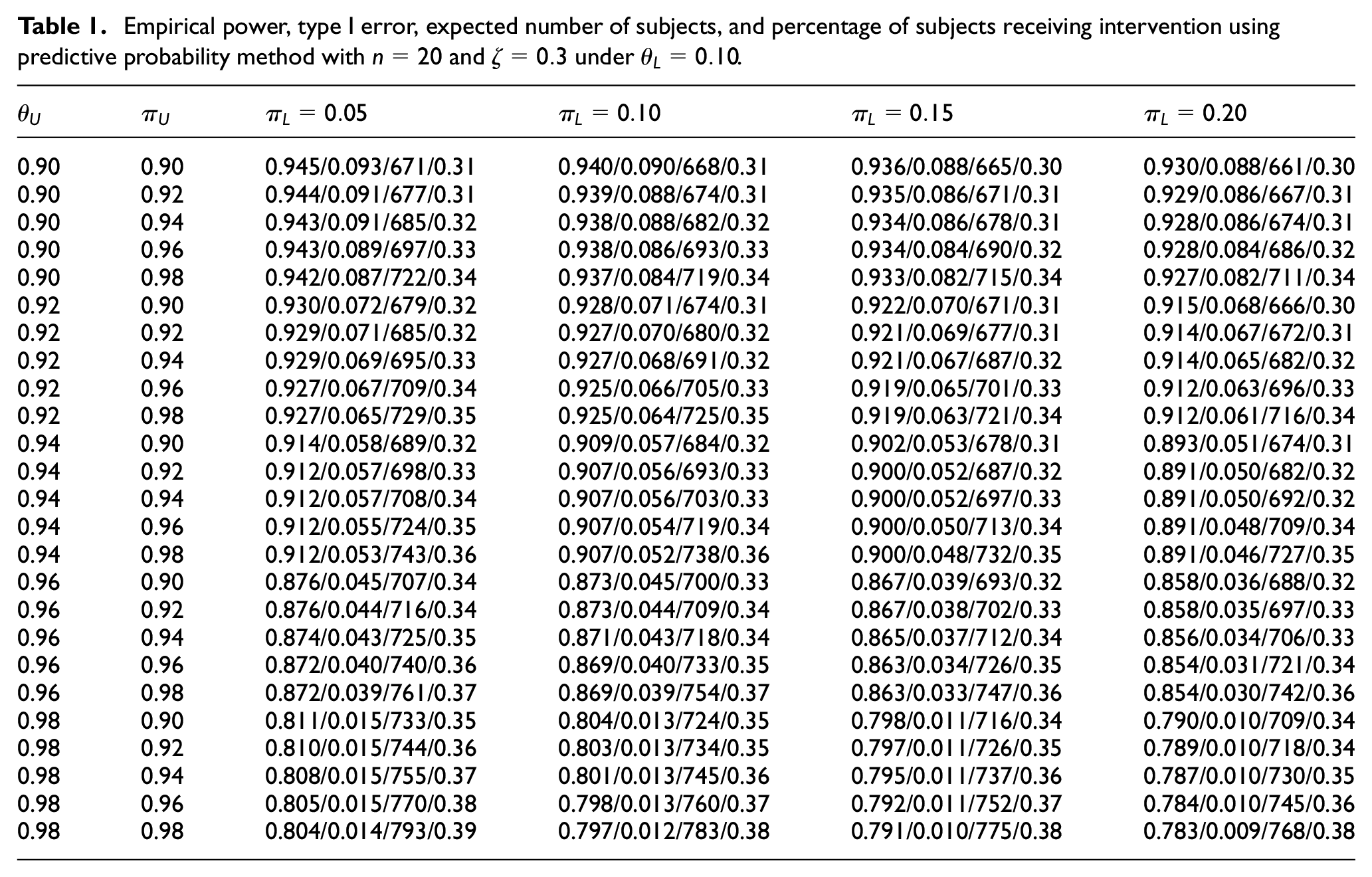
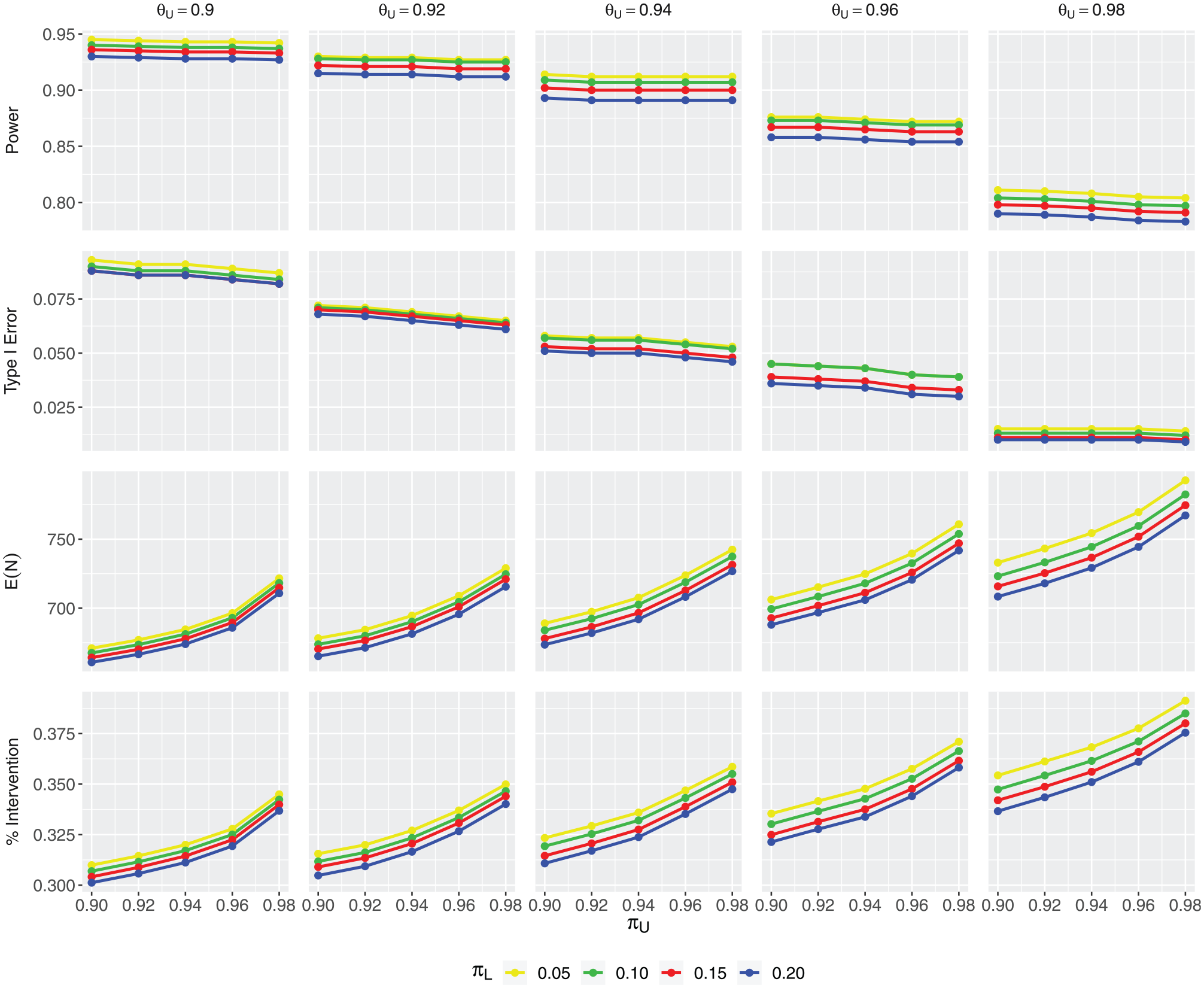
We first assess the impact of various decision thresholds on operating characteristics, including power, type I error, expected sample size (denoted by ), and the percentage of patients receiving intervention (denoted by intervention%). Table 1 presents the simulation results based on Algorithm 1, given , , and . First note that with , , and , the sample size in a complete SW-CRT is 1000. Under the Bayesian adaptive design, due to the possibility of early stopping, ranges from 793 to 661. Also, intervention% = 0.5 in a complete trial. Because all clusters start from control, early stopping would always result in intervention% < 0.5. In Table 1, we observe a range of 0.31–0.39 in intervention%. A larger probability of early stopping is generally associated with a smaller and intervention%. Along each row, with all the other thresholds fixed, as increases, we observe simultaneous decrease in empirical power, type I error, , and intervention%. A larger makes it easier to stop early for futility, which leads to a decreased and intervention%. Furthermore, a greater probability of stopping early for futility tends to reduce the chance of crossing the efficacy threshold, hence decreased power and type I error. However, along the columns, as increases, we observe decreasing power and type I error, but increasing and intervention%. The reason is that a larger makes it harder to stop early for efficacy, hence reduced power and type I error. A smaller probability of early stopping also leads to larger and intervention%. The impact of is in the same direction as , but more pronounced. For example, under , the (power, type I error, , intervention%) are (0.945, 0.093, 671, 0.31). When increases from 0.9 to 0.92, the operating characteristics only change slightly to (0.944, 0.091, 677, 0.31). However, when increases from 0.9 to 0.92, the operating characteristics change more dramatically to (0.93, 0.072, 679, 0.32). The reason is that is involved both in interim decisions (through ) and the decision at the end of study. Finally, the effect of is minimal because it only affects the study when the study doesn’t stop early and continues to the last step. The results under are the same as those presented in Table 1 on rounding to the fourth digit after the decimal point. To better illustrate the impact of decision thresholds on trial properties, we have constructed a series of plots corresponding to Table 1. Figure 1 contains panels. The four rows show empirical power, type I error, , and intervention%, respectively. The five columns correspond to different values of explored. Within each panel, the horizontal axis shows values of and the color of each curve indicates the value of . Due to page limit, the plots for and are presented in the Supplemental Material.
Empirical power, type I error, expected number of subjects, and percentage of subjects receiving intervention using predictive probability method with and under .
0.90
0.90
0.945/0.093/671/0.31
0.940/0.090/668/0.31
0.936/0.088/665/0.30
0.930/0.088/661/0.30
0.90
0.92
0.944/0.091/677/0.31
0.939/0.088/674/0.31
0.935/0.086/671/0.31
0.929/0.086/667/0.31
0.90
0.94
0.943/0.091/685/0.32
0.938/0.088/682/0.32
0.934/0.086/678/0.31
0.928/0.086/674/0.31
0.90
0.96
0.943/0.089/697/0.33
0.938/0.086/693/0.33
0.934/0.084/690/0.32
0.928/0.084/686/0.32
0.90
0.98
0.942/0.087/722/0.34
0.937/0.084/719/0.34
0.933/0.082/715/0.34
0.927/0.082/711/0.34
0.92
0.90
0.930/0.072/679/0.32
0.928/0.071/674/0.31
0.922/0.070/671/0.31
0.915/0.068/666/0.30
0.92
0.92
0.929/0.071/685/0.32
0.927/0.070/680/0.32
0.921/0.069/677/0.31
0.914/0.067/672/0.31
0.92
0.94
0.929/0.069/695/0.33
0.927/0.068/691/0.32
0.921/0.067/687/0.32
0.914/0.065/682/0.32
0.92
0.96
0.927/0.067/709/0.34
0.925/0.066/705/0.33
0.919/0.065/701/0.33
0.912/0.063/696/0.33
0.92
0.98
0.927/0.065/729/0.35
0.925/0.064/725/0.35
0.919/0.063/721/0.34
0.912/0.061/716/0.34
0.94
0.90
0.914/0.058/689/0.32
0.909/0.057/684/0.32
0.902/0.053/678/0.31
0.893/0.051/674/0.31
0.94
0.92
0.912/0.057/698/0.33
0.907/0.056/693/0.33
0.900/0.052/687/0.32
0.891/0.050/682/0.32
0.94
0.94
0.912/0.057/708/0.34
0.907/0.056/703/0.33
0.900/0.052/697/0.33
0.891/0.050/692/0.32
0.94
0.96
0.912/0.055/724/0.35
0.907/0.054/719/0.34
0.900/0.050/713/0.34
0.891/0.048/709/0.34
0.94
0.98
0.912/0.053/743/0.36
0.907/0.052/738/0.36
0.900/0.048/732/0.35
0.891/0.046/727/0.35
0.96
0.90
0.876/0.045/707/0.34
0.873/0.045/700/0.33
0.867/0.039/693/0.32
0.858/0.036/688/0.32
0.96
0.92
0.876/0.044/716/0.34
0.873/0.044/709/0.34
0.867/0.038/702/0.33
0.858/0.035/697/0.33
0.96
0.94
0.874/0.043/725/0.35
0.871/0.043/718/0.34
0.865/0.037/712/0.34
0.856/0.034/706/0.33
0.96
0.96
0.872/0.040/740/0.36
0.869/0.040/733/0.35
0.863/0.034/726/0.35
0.854/0.031/721/0.34
0.96
0.98
0.872/0.039/761/0.37
0.869/0.039/754/0.37
0.863/0.033/747/0.36
0.854/0.030/742/0.36
0.98
0.90
0.811/0.015/733/0.35
0.804/0.013/724/0.35
0.798/0.011/716/0.34
0.790/0.010/709/0.34
0.98
0.92
0.810/0.015/744/0.36
0.803/0.013/734/0.35
0.797/0.011/726/0.35
0.789/0.010/718/0.34
0.98
0.94
0.808/0.015/755/0.37
0.801/0.013/745/0.36
0.795/0.011/737/0.36
0.787/0.010/730/0.35
0.98
0.96
0.805/0.015/770/0.38
0.798/0.013/760/0.37
0.792/0.011/752/0.37
0.784/0.010/745/0.36
0.98
0.98
0.804/0.014/793/0.39
0.797/0.012/783/0.38
0.791/0.010/775/0.38
0.783/0.009/768/0.38
The plot of operating characteristics under and . The four rows show empirical power, type I error, , and intervention%, respectively. The five columns correspond to different values of . Within each panel, the horizontal axis shows values of and the color of each curve corresponds to a different value of .
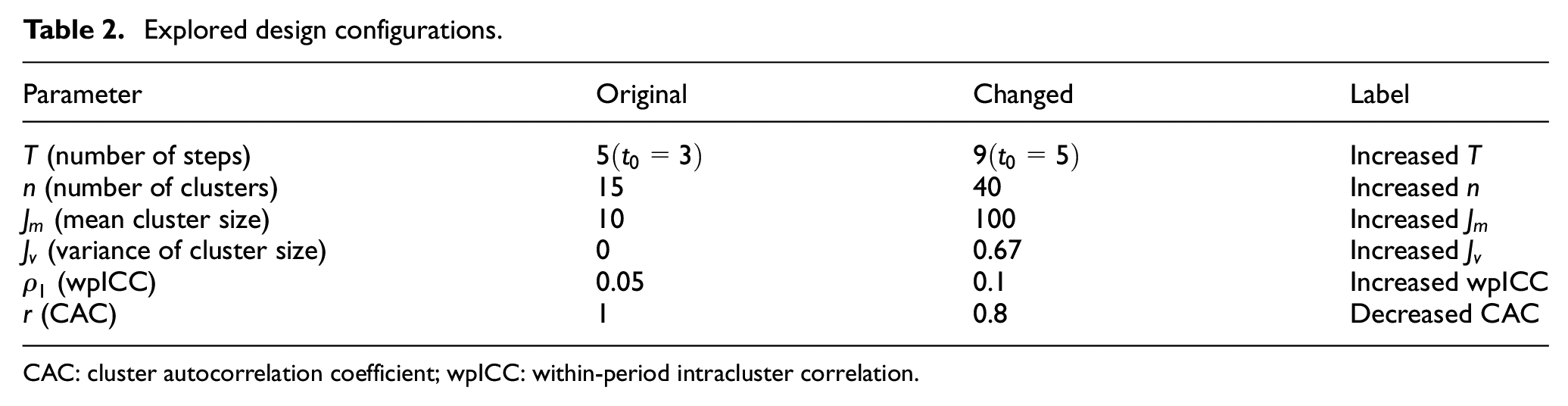
To evaluate the impact of various design factors, we start from an “Original” configuration, and one-by-one change each of the design parameters to assess its marginal effect on trial properties. In Table 2, the second column contains the parameter values under “Original.” Note that indicates a constant cluster size, and indicates an exchangeable correlation structure. The third column contains the changed value of each parameter, with the corresponding label listed in the last column. For example, under “Increased n,” the number of clusters is changed from 15 to 40, while all other parameters remain unchanged. For “Increased ,” we assume that cluster sizes follow a discrete uniform distribution between 8 and 12, denoted by DU[8,12]. It centers around mean with variance . Hence, comparing “Increased ” versus “Original” allows us to assess the impact of random variability in cluster size. For “Decreased CAC,” changes from 1 to 0.8, which leads to a block exchangeable correlation structure, with a bpICC . Under the block exchangeable correlation structure, is a model parameter with a Beta(5,2) prior, which has a mode of 0.8.
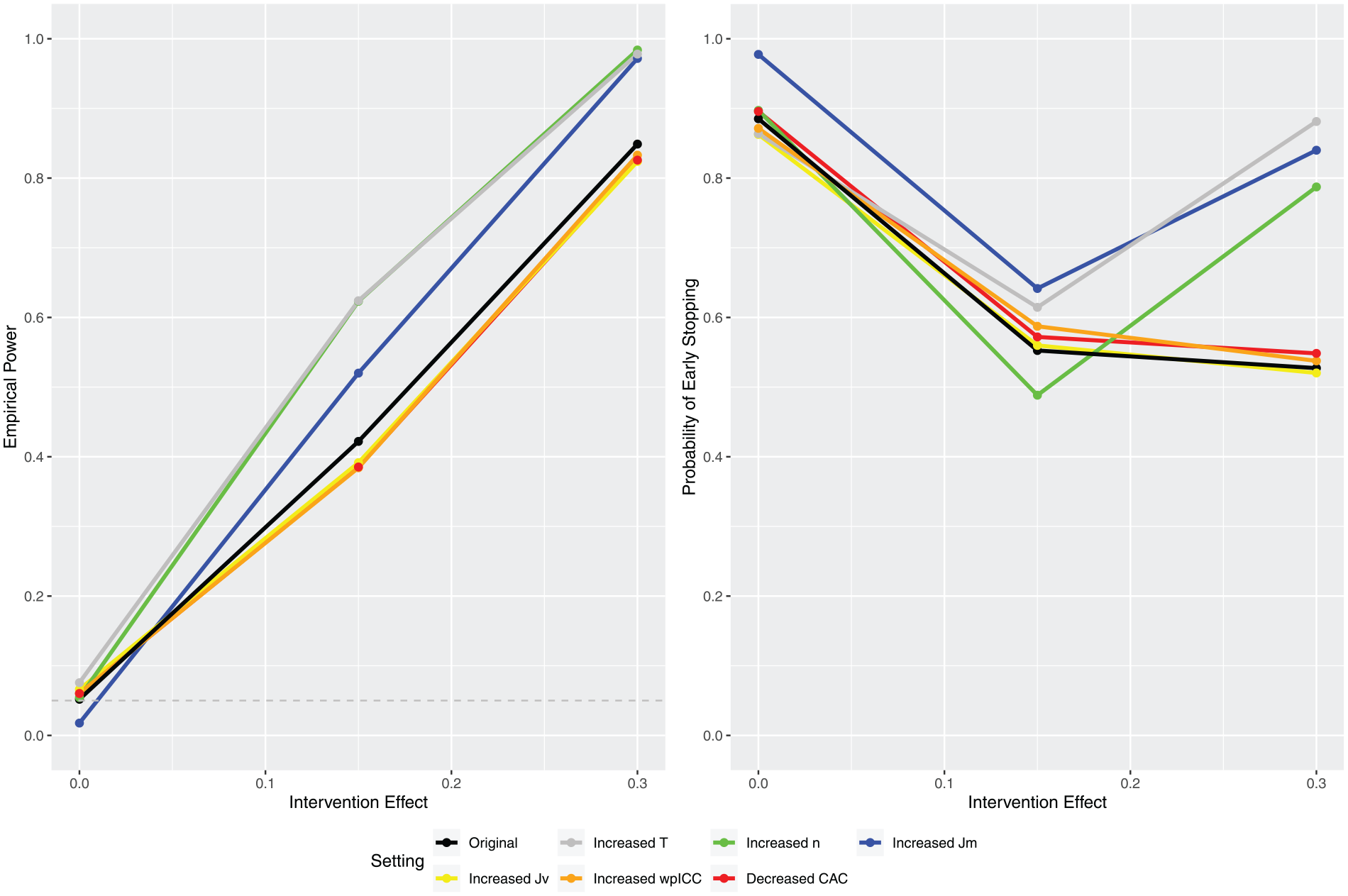
In Figure 2, the left panel presents the empirical powers under different configurations where the true values of intervention effect are set at , and 0.3. The right panel shows the corresponding probabilities of early stopping. The power at is the type I error. The threshold values are selected under “Original” to achieve power and type I error around 0.85 and 0.05, respectively, at . To examine the change in operational characteristics without confounding by thresholds, the same threshold values are used across all configurations. As a result, the type I errors obtained under configurations other than “Original” do not necessarily fall at 0.05. If the results show much greater increase in power than in type I error, however, we can generally conclude a net gain in power. We observe significant increase in power under an increased number of steps , an increased number of clusters , and an increased cluster size . However, the additional variability in cluster size (increased ) leads to reduced power. Finally, increasing the correlation under an exchangeable correlation structure (“increased wpICC”) and changing the correlation structure from exchangeable to block exchangeable both lead to decreased power. These observations are consistent with the findings by Matthews and Forbes30 and Hooper et al.,26 who reported that the relationship between wpICC or CAC and the variance of estimated treatment effect generally follows a ∩ shape, increasing from 0 and decreasing approaching 1. When wpICC increases from 0.05 to 0.1, it follows the initial ascending trend, which leads to an increased variance of estimated treatment effect and a decreased power. However, when CAC decreases from 1 to 0.8, it traces back the descending trend around 1, which also leads to an increased variance and a decreased power.
The marginal impact of various design parameters.
In the right panel of Figure 2, the impact of design parameters on the probability of early stopping is less straightforward. Our experience has been that the thresholds’ impact on power (especially when considering net gain described above) is relatively smaller compared with their impact on the probability of early stopping because the interim thresholds and directly affect early stopping decisions. Hence, we caution against over-interpreting the right panel because the thresholds are selected to achieve certain characteristics under “Original,” which have no bearing on the other configurations. Nonetheless, we have a few useful observations. First note that the probability of early stopping usually follows a . To explain, define and to be the probability of early stopping due to futility and efficacy, respectively. When the true intervention effect is small, the probability of early stopping is large due to large ; as the intervention effect increases, decreases faster than increases, and the overall probability of early stopping continues to decrease; when the intervention effect is sufficiently large, begins to increase faster than decreases, and the overall probability of early stopping passes the bottom of the and begins to increase continuously. We observe that under larger cluster sizes (“Increased ”), more steps (“Increased ”), and more clusters (“Increased ”), the overall probabilities of early stopping all follow the typic because these configurations significantly increase power, resulting in the extreme intervention effect being well above the bottom of the . However, we observe that under “Original,” the probability of early stopping remains on the left-hand side of the due to its relatively smaller power. Finally, we observe that variability in cluster size (“Increases ”), stronger correlation (“Increased wpICC”), and changing to a block exchangeable correlation structure (“Decreased CAC”), have relatively smaller effect on the probability of early stopping.
Finally, we investigate the impact of informative priors. We conduct simulation using the same design configuration as that of the “Original” in Figure 2, except that the prior of treatment effect is changed to and . Recall that a non-informative prior is assumed for under the “Original.” Given true intervention effect , the prior centers around the true effect with variance 1, while represents a mis-specified prior. The (power, type I error) under the “Original,”, and are (0.849, 0.052), (0.851, 0.063), and (0.862, 0.07), respectively. We observe a trend of slight increase both in power and type I error. This is to be expected because compared with the non-informative prior, both and shift the posterior distribution of toward the direction of true intervention effect, increasing the probability of rejecting the null hypothesis, hence increased power and type I error. Overall, the gain in power using an informative prior is pretty much canceled by increased type I error. In Bayesian Phase I or Phase II trials because the sample sizes are usually small, informative priors can have greater impact on trial properties. For Phase III or SW trials, where the sample sizes are usually large, the impact of informative priors is less obvious.
An application example
We illustrate the proposed Bayesian adaptive method using a pragmatic cross-sectional SW-CRT, which evaluates the effect of a combined intervention on preventing malnutrition and reducing weight loss in hospitalized patients with acute tertiary care.31 The evidence-based intervention consists of three linked activities: the introduction and use of the Malnutrition Universal Screening Tool (MUST), the provision of food supplements to patients at risk of malnutrition, and a system that uses red feeding trays to flag patients requiring full feeding assistance. Two trained local facilitators (a nurse and dietitian for each group) will introduce the intervention. The control arm receives the standard care. There are steps and the randomization unit is ward, each with patients. The wards are randomized to sequences. The primary outcome is the rate of change in patient’s body mass index. We assume an exchangeable correlation structure with . The assumed target intervention effect is . The adaptation starts from step . A recent implementation project on nutrition screening and documentation found substantial improvement in hospital wards and identified widespread interest in further improvement to nutritional status and care of vulnerable patients.32,33 A number of internal, unpublished audits have identified that up to half of patients are at risk of nutritional decline in systems that do not prioritize patient nutrition. Hence, implementing the Bayesian group sequential strategy makes it possible for the SW-CRT to stop early, hastening the adoption of effective interventions in the patient population with high prevalence of risk. The goal is to determine the design configuration, including n (the number of wards) and decision thresholds , that achieves desired trial properties.
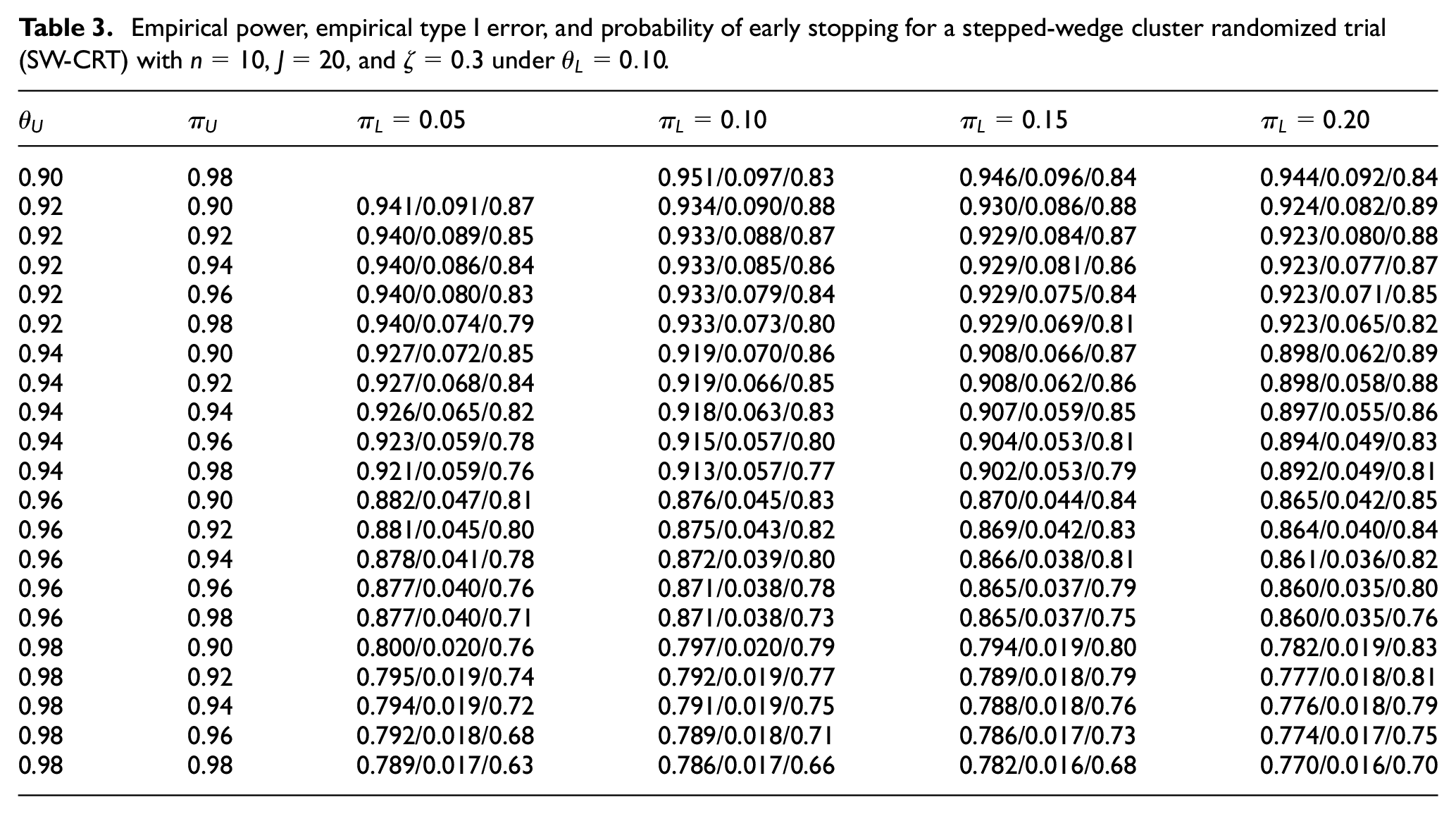
For each n, a range of thresholds values: for and ; and for are explored. Because simulation studies suggest that has minimal effect on trial properties, we fix it at . For illustration purpose, Table 3 presents results under wards, where each cell shows empirical power, type I error, and the probability of early stopping given a combination of threshold values. Cells with empirical type I errors greater than 0.1 are considered unacceptable and omitted. The table is divided into four areas. From top to bottom:
Empirical power, empirical type I error, and probability of early stopping for a stepped-wedge cluster randomized trial (SW-CRT) with , , and under .
0.90
0.98
0.951/0.097/0.83
0.946/0.096/0.84
0.944/0.092/0.84
0.92
0.90
0.941/0.091/0.87
0.934/0.090/0.88
0.930/0.086/0.88
0.924/0.082/0.89
0.92
0.92
0.940/0.089/0.85
0.933/0.088/0.87
0.929/0.084/0.87
0.923/0.080/0.88
0.92
0.94
0.940/0.086/0.84
0.933/0.085/0.86
0.929/0.081/0.86
0.923/0.077/0.87
0.92
0.96
0.940/0.080/0.83
0.933/0.079/0.84
0.929/0.075/0.84
0.923/0.071/0.85
0.92
0.98
0.940/0.074/0.79
0.933/0.073/0.80
0.929/0.069/0.81
0.923/0.065/0.82
0.94
0.90
0.927/0.072/0.85
0.919/0.070/0.86
0.908/0.066/0.87
0.898/0.062/0.89
0.94
0.92
0.927/0.068/0.84
0.919/0.066/0.85
0.908/0.062/0.86
0.898/0.058/0.88
0.94
0.94
0.926/0.065/0.82
0.918/0.063/0.83
0.907/0.059/0.85
0.897/0.055/0.86
0.94
0.96
0.923/0.059/0.78
0.915/0.057/0.80
0.904/0.053/0.81
0.894/0.049/0.83
0.94
0.98
0.921/0.059/0.76
0.913/0.057/0.77
0.902/0.053/0.79
0.892/0.049/0.81
0.96
0.90
0.882/0.047/0.81
0.876/0.045/0.83
0.870/0.044/0.84
0.865/0.042/0.85
0.96
0.92
0.881/0.045/0.80
0.875/0.043/0.82
0.869/0.042/0.83
0.864/0.040/0.84
0.96
0.94
0.878/0.041/0.78
0.872/0.039/0.80
0.866/0.038/0.81
0.861/0.036/0.82
0.96
0.96
0.877/0.040/0.76
0.871/0.038/0.78
0.865/0.037/0.79
0.860/0.035/0.80
0.96
0.98
0.877/0.040/0.71
0.871/0.038/0.73
0.865/0.037/0.75
0.860/0.035/0.76
0.98
0.90
0.800/0.020/0.76
0.797/0.020/0.79
0.794/0.019/0.80
0.782/0.019/0.83
0.98
0.92
0.795/0.019/0.74
0.792/0.019/0.77
0.789/0.018/0.79
0.777/0.018/0.81
0.98
0.94
0.794/0.019/0.72
0.791/0.019/0.75
0.788/0.018/0.76
0.776/0.018/0.79
0.98
0.96
0.792/0.018/0.68
0.789/0.018/0.71
0.786/0.017/0.73
0.774/0.017/0.75
0.98
0.98
0.789/0.017/0.63
0.786/0.017/0.66
0.782/0.016/0.68
0.770/0.016/0.70
Area 1: Empirical power and 0.05 ≤ Empirical type I error < 0.10;
Area 2: Empirical power < 0.90 and 0.05 ≤ Empirical type I error < 0.10;
Area 3: Empirical power < 0.90 and Empirical type I error < 0.05;
Area 4: Empirical power < 0.80 and Empirical type I error < 0.05.
If researchers would like to achieve power and type I error , then we can search within Area 1, and thresholds might be chosen, based on the consideration that it maximizes the probability of early stopping (0.89). However, if the goal is to achieve power and type I error , then might be selected to achieve the maximum power (0.894). We cannot find thresholds that achieve power and type I error . It means that adjustment of threshold values is insufficient, and a larger number of clusters is needed to achieve the higher level of power.
Conclusion
In this study we proposed to incorporate Bayesian adaptive strategies into SW-CRTs, where adaptive decisions are made based on the predictive probability of declaring the intervention effective at the end of study given interim observations. The proposed method offers flexibility to stop the trial early if overwhelming evidence of effectiveness or futility is observed at interim. Compared with frequentist design methods for SW-CRTs, the proposed Bayesian method requires additional specification of decision thresholds . Design parameters are determined through numerical studies to achieve desired operating characteristics. We conducted extensive simulation studies to examine the performance of the Bayesian SW-CRTs over different design configurations. We presented the Bayesian adaptive method based on a cross-sectional SW-CRT. By modifying the likelihood function, this method can also be applied to closed-cohort SW-CRTs where the same cohort of subjects is followed through the whole study period.
Incorporating Bayesian adaptive strategies into SW-CRTs can offer notable gains in terms of saving time and resources, and in improved ethics. However, several practical considerations are needed. Bayesian adaptive strategies generally require additional resources to conduct extensive simulation studies in trial design, and timely data collection, processing, and analysis to support adaptive decisions at interim. Although the crossover scheme of SW-CRTs lends themselves well to the Bayesian adaptive strategies, it has a strict requirement on time frame. The intervention is assumed to show measurable effect within the duration of a step. The proposed adaptive design is feasible when there is enough time between steps to allow measuring outcomes and conducting interim analysis.34–36 In this study, we assume a constant intervention effect, which effectively assumes no apparent learning-curve effect in the implementation of intervention.
A potential extension is to introduce a mechanism that adaptively adjusts assignment probabilities based on interim results. For example, if interim analysis suggests that the intervention is promising, this mechanism allows researchers to probabilistically hasten the transition of remaining clusters (under control) to intervention. Such an adaptive strategy has been shown to increase the number of patients receiving a more effective intervention and improve patient outcomes.37 Grayling et al.38 proposed a frequentist response adaptive approach that permits modification of the intervention allocation during an SW-CRT. Incorporating a Bayesian response adaptive strategy into SW-CRTs to adjust assignment probabilities will be the topic of our future research.
Supplemental Material
sj-7z-2-ctj-10.1177_17407745231221438 – Supplemental material for A Bayesian adaptive design approach for stepped-wedge cluster randomized trials
Supplemental material, sj-7z-2-ctj-10.1177_17407745231221438 for A Bayesian adaptive design approach for stepped-wedge cluster randomized trials by Jijia Wang, Jing Cao, Chul Ahn and Song Zhang in Clinical Trials
Supplemental Material
sj-pdf-1-ctj-10.1177_17407745231221438 – Supplemental material for A Bayesian adaptive design approach for stepped-wedge cluster randomized trials
Supplemental material, sj-pdf-1-ctj-10.1177_17407745231221438 for A Bayesian adaptive design approach for stepped-wedge cluster randomized trials by Jijia Wang, Jing Cao, Chul Ahn and Song Zhang in Clinical Trials
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: PCORI (Patient-Centered Outcomes Research Institute) ME-1609-36761, NIH (National Institutes of Health) 1UL1TR003163-01A1, and NCI (National Cancer Institute) 2P30CA142543-11.
ORCID iD
Song Zhang
Supplemental material
Supplemental material for this article is available online.
References
1.
JennisonCTurnbullBW. Meta-analyses and adaptive group sequential designs in the clinical development process. J Biopharm Stat2005; 15(4): 537–558.
2.
ChowSCChangMPongA. Statistical consideration of adaptive methods in clinical development. J Biopharm Stat2005; 15(4): 575–591.
3.
GraylingMJWasonJMManderAP. Group sequential designs for stepped-wedge cluster randomised trials. Clin Trials2017; 14(5): 507–517.
4.
ZhouXLiuSKimES, et al. Bayesian adaptive design for targeted therapy development in lung cancer: a step toward personalized medicine. Clin Trials2008; 5(3): 181–193.
ShiHYinG. Control of type I error rates in Bayesian sequential designs. Bayesian Anal2019; 14(2): 399–425.
14.
KelterR. Analysis of type I and II error rates of Bayesian and frequentist parametric and nonparametric two-sample hypothesis tests under preliminary assessment of normality. Computation Stat2021; 36(2): 1263–1288.
15.
GolchiS. Estimating design operating characteristics in Bayesian adaptive clinical trials. Can J Stat2022; 50(2): 417–436.
16.
Van HollandBJDe BoerMRBrouwerS, et al. Sustained employability of workers in a production environment: design of a stepped wedge trial to evaluate effectiveness and cost-benefit of the POSE program. BMC Public Health2012; 12(1): 1003.
17.
MhurchuCNGortonDTurleyM, et al. Effects of a free school breakfast programme on children’s attendance, academic achievement and short-term hunger: results from a stepped-wedge, cluster randomised controlled trial. J Epidemiol Community Health2013; 67: 257–264.
18.
LenguerrandEWinterCSiassakosD, et al. Effect of hands-on interprofessional simulation training for local emergencies in Scotland: the THISTLE stepped-wedge design randomised controlled trial. BMJ Qual Saf2020; 29(2): 122–134.
19.
BrownCALilfordRJ. The stepped wedge trial design: a systematic review. BMC Med Res Methodol2006; 6(1): 54.
20.
HusseyMAHughesJP. Design and analysis of stepped wedge cluster randomized trials. Contemp Clin Trials2007; 28(2): 182–191.
21.
BrownCHWymanPAGuoJ, et al. Dynamic wait-listed designs for randomized trials: new designs for prevention of youth suicide. Clin Trials2006; 3(3): 259–271.
22.
ReutherSHolleDBuscherI, et al. Effect evaluation of two types of dementia-specific case conferences in German nursing homes (FallDem) using a stepped-wedge design: study protocol for a randomized controlled trial. Trials2014; 15(1): 319.
23.
CamachoAEggoRMFunkS, et al. Estimating the probability of demonstrating vaccine efficacy in the declining Ebola epidemic: a Bayesian modelling approach. BMJ Open2015; 5(12): e009346.
24.
CunananKMCarlinBPPetersonKA. A practical Bayesian stepped wedge design for community-based cluster-randomized clinical trials: The British Columbia Telehealth Trial. Clin Trials2016; 13(6): 641–650.
25.
ZhanDOuyangYXuL, et al. Improving efficiency in the stepped-wedge trial design via Bayesian modeling with an informative prior for the time effects. Clin Trials2021; 18: 295–302.
26.
HooperRTeerenstraSDe HoopE, et al. Sample size calculation for stepped wedge and other longitudinal cluster randomised trials. Stat Med2016; 35(26): 4718–4728.
27.
GranthamKLKaszaJHeritierS, et al. Evaluating the performance of Bayesian and restricted maximum likelihood estimation for stepped wedge cluster randomized trials with a small number of clusters. BMC Med Res Methodol2022; 22(1): 112.
28.
GelmanA. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal2006; 1(3): 515–534.
29.
BerrySMCarlinBPLeeJJ, et al. Bayesian adaptive methods for clinical trials. Boca Raton, FL: CRC Press, 2010.
30.
MatthewsJForbesAB. Stepped wedge designs: insights from a design of experiments perspective. Stat Med2017; 36(24): 3772–3790.
31.
KitsonALSchultzTJLongL, et al. The prevention and reduction of weight loss in an acute tertiary care setting: protocol for a pragmatic stepped wedge randomised cluster trial (the PRoWL project). BMC Health Serv Res2013; 13(1): 299.
32.
KitsonASilverstonHWiechulaR, et al. Clinical nursing leaders’, team members’ and service managers’ experiences of implementing evidence at a local level. J Nurs Manag2011; 19(4): 542–555.
33.
WiechulaRKitsonAMarcoionniD, et al. Improving the fundamentals of care for older people in the acute hospital setting: facilitating practice improvement using a Knowledge Translation Toolkit. Int J Evid Based Healthc2009; 7(4): 283–295.
34.
CampbellG. Similarities and differences of Bayesian designs and adaptive designs for medical devices: a regulatory view. Stat Biopharm Res2013; 5(4): 356–368.
GraylingMJWasonJManderAP. Stepped wedge cluster randomized controlled trial designs: a review of reporting quality and design features. Trials2017; 18(1): 33.
37.
WarnerPWeirCHansenC, et al. Low-dose dexamethasone as a treatment for women with heavy menstrual bleeding: protocol for response-adaptive randomised placebo-controlled dose-finding parallel group trial (DexFEM). BMJ Open2015; 5(1): e006837.
38.
GraylingMJWasonJMVillarSS. Response adaptive intervention allocation in stepped-wedge cluster randomized trials. Stat Med2022; 41(6): 1081–1099.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.