
Abstract
As interest in image-based rendering increases, the need for multiview inpainting is emerging. Despite of rapid progresses in single-image inpainting based on deep learning approaches, they have no constraint in obtaining color consistency over multiple inpainted images. We target object removal in large-scale indoor spaces and propose a novel pipeline of multiview inpainting to achieve color consistency and boundary consistency in multiple images. The first step of the pipeline is to create color prior information on masks by coloring point clouds from multiple images and projecting the colored point clouds onto the image planes. Next, a generative inpainting network accepts a masked image, a color prior image, imperfect guideline, and two different masks as inputs and yields the refined guideline and inpainted image as outputs. The color prior and guideline input ensure color and boundary consistencies across multiple images. We validate our pipeline on real indoor data sets quantitatively using consistency distance and similarity distance, metrics we defined for comparing results of multiview inpainting and qualitatively.
Keywords
Introduction
The rendering of real indoor spaces is typically achieved via an image-based rendering (IBR) method 1 –3 that allows a free-viewpoint exploration in a virtual world. Recent IBR applications 1 have reduced geometric complexity for the real-time rendering of large-scale indoor spaces. The key idea of the method 1 is to render only the architectural components without objects, which requires a consistent object removal over multiple images, as suggested in the literature. 3,4
Multiview inpainting is a task to achieve image inpainting on multiple images while satisfying two conditions: color consistency and boundary consistency. For example, in Figure 1, images of C2 and C3 require image inpainting as ideal case. However, typical image inpainting methods might result in color or boundary inconsistency (cf. Figure 1(b)).
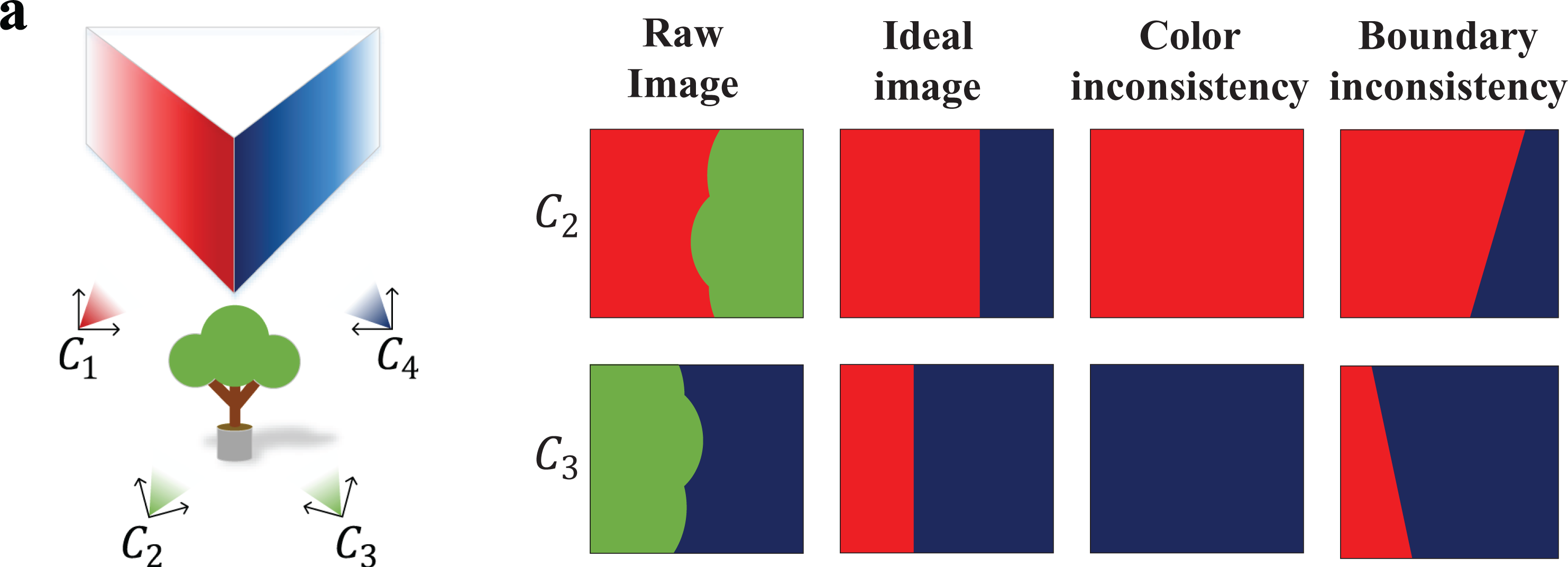
Example of multiview inpainting: (a) Architectural component visible directly in images C1 and C4 but occluded by an object in images C2 and C3; (b) image inpainting is required in C2 and C3 as ideal image, avoiding color or boundary inconsistencies.
Philip and Drettakis 3 proposed a method for multiview inpainting. Their proposed method begins with estimating the plane, projecting visible quadrangle parts of images into a common rectified plane, and then filling in the occluded parts using a conventional patch-based method. 5 Although this method can ensure the color consistency up to the performance level achieved in traditional inpainting algorithm named PatchMatch, 5 the boundary consistency is not secured as the planar assumption is not applicable in nonplanar or complex environments.
Recent advances in image inpainting are based on deep learning approaches, 6 –8 which have shown their efficiency and effectiveness on applying any form of mask. Recent studies 7,8 further enhance the performance by utilizing guidelines. Although the guidelines themselves ensure the boundary consistency in case the user sets consistent guidelines over the multiple images, the color consistency over multiple images cannot be secured as such approaches consider only a single image.
In this study, we target object removal in the images covering large-scale indoor spaces. We propose a novel pipeline that fills in occluded regions of multiple images in such a way that both the color and the boundary consistencies are well preserved. The proposed pipeline extends the state-of-the-art GConv 8 applied to a single-image inpainting problem.
First, for the color consistency, we create a color prior image, which is a pixel-wise color information observed from visible cameras (e.g. C1 and C4 in Figure 1(a)). This color prior is added along with other inputs of the inpainting network such as a masked image, a guideline input, and a mask similar to that of GConv, 8 allowing the inpainted colors to be consistent in multiple inpainted images.
Second, for the boundary consistency, we extend GConv 8 in such a way that imperfect guideline input can be refined within the network. Ideally, there should be no boundary inconsistency when the guidelines are perfectly set by users. However, because it is a laborious task to set the guidelines over multiple images, typical guidelines include various errors such as in the angle or location or missing information.
For an experiment validation, we utilized real indoor data sets 1,9 enabling a real-time rendering of large-scale indoor spaces. For the color consistency, we developed new measures to evaluate intensity-free color consistency among multiple inpainted images, as well as the similarity between multiple inpainted images and images without occlusions. Given the metrics, the proposed method yields improvements of up to 46.4% and 30.6% over the previous single-image inpainting method EC 7 and GConv, 8 respectively. Regarding the boundary consistency, we conducted a qualitative comparison to determine whether the proposed pipeline predicts the enhanced guidelines.
This article is organized as follows: the second section briefly summarizes related works. The third section describes the proposed pipeline. The fourth section details the experiment results of multiview inpainting on real data sets. Finally, some concluding remarks are given in the fifth section. Our codes are available at https://github.com/kimjh069/generative-MVI. 10
Related work
Indoor modeling and IBR
Typical IBR methods require 3D map or model of the environment. Henry et al. 11 use depth cameras integrating depth and color information for robust 3D mapping of indoor environments. The map, however, remains in point cloud rather than mesh, which makes hard for rendering novel viewpoints. Shao et al. 12 introduce interactive approach for semantic modeling of indoor spaces. The approach retrieves 3D models from predefined database, which has limitations on reconstructing the real scene. More recent works focus on the architectural components for better representation of indoor spaces. Ikehata et al. 13 devise structural grammar that divides the elements of indoor environments such as rooms, walls, and objects. The approach builds the indoor model with Manhattan assumption in a single-story buildings. Recent works overcome Manhattan assumption for indoor modeling or integrate the 3D model with IBR. 9,14
Hedman et al. 2 proposed a real-time IBR method. However, this method has limitations in rendering larger than room-scale spaces. Turner et al. 15 reconstruct an architectural mesh but do not remove objects in the images, which results in flattened object textures on the architectural mesh. In addition, recent studies 1,9 have focused on architectural component modeling and objects removal in images. However, the object removal in an image might cause a discordance of colors between multiple images.
Recently, there are attempts to use learning-based methods for IBR. Hedman et al. 16 use deep learning approach for blending novel views for IBR. It showed feasibility of using deep learning-based blending but needs further research to reduce blurriness and flicker. Thies et al. 17 use a novel deep learning-based method for image synthesis and real-time rendering. However, the method needs training for every new object requiring more research for the generalization.
Multiview inpainting
To achieve color consistency through multiview inpainting, other studies 3,4 warp multiple images onto a common rectified target image plane and optimize the objective function or process traditional patch-based algorithms. Li et al. 18 apply RGB-D sensor, a device that augments the image with depth information, and employ exemplar-based image inpainting with sequential data. However, RGB-D sensors are inappropriate for large-scale indoor scanning or rendering owing to a short range of depth and an extremely large number of required images. Other approaches such as video inpainting 19 for recovering consistent color using dense sequential data, however, are not applicable on sparse data or wide-baseline data used for IBR. 1,9,3
Single-image inpainting
Traditional inpainting algorithms 5,20 use patch based or diffusion-based approaches with low-level features. Recent studies have focused on rapidly advanced deep learning-based approaches, such as a convolutional neural networks and generative adversarial networks (GANs), 21 which are capable of using high-level features.
Yu et al. 6 employed a GAN and proposed a coarse-to-fine network as well as a contextual attention module (CAM). CAM attends to known patches of features directly, and explicitly borrows patches to fill in unknown regions of features. It has inspired numerous recent studies 8,22 making use of CAM for image inpainting. Yu et al. 8 proposed a gated convolution that enables a sketch channel input to propagate through a network along with semantic information.
An increasing number of recent studies 7,23,8 have applied edge information (i.e. guideline) as an additional input for the purpose of enhancing the quality or achieving editable results. However, no studies have focused on combining the inputs of color and imperfect guidelines and a guideline refinement at the same time.
Method
In this section, we introduce the initial data and a multiview inpainting pipeline, which is shown in Figure 2, including a method for creating the color prior images and an image inpainting network. The color prior image is used as the additional input for the image inpainting network.

Overview of our multiview inpainting pipeline. “Initial data” section describes the initial input data of the pipeline that was acquired by a mobile sensor robot system. The method of generating color prior images is described in “Color prior generation” section. Using the color prior images, “Image inpainting” section describes image inpainting that aims for the color consistency in multiview.
Initial data
Initial data consist of architectural mesh, images, and camera poses of each image of large-scale indoor spaces that were introduced in recent works. 1,9 The data sets were acquired by scanning the indoor spaces employing a mobile robot system (cf. Figure 2). Global guidelines are obtained by automatic algorithm, 9 which are overlaid with user guidelines. Masks were made manually for the purpose of thorough multiview inpainting.
Color prior generation
A color prior image is a synthetic image created by projecting a colored point cloud data (PCD) onto the image plane. We introduce a method for coloring the PCD with only architectural component colors and projecting the colored PCD onto the images.
The PCD is initially sampled from the object-free architectural mesh. From the sampled PCD, we adopt the hidden point removal (HPR) algorithm,
24
which is a simple and fast algorithm that approximates the visibility of the PCD for a given camera pose by flipping the point clouds and computing a convex hull onto it. To be more specific, for each given camera position,

where
The next step is coloring the PCD with architectural colors and creating color prior images. For each point, we make candidates of the proper color by projecting the point onto each image plane where the point is visible. We can refer to a row of the relation matrix,

Creating the color prior image: (a) The color for a given point is computed from a set of images that are not occluded by objects; (b) a colored point with the coverage space is projected onto the image plane to create the color prior image.
The colored point can be projected onto each visible image plane to produce a color prior image, where we assume a 360-camera model as a cubemap format

where
The color prior image, however, depends on the sampling rate and the distance to a point from the camera pose. To be more precise, the sparse PCD originates from minimum sampling distance of r from a mesh. In addition, the points closer to an image plane appear even sparser in the image than those in farther (cf. Figure 4(a)).

Example of created color prior: (a) The colored point closer to the camera appears sparser than that farther away; (b) we resolve the sparsity issue by defining the coverage area; (c) the original image from the given viewpoint.
To resolve the dependencies, we define point coverage area,

where

Combining these matrices, the coverage area

The coverage area,

where
Image inpainting
Typical image inpainting networks 8,7 take a masked image and a guideline image as inputs and output an inpainting result. By contrast, to preserve color consistency over multiple images, we train a network that is capable of receiving the color prior information as an additional input. In addition, the network is able to perform two different tasks concurrently such as the image inpainting and guideline refinement. In the following sections, we introduce the input data we generated to train the network, architecture, and loss functions to achieve our goal: the color consistent inpainting and guideline refinement.
Input data generation for training
Given the ground truth image

From the left two ground truth images (image and guideline), we generate the other five images by automatic generation algorithms for training process of our model. The image is a sample validation image from Places2 data set.
For the generation of color prior input
An imperfect guideline
The mask
No-guideline zone is another binary mask used for a loss function. The usage of no-guideline zone is explained later in detail. The codes of generating the input data for the training are also available at the link. 10
Network architecture
We modify the coarse-to-fine network used in GConv
8
based on the key ideas from the recent works
22,26
as shown in Figure 6. The coarse network receives an input tensor

The blue, orange, yellow, and green blocks in the generator represent a gated convolution, dilated convolution, self-attention module, and CAM, respectively. Each of upsampling layer consists of nearest-neighbor interpolation followed by a gated convolution. The refine network is simplified for visualization. Red blocks in the discriminator represent spectral normalized convolutions. CAM: contextual attention module.
The size of the output tensor of the coarse network is
The discriminator is similar to the SN-patchGAN structure in GConv 8 except that instead of having a stride 1 convolution at the very first layer, our discriminator starts with a stride 2 convolution directly and uses Leaky ReLU as the activation function. We also adopt a spectral normalization technique recently proposed by Miyato et al. 27 The discriminator takes eight channels of input consisting of the image, guideline, mask, and color prior.
Loss functions
The coarse-to-fine network is trained in an end-to-end manner over several joint losses consisting of an adversarial loss,
Let G and D be the generator and discriminator, respectively. We use the hinge loss as the objective function


where
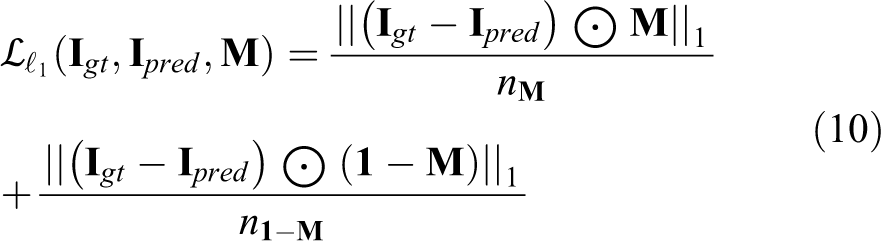
where
We also include the perceptual loss

where

where
The guideline refinement is trained using the focal loss

where H is the binary cross entropy.
As can be seen in Figure 7, we found that the black region in the color prior affects on the prediction of the guideline and results in black holes. This is because the network regards a black region in the color prior as the proper color and predicts a borderline around the region. However, a black region is where no prior color information exists and should be filled in appropriately.

(a) Masked image is overlaid with imperfect guideline. (b) Masked image is overlaid with color prior. When the model is trained without
We resolve this problem by proposing two new losses, anti-specificity loss

It is where guideline prediction should be negative that belongs to the negative ground truth guideline
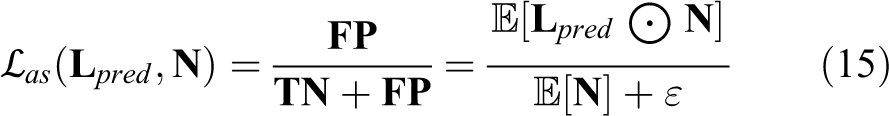
where
An adversarial loss, a perceptual loss, and a style loss are used to regularize the entire generator, whereas the others are additionally used to regularize both the coarse network and the entire generator. The overall loss function for our generative network



In short,
Experiments and results
We evaluate our multiview inpainting pipeline on real indoor spaces introduced in recent works. 1,9 The properties of each space are summarized in Table 1. The degree of light difference, occlusions, or environmental complexity of a space is indicated qualitatively by “+” sign, where more “+” signs represent harder conditions for multiview inpainting (Experiencing real-time rendering using our multiview inpainting results is available at www.teevr.net:2019/generative-mvi. 33 )
Properties, statistics, and results on real data sets.
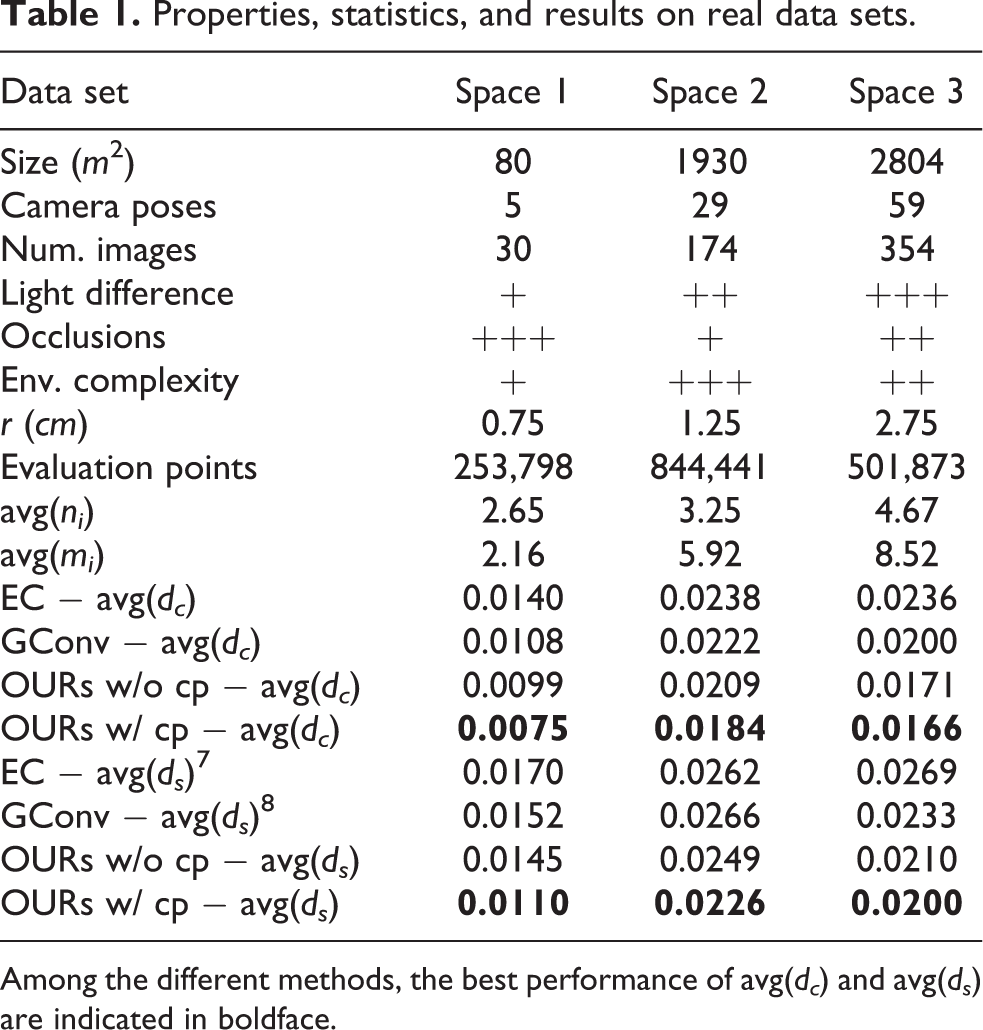
Among the different methods, the best performance of avg(dc) and avg(ds) are indicated in boldface.
For comparison, we selected recent two state-of-the-art papers that utilize the edge information, EC
7
and GConv.
8
EC consists of two separate generative networks, one predicting the image edge and the other completing the inpainting with the use of the edge prediction. By contrast, GConv uses a user-sketch input for the image inpainting but does not predict the edge. Our model uses imperfect guideline as well as the color prior as input and refines the guideline and completes the image inpainting concurrently. We used 512
Color evaluation
Before beginning color evaluation for multiview inpainting, pre-processing is necessary to alleviate luminance dependency due to a lot of light sources affecting differently on color intensity w.r.t. camera poses. To resolve the problem, all images are normalized for conversion into the intensity-free rg chromaticity space 35 as

where r and g are bounded between 0 and 1.
Following data arrangement is also processed for pixel-wise evaluation. For a given 3D point pi from the sampled PCD, two sets of images are defined,

where rj and gj are the rg chromaticity of the pixel corresponding to the point pi in jth inpainted image belonging to the set
For the evaluation, we compare two factors, consistency over ni images (dc) and similarity between the sets


where
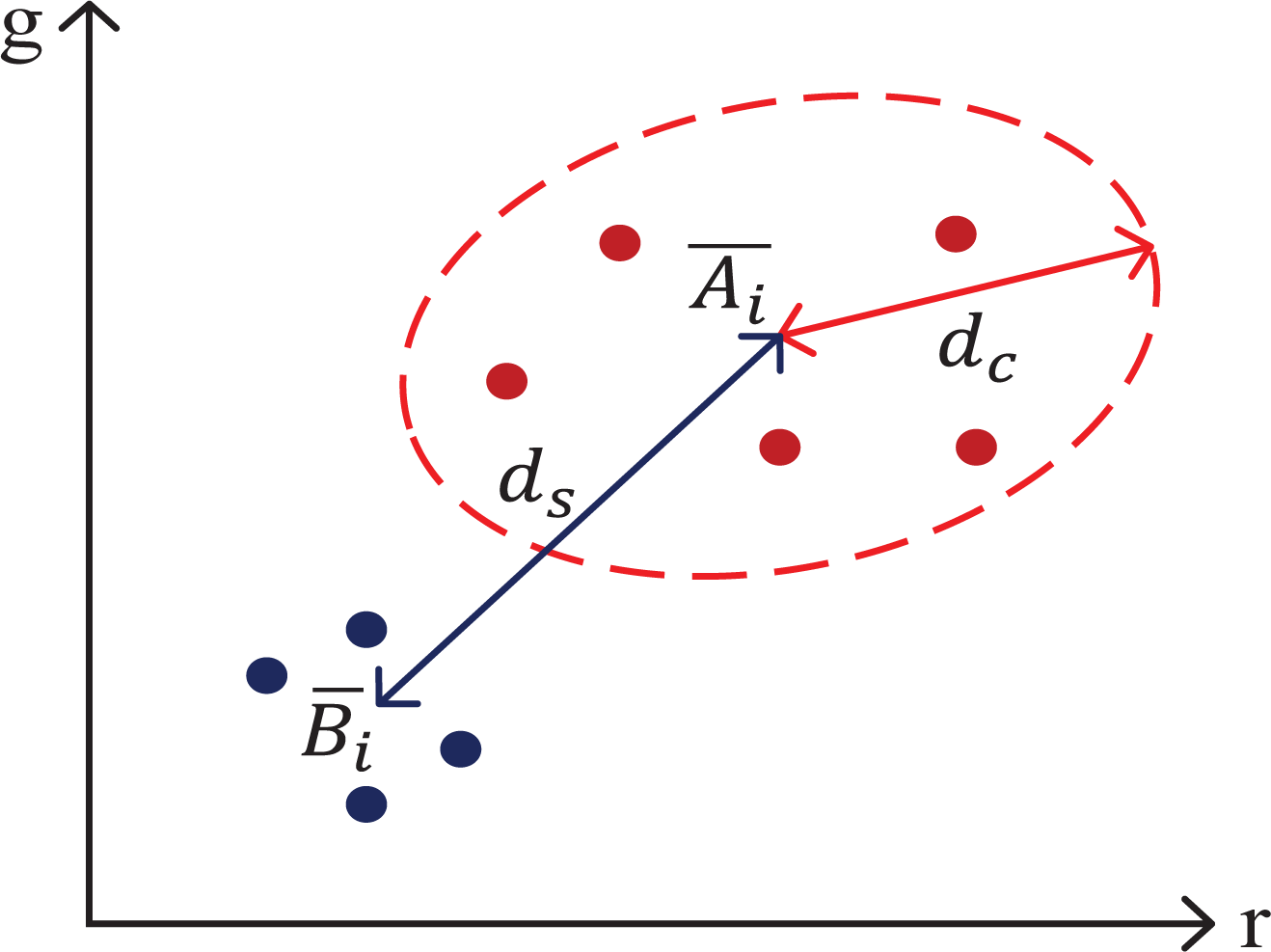
Let a given 3D point pi be occluded by objects in five images (
Second, similarity distance ds is the Euclidean distance between the means of the matrices

Finally, since dc and ds are point-wise measures, they are averaged over all points. Evaluations were conducted on EC, GConv, OURs in the absence of the color prior to verify the effects of the color prior, and OURs using the color prior. The results are presented in the Table 1. Improvements of up to 46.4% and 30.6% in the consistency distance and also up to 35.6% and 27.3% in the similarity distance were achieved compared to EC and GConv, respectively. The qualitative comparisons are shown in Figure 9.

Sample test results of Space 3. Other methods result in color inconsistency while our method using color prior preserves color consistency in the results of multiview inpainting.
Boundary evaluation
We evaluate boundary consistency qualitatively. As can be seen in Figure 10, We observed that EC is good at finding finer edges because it was trained using a Canny edge detector followed by nonmaximum suppression. However, it often fails to generate proper edge on the area where the architectural boundary should exist in a real data set (cf. Figure 10(b) and (c)). By contrast, both GConv and our approach achieve better results in terms of the architectural boundary because of the explicit guideline inputs. Furthermore, with the approach of guideline refinement in the network, Figure 11 shows that our model is able to find the missing guidelines in the images.

(a) The original image. (b) Boundary comparison on the left side pillar. (c) Boundary comparison on the right-side pillar.

A sample result of missing guidelines. Line patterns on the left side pillar in the input guideline image are not drawn but are visible in the refined guideline output. For visualization, the output guideline corresponding to the mask is colored in blue and emphasized.
Ablation studies
For the quantitative evaluation of multiview inpainting on the real indoor data sets, 1,9 we defined the point-wise consistency metrics, consistency distance and similarity distance, which are averaged over all points. However, averaging over the number of all points might blur the point of multiview inpainting, which is color-consistent inpainting regardless of the number of inpainted images.
This time, we further analyze the impact of the number of inpainted images on the color consistency. For this, each point, pi, is classified according to the number of times, ni, that it is used for inpainting. Then, the consistency distance and similarity distance of each classified group of points are averaged over the number of the group’s points. In specific, ni is the number of rows in the matrix

Quantitative comparisons of consistency distance for different models: (a), (b), and (c) are the results of the Space 1, 2, and 3, respectively. The dashed vertical line represents the average value of ni’s of the given space. Our approach shows lower value on every n compared to the other methods. It means our approach outperforms the others on the perspective of consistency distance regardless of the number of inpainted images of the multiview inpainting task.
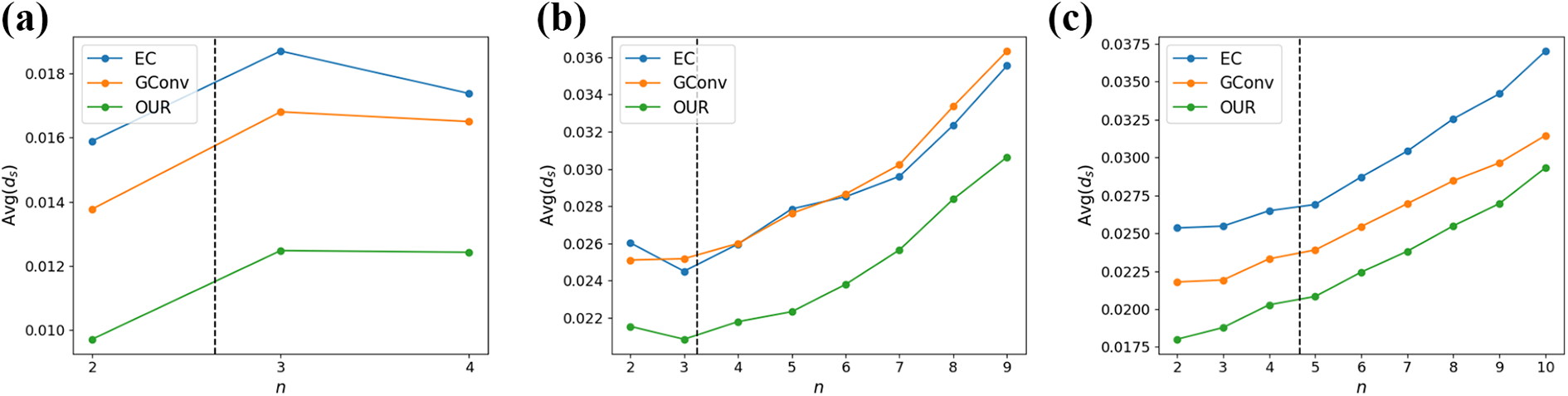
Quantitative comparisons of similarity distance for different models: (a), (b), and (c) are the results of the Space 1, 2, and 3, respectively. The dashed vertical line represents the average value of ni’s of the given space. Our approach shows lower value on every n compared to the other methods. It means our approach outperforms the others on the perspective of similarity distance regardless of the number of inpainted images of the multiview inpainting task.
Figure 12 shows the impact of ni on consistency distance. Consistency distance tends to increase as the number ni increases. Our approach consistently shows lower value on every ni compared to other single-image inpainting methods. Likewise, Figure 13 also shows similar results and that our approach outperforms other methods on every ni in similarity distance. Both results suggest that our pipeline using the color prior is more effective on the multiview inpainting task regardless of the number of inpainted images compared to the single-image inpainting approaches. Figure 14 shows more qualitative comparisons on the real data sets.

Qualitative comparisons on real data sets. Each pair of rows is Space 1, 2, and 3 of the real data set, respectively.
Conclusions
We proposed a multiview inpainting pipeline, that is, creating color prior images and an image inpainting network. Our pipeline aims at achieving both color and boundary consistency for multiview inpainting by introducing a color prior and guideline input, respectively. While training the network, we introduced new losses to resolve the black hole problem and achieve two goals, inpainting and guideline refinement, concurrently. We evaluated the results of our pipeline using a consistency distance and a similarity distance, which indicate that the method outperforms other methods applied to multiview inpainting.
We plan to extend the proposed multiview image inpainting with a better pipeline to further stabilize the light effects during the color prior generation step. There are also other promising applications and future works using our pipeline. Since the inpainting is affected by the color prior images, user-interactive inpainting can be possible. Users may remodel their virtual spaces as the inpainting can be modified by user input. Similarly, our method can be used for image synthesis in indoor or outdoor of target space if the point clouds and poses of images are given. Also, our pipeline may be used as a preprocessing and extended to recent deep learning-based rendering approaches.
Footnotes
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Korea University and TeeLabs Inc.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Technology Innovation Program (10073166) funded By the Ministry of Trade, Industry & Energy (MOTIE, Korea)