
Abstract
With the urgent demand of consumers for diversified automobile modeling, simple, efficient, and intelligent automobile modeling analysis and modeling method is an urgent problem to be solved in current automobile modeling design. The purpose of this article is to analyze the modeling preference and trend of the current automobile market in time, which can assist the modeling design of new models of automobile main engine factories and strengthen their branding family. Intelligent rapid modeling shortens the current modeling design cycle, so that the product rapid iteration is to occupy an active position in the automotive market. In this article, aiming at the family analysis of automobile front face, the image database of automobile front face modeling analysis was created. The database included two data sets of vehicle signs and no vehicle signs, and the image data of vehicle front face modeling of most models of 22 domestic mainstream brands were collected. Then, this article adopts the image classification processing method in computer vision to conduct car brand classification training on the database. Based on ResNet-8 and other model architectures, it trains and classifies the intelligent vehicle brand classification database with and without vehicle label. Finally, based on the shape coefficient, a 3D wireframe model and a curved surface model are obtained. The experimental results show that the 3D curve model can be obtained based on a single image from any angle, which greatly shortens the modeling period by 92%.
Introduction
With the development of robot technology, the application of robot is wider. At the same time, the concept of robot is also broader, has been from the narrow sense of robot, and began to expand to robot technology. In early 2004, senior members of the IEEE’s future industry pointed out that biotechnology, nanotechnology, supercomputer technology and intelligent robotics technology are the most influential technologies in the future. Japan regards robotics as a strategic industry and addresses the current problems faced by the Japanese robotics industry, puts forward specific measures to strengthen robot research and promote robot industrialization. South Korea has listed robot technology as an “engine” industry for future national development and has given key support to robot technology. The United States has classified robotics as a technology of vigilance, which believes it will have a huge impact on future wars and has imposed a technological blockade on other countries. Experts suggest that the research on robot technology should be further strengthened to promote the development of China’s intelligent robot industry.
In foreign countries, with the rapid development of the modern automobile industry, the competition among automobile enterprises has become increasingly fierce. Other services derived from automobile products also affect consumers’ purchase choices, but the most core influencing factor is still automobile products themselves. In the face of consumers’ diversified purchase demand, the fierce competition market, and the deteriorating ecological environment, enterprises shorten the cycle of automobile design, and development is one of the key factors to enhance market competitiveness. According to the research of the domestic automobile industry, automobile product development can be divided into two categories: research, development, and design of new models and modification and design of existing models. About 70% of the development of automobile products is based on the existing data to develop the original models, which can not only shorten the design cycle but also save resources and realize the reusable use of the automobile production platform. Although parameterized design has been successfully applied to modern body design, there are still many links that are not fully parameterized, which also restricts the development and design cycle of the vehicle to a large extent.
Lei and Liu proposed a method for quantitative measurement of polarization direction based on polarization axis detector and digital image processing. The Pakistan air force as an azimuth analyzer determines the polarization direction and pattern of linearly polarized light, forming an “hourglass” intensity, and a digital camera is used to record the pattern, and then, the polarization direction of the light waves is obtained accurately by analyzing the pattern with a specially designed digital image processing algorithm. Quantitative measurement experiments were conducted. 1 Fault tree analysis (FTA) is a very important method for analyzing risks associated with key security and economic assets, such as power plants, aircraft, data centers, and web stores. The FTA approach consists of a variety of modeling and analysis techniques supported by a variety of software tools. Ruijters and Stoelinga investigated more than 150 articles on FTA and gave an in-depth overview of the status quo of the FTA. Specifically, Ruijters and Stoelinga review the standard fault tree and extensions, such as dynamic FT, repairable FT, and extended FT. 2 Quyen et al. proposed two direct sampling correlator receivers for differential chaotic shift keying communication systems in frequency nonselective fading channels. These receivers operate on the same hardware platform and different architectures. In the first scenario, the safety data sheet (SDS) receiver, the sum of all samples within a chip cycle, is related to its delayed version. Then, the relevant values obtained from each bit cycle are compared with a fixed threshold to determine the binary value of the bits recovered at the time of output. 3
The organizational structure of this article is as follows. The first part introduces the background and research significance of this field as well as the innovation points and organizational structure of this article. The second part introduces the meaning and classification of image processing. In the third part, the vehicle modeling based on single view is selected as the target, and the mapping relationship between vehicle image and 3D wireframe model is established by deep learning. The fourth part introduces the analysis of the dimension unification of the intelligent vehicle modeling model, the analysis of the control point and the curve sampling point in the vehicle modeling, and the analysis of the reconstruction error. The fifth part is the summary of the intelligent vehicle modeling design based on image processing.
Proposed method
Image processing
1. Smooth image
Image smoothing can remove the details in the image and keep the main structure of the image. The extracted image structure can be used for detail enhancement, image abstraction, background smoothing, and other visual applications. Many traditional image smoothing methods based on filtering, such as anisotropic propagation and bilateral filters, determine the image’s significance structure by balancing the relationship between each pixel and its neighborhood, thus smoothing out noise or details. In recent years, the numerical optimization method has replaced the spatial filtering method because of its robust, flexible solution and high-quality smoothing effect. These methods implicitly encode important image structure information into the energy function.
The above image smoothing algorithm only depends on the size of the image gradient to understand the image structure. In 2012, the previous researchers proposed relative total variation to remove the repeated texture with small mesoscale. 4,5 Eliminate fine-grained repetitive textures by fusing the appropriate image structure of the dynamic boot diagram and the static boot diagram. Although the algorithm used for texture removal is still sensitive to image structure, texture edges are different from stylized edges, and texture removal algorithms may still fail when used to generate stylized images.
Previous work shows that regularization terms can also be converted into image priors in depth network or image denoising engine. By deducing the process of minimizing the image smoothing energy function, the methods based on image filtering and energy optimization are connected theoretically. More discussion of Lp norms can be found in the past literature. However, the traditional optimization method does not make explicit use of deep learning technology, and its need to solve large-scale linear equations makes such methods generally time consuming. 6,7 Some work has been done recently to solve this problem. The depth neural network is used to fit the results of the traditional image smoothing algorithm to accelerate the smoothing. However, these methods take the smooth image generated by the traditional algorithm as the truth value of network training, essentially simulating the traditional algorithm instead of creating a new image smoothing effect.
To integrate image structure into deep learning solution more effectively, this article proposes to design important image structure into energy function explicitly and learns the energy function of optimizing image smoothness in an unsupervised way. This is fundamentally different from past deep learning methods in terms of training objectives, training data, and algorithms. The deep learning work mentioned above is to simulate the smoothing effect of traditional algorithms, while this article is to create some higher quality smoothing effect, which makes the work of this article not comparable with the work of deep learning in the past. Deep learning has been applied to many image processing tasks, but most of the previous work treat it as a regression or classification problem, while this article treats a deep neural network as an unsupervised optimizer. 8,9
2. Restoration based on reflective images
Influenced by the shooting environment, camera hardware, and user photography technology, the photos taken by people in daily life have various degradation phenomena. For example, in the dark of night, the user will increase the camera’s sensitivity (ISO) to get enough exposure to take a bright photo, but this will often increase the noise of the photo. When there are high speed moving objects in the shot scene or the camera shifts at the moment of pressing the shutter, motion blurring phenomenon is likely to occur in the photo: affected by the weather conditions, when the rain, snow, and fog appear in the scene, the focus of the background object in the photo will become unclear. Recovering clear and clean background information from degraded photographs is collectively referred to as image restoration in the field of image processing. 10,11
Reflective removal is a common problem in image restoration. When a user takes a photo through glass, the camera’s image comes from two sources: the background light from the opposite side of the camera and the reflection from the glass on the side of the camera. When the reflection is stronger than the background light, there are likely to be reflective areas that block the background. Essentially, the synthesis of reflective images is the superposition of two completely different light sources, so image reflective removal is a highly pathological problem. 12,13
Traditional methods use a lot of prior knowledge to remove glare. By far, the most commonly used a priori is the use of the relationship between multiple images to differentiate between the reflective area, such as flash image of the flash/focus/virtual confocal images on, before the background motion of different video sequences or by adjusting the angle of the polaroid image of the sequence, including handheld camera to users. The most convenient and practical method is to use from the different angle of view images to remove the reflection. When the user shoots a video sequence while moving, the front background motion from different perspectives is usually different due to parallax. The motion information of the front background can be represented by various parameterized models like fixed parameterized models such as translation, affine transformation, or monotonic matrix. Either the optical stream or scale-invariant feature transform stream, more general dense field, each pixel represents a motion vector. Methods based on multiple images can often produce more perfect results, but their requirements for special shooting equipment or environment limit the application of these methods to actual scenes, especially for images downloaded from mobile devices or networks. 14,15
3. Eigenimage decomposition
Eigenimage decomposition involves the extraction of physical features of the image to assist more advanced visual tasks, which can recolor objects with the extracted reflectivity information or render new 3D objects with the extracted illumination information and reset them to 2D scenes. The representation of these extracted physical attributes in 2D space is called the eigenimage, and the process of extracting these features is called the decomposition of the eigenimage. In the narrow sense, eigenimage decomposition refers to extracting reflection and illumination information from images. In a strictly diffuse scenario, the product of reflection and light at each pixel equals the original image, so this is also a highly distorted problem. 16
In the past, the solutions of eigenimage decomposition can be divided into two categories: the method based on a single image and the method based on multiple images. Since the problem is completely pathological in the case of a single image, traditional methods often rely on a series of priors to disambiguate the problem. Some of the work proposes to distinguish and reconstruct the eigenimages according to the intensity of the gradient of reflection and illumination. Other methods deal with smooth transition areas in the image using statistics of reflected textures. 17,18 Although much of the past work have focused on designing a variety of priors due to the complexity of real-world photographs, no single method can capture all the features of an eigenimage. In contrast, when there are more input images in real-world application scenarios, such as image sequences, multimodal input, or user interaction, the problem becomes relatively adaptive.
Different from the traditional method, when there is intrinsic image data with true value, the depth of the convolutional neural network provides a more general data-driven method to solve the morbid inverse problem, at the same time can also avoid the build prior overly complex images, such as some of the recent work using the depth the characteristics of the neural network learning ability directly from massive data set eigenimage statistical prior learning. Using the deep learning features of two local image blocks to learn the relative size of sparse reflection points in the image on the relative reflection labels of the IIW dataset, a multichannel network structure is designed to integrate local and global image information. To maintain the global consistency of the reflection map, they predicted the relative reflection classification value of the image by optimizing a hinge loss function. The sparse color priors of the reflection map are constructed by dividing the input image into superpixel blocks. 19,20
In the above methods, the eigenimage decomposition is treated as a classification problem, and each pair of image blocks in the image should be put into the network to predict separately. To solve this efficiency problem, it is proposed to use hinge loss function to monitor sparse point pairs of IIW data set while also predicting dense reflection images. However, since the IIW data set does not provide good supervision of the overall structure of the image, the predicted eigenimages in this way cannot maintain the piecewise smoothing characteristics of the reflection image, so they then smoothen the reflected image with the guide filter and the joint bilateral filter. 21,22
4. Main work and innovation of image processing
This article studies three classical image processing problems: image smoothing, reflective removal, and eigenimage decomposition. As shown in Figure 1, these three problems extract different structural features of the image, respectively: the image smooths out the details of the image to extract the main edge structure of the image; reflective removal to extract a clean background structure from the noise area of the image; and eigenimage decomposition extracts physical features (reflectivity and illumination) in the image scene. 23 Although their specific goals are different, the extracted contents can be summarized as the distinguishable structural features of a certain level in the image, and these three problems can also be abstractly classified as the classical image decomposition problem. As shown in Figure 1, for image smoothing, the input image can be decomposed into smoothing layer and detail layer. For reflection removal, the input image can be decomposed into background layer and noise layer, and for intrinsic image decomposition, the input image can be decomposed into reflection layer and illumination layer. Since the image structure at different levels has distinguishable feature information to make better use of the deep learning-based solution, we encode the structural features of the target image into the algorithm design of deep learning. According to the defects of the above three image processing problems, such as no label, only weak label, or fake label, we proposed corresponding deep learning solutions based on unsupervised learning, weak supervised learning, or multilabel joint training. Finally, this article proposes a decoupling learning framework and extracts the core solution space of image processing problems through joint training of 10 different image processing problems, which play an important role in understanding the application of deep learning technology in the field of image processing. 24 –30

Main contents of image research and processing.
Experiments
Experimental modeling
Experiments to automobile modeling based on single view modeling as the goal to adopt the method of deep learning automotive images and 3D wireframe model set up the mapping relationship, as shown in Figure 2. This article based on the deep study of automobile modeling process mainly includes three aspects. First, create a 2D image database and 3D curve database. Second, the deep learning method is used to train the mapping learning of the two databases previously created to obtain the predictive machine. Third, the use of forecasting machine can quickly generate any test image reconstruction of 3D curve model under the first introduces the definition and shape of car 3D curve model coefficient of extraction method, and then introduces automotive 3D curve model database and multiangle image database creation process and method, finally, in detail, in this article, the numerical experiments are described.
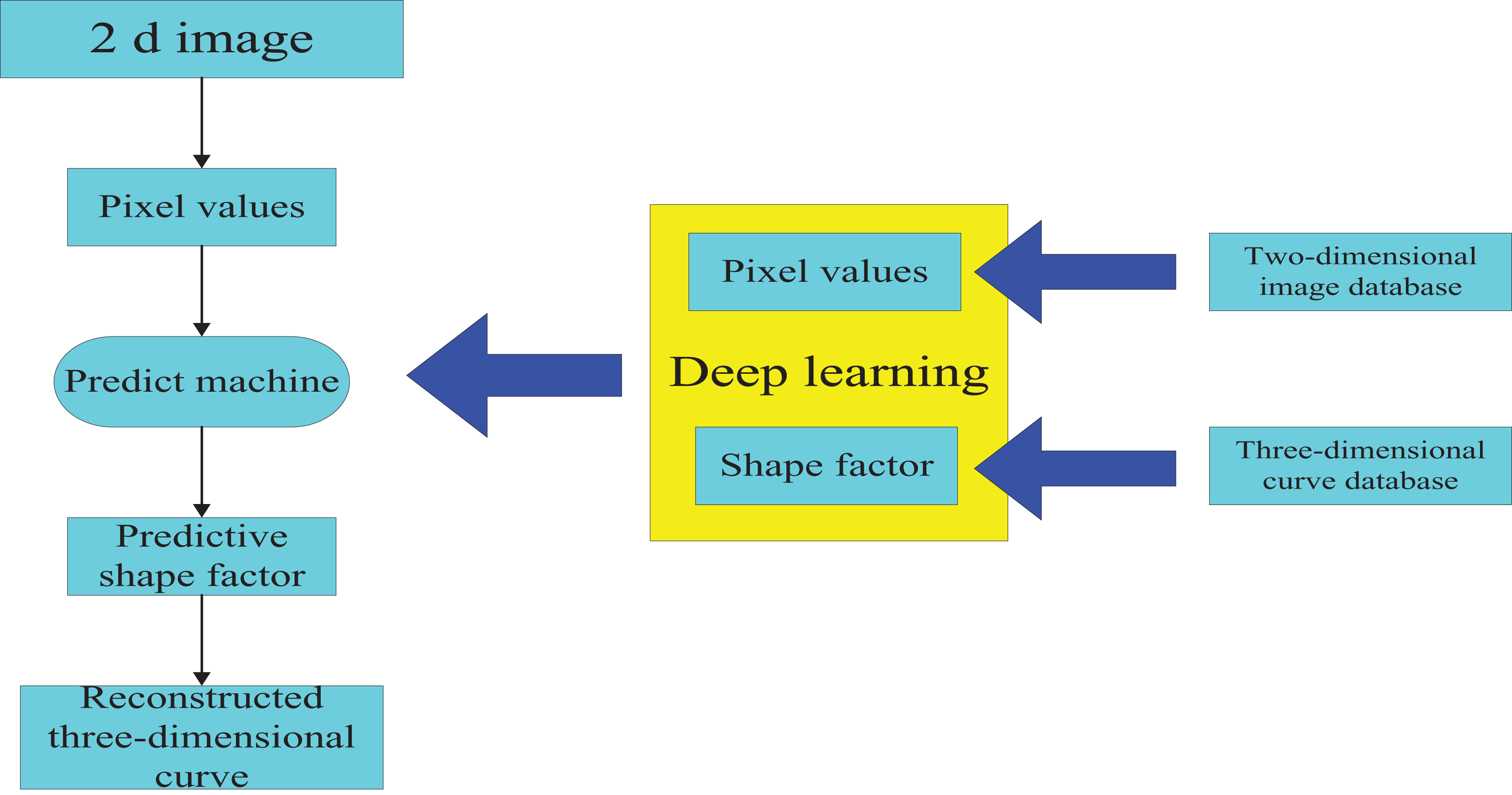
Modeling process of intelligent vehicle based on deep learning.
5. Three-dimensional curve model of intelligent vehicle
To maximize the expression ability of the shape details of the model and meet the requirements of simple ediTable friendly interaction, this article chooses 3D curve as the expression form of the 3D deformable model of automobile based on the previous research work. The 3D curve model of automobile adopted in this article is defined in Table 1.
Curve numbers and semantics of the 3D curve model of automobile.

6. Shape coefficient
It can be seen from the above that each 3D curve model of an automobile can be represented by 121 × 4 = 484 3D coordinate points. Therefore, a 3D curve model of an automobile can be expressed in the following mathematical form

where

To realize automation, modeling based on the image of automobile modeling can be trained to build image and shape vector convolution of the neural network mapping, however, to minimize the number of ginseng in the neural network, based on principal component analysis (PCA) method, the article proposes another kind of representative car 3D space curve model approach

where
Experimental data
In determining the automobile modeling based on image modeling tasks and data format, the smart car model based on image modeling problem also creates the 3D curve model library, car, however, their work based on body side view is not in conformity with the text based on any view of automobile modeling task, moreover, their smart car 3D curve model also does not have the corresponding image data from multiple perspectives for image data from multiple perspectives, available to download, or the way the production, however, these methods are not only time-consuming, laborious, and difficult to guarantee the quality of data and scale but also, most importantly, these image data corresponding to the 3D curve model creation and quality assurance are a big problem to meet the automotive multiangle images and 3D curve model one-to-one requirement. This article puts forward with the method of digital model car, rendering to create image database, at the same time, the use of car model data to ensure the quality of the 3D curve model is based on the Net Shape 3D model library to create a 3D curve model library and multiangle image database.
From ShapeNet model, the library of vehicle categories selected 150 model car, model for obj file format, and then based on KeyShot5.0 Pro rendering software rendering for each model, including the color of the body (this article selected body color to red), windshield, and the material of the wheel model, is set to white background, to ensure the position of car models in the image and proportion, and camera parameters settings. Finally, obtain various angles in the image rendering output settings of the car model. In this paper, the horizontal sampling number frame is set to 36, and the car rendering image is output at the same time every 10 angles. Taking into account the designer's sampling of the appearance sketch, this article sets the vertical direction from 0 to 10 points downward, and then horizontal sampling will be performed again every 5 angles. Therefore, the rendering output image of the car model based on the above method totals 36 × 3 = 108 pieces. Based on the horizontal part of the rendered image, this paper creates a car multi-angle image database with a total of 150 × 108. The advantage of this method is that it is easy and fast to obtain image data. Once you have a digital model of the car, KeyShot rendering software can quickly render a realistic body effect, and from rendering to output, it only takes 3 min to obtain a multiangle rendering image of the car model.
Experimental platform and parameter setting
According to the process to create a car after 3D curve model database, using the PCA method to PCA of the database, a preliminary car shape factor dimension of 3D curve model to 40, and extracting the database of all models in determining the shape coefficient of the car image data from multiple perspectives and training TAB - shape factor, this article selects the ResNet network training-50 structure to be sure, each of the 3D curve model (shape factor) of the same ShapeNet model corresponds to the image in the database 108 car image, that is to say, the 108 cars have a phase image from multiple perspectives. The platform for numerical experiments in this section is given below.
The system is Windows10 x64, the processor is Intel(R)Core(TM)i7-8750HCPU@2.20 GHz, the memory is 8 GB, the graphics card is GTX1050Ti, and the deep learning framework is PyTorch.
First, car 3D curve model database according to the ratio of 3:1:1 was divided into training set, validation set, and test set. The training set and validation set are used for classification and the performance of the test set is used for training after the model test. Car multiangle image database is according to the car 3D curve model database, and the corresponding model is also divided into training set, validation set, and test set. The above three network models are the same training parameters; specific settings are as follows: Epoch of 50; the training batch is 8; the initial learning rate was 0.01; the learning rate was adjusted to 0.001 when the epoch was within the range of 31–40, and 0.0001, when the epoch was within the range of 41–50; momentum (momentum) is 0.9, and the attenuation τ weightdecay v is 0.0005 for each model. This article adopts the training model on ImageNet database as a car brand modeling data classification training of the training model.
Discussion
Uniform dimensions of intelligent vehicle modeling model
Due to the lack of vehicle information, such as the size of the depth image information, the only car 3D model generated from the image is a defect, although the size information can be input to adjust the final output of the model, but the problem caused by the large-size mismatch loss during the training process interferes with the judgment of the training result. To this end, this article separately trained the original 3D curve model and the unified 3D curve model, unified all the model size, the length is 5000 mm, the width and height change with the length of the scale, this processing can make the network model in training Focus on the shape of the car rather than the size.
Firstly, ResNet-34 was used to train the original 3D curve data and the 3D curve data after size unification, and the change of loss value in the training process was shown in Figure 3. Figure 3(a) shows the result of the training of the original 3D curve model, and Figure 3(b) shows the result of the training of the 3D curve model after size unification. As shown in Figure 3(a), as the training period increases, the loss of the training set gradually decreases and converges. However, after the electric shock, the training set will not be reduced due to the loss under normal circumstances. This phenomenon is called fitting. The lower the reduction of the training set, the better the fitting effect. However, in this case, the performance of the verification set and the test set is very poor, and the generalization ability is also poor. To this end, this article combines the original 3D data training network model to train the image data, set and test the image data.

Loss value during network training: (a) Original 3D wire frame models and (b) size-unified 3D wire frame models.
Control points and curve sampling points
By above knowable, this article uses the car 3D curve model of file storage content for Bezier control point, direct training data are calculated according to the control points, and the shape factor while the Bezier control point can represent the shape of the curve, but the car 3D curve model database control point distribution is not uniform, and the curve shape of indirect training may damage the accuracy of the results of the model to this end, this article adopts auto 3D curve model and the curve of the sampling points instead of curve control points. Figure 4 shows the difference between the control points and sampling points for each a Bezier curve model car, in this article, the sampling step length is 1/10th of the curve and can take 11 points on each curve.

(a) Curve control point and (b) sampling point.
After the completion of sampling, the 3D curve model of each vehicle is represented by a vector of 121 × 11 × 3 = 3996 dimensions. Similarly, PCA is used in this article to obtain the shape coefficient of the 3D curve model. The shape coefficient dimension here is still 40, which is consistent with the above.
Reconstruction error analysis
To quantify the image generated 3D curve model, the ability of reconstruction error analysis, experimental results of the model of 3D curves of raw data size after unified control point data as well as the size curve after the unification of sample point data of the three different training data reconstruction error are analyzed, which, in the reconstruction of the training model to calculate the original data error, this article will first test the label and reconstruction data are scaling to the size of the unified data size, which guarantees the error statistics on the same scale.
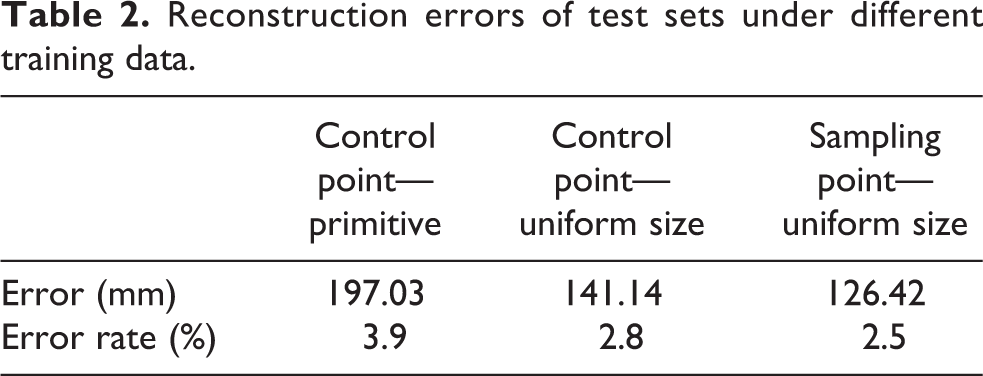
Since some lines (auxiliary lines) in the 3D curve model defined in this article do not exist in the image, these lines (frontal modeling lines) are not visible in most viewing angles. In order to calculate the reconstruction error, in this paper, the wheel line (8), the hub line (8), the grille profile (12), the profile line (4), the hood (1) and the modeling auxiliary line (16) 3D curve model, a total of 49 lines are excluded, and only 72 modeling characteristic line reconstruction errors are retained. For each curve, this article uses two sampling points (table 2), the starting point at the end and the error point in the middle. Record test data under different model training data sets. The reconstruction error in Table 2 shows that in the original control point data, the reconstruction error of the training prediction model is relatively large, 185.24 mm. When the size of the model was 5000 mm, the error rate of the prediction model was 3.7% and the error rate of the control point data was 2.3%, after the size was unified, while the reconstruction error of the test set of the training data of the curve sampling point was the least, the error rate was 2.1%.
Reconstruction errors of test sets under different training data.
Under different angle of view to analyze training model for the reconstruction of the car image, Figure 5 shows statistics in the curve sample point for training data under the condition of different car image reconstruction error, the different angle of abscissa and perspective way is the definition of a depression angle—horizontal rotation angle—by car before the face of frontside direction 0°, level off the bus clockwise rotation angle in the vertical under the condition of increasing. Face can be seen from Figure 5 before the frontside direction.
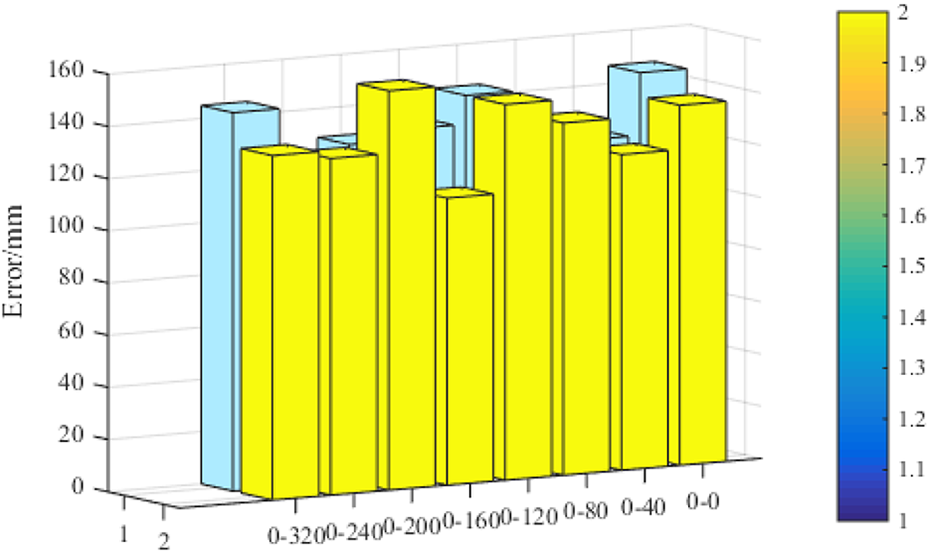
Reconstruction errors of test set images at different angles.
As a benchmark, there are about 30 rotation ranges (0–0, 0–10, 0–20, 0–350, 0–340, etc.) in car image reconstruction.The greater the error, the greater the rotation range. Toward the slats and rotate around the range of 30,when the 3D curve reconstruction error is the smallest, the depression angle is 0 and the horizontal rotation angle is 90°. At this time, the reconstruction error is relatively small, up to 110.19 mm. Before face-to-face, this article believes that car images cannot express body shape modeling information, such as training models. Extracting an image representing shape features from an image will result in large reconstruction errors. For side elevations that express body shape information such as car images, the training model can extract shape features for reconstruction.
As car 3D by multiple can be connected with the Bezier curve model to further analyze each Bessel curve reconstruction error, Figure 5 shows statistical test set; all image data reconstruction model of each Bezier average error of Figure 5 shows most of the reconstruction error of curve about 100 mm, the number 635364748 Bessel curve reconstruction error is bigger, more than 200 mm, and the curve of the number of 47 error of 264.31 mm. Figure 5 shows the four curves in car position in 3D curve model.
Three-dimensional curve model of automobile
To maximize the expression ability of the shape details of the model and the requirement of simple ediTable friendly interaction, this article chooses 3D curve as the expression form of the 3D deformable model of automobile. The 3D curve model definition of automobile adopted in this article is shown in Figure 6 and Table 3.

The 3D curve model of automobile.
Curve numbers and semantics of the 3D curve model of automobile.

As shown in Figure 6, this article using the car 3D curve model consists of 121 curves, each curve for three times Bezier curve, namely, each curve, such as the shape of the curve length, is decided by four 3D control points based on the predecessors work. This article also adopts LQB text file format stored car 3D curve model, based on the secondary development program, the format of the file can be read and edited in the Siemens NX7.0 version.
Conclusions
Intelligent vehicle design is an important stage of vehicle R&D and design. Due to the lack of 3D modeling foundation, market research such as complicated and time-consuming work such as manual 3D modeling not only affects the efficiency of R&D modeling, but also is not conducive to the design and market application of smart vehicles. According to the subjective perception characteristics of automobile modeling analysis, the preliminary extraction, and so on, a lot of artificial intervention and laborious manual digitization modeling problem, in this article, based on the model of image processing, analysis, and modeling of ideas, put forward the automobile modeling analysis and modeling method based on the deep learning and learning based on the database mining, automobile modeling analysis, and modeling, which can realize the whole process automation without any interaction. For intelligent vehicle model modeling method based on image processing, a limit point that lies in single-view 3D reconstruction can lead to some perspectives for incomplete shape features under reconstruction error of the larger problem, in the future work, which can realize multiple views of the 3D model reconstruction, in addition, in this article, the reconstruction of the data is only 3D wireframe data, lack of automobile body modeling detail information, such as waist fender, and engine cover area of concave and convex characteristics, follow-up studies can be extracted from the image detail characteristics of car body so as to rebuild the implementation more detailed 3D model of car.
Firstly, the family analysis of automobile front face is transformed into the brand classification of automobile front face, and a database of automobile front face image is created for family analysis of automobile front face. Then, use before the deep learning method based on face shape brand classification, finally, using category activation mapping method mining and visualization family-based modeling regional experimental results conform to the subjective analysis results of predecessors, verify the validity of the method, at the same time, the method proposed in this article can quickly and automatically get the results of family modeling analysis without human intervention, such as feature perception extraction, in addition, in this article, the data-driven method not only can be used in the modeling of family-based analysis but can also be applied in the study of semantic analysis of modeling. First, a ShapeNet-based multiangle rendering image database and a 3D curve database were proposed, and a large-scale multiangle rendering image database with 108 angles for 150 models and a 3D curve database for 150 models were created. After extracting the shape coefficient of the 3D curve model by PCA, the mapping of the image to the shape coefficient of the 3D curve model was studied by deep learning, and the shape coefficient predictor was obtained. The shape coefficient of the pretest machine is used to estimate test image shape factor of the car, then into a 3D curve model, experiment results show that this method without human intervention can automatically, efficiently, and accurately according to any car image reconstruction of 3D curve model, in addition, the autogenerated 3D curve model has many characteristics, such as ediTable, which can further generate car 3D surface model, as the transition model of a 2D-3D model in the stage of modeling design.
This article briefly introduces the basic principles, related technologies, algorithms, and application fields of data mining (DM). DM can be understood as mining potential patterns from a data set and then evaluate them. The data can come from a database, a data warehouse, text, or other storage devices. DM is a new interdisciplinary technology, involving machine learning, database, statistics, and other fields. The research of multisensor data fusion based on mobile robot is an important development direction of robotics. With the deepening and expansion of mobile robot application, data fusion system is required to have better autonomy, adaptability, interactivity, and higher accuracy. In this article, the key technology of robot, multisensor information fusion technology, has been studied and some achievements have been made in theory and experiment. On the platform of moving machine, a multisensor system is designed, and a simple and effective partitioning algorithm is proposed, which is successfully applied to the preliminary fusion of sensor data, and the distance and orientation of obstacles can be determined accurately. It can provide more accurate obstacle information for the navigation control of the robot.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.