
Abstract
Aiming at the problem of servoing task failure caused by the manipulated object deviating from the camera field-of-view (FOV) during the robot manipulator visual servoing (VS) process, a new VS method based on an improved tracking learning detection (TLD) algorithm is proposed in this article, which allows the manipulated object to deviate from the camera FOV in several continuous frames and maintains the smoothness of the robot manipulator motion during VS. Firstly, to implement the robot manipulator visual object tracking task with strong robustness under the weak FOV constraints, an improved TLD algorithm is proposed. Then, the algorithm is used to extract the image features (object in the camera FOV) or predict image features (object out of the camera FOV) of the manipulated object in the current frame. And then, the position of the manipulated object in the current image is further estimated. Finally, the visual sliding mode control law is designed according to the image feature errors to control the motion of the robot manipulator so as to complete the visual tracking task of the robot manipulator to the manipulated object in complex natural scenes with high robustness. Several robot manipulator VS experiments were conducted on a six-degrees-of-freedom MOTOMANSV3 industrial manipulator under different natural scenes. The experimental results show that the proposed robot manipulator VS method can relax the FOV constraint requirements on real-time visibility of manipulated object and effectively solve the problem of servoing task failure caused by the object deviating from the camera FOV during the VS.
Keywords
Introduction
Robot manipulator has been used in a wide range of industries and played an important role in replacing people working in hazardous environments 1 (radioactive places and polluted environments) or human unreachable extreme (harsh) environments (deeper coal mines, deeper seas, 2,3 and space 4 ) as well as tracking or sorting of objects. 5 To make robots competent for more complex tasks, robots not only need a better control system but also the ability to percept environmental changes in a timely manner. Among all robotic sensors, visual sensor has become one of the most important robot sensors for its rich information, extensive application, noncontact detection, and so on. Visual information is used to control robot motion, which is generally called robot visual servoing (VS). The purpose of VS is to make the relative posture of the robot and the manipulated object equal to 0.
Researchers have proposed a large number of robot VS methods. According to the form of VS system error, the current robot VS methods can be divided into three categories: image-based visual servoing (IBVS), position-based visual servoing (PBVS), and hybrid visual servoing. All of these methods require that the object remains in the camera field-of-view (FOV) throughout the VS process. When the initial posture of the robot manipulator is far from the desired posture, that is, when the initial relative posture is large, the VS system needs to perform a wide range of motion. In this process, the object is easy to deviate from the camera FOV, resulting in servoing failure. 6 This is called the FOV constraint problem in VS. This problem will degrade the VS performance and even fail the VS task. To solve the problem of “FOV constraints” in robot VS, the researchers have proposed a variety of methods, which can be divided into two categories: trajectory planning and nontrajectory planning methods.
The main idea of the method based on trajectory planning is to first plan a feasible image trajectory under a certain constraint condition and then control the robot to move along this planned trajectory. 6,7 At present, researchers have proposed a large number of trajectory planning algorithms for VS systems. These algorithms can be roughly divided into five categories, 7 that is, image space-based planning, 8,9 optimization-based planning, 10 –13 potential field-based planning, 14,15 global planning, 16 –18 and uncertainty VS path planning. 19,20 Tracking a well-planned trajectory can make the posture change of the robot, which always remain within a small and predefined range. Therefore, the introduction of trajectory planning in VS can better solve the “FOV constraints” problem of the object, but the method is sensitive to changes of camera parameters. In addition, the noise introduced by the image acquisition and processing will affect the robot tracking performance on the planned trajectory, and even, there is a large deviation from the planned trajectory.
To overcome the shortcomings of the trajectory planning method to solve the problem of “FOV constraints,” researchers at home and abroad put forward a series of nontrajectory planning methods. By combining different visual servo structures or designing a new VS structure, the object is always in the camera FOV, such as combining IBVS and PBVS approach, 21 switching approach, 22 zooming VS approach, 23 direct VS approach, 24 and IBVS with a Kalman-neural-network filtering approach. 25 Besides, some advanced control laws are designed to deal with the FOV constraint problem, such as sliding mode control, 26,27 model predictive control, 28 –30 prescribed performance control, 31,32 switched controller, 6,33 and so on. Furthermore, some proposals are relying on robot–camera configuration, such as multicamera scheme, 34 the light field camera scheme, 35 and so on. The camera’s FOV is increased by switching between multiple cameras to ensure that the object is always in the FOV so as to fulfill the FOV constraints. 34 The disadvantage of this method is that the robot motion trajectory is prone to occur oscillating, discontinuous, or even unstable when the camera is switched. In light field camera scheme, Tsai et al. 35 combine the robot IBVS with a light field camera to reduce partial occlusion of the manipulated object compared to the monocular VS method.
The above two kinds of methods can solve the problem of FOV constraints from different aspects. The common purpose of the proposed methods is to always keep the manipulated object in the camera’s FOV during the robot manipulator VS. Contrary to the above methods, we integrate the tracking learning detection (TLD) algorithm into a classical VS loop and propose a robot manipulator VS method based on improved TLD algorithm to achieve the VS of the robot manipulator with weak FOV constraints.
The TLD algorithm was proposed by Kalal. 36 The significant difference between the TLD algorithm and the traditional tracking algorithm is that it combines the traditional tracking algorithm with the traditional detection algorithm to solve the problems of deviation from FOV, deformation, and occlusion of object in the process of tracking. At the same time, the feature point of the tracking module and the model of the detection module are continuously updated through the online learning mechanism so that the tracking results have better stability, robustness, and reliability. To realize the robot manipulator visual object tracking task with high robustness under the weak FOV constraints, an improved TLD algorithm is proposed in this article. Compared with the TLD algorithm, 36 this article uses LOG-FAST 37 operator to extract features in the tracking module, which makes the learned feature points to have higher robustness, reliability, and stability, thus improving the robot manipulator tracking performance. Meanwhile, this article designs the new analysis module to obtain the image feature of the manipulated object (object in/out the camera FOV). Furthermore, it is more stable, robust, and reliable to complete the robot manipulator VS task under the weak FOV constraints. On this basis, we further combine the TLD algorithm with the IBVS method and propose a VS method based on improved TLD algorithm, which effectively solves the servoing task failure problem caused by the manipulated object deviation from the camera FOV during the VS. To the best of our knowledge, very few experimental results have been obtained on this topic.
The main contributions and novelty of this article can be outlined as follows: Aiming at the robust object tracking for VS of robot manipulator with weak FOV constraints, the LOG-FAST operator is used to extract the feature points in the improved tracking module, which makes the learned feature points to have higher robustness, reliability, and stability. Based on this, a new analysis module is designed to obtain the current image features used for the VS, including the object both visible and invisible. Integrating the improved TLD algorithm into a classical VS loop, a visual sliding mode control law is designed under the IBVS framework, which better solves the problem of the failure of the servo task caused by the manipulated object deviation from camera FOV during the VS. The effectiveness of the proposed VS method of dealing with the FOV issue has been successfully tested using a real six-degrees-of-freedom (6DOF) industrial robot manipulator MOTOMANSV3 with eye-in-hand configuration.
The remaining part of this article is organized as follows: The overview of algorithm framework is briefly introduced in the second section. The detailed description of the principle and the implementation are described in the third section, where we proposed a new analysis module and VS method of dealing with the FOV issue. Real robot manipulator VS experimental results and analysis are given in the fourth section. The fifth section will conclude the article by discussing the proposed approach and give further research work.
Overview of algorithm framework
This article integrates the improved TLD method into a classic IBVS structure and proposes a robot manipulator VS method based on improved TLD to solve the FOV constraint problem and achieve the VS of the robot manipulator with weak FOV constraints. The system block diagram is shown in Figure 1. The main implementation process of the proposed method is as follows:
Step1: Initialization. The object to be manipulated is selected in the initial frame and it is defined by a bounding box. Then, the object model, improved tracker, and detector are initialized, respectively.
Step 2: Estimating the manipulated object position in the current image frame. The image features
Step 3: Designing the visual control law. The visual sliding mode control law is designed according to the image feature errors for controlling the motion of robot manipulator. Finally, the robot manipulator VS task with weak FOV constraints is completed.
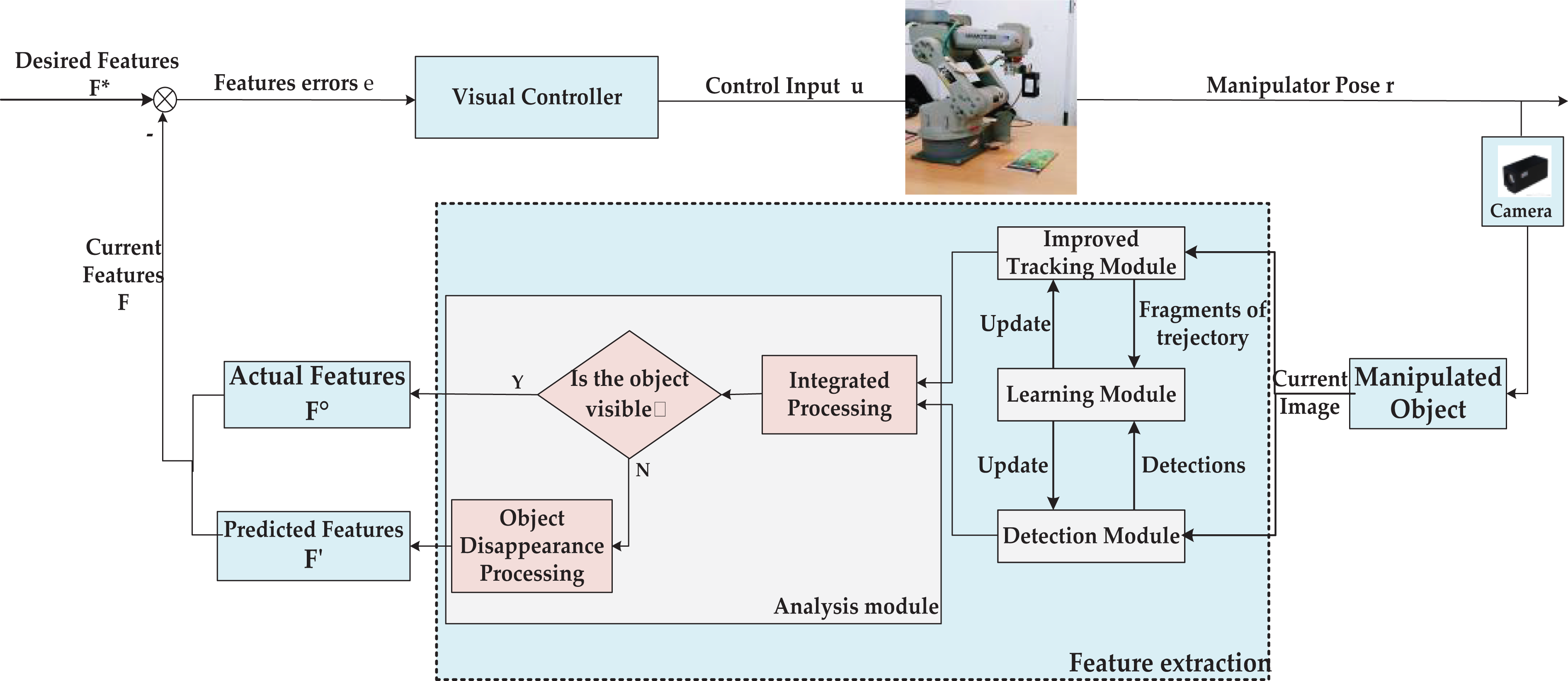
The block diagram of the proposed robot manipulator VS system based on the improved TLD. TLD: tracking learning detection; VS: visual servoing.
Obviously, visual feature extraction and visual control law design are the two main parts of the proposed VS method. In the following section, we will further give a detailed description of the principle and the implementation of the two parts.
Feature extraction
The purpose of the feature extraction is to estimate the manipulated object position in the current image frame, including the object both visible and invisible. It can be realized using video object tracking technology. To meet the requirements for robust, stable, and reliable tracking of the manipulated object under weak FOV constraints, this article provides an improved TLD algorithm for VS with weak FOV constraints. The block diagram of the proposed improved TLD algorithm is shown in Figure 2. Firstly, the object to be manipulated is selected in the initial frame, and the object model, improved tracker, and detector are initialized, respectively, according to the selected object area. Then, the improved tracking module and the detection module process in parallel to estimate the manipulated object position in the current frame, respectively. At the same time, both results are involved in the learning process. After learning, the object model reacts on the tracker and detector to update the detector in real time so as to improve its performance. After that, the analysis module integrally processes the output of the improved tracking module and the detection module to judge whether the manipulated object is visible. Thus, the actual image features or predicted image features are obtained.
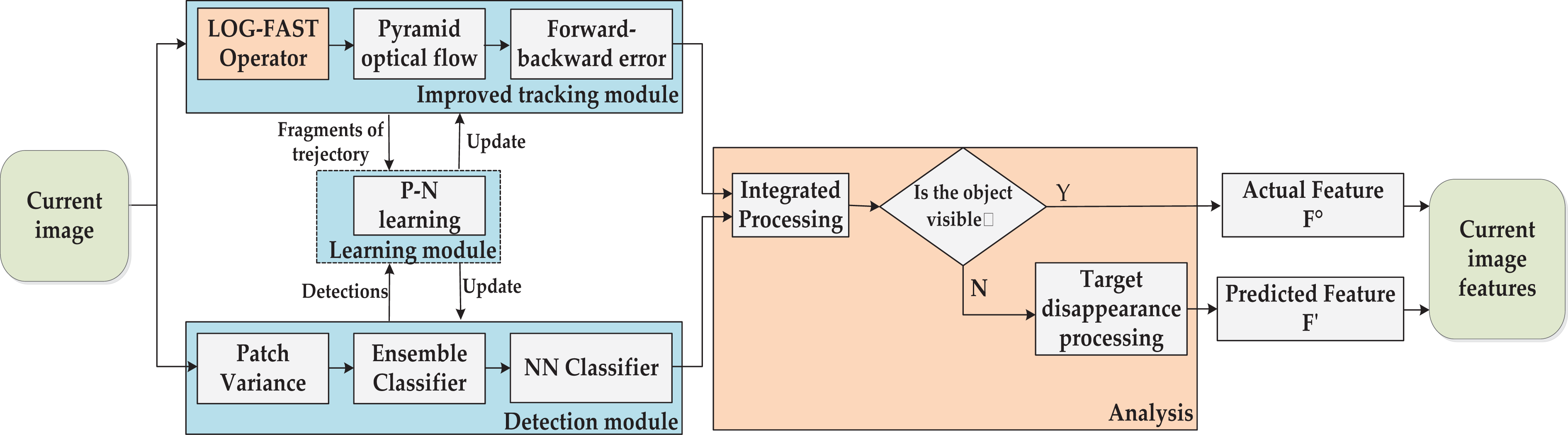
Schematic diagram of the proposed improved tracking-learning-detection algorithm for VS with weak FOV constraints. VS: visual servoing; FOV: field-of-view.
In summary, feature extraction is mainly composed of four modules: improved tracking module, detection module, learning module, and analysis module. In the following subsections, we will focus on the principles and specific implementation of each module.
Improved tracking module
The function of the tracking module is to estimate the manipulated object position in the current image frame. The original TLD tracking module algorithm extracts feature points uniformly on the object for tracking, but it cannot guarantee that each point can be reliably tracked by the pyramid L-K optical flow method. If the gray value of the selected feature points changes smoothly or even unchanged, it will lead to tracking drift or even failure. Therefore, this article uses LOG-FAST operator to extract features with higher robustness, reliability, and stability, and to improve the performance of tracking module. Figure 3 shows the basic process flow of the improved tracking module.

The schematic diagram of the improved tracking module.
The implementation process is as follows: First of all, LOG-FAST operator is used to select several pixels as feature points on the object bounding box of the previous frame, and pyramid L-K optical flow tracking algorithm is used to track these feature points. Then, the displacement changes of these feature points between adjacent frames are sorted to get the median value of displacement changes. Using the median value, 50% feature points that are less than the median value are obtained, and the 50% feature points are taken as the feature points of the next frame, and proceed in turn so that the dynamic updating feature points are realized. In the tracking process, di represents the displacement of a feature point and dm represents the median of all feature point displacements. If the residual
Detection module
The purpose of the detection module is to filter the scanning window containing the object of the current image. Detection results can be obtained using the cascade classifier to filter the scanning window, which is formed by the current frame. Cascade classifiers mainly contain patch variance, ensemble classifier, and nearest neighbor classifier. Because the three classifiers are cascaded, only the scanning windows satisfying all classifiers are considered to contain the manipulated objects. Figure 4 is the principle schematic diagram of the detection module. The algorithm uses the detection module to detect the object position quickly and reliably in the current image.

The principle schematic diagram of detection module.
Learning module
The function of the learning module is to initialize the detector in the initial frame and update the parameters of the detector in the following tracking process using the estimated results of the tracker to improve tracking performance.
The learning module is an algorithm based on PN (P-N experts) learning. In the PN learning algorithm, P refers to positive constraint, also called P-expert or growing event, and N refers to negative constraint, also called N-expert or pruning event. The role of P-expert is to discover the new appearance (deformation) of the object and to increase the number of positive samples, thereby making the detection module more robust. The role of N-expert is to generate negative training samples. The premise of N-expert is that the (tracked) foreground object can only appear in one position in the video frame. Therefore, if the position of the foreground object is determined, then its surroundings must be negative examples. In other words, P-experts increase the robustness of the classifier, while N-experts increase the discriminative ability of the classifier. So, P-N learning is used for online learning of the detector during the tracking. The entire working process of the learning module based on the PN learning algorithm can be summarized as follows: First, according to some classified samples, use the supervised learning method to train and obtain the initial classifier; after that, use the classifier obtained in the previous iteration to classify all unlabeled samples, and use the P-N learning method to find and correct the misclassified samples, and then add them into the training sample; finally, the parameters of the classifier are updated by supervised training.
Analysis module
When the object is invisible, the original TLD algorithm can only judge the object disappearance and stop tracking. When the object enters the FOV again, it can track the object again. However, the robot manipulator VS system needs to continuously calculate the visual control input according to the image features errors, to realize the long-term and smooth tracking for the object and prevent the robot manipulator from getting out of control. Therefore, this article designs an analysis module to acquire the current image features of manipulated object and adopts an integrated processing strategy to comprehensively process the output results of the improved tracking module and detection module, and judge whether the manipulated object is visible. If the manipulated object is visible, the actual detected image features are obtained. If the manipulated object is not visible, the predicted image features can be obtained through the object disappearance processing strategy. Obviously, the integrated processing strategy and the object disappearance processing strategy are the two core parts of the analysis module. Next, we will introduce the specific implementation of the two parts from the following two cases such as object visibility and object invisibility.
Case1 object visible
If the manipulated object is in the camera FOV, the object position can be determined by integrally processing the output results of the tracking module and the detection module, and the current image features are obtained.
In each frame image of the robot VS, the object to be manipulated is detected and represented by a rectangular bounding box. Then, the current image features can be represented according to the length, width, and center of the rectangular box as

where
Case1 object invisible
In the process of the manipulator tracking a moving manipulated object, if the manipulated object is seriously occluded or even disappeared in the camera FOV, the integrated processing strategy can judge that the object disappears according to the output of the detection module and the tracking module. To continue the servoing task of robot manipulator, this article proposes an object disappearance processing strategy to predict the position of manipulated object in the current image and to calculate the image features errors by using the predicted object position.
Generally, the main reason for the object disappearance is that the object is heavily occluded or out of the camera FOV, so, the probability of the object reappearing near the vanishing point is very high. Therefore, it is a good solution to search the manipulated object near the object vanishing point according to the image features of the previous frame before the disappearance of the object. The manipulated object position
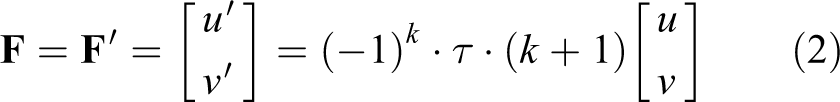
where
Design of visual sliding mode control law
In this article, an improved TLD algorithm is integrated into a classical IBVS framework for solving the problem of FOV constraints during the VS. The whole servoing system is mainly composed of two parts, such as image feature extraction and visual controller design. This section will introduce the design of visual control law in detail.
Sliding mode control theory is applied to the design of the visual control law under the IBVS framework in this article. The whole design process consists of two parts, including the design of the sliding mode surface (sliding manifold) function and the design of the sliding mode control law. Firstly, the sliding mode surface function s is designed to make the sliding mode asymptotically stable and have good dynamic properties; then, the sliding mode control law
So, the sliding surface function can be designed as

In robot manipulator VS system, the relationship between the motion velocity

where
Therefore, the visual sliding mode control law
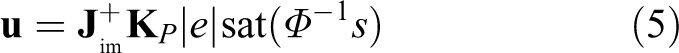
where

Experiment results and analysis
To verify the effectiveness of the VS method based on the improved TLD algorithm with weak FOV constraints proposed in this article, two groups of experiments under weak FOV constraints were carried out, including video object tracking experiments and robot manipulator VS experiments.
Video object tracking experiments
This experiment purpose is to verify the tracking performance of the proposed tracking algorithm with weak FOV constraints. The video used in the experiment comes from OTB-100 data set in VTB (http://cvlab.hanyang.ac.kr/tracker_benchmark/datasets.html), which is a standard object tracking evaluation benchmark. The selected test video sequence contains various challenging attributes, such as background clutters (BC), deformation (DEF), out-of-view (OV), and low resolution (LR), which are the representative scenarios for robot VS system, especially in weak FOV constraints.
In this experiment, the tracking object is the pedestrian in the video, and the tracking result is shown in Figure 5. It can be seen from Figure 5 that the appearance of the object is greatly deformed for the pedestrian turning into the store in #128 and #149, as shown in Figure 5(c) and (d), and the improved TLD method proposed in this article can still track the object accurately. When the object is completely beyond the FOV, as shown in Figure 5(e), the tracking algorithm can judge that the object disappears in the current image frame. When the object appears in the camera FOV again, as shown in Figure 5(f), the pedestrian walks out of the store in #546, and the tracking algorithm can continue to track the object.
It can be seen from the experimental results of video object tracking, as shown in Figure 4, that the proposed tracking algorithm has good tracking performance in some challenging scenarios, such as BC, DEF, OV, LR, and so on.

Pedestrian tracking experiment results: (a) #1, (b) #61, (c) #128, (d) #149, (e) #200, and (f) #546.
Table 1 presents the quantitative comparison results of the improved TLD method proposed in this article with the original TLD method, 36 using three tracking performance evaluation indicators, 36 such as precision P, recall R, and f-measure F.
Comparison of video test results.

TLD: tracking learning detection.
It can be seen from Table 1 that the tracking performance of the proposed tracking method is better than that of the original TLD method, 36 and it can be used for the robot VS system with weak FOV constraints.
Robot manipulator visual servoing experiments
Experimental platform and related parameter setting
The experimental platform of online object tracking is mainly composed of a 6DOF MOTOMAN-SV3XL industrial manipulator, robot control cabinet, digital camera, and control computer. The digital camera is mounted on the robot manipulator end-effector and could be moved with the robot manipulator, which is called eye-in-hand camera-robot configuration, as shown in Figure 6(a).

(a, b) Experimental platform.
In this experiment, the object to be manipulated is the cartoon character (little girl) on a booklet cover, and the color and texture of the cover of a booklet are very complex, as shown in Figure 6(b). The blue rectangular bounding box is used to represent the object to be manipulated. The red points in the rectangular bounding box are the feature points extracted by the proposed tracking module mentioned in “Improved tracking module” section. The resolution of the captured image in the experiment is 1024 × 768 (pixels), then the desired image features
Robot manipulator visual tracking experiment
In this section, two robot manipulator visual tracking experiments, including VS with deviation from FOV and the VS with heavy occlusion, were conducted to verify the effectiveness of the proposed VS method under the weak FOV constraints.
Experiment 1: VS of robot manipulator with deviation from FOV
To verify the effectiveness of the proposed VS method for manipulator tacking an object in the natural scene, the manipulated object is artificially moved outside the camera FOV and appears in the camera FOV again during the VS. Experimental results are shown in Figure 7. At the beginning of the VS task, the robot manipulator stays its predefined initial posture and the camera attached to the end-effect of the manipulator will capture the current image frame, as shown in Figure 7(a). In Figure 7(a), the blue rectangular bounding box represents the object to be manipulated, that is, the cartoon characters (little girls), and the red points in the rectangular box are the feature points selected by the tracking module. Figure 7(b) shows one of the tracking results during the VS. After that, the tracked or manipulated object is artificially moved out of the camera FOV, as shown in Figure 7(c), the feature extraction algorithm proposed in this article can detect the object disappearance, and the object disappearance processing strategy proposed in section 3.4 is used to make robot manipulator search near the disappearance of the manipulated object, and the current image features, in this case, can be computed by equation (2). When the manipulated object appears in the camera FOV again, and the robot manipulator continues to execute the servoing task until the image feature errors equals zero or is smaller than a threshold, the robot, manipulator VS task will be accomplished, as shown in Figure 7(d).

VS results of robot manipulator with deviation from FOV: (a) #1 (initial frame), (b) #8 (middle frame1), (c) #14 (middle frame2), and (d) #39 (end frame). FOV: field-of-view.
Experiment 2: VS of robot manipulator with occlusion
To verify the effectiveness of the proposed algorithm for handling occlusion on the manipulated object, the occlusion is artificially placed on the manipulated object in this VS experiment. On the basis of experiment 1, the occlusion (the bear ornaments) is placed artificially on the manipulated object in the VS process, as shown in Figure 7. First, the manipulated object is continuously translated and rotated in the whole VS process, as shown in Figure 8(a) and (b); then, after #23, the occlusion is artificially set, and the occlusion occludes the manipulated object area more than 90%. The robot manipulator finds that the object is severely occluded in the next frame, and the similarity with the existing object model is very low. So, it considers that the manipulated object is invisible, as shown in Figure 8(c); after that, the robot manipulator uses the object disappearance processing strategy proposed in “Analysis module” section to find the manipulated object. Finally, when the occlusion is removed, the robot manipulator can quickly redetect the manipulated object and continue the servoing task.

VS results of robot manipulator with occlusion: (a) #1 (initial frame), (b) #18 (middle frame1), (c) #23 (middle frame2), and (d) #28 (end frame). VS: visual servoing.
Further discussion
In summary, the above two experiments can qualitatively show that the proposed VS method based on improved TLD can complete the VS task in a complex environment with weak FOV constraints. To analyze the experiment quantitatively, we further give the corresponding change curves for each variable, such as control input change curves, the tracking trajectory, and the tracking error curve in the directions u and v, and so on, as shown in Figure 9.

The results of tracking experiment. ① VS of robot manipulator with deviation from FOV; ② VS of robot manipulator with occlusion. (a) The control input change curves in directions u and v; (b) the tracking trajectory in directions u and v; (c) the tracking error curves in directions u and v; and (d) the error curves of image plane. FOV: field-of-view.
It can be seen from the tracking trajectory curve in directions u and v, as shown in Figure 9①(b) to (d), that the current image features can still eventually converge to the desired image features, that is, the manipulator can still track the object even the object deviates from FOV and appears in the camera FOV again during the VS. Meanwhile, it can be seen from the control input change curves in directions u and v, as shown in Figure 9①(a), that our method allows the object to deviating from the camera FOV in continuous several frames and maintains the smoothness of the robot manipulator motion. Figure 9 ③(a) to (d) shows that our method can make robot manipulator smoothly move when the manipulated object is severely occluded and make the image feature errors quickly converge to zero when the occlusion disappears.
The tracking performance indicators of the above three VS experiments are listed in Table 2. It can be seen from Table 2 that the object is affected by deviation from FOV and occlusions in different situations during the servoing process, but its precision P can still reach 1, the recall R reaches 0.95, and the f-measure F at around 0.97.
Tracking performance indicators of the three VS experiments.

①: VS of robot manipulator with deviation from FOV; ②: VS of robot manipulator with Occlusion; VS: visual servoing; FOV: field-of-view.
In summary, the robot manipulator VS method based on improved TLD with weak FOV constraints proposed in this article can accomplish the object tracking task in a complex environment. Therefore, although the object is interfered by deviating from FOV and occlusion during the servoing process, VS system still can continue to track the manipulated object successfully through online learning to reduce the influence of interference.
Conclusion
In this article, a VS method based on improved TLD of robot manipulator with robustness under the weak FOV constraints is proposed. The results of VS experiments under the weak FOV constraints on the MOTOMAN SV3 6DOF Industrial robot manipulator in complex natural scenes show that the method proposed in this article allows the manipulated object to deviate from the camera FOV in continuous several frames while maintaining the smoothness of the manipulator motion in the VS process. The servoing algorithm has good robustness to the occlusions, and so on, and effectively solves the problem that the servoing task fails caused by the object deviation from the camera FOV during the VS process. In the future, we will further study the visual-based robot manipulator dynamic object autonomous grasping based on the work of this article combined with deep learning and deep reinforcement learning.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Chinese National Natural Science Foundation under grant nos 61873200, 61833013, and U20A20225.