
Abstract
Visual tracking is fundamental in computer vision tasks. The Siamese-based trackers have shown surprising effectiveness in recent years. However, two points have been neglected: firstly, few of them focus on fusing the image level and semantic level features in neural networks, which usually resulting in tracking failure when differentiating the target from other distractors of the same class. Secondly, the robustness of the previous redetection scheme is limited by simply expanding the search region. To address these two issues, we propose a novel multilevel feature-weighted Siamese region proposal network tracker, which employs a feature fusion module to construct discriminative feature embedding and a similarity-based attention module to suppress the distractors in the search region. Furthermore, a color-based constraint module is presented to further suppress the distractors with the same class to the target. Finally, a well-designed global redetection scheme is built to handle long-term tracking tasks. The proposed tracker achieves state-of-art performance on a series of popular benchmarks, including object tracking benchmark 2013 (0.699 in success score), object tracking benchmark 2015 (0.700 in success score), visual object tracking 2017 (0.470 in expected average overlap score), and visual object tracking (0.485 in expected average overlap score).
Introduction
Visual tracking is a technique to track the target in an image sequence given the target’s bounding box in the first frame as the template. With the progress of computer vision, this task has received close attention in recent years and is widely used in intelligent applications, such as robotics, autonomous car, and video surveillance. In the development of visual tracking, many excellent works have been proposed. Most of them have addressed several challenging problems such as vague target, rotation, deformation, and illumination variation. Furthermore, other works in long-term (LT) visual tracking focus on overcoming the target disappearance in a video.
Recently, due to the trade-off between accuracy and speed, trackers based on the Siamese network 1 –15 are considered as the mainstream methods. Siamese-based trackers were proposed. They extract features of the template and a search frame by two convolution structures with shared weights and generate a similarity map between the template and this frame. What’s more, some improved Siamese-based trackers can be used to predict target deformation 5 –7,9,16 –24 or even directly output target segmentation, 15 which have made significant achievements. However, two key issues remain. Firstly, the existing Siamese-based methods perform poorly in distinguishing the target and the distractors with the same class of the target. The reason is that conventional Siamese-based trackers utilize the backbone of the classification task. Thus, the high-level features fail to represent the difference between the target and other objects with the same class. Based on these features, the obtained similarity map is also unreliable to distinguish the target and others. As shown in Figure 1, the previous method has high responses on the distractors, that is, the referee, athletes marked in red, where the response indicates the similarity between these candidates and the template. Secondly, the previous redetection scheme simply expands the search region, thus limiting the performance of the LT tracking.

Visualization of the similarity of Siamese-based tracker. (a) The template, (b) the search region, target, and distractors are marked in green and red boxes, respectively, and (c) the similarity maps of different Siamese-based trackers. Yellow and blue indicate high and low similarity.
In this article, we argue that since the high-level cue of the target and a same-class object are similar, the low-level cue plays a key role in this case. In contrast, high-level cues are essential to distinguish the target from other similar appearance objects. Thus, the features of different levels are useful in different conditions. For this reason, we propose a multilevel feature-weighted Siamese region proposal network (MFW-SiamRPN). In contrast to the previous works, a feature fusion module (FFM) is designed to fuse all level features to a unified representation, which is used to encode the similarity between the template and each sliding window in the search region. Then, we design a similarity attention module. It utilizes channel attention to suppress channels that fail to distinguish template and distractors and utilizes spatial attention to suppress the similarities between template and distractors. Besides, to make full use of the color information lost in the deep network, a color-based constraint module (CCM) is proposed to suppress the network’s output. Finally, to track a target in LT scenarios, a global redetection scheme is proposed to detect the occurrence that the target is out of the view and redetect the target, which is simple but efficient.
In general, the main contributions can be summarized as follows: To distinguish the target and other distractors, we propose an MFW-SiamRPN (MFW-SiamRPN). It utilizes multilevel cues to template and search region and suppresses other distractors by a similarity attention module. A CCM, which takes full use of color information, is designed to constraint the network output. A well-designed global redetection scheme is proposed, which ensures the robustness of the proposed tracker and outperforms other Siamese-based trackers in LT tracking. Our method outperforms the existing state-of-the-art methods on the fashionable benchmarks: object tracking benchmark (OTB)-2013,
25
OTB-2015,
26
visual object tracking (VOT)-2017,
27
VOT2018,
28
and VOT-2018-LT.
29
Moreover, abundant ablation studies verify our point of view and the effectiveness of each module.
Related work
Review of Siamese-based trackers
Recently, trackers based on the Siamese network draw great attention for their remarkable performance in both accuracy and efficiency. These methods employ two identical networks initialized in the classification task (e.g. AlexNet, 30 Visual Geometry Group (VGG), 31 ResNet, 28 and MobileNet 32 ) to extract features from the template and search region and locate the target by matching the template. Generic Object Tracking Using Regression Networks (GOTURN) 33 directly concatenates the features of the template and search region and employs several fully connected layers to locate the target. Siamese Instance Search for Tracking (SINT) 34 constructs the vectors of the target and several candidates by region-of-interest pooling and then outputs the candidate most similar to the template. Fully convolutional (FC) Siamese networks (SiamFC) 1 proposes a cross-correlation layer to obtain the similarity between the target and the search region, improving accuracy and efficiency. Based on SiamFC, RasNet 3 proposes a residual attention module, which reduces the noise in the deep features. As shown in Figure 2(a) and (b), SiamRPN 5,24 and SiamRPN++ 7 use a well-designed region proposal network (RPN) 35 to predict the position and deformation of the target simultaneously and outperform other Siamese-based trackers. However, since the backbones used in these methods are all pretrained in the classification task, the inherent difference between the two tasks, namely, classification and tracking, making the deep feature fail to represent the difference between the target and other objects with the same class. We propose MFW-SiamRPN and CCM to overcome this issue. As shown in Figure 2, different from others, all level features are fused to represent the template and the search region.

Structure comparison. (a) SiamRPN 5 exploits the highest-level feature for similarity calculation. (b) Siam RPN++ 7 employs the last three-level features of encoder to construct the similarity. (c) Our network takes both the low-level image information and the high-level semantic information into account by a fusion module and further designs the attention of similarity to improve the accuracy. RPN: region proposal network.
LT tracking and redetection scheme
In visual tracking, the target is usually occluded or moved out of the view. To address the issue, the LT tracking redetects the target when the target returns to the view of the camera. There are mainly two types of methods for LT tracking. Firstly, some methods redetect the target by expanding the search region in the frame. DaSiamRPN 6 and SiamRPN++ 7 establish the reliable confidence score by specially designed training samples but thoughtlessly enlarge the search region while losing the target, which limits the performance of the LT tracking. Secondly, a few methods construct a redetection scheme. Skimming-Perusal Long-term Tracking (SPLT) 14 builds a global redetection scheme by training an additional network called skim-module and surpasses other methods that enlarge the search region. However, the additional skimming model requires feature maps of the whole search region and downsamples it to a vector, which brings high Graphics Processing Unit (GPU) cost and risk of low accuracy.
The redetection task could be divided into two steps, object detection and target identification. We find several simple but effective proposals to locate an object, 36 –40 and the excellent Siamese-based trackers could handle the target identification. 18 In the section “Redetection scheme for LT tracking,” we apply object proposal to locate candidate objects and combine our CCM with the Siamese network to identify the target.
Method
Our method is described in the following order. In the section “Multilevel feature-weighted SiameseRPN,” considering that the low-level feature plays a vital role in distinguishing the target and other objects, the MFW-SiamRPN is presented, which weights features of all levels and then suppresses the similarity between the false positives and the target. In the section “Color-based constraint module,” to take color information into account, a CCM is presented to constrain the network’s output. In the section “Redetection scheme for LT tracking,” the redetection scheme for LT tracking is proposed to address the issue that the target disappears or is fully occluded.
Multilevel feature-weighted SiameseRPN
Overview
We adopt SiamRPN
5
as the basic tracker. Figure 3 shows the structure of our network. Given the first frame I
1 and the current frame In
, the whole network takes a template

The pipeline of our network. The ResNet-50 is employed to extract the feature of the template region and the search region. Then an FFM is used to aggregate features of all levels to a unified feature map that is further used to calculate the similarity between template region and search region. Subsequently, two attention modules are introduced to improve the similarity map. After all, the predictor locates the target in the search region. FFM: feature fusion module.
Mathematically, let
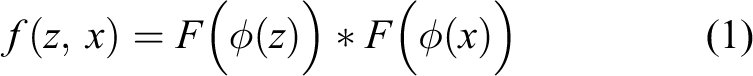
where ∗ denotes the depth-wise cross-correlation operation,
7
ϕ?represents the feature extraction of the backbone, that is, a ResNet-50 pretrained on ImageNet.
41
The channel number of the similarity map
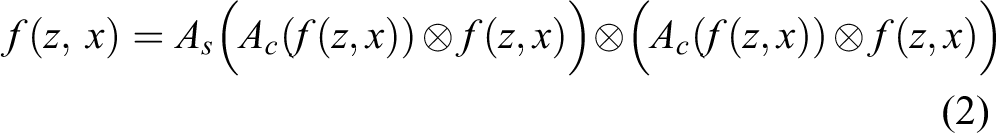
where

where C 1 denotes a 1 × 1 convolution operation, which adjusts the channels of f(z,x) to 2 (for CLS) and 4 (for REG). By using a SoftMax operation, CLS(z,x) is transformed into a similarity map of template and search region in the corresponding positions.
During training, we use the SoftMax loss function to supervise the CLS branch, while the REG branch is optimized by Smooth L1 loss function. The total training loss is the summation of them. Formally, for the CLS branch in our network, the prediction is denoted as

For the REG branch in our network, the prediction is denoted as

Feature fusion module
Based on the motivation: both the low-level feature and the high-level feature are crucial to distinguish the target and others, a FFM is proposed to capture the feature from all levels. In detail, the stage-n side-outputs of the backbone are represented as Res n. The features of the first two stages, namely Res 1 and Res 2, are down-sampled to one-eighth size of input images by two parallel pooling layers, namely average pooling and max pooling. The average pooling is to capture the relation between channels, and the max-pooling is to gather another important cue about distinctive object features. 42 Then, these down-sampled features are concatenated with Res 3, Res 4, and Res 5. Finally, a bottle-neck structure, namely a sequence of two 1 × 1 convolutions and a 3 × 3 convolution, is utilized to nonlinearly compress all the features and reduce the channel number to 512. Formally, the FFM can be formulated as follows

where MP()denotes the max pooling operation, AP()denotes the average pooling operation, Cat() denotes the concatenation operation, C 3() denotes the 3 × 3 convolution operation, relu() denotes the Rectified Linear Unit (ReLU) activation.
Since the low-level features contain little semantic information, such features could be used to distinguish two objects of the same class. In contrast, high-level features could be used to separate objects with different classes. Hence, multilevel features are all necessary to distinguish the target and other objects, and the fused features are better to represent all the objects than those in the previous works.
Attention based on similarity
As shown in Figure 3, the similarity

The detail of our channel attention (left), spatial attention (middle), and similarity maps after attention (right).

where Sig() denotes the sigmoid function, and X denotes the input feature. The spatial attention module As () is utilized to capture the interspatial relationship of similarity. Specifically, the feature map is firstly passed through a channel-wise max-pooling layer and a channel-wise average pooling layer to be down-sampled to two feature maps with one channel, respectively. For the input feature X with C channels, the channel-wise max pooling and average pooling can be formulated as follows

Then, these two one-channel feature maps are concatenated and passed through a 3 × 3 convolution and a sigmoid to generate the spatial attention

Finally, the output feature map can be formulated as follows

where the bolded
For the channel attention, since each channel’s discriminative ability in f(z,x) is different, the channel attention gives high weights to the channels of similarity f(z,x) with intense discrimination. Thus, compared to directly applying the original similarity to match the target, the weighted similarity better distinguishes the target and other distractors. For the spatial attention, since the pooled features contain each pixel’s discriminative channel, the spatial attention module weights all pixels, which enhances the response of the target and suppresses that of the distractors. Thus, our similarity attention enhances the difference between target and distractors in feature representation.
Color-based constraint module
Due to the normalization operation in Convolutional Neural Network (CNN), normalized color in different search regions and templates ranges variously, resulting in limited color information expression. To make full use of the color information, we propose the CCM, which takes the boxes predicted by the network as inputs and computes the color-based similarities between these boxes and the target. In detail, CCM contains three steps.
Firstly, assuming that the template z consists of two disjoint regions: the rectangle region of the target with size wT
×hT
(i.e. T) and the rest of the template z is denoted as background area (i.e. B), this module constructs the color histograms of the two regions, respectively. Specifically, we present one pixel in the template with RGB channels by a triplet
Secondly, according to the color histograms HT and HB , the probability that a pixel i in search region x belongs to target is obtained by the Bayes rule (see additional materials for detailed formula)

where

The area with blue in (a) is the region of the target (T), while the rest surrounding area is background (B), (b) is a similarity map generated by MFW-SiamRPN, (c) is the target probability map of x, and (d) is the search region x, the distractors with high NA scores are in red bounding boxes and the selected target is in green bounding boxes. MFW: multilevel feature-weighted; RPN: region proposal network.
Thirdly, we rerank the boxes given by the MFW-SiamRPN. Specifically, assuming that A = (xA , yA , hA , wA ) denotes a bounding box with the same representation of other articles. Thus, the target probability of box A is stated as the mean probability of all pixels inside A

where S(i) denotes the value of pixel i on the probability map S.
Then, we combine this color-based probability TSA with the score given by the network

where NA is the similarity score predicted by the CLS branch of our MFW-SiamRPN, Dxy is the distance between box A and the center of region x, PA is the deformation penalty of the bounding box A, which is referred to ref. 7 α is a constant to balance the Siamese network and the CCM. By utilizing Eq. (13), a more reliable target prediction is obtained than utilizing the network only, as shown in Figure 5(d).
Redetection scheme for LT tracking
To extend our network for LT tracking, we propose a redetection scheme, as shown in Figure 6. Since the score of the target SC given by CCM is reliable, the redetection scheme is activated if SC<0.7×SC2, where SC 2 denotes the target score in the second frame of the input video. The redetection scheme is composed of three steps: probability map-generating, object proposal, and target selection. Initially, the whole image is taken as the input, and a target probability map of this image is generated by Eq. (13) in CCM. Secondly, we employ the object proposal method, i.e. Edge boxes, 39 to obtain various bounding boxes with the same size as the target in the template or in the last frame. For clarity, we denote the bounding box as A, and its objectness score predicted by Edge boxes as OS (A). Finally, the boxes with the top 200 objectness scores are retained to the third step. Thirdly, all the bounding boxes {Ai |1≤i≤200} are reranked by the color-based probability. In more detail, by utilizing the target probability map given by the first step and utilizing Eq. (13), the target probability TS Ai is obtained. Then, the score for LT tracking SL Ai is formulated to rerank all the boxes


Comparisons of our MFW-SiamRPN tracker with state-of-the-art Siamese-based trackers in challenging scenes of OTB2015 benchmark. Our tracker shows more robustness on scenarios with similar distractors, occlusion, flurries, illumination variation, and so on. MFW: multilevel feature-weighted; OTB: object tracking benchmark; RPN: region proposal network.

where OS A is the objectness score of a bounding box A, TS A is the CCM score in the section “Color-based constraint module,” β is a constant to balance the object proposal Module and the CCM. Dxy is the distance between the bounding box and the center of an image, wI and hI are the width and height of an image, respectively. By top selection of the Sl A score, the top five candidate bounding boxes are left. These five candidates have a high probability of including objects and are similar to the target in color. Finally, five search regions centered on these candidates are sent into our Siamese network to predict the target’s location and size.
The whole redetection scheme in LT tasks could be seen in Figure 6. When the target disappears from the search region, it will obtain a low SC score and the tracker activates the global redetection scheme. The object proposal method helps our tracker locate candidate objects and the CCM helps our tracker filter out objects that are not similar to the target in color. Consequently, the Siamese network predicts the bounding box of the target precisely.
Experiments and evaluations
Implementation details
The training pairs of our Siamese network come from three data sets. Large-scale video detection data set (ImageNet Large Scale Visual Recognition Challenge [ILSVRC] 2015
41
) contains 4417 videos of 30 different objects and over 1 million images of 1000 different objects. Microsoft Common Object in Context (COCO)
43
data set contains 328,000 images of 91 different objects. YouTube-BoundingBoxes
44
data set contains 210,000 videos of 13 different objects. All labeled objects in these images and videos are cropped with the target centered in it and double the size of
The proposed Siamese network is trained for 20 epochs with a batch size of 20 and an initial learning rate of 10− 2 by using the stochastic gradient descent (SGD) solver. The momentum and weight decay are set to 0.1 and 0.5, respectively. Parameters of the backbone are frozen in the first 10 epochs and unlocked in the last 10 epochs to adapt to tracking tasks.
Evaluation on OTB data set
OTB2013 16 consists of 50 labeled videos and brings challenging scenes such as rotation, blur, and occlusion. OTB2015 26 is an extension of OTB2013, including 100 labeled sequences, and contains more complicated scenes. The precision score and the success score are used to evaluate the performance.
The precision score represents the ratio of predicted results (the distance between the predicted center and ground-truth center is within 20 pixels). The success score shows the Area Under Curve (AUC) of the successful plot. The x-axis of the success plot indicates the IOU threshold between the predicted and ground-truth result (varies from 0 to 1), whereas the y-axis shows the proportion of successful frames, which satisfied the IOU threshold. One-pass evaluation is employed for the evaluation.
Our tracker is compared with several state-of-art Siamese-based trackers, including SiamFC, 1 parallel tracking and verifying (PTAV), 4 RasNet, 3 Correlation Filter based Network (CFNet), 2 SiamRPN, 5 DaSiamRPN, 6 SiamRPN++, 7 SiamDW, 8 Siamese Cascaded Region Proposal Network (C-RPN), 9 Discriminative Model Prediction (DIMP), 10 GradNet, 11 and Meta-Learning Tracker (MLT). 12 Table 1 presents the precision scores and success scores of Siamese-based trackers mentioned earlier. As presented in Table 1, our tracker outperforms these state-of-art Siamese-based trackers over two benchmarks. Specifically, our tracker achieves the best precision (0.930 on OTB2013 and 0.915 on OTB2015). For the success score, our tracker superiorly performs against other evaluated methods (0.699 on OTB2013 and 0.7 on OTB2015). Compared with the AlexNet-based methods, our tracker benefits from the Res50 backbone and outperforms DaSiamRPN by 3.5% on the precision of OTB2015. Note that our method only achieves a little improvement over SiamRPN++, which is due to a lot of gray-scale videos in OTB 2015, and no color cue can be utilized. Besides, compared with other methods, whose backbone are deep CNNs, our tracker benefits from the FFM, the attention module, and the CCM. The res50 backbone extracts features that help to distinguish the target from the background. Low-level cues utilized by the FFM help our tracker distinguish the target from distractors with the same class, while high-level cues help our tracker distinguish the target from distractors with a similar appearance. The CCM replenishes color information, which is lost in normalization operation. The performance of our tracker proves the effectiveness of these modules.
Precision and success results on OTB2013 (left) and OTB2015 (right). Red bold type indicates the best performance, and blue bold type indicates the second-best performance (the same below).

FC: fully convolutional; OTB: object tracking benchmark; RPN: region proposal network; PTAV: parallel tracking and verifying.Evaluation on VOT data set
VOT2017 27 and VOT2018 28 consist of 60 sequences and show more difficult scenes than OTB benchmarks. We use the most-watched expected average overlap (EAO) score on the baseline benchmark as the evaluation standard. EAO is an estimator of the average overlap a tracker is expected to attain on a large collection of short-term sequences. Besides, we also choose the accuracy (average overlap when tracking successfully) and the Robustness (failure times) as evaluation standards.
As shown in Table 2, our tracker is compared with the state-of-art tracking algorithms, including SiamFC, SiamRPN, DaSiamRPN, SiamRPN++, SiamDW, C-RPN, GradNet, DIMP, UpdateNet. 13 Our approach shows the best EAO score (0.470 on VOT2017 and 0.485 on VOT2018). SiamRPN++ and DIMP have the same backbone as our tracker. These three Res50 based trackers have similar accuracy scores. Moreover, DIMP shows less tracking failures (0.153) followed by our tracker (0.201). As to the most concerned EAO score on VOT2018, our tracker outstands the DIMP by 4.5% and SiamRPN++ by 7.1%, respectively, which sufficiently proves the effectiveness of the proposed method.
Evaluation results on VOT2017 (left) and VOT2018 (right).

FC: fully convolutional; VOT: visual object tracking; A: accuracy; EAO: expected average overlap (both larger are better); R: robustness score (smaller is better); RPN: region proposal network.
Evaluation on the VOT2018-LT data set
We choose the VOT2018-LT 29 data set with a lot of completely lost scenes to show the superiority of our redetection scheme. This data set includes totally 146,847 frames with 35 sequences of various objects. Each sequence contains at least 1000 images and average 12 LT object disappearances. The main evaluation protocol of the VOT2018-LT data set is F1 score which is defended by

where θ is a given threshold. Pr(θ), Re (θ) are the precision, recall, and F1 score under the corresponding threshold, respectively. The threshold varies from 0 to 1 to find the maximum F1 score.
Accordingly, we choose some trackers specifically optimized for LT tracking to compare their performance, including, SiamFC, DaSiamRPNLT, SiamRPN++LT, PTAVplus, 4 and SPLT. 14 The evaluation result is placed in Table 3.
Evaluation results on VOT2018-LT (for all metrics, larger is better).

FC: fully convolutional; VOT: visual object tracking; RPN: region proposal network; LT: long-term; PTAV: parallel tracking and verifying.
Compared with none redetection trackers, our tracker has advantages in the F1 score for these two trackers only enlarge the search region without an appropriate redetection scheme. Based on its outstanding network backbone and redetection scheme, even our tracker still has advantages over SPLT that build a redetection scheme from the F1 score (an improvement of 2.5%).
Ablation studies
In this section, we firstly present the positive function of the MFW-SiamRPN and CCM in short-term tracking tasks. Then, the analysis of LT tasks is brought out to show the contribution of the redetection scheme in Table 4.
Ablation study of our tracker on OTB2015 (success score), VOT2018 (EAO score), and VOT2018-LT (F1 score).

OTB: object tracking benchmark; VOT: visual object tracking; FFM: feature fusion module; CCM: color-based constraint module; RPN: region proposal network; LT: long-term; L1–L5: Res1–Res5, respectively; Att: the proposed attention module; Ta: the proposed CCM; Re: the proposed Re-detection scheme.
Analysis of FFM
To pursue the influence of our FFM on the tracking result, the features of the first two layers are trained with a single output structure. The comparison among iv–viii shows that by independent operation, the features of Res1 and Res2 perform terribly in both OTB2015 and VOT2018 benchmarks. ix and xii show that the introduction of features from Res1 and Res2 can improve the performance on the VOT2018 benchmark by 0.6% but reduce the performance on OTB2015 by 0.6%, which is due to the inefficient features fusion. The performance gap between independent operation (iv–viii) and collaborative operation (ix, xii) of multilevel features confirms our conclusion that all features of the backbone should be taken into consideration. From ix, xii, and xiii, we find that simply using the average outputs of multilayers is not an appropriate solution. The FFM gains an improvement of 1.1% over the average type baseline, which fully proves the effectiveness of the proposed FFM.
Analysis of attention structure
From Table 4, we can also deduce the advantages of our attention structure. The xiii and xiv present that, through our attention structure, the feature-fused Res50 tracker gets a competitive performance (0.461 on EAO) 4.7% better than SiamRPN++ and 3.0% than the fused baseline. What’s more, to investigate the impact of different attention types, some additional attention evaluations are proposed in Table 5. Evaluations in Table 5 show that by changing the order of channel attention and spatial attention, there is a slight drop of 0.4% on the success score in OTB2015, which is in contrast to an increase of 0.1% on EAO in VOT2018. In the VOT2018 benchmark, channel attention and spatial attention bring an increase of 0.9% and 2.4%, respectively.
Evaluation results on different types of attention.
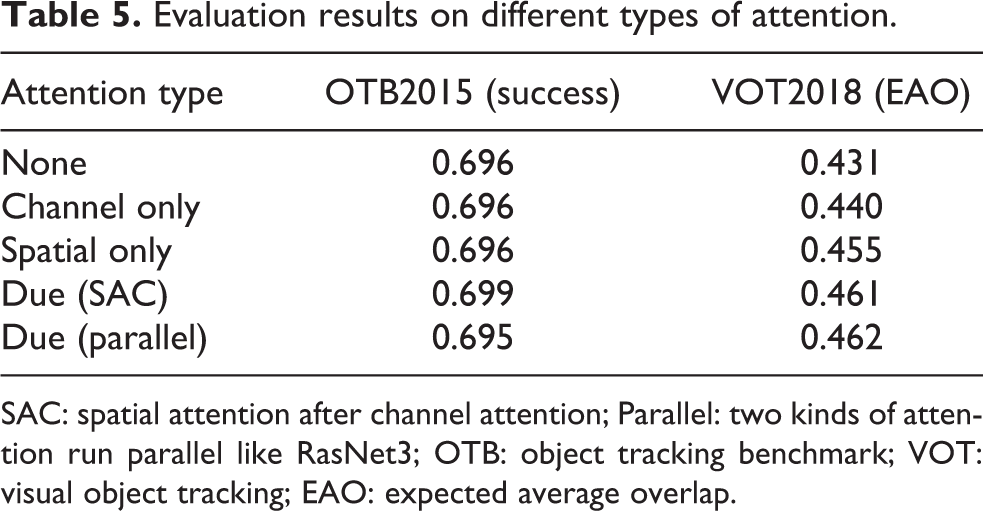
SAC: spatial attention after channel attention; Parallel: two kinds of attention run parallel like RasNet3; OTB: object tracking benchmark; VOT: visual object tracking; EAO: expected average overlap.
Analysis of color-based constraint module
The xiv and xv in Table 4 prove the advantages of our CCM. Our tracker gains an improvement of 2.4% on the VOT2018 benchmark. However, our CCM does not work on gray sequences and brings little improvement in OTB2015. Furthermore, we infer that the absence of color information should be a generality problem for all Siamese networks. The ii, x, and xv in Table 4 confirm this speculation. Our CCM brings an improvement of 3.4% for DaSiamRPN and 0.7% for SiamRPN++.
Analysis of redetection module
The comparison of xv and xvi in Table 4 shows that the MFW-SiamRPN tracker with our global redetection scheme has an improvement of 2.6% on the VOT2018-LT benchmark. What’s more, any tracker that lacks a global redetection process could benefit from our redetection scheme on LT benchmarks. The comparison of x and xi in Table 4 shows that SiamRPN++ with our global redetection scheme gains a 0.2% improvement. At the same time, ii and iii in Table 4 show that our global redetection scheme brings an improvement of 1.4% for SiamRPN.
Conclusion
In this article, we present a novel MFW-SiamRPN to track the template in a video. Our contributions are motivated by two intuitions. Firstly, too much attention to high-level features leads to ignorance of the capability of low-level features to differentiate between same-class objects. For this reason, the FFM is designed to aggregate features from the lowest level to the highest level. Then, similarity attention is proposed to select more discriminative features and suppress the similarity between distractors and the target. And the CCM is proposed to make full use of the color information lost in the deep network. As a result, our method tracks the target stably even when same-class objects interfere. Secondly, to track the target robustly in an LT video, a global redetection scheme is proposed to precept the target’s condition and redetect the target. Numerous experiments on several data sets demonstrate the effectiveness of our method.
Footnotes
Author contribution
Song Guiling and Zhang jingyi are contributed equally to this work, and the contributions of other authors are in the order of the author sequence.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.