
Abstract
Human action segmentation and recognition from the continuous untrimmed sensor data stream is a challenging issue known as temporal action detection. This article provides a two-stream You Only Look Once-based network method, which fuses video and skeleton streams captured by a Kinect sensor, and our data encoding method is used to turn the spatiotemporal temporal action detection into a one-dimensional object detection problem in constantly augmented feature space. The proposed approach extracts spatial–temporal three-dimensional convolutional neural network features from video stream and view-invariant features from skeleton stream, respectively. Furthermore, these two streams are encoded into three-dimensional feature spaces, which are represented as red, green, and blue images for subsequent network input. We proposed the two-stream You Only Look Once-based networks which are capable of fusing video and skeleton information by using the processing pipeline to provide two fusion strategies, boxes-fusion or layers-fusion. We test the temporal action detection performance of two-stream You Only Look Once network based on our data set High-Speed Interplanetary Tug/Cocoon Vehicles-v1, which contains seven activities in the home environment and achieve a particularly high mean average precision. We also test our model on the public data set PKU-MMD that contains 51 activities, and our method also has a good performance on this data set. To prove that our method can work efficiently on robots, we transplanted it to the robotic platform and an online fall down detection experiment.
Introduction
In modern society, more and more people spend their elderly life living alone. These phenomena may cause a potential risk due to the inadequate ability of the elder people to take good care of themselves. That is also the reason why the supervision of the elderly has become a concerning issue. The United States Centers for Disease Control and Prevention 1 provides a research that has shown that the most likely to cause injury or even death to people over 65 years of age is falling. The study showed that elderly people who get help in time after a fall can effectively reduce the risk of death by 80% and the risk of hospitalization for long-term treatment by 26%. 2 To cope with these problems in a better way, an intelligent service robot that can corporate with people in the family environment is needed. With the help of a reliable algorithm, intelligent service robots can provide better performance in the family environment, which means researches that focus on human action detection become more and more crucial.
Human action detection has been paid more and more attention since its massive potential applications in video analysis, surveillance, and other areas. 3 –8 Generally, without automatic action fragment extraction, human action recognition, as a special case of temporal action detection (TAD), requires a well-trimmed video that contains only target action. 9 TAD, however, must determine both time intervals and types of human actions from possibly untrimmed long video sequence. 10 The spatial–temporal properties embedded in TAD provide an additional clue for possible reliable recognition but far more complex than image classification problems. 7 Substantial progress has been made in TAD 11 –13 in the recent years, most of them focused on the field of video analysis, and the mean average precision (mAP) of the state-of-the-art TAD approach, to our knowledge, is approximate to 60% achieved on video database THUMOS. 14
Recently, researchers introduced additional sensor information for TAD. For example, skeleton data from Kinect sensor that is assumed to be more robust to the illumination change and easier to distinguish from cluttered background compared with some video approaches. 15 Li et al. 16 proposed a skeleton-based approach for TAD, which demonstrates some promising results on gaming three-dimensional (3D) data set. Currently, video- and skeleton-based TAD methods are rarely addressed. However, it is reasonable to extend TAD research by fusing these two kinds of information since Kinect naturally outputs both video and skeleton simultaneously.
In this article, as shown in Figure 1, we propose a TAD framework with two streams, video-based stream and skeleton-based steam. In skeleton-based, the skeleton data were converted into a color map whose width indicates the time line and height is equal to the number of skeletons. With a color map, the problem is transformed into a one-dimensional (1D) object detection problem. We propose an innovative structure with two separate recognition streams, video-stream and skeleton-stream, which are combined by boxes-fusion or layers-fusion manipulation subsequently. Two-stream network will fully utilize the features we get from both video sequence and skeleton sequence. Besides, it can also solve the problem of missing frames effectively. As for video-stream, 3D-convolutional neural network (CNN) based on motion feature (C3D) extractor 17 is used to extract continuous short-term motion features, which are subsequently encoded into the feature space and was represented as an augmented color map. In skeleton-stream, we apply view-invariant transform on skeleton sequence to extract view-invariant feature (VIF), which may eliminate view change influence and retain more relative motions than some traditional skeleton-based methods. 18 The skeleton VIF sequence is also encoded into color map whose width indicates the time line and height is equal to the number of skeletons, preserving the temporal information and the spatial information of original action. With a color map, we find that it can be easily solved by an object detection framework. Inspired by this idea, we chose the You Only Look Once Version 2 (YOLOv2) detector that well balances the speed and precision. To be suitable for our work, we modify it as a 1D object detection model that only predicts two one center point coordination and the box’s width for a bounding box. YOLO-based network that provides two information fusion strategies, boxes-fusion and layers-fusion, for TAD of color maps encoded from two input streams. To validate the proposed TAD method, we also build a seven-category data set with 200 human videos and skeleton action sequences collected by Kinect V2 sensor, each sequence contains 3–10 effective actions.

Pipeline of our method. For the video input line, we use C3D to extract short-term action features. The continuous C3D features are encoded into a color map. For the skeleton input sequence, we use the view-invariant transform to get the VIF and encode the continuous VIFs as a color map. They are then used as the input of our proposed two-stream YOLOv2 network. After the two streams are fused, the bounding boxes are filtered by the NMS algorithm. Finally, the sequence of actions is split in time. VIF: view-invariant feature; NMS: nonmaximum suppression YOLOv2: You Only Look Once Version 2; C3D: three-dimensional convolutional neural networks.
The main contributions of this work are summarized as follows. We propose a novel idea that innovatively transforms the TAD problem into a 1D object detection problem based on a two-stream YOLO-based deep learning network that fuses the encoded video and skeleton stream of Kinect sensor. We also investigate the performance of two different fusion methods, boxes-fusion and layers-fusion operating at a different stage of our processing pipeline.
Another highlight lies in the stream processing for video and skeleton data. The resulting red, green, and blue (RGB) feature spaces encoded from C3D features and VIFs not only capture the underlying spatiotemporal structure of action sequence data but also allow a unified representation as to the input of the 1D YOLO network, which accordingly makes it easy to design and reduce the network complexity.
The remainder of this article is organized as follows. In the second section, we briefly review some works about our issue. The third section presents the feature extraction and encoding methods of video and skeleton data. The fourth section provides our two-stream YOLO-based network. We demonstrate some experimental results in the fifth section.
Related works
According to the research for Chinese elder people, 19 people’s demand for the performance of elderly care service robots is mainly focused on intelligence and safety. Specific to the realization of functions, fall warning, sanitation, and health monitoring are the most demanded by people. This shows that researches on robot visual system are necessary.
Recently, researches on action recognition had accumulated amounts of achievements in model constructing, temporal information analysis, and high-level semantic recognition. To achieve the robot’s capability to understand and interpret human behavior during human–robot cohabitation, a lot of attempts had been made. Kostavelis et al. 20 proposed a method named the Interaction Unit analysis, which modeled human behaviors based on a Dynamic Bayesian Network, and tried to tackle the comprehensive representation of the high-level structure of human’s behavior for the robot’s low-level sensory input. Ramrez-Amaro et al. 21 presented semantic-based methods for understanding human movements in robotic applications. They made a segmentation of human activities and tried to identify the important features of actions. They also learned different parameters between activities and obtain the mapping between the continuous data and the symbolic and semantic interpretations of the human movements. With the development of computer vision, deep neural networks have performed well in the field of action recognition. Deep learning provides new solutions for the robot to understand and detect human actions.
Action recognition
Action recognition is now widely applied in various fields and an impressive progress has been made. 22 –27 Early action recognition methods were mainly based on hand-crafted visual features. 28 Although CNNs can deal with most image classification problems, 29 it may not adapt to classify human action since human action is a 3D spatiotemporal signal sequence. Yeung et al. 8 proposed a two-stream CNNs architecture that learns the spatial motion characteristics of actions through static images and the temporal motion characteristics of actions through inter-frame optical flow. Wang et al. 30 proposed a global spatial–temporal three-stream CNNs architecture. The three-stream CNNs comprise of spatial, local temporal, and global temporal streams generated, respectively, from deep learning single frame, optical flow, and global accumulated motion features in the form of a new formulation named motion stacked difference image. Ji et al. 31 proposed 3D-CNNs to extract the temporal and spatial features of video data. Tran et al. 17 also proposed a simple but effective approach for spatiotemporal feature learning using deep 3D-CNN later. Compared with CNNs, recurrent neural networks (RNNs) can store action temporal correlation information and process time-domain signals better. 18 However, long-term action may not be well handled due to exponential decay of the gradient in time direction. To solve this issue, RNNs with long- and short-term memory (LSTM) were proposed. 32 For example, Donahue et al. 33 put forward an effective unified model that combines LSTM and CNNs to describe human movements.
Besides video, dynamics of human body skeleton also convey significant information. Liu et al. 34 proposed a skeleton visualization method that used CNNs to extract human motion discrimination features. Actually, the joints of human skeleton constitute a graph structure, after graph convolutional networks (GCNs) were developed 35 and spatial–temporal GCNs based on GCN were generalized to human skeleton graphs. 36 Li et al. 37 proposed a CNN-based detection framework and innovatively designed a skeleton transformer that can convert the skeleton sequence into a skeleton image as the input of the network. Liu et al. 38 proposed a novel method to map skeletal data to images that are effectively processed by CNN architectures. The skeletal data were arranged in a two-dimensional (2D) grid to take full advantage of the 2D kernels in CNNs. They also use different colors to represent different joints; this makes it clear to notice the movement of the joints. The joint differences between the consecutive skeleton frames are used to construct the velocity images and append them to the location images. All these methods give a strong proof on skeleton-based action detection.
Temporal action detection
Existing human action recognition methods usually test their recognition algorithms on some human action database. Generally, these databases all consist of well-trimmed video that only contains one kind of target action, which is difficult to achieve in the real application. Unlike action recognition, one aim of TAD is to locate the action fragments from the input sequence accurately. Gaidon et al. 39 proposed the TAD method without over-segmentation of video to locate some simple actions. Some researchers also developed several large-scale video data sets, such as THUMOS. 14 The typical approach used in most systems is to extract a pool of features, which are fed to support vector machines and then apply these classifiers on sliding windows or segment proposals for action prediction. 40
Recently, deep learning-based methods present some improved performance, and RNN becomes widely used in TAD. Escorcia et al. 41 built a temporal action proposal system based on LSTM. Sun et al. leveraged web images to train the LSTM model when only video-level annotations are available. 42 Such sequential prediction is often time-consuming when processing long-time videos and it does not support joint training of the underlying features extracted. Shou et al. 7 proposed an end-to-end segment-based 3D-CNN framework (S-CNN), which outperformed other RNN-based methods by capturing spatial–temporal information simultaneously. However, the feature adopted by S-CNN is initially designed for snippet-wise action classification and might require an undesired large temporal kernel stride when detecting long action proposals.
Object detection
Object detection aims to classify objects and to estimate their locations in images. 43 It has two categories: two-stage and one-stage. For two-stage detectors, the detectors are usually be divided into region proposal network (RPN) and detection head. On the other hand, one-stage detectors usually use a single network to detect objects and can be trained by end-to-end. The former is often more accurate but with low speed, whereas the latter is faster and slightly less accurate. Here are some typical object-detection networks, for example, R-CNN-based architecture received attention and an effective method has been proposed. 44 Compared with R-CNN, fast R-CNN introduces region of interest pooling and integrates all models into one network. Later, faster R-CNN was proposed with a RPN that shares full-image convolutional features with the detection network, which makes nearly cost-free region proposals possible. 38 With the academic’s pursuit of faster and more accurate object detectors, one-stage detector has received more attention. As a regression problem, YOLO-based object detection method spatially separates bounding boxes and associated class probabilities, which enables real-time object detection YOLO9000. 45 This system is improved by model YOLOv2, which can predict multiple box positions and categories at one time, offering a trade-off between speed and accuracy. 46 YOLOv2 does not choose the sliding window or extracts proposals to train the network but selects the whole image to train the model. Therefore, it is better to distinguish between the target and the background area. Other state-of-the-art object detection methods such as YOLOv3, 46 mask R-CNN, 44 and SSD 47 also improve the detection progress in some aspects.
Discussions
Detecting target action in an untrimmed video is still a thorny problem, majority of existing methods are focused on the field of video analysis, and the best mAp, to our knowledge, is approximate 60% on video database THUMOS. In practice, especially some robotic applications such as human–robot interaction, video-based TAD lacks robustness due to changes of environment illumination. Most action recognition methods mentioned above are usually based on only images or skeleton and need a well-trimmed data sequence, which means the target action must be localized manually or predefined accordingly. Although skeleton-based and RGB video-based methods have achieved many progresses on action recognition research, TAD is still a new temporal–spatial issue arising from action recognition field. As far as we know, there are only a few reports on the video analysis, but the works based on the fusion of multisource, especially of video and skeleton from Kinect sensor, are much less reported. Therefore, a more efficient and accurate method that can perform well both on video and on skeleton is researchable. To address this problem in a unified way, it is necessary to transform different transient sensor information into augmented RGB-like images that capture invariant context or slow change properties in original data. Actually, TAD focuses on the detection and recognition of special action segments from continuous temporal action sequence. Compared with other complicated spatiotemporal modeling methods, if action sequence is transformed into an augmented image, each action segment may form like an object arranged in time order, and it is much more easier to detect the slice of action data in RGB-like images through a YOLO-based object detection framework. This one-stage model with good balance of speed and precision is much more suitable for portability and deployment on robot platform than some big networks such as YOLOv3.
Data encoding
In this section, to ensure the consistency of the proposed networks architecture for two different data channels, we encode two types of data. As for video data, we designed a C3D feature extractor. The extracted video features are encoded into color maps according to a certain rule. As for skeleton data, we apply view-invariant transform to extract VIFs. Similarly, the VIF is also encoded into color maps according to a certain rule.
Video data encoding
Each video in the data set contains T frames, we set
We use C3D network to extract abundant spatiotemporal features from a given input video unit. The 3D convolutional deep networks perform well in extracting model appearance and motion features simultaneously. The structure of our C3D network is presented in Table 1. The input of the model is a video unit with dimension
Structure of our C3D network.

C3D: three-dimensional convolutional neural networks.
Du et al.
18
empirically find that
The first fully connected layer has 1024 output neurons, and the second fully connected layer has 512 output neurons, both using relu as the activation function. Different from Du et al.,
18
we add an additional layer that has
After training the C3D network, we remove the last layer; therefore, we can extract feature with dimension
Like an RGB image, which has three channels, we write feature vector obtained by the fth unit through C3D extractor as a

Convert it into a column of an RGB image

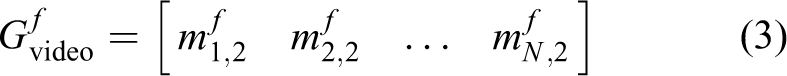

Representations of all units are arranged in chronological order to represent the whole video. Next, a mapping function is used to convert C3D features into RGB components. The arranged float matrix is quantified to integral image representation. Since the activation function of our last fully connected layer is

where
As shown in Figure 2, the top is a video in our data set. Below is the corresponding RGB image encoded from the features extracted by C3D. It can be observed from the encoded color map that there are some similar sequences, since several consecutive video units are similar. We can also see that there are many mutations in the color map, which is due to the large change in the state of the video unit. Generally, these mutations reflect that the object has undergone a change of motion during the period of time.

Illustration of our video encoding method. We arrange the features extracted by C3D in order. Then they are encoded into a color map. C3D: three-dimensional convolutional neural networks.
Skeleton data encoding
To make the skeleton sequence robust to viewpoint changes, Raptis et al. 48 converted each skeleton into a standard pose. This method effectively eliminates the influence of viewpoint change and eliminates the partial relative action between the original skeletons. For example, the rotation of the waist will be eliminated by this transformation. Liu et al. 34 proposed a sequence-based view-invariant transform to solve the problem of view variations. However, this method eliminates the relative action between the original skeleton and the space. Since the coordinate system is fixed on the human body, actions like body rotation cannot be described. Compared with the traditional skeleton-based transformation method, we propose a coordinate transformation based on the camera coordinate system, which eliminates the influence of the viewpoint change by retaining more relative actions in the original skeleton joints.
In general, the skeleton sequence we collect is based on the camera coordinate system, so the local coordinates

Illustration of our view-invariant transform. Figures (a) and (c) show the camera coordinate system. Figures (b) and (d) show our coordinate system.
In detail, given F frames of skeleton sequence, we can represent the nth skeleton joint of the fth frame as
Our method doses a translation to the camera coordinate system and makes its origin on the human body. After that, we choose the spinal joint point of the human body as the coordinate origin, whose joint number is 1. In the new coordinate system, the nth skeleton joint of the fth frame is represented as VIF
This method has three advantages: first, the viewpoint influence can be eliminated. Even if the distance and angle between people and the camera are different, with a coordinate system that moves with the human body, it will not affect our algorithm. As shown in Figure 3(a) and (b), in the camera coordinate system, actions performed at different positions turn out to be the same after coordinate transformation, which means actions are independent of positions. Second, the relative action features of the joints are more obvious. Figure 3(c) shows the movement of the human’s right shoulder, right elbow, and right wrist joints, but since they are all in the camera coordinate system, the joint rotation is not described as it is in Figure 3(d). Third, as the coordinate system is not connected to the joints of the human body, rotation can also be well described.
From VIF to color maps
Since the position information

Convert it into a column of color maps
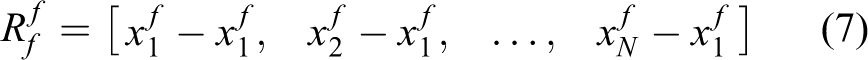


To maintain time consistency with the C3D features input, the skeleton sequences are down sampled. Next, a mapping function is created to convert the spatial coordinates into RGB components

where
Figure 4 shows that all the images encoded by the frame skeleton sequence are finally arranged in chronological order to represent the entire action sequence. The horizontal axis of the new RGB graph represents temporal information, whereas the vertical axis represents the spatial information. This RGB graph makes the global discrimination obvious and also shows the clear spatial distribution of the action features.

Illustration of our skeleton sequence encoding method. We arrange the VIFs in time order. Then they are encoded into a color map. VIF: view-invariant feature.
Two-stream YOLO-based network
TAD based on Kinect can be handled by using our two-stream YOLO-based networks. The spatiotemporal skeleton sequences and action videos are encoded into two separated RGB-like image streams. In general, YOLO uses the entire image as the input of the network and directly output the position and category of the bounding box and the confidence in the output layer. It predicts the positions and categories of multiple boxes simultaneously, enabling real-time end-to-end object detection and recognition. In this work, our networks are used to predict the action bounding box and corresponding categories and fuse them to refine the final result. Compared with standard YOLO-based object detection in 2D images, our TAD method is much simpler since the action detection problem is transformed into a 1D detection of the time slice of action.
YOLO-based TAD
In this work, each channel of our two-stream YOLO-based network receives an encoded RGB-like image stream, the width of each input image is augmented with time T, and the height is equal to the number of Kinect skeletons


where

YOLO-based TAD, only skeleton stream is used for demonstration. Our method divides the encoded RGB-like image into S grids and attempts to predict the time slice (
The image is divided into S grids (


Another network output is the confidence score
Two-stream network
Figure 6 shows the structure of our network. The input of video-stream is the image encoded from the video features. The input of skeleton-stream is the image encoded from the skeleton sequence.

Structure of our two-stream YOLO network. The input of the video-stream is the image encoded by the C3D features. The input of skeleton-stream is the image encoded by the VIFs. Each stream consists of four blocks and a convolutional layer with
We implement this model as a fully convolutional network to reduce the number of parameters. The structure of the two streams is the same. Each stream consists of four blocks and a convolutional layer with

where α is a very small positive number to preserve the information of negative axis. To improve the effect of short-term action detection, we reshape the feature maps of the previous block and merge them with the feature maps of the last block.
Consider two kinds of fusion methods, boxes-fusion and layers-fusion, respectively. The boxes-fusion directly fuses the predicted bounding boxes from each stream and aims to solve the problem of missing frames. The layers-fusion is to fuse the second-to-last layers of two streams and then add a convolutional layer to output the bounding boxes. This method aims to fusing the features of two streams deeply and get some new features that would be better to detect. Finally, we use nonmaximum suppression (NMS) algorithm to filter the bounding boxes from two proposed fusion methods and generate the action detection result.
Loss function
The YOLOv2 algorithm uses the mean square error (MSE) loss function as it treated object detection as a regression problem. Our loss function has two main parts: position error and classification error.
The position error corresponds to the position error of the predicted bounding box, we use weight
Finally, the total loss function is defined as follows

where
Experiments
To validate the algorithm presented in this article, we collected and manually annotated two data sets. We use separate training methods for two streams. For video-stream, we first train the C3D model. After extracting the features of video, we use the trained C3D model to encode the video as color maps. Then, these color maps are used to train the video-stream. For skeleton-stream, we encode the skeleton sequence into color maps and then use these color maps to train the two streams. Finally, we use two methods to fuse the two streams and some experimental results are presented accordingly.
HITVS-v1 data set
Most of existing data sets for TAD are video-only, such as THUMOS 2014 data set 49 and MEXAction2 data set. 50 Due to the particularity of our method, we built our own data set Harbin Institute of Technology Vision and Skeleton-version 1 HITVS-v1. HITVS-v1 is labeled manually at the frame level; we divide different actions in a video making the proposal accuracy up to one frame. Tagging format is start frame, end frame, and action class. All scenarios and human actions are coherent. The video of current existing data sets is basically built by using a montage method of different scenes and different human motion videos, and the coherence is very poor. Our data set is more consistent with the actual scene. Our two-stream approach requires one-to-one video and skeleton information, and the skeleton data are strictly corresponding to the video data, which are rare in current existing data sets.
We build the data set HITVS-v1 in a domestic scene. We use student dormitory with an area of about 10 m2, which contains daily necessities such as chairs, desks, and single beds to simulate the family environment. We use Kinect V2 to collect data from two viewpoints, which can improve the collection efficiency and the generalization of the model. The data set contains two types of data: skeleton coordinate data (.txt) and RGB video (.avi). There are 2 × 100 files for each channel. We set the sampling frequency to FPS = 15 f/s. There are 7 activities: eat, drink, read, sit down, stand up, lying down, and get up and 5 subjects, each subject performs 7 types of actions randomly for 20 times. Each time we collect 1000 frames and the duration is
As shown in Figure 7(a), we take action sequences from two different viewpoints to highlight the advantages of our representation. Besides the change of viewpoint, five subjects’ actions were collected since there are significant variations among different subjects when they perform the same action, as shown in Figure 7(b).

Our data set examples.
Train C3D
The C3D model is not pretrained but trained directly with our own data set. For our data set HITVS-v1, the number of categories is eight (seven class actions and one background class). The input of the network is
Since the samples of the background action are much more than other actions, the number of each class of action in the mini-batch is set the same during the training. We use the Adam-gradient descent method with a learning rate of 0.001. When the loss of the validation set is no longer lowered for 10 consecutive times, the iteration stops. Figure 8 shows the training process and the confusion matrix for our data set. Finally, the accuracy in the test set of our data set is 88.22%. Due to the limited amount of data, our model performs overfitting as the training epoch increases, but we finally choose the model when the mAP reaches the highest value, and at this point, the model is not overfitting, so this phenomenon will not have an excessive impact on our experimental results.
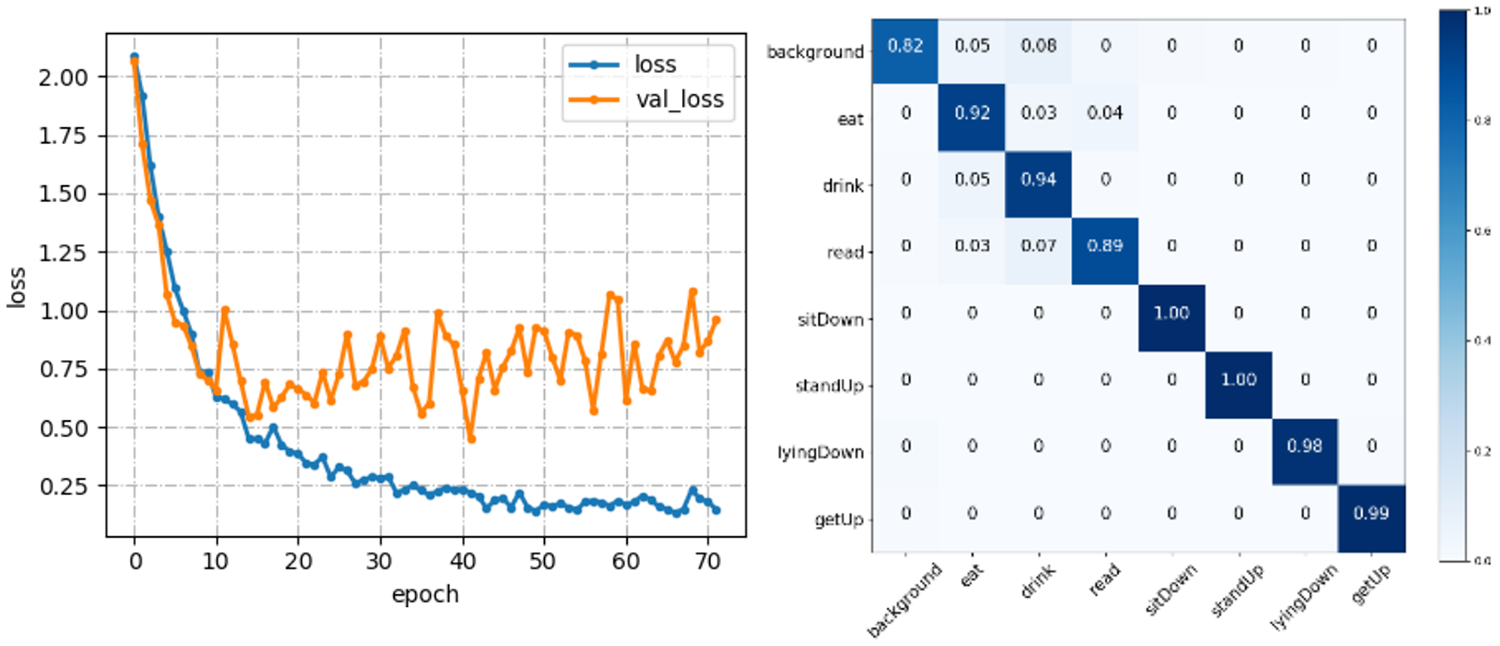
C3D training process and the confusion matrix. C3D: three-dimensional convolutional neural networks.
Data enhancement
Our database is a moderate scale database; therefore, it is necessary to increase the samples from original data. We then propose a data enhancement method described as follows. For a data sequence with L frames, the frame rate is FPS and the duration is

Diagram of our data augmentation method.
Train video-stream network
We use the trained C3D model to encode the video of the entire data set into color maps. Since our data set has 1000 frames per video, we set
To automatically find good prior anchor boxes from the input stream, we follow the same idea in the YOLOv2 detection framework, which adopts K-means clustering to predict the prior shape of action anchor box by using a IOU-based distance. Let bj be the jth candidate anchor box representing action duration, we then define the distance

where M is the number of actions in the training data set and K is the number of possible actions randomly chosen in a stream image grid. Through this algorithm, we can get K cluster centers representing K good prior anchor boxes. When training our network, we assign K good prior anchor boxes to each grid to predict action durations.
In this article, for HITVS-v1, we set
The length of sample actions ranges from 10 to 140 frames in our data set. Therefore, the setting of the receptive field has a great influence on the accuracy rate. The original receptive field of our network is 105. We increase the receptive field by dilated convolution and expand the receptive field to 121 and 137 to test the video-stream.
The AP@IOU = 0.5 (average precision) of video-stream for each class in our data set is shown in Figure 10. When the receptive field is 105, 121, 137, the mAP of video-stream is 74.64%, 80.79%, and 77.86%, respectively. The impact of receptive field on our method is relatively large. However, it does not mean that the bigger the receptive field, the higher the precision. The precision may be related to the duration of the actions in our data set.
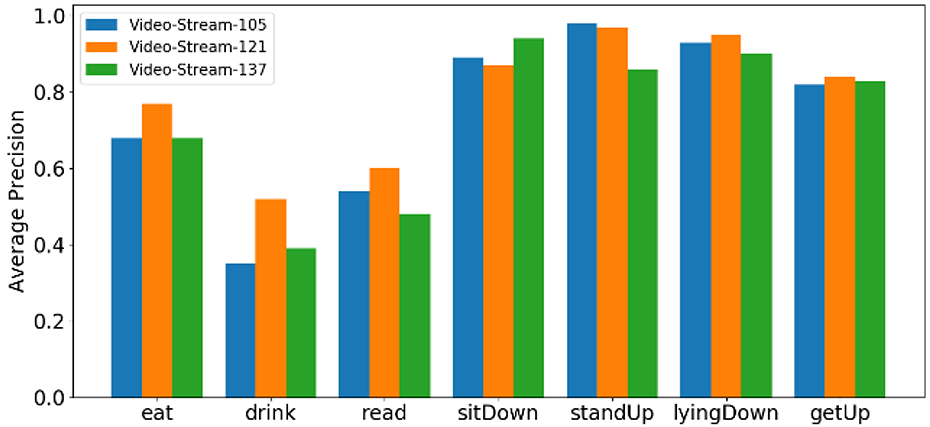
The performance (AP@IOU = 0.5) of video-stream evaluated on different receptive field. AP: average precision.
Train skeleton-stream network
In our data set, we set
The anchor boxes are the same as video-stream. We also use the dilated convolution method to expand the receptive field. The experimental results are shown in Figure 11. When the receptive field is 105, 121, and 137, the mAP of skeleton-stream is 74.22%, 78.88%, and 72.81%, respectively. This is similar to the experimental results obtained by video-stream, which is the highest when the receptive field is 121.

The performance (AP@IOU = 0.5) of skeleton-stream evaluated on different receptive fields. AP: average precision.
To verify our VIF-based skeleton-stream network, we test the precision with skeleton-stream-121. As no coordinate transformation is used, the feature is defined as follows

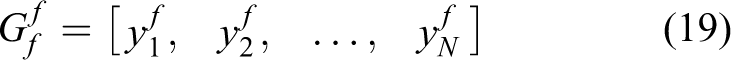

We encode the skeleton sequences in two ways. Then we train skeleton-stream network with the encoded images. Figure 12 shows the recall–precision curves for two kinds of actions. When there is no coordinate transformation on the skeleton sequences, the mAP is 76.51%. Our method can increase the mAP to 80.79%, which proves that our coordinate transformation method can effectively improve the precision.

The RP curves for two classes evaluated on our view-invariant transform. RP: recall–precision.
Two-stream fusion
The boxes-fusion is to fuse the predicted bounding boxes separately generated from two streams. The layers-fusion is to fuse the second-to-last layers of two streams and add a convolutional layer. We fix the parameters of other layers and train this convolutional layer separately. Finally, the NMS algorithm is used to filter the bounding boxes after two streams fusion.
The test results with
TAD performance (mAP@IOU = 0.5) on HITVS-v1 data set.

TAD: temporal action detection; mAP: mean average precision; HITVS: high-speed interplanetary tug/cocoon vehicles.
However, the mAP of boxes-fusion is always greater than the others. As can be seen from Figure 13, the AP of each class of video-stream and skeleton-stream is different. The two streams are complementary; therefore, using the fusion of two streams to detect can improve the final TAD performance.

The IOU-mAP curves for video-stream, skeleton-stream, boxes-fusion and layers-fusion. mAP: mean average precision.
Figure 13 shows the IOU-mAP curves for the four methods when the receptive field is 121. We can see that the boxes-fusion detection effect is better than other methods when the IOU is less than 0.67. Layers-fusion detection effect is better than other methods when IOU is greater than 0.67.
As shown in Figures 14 and 15, we present two TAD examples in which two encoded input streams of untrimmed Kinect data, which include action video and skeleton streams, are fed into our network. The ground truth of each action (lying down, get up, read, stand up, eat, drink, and sit down) is shown below, notice that the duration and time slice of each action are different from each other. We illustrate four different TAD methods based on, video-stream only, skeleton-stream only, boxes-fusion, and layers-fusion. As human action in Kinect is a high-dimensional spatiotemporal signal, which includes video and skeleton information, TAD based on single information is difficult. Notice that, using video sequence or skeleton sequence alone for TAD will cause large errors, there are missed detections of some actions. However, based on boxes-fusion of our two-stream fusion method, the missed actions (read in Figure 14 and eat in Figure 15) are detected correctly. Another observation reveals that the boxes-fusion method sometimes performs better than the layers-fusion method, since no action detections are missed in both figures.
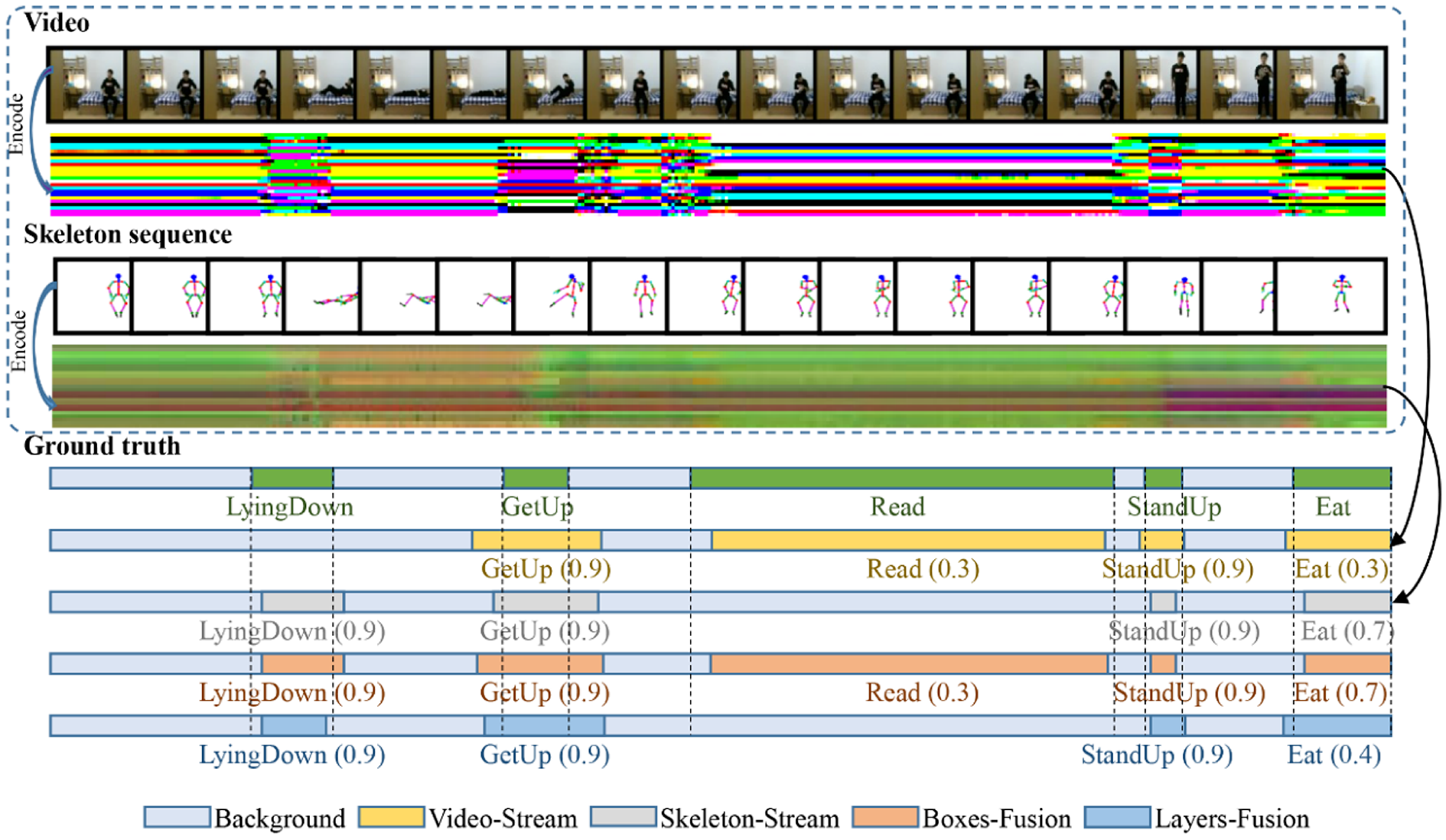
From top to bottom, it is: an untrimmed video, the color map encoded by this video, a skeleton sequence corresponding to the video one by one, the color map encoded by this skeleton sequence, ground truth after artificial cutting, the action detection results of four methods in this article. The numbers in parentheses represent the confidence score.
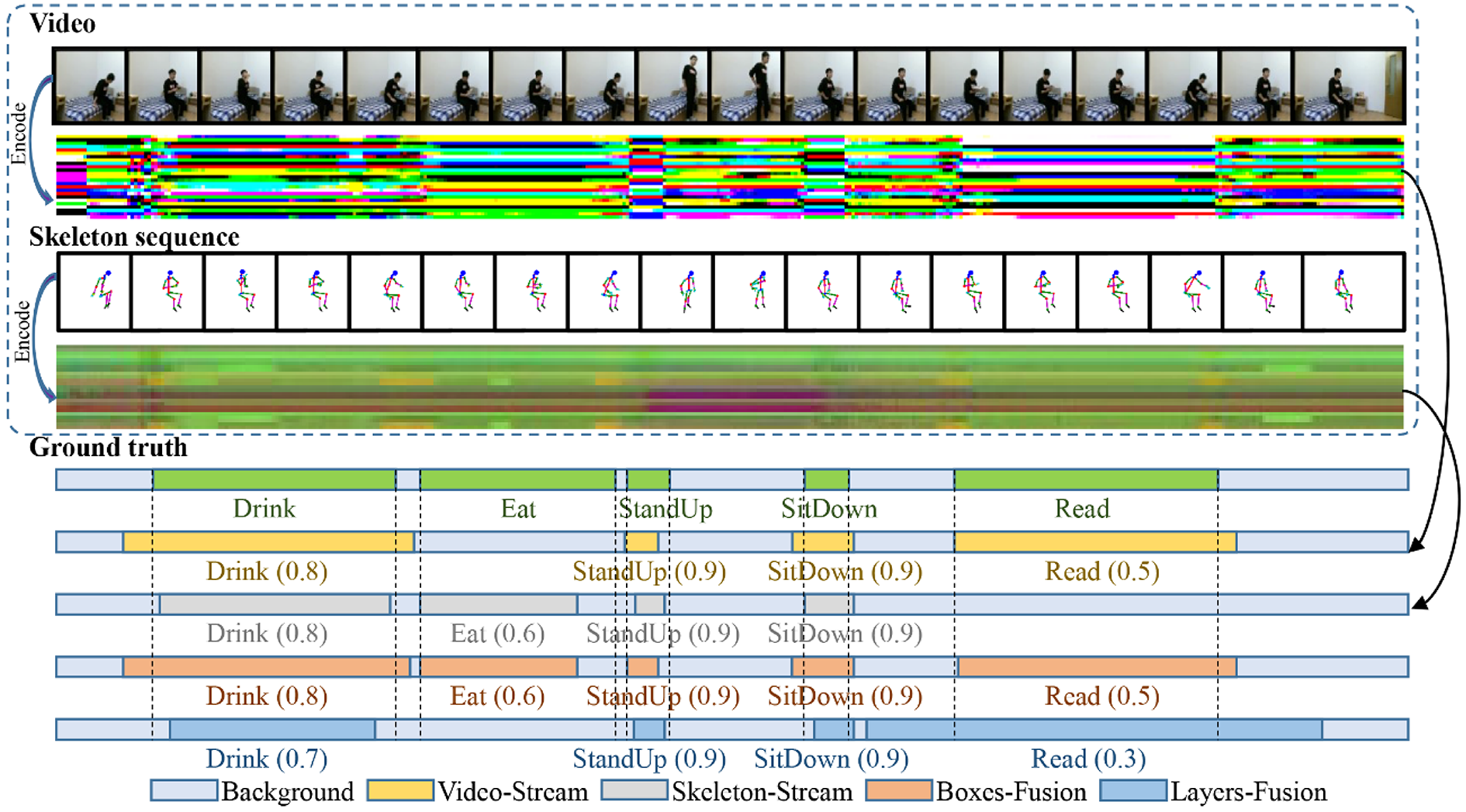
Another example of our detection. From top to bottom, it is: an untrimmed video, color map encoded by this video, a skeleton sequence corresponding to the video one by one, color map encoded by this skeleton sequence, ground truth after artificial cutting, the action detection results of four methods in this article. The numbers in parentheses represent the confidence score.
The reason why boxes-fusion performs better than layers-fusion possibly is due to the misalignment of semantic features when different feature layers, which do not have strong relationships, are fused together, while the boxes-fusion directly uses the bounding boxes generated from two separated stream channels.
Stabilization performance
In this experiment, we present stable performance comparison between video-based method and our two-stream fusion method based on a Kinect data stream over 58 s. In this test data stream, the actions include read, eat, sit down, stand up, drink, lying down, get up, and other, which mean doing nothing. As shown in Figure 16(a), some video keyframes are sampled from data streams in temporal order. We here use the box-fusion method for our two-stream fusion method, and the networks’ parameters are chosen as before. As shown in Figure 16(b), the black line represents the ground truth, the red line corresponds to our box-fusion method, and the blue line is the video-based method, the latter two lines are slightly offset from each other for clarity. The observation reveals that our method almost tracks the ground truth, and no actions are recognized incorrectly except that there are slight errors on the start or end time of some actions. Video-based method is sensitive to the changes between two consecutive actions, and it can be seen that, in the video-based method, significant misclassifications happened near the boundary of two consecutive frames during these transitions. Some sampled frames during the changes of action states are shown in Figure 16(c), the first row corresponds to some images misclassified by the video-based method, whereas the second row shows the corresponding frames classified by our method, and the recognized action class with confidence sore for each frame is overlapped the left top of each image. The first three images from the first row demonstrate that similar images grabbed from other action video sequences are recognized incorrectly as read, get up and eat. The people just finished drink action and do nothing, and at this point, the video-based method just thinks the people are planned to stand up while our method remains the decision. The last column image tells that there are some confusing frames in action lying down and get up, they occur at different points of time, and the video-based method cannot distinguish the difference; however, our method presents the stable result. Therefore, our method is much more stable in TAD performance than the video-based method.

TAD performance comparision between video-based method and two-stream fusion method on real Kinect data. (a) Video streams from Kinect. (b) TAD performance comparison between video-based method and two-stream fusion method. (c) Some recognized frames sampled from Kinect video stream. TAD: temporal action detection.
Comparisons with the state-of-the-arts
Although there are many attempts for TAD, TAD methods based on the fusion of video and skeleton sequence are very rare. Hence, we compared the quality of our work to the methods 7,8,51 that are closely related to our work but tests on a quite different data set.
As presented in Table 3, these methods use well-trimmed video clips as their train set, whereas untrimmed video clips as validation set and test set. Even though their data set contains a richer variety of actions, the well-trimmed train set will reduce the training difficulty. Besides, skeleton sequence contains abundant action information, and the lack of skeleton data is not conducive to the improvement of results. As HITVS-v1 contains both video and skeleton data, our method was trained and tested on them, which makes ours clearly perform better. Without fusion, single stream from video and skeleton achieves mAP@IOU = 0.5 to 78.88% and 80.79%, respectively. Based on multisource fusion, the results of two-stream boxes-fusion can significantly improve mAP@IOU = 0.5 to 87.01%.
Comparison with the state-of-the-arts.

mAP: mean average precision; HITVS: high-speed interplanetary tug/cocoon vehicles.
Experiment on PKU-MMD data set
To better prove the effectiveness of our TAD approach, we conduct experiments on the PKU-MMD public data set. 52 This 3D human behavior public data set is a new large-scale data set for continuous multimodality 3D human action understanding and covers a wide range of complex human activities. It contains 1076 long video sequences in 51 action categories, performed by 66 subjects in 3 camera views. The data set provides multimodality data sources, including RGB, depth, infrared radiation, and skeleton, which are quite consistent with our methods. The data set has two parts: cross-view evaluation and cross-subject evaluation. Cross-view evaluation aims to test the robustness in terms of transformation, whereas the cross-subject evaluation aims to test the ability to handle intra-class variations among different actors. Our four methods are all tested on both evaluations. We fixed the receptive field as 121 and IOU as 0.5, and the results in Figure 17 show that box-fusion performs best among the four methods, video-streams is the next, and layers-fusion in the worst. The highest mAP can reach 80.90% on cross-subject evaluation and 91.32% on cross-view evaluation. We also present some comparisons with the work 52 in Table 3, which proves that our method provides an excellent performance for TAD based on PKU-MMD data set.

The experiments results on PKU-MMD data set. (a) Cross-subject evaluation and (b) cross-view evaluation.
Fall down detection
For an elderly care service robot, it is of great importance to detect dangerous human actions such as falling or fainting. When the robot predicts that the behavior of interactive person is abnormal, it will capture the abnormal state picture or video, turn on the remote monitoring mode to communicate with the remote person, and execute the corresponding action accordingly. This requires our detection method to have a good online detection effect. To prove the significance of our method for elderly care service robot, we conduct an experiment on fall down detection, as shown in Figure 18. Our experiment platform is an intelligent service robot, as shown in Figure 19; Kinect is used to capture human actions. Figure 20 shows a user interface (UI) for fall down detection. The interface mainly includes current video frame overlapped with skeleton node, coded color map, and recognition result.

Fall down action detection. (a) Walk normally and (b) fall down.

The robot platform of our experiment.

An interactive interface for fall down detection.
As shown in Figure 21, in this experiment, volunteers are asked to walk back and forth within the robot viewpoint and randomly perform different actions such as sit, squat, stand, wave, walk, and fall down. The robot will determine whether the observed people have fallen by using its recognition results based on Kinect. The robot outputs all the recognized actions except fall down as “not-down,” while classifies the action as “down” in UI when the volunteer falls down completely. Considering that only one recognition result will not make a proper decision; therefore, a simple voting scheme (three positive decisions out of five) is used which may lead to a certain lag in the recognition process, as shown in Figure 21(b).

Online fall down detection experiment. (a) The results of detection based on different actions. (b) A certain lag in the recognition process.
We also present our robot with 20 data sequences from different people by using our algorithm; among them, 10 sequences are from falling down while others are background sequences, and we get recall = 1 and accuracy = 95% on these sequences. Figure 22 is an example sequence for our online detection. The result shows that our model can detect falling actions very well, which provides the possibility to realize the fall warning function of the elderly care robot.

Fall down detection from a data sequence sample.
Conclusion
In this article, we proposed a TAD deep learning network, which incorporates video and skeleton information from Kinect sensor. We adopt 3D-CNN to extract C3D motion features from video and apply to view-invariant feature transformation on skeleton data. Both types of features are encoded into RGB-like feature space, so that the TAD problem can be naturally transformed into the object detection problem. We then use the proposed Two-Stream YOLO-based network and fuse every stream based on Boxes-Fusion or Layers-Fusion methods. Experimental results show that it is feasible to convert the TAD problem into the object detection problem. Both video-stream and skeleton-stream can effectively locate the action time and classify the corresponding action. The two kinds of data streams are complementary. When two streams are fused, the precision can be improved and the final recognition results will be more stable than the video-based method. Another observation reveals that as IOU gets larger, the precision turns higher for boxes-fusion and turns lower for layers-fusion. We also found that the receptive field has a great impact on accuracy. Receptive field too big or too small will reduce the accuracy. To prove the practicability of our model, we also carried out a fall detection experiment based on an elderly care service robot. The result shows that our model can detect falling actions very well, which provides the possibility to realize the fall warning function of the robot. However, our approach has to train C3D networks and to extract VIF features before using two-stream networks; this is not as convenient as an end-to-end model. Another issue is that the method we proposed in this article is mainly suitable for single-person action recognition in fixed scenes; however, it is not yet possible to deal with multi-person action recognition in changing scenes. In this article, we mainly focus on the TAD problem for one person, whereas for multi-person TAD problem, our method is not applicable. In addition, when dealing with changing background or dynamic scenes, our method is also not suitable. In the near future, we will investigate some of these issues to improve the performance of our method.
Supplemental material
Supplemental Material, sj-rar-1-arx-10.1177_17298814211038342 - Temporal action detection based on two-stream You Only Look Once network for elderly care service robot
Supplemental Material, sj-rar-1-arx-10.1177_17298814211038342 for Temporal action detection based on two-stream You Only Look Once network for elderly care service robot by Ke Wang, Xuejing Li, Jianhua Yang, Jun Wu and Ruifeng Li in International Journal of Advanced Robotic Systems
Footnotes
Declaration of conflicting interests
I would like to declare on behalf of my coauthors that any figure or text taken from another article is clearly indicated with the full source and permission of the authors of the said source. Besides, our manuscript has not been published previously and is not under consideration for publication elsewhere in whole or in part. All the authors listed have approved the present submitted version.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Key Research and Development Program of China (2019YFB1310004) and the Self-Planned Task (NO. SKLRS202111B) of the State Key Laboratory of Robotics and System (HIT).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.