
Abstract
In this article, an online path planning algorithm for multiple unmanned aerial vehicles (UAVs) has been proposed. The aim is to gather information from target areas (desired regions) while avoiding forbidden regions in a fixed time window starting from the present time. Vehicles should not violate forbidden zones during a mission. Additionally, the significance and reliability of the information collected about a target are assumed to decrease with time. The proposed solution finds each vehicle’s path by solving an optimization problem over a planning horizon while obeying specific rules. The basic structure in our solution is the centralized task assignment problem, and it produces near-optimal solutions. The solution can handle moving, pop-up targets, and UAV loss. It is a complicated optimization problem, and its solution is to be produced in a very short time. To simplify the optimization problem and obtain the solution in nearly real time, we have developed some rules. Among these rules, there is one that involves the kinematic constraints in the construction of paths. There is another which tackles the real-time decision-making problem using heuristics imitating human-like intelligence. Simulations are realized in MATLAB environment. The planning algorithm has been tested on various scenarios, and the results are presented.
Introduction
Path planning problem (PPP) is defined as designing the route of a vehicle, which must follow in such a way that a certain objective is maximized and a goal is reached. 1 In our previous studies, the objective of the PPP was to maximize the collected information from targets in a region of interest (ROI) in a fixed time while avoiding forbidden regions. 2,3 In this study, we generalize our previous studies for online PPPs. It is assumed that the information taken from targets decreases over time (i.e. it becomes out-of-date as time increases). In the literature, 4 rewards taken from the time-varying reward values of targets are to be maximized. It may be necessary to collect information from the region, where a radio frequency source is located (i.e. detection and tracking) 5 to cover the maximum area (i.e. search mission), 6 to overcome uncertainties in the environment, 7,8 and to monitor the slope of the region of the mine. 9 In the literature, 10 path planning is considered for multiple robots to collect information from an unknown environment. It is aimed that robots collect more information from some regions while avoiding collecting redundant information. In our case, however, the collected information is the captured images from target locations. It is aimed to maximize the collected data from the targets in unit time. There are studies that have designed navigation algorithms for unmanned vehicles for many different purposes. For example, in the literature, 11,12 navigation algorithm is designed to improve the capabilities of an all-terrain unmanned ground vehicle by optimizing its configuration. In the literature, 13 it is aimed to optimize the data collection utility by jointly optimizing the communication scheduling and trajectory of each UAV. The data collection utility is determined by the amount and value of the collected data. In the literature, 5 an online path planning algorithm is proposed to detect and track multiple unknown RF targets, but changes in targets with time are not considered.
Moreover, UAVs are not supposed to fly over forbidden zones. In the literature, there are several different solutions to solve the online PPP; a few are utilizing mixed integer linear programming (MILP). 14 –18 A collision-free path planning is realized by continuously adjusting the points defined between the start and goal points. 19 Most of the remaining studies concentrate on the receding horizon control technique to solve the problem. 4,20,21
In this study, the proposed algorithm finds each vehicle’s path by solving an optimization problem over a planning horizon while obeying certain rules. The basic structure in our solution is the centralized task assignment problem, and it produces near-optimal solutions. The solution can handle the case with moving targets, pop-up targets, and UAV loss. It is a complicated optimization problem, and its solution is to be produced in a short time. To simplify the optimization problem and obtain the solution in nearly real time, we have developed many rules. The proposed method ensures that the forbidden zones are not violated, and it works fast enough.
In the literature, 14,15,17,18 where MILP is used, the optimum path from a given starting point till a given ending point is found under vehicle timing and capacity constraints. In the literature, 18 the online PPP is modeled as a multi-UAV task allocation problem by defining the problem as a multitraveling salesmen problem.
In addition to these two approaches, there are approaches based on genetic algorithms (GAs). 22 –24 Unfortunately, these methods are at most quasi-online because of the computational effort required in GA. In the literature, 25 they have attacked a similar but slightly modified problem using a rule-based approach.
It is not easy to compare all these approaches’ performance since each study tries to solve a PPP that is different from all the others in constraints or objectives. According to our experience, the critical issue here is how the problem formulation reflects the actual realistic applications. On the other hand, it is always possible to measure each method’s performance over specifically developed scenarios. For example, in the literature, 4,26 exhaustive testing is used to check the performance. As part of their objective, there is the constraint: “every target should be visited only once.” This method for evaluating performance is considered reasonable.
On the other hand, it is not convenient to compare our study with theirs since we do not have such a constraint in our problem definition (on the contrary, targets are expected to be visited repeatedly). As another example, in the literature, 27,28 the results are given for a short mission time. Due to time-varying information values (rewards in their case), re-evaluating the problem after each target visit is not suitable for comparison. Because of these, we have created distinctive scenarios to evaluate our algorithm’s performance, as described in detail in the fifth section.
The main contributions of our study are listed below: Path planning algorithm has been proposed for environments where the data obtained becomes outdated over time. The proposed method has been shown to produce successful results in cases, where there are moving or pop-up targets. Also, the algorithm has been tested for possible UAV loss situations. PPP has been converted to a task assignment problem by creating an appropriate objective function. By defining rules which imitate a human path planner, the total amount of “information” is optimized. To the best of our knowledge, this type of study has never been done before in cases where the information gathered changes over time, and variable environmental conditions exist.
The article is organized as follows. The definition of the problem is given in the second section. In the third section, we present the objective function construction. The proposed path planner is introduced in the fourth section. Next, the performance of our path planner is given based on the constructed scenarios in the fifth section. Finally, summary and conclusions and some comments for further studies are shown in the last section.
Problem definition
This study proposes a solution for online PPP for multiple UAVs (N > 1). It is assumed that the UAVs fly at a fixed height. The number of forbidden region (FRs) and desired region (DRs) are M and K, respectively. Since we presume constant-altitude flight, the first step is to define the ROI as a 2D world. We also think that the UAVs sustain a constant speed during the mission. These assumptions are per real-world operational scenarios. 29
To define FRs and DRs, we use semialgebraic models. 30 Forbidden zones are described using the algebraic primitives of the form

(see blue regions in Figure 1) and


Scenario for online path planning.
where ri
and

In the same way, the definition of the DR can be written as in equations (4) to (6)


Here,
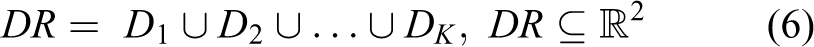
It is possible to test the algorithm using any other convex shapes; in this case, the algebraic primitives will be changed (i.e. the functions fi (x, y) and gj (x, y)). Also, we can define nonconvex regions by a combination of convex regions. Having complex areas in the scenario imposes an extra computational burden but does not affect the algorithm’s performance.
UAVs are modeled as Dubins’ vehicles. 31 Dubin’s vehicle model has been used extensively as a kinematics model in PPP. 32 In the literature, 31 Dubin has shown that the path a vehicle follows always consists of three segments from the list {RSR, RSL, RLR, LRL, LSR, LSL}. R, L, and S denote right turns, left turns, and straight lines, respectively. The problem that is to be underlined is determining the vehicle’s angle for approaching toward targets. The time required to complete the task will increase, and the next choice will be affected due to this crucial detail.
Our study’s focal objective is to maximize the gathered information from DR (i.e. targets). Captured images from targets are considered as gathered information. Besides, it is assumed that the importance of information collected from a target decreases from the time it has been captured if no UAV is flying over the same target. The significance of the images taken from each target decreases with time according to

where
Actually, the problem is solved anew at every occurrence of an event (an event is a change in the information as regards the availability of UAVs and completion of the assignment of any target). As already mentioned in our comment, the problem we are supposed to solve is basically an assignment problem. To formulate the problem, we need to construct the “reward (which involves cost implicitly)” matrix. A reward is supposed to decrease with time (we have preferred using exponential decrease associated with a time constant
The parameter It
is the information gained when target j is visited at the time
Naturally, maximizing the instantaneous information gathered can be formulated as an optimization problem based on the expected reward expressed in equation (8)

where
The α value is used to adjust the effect of the ETA ij value in the objective function. When the time constant and Ij value, which are used to calculate the freshness of information, are kept constant in different scenarios, ETA ij can be very high for targets located at distant positions. In those cases, the ETA ij value becomes the dominant term in equation (8), which is not desired, as we aim to keep instant information updated. On the other hand, we need to add ETA ij directly to the objective function for the reasons explained below.
To ensure that ETA ij value is not dominant in the first term in equation (8), the α value is determined by dividing Ij by the largest ETA ij value. Thus, it is ensured that the RI values go to zero, not because of the large ETA ij values. Since we work with fixed targets initially, it is wise to calculate the largest ETA ij value from the distance between two targets with the maximum distance. We still need to work with pop-up and moving targets later, we use the time to go from one corner to another by following the ROI circumference of the UAV as the largest ETA ij value.
We calculate the expected time using the waypoints obtained from Dubin’s model by finding Dubin’s paths from each vehicle to each target. This model is prevalent in the literature on UAV motion planning. 32 Paths between UAVs and targets are calculated using the following model



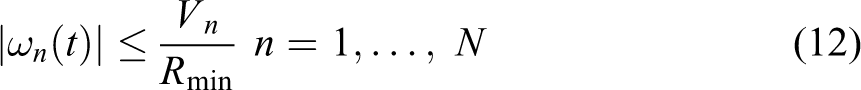
where N is the number of vehicles,

where
We want to solve a real-time assignment problem whose solution is strongly dependent on the vehicle entrance angle to targets. As described in the literature, 31 the desired heading and the vehicle’s desired location must be initialized as an input to the vehicle model. Luckily, we have the initial heading and location of vehicles and the desired locations (i.e. the targets’ centers).
Unfortunately, UAVs’ heading angles at the targets are not known (i.e. they are among the unknowns). We can calculate the distances between centers of target areas and construct the distance matrix at the beginning of a mission. The desired departure angle is determined based on the assignment of the next probable (closest) target. This idea may better be described by investigating Figure 2. For instance, when we calculate Dubin’s path to the sixth goal position, the vehicle’s final heading angle at the end of Dubin’s path will be the angle between North and the line connecting the sixth goal to the 11th position since it is the closest goal to sixth goal position. We can apply this rule only to target regions that are not already assigned to any vehicle. If the 11th position has already been given to a vehicle, then the closest target to the sixth one will be the seventh goal position, which is the second closest position to the sixth (see Figure 2).

UAV paths to illustrate the critical points in objective function construction. UAV: unmanned aerial vehicle.
Objective function construction
Now, we can express the optimization problem associated with information gathering maximization. But, there are a few critical points to be clarified. We explain them in the following items: During our studies, it has been witnessed that once a vehicle enters a target, it visits the same target after exiting or it remains inside the same target instead of flying toward other targets (Figure 2, UAV 5). If the j’th target is visited by i’th UAV recently, because the importance level of the information gathered from this target decreases a little, revisiting the j’th target in a short time will make a small contribution to the amount of information. To overcome this situation, we have inserted an extra rule for recently visited targets. The same UAV should not visit target j for a duration of Frequently changed assignments for the same vehicle may lead to entirely infeasible paths, as shown in Figure 2 (see UAV 1). To prevent this situation, we append a penalty term to the objective function in the optimization. The following normalization in reward values is made to approach all the vehicles objectively
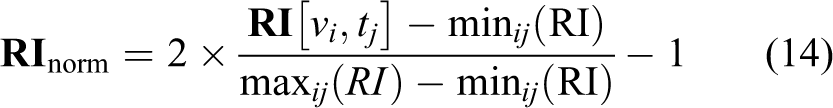
In Figure 2, one can observe all these problems and more simultaneously. In this figure, the assigned goal positions (i.e. targets) are changed mechanically if the ETA is not considered. The first vehicle flies toward to 10th goal position, but, at the instant, the 10th goal position was visited by the fifth vehicle, it turns toward the seventh goal position. This rotation continues with the 16th goal position, 6th goal position, and 11th goal position. Hence, vehicle 1 is in vain to spend time over the white region. The fifth UAV is also incessantly visiting the second goal position and trying to visit the eighth goal position, but it could not, because of the minimum turn radius limitation. It could not escape this vicious circle until the third UAV visits the eighth goal position.
UAVs must not violate FRs, which are defined in equation (3). These can be considered as threats in regions that vehicles function. To avoid forbidden areas, the method used in this study resembles the technique used in the literature. 33 However, we have to find the solution quicker than the manner described in the literature 33 because of timing constraints. The methodology used to do this job is described in detail below. To provide a safety margin around an FR, we define a circle with radius Ri + R min as the forbidden zone. This circle is divided into pieces of length along which a vehicle can travel in a one-time step (i.e. 1 s). While a vehicle escapes from the forbidden zones, it is needed to avoid a turn in Dubin’s path calculation to pass to a point inside the forbidden zones.
In constructing the distance matrix used in the assignment problem, Euclidean distances between each vehicle to desired locations are calculated. The forbidden region violation is also checked during this calculation, which is completed very fast due to the definition (1). For each point on the Dubin’s path, it is checked whether the point is closer to the center of Fi
than Ri

Avoiding from forbidden zones (a) initial configuration, (b) collision-free path (red), (c) zoomed view collision-free path between wp1 and wp2, and (d) zoomed view collision-free path between wp3 and wp4.
Firstly, the waypoints are calculated to move from wp2 to wp3 by traveling on the circle with radius Ri + R min. It is possible to move from wp2 to wp3 either clockwise or counterclockwise. The bearing having the minimum number of points should be selected. The distance between two consecutive points is the distance that the vehicle can go in one second. Afterward, Dubin’s paths between UAV and wp1 and wp3 and wp4 are found by calculating the approach and departure angles appropriately.
While finding a path between wp1 and wp2, the approach angle is calculated using wp2 and immediately after this point on the circle. The departure angle for the path between wp3 and wp4 is calculated using the same approach. Dubin’s path may include a semicircle (i.e. the distance to a final point may be 2 × R min) depending on approach and departure angles. Because of this, we left a 4 × R min distance between wp1 and wp2 and between wp3 and wp4. In this way, we guarantee that there is no FR violation during Dubin’s path generation.
In general, we can describe the assignment problem as follows: There are a number of vehicles and a number of targets. Any vehicle can be assigned to an arbitrary target, associated with a cost that may vary depending on the vehicle-target assignment. It is required to attend to all targets by assigning exactly one vehicle to each target so that the assignment’s total reward is maximized. We have formulated the problem as a linear sum assignment problem (LSAP) using the reward matrix
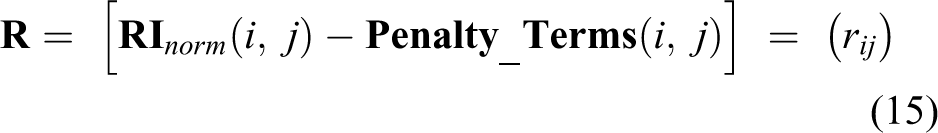
The general LSAP can be modeled for N-agent and K-task by introducing a binary matrix

subject to


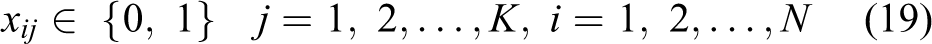
But in our case, N and K do not have to be equal, so we need to use the rectangular form of the LSAP. The algorithms based on exhaustive search have exponential complexity increasing with the number of UAVs. 32 For this reason, we need an efficient and fast algorithm to solve this assignment problem. If you have noticed, this is quite similar to the assignment problem formulated in the literature, 34 except the constraint K = N is replaced by N ≤ K. This assignment problem can be quickly solved both in a centralized or decentralized way.
Path planner
The solution of the PPP has been obtained by solving the assignment problem given in equations (16) to (19) and by applying basic rules like
The total mission time (t f) is fixed and mission duration [t 0, t f] is divided into (T > 0) subintervals [t 0; t 1]; [t 1; t 2];…; [tT− 1; t f] of 1 s. The solution to the assignment problem must be found within 1 s by considering all UAVs, including those appointed before. In Figure 4, a high-level flow diagram of the proposed solution is presented.

Flow diagram of the proposed method.
Results and discussions
We tested the performance of the proposed algorithm on several scenarios, starting with relatively modest scenarios. For these scenarios, one can predict optimum routes easily. Afterward, we presented results for more “complex” scenarios to demonstrate the proposed algorithm’s effectiveness.
The aim of this scenario (Figure 5) is whether our algorithm makes decisions similar to a human path planner. There are four targets, two forbidden zones, and two UAVs. The expected solution is “Assign one of the UAVs to the first and second targets and the other UAV to the third and fourth targets.”

Resultant paths for scenario 1.
It is observed in Figure 4 that the solution is as expected. In Figure 6, you can see the enlarged view of a path traversed more than once. In Figure 7, the total reward/information gained from targets is given. The collected information defined in equation (7) decreases exponentially over time, as seen from the figure. The graph’s peaks indicate when the UAV visits the targets and starts collecting information from the targets. As the information gathered from targets becomes outdated over time, each target needs to be revisited after a while.

Scenario 1: zoomed into the path of the second UAV. UAV: unmanned aerial vehicle.

Rewards/information for Figure 4 (scenario 1).
This scenario aims to observe the effects of increasing the number of UAVs. There are four targets, two forbidden zones, and three UAVs (This scenario is similar to scenario 1, except there is one more UAV). The expected solution is “Assign one of the vehicles to the first and second targets and the other vehicles to the third and fourth targets.” There are two possibilities for those assigned to target 3 and target 4. The first possibility is to imitate the situation in scenario 1, and UAVs will visit these targets periodically (Figure 8). In the other opportunity, UAV 2 and UAV 3 will concentrate on target 3 and target 4, respectively (Figure 10, and Figure 11). This modification is the consequence of using rule 3. As expected, the instantaneous collected reward is more extensive when compared to scenario 1 (Figure 12).

Resultant paths for scenario 2.

The zoomed view of the path in Figure 8 (scenario 2).

Resultant paths for scenario 2, rule 3 is applied (scenario 2).

The zoomed view of the path in Figure 10, rule 3 is applied (scenario 2).

Rewards/information for Figure 10 (scenario 2).
In this scenario, there are five targets and five UAVs. It is expected that each UAV will be assigned to a different target and will stay around it. In Figure 13, we observe an expected output: Each UAV is set a specific target and stays there. Due to the dynamics of vehicles, they cannot continuously take information from their targets. We can solve this situation using rule 1.
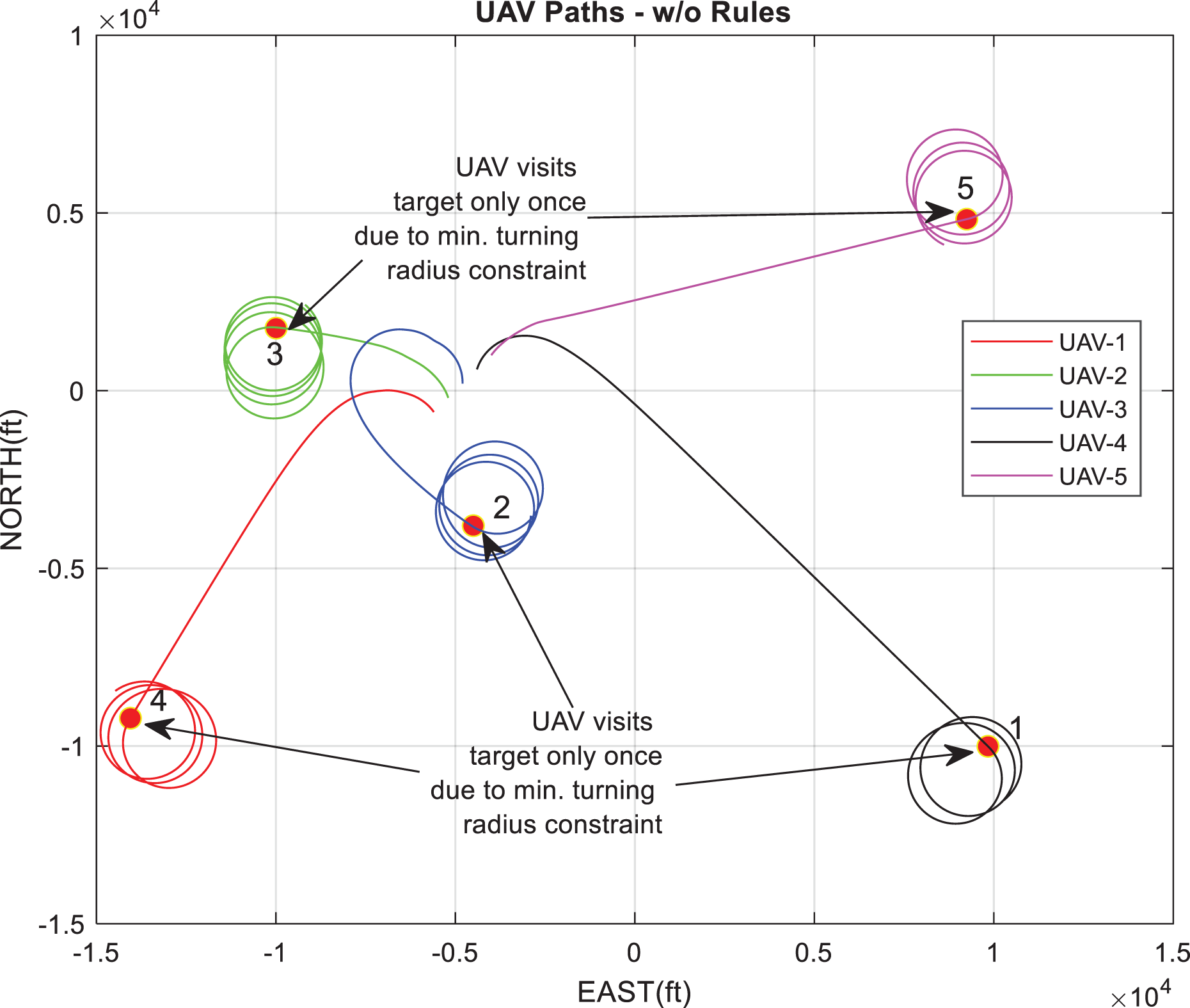
The resultant path for scenario 3, rule 1 is not applied.
It is not permitted to re-enter the same target within a certain duration. Proceed to the route with the same heading angle (rule 4). The result of this rule can be better observed in Figures 14 to 16.

The total amount of gathered information wrt. Time for scenario 3, rules are not applied.
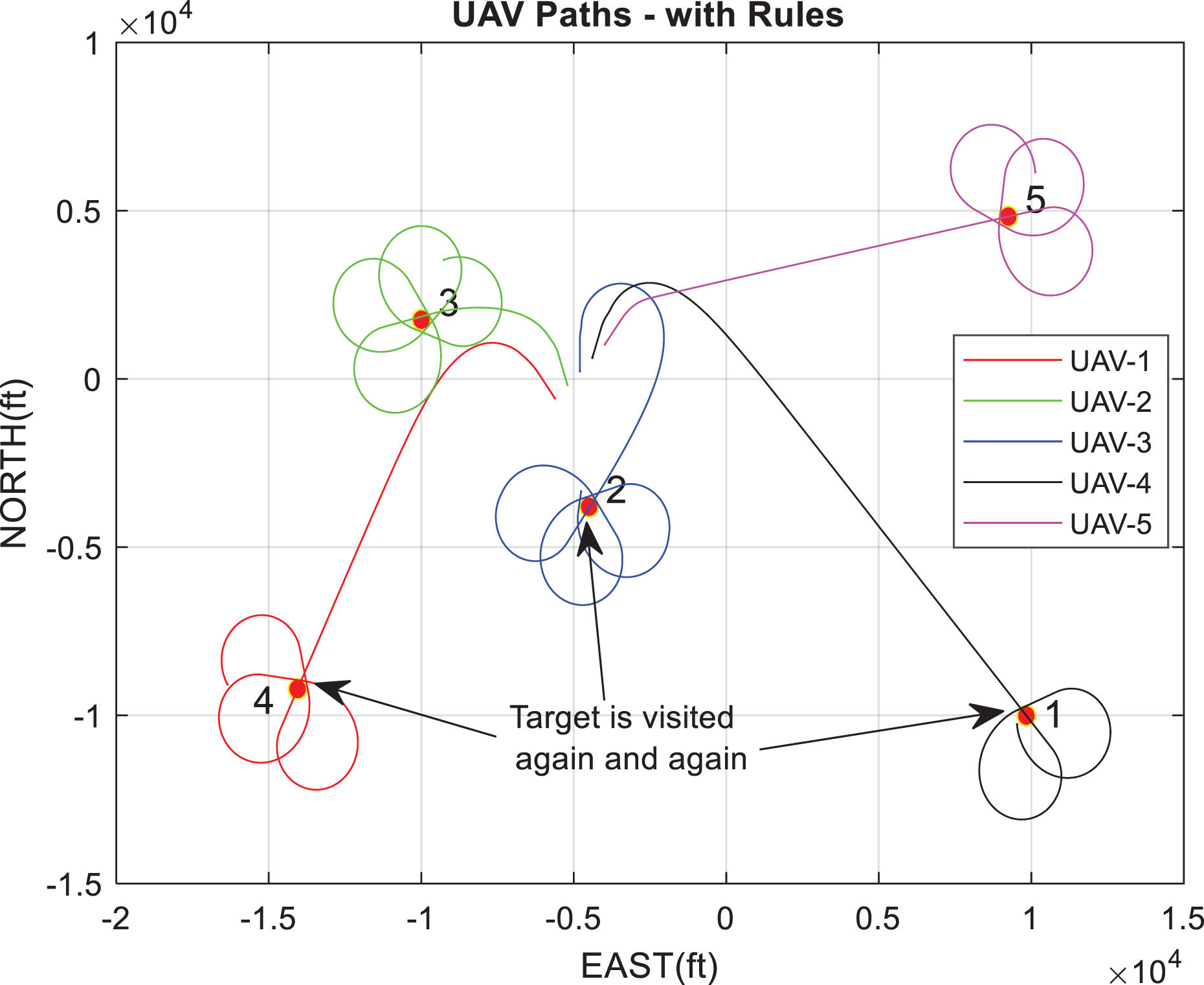
Paths of UAVs in scenario 3, rule 1 is applied. UAV: unmanned aerial vehicle.

The total amount of gathered information wrt. Time for scenario 3, rules are applied.
The complexity level of a problem is related to the number of regions (both FRs and DRs), the location of the regions relative to each other, and the number of vehicles used to solve the problem. There is no such study investigating the complexity of the path planning scenario to the best of our knowledge. In the literature, 19 we present a modest way of determining the complexity topologically in the offline PPP. However, it is a relative measure, and it cannot be used in the online case as a performance metric. It might be interesting to examine the complexity of the PPP for future studies.
Although there is no accepted norm for deciding on the complexity level of the problem, it is evident that the PPP presented in Figure 17 is intuitively more complicated than that in Figure 5.

Paths of four UAVs in scenario 4. UAV: unmanned aerial vehicle.
In this scenario, there are 10 targets, 9 forbidden zones, and 5 UAVs. It is observed that the algorithm performs no different than simple scenarios.
The aim is to observe the effect of the value of the time constant
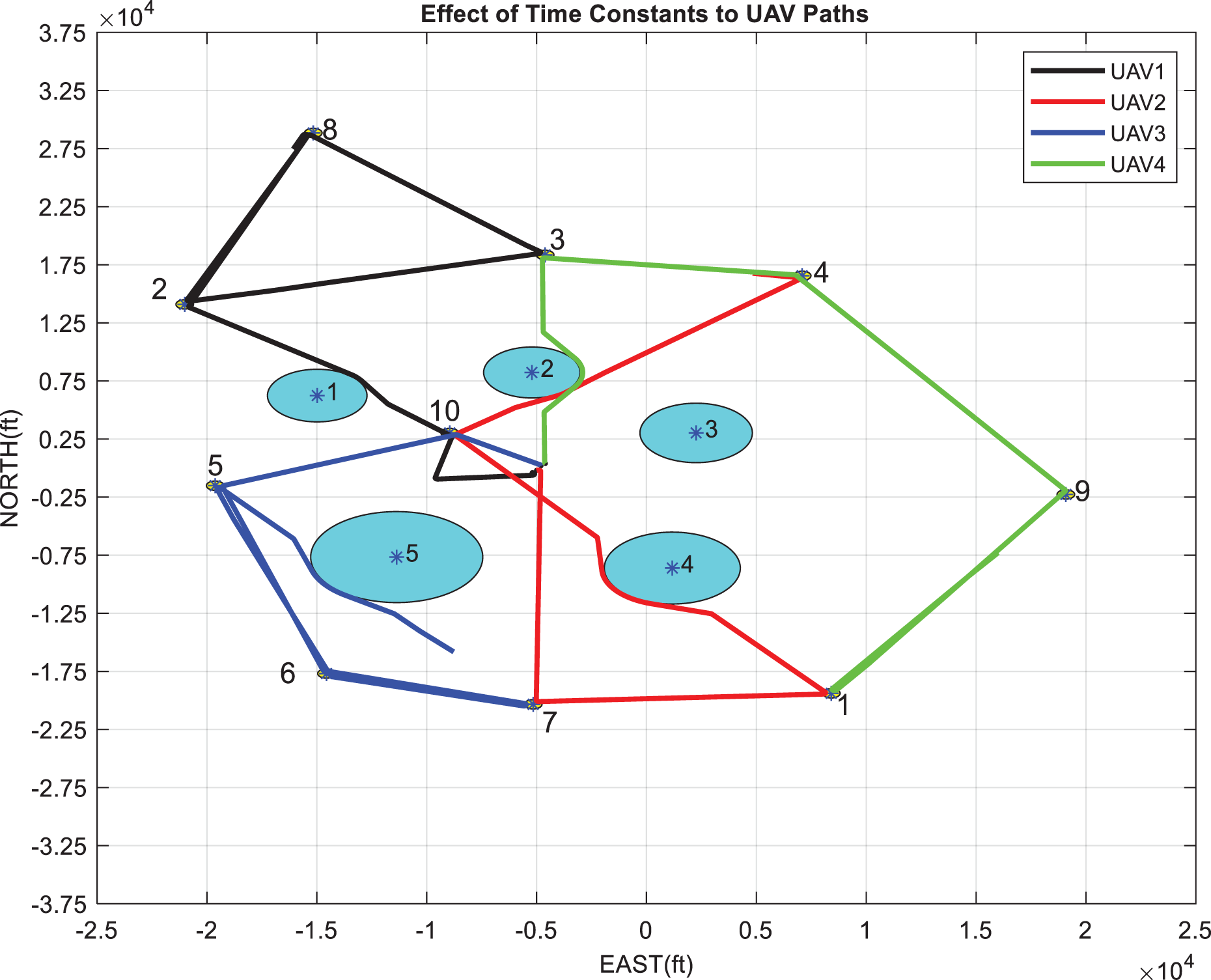
The effect of the time constant (scenario 5): Paths of UAVs for time constants of all targets are the same (
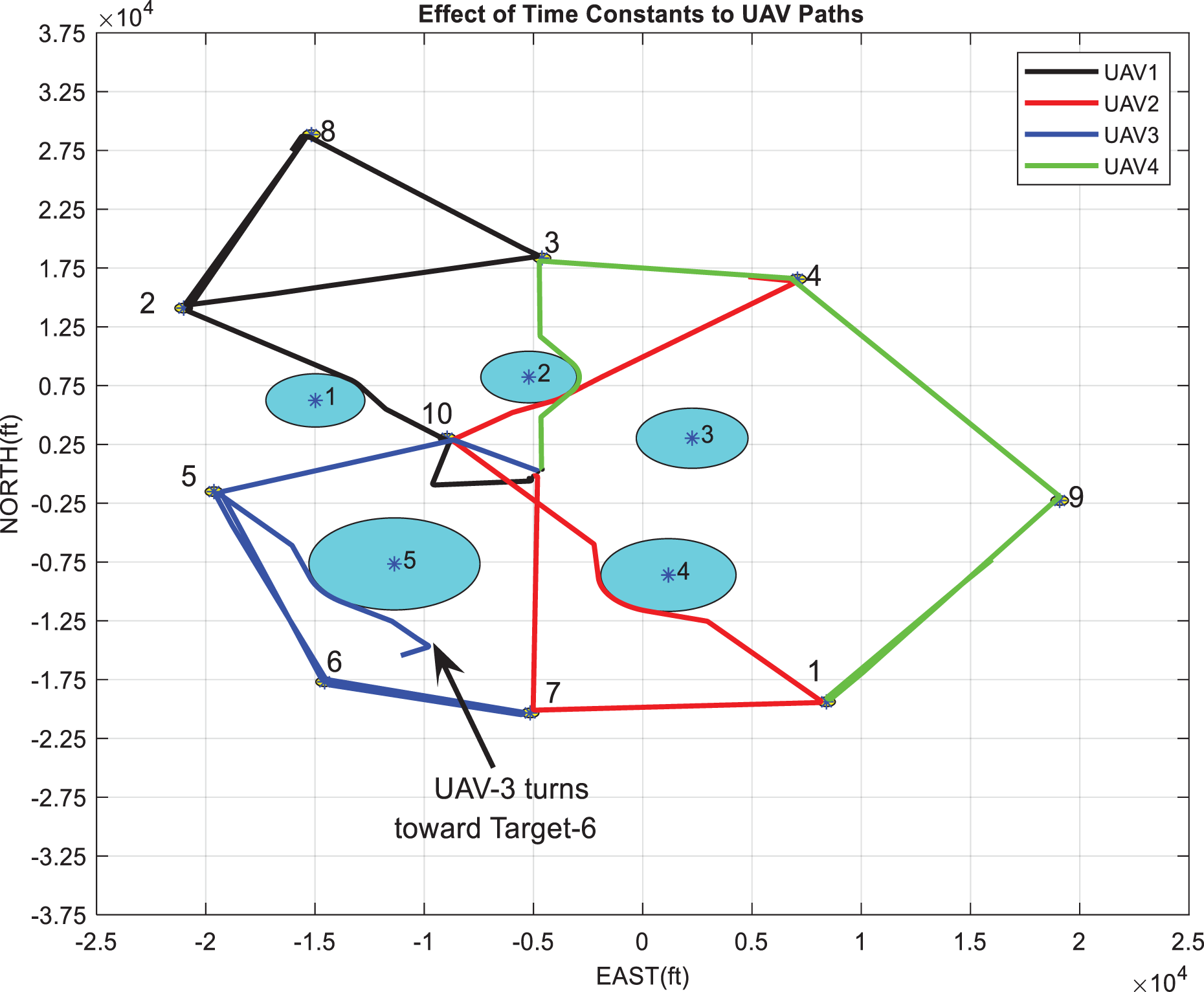
The effect of the time constant (scenario 5): Paths of UAVs when the time constant of target 6 is decreased to 70 s (

The effect of the time constant (scenario 5): Paths of UAVs when the time constant of target 6 is decreased to 55 s (
In Figure 18, UAV 4 goes toward target 7 after visiting target 5. In Figure 19, UAV 4 changes its decision to reach target 7 midway and turns toward target 6. In Figure 20, UAV 4 changes its decision earlier and turns toward target 6.
It can be concluded that the time constant parameters can be used to assign priorities to targets in the objective function construction.
Our algorithm can find paths for scenarios having moving targets. In this scenario, we have tested our algorithm using the scenario where moving targets exist. There are five moving targets and one stationary target, four forbidden zones, and three UAVs. It is assumed that the information about these moving targets’ locations is provided by surveillance assets. 28
The performance of the algorithm is examined in this kind of scenario with the assumption that targets must not fly over the FRs. The heading angles of moving targets are −90°, −60°, −30°, 0°, 45°, 90° with respect to North, and the speeds of targets are 15, 10, 10, 0, 5, 5 ft/s, respectively. The resultant paths can be observed in Figure 20; the first vehicle (i.e. UAV 1) visits targets 5 and 6, the second one visits targets 1 and 2, and the last one visits targets 3 and 4 in order, as expected intuitively.
If the heading angles of targets are changed to 0°, 70°, −30°, 0°, 45°, −90° with respect to the North, we can see the resultant paths in Figure 21. To observe UAVs’ motion to time, we present their positions at different instants in Figures 22 to 25.

Paths of UAVs and targets at the end of the scenario 6 (t = 3000 s). UAV: unmanned aerial vehicle.

Paths of UAVs and targets at the end of the scenario (t = 3000 s) (scenario 7). UAV: unmanned aerial vehicle.

Paths of UAVs after 500 s (scenario

Paths of UAVs after 750 s (scenario 7). UAV: unmanned aerial vehicle.
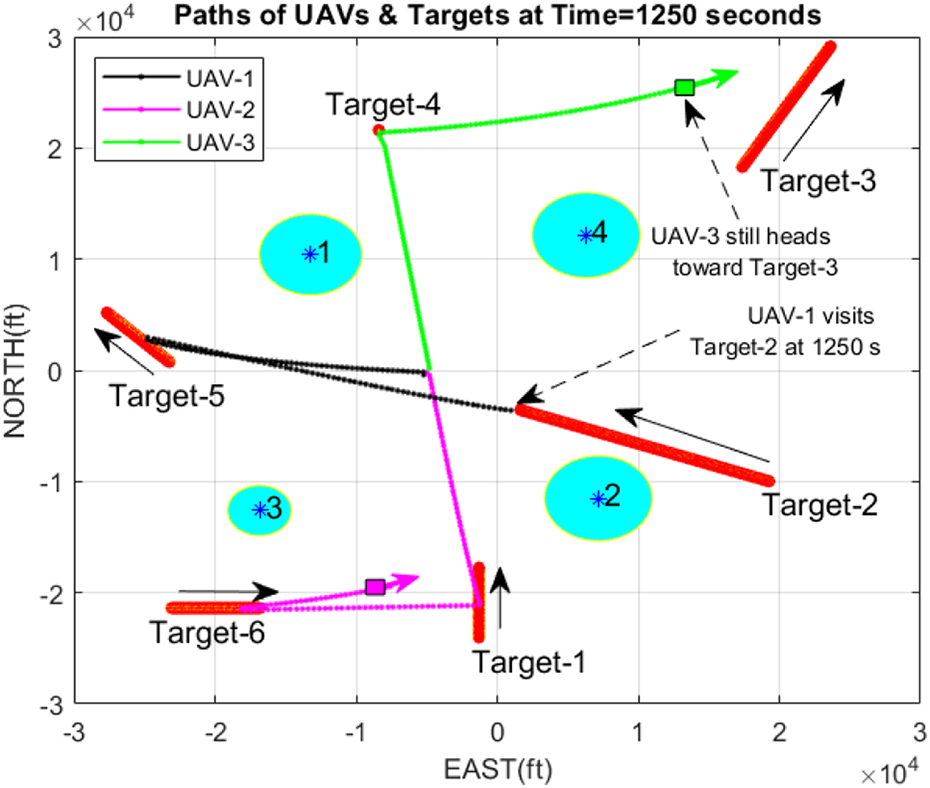
Paths of UAVs after 1000 s (scenario 7). UAV: unmanned aerial vehicle.
In this scenario, the problem is investigated for the case in which some of the UAVs are lost during the mission. There are 12 targets, 6 forbidden zones, and 5 UAVs. In Figure 26, we can observe the resultant path when there is no UAV loss. At 1000 s, UAV 2 and UAV 4 are lost. The remaining three UAVs continue the mission. As seen in Figure 27, UAV 1 takes target 1, which was assigned to UAV 2 before its loss, and UAV 5 takes target 2 and target 9, which are assigned to UAV 4 previously.

Paths of UAVs just before the loss of vehicles (scenario time = 1000 s) (scenario 8). UAV: unmanned aerial vehicle.

Paths of UAVs after the loss of vehicles (scenario 8). UAV: unmanned aerial vehicle.
In this scenario, the problem is investigated for the case in which some new targets emerge during the mission. There are six targets at the beginning of the scenario, six forbidden zones, and three UAVs. At t = 1000 s, two new targets are emerged (target 7 and target 8). We can observe the resultant paths before and after the emergence of new targets in Figures 28 and 29, respectively. In Figures 30 and 31, we can observe the instantaneous positions of the UAVs a few seconds before and after pop-up, respectively.

Scenario 9 without pop-up targets.

Scenario 9 with pop-up targets, after the pop-up.

Scenario 9 with pop-up targets, just before pop-up.

Scenario 9, with pop-up targets, has just appeared.
It is possible to increase the number of scenarios. Due to the page limitations, we have constructed some scenarios just enough to show the most critical issues regarding the performance of our approach.
The algorithm checks new events at every second. Hence, in the worst case, it can be assumed that the problem is solved once at each second (the processing time of scenario with eight UAVs and 20 targets is about 2.5 ms). The worst case computational complexity of the method to solve rectangular form of assignment problem is O(N 3 ) (see Figure 32). Since the problem is solved anew at every occurrence of an event then the complexity of the presented algorithm is O(VN 3 ), where V is the number of events. The computational complexity of RI matrix calculation is O(KN). In particular, the simulations were performed in MATLAB and executed on a personal computer, which has the following configuration: 3 GHz processor and 32 GB memory (RAM). The most time consuming part of the algorithm is the assignment problem solution we presented in Figure 32, the processing time versus number of UAVs for the sample scenario having 20 targets.
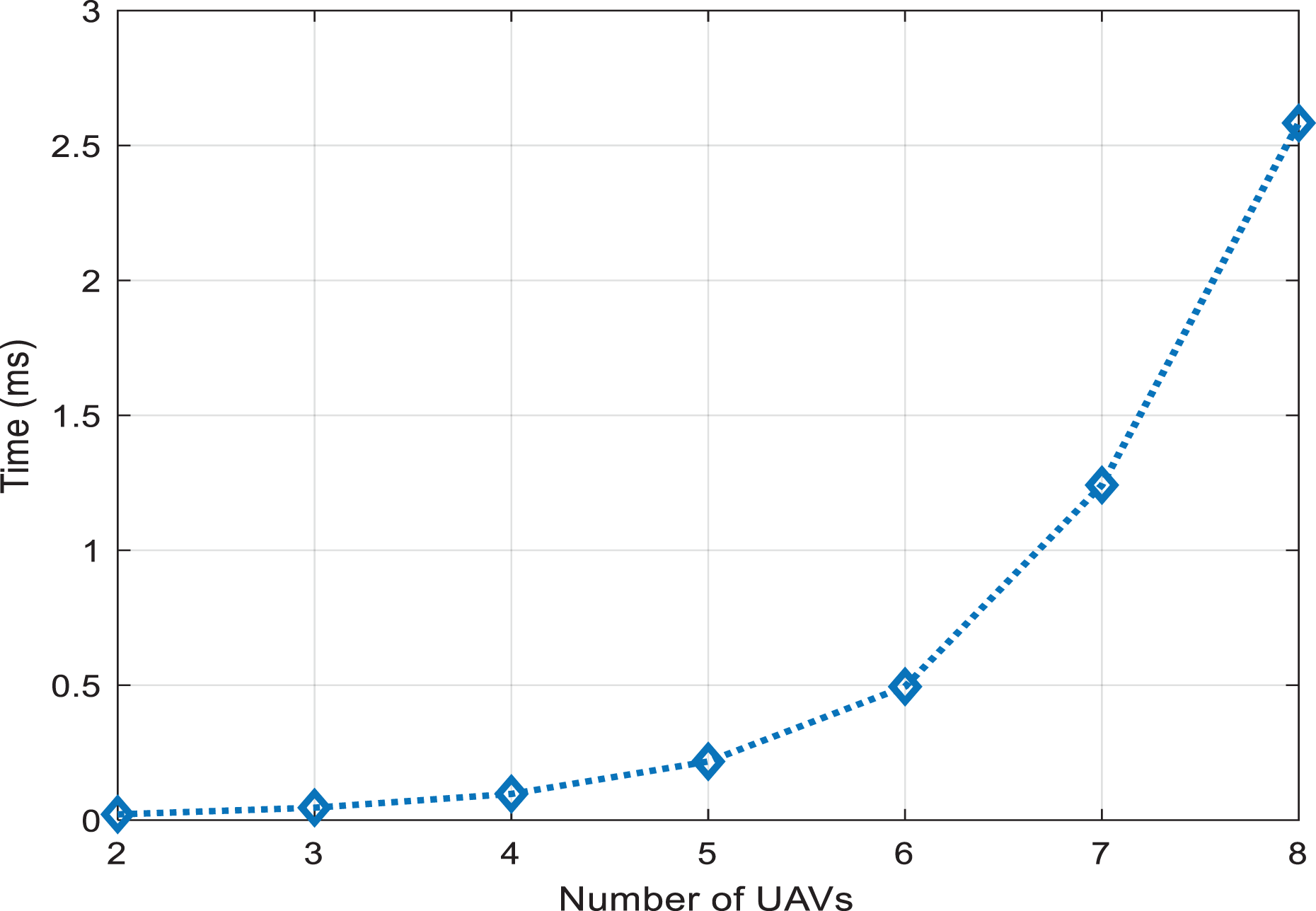
Processing time vs. number of UAVs for the sample scenario having 20 targets.
Investigation of convergence
To examine whether the problem converges or not, we need to examine our algorithm under two main headings: the solution to the assignment problem and the tasks’ status between two consecutive solutions. Frank 34 and Burkard et al. 35 show that the Kuhn–Munkres algorithm converges to the optimal solution. As we will see from equation (15), the RI matrices we use in the assignment problem take finite values. On the other hand, before the tasks assigned to the vehicles are completed, new tasks can be assigned to the vehicles, or the vehicle may not perform the task due to the kinematic constraints. These problems have already been noted in the manuscript, and they have been taken care of by defining special rules, as given and explained in the fourth section. These rules ensure that vehicles fulfill the tasks. In summary, it can be concluded that the overall algorithm converges a solution.
Conclusions
As indicated before, when the environment is varying, or there is no exact knowledge in advance about the environment, a UAV needs to intelligently plan its path online. Also, in our case, the information taken from targets become outdated. Hence, an online path planner is required to guide multiple UAVs in coordination. We have proposed an online path planning algorithm to guide a group of UAVs to maximize the total amount of information gathered over a given time interval. This centralized algorithm gives acceptable results. As in our offline path planning algorithm, 2,3 some basic rules have been defined to overcome unwanted situations.
In the future, this work can be expanded for the 3D case. In this case, different subproblems such as 3D obstacle avoidance, fuel consumption (will be useful in making descend or ascend decisions), if the information obtained is an image, collecting data in different resolutions, visiting each target at various expeditions at different heights
will need to be included in the problem. Also, in the 3D case of this problem, vehicles’ velocity and altitude should be taken as optimization variables. It may be interesting to find a path for desired locations obstructed by forbidden zones for the 3D case for future studies. If moving targets and their velocities are uncertain, the estimation of the targets’ velocity will be required.
The proposed algorithm need not to be centralized. It could be completely decentralized with the addition of powerful processors on each vehicle. This also requires complete information exchange between the vehicles. In the decentralized case, each vehicle is supposed to run the same algorithm on its own processor based on the information it has. But, while the algorithm is running on a particular vehicle, the available information may change in real time, and the optimum decision of that particular vehicle may be obsolete. Furthermore, there are delays, and sometimes, communication breaks during information exchange. These are very important, of course, not easy to solve problems. We plan to deal with these cases in the future.
Supplemental material
Supplemental Material, sj-docx-1-arx-10.1177_17298814211010379 - Online path planning for unmanned aerial vehicles to maximize instantaneous information
Supplemental Material, sj-docx-1-arx-10.1177_17298814211010379 for Online path planning for unmanned aerial vehicles to maximize instantaneous information by Halit Ergezer and Kemal Leblebicioğlu in International Journal of Advanced Robotic Systems
Supplemental material
Supplemental Material, sj-pdf-1-arx-10.1177_17298814211010379 - Online path planning for unmanned aerial vehicles to maximize instantaneous information
Supplemental Material, sj-pdf-1-arx-10.1177_17298814211010379 for Online path planning for unmanned aerial vehicles to maximize instantaneous information by Halit Ergezer and Kemal Leblebicioğlu in International Journal of Advanced Robotic Systems
Supplemental material
Supplemental Material, sj-pdf-2-arx-10.1177_17298814211010379 - Online path planning for unmanned aerial vehicles to maximize instantaneous information
Supplemental Material, sj-pdf-2-arx-10.1177_17298814211010379 for Online path planning for unmanned aerial vehicles to maximize instantaneous information by Halit Ergezer and Kemal Leblebicioğlu in International Journal of Advanced Robotic Systems
Supplemental material
Supplemental Material, sj-rar-1-arx-10.1177_17298814211010379 - Online path planning for unmanned aerial vehicles to maximize instantaneous information
Supplemental Material, sj-rar-1-arx-10.1177_17298814211010379 for Online path planning for unmanned aerial vehicles to maximize instantaneous information by Halit Ergezer and Kemal Leblebicioğlu in International Journal of Advanced Robotic Systems
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Appendix
Path planner


|
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.