
Abstract
Recently, convolutional neural network (CNN) has led to significant improvement in the field of computer vision, especially the improvement of the accuracy and speed of semantic segmentation tasks, which greatly improved robot scene perception. In this article, we propose a multilevel feature fusion dilated convolution network (Refine-DeepLab). By improving the space pyramid pooling structure, we propose a multiscale hybrid dilated convolution module, which captures the rich context information and effectively alleviates the contradiction between the receptive field size and the dilated convolution operation. At the same time, the high-level semantic information and low-level semantic information obtained through multi-level and multi-scale feature extraction can effectively improve the capture of global information and improve the performance of large-scale target segmentation. The encoder–decoder gradually recovers spatial information while capturing high-level semantic information, resulting in sharper object boundaries. Extensive experiments verify the effectiveness of our proposed Refine-DeepLab model, evaluate our approaches thoroughly on the PASCAL VOC 2012 data set without MS COCO data set pretraining, and achieve a state-of-art result of 81.73% mean interaction-over-union in the validate set.
Introduction
Semantic segmentation, which aims at predicting pixel-level semantic labels for an image, provides detailed semantic annotation of the surrounding environment for the robot 1 –3 and is a fundamental topic in computer vision. The ability to interpret scenarios is an important capability for robots interacting with the environment. Leveraging the strong capability of convolutional neural network (CNN), which have been widely and successfully applied to image classification, 4 –6 most state-of-the-art works have made significant progress on semantic segmentation 7 –13 of robot to tackle the challenges (e.g. reduced feature resolution and objects at multiple scales) in CNN-based semantic segmentation. Researchers propose various network architectures. For example, the application of atrous convolutions, 14 –18 while keeping the number of backbone network parameters unchanged, and the convolution layer receptive field of each stage unchanged, the higher convolution layer can also maintain a large feature map size to facilitate small targets. The detection improves the overall performance of the model. In general, CNN 6,19 often faces three challenges in image semantic segmentation: (1) reduced feature resolution, (2) the existence of multiscale objects, and (3) reduced positioning accuracy due to CNN invariance.
Dilated convolution 14,15,18 increases the receptive field and maintains the resolution of the feature map by injecting holes into the standard convolution (max-pooling or strided convolution will reduce the feature map resolution). Compared to the original standard convolution, the dilation convolution has a hyperparameter called dilation rate, which refers to the number of intervals of the convolution kernel (e.g. standard convolution is dilatation rate = 1). Although the dilated convolution eases the contradiction between the resolution of the feature map and the size of the receptive field, it still faces many problems. For example, the neurons in the feature map have the same receptive field, which means that the semantic mask generation process only utilizes features on a single scale. However, experiences 13,10,18 show that multiscale information would help resolve ambiguous cases and result in more robust classification. Similarly, as the resolution of feature map decreases, when the dilation rate increases, the effect of dilated convolution will be ineffective in the dilated convolution framework. This problem is defined as “gridding issue.” 20 Since the hole convolution is a discrete sample on the feature map, there is a lack of correlation. However, in the case of a continuous stack of hole convolution, the convolution kernel is not continuous, that is, not all pixels are used for calculation. So, the way information is treated as a checkerboard here loses the continuity of the information. This is called the “gridding” problem. In this work, we propose a multiscale hybrid dilated convolution method similar to pyramid pooling to solve this problem.
In general, low-level features and high-level features complement each other; low-level feature space information is rich but lacks semantic information and high-level features are the opposite of low-level features. However, many excellent models 18,9 only use the highest layer features. DeepLabV3 10 finely tunes the extracted highest layer features through the atrous spatial pyramid pooling (ASPP) module to obtain excellent results. DeepLabV3+ 13 uses the lowest layer feature to improve the performance of segmentation. DFANet 10 proposed to extract semantic features by subnetwork and substation cascade aggregation, starting with a single lightweight backbone network. So, the use of multilevel features is necessary. Therefore, we use the feature information between different levels in the backbone network to perform feature aggregation to achieve the effect of multilevel feature utilization. At the same time, we consider the resolution of each level feature map and design multiscale hybrid dilated convolution, which alleviates the “grid” problem (Figure 2) caused by dilated convolution.
Capturing multiscale context information is critical to semantic segmentation tasks. SSD 21 uses a feature map of different stride as detection layers to detect targets at different scales, users can make plans based on the target scale of their tasks. PSPNet 18 proposes a pyramid pooling module that can aggregate context information of different grid scales, thereby improving the ability to obtain global information; DeepLabV3 10 uses dilated convolution with different dilation ratios to form a hole pyramid pooling model (called ASPP 13 ), even if rich semantic information is encoded in the final feature map, due to the pooling and striding operations of the backbone network convolution lacks the ability to extract target boundary information. Therefore, DeepLabV3+ 22 proposes to fuse the final feature map information with the lower layer information by combining the multiscale context information coding network to obtain a more detailed segmentation effect. However, some previous works neglect the role of the backbone network. The effective use of the information of each level of the backbone network can reduce the size of the model and improve the segmentation performance. Finally, we demonstrate the effectiveness of the proposed model on the PASCAL VOC 2012 23 data set to achieve excellent results.
We summarize our main contributions as follows: We propose a multilevel extraction feature module, which greatly utilizes the feature extraction capability of the backbone network; A multiscale hybrid dilated convolution module has been introduced into our structure to alleviate the “gridding” problem; Our proposed model exceeded the results of DeepLabV3+ on PASCAL VOC 2012 without MS COCO pretraining.
In the next sections, in related works, method, and experiments, we will expand from three perspectives: multiscale hybrid dilated convolution, multiscale feature aggregation, and decoder/encoder.
Related works
Recently, driven by intelligent manufacturing technology and unmanned driving, semantic segmentation has significantly improved the understanding performance of robot scene. Especially, fully convolutional network (FCN) 7 -based approaches achieve promising performance on scene parsing and semantic segmentation task. Driven by powerful deep CNNs, 5,6,19 pixel-level prediction tasks such as scene parsing and semantic segmentation achieve great progress inspired by replacing the fully connected layer in classification with the convolution layer.
To enlarge the receptive field of CNN, 14 –18 use dilated convolution. In recent years, to solve computer vision problems more effectively, multiscale features are widely used in computer vision tasks. At the same time, multiscale features are another important factor in segmentation tasks. Based on the spatial pyramid structure, 24 PSPNet 18 and ASPP 13 are fusing multiple multiscale feature maps to form a pyramid structure for final prediction, where PSPNet 18 employs four spatial pyramid pooling (downsampling) layers in parallel to aggregate information from multiple receptive field sizes and assigns to each pixel via upsampling. In this work, we mainly discuss about multiscale hybrid dilated convolution, multilevel feature aggregation, and the structure of the encoder–decoder.
Multiscale hybrid dilated convolution
The multiscale feature plays a key role in semantic segmentation, especially for objects/stuff with a vast variation of scales. SegNet, 25 UNet, 26 and DeepLabV3 10 design encoder–decoder architecture are used to fuse low-level and high-level feature maps from encoder and decoder, respectively. Spatial pyramid pool 18 uses several parallel dilated convolution to extract multiscale information. ASPP 13 concatenates feature maps with different dilation rates so that the output feature map aggregates multiple-scale semantic information, which can improve segmentation performance. ASPP in DeepLabV2 10 uses dilated convolution with four different sampling rates in the top map of features. Deeolabv3 13 adds batch normalization 27 to ASPP. Dilated convolution with different sampling rates can effectively capture multiscale information, but it will be found that as the sampling rate increases, the effective weight of the filter (the weight is effectively applied to the feature area instead of filling 0) gradually becomes smaller. MFCAN 28 uses dilated convolution instead of standard convolution, combines feature maps of different levels, and aggregates information from different receiving fields. Through multiscale information extraction, the model shows effective results on several segmentation benchmarks. However, while the PSPNet 18 blindly enlarges the receptive field of neural networks, with the reduction of receptive field, as the dilation rate increases, the dilated convolution becomes more and more ineffective and gradually loses its modeling power. We use this feature to combine the resolution of each layer feature map to propose a multiscale hybrid dilated convolution module instead of the space pyramid pooling module.
Multilevel feature aggregation
With the deeper convolutional network, the resolution of feature maps is decreasing to capture high-level semantic information, but the application of low-level information is often ignored. DeepLabV3+ 22 aggregates lower-level information with higher-level information for finer segmentation. DUpsampling 29 spliced the highest layer of the backbone network with the second layer and achieves new state-of-the-art performance. MLFFNet 11 implements feature reuse through multilevel feature fusion, which greatly reduces computational complexity. To alleviate these issues in video crowd counting, a multilevel feature fusion-based locality-constrained spatial transformer (LST) network 30 is proposed, which consists of two components, namely, density map regression module and LST module. RFEB 31 introduces multilevel feature fusion into super-resolution reconstruction tasks and achieves excellent performance. However, the capability of feature extraction at all levels of the backbone network has not been properly applied. We have found that the segmentation effect of large target objects is not ideal. In our work, we use hierarchical aggregation to make efficient use of each level of features. Experiments have shown that the segmentation effect is effectively improved. At the same time, when using multiscale mixed dilated convolution modules for different levels, we comprehensively consider the size of the feature map and use different dilation rations to greatly alleviate the gridding problem caused by dilated convolution.
Encoder–decoder
To obtain more fine-grained performance, encoder–decoder networks are widely applied to many computer vision tasks and have been successfully applied in semantic segmentation tasks. The encoder is usually a pretrained classification network, such as VGG 6 and ResNet. 32 The decoder projects the recognition features (low resolution) learned by the encoder onto the pixel space (high resolution) semantics to obtain dense classification. DeconvNet 33 uses stacked deconvolutional layers in the decoding stage to gradually recover the full-resolution prediction gradually, but it is difficult to train because of many parameters introduced by the decoder. Through the index of the pooling layer in the encoding stage and the recovery process through the index in the decoding stage, SegNet 25 significantly improves the performance of semantic segmentation. RefineNet 9 systematically proved the effectiveness of the encoder–decoder based structure in the semantic segmentation model. Recently, DeepLabV3+ 22 combined a decoder–encoder with ASPP to achieve state-of-the-art segmentation performance on a few data sets to date. Although efforts have been spent on designing a better decoder, so far almost none of them can bypass the restriction on the resolutions of the fused features and exploit better feature aggregation.
Although each model achieves good results on multiple data sets through multiscale information extraction, the “gridding” problem caused by dilated convolution is rarely mentioned. At the same time, multiscale aggregation is used in many works, but the backbone network utilization rate is insufficient. Therefore, in this work, we propose to use multilayer feature aggregation to maximize the use of backbone network features. The introduction of multiscale hybrid dilated convolution can effectively alleviate the “gridding” problem.
Method
We propose a new framework that can be applied to any backbone network. In this section, we will briefly introduce three modules: multiscale dilated convolution, multilevel aggregation module, and encoder and decoder.
Multiscale dilated convolution
Dilated convolution is first introduced by Holschneider et al. 14 and can maintain the high resolution of the feature map by replacing the max-pooling or stride convolution, and at the same time, maintain the size of the corresponding layer of the receptive field to capture multiscale information. Dilated convolution is to inject holes in the standard convolution map to increase receptive field. Compared to the original normal convolution, the dilated convolution has a hyperparameter called dilation rate, which refers to the number of kernel intervals (e.g. normal convolution is dilatation rate = 1). In one dimension, dilated convolution is defined as
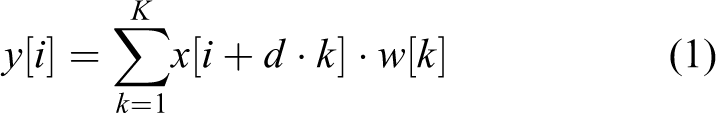
where dilation rate d determines the stride of the sampled input signal. We refer interested readers to see the literature
20
for more details. It is worth noting that when
To solve this problem, we combine the dilated convolution based on the image pyramid to propose a multiscale hybrid dilated convolution module different from hybrid dilated convolution (HDC).
20
At the same time, we consider the dilated convolution of different dilated ratios by considering the resolution of each layer’s feature map and balance the contradiction between the receptive field and the feature map. It is worth noting that it is necessary to avoid the use of a common factor conversion factor in the same group. Figure 2 shows that when we use the dilated ratio of 2, 3, 4 to superimpose, the number of pixels used is
To simplify notations, we use

Multilevel aggregation module
The structure of Refine-DeepLab is shown in Figure 1. We divide the backbone network into four blocks. We control the resolution of the feature maps of the first block and the second block to be the same, and the output feature map size is129 × 129; the resolutions of the third block and the fourth block are consistent, and the feature map size is 64 × 64. The MDC dilated ratio of each layer is adjusted according to the resolution of each layer’s feature map. The output of each atrous layer is concatenated with the input feature map, and the concatenated feature map is fed into the following layer. The semantic information at all levels in the backbone network is aggregated, and the information at all levels is extracted by multiscale hybrid dilated convolution for feature aggregation of semantic information at different levels. At the same time, the use of low-level information is not only conducive to the use of features but also integrates high-resolution information, and the boundary segmentation effect is more obvious.

An overview of the multilevel feature fusion dilated convolution network. The input image is fed into a backbone network to obtain four levels of feature maps (f1,f2,f3,f4). We propose MDC module, which is different from ASPP. 13 We input the four hierarchical feature maps obtained by CNN 6,19 into the MDC model to obtain multiscale feature maps for each level. The multiscale feature map is spliced with the hierarchical feature map. Refine-DeepLab consists of four parallel MDCs. The F1 and F2 feature maps are upsampled by 2 and then spliced with the lower level two features. Finally, Refine-DeepLab connects MDCs from different scales to predict the semantic labels of input pixels. MDC: multiscale dilated convolution; ASPP: atrous spatial pyramid pooling.

Illustration of the gridding problem. The convolution with kernel size
Network architecture
The whole architecture is shown in Figure 1. In general, our semantic segmentation network could be seen as an encoder–decoder structure.
Encoder: We will integrate the resolution size of the output feature graph at all levels to design dilated convolution dilation rate. The purpose of this is to alleviate the generated “gridding” effect. When the size of feature graph is not large enough, if we adopt a convolution with a large dilated rate, the consistency of local information will be destroyed. As the dilation rate increases, the data used in the input will become more and more sparse, which is not conducive to convolution learning. When the local information is lost, the correlation of the remote information will also be destroyed. We designed the

Decoder: Our proposed decoder module is shown in Figure 1. As discussed above, the encoder is an aggregation of four aggregation modules, composed with multiscale hybrid dilated convolution and low-layer features. For inference, we do not put too much focus on designing a complicated decoder module. According to DeepLabV3+, 22 we propose to fuse high-level and low-level features directly. First, F3 and F4 are upsampled by a factor of 2, and fuse four F modules. Because our encoder is composed of four multilevel aggregation modules, we firstly fuse high-level representation from the bottom of four multilevel aggregation modules. Then, the high-level features and low-level details are added together and upsampled by a factor of 2 to make the final prediction. In the decoder module, we only implement a few convolution calculations to reduce the number of channels.
Experiments
The proposed models are evaluated on the PASCAL VOC 2012 semantic segmentation benchmark, 23 PASCAL context. 34 We measure the performance in terms of pixel mean intersection-over-union (mIOU) averaged across the present classes (i.e. mIOU).
Experimental details
We implement our methods on Pytorch.
35
We use ResNet-101
32
or ResNet-152
32
networks that have been pretrained on the ImageNet
5
data set as a starting point for all of our models. Our proposed model is evaluated on the PASCAL VOC 2012 semantic segmentation benchmark,
23
which contains
Learning rate policy: We use a “poly”
36
learning rate policy to initialize the learning rate:
Crop size: Randomly crop from the image during training corresponding to a large dilated convolution rate that requires a large cropped picture; otherwise, the filter weight with a large dilation rate is mainly applied to the padded zero area. Therefore, during the training and testing of the PASCAL VOC 2012 data set, we used a picture crop size of
Multiscale hybrid dilated convolution
We use the ResNet-101 framework as the backbone of our model. We divide the backbone network into four blocks, and the feature maps of the four module outputs are, respectively, defined as a first feature map (f1), a second feature map (f2), a third feature map (f3), and a fourth feature map (f4). We extracted multiscale features from four feature modules through multiscale mixed dilated convolution. To verify the validity of multiscale mixed dilated convolution, we did some comparative experiments. We use the highest level features for verification. We use the multiscale hybrid dilated convolution module to process the highest layer features to get the The receptive field after using dilated convolution should not exceed the size of the feature map; The dilation rate combination cannot have a common divisor greater than 1.
Therefore, we first select several combinations of dilation ratios with comparative significance to verify our conclusions. We used different dilated ratio (MDC) and convolution KS settings to study the performance of multiscale hybrid dilated convolution modules. The results are listed in Table 1. From the table, we get the following observations. First, all multiscale hybrid dilated convolutions significantly improve performance compared to the underlying backbone network. Second, MDC
Multiscale dilated convolution and different dilation rates for model performance.

mIOU: mean interaction-over-union; MDC: multiscale dilated convolution.
Multilevel aggregation network
To further validate the effectiveness of our multilevel multiscale hybrid dilated convolution network, we use ResNet-101
32
as our backbone network. It can be seen from Table 2 that the multilevel multiscale hybrid dilated convolution network performance is far superior to the single-level multiscale hybrid dilated convolution. The reason is that the single-level multiscale hybrid dilated convolution often ignores the low-level features. This results in poor segmentation performance for large targets. To verify the multilevel module, we designed all multiscale hybrid dilated convolution modules with a dilation ratio of

Examples of visualization on the PASCAL VOC2012 segmentation validation set. Comparison with baseline method. Refine-DeepLab produces more accurate and detailed results. (a) Image, (b) ground truth, (c) DeepLabV1, (d) DeepLabV3, and (e) ours.

An overview of the single-level feature dilated convolution network.
Exploring different dilation ratio combinations to alleviate grid problems based on improving model performance.

mIOU: mean interaction-over-union; MDC: multiscale dilated convolution.
The effect of each level of feature aggregation on the performance of the model.

mIOU: mean interaction-over-union; MDC: multiscale dilated convolution.
To evaluate the PASCAL VOC 2012val set, we set the multiscale hybrid dilated convolution to
Experimental results of multilevel aggregation network on other backbone networks.

The result is the result on the PASCAL VOC2012 validation set.a

mIOU: mean interaction-over-union.
a Our method is superior to all previous advanced methods, reaching

Experimental results of multilevel aggregation networks on the PASCAL VOC2012 validation set based on different backbone networks. The first line is based on the DeepLab model, and the second line is based on our multilevel aggregation network. (a) MobileNet, (b) DRN, (c) Xception, and (d) ResNet.
Summary
Compared to DeepLabV3 13 and PSPNet, 18 our method achieves better results on PASCAL VOC 2012. These results show that Refine-DeepLab can effectively use multiscale hierarchical features and multiscale spatial information. Compared with DeepLabV3, we construct multiscale context information by maximizing the multilevel features extracted by the backbone network to make the global information affinity more reasonable and higher performance.
Conclusion
In this article, we discuss the properties of multiscale features and propose a multiscale context representation of multilevel multiscale hybrid dilated convolution for semantic segmentation and scene analysis. Refine-DeepLab introduces multiscale expansion convolution while capturing rich context information, which can effectively alleviate the contradiction between the size of the acceptance field and the expansion convolution operation. Through the aggregation of multiple layers of semantic information, high-level semantic information and low-level semantic features are extracted to aggregate global information. Through our well-designed dilation ratios, the “gridding” problem caused by dilated convolution is alleviated, and the segmentation effect of large-size targets is solved. At the same time, our proposed Refine-DeepLab can be embedded not only in any backbone network but also in any network layer independent of the size of the input feature map. Considering the limitations of computing resources, we did not perform pretraining on MS COCO, 45 but our experimental results show that our multilevel feature fusion dilated convolution network can be extended to other scenarios. It is worth noting that Refine-DeepLab proves that the features of each layer of the backbone network are extremely effective in improving segmentation performance. However, when we are extracting multilevel features, how to effectively extract multilevel features while ensuring that the amount of calculation remains unchanged or reduced is a problem worthy of our further solution.

Examples of visualization on the PASCAL VOC2012 segmentation validation set. (a) image, (b) ground truth, and (c) Refine-DeepLab.
Footnotes
Author contribution
The authors TK and QY contributed equally.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed the receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Program of China under grant no. 2020YFB1708503.