
Abstract
Existing visual simultaneous localization and mapping (V-SLAM) algorithms are usually sensitive to the situation with sparse landmarks in the environment and large view transformation of camera motion, and they are liable to generate large pose errors that lead to track failures due to the decrease of the matching rate of feature points. Aiming at the above problems, this article proposes an improved V-SLAM method based on scene segmentation and incremental optimization strategy. In the front end, this article proposes a scene segmentation algorithm considering camera motion direction and angle. By segmenting the trajectory and adding camera motion direction to the tracking thread, an effective prediction model of camera motion in the scene with sparse landmarks and large view transformation is realized. In the back end, this article proposes an incremental optimization method combining segmentation information and an optimization method for tracking prediction model. By incrementally adding the state parameters and reusing the computed results, high-precision results of the camera trajectory and feature points are obtained with satisfactory computing speed. The performance of our algorithm is evaluated by two well-known datasets: TUM RGB-D and NYUDv2 RGB-D. The experimental results demonstrate that our method improves the computational efficiency by 10.2% compared with state-of-the-art V-SLAMs on the desktop platform and by 22.4% on the embedded platform, respectively. Meanwhile, the robustness of our method is better than that of ORB-SLAM2 on the TUM RGB-D dataset.
Keywords
Introduction
In recent years, the visual simultaneous localization and mapping (V-SLAM) technology has developed significantly. As a low-cost solution, V-SLAM technology has lower requirements on its hardware system. 1 –6 Therefore, it has preliminary applications in many fields, such as robot industry, virtual reality, and autonomous driving. 7,8 However, the state-of-the-art V-SLAMs are usually sensitive to the sparse landmarks in the environment and large view transformation of camera motion. Due to the decrease of the matching rate of feature points, the tracking thread often has a large drift or even causes failures on the loop detection and the back-end optimization process, 9 –11 which may finally result in instability or even collapse of the whole V-SLAM system. 11
Aiming at the above problems, this article proposes an improved V-SLAM method based on scene segmentation and incremental optimization. Different from those mainstream V-SLAM systems using all feature point information in the keyframe, this article selects the landmarks near the current line-of-sight vector to match with the last motion direction of the camera so as to improve the positioning accuracy. In the front-end module, by adding scene segmentation, camera motion direction to the tracking thread, and segmenting the camera trajectory, the effective prediction of camera motion in the road segments with sparse landmarks and large view transformation is realized. In the back-end optimization module, this article proposes an incremental optimization method combining camera motion direction and angle. By incrementally updating the state parameters and reusing the computed results, high-precision results of the camera track and feature points are obtained with satisfactory computing speed. The experimental results demonstrate that our method improves the computational efficiency by 10.2% compared with state-of-the-art V-SLAMs on the desktop platform and by 22.4% on the embedded platform, respectively. Meanwhile, the robustness of our method is better than ORB-SLAM2 3,4 on the TUM RGB-D dataset. 1
Literature review
Existing mainstream V-SLAMs could be roughly divided into three categories: based on filter, based on keyframe bundle adjustment (BA), and based on direct method.
Regarding the filter-based V-SLAM systems, Davison et al. 12 proposed a most representative SLAM system named mono SLAM, in which the front end is able to track sparse map feature points and determine their poses in real time, and the back end uses an extended Kalman filter to update its mean and variance. To apply filtering-based SLAM in large scenes, Gu and Liu 13 proposed a robust visual inertial odometry, and in its extended Kalman filter update process, the direct intensity error is used as the visual metric, however, such kinds of algorithms are only suitable for the environment with rich visual feature points. In general, filter-based V-SLAM system has poor performance in large scale and high dynamic scenes, which are likely to cause cumulative errors. 14
The first V-SLAM system based on keyframe BA, with its name parallel tracking and mapping (PTAM), was proposed by Klein and Murray. 15 PTAM supports keyframe and back-end nonlinearly optimization, which uses a multithread strategy to track and map the scene, however, the main issue of PTAM is that its efficiency could be strongly affected in a medium range scenario with thousands of points. Currently, ORB-SLAM2 proposed by Mur-Artal et al. 3,4 is one of the best keyframe-BA based V-SLAM systems, in which based on the improvement of PTAM, the ORB feature is used to track the surrounding environment, and loop-detection is established to eliminate cumulative errors. Similar to filter-based V-SLAM systems, keyframe-BA-based V-SLAM is dependent on the richness of environmental features, therefore, tracking failures and mapping accuracy errors often occur in the scene with sparse landmarks and large view transformation.
Instead of using keypoints, large-scale direct SLAM (LSD-SLAM), as the most-widely known direct method V-SLAM, directly operates on image intensities both for tracking and mapping, which are able to recover the semidense map in the scene. 16 Engel et al. 17 proposed direct sparse odometry (DSO) in 2017, which improves the scale of dense map restoration, and is more robust than LSD. The key problem of such kind of V-SLAMs is that they are usually sensitive to outdoor scene illumination changes and dynamic interference, so the robustness of location and mapping is not strong enough. 13
It is generally believed that the large view transformation of camera and sparse landmarks are two big technical challenges of V-SLAM. Morel and Yu 18 proposed affine scale-invariant feature transform (ASIFT) algorithm in 2009. ASIFT uses affine sampling to simulate the angle deformation, which makes the algorithm to have the ability of antiangle transformation and antiscale transformation, however, it could not provide real-time performance. Based on ASIFT, after surf (ASURF), after ORB (AORB), and AFREAK use SURF, ORB, and FREAK algorithms to replace SIFT algorithm, respectively, which are able to improve the operation speed. 19 Han 20 proposed a visual slam method to integrate the information of 3D structure, which uses the 3D point cloud structure to render virtual keyframes, expanding the scene coverage of matching view angle, as a result, the recall rate of loopback detection is improved in changing scenes.
In the view of the situation with sparse landmarks in the environment and large view transformation of camera motion, Pumarola et al. 21 proposed a SLAM algorithm combining semantic information and line features, which sample the straight lines by matching the 3D points. However, the accuracy of the algorithm is not ideal and has high computational complexity since some of those 3D points are obtained using interpolation method. 22 Zhang et al. 23 proposed an RGB-D V-SLAM method based on line features, which use Mahalanobis distance to measure the distance from a 3D point to a 3D straight line and use random sample consensus (RANSAC) algorithm and maximum likelihood estimation to estimate the parameters of 3D lines so that it guarantees the accuracy of coordinate extracted in 3D line segments. Nerurkar et al. 24 proposed C-KLAM based on the keyframe constraint. In the algorithm, during the back-end optimization, the sparse structure of the correlation information matrix is maintained through marginalization, and the information matrix of nonkeyframes is projected into other adjacent keyframes to realize the optimization of camera pose and feature points. This method has strong robustness, but it relies on IMU or other inertial sensors to provide accurate camera pose output. Kaess et al. 25 proposed iSAM2 based on incremental direct inference method with strong robustness for landmark points, which uses Bayes tree to solve the nonlinear optimization equation in an incremental way. Zhang et al. 26 proposed a tracking method for discontinuous features through extracting the discontinuous SIFT features, in which K-means and matching matrices are used to cluster SIFT features, consequently feature points are segmented and fused. This method is suitable for large-scale scenes, however, its real-time performance is poor due to the large computing cost. Liu et al. 27 proposed an RGB-D SLAM system using an incremental cluster adjustment algorithm, and it implements local and global BA in a unified optimization framework, which can save a lot of computing time in the back-end optimization of discontinuous segments and improve the processing speed. The disadvantage is that based on the direct method, the RGB-D SLAM system is sensitive to illumination changes and has the problems of feature point drift when there are few landmarks.
Overall speaking, V-SLAM technology has developed rapidly in recent years. However, when the V-SLAM technology is used in the situation of road segments with sparse landmarks or large view transformation, the number of matching feature points may be sharply reduced, which often leads to the problems of large drift or tracking failure in the V-SLAM system. These problems limit the further applications of V-SLAM.
Aiming at the aforementioned problem, this study proposes an improved V-SLAM method based on scene segmentation and incremental optimization strategy. The main contributions of this article are as follows:
In the front end, this article proposes a scene segmentation algorithm combined with camera motion direction and angle. By segmenting the camera trajectory and adding the camera motion direction to the tracking thread, an effective prediction model of camera motion in the scene with sparse landmarks and large view transformation is realized.
In the back end, this article proposes an incremental optimization method combining segmentation information and a prediction model optimization for unstable tracking state. By incrementally adding the state parameters and reusing the computed results, high-precision results of the camera trajectory and feature points are obtained with satisfactory computing speed.
Framework
The framework of the algorithm in this article is shown in Figure 1. Similar to ORB-SLAM2, our algorithm also includes three modules: a tracking thread, a local mapping thread, and a loop detection thread.

The framework of the proposed V-SLAM based on scene segmentation and incremental optimization. V-SLAM: visual simultaneous localization and mapping.
As shown in Figure 1, in the front end, a scene segmentation decision method is adopted. Then, the information of camera motion direction and angle is used to establish a prediction model, which can track the sparse landmarks more effectively. Consequently, more robust keyframes are selected by this algorithm. At the same time, in the back end, combined with the incremental optimization method, a prediction model of unstable tracking state and an optimization method of V-SLAM are adopted. By incrementally adding the state parameters to be optimized and reusing the existing calculation results, high-precision results of the camera trajectory and feature points are obtained with satisfactory computing speed.
Method
Visual simultaneous localization and mapping tracking with scene segmentation and prediction model
The framework in this section is shown in Figure 2. By segmenting the camera trajectory and adding camera motion direction and angle, this algorithm establishes a prediction model in the road segments with sparse landmarks. The specific steps of the V-SLAM front-end algorithm are as follows:
Extract the ORB features of video frames for tracking, and then, make the scene segmentation decision according to the landmarks and road segments information.
Establish the prediction model according to the camera motion direction if the tracking thread is in the unstable state, otherwise use the stable tracking model.
Use the prediction model established in this article to track the surrounding scene and carry out the camera localization and local mapping.
Finally, the keyframe decision based on ORB-SLAM2 algorithm is made according to the tracking results.
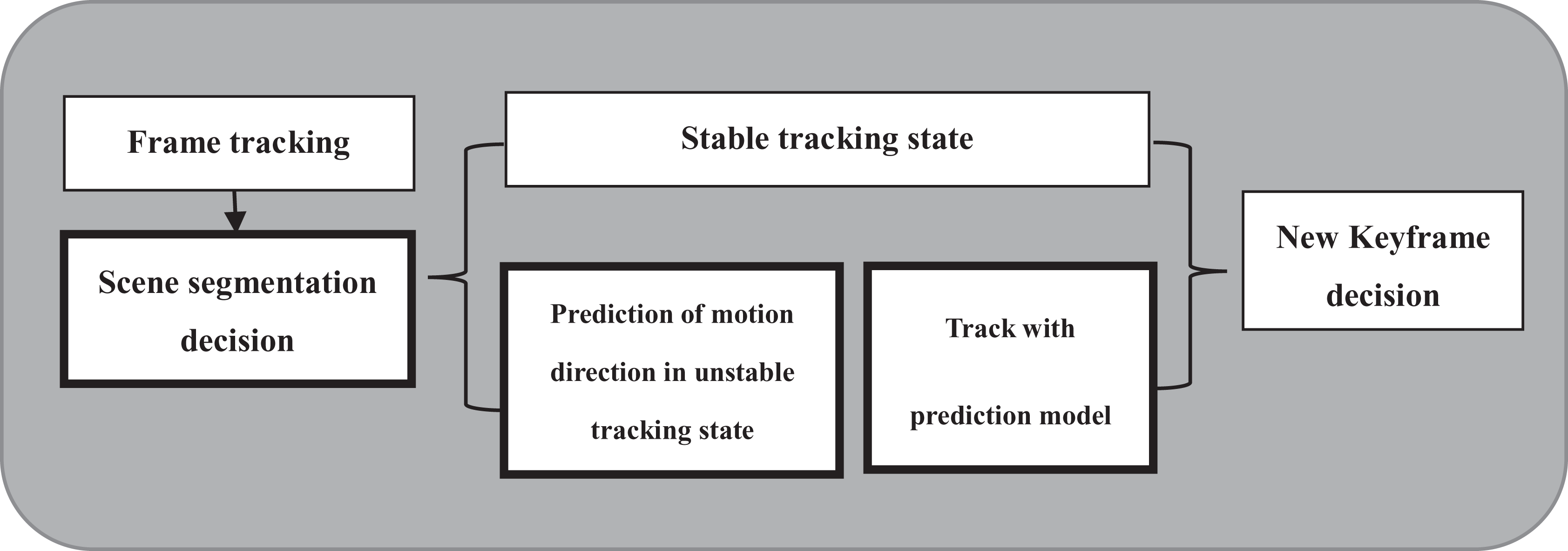
The overall framework of V-SLAM tracking thread. V-SLAM: visual simultaneous localization and mapping.
Tracking with landmarks and feature points
Firstly, the uniform motion model 24 of the visual camera is established

where F is the motion equation of the camera between two frames, and
At time step i, the camera observation model is

where
Suppose in the road segment Seg, there are M landmark positions fj
,

where Zi denotes a set of observation models for other landmarks at each camera pose xi . Combined with the above model, under the Gaussian and independent noise assumptions, the overall error model can be established as follows
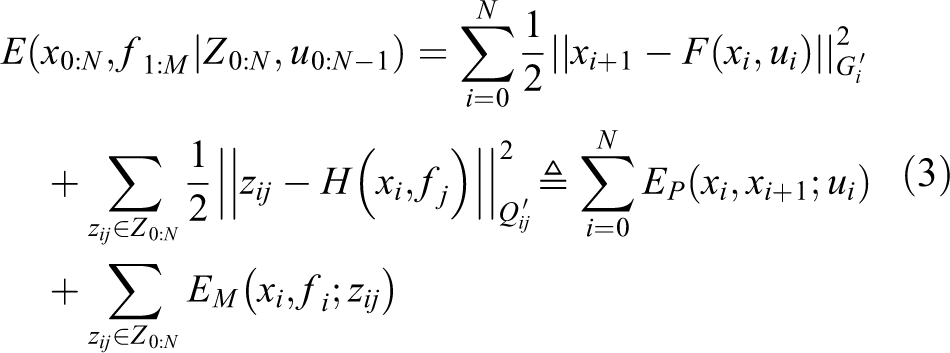
where
Scene segmentation based on camera motion direction and angle
In the tracking thread of existing V-SLAMs, the large view transformation and the sparse road landmarks often lead to errors in the tracking thread, and finally, give rise to the drift of optimization iteration direction. 28 Therefore, some researchers put forward a strategy based on scene segmentation optimization, 27 which uses different clustering methods based on IMU and pose information to realize scene segmentation. It can not only reduce the error accumulation in the tracking thread but also improve the accuracy of BA optimization. Inspired by the above ideas, this article proposes a scene segmentation method combined with camera motion direction and angle.
The stable tracking algorithm in this article is basically the same as ORB-SLAM2, which uses the uniform motion mode to predict the camera pose. Our algorithm is different from ORB-SLAM2 when the number of matching feature points sharply decreases. In this case, ORB-SLAM2 will compute the bag of words (BoW) vector of the current keyframes and find matched features based on the BoW dictionary. Instead, our algorithm does not use all the feature point information in the keyframes but uses the last camera motion direction and angle as constraints, at the same time, selects the feature points near the current line-of-sight vector to optimize the camera pose. The specific steps are as follows.
Firstly, camera positions
Secondly, in the segment decision phase, select the vector
Select the direction vectors
Scene segmentation based on camera motion direction and angle


Prediction model combined with segmentation information
Based on the scene segmentation rule of “strict in and wide out,” after the scene segmentation, a reliable and efficient camera motion prediction model is needed in the case of discontinuous segments with sparse or even missing landmarks so as to select feature points as accurately as possible and maintain the tracking state until entering the stable road segments with dense landmarks.
After entering this kind of road segments, it is very important to select the appropriate road segments. Firstly, based on the direction constraint of the camera’s main motion angle in the segment, the landmarks which are close to the distance
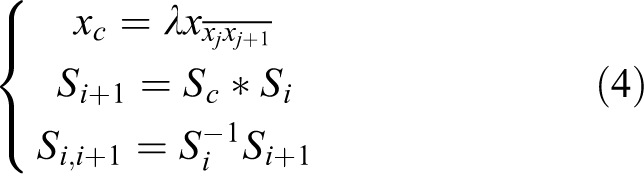
where xc
is the predicted increment of camera pose xi
in the main motion direction,
Through the prediction of camera motion, the calculation
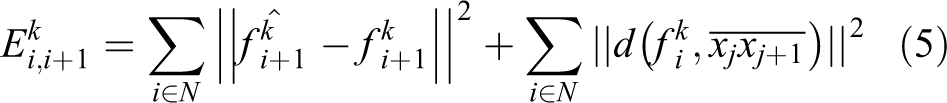
where
By minimizing the error objective function, we can effectively select landmarks to maintain the tracking state in the segments in the scene with large view transformation and sparse landmarks. The process will not end until the scene segments with normal tracking state are entered.
Incremental BA with fusion of segmentation information
In the back-end optimization process, ORB-SLAM2 uses covisibility graph, essential graph, and spanning tree. When inserting keyframes in the local mapping thread, keyframes with a certain number of covisibility landmarks will be established, and the spanning tree saves all nodes (i.e. keyframes) as a subset of the covisibility graph. After that, the loop closing thread will compute the similarity of the covisibility graph and optimize the camera pose according to the essential graph. This algorithm heavily relies on covisibility landmarks to establish edge connections. At the same time, the setting and deletion strategies of redundant keyframes also increase computational complexity. The reduction of covisibility landmarks in scenes with large view transformation and a large number of invalid keyframes added frequently causes graph maintenance failure and tracking failure.
In this article, we still follow the tracking and optimization framework of ORB-SLAM2: (1) Optimize pose Euclidean transformation matrix in local BA (tracking thread) and (2) optimize pose similarity transformation matrix and global pose in global BA. But different from ORB_SLAM2, we use the factor graph to represent feature points and camera poses of keyframes. After that, we use the Bayes tree to run incremental optimization, which enables us to add the camera motion direction and angle factor to the optimization process, which consequently reduces both the dependence on covisibility landmarks and the computational complexity.
According to iSam and iSam2,
25
the optimization process in SLAM can be expressed as a dynamic Bayesian network, and the motion and observation equations can express the conditional probability between state variables. As shown in equations (1) and (2), we add the observation equation and the direction of camera motion to the Bayes tree as factor graphs. In the Bayes tree, the nodes are classified by clique, and the k’th clique can be expressed as Ck
. We define the conditional probability density
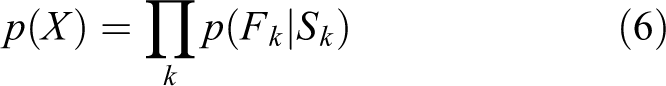
In this article, an example of factor graph and Bayes tree is shown in Figure 3, where fi
is the landmark, xi
is the camera pose, and the segmented part
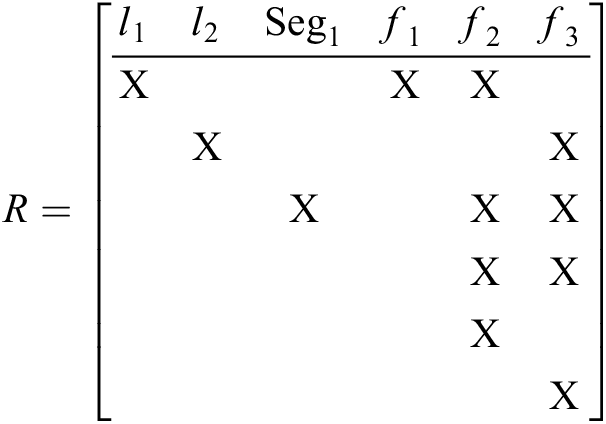
Then, we will introduce how to perform incremental optimization based on the matrix formed by the factor graph.
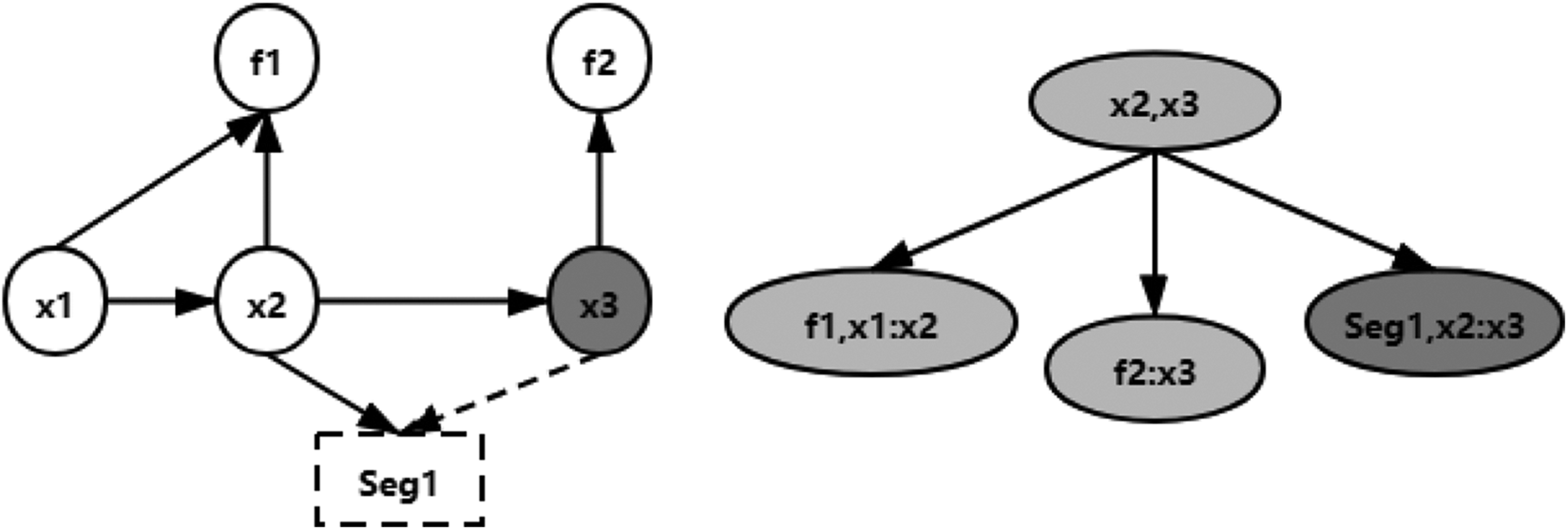
Schematic diagram of factor graph and Bayes tree.
The incremental optimization algorithm is often used with IMU, 26 so that the camera can obtain reliable pose information and improve the accuracy of the optimization algorithm. In this article, without IMU, we use an incremental BA method with fusion of segmentation information to optimize the camera pose, feature points, and the prediction model in the unstable state. Compared with the traditional method, it is able to improve the optimization speed and the robustness of the drawing thread.
In the case of incremental updating optimization, to optimize the new parameters, we update the nearest matrix to reuse the results of the existing measurements. A nonlinear error optimization objective function can be obtained using a classical linearization method

where Δ is the state update vector, including camera pose, landmark position, predicted landmark, and predicted main motion direction in the prediction model; A and b represent the parameters of a sparse linear system with Δ as the solution. Through householder QR decomposition, the objective function is rewritten as
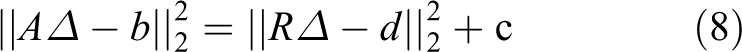
where c represents the sum of squares of the residuals of the least squares. When the new vectors need to be reoptimized and updated, the previous decomposition can be modified through the classic QR update.
The classical QR update increases
After obtaining the state quantity update, we use Givens rotation to cancel the newly added row element on the left side and then change the new linear system into the upper triangle form in an incremental way. The specific method is shown in Figure 4

(a–c) Elimination diagram of Givens rotation matrix.
Therefore, the matrix of QR decomposition is multiplied by several Givens rotation matrices to the left and for the nonzero elements of the row state cell added by the increment, consequently, an upper triangular matrix containing the update factor

Similarly, using Givens rotation matrix to update the right state vector da
incrementally, we get
where
In fact, there is still some work to do for the incremental optimization based on Bayes tree in GTSAM. Our work in this part is the same as iSam2, so it will not be repeated.
Through the incremental updating of error objective function, the incremental optimization results of camera pose and feature points can be obtained from the optimization of the prediction model in an unstable state so as to improve the optimization speed and the robustness of the mapping thread.
Experiments
By implementing the aforementioned algorithm, considering that ORB-SLAM2 uses g2o library based on graph optimization and OpenVSLAM 29 reproduces it with high readability, we developed a V-SLAM system based on ORB-SLAM2 and OpenVSLAM. Its user interface is shown in Figure 5, where Figure 5(a) shows the mapping and tracking thread, and Figure 5(b) shows the mapping results.

(a, b) Software interface of our SLAM system. SLAM: simultaneous localization and mapping.
Test configuration
To evaluate the performance of our algorithm, we choose TUM RGB-D dataset and NYUDv2 RGB-D dataset to run the comparative experiments. In the aforementioned datasets, scenes have sparse landmarks and large view transformation. The basic conditions of the selected datasets are as follows:
TUM fr1_desk and fr2_xyz are basic datasets with desktop and empty indoor space. The size of their environment space is 5 × 5 × 0.5 m3. And the size of datasets is 1–2 GB, and there are about 5000 pictures.
TUM fr1_floor and fr3_nostructure_notexture_near_withloop are scenes with sparse landmarks and large view transformation of camera motion. In the 15 × 5 × 0.5 m3 space, the floor and empty corridors are mainly included, and there are about 8000 pictures in the datasets. According to our experiments, ORB-SLAM, OpenVSLAM, and our method extract feature points within 200 in each frame of image in such scenes, so the probability of tracking failure and reinitialization is more than 70% in ORB-SLAM.
TUM fr2_large_with_loop and NYUDv2 lab1 are scenes with sparse landmarks in 10 × 50 × 0.5 m3 large-scale environment. The size of them is 4–5 GB and there are about 12,000 pictures. In these scenes, the number of feature points extracted in each frame of image is within 300, and about 20% of the images are with weak texture.
The hardware platform concludes with a desktop platform and an embedded development platform. The configurations of them are given in Table 1.
Configuration of the experimental platform.

Experimental results
We select the state-of-the-art V-SLAM systems, such as RKD-SLAM, 27 ORB-SLAM2, 4 ElasticFusion, 30 OpenVSLAM, 29 and LSD-SLAM, 16 to compare with and evaluate our algorithm and system.
Experimental results on desktop platform
As given in Table 2, the experimental results of relative pose error (RPE) between tum TUM RGB-D dataset and NYUDv2 RGB-D dataset are compared. It could be found that the average accuracy of our method is 51.7% higher than the average accuracy of the ORB-SLAM2 on the datasets fr1_floor and fr2_large_with_loop with serious landmark missing and large view transformation of the camera, and is 59.2% higher than the RKD-SLAM in NYUDv2 lab1, respectively. As shown in Figure 6, the average processing time of frames in the dataset fr2_xyz is given. In our method, the average processing time of a single frame is 28 ms, which is 82.7% faster than ORB-SLAM2, while the absolute track accuracy is basically unchanged. Through the experiments of a large number of TUM RGB-D datasets, the average processing time of the keyframe of this algorithm is 10.2% higher than ORB-SLAM2 and its improved algorithm.
RPE comparison of absolute trajectory error in the TUM RGB-D and NYUDv2 RGB-D benchmark.

RPE: relative pose error.
a No final results represents the failure of localization and mapping.

Average processing time of frames in TUM (average of FR1 desk and FR2 xyz).
Figure 7(a) shows the scene segmentation result based on the RKD-SLAM on the dataset NYUDv2 lab1, and Figure 7(b) shows the scene segmentation result based on the method in this article, where the black track is the ground truth and the color track is the segmentation result. The absolute trajectory error of this algorithm is 62% higher than that of RKD-SLAM in this dataset. As shown in Figure 8, the left figure shows the results of the ORB-SLAM2 and OpenVSLAM in TUM datasets, and the right figure shows the results of the methods in this article in the sequences fr1_desk, fr1_floor, fr2_xyz, fr3_ nostructure_notexture_near_withloop.

Scene segmentation results in NYUDv2 lab1 datasets (a) based on RKD-SLAM and (b) based on this article.

Running results of TUM datasets: (a) fr1_desk, fr1_floor based on ORB-SLAM2, (b) fr1_desk, fr1_floor based on this paper, (c) fr2_xyz, fr3_nostructure based on OpenVSLAM, and (d) f2_xyz, fr3_nostructure based on this article.
Experimental results on embedded development platform
To evaluate the performance of the proposed algorithm in the embedded development platform, we conducted a comparative experiment based on HUAWEI Kirin970.
The configurations of the embedded platform and the camera are presented in Table 3. The V-SLAM system based on Kirin 970 is shown in Figure 9, and it could be found that our algorithm improves computational efficiency by 22.4% than LSD-SLAM and ORB-SLAM2, which is essential for the application of V-SLAM in embedded development platform.
Configuration of the MYNT-eye RGB-D camera.


Visual-SLAM system based on Kirin 970 (a) HUWAEI-Hisilicon Kirin 970-HiAi, (b) Mynt-eye RGB-D camera, (c) Kirin 970 with Lebuntu system, and (d) hardware system based on Kirin 970. SLAM: simultaneous localization and mapping.
As given in Table 4, the experimental results of the RPE and running time of the algorithm in this article with ORB-SLAM2, LSD-SLAM, and OpenVSLAM on the TUM dataset are listed. Experiments show that the average running speed of the method in this article is 19.5% higher than that of ORB-SLAM2 and 25.3% higher than that of RKD-SLAM.
RPE comparison of absolute trajectory error in the TUM RGB-D dataset.

LSD-SLAM: large-scale direct simultaneous localization and mapping; RPE: relative pose error.
At the same time, as shown in Figure 10, on the fr1_floor, fr2_large_with_loop, and fr3_nostructure_notexture datasets, our algorithm shows better tracking stability than both ORB-SLAM2 and LSD-SLAM. And in the actual test, we chose a 25 × 25 m2 indoor scene. The scene is mainly empty rooms and corridors. The number of feature points in each frame of image is not more than 300. Meanwhile, it is a three-story building with a height of 10 m that has large view transformation of camera motion in the process of going up and down. The closed loop error of our algorithm is 0.5 m, and the average trajectory error is 0.83 m. For comparison, the closed loop error of ORB-SLAM2 is 1.8 m, and the average track error is 2.1 m. As shown in Figure 11, our algorithm has better positioning accuracy and loopback accuracy than ORB-SLAM, and the tracking performance is more stable.

Running results of TUM datasets based on Kirin 970: (a) fr1_desk based on OpenVSLAM, (b) fr1_desk based on this article, (c) fr3_nostructure based on LSD-SLAM, and (d) fr3_nostructurebased on this article.

Running results in the actual test based on Kirin 970. (a, b) the pictures of the test place; (c) running result based on ORB-SLAM2 and (d) running result based on our method.
Conclusion
Considering the problem that existing V-SLAM systems are usually sensitive to the situation of sparse landmarks or large view transformation, this article proposes an improved V-SLAM method based on scene segmentation and incremental optimization strategy. And the experimental results demonstrate that our method improves the computational efficiency by 10.2% compared with state-of-the-art V-SLAMs on the desktop platform and by 22.4% on the embedded platform, respectively. Meanwhile, the robustness of our method is better than that of ORB-SLAM2 on the TUM RGB-D dataset. In general, our improved algorithm provides strong support for the effective application of V-SLAM under embedded platforms.
In future research, we plan to tightly integrate GNSS/BEIDOU information to further improve the SLAM accuracy in large scale and missing closed-loop scenarios.
Footnotes
Acknowledgements
The authors would like to acknowledge Jiangsu Overseas Visiting Scholar Program for University Prominent Young & Middle-aged Teachers and Presidents.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China [Grant Number: 62073078] and the Natural Science Foundation of Jiangsu Province of China [Grant Number: BK20160696].