
Abstract
Audiovisual speech recognition is a favorable solution to multimodality human–computer interaction. For a long time, it has been very difficult to develop machines capable of generating or understanding even fragments of natural languages; the fused sight, smelling, touching, and so on provide machines with possible mediums to perceive and understand. This article presents a detailed review of recent advances in audiovisual speech recognition area. After explicitly representing audiovisual speech recognition development phase divided by timeline, we focus on typical audiovisual speech database descriptions in terms of single view and multi-view, since the public databases for general purpose should be the first concern for audiovisual speech recognition tasks. For the following challenges that are inseparably related to the feature extraction and dynamic audiovisual fusion, the principal usefulness of deep learning-based tools, such as deep fully convolutional neural network, bidirectional long short-term memory network, 3D convolutional neural network, and so on, lies in the fact that they are relatively simple solutions of such problems. As the principle analyses and comparisons related to computational load, accuracy, and applicability of well-developed audiovisual speech recognition frameworks have been conducted, we further illuminate our insights into the future audiovisual speech recognition architecture design. We argue that end-to-end audiovisual speech recognition model and deep learning-based feature extractors will guide multimodality human–computer interaction directly to a solution.
Introduction
When it comes to the issues of human–computer interaction (HCI), human–computer harmony is as eternal a pursuit of HCI as human–computer collaboration. As the booming of artificial intelligence dramatically promotes the intellectualization of machines, the HCI technology, therefore, is currently facing increasing challenges and complications than ever before. Under this background, a more powerful and humanized means in terms of audio perception seems to be realistic when dealing with high-accuracy rate HCI problems, regardless of a tranquil work envelope or a noisy work volume within which the machines operate. Audio speech recognition (ASR) essentially functions as a favorable bridge joining these two parts: humans and machines.
At present, machines share the same ASR cognition level with humans under quiet environments, but in cases where the work spaces are noisy, generally, the recognition result by machines lags far behind in accuracy when compared to humans. 1 The reason that humans are more competent to identify noisy speech consists of the fact that speech perception by them appears to be a multimodal process. As the superior intelligent creatures that exist in nature, humans, respectively, acquire acoustic information and visual information by cochlear and eyes; with the derived multimodal information has been comprehensively analyzed and processed by brains, they consequently present the desired perceptual speech results. 2 By simulating human brain mechanism on multimodality-based speech recognition, the audiovisual speech recognition (AVSR) has been put forward. The perceptual vision results favorably remain reliable irrespective of the noise fed to the vision channel; the extracted visual modal information in AVSR frame is therefore applied to compensate or correct the missing or insufficient audio recognition results. Specifically, the adoption of video information source with dynamically adjusting the weight between audio output (or we say stream) and visual output (stream) between audio and visual channel results provides solutions for robust AVSR under severe noise conditions. It has been proved that robust AVSR significantly improves the recognition accuracy of ASR systems under a variety of unfavorable acoustic conditions. 3
Lately, there has been more research in the area of AVSR-based HCI. According to the retrieval statistics of Web of Science, the subject word “AVSR” is highly cited. The overall increase in paper publication amount and paper citation amount is diagrammatically represented in Figure 1 (by mid-2019). As shown, AVSR is now attracting more and more research attention.

The retrieval statistics of subject word “AVSR” by Web of Science. AVSR: audiovisual speech recognition.
AVSR system can be applied to a vastly wider range of applicating scenarios, such as command recognition in land vehicles,
4
text translating of mobile phones,
5,6
lipreading for people who are hearing impaired,
7,8
speech recognition of individual speaker from lots of people who are talking at once,
9
and so on. In practice, the difficulties in building an efficient AVSR system mainly concentrate on the following three aspects: How to build public databases for general purpose. How to extract the representative visual features for a specific use. How to dynamically fuse audio features and visual features for a better speech recognition.
As illustrated, the knowledge associated with image or vision is closely related to AVSR research. In fact, the visualized information was the original inspiration for these fundamental ideas of AVSR. Research shows that the extraction of visual features largely relies on robust face recognition, 10 –12 mouth region tracking, 13,14 and visual feature representation. 15,16 The eminent computing capacity of deep learning-based algorithms enables AVSR to precisely locate the region of interest (ROI), to efficiently extract the visual features, and to accurately determinate the weights (which balance audio stream and visual stream), which therefore facilitates the algorithmic framework enhancements of AVSR.
The main contributions to this article are shown in the following aspects:
First, we analyzed the historical phase of AVSR. With mathematically expressing the AVSR process, we summarized the traditional and deep learning-based tools that are employed in AVSR systems. Meanwhile, we conducted a comparative analysis of existing AVSR databases in terms of task, number of testers, corpus, recording angle (or view), and so on, and we explicitly expound our views of open-source audiovisual databases qualified by actual scenario applications.
Second, we emphasized two main concerns of structuring an AVSR anatomy. In principle, the feature extraction (in terms of audio/visual modality) and dynamic audiovisual fusion are fully analyzed. The convolutional neural network (CNN)-based extractors that enable the efficient feature extractions and the advanced neural networks or encoders-based weight training models are summarized. From robustness point of view, we explicitly illuminate that we remain bullish on the prospects of end-to-end AVSR models under environments with multisource noises.
Third, in terms of case studies, a possible AVSR architecture design that fuses multisource information derived from audio, vision, and depth channels is proposed. The formalization of the speech recognition process using deep learning ideas has been directed at making HCI practicable in many situations. We believe, with fully developed frameworks, the deep learning-based AVSR that fuses reliable depth for image description will provide an important model reference for a class of understanding-driven multimodality HCI.
The outline of the remainder of the article is as follows. In the following section, the principles of AVSR and related theories are firstly concerned and stated. The third section stresses a detailed description of recently developed audiovisual speech databases, which covers the applicability analyses under different types of tasks for solving “public databases for general purpose” problem. The independent audio/visual feature extraction is theoretically illustrated in the fourth section, together with the graphic interpretations of dynamic audiovisual fusion in terms of feature level and decision level in the fifth section, which underpins our vision for future AVSR architecture design. The sixth section also emphasizes the discussions of deep leaning-based frameworks for efficient feature extraction and dynamic feature fusion. The seventh section presents the main conclusion of this review study.
Principles of AVSR and related theories
Mathematical model of AVSR system
AVSR (also being referred to as dual-modality-based speech recognition) is to combine visual information (reflecting mouth movements) with original acoustic information to improve the accuracy rate of HCI. As in Figure 2, a typical AVSR system is constructed of a visual stream channel (VSC), an audio stream channel (ASC), and a dynamic audiovisual fusion part. Together with the acoustic features derived from the paralleled ASC, the VSC results via ROI location of video sources, vision-to-image transformation, digital signal processing, and visual feature extraction constitute the inputs of dynamic audiovisual fusion part. Let

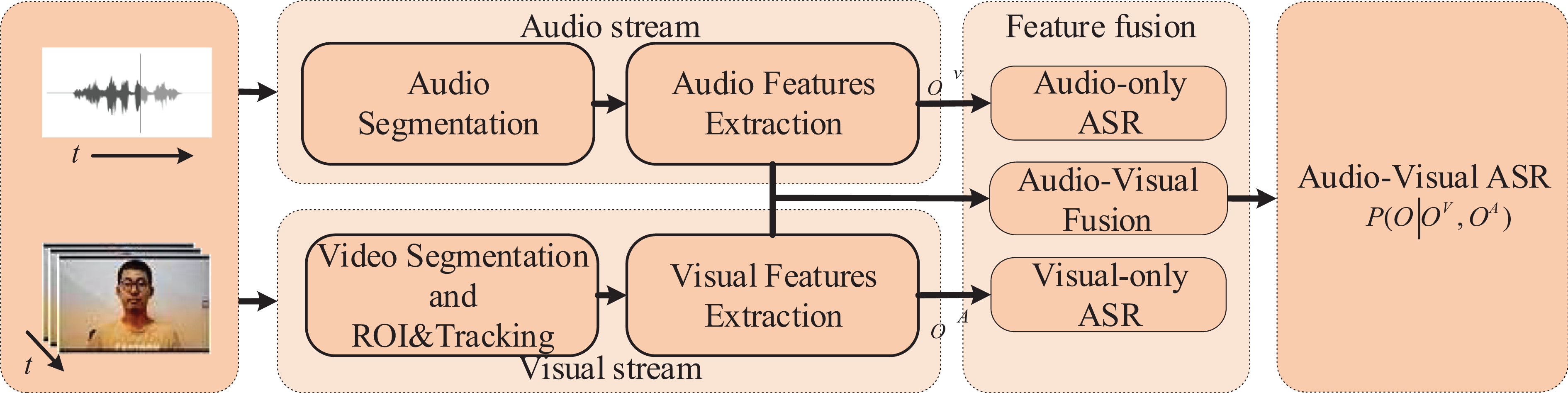
Block diagram of a typical AVSR. AVSR: audiovisual speech recognition.
Relevant models and theories of AVSR during different developing stages
Stimulated by practical demands of HCI, the models and theories of AVSR evolve during the past decades of years. As illustrated in Figure 3, the development of AVSR, from the macroscopical point of view, experiences three distinguishable stages, in which theories research, traditional tools-based solutions, and deep learning-based solutions are concerned.

AVSR development timeline. AVSR: audiovisual speech recognition.
Theories research:
This stage is characterized by the facts that related AVSR research has not concluded with well-established theories. This stage lasts for about 40 years long (from 1950 to 1990). As early as 1954, Pollack and Sumby were the advocate of AVSR, who explicitly stated that visual information contributes to the understandings of speech in noisy environments. 17 Representative McGurk effect (described in article titled “Hearing Lips and Seeing Voices” by Harry McGurk and John MacDonald) further presented the positive roles of visual modality information on speech perception. The theories research remained a limited prosperity until 1984; the first AVSR system was simply structured, which was mainly concerned with notably different mouth features of width, length, perimeter, and area as it aims to extract lip images in terms of image thresholds. With dynamic time warping algorithm, it significantly accomplished the speech recognition of isolated words. 18
Traditional tools-based solutions:
The above model forms the basis of lip feature-based methods for efficient speech recognition under nonideal circumstances likely to be encountered. Generally, considering the manners of simultaneous speech-related feature maximization and extraneous feature restrain, the solutions with respect to visual feature extractions can be classified into two categories, one is to match a statistical model of lip shape and appearance, for instance, active appearance modal (AAM) is used for visual feature acquisition via image sequences of speakers. 19,20 Another one is to directly extract the lip features in terms of pixels without regard to the priori lip models. In fact, the former is termed model-based feature extraction. 21 In AAM, high-grade features of lip shape and appearance constitute the source from which a training supervisor derives accurate coordinates of landmarks via quantitatively training phase. The latter is termed image-based feature extraction, which distinguishes itself by no need for specific lip models or coordinates of landmarks for training; a solution by directly extracting inferior pixel-based features via discrete cosine transform (DCT) or principal components analysis (PCA) methods may be possible. 22,23 However, this pattern is essentially restricted to lighting conditions, translational motions, or rotational motions of images. The AVSR system may evolve with the desirable feature extraction results. It is important to appreciate that hidden Markov model (HMM) and multi-stream hidden Markov model (MSHMM) 24 are preferred methods for time sequence modeling to underpin the following dynamic audiovisual fusion.
Deep learning-based solutions:
The deep learning methods are devoted to an enhancement of multimodality information fusion in terms of vision, auditory, tactility, and so on. 25 An illustrative system is “Lip Net,” which was developed at Oxford University in 2017. With multiple sets of testing on GRID data set, the superiority of Lip Net over lip-reading experts on total accurate rate of voice recognition has been numerically validated by a 93.4–52.3% lead. 26 Last year, by a method of modeling Chinese lip-reading sequences, a lip-reading program was launched by Sogou Inc. It reveals that it got 60% correct in a speaker-independent open oral test and up to 90% correct in certain (smart home and in-vehicle) scenarios. 27 Throughout the timeline, the beginning of deep learning era in AVSR is 2010, breakthroughs have occurred ever since. Algorithmically, CNN is now taking the places of traditional DCT and AAM in aspects of feature extractions. Also, HMM and MSHMM are currently being substituted by long short-time memory network (LSTM) 28 or bidirectional long-term memory networks (Bi-LSTM) 29 in aspects of time sequence modeling. Due to space limitations, please refer to the enlarged region of Figure 3 for more detailed illustrations of deep learning-based solutions.
The audiovisual speech databases
Special attention should be paid to audiovisual speech databases because suitable data sets for certain purpose are so essential. As a consequence of multiplicity and complexity of languages, together with diverse research aims and requirements, it may be not realistic to create one audiovisual speech database that can meet all kinds of research needs, and also, it is impossible to assign one universally accepted standard which is sufficiently good to evaluate such databases or compare them in a wide range of potential applications. Differing from simple speech databases, the establishment of corpus linguistics with certain scale is dependent on many other factors. Interests are focused not only upon the subjects of recorded or the number of times that testers repeat the corpus, but upon the lighting conditions of testing environments, the head posture of testers, the amount of recorded vocabularies, the resolution of recorded video, and so on.
The entire section is devoted to summarize the typical audiovisual speech databases and further analyze their applicabilities in different types of tasks. Five forms, more precisely Alphabet (A), Digits (D), Words (W), Phrases (P), and Sentences (S), are concerned, to one of which all speech sources approximate. Considering the possible views of recording videos, we have single view databases and multiview databases, whose principal attributes (like task, language, corpus, etc.) are, respectively, described in Tables 1 and 2.
Single view database
The typical single view databases and relative descriptions are listed in Table 1. As indicated, from the alphabetic AV Letters to the phrases-type OuluVS1 or from the sentence-level LRS-TED for reference to the complex Mandarin-based LRW-1000, we may conclude the newly developed single view databases appear to be sentence-level, enriched language-type, large scale, and more testers involved. The above research indispensably benefit from enhanced data processing performances of machine learning (which has been largely applied to the industrial areas such as fault recovery, 30 parameter prediction, 31 or classification 32 ). Meanwhile, as the optimized databases stand up to the requirements of high-grade HCI, it allows the AVSR to be conducted with more favorable and natural human–machine interaction means.
Descriptions of single view audiovisual databases.a

AVSR: audiovisual speech recognition.
a For “resolution” item, A stands for audio, V stands for video, V-H stands for visual higher quality version, V-L stands for visual lower quality version.
Multi-view database
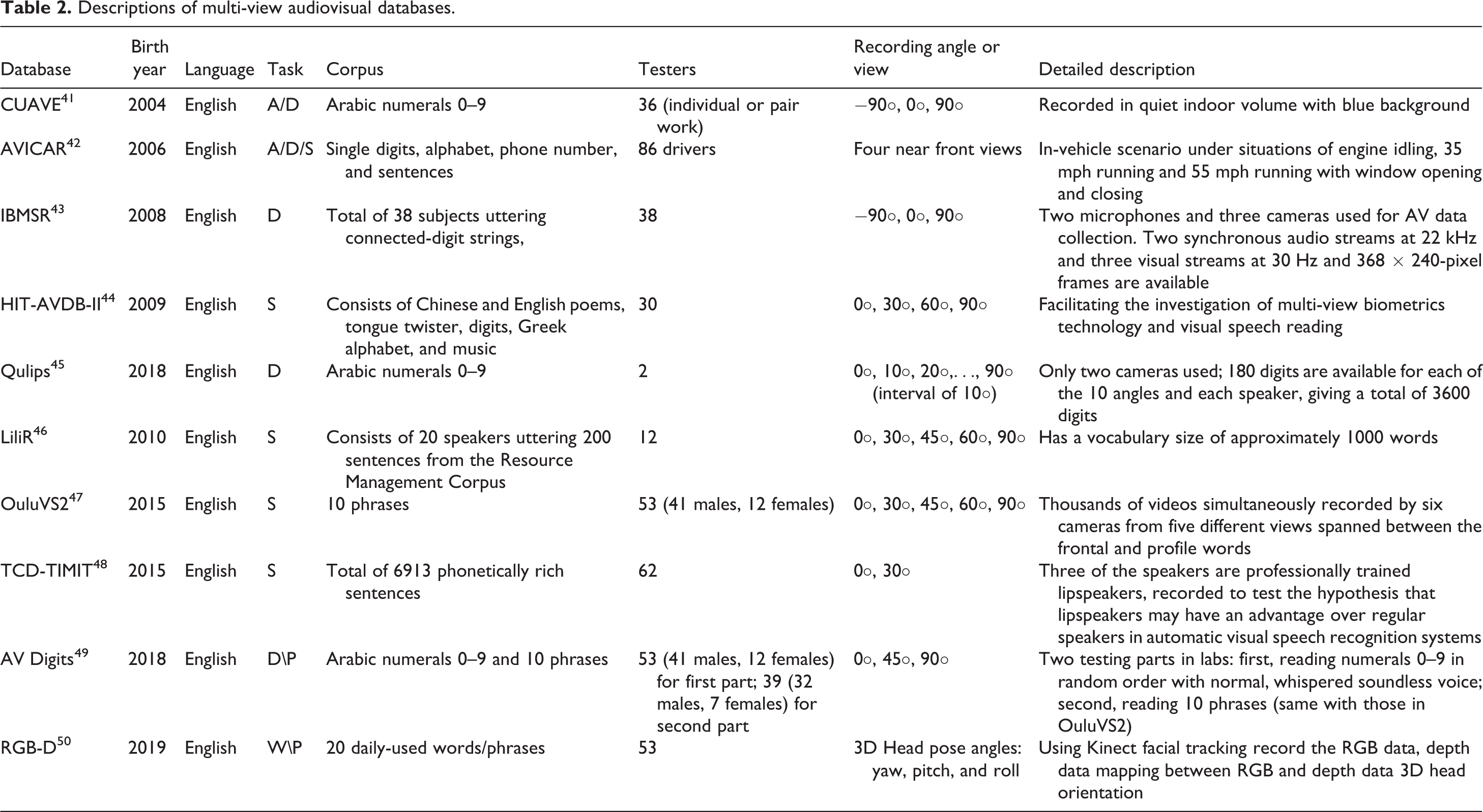
Table 2 summarizes the multi-view audiovisual databases used in recent work in AVSR area. It lists the birth year, language, task type, corpus, recording angle or view, and so on. As indicated, the database transition from single view to multi-view describes the requirement of scenarios likely to be encountered in practical speech perception. During the last few years, multi-view database-based AVSR technology has advanced rapidly and now is laying the foundation of harmonious human–machine interactions. Even though audiovisual databases are being recognized as powerful and eminently practical benchmarks for the solution to comparative analyses problems, these tools, however, still face some challenges like the language of open-source database is basically English, the contents of corpus are short of pertinence with being not truly encompassed by the complex realities, the recorded audio or video is generally of inferior quality, and so on. It’s worth mentioning that, as in Table 2, the newly developed database “RGB-D” employs an RGB-D (Kinect) camera to record visual resources, and the multisource inputs could be audio, 2D image, and 3D visual information. The significance of “depth” can also be found in the literature. 39,40
Descriptions of multi-view audiovisual databases.
We further summarize the following qualifications of a much-needed audiovisual database based on the analysis hereinabove: Publicly accessible, rich in subject matter, widely covering visemes and phonemes Being recorded under high-quality visual and audio conditions Multimodality information (audio, vision, depth, etc.) fusion acceptable Multi-view video acquisition acceptable Large amount of testers with balanced sex ratio.
We are convinced of their progress in AVSR with the advance of deep learning technology, and we look forward to their improvements in the near future.
Feature extraction
This section mainly discusses the principles of audio feature extraction and visual feature extraction in algorithmic domain. Together with the following dynamic audiovisual fusion section, it theoretically leads to the final discussion with our vision for future development.
Audio feature extraction
Mel-frequency cepstral coefficients (MFCCs) are basically recognized as desirable audio features because of their superior robustness when dealing with channel noise and spectral distortion. 51 The detailed feature extraction process for MFCC is given in Figure 4.

Flow diagram of MFCC feature extraction process. MFCC: Mel-frequency cepstral coefficients.
As shown, the process of extracting MFCC features consists in first performing pre-emphasis of speech signals that are separated from videos. A filter
Visual feature extraction
As stated in “Relevant models and theories of AVSR during different developing stages” of the second section, early studies on visual feature extraction focus upon model-based AAM method or image-based DCT/PCA methods. Differing from the lower pixel-level DCT, AAM is now being recognized as a powerful statistical tool which is characterized by constructing its model in terms of shape and texture, more precisely, which is followed by the gradient-descent fitting algorithm to fit the trained model into the target image. 52 The paralleled training and fitting parts form the basic AAM anatomy. Take RIO of lip as an example of such AAM frameworks, for the images to be trained, the mouth region extraction and landmark annotation tasks should be firstly taken, as illustrated by the amplified “close look of annotated image” part in Figure 5.
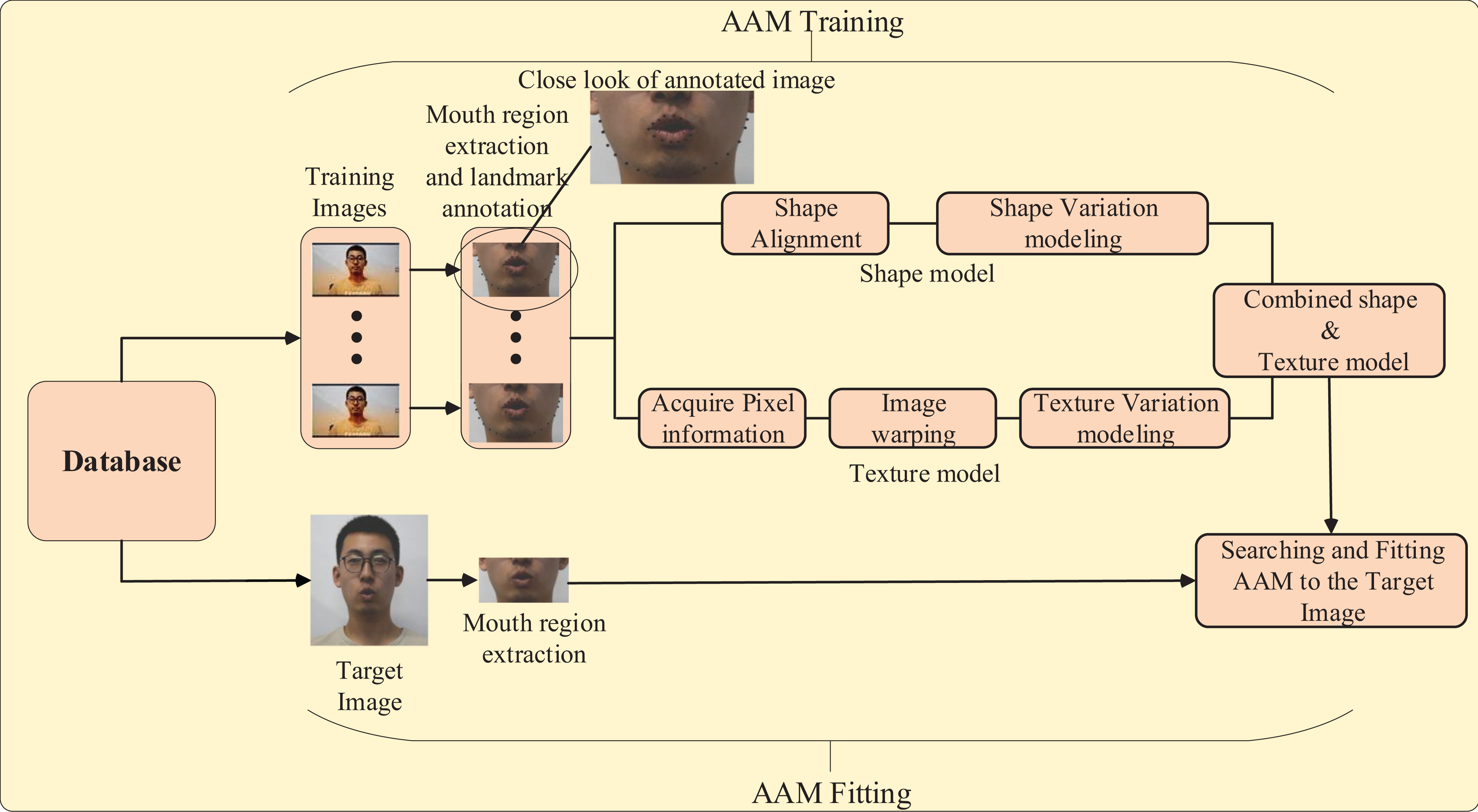
Framework of AAM training and fitting. AAM: active appearance modal.
Three models contribute to the paralleled AAM training and AAM fitting, they are shape model, texture model, and appearance model. Based on the annotated images, the shape feature vector of all samples (images) is defined and represented as

where

where a 0 denotes mean texture, pa denotes a set of orthogonal modes of variation, and ba denotes a set of texture parameters.
Combine bs and ba into one vector and define

In consequence, formula (4) mathematically represents the appearance model of AAM. Note that, vector c is directly used to search and fit AAM to the target image. By a method similar to that adopted for de-correlation and dimensionality reduction (more precisely PCA method), the AAM may be mathematically idealized by


where Qa and Qs , respectively, represent shape feature matrix and texture feature matrix.
Dynamic audiovisual fusion
The principal importance of audiovisual fusion lies in its adaption to quality change of audio/visual signals. Let’s consider a destroyed audio file or a lost face, the unavailability of which does not allow AVSR system to directly combine the corresponding features. Dynamic audiovisual fusion is the answer to this challenge issue. Fusion can be performed at either feature level or decision level.
Feature-level fusion
Assume vector
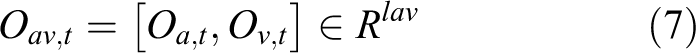
represents the newly formed audiovisual feature with dimension

Flow diagram of feature-level fusion.
As indicated, with simple cases, it is relatively easy to construct the fused audiovisual feature vector that yields to independent streams. But for complicated cases where the weight between these two forms of features should dynamically changes with the variation of the reliable channels, the decision-level fusion must be used.
Decision-level fusion
Decision-level fusion is more adaptable to changes than feature-level fusion. A basic decision-level fusion can be constructed from two paralleled channels as connected in Figure 7. Similarly, assume vector

where

Flow diagram of decision-level fusion.
The key to dynamically adjust weights consists in determining the most relevant features used for reliability scaling of matched modalities. In this sense, the results of adjustments are typically measured in quality of audio signals. In research of AS Saudi et al., 54 six-dimensional vector (three in time domain and three in frequency domain) extracted from each audio frame is used to describe this so-called quality. The stream weight adjusting tests are firstly conducted under different signal-to-noise ratios (SNRs), and the optimized weights are subsequently assigned to the matched SNR. In fact, the principal attribute of dynamic weight adjusting is that the optimal weights under different SNR are eventually determined by multilayer perceptron (MLP) model. By comparison, decision-level fusion deals with two channel streams by dynamic weight adjusting strategy rather than directly combine the corresponding features. 55 This solution makes it more applicable to high robustness-required circumstances.
Discussions
Based on the foregoing research work on AVSR, we would like to discuss the core techniques from certain aspects: feature extraction and dynamic audiovisual fusion. Meanwhile, we would like to further state our vision for future AVSR architecture design.
Feature extraction
Audio feature extraction
A gloomy fact in AVSR field has always been that researchers would like to pay their attention to well-established visual feature extraction techniques rather than audio feature extraction means. Lately, an increasing number of papers in the fields of AVSR are devoted to MFCC-based acoustic feature acquisition. The first-order transformation (denoted by

It is gratifying to see lots of novel frameworks on audio recognition have been put forward. An example of such a framework is deep fully convolutional neural network (DFCNN) fused model (given by iFLYTEK). 56 The significant advantage of which over the classical frameworks is that it directly implements “speech to spectrogram transformation” without concerning the matched MFCC features. Here, the combined convolutional layer and pooling layer of DFCNN enable the models of speeches to be formed, so that the output explicitly corresponds to the final recognition results, like syllables or Chinese characters, and so on. A notable comparison between DFCNN-based framework and BLSTM-CTC (known as the best in audio recognition area) shows, via tens of thousands of hours testing with Chinese data sets, the former presents an additional 15% recognition rate enhancement.
Concerning the reasons that spectrograms are generally superior to MFCC features, the unexpected information losses both in frequency domain and in time domain would certainly be highly mentioned. The former corresponds to the losses of high- frequency components as described in part A of Section 4, and the latter refers to over condensed computation caused by large frame shifts, especially in cases where the speakers speak fast.
As a summary, heavy emphasis should be placed upon developing various types of acoustic feature vectors. The latest delivered research confirmed our vision for audio recognition. According to the literature, 57 the authors directly extracted acoustic features from speech spectra via encoders and combined them with visual features, with modeling the fused features in terms of BLSTM, the accuracy and reliability of AVSR remain optimal with the variation of noise and visual angle interferences.
Visual feature extraction
As noted in Figure 3, the tools applied to AVSR are now experiencing the transition from surface feature-based AAM/DCT to deep learning-based CNN. Stimulated by deep neural networks (DNNs) and large-scale databases, K Noda et al. 58 found the deep-level features enhancements for visual extractions of images in translational sliding motion and rotary motion. In their work, the lip feature and audio feature are, respectively, extracted by CNN and deep denoise autoencoder, while no pretrained models by landmarks are required.
With the increasing enthusiasm for CNN, some research focuses on issues of temporal and spatial correlations that are frequently overlooked in deep-level feature extractions toward images in motion. A Torfi et al. 59 made their first successful attempts to fulfill AVSR using 3D CNN. As we shall see in Figure 8, two paralleled DNNs are initially trained by audio stream and visual stream; as the trainings end, they will be coupled together in the last layer which is fully connected by contrastive cost criterion. Note that, a cube that is composed of six successive lip gray-scale images (used as input of visual stream) represents the temporal information, and the lip’s motion represents the spatial information. In this sense, the temporal sequence (frames) and spatial sequence (motions) concepts are in separately related, and the fusion of these two via 3D CNN reflects an abstract temporal and spatial correlation idea.

Architecture of 3D CNN. CNN: convolutional neural network.
In addition, lipreading is highly related to AVSR, and the developments of AVSR have been greatly promoted by advances in lipreading. Take GRID with task type P (phrases) as reference data set, the authors summarize the performances of typical methods for visual feature extraction in terms of word recognition rate (WRR); more detailed descriptions associated with methods, models, database, tasks, and WRR are presented in Table 3.
Comparative WRR in GRID data set.

CNN: convolutional neural network; Bi-GRU: bidirectional gated recurrent unit; LSTM: long short-time memory network; AAM: active appearance modal; DCT: discrete cosine transform; HMM: hidden Markov model; WRR: word recognition rate.
As in Table 3, the worthy-noted WRR by K Xu’s lip region extraction strategy with 3D CNN is up to 97.1%. It is fair to say that typical DCT and AAM for AVSR are now being replaced by deep learning-based CNN tools.
Dynamic audiovisual fusion
The development and maturation of deep learning also opens the door to facilitate AVSR in terms of dynamic audiovisual fusion. S Petridis et al. 57 initially put forward an end-to-end audiovisual model that is based on bidirectional long short-term memory (BLSTM) networks, whose graphic interpretation is illustrated by an encoder layer and a classification layer in Figure 9. The functions of encoder layer are to extract features from raw images and spectrograms and to model their own temporal dynamics via a BLSTM network. The classification layer located above is mainly used to fuse the audio information that is derived from BLSTM networks in encoding layer. The final classification results (target classes) are given in terms of labels (one label per input frame, Softmax provides). By contrast, the end-to-end audiovisual model presents a better classification performance over typical AVSR models in AVIC data set without any additional load in complexity.

The graphic interpretation of end-to-end audiovisual model.
In another similar research proposed by S Petridis et al., 64 a new type of end-to-end model has been proposed. Whose model features are directly derived from waveforms and pixels, and the networks for modeling are bidirectional gated recurrent units (Bi-GRU) networks. Compared with the former models that mainly comprise of LSTM networks or encoders, this model may learn more knowledge on account of new form input “waveform.” However, more time is required for training. Overall, the quality of audio signals as the measurement for dynamic weight adjustments is no longer the only applicable solution to dynamic audiovisual fusion. Since the favorable input forms facilitate the learning abilities for parameter adjustments and further enhance the robustness of AVSR, the end-to-end models are supposed to be the mainstreams in the fields of predictable dynamic audiovisual fusion.
Future AVSR architecture design
In this part, we would like to conduct a comparative analysis of three representative case studies on AVSR and further illuminate our insights into the future AVSR architecture design. As in Table 4, the studies mainly concern typical MFCC/DCT-based audio/visual feature acquisition, adaptive weight adjustments for dynamic audiovisual fusion, and end-to-end AVSR design. The research of JN Gowdy et al. represents a class of traditional tools-based AVSR solutions. In their studies, the eyes are chosen as the references to locate the lip, and the 30-dimensional matrices via 2D DCT (and its first order differential transform) are adopted as the visual features, together with 13-dimensional MFCC features, they constitute the VSC and ASC of an AVSR, whose audiovisual fusion is performed at a decision level. It has been learned from the experiments that the lower the SNR, the higher the recognition rate of such an AVSR exhibits. 12 When MSHMM-based time sequence modeling method is invited as a tool for dynamic audiovisual fusion, this type of AVSR also follows the traditional designing lines of thought.
Comparative analysis of typical case studies on AVSR.

GAF: Gabor audio feature; GVF: Gabor visual feature; DF: decision fusion; MSHMM: multi-stream hidden Markov model; MFCC: Mel-frequency cepstral coefficient; PCA: principal components analysis; AVSR: audiovisual speech recognition; HMM: hidden Markov model; DCT: discrete cosine transform; SNR: signal-to-noise ratio; BGRU: bidirectional hated recurrent unit.
However, AS Saudi et al. 54 focus more upon the studies of efficient audio/visual feature extraction and adaptive weight adjustment of audio/visual features for dynamic fusion. In this AVSR, a Gabor filter is used for the audio/visual feature extractions, and a MLP-based adaptive weighting framework that jointly connects six-dimensonal feature vector and an optimal weight is proposed. Differing from the typical audiovisual fusion on feature level or decision level, this dynamic weight adjusting scheme enables an AVSR to present optimal weights in terms of different SNR, and the average accurate rate of speech recognition has been tested to be increased by 5.5%.
Even though the overall performance of AVSR designed by AS Saudi has enhanced a lot, the problem remains of how to efficiently extract the audio/visual features from an engineering perspective. When compared with DNNs, the Gabor filter can hardly fulfill the deep-level audio/visual feature acquisition; meanwhile, the MSHMM-based time sequence modeling also faces challenges such as nondeep-level modeling, repeated trainings, poor practicality, and so on. It is fair to say that the end-to-end model is favorable for the overall progress of AVSR. The experimental results verify its effectiveness even though the audio signal is under noising attacks by babble noise whose SNR ranges from −5 db to 20 db, and the accuracy of speech recognition has been numerically validated by a 14.1% (−5 db SNR) increase with comparison to that of ASR under the same conditions (more precisely, a 1.3% and 3.9% increases, respectively, correspond to 5 db SNR and 0 db SNR). 64
At present, the end-to-end AVSR model generally takes two of many forms of modality streams, for example, pixels, spectrogram, waveforms, and so on, as illustrated by the two-channel model in Figure 9. Taking such an AVSR (proposed by S Petridis) as an example, the training module of which directly extracts desired features from pixels and speech waveforms, and a two-layer classifier “bidirectional hated recurrent unit” is invited to classify the training results. When compared with the previous research, quite clear, the end-to-end-based AVSR adopts much larger data sets; also, it adapts to a much wider range of lip views (indicating that more angles of view are available).
Shrivastava et al.’s study 65 also discusses the end-to-end networks (MobiVSR) in lip-reading domain when the efficient lipreading itself is restricted to some cases with limited computational resources, like mobile devices, embedded systems, and so on. It has been proved that MobiVSR efficiently balances the speech accuracy and parameters involved, and this end-to-end design takes up less memory resources. These clues make us believe, the end-to-end AVSR has broad prospects. Also, we believe that the future AVSR would not be limited to two-channel information (such as visual and auditory modalities) fusion, videlicet, multimodality mechanism would be possible.
Refer to the physical structures of end-to-end networks, let’s consider an optimized framework that integrates superior audio feature estimation and the matched visual feature results. We present a possible AVSR architecture (see Figure 10). For the ASC, 3D CNNs may be chosen so that, as far as possible, the spectrogram exhibits as more comprehensive feature extraction source so replacing the features that are denoted by MFCC. For the multi-view lip-reading-based VSC, the pixel and depth used for image description could be extended to deal with the visual feature representation, so that the 3D structure understanding of lip spatial motion could be enhanced accordingly. BLSTM network is a solution to the audiovisual modality-based temporal sequence modeling. The major concerns of computational load, accuracy, and applicability should be given in future studies because these aspects are so essential. We may predicate, on basis of the maturing audiovisual recognition and representation, the further “sight-listening-touching-tasting-smelling” multimodality interaction tools will push the typical HCI to the direction of naturally complementary supervision pattern. Also, the fully developed AVSR that is applied to a range as small as voice inputting of mobile phones, lip-reading password, and biometric authentication or as large as robot, smart home, and in-vehicle scenarios will dramatically promote the development and maturation of HCI.

A possible AVSR architecture with BLSTM temporal sequence modeling. AVSR: audiovisual speech recognition; BLSTM: bidirectional long short-term memory.
Conclusion
AVSR that used to guide the dialogue between humans and machines is now attracting more and more scientific attention. In this review study, several problems that confront the designers of such complex speech recognition systems have been stated and elaborately discussed. From our point of view, finding solutions to large-scaled public databases for general purpose, efficient audio/visual feature representation, eminent feature extraction, and intelligent dynamic audiovisual fusion allows AVSR to move forward. Also, the evolution of such techniques has apparently exploited the opportunity for researchers to invite the deep learning-based tools in developing AVSR’s algorithmic frameworks. One of the important contributions of this review is the attempt that has been made to describe a possible AVSR architecture in foreseeable future. As the comparative analysis of typical case studies presents, we hold that deep learning and AVSR are now inseparably related, and the favorable anti-noise performances of end-to-end AVSR model and deep-level feature extraction capacities of deep learning-based feature extractors will guide a class of multimodality HCI directly to a solution.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Science and Technology Program of Department of Education, Jilin Province under Grant JJKH20200117KJ and Research Fund for Distinguished Young Scholars of Jilin City under Grant 20190104128.