
Abstract
In this work, we propose a robust place recognition measurement in natural environments based on salient landmark screening and convolutional neural network (CNN) features. First, the salient objects in the image are segmented as candidate landmarks. Then, a category screening network is designed to remove specific object types that are not suitable for environmental modeling. Finally, a three-layer CNN is used to get highly representative features of the salient landmarks. In the similarity measurement, a Siamese network is chosen to calculate the similarity between images. Experiments were conducted on three challenging benchmark place recognition datasets and superior performance was achieved compared to other state-of-the-art methods, including FABMAP, SeqSLAM, SeqCNNSLAM, and PlaceCNN. Our method obtains the best results on the precision–recall curves, and the average precision reaches 78.43%, which is the best of the comparison methods. This demonstrates that the CNN features on the screened salient landmarks can be against a strong viewpoint and condition variations.
Introduction
Visual place recognition consists of identifying locations from a database that corresponds to the same place. From the perspective of image processing, place recognition can be considered to be an image retrieval problem. Many researchers have tried to find invariant features of scene images. Typical features include Haar-like features, 1 scale-invariant feature transform (SIFT), 2 histogram of oriented gradient (HOG), 3 local binary patterns (LBP), 4 and so on. These handcrafted features can be part of a bag-of-words model, which is widely used in some computer vision applications. 5,6
However, in real applications, such as navigating vehicles through an unstructured environment, 7 these handcrafted features have their inherent limitations, and they cannot work well in some situations, such as dynamic place recognition. Recently, with the development of deep learning, deep features trained on large-scale annotated datasets have shown great power in representing images that are robust to such variations. 8,9 On the other hand, deep learning methods also have shortcomings in obtaining high-quality data annotations and the lack of various filtering mechanisms. For instance, when we need to recognize a place, using features extracted from dynamic objects, such as pets or bicycles, may lead to recognition failure or decrease recognition performance. In summary, except for some specific simple cases, the global features of images extracted by convolutional neural networks (CNNs) contain redundant information, which affect the accuracy of retrieval.
This article proposes a robust place recognition measurement in natural environments based on salient landmark screening and CNN features. We use the salient object detection algorithm to extract salient objects in the image. Then, we use the category-screening network to obtain candidate landmark sets by removing specific objects that are not suitable for environmental modeling. Finally, a Siamese network is designed to complete the scene recognition task. The overall flowchart of the proposed method is shown in Figure 1. The main contributions of our work can be summarized as follows.

Illustration of our approach.
We propose a novel salient landmark detection technique that can extract the salient candidate targets and then automatically remove the specific object regions according to the predefined categories, which improve the quality and effectiveness of image retrieval in the later stage.
We use CNNs to learn the representations of image patches and train a Siamese network architecture to compare pairs of patches corresponding and noncorresponding for better matching.
The remainder of this article is organized as follows: the second section gives a brief overview of related work. Our method is introduced in detail in the third section. In the fourth section, three datasets used in this article and their characteristics are firstly described. Then, experimental results compared with other methods are also provided. Finally, the article is concluded in the fifth section.
Related Work
The visual place recognition task can be considered as an image retrieval problem, and many researchers have explored this area. Many researchers have tried to operate directly on raw pixels 10 or find the condition-invariant feature of places. Ali et al. 11 used SIFT and SURF to describe the image. Gálvez-López and Tardos 12 experimented with using a BRIEF features-based bag-of-words model in several datasets and demonstrated its effectiveness. However, in a real-world scenario, the characteristics of a place change all the time, and it is challenging to find correspondences between handcraft features.
Considering the above challenges, deep neural networks have become the mainstream image representation framework. 13 Both viewpoint and appearance robustness have been demonstrated when CNNs are used for a wide variety of vision jobs like object recognition, 14 object detection, 15 and scene recognition. 16 Inspired by these works, many researchers have tried to utilize intermediate representations from CNNs and have achieved competitive results. Wang et al. 17 proposed a novel omnidirectional CNN to handle severe camera pose variation for place recognition. Sun et al. 18 proposed a novel point-cloud-based place recognition method using a pretrained CNN. Park et al. 19 proposed a lightweight CNN place recognition method for embedded systems, and the experimental results show that the method is significantly better than traditional methods in accuracy and calculation time. By combining the deep learning features with spatiotemporal filtering, Chen et al. 20 completed the place recognition task based on CNN models. Sünderhauf et al. 21 provided an in-depth analysis of the viewpoint-invariant properties of deep learned features for place recognition; however, there is at least one problem with the above approaches. The training process of deep learning network needs high-performance hardware devices and is time consuming. The deep model trained on the object recognition dataset (e.g. ImageNet) is not fully adapted to the application task of place recognition. 22 In the real scene, the image of a place will change over time due to illumination, dynamic objects, and so on. Therefore, it is also inappropriate to extract features on the entire image, and a whole-image approach such as this is sensitive to viewpoint variations.
Some researchers have attempted to intelligently select useful information within an image for recognizing places. Sünderhauf et al. 21 developed a landmark extraction algorithm and computed the neural responses to each landmark region in a scene. Hou et al. 23 designed an objectness measure method to detect the landmarks and then expressed these regions as the features computed by the CNNs for matching in the next step. Additionally, saliency detection has attracted extensive research efforts in recent years. Salient detection is widely used in many applications, such as image classification, 24 image retrieval, 25 and visual place recognition. 26 Visual attention can guide computing resources to fixed important areas. Compared with image processing on the entire image, it can effectively improve the recognition performance, that is because not all contents in the image play a positive role in representing a place. 27 –29 Among these methods, feature extraction on the entire image for place recognition introduces redundant information and reduces efficiency. Considering that CNN leads to the large space of image representation, Chen et al. 30 proposed a new method of reserving salient feature maps and make adaptive binarization on it, and the experimental results proved the effectiveness. Since the highly representative landmark features are robust to appearance changes, Xin et al. 31 proposed an effective method based on CNNs and content-based multiscale landmarks to complete the task of place recognition. Chen et al. 32 proposed a method for place recognition based on CNN features, which achieved the aim of recognizing the place. However, their landmark detectors are based on all the salient objects in the image. In contrast, our method is able to remove salient objects that are not suitable for place recognition, and furthermore, a Siamese network is used to calculate the similarity, which can improve the matching efficiency.
Proposed system
This article proposes a robust place recognition measurement in natural environments based on salient landmark screening and CNN features. The main contribution is that our category-screening network removes the salient objects that do not suit the recognition in the current environment. Moreover, a Siamese network is used to calculate the similarity for efficiency optimization.
Category-screening network for salient landmarks
The category-screening network includes two parts of functions: salient object detection and object category recognition. Its core innovation lies in trying to exclude certain types of objects that are not suitable for environmental modeling. To achieve this, we firstly needed to select a state-of-art saliency object detection method. Since deep learning-based processing methods have gained great advantages in various fields of computer vision, our focus is on a salient object detection scheme based on CNN-based saliency approaches. Hou et al. 33 found that in most CNN-based salient models, the outputs of the deeper side and the shallower side have their respective contributions to the correct results. They found that making short connections between the shallower and deeper side output layers improved the performance. After considering the performance and execution efficiency, in this article, we choose the DSS [33] method as the salient object detection algorithm.
After obtaining a large number of salient object images, pictures must be identified as to whether they belong to some specific categories. The above requirements can be considered to be a typical image classification problem, and good results have been achieved by the conventional CNN-based approaches. One of the characteristics of these methods is the large number of labeled training samples and powerful GPU resources required. For those who lack these conditions, parameter transfer learning can be used to improve performance by fine-tuning on the target dataset.
For this study, we built an AlexNet based on Caffe and trained it on the ILSVRC2012 dataset. Then, the pretraining model is used to estimate the training samples in the target domain. The purpose of optimization is to purify the samples on the training set. According to the study results of Koh and Liang, 34 even a single sample in the training set can affect the final testing loss. Wang et al. proposed an optimal scheme for the training data. 35 In our work, their implementation was modified, which is detailed in Algorithm 1. A pretrained model using training data from the ImageNet is chosen as the initial model, and then, the influence of each sample in the dataset based on the pretrained model is calculated. Finally, after removing the samples that reduce the loss of the verification set, the final model can be trained again with the new training set. In the scheme, xi denotes a single training sample and fθ (x) represents a CNN model with input x. Let L(fθ (x)) be the loss. After the removal of sample x, the influence on the validation xj is defined as I loss (x, xj ). According to Koh and Liang, 34 the I loss (x, xj ) can be approximated as follows

where L is usually a loss function like cross entropy, and so on.


After following the above-stated steps, a newly optimized training set is obtained. Next, the weights of all convolutional layers of pretrained AlexNet are frozen, the weights of the last three fully connected layers are finely tuned, and the last layer of the network is truncated. Since the pretraining model we selected is generated based on the ImageNet dataset, and the softmax layer output of the model is 1000. Because the number of categories we need to recognize is far less than the number, a redesign softmax layer is required. For example, if 10 object categories that are not suitable as landmarks in the environment, the new softmax layer of the network should be 11 (including the type other than the target categories). After the model is trained, the salient images are sent into the model for classification, and the images classified into specific target categories, which are unsuitable for environmental modeling, will be removed. The whole process is shown in Figure 2.
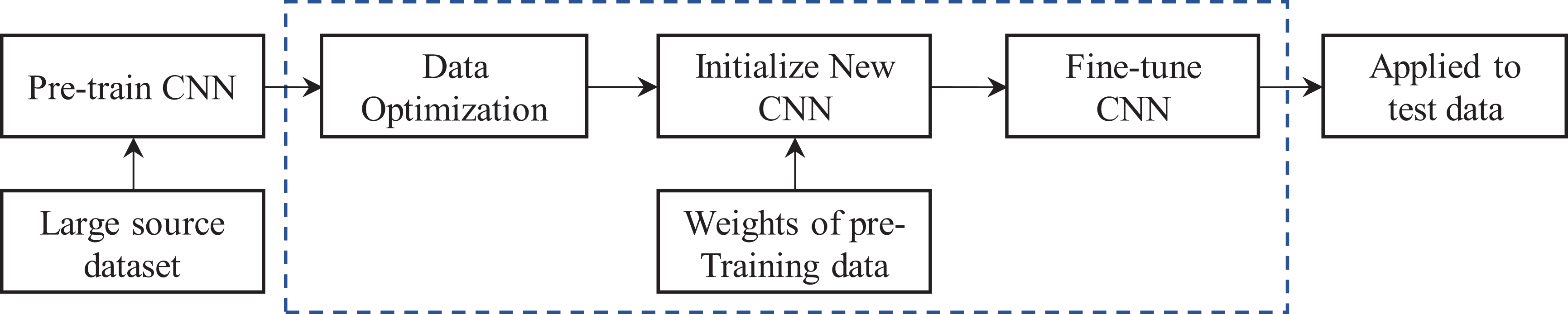
The workflow of the transfer learning method.
Similarity computing
Traditional classification methods require an accurate label for each sample. When the number of categories to be classified is large and the number of samples in each category is small, the traditional method is not suitable. On the other hand, the Siamese network can learn a similarity measure and can be applied to a classification problem, where the number of categories is large or the training sample cannot be trained with the previous method. Therefore, after the landmark proposals have been extracted, we use a Siamese network to enforce descriptor similarity and dissimilarity for better matching. The Siamese network architecture that employs two CNNs with identical parameters to learn the representation of the image patches compares pairs of patches, 36 and we minimize a loss that enforces the L2 norm of their difference to be small for corresponding patches and large otherwise. Figure 3 shows the overall idea of the similarity computing method.

Diagram of the proposed Siamese network.
Taking into account, factors, such as the size of the dataset, a mature three-layer CNN architecture is used to make the matching process more efficient, as shown in Figure 3. Considering the pixel size of salient objects, the sizes of the salient landmarks were adjusted to 64 × 64, while only CNN3’s output is used as the descriptors, and then, their L2 norm is computed, which is commonly used for image similarity measure. This is an instance of semisupervised embedding. The margin-based loss function, which has been shown to outperform other methods in such applications, 37 was used in this study

where fi is the CNN3’s output of salient landmark xi in proposal landmark dataset, fj is the CNN3’s output of new input salient image patch xj ; wij is a label, and if xi and xj should be similar, then wij =1, or otherwise wij = 0; and m is Euclidean distance that dissimilar patches should be away from each other.
Experiments
To verify the effectiveness of the method, we designed a series of experiments on place recognition problems.
Datasets
We selected three datasets that are widely used in the field of place recognition for verification. 21,22,38,39 The details of the datasets are summarized in Table 1.
Dataset descriptions.

The Gardens Point dataset contains three image sequences, which were recorded on the Gardens Point Campus of QUT and along the Brisbane River by a pedestrian. The St Lucia dataset is a dataset gathered from a car with a forward-facing web camera driven in a 9.5-km circuit around the University. The synthesized Nordland dataset contains video clips from four different seasons of train driving perspectives. A special feature of the dataset is that the viewpoint and the field-of-view are in all four videos.
Evaluation methodology
We compared our work with three advanced place recognition methods, the FABMAP, 40 SeqSLAM, 10 SeqCNNSLAM, 41 and Place-CNN. 22 FABMAP is a method, which makes use of the handcrafted features for place recognition and mapping. SeqSLAM is a sequence-based approach, which uses a global HOG descriptor and has been considered to be one of the most successful algorithms for place recognition. SeqCNNSLAM is an improvement of SeqSLAM, SeqCNNSLAM uses state-of-the-art deep learning techniques to generate robust feature representations of images. Place-CNN is a deep learning-based recognition model trained on the Places205 dataset. In view of the good performance of the conv3 layer in the deep network, when the appearance changes, we choose conv3 layer to extract the features. The experimental results adopt the conventional precision–recall (PR) curves, which is often used in visual place recognition. 42 –44
Results and discussion
As shown in Figures 4 to 6, the PR curves are computed on all three test datasets for our proposed approach against the other four algorithms. In all three results, our method, which combines the advantages of salient object detection, category-screening network, and CNN features, is always superior to other comparison methods.

Precision–recall curves on the Gardens Point dataset.

Precision–recall curves on the St. Lucia dataset.

Precision–recall curves on the Nordland dataset.
Figure 4 shows the PR curves generated by these methods on the Gardens Point dataset. Our model achieves slightly better performance than SeqSLAM and SeqCNNSLAM. The average accuracy (AP) of FABMAP is only 10.4% in three datasets, which is the worst performance. However, there is still unfairness when the FABMAP method is directly compared with other methods in the article. One of the reasons is that FABMPA is focusing on place recognition to be used in mapping and localization applications, and the handcrafted features used by FABMAP have no advantage over the deep features in dealing with environmental changes. On the other hand, the SeqSLAM method gets better performance than the place-CNN method. This is mainly because the SeqSLAM method adopts sequence matching rather than single-image matching for place recognition, which fits well with the image features of the test dataset.
Figure 5 shows the PR curves generated by these methods on the St Lucia dataset. The images in the Lucia dataset change dramatically in light and appearance, both the FABMAP method and the SeqSLAM method based on handcrafted features do not perform well. When the SeqSLAM method replaces the features with CNN features, we can observe that SeqCNNSLAM method performs far better than the original one. In addition, our method performs best among all the comparison methods using CNN features, leading by about 20% on the average accuracy, indicating the benefits of using salient object detection and category-screening network.
Figure 6 shows the PR curves generated by these methods on the Nordland dataset. Our method is still ahead of other comparison methods. Compared with the SeqSLAM method, the SeqCNNSLAM method has improved the average recognition accuracy by about 20.29%. In addition, it is noteworthy that the PlaceCNN method performed poorly on the Nordland dataset, which is mainly because the appearance of the sequence in the dataset changes dramatically and was recorded only once per season. Since the PlaceCNN method extracts features from the whole image, there were a lot of redundant features. The performance of the model decreases seriously when the environment appearance changes dramatically.
Conclusion and future work
Inspired by the success of saliency attention models in other computer vision tasks and the vigorous development of deep learning techniques, in this article, we propose a place recognition method that takes advantage of the salient landmark screening and CNN features, which achieved good recognition results. Compared with the method of extracting features on the entire image, our method can automatically select informative regions for recognizing places. To get more accurate landmarks, we also designed a category-screening network, which can effectively remove specific object categories, and it makes the subsequent CNN features more stable. Evaluation against the state-of-the-art on several datasets reveals that our method obtains the best results on the PR curves, and the AP reaches 78.43%, which is nearly 15% points ahead of the second.
In the future, we will try to optimize the network structure in an end-to-end fashion, such as retaining the CNN features for the Siamese network while detecting the object class, to improve the place recognition performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Changzhou Applied Basic Research Planned Project [CJ20180010], “QingLan” Project of Jiangsu Province, CCIT Key Laboratory of Industrial IoT [KYPT201803Z], Natural Science Foundation of CCIT (XJ2020000601), and Changzhou Key Laboratory of High Technology [CM20183004].