
Abstract
Grasp using a prosthetic hand in real life can be a difficult task. The amputee users are often capable of planning the reaching trajectory and hand grasp location selection, however, failed in precise finger movements, such as adapting the fingers to the surface of the object without excessive force. It is much efficient to leave that part to the machine autonomy. In order to combine the intention and planning ability of users with robotic control, the shared control is introduced in which users’ inputs and robot control methods are combined to achieve a goal. The shared control problem can be formulated as a Partially Observable Markov Decision Process. To find the optimal control policy, we adopt an adaptive dynamic programming and reinforcement learning-based control algorithm-Deep Deterministic Policy Gradient combined with Hindsight Experience Replay. We proposed the algorithm with a prediction layer using the reparameterization technique. The system was tested in a modified simulation environment for the ability to follow the user’s intention and keep the contact force in boundary for safety.
Keywords
Introduction
A major task for an anthropomorphic prosthetic hand is to perform a dexterous and stable grasping in daily life. 1,2 A success grasp control consists of problems in different phases. In the pre-grasp phase, the control problem is about grasp planning which can be addressed as several complex factors including positioning the arm, orienting the wrist, and shaping the fingers subject to object placement and distribution, environment obstacles, and so on. On most occasions, these factors lie in a higher multimodal dimension and the solution may be intractable. Many studies have proposed different methods for grasp planning, 3,4 but in anthropomorphic robots, human planning still has its privilege over robot algorithms. 5 Meanwhile, the precise force control is also needed in the grasping phase, especially during the manipulation tasks. 6 –8 Traditional robotic hands or prostheses are lack of rapid and intuitive feedbacks in control. In practice, prosthetic hand control for amputees usually takes a long time in training and is hard for the user to comprehend the states of the robotic hand. The limited sensory-motor control abilities make it difficult for subjects to adjust their fingers to the shape of the object. To avoid the drawbacks in two different phases, the shared control (SC) is introduced which combines human grasp planning ability with the automated grasp algorithm. SC makes fine adjustments to the fingers by processing information from the force sensors placed on the prosthetic hand fingers. 9 In the pre-contact grasp phase, the movement planning can be done by users to achieve better embodiment since it is more intuitive. After the contact, the algorithm should try to keep grasp stable while taking the users’ intention into consideration. More generally speaking, SC strategies aim to bridge the gap between human intentions and efficient execution of the intended task by using information from the sensors.
The idea of “shared control” of combining the user’s command with robot algorithms has a long history and is widely applied in the robotic field. Salisbury 10 proposed a control strategy for a robotic hand, where the robot autonomy can be intervened by the users’ commands, and user control could be augmented by the robot. Kim et al. 11 proposed an SC structure for brain–machine interfaces where the goal is to share control arising from the user’s brain and robot sensors. Fong et al. 12 designed a cooperative system relying on dialogue via prompting for decision-making and robot assurance. Especially, SC is widely used in dexterous manipulation in teleoperation 10,13,14 and prostheses, 11,15 –17 where the target of the robotic hand is given remotely or by decoding the electrograms (e.g. electromyography (EMG), electroencephalogram (EEG), etc.). Since the input signal type of users varies from case to case, in order to illustrate the SC problem, we focus on the algorithms about how the target signal generated by the different controller mixed with each other without considering how these signals are extracted. Some adaptive algorithms used in SC are aimed to help people complete their tasks by keeping them in safety. Lopes et al. 18 presented a fuzzy control-based SC algorithm for the navigation of assistive mobile robots. Saen et al. 19 implemented an SC method in grasp tasks of a robotic hand by regulating the finger force with tactile sensors. By attaching force sensors to the surface of the hand, the robot can predict the properties of the grasped object and deal with the uncertainties. 20 Javdani et al. 21 address the SC approach as a Partially Observable Markov Decision Process (POMDP) in which the environment was not fully observable. POMDP can be solved with adaptive dynamic programming (ADP), 22 which is a model-free approach suitable for application.
Recently, the reinforcement learning (RL) techniques have aroused attention in robot SC with ADP. Xu et al. 23 proposed an RL-based SC algorithm for walking-aid robot 24 where the robot is able to autonomously adapt to different user operation habits and motor abilities. The RL algorithm used here is Q-learning, which updates the action-value function for control. The Q-learning can only be applied to sparse action space, whereas the action inputs of the prosthetic hand are usually continuous signals. Besides, the Q-learning cannot update the action policy directly. Lillicrap et al. 25 combined the deep learning techniques with RL for continuous control with an actor-critic network structure shown in Figure 1. The algorithm originating from ADP is called Deep Deterministic Policy Gradient (DDPG). DDPG can directly update the parameterized policy and intrinsically suit for continuous application. The object grasp task contains multiple considerations and the goal of it is consequently complex. To improve DDPG performance in a multi-goal environment, the Hindsight Experience Replay (HER) is introduced. 26

Overview of the actor-critic network structure.
We proposed an SC system for robotic hand control with DDPG and HER algorithms. The data flow of the system is shown in Figure 2. The user intention controls the movements of fingers and the agent regulates the user control signal by taking the robot states and sensors into consideration. Before the robot finger contact with the surface of the object, agent should act like transparent by deliver the user control signal directly to the robot. Once the fingers contact with the object, the force should be constrained to keep a steady grasp.

The signal flowchart of the proposed system.
In the following sections of this article, a simulation environment of grasp task was built. The agent with DDPG + HER algorithm and environment predictor was trained in the simulator. In the end, the trained agent was tested concerning the performance in free move and force adjustment in grasping.
Methods
Environments setup
The simulation environment for grasping tasks is built using OpenAI Gym. 27 The environment contains a model of a Shadow Dexterous Hand (Shadow Robot Company, London, UK) which is an anthropomorphic robotic hand function as a prosthesis. There are 24 degrees of freedom in the hand and 20 of them can be controlled independently. In grasp task, a block is placed on the palm of the hand for grasping. The goal of the grasp task is a 15-dimensional vector containing the Cartesian position of each fingertip of the hand. The OpenAI gym uses the MuJoCo 28 physics engine for fast and accurate simulation.
The initial states environments are shown in Figure 3, which simulate the starting of the contact phase in a grasping task. Notice that the block may randomly not appear, which indicates that the fingertip position is in a free moving trial. The simulation runs step by step with an action frequency of

The initial states with or without the target block in a grasp environment. (a) The block is put on the palm with random position and rotation. (b) The block is not put on the arm on some occasion and the colored ball indicates the goal of the fingertip.
At the beginning of each trial, an object appears, and its position and rotation are not directly observable. Then, the fingertip goals are generated. The main goal of this environment is to achieve mean distance between fingertips and desired positions less than a certain threshold, which assumed to be generated by a user’s intention. When the goal lies outside of the boundary of the block, the corresponding finger is not intended to contact with the object. If the goal lies inside, the finger should try to contact with the object surface within presetting force bounds. The safety requirements and grasp conditions were taken into consideration in choosing the adequate lower and higher boundaries.
The reward function of this environment can be continuous or sparse. However, considering the DDPG algorithms described in the following sections, the sparse reward function has better performance. Thus, the reward will be 0 if the distance between the finger position and the goal is less than the threshold or the reading of touch sensors on the fingertip lie in the force boundary. Otherwise, the trial is considered failed and the reward will be −1. The detailed trial setup will be explained in the following sections.
Shared control
SC algorithms combine control ability and machine control ability in grasping tasks by following the users’ intention while taking grasp stability, force limitation, and other limitations into consideration. An SC problem can be defined as a POMDP.
29
In a Markov Decision Process (MDP) with states
In this article, the states
DDPG with HER
One algorithm for finding the optimal policy of POMDP in continuous action space by improving the deterministic policy function π is DDPG.
25
DDPG is a model-free policy gradient method which requires no prior knowledge of the system. Comparing to other RL algorithms such as Deep Q-Network, DDPG has advantages in sample efficiency, action exploration, generalization, and reproducibility in solving problems with continuous high-dimensional action and state space.
30
Specifically, DDPG maintains a parametric approximation

where a is determined by policy

The original DDPG algorithms added experience relay which collects experiences into a buffer and update θ and ϕ using random selection of mini-batch from the buffer. However, in a multi-goal environment, the agent usually failed to reach the goals. If agents only learn from success, the experience stored in buffer provides little toward the optimal policy. HER 26 can learn from the failures as well. During failure episodes, HER considers whatever the agent reaches as a modified goal and stores them in the buffer as well. HER does great in a sparse rewards environment with multiple goals.
The network structure of implementation of DDPG with HER is shown in Figure 4. There are some modifications in the input layer where a predictor is added for feature extraction of the object via force sensors. The predictor using a technique called reparameterization trick which widely used in variational autoencoders. The predictor assumes a bunch of hidden variables
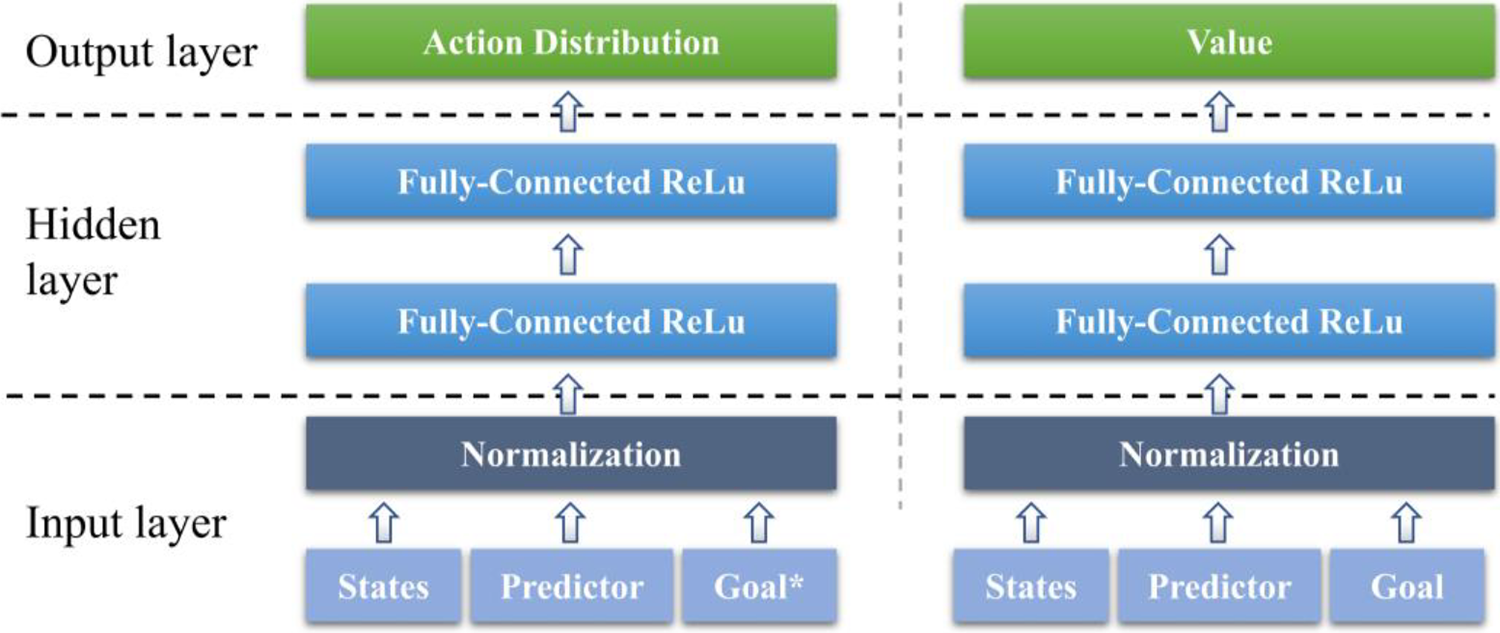
The structure of policy network (left) and value network (right) in DDPG + HER. Each network consists of an input layer with additional predictor, a single fully connected layer with rectified linear unit (ReLU) activations, 31 and output layer with clipping. The normalization layer subtracts the mean value of each axis, divides by the standard deviation, and removes outliers by clipping. DDPG: Deep Deterministic Policy Gradient; HER: Hindsight Experience Replay.
The algorithms were implemented in PyTorch 32 with CPU on Windows platform. The training process utilized Message Passing Interface for distributed computation to enhance the training speed and the detailed algorithms are presented in Table 1.
The implemented DDPG with HER algorithm.


DDPG: Deep Deterministic Policy Gradient; HER: Hindsight Experience Replay.
Simulation experiments
The simulation environment ran in OpenAI Gym with MuJoCo physics engine and the algorithm was implemented in PyTorch. The source code of the environment and agent is available at https://github.com/ZhaolongGao/sc_ddpg.git. Trail detail: The environment runs in a stepwise mode. Each step contains 20 sub-steps sum up to 0.04 s which means the environment responds to the action control signal at a frequency of 25 Hz. At the beginning of each trial, the object is placed on the palm by chance. The object position and rotation are randomly selected in a preset range. The desired goal of the trial was selected randomly for each fingertip. During the trial, an action vector of 20-dimensional is fed into the environment at each step. The states of the robot and sensors will update afterward. The reward will be calculated as well. A sparse reward function was chosen for better performance according to Plappert et al.
33
The achieved goal is set to be the current fingertips positions. When there is no contact, the trial will be considered successful if the distance between achieved goal and desired goal is under the presetting threshold. When contacting with the object, the trial will be considered successful if the reading lies inside the boundary. Reward function will return 0 if the trial is successful, otherwise −1. Training: Multiple agents which instantiate the DDPG + HER were generated and attached to an environment separately. The parameters of the agents are sharing with each other during training. The training takes 200 more epochs with early stop if the evaluation successful rate stays above 0.9 for 5 epochs. Evaluation: Evaluation will be done after each step. At the evaluation phase, the reparametrized hidden variables will not be sampled from the probability. The μ learned from the trials will be used instead.
Results and discussions
The trained agents are tested with two scenarios: free movement and object grasping. In both scenarios, the desired goals are prearranged randomly by the environments which are observable to the agent. These goals will be replaced by the goals generated from user’s intention in practice. Meanwhile, the object position is unknown to the agent, which represents the unknown target in a grasping task.
In free movements, the desired goal was set as a step signal for all fingertips. The goal of each finger represents the desired goal of user. A result is shown in Figure 5, in which the dashed lines are the goals of corresponding fingertips and the solid lines are the positions of the fingertips. The average response time is about 4–6 steps (approximately 200 ms). As a study 34 suggest that the delay should be less than 200 ms to maximize sense of body ownership. Thus, the response time is acceptable for application. Since the last steps are within a small range, the standability of the control algorithm is acceptable as well. This experiment aims to reproduce the situation when the prosthesis user’s movement in a pre-grasping phase. The target goals position represents the user’s plan, for example, the grasp locations, pre-grasping hand gestures, fingers usage, and so on. In this situation, the fingers of the prosthesis should always follow the goals. The results in Figure 5 indicate the trained agent can meet the daily use standard.
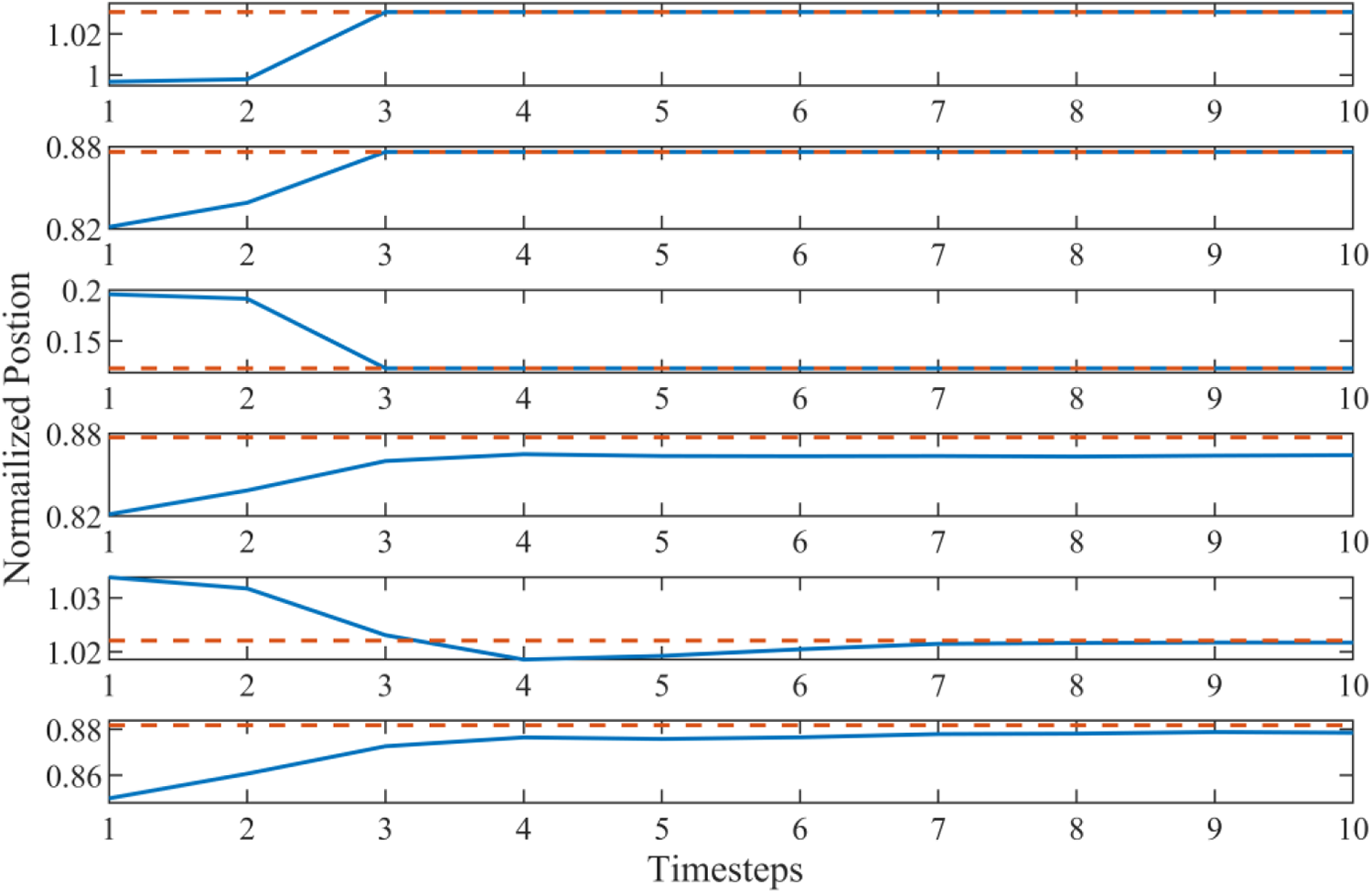
The step responses of fingertips in free move. This figure shows position (solid lines) of fingertips in Cartesian coordinate following the target positions (dashed lines) set by the desired goals.
In the grasping scenario, the finger will try to approach the desired goal at the beginning of the trial. If the desired goal is inside the block beyond reach, the finger will contact the surface of the object. The force sensors attached to the surface of the fingertips are utilized to predict the unobservable information of grasped object in a lower space. Contacting force of three fingertip sensors during grasping are shown in Figure 6. The contact between fingertip and object happened at the timestep marked by the dashed line. After the contact, the force was kept by the algorithms subject to the force boundary and considered irrelevant to the desired goal until the desired goal leaves the boundary of the object. This will help the robot hand hold the object properly without consuming too much attention about precise finger positions. This experiment tests the force control ability of the agent which plays a key role in grasping stability and safety. The lower bound of the contacting force is chosen to be the least force for stable grasping, and the higher one is the break force. The algorithm did not require explicit stability evaluation metrics; the stability can be implicit from the success rate of the trial. In this article, the success rate during the evaluation session is over 90.7%. The success rates during training and testing are shown in Figures 7 and 8 separately. We notice that the average success rate is different during grasp and free move, as shown in Figure 8. The higher success rate and lower variance in free move trials indicate that the stability of grasp can be further improved by enhancing the switch ability of the system. Since the switching between these two types of movements are fully controlled by agent which no specific parameter assignment is required, the sacrifice of success rate is acceptable comparing to the SC approaches with a specific structure for algorithm switching.

The force of the fingertips in a trial. The shaded parts are the boundary of force.

Success rates during training epoch.

Success rates during evaluation of free move and grasp trials.
The proposed SC system outperformed human user when trying to achieve a proper contact force as shown in Figure 9. When the user was asked to control the finger directly, it takes more time before the contact force stabilized comparing to an SC agent. The gap between the human user and SC agent is mainly attributed to the lack of feedback with high embodiment other than visual clue. In other words, SC agent can enhance the embodiment of a prosthetic hand.

Comparison of force stabilization time between human control and proposed SC. SC: shared control.
In summary, these results show that the algorithms introduced in this study is capable of achieve finger following and stable grasping by combining the user intention and machine autonomy. In the meantime, the slightly reduced success rate is a trade-off of generalization in terms of switching between different modes.
Conclusions
In this article, we introduced an SC approach to the prosthesis grasping control problem. We formulated the SC approach as a partially observable MDP and tried to find its optimal policy by DDPG with HER. The algorithm is tested in a modified simulation environment which aimed to test the prosthesis in free move and object grasping task. The results showed that the algorithm is applicable with good performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key R&D Program of China (2018YFB1307300) and the National Natural Science Foundation of China (91648207 and 61673068).