
Abstract
To tackle the water surface pollution problem, a vision-based water surface garbage capture robot has been developed in our lab. In this article, we present a modified you only look once v3-based garbage detection method, allowing real-time and high-precision object detection in dynamic aquatic environments. More specifically, to improve the real-time detection performance, the detection scales of you only look once v3 are simplified from 3 to 2. Besides, to guarantee the accuracy of detection, the anchor boxes of our training data set are reclustered for replacing some of the original you only look once v3 prior anchor boxes that are not appropriate to our data set. By virtue of the proposed detection method, the capture robot has the capability of cleaning floating garbage in the field. Experimental results demonstrate that both detection speed and accuracy of the modified you only look once v3 are better than those of other object detection algorithms. The obtained results provide valuable insight into the high-speed detection and grasping of dynamic objects in complex aquatic environments autonomously and intelligently.
Introduction
Water insecurity (quantity and quality) affects health and livelihoods. Contaminated water causes 1.7 million fatalities from treatable diseases annually. Wetlands conservatively valued at up to USD 800,000 ha/year are being lost rapidly. Poor ocean health affects access to cheap protein (i.e. fish) for approximately 275 million people and the access to 20% of the animal protein supply for 3.1 billion people in total. Meanwhile, it threatens livelihoods in the tourism and commercial fishing sectors. 1 The reserves of water resources are not only very limited but also faced with severe pollution, especially as plastic waste pollution. Therefore, the protection of water resources is one of the greatest and most sacred duties of human beings. With the development of science and technology, the robots for water surface garbage cleaning are emerged as new tools.
The researches about cleaning robot are gradually becoming prevalent, 2 –9 and performances in the grasping are fascinating. 10 –13 In this context, a water surface garbage cleaner robot has been developed in our lab, which can be applied to clean up water surface garbage, reduce the labor volume of sanitation workers, and improve the water ecological environment. 14 There are three primary tasks for the garbage capture robot, that is, garbage detection, garbage capture, and garbage collection. Notably, garbage detection is particularly significant in the above three parts, because it is in charge of providing reliable object location information for the robot. Besides, garbage detection is the prerequisite for the successful implementation of garbage capture and garbage collection. Consequently, an efficient detection method is highly demanded.
Object detection is not difficult for the human eye, because people can locate the object by perceiving its color, texture, and edges of the image easily. However, it is complicated for computers. With respect to the traditional object detection methods, computers execute object detection according to feature extraction like human beings. Among these methods, Haar 15 has been widely used due to both its fast feature extraction speed and ability to express the edge information of objects. Local binary pattern (LBP) 16 can better express texture information of objects. Histogram of oriented gradient (HOG) 17 uses histogram to count the edges of objects, which has satisfactory performance to express features and is widely applied. In addition, a grayscale-based detection method is applied. 18 But the aforementioned methods are based on some manual-designed features, whose shortcomings are detailed as follows. First, designing features manually is particularly troublesome. Second, there are great limitations, for example, application scenarios. Third, extracted features may be insufficient and incomplete. Fortunately, the convolutional neural network (CNN) is utilized for object detection, where all of above shortcomings have been overcome. 19 –21
With the improvement of computing power, the development of graphics processing unit processor, and the maturity of big data technology, the deep learning technology has achieved considerable performance in object detection in different fields. 22 –26 For example, in the field of medicine, based on deep learning, a technique using mask regions with convolutional neural network (R-CNN) was developed for lesion detection and differentiation between benign and malignant. 27 Nowadays, the prevalent object detection methodologies are mainly divided into two categories. One is the two-stage network represented by R-CNN, 28 Fast R-CNN, 29 and Faster R-CNN, 30 all of which include a region proposal network (RPN) to get region proposals. The other is the one-stage network represented by you only look once v1 (YOLOv1), 31 YOLOv2, 32 YOLOv3, 33 and single shot detector (SSD), 34 which transform classification and detection problems into regression problems. Especially, the comprehensive performance of YOLOv3 in detection speed and accuracy is very prominent, which can achieve 57.9 average precision (AP50) in 50 ms on a NVIDIA Titan X processor. 33 Hence this article employs the YOLOv3 algorithm and modifies it to detect three kinds of water surface garbage, including plastic bottles, plastic bags, and styrofoam.
The primary contributions of this article are as follows: A modified YOLOv3 network is proposed to detect floating garbage. Due to that, there are three types of garbage during detection; the three-scale prediction of YOLOv3 is changed to a two-scale prediction. The two-scale can achieve 54.04 frames/s on the GeForce technology eXtreme (GTX) 1080, which guarantees the real timeness. The anchor boxes of the original YOLOv3 are obtained by utilizing K-means clustering in the common object in context (COCO) data set, which is exactly appropriate to the COCO data set, but improper for our data set. Thus, all the boxes in the water surface garbage data set are reclustered to replace the original anchor boxes. The modified anchor boxes YOLOv3 can reach 91.43 mean average precision (mAP) in our data set, which compensates for the detection accuracy.
The rest of this article is organized as follows. After reviewing the related work, we will elaborate on the proposed detection method. Then, the experimental results are presented, and finally, we conclude the article.
Related works
Object detection is one of the classical problems in computer vision. Its task is to mark the position of the object in the image and to label the category of the object. Originating from the traditional artificial design feature and shallow classifier framework to the end-to-end deep learning detection framework, object detection algorithms have gradually become maturer and maturer.
There are numerous methods for object detection. With respect to the conventional object detection algorithms, a region in the image is selected by sliding window, which will be regarded as a candidate region. Then one or more features, such as Harr, HOG, LBP, or local ternary pattern, are extracted from the candidate regions. Finally, the candidate regions are classified by related classification algorithms such as Adaboost 35 and support vector machine. 36 Noticeably, in 2001, Viola’s cascade + Harr scheme 37 achieved outstanding results in face detection. Furthermore, deformable part module (DPM) is a popular competitive detector. A fast category object detector based on DPM was presented 38 that divides the object into root model and part model, in which the root model is equivalent to the traditional HOG feature and the part model is the template of some parts of the object. During the detection, the root model is used to locate the possible position of the object and the part model is used for further confirmation. However, the performance of DPM is rather ordinary, which cannot be adapted to the images with sharp rotations. Thus, its stability and robustness are undesirable. Additionally, the workload is relatively heavy.
Traditional methods can no longer meet the needs of production and life, for which the module of RPN and deep learning classification was put forward. A new pooling method “Sspatial pyramid pooling network” was proposed in He et al., 39 which can produce fixed-length output despite the input image with any size, as well as the network has good robustness to object deformation. Meanwhile, the speed and accuracy have been improved unprecedentedly, whereas the primary downside is that the training process is very complex and needs a lot of storage space. R-CNN-based networks 28 –30 have capability to the accurate detection, but the computational burden from RPN reduces the speed dramatically.
The RPN is not simple; as a result, the regression method based on end-to-end deep learning was born for object detection. YOLOv3 can detect objects according to three scales as shown in Figure 1(a). Its feature extraction network comes from Darknet-53, which adopts the full convolution structure and takes advantage of the residual structure as illustrated in Figure 1(c). Furthermore, it uses the strategy of multiscale fusion, which greatly improves the recall rate and accuracy of YOLOv3. By utilizing the deep and shallow features through the route layer, YOLOv3 achieves unprecedented high accuracy and speed. In particular, YOLOv3 was compared with Faster R-CNN and SSD, respectively 40,41 ; the results show that YOLOv3 is in a leading position in both speed and accuracy.

Network architecture. (a) The structure of the original three-scale YOLOv3. (b) The structure of two-scale YOLOv3. (c) The legends for (a) and (b). YOLOv3: you only look once v3.
Water surface garbage capture robot
Traditional water decontamination mainly relies on manual salvage operation, which is not only difficult, risky, and inefficient but also exists some limitations. If cleaning missions are conducted on the small rivers, man-made lakes, and water amusement parks, where ships cannot voyage due to narrow areas and shallow water, dustmen will be hindered. At the same time, for some water areas with serious chemical pollution, it is not suitable for workers to clean trash. In addition, for some landscape lakes and rivers, artificial cleaning will affect the beauty of the surrounding environment. In this context, we have designed a floating garbage capture robot system, which can identify and search the surface garbage independently according to the visual system, then accurately locate it, and finally approach and capture it.
The structure of the robot is shown in Figure 2. The robot is about 64 cm long, 49 cm wide, 47 cm high, and 25 kg weight. It is made of light and solid materials, so that it can voyage on the water surface. A binocular camera is located on the device to detect and track the object, which can provide the robot with the position information of the target. The robot can dynamically adjust the position and pose according to the grasping objects position information in real time. Once the target is locked, robot will gradually swim toward the object actuated by four propellers symmetrically mounted at the bottom. A three degrees of freedom robot manipulator is placed in front of the device, whose length is approximately 48 cm. Note that the joints can rotate from 0° to 180°, which can promote the robot to grasp and collect garbage flexibly. A replaceable garbage collection box is placed at the rear of the robot for temporarily storing. Once the box is full, it will be replaced in time.

Configuration of the developed vision-based water surface garbage capture robot.
Water surface garbage detection
In this cleaning mission, the detected objects include floating plastic bottles, plastic bags, and styrofoam. The modified YOLOv3 network is used to realize the detection. The YOLOv3 can detect and classify multiclass objects from 3 scales and 9 ranges, and its main network architecture comes from the first 52 layers of the DarkNet-53 network, which can fully extract features from images. Note that Figure 1(a) describes its architecture, where three-scale feature map will be output. However, our data are completely different from the COCO data set; moreover, the water surface situation is changeable for the actual application scenario. This characteristic results in the high real-time requirements for detection. Motivated by this demand, we transformed YOLOv3 from three-scale detection to two-scale detection by removing the last scale, which better ensures real timeness. The modified YOLOv3 network structure is shown in Figure 1(b).
YOLOv3 will scale the input image with any size to 416 × 416 pixels firstly; after one image passing through the network, YOLOv3 will output feature maps in three sizes of this image, including 13, 26, and 52 are the side length of the feature map; in other words, images are divided into 13 × 13, 26 × 26, and 52 × 52 cells after they go through the network.
3 indicates that there will be three sizes of bounding boxes to predict objects, while these bounding boxes are clustered from data set object boxes.
Furthermore, the loss function of YOLOv3 is defined below






where
YOLOv3 will predict four coordinate values





Prediction of bounding box. YOLOv3 will predict the width and height of the box as offsets from cluster centroids and the center coordinates of the box relative to the location of filter application using a sigmoid function. YOLOv3: you only look once v3.
The actual prediction value of the network is
As for obtaining the initial sizes of bounding boxes in YOLOv3, the K-means clustering method in YOLOv2 is still adopted. Clustering is the process of gathering similar things together and dividing them into different categories, which is a very important method in data analysis. Among many clustering methods, K-means is the most commonly used iterative clustering algorithm, 42 –44 whose idea is to randomly select K objects as the initial clustering center, then calculate the distance between each object and each seed clustering center, and finally assign each object to the nearest clustering center. Although there are many alternatives to measure the distance, the standard of measurement is usually Euclidean distance


where dxy
denotes the linear distance (i.e. Euclidean distance) between two points

Clustering result. The width and height information of boxes in our data set are clustered as abscissa and longitudinal coordinates, and small icons with different colors and shapes represent different clustering categories.
Experiments and results
Data set preparation
Since there is no ready-made data set of water surface garbage, we need to establish our own data set of garbage. The images in the data set are mainly taken by the camera in real environment from different scenes, such as playground, floor, river bank, and so on. Only several images are downloaded from the Internet. We randomly selected some of the images and rotated them at different angles to simulate the camera shooting from different directions. Besides, we adjusted their brightness to simulate various illumination conditions. The data augmentation process is shown in Figure 5. Next, we used the LabelImg to annotate the images; we circle the target objects in the image with rectangular boxes. The coordinates of the upper left corner and lower right corner of the rectangular boxes will be recorded in the extensible markup language file. Finally, they are made into visual object classes format data set. The number of final training images is 1204, and the number of test images is 301. The number of objects of each class in the data set and the specific experimental parameters are listed in Table 1. The area distribution histogram of the object bounding box in the data set is shown in Figure 6.

Data set images. Note that (a) comes from shooting, the other three are obtained by rotating (a) with different angles. The state of A represents the direction of the image. In addition, the brightness conditions of the images are different, so as to better simulate the different illumination conditions similar to the real environments. In addition, the background of (a), (e), (f), and (g) comes from different scenes, respectively, thus enhancing the robustness of detection.
Experimental parameters.
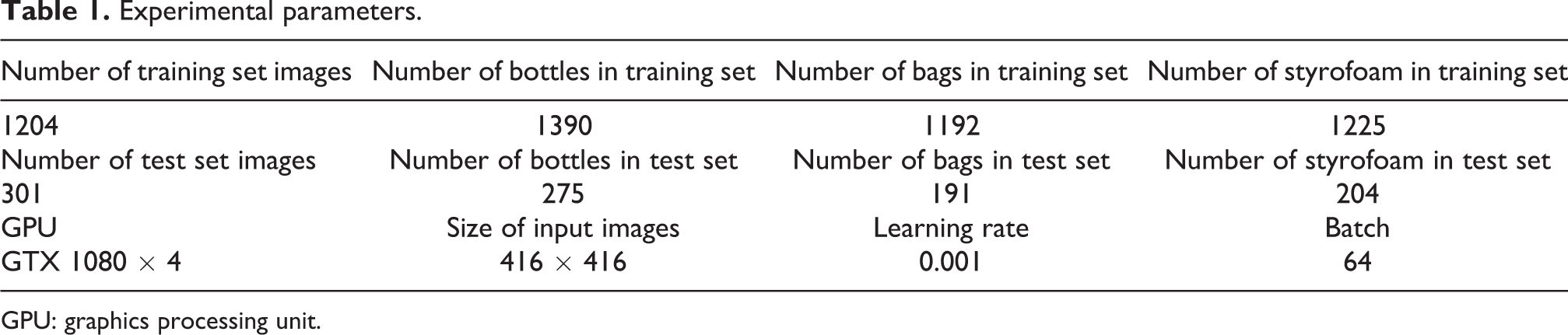
GPU: graphics processing unit.

Size distribution of object bounding box in training set.
Detection experiment
In this experiment, we detected three types of water surface garbage: plastic bottle, plastic bag, and styrofoam on the GTX 1080. Then, we measured frames per second, mAP, and AP for each category of the three-scale YOLOv3 (YOLOv3-3S), two-scale YOLOv3 (YOLOv3-2S), and modified the anchor boxes of the two-scale YOLOv3 (YOLOv3-2SMA: modified the anchor boxes of two-scale YOLOv3), respectively. In addition, we trained the SSD network, Faster R-CNN with visual geometry group (VGG16) backbone (Faster R-CNN [FR]16), and Faster R-CNN with Res101 backbone (FR101) in our own data set. The final quantitative results are listed in Table 2 and the detection performance of YOLOv3-2SMA is shown in Figure 7. Note that some of the images come from the water surface scenes and some from other scenes. Different surroundings enhance the robustness of the detection method, so that the robot can be adapt to complex environments.
Detection results on data set.

FPS: frames per second; YOLOv3: you only look once v3; SSD: single shot detector; AP: average precision; mAP: mean average precision.

Detection results.
The results show that the YOLOv3-2SMA is remarkable in all aspects in this experimental scenario. After removing one scales of YOLOv3, the YOLOv3-2S is slightly inferior to the YOLOv3-3S in terms of accuracy, but the speed of YOLOv3-2S is apparently superior to the YOLOv3-3S. Therefore, YOLOv3-2S can better meet the real-time requirements significantly. Meanwhile, some original anchor boxes of YOLOv3-3S are replaced with the anchor boxes reclustered from our own data set so that YOLOv3-2SMA can achieve the same accuracy of YOLOv3-3S.
SSD network also adopts the idea of regression. The network architecture is based on VGG16, 45 which is composed of 13 convolutional layers, 5 pooling layers, and 3 fully connected layers. In the ImageNet Image Classification and Location Challenge in 2016, this model achieved excellent results. 34 Moreover, SSD can detect objects from multiple scales, whose performance is outstanding. Experiments show that SSD network is inferior to the YOLOv3 network in all aspects. It is close to YOLOv3 in the detection of bottles, but it is far worse in the detection of bags and styrofoam.
Faster R-CNN-based networks are weaker than YOLOv3 in both speed and accuracy, especially in speed. Faster R-CNN takes nine anchor boxes from each pixel of feature map, resulting in that the computation for each anchor box classification is heavy. Furthermore, the feature extraction network of Faster R-CNN is not more sufficient than that of YOLOv3. Besides, YOLOv3 can predict objects from three-scale feature maps, whereas Faster R-CNN only predicts from one.
Field experiment
In addition, we conducted field experiments to verify whether the robot can be adapted to different environments and observed its states in complex surroundings to judge whether it has the ability to solve practical problems. The field experiments are shown in Figures 8 and 9.

The detection of field experiment.

Scenario of a field experiment. When the target object was detected, the robot approached to the object gradually. Once the robot approached into the graspable distance range, it implemented grasping.
The workflow of the robot is illustrated in Figure 10. When the device launches, it will cruise on the water surface with a random path. At this moment, the detection module will start to detect whether there is a target object in the visual range. When more than one garbage is detected in the visual range, we will first select the garbage closest to the center coordinate as the target. Because it is nearest the center of the field of vision, which the possibility of box loss is less when the robot approaches to the target. If a target is found, the robot will immediately adjust its pose and accelerate to the target based on the detected target information. Until the distance between robot and the target is proper for grasping, the manipulator will grasp the target. After the target is successfully captured, it will return to the detection module for redetection.

Workflow chart for the garbage capture robot.
In the field environment, the robot detected the objects accurately and in real time. According to the detected object information, it then approached the object and implemented the grasping successfully.
Discussion
The experimental results demonstrated that YOLOv3-2SMA outperformed the other detection methods. High-speed detection can process the image in real time and provide the object information for the robot in time in the changeable and complex environment. Even though Faster R-CNN has made a significant breakthrough in accuracy, it cannot achieve real-time performance due to the computational burden from the two-stage network. YOLOv3 stands out in detection networks in terms of speed, owing to YOLOv3-2S is one scale less than YOLOv3-3S, which means reducing computation load and resulting in a significant increase in detection speed. YOLOv3-2S can realize the detection task faster.
High-precision detection can help the robots complete tasks more accurately, reliably, and stably. The performances of SSD and Faster R-CNN in accuracy are far less than the YOLOv3 network. The basic frameworks of SSD and Faster R-CNN are VGG16, VGG19, and Res101, while the basic network of YOLOv3 is Darknet-53. Note that Darknet-53 performs on par with state-of-the-art classifiers but with fewer floating-point operations and more speed. Darknet-53 is better than ResNet-101 and 1.5× faster. Darknet-53 has similar performance to ResNet-152 and is 2× faster. Darknet-53 also achieves the highest measured floating-point operations per second. 33 Because YOLOV3-2S lacks one-scale prediction results, the accuracy will inevitably be affected. YOLOv3 is remarkable in precision and speed, so when it is improved, the rising space will not be very conspicuous. Thus, our goal is to achieve high speed while maintaining the original precision at least. The anchor boxes after reclustering will be more appropriate to the garbage data set; therefore, the accuracy of YOLOv3-2SMA can be compensated. In conclusion, YOLOv3-2SMA possesses a better performance than the others in both the speed and the accuracy closely related to the capability of autonomous cleaner robot.
Based on the aforementioned results, the proposed algorithm outperforms previous studies and is suitable for autonomous cleaner robot. However, for a better robustness in the complex aquatic environments, a more adequate data set is indispensable.
Conclusion and future work
A real-time and high-precision detection method is extremely critical for the successful grasping of water surface garbage robot; however, conventional detection methods cannot meet the requirements at the same time. For a comprehensive consideration, a modified YOLOv3 network is developed in this study. First, we transform three-scale detection into two-scale detection for a high speed. Second, we adjust the prior anchor boxes according to K-means clustering over our own data set to compensate for the detection accuracy. Compared with other detection networks during the experiment, YOLOv3-2SMA can achieve 91.43 mAP in 18.47 ms on GTX 1080, which ensures the real-time and accurate garbage detection. Furthermore, field experiments reveal that this method can be applied to the robot in complex aquatic environments. The high-speed and high-precision detection of YOLOv3-2SMA provides overwhelming visual support for the robot’s cleaning tasks, which make the water surface garbage cleaning autonomous and intelligent. Meanwhile, it can greatly improve the efficiency of the waste cleaning industry and make outstanding contributions to protecting the water surface environment. Additionally, it will reduce the investment of human resources and ensure the personal safety of cleaners.
The next step is to obtain more complex scene image data, so as to make its detection more robust and accurate. Besides, studies indicate that plastic garbage poses a serious threat to marine life, human health, and the economy. 46 –51 In the future, we will extend the domains of garbage cleaning missions from water surface to underwater for widespread use.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant 61725305, Grant U1909206, Grant 61873291, and Grant 61773416 and in part by the Minzu University of China 111 Project.