
Abstract
This article presents a lane-level localization system adaptive to different driving conditions, such as occlusions, complicated road structures, and lane-changing maneuvers. The system uses surround-view cameras, other low-cost sensors, and a lane-level road map which suits for mass deployment. A map-matching localizer is proposed to estimate the probabilistic lateral position. It consists of a sub-map extraction module, a perceptual model, and a matching model. A probabilistic lateral road feature is devised as a sub-map without limitations of road structures. The perceptual model is a deep learning network that processes raw images from surround-view cameras to extract a local probabilistic lateral road feature. Unlike conventional deep-learning-based methods, the perceptual model is trained by auto-generated labels from the lane-level map to reduce manual effort. The matching model computes the correlation between the sub-map and the local probabilistic lateral road feature to output the probabilistic lateral estimation. A particle-filter-based framework is developed to fuse the output of map-matching localizer with the measurements from wheel speed sensors and an inertial measurement unit. Experimental results demonstrate that the proposed system provides the localization results with submeter accuracy in different driving conditions.
Keywords
Introduction
Vehicle self-localization is one of the essential functions in advanced driver-assistance systems. The most accessible localization technique is the global navigation satellite system (GNSS). However, GNSS cannot always have submeter accuracy when the signal is blocked by surrounding buildings. Much effort has been made to increase the localization accuracy, including map-matching methods based on light detection and ranging (LiDAR) or cameras. LiDAR-based approaches 1 –3 are able to achieve centimeter-level accuracy. Nevertheless, LiDAR is not feasible for mass deployment because of its high price currently. As cameras are relatively cheaper, and images contain abundant information, vision-based methods have gained a lot of attention. 4
Despite decades of research, most vision-based methods can hardly perform self-localization adaptive to different driving conditions without much manual effort. Image-feature-based methods 5 have poor performance during heavy traffic condition. Semantic-feature-based methods (such as lane, ground, and curb detection) gain much attention recent years. Rule-based methods 6,7 always have high accuracy for some specific driving conditions, but a perfect rule is difficult to design to suit for all kinds of real driving conditions, especially when many arrows exist, lanes are splitted, or vehicle is changing lanes. Deep-learning-based methods 8,9 extract features in diverse driving conditions. However, manual labeling in a large data set is required for most deep-learning-based methods. It costs much and limits the application of deep-learning-based methods on a large scale. In this article, we develop a cost-effective localization system adaptive to different driving conditions (see Figure 1).

Illustrations of different driving conditions. (a) The ego vehicle (the red rectangle) is driving on a lane-splitting multi-lane road. Another vehicle (the yellow rectangle) is at the left side of the ego vehicle. (b) Arrows are painting on the ground. (c) The vehicle is changing lanes. There are many other driving conditions not shown here. It is difficult for rule-based methods to take into account all the real driving conditions.
In the proposed system, a map-matching localizer (MML) is proposed to estimate the probabilistic lateral position based on raw images from surround-view cameras and the lane-level road map. MML contains a sub-map extraction module, a perceptual model, and a map-matching model. The proposed system fuses the information from MML and low-cost sensors including inertial measurement unit (IMU), wheel speed sensors (WSS), and a GNSS receiver to provide the lane-level localization. The key contributions of our article are the following: We devise a probabilistic lateral road feature (PLRF) as a sub-map which contains the lateral information of the lane-level map. PLRF is a general feature which requires no assumptions of road structures. We design a deep learning network as the perceptual model to process raw images from surround-view cameras. Unlike conventional deep-learning-based methods, the perceptual model is trained by auto-generated labels from the map information to reduce manual effort. We develop a particle-filter-based framework to fuse the results of the MML and the measurements from low-cost sensors. This framework provides robust lane-level localization results in different driving conditions.
Related work
Related work about map-based localization systems can be divided into three parts: the choice of maps, detection, and localization.
Map
Many different types of digital maps have been used for localization, including the roadway map, 10 the 3D dense map, 11 the feature map, 12 and the lane-level road map. 13 The roadway map, for example, OpenStreetMap, models roads as polygons without the information of width, so it is not sufficient for a localization method to achieve the lane-level accuracy. The 3D dense map contains many points that can construct the surface of surrounding objects with centimeter-level accuracy, but it requires too much storage when the area is large. The feature map is designed including features related to detection results. Users often have to self-generate them in advance, which is infeasible on a large scale. The lane-level road map contains the positions of lane lines, centerlines, and curbs, which does not require much storage and has lane-level information. Besides, many researchers focus on auto-generation of lane-level road maps. 14,15 Thus, we design our localization system using the lane-level road map.
A sub-map should be extracted for efficiently matching with observations. Typical sub-maps of lane-level road maps fit lane lines as splines, 16 clothoids, 17 or cubic polynomials, 18 leading to inevitable errors when the shapes of lanes are irregular. In this article, we propose a PLRF that represent the distribution of lateral features without limitations of road structures.
Detection
Vision-based map-matching methods exploit visual features from images, for example, SIFT, 19 SURF, 20 DIRD, 21 ORB, 22 CNN features, 12 and so on. However, these features suffer from heavy traffic conditions, since surrounding vehicles also have these local features which are noises for map matching. To provide robust localization, some researchers detect semantic features and then match them with the lane-level road map. Brown and Brennan 6 presented mapped lane features for lateral localization using a mono camera. The mono camera is frequently blocked by front vehicles. To avoid the influence of occlusions, some researchers 23 utilize surround-view cameras: four fish-eye cameras mounted around the vehicle. Raw images from surround-view cameras have the strong distortion, and therefore, most methods use the composite bird’s-eye view synthesized from raw images. Dongwook Kim et al. 7 presented a rule-based method that detects the lane lines and the stop lines in the bird’s-eye view image. Alexandru Gurghian et al. 9 designed an end-to-end method to estimate lane positions in the bird’s-eye view image.
To generate bird’s-eye view image, it is supposed that the camera intrinsics and model are accurate and that the ground is flat. As it is hard to avoid the error of projection and undistortion, the features far from the cameras are always vague in the bird’s-eye view image. Therefore, most surround-view camera-based methods restrict the observation region of bird’s-eye view images to only detect 2 m or 3 m away from the ego vehicle (see Figure 2). However, it is important for lane-level localization system to get the observation of the curbs on multilane roads. For accurate features of the curb on the road, we design the perceptual model using raw images from surround-view cameras instead of bird’s-eye view image.

An example of raw images and the bird’s-eye view image from surround-view cameras. (a) The front raw image. (b) The rear raw image. (c) The left raw image. (d) The right raw image. (e) The bird’s-eye view image. The valid region is inside the blue rectangle.
Localization
As noises and outliers are inevitable in the observed data, robust localization methods are developed for consistent position estimation. The Kalman filter 24 is the most widely used localization method on linear systems. To work on nonlinear systems, the extended Kalman filter 25 and the unscented Kalman filter 26 were developed. Optimization-based methods 27,28 have been demonstrated to have better performance than the Kalman filter and its variants on sophisticated nonlinear systems. Most localization methods suppose that all errors are Gaussian. Particle filters, 29,30 however, generate samples without the assumptions of the state-space model and the state distribution.
Lane-level localization system
In this section, we present the lane-level localization system which outputs the robust positioning result using surround-view cameras, other low-cost sensors, and a lane-level road map (see Figure 3).

Framework of the lane-level localization system. The MML contains a sub-map extraction module, a perceptual model, and a matching model. The system fuses the result of the MML with measurements from other low-cost sensors based on particle filters. MML: map-matching localizer.
An MML is designed to provide the probabilistic lateral estimation as the observation. As the distribution of the MML outputs are non-Gaussian, we develop this system based on particle filters to fuse with the prediction from the IMU and WSS. The particle filter includes initialization, prediction, observation, weight update, resampling, and output estimation.
The steps of the proposed system are listed as follows: The system initializes with several particles. Each particle contains a state of the vehicle and the probability of being this state. Each particle predicts the motion estimation using the measurements of IMU and WSS. The local PLRF is output from the perceptual model and matched with the sub-map to get the position observation. The weight of the particles is updated by the distribution of observation. The system decides if the resampling step should be performed, and outputs the posterior position estimation.
Initialization
An example of initialization is illustrated in Figure 4.

The illustration of initial particles. The purple lines are the curbs of the road. The yellow line is the lane line of the road. The green dot represents position which cannot be observed in the system. The red dot represents the position from the low-cost GNSS. The white triangles indicate the position and direction of initial particles.
During initialization, we sample a number of particles close to the measurement from a low-cost GNSS receiver. Specifically, the state of the ith particle at time k, denoted as
Prediction
At time
Map-matching localizer
The MML estimates the probabilistic lateral position using three main components: a sub-map extraction module, a perceptual model, and a matching model. At time step k, each particle gets a sub-map
Sub-map extraction
Given the predicted position of a particle and a lane-level road map, the sub-map extraction module outputs a sub-map as prior knowledge. Unlike 3D dense maps, a lane-level road map only requires low-cost sensors, small storage, and little manual effort.
As most open-source digital maps only contain information at the road level, we generate a lane-level road map 15 including the precise position of road centerlines, lane lines, and curbs. Unlike typical sub-maps, we devise a PLRF as our sub-map. The PLRF (see Figure 5) is a mixed representation of lane lines and the road surface in the lateral direction without limitations of driving conditions.
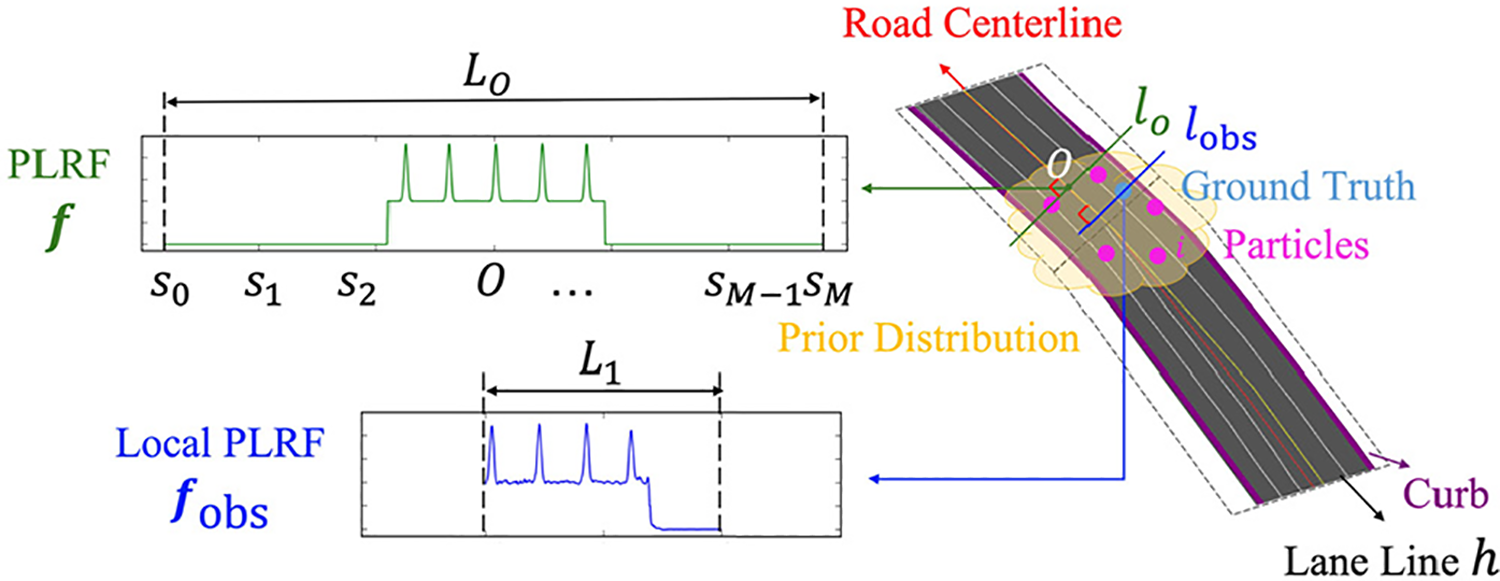
The illustration of a PLRF and a local PLRF. A PLRF is a vector which contains the data correlated with the probability of the existence of lane lines and road surface on a lateral line segment whose midpoint is on the road centerline. A local PLRF is a vector shorter than the PLRF, and it represents the data on a lateral line segment whose midpoint is a possible ego position. PLRF: probabilistic lateral road feature.
The sub-map is generated as follows.
Given a lane-level road map and the expected position of all the particles, we draw a line l on the road through the expected position, perpendicular to the centerline of the road. As the generated map contains all the road centerlines, the centerline of this road is extracted by searching the centerline nearest to the expected position. We denote the intersection of the line l and the road centerline as O. We extract a line segment lO
from l whose midpoint is O with a length of L
0. Note that L
0 should be greater than the width of all the roads in the map to guarantee that the lO
includes all the lateral information of the road. To simplify the computation, we discretize lO
as a list of equidistant points
To compute PLRF, we estimate

where
The event B that a point is on the road is defined as follows:
If l intersects no curb, then all elements in
If l intersects once the curb of the road, all elements in
If the line l intersects twice the curbs of this road and the road is straight here, then all elements in
As we have defined the event B above,

It is noted from equation (2) that the position close to a lane line tends to have a larger value. If the position is on the road, it has a value not less than 1. Otherwise, the value is −1. Our PLRF mixes all the lateral characteristics in one vector to simplify further computations. The PLRF
Perceptual model
The perceptual model extracts a local PLRF,
The task of estimating the local PLRF from images is formulated as a regression problem. Designing a rule-based algorithm to extract local PLRF from raw images is a challenging task as raw images of fish-eye cameras have large distortions. Since deep neural networks have outperformed traditional machine learning approaches in challenging tasks like classification and regression, we design a deep neural network shown in Figure 6 to estimate the local PLRF

The perceptual model takes raw images from surround-view cameras as inputs and outputs a local PLRF using a deep neural network. The net contains four parallel subnetworks. Each subnetwork has the same structure as the convolutional layers of AlexNet to extract the features. Each subnetwork followed by a fully connected layer and then these outputs are concatenated together. The remaining three are fully connected. PLRF: probabilistic lateral road feature.
At time k, four raw images from surround-view cameras are cropped and resized to the color ones with a dimension being 210 (height) × 280 (width). These images are fed into four shared-weight subnetworks. We take layers from off-the-shelf CNNs and load the pretrained weights for better performance. Specifically, we use the first five layers of AlexNet in this article. Each subnetwork followed by a fully connected layer with 512 neurons and then outputs are merged. To output a local PLRF, we apply three fully connected layers with 512 neurons each. The LeakyReLU activation function in this neural network is with the negative slope of 0.1.
Unlike conventional deep-learning-based methods, our model requires no manual labels. Our instrumented vehicle is equipped with real time kinematic-global positioning system (RTK-GPS) to provide the ground truth position, and we generate lane-level map in the test region. Given the ground truth position and a lane-level road map, the true local PLRF for training can be auto-generated. First, the sub-map (PLRF) through the ground truth GT is extracted by equation (2). Then, we get the local PLRF by cropping the sub-map to change the midpoint to GT and shorten the length of the vector. Therefore, the training data set for the perceptual model is generated without much manual effort. We take least square errors as the loss function. Note that the accuracy of ground truth positions and the lane-level map are crucial to the performance of the perceptual model as they determine the accuracy of labels. If the lane-level road map is not accurate or noisy, the label may be influenced and then lead to a risky result. Therefore, the map should be checked before learning. If there is something wrong in the map, we should modify the map generation module or manually correct the map. It is supposed that the lane-level map is reliable and that it can be obtained from other sources such as the map company, so we do not introduce the method of map generation and maintenance in this article.
Matching model
The matching model (see Figure 7) estimates probabilistic lateral locations by computing the correlation between a local PLRF and a sub-map (PLRF). We adopt the idea of the correlation layer
32
and define the probabilistic result as

where Nm
is the length of the sub-map

The matching model.
After the correlation, the probability of locations is discretely stored in a vector. To model the continuous probability distribution in the lateral direction, we use Gaussian mixture models (GMM) to fit the vector
Weight update
After the estimation of

Resampling and output estimation
Resampling is performed according to the effective number of particles 33 which is computed by

If the
The output of the localization system is set to the weighted average of the particles.
Experiments
To evaluate our proposed system, we first generated the lane-level road map of the test region (see Figure 8) based on Ladybug3 spherical camera systems. 15 In the whole area, we collected data several times in different days by our instrumented vehicle which is a Chery Tiggo car equipped with a Xsens MTi IMU, two WSS mounted on rear wheels, a low-cost GNSS receiver, and a RTK-GPS receiver. RTK-GPS was used to provide ground truth positions for evaluation. In the data-collection area, the accuracy of RTK-GPS is 2 cm. The Xsens MTi IMU is a nine-axis industrial-grade inertial sensor, and its yaw rate gyroscope is used for DR. We selected three regions to test the localization accuracy, while the data collected at the other regions were used for training the perceptual model of the MML.

The areas where we generated a lane-level road map. Samples for testing were collected on the roads within the red rectangles. The regions in red rectangles are shown as enlarged views besides satellite images. Samples for training were collected in other regions for the perceptual model.
Given the length of local PLRFs, we set the parameters of the last six layers of the perceptual model. The first convolutional layer after the concatenate layer contains 384 filters of 3 × 3 with a stride of 1. The second convolutional layer contains 384 filters of 3 × 3 with a stride of 2. The last convolutional layer is same as the second one. The first two fully connected layers are with the size of 384, followed by the last one of
The perceptual model was built upon PyTorch, and we used the pretrained weights of AlexNet convolutional layers to initialize the weights. We chose the Adam optimizer 34 with a learning rate of 0.0001 and the weight decay of 10−5. The batch size is set to 64. After 300,000 iterations, we stopped the training process. For comparison, we also build a CNN-based model using the mono image. The nets and parameters are almost same, except for the number of input subnetworks. The parameters for experiments are presented in Table 1.
Parameters for experiments.

PLRF: probabilistic lateral road feature.
The test data were used to evaluate the performance of both the perceptual model and the lane-level localization system. Note that the data for testing and training were collected in different regions (see Figure 8) to evaluate the generalization ability of the perceptual model to extract the features of lane lines, ground, and curbs. The detailed description of test regions is presented in Table 2. The plants distribute periodically and grow gradually on both sides of most roads in the test regions, so it is difficult to locate the vehicle by observing the vegetation. To reduce restrictions on the surroundings, our method only observes the lane lines and curbs as features. There are curves, lane splitting, and multi-lane roads in the test regions. The vehicle was driving on the test roads several times to collect data for different conditions of illumination and traffic. Note that the results in this test cannot be applied directly in new areas with entirely different roads. If we also apply this method in a new area, additional learning should be performed by adding new training data similar to this area. Nevertheless, the results in test regions are typical at this stage, as the data are collected in different conditions and can be used to evaluate the generalization ability on unseen roads. The processing system is a desktop with an Intel i7 CPU and an NVIDIA GTX TITAN X GPU. The proposed method is implemented using Python 2.7. The processing time of the proposed method is about 50 ms for one cycle.
The description of test regions.

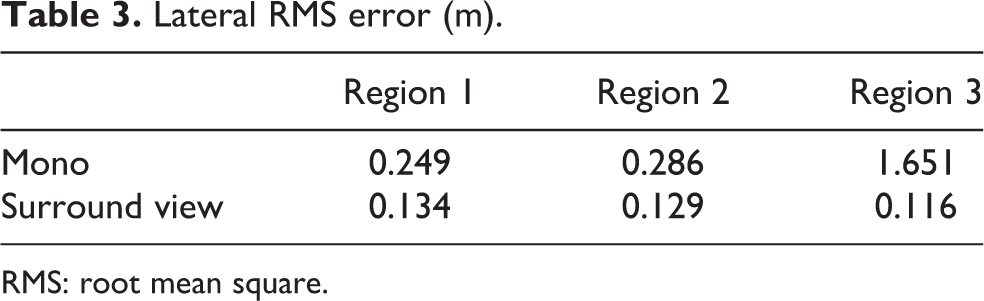
If we take the position with the maximum probability as the output, the results of all the test data in three test region is shown in Figure 9, and the lateral positioning root mean square (RMS) errors are listed in Table 3. It is noted that the MML has better performance to use surround view images than the mono image. The success rate is listed in Table 4, which defines the inlier percentage of localization results. In the first and second regions, the success rate using surround-view images is higher than that using the mono image. Although in the third region, the success rate using the surround-view images is lower than that using the mono image, its results have a smaller RMS error.
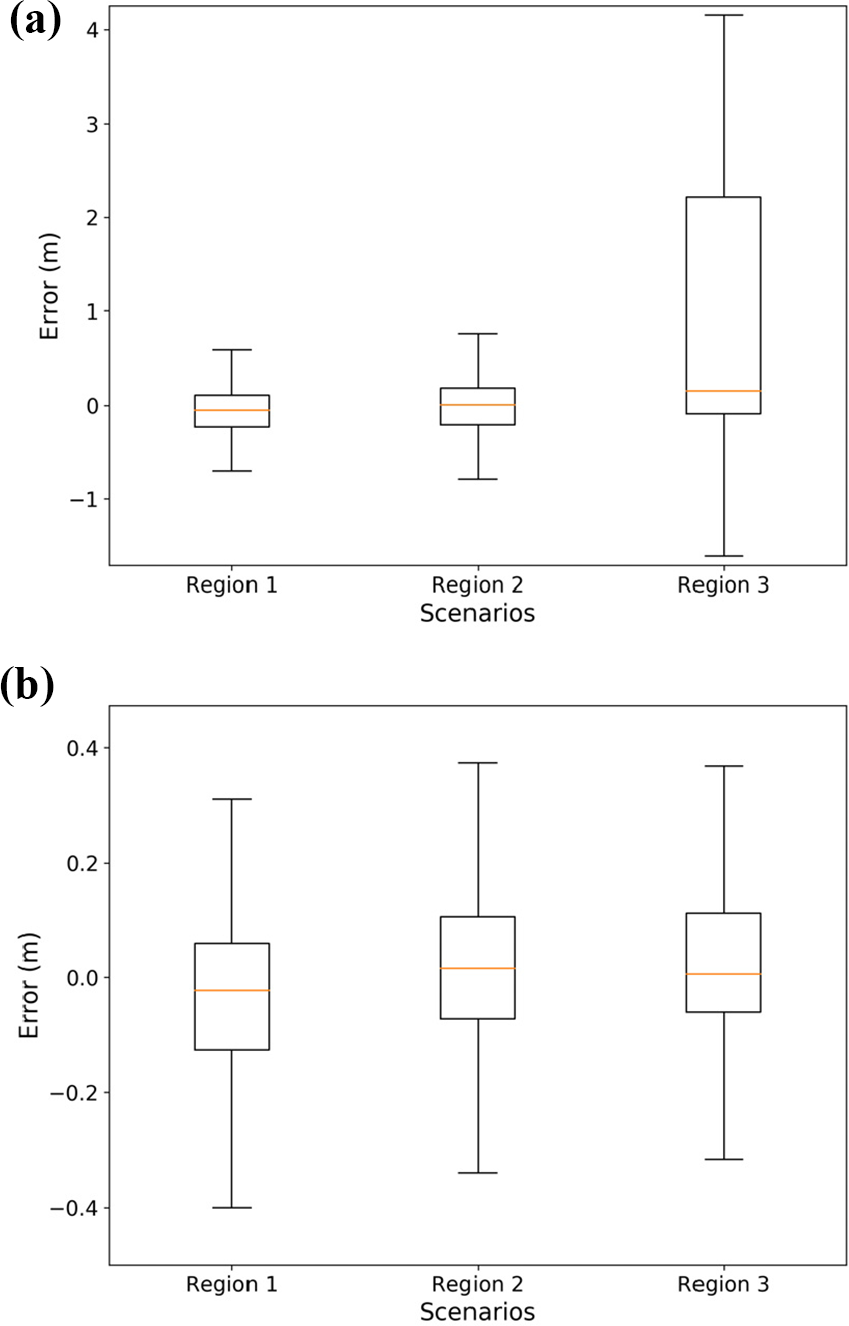
The lateral error distribution of the MML in the test regions. (a) The input is the mono image. (b) The input is surround-view images. MML: map-matching localizer.
Lateral RMS error (m).
RMS: root mean square.
Success rate (%).

Figure 10 shows the accurate results in different driving conditions. In this figure, the sub-map at the position of ground truth is extracted so that the matching result evaluates the performance of the perceptual model. It is evident that the matching results show a large probability near ground truth, which demonstrates that the perceptual model provides effective local PLRFs adaptive to different driving conditions. Figure 10(a) shows that the car is changing the lane. The second case in Figure 10(b) is that the white arrows are on the ground. The car is driving into the sun before sunset in Figure 10(c). These cases are challenging to common rule-based lane-detection methods. Without extra effort, our deep-learning-based method overcomes this challenge, both the outputs using mono images and surround-view images are accurate.

Inputs and results in different driving conditions including the input images of the perceptual models, the local vector map, and the lateral localization errors from the MML. In the local vector map, the rectangle filled in green represents the ground truth of the ego vehicle, blue lines are curbs, and yellow or white lines represent lane lines. Although these conditions are difficult for most existing methods, the proposed method is still accurate. (a) The car is changing the lane on multi-lane roads. (b) Arrows on the ground of multi-lane roads. (c) The car is driving into the sun just before sunset. MML: map-matching localizer.
Figure 11 shows the cases when the method using surround-view images outperforms that using the mono image. Figure 11(a) shows that the car is driving on the curve. Figure 11(b) shows a lane splitting case. In these two cases, the localization result using surround view images is still accurate, however, the result using the mono image does not have a large probability near the ground truth. That is because the mono image cannot capture the lateral features exactly at the left and right side of the vehicle. Using the mono image, the output of the perceptual model is confusing when the road condition is changing.

Inputs and results in different driving conditions. Although the driving condition is typical and the image quality is good, the method using mono image is not as accurate as that using surround view images. (a) The car is on the curve. (b) Three lanes after lane splitting.
Figure 12 shows typical failure cases near the intersections. PLRF contains no more than one curb in these cases, so the features are mainly determined by the lane lines. As most lane lines on the test roads periodically distributed, the results will have multi-modal noise. If the localization fails near the intersection, the error may be a multiple of the lane width. Figure 13 shows the probabilistic lateral error from a surround-view image sequence in the first region. It is noted that both the maximum probabilistic position and the expectation are far from the ground truth at about 20 s when the car is at the T-shaped intersection (see Figure 12(b)).

Inputs and results near the intersections. Both methods fail with a low probability at ground truth position. (a) The car is near the crossroads. (b) The car is at the T-shaped intersection.

The MML outputs from a surround view image sequence in the first test region. The red color indicates the probability of the ego vehicle at that time. At 20 s, the localization result has a large noise distribution. To have robust positioning estimation, we adopt particle filters to fuse these results with the measurements from IMU and WSS. MML: map-matching localizer; IMU: inertial measurement unit; WSS: wheel speed sensors.
To have robust positioning estimation, the proposed system fuses the results of MML with the prediction from IMU and WSS. The features on multi-lane roads are always periodic, so the noise can be under the multimodal distribution. Particle filters are adopted as the noises of MML is non-Gaussian. To compare with the proposed system, we also implement the Kalman filter. In the Kalman filter-based system, we use Gaussian distribution to approximate the observation probability. In the particle filter-based system, the particles update their weights by equation (4).
Figure 14 shows the result of localization systems from a sequence in the first test region. We can see that the system based on particle filters shows the better accuracy than that based on the Kalman filter, which demonstrate that the system based on particle filters is more robust to different driving conditions.
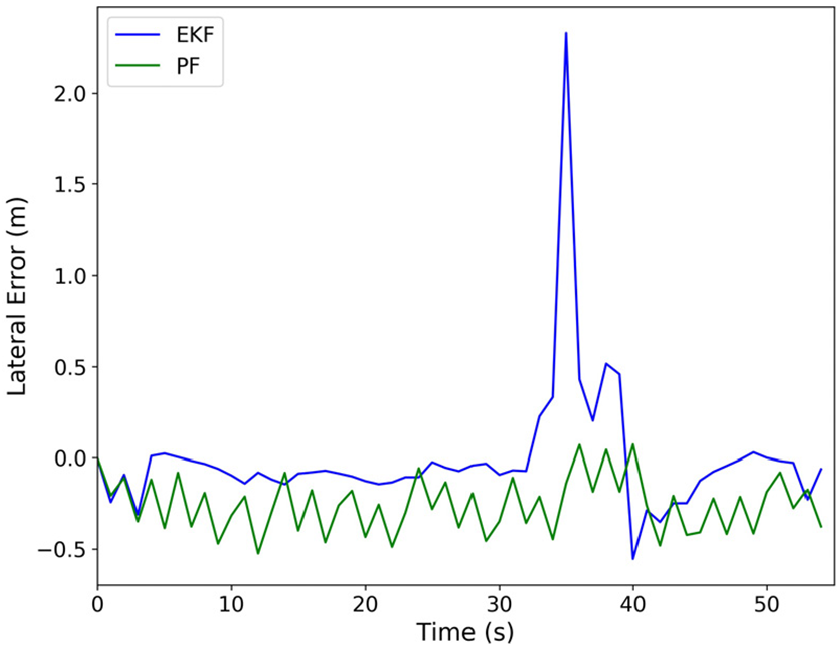
The localization result of the systems. The system based on particle filters shows the better robustness than that based on the Kalman filter.
The results from numerous test cases verify that the localization method has a submeter accuracy even in different driving conditions. The accuracy is related to noises of the lane-level road map, as the map determines the PLRF and auto-generated labels. Most surround-view camera-based localization systems only provide the precise positioning estimation in the ego lane but cannot determine the lane on multi-lane roads, as they use the bird’s-eye view image from surround-view cameras. Some rule-based methods achieve centimeter-level accuracy in specific driving conditions. However, rule-based methods could meet challenges in diverse driving conditions. Conventional deep-learning-based methods may gain robust and accurate results, but their labels require much manual effort. Our proposed system is quite feasible with submeter accuracy in different driving conditions, which helps lane-level applications on a large scale.
Conclusions
In this work, we proposed a lane-level localization system adaptive to different driving conditions. The proposed system used surround-view cameras, other low-cost sensors and a lane-level road map. We proposed an MML that provided the probabilistic lateral estimation. In the MML, we devised the PLRF as the sub-map. The CNN-based perceptual model extracted a local PLRF from raw images captured by surround-view cameras. The matching model calculates the correlation between a sub-map and a local PLRF and outputs the probabilistic lateral estimation. The proposed localization system integrated the output of MML with the measurements from IMU, WSS, and a low-cost GNSS receiver based on particle filters. The proposed system is more feasible than common rule-based methods, as rule-based methods can hardly find out a perfect rule for diverse driving conditions. Besides, the proposed system requires little manual effort as the perceptual model was trained using auto-generated labels, unlike conventional deep-learning-based method. We evaluated the proposed system using data collected in different driving conditions. Experimental results demonstrated that the performance of MML is reliable in different driving conditions and that the localization method achieved submeter accuracy even in complicated situations.
The localization error of the proposed system is inevitable due to the noises of the lane-level road map. Future work could improve the localization accuracy by fusing with more observations.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under Grant U1764264/61873165, in part by the International Chair on Automated Driving of Ground Vehicle, and in part by the Shanghai Automotive Industry Science and Technology Development Foundation under Grant 1733/1807.