
Abstract
Scan registration is a fundamental step for the simultaneous localization and mapping of mobile robot. The accuracy of scan registration is critical for the quality of mapping and the accuracy of robot navigation. During all of the scan registration methods, normal distribution transform is an efficient and wild-using one. But normal distribution transform will lead to the unreasonable interruption when splitting the grid and can’t express the points’ local geometric feature by prefixed grid. In this article, we propose a novel method, composite clustering normal distribution transform, which comprises the density-based clustering and k-means clustering to aggregate the points with similar local distributing feature. It takes singular value decomposition to judge the suitable degree of one cluster for further division. Meanwhile, to avoid the radiating phenomenon of LIDAR in measuring the points’ distance, we propose a method based on trigonometric to measure the internal distance. The clustering method in composite clustering normal distribution transform could ensure the expression of LIDAR’s local distribution and matching accuracy. The experimental result demonstrates that our method is more accurate and more stable than the normal distribution transform and iterative closest point methods.
Introduction
In unknown environment, simultaneous localization and mapping technology (SLAM) 1 is the cornerstone for the autonomous and intelligence of mobile robot. 2 Scan registration is a fundamental step for SLAM and autonomous navigating. 3 Surrounding information of robot is obtained by distance sensors, such as LIDAR or depth camera. Scan registration algorithm first establishes the association of two near LIDAR frames, then constructing the objective function. Finally, it will be optimized to get the transform between two LIDAR frames. With continuing scan registration, the environment model around the robot is built.
At present, there are two mostly widespread scan registration algorithms. The first one is based on iterating the closest points. The objective function is constructed by the geometric constraints of points, lines, and surfaces between two frames. The typical algorithm is iterative closest point (ICP). 4 The second one is based on the probability density function to build the relation. The objective function is built by the probability distributing model of current frame in reference frame. Its typical algorithm is normal distribution transform (NDT). 5 The main idea of this article is based on NDT method.
In this article, by analyzing the characteristic of NDT, we find that when fitting the local region of LIDAR data, NDT method will lead to unreasonable interruption while splitting points by normal distribution. Also NDT can’t express the local geometric features by prefixed grid cells. A new scan registration algorithm based on composite clustering is proposed in this article, in which the points with similar local feature in the reference frame are aggregated. The points are clustered by density-based spatial clustering of applications with noise (DBSCAN) and k-means method. DBSCAN is used to aggregate the region with continuous point distribution in reference frame. Then, the unsuitable clusters are selected by singular value decomposition (SVD)-based method and subdivided again by k-means if this cluster is unsuitable for normal fitting. The bounding box of each cluster is built for search and index. Finally, objective function of all matches is formed by normal distributing function and then optimized by trust region method.
The main contributions of this article are as follows: We propose a novel clustering method to aggregate LIDAR points by their local features, which is a combination of density-based clustering and k-means clustering. To judge a cluster’s suitable degree for NDT matching after DBSCAN, we propose a ratio factor based on SVD decomposition to get a cluster’s singular values. We propose a novel distance measuring method based on trigonometric to evaluate the neighbor LIDAR points, which eliminate the LIDAR’s radiation phenomenon.
This article is organized as follows. In “Related work” section, we discuss the related work about scan registration. In “Problem statement” section, the basic procedure of NDT is narrated, and the disadvantage of original NDT method is discussed. Section “Composite clustering scan registration” is the main text of this article, and the overall procedure of composite clustering NDT (CCNDT) is narrated in detail. In “Experiments” section, the comparing experiments among CCNDT, NDT, and ICP are designed and discussed. The last section is a brief conclusion of this article.
Related work
LIDAR is a main exteroceptive sensor in mobile robot 6 when acquiring distance data from the robot’s surrounding. In contract with wheel odometer and IMU, LIDAR information represent the correlation between robot and environment. With the map built by LIDAR data, robot can realize where it locates and where it is the destination and path. Scan registration is a method to get the transform between LIDAR frame, which is critical for robot.
Scan registration aims to construct the relation of two LIDAR frames by matching their points, then building the objective function and optimizing. The most representable scan registration methods are ICP and NDT methods.
ICP is first proposed by Besl and Mckay, 4 in which the frame relation is built by matching the closest point pairs. But without additional information such as geometric characteristics, the matching is worse when there is a large transform. Then, Segal et al. 7 propose a general ICP method using the local inner points to get the face structure, which makes the result more accurate. Serafin and Grisetti 8 –10 use the surface characteristics around the points to search for ICP corresponds. Cox and colleagues 11 extract line features from LIDAR data and match the points with relevant lines. Iterative dual correspondence method 12 is used to improve matching accuracy by maintaining two relevant sets. Wang et al. 13 come up with a multilayer matching method to deal with the data-association problem, in which the uncertainty of the matching results is described by Fisher information matrix. MbICP 14 is designed to improve convergence with large initial orientation errors, which explicitly put a measure of rotational error as part of the distance metric. Those ICP methods are easy to deploy and use, but their two weaknesses 15 are considerable: the nearest match is not correct matching in many conditions and the computing cost is very heavy when searching the nearest points.
To avoid the heavy matching of ICP, Biber and Strasser 5 come up with the probability-based method named as NDT (normal distribution method). It divides the reference frame into grid cells. Then, the normal distributing parameter is calculated for each cell. Next, each point of current frame is matched with a grid by their coordinate to get the probability density. With this method, it needn’t match each point but the grid cells to reduce computational cost. Moreover, normal distribution can provide the geometric representation of points, which gives the higher order derivatives for optimizing. 16
Based on NDT, Gutmann and Konolige 17 registrant current frame with serval previous frame to improve precision. Mitra et al. 18 use quadratic approximants to get the distance from target surface, describing the model surface implicitly. Ulas and Temeltas 19 come up with a feature-based NDT method. Kunjin Ryu et al. 20 use ND-to-ND method to get global matching, which can not only provide the internal frames transform but also be used for loop closure detection 21 for graph optimization. Gouveia et al. 22 use the multithreading to parallelize the data fusion step. Even more, Bosse et al. 16 match all the LIDAR frames by registering the subregions and global map. And in kinect fusion by Newcombe et al., 23 the relationship is built by a global optimizing model, but it is too heavy and slow for most calculating platforms. There are also many other scan-matching methods such as expectation-maximization (EM) matching method by Thrun et al. 24 and the graph model method by Feng and Milios. 12
Problem statement
Compared with other scan registration methods, NDT has the following two advantages when building the correlation:
The normal distributing model gives the points in one cluster a common attribute, which reduces the quantity in matching.
Compared with the error function of point distance, the normal distributing error function has higher-order derivation, which makes it possible to use the optimizing method with the second-order gradient.
The scheme of NDT includes three parts, as shown in Figure 1. Firstly, the points in reference frame are divided into grid cell and constructed the normal distribution of the points in each cell. Then, the points of current frame are linked with those cells by their relevant coordinate. Finally, the error of those links is minimized to get the transform. Next, we’ll have an elaborate narration of the inference.

Schematic illustration of NDT method. When a robot moves from x
1 to
When the robot moving, distance points are obtained from LIDAR. Let
In NDT method, the reference frame is first divided into grids, as shown in Figure 2. In advance, it needs to get the grid span in vertical and horizontal. Then, the frame is divided into span distance and cell interval. The values of span distance and cell interval are manually tuned.
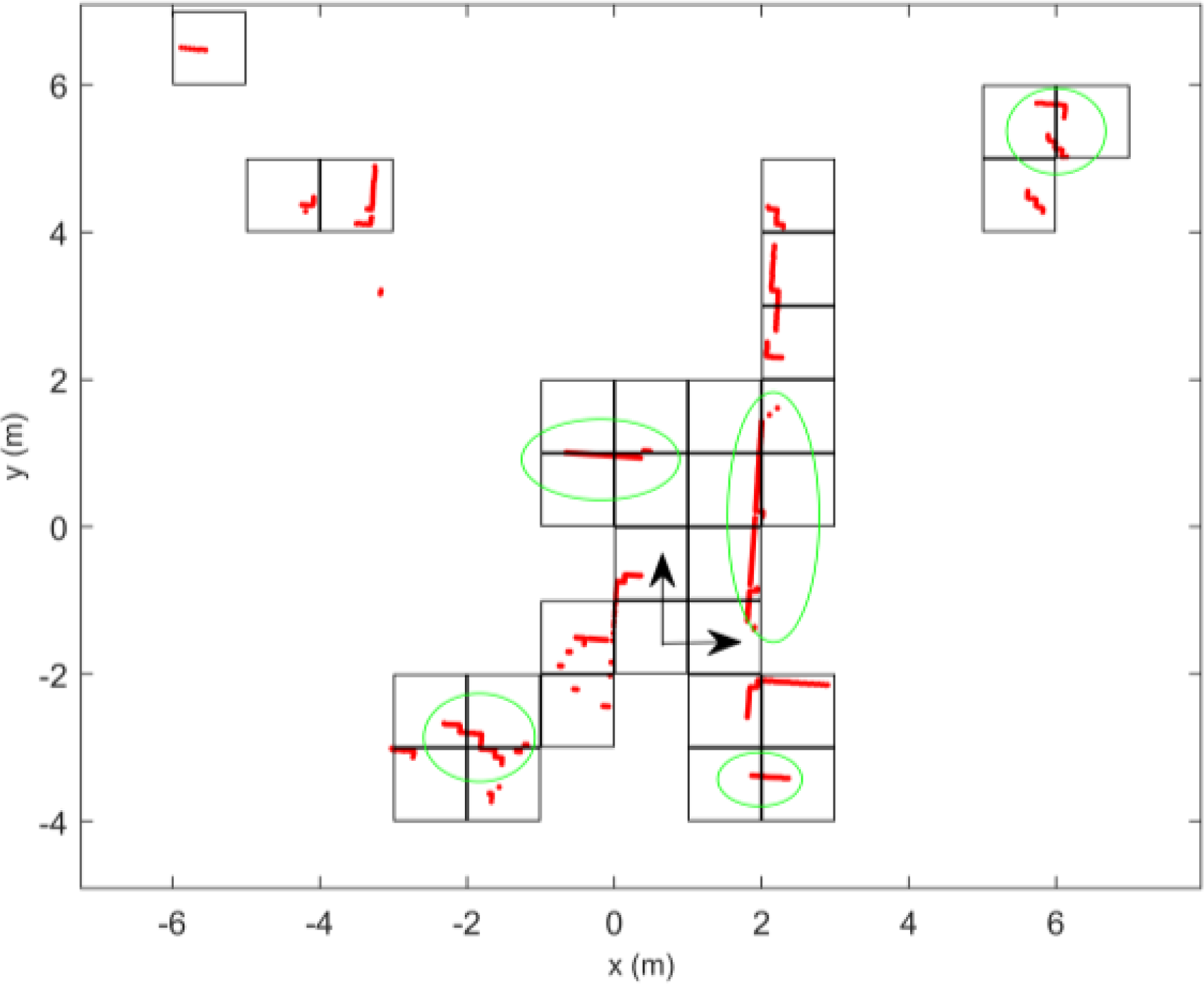
Grid splitting illustration with LIDAR data from ACES building at the University of Texas. The points as green ellipse marked should belong to one collection, but they are divided into different grid cells by NDT. Where the red points are LIDAR points, the arrows indicate the robot’s position. NDT: normal distribution transform.
Each point will be filled into cells according to their inclusion relation. Then, each cell is represented by normal parameter. For instance, the parameter of points in one cell is

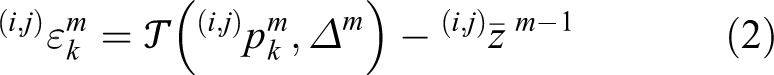

where

Here the coordinate of p is
With the reference frame has been represented by normal distribution, the point in current frame can be linked to the reference cells. The current frame is transformed to the coordinate of reference frame with the initial value from Odometer or IMU. If no input source, initial value will be set as

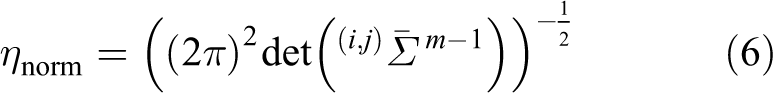
where f is a normal distributing probability density from points k to grid cell
And the overall objective function is

The gradient and Hessian of objective function are calculated to optimize the displacement of the two robot poses, which will be deduced in “Range-based decomposition” section. Then, Newton method is used to optimize the transform parameter
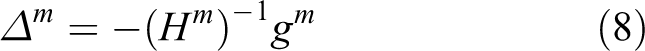
Here, gm is the gradient of overall objective function, and Hm is its Hessian matrix.
The inference above is NDT’s scan-matching procedure. It is ingenious to use normal distribution to represent the reference LIDAR frame. Thus, the optimizing step could utilize the normal probability density function to get the first-order and second-order derivatives.
But while using NDT method in real LIDAR data, it is found that the points should belong to one cluster according to their local feature, but they are split unsuitable by prefixed grid boundary, which make points aggregate to the wrong cluster.
As shown in Figure 2, the LIDAR frame should be divided into 20 local sets according to its local shape but resulted into 31 by the fixed interval division of NDT, where the unsuitable split is 35.5%.
As shown in Figure 3, the left figure illustrates the points are divided based on their local distributing feature, the set’s center is same as the points’ centroid. Then, as shown in the arrow of Figure 3(a), the new point will get good match with the cluster. But the ineligible division in Figure 3(b) will lead to unreasonable matching, where points are divided by the prefixed boundary, like NDT method, and the point after matching can’t link with the target cluster’s centroid. So, the precision of NDT is limited by the prefixed grid boundary, which can’t adapt to the local distribution’s variety.

Example of suitable (left) and unsuitable (right) splitting results. The orange dots are the LIDAR points in current frame, and the green and blue dots are the points in reference frame. Each arrow represents a matching result. And the boundary of grid cell is denoted as blue line. (a) Left: the points are divided based on their local distributing shape. (b) Right: the points are divided by prefixed boundaries, like NDT method, which can’t link to the centroid of cluster after matching. NDT: normal distribution transform.
The core thought of our method is motivated by the disadvantage of ineligible grid splitting of NDT. To deal with this problem, we compose a new point dividing method based on composite clustering, which can adapt to the local distribution of LIDAR points. In this way, the accuracy of scan registration is improved as shown in the “Experiment” section.
Composite clustering scan registration
Algorithm overview
The scheme of CCNDT method is introduced summarily, of which the core goal is to get the transform between two robot poses by their LIDAR and Odometer data. As shown in Figure 4, the whole process includes five steps:

The scheme of CCNDT method. Where the inputs are current frame and reference frame, the output is the transform between two LIDAR frames. The reference frame is processed by DBSCAN clustering, SVD selection, and k-means clustering. Then, the normal distributing parameters are calculated and matched with the current frame by bounding box. Finally, with the matching indexes, the transform between two LIDAR frames can be calculated. CCNDT: composite clustering normal distribution transform; DBSCAN: density-based spatial clustering of applications with noise; SVD: singular value decomposition.
It is started from the reference frame, where the inputted reference LIDAR data are first processed by the density clustering (see “Local distributing-based clustering” section). And the trigonometric-based distance method (see “Distance measuring method-based on trigonometric function” section) is used to measure the interval between each point. The reference LIDAR points are clustered by their local distributing shape.
The outputted clusters from (1) are filtered by SVD method to judge their eligible degree. Otherwise, the ineligible clusters will be further divided (see “Range-based decomposition” section).
After the filter process, the ineligible cluster will be divided into k‘s small cluster by k-means method. The value of k is proportional to the ratio scale of this cluster’s singular values (see “Range-based decomposition” section).
Each clustering result will be given a bounding box for matching. Those points in current frame can be mapped into the bounding box by their relative coordination (see “Registration and objective function” section).
With the links from current frame’s points to reference frames’ clusters, the objective function is obtained by gathering each link’s normal distribution error. The transform between these two LIDAR frames is calculated by the objective function (see “Optimization and solving” section).
In the next several sections, we will walk through each of those steps in detail.
Local distributing-based clustering
The characteristic of LIDAR points should be analyzed firstly. LIDAR is a surveying sensor, as shown in Figure 5, which measures distance to a target by pulsing laser light and measuring the flying time from launching to receiving the reflected pulses by a laser receiver. LIDAR will record each measurement’s angle and distance when rotating. So, the obstacle in the laser illuminating path will be captured.

LIDAR measure object’s position by flying time. Where the red line denotes the LIDAR’s beam. The LIDAR is located at the center of the radius in dark circle. The blue shapes are obstacles in the surrounding.
As shown in Figure 5, LIDAR points captured from the wall-like shape will form a straightline LIDAR distribution and from the cylinder shape will form an arc distribution. To make those points from same region clustered together and from different regions separated, it needs to get a method to identify the similarity and otherness among each object.
As the continuous of object boundary, the LIDAR point from the same obstacle is more continuous and has a higher reachable density than other areas. This condition is suitable for the density-based clustering named DBSCAN, 25 in which the points from the same cluster have a higher density than from the different clusters. DBSACN provides a model named “Density Reachability,” which selects points satisfied the distance thresholds into one cluster. It is good at clustering the points in arbitrary distributing shapes.
In DBSCAN,

where β is the distance threshold. In “Distance measuring method based on trigonometric function” section, we will introduce a new method to initialize and calculate this threshold.
And the points satisfied with the limitation are put into set

Searching for the points belonging to one set with DBSCAN. The dash lines are the searching boundary. The red points belong to one density cluster. DBSCAN: density-based spatial clustering of applications with noise.
For the left points in

Each of those clusters has two characteristics. (1) The points in one cluster are density connected within threshold β. (2) All of the density reachable points from one cluster must belong to this cluster.
If the points in one cluster are too few
Distance measuring method based on trigonometric function
After clustering LIDAR points by DBSCAN, we find a disappointed weakness. As the radiating phenomenon of LIDAR, the LIDAR points from the straight facet would not be uniformly distributed in a line. The LIDAR point captured on the same object from different distance will be sampled in different interval, as shown in Figure 7. The nearby interval is close and the further interval is distant. So, the threshold β is unsuitable to be a constant when measuring the points interval.

Radiation of the laser beam from a straight obstacle. The interval will be formed as the nearly points density and the further points sparsity.
Here, we use a new method based on trigonometric function to measure the density reachability. When starting a new cluster, there is only one initial father point in the cluster. So, it just needs to consider the distance. And the threshold β is

where Δθ is the LIDAR’s angular resolution, and

The measurement after initializing, where o is the LIDAR center and
After the initial procedure, the value of angle a can be obtained by the law of cosines with the initial points

where the formula is based on the law of cosines, and
Then, in triangle
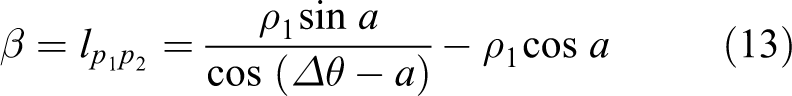
where β means that if the third point is collinear with the two initial points, the distance of
Finally, the combined distance measuring threshold is

where
As an example, to show the result after density clustering, one LIDAR scan of the ACES building is tested, which contains 1081 points. And after applying the density clustering and our trigonometric distance method, the LIDAR points are divided by their local distribution properly, as shown in Figure 9.
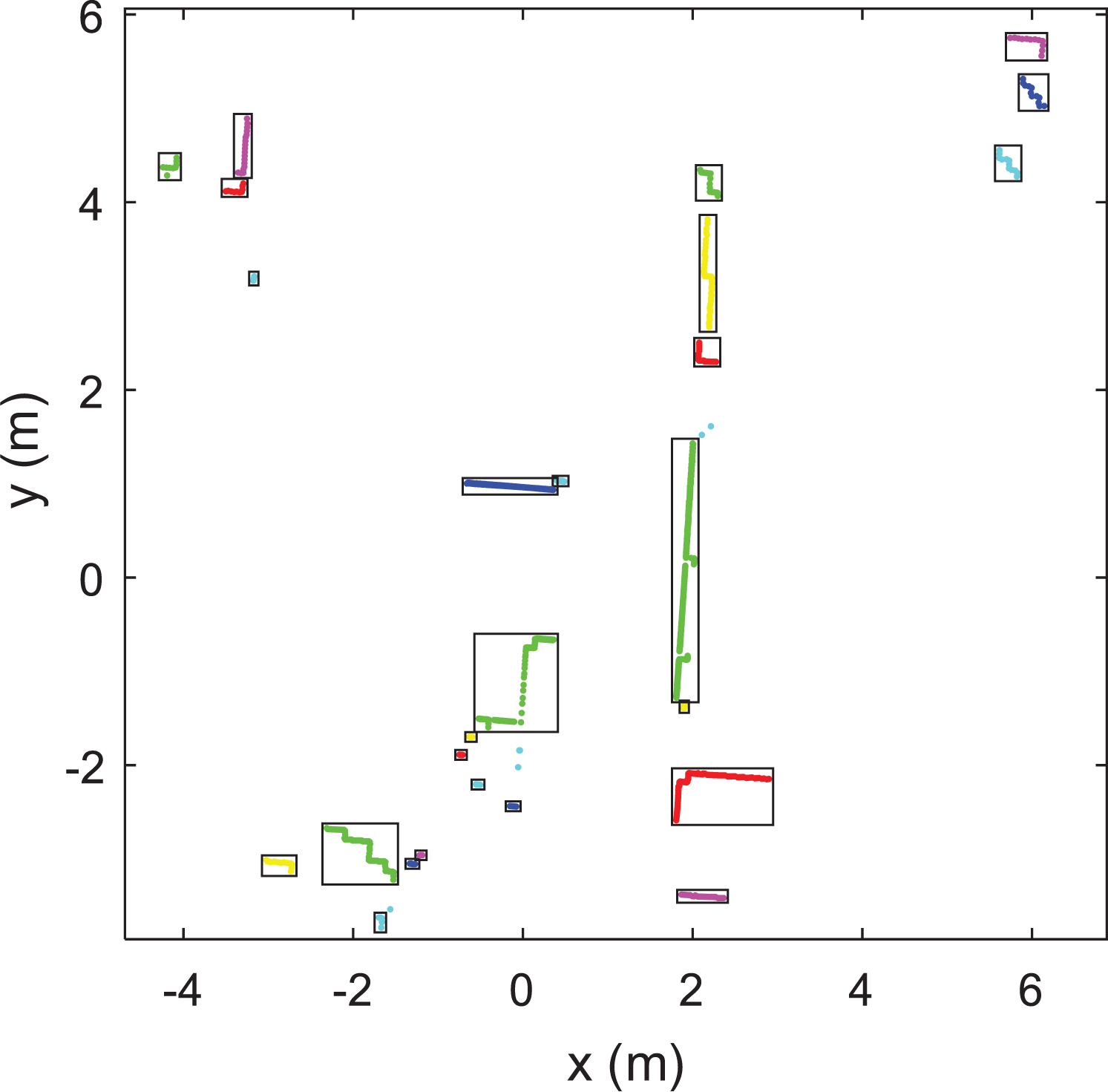
Example of LIDAR points after DBSCAN clustering with trigonometric distance method. Each box region represents a point cluster. DBSCAN: density-based spatial clustering of applications with noise.
Range-based decomposition
After DBSCAN processing, the continual regions of LIDAR data have been aggregated together, as shown in Figure 9. But on the one hand, as the larger cluster has a larger bounding box, so a point may be included by this bounding box but far from the cluster’s center, which will lead to heavy distorted links. On the other hand, the larger cluster has a strong attraction for its nearby points than a smaller cluster, which is because the weight of one cluster is in direct proportion to its quantity of points. And it will make the relaxing iteration unbalance. So, the result of DBSCAN is unsuitable for matching till now.
It needs to further decompose the larger cluster. The first question is how to select out the unsuitable clusters. It is noticed that such kind of clusters not only have a wider boundary but also have a big disparity of primary and secondary eigenvalues. So, each cluster in

where
The ratio from the biggest to the second singular value can denote the ineligible degree of one cluster.

where
The second question is how to further divide the unsuitable clusters. Those larger clusters can be divided by k-means method 26 into k smaller clusters. k-Means makes their inner distance of one cluster minimum and their outer distance maximum. The unsupervised learning method of k-means can adaptively select the coordinate of initial points. And with the Euclidean distance, the shapes of clusters outputted from k-means are suitable for normal fitting.
And its most important parameter is the clustering quantity k. Here, we use the previous SVD result to calculate the value of k

where
The result of k-means is

where
The cluster with few numbers of points also needs to be removed and puts into
As an illustration, we select the unsuitable clusters in Figure 9 by SVD ratio factor, then applying k-means method to divide those unsuitable clusters. The change from Figure 9 to Figure 10 demonstrates that the unsuitable clusters are decomposed into smaller clique by k-means. Each of the clusters as the box marked in Figure 10 is more balance in each direction, which is more suitable for normal distribution fitting.

Example of LIDAR clusters after k-means clustering. Each box region represents a set of clustered points. Those clusters are first selected by SVD-based method, then the unqualified clusters are further divided by k-means. SVD: singular value decomposition.
Till now, there are two groups of the cluster: the first group is the suitable results of DBSCAN and the second group is those unsuitable clusters decomposed by k-means. Then reorder them as

where c is the number of elements in
For uniform, those two groups of clusters are integrated together and denoted as

This step just changes the index of the clusters for their lower right corner.
Registration and objective function
After obtaining the proper clusters, here it is going to inference their matching parameters. As the origin NDT method inferred in “Problem statement” section, the normal distributing parameter of each cluster includes its mean and covariance. The mean of cluster

where
And its covariance is

When building the matching relation, the original NDT method uses grid cells to link the points and the clusters. But in CCNDT, the cluster’s size and position are not regular, so here we use the bounding box as shown in Figure 11, for searching.



where
For each cluster

The bounding box
To judge whether a point belongs to this cluster, it just needs to compare the point’s coordinate with the bounding box’s two corners.
Till now, the relation between points in current frame and the clusters with bounding box in reference frame are constructed.
When the new LIDAR frame Pm
obtained, named current frame, we need to match each point in Pm
to their relevant cluster in
The objective function of
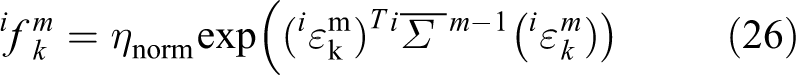

where
All the points’ objective functions are gathered as

which uses the logarithm to convert multiplication into sum, the inner summary layer is the errors of one point i with all of its linked clusters
Optimization and solving
To solve the objective function, the Jacobin gm and Hessian Hm of objective function are needed first.


where Jacobin
For each point’s PDF, the gradient is
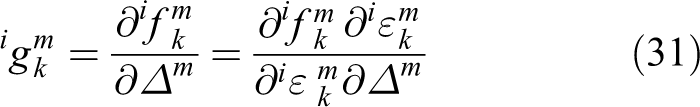
where

After substituting the normal parameters, the objective function is reshaped as

In which the Jacobin matrix is obtained by

which is the partial derivative of the error function
The Hessian matrix is the second derivation of objective function

where l and r are the point indexes of the first-round derivation and second-round derivation, respectively.
With objective function ubstituted in, Hessian is reshaped as



In which the second derivative of
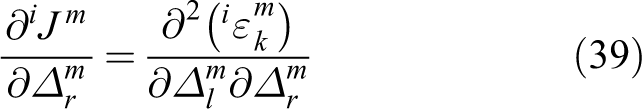

where the result is 6 × 3 matrix, almost elements are 0, expect the elements in position
With the deduction above, we have got the overall objective function fm , gradient gm , and Hessian matrix Hm . There are many methods to optimize this objective function. As Tyler fitting can only get the high-quality fitting nearby the initial point, the linear searching methods, such as the gradient method and newton method, are not suitable for the nonlinear optimizing condition.
In this article, the trust region-based method 27 is adopted to solve the objective function. This method evaluates the fitting condition by comparing the ratio of expected improvement from the model approximation and the actual improvement from objective function. It is a criterion to decide whether to expand or shrink the forward step. It evaluates the fitting condition with

where the denominator is the actual improvement, which is calculated by the second-order Taylor expansion of object function f m
. The numerator is the expected improvement, where
With the fitting condition ρ, the forward step is larger in the well-fitting place and shorter in the worse. So, with the trust region-based method, the fitting is more flexible and adaptable.
Experiments
To evaluate the result of our method in real robot data, we use public data sets to test the mapping quality of our method. The first data set is from Intel Research Lab in Seattle, 28 which was recorded by a Pioneer II robot equipped with a SICK sensor and an odometer. The area of this data set is about 26 × 26 m2 and the robot traveled 506 m. The second data set was from the ACES building at the University of Texas provided by Patrick Beeson, 29 which includes 13,632 LIDAR frames.
To illustrate the final mapping results, we use the Karto SLAM 30 as a framework, in which the scan-matching parts are replaced by our CCNDT method to calculate the transform between two neighbor frames. It first takes the odometer data as the initial guess. Then, the output transform is aggregated into the Karto SLAM to generate the occupied grid map, as shown in Figure 12, which is deployed in ROS Kinetic environment. In addition, as the scale of the environment is very large and including many trajectory loops, the Karto SLAM is also used for loop closure matching and global optimization with sparse pose adjustment (SPA) method. 31

The mapping result by CCNDT method with the data set from Intel Research Lab in Seattle. The white region is the free area (no obstacle), the black points are obstacles, and the brown area is the unknown area. CCNDT: composite clustering normal distribution transform.
From the mapping result in Figures 12 and 13, it is clear that the maps built by CCNDT have high-quality and clear edges. Even in large environment, the mapping result still has very little distorted, which partly is contributed by Karto SLAM’s loop closure and SPA optimization.

The mapping result by CCNDT method with the data set from ACES building at the University of Texas. CCNDT: composite clustering normal distribution transform.
As there is no absolute ground truth in Intel Research Lab and ACES data sets, Burgard 32 provide a manual calibrating method to align the robot path with LIDAR frames, which perform a pair-wise registration to refine the estimates. This calibrated data were accessible online. 29
Then, we use three different methods, NDT, ICP and CCNDT, to process the LIDAR data set frame by frame. The output results are the transforms of each neighbor frame. They are compared by the metrical benchmark method 33 with the manually calibrated data. As the time stamps of scan matching and manual calibration are not one-to-one matched, so the calibrating series are interpolated to be synchronic with the scan-matching series, which will be regarded as the ground truth
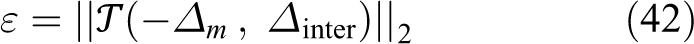
where
The comparing results of each method are shown in Figure 14.

The comparing results of CCNDT (red dot), NDT (blue), ICP (green), where the horizontal axis is the pose index of each comparing pairs, which include 1774 pairs, and the vertical axis is the error calculated by the metrical benchmark method; the red dots (CCNDT) are located at the lower part than green (ICP) and blue (NDT) dots. CCNDT: composite clustering normal distribution transform; ICP: iterative closest point.
After statistical analysis for these error results from Figure 14, we got the mean and covariance of the error results in Table 1.
Statistical error of scan-matching result.

CCNDT: composite clustering normal distribution transform; ICP: iterative closest point.
From Table 1, the mean error of CCNDT is 0.1879 m, which is lower than NDT 0.2726 m and ICP 0.2619 m. The sum error sources from three parts: the manually calibrating error, the scan-matching error, and the linear interpolating error by metrical benchmark method. Besides, the covariance of the CCNDT is 0.0295 m2, which is lower than the other two methods. Experimental result demonstrates that our method is more accurate and more stable than NDT and ICP methods.
Comparing the speed, CCNDT method processes the total data set costing 2791 s, which is obviously slower than NDT and ICP. This is because CCNDT method spends too much time in clustering procedure. In terms of matching speed, CCNDT method is not suitable for the robot with lower computing capability, but if the computing capability is sufficient, it is recommended taking CCNDT to get a better matching quality.
Conclusion
In this article, we compose a novel scan registration method, CCNDT, which based on normal distributing transforming method. In CCNDT, a composite clustering method, combining DBSCAN and k-means, is used to get the suitable splitting of LIDAR data. This method can adapt to the local distribution of LIDAR points. Meanwhile, we come up with a new distance measuring method based on trigonometric function, which can avoid the radiating distribution of LIDAR points.
We test CCNDT method with the public data set from Intel Research Lab and ACES building at the University of Texas. The experimental results indicate that CCNDT is more accurate and more stable than NDT and ICP methods. And the point clusters of CCNDT could ensure the continuity of the local region and get the eligible matching from points to clusters.
In our future work, we are going to deploy the proposed CCNDT method on the scan-to-map registration, because the CCNDT can express the feature of local point distribution and decrease the number of reference points by replacing them with clusters.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by The General Program of National Natural Science Foundation of China [Grant No. 51775202]. This work is also funded by the Graduates Innovation Fund, Huazhong University of Science and Technology [No. 2019ygscxcy078].