
Abstract
This article proposes a semantic grid mapping method for domestic robot navigation. Occupancy grid maps are sufficient for mobile robots to complete point-to-point navigation tasks in 2-D small-scale environments. However, when used in the real domestic scene, grid maps are lack of semantic information for end users to specify navigation tasks conveniently. Semantic grid maps, enhancing the occupancy grid map with the semantics of objects and rooms, endowing the robots with the capacity of robust navigation skills and human-friendly operation modes, are thus proposed to overcome this limitation. In our method, an object semantic grid map is built with low-cost sonar and binocular stereovision sensors by correctly fusing the occupancy grid map and object point clouds. Topological spaces of each object are defined to make robots autonomously select navigation destinations. Based on the domestic common sense of the relationship between rooms and objects, topological segmentation is used to get room semantics. Our method is evaluated in a real homelike environment, and the results show that the generated map is at a satisfactory precision and feasible for a domestic mobile robot to complete navigation tasks commanded in natural language with a high success rate.
Introduction
Occupancy grid map is one of the most important environment representation methods in mobile robotics. Unlike topological map modeling the environment as a graph, 1,2 the grid map discretizes the space as many grids with unknown, free, and occupied attributions. 3,4 Recently, the methods used to create occupancy grid maps for 2-D small-scale environments have matured. 5 Based on these maps, the robots can successfully complete point-to-point navigation tasks. 6 However, when it comes to using the grid maps in the real domestic scene, they are lack of semantic information for end users to order the robots to complete navigation tasks conveniently. For example, if an end user asks a robot to navigate to the position of a bed, he/she should know where the bed is in the grid map and manually specify a free grid as the goal point. Unfortunately, this approach is not feasible for two reasons: (1) most of the end users have little knowledge of robotics and cannot operate the map easily; (2) it cannot be accepted by the end users to repeat this operation all the time. For that, semantic map, 7,8 which describes not only the geometric arrangement of the environment but also semantic concepts, has come up to solve these problems.
In this article, we focus on creating semantic grid maps for robot navigation in domestic environments. Our method enhances the occupancy grid map with semantic concepts of objects and rooms. In this way, the robots can not only utilize traditional robust navigation algorithms but also make natural interactions with end users.
To build this map, we first create an occupancy grid map with sonar sensors. Point clouds of objects are then built by using object detection with a stereovision. A filtering approach based on the information of the grid map and the size of objects is used to remove outliers, and density-based spatial clustering is adopted to get the final point clouds. We then employ minimum bounding rectangles (MBRs) to approximatively represent the objects and create the topological spaces of objects. The concepts of rooms are acquired by spectral clustering and region growing with domestic common sense. The experimental results show the semantic grid mapping approach is affordable to represent the environment and enable domestic robots with the capability of robust, efficient, and human-friendly navigation skills.
The proposed method has the following contributions:
A novel method for building domestic semantic maps with low-cost sonar and binocular vision sensors;
Object and room semantics are contained;
Make end users order the robots to complete navigation tasks conveniently;
Take advantage of the information from occupancy grid map and domestic common sense to remove outliers;
Build topological spaces of objects for robots to autonomously select navigation goals.
Use domestic common sense to merge segment results.
The remainder of this article is organized as follows. The “Related work” section presents related work about semantic mapping. Then, the “Grid map with object semantics” section introduces our semantic grid mapping method. Based on the generated object grid map, the “Semantic concepts of rooms” section subsequently describes our method for acquiring room concepts. The suitability of our approach is demonstrated in the “Experimental results” section. Finally, the “Conclusion” section concludes this article.
Related work
In recent years, there are many authors focus on creating semantic maps for robot navigation. According to the different goals of semantic mapping methods, they can be divided into two classes: One aims to augment metric/topological models with semantic labels like types of objects or rooms. For example, on the basis of the grid map, Mozos et al. 9 added the semantic labels of the scene through supervised learning. Using a laser sensor to construct a grid map and a visual sensor to identify objects, Meger et al. 10 constructed a map containing both space arrangements and object semantics. Pillai and Leonard 11 combined monocular simultaneous localization and mapping (SLAM) and object recognition to create a point cloud map with object semantics.
The other aims to study semantic map representation and reasoning. These methods use multilayer maps to represent the environment, providing the robot with capability of complex task planning, and implicit knowledge reasoning. For instance, Ruiz-Sarmiento et al. 12 used RGB-D sensors with the conditional random field to construct a multiversal semantic map containing spatial relationships and symbolic grounded uncertainty. Pronobis and Jensfelt 13 fused multiple sensor information and used a probability method to create a multilayer map. Zender et al. 14 conceptualized the environment at different levels of abstraction.
The key part of these methods is to get the semantic information of the environments. For that, object recognition, 15,16 scene recognition, 17,18 database of geometric model, 19,20 human–computer interaction, 21,22 artificial landmark 23,24 are used to get semantic concepts. In recent years, with the advancement of deep learning, the methods based on neural networks occupy a leading position. The interested reader can refer to the work by Kostavelis and Gasteratos 25 for a comprehensive review of semantic mapping approaches for robotic tasks and the work by Landsiedel et al. 26 for spatial reasoning and interacting.
Although these methods successfully created semantic maps, they only describe the occupied grids in occupancy grid maps and could not be used for the robot navigation as the path planning algorithms need the goal points located on free grids. Moreover, these methods do not consider the computational resources consumption and the price of robot sensors which are of great importance for domestic robots.
As for robot navigation, classical methods, such as AStar, 27 dynamic window approach (DWA) 28 can make the robots complete point-to-point navigation tasks successfully while lacking of semantic information. Inspired by the fact that human beings and higher animals only need significant landmarks and spatial relationships to navigate, some authors try to endow the robots with the capacity of cognitive navigation. For example, Ko et al. 29 first built a topological-semantic-metric map, then proposed a humanlike semantic navigation method for mobile robots. Crespo et al. 30 proposed a semantic relational model for robot path planning. However, as these methods do not yet have high robustness and real-time performance, they cannot be applied in the real scene application at the current stage.
Different above, this article describes a novel semantic grid mapping method with sonar and stereovision sensors for domestic robots. Our method directly adds semantics on the grid map and builds topological space of objects, taking advantage of classical navigation algorithms and human concepts for robust and human-friendly robot navigation.
Grid map with object semantics
This section introduces our object semantic grid mapping method. An overview of our approach is depicted in Figure 1. Based on the sonar grid mapping method, we first use sonar and odometry readings to build a grid map, which has two functions. On one hand, it is the basis for building an object grid map. On the other hand, it provides a priori knowledge for building the object point clouds. Based on the odometry and stereovision information, we then employ the object detection and triangulation method to create the original point clouds with object semantics. To remove the outliers and solve the problem that object detection cannot distinguish different instances of the same concept, the original point clouds are filtered and clustered. Next, we adopt the MBRs to describe the topological space of the objects. Finally, the topological space is merged into the grid map to form an object grid map. In addition, to make the article more readable, Table 1 shows the list of the abbreviation and annotations which are used in this article.

Overview of object semantic grid mapping method.
List of abbreviation and notations.

Occupancy grid map
Sonar sensors are widely used in domestic robots. Compared with laser scanners, they are low-cost, low weight, and low computational resource consumption. Thus, we adopt sonar sensors to build an occupancy grid map. Since the sonar measurements are always erroneous and no angular information, the map quality may be severely degraded. In this article, we use the off-line grid mapping method proposed by Lee et al., 31 which is based on the approximate maximum likelihood estimation theory to solve these problems. In his method, the sound pressure map is used to distinguish the correct and incorrect readings. The sub-map M1 is constructed based on the correct data, and the erroneous observation data are reprocessed based on M1. Then, the sub-map M2 is created by using the reprocessed data. Finally, the grid map M is the union of sub-map M1 and M2.
Object detection
Our method uses object detection to provide semantic information. In domestic environments, there are a large number of object classes. We first have to determine the categories of detected objects. As we extract the semantic information of the rooms based on the common sense of the relationship between rooms and objects, and consider that the objects are only used for robot navigation, we determine to detect 10 classes of objects, including: sofa, coffee table, TV cabinet, TV, bookcase, bed, bedside table, dining table, and wardrobe. Since region-based fully convolutional networks 32 can maintain or even improve the accuracy of position and classification of objects, as well as has high computational efficiency, we use it to detect the object. Specifically, we use it to detect the left image and get the object bounding boxes. We then triangulate the feature points in these regions. In addition, since open source data sets cannot meet our requirements for domestic robot navigation, we train and test the net using our data set and the confusion matrix of our object detection is shown in Figure 2.
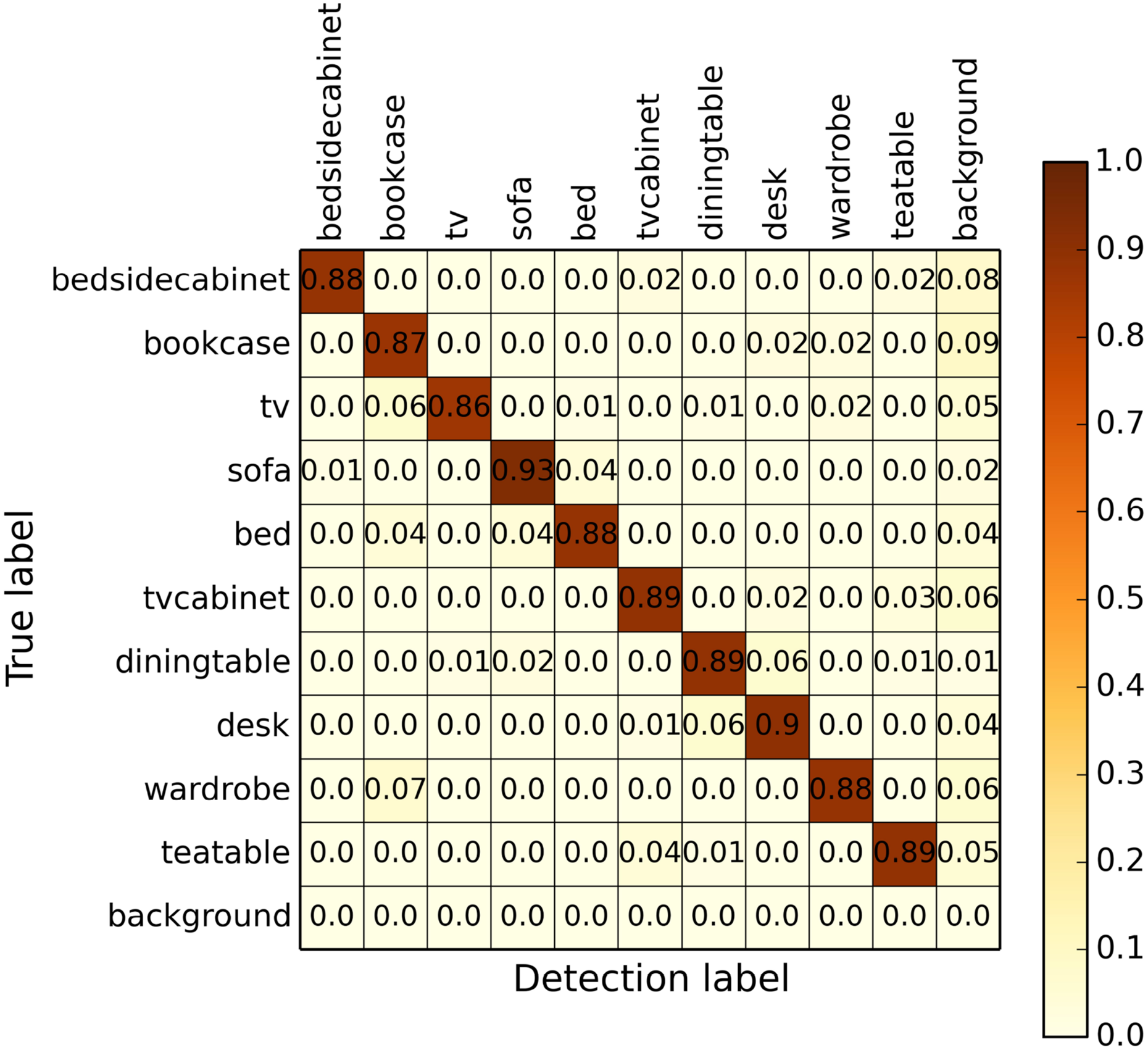
The confusion matrix of object detection.
Original point clouds with object semantics
Figure 3 shows the coordinate frames of our system. Since the domestic environment is usually a small-scale scene and the resolution of the grid map is more than 5 cm, we directly employ triangulation method to acquire original point clouds instead of the state estimation method like ORB-SLAM
33
or LSD-SLAM.
34
In addition, to simplify system complexity and speed up calculations, the robot does not need to visit the complete environment and record all images. So we make the robot navigate to specified points to take images. Speak specifically, based on the occupancy grid map, the robot moves to the points specified by users, and turns around to record images and corresponding poses. Object detection is then used to acquire the region of interest (ROI) of objects. For the points in ROI, ORB
35
is exploited to find corresponding points Coordinate frames of our system: world (FW), robot (FR), and camera frame (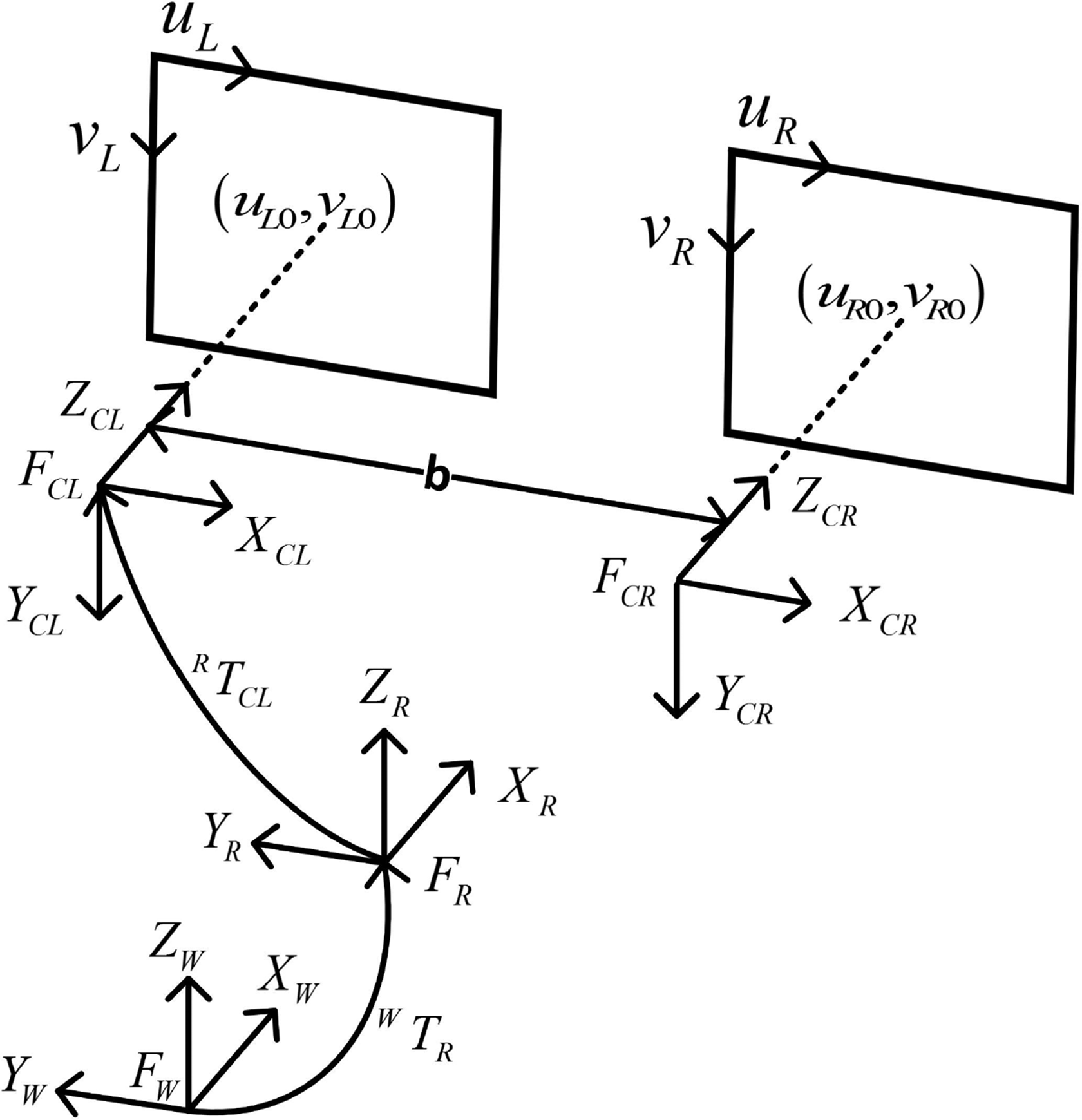



where

where
Filtering and clustering for original points
As shown in Figure 4, the original points include many outliers and object detection cannot distinguish different instances of the same concept. The information of grid map, size of objects, and density-based clustering are used to address these problems. As the objects are obstacles and they can only locate on occupied grids, we first exploit the free grids to remove some outliers. Then, the occupied grids are abstracted to form a set O and the shortest distance between point Problems in original points. (a) Incorrect measurements caused by specular surfaces. (b) Different instances with same sofa label.

Next, the minimum length

Finally, density-based clustering 36 is employed to further filter out the outliers and distinct different instances with the same concept.
Object representation
While point clouds use feature points to represent objects, we can take a compact way of representation. Consider the detected objects can be approximated as rectangles and are always parallel to walls, MBRs are thus used to represent objects. In addition, as the MBRs of objects usually include occupied grids that cannot be goal points for navigation tasks, it needs to define the free spaces nearby the objects to make the robot autonomously select goal points. We thus expand the MBRs to build the topological spaces of objects.
Figure 5 shows our expanding approach uses a three triple The triple 


Then, the expanding edge is defined as

Based on the result of expanding edge

Finally, the expanding length

where
According to the tripe
Semantic concepts of rooms
In order to acquire concepts of rooms, we first use spectral clustering to coarsely segment the grid map, and then use the topological spaces of objects and domestic common sense to merge segment results.
Normalized graph cut and spectral clustering
Suppose an undirected weight graph

where

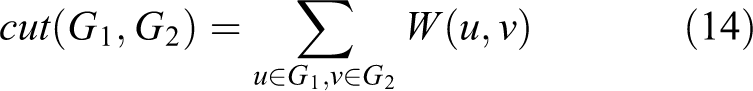
and

However, it is an NP-hard problem to find the minimum value of
Down sampling the grid map into a graph
Compute affinity matrix W by
Define
Select a desired number of subgraphs k.
Find
Set
Use k-means clustering on each row of Y.
Assign Vi to cluster j if and only if row i of Y is assigned to cluster j.
Assign other grids to cluster k with n-nearest neighbor if and only if the most neighbors are in the cluster k.
Using common sense to improve the results of segmentation
Based on the results of spectral clustering, the grid map can be segmented into k clusters. Figure 6 shows that some of them contain object semantics and some do not. As spectral clustering is one of unsupervised learning methods, the number of clusters k is a predefined parameter need to be tuned in different domestic environments. In addition, although the number k is equal to the number of rooms, the spectral clustering is not able to get the correct results. It thus needs to tune many magic parameters manually. To overcome this limitation, we choose a larger number k to coarsely segment grid map and use object semantic map and domestic common sense to merge the segment results.

Example of the graph generated by using topological segment: some nodes have object semantics, and some do not.
According to the clusters k, a region adjacency graph

For each node including object semantics, region growing with the threshold ld based on the length of doors in domestic environments is used to merge the regions without semantics.
Experimental results
This section presents the experimental results of the proposed semantic grid mapping method and navigation performance using the generated map. Figure 7 shows that our experiments have been conducted using a FABO robot in a homelike environment containing three rooms and some domestic objects. The robot is a differential drive robot equipped with 13 sonar sensors and a stereovision. In addition, it also has the capacity of speech recognition for end users to command navigation tasks in natural language to evaluate the navigation performance.

Experimental setup. (a) A FABO robot with 13 sonar sensors and a stereovision. (b) Experimental environment.
The robot was first manually controlled at an average speed of about 0.2 m/s while acquiring sensor data at a rate of 4 Hz and recording the coordinates of designated positions used to take images. Then, an occupancy grid map is built and the grid size of the generated grid map was 12 cm × 12 cm. Based on the grid map, the robot autonomously went to each recording positions to collect images and built a semantic grid map. Finally, the robot was asked to six different places by an end user in natural language.
Semantic grid map
The performance of sonar grid mapping was compared with an open source laser-based SLAM method called Cartographer. 38 Since the FABO does not have a laser sensor, a TurtleBot equipped with a SLAMTEC RPLIDAR A2 was used to build the laser-based grid map. Figure 8 shows the results of occupancy grid maps. Although the laser-based grid map captures the overall shape of the environment more successfully and provides the environment information more detailedly, the sonar-based grid map is able to make the robot navigation successfully. In addition, the 2-D laser sensor scans in a two-dimensional plane, while the sonar projects a three-dimensional cone. Thus, as shown the dashed red areas in Figure 8(a) and (b), the laser sensor cannot detect obstacles that are above or below the laser plane, but still detectable by the sonar. These results further provide the evidence of the advantages of sonar sensors in domestic environments. In addition, we use the sonar maximum sound pressure map 31 to evaluate the sonar sensor errors and its improvement. There are 6975 sonar readings and 22.29% of them are correct. Namely, the method can filter out 77.71% sonar readings, which are incorrect. Based on the sonar-based grid map, Figure 9 shows the process of the proposed object semantic mapping method. Using object detection and triangulation, the original object point clouds are generated as described in Figure 9(a). Most of the object points are locating on the unknown areas for the reason that objects are obstacles in the occupancy grid map.
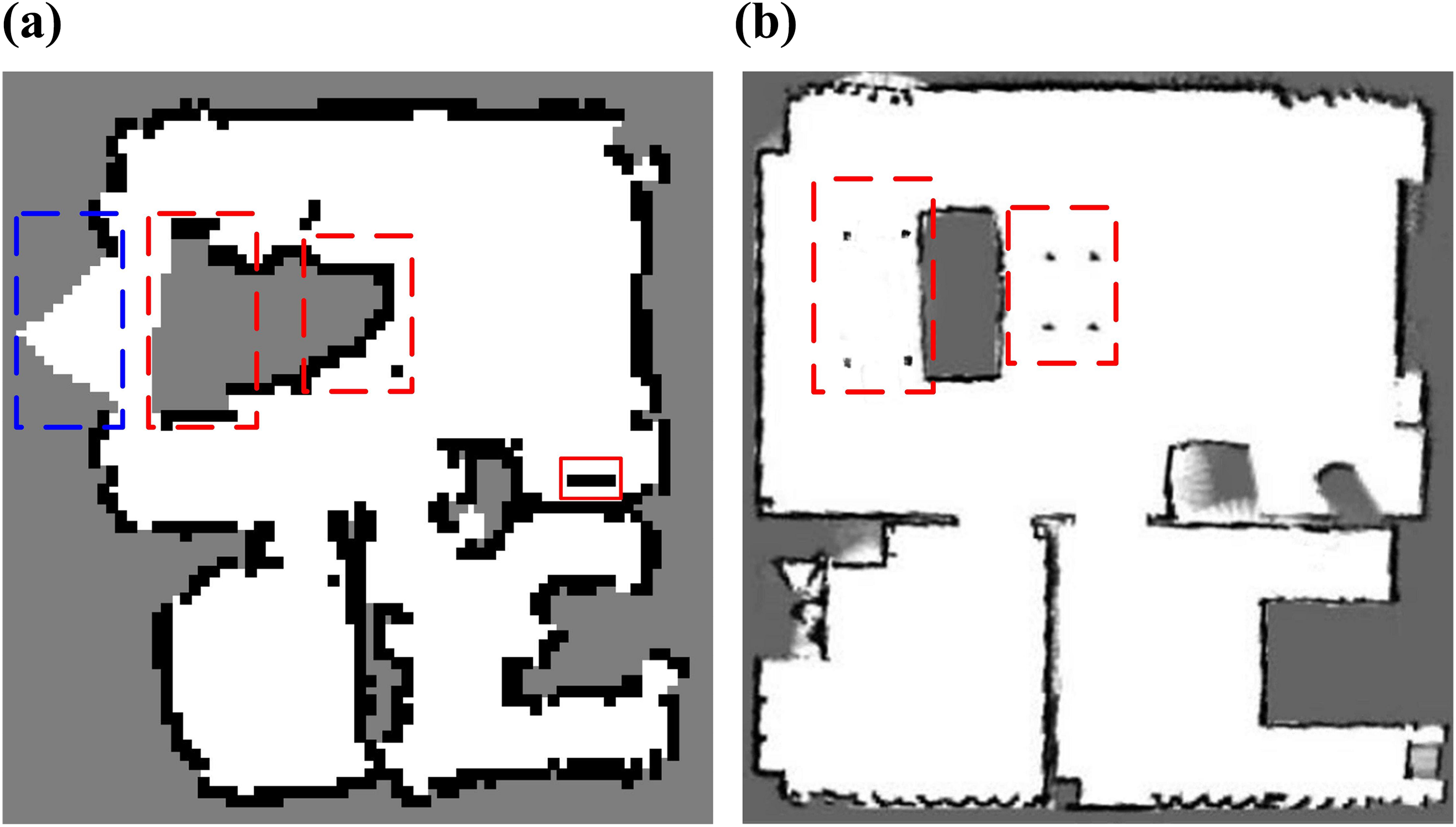
Experimental results of occupancy grid maps. (a) Sonar-based grid map. The blue dashed area indicates that the map does not model the environment completely because the size of FABO robot is larger than TurtleBot. The occupied grids in the red line rectangle represent robot charging pile. (b) Laser-based grid map. The black, white, and grey colors represent occupied, free, and unknown areas, respectively. The red dashed areas in both figures indicate that the sonar sensors can completely model the area but the laser cannot.

The process of object semantic grid mapping method. (a) Original object point clouds. (b) The object point clouds generated by using filtering and clustering. (c) Representation of objects and the corresponding topological space.
Based on our filtering and clustering method, the outliers are easily filtered out and the different instances of the same concepts can be distinct. Note that the size of the robot should be considered in the grid map, so the two free grids that near the occupied grids are treated as the occupied grids as shown in Figure 9(b). Figure 9(c) shows that MBRs and expanding rectangles are used to represent the object compactly. Although some objects such as bed1 and sofa2 slightly deviate from the corresponding positions in the grid map, it does not make a significant impact on the generated topological space of these objects. Therefore, the experimental results of object semantic mapping show that the proposed method can successfully add the object semantics on the grid map.
Therefore, the experimental results of object semantic mapping show that the proposed method can successfully add the object semantics on the grid map.
Room concepts
Figure 10 shows the results of topological segmentation of rooms. Even if we know the correct result is that the environment contains three rooms, Figure 10(a) and (b) indicates it is hard for the topological segmentation to divide the map into correct rooms. We thus need to tune the magic parameters to get the correct results. However, based on the object grid map and domestic common sense, we only need to tune the cluster number k. The domestic common sense used in our experiments includes: the living room contains a TV, TV cabinet, sofa, tea table; the bedroom contains a bed, desk, and wardrobe. One example of our segment and merging results is shown in Figure 10(c) and (d). To prove the effectiveness of our method, we test two different parameters and varied the cluster number k from 3 to 20. The former test uses the parameters of kth nearest-neighbor number knn = 3, scaling parameter ks = 7 and the latter is knn = 3 and ks = 3. Figure 11 shows that the topological segmentation based on the object semantic grid map can successfully get the correct room concepts by only changing the cluster number k.

Results of topological segmentation and each cluster is a different color. (a) Incorrect segmentation by using the parameters as cluster number k = 3, kth nearest-neighbor number knn = 3, scaling parameter ks = 7. (b) Incorrect segmentation by using the different parameter of ks = 3. (c) Segmentation by using the different parameter of cluster number k = 20. (d) Correct segmentation by merging the results of (c).
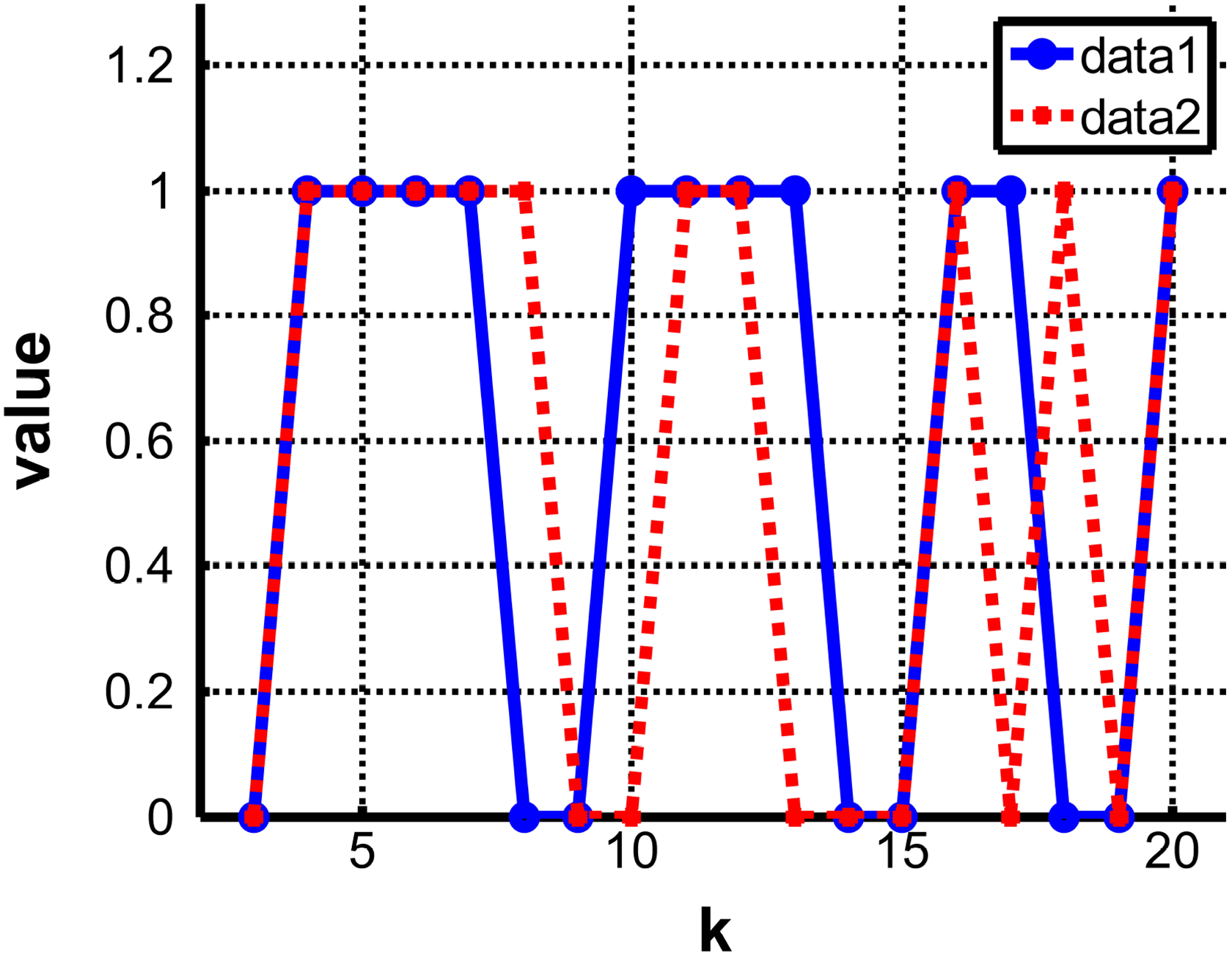
Two data was used to test the topological segment. The parameters of data1 was the kth nearest-neighbor number knn = 3, scaling parameter ks = 7 and data2 was knn = 3 and ks = 3. The cluster number k was varied from 3 to 20. Value equals 1 representing success and 0 representing failure.
Navigation
To evaluate the effectiveness of proposed semantic grid map, a user in turn commanded the robot go to TV cabinet, sofa1, desk, wardrobe, bed1, sofa2. As shown in Figure 12(a), the user asked the robot to go to the TV cabinet. According to the generated semantic grid map and consider the factor of radius of FABO, we inflated the occupied grids with two free grids. In order to increase the diversity of navigation behavior, the goal points were generated using random selection in topological spaces of objects except the inflated grids. AStar was then used to generate navigation paths. Figure 12(b) shows the final pose for the first navigation task. The whole goal points and paths for the navigation tasks are described in Figure 12(c).

Results of commanding a FABO robot to navigate to six different places. (a) A user command a FABO to navigate to TV cabinet. (b) The final pose of first navigation task. (c) The generated goal points and robot paths. The color circles are navigation goals and color lines are generated paths. The numbers represent the path sequence.
Since we only used the odometry to build the semantic grid map and navigate in it, we couldn’t get the ground truth. We thus adopted the maximum pose error to evaluate the navigation perforation. We used the manual loop closing to make the robot start from the charging pile and finally return it to get an optimal trajectory. Specifically, we recorded the odometry readings and use g2o 39 to optimize the initial trajectory. Please note that since the pose graph only has one loop position, the error will propagate far away from the charging pile. However, we compare the maximum error mapped onto trajectory pose error and the moving distance is not long, this method can get a relatively accurate result.
As can be seen from Figure 13, the maximum error of the robot is 9.6 cm. The resolution of grid map is 12 cm × 12 cm and the error is no more than 1 grid size. Additionally, from the perspective of indoor applications, as long as the position of the robot near the specified object, and there is no collision during the navigation, it can be regarded as successful navigation. Thus, the FABO successfully completed the navigation task. However, the uncertainty of the robot becomes larger as the moving distance increases. This may make the robot cannot complete other navigation tasks. To solve this problem, we will use the charging pile as a global landmark to reduce the uncertainty of the robot in our future work.

Comparison between initial and optimized trajectory.
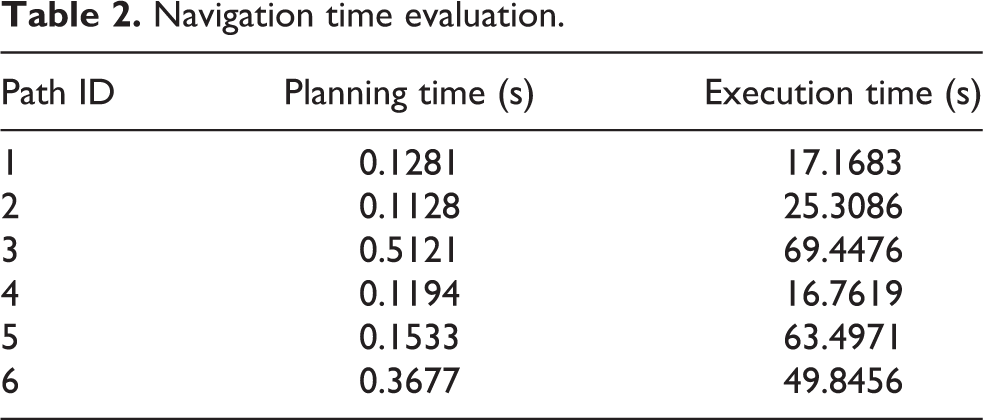
Table 2 presents the time evaluation of this navigation task, which includes planning time and execution time. In terms of planning time, planning the third path is the most time consuming, which costs 0.5121 s. The sixth path costs 0.3677 s, and other paths are around 0.1 s. As the domestic environment is small scale, it can meet the requirements of actual applications. In terms of execution time, it is much longer. One reason is that we set the average moving speed of the robot to 0.2 m/s. If we want to reduce the execution time, we can increase the moving speed of the robot. However, for indoor service robots, security is first considered.
Navigation time evaluation.
In general, the results indicate that the robot can successfully complete the navigation tasks as the robot was in 2-D small-scale environment. At the same time, the users can conveniently command the robot in natural language.
Conclusion
As more and more robots are coming into domestic environments, they need semantic knowledge to make human beings operate conveniently. In this work, we present a novel semantic mapping method for domestic navigation application. Our method enhances the occupancy grid map with semantics of objects and rooms, endowing the robots with robust navigation skills and the semantic knowledge about environments. Concretely, the proposed method first build occupancy grid map and object point clouds respectively and then fuse them correctly to get an object grid map. Based on the generated map and domestic common sense, topological segmentation is used to get room concepts. The experiments of semantic mapping and navigation were conducted with a FABO robot in a homelike environment. The experimental results prove the mapping method has a satisfactory precision to represent the environment and makes the robot can complete domestic navigation tasks in a human-friendly operation way.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (nos 91748101.