
Abstract
Path planning of lunar robots is the guarantee that lunar robots can complete tasks safely and accurately. Aiming at the shortest path and the least energy consumption, an adaptive potential field ant colony algorithm suitable for path planning of lunar robot is proposed to solve the problems of slow convergence speed and easy to fall into local optimum of ant colony algorithm. This algorithm combines the artificial potential field method with ant colony algorithm, introduces the inducement heuristic factor, and adjusts the state transition rule of the ant colony algorithm dynamically, so that the algorithm has higher global search ability and faster convergence speed. After getting the planned path, a dynamic obstacle avoidance strategy is designed according to the predictable and unpredictable obstacles. Especially a geometric method based on moving route is used to detect the unpredictable obstacles and realize the avoidance of dynamic obstacles. The experimental results show that the improved adaptive potential field ant colony algorithm has higher global search ability and faster convergence speed. The designed obstacle avoidance strategy can effectively judge whether there will be collision and take obstacle avoidance measures.
Introduction
There are abundant unexploited resources on the moon. Many countries are promoting the lunar exploration project actively. The lunar robot is an indispensable part of the lunar exploration project, and the path planning is the guarantee for the lunar robot to complete its tasks safely and accurately in the lunar environment. The goal of path planning is to enable the robot to find an optimal path from the start point to the destination. Limited by the energy carried by lunar robot, seeking the shortest path is the optimal goal of the path planning algorithm.
In various traffic planning problems, route planning has been widely studied and discussed. These algorithms mainly include A* algorithm, simulated annealing algorithm, genetic algorithm, differential evolution algorithm, particle swarm optimization algorithm, ant colony algorithm, and so on. Those algorithms have been widely used in engineering practice. A* algorithm 1 determines the next path grid step-by-step by comparing eight adjacent heuristic function values of the current path grid. In the simulated annealing algorithm, 2 by controlling the temperature parameter T and using the Metropolis criterion, the attenuation function is used to change the temperature t to minimize the objective function and determine the next target point. Genetic algorithm 3 uses crossover and mutation to determine the next target point and to achieve the optimal path selection. The differential evolution algorithm based on the evolution idea of genetic algorithm 4 solves the shortest path problem through hybridization, mutation, and selection. Particle swarm optimization algorithm 5 is to know the next iteration position of particles using the current position, global extremum, and single extremum. Ant colony algorithm 6 is a kind of bionic algorithm that simulates the way ants search for food in nature. The basic idea is to find the shortest path according to the concentration of pheromone left by ants. In these methods, with the increasing complexity of obstacles, the convergence speed of genetic algorithm, simulated annealing algorithm, 7 A* algorithm, 8 and differential evolution algorithm 9 will slow down. The robustness of particle swarm optimization algorithm is poor slightly, and the optimal solution depends on initialization. Ant colony algorithm has advantages in positive feedback, robustness, and so on. It is easy to combine with various heuristic algorithms to speed up convergence speed and reduce resource consumption when the algorithm is running, so it has been widely used in robot path planning.
Considering the energy consumption and dynamic obstacle avoidance, the grid method is used to process the simulated map data. Then the adaptive potential field ant colony algorithm is used to do the path planning. This method adjusts the heuristic function dynamically by introducing the inducing heuristic factor, so as to improve the global optimization ability and accelerate the convergence speed. The proposed adaptive potential field ant colony algorithm is called A-APFACO. In addition, predictable and unpredictable obstacle avoidance strategies are also considered. Therefore, we propose a geometric method for detecting dynamic obstacles.
The organizational structure of the article is as follows. The second section describes the related work. The third section mainly describes the environment modeling based on grid map method and an A-APFACO. The fourth section describes the dynamic obstacle avoidance strategy. The fifth section describes the experiments and results. The sixth section summarizes the whole paper.
Related work
Ant colony algorithm has been proved as good performance in path planning. However, it still has unavoidable shortcomings, such as long search time, slow convergence speed, and falling into local optimum easily. To improve the performance of ant colony algorithm, many researchers proposed improvement schemes. Stutzle and Hoos 10 proposed the maximum and minimum ant system algorithm, which introduced the definite maximum and minimum trajectories into the path. By constraining the maximum and minimum trajectories, the problem of stagnation was solved. Liu et al. 11 proposed an algorithm for path planning of mobile robots. This algorithm uses grid method to simulate the environment, and in the process of global optimization, pheromone diffusion and geometric local optimization are combined to accelerate the convergence speed of ant colony algorithm. Cheng et al. 12 combined simulated annealing algorithm with ant colony algorithm to speed-up pheromone updating. Long et al. 13 combined the evaluation function of A* algorithm with ant colony algorithm to improve the speed of convergence and the smooth of planned path. As can be seen, the methods mentioned in the literature 10 –13 have improved the state transition rule and accelerated the convergence speed of ant colony algorithm, but they cannot adjust the state transition rule adaptively, which made the algorithm easily fall into local optimum. Akka and Khaber 14 used new pheromone updating rule to adjust the evaporation rate dynamically, accelerated convergence speed, and expanded the search space of ant colony algorithm. Yang et al. 15 proposed a double-deck ant colony optimization algorithm, which consisted of a parallel elite ant colony optimization algorithm and smoothness optimization algorithm. It was mainly used for autonomous navigation of robots. This method can generate better collision-free paths effectively and consistently. However, the method mentioned in the literature 14,15 can only be applied to fixed environment, which means the distribution of obstacles is fixed. Once the environment changes, the parameters of algorithm need to be readjusted.
Dynamic obstacle avoidance problem is also a key point for robot. Many scholars have proposed solutions. Aiming at distributed robots, Javier et al. 16 proposed a method of combining constrained nonlinear optimization with consistency to avoid static and dynamic obstacles. However, this method can only be applied to predictable dynamic obstacle, it is invalidation for unpredictable obstacle. Hu et al. 17 used global routes to construct centerlines, generated a set of candidate paths in the s–q coordinate system, and converted them into Cartesian coordinates. The optimal path was selected by considering the total energy consumption. Wang et al. 18 proposed a probabilistic model for three kinds of robot dynamic obstacle avoidance based on Markov decision algorithm in uncertain dynamic environment. With PRISM software, the minimum time and energy consumption of each obstacle avoidance strategy were obtained, and the optimal obstacle avoidance strategy under different conditions was determined. However, only a single form of dynamic obstacle avoidance is considered in the studies by Hu et al. 17 and Wang et al., 18 just codirectional motion is considered in the study by Hu et al., 17 while intersecting motion is considered in the study by Wang et al. 18 Sun et al. 19 proposed a new artificial potential field algorithm danger index artificial potential field (DIAPF) based on hazard index, which considered the relative distance as well as the relative velocity between the robot and the moving obstacle. However, when encountering dynamic obstacle, this method needs to replan the path according to the speed of dynamic obstacle. Wang 20 proposed an autonomous obstacle avoidance optimization algorithm. The problem of autonomous obstacle avoidance of unmanned aerial vehicle is transformed into the problem of solving quadratic equation of one variable, and the expected speed and angle are calculated to achieve obstacle avoidance. However, the premise of this method is that the robot and obstacles need to maintain a fixed speed. If the speed changes, it will lead to the failure of obstacle avoidance.
An adaptive potential field ant colony algorithm
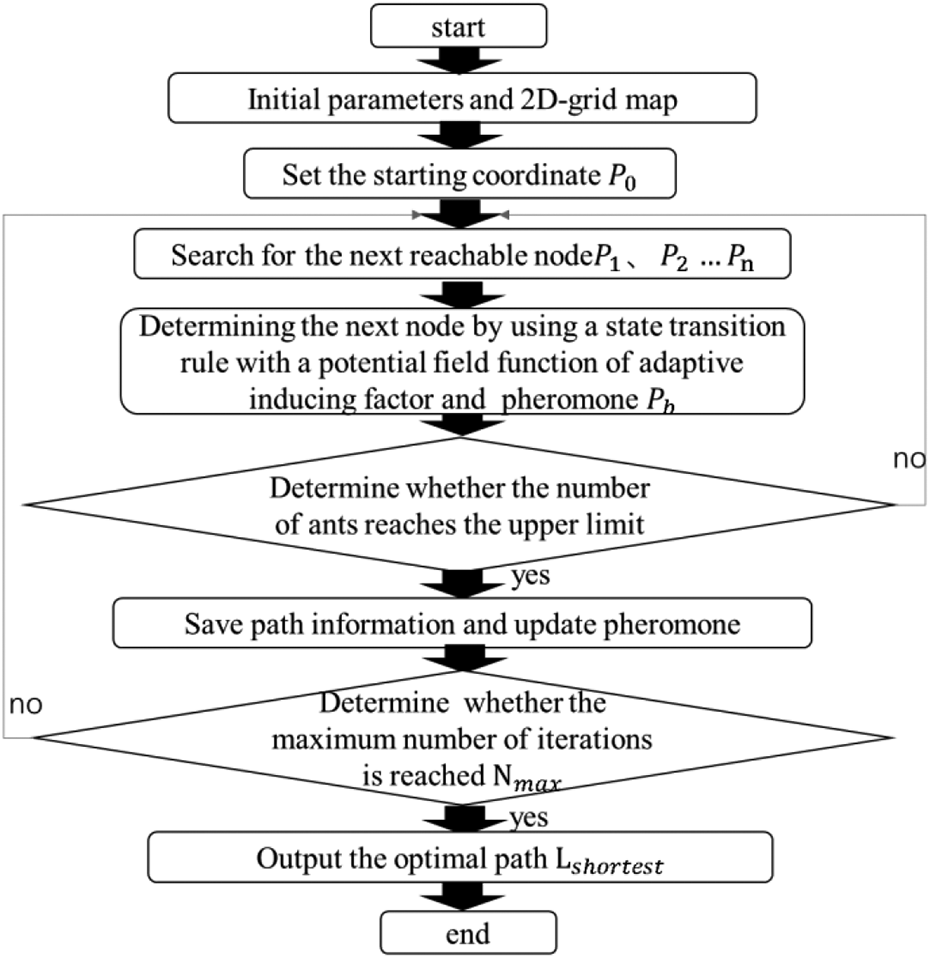
Aiming at the problems of falling into local optimum, slow convergence, and dynamic obstacle avoidance in ant colony algorithm, firstly, we propose an improved potential field ant colony algorithm based on dynamic obstacle avoidance. Then, we improve the heuristic function in the transfer probability based on the ant colony algorithm. Finally, a dynamic transfer strategy, which enables robots to avoid obstacle in dynamic environment, is proposed. The main flowchart is as shown in Figure 1.

Flowchart of A-APFACO based on dynamic obstacle avoidance strategy.
Environment modeling based on grid method
Considering that, the lunar environment is relatively simple and full of ring mountains and plains. The environment model is simplified to a two-dimensional (2D) grid map, and the moving path of robot is planned in map as shown in Figure 2.

Grid map.
Figure 2 shows a 2D grid map with 20 rows and 20 columns, where black grid represents obstacle and white grid represents accessible space. In the 2D plane, the coordinates of each grid are calculated in the orthogonal reference coordinate XOY. Assuming that the entire grid is marked with integer and their length are equal to the unit length of coordinate, the following coordinate can be obtained as
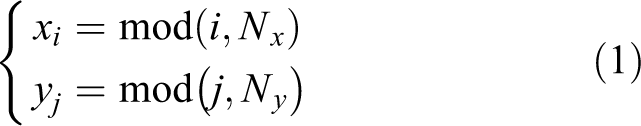
Among them, Nx denotes the number of grids of each row, Ny denotes the number of grids of each column, and mod is the remainder operation. Here, Nx = 20, Ny = 20, the coordinate of point A is xi = 13, yj = 19.
Adaptive potential field ant colony algorithm
Ant colony algorithm
Dorigo et al. 6 proposed an ant colony algorithm (ACO) in 1996, which is a heuristic algorithm for finding the optimal solution. It simulates the foraging behavior of ants. Assume at time t, the ant k chooses the next node according to formula (2)

Here,

where dij denotes the distance from point i to point j, dij is defined as

The updated pheromone is determined by the volatile pheromone and the pheromone left by ants. The updated formula of pheromone is as follows

Here, ρ represents the evaporation rate of pheromone, m is the number of ants, and

Improvement of heuristic function
(1) Improvement of heuristic function based on artificial potential field method.
Artificial potential field method is an effective method to solve the problems of slow convergence caused by blind search in the early stage of the ant colony algorithm. Artificial potential field is a virtual force field exerting on the environment, usually consisting of gravity and repulsion. Let the gravitational function be G(t), which is defined as the relative distance between the robot and the target. The calculation formula is as follows
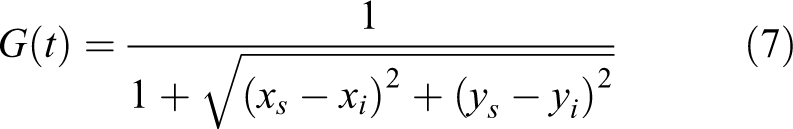
Among them,
The repulsion function in the artificial potential field is R(t). The repulsion function takes advantage of the position information of the obstacle. It is defined as a function between the robot and the obstacle. The calculation formula is as follows

After introducing artificial potential field, the heuristic function is as follows

(2) Improvement of heuristic function based on adaptive inducement heuristic factor.
The heuristic function solves the problem of convergence speed for the original heuristic function in ant colony algorithm, but it is still unable to solve the problem of weak global search ability in the later stage of the algorithm. In this article, iteration is considerate as the negative feedback coefficient to make the pheromone change adaptively, which ensures the consistency between the optimization ability and the convergence speed. We define λ as an adaptive inducing heuristic factor

Here, N max and N are the maximum and current number of iterations, respectively. In the prophase, the heuristic factor is more than 1, the heuristic function is dominant, and the heuristic function is strengthened, which leads ants to move in a directional manner. In the anaphase, N becomes larger and the heuristic factor is less than 1. At this time, the heuristic function will be weak and the pheromone will play a main role in the stage, which helps ants to find a new way based on pheromone updating.
Finally, the heuristic function after introducing adaptive inducing heuristic factor is as follows

A-APFACO compared with the maximum and minimum ant colony algorithm proposed in the study by Stutzle and Hoos 10 ; although the maximum and minimum ant colony algorithm improves the local optimization ability to a certain extent, this article combines the artificial potential field with the ant colony algorithm, which has better convergence and global optimization characteristics. Compared with the ant colony optimization with pheromone diffusion model and geometrical optimization path method (ACO-PDG) algorithm proposed in the study by Liu et al. 11 , the convergence speed of the algorithm in Liu et al.’s work will be slower in the later stage, and the adaptive heuristic function designed in this article can further accelerate the convergence speed of the algorithm in the later stage.
Adaptive artificial potential field ant colony algorithm
The flowchart of the A-APFACO is as shown in Figure 3. The pseudocode of the adaptive artificial potential field ant colony algorithm is presented in Table 1.
Flowchart of ant colony algorithm.
Algorithm of A-APFACO.


Robot dynamic obstacle avoidance strategy
Obstacle avoidance strategy
Ant colony algorithm can plan to avoid known static obstacles. However, the dynamic obstacle avoidance between lunar robots should also be considered when a lunar robot cluster appears. Since the scene is set on the surface of the moon, the number of lunar robots is limited at present. Assuming that the number of robots is n,
In the case of dynamic obstacle avoidance, moving obstacle can be divided into predictable obstacle and unpredictable obstacle. Since all lunar robots have path planning, and their moving speed is fixed or known, the collision point is predictable. We define this kind of obstacle avoidance problem as predictable obstacle avoidance. However, if something goes wrong while robot is moving, the obstacle avoidance problem will be unpredictable.
Defining robot R has a set of traveling attributes {
Predictable dynamic obstacle avoidance strategy
1. Minimum safe distance.
For multi-robot working environment, collision avoidance rule should be given to enable robots to work cooperatively and improve work efficiency. To avoid collision, the distance between two lunar robots should be greater than the minimum safety distance.
Assuming that the two robots are R
1 and R
2, and their current coordinates on the 2D grid map are

2. Obstacle avoidance strategy.
To avoid obstacles, priority-based alternative traffic strategy is adopted in this article.
Let two robots be R 1 and R 2 respectively, because obstacles are predictable and their trajectories are known. The obstacle avoidance strategies are as follows:
i. Strategy 1:
If
At time t, the distance d between R 1 and R 2 is less than h. If R 1.priority > R 2.priority, R 2 judges whether there are obstacles on its left or right side based on the map information.
If bilateral or unilateral obstacle-free, at moment t + 1, R 2 conducts lateral avoidance. R 2.direction = left or right. Then R 2.action = stop until R 1 passes through. Then R 2.action = move, R 2 returns to the original route and continues to drive.
If there are obstacles on both sides, at moment t + 1, R 2.action = move, R 2.direction = backward, until R 2 retreats to the barrier-free area, R 2.direcrion = left or right, R 2 executes lateral avoidance, R 2.action = stop, until R 1 passes through, R 2.action = move, R 2 returns to the original route and continues to drive.
ii. Strategy 2:
If
If R 1 is in front of R 2, R 1.velocity > R 2.velocity, no evasion is required.
If R 1 is in front of R 2, R 1.velocity < R 2.velocity, R 1 executes lateral avoidance.
Firstly, R 2.action = stop. Secondly, R 1 judges whether there are obstacles around it. If there is no obstacle, R 1.direction = left or right, and then R 1.action = stop, R 1 executes lateral avoidance. R 2 restarts to move, R 1.action = move. Finally, R 1 restart to move until R 2 pass through. If there are obstacles, R 1.direction = forward, R 1 drives to obstacle-free point, then executes lateral avoidance until R 2 passes through, R 1.action = motion, R 1 returns to the original route and continue to move.
iii. Strategy 3:
Intersectional motion can be regarded as an extension of the opposite motion. By setting priority, obstacle avoidance strategy can be applied to multi-robots.
If
Unpredictable obstacle avoidance strategy
When robots moving on the moon, the most complex situation is obstacles are unpredictable. This article presented a geometric method based on moving route of robot to detect the location of the unpredictable obstacle. The method mainly calculates the distance between two objects. If the distance between two robots is less than the minimum safe distance, it is considered that there will be a collision. The geometric model is shown in Figure 4. Figure 4(a) is based on R 1 and Figure 4(b) is based on the ground.

Collision detection model. (a) is based on R1 and (b) is based on the ground.
In Figure 4(a), let robot R 1 be a reference. R 2 moves relative to R 1, and the arrow represents the direction of the robot’s movement. Then there exists a minimum distance L min between two robots along the motion route at some moment. 22
According to the geometric relationship in Figure 4(a), it can be deduced that the minimum distance between two robots is

In Figure 4(b), the lunar surface is taken as the reference. Suppose that the robot R
1 locates at point A
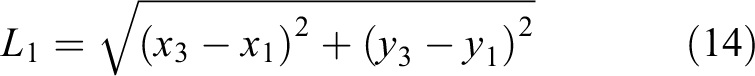
The calculation formulas of L 2, L 3, L 4, L 5, and L 6 are similar with L 1 and will not be described again.
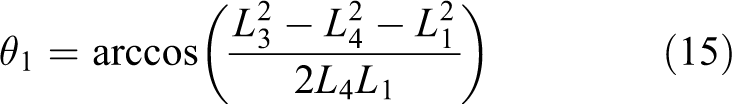
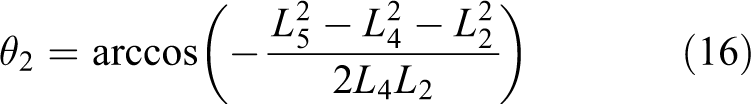
If it is predicted that R
1 will collide with R
2 at t moment, R
1 will be stopped. The minimum distance is changed to the distance

Assuming that the lunar robot always travels along a straight line (non-curve), the moving direction of R
1 is
In this method, the distance and azimuth angle are measured by binocular camera, radar, or other equipment on the lunar robot and can also be estimated by the position of the robot in the grid map.
Experimental results and analysis
Experimental environment and evaluation indicators
In the following experiments, the ant colony algorithm is implemented in a 20 × 20 2D grid map. To verify the effectiveness of the proposed algorithm, the proposed algorithm is compared with the initial ant colony algorithm, the improved algorithm in the study by Liu et al., 11 the genetic algorithm, and the A* algorithm under the same environment.
The main evaluation index of the experiment is the parameter evaluation degree. It is a comprehensive evaluation criterion under which the algorithm can obtain both a higher success rate of the shortest path and fewer average iterations

Among them, N represents the average number of iterations and S(x) is the shortest path success rate when the parameter value is x.
In this article, experiment platform is Python 3.7. The computer operating system is Windows 10, the CPU is Core i7-8750H, and the memory is 8.00 GB.
Ant colony algorithm experiment
Experiment 1: Parameter choice
This experiment is used to seek the appropriate pheromone parameter α, heuristic information parameter β, pheromone evaporation parameter ρ to make the algorithm obtain high success rate, and fewer number of iterations. The obstacle environment is shown in Figure 5, the number of ants is 20, the number of iterations is 100, the start point is (5, 18), and the end point is (19, 0). The initial parameters α = 1.0, β = 18, and ρ = 0.5 are specified. The experimental results are presented in Tables 2 to 4. When the algorithm runs 50 times, the proportion of the shortest path is planned.
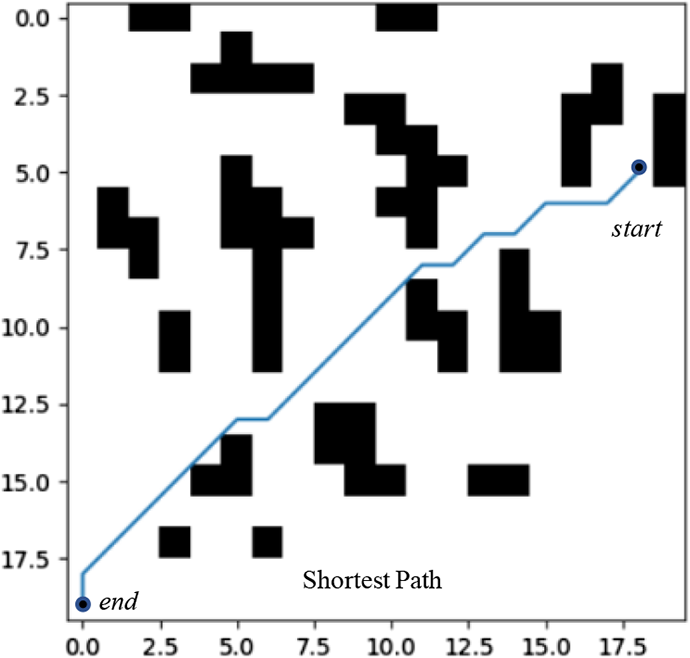
Test environment diagram.
Control parameters β and ρ, the success rate in shortest path and average iteration number evaluation with change of parameter α.

Control parameters α and β, the success rate in shortest path and average iteration number evaluation with change of parameter β.

Control parameters α and β, the success rate in shortest path and average iteration number evaluation with change of parameter ρ.

In the table, the number of iterations represents the average number of iteration. It can be seen that the maximum parameter evaluation is achieved when the parameters are α = 1.0, β = 27, and ρ = 0.2, respectively. With these parameters, the convergence curve of the algorithm is shown in Figure 6. The convergence curve is stable, and the algorithm converges at the 12th iteration. In addition, the success rate of the shortest path is 96%.

Curve of convergence with selected parameter.
Experiment 2: Scene simulation
To verify the effectiveness of the proposed algorithm, this experiment compares other path planning algorithms in four different typical obstacle scenes. These scenarios are shown in Figure 7, four kinds of obstacle environments.

((a) to (d)) Four obstacles with different scenes.
They separately express the location of obstacles locate near the starting point, near the terminating point, in the middle of path with simple distribution, and in the middle of path with complex distribution. Assuming that the start point is (0,0) and the end point is (19,19), the experiment runs 100 times. The planned shortest paths are shown with the straight line in Figure 7.
Here, the number of population is 40, α = 1, β = 27, ρ = 0.2 in the traditional ACO and A-APFACO algorithm, α = 1.1, β = 12, ρ = 0.5 in the ACO-PDG algorithm, crossover probability is 0.8, mutation probability is 0.2 in GA algorithm, inertia weight is 0.9, and learning factor c 1 = 2, c 2 = 2 in the PSO algorithm.
From Table 5, in the scene (a), all the paths are 28.042, but A* algorithm cannot converge. In the scene (b), the shortest path planned by ACO-PDG, A-APFACO, and PSO is 28.042. In the scene (c), the entire algorithm can plan the shortest path, which is 27.456. In the scene (d), the shortest path is planned by A-APFACO and genetic algorithm. Compared to other algorithms, our A-APFACO algorithm gets all the shortest path in the four scenes. As a result, A-APFACO has better performance of path planning in the four obstacle scenes.
The shortest path length under four obstacle scenes.

The convergence curves of traditional ACO, ACO-PDG, A-APFACO algorithms in complex scenes are shown in Figure 8. In scene (c), the convergence iterations of the three algorithms are 7, 11 and 8 respectively with similar performance. In the scene (d), only A-APFACO can plan a better path, and the algorithm converges only after four iterations. Experimental results show that the proposed method has better robustness for complex scene.
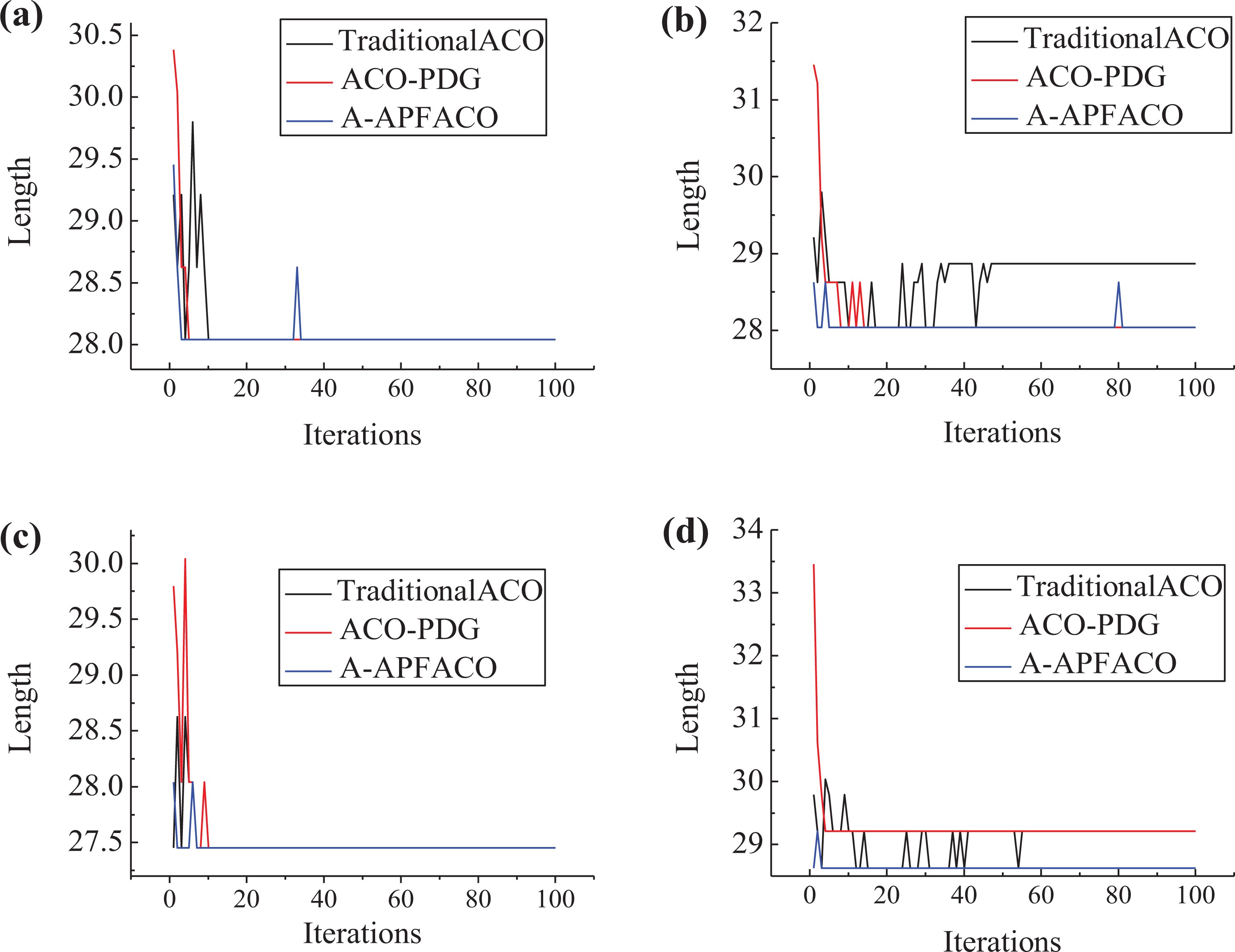
((a) to (d)) Convergence curves of three algorithms under complex scenes.
Dynamic obstacle avoidance experiment
This experiment is used to verify the effectiveness of the strategy for predictable dynamic obstacle avoidance. In the experiment, a 20 × 20 grid map was used with a moving speed of one step per second.
Experiment 3: Predictable obstacle avoidance of two targets
1. Opposite motion.
This experiment verifies the strategy of obstacle avoidance when two targets collide in opposite motion. In Figure 9, the red “*” represents R
1, and the blue “•” is R
2,  represents the collision point.
represents the collision point.

((a) and (b)) The opposite movement of two targets under obstacles.
The starting point of robot R 1 is (19, 10) and the ending point is (1, 10). The starting point of robot R 2 is (1, 10) and the ending point is (19, 10). The priority of R 1 is higher than that of R 2. The motion path planned by ant colony algorithm of R 1 is 7 → 6 → 5 → 3 → 2, and that of R 2 is 1 → 3 → 5 → 6 → 7. It can be seen in Figure 9, there will be a collision in opposite directions at the position of node 5, and there are obstacles beside the collision point.
Implement obstacle avoidance strategy 1, the motion path of R 1 is 7 → 6 → 5 → 3 → 2, and that of R 2 is 1 → 3 → 5 → 4 → 4 → 4 → 5 → 6 → 7, as shown in Figure 9(b). Here the second “4” in the path of R 2 represents that R 2 stopped a step at node 4. In the later experiments, if there are many identical nodes in the traveling path of robot, it means the same thing, and no further explanation is given.
2. Codirectional motion.
This experiment verifies the strategy of obstacle avoidance when two targets collide in codirectional motion. In Figures 4 to 9, the red “*” is R 1, and the blue “•” is R 2, is the collision point.
The starting point of robot R 1 is (19, 10) and the ending point is (0, 10). The starting point of robot R 2 is (13, 10) and the ending point is (0, 10). The priority of R 1 is higher than that of R 2. The speed of R 1 is two steps per second and R 2 is one step per second. The motion path planned by ant colony algorithm of R 1 is 1 → 3 → 5 → 7 → 9, and that of R 2 is 3 → 4 → 5 → 6 → 7 → 8 → 9. It can be seen from Figure 10 that there will be a collision in codirection at the position of node 5.

((a) and (b)) The codirectional movement of two targets under obstacles.
Implement obstacle avoidance strategy 1, the motion path of R 1 is 7 → 6 → 5 → 3 → 2, and that of R 2 is 1 → 3 → 5 → 4 → 4 → 4 → 5 → 6 → 7, as shown in Figure 10(b).
3. Intersectional motion.
This experiment verifies the strategy of obstacle avoidance when two targets collide in intersection motion. In Figure 11, the red “*” represents R
1, and the blue “•” is R
2, is the collision point.

((a) and (b)) The intersection movement of two targets under obstacles.
The starting point of robot R 1 is (0, 14) and the ending point is (9, 7). The starting point of robot R 2 is (0, 6) and the ending point is (9,15). The priority of R 1 is higher than that of R 2. It can be seen in Figure 11, according to the route planned by ant colony algorithm, there will be a collision at the position of node 10.
Implement obstacle avoidance strategy 3, R 2 with low priority stops two steps at node 4 until R 1 passes and R 2 continues to move forward. The motion path of R 1 is 6 → 7 → 8 → 9 → 10 → 11 → 12, and that of R 2 is 1 → 2 → 3 → 4 → 4 → 4 → 10, as shown in Figure 11(b).
Experiment 4: Comprehensive movement of three targets
This experiment verifies the strategy of obstacle avoidance when three targets collide. In Figure 12, the green “+” represents R
1, the blue “•” is R
2 and the red “*” represents R
3, represents the collision point.

((a) and (b)) Comprehensive movement of three targets.
The starting points of robot R 1, R 2, and R 3 are (19,0), (19,1), and (19,10), respectively, and the ending points of robot R 1, R 2, and R 3 are (0,19), (6,14), and (0,10).
The motion path planned by ant colony algorithm of R 1 is 9 → 10 → 11 → 4 → 12 → 13 → 14, and that of R 2 is 7 → 6 → 5 → 4 → 3 → 2 → 1, R 3 is 1 → 2 → 3 → 4 → 5 → 6 → 7. It can be seen in Figure 12, there will be a collision at the position of node 4.
As can be seen from Figure 12, at node 4, R 1 will intersect with R 2 and R 3, while R 2 and R 3 are in opposite motion. If the priority is R 2 > R 3 > R 1, R 1 adopts the stop obstacle avoidance strategy in the safe range, while R 3 with the second priority avoids at node 8. After robot R 2, which has the highest priority, moves out of the safe range, R 3 and R 1 move in turn according to the original planning path. The process of obstacle avoidance is completed.
Implement obstacle avoidance strategy 1 and 3, the motion path of R 1 is 9 → 10 → 11 → 11 → 11 → 11 → 11 → 11 → 11 → 11 → 4 → 12 → 13 → 14, and that of R 2 is 7 → 6 → 5 → 4 → 8 → 8 → 8 → 4 → 3 → 2 → 1, R 3 is 1 → 2 → 3 → 4 → 5 → 6 → 7.
Experiment 5: Dynamic avoidance of unpredictable obstacles
This experiment is designed to verify the strategy of dynamic avoidance of unpredictable obstacles. In Figures 4
to 9, the red “*” represents R
1, and the blue “•” is R
2, represents the collision point. Suppose the robot R
1 cannot predict where it will collide with R
2. And the priority of R
2 is higher than that of R
1.
In Figure 13, the distance and angle are calculated based on the grid in the map. Assuming the detection radius r of the robot R
1 is 8, the safe distance h = 1.5. At t + 1 moment, when the robot R
1 reaches point A, it detects that R
2 reaches point C. At the next moment, R
1 moves to point B and R
2 moves to point D. According to formula (13), L
min ≈ 0, L
min is less than the safe distance, which means that the two robots will collide at some point. At this time, robot R
1 stops at point B, R
2 continues to move to point E. Here, according to formula (17),

((a) and (b)) Dynamic prediction model.
After completing the obstacle avoidance, the motion path of R 1 is A → B → B → B → E.
Table 6 presents the shortest distance predicted by R
2. Because R
1 stops avoiding at point B, the azimuth angle
Geometric model table.

Comparative experiment of dynamic obstacle avoidance
In this section, the effectiveness of the proposed method is further verified by comparing the unpredictable dynamic obstacle avoidance strategy with the dynamic obstacle avoidance strategy in the literature. 18,20 .
Figure 14 shows the 2D grid environment map used in the comparative experiment. The rectangular box in the figure is the area involved in the subsequent obstacle avoidance experiment.

Grid map of comparative experiment.
Experiment 6: Dynamic obstacle avoidance of robot with constant velocity
As shown in Figure 14, the red “*” represents R
1, and the blue “•” is R
2, represents the collision point. The speed of R
1 is one step per second, R
2 is two steps per second, and the speed remains constant. The detection radius of R
2 is 8, and the priority of R
1 is higher than that of R
2.
Figure 15(a) shows the robot’s path map formed according to our obstacle avoidance strategy. Within the detection radius of the robot, the collision will be judged according to formula (13) for each position the machine travels. When R 1 moves to position 3 and R 2 moves to position 11, R 2 calculates L min ≈ 0. And the two robots will collide at a point in front. At this time, R 2 stops at position 11 and starts obstacle avoidance. Finally, the motion path of R 1 is 1 → 2 → 3 → 4 → 5 → 6 → 7 → 8, the motion path of R 2 is 9 → 10 → 11 → 11 → 11 → 12 → 5 → 13 → 14 → 15. R 2 avoid obstacle successfully.

((a) to (c)) Contrast experiment with constant speed.
Figure 15(b) is a path map of the robot formed by adopting the obstacle avoidance strategy in the study by Wang et al. 18 Because the hypothesis of the strategy is that the dynamic collision point is known, the algorithm cannot calculate the collision point for the obstacles suddenly appearing in the path, and the obstacle avoidance fails. R 1 and R 2 collide at position 5. The motion path of R 1 is 1 → 2 → 3 → 4 → 5, and that of R 2 is 6 → 7 → 8 → 9 → 5.
Figure 15(c) shows the path map of the robot formed by the obstacle avoidance strategy in the study by Wang. 20 Since the speed of the robot remains the same, according to the obstacle avoidance algorithm, we can calculate that collision will occur, start the obstacle avoidance strategy, R 2 accelerates the movement, and the speed will return to the original after the obstacle avoidance is successful. The motion path of R 1 is 1 → 2 → 3 → 4 → 5 → 6 → 7 → 8, and that of R 2 is 9 → 10 → 11 → 5 → 12 → 13.
Experiment 7: Dynamic obstacle avoidance in case of sudden change of robot speed
As shown in Figure 16, the red “*” represents robot R
1, and the blue “•” represents robot R
2, is the collision point. The initial velocity of R
1 is two steps per second, R
2 is one step per second. The detection radius of R
2 is 8, and the priority of R
1 is higher than that of R
2. When R
1 is in position 3, the speed changes suddenly for some reason, and R
1 speed changes to one step per second.

((a) to (c)) Contrast experiment with variable speed.
Figure 16(a) is the path map of the robot formed according to our obstacle avoidance strategy. Within the detection radius of robot R 2, the collision will be judged according to formula (13) for each position the machine travels. When R 2 is in position 8, R 1 is in position 1 and enters R 2 detection range. Then, R 2 moves to position 9, R 1 moves to position 2, and the speed suddenly changes to one step per second. Then, when R 1 is at 4, R 2 is at 12 and R 2 is calculated to be L min ≈ 0, the collision will occur at a later position. R 2 starts obstacle avoidance strategy 3, stops two steps at position 12 and continues to move. The movement path of R 1 was 1 → 2 → 3 → 4 → 5 → 6 → 7, and that of R 2 was 8 → 9 → 10 → 10 → 10 → 4 → 11 → 12 → 13. R 2 avoided obstacles successfully.
Figure 16(b) is a path map of the robot formed by adopting the obstacle avoidance strategy in the study by Wang et al. 18 Because the assumption of the strategy is that the collision point is known, the algorithm cannot calculate the collision point for the obstacles that suddenly appear in the path and the speed changes. The obstacle avoidance fails, R 1 and R 2 collide at position 4. The motion path of R 1 is 1 → 2 → 3 → 4, and that of R2 is 5 → 6 → 7 → 4.
Figure 16(c) is the path map of the robot formed according to the obstacle avoidance strategy in the study by Wang. 20 Because of the sudden change of R 1’s speed in position 3, and the change of moving obstacle’s speed is not considered in the obstacle avoidance strategy. It is impossible to use acceleration or deceleration strategy to avoid obstacles. The obstacle avoidance fails, and R 1 and R 2 collide in position 4.
Conclusion
In this article, for the issue of lunar robot path planning, a heuristic function of ant colony algorithm is improved by adjusting the heuristic function dynamically. By adding adaptive parameters, the success rate of shortest path planned by ant colony algorithm is improved, while the convergence speed is reduced in complex environments. For the predictable and unpredictable dynamic collision problems in the moving route of lunar robot, the corresponding obstacle avoidance strategies are proposed. Especially for detecting unpredictable dynamic obstacles, a collision prediction model based on geometric estimation is proposed, which can avoid collision between robots. The simulation results show the effectiveness of the proposed method. The proposed method enables the lunar robot to travel in the s energy-saving path, that is, the shortest path, and effectively avoids collisions with each other.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Shanghai Aerospace Science and Technology Innovation Fund (SAST2018-086).