
Abstract
Gesture recognition has remained a challenging problem in the fields of human robot interaction. With the development of depth sensors such as Kinect, different modalities become available for gesture recognition while its advantages have not been fully exploited. One of the critical issues for multi-modal gesture recognition is how to fuse features from different modalities. In this article, we present a unified framework for multi-modal gesture recognition based on dynamic time warping. The 3D implicit shape model is applied to characterize the space-time structure of the local features extracted from different modalities. And then, all votes from the local features are incorporated into a common probability space which is then used for building the distance matrix. Meanwhile, an upper-bounding method UB_Pro is proposed to speed up dynamic time warping. The proposed approach is evaluated on the challenging ChaLearn Isolated Gesture Dataset, showing comparable performance in comparison to the state-of-the-art approaches for multi-modal gesture recognition problem.
Introduction
Gestures are elementary movements of human’s arms and hands and are natural and intuitive ways for human robot interaction (HRI). 1 Due to its potential applications in many fields like HRI, 2 sign language recognition, 3 industrial control, 4 computer games, 5 among others, there has been huge interest by the machine learning communities to analyze human gestures from visual data in order to enable robots to read and understand human commands. Recently, the irruption of commercial 3D sensors, such as Kinect, has greatly promoted the research of hand gesture recognition with an extreme enrichment of visual data. As an advanced sensing technology, 3D sensors can capture more comprehensive signals, including RGB video, depth video, and audio. Depth image contains structural information which makes gesture recognition can deal with illumination changes, complex background changes, and be less sensitive to clothing and skin changes. 6 On the other hand, salient information can be extracted from the RGB-D stream, as well as the skeletal information, both of them can be important supplements to the RGB-D videos. As a consequence, with more complete information, multi-modal-based algorithm can improve the performances significantly.
In order to push the boundary of multi-modal methods for gesture recognition, ChaLearn organized several challenges on gesture recognition with Kinect as 3D sensor. 7 In 2013, the challenge focused on user independent multiple gesture learning. 8 A large multi-modal gesture dataset of 13,358 gestures was released, the dataset providing the audio, skeletal model, user mask, RGB, and depth videos. In 2016, the organizer presented two larger multi-modal datasets, the ChaLearn LAP RGB-D Isolated Gesture Dataset (IsoGD) and the Continuous Gesture Dataset (ConGD). 9 The results of two challenges show that the deep learning methods demonstrate the absolute dominance in this field. Neverova et al. 10 developed a deep learning-based framework with an effective fusion strategy which placed first in the first challenge. In the second challenge, the team ASU ranked first, and they used C3D network 11 and Temporal Segment Network (TSN) to extract features. 7 But one of the drawbacks of deep learning based algorithms is the tedious and time-consuming training process. When a new gesture is defined, the model should be retrained and large amounts of processing power is required.
In this article, we pay attention to build an effective and efficient framework to fuse features extracted from different modalities. Our approach integrates several modalities, include RGB and depth images, optical flow fields from RGB channel, and salient information extracted from depth channel, as shown in Figure 1. We make use of different modalities to extract some representative features. And then, 3D implicit shape model (3D-ISM) is applied to characterize the space-time structure of the local features. All votes from local features are incorporated into a common probability space which is then used for building the distance matrix. Finally, dynamic programming algorithm is applied to find an optimal alignment path in the distance matrix. In order to speed up dynamic time warping (DTW), we try to use a cheap upper-bounding calculation to abandon some expensive computation. The major contributions of our work are the following: (1) We propose a unified framework for multi-modal gesture recognition, which can incorporate all features extracted from different modalities into a common voting space; (2) a consensus voting-based extension of DTW method is proposed to achieve a sequence-to-class alignment, which can align one test sequence to the specific class implicitly; (3) a cheap upper-bounding calculation is used to speed up DTW; (4) the proposed approach performs competitively to the state-of-the-arts on the ChaLearn IsoGD dataset.

Examples of different types of modalities. (a) RGB image, (b) depth image, (c) optical flow field, and (d) saliency.
The remainder of the article is organized as follows. The second section briefly reviews the related works on gesture recognition. The third section describes the details of the proposed approach. Experimental results are presented in the fourth section. The fifth section concludes the article.
Related work
The field of gesture recognition has advanced rapidly, researchers have proposed a large amount of gesture recognition algorithms which achieved impressive performances in both accuracy and speed.
Gesture recognition
Early gesture recognition approaches relied on wearable devices. Keskin et al. 12 developed a real-time hand tracking system with the help of a colored glove, and then the trajectory of hand can be obtained via 3D reconstruction. Using electromyogram sensors, the “Myo” armband measures electrical activity from muscles to detect five gestures. 13 Although these wearable devices perform well, but additional burden would make users feel uncomfortable to perform gestures, which is the fatal weakness for HRI applications. 1
Vision-based gesture recognition can offer a natural way to enable human to communicate with robot efficiently. Traditional machine learning algorithms pay more attention on hand-crafted features. Wu et al. 14 Extended-Motion-History-Image (Extended-MHI) feature to capture holistic structural information. Hernndez et al. 15 proposed a mixed feature descriptor named Viewpoint Feature Histogram Camera Roll Histogram (VFHCRH) to address the information loss of the VFH feature on the roll view. Wan et al. 16 proposed a novel spatiotemporal feature named Mixed Features around Sparse Keypoints (MFSK), which used Speeded Up Robust Features (SURF) detector 17 to initial keypoint detection and used optical flow method to filter the points with less motion. However, this kind of method uses the bag-of-vision-word model 16 to integrate all features, the main drawback is their negligence of global structure information.
Feature extraction is the first step of gesture recognition and gesture classification is the last but most important step. Hidden Markov Model (HMM) is a widely method used for gesture recognition. Wu et al. 18 used audio data to segment continuous gesture into isolated clips, and a late fusion strategy was employed to fuse the results of HMM classifiers applied to both audio and skeleton features. Miranda et al. 19 represented gesture as the sequence of key poses and decision forest is applied to label gestures. Zhang et al. 20 trained Support Vector Machines (SVMs) to classify the dynamic American Sign Language (ASL) gestures in the MSRGesture3D dataset. Lin et al. 21 combined Kernel Principal Component Analysis and Nonparametric Discriminant Analysis to extract discriminative features and achieve a robust gesture recognition with a simple Nearest Neighbor (NN) classifier. Hence, the DTW approach has been successfully used for recognizing signed digits. 22 Recently, some specific neural networks have been proposed to extract robust feature 7 or achieve an end-to-end classifier directly. 23
Multi-modal fuse
A survey by Escalera et al. 7 provided a high-level overview of the recent approaches for multi-modal gesture recognition. As we can see, the performance of gesture recognition has been improved due to the enrichment of information. Wu and Cheng 6 proposed a novel Bayesian Co-Boosting framework for multi-modal gesture recognition. Multiple HMM classifiers were trained collaboratively to construct a strong classifier which achieved 97.63% on the ChaLearn Multi-modal Gesture Recognition dataset. Molchanov et al. 23 used 3D convolutional deep neural networks to fuse information from multiple spatial scale for gesture recognition in driver assistance scenario. Also for dynamic car-driver gesture recognition, Molchanov et al. 24 applied convolutional deep neural networks to fuse data from multiple sensors (RGB camera, Time of Flight depth and Radar). To handle the problem variable-length gestures, Long Short-Term Memory (LSTM) cells were integrated into the Recurrent Neural Networks to consider temporal dynamics. 25 Neverova et al. 10 proposed a multi-scale and multi-modal deep learning to classify gestures robustly with restricted number of free parameters. Duan et al. 26 proposing a unified framework to fuse information from multi-modalities, and a depth-saliency stream was used to remove the noises from backgrounds.
DTW
Considered as the sequential data, the dynamic gesture recognition can be also handled by DTW. Typically, DTW was regarded as the preprocessing step to perform the begin–end segmentation of continuous gestures. Reyes et al. 27 presented a begin–end gesture recognition approach using feature weighting in the DTW framework. Cheng et al. 28 proposed a Windowed DTW to detect the beginning and end of the specific gesture from an infinite trajectory gesture sequence. A searching window was used to handle the problem of gesture overlapping. Hernndez-Vela et al. 15 presented a probability-based DTW that utilizes Gaussian Mixture Models to model the variance caused by environmental factors. And the proposed approach was used to segment continuous gesture into isolated clips. However, combining with NN algorithm, DTW is a powerful method to recognize gesture as a distance measure. Konecny al. 29 aggregated Histogram of Oriented Gradient (HOG) and Histogram of Flow (HOF) features as representation of each frame and used Quadratic-Chi distance to build the temporal cost matrix, finally Viterbi algorithm was applied to find the shortest path. Krishnan and Sarkar 30 proposed a conditional distance which got the distances named warp vectors between two gesture sequences using a third sequence, and DTW process was performed again between the two warp vectors to get final label.
Methodology
The overview of the proposed approach
In this article, we focus on isolated gesture recognition with RGB-D video. The global pipeline of the proposed approach is illuminated in Figure 2. The first step is feature extraction, besides RGB data and depth data, optical flow fields and saliency map are used to extract efficient features. And then, 3D-ISM is applied to model the spatiotemporal structure of the local features. In the classification step, after feature extraction, all votes from the local features are incorporated into a common probability space which is then used for building the distance matrix of DTW. Finally, we adopt dynamic programming algorithm to find the optimal path and label the gesture with NN method.

General pipeline of the proposed approach.
Preprocessing
The purpose of preprocessing is to improve the robust of feature extraction. Firstly, a median filter and in-painting are applied to remove the noise in depth data, especially the holes occur usually along the edges. Secondly, because of the structural information contained in depth data, some image segmentation algorithm can be applied to achieve background subtraction. The effects of median filter and background subtraction are shown in Figure 3.

The results of the preprocessing step. (a) Origin image, (b) image smoothing, and (c) background subtraction.
Feature extraction
In this article, we extract two kind of local features to represent the gesture, MFSK and Salient Features based on Reference Frame (SFRF). MFSK feature is a novel spatiotemporal feature which is robust and invariant to scale, rotation, and partial occlusions. 16 MFSK uses SURF detector 17 to initiate the keypoint detection. And then optical flow field are acquired to calculate the velocities of all keypoints. The keypoints with small velocities will be treated as motionless points and be deleted. The velocity threshold of layer l is defined as

where

The descriptors of MFSK feature.15 MFSK: Mixed Features around Sparse Keypoint.
The SFRF feature extracts salient region through a bidirectional reference frame search algorithm, and the features outside the salient region will be deleted. Reference frame search contains forward search and backward search. The reference frame

where

Finally, keypoints will be filtered by salient region, and HOG descriptor is computed on both RGB and depth patches around keypoints. HOG features are computed with a small patch around the point. We extract local patches on both color and depth images. The local patch is a square area which has
3D-ISM learning
The ISM is a classical algorithm used for detecting and localizing objects of a visual category. The ISM has two basic steps: learning appearance codebook and learning spatial distributions. 31 The first step extracts local features at interest points and groups them with an agglomerative clustering scheme. The second step performs a second iteration over all features and stores all relative positions for each codebook. The 3D-ISM is an extension of ISM on temporal domain, Figure 5 shows the difference of them.

ISM and 3D-ISM. ISM: implicit shape model.
Given a training dataset VD
, we can extract different features separately,
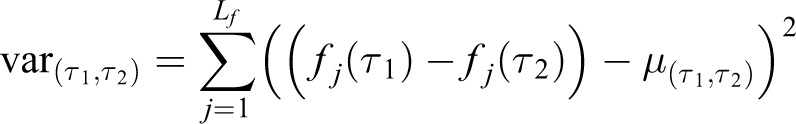
where

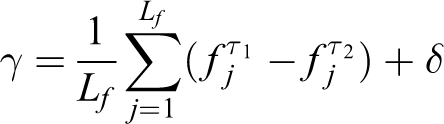
where
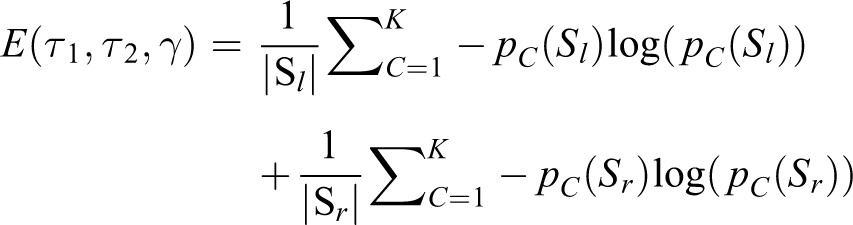
where
Based on the above steps, each leaf is treated as a codebook entry and the next step is to learn the spatiotemporal probability distribution. As shown in Figure 6, for all features in training data, a second iteration is performed to find the best-matching codebook entry, and the position information will be merged into the list of occurrences which represents the spatiotemporal probability distribution implicitly.
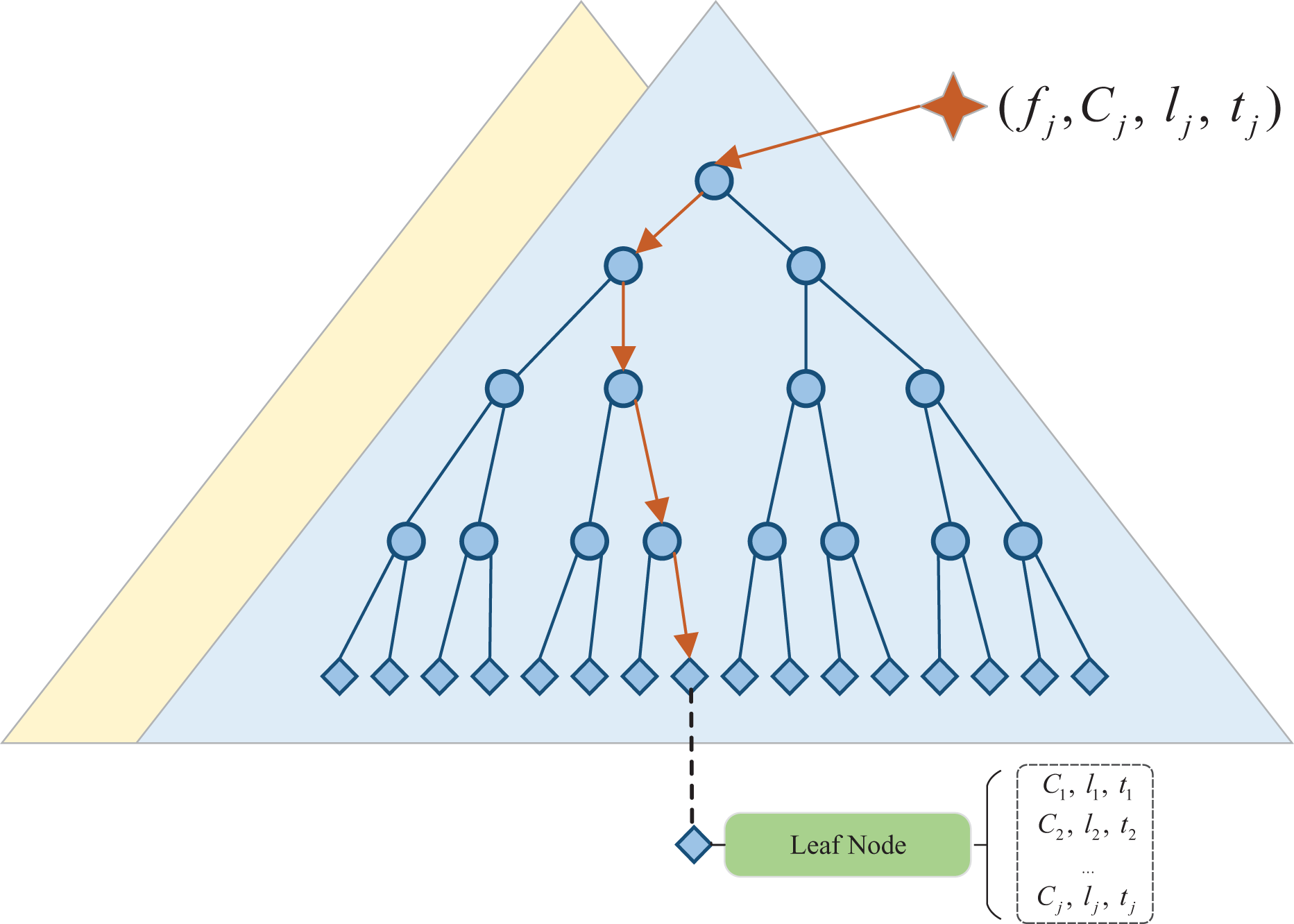
Building the voting space of the 3D-ISM. ISM: implicit shape model.
Consensus voting strategy
Let
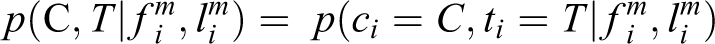
We define the 3D-ISM as

The previous item refers to the similarity based on the spatial shifts and be computed as:

where Z is a normalization constant and 2 is a bandwidth parameter. The latter item can be considered as a weighting coefficient and be calculated as

where LT
refers to the number of trees,
Therefore, given an feature

where each column is the temporal probability of each feature and each row refers to the temporal probability of each frame. Finally, we can obtain the cost matrix

Classification
The naive DTW attempts to find an optimal alignment between two temporal sequences
As shown in “Consensus voting strategy” section, 3D-ISM is applied to characterize the space-time structure of features extracted from all training samples. And then we can extract features from test sequence Q,

Following three basic constraints: boundary, continuity, and monotonicity constraints, there still can find various warping paths VW
. Let

where
Contrary to the classical DTW, the cost matrix represents the similarity of two sequences, which means the optimal path is the path has maximal value
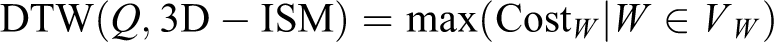
This path optimization problem can be solved by dynamic programming28

where
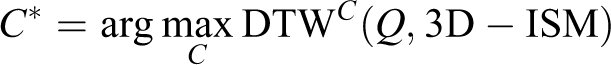
As we know, the DTW is a robust distance measure, while it needs mass computing. Lower-bounding methods can address this problem by using a cheap lower bounding function to abandon invalid matching. 33 Similarly, we proposed a upper bound function named UB_Pro, which is defined as

where
An algorithm that uses UB_Pro to speed up DTW.

Experiments and results
Datasets
The ChaLearn LAP RGB-D IsoGD is a very representative gesture dataset released on Look At People challenge, and it is the first large-scale RGB-D gesture dataset. 9 The dataset contains 47,933 gesture samples labeled into 249 categories, including 35,878 training samples, 5784 validation samples, and 6271 test samples. Each sample contains only one gesture. The dataset uses a depth camera to record RGB and depth videos by 21 different people. Figure 7 shows some examples from the gesture dataset.

Some samples from the ChaLearn IsoGD. IsoGD: Isolated Gesture Dataset.
Experimental setup
In this article, all models are trained using training samples, parameters are validated on the validation set, and we report our result based on the test set. We extract two local features, the first one is MFSK feature and SFRF feature. The MFSK feature are extracted using the code given in the study by Wan et al.,15 and the parameters follow the default setting. The dimension of the MFSK Feature is 1024. We use significant local features, which is based on the reference frame and have been filtered out invalid features, to extract the local HOG feature descriptor of depth image and RGB image respectively to obtain the 256-dimensional feature descriptor.
In the process of 3D-ISM learning, it is unnecessary to use all training samples. So we used one-tenth of the training set to train the random forest, and using all samples to learn the spatiotemporal probability distribution. On the other hand, the number of trees is set to 100 and the tree depth is set to 15 as given in the study by Yu et al. 32 In order to ensure the balance of category voting, the number of samples from each category used for random forest learning process is the same. To ensure the spatial information is not disturbed by the movement of human body, we detect the human face center using the code from the study by Zhang et al., 34 and then treat it as the reference center to correct the movement bias.
In order to verify the effectiveness of the proposed approach, the approach is compared with the winners of ChaLearn 2017 large-scale gesture recognition challenge, all of them used deep learning totally or partly. 9 The team ASU and SXDETVP used the deep neural networks to extract features, and then support vector machine was applied achieve classification. While other teams used post fusion framework to integrate multiple deep neural network streams to predict label. 9 In this article, we use the same data and evaluation measure as the above approaches, then the results are shown in the following section.
Results
The proposed approach can fuse multiple features, such as MFSK features and SFRF features used in this article. In order to find the effectiveness of each feature, we evaluate the features in our experiments separately and jointly. Table 2 shows the results. We can see that although MFSK feature is more powerful, but the result is poor. The reason for this gap should be that SFRF can retain the information in both movement and holding phases which is more suitable to DTW. Overall, the combination of these two features can achieve better performances than using individual features. The results show that the verification set has been improved by 6.78% and 5.91% for the test set.
The performances of different features on dataset.

MFSK: Mixed Features around Sparse Keypoint; SFRF: Salient Features based on Reference Frame.
We expect the number of training samples to be an important constraint for the learning of codebook in 3D-ISM. Hence, we quantitatively measure the impact of the different number samples

Results on ChaLearn IsoGD for using different numbers of samples to learning the codebook of 3D-ISM. IsoGD: Isolated Gesture Dataset; ISM: implicit shape model.
Table 3 shows that, compared with the start-of-the-art approaches, the proposed approach in this article has competitive results. However, compared with the best approach ASU, 9 it is 0.93% lower in the validation set and 2.49% lower in the test set. Because they use C3D and TSN networks to extract powerful features which provides strong support for the performance. While our approach is a kind of traditional machine learning approach, which does not need complex and tedious training process.
Comparison with the state-of-the-art approaches.

TSN: Temporal Segment Network; LSTM: Long Short-Term Memory; ISM: implicit shape model.
Conclusion and future work
In this article, a unified framework for multi-modal feature fusion based on consistent voting is proposed, in which 3D-ISM is used to learning the space-time structure of features. And then, all votes from the local features are incorporated into a common probability space which is then used for building the distance matrix. The approach proposed in this article gets comparable results on the large-scale ChaLearn IsoGD. Although there is a slight gap between the final results and the approaches based on deep learning, while it avoids the tedious and fussy training process, and the flexible framework can merge new samples efficiently without retraining.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.