
Abstract
This article addresses the robot pathfinding problem with environmental disturbances, where a solution to this problem must consider potential risks inherent in an uncertain and stochastic environment. For example, the movements of an underwater robot can be seriously disturbed by ocean currents, and thus any applied control actions to the robot cannot exactly lead to the desired locations. Reinforcement learning is a formal methodology that has been extensively studied in many sequential decision-making domains with uncertainty, but most reinforcement learning algorithms consider only a single objective encoded by a scalar reward. However, the robot pathfinding problem with environmental disturbances naturally promotes multiple conflicting objectives. Specifically, in this work, the robot has to minimise its moving distance so as to save energy, and, moreover, it has to keep away from unsafe regions as far as possible. To this end, we first propose a multiobjective model-free learning framework, and then proceed to investigate an appropriate action selection strategy by improving a baseline with respect to two dimensions. To demonstrate the effectiveness of the proposed learning framework and evaluate the performance of three action selection strategies, we also carry out an empirical study in a simulated environment.
Introduction
The pathfinding problem has been extensively studied in the robot domain, where the robot has to generate a collision-free path in a given or an unknown environment. 1,2 In this work, we seek to address the robot pathfinding problem with environmental disturbances. The major challenge of such a problem is that the movements of the robot can be disturbed by its environment. As a result, the robot cannot execute a planned trajectory with high precision towards its destination. For example, the motion of an underwater robot can be seriously disturbed by ocean currents, and thus any applied control actions to this robot cannot exactly lead to desired locations. 3 Therefore, traditional offline planning approaches cannot be applied to solve such a problem with dynamic environmental disturbances.
Reinforcement learning (RL) is an effective paradigm for sequential decision-making by learning through trial-and-error interactions with its environment. Currently, most RL algorithms are dedicated to maximise only one long-term objective, encoded by the sum of a (discounted) scalar reward. However, in practical applications, the robot pathfinding problem with environmental disturbances naturally can promote multiple conflicting objectives. Specifically, in this work, we consider that the robot has to minimise its moving distance so as to save energy, and, moreover, it has to keep away from potential unsafe areas as far as possible. The former issue has been heavily researched in the typical robot pathfinding problem, whereas the latter issue only occurs in the environment with uncertain disturbances.
In this work, the trade-off between multiple conflicting objectives will be realised by a multiobjective model-free learning framework. In RL algorithms, a learning agent has to decide whether to search for new information or to apply its current knowledge so as to select the action that leads to the maximal reward. Of course, the learning agent is expected to find the optimal policy in as few actions as possible. However, for a specific learning task, it is impracticable to directly reach a conclusion on which action selection strategy will perform the best. The action selection strategy is also called exploration strategy in some literature. 4 Typically, the set of learning parameters will be adjusted throughout hand-tuning for determining the appropriate parameters. In this work, we also seek to investigate an online method for adjusting the set of learning parameters so that the optimal policy for pathfinding can be obtained in as few steps as possible.
This work focuses on the robot pathfinding problem in an initially unknown, stochastic environment with several conflicting objectives. The main contribution of this work includes: a multiobjective model-free learning framework that can handle multiple conflicting objectives; an action selection strategy for the pathfinding problem with respect to two dimensions (D1: the learning agent is expected to prefer exploring the environment in the beginning, while it will gradually adopt its obtained knowledge to select the best known action instead of always keeping exploration. D2: the learning agent should pay more attention to potentially promising actions so that the learning process can quickly coverage to the optimal policy); and an empirical study to demonstrate the effectiveness of the proposed model-free learning framework, as well as to evaluate the performance of three action selection strategies in a simulated environment.
The article is organised as follows. We begin our work by discussing the state-of-the-art literatures in the ‘Related work’ section. We then discuss the preliminaries of the RL paradigm in the ‘Preliminaries’ section. The proposed multiobjective model-free learning framework is discussed in the ‘Multiobjective model-free learning framework’ section. In the ‘Action selection strategies’ section, we investigate how to improve a baseline action selection strategy with respect to two dimensions. In the ‘Empirical study’ section, we carry out an empirical study by means of a simulator to evaluate the relative performance of three action selection strategies based on the proposed learning framework. Finally, we conclude this work in the ‘Conclusion’ section.
Related work
Pathfinding with uncertainty
The robot pathfinding (or called path planning) problem has been extensively studied in both the robot and agent domains. Some pathfinding solutions ignore uncertainty, and thus a global planner is usually employed to guide the robot towards its destination, 5 such as Dijkstra, Bellman–Ford, Floyd–Warshall, A-star and its variants. 6 –8 A recent advance 9 adopts multiobjective optimisation tools for producing a good path distribution in a known environment, and thus, all the computation is done offline.
Taking account of uncertainty, the robot typically works in a dynamic, stochastic environment where it needs to avoid potential collisions with dynamic obstacles or other moving robots. In such a problem, a scheduled path should be redefined based on local information so that the robot can keep away from nearby obstacles or other robots. The common method that tries to push the robot away from obstacles or unsafe areas is based on artificial potential fields (APFs). 10,11 The basic idea is that the path planner can generate repulsive forces for obstacles/agents and attractive forces for the destination. To this end, many heuristic functions (e.g. the work 11 ) are developed to realise the potential fields of repulsion and attraction. However, an inherent disadvantage of APFs is the tendency to get stuck in local minima of potential functions, especially when generating paths in crowed areas. This is because it is still a challenge for the models of repulsion and attraction to properly integrate local and global information for finding the optimal path. To escape from potential local minimums, the work 12 proposes a sampling-based path planner by utilising the heuristic rules of tabu search to generate paths in unknown environments. Those heuristic rules are developed by capturing the connectivity of environmental configurations and can allow the robot incrementally form a path from the start to the destination.
Evolutionary algorithms are also popular to solve the pathfinding problem in an environment with complex configurations. For example, the work 13 proposes a genetic algorithm to find optimal paths in road networks with time-dependent stochastic travel times. The work 14 also introduces a genetic algorithm to minimise travel distance and maximise path safety. Particle swarm optimisation 15 is applied for a robot to navigate in an environment with various danger sources. In Hidalgo-Paniagua et al., 16 a swarm intelligence algorithm based on the flashing behaviour of fireflies is discussed to generate the optimal path in a static environment.
Most of the evolutionary algorithms focus on the complexity of environmental configurations, but for a dynamic environment, it is still a challenge to generate the optimal path in an efficient manner.
Learning is an effective way for guiding a robot towards its goal in a dynamic environment. Early research 17 has employed supervised learning to train a robot in a given map for deciding its next optimal position. However, a small change in the environment can lead to the failure of executing a planned path. RL is an alternative learning paradigm, in which a learning agent can adapt its parameters based on feedbacks from the environment. 18 Thus, the primary advantage of RL lies in the inherent capability of dealing with the changes of the environment. For example, Q-learning is a popular algorithm for guiding a robot across obstacle areas. 19,20 A mixed learning method that combines supervised learning and RL is presented in the work, 21 where an RL module is employed for searching a better movement, while a supervised learning module is used to prevent the robot from moving out of the boundary. Currently, most RL algorithms consider only a single objective encoded by a scalar reward, so we cannot simply employ a standard algorithm to handle environmental disturbances in the pathfinding problem discussed in this work.
Multiobjective RL
As mentioned above, the pathfinding problem with environmental disturbances naturally can promote multiple conflicting objectives. In the past decades, a great deal of effort has been made to improve computational performance on estimating value functions or policies, and some good results have been achieved in many practical applications. 22,23 Despite the recent advances of those algorithms, a challenge that still needs to be addressed in an RL task is how to model different rewards. Different rewards can be treated as multiple objectives, so the learning agent needs to find the policy that can optimise multiple objectives at each state.
In general, multiobjective RL tasks can be divided into three categories. 24 In the first category, all the objectives are independent of each other, so they can be optimised separately. In the second category, all the objectives are positively interdependent on each other, so an overall objective needs to be derived by integrating all of them. In the third category, some of the objectives are negatively interdependent on each other, so a trade-off among the conflicting objectives needs to be investigated. Two common strategies are used to solve the multiobjective RL problem, that is, single-objective strategy 25,26 and the Pareto strategy. 27 The basic idea of the single objective strategy is to find the best single criterion to represent the preferences or priorities of multiple objectives. Many variants of the single objective strategy are produced by defining a function to express the preferences for a specific task. 28 In contrast, the Pareto strategy can cope with cases in which the preferences among the objectives cannot be easily identified. In this case, a solution is required to find the set of policies that approximate the Pareto front.
In this work, we assume that the robot has two conflicting objectives: one is to minimise its path costs and the other is to keep away from unsafe areas as far as possible while navigating to its destination. Thus, we cannot simply define preferences between these two objectives or find a dominate one. We aim at designing a Synthetic Objective Function that can take account of the interests of both objectives.
Preliminaries
The standard RL framework is modelled by the Markov decision process (MDP) that can be defined as a tuple
In RL, the learning agent interacts with its environment via perceptions and actions. At each time step t, the agent perceives its current state
The reward function only captures the immediate impact of taking an action. A policy
The goal of the agent in RL is to find the optimal policy that maximises the long-term sum of discounted rewards from any initial state s. This long-term sum of discounted rewards is captured in a value function

where
Given a fixed policy π, the value function

The idea of dynamic programming can be used to iteratively update the value function. If the optimal value function is defined as

Value-based RL algorithms
29
are frequently used to maximise the long-term sum of discounted rewards. In addition to the value function
Multiobjective model-free learning framework
In RL, if the model that predicts the behaviour of the environment is known, the state transition function P and reward function R are available for the learning agent to predict the next state and immediate reward. In this case, the value function can be obtained by performing a full-width lookahead over all possible actions and state transitions, and thus model-based algorithms such as dynamic programming can be used to update the value function by a full backup. In contrast, if the model is unknown, the agent needs to interact with the environment to learn the model, and then the value function is updated from sampled experience.
In this work, as we address the problem in which the environment is initially unknown, we focus on the model-free RL task. Thus, the learning agent needs to learn the state transition and reward from experience. Q-learning is one of the model-free RL methods that can directly learn from experience without the model of the environment’s dynamics. In this section, we will introduce a multiobjective Q-learning (MQ-Learning) algorithm to resolve the pathfinding problem studied in our article.
Temporal difference prediction
In standard single-objective Q-learning, the learning agent can directly estimate the action-value function (or called Q-value)
In this work, we use
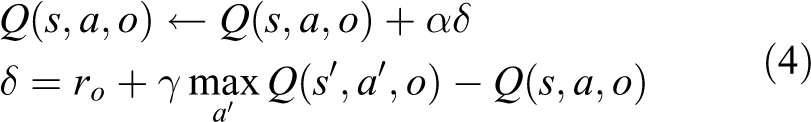
where α is the learning rate, γ is the discount factor and δ is the temporal difference error. It is obvious that the above equation only needs one time step to back up the Q-value, and such an approach can be implemented in an online, fully incremental fashion.
As the robot pathfinding problem may have very long steps in each episode, it is intractable to delay all learning until an episode’s end. Thus, we can say that MQ-Learning takes the advantages of temporal difference and does not need to update the Q-values until the end of an episode. Such an online learning property ensures that the learning agent can learn from each transition regardless of what subsequent actions will be taken.
Synthetic objective function
According to equation (4), the learning agent can recursively obtain the true value of

When all the objectives are dependent on each other, we can combine those objectives together by a synthetic objective function
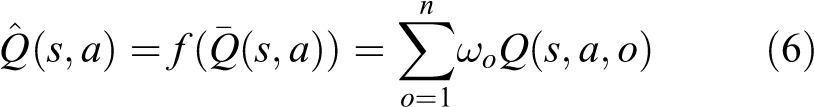
In the above linear weighted scalarisation formula, the relative importance of each objective o is defined by its weight
EEV of multiple objectives
In multiobjective RL, when the learning agent moves to a new state, it will receive a vector-valued reward that is then employed to update the vector of the Q-value

In the above equation, the EEV
MQ-learning framework
Based on the synthetic objective function and the theory of single-objective learning, we come up with an MQ-Learning framework, and its pseudocodes are outlined in Algorithm 1.
Multiobjective Q-Learning framework.


We can see that the temporal difference error of the MQ-learning is corrected by
In line 8, we can see that a synthetic objective function is used to obtain an estimated Q-value
Action selection strategies
For the pathfinding problem in an initially unknown environment, the learning agent first needs to learn the Q-values to generate an optimal path. In learning periods, the agent must try out available actions in each state and learn from the experiences over time. In each state, the robot needs to select an action according to a particular policy to update the Q-values. Such an action selection strategy is confronted with the trade-off dilemma between exploitation and exploration. Specifically, finding a good balance between exploiting current knowledge to generate the best known path, or exploring new actions in the hope of improving the current policy.
In this section, we seek to investigate an appropriate action selection strategy that is particularly suitable for the pathfinding problem in an initially unknown and stochastic environment. To this end, we will first discuss a baseline strategy, and then try to improve the baseline with respect to two dimensions.
Baseline: Standard ε-greedy strategy
As the goal of the learning agent is to maximise the reward over time, a naive action section strategy is to simply choose the action that can lead to the greatest reward. This is a greedy method, in which the learning agent always exploits its current knowledge about the reward distribution of the environment to select actions. Thus, the greedy strategy will never allow the robot to explore new actions. Consequently, it almost universally arrives at a suboptimal solution.
A popular action selection strategy in RL is the ε-greedy strategy that combines the greedy property with the random property. In this strategy, the learning agent will select what it believes to be the optimal action with high probability but occasionally select the other actions randomly with equal probability. The other random actions may not be estimated to be optimal, but they may provide new information about the environment to the agent. The ε-greedy action selection strategy is expressed as follows

According to the baseline ε-greedy rule, the action with highest value will be selected at the most time with probability
Thus, ε is the adjustable parameter that determines the probability of selecting an action. In this work, when the proposed MQ-Learning framework adopts ε-greedy strategy for selecting actions, the resulting algorithm is called standard MQ-Learning.
For the pathfinding problem studied in our work, an appropriate action strategy still needs to take account of the following two dimensions:
Dimension 1: Initially explore more, gradually exploit more. Ideally, a learning solution for pathfinding in an initially unknown environment should encourage the agent to explore the environment in the beginning. When the agent gradually gains more information about the environment, it should naturally prefer using the current knowledge to plan the best known path, instead of always keeping exploration.
Dimension 2: Considering relative values of all actions. Ideally, to facilitate the learning agent’s ability of gathering enough information about the environment, all the non-optimal actions should not be selected with equal probability, but the relative value of each action should be taken into consideration. Thus, the action selection strategy is expected to ensure that the learning agent can pay more attention to potentially promising actions and ignore suboptimal actions.
Considering dimension 1: Adaptive ε-greedy strategy
According to the first dimension discussed above, a disadvantage of the standard ε-greedy strategy is that with the increase of the number of exploration, all the non-greedy actions are always tried with equal probability ε. However, to enhance learning performance, we hope that observed best actions should progressively receive more trials instead of with a fixed probability
In other words, at the start of the learning process, the parameter ε should be initialised to a large value so as to encourage exploration for the sake of knowing little about the environment. However, the parameter should be annealed down while the robot has already learnt enough knowledge about the environment.
To adapt the parameter ε during the learning process, the standard ε-greedy action selection strategy can be improved by iteratively updating the parameter ε according to the number of learning episodes

where
Consequently, the action with the best value can progressively receive more trials, which is in line with the expectation for pathfinding in an initially unknown environment.
In this work, when the proposed MQ-Learning framework adopts the adaptive ε-greedy strategy, the resulting algorithm is called adaptive MQ-Learning.
Considering dimension 2: Fitness proportionating strategy
According to the second dimension discussed in the ‘Baseline: Standard ε-greedy strategy’ section, a disadvantage of both standard and adaptive ε-greedy strategies is that the action with highest value is selected with probability
Therefore, we can claim that such an action strategy cannot reveal the importance of the relative value of each action. To address this issue, the fitness proportionating strategy that borrows the idea of the fitness function of genetic algorithms 30 can satisfy this requirement. The probability of choosing an action is calculated based on the estimated Q-values
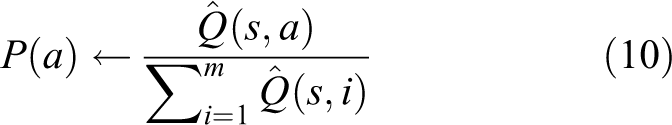
Once the probability of selecting an action is obtained, the action selection mechanism can be realised by means of the roulette wheel selection method. For example, Algorithm 2 shows how to apply the fitness proportionating strategy for selecting actions.
Roulette wheel action selection using fitness.


However, it should be noted that the fitness proportionating strategy can be only applied in the cases, where the estimated Q-values must be represented with positive values. Otherwise, the calculated probability cannot be applied for action selection. However, in the pathfinding problem, the learning agent may receive negative rewards when it is close to unsafe areas, so the estimated Q-values might be negative. Thus, this strategy cannot be directly applied to the pathfinding problem studied in our work. Besides, although the fitness proportionating strategy indeed takes account of the importance of the estimated Q-values, it leaves out the parameter ε. Thus, it does not address the issue of ‘Dimension 1: Initially explore more, gradually exploit more’. In the next subsection, we will discuss a more complex strategy that combines the properties of the adaptive ε-greedy strategy and the fitness proportionating strategy.
Considering both dimensions: Boltzmann distribution strategy
Taking account of ‘Dimension 1: Initially explore more, gradually exploit more’ and ‘Dimension 2: Considering relative values of all actions’, we come up with the Boltzmann distribution strategy for multiple objectives that combines the advantages of the adaptive ε-greedy strategy and the fitness proportionating strategy, as depicted in Figure 1.

The Boltzmann distribution strategy considers both dimensions.
According to the combined feature, the learning agent should select an action based on its weighted relative value, instead of always selecting the optimal action or a random action. To this end, we use the following softmax function to obtain the probability of choosing an action:

where the parameter τ is called the temperature. In the above softmax function, the estimated Q-values can be negative or positive, which remedies the defect of equation (10). At the beginning of the learning process, the temperature is high, so all actions will be selected with almost equal probability regardless of their relative values. To address the issue of ‘Dimension 1: Initially explore more, gradually exploit more’, the temperature should be annealed down over time during the learning process. As a result, the learning agent will most likely choose higher value actions, but it is not guaranteed. Thus, the temperature parameter can decide to what extent the softmax distribution will be spread. At the end of the learning process, the parameter will approach zero, so all actions are sparsely distributed, and the action selection converges towards a greedy method.
In this work, when the proposed MQ-Learning framework discussed in the ‘Multiobjective model-free learning framework’ section (see Algorithm 1) adopts the Boltzmann distribution strategy for selecting actions, the resulting algorithm is called softmax MQ-Learning. Since the proposed softmax MQ-Learning algorithm completes the previous framework in many places, we provide the pseudocodes that detail how to implement the algorithm for the robot pathfinding problem in Algorithm 3.
Softmax MQ-Learning algorithm for pathfinding.


We can see from the pseudocodes that the temperature parameter will be annealed down during the learning process (line 7), so all actions will be selected with almost equal probability in the beginning. Gradually, the learning agent will most likely choose higher value actions. Moreover, the information about the estimated Q-values is taken into consideration, and all the actions are weighted by their relative values (lines 14 and 15). Similar to Algorithm 2, once the probability of choosing actions is obtained, the action selection mechanism is realised by the roulette wheel method (lines 12–19). In the pathfinding problem, such a softmax probability distribution can ensure that the learning agent will pay more attention to potentially promising actions and ignore suboptimal actions. Finally, the learning process can coverage to the optimal policy.
To sum up this section, we can utilise three feasible action selection strategies to produce the following algorithms: standard MQ-Learning algorithm, adaptive MQ-Learning algorithm, and softmax MQ-Learning algorithm. The performance of those algorithms will be evaluated in the next section.
Empirical study
To demonstrate the effectiveness of the proposed MQ-Learning framework, as well to evaluate the performance of three action selection strategies, we carry out an empirical study in a simulated environment. In the experiment, we consider two conflicting objectives: one is to generate a collision-free path as short as possible and the other is to keep trajectory points away from unsafe areas as far as possible.
Experiment setup
As shown in Figure 2(a), the environment is built up by a grid map, where the robot needs to start from the upper left corner of the map and then move towards its destination located at the lower right corner of the map by following a collision-free path. In the grid map, the blue cells with different shades represent the areas with different dangerous levels, so the robot needs to keep away from those blue cells. For the pathfinding problem with environmental disturbances, the robot may be at risk if its trajectory points are too close to those blue cells.

The environment and the generated paths by different algorithms: (a) the simulated environment, (b) generated path by standard MQ-Learning, (c) generated path by adaptive MQ-Learning, and (d) generated path by softmax MQ-Learning. MQ-Learning: multiobjective Q-learning.
In the experiments, the proposed MQ-Learning framework with three action selection strategies are evaluated, respectively. In the figures throughout this work, the corresponding algorithms are labelled as standard MQ-Learning, adaptive MQ-Learning and softmax MQ-Learning. The learning parameters for those algorithms are the same for each simulation run. In the learning periods, the Q-table is obtained by these algorithms. After learning is over, the optimal path is generated from the robot’s starting location towards the destination. Each simulation has been run for 10 times to reduce variance and filter out random effects.
Effectiveness of finding paths
As mentioned before, in this work, we study the problem where the environment is initially unknown, so the state transition function and reward function are not available in advance for directly generating a feasible path.
Instead, the learning agent has to interact with the environment to learn the model of the environment during the learning process. Gradually, the Q-value of selecting an action in each state is updated from experience. We set the upper bound of the learning episodes to 1000 (i.e.
In general, we can see that when the proposed multiobjective learning framework adopts three different action selection strategies, all the resulting algorithms can successfully generate a collision-free path after the learning process. Of course, the collision-free path generated by a specific algorithm can be different in each simulation run. Only looking at the final generated paths, we cannot simply identify which algorithm performs the best with respect to the shortest distance and the safety concern. Nevertheless, we can still claim that the proposed multiobjective learning framework can provide an alternative solution for finding a feasible path in an initially unknown and stochastic environment.
Learning performance
We can further evaluate the three algorithms by looking at their respective learning curves, as shown in Figure 3. To clearly distinguish those algorithms, Figure 3(a) depicts the complete 1000 learning episodes, whereas Figure 3(b) zooms in the last 200 learning episodes. The value of the vertical axis indicates how many moving steps the learning agent will take from the start location to the destination in each episode.

Relative learning performance of the proposed algorithms: (a) all 1000 learning episodes and (b) last 200 learning episodes.
In Figure 3(a), we can see that the learning curves of the standard and adaptive MQ-Learning algorithms almost overlap. Actually, when we zoom in the last 200 episodes (see Figure 3(b)), we can notice that the standard MQ-Learning algorithm cannot converge to the optimal value at the end of learning. This is because the Standard MQ-Learning applies a fixed ε-greedy rule, and, thus, the learning agent always selects the action with the highest value with probability
Therefore, at the end of the learning process, the agent still has the tendency to explore the non-optimal actions with probability ε. Comparatively, according to the rule of adaptive MQ-Learning, the parameter ε will adapts itself according to the number of learning episodes. It will approach zero at the end of the learning process, so the learning agent will select the optimal action in a greedy manner. Thus, we can say that in the early stage of learning both of the algorithms cannot show significant differences.
However, in the later stage of learning, the adaptive MQ-Learning algorithm gradually needs fewer moving steps for each episode and finally converge to the optimal policy in the end.
Different to the standard MQ-Learning algorithm and the adaptive MQ-Learning algorithm, the softmax MQ-Learning algorithm put in a great deal of effort to explore the state space during the learning process (see Figure 3(a)). Nevertheless, at the end of the learning process, the softmax MQ-Learning algorithm still can quickly converge to the optimal policy. Thus, we can believe that, compared to the other two algorithms, the softmax MQ-Learning algorithm can encourage the learning agent to explore the state space more thoroughly, and, moreover, it can converge to the optimal policy at the end of the learning process, as shown in Figure 3(b). The benefits of encouraging the learning agent to thoroughly explore the state space during the learning process will be analysed by looking deeper into the final policy in the following subsection.
Final policy and optimal actions of all states
Figure 4 depicts the final policy after the learning process is over. The arrows in the cells of the map indicate the optimal action that the robot will choose when it is locating in each state. As can be seen from Figure 4(a) and (b), although both of the standard MQ-Learning algorithm and adaptive MQ-Learning algorithm can produce collision-free paths, but the learning agent does not carefully examine the entire state space during the learning space. As a result, only the cells that are close to the generated path have been explored, and thus their choices for selecting actions can correctly push the robot away from the unsafe areas. However, if we look at the cells deviating from the generated path (e.g. cells located at the bottom left corner and the top right corner), the final policy cannot ensure that the robot will be guided to the right direction. Therefore, we believe that if the robot is located in those cells occasionally by environmental disturbances (e.g. an underwater robot is drifted away from the generated trajectory by ocean currents), the robot will make incorrect decisions by following the final policy.

The final policy for each state after learning. the final policy produced by (a) standard MQ-Learning, (b) adaptive MQ-Learning, and (c) softmax MQ-Learning. MQ-Learning: multiobjective Q-learning.
Comparatively, if the final policy is obtained by applying the softmax MQ-Learning algorithm (see Figure 4(c)), the robot will always be pushed away from the unsafe areas in any cells, and the optimal action can always guide the robot towards the destination. Thus, we can claim that if the robot is drifted away from the generated path due to uncertain environmental disturbances, it still can make appropriate adjustments according to the final policy. In other words, after the learning process, the softmax MQ-Learning algorithm is capable of producing optimal actions for all the states. This is because the softmax MQ-Learning algorithm allows the learning agent to explore the environment thoroughly for gathering enough information, which can also be found in Figure 3.
To sum up this section, we conclude that the adaptive MQ-Learning algorithm and the softmax MQ-Learning algorithm can produce the shortest path after the learning process. Most importantly, the softmax MQ-Learning can ensure that even if the robot is drifted away from the generated path by environmental disturbances, the final policy can provide correct information for the robot to make appropriate adjustments.
Conclusion
In this article, we focus on the robot pathfinding problem in an initially unknown and stochastic environment with conflicting objectives. To resolve this problem, we are interested in an RL approach, in which a learning agent needs valuable experiences to learn a good policy that can lead to the optimal path, but it also needs a good policy to guide itself and obtain those experiences. We come up with an MQ-learning framework, and to produce an appropriate action selection strategy, we proceed to improve a baseline strategy with respect to two dimensions, resulting in three learning algorithms. We evaluated those algorithms in a simulated environment. The results show that the adaptive MQ-Learning algorithm and the softmax MQ-Learning algorithm can produce the shortest path at the end of learning. Only the softmax MQ-Learning algorithm can ensure that even if the robot is drifted away from the generated path by environmental disturbances, the final policy can provide correct information for the robot to make appropriate adjustments. This is because, according to the softmax MQ-Learning algorithm, the learning agent can thoroughly explore the state pace during the learning process. As a result, enough information about the environment can be obtained to find the true Q-values of all states. As many practical applications involve several conflicting objectives, we believe that the proposed learning framework and associated action selection strategies can also be applied to any tasks as long as the system can be modelled as a multiobjective MDP.
In future, we would like to investigate the RL approach to the pathfinding problem in large or continuous state space. In such a case, we must employ function approximation to estimate the values of each state because it is intractable to store all the values of so many states, and the learning agent cannot sufficiently explore all the states to obtain the true values of all the states.
Footnotes
Acknowledgement
We would like to thank the anonymous reviewers, whose insightful comments can greatly improve the quality of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the National Natural Science Foundation of China (grant no. 61703138) and Natural Science Foundation of Jiangsu Province (grant no. BK20170307).