
Abstract
Robust locomotion in a wide range of environments is still beyond the capabilities of robots. In this article, we explore how exploiting the soft morphology can be used to achieve stability in the commonly used spring-loaded inverted pendulum model. We evolve adaption rules that dictate how the attack angle and stiffness of the model should be changed to achieve stability for both offline and online learning over a range of starting conditions. The best evolved rules, for both the offline and online learning, are able to find stability from a significantly wider range of starting conditions when compared to an un-adapting model. This is achieved through the interplay between adapting both the control and the soft morphological parameters. We also show how when using the optimal online rule set, the spring-loaded inverted pendulum model is able to robustly withstand changes in ground level of up to 10 m downwards step size.
Keywords
Introduction
Despite the increasing success of robots, autonomous locomotion in rough terrain still remains a challenge. Although some advances in this area have been made, most notably BigDog 1 and the MIT cheetah, 2 the main success of robots has been confined to controlled environments, rather than locomotion in complex, noisy environments. If the environment is too hard to model, even state-of-the-art robots fail and fall over. In contrast to robotics, biological systems in nature are able to successfully navigate and locomote through a wide range of different environments without any loss of stability. 3 –6
There are two main suggestions as to why nature is so successful at locomotion. First, some of the control is outsourced from the controller (or brain) to the body. This is often referred to as morphological computation. 7 –9 It is hypothesized that the soft body is able to navigate rough terrain due to its compliance and, hence, there is no need for an exact model of the environment. Furthermore, the soft morphology is able to facilitate the storage and interchange of energy, making biological systems extremely energy efficient. 10 Another reason why animals are so successful at locomotion is their ability to learn to adapt. They have a remarkable set of intrinsic adaption mechanisms, neurally, as well physically. However, only few of these have been used as inspiration to build better locomotion systems. There have been attempts to adapt the stiffness of legs with variable compliant mechanisms. 11,12 For example, both Quy et al. and Galloway et al. used the adaption of stiffness to improve energy efficiency in single-legged hoppers. 3,13 In this work, we propose a method that incorporates adaptation into an existing (well-established model) for locomotion, that is, the spring-loaded inverted pendulum (SLIP) model, which is commonly used for analysing running and hopping for a wide range of species. 14,15 It combines morphological parameters (stiffness k, resting length l 0 and mass m) with a control parameter (attack angle, α), see Figure 1. For a given fixed set of parameters, it can tolerate small perturbations without losing its periodic locomotion pattern; it is self-stabilizing. However, when perturbations are too high, the system fails and falls over. 16

Diagram showing the standard SLIP model. Stiffness and attack angle will be adapting in our approach. SLIP: spring-loaded inverted pendulum.
There have been a number of attempts to widen the area of self-stability. Some researchers have investigated how adapting the attack angle and, therefore, controlling the SLIP model can be used to improve stability, for example, Seyfarth et al. 17,18 In their approach, the stiffness and horizontal velocity dictate how the leg should retract during the flight phase and therefore change the attack angle before touchdown. In a different approach, Schmitt 19 changes the attack angle based on the angle at lift-off and a desired angle.
Another approach is to change the morphology (usually the stiffness) of the model. For example, Karssen and Wisse 20 optimized offline the stiffness function with respect to disturbance rejection. Also increasing the number of leg segments can lead to nonlinear stiffness functions and a bigger region of self-stabilization. 21,22 Some work has investigated how the shape of the leg can be used to achieve variable stiffness and relative leg length changes during the stance phase. 23,24 Similarly, Owaki et al. investigated different nonlinear stiffness functions and identified the ones that are beneficial, 25 although this was done using a compass gate, rather than the SLIP model. Andrews et al. explored changing the length of the spring, rather than its stiffness in their work. 26 An alternative approach is to consider changes in the controller (attack angle) and the morphology (stiffness). Blum et al. 27 combined both previously mentioned methods by adding control strategies to change both angle and stiffness in the flight phase, ready for touchdown. Iida and Tedrake 28 used reinforcement learning to tune the motor frequency of a one-legged robot based on the SLIP model.
All the above approaches help to widen the area of stability, but they do not allow the model to learn from past experiences. In our previous work, 29 we systematically tested over 3200 different adaption strategies based on an offline learning approach that introduces changes of either the stiffness or the attack angle. The SLIP model, with an initial set of parameters, was allowed to attempt locomotion until it either fell over or a certain amount of time had passed. If the model has not fallen over at the end of an episode, it was considered stable. However, if the model was not stable, it should follow a particular adaption strategy to change its parameter for the next episode (i.e. stiffness or attack angle). This continued until the system was stable, or a set number of episodes was expired. Using this method, we found that the best angle changing rule set was able to significantly expand the area of stability by over 50%.
However, our previous work had some limitations. Firstly, the model was required to fail before it could reattempt. While this is feasible in simulation, this is a problem for a real physical robot. The second limitation is that the previous work focused only on adapting either the stiffness or the attack angle. This was due to the limitation of a large search space which prohibited us from testing systematically all combinations of rules.
Therefore, in this article, we expand this previous work using evolutionary algorithms to explore a wider range of rule sets that allow adaption of both stiffness and attack angle. Using this new approach, we are therefore able to exploit the tight interplay between the control parameter and soft morphology of the body. It should be noted that we do not genetically encode the stiffness or attack angle directly, rather we evolve the adaptation or learning rules that adjust these parameters. In addition, we also investigate online learning. This has the advantage of not requiring failure for the learning process. Clearly, this would be highly beneficial for implementation on a real robot.
Firstly, we introduce the concept of the SLIP model for readers who might not be familiar with the model. We then explore the use of genetic algorithms to optimize offline learning rules described in our previous work. 29 In offline learning, the model is simulated until it fails (i.e. falls over). This is referred to as one episode. Between two episodes, the parameters (stiffness and attack angle) are updated. Simply put, the model is allowed to fail and the system attempts to learn from this failure using its adaptation rules for each parameter. The offline learning methodology uses genetically encoded rule sets to adapt the attack angle and stiffness. The corresponding section presents the overall design of the evolutionary algorithm and a discussion of the obtained results. In the case of online learning, the system does not have the opportunity, or the time, to cope with failure, reset itself and adapt until a successful configuration is found. We discuss how the rule sets that were used in offline learning were modified to accommodate this new paradigm. We also present the results from using a genetic algorithm to optimize an online learning rule set. Finally, in the discussion section, we compare and contrast both learning methods.
SLIP model
In this first section, we describe the standard SLIP model, which is used in the simulations for both offline and online learning. The working principle of the SLIP model is shown in Figure 1. It consists of two phases, the flight and the stance phase. In the flight phase, the point mass follows a ballistic trajectory until the foot touches the ground with a fixed angle. This is known as touchdown and signals the start of the stance phase. At this point, the foot position remains fixed, the spring starts to compress and the point mass remains moving. When the spring length is equal to the resting spring length
The SLIP model is commonly used as a model for legged locomotion. It was first introduced in Blickhan.
14
In this work, we follow the simulation set-up described in Seyfarth et al.,
17
with some adaptations that are detailed below. The leg was simulated in Matlab using the forward Euler method for integration with a time step of
As previously discussed, the standard SLIP model is only stable for a small set of attack angle/stiffness combinations. Figure 2 shows the stable starting configurations for the basic SLIP model, shown in yellow. Due to its shape, it is commonly called the ‘J’ curve. 16

The stable starting configurations for the standard SLIP model. The grey areas show the starting parameters (k and α) where the model is not stable. The yellow areas are the combinations that are stable. SLIP: spring-loaded inverted pendulum.
Offline learning
The first part of the article considers offline learning, that is, learning happens between two episodes. The time from start to when the SLIP model falls over (or the maximum time expires) is called an episode. The SLIP model is simulated as discussed in the previous section. After each episode the distance travelled is compared with the distance travelled in the previous episode (

Diagram showing how the SLIP model changes its attack angle (α) and stiffness (k) between episodes to find stability. SLIP: spring-loaded inverted pendulum.
Figure 8 shows the individual rules, which are genetically encoded and optimized using the generic algorithm, that the SLIP model should follow using offline learning. These rules are combined to create a set of 12 individual rules—1–6 relate to the angle change (shown in grey in Figure 4) and 7–12 relate to the stiffness change (shown in blue in Figure 1).

Individual rules that are genetically encoded and combined to build a rule set. The top 5 grey rules show those relating to angle adaption. The bottom rules shown in blue relate to stiffness adaption.
Rules 1 and 6 relate to whether the angle (rule 1) or the stiffness (rule 6) should increase or decrease between episodes. If the change between current distance
Rules 4, 5, 9 and 10 dictate either the fixed amount the parameter (α or k) should change by or the learning rate if the corresponding rules are unfixed.
The number of combinations of the 10 individual rule sets is vast and, as previously discussed, too big to explore exhaustively. Using only 10 different discrete values for rules 4, 5, 9 and 10, we would already have 640,000 different rule set combinations. Therefore, we propose using a genetic algorithm to find the most successful rule set for achieving stability. The individual rules were encoded as a genome, and a genetic algorithm was used to optimize. The design and details of the evolutionary algorithm are described in the following section.
Evolutionary algorithm
This section details the key characteristics of the algorithm and the fitness criteria used.
The 10 different individual rules form the genome. An initial population of 50 different genomes were formed from 10 randomly initialized rules. To explain further, rules 1, 2, 3, 6, 7 and 8 were randomly assigned one of the two values. In the case of rules 1 and 6, these values were either ‘Increase’ or ‘Decrease’. To encode this ‘Increase’ was represented as a ‘1’ and ‘Decrease’ as a ‘0’. In the case of rules 2, 3, 7 and 8, these values were ‘Fixed’ (encoded as ‘1’) or ‘Unfixed’ (encoded as ‘0’). For the non-binary rules (4, 5, 9 and 10), a random value was selected between 0.01 and 0.99 and directly encoded as thus. We used two different fitness criteria to test the success of each of these rule sets/genomes. This allowed us to explore which selection criteria would produce better results overall.
The first criterion was the percentage success rate. This is the same criterion that was used in our previous work. 29 For these criteria, 1600 different starting combinations of attack angle (40 values equally spaced between 20° and 90°) and stiffness (40 values equally spaced between 2000 and 80,000) are tested. This region was selected as it fully encompassed the ‘J’ curve region of stability detailed in the work by Blinkhan 14 and as shown in Figure 2. The percentage success rate of a rule set is defined as the percentage of starting combinations, within our chosen range, for which the SLIP model could find stability when following that particular rule set. The percentage success rate is a way to measure the range of perturbations that the SLIP model could recover from. It should be noted that the percentage success rate is a relative term, a 100% success rate means that a particular rule set is able to find a solution for a 100% of the starting conditions in the range we have explored (see range above), and this does not mean it works on 100% of all possible starting configurations, that is, beyond our tested values. However, using our percentage success rate allows easy comparisons between rule sets.
The second criterion we considered was the so-called mean recovery time. The individual recovery time is how long the SLIP model takes, starting at a particular parameter combination, to stop adapting its parameters and to maintain a stable solution. For offline learning, this is the number of episodes the model takes to become stable. To calculate the mean recovery time, the individual recovery times across all the tested starting combinations are averaged. The lower the mean recovery time, the better the rule set.
For offline learning, the genetic algorithm was run six times: three times using the percentage success rate as the fitness and three times using the mean recovery time. Each time the genetic algorithm was run for 100 generations—each new generation was formed as following. The top 5 best rule sets from the previous generation were automatically passed onto the next generation. The next 15 rule sets of the new generation were produced by multipoint crossover, as demonstrated in Figure 5 between randomly selected parents from the 50% most successful genomes from the previous generation. The next 15 rules sets were generated by mutating the nonbinary rules (rules 4, 5, 9 and 10). This was done by randomly selecting a new value between 0.01 and 0.99 for these rules, see Figure 6. The final 15 rule sets were randomly generated. This simulation was run in C++, in windows, on a computer with the following specifications: Intel (R) Core (TM) i7-6700 CPU 3.40 Hz with 16.0 GB of RAM. For the offline learning, each simulation took approximately 48 h.

Two example genomes and the points at which multipoint crossover occur to create offspring for the next generation.

Diagram showing how an offspring genome is created via mutation.
Offline results
In this section, the results for offline learning are presented and the implications of these results are discussed. Table 1 presents the most successful rule sets for each of the six different optimization runs. It also shows the percentage success rate and mean recovery time for each of the evolved rules. For comparison, an SLIP model without learning has a percentage success rate of 3% and a mean time to recovery of 97 episodes (compare Figure 2).
This table shows the results from the offline learning genetic algorithms. The 6 optimal genomes are presented.
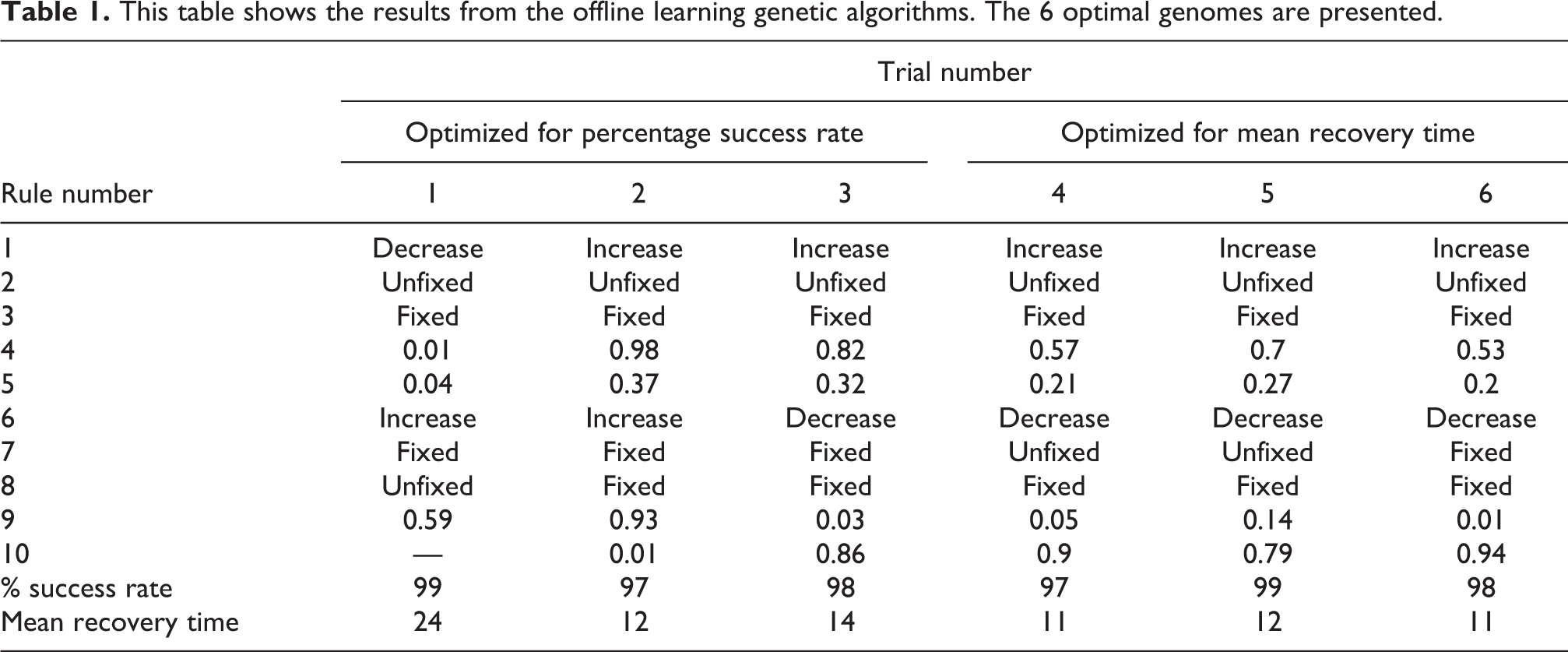
It can be seen from Table 1 that the optimal solutions found when using the first criteria (mean time to recovery) significantly outperform those using the second criteria (percentage success rate). This implies that using mean time as the fitness function results is a more appropriate measure. It can also be noted that genomes evolved for best mean recovery time are all very similar, whereas the less successful genomes (evolved for percentage success rate) are different. All results significantly outperform the non-learning SLIP model and are able to find stability for almost all starting combinations in our exploration region, showing a large increase in robustness. The only cases where the rule sets were unsuccessful were at the limits of our testing values (i.e. starting angle of 90°). Note that 90° is unnatural as this constitutes a horizontal leg.
If this is compared with the findings in our previous work, 29 it can be seen that the genetic algorithm approach yielded better performing solutions. Specifically, in our previous work, the top angle changing rule set with the top stiffness changing rule set resulted in a percentage success rate of only 78%. This is significantly lower than the rule sets found with genetic algorithms which have percentage success rates of 99%. While this is certainly a promising result, offline learning also has its limitations. The SLIP model is required to fail and reattempt to learn to achieve stability. For an implementation on a physical robot, this failure could be costly. Therefore, we propose an extension to online learning.
Online learning
Given the limitations outlined above, we propose update rules that allow online learning. Instead of learning based on information received only after a failed episode, we propose a new measurement. The new measurement is the difference in kinetic energy between consecutive flight apexes (

Diagram shows how the basic SLIP model is adapted to incorporate online learning. SLIP: spring-loaded inverted pendulum.
As in the previous experiments, the online learning uses genetically encoded update rules to define how the parameters should change. The update rules for online learning are similar to the offline learning rules, however, with some minor changes. These are detailed in Figure 8.

Table shows how the online learning rules.
The main difference is the change in rules 2, 3, 8 and 9. Instead of using change in distance between episodes (

Showing time to stability for an online learning SLIP model with stable starting parameters. Here the threshold value was 0.01. SLIP: spring-loaded inverted pendulum.
Online results
In this section, the results from online learning are presented. The genetic algorithm was run three times with three different randomly initialized starting populations. In the case of the online learning, using the same computer as before, each simulation took approximately 4 h. This simulation time is considerably shorter than the previous offline learning because it is no longer necessary to have multiple episodes. Figure 10 summarizes the results from the genetic algorithm and compares them with the non-adapting SLIP model. Figure 10 details the mean recovery time for each of the three top rules sets with corresponding percentage success rate that were calculated after the simulation. In Figure 10, the different colours represent the time to stability. The darker the colour, the quicker it reached stability. Areas of grey represent areas where the starting combination of parameters could not find stability with a given rule set.

Comparison of the three most successful rule sets. Each subfigure shows the amount of stable parameter starting combinations. A grey area represents an unstable parameter combination. The coloured areas represent the individual recovery time. The darker the colour, the shorter the recovery time for that starting combination. (a) The standard SLIP model. Each of the blue areas shows a stable starting configuration with a mean recovery time of 0 s. (b) The top rule set. This rule set is shown in Table 2. (c) The second most successful rule set. This rule set is shown in Table 2. (d) The third most successful rule set. This rule set is shown in Table 2. SLIP: spring-loaded inverted pendulum.
Table showing the results from the online testing.

It can be seen that the top three rule sets alter the region of stability in the same way, that is, through expanding the region to the left-hand side of the curve. None of the found rule sets are able to expand the region of stability for higher angle values (i.e. the right-hand side of the curve). It can also been seen that these rule sets reach stability in a shorter time if the angle is low, compared with starting parameter configurations that are close to the standard ‘J’ curve.
It should also be noted that all three top rule sets have very similar angle changing rules. All the rule sets aim to change the angle opposite to the change in kinetic energy by amounts proportional to the change. Rules 4, 5 and 6 also have similar values across all three top rule sets. Similarly, the stiffness changing rule also has good consistency between the top two results. However, in the third rule set, the first three rules are the opposite to the other top rule sets. This could explain why the mean recovery time for this third rule set is longer and the percentage success rate is lower.
Investigating instability regions
To understand the dynamics of the rule sets, the unsuccessful regions such as particularly low/high angles and the regions of instability in the number 2 rule set, that is, the holes, were investigated (e.g. see Figure 11). The area behind the curve, that is, high angles and low stiffness, fails before any adaption takes place—that is, it falls over on the first touchdown. In contrast, the area in front of the curve, low angles, fails on second touchdown. There is such a large percentage difference in kinetic energy that the angle is changed to be outside the range of acceptable angles. Therefore, the system fails. The changes in attack angle and stiffness for the unstable holes are shown in Figure 9. Three different unstable starting configurations were tested and interestingly the patterns of parameter changes are the same for all three. Initially, the parameters are increased to an angle just higher than within the stable range. The combinations of parameters then follow the line of the curve, but the angle being always too large. Eventually, the model simply fails.

Plot showing how the attack angle and stiffness change, while using rule 2, during the online learning process for three different unstable starting conditions (the gray areas). The coloured diamonds show the starting parameter configurations and the green star shows the final configuration. It is at this configuration that the SLIP model has fallen over (i.e. y < 0). SLIP: spring-loaded inverted pendulum.
For the top rule set, the two parts of the total rule set were tested separately. First, only the angle was allowed to adapt, following the first six rules from the top rule set. The stiffness remained constant throughout this simulation. Second, it was the attack angle that remained fixed and the stiffness was allowed to adapt to follow the last six rules from the top rule set. Figure 12 shows the two mean time to recovery plots for these individually tested rules. Interestingly, it can be seen that the angle adaption rule maintains the high percentage success rate seen in the top combined rule, that is, it is still able to find stability for a wide range of starting parameters. The stiffness adaption is much less successful when on its own. However, it appears that the stiffness adaption is needed for the model to settle quickly. When only the angle is adapting, the mean recovery time is much higher, in some cases, while not falling over, not finding stability at all. This finding is consistent with the other two top rule sets (i.e. both the other rule sets maintain a high percentage success rate when only adapting the attack angle but show a much higher mean recovery time than when also adapting stiffness).

Diagram showing the mean time to recovery plots for the two individual parts of the top rule set, that is, just adapting the angle and just adapting the stiffness. (a) This graph shows how the rule set behaves when the stiffness adaption is turned off (only the angle changes). (b) This graph shows the behaviour when only the stiffness is allowed to change.
This is explored further in Figure 13 showing the top rule set. On the top graph, the stiffness adaption part is not included. The model is started in three different starting configurations. For all configurations, initially the angle changes significantly, but then the changes are small, until stability is reached. However, on the bottom graph, the stiffness adaption is included—this small change in stiffness allows the model to find stability much quicker.

Graphs show comparison between adapting just the angle and adapting both parameters in online learning. Both (a) and (b) relate to when only the angle is adapted. (a) shows how the angle changes with respect to the stability region and (b) shows how the angle changes with respect to time. (c) and (d) relate to when both stiffness and attack angle are able to adapt. (c) shows how the attack angle and stiffness change with respect to the stability region and (d) shows how the attack angle changes with time.
Investigating environmental change
To further investigate how robust these learning rule sets are, we introduced a sudden change in environment; either by increasing or by decreasing the ground level. In this case, the step height is set to −2.5 m and the starting configuration of parameters is the same for both the online and offline learning (69°, 26,000 N/m). Figure 14 shows two SLIP models, one with offline and one with online learning, both facing the same step change. The online learning method is able to immediately react to the step change and adapt its parameters without failure. In the offline learning method, the SLIP model fails upon reaching the step. It is reset with updated parameters and another attempt is made, but it always fails when reaching this step. It can be seen from the top graph (Figure 14) that offline learning has numerous attempts at overcoming the step, shown in different colours which represents different episodes, but given it is reset to the start (x = 0 m) each time it is unable to maintain stability for the distance. In addition to this, it has failed many times. The online learning method however is successful on the first attempt and able to maintain stability.

Comparison of offline and online learning approaches when faced with a change in ground level. (a) The offline learning approach dealing with the change in environment. Each of the different colours represent a different episode, all starting from the same position but with different stiffness and attack angle values. The model fails many times, including when it encounters the change in ground level. (b) The online approach. In one attempt, the online learning is able to overcome the change in ground level and maintain stability throughout the simulation.
To explore this robustness further, the top three online rule sets were tested over the same range of starting conditions to determine the percentage success rate and mean recovery time. However, instead of a flat landscape, a step is introduced half way through the simulation (50 s) as shown in the previous figure. Figure 15 shows how the mean time to stability changes with step height for a non-adapting SLIP model, one following the first evolved rule set and one following the third best rule set. Rule set 2 was not tested due to its similarity with rule set 1. To calculate this, the model was run with increasing relative step sizes and the percentage success rate was recorded.

Graph showing how the mean stability time varies with step height for the top online update rules. Note that the increase in settling time (when compared to Figure 10) is due to the addition of the step at 50 s).
It can be seen clearly in Figure 16 that an SLIP model without the capability to adapt can only withstand a very small change in environment, and this decreases to a percentage success rate of zero when a downwards step of 0.5 m is introduced. This is shown by the blue line in Figure 16. The un-adapting SLIP model is not able to withstand any upwards steps (and increase in ground level). However, when following the optimal online rule set, the model is able to withstand a downwards step height of up to 2.5 m without any change to the percentage success rate when compared with a level ground (i.e. a step change of zero). This is shown by the orange line in Figure 16. We have observed that at some starting conditions it is also able to withstand changes to the ground level of up to 10 m and remarkably it is also able to withstand increases in step heights up to 0.3 m. As seen in Figure 16, the percentage success rate of the rule set decreases as the step height increases. However, it is interesting to see that the shape of the successful starting combinations change as the ground level change increases. As the change in ground level increases, the amount of stable starting parameters decreases and favours higher stiffness values. However, for a given step height, if starting at a lower stiffness, it is possible to quickly find a stable solution (i.e. it will have a smaller settling time). Another point of interest is shown in Figure 17. The attack angle and stiffness changes are shown in red. First, the model settles in the curve shown in the un-adapting SLIP model; the SLIP model is becoming stable before any change in ground level. When the ground level changes, the angle changes again, this time settling in a very different area, shown by the red star. Although it is speculated that this could be due to the increase in energy in the system due to the step and therefore we aim to explore this in future work.

Graph showing how the percentage success rate varies with step height for two online update rules and the non-adapting SLIP model. SLIP: spring-loaded inverted pendulum. (a) shows the stability region for a step of 0.2m downwards. (b) shows the stability region for a downwards step of 2.5m. (c) shows the stability region for a downwards step of 5.5 and (d) shows the stability region for a downwards step of 7.5m.

Graph showing how the attack angle/stiffness change at a particular starting configuration, when the model encounters a down step of 7.5 m. The green diamond shows the starting position and the red stars shows the finishing configuration.
Discussion
In this article, we showed that it is possible to evolve optimal update rules for both offline and online learning for the SLIP model. In both cases, it can be seen that when adapting both stiffness and attack angle, the region of stability considerably widens. Interestingly, the way the optimum rule sets achieve this widening is different if offline or online learning is used (i.e. the two optimal rule sets for the two methods are different). This is particularly the case for the angle changing rules. For offline learning, the attack angle increases with an increase in distance between episodes. In addition, the decrease is always a fixed amount. However, for the online learning, the attack angle always decreases with an increase in energy and the decrease is changing. It can also been seen that the offline learning has a much higher percentage success rate than the online learning, however, as previously discussed, in the event of a sudden change of environment, the offline learning model would have to fail to relearn over a number of episodes to be successful. We have demonstrated the robustness of the top learning rule sets by observing how the models deal with changes in the environment.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the EPSRC Centre for Doctoral Training in Future Robotics and Autonomous Systems (FARSCOPE)EP/L015293/1. The research was also partly supported by the Leverhulme Trust Research Grant RPG-2016-345.