
Abstract
In this study, we propose an improved iterated greedy algorithm for solving the distributed permutation flowshop problem, where there is a single robot in each factory and the makespan needs to be minimized. In the problem considered, the robot is used to transfer each job from the predecessor machine to the successor machine. A blocking constraint between machines is considered, thus jobs should remain on the completed machine while waiting for the robot. The loading and unloading times are considered and different for all of the jobs conducted by the robot, and the deteriorating time is also considered. In the proposed algorithm, first, four types of neighborhood structures are developed. Then, the simulated annealing algorithm is embedded in the proposed algorithm to enhance the exploration abilities. Furthermore, a problem-specific destruction and construction strategies are investigated. Finally, several realistic instances were generated to test the proposed algorithm, and its competitive performance was verified based on detailed experimental comparisons.
Keywords
Introduction
During recent years, the intelligent manufacturing has gradually penetrated into both the industrial and academic fields. 1 –4 It is a common understanding that the intelligent manufacturing is a new production model which integrates lots of new technical means, such as intelligence production, intelligent scheduling, and integration. In the realistic production, the scheduling is generally one of the key issues in the intelligent manufacturing. The distributed permutation flowshop scheduling problem (DPFSP), as an extension of the classical flowshop scheduling problem (FSP), has gained more and more research focuses during recent years.
The definition and several types of mathematical models for the DPFSP were first proposed by Naderi and Ruiz. 5 The DPFSP involves two main important tasks comprising assigning jobs to suitable factories and scheduling the jobs in the assigned factories. 6 –8 In the DPFSP, in addition to the number of job and factory, the factory includes a number of machines, while the machine number and other factors must also be considered. 9,10 The sequence of jobs assigned to factory f was given, where each job on each machine has a processing time. 11 The general objective is to minimize the total processing time. 12,13
The method to solve related DPFSP has attracted much attention. Generally, the artificial bee colony (ABC) algorithm 14 –17 and shuffled frog-leaping algorithm 18 were used to solve the job shop scheduling. However, Li et al. 19 used hybrid ABC algorithm to solve the problem of parallel batch distributed flowshop with deteriorating jobs. Many algorithms have been proposed for solving the DPFSP, such as tabu search (TS) algorithm, 20 genetic algorithm (GA), 21 simulated annealing (SA) algorithm, 22 and iterated greedy (IG) algorithm 23 –28 solved a casting scheduling problem by a new coevolutionary artificial bee colony that proposed by Pan (P-ABC). Li et al. 29 used a multi-objective algorithm to solve the problem of batch mixed flowshop with variable sub-batches. Deng and Wang 30 presented a competitive memetic algorithm to solve the multi-objective DPFSP as well as developed several local search operators in proposed algorithm. However, few studies have considered that robotic distributed flowshop problem.
At present, artificial intelligence (AI) applications are infiltrating into various industries, especially the robot that can transport jobs. In some industries, such as logistics warehouses, steel ball factories, and automobile parts factories, robots transport jobs between machines for reducing costs and worker requirements and then greatly improve the throughput in factories. He et al. 31 and Dong et al. 32 studied on the dynamics of robot system and the accuracy of robot control system. In robot scheduling and path planning, real-world flowshop systems often involve uncertainty; however, various types of metaheuristics have been developed for solving realistic optimization problems. Hurink and Knust 33 considered that jobs must be transported between machines by a single robot in the flowshop factory. Subsequently, they applied the TS algorithm to minimum manufacturing time. 34 Arviv et al. 35 developed a collaborative reinforcement learning method to solve the problem of two robots transporting jobs between successive machines on a parallel trajectory, where the objective was to obtain a robot scheduling table that minimizes the manufacturing cycle time on the machines. Che and Chu 36 and Che et al. 37 presented a multiple degrees of freedom cyclic scheduling algorithm for two robots in a no-wait flowshop with the objective of minimizing the cycle time. Che et al. 38 proposed an efficient bicriteria algorithm to consider a robot transportation time with an allowed small disturbance. Gultekin et al. 39 also considered the objectivity of minimizing cyclic time of robots and maximizing the throughput and developed a hybrid metaheuristic algorithm that combined GA with TS algorithm. Kats and Levner 40 discussed the robot path with the minimum cycle time for two-loop scheduling. Nouri et al. 41,42 proposed two NP-hard problems, that is, the flexible job shop scheduling and robot path, and they used hybrid metaheuristics to solve these problems simultaneously. Zabihzadeh and Rezaeian 43 considered the limitation caused by blocking in a mixed flowshop with robot, where their main contribution was to use two metaheuristic algorithms. Both Elmi and Topaloglu take into account the loading and unloading time of robots. 44,45 Chen et al. 46,47 designed two algorithms to systematically schedule the multi-robot to obtain resources and objective to improve the cost efficiency.
These literatures provide a good idea to solve the robot scheduling problem, but do not provide a good solution for the practical problems of distributed factory scheduling in the intelligent manufacturing. According to our knowledge, there is few literature aimed at solving the robot scheduling problem in DPFSP and none have applied the improved iterated greedy (IIG) algorithm to solve this problem: (1) most of the literatures about the intelligent scheduling problems consider the production in one factory; however, the distributed manufacturing features in the realistic manufacturing should be considered; (2) in the realistic production, considering the weight of jobs, the transportation process of a robot or crane should be investigated, which has less been studied; and (3) most of the studies considered to minimize the time-related objectives, such as makespan and earliness/tardiness values. However, the energy consumptions during the processing and robotic transportations should be considered simultaneously. Therefore, the IIG algorithm is proposed to solve the NP-hard problem, that is, the single-robot scheduling of distributed flowshop in this study. In the study, we add a single robot to the traditional DPFSP to transform it into an NP-hard problem and consider deteriorating time of jobs. 48 –50 The blocking constraint between machines is also considered, and jobs should remain on the completed machine while waiting for the robot. Finally, the IIG algorithm is compared with the cooperative ABC (CABC) algorithm, 51 P-ABC algorithm, and TS algorithm.
The remainder of this article is organized as follows. Firstly, the constraints, mathematical models, and problem description are briefly described. Next, the canonical IG algorithms and the elaborated proposed algorithms with strategies in detail are introduced. Then, the results obtained in experiments and parameter analysis are illustrated. Finally, the study conclusions are given.
Problem formulation
Problem description
The robotic distributed permutation flowshop scheduling problem (RDPFSP) involves scheduling each job in a factory selected from multiple candidate factories and minimizing the maximum completion time for all factories. The production line considered comprises All of the jobs follow the same processing sequence from the first machine to the last machine in the assigned factory. The processing times for all jobs are nonnegative, known, deterministic, and uninterrupted. Each machine can process only one job at one time and one job can be processed on one machine at most at one time. Each job can be transferred to the next machine only after the completion time on the previous machine. The loading and unloading time for each job should be considered, which are related to the processing time for the job. There is only one robot in each factory. The job should remain on the completed machine if a robot is not available. The setup times for jobs are relatively short, and thus they can be considered in the loading times. Preemption is not permitted, so any job should remain on the assigned machine until the work is completed. Some jobs may be deteriorating jobs, so they generate deteriorating time on some machines.
Problem model
The model is an expansion of the DPFSP with a robot system. Different binary variables to handle the sequence of jobs between the factories and the processing sequence in the factory are defined, as well as robot-related constraint variables. The variables in the model are defined in Table 1.
The variable definitions.

The objective function (1) is minimizing the makespan. Constraints (2) to (4) involve searching for and determining the job position. Constraint (5) indicates that the mth machine of the fth factory has the ability to process the
In addition, the corresponding formulas are shown in Table 2.
The corresponding formulas.

Illustrative example
The 10 jobs are assigned to the three factories and each factory has a processing sequence for the jobs (Figure 1). Each factory has a robot that is responsible for transporting the jobs (Figure 2). Each job has a processing time, loading time, and unloading time. The processing time on the machine may differ for jobs. The time required by the robot to transport the job is ignored and the robot can only transport one job at the same time. The robot unloads the job and the robot requires a loading time to transport it to the next machine, after a job is completed on the previous machine. The longer the wait time of jobs, the longer the deterioration time. If the job is completed on two machines at the same time and the robot is idle, the robot randomly selects a machine to transport the processed job.

The sequence of jobs in factories.
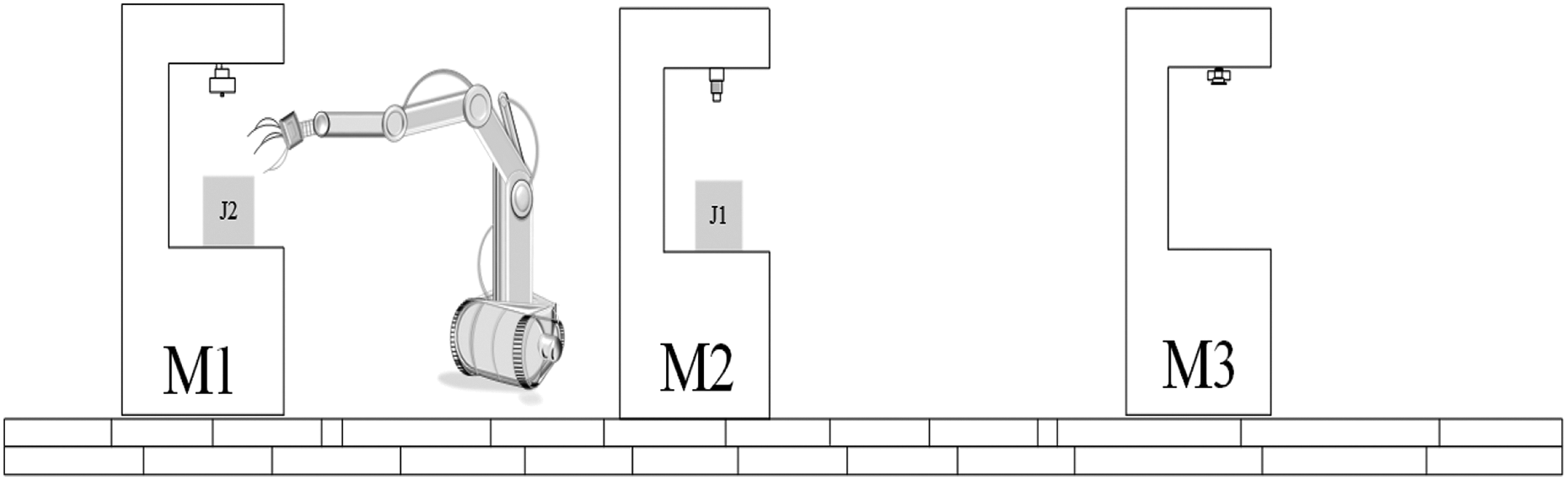
Illustrative example.
The transit time and the distances between the machines are negligible. An example was given to illustrate problem. The jobs are assigned to the factory F1, then the processing sequence for M1 is {1,2,3}, the processing sequence for M2 is {1,2,3}, and the processing sequence for M3 is {1,2,3}. As shown in Table 3, the time required for loading J1 is 1 and its unloading time is 1. However, the processing completion time for J1 on M1 and the processing time for J3 on M3 are the same, and the transport of J1 or J3 for the robot is to judge.
The various time of jobs.

In addition, if the job has been processed and no robot can unload it, then the job will stay on the original machine for a waiting time. We objectively consider the green manufacturing process under the condition of deterioration time in jobs processing.
As shown in Figure 3, the whole path of the robot is given as follows

Gantt graph of problem description.
The canonical algorithm
The Nawaz-Enscore-Ham (NEH) variant used in most studies might not obtain new solutions that are better than the existing solutions,
52
but it can still be accepted in probability in a similar manner to SA so the solutions in other regions can be explored.
53
Therefore, assigned jobs by the NEH strategy to each factory and obtained jobs sequence by the destruction and construction phases. The NEH heuristic algorithm or a variant of the NEH algorithm has been employed frequently to initialize the DPFSP when assigning factories to jobs.
53
–55
The NEH method can be described in the following steps. Finally, the SA algorithm is selected as the acceptance criterion. (1) For each job compute the total processing time on m machines as follows
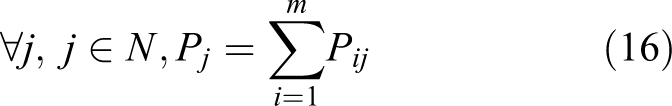
(2) Next, the first operation is selected and evaluated for n jobs with the largest operation processing times.
The IG algorithm was not applied to scheduling problems until its implementation was presented by Ruiz and Stützle.
56
IG is a simple stochastic metaheuristic algorithm, which starts with the initial solution and then improves the current solution by iterating in three main phases: destruction, construction, and acceptance phases.
57
Ruiz and Stützle
58
proposed a new IG algorithm, which they applied to randomly select d non-repetitive jobs from the sequence
Iterated greedy.


The proposed algorithm
Framework of the proposed algorithm
In the proposed Algorithm 2, in the first stage, some elements are randomly removed from the current solution to obtain partial solutions. In the second stage, a greedy constructive heuristic method is used to reinsert the deleted elements to form a new complete solution. After the candidate solution is obtained, the acceptance criteria determine whether the new solution replaced the current solutions. To further improve the performance of the IIG algorithm, we add four kinds of neighborhood structures to generate new solutions, and use SA algorithm to jump out of the local optimal solution. Finally, the current solution is replaced by a better new solution.
Improved iterated greedy.


Problem encoding
The jobs are scheduled and assigned to the factories randomly according to the NEH strategy (Table 4). Next, we consider the constraints on the problem where two vectors are utilized to encode the solution, that is, a two-dimensional (2-D) vector and a time matrix. To address the problem where the number of jobs is much larger than the number of factories, the jobs are randomly assigned to the factories. The first dimension of the 2-D vector is used to represent each factory and the second dimension represents each job that needs to be processed. The processing time, loading time, and unloading time of each job store in a 1-D vector, and the example is shown in Figure 4. Three factories each process six jobs. The processing sequence for a job in F1 is {12,4,8,15,14,18,17} and that for a job in F2 is {3,13,1,5,9}, and the job sequence in F3 is {2,11,6,7,10,16}. The processing time of
Initial schedule.


Two-dimensional vector and one-dimensional vector.
Problem decoding
In the decoding, the 2-D vector is used for decoding, and we determine the corresponding positions for the jobs in the 2-D vectors according to the job number. Only one robot can transport each job and a block of time is available for a robot. A 2-D vector is needed to store each factory, the idle time of the robot, and one robot in each factory. If all of the jobs in a factory are deleted during the destruction phase in the IIG algorithm, the factory does not exist. We must assess whether the robot is transporting or not when a job is processed, as well as comparing the processing time after the robot loads or unloads the previous job. If the former is less than the latter, the job needs to continue to wait on the machine, and thus a waiting time and deteriorating time are considered, so the processing time period for the job is the exact time block available to the robot.
Each job number in the vector corresponds to the processing time, load time, and unload time for the jobs in the time matrix. The jobs may be processed at the same time on different machines. We need a strategy to solve the problem where two jobs finish at the same time and they must be transported by the robot. After a job has been processed, it is necessary to determine whether the robot is idle to obtain the entire path of the robot. Thus, on each machine, there is a time for unloading, another job, and a loading time after processing a job. If a job is processed, the robot will move to the current machine to load and unload the job. Robots cannot unload when they are loading. The deteriorating time is processing time multiplied by a coefficient so that some jobs have not only loading time and unloading time, waiting time, but also deteriorating time. The decoding heuristic is given in Algorithm 3.
Decoding heuristic.


Problem-specific neighboring structures
For solving the DPFSP, the neighborhood structures commonly used in the literature are insertion, such as insertion, swap, pairwise exchange, and variable neighborhood search algorithm.
61
–63
Considering the characteristics of the problem in this article and the development and exploration ability of the proposed algorithm, we propose four kinds of neighborhood structures, namely two kinds of insertion and two kinds of swap neighborhood structure, as given in Algorithm 4. In the neighborhood structures, we use two kinds of search operators, namely insertion operator and exchange operator. Considering the balance between the problem structure and the exploration and development ability, we will randomly select one of the four neighborhood structures for job scheduling in the RDPFSP. Algorithm 4 gives an example of neighborhood structure in local search, and Figure 5 shows four examples of neighborhood structure. The first kind of insertion neighborhood structure: randomly select a factory, and randomly select two positions x and y from the job list, then insert the job of y position into the x position. The second kind of insertion neighborhood structure: randomly select a job of a factory and insert it into a different factory, four kinds of insertion are as follows: (a) append to the last position of the new factory, (b) insert to the first position, (c) maintain the previous position, and (d) try to select a good position. Figure 5(b) shows one of the examples. The first swap neighborhood structure: randomly select two positions x and y from the job list in a randomly selected factory and swap the two elements in the two positions. The second swap neighborhood structure: randomly select two position x and y from the job list in two different factories, which are also randomly selected, and swap the two elements in the two positions.
Local search strategy.



Four neighboring structures: (a) the first kind of insertion neighborhood structure, (b) the second kind of insertion neighborhood structure, (c) the second kind of swap neighborhood structure, and (d) the second kind of swap neighborhood structure.
From the steps of the four neighborhood structures presented in Algorithm 4, it is obvious that the time complexity of these structures are all of O(1). Therefore, the proposed neighborhood structures are simple and efficient.
Destruction heuristic
The random deletion of jobs from the generated sequence and the distributed sequence that was proposed by Tavares-Neto and Nagano. 64 Finally, the reconstruction phase is completed by applying the same insertion heuristic to the partial solution.
In the proposed IIG algorithm, the core phases are the destruction phase and the construction phase. These two phases optimize the solution by searching new regions in the solution space during each iteration. In the destruction phase, calculating the completion time for each factory by adding the time spent on jobs in each factory at first, where each job has a processing time on each machine and all of the jobs are distributed to each factory as shown in Figure 6(a).

The destruction and construction phase: (a) the first kind of insertion neighborhood structure, (b) the second kind of insertion neighborhood structure, and (c) the second kind of swap neighborhood structure.
The strategy of destruction phase is conducted as follows. Calculate the maximum completion time for each factory and give priority to deleting the jobs from the factory with the largest
Construction heuristic
In the construction phase, an example to illustrate how the construction phase starts with a partial plan is considered, before then reassigning one job at a time using greedy insert heuristics in Figure 6(b). Each job in the
Acceptance criterion
Acceptance criterion is able to avoid local best solutions, and thus random factors are introduced during the local search process. A worse solution than the current solution with a certain probability is accepted, so it is possible to escape from a local best solution and reach the global best solution. The SA algorithm is calculated according to Osman and Potts,
65
formula (17) is the method to calculate temperature, where T is an adjustable parameter. Ding et al.
66
explained the method of setting the initial temperature and cooling rate in formula (18), where


SA starts at a relatively high temperature, before continuously decreasing the temperature parameter, where probability jump characteristics are also considered in the solution space to find the global optimization for the objective function. To avoid local optimization, we conduct global optimization according to the characteristics of the probability of escaping.
Experimental analyses
Experimental instances
In this article, to test the performance of the proposed IIG algorithm by solving robotic distributed flowshop problem, we randomly generated 20 instances according to the actual production data, where the test cases for the problem ranged in size between 20 and 500 jobs. The experimental instances comprised 20 instances denoted as “inst1” to “inst20.” The scale of the problem is as follows: (1) the number of factories is set to 2 and the number of machines is set to 3 for all the 20 instances, the number of jobs is different in each instance; (2) all of the jobs had a set of data that processing time and the processing time of each job is randomly generated in the range of [30, 50] in each instance; (3) each instance also included a set of data for each loading and unloading time, then the load time and unload time of jobs are randomly generated in the range of [0.5, 2]. The instances can be found in the website https://www.researchgate.net/publication/334735267_IJARS-realistic_instances.
Experimental parameter analysis
This section discusses the computational experiments used to evaluate the performance of the proposed algorithm. Our algorithm was implemented in C++ on an Intel Core i7 3.4-GHz PC with 16 GB of memory. To verify the effectiveness and efficiency of the proposed algorithm, after 30 independent runs, the resulting best solutions were collected for performance comparisons.
In the proposed algorithm, there are two main parameters as follows: (1) number of deleted jobs d, which determined the number of jobs deleted in the deletion phase; and (2) temperature T, that is, the temperature set in the acceptance criterion. Similar to Ruiz and Stützle, 56 in the proposed IIG algorithm, SA heuristic is also used for the acceptance criterion, and therefore to enhance the algorithm with the ability to escape from the local best solution. In this study, we also adapt a very simple constant temperature acceptance, as in the following formula (19), and T is a parameter and to be calibrated. According to many literatures and our detailed experimental comparisons, the two parameters are set as follows: d = 3 and T = 0.2

Efficiency of the local search
In the proposed algorithm, four neighborhood search strategies to enhance the search ability are proposed. To study the effectiveness of local search, we implement the IIG algorithm proposed in the “The canonical algorithm” section and the IIG without local search (IIG-NL) algorithm. The parameter settings of the two comparison algorithms are the same as the sections of experimental parameter analysis. The two comparative algorithms are tested with the same instance on the same PC. After 30 independent runs, the average results of each instance are collected and compared, as presented in Table 5. Table 5 records the data for the IIG and the IIG-NL algorithm. The last two columns give the percentage deviation obtained by the two algorithms, and the calculation formula is given as

Comparison of best fitness between IIG and IIG-NL.a

IIG: improved iterated greedy; IIG-NL: IIG without local search.
aThe best values are in bold.
The results in Table 5 can be summarized as follows: (1) IIG algorithm obtains 13 best solutions in a given 20 instances, while the IIG-NL algorithm obtains only 7 best solutions. (2) From the last two columns in Table 5, it can be seen that the average percentage of deviation obtained by the IIG algorithm is smaller than the IIG-NL algorithm. (3) Therefore, the performance of the proposed IIG algorithm is better than that of the IIG-NL algorithm.
To further test whether the differences in the above tables are significant, we have also made a detailed comparison, as shown in Figure 7. Figure 7 shows the fitness and 95% Fisher's Least Significant Difference (LSD) intervals from IIG and IIG-NL, and the p value = 0.0445. Obviously, IIG has a statistically significant advantage over the IIG-NL algorithm.

Means and 95% LSD interval for the values of the two compared algorithms (p value = 0.0445).
Efficiency of the SA acceptance criterion
To study the effectiveness of the IIG algorithm, we implement the IIG algorithm proposed and the IIG without SA (IIG-NS) algorithm. The parameter settings of the two comparison algorithms are the same as the sections of experimental parameter analysis. The only difference between IIG and IIG-NS is that we use SA algorithm in the IIG algorithm proposed in this article; however, the IIG-NS algorithm does not use the SA algorithm when using the IIG algorithm to solve the problem. The two comparative algorithms are tested with the same instance on the same PC. After 30 independent runs, the average results of each instance are collected and compared, as shown in Table 6. In Table 6, the first column provides the name of the instance, and the second lists the best solution of the two algorithms. In the last two columns, the percentage deviation of the two algorithms is given, and the calculation formula is given in formula (20).
Comparison of best fitness between IIG and IIG-NS.a
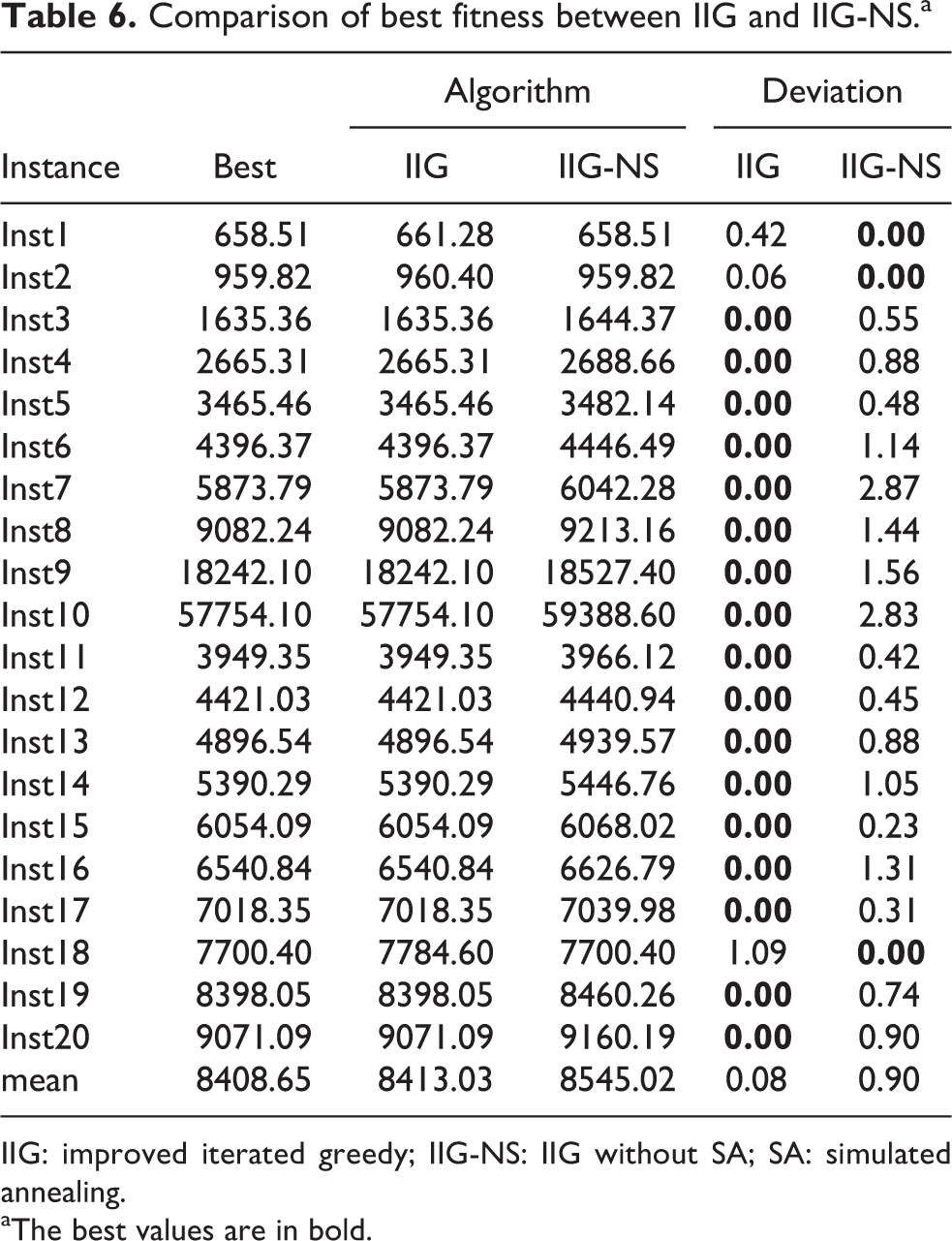
IIG: improved iterated greedy; IIG-NS: IIG without SA; SA: simulated annealing.
aThe best values are in bold.
The results in Table 6 can be summarized as follows: (1) IIG obtains 17 best solutions in a given 20 instances, while IIG-NS has 3 best solutions. (2) The percentage deviation of the two algorithms in the last two columns shows that the performance of IIG is better than IIF-NS.
To further test whether the differences in the above tables are significant, we have also made a detailed comparison, as shown in Figure 8. Figure 8 shows the fitness and 95% LSD intervals from IIG and IIG-NS, and the p value = 0.0001. Obviously, IIG has a statistically significant advantage over IIG-NS. The advantages of the SA algorithm are as follows: (1) avoid obtaining the local best solution and jump out of the local best solution to approach the global optimal solution, so as to improve the search ability; (2) the algorithm has a certain probability to accept the solution which is worse than the current solution, so it can jump out of the local optimal to a certain extent; (3) when the algorithm following into a local optimal, a SA-based heuristic is embedded and used to enhance the exploration abilities; (4) the algorithm broadens the search space.

Means and 95% LSD interval for the values of the two compared algorithms (p value = 0.0001).
Comparisons with efficient algorithms
To verify the effectiveness of the IIG algorithm in solving the problems considered in this study, we compared its performance with the P-ABC, CABC, and TS algorithm. Numerous computational tests were conducted to compare the three algorithms. The four algorithms used the same encoding and decoding strategy, the same initialization function, and the same acceptance criteria. The comparison of the experimental images based on data showed that the proposed algorithm has obvious advantages compared with the other classical algorithms. The reliability of the four algorithms was tested by extending the RDPFSP instances. The fitness values obtained in the experiments are presented in Table 7. Table 7 contains 10 columns with the instance names in the first column. Data of the second column shows the best solution obtained for each instance. In the last four columns, the percentage deviation for each algorithm relative to the corresponding best solution is shown, which was calculated as the calculation formula (20).
Comparison of the best fitness with the different heuristics.a

IIG: improved iterated greedy; IIG-NS: IIG without SA; SA: simulated annealing; CABC: cooperative artificial bee colony; TS: tabu search.
aThe best values are in bold.
The results in Table 7 can be summarized as follows. (1) The P-ABC, CABC, and TS algorithm only calculated one best solution and the other best solutions were calculated by IIG. Compared with the P-ABC, CABC, and TS algorithms, the IIG algorithm obtained better results than the other three algorithms in terms of obtaining the best fitness value. (2) The average percentage deviation with the IIG algorithm was always less than the other three algorithms. Therefore, the results in Table 7 show that the performance of the proposed algorithm is better than that of other classical algorithms when solving the problem in this study.
To test whether there are significant differences between the four algorithms, we performed an analysis of variance, and the results are shown in Figure 9. Figure 9 shows that the performance of IIG of the four algorithms compared is significantly better than that of the other three algorithms.

Results of comparison algorithms for comparisons with P-ABC, CABC, and TS. CABC: cooperative artificial bee colony; TS: tabu search.
In the next subsection, we analyze the reason why the IIG algorithm is better than the other efficient algorithms, such as P-ABC, CABC, and TS algorithms. IIG algorithm not only maintains the detection ability but also maintains the search ability.
We randomly selected eight instances of “Inst4, Inst6, Inst8, Inst13, Inst14, Inst15, Inst17, and Inst20.” Figure 10(a) to (h) records the convergence curves of these examples, showing the effectiveness of the proposed IIG algorithm. We can clearly see that in the convergence curve of each example, the IIG algorithm is the most effective.

Convergence curve for instances: (a) Inst4, (b) Inst6, (c) Inst8, (d) Inst13, (e) Inst14, (f) Inst15, (g) Inst17, and (h) Inst20.
Figure 11 shows a Gantt chart of the processing time of the jobs in the two factories in the example, where each rectangle corresponds to one artifact. The jobs assigned to F1 using the NEH strategy are {0, 1, 2, 12, 5, 6, 7, 11, 13, 15}, and the jobs assigned to F2 are {4, 9, 10, 3, 14, 16, 17, 18, 19}. Take F1 as an example, {0, 1, 2, 12, 5, 6, 7, 11, 13, 15} is the processing sequence of the jobs in F1 on each machine. The robot transports J0 to M1 for processing. After the processing of J0 is completed, the robot unloads J0 from M1 to M2 for further processing, that is, operations path for robot transporting is

Gantt chart for the solution of the example.
Experiments analysis
Through the experimental comparisons, the proposed IIG algorithm shows significant better performance compared with other efficient algorithms. The main reasons that the IIG is superior to the other efficient algorithms, such as P-ABC, CABC, and TS algorithm, are as follows: (a) four neighborhood structures are presented to improve the exploitation abilities of the proposed algorithm; (b) when the algorithm following into a local optimal, an SA-based heuristic is embedded and used to enhance the exploration abilities; and (c) a problem-specific destruction and construction strategies are developed, which can further enhance the exploitation abilities.
Conclusion
In this study, we proposed an IIG algorithm to solve the problem that a robot is used to transport jobs in the DPFSP, where each factory has only one robot and the aim is to minimize the working time for the robot. In this problem, the robot must transfer each job from one machine to the next. The blocking constraint between the machines is considered, so it is necessary to determine whether the robot is idle when the job is completed. If the robot is not idle, the job will wait on the machine. The loading and unloading times are considered and different for all of the jobs conducted by the robot, and deteriorating time is also considered. Firstly, four types of neighborhood structures are developed in the proposed algorithm after studying the characteristics of the problem. Then, the SA algorithm is embedded in the proposed algorithm to enhance the exploration abilities. Furthermore, a problem-specific destruction and construction strategies are investigated. The ultimate objective is to minimize the makespan. We compared the performance of the proposed IIG algorithm in the test problem with three algorithms. The reliability and robustness of the IIG algorithm based on detailed experimental analyses was verified.
In the future research, we will investigate other scheduling methods for robots in various situations such as by (1) considering the scheduling of multi-robot cycle under the condition of saving energy consumption; (2) considering the situation where multiple robots handle the problem, where the objective is to minimize the number of robots used; and (3) considering other realistic application of robot green scheduling to improve the economic benefits.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.