
Abstract
In teleoperation, the operator is often required to command the motion of the remote robot and monitor its behavior. However, such an interaction demands a heavy workload from a human operator when facing with complex tasks and dynamic environments. In this article, we propose a shared control method to assist the operator in the manipulation tasks to reduce the workload and improve the efficiency. We adopt a task-parameterized hidden semi-Markov model to learn a manipulation skill from several human demonstrations. We utilize the learned model to predict the manipulation target given the current observed robotic motion trajectory and subsequently estimate the desired robotic motion given the current input of the operator. The estimated robotic motion is then utilized to correct the input of the operator to provide manipulation assistance. In addition, a set of virtual reality devices are used to capture the operator’s motion and display the vision feedback from the remote site. We evaluate our approach through two manipulation tasks with a dual-arm robot. The experimental results show the effectiveness of the proposed method.
Introduction
Recently, advancements in robot learning theories, such as deep reinforcement learning 1,2 and imitation learning, 3 enable robots carry out many tasks independently, but human intervention is still indispensable for many complex tasks, such as handling hazardous materials, underwater and space exploration, minimally invasive surgery, and so on. In these cases, teleoperation that combines human manipulation capabilities and the robot is required. In conventional teleoperation systems, a human operator is directly required to control the remote robot in detail while monitoring its behavior, which results in a heavy workload. 4 Some bimanual tasks, such as peg-in-hole, require two arms to act cooperatively. However, teleoperating a dual-arm robot to accomplish such cooperative tasks is a complicated skill. In such scenarios, shared control methods can reduce the workload and improve operation efficiency by combining manual teleoperation with autonomous assistance.
Intensive research studies in developmental psychology indicate that human actions are often goal-directed. 5,6 Accordingly, in order to assist the operator in the manipulation tasks, the robot needs to first predict the manipulation goal and then provides assistance based on the predictions. For example, in reaching-and-grasping task, which object to reach and how to reach are essential for providing manipulation assistance. To do the predictions while performing the task, a robotic motion model is needed. Additionally, since the type of teleoperation tasks may vary frequently, the robotic motion model for a specific manipulation task is required to be built efficiently and rapidly. Among the robotic learning algorithms, learning from demonstrations (LfD) enables a robot to be programmed by simply showing it how to perform a desired task, which is efficient and intuitive.
In this work, we propose a shared control method based on task-parameterized hidden semi-Markov model (TP-HSMM). 7 The task parameters here refer to the variables that describe the manipulation context, such as the positions of some task-related objects, which can be used to reshape the robotic movement. For bimanual tasks, we set the pose of a robotic arm as a task parameter to model the cooperation behaviors between two arms. The demonstrations used to train TP-HSMM can be obtained from direct teleoperation. During teleoperation, our approach evaluates the probability distribution over the possible targets given the current observed robotic motion trajectory based on the learned robotic motion model. The object with the highest probability is assumed to be the manipulation target. To provide operation assistance, many shared control works blend operator input with some autonomous policy, which selects assistance actions independent of the operator input. 8 In this work, the desired robotic movement is estimated based on the current operator input and most likely target. The desired robotic movement is then used as an assistance action to blend with the operator input. Moreover, the virtual reality (VR) techniques are adopted in our teleoperation system to give the operator a better operation experience. Concretely, we utilize a pair of VR controllers to capture the motion of the operator and display the vision feedback from the remote site in the headset to improve the transparency of the teleoperation system.
The contributions of the proposed method are as follows: (i) we adopt TP-HSMM to learn a robotic manipulation skill so that our shared control method can adapt to new tasks rapidly. (ii) The assistance action is dependent on the current operator input and manipulation target. (iii) VR techniques are utilized as the human–robot interface to improve the transparency of the teleoperation system. We evaluate the approach on a reaching task and a bimanual peg-in-hole task. The experiments reveal that our method can provide the operator useful assistance and improve the operational efficiency.
The remainder of this article is organized as follows. The second section reviews the related work. The proposed VR-based dual-arm teleoperation system, the goal prediction method, and manipulation assistance method based on TP-HSMM are described in the third section. The fourth section presents the experimental settings and results. Conclusions and future work are presented in the fifth section.
Related works
In recent years, the research studies on the field of robotic teleoperation have obtained fruitful achievements, such as adopting new human–machine interfaces and introducing autonomy to assist the operators. These advancements intend to provide the operators more natural and efficient means to accomplish teleoperation tasks.
The human–robot interface is a vital part in teleoperation, which directly impacts the operation experience of the user. The currently widely used motion capture sensors, such as exoskeletal mechanical devices, 9 data glove with angle sensors, 10 and inertial motion tracking sensors, 11 have the merits of accurate detection and stable performance but are invasive and hindrance to natural human motions. Vision-based techniques 12 –14 do not require operator to wear extra devices; however, the problems of object occlusion and loss of tracking result in bad user experience. VR interfaces offer intuitive means for mapping a user’s motion actions to robot. In the work of Lipton et al. 15 and Zhang et al., 16 VR devices were utilized to directly control a humanoid robot. In this work, we also built our teleoperation system using current consumer VR hardware, but we adopt a shared control strategy to provide assistance in manipulation tasks.
Recently, many shared control methods have been proposed to reduce the workload of the operators by improving the autonomy in teleoperation systems. 17 –20 Some researchers investigate to assist the operator with some force feedback, such as haptic guidance to a target position or desired trajectory. 21,22 Our work adopts a predict-then-blend framework, 17 which predicts the most likely goal of the operators and then provides assistance in the manipulation tasks for that goal.
There are a large number of works on predicting the goal of the user. Narayanan et al. 18 proposed an approach to predict the short-term goal of the user based on the distance between the current and the goal configuration. This method is intuitive but very crude, since it does not take the history information into account. In the work of Javdani et al. 17 and Dragan and Srinivasa, 19 the prediction problem is formulated based on maximum entropy inverse reinforcement learning (MaxEnt IRL). 23 –25 In MaxEnt IRL, the user’s input is assumed to be noisy that optimizes a goal-dependent cost function, which is relevant to the historic trajectory of the user. However, learning a robotic motion skill by IRL is time-consuming. In our work, we adopt an efficient LfD method, namely TP-HSMM, as the motion planner to generate goal-dependent trajectory. Moreover, in TP-HSMM, the state duration is modeled explicitly, which is beneficial for resisting temporal perturbations and representing the time constraint of the tasks. 7
There are also a few works which address the prediction problem by utilizing other machine leaning methods. Koppula and Saxena 26 proposed to use anticipatory temporal conditional random field to predict human motions. Martinez et al. 27 utilized a recurrent neural network to model human motion to do short-term prediction.
After predicting the goal, shared control teleoperation system provides the user operation assistances for that goal. There are many approaches to offer the assistances. El-Hussieny et al. 28 proposed a teleoperation system, which turns to autonomous mode if the confidence of the prediction is high. However, in some tasks, human intervention is indispensable, even though the prediction confidence is high. Rosenberg proposed a method called virtual fixtures 29 which can be seen as a ruler so that the user can teleoperate a robot to achieve some precise motions. 30,31 Therefore, virtual fixture-based methods are usually used to guide the user along a predefined path. Our work is similar to Tanwani and Calinon. 32 We advance it in two directions. First, we blend the desired robotic motion with the input of the operator so that they can complement each other, which can avoid manipulation failure led by bad estimation or improper input. Second, we model the cooperation behaviors between two arms so that the operator can obtain assistance in bimanual manipulation tasks.
Proposed approach
In this work, the technology of motion mapping between operator and robot is divided into position mapping and orientation mapping. The basic idea of position mapping is that the position displacements of the user’s hands correspond to those of the robot’s end-effectors. In order to make the teleoperation more intuitive, the orientations of the user’s hands are mapped to the robot directly.
We improve the autonomy in teleoperation system to assist the human operator in performing tasks. TP-HSMM is used to encode the human demonstrations observed from multiple task-parameterized frames. The parameters of HSMM are estimated using an expectation maximization (EM) algorithm. 33 The learned HSMM is used as a motion planner to evaluate probability distribution over the possible targets. To avoid improper assistance, a prediction confidence is defined based on the entropy of the evaluated probability distribution. When the confidence is higher than a predefined threshold, the teleoperation system switches to assist mode from direct mode. To assist operator, we estimate the intended robotic movement and blend it with the input of the operator to teleoperate the remote robot.
Motion mapping in direct teleoperation
We build the direct teleoperation system based on a set of VR devices, a dual-arm robot, and a Microsoft Kinect V2.0. During teleoperation, we map the poses of the operator’s hands from the VR frame into the robot frame to get the target poses of the robotic arms. And then the target poses are sent to the robot through network.
Since the dual-arm robot is right-and-left symmetrical, we shall discuss only the right side for the sake of brevity. Some of the used frames of reference in this work are illustrated in Figure 1. The pose of the right robotic arm in the right base frame at each time step is denoted as

Teleoperation diagram. The VR controllers capture the motion of operator’s hands and the VR headset shows the vision feedback from the Kinect mounted on the robot. The coordination systems of VR devices, dual arm robot, and Kinect are used in motion mapping from operator to robot. VR: virtual reality.
As is illustrated in Figure 1, in the VR frame, the x-axis is pointed right (red arrow), the y-axis is pointed upward (green arrow), and the z-axis is pointed backward (blue arrow). In the robot frame, the x-axis is pointed forward; the y-axis and the z-axis are pointed left and upward, respectively. In teleoperation systems, the translation between these two reference frames is not a concern. The rotation matrix between the robot frame and the VR frame is

Then, we convert the orientation of the operator’s hand from the VR frame to the robot frame by

where
The displacement of the operator’s hand is transformed to the robot frame as

Finally, the target position and orientation of right end-effector in the right base frame is


where
Task-parameterized HSMM
Hidden markov model (HMM) is composed of several discrete states, which emit observations drawn from a set of probability density functions. We adopt a multivariate Gaussian distribution to represent the emission probability distribution of each state. In LfD, HMM segments the demonstrations into a set of movement primitives, which correspond to the hidden states.
The parameter of an HMM with K hidden states is described by
Task parameters here are the positions and orientations of the reference frames, which are attached on the task-relevant objects. The task-parameterized models learn to describe a movement from different frames of reference. Therefore, a TP-HSMM with K states and P frames of reference are described by
The demonstrations used to train TP-HSMM can be obtained by direct teleoperation or kinesthetic teaching. In order to learn the relation between the robot’s movement

where
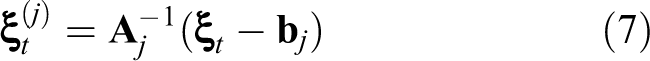
where
Target prediction
In this section, we describe our approach to predict the manipulation target based on the learned TP-HSMM. In what follows, S denotes the initial position of the robot’s end-effector, C denotes the current position, G denotes a potential target, and
To adapt to a new environment, the parameters of the ith state of the learned TP-HSMM in the jth reference frame

The center and covariance

According to the block form of
Then, we can synthesize the transformed model from the P task-parameterized frames and the right base frame by computing the product of Gaussians

where

This product model can plan the motion of the robot given the current observation

Secondly, a state sequence is generated by the means of forward variable
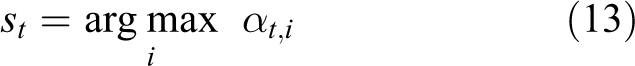
The state sequence is then used to retrieve a stepwise reference trajectory

The reference trajectory is tracked by a finite horizon discrete-time linear quadratic regulator to generate an executable and smooth trajectory.
In this work, the observation sequence of robotic motion from initial position S to current position C is denoted as

where Θ is the parameters of TP-HSMM. Rewriting equation (15) according to the Bayes’ theorem

The learned TP-HSMM is utilized to plan the robotic motion from S to G, denoted as

Based on the principle of maximum entropy, we induce the likelihood in equation (16) by the similarity

where β is an adjustable coefficient that increases the importance of similarity on the distribution. Substituting equation (18) into equation (16), the prediction becomes

In the preceding, S is the initial position, in fact, it can be any point in the observation sequence. Before making predictions, the robot is teleoperated directly at the beginning to get some observations
Many previous works studied the impact of autonomy on the performance of teleoperation and analyzed various influencing factors. Among all of the factors, prediction correctness has a substantial effect on the operation performance and user experience. Thus, the assistance should take into account how good the prediction is. In this work, a prediction confidence is defined based on the entropy of the prediction to measure the quality or correctness of the prediction

At the beginning of the operation, since there is little information for the robot to predict the user’s intent, the prediction confidence is usually low. As the manipulator expresses apparent tendency toward a target in the course of teleoperation, the prediction confidence increases. In order to avoid bad assistance based on the incorrect predictions, we define a switching threshold to decide when to assist the operator

where
Operation assistance
In the direct mode, the position and orientation of the operator hand at time t are mapped to the robot as

In assist mode, we first obtain the task parameters based on the predicted target. Then, our approach corrects

The center and covariance of conditional probability distribution


with

Synthesizing the information from all task-parameterized frames using the product of Gaussians, we can get the conditional probability distribution of the end-effector’s position at time t
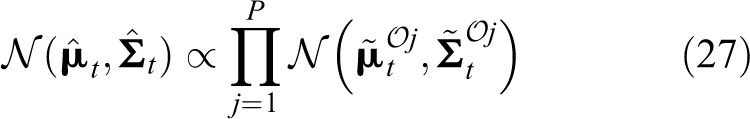
Evaluating the product of Gaussians yields

The mean

where
Our approach for shared control teleoperation is summarized in Algorithm 1. The TP-HSMM is used to predict the manipulation target and estimate the intended position of the robotic end-effector. When the confidence of the prediction is higher than a switching threshold, the operation assistance is provided by correcting the input of the operator.
Shared control teleoperation.


Experiments
In this section, two experiments are conducted to validate the proposed shared control teleoperation method. In the first experiment, we evaluate the performance of predicting the manipulation target in a working environment that contains more than one candidate objects. In the second experiment, we apply the proposed method in a bimanual manipulation scenario to show how the cooperation behaviors can be learned and used to assist the operator during teleoperation.
Experimental setup
In the following experiments, the AprilTags are used to help to detect the poses of the interested objects in the manipulation environment. The experimental platform consisted of a Microsoft Kinect 2.0 sensor, a dual-arm robot, and a set of HTC Vive VR devices. The Kinect is placed on the robot whose view is as shown in Figure 2(a). The dual-arm robot is composed of two six-DoF Universal Robot 3 (UR3), and each UR3 is equipped with a two-finger gripper as shown in Figure 5(a). UR3 can be controlled by torque and position mode, and all its joints contribute to the transformational and rotational movements of its end effector. We operate each UR3 in position control mode by sending the target pose of its end-effector

Manipulation environment, demonstrations, and the learned HSMM. (a) The manipulation environment captured by the Kinect fixed on the robot and two object frames. Demonstrations and models in (b) right base frame and (c) object frame. The lines are the recorded demonstrations, and the ellipsoids represent the Gaussian hidden states of the learned HSMM. HSMM: hidden semi-Markov model.
Goal prediction
Reaching is a standard benchmark in robotics because many tasks can be represented by one or more reaching tasks. In order to assist the user in these tasks, the robot has to know which object the user is intended to reach. In this experiment, more than one object were placed in the manipulation environment (see Figure 2(a)), and the operator teleoperated the robot to pick one of the two objects. During the operation, the intended goal object was predicted in real time. This scenario allows us to demonstrate the ability of the proposed method to predict the manipulation target.
This experiment consists of a learning phase and a prediction phase. In the learning phase, the user teleoperated the robot directly to reach an object from initial pose and recorded the pose of the end-effector as human demonstrations. There were 15 demonstrations (see Figure 2) recorded for different locations of the target object.
In this experiment, one task-parameterized frame (P = 1) is utilized to describe the manipulation context, namely the object frame, which is located at the center of the AprilTag marker attached on the object as shown in Figure 2(a). The demonstrations were used to train a TP-HSMM with
Given the current pose of the object, the model in the object frame (Figure 2(b)) is transformed to the right base frame to get the transformed model (Figure 3(b)) using equation (8). Therefore, the transformed model contains the information about the location of the object while the base frame model (Figure 3(a)) contains the information about the initial position of the robotic end-effector. The information of the two models can be used to complement each other. An all-round description of the task is obtained by computing the product of the base frame model and the transformed model. The product of two Gaussian is still a Gaussian, and the product is closer to the one with smaller variance. Since the variance of the first state of the base frame model is small and that of the transformed model is large, the first state of the product model is closer to that of the base frame model. Analogously, the third state of the product model is closer to that of the transformed model. Therefore, the product model reflects the synthesizing of the information from different frames of reference. On the other hand, the product model is the motion trajectory distribution of the reaching task. In a specific reaching task, since the start and end position of the motion is fixed, the variances of the trajectory segments corresponding to the start and end phase are small. However, the middle part of the trajectory is not fixed, so the variance is high. Therefore, as shown in Figure 3(c), the size of the first and third ellipsoid is small while that of the second one is large.

The adaptation of the learned model to new environment. (a) The base frame model is the HSMM model in the right base frame. (b) The transformed model is obtained by transforming the learned model in object frame to the robot base frame according to the current pose of the object. (c) The product model is the product of the base frame model and the transformed model. HSMM: hidden semi-Markov model.
The product model is used as a motion planner to evaluate probability distribution over the possible targets. The dotted lines in the left column of Figure 4 are the planned trajectories to the two objects at different locations. At every time step, the probability to each object is estimated based on the similarity between the planned trajectory and the recorded actual trajectory. The β in equation (18) is set at 50 to evaluate the probabilities. In the first two cases (see Figure 4(a) and (d)), since the operator teleoperated the robot to reach one of the objects directly, the estimated probabilities to that object increased rapidly and the prediction confidence also increased monotonically. In the third case, the robot moved toward object 2 at the beginning and then turned to object 1 as shown in Figure 4(g). Since the user changed mind during the operation, the estimated probability and the prediction confidence exhibit fluctuations apparently. Therefore, the probabilities to each objects and the prediction confidence in these three cases can reflect the intent of the user clearly.
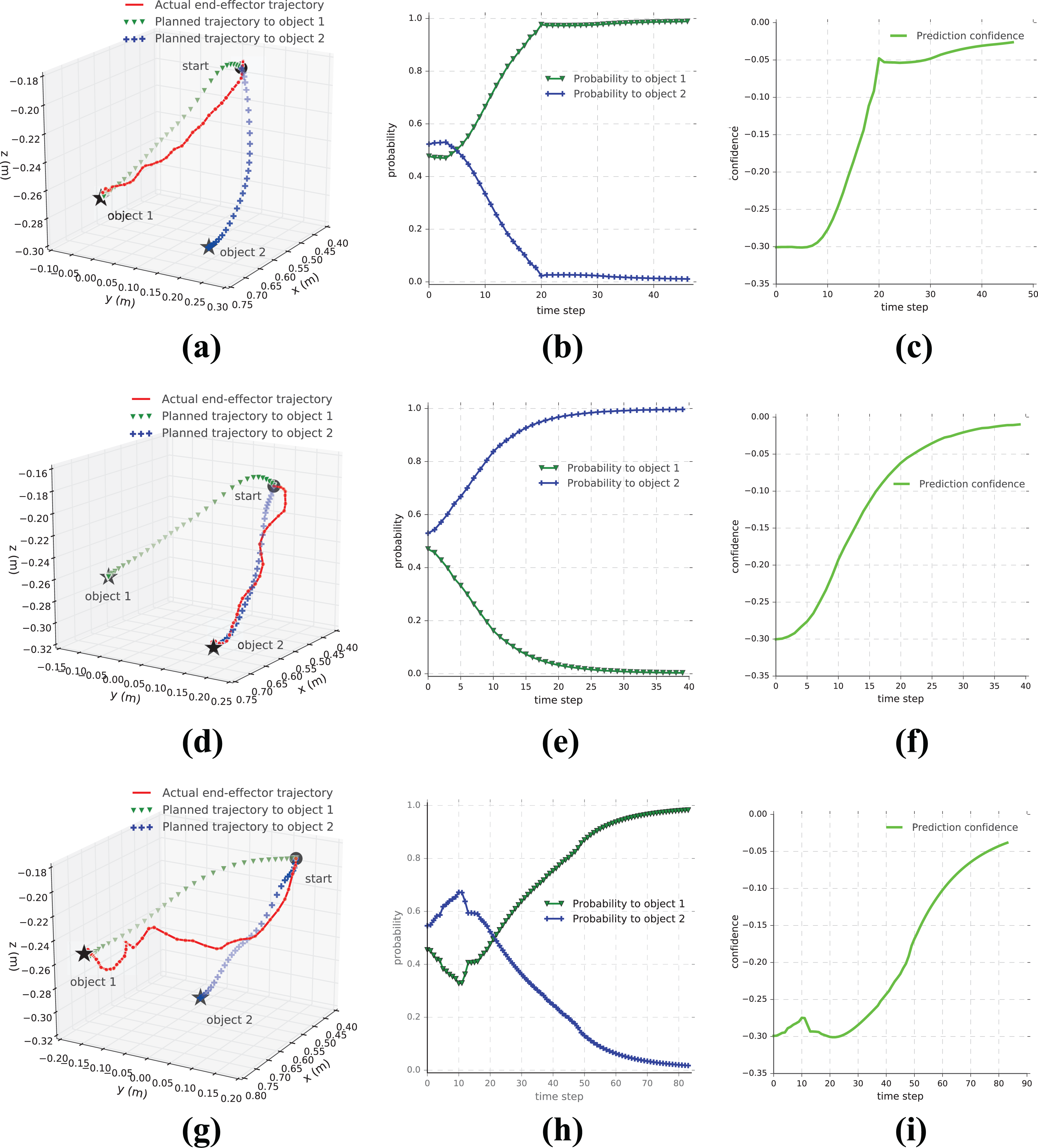
Goal prediction in three different cases (three rows): left column illustrates the actual trajectories and the planned trajectories of the end-effector to each of the two objects in the manipulation environment; the middle column illustrates the estimated probabilities move to one of the objects during operation; the right column gives the confidence of the predictions. The black stars represent the positions of different objects and the black circles represent the start position of the robot’s end-effector. (a), (d), and (g) The actual and planned trajectories; (b), (e), and (h) the probabilities to different objects; and (c), (f), and (i) the prediction confidence.
Bimanual peg-in-hole
Bimanual teleoperation tasks involve up to two robotic arms at the same time, thus increasing the operational difficulty. In this example, the user teleoperated the dual arm robot to insert a peg held by the right end-effector into a slot held by the left end-effector as shown in Figure 5(a). Due to the heterogeneity between human and the dual arm robot, this kind of manipulation task is often difficult for the operator.

The dual arm robot, demonstrations, and learned HSMM. The ellipsoids represent the Gaussian hidden states of the learned HSMM: (a) the dual arm robot and some frames of reference used in the experiment; (b) demonstrations and models in the base frame; and (c) demonstrations and models in left end-effector frame. HSMM: hidden semi-Markov model.
In bimanual manipulation tasks, the relative motions can be used to specify the desired motions of both robotic arms. In order to describe the relative motion between the two robotic arms in the task, we attached a task-parameterized frame on the left end-effector called left end-effector frame. A task-parameterized model with
The demonstrations and the learned models in the robot base frame and in the left end-effector frame are illustrated in Figure 5(b) and (c). The red ellipsoids represent the fourth state of HSMM, which correspond to the insertion phase of the peg-in-hole task. Since the position of the left end-effector is different between demonstrations, the trajectories in the robot base frame show great variance in the insertion phase. Conversely, in the left gripper frame, all trajectories finally gather at the position of the peg. Therefore, the red ellipsoids are large in the robot base frame but rather small in the left end-effector frame.
During teleoperation, the position and orientation of the task-parameterized frame are updated at each time step. Then, learned model is transformed by equation (8) according to the new task parameter.
We compare the shared control teleoperation with direct teleoperation by analyzing the corresponding trajectories of the right end-effector. The operators teleoperated the robot to do the bimanual peg-in-hole task in the direct mode and the assist mode 10 times, respectively. In assist mode, the value of α was empirically set to 0.2. The learned model assisted the operator in controlling the position of the right end-effector while the orientation was controlled by the operator directly. In the direct mode, the operator controls the robot directly without corrections as shown in Figure 6(b) and (d). The purple part of the trajectories indicates that the operator is continuously adjusting the position of the peg in order to insert into the slot. In assist mode, the purple part is smoother which illustrates that the operator did less adjustment during operation. The corrections in the assist mode are illustrated in Figure 6(a) and (c). The purple rectangle regions correspond to the purple part of the trajectories.

The trajectories and corrections during teleoperation. The red circles represent the position of the slot and the purple part of the trajectories indicate less than 10 cm to the slot. Plots in the second and fourth columns show the corrections to the input of the operator, in which the purple rectangle regions correspond to the purple parts of the trajectories. Trajectory and corrections in (a) and (c) assist mode and (b) and (d) direct mode.
To investigate the influence of α in shared control, we set the value of α to different values and teleoperate the robot to do the peg-in-hole task 10 times for each value. The duration time of the insertion phase for different values of α is illustrated in Figure 7. We compare the performance of teleoperation from the perspectives of mean and variance of the duration time of the insertion phase. When

Duration time of the insertion phase for different α values.
Conclusion
In this article, a shared control method based on LfD is proposed to assist operator in manipulation tasks. The VR devices are used to capture the motion of the human operator and display the vision feedback from the remote site. A motion mapping approach is developed to map the operator motion to the robot. We adopt a predict-then-blend framework to correct the operator input during operation. A TP-HSMM is utilized to encode human demonstrations so that the model can adapt to new situations. The learned model is used as a motion planner to predict the manipulation target based on the principle of maximum entropy and Bayes’ theorem. Then, the desired motion of the robot is estimated given the current operator input and task parameters. We utilize the estimated desired robot motion to correct operator input. Our method can apply to bimanual teleoperation tasks to reduce the operator workload. We set the pose of left end-effector as a task parameter to describe the relative behavior of the two robotic arm in bimanual tasks. The experimental results show that the proposed method can predict the manipulation target accurately and provide useful assistance to the operator to reduce the manipulation workload and improve the operational efficiency. In this work, only the input position of the operator is corrected. We plan to investigate a way to assist the operator in controlling the orientation of the end-effector in future work.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflict of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China under grant 61773378, grant U1713222, and grant 61703401; in part by the Early Career Development Award of SKLMCCS; and partly by the National Key R & D Program of China (grant 2017YFB1300202) and Science and Technology on Space Intelligent Control Laboratory for National Defense, no. KGJZDSYS-2018-09.