
Abstract
Multi-turn response selection is essential to retrieval-based chatbots. The task requires multi-turn response selection model to match a response candidate with a conversation context. Existing methods may lose relationship features in the context. In this article, we propose an improved method that extends the learning granularity of the multi-turn response selection model to enhance the model’s ability to learn relationship features of utterances in the context, which is a key to understand a conversation context for multi-turn response selection in retrieval-based chatbots. The experimental results show that our proposed method significantly improves sequential matching network for multi-turn response selection in retrieval-based chatbots.
Introduction
Dialogue systems and conversational agents—including chatbots, personal assistants, and voice-control interfaces—are becoming ubiquitous in modern society. 1 Recently, more and more attention from both academia and industry is paying to build non-task-oriented chatbots that can naturally converse with humans on any open domain topics. 2 Existing work on building chatbots includes generation-based methods and retrieval-based methods. 3 Retrieval-based methods have been applied to many chatbots such as the MILABOT from Montreal Institute for Learning Algorithms 1 and the XiaoIce from Microsoft, 4 because they can return informative and fluent responses.
A key step to response selection is measuring the matching degree between a response candidate and an input. 2 Single-turn response selection in retrieval-based chatbots matches between a response and the last input message. 5 However, multi-turn response selection in retrieval-based chatbots requires matching between a response and a conversation context (also known as previous utterances in a continuous conversation session). 6 The key for retrieval-based multi-turn response selection task is to understand context in a continuous conversation. In a multi-turn conversation, if a chatbot can completely understand the whole context in a continuous conversation, it can reply the best answer to user. Understanding the conversation context is difficult for chatbots, because it is challenging to catch utterance-level discourse information and dependencies. 7 Identifying important information in the context and model relationships among utterances in the context are challenges of multi-turn response selection task. 3
In response to those challenges, many retrieval-based multi-turn response selection models have been provided. Sequential matching network (SMN) 3 is the most distinguished method that significantly outperforms the state-of-the-art methods for response selection in multi-turn conversation. 3 However, SMN is not good enough for learning relationship features among utterances in the context. Understanding relations of utterances plays a key role in mastering dialogues. 8 Modeling relationships among utterances in the context is challenging, while acquiring human annotation on discourse relations is a time consuming and expensive process and does not scale for large data sets. 8
In this article, an improved method is proposed to facilitate SMN to learn more relationship features among utterances in the context. This method is inspired by the idea of the N-gram model proposed by Shannon (1948), 9 who used it to explore language modeling in the context of information entropy, which was also introduced in the same paper. Since then many studies have improved the natural language processing model by changing the granularity of natural language modeling. In natural language processing model, if the phrase “white house” is separated into two independent units to process, this phrase “white house” will be understood as a house with white color. If the words in this phrase were concatenated into one unit to process, natural language processing model will be understood “white house” as the US presidential palace. This example indicates that bigram model has a better performance than unigram model in some natural language understanding tasks. Most studies improve the natural language processing model by changing word-level granularity or character-level granularity in processing unit. Few studies have focused on changing larger granularity natural language processing unit to improve the natural language processing model. Our study improves multi-turn response selection model by changing utterance-level granularity in the processing unit. For one thing, utterance is the most important learning granularity in multi-turn response selection task. By analyzing Multi-view and SMN models on Ubuntu Corpus, it shows that utterance-level granularity plays a more important role in the context understanding of multi-turn dialogue, as shown in Table 1. In Multi-view model, Utter-seq-GRU and Word-seq-GRU are based on utterance-level granularity and word-level granularity, respectively. In SMN model, M2 and M1 are based on utterance-level granularity and word-level granularity, respectively. Details of M1 and M2 will be introduced in “SMN method” section. For another, modeling the relationship between utterances is one of the two major challenges of multi-turn response selection task (another challenge is to identify important words in the context). In addition, good features can be learned automatically using a general-purpose learning procedure. In most tasks of natural language processing, word vectors are composed of learned features that were not determined ahead of time by experts but automatically discovered by the neural network. 10 Thus, in this article, we propose a method that concatenates each two adjacent utterances as a unit into a neural network model, which can facilitate the model to learn more good relationship features among utterances in the context. We refer to this method as learning bi-utterance (LBU), because it has learned more good relationship features among utterances in the context by LBU. By adding our method to SMN, the experimental results on two public data sets show that LBU significantly improves SMN for multi-turn response selection in retrieval-based chatbots.
Experimental results of Multi-view and SMN model ablation.a

SMN: sequential matching network.
The rest of this article is organized as follows. Second section gives the detailed description about related work. Third section shows principle of the proposed method through three parts. The experimental results and analysis are included in fourth and fifth sections, respectively. Finally, the work is concluded and future research directions are identified in sixth section.
Related work
In this section, we briefly reviewed the existing literature that closely relates to the proposed method. At first, we introduced the chatbots system. Then, we reviewed basic and advanced models of multi-turn response selection in retrieval-based chatbots.
Chatbots system
The research of chatbots system originated from the development of conversation system. Owning to the lack of conversational data, the early conversation system is usually closed domain which aims at a specific domain such as psychological consultation. The method for building early conversation system is based on rules or templates, which requires many manual efforts. And, it is difficult to change an existing conversation system for other domain in early stage. With the advent of big data, the tremendous development of social networks has made it possible for researchers to obtain a large amount of conversational data. The chatbots system research is emerging and receiving increasing attention from academia and industry. Unlike the early conversation system, the chatbots system is an open domain. Users can naturally converse with chatbots on any open domain topics. There are two promising methods presented for building chatbots system including retrieval-based method, 2,3,6,7,11 –15 which selects a response from a large corpus and generation-based method, 16 –24 which directly generates the next utterance from a trained model. Our study focused on retrieval-based method.
Basic models of retrieval-based chatbots
Corpus is the basis of natural language processing. Due to the lack of large data sets, it has become a barrier for research in multi-turn response selection. 25 Until Lowe et al. 25 released the Ubuntu Dialogue Corpus that founded data for research in multi-turn response selection. In addition, Lowe et al. 25 presented three benchmark methods including term frequency-inverse document frequency (TF-IDF), recurrent neural networks (RNN), and long short-term memory (LSTM) for analyzing this data set. Kadlec et al. 26 improved baselines for the Ubuntu Dialogue Corpus using a better word embedding method to improve LSTM and presented convolutional neural networks (CNN) and bidirectional long short-term memory (Bi-LSTM) as new methods. Moreover, Kadlec et al. 26 created an ensemble of multiple neural networks that further enhanced the performance and achieved a better result. 26 TF-IDF, RNN, CNN, LSTM, and Bi-LSTM are considered as basic models. 3
Advanced models of retrieval-based chatbots
Ensemble models using multiple neural networks are considered as advanced models. 26 The Deep Learning to Respond (DL2R) proposed by Yan et al. 6 is one of the earliest advanced models. This model is an ensemble of three different neural networks, including Bi-LSTM, CNN, and MLP, which significantly outperforms basic models for response selection in multi-turn conversation. Yan et al. 6 also contributed to an approach to model context in a continuous conversation in multi-turns that reformulates the message with other utterances. 3 At the same time, Zhou et al. 7 considered the works of Lowe et al. 25 and Kadlec et al. 26 viewing the context and response as word sequences that have left out the utterance-level discourse information and dependencies. Thus, they presented a new ensemble model called Multi-view 7 which integrates information from both word sequence view and utterance sequence view, and each view can represent relationships between context and response from a particular aspect. Features extracted from the word sequence and the utterance sequence provide complementary information for response selection. 7 Wu et al. 3 verified that Multi-view 7 is not only superior to the methods of Lowe et al. 25 and Kadlec et al. 26 but also better than the DL2 R 6 on the Ubuntu Dialogue Corpus. Then, Wu et al. 3 provided a brand new ensemble model called SMN 3 for response selection in multi-turn conversation. This model is an ensemble of two GRUs and one CNN. Especially, it constructs a word–word similarity matrix and a sequence–sequence similarity matrix to link the first GRU and CNN in the model. These two matrices capture important matching information in a word level and a segment (word subsequence) level, respectively, which means important information from multiple levels of granularity in the context is recognized under sufficient supervision from the response and carried into matching with minimal loss. 3 An empirical study on two public data sets shows that SMN can significantly outperform state-of-the-art methods for response selection in multi-turn conversation. 3 Wu et al. 3 also published Douban Conversation Corpus which is the first human-labeled multi-turn response selection data set to research communities. The SMN has been described in detail in “SMN method” section.
It is worth noting that some leading researchers 3,7 of chatbots think it is essential to learn relationship features of utterances in the context for retrieval-based multi-turn response selection model. Therefore, in our study, we focus on improving retrieval-based multi-turn response selection model by enhancing model’s ability of learning relationship features of utterances in the context.
The method principle
The principle of retrieval-based multi-turn response selection task is to retrieve candidate answers from the corpus according to a conversation context, instead of only considering the last input information of user in single-turn response selection task. And then selecting the best answer to the user from retrieval candidate answers. The key of this task is to select the best answer among all candidate answers according to a conversation context. 12 It is necessary to score retrieval candidate answer and provide the answer with the highest score for user.
In the proposed method, we add a bi-utterance constructing process to SMN which concatenates each two adjacent utterances as a unit. In addition, a concatenating vectors process is added to manage the generated additional vectors from SMN. The process of SMN with LBU is illustrated in Figure 1.

SMN with LBU. SMN: sequential matching network; LBU: learning bi-utterance.
Multi-turn response selection formalization
The problems solved by the retrieval-based multi-turn response selection task can be expressed as
SMN method
The first step of SMN is word embedding which finds the embedding table and then expresses u as
SMN establishes a word–word similarity matrix and a sequence–sequence similarity matrix, where the word–word similarity matrix is denoted by M1. Since

where
The sequence–sequence similarity matrix of SMN is represented by M2. To get M2, the first gated recurrent unit (GRU) is used to convert U and R into hidden vectors. Assuming the hidden vectors of U are represented by
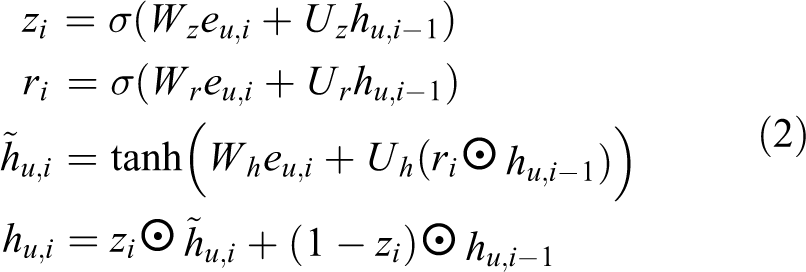
where

where
After that, the word–word similarity matrix M1 and the sequence–sequence similarity matrix M2 are as input of CNN to extract important matching information to form a matching vector v. Let

where

Through the above steps, SMN gets a matching vector

where l′ represents the last layer of the feature map, I and J are the maximum index of the feature map, and Wc and bc are parameters. It means that SMN uses two different text granularities to extract matching information from multi-turn dialogue corpus and maps it as a vector.
Afterward, SMN inputs the obtained matching vector v into the second GRU for processing. The method is the same as equation (2), and

where W 1 and b 1 are parameters.
In the model training process, SMN uses cross-entropy as the loss function, so that the training obtained θ to denote parameters of

where N is the number of utterances in data set D.
LBU method
The principle of proposed method LBU is to concatenate each two adjacent utterances as a unit into SMN, so that SMN can learn more relationship features among utterances in the context. The bi-utterance constructing step was added in the middle of the processing of the first GRU and the construction of the similarity matrix. LBU has two steps and the most important one is to construct bi-utterance at first. It is defined as equation (9)

where
The second step of LBU is a vector fusion operation which is used to cope with a new generated vector b. Vector b contains more relationship features between two adjacent utterances. In the process of SMN, it gets a matching vector
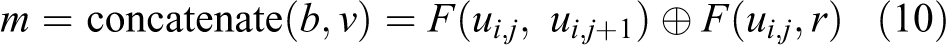
where
Algorithm 1 shows the processing of the proposed method. It is noted that proposed method uses an essential padding strategy. After concatenating each two adjacent utterances into one, the total number of input data is reduced by 1. For example, we originally had 10 utterances, and then we add each two adjacent utterances together to get one bi-utterance, then we end up with 9 bi-utterances. To make up for this missing data, our method has a padding process by taking the last utterance again and adding it with itself to form a new bi-utterance in the process of reading data.
Learning bi-utterance for SMN.


Experiment
In the experimental section, we verified the proposed method on two public corpus data sets including Ubuntu Corpus and Douban Conversation Corpus. To compare with SMN method, the data sets and parameters are kept the same as SMN 3 to ensure that no other factors affected the experimental results.
Experimental data sets
The Ubuntu Corpus 25 is an English multi-turn dialogues data set. This data set consists of 1 million multi-turn dialogues for training, 0.5 million multi-turn dialogues for validation, and 0.5 million multi-turn dialogues for testing. The Ubuntu Corpus extracted from the Ubuntu chat logs, which is used to receive technical support for various Ubuntu-related problems. Positive responses are true responses from humans and negative ones are randomly sampled. The ratio of the positive and the negative is 1:1 in training data set and 1:9 in validation and testing data sets. This study uses the preprocessed data from the Ubuntu Corpus in which numbers, URLs, and paths are replaced by special placeholders. 27 The evaluation metrics of the Ubuntu Corpus is recalled at position k in n candidates (R n @k). 25
The Douban Conversation Corpus 3 is a Chinese multi-turn dialogues data set, which is crawled from the Chinese popular social networking service Douban group. This data set consists of 1 million multi-turn dialogues for training, 50,000 multi-turn dialogues for validation, and 10,000 multi-turn dialogues for testing. In the test set, every context has 10 response candidates, and each of the response has a label “good” or “bad” by human annotators. 2 The evaluation metrics of the Douban Conversation Corpus includes recalling at position k in n candidates (R n @k), 25 mean average precision (MAP), 28 mean reciprocal rank (MRR), 29 and precision at position 1 (P@1). The Douban Conversation Corpus did not use R2@1 as evaluation metrics to prevent bringing bias to evaluation, because one context could have more than one correct response in the Douban corpus.
Statistics of Ubuntu Corpus and Douban Conversation Corpus are displayed in Table 2.
Statistics of Ubuntu Corpus and Douban Conversation Corpus.a

Experiment setup
Models in this work are implemented with Theano,
30
and all experiments are processed on a single GPU. Word embedding is initialized by the results of Word2Vec,
31
which runs on the training data, and the dimensionality of word vectors is 200. We followed the work of Wu et al.
3
to set the dimensionality of the hidden states of the first GRU as 200. The window size of convolution and pooling is (3, 3). The number of feature maps is eight. In the second GRU, we set as 100 rather than 50, because LBU requires more space. The experimental results show that tuning the dimensionality of the hidden states of GRU cannot improve SMN. Parameters of models are updated by stochastic gradient descent and optimized by Adam algorithm.
32
The initial learning rate is 0.001, and parameters of Adam,
Experimental results
We choose three retrieval-based multi-turn response selection models as baselines, including DL2R, 6 Multi-view, 7 and SMN. 3 Three different methods SMNlast, SMNstatic, and SMNdynamic are used to calculate final score of response candidates in SMN. Our proposed method is an improvement with final score calculation method provided by SMNlast. Table 3 shows the evaluated results on two data sets. It demonstrates that our proposed method significantly improved SMN and is better than other models. Experimental results of our proposed method are the best among all methods on the Ubuntu Corpus. Furthermore, the effectiveness of our proposed method is more significant on the Douban Conversation Corpus.
Experimental results on two data sets.a

MAP: mean average precision; MRR: mean reciprocal rank; LBU: learning bi-utterance; DL2 R: deep learning to respond; SMN: sequential matching network.
aBold font indicates the experimental results of proposed method. All the results except ours are from the article of Wu et al. 3
Analysis
We verified the effectiveness of our proposed method via model ablations and explored the possibilities of learning granularity tuning about further improved model.
Model ablations
We ablated model to further analyze the effectiveness of our proposed method, as shown in Table 4. There are two channels in SMN to capture important matching information, which are M1: word–word similarity matrix and M2: sequence–sequence similarity matrix. The performance of the model reduced significantly, when SMNlast only uses one channel to capture important matching information. If SMNlast only uses M2 (the sequence–sequence similarity matrix) channel, the performance is better than when SMNlast only uses M1 (word–word similarity matrix) channel. In addition, our proposed method can use two channels M1 and M2 simultaneously to capture important matching information. M1 with LBU is referred as word–word similarity matrix with LBU, and M2 with LBU is referred as sequence–sequence similarity matrix with LBU. The performance of the model reduced significantly, when LBU with SMNlast only uses one channel to capture important matching information. Noting that when the proposed improved model only uses one channel M1 with LBU is better than SMNlast only uses one channel M1. Identically, when the proposed improved model only uses one channel M2 with LBU than SMN only uses one channel M2. It demonstrates that LBU is effective in improving the performance of whole SMN or the different parts of SMN.
Experimental results of SMN model ablation on Ubuntu Corpus and Douban Conversation Corpus.a

MAP: mean average precision; MRR: mean reciprocal rank; LBU: learning bi-utterance; SMN: sequential matching network.
aBold font indicates the experimental results of proposed method.
Learning granularity tuning
Our proposed method concatenates each two adjacent utterances as a unit into the model. We also try out learning tri-utterance or n-utterance (n > 3) methods to figure out whether it is possible to make more progress with different n. The results show that concatenating three or more adjacent utterances as a unit into the model cannot improve the model. On the contrary, continuously extending learning granularity will reduce the effectiveness of the model, since it will generate redundant relationship information among utterances in the context, which make the model become harder to learn good features of the context. Therefore, concatenating each two adjacent utterances as a unit into the model is the best learning granularity for improving multi-turn response selection in retrieval-based chatbots.
Conclusions
In this article, we propose an improved method based on SMN for multi-turn response selection in retrieval-based chatbots. This method facilitates SMN to learn more relationship features of utterances in the context, which is a key to understand context in a continuous conversation. The experimental results show that our proposed method significantly improves the SMN for response selection in multi-turn conversation. In the future, we will try to apply our proposed method to other tasks of text matching.
Footnotes
Acknowledgement
We appreciate the support and advice of Yu Wu.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article was supported by National Key Research and Development Program of China (2016YFB0502600), Beijing Municipal Science and Technology Project (BJMSJY-170167) and Open Fund of Key Laboratory for National Geographic Census and Monitoring, National Administration of Surveying, Mapping and Geoformation (2017NGCMZD03).