
Abstract
Temporal information plays a significant role in video-based human action recognition. How to effectively extract the spatial–temporal characteristics of actions in videos has always been a challenging problem. Most existing methods acquire spatial and temporal cues in videos individually. In this article, we propose a new effective representation for depth video sequences, called hierarchical dynamic depth projected difference images that can aggregate the action spatial and temporal information simultaneously at different temporal scales. We firstly project depth video sequences onto three orthogonal Cartesian views to capture the 3D shape and motion information of human actions. Hierarchical dynamic depth projected difference images are constructed with the rank pooling in each projected view to hierarchically encode the spatial–temporal motion dynamics in depth videos. Convolutional neural networks can automatically learn discriminative features from images and have been extended to video classification because of their superior performance. To verify the effectiveness of hierarchical dynamic depth projected difference images representation, we construct a hierarchical dynamic depth projected difference images–based action recognition framework where hierarchical dynamic depth projected difference images in three views are fed into three identical pretrained convolutional neural networks independently for finely retuning. We design three classification schemes in the framework and different schemes utilize different convolutional neural network layers to compare their effects on action recognition. Three views are combined to describe the actions more comprehensively in each classification scheme. The proposed framework is evaluated on three challenging public human action data sets. Experiments indicate that our method has better performance and can provide discriminative spatial–temporal information for human action recognition in depth videos.
Introduction
Human action recognition has attracted increasing attention throughout the computer vision community over the past years. The traditional methods based on the red, green and blue (RGB) data for action recognition usually focus on body shape feature, 1 key poses 2 and son on. Although they may have achieved high performance in some specific contexts, however, RGB action recognition methods are sensitive to changes of lighting conditions and fail to recognize actions in more challenging scenarios when there exist occlusions and clutter backgrounds.
The introduction of low-cost integrated depth sensors (such as Microsoft Kinect™, Redmond, Washington) that can capture both RGB video and depth information has significantly advanced the research of human action recognition. Compared with conventional RGB cameras, Kinect depth sensors provide us the 3D structural information of the scene that is useful in facilitating the recognition task by simplifying intra-class motion variations and removing cluttered background noise. Furthermore, the depth information can eliminate the effects of illumination and colour variations. Therefore, researchers have put lot of attentions to the depth-data-based human action recognition and proposed effective features such as depth motion maps (DMM), 3 local occupancy pattern (LOP), 4 histogram of oriented 4D normal, 5 super normal vector (SNV), 6 depth cuboid similarity feature (DCSF) 7 and {Xia, 2013 #8}range-sample depth feature. 8
In the last decade, thanks to the significant advancements in computational capabilities and the availability of large amount of annotated data sets, 9,10 deep learning has gained a lot of focus and been widely used to address various computer vision challenges. The most popular deep neural network model is convolutional neural networks (CNNs) introduced by LeCun et al. 11 CNN can automatically learn powerful and discriminative image features and has been demonstrated as an effective model for understanding image content. An increasing number of researchers start to apply CNN in video-based action recognition tasks. 12 –21 However, most of the existing action recognition works rely on RGB data or skeleton data, moreover, currently existing public available action recognition data sets that almost all deep neural network models are evaluated on are composed of RGB videos alone, such as UCF-101, 22 HMDB51 23 and Kinetics. 24 There are only few researches on depth-based human action recognition using CNN, 25 –28 because the depth training data are relatively small-scale. Recently, a new large-scale benchmark data set named NTU RGB + D data set 29 is proposed to overcome the limitations of depth data-based human action recognition with CNN.
In this article, we construct a CNN-based action recognition framework with the proposed hierarchical dynamic depth projected difference images (HDDPDI). HDDPDI are presented as a simple and efficient descriptor to extract the spatial–temporal motion information in depth videos. For a depth video sequence, each depth frame is projected onto three orthogonal Cartesian views. Then depth maps in each projected view are sampled at several different temporal scales. Depth projected difference image (DPDI) is defined as the absolute difference image between two consecutive depth maps. We compute DPDI sequences at different temporal scales for each projected view, which can reflect the spatial motion and variation of an action more comprehensively. Dynamic image is introduced as a simple and powerful representation for a video. Bilen et al. 30 applied rank pooling 31 that is an effective temporal pooling method on the raw image pixels of a RGB video sequence to produce the RGB dynamic image. Inspired by this idea, we extend dynamic image to depth data and propose that utilizing rank pooling encodes a DPDI sequence to generate the dynamic depth projected difference image (DDPDI). DDPDI integrates the whole changing process of an action into a single dynamic image in time order and captures the spatial–temporal variations of a depth video effectively. DDPDIs at different temporal scales in each view form HDDPDI. Finally, the HDDPDI in three views for depth videos are fed into three identical CNNs independently. Three CNNs pretrained on ImageNet are finely retuned using HDDPDI in corresponding view, respectively. To fully verify the validity of the proposed HDDPDI video representation as well as to compare the influences of different CNN layers on action recognition, we design three classification schemes in the recognition framework where different CNN layers are used. Since three projected views can offer complementary characteristics for human actions, multimodal information fusion 32 –34 is applied in each classification scheme and results of three views are combined for action recognition. The proposed action recognition framework is described in Figure 1.

Overview of the proposed HDDPDI-based action recognition framework. (a) Depth videos are projected onto three orthogonal views. (b) Depth maps in each view are sampled at different temporal scales with stride s. (c) DPDI sequence is generated by computing absolute difference image for two consecutive images across a sampled depth map sequence. (d) Rank pooling is applied on DPDI sequences at different temporal scales to produce HDDPDI in each view. (e) HDDPDIs of three views are used to train three CNNs independently and results of three views are fused for action recognition in each classification scheme. HDDPDI: hierarchical dynamic depth projected difference images; DPDI: depth projected difference images; CNN: convolutional neural network.
A major source of inspiration comes from DMM. 3 Each frame in a depth video sequence is projected onto three orthogonal Cartesian planes to form three projected image sequences. Under each projection view, the thresholded absolute difference between two consecutive projected maps is accumulated across an entire depth video sequence forming DMM. DMM contain the motion change information in a depth video; however, the accumulation operator ignores the time sequence. Temporal order is an important factor in videos and contributes significantly to the final action recognition. Hence, to capture the temporal information effectively, we apply rank pooling 31 on DPDI sequences in each projected view to get DDPDIs that include the spatial–temporal variances of the whole video. It’s worth mentioning that pseudocolour coding 25 can remap the spatiotemporal information of human actions. Compared with this work, rank pooling models the evolution of appearance and dynamics over time in a video. It not only captures the temporal dynamics in videos robustly but also is easily implemented and fast computed. Therefore, rank pooling method is utilized in this article to get the dynamic representation for a depth video.
The major contributions of this article can be summarized as follows: (1) HDDPDI are proposed as a representation of a depth video for extracting the spatial–temporal dynamics. With the help of rank pooling and dynamic image, this method overcomes the drawback of ignoring video temporal information in original DMM 3 and improves the discrimination of human action recognition. (2) We extend the dynamic image to depth data by applying rank pooling on DPDI sequences. DDPDIs of different temporal scales can hierarchically describe the spatial–temporal dynamics of an action. (3) We construct a HDDPDI-based action recognition framework to demonstrate the effectiveness of HDDPDI representation, where HDDPDIs in three views are inputted into three CNNs independently and three classification schemes are designed using different CNN layers. The results of three views are fused for action recognition. (4) State-of-the-art recognition performance is achieved on three challenging action data sets. The results are analysed in detail for more findings.
The rest of this article is organized as follows: The second section briefly presents the related works. In the third section, we elaborate the construction procedure of the proposed HDDPDI. In the fourth section, we describe the details of the action recognition framework. Experimental results and analysis are reported in the fifth section. The sixth section concludes the article.
Related works
Depth-based action recognition
Emergence of low-cost depth sensors makes depth data available, which extends the researches for human action recognition from RGB to depth. Various algorithms are developed for depth video-based action recognition. We review them from two aspects: handcrafted and deep learning approaches. More comprehensive surveys 35 –37 summarize these works in detail.
Handcrafted algorithms
Many approaches for human action recognition in videos are based on depth data. Yang et al. 3 accumulated depth maps projected onto three orthogonal planes to generate DMM. The histograms of the oriented gradients (HOG) were used to extract features from DMM. Chen et al. 38 used local binary patterns (LBPs) to get feature representations based on DMMs as well. Wang et al. 4 proposed a 3D LOP feature for capturing the local depth appearance information based on the joint locations. Oreifej et al. 5 extended surface normals to 4D space and constructed histogram of oriented 4D normals (HON4D) as the feature descriptor. An action recognition scheme was proposed to aggregate the low-level polynormals produced by clustering hypersurface normals in depth sequences into the SNV. 6 The spatial–temporal DCSF 7 was presented to describe the local 3D depth cuboids around the spatial–temporal interest points (STIPs) extracted from depth videos. Lu et al. 8 proposed a binary range-sample feature that can exclude clutter background and complex occlusion to capture shape and motion of the human body in depth sequences.
Deep learning algorithms
A large amount of work 12,21 based on CNN has been done for human action recognition in videos inspired by its remarkable performance. There are some state-of-art achievements that perform well for action recognition in RGB videos, for example, 3D convolutional networks (C3D), 12 two-stream convolutional networks, 13 trajectory-pooled based deep-convolutional descriptors, 15 temporal segment networks (TSN) 16 and so on. However, depth-based action recognition methods with CNN are rare. Wang et al. 25 used weighted hierarchical depth motion maps (WHDMM) as the inputs of CNN and produced a three-channel architecture to acquire the final classification results. Dynamic depth images (DDI), dynamic depth normal images (DDNI) and dynamic depth motion normal images (DDMNI) were proposed as three representations for depth sequences and were fed into CNN for action classification. 26 Features learned from RGB videos are utilized for depth videos directly by domain adaptation to do action recognition. 27 Motion history images (MHI) generated from RGB videos are added into DMM to construct a four-channel deep CNN. 28 In this article, we focus on human action recognition in depth videos with the purpose of taking full advantage of the depth data.
Temporal order modelling
Different from the image classification tasks, action videos are 3D and contain rich spatial–temporal information. Since videos can be represented as image sequences, most existing feature extraction algorithms 3,8 are all frame-level, so how to model the temporal structure within a video is a considerable problem. Some early works used conditional random fields (CRFs) 39 and hidden Markov models (HMMs) 40 to model temporal information. These two methods need a large amount of training samples to learn model parameters. Wang et al. 41 applied Fourier temporal pyramid (FTP) to encode the temporal changes, which is robust to the noisy data. Optical flow 13 was also commonly used to capture the time variations. However, computation of optical flow is heavy and time consuming. It is not suitable for depth videos that lack the texture information. Pseudocolour coding 25 is another commonly used approach to reflect the temporal order of a video. Pseudocolour coding maps indicate the motion temporal order by colour intensity. Recurrent neural networks (RNN) 42 is proposed to handle the sequential data. It can display the action time dynamics by internal states and is generally combined with CNN for action recognition. 43 As a new efficient temporal pooling method, rank pooling 31 captures temporal dynamics of the whole video by modelling the evolution of appearance and dynamics over time. It is easily implemented and fast computed serving as a robust video representation.
Hierarchical dynamic depth projected difference images
To describe the human 3D spatial motion information and temporal dynamics for actions in depth videos, we propose HDDPDI as an effective video representation method. In this section, we firstly introduce the depth video projection and then we describe the sampling procedure on the projected depth maps under different temporal scales. Finally, the construction of HDDPDI using rank pooling is explained elaborately.
Depth video projection
Depth videos contain rich 3D structure and shape information and can help to improve the human action recognition performance significantly. Yang et al. 3 proposed DMM to capture the 3D motion information of human actions in depth videos. Considering this advantage, we use the same approach for depth video projection. Specifically, each frame in a depth video sequence is projected onto three 2D orthogonal Cartesian planes where X-Y plane represents front view, Y-Z plane represents side view and X-Z plane represents top view. For a point (x, y, z) in a depth image, its pixel value in projected front\side\top view is z\x\y. Therefore, we get depth maps in three projected views, respectively, for each depth video sequence. Depth maps in three views for some actions in NTU RGB + D data set are illustrated in Figure 2.

Depth maps in three views for some actions in NTU RGB + D data set.
Scaled sampling of depth maps
Each frame of a depth video is projected onto three views using the same method as DMM 3 for capturing the 3D human shape and motion information. Besides, we make two extensions based on the projected depth maps. The first one is that to describe the motion changes of human actions from coarse to fine and suppress noise as well, the depth map sequence in each projected view is scaled-sampled progressively along the time dimension, which produces a set of sampled sequences with different lengths named as different temporal scales. This process can also be regarded as a data augmentation method for increasing the number of action samples.
For a depth video projected sequence

Flow chart of the scaled sampling. The original depth map sequence has N frames. T is the number of temporal scales. Sampling stride is s and start-frame stride is sf . [X] represents the nearest integer larger than X.
HDDPDI construction with rank pooling
For a depth video, we have obtained a group of scaled depth map sequences sampled at several time scales. The thresholded absolute difference between two consecutive maps is accumulated across an entire depth map sequence in the original DMM.
3
Similarly, we compute the absolute difference without thresholding for two consecutive maps to extract the motion changes, referred to as DPDI. It can be expressed as equation (1). Let
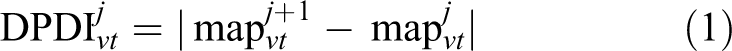
where
Different from the original DMM, 3 rather than accumulation, we then apply rank pooling on a DPDI sequence temporally to get a single dynamic image for encoding the spatial–temporal information of human motion changes effectively. Rank pooling 31 is a new temporal pooling method which not only captures the temporal changes of videos robustly but also is easily implemented. It utilizes pairwise linear ranking machines to learn a linear function whose parameters can encode the frame order within a video and be used as a new video representation. We consider the chronological order of one DPDI sequence and aggregate the motion changing information into a dynamic image using rank pooling.
Rank pooling is applied directly on the pixels of DPDIs in this article. Let a DPDI sequence with k frames at temporal scale t in projected view v be represented as

The smoothed vector sequence

where
In each projected view for a depth video, DPDI sequences of all temporal scales are processed using rank pooling to form DDPDIs, as shown in Figure 1(d). Part of DDPDIs along the different temporal scales in the front view for some actions in NTU RGB + D data set are shown in Figure 4. Since the original depth map sequences are sampled progressively along the time, so DDPDIs are also dynamically progressive along the temporal scale for human actions. These DDPDIs at different temporal scales in each projected view for a depth video are named as HDDPDI, which can be used as an effective representation for the video.

DDPDIs along the temporal scale in the front view for some actions in NTU RGB + D data set. DDPDI: dynamic depth projected difference images.
HDDPDI-based action recognition with CNN
CNN training
After the construction of HDDPDIs in three views, VGG16 44 is adopted as the basic network structure of our action recognition framework in this article. VGG16 contains five convolutional layers, three fully connected (FC) layers and a softmax classifier layer. We train a VGG16 network independently for each view, seen in Figure 1. Three VGG16 networks pretrained on the ImageNet data set are fine-tuned to avoid training a lot of parameters from scratch. The implementation is completed using Pytorch. 45
During the training process of each view, HDDPDIs are human-centric cropped to
Classification schemes
To verify the effectiveness of the proposed HDDPDI representation, we construct a CNN-based action recognition framework. CNN features at different layers encode different levels of information. So with the purpose of comparing the influences of different CNN layers on action recognition, three classification schemes are designed in the framework, with the last convolutional (LC) layer, the FC layer and the softmax layer of CNN, respectively. In this article, LC layer is defined as the fifth convolutional layer in VGG16. FC layer is the second FC layer in VGG16. Softmax layer is the final classification function of VGG16. In the classification schemes with LC layer and FC layer, HDDPDIs of a depth video in three views are fed into three corresponding CNNs, respectively, for feature representation. Features of three views are fused to capture the complementary characteristics of human actions. For the scheme with softmax layer, we use CNN in an end-to-end mode and fuse the prediction scores of three views for recognition. We describe the classification schemes in detail as follows.
Recognition with LC layer
Convolutional features focus on spatial structure information of actions in HDDPDIs, such as colour, edge and texture. The LC layer in VGG16 has a larger receptive field and encodes more complex spatial features. Therefore, for each view we, extract the LC layer feature maps for HDDPDI of a depth video to get the corresponding feature representation. Take the front view as an example, we assume that the LC layer feature maps of HDDPDI of a depth video in this view are represented as a 4D tensor

where

The generation flow chart of the LC layer feature descriptor in each view for a depth video. LC: last convolutional.
Recognition with FC layer
Compared with convolutional features, FC layer features pay more attention to the abstract semantic information. HDDPDIs of three views of a depth video serve as inputs to the three trained CNNs and then we obtain the FC layer feature descriptor for each view. For a depth video, FC layer output of HDDPDI in front view is represented as a 2D tensor

where

The generation flow chart of the FC layer feature descriptor in each view for a depth video. FC: fully connected.
Recognition with softmax layer
CNN is a deep neural network which can capture features and make classification automatically for images by end-to-end learning. Output of softmax layer in CNN represents the class probability. For each view, we take HDDPDI of a depth video as the input and get the softmax output denoted as a 2D tensor

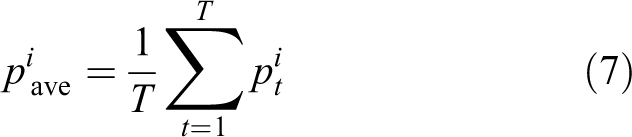

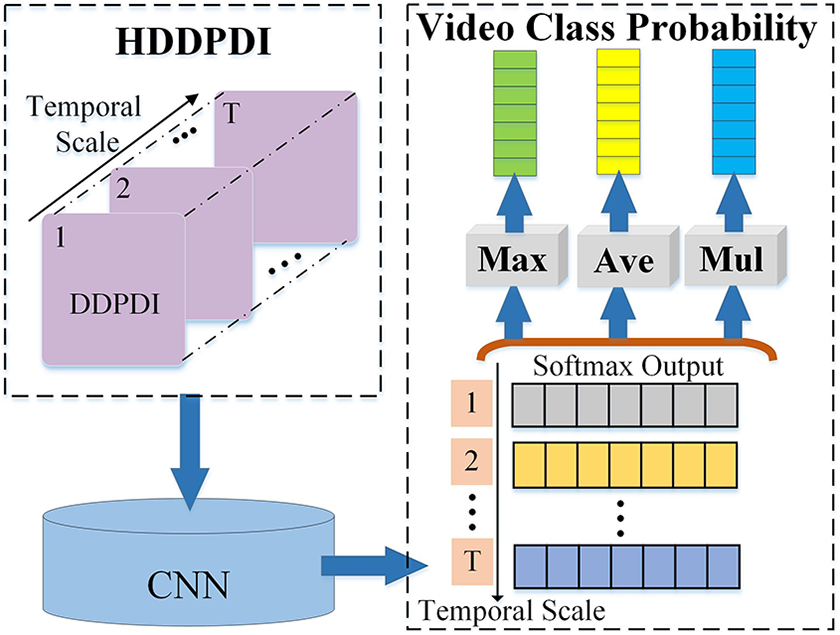
The generation flow chart of the class probabilities of a depth video in each view under three operators.
Experiments and discussions
We evaluate the proposed HDDPDI-based action recognition framework on three challenging data sets. In this section, we first introduce the three human action data sets and the basic experimental settings. Next, we present and analyse the recognition results on the three data sets. Furthermore, we also conduct the experiments separately on each single- view to demonstrate the fusion advantages that three projected views can provide complementary information for action recognition. Finally, we show the comparisons with the state-of-the-art methods.
Data sets
In our experiments, we evaluate the proposed HDDPDI video representation with three CNN-based classification schemes on the following publicly available human action data sets: SDUFall, 46 MSRAction3D 47 and NTU RGB + D. 29
The SDUFall data set 46 was built by our Robot Research Center in Control Science and Engineering College, Shandong University. The data set is collected by a Kinect camera installed 1.5 m high in a laboratory environment. It contains six action classes: bending, falling, lying, sitting, squatting and walking. Each action is performed 10 times by 20 subjects, and there are total 1200 samples. Furthermore, SDUFall data set contains rich variations such as illumination, direction and position changes.
The MSRAction3D data set 47 was built by the Advanced Multimedia Research Lab in University of Wollongong. It contains 20 action types performed by 10 subjects. Each subject performs each action 2 or 3 times. There are 567 depth sequences in total. The 20 actions are high-arm wave, horizontal-arm wave, hammer, hand catch, forward punch, high throw, draw X, draw tick, draw circle, hand clap, two-hand wave, side boxing, bend, forward kick, side kick, jogging, tennis swing, tennis serve, golf swing and pick up and throw.
The NTU RGB + D dataset 29 was built by the ROSE Lab in the Nanyang Technological University. It is the largest RGB-D action recognition data set till now. This data set is captured by three Microsoft Kinect v.2 cameras concurrently. NTU RGB + D action recognition data set consists of 56,880 action samples, containing 60 different action classes performed by 40 volunteers. The 60 actions are drinking, eating, brushing teeth, brushing hair, dropping, picking up, throwing, sitting down, standing up (from sitting position), clapping, reading, writing, tearing up paper, wearing jacket, taking off jacket, wearing a shoe, taking off a shoe, wearing on glasses, taking off glasses, putting on a hat/cap, taking off a hat/cap, cheering up, hand waving, kicking something, reaching into self-pocket, hopping, jumping up, making/answering a phone call, playing with phone, typing, pointing to something, taking selfie, checking time (on watch), rubbing two hands together, bowing, shaking head, wiping face, saluting, putting palms together, crossing hands in front, sneezing/coughing, staggering, falling down, touching head (headache), touching chest (stomach ache/heart pain), touching back (back-pain), touching neck (neck-ache), vomiting, fanning self, punching/slapping other person, kicking other person, pushing other person, patting other’s back, pointing to the other person, hugging, giving something to other person, touching other person’s pocket, handshaking, walking towards each other and walking apart from each other. This data set is challenging due to a large number of action samples and classes as well as rich intraclass variations.
Experimental settings
Since the proposed HDDPDI representation is based on depth videos, we project all depth video sequences in a data set onto three 2D orthogonal Cartesian planes to get depth map sequences with the same method as the original DMM. 3 The depth map sequence of a video in each projected view is scaled-sampled at different temporal scales. The start frame stride sf , sample stride s and ratio r are different for different data sets in the sampling process. We empirically select these parameters depending on characteristics of different data sets. For SDUFall data set, sf = 5, s = 3 and r = 0.7. For MSRAction3D data set, sf = 2, s = 3 and r = 0.3. For NTU RGB + D data set, sf = 5, s = 3 and r = 0.3. In our experiments, the number of temporal scales in HDDPDI representations of depth videos in different data sets ranges from 3 to 20, which is far less than the number of total frames. Therefore, the HDDPDI representation can not only capture the informative spatial–temporal dynamics for human actions but also help to reduce the computation complexity.
In each projected view, we take HDDPDIs of depth videos as inputs of VGG16 for finely retuning. To avoid overfitting, drop out ratio after FC layer is adjusted to 0.5. Moreover, data augmentation methods such as horizontal flip and rotation are also applied. For action recognition, we design three classification schemes based on CNN, with LC layer, FC layer and softmax layer, respectively. The spatial size of the feature map in LC layer is
HDDPDI performance evaluation with three classification schemes
SDUFall data set
We evaluate the proposed HDDPDI-based action recognition framework with CNN on the SDUFall data set. In our framework, HDDPDI are used as a new representation of a depth video and then fed into CNN for action recognition with three classification schemes. Three views are fused for recognition in each scheme. Three-fifth of subjects in the SDUFall data set are selected randomly for training and the remaining for testing. Three CNNs pretrained on ImageNet are retuned independently using the corresponding HDDPDIs of depth videos in the training set.
Table 1 shows the recognition accuracies of the proposed method with different classification schemes. The FC layer gets the best recognition result with the highest accuracy of 97.08%. Compared with the LC layer, it achieves an improvement of 3.44%, demonstrating that high-layer features in CNN are more effective for action recognition. Figure 8 is the confusion matrix of six actions in SDUFall data set with the FC layer classification scheme. From Figure 8, we observe that all actions are classified extremely correctly. The action lying and the action falling are also well classified although these two actions have great similarity. The superior experimental results prove that the proposed HDDPDI representation is effective and discriminative for human actions in the SDUFall data set. Moreover, action characteristics in three views are fused for recognition, which is helpful to improve the recognition performance by capturing the 3D motion information for actions.
Recognition accuracies on the SDUFall data set with different classification schemes in the proposed HDDPDI-based action recognition framework.

Bold values denote the highest recognition accuracy and the corresponding classification scheme in SDUFall. HDDPDI: hierarchical dynamic depth projected difference images; LC: last convolutional; FC: fully connected.

Confusion matrix on the SDUFall data set for the FC layer classification scheme. FC: fully connected.
MSRAction3D data set
We test the HDDPDI representation with the three classification schemes on MSRAction3D data set. For this data set, the cross-subject setting is used to get the training set and the testing set: samples of subjects 1, 3, 5, 7, 9 for training and samples of the remaining subjects for testing. The experimental results are shown in Table 2. From the table, it can be seen that the FC layer classification scheme also achieves the best recognition accuracy on MSRAction3D data set, which illustrates that the HDDPDI can effectively capture the spatial–temporal dynamics of actions for improving the recognition performance significantly. The accuracy 96.15% demonstrates that abstract high-level features in FC layer are more discriminative for actions in this data set, and features fusion of three views is more effective compared with the classification results fusion in softmax layer.
Recognition accuracies on the MSRAction3D data set with different classification schemes in the proposed HDDPDI-based action recognition framework.
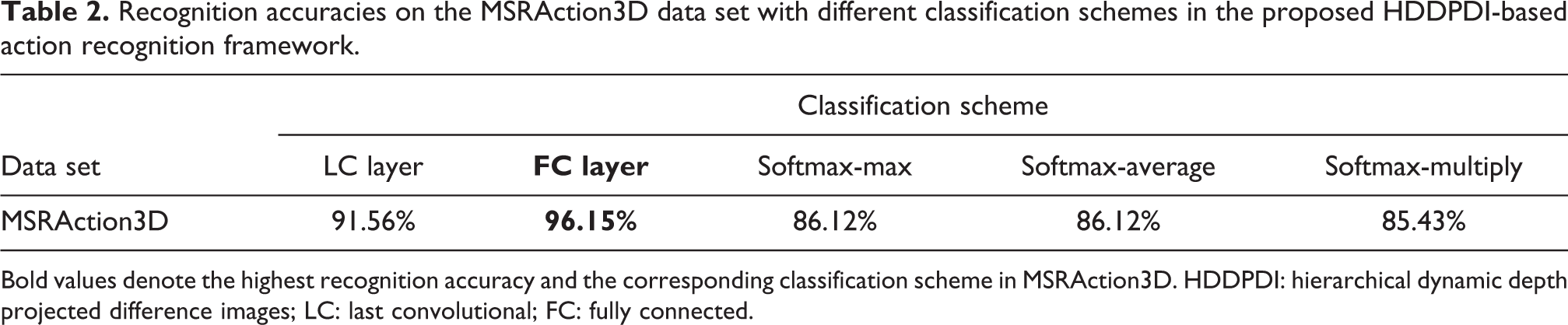
Bold values denote the highest recognition accuracy and the corresponding classification scheme in MSRAction3D. HDDPDI: hierarchical dynamic depth projected difference images; LC: last convolutional; FC: fully connected.
The confusion matrix of the best classification scheme on MSRAction3D data set is shown in Figure 9. We can see that the most actions are recognized well except for several confused actions such as ‘draw circle’, ‘draw tick’ and ‘draw X’. Accuracies of these actions are relatively lower due to their similar HDDPDI representations.

Confusion matrix on the MSRAction3D data set for the FC layer classification scheme. FC: fully connected.
NTU RGB + D data set
There are two evaluation criteria on the NTU RGB + D data set: cross-subject and cross-view. We evaluate the proposed HDDPDI video representation with three classification schemes on these two baselines, respectively. The training and testing sets are the same with the original protocol. 29 The results are shown in Table 3. From the table, we can conclude that the HDDPDI-based FC classification scheme still achieves the highest recognition accuracies of 82.43% in the cross-subject evaluation and 87.56% in the cross-view evaluation.
Recognition accuracies on the NTU RGB + D data set with different classification schemes in the proposed HDDPDI-based action recognition framework.
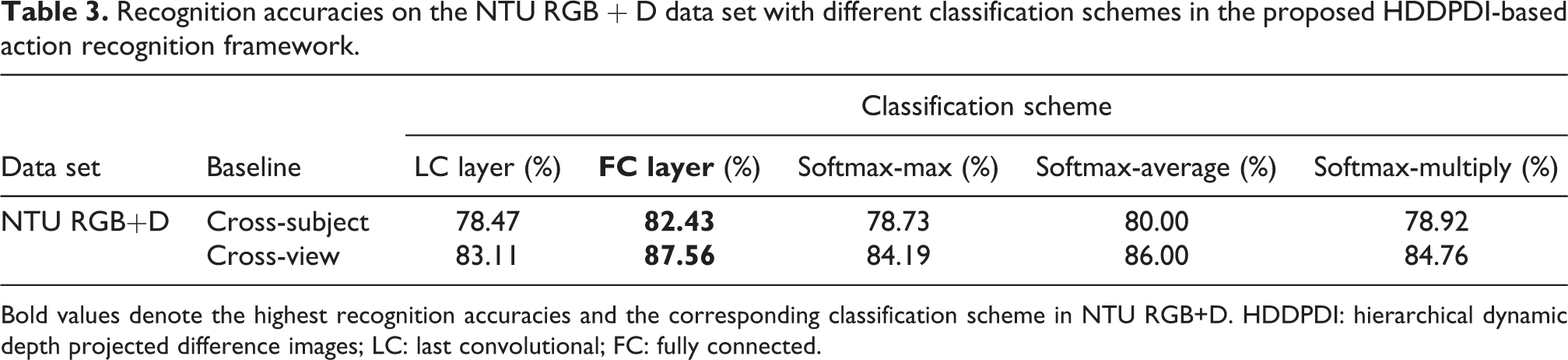
Bold values denote the highest recognition accuracies and the corresponding classification scheme in NTU RGB+D. HDDPDI: hierarchical dynamic depth projected difference images; LC: last convolutional; FC: fully connected.
Figure 10 presents the confusion matrix of the FC classification scheme in the cross-subject evaluation. From the confusion matrix, we can see that most actions are recognized correctly including the mutual actions. And even for some close actions such as ‘wearing jacket’ and ‘taking off jacket’, ‘putting on a hat’ and ‘taking off a hat’, the proposed HDDPDI video representation with the FC classification scheme still achieves good results although only time orders are reversed for these actions. This demonstrates that the HDDPDI representation can well capture the temporal dynamics for actions in videos. However, our method cannot distinguish some actions that have similar motion changes, such as ‘clapping’ and ‘rubbing two hands together’. Moreover, since the objects in the actions are difficult to be recognized for depth videos and the HDDPDI representation is not discriminative enough for actions that contain fine-grained small motion changes, actions such as ‘reading’ and ‘writing’ are easily confused. Such cases may be improved by combining the information extracted from the RGB modality.

Confusion matrix on the NTU RGB + D data set for the FC layer classification scheme in the cross-subject evaluation. FC: fully connected.
The proposed HDDPDI-based action recognition framework achieves the best experimental results with the FC classification scheme on all three data sets, which verifies the effectiveness of the HDDPDI video representation. Compared with the results of the LC classification scheme, it can be seen that the FC layer features of CNN are more discriminative for action recognition. Furthermore, since the HDDPDI representation of a depth video in one projected view contains several dynamic images at different temporal scales, and the softmax classification scheme processes the prediction class probabilities of all these dynamic images, misclassification of one dynamic image will affect the recognition result in this view. Therefore, the softmax classification scheme may cause misclassification more easily than the FC scheme that aggregates features for effective action recognition. Besides, Tables 1 to 3 show that the advantages of FC layer scheme over other mechanisms are bigger on MSRAction3D and NTU than on SDUFall. The main reason is that SDUFall data set is relatively small and contains only six simple human actions that have discriminative features. So, differences among the results of three classification schemes in SDUFall data set are small. However, actions in other two data sets are more complex and, especially in MSRAction3D, some human actions are similar and easily confused, which may increase the misclassification possibility of the softmax scheme that aggregates the recognition results directly.
Contribution evaluation of three projected views
For the construction of the HDDPDI video representation, we firstly project a depth video onto three views to capture the human 3D structure and shape information. Depth maps in three views describe the human motion from different perspectives. In the proposed HDDPDI-based action recognition framework, feature descriptors or softmax prediction results of three views are fused in different recognition schemes for expressing the spatial–temporal dynamic information of human actions more comprehensively. However, in this section, we evaluate the contribution of each projected view to the action recognition. We use the three classification schemes without fusion and conduct the recognition separately in each view. The training set and the testing set remain unchanged for the three data sets. We present the recognition results on the three data sets with different classification schemes for the single-view recognition and the fusion-view recognition in Table 4.
Comparisons of recognition accuracies on the three data sets with different classification schemes for the single-view recognition and the fusion-view recognition.

Bold values denote the highest recognition accuracies achieved by fusion-view method in different datasets. FC: fully connected; LC: last convolutional.
From Table 4, we can see that for the three data sets, action recognition with the three-view fusion outperforms the single view in each classification scheme. Since HDDPDIs in three projected views can describe the spatial–temporal motion dynamics from different perspectives and offer the complementary characteristics for human actions, multimodal information fusion is necessary and plays an important role for improving the recognition performance. For the single-view experiments, because most of the human actions are facing the camera, recognition results in the front view are the best for the three data sets in each classification scheme. HDDPDI in the front view are more discriminative for the most human actions, while the side view and the top view are more effective for actions such as ‘forward punch’ and ‘forward kick’. In the NTU RGB + D data set, recognition accuracies in the top view are much lower than that in the side view. This is because the ground background of this data set produces much noise in depth maps of the top view.
Comparison with the state of the arts
Tables 5, 6 and 7 compare the performance of the proposed method with the previous works, respectively, on the SDUFall data set, the MSRAction3D data set and the NTU RGB + D data set. From the tables, we can conclude that the FC layer classification scheme in the proposed HDDPDI-based action recognition framework outperforms those previous methods for all three data sets. The possible reasons are summarized as follows: (1) The HDDPDI representations of depth videos can describe the spatial–temporal motion dynamics for human actions from different temporal scales and contain rich action changing information that is effective for recognition. (2) FC layer in CNN provides the discriminative abstract features for different actions. (3) Three CNNs are finely retuned based on the pretrained models on ImageNet, which can ensure that the model parameters are well initialized for action classification. (4) HDDPDIs in three projected views offer 3D human motion information and the complementary features for actions. Therefore, fusion of three views can improve the action recognition performance significantly.
Performance comparison of the proposed HDDPDI-based action recognition with the FC layer classification scheme with the state-of-the-art methods on the SDUFall data set.

Bold value denotes the highest recognition accuracy achieved by our method for SDUFall. HDDPDI: hierarchical dynamic depth projected difference images.
Performance comparison of the proposed HDDPDI-based action recognition with the FC layer classification scheme with the state-of-the-art methods on the MSRAction3D data set.

Bold value denotes the highest recognition accuracy achieved by our method for MSRAction3D. HON4D: histogram of oriented 4D normal; DMM: depth motion map; SNV: super normal vector; FC: fully connected; HDDPDI: hierarchical dynamic depth projected difference images.
Performance comparison of the proposed HDDPDI-based action recognition with the FC layer classification scheme with the state-of-the-art methods on the NTU RGB + D data set.

Bold values denote the highest recognition accuracies achieved by our method in cross-subject and cross-view respectively for NTU RGB+D. RNN: recurrent neural network; HBRNN: hierarchically bidirectional RNN; LSTM: long-short term memory; ST-LSTM: spatio-temporal LSTM; DSSCA-SSLM: deep shared-specific component analysis-structure sparsity learning machine; MTLN: multi-task learning network; HON4D: histogram of oriented 4D normal; HDDPDI: hierarchical dynamic depth projected difference images; FC: fully connected; CNN: convolutional neural network; SNV: super normal vector.
For the SDUFall data set, human actions change significantly. HDDPDI can well capture the large body motion changes, so the recognition results in this data set are extremely superior. From the Table 7, we can see that our method outperforms the previous works significantly in the NTU RGB + D data set, which verifies that the proposed video representation is effective for describing the spatial–temporal information. However, in the MSRAction3D data set, our method is only slightly higher than the range sample. 8 This is because that our method is limited to differentiate some similar actions containing fine-grained small motions, such as ‘draw tick’ and ‘draw X’. Besides, our method is applied on depth videos where the absence of colour and texture may reduce the discriminative power of CNN models which are more suitable for texture-based feature learning and classification.
Conclusion and future work
In this article, we propose the HDDPDI representation for a depth video to describe the spatial–temporal dynamics of human actions from different temporal scales. We project a depth video sequence onto three orthogonal planes to capture the 3D human shape and motion information. HDDPDI are produced in each projected view by applying rank pooling on DPDI sequences at different sampling temporal scales. In addition, we construct a HDDPDI-based action recognition framework that contains three classification schemes to verify the effectiveness of the HDDPDI representation. Information of three views is fused for recognition in each scheme. We test the framework on three publicly available data sets and compare the recognition results of the three classification schemes. Presented experimental results show that the HDDPDI representation is efficient and practicable for human action recognition.
Although the proposed HDDPDI-based action recognition with the FC classification scheme has achieved outstanding results, there are some limitations of the work that need to be solved in the future. Firstly, HDDPDI representation performs better for actions containing significant human motions. For some similar actions that have tiny motion variations such as ‘read’ and ‘write’, HDDPDI representation is not discriminative enough. Therefore, to differentiate these actions, colour and texture features extracted from the static RGB images are considered to be combined with the HDDPDI representation. Secondly, feature descriptors in the three views for the LC\FC classification scheme or prediction results for the softmax classification scheme are fused for action recognition. But how to fuse multimodal information effectively is still a challenging problem in our future work.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of following financial support for the research, authorship, and/or publication of this article: This study has been funded with the National High-tech Research and Development (863 Program) of China under Grant No. 2015AA042307 and the National Natural Science Foundation of China under Grant No. U1706228 and No. 61673245.