
Abstract
There are still some problems need to be solved though there are a lot of achievements in the fields of automatic driving. One of those problems is the difficulty of designing a car-following decision-making system for complex traffic conditions. In recent years, reinforcement learning shows the potential in solving sequential decision optimization problems. In this article, we establish the reward function R of each driver data based on the inverse reinforcement learning algorithm, and r visualization is carried out, and then driving characteristics and following strategies are analyzed. At last, we show the efficiency of the proposed method by simulation in a highway environment.
Keywords
Introduction
Intelligent driving in intelligent vehicles is a technical high point in industrial technology and is studied by various countries and major technological companies. Car following is one of the most significant and common conditions for manual driving, assisted driving, or unmanned driving. 1 With the rapid growth of urban traffic scale, car following has become the most primary condition encountered by drivers. 2,3 Car-following models have been extensively studied since 1950s, 4 and the research currently focuses on different fields, such as vehicle engineering, traffic safety, big data and artificial intelligence, psychology, and cognition. Research on car-following behavior gradually extends from the original operation of acceleration, deceleration, and other specific operations to perception, psychology, and physiology. The methodology for studying such behavior has been extended from early mathematic modeling to various fields, such as logistics, planning, transportation, cognitive science, neuroscience, data science, machine learning, and artificial intelligence. 5,6
In 1950, Reuschel studied the car-following behavior of drivers from an operational research perspective, 7 whereas Pipes proposed the first car-following problem in 1953. 8,9 Existing car-following models (algorithms) can be divided into two categories. The first category is explanatory car-following model. First, the model predetermines some physical quantities in the car-following process to describe the expression using parameters. Then, the unknown parameters of the expression can be determined based on statistics or experience. This type of car-following model often requires assumptions and explanations of the car-following process. The second category is nonexplanatory car-following model. The car-following behavior of drivers is based on a learning algorithm, namely, the fitting or induction of a large number of data.
Explanatory models include linear car-following model, distance inverse model, nonlinear car-following model, memory function model, expected distance model, and physiological–psychological model. In 1958 and 1959, Chandler 10 and Herman 11,12 respectively proposed linear car-following models. In 1959, Gazis et al. presented a range inverse car-following model. 13 After 2 years, Gazis et al. further proposed a nonlinear car-following model. 14 In 1967, May and Keller completed the fitting of the nonlinear model with actual vehicle data under highway and tunnel conditions. 15,16 In 1993, Ozaki divided driver motion into four stages: acceleration start, deceleration start, acceleration maximum, and deceleration maximum. When separately fitted, the reaction time is strongly dependent on the stage of driving action. In particular, the reaction times are quite different in the acceleration and deceleration stages. Ozaki suggested that the possible reason for this difference is the use of the taillight of a front car during deceleration stages. 17 Lee introduced a memory function model in 1966, in which he thought that drivers responded to the integral of the relative speed of the front vehicle rather than the instantaneous value. He then analyzed its stability. In 1972, Darroch and Rothery used spectral analysis methods. The shape of the memory function was estimated based on the experimental data. They found that Dirac delta function can approximate experimental data; in fact, it corresponds to the linear following model. 18 In 1961, Helly suggested that the driving strategy of drivers not only minimized relative speed but also the difference between real and expected vehicle distances. In 1982, Gabard et al. used Helly’s model in SITRA-B (microscopic traffic flow model). 19 In 1974 and 1988, Weidmann and Leutzbach proposed two unreasonable points of the traditional car-following model: (1) In the previous car-following model, even with a large distance to a front vehicle, testing vehicle will also keep following. (2) The previous car-following model assumed that the drivers had the perfect perception and reaction, even if the external incentive was very small. Therefore, they introduced a perceptual threshold to define the minimum environmental incentive, which can be reacted to by the drivers. Evidently, the perceived threshold increased monotonically with the distance to the car. At the same time, they also found that the perception threshold is different during the acceleration and deceleration phases. 20 Explanatory model can generally guarantee the safety of the following process of the car, but accurately describing the highly nonlinear car-following behavior is difficult. Moreover, the model does not have adaptive adjustment ability for different drivers or different conditions. 21,22
With the development of artificial intelligence research, a variety of machine learning methods are the most prominent. These methods have outstanding advantages in dealing with nonlinear problems, 2,7 such as convolutional neural network, reinforcement learning (RL), and inverse reinforcement learning (IRL). A considerable number of researchers have begun to focus on the car-following model based on machine learning methods. 2,7 Richard S Sutton proposed a temporal-difference learning (TD) method. 23 Bradtke and Andrew G Barto established two algorithms which were called least-squares TD (LSTD) and recursive least-squares TD (RLSTD) with the help of the theory of linear least-squares function approximation. 24 Michail G Lagoudakis and Ronald Parr proposed an approach called least-squares policy iteration (LSPI) by combining value function approximation with linear architectures and approximate policy. Xu et al. proposed a kernel-based least-squares policy iteration (KLSPI). 25 Wei Xia et al. proposed a new control strategy of self-driving vehicles using the deep RL model, in which learning with an experience of professional driver and a Q-learning algorithm with filtered experience replay are proposed. 26 Pyeatt and Howe applied RL to learning racing behaviors in Robot Auto Racing Simulator, precursor of the The Open Racing Car Simulator (TORCS) platform. 27,28 Daniele et al. used the tabular Q-learning model to learn the overtaking strategies on TORCS. 29 Riedmiller proposed a neural RL method, namely neural fitted Q-iteration (NFQ), to generate control strategy for the pole balancing and mountain car task with least interactions. 30 Zheng et al. established a 14-Degree of Freedom (DOF) dynamic model of an autonomous vehicle and use R to build a decision-making system for autonomous driving. 31 The nonexplanatory model, represented by artificial neural network (ANN), fully demonstrates the high nonlinearity of car-following behavior and has been proven by some researchers to be stable and safe under certain conditions (such as slope input and sinusoidal input). However, the model treats the drivers as a “black box” because such models are not interpretative. Theoretically analyzing whether or not the model is stable or has existing “bad spots” is difficult. Meanwhile, such models are more capable of “cloning” rather than “learning” driving strategies and thus have difficulty in intuitively reflecting “adaptability”. With the change in working conditions and drivers, the change of the model itself is only the weight between nodes, but a direct relationship between the weights and driving behaviors is difficult to establish. As a result, further analysis is also difficult to perform. The lack of flexibility is another major problem with car-following models based on ANNs. A network trained by a data set may not be well applied to another data set. Thus, this present work proposes a learning algorithm with a certain interpretation for car-following model and establishes an anthropomorphic following model. The vital RL and its associated IRL in machine learning provide us a novel idea. Analyzing the car-following behavior of drivers by the following model and proposing the intelligent following algorithm have great value and significance in many fields, such as road safety, driving assistance system, and intelligent driving. The explanatory model is too simple to accurately describe the highly nonlinear car-following behavior and cannot adapt to different drivers and working conditions. Although the nonexplanatory model represented by ANN can fit complicated nonlinear relations, such models are not interpretable. Moreover, the theoretical analysis on the stability or the establishment of the relationship between driving behaviors and neural network structure for further analysis becomes difficult because the drivers are treated as “black box.” Therefore, to implement the anthropomorphic car-following model, the machine learning-based method is used to optimize auto-following algorithm, which is of great value for research. The contribution of this article is briefly described as follows: (1) A learning car-following algorithm with a certain explanation by using IRL combined with the car-following data of driving simulator. (2) The IRL algorithm is designed to learn the reward function R of drivers from driving simulator data. (3) The reward function R of different drivers is visualized under different conditions. (4) The similarities and differences are analyzed, and the IRL algorithm is optimized.
The remaining part of this article is organized as follows: The second part is “Reinforcement learning and inverse reinforcement learning.” The third part is “Design of IRL algorithm.” The fourth part is the “Experiment and analysis” based on the simulation platform and the rest part is “Conclusion and future work.”
Reinforcement learning and inverse reinforcement learning
Reinforcement learning
RL is a vital branch of machine learning, and a typical RL task is usually described by the Markov decision process. The machine (or agent) is in environment E, defining a state space S, where each state is a description of the environment that the agent can perceive. The actions that an agent can perform constitute action space A;

Illustration of RL. RL: reinforcement learning.
The relative merits of the strategy depend on the cumulative reward of long-term execution, rather than the instant reward for performing an action. Consequently, the RL task maximizes the long-term cumulative reward generated by the policer. Therefore, this work uses the “γ-discounted cumulative reward” to estimate the long-term cumulative reward, as shown in equation (1)

γ is the discount rate, a positive number less than 1, and represents the degree of emphasis that the agent has on future rewards. The greater the value of γ, the more the attention is paid to the future received rewards. rt
is the instant rewards of the tth step, and
Inverse reinforcement learning
The reward function R plays a crucial role for a deterministic RL task. The setting of R directly determines which strategy the agent will adopt. However, for many RL tasks, the reward function R cannot be predetermined, or the suitable state (strategy) for an agent is unknown. For the car-following decisions studied in this work, different explicit R values for different driver models are difficult to determine, and distinguishing which state (strategy) is good or bad is unclear. Although the relative merits of a strategy are known, specific reward function values are difficult to quantify. IRL is based on a sample data provided by experts, which is reversely introduced as the reword function.
33
The basic idea is to define the strategy with the sample data as π
* and another strategy as π. The reward function is expressed as a linear function of the state s, that is,

The goal of IRL is to calculate π *. When the difference between the optimal and other samples is maximized, some parameters are computed to ensure that the strategy with example data π * can be better than any strategy π. The objective function is shown in equation (3)
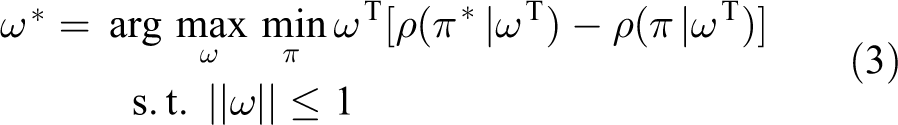
Design of IRL algorithm
The main purpose of IRL is to obtain the reward function R of drivers. In this work, an IRL algorithm based on the max-margin algorithm is proposed.
34
As shown in equations (2) and (3), the algorithm is divided into the following steps: Determine the state space and implement the transformation of the kernel function. Obtain the various components Determine the weight of
Determine the state space and transform kernel function
The physical quantities that reflect the process of car-following method are as follows: car-following distance d (which is the leading distance between the front vehicle and testing vehicle, and the unit is m), velocity of the testing vehicle v (in unit of

The car-following distance d can be divided into equal intervals, and the interval is
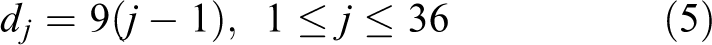
Given that the data size of vehicle speed v and distance d is inconsistent, the normalization of all these data is required. The state vector

If σ
2 is selected, then the space expanded by the kernel function can be neither overfitting nor underfitting. After experimental verification,
Calculate reward function and cumulative reward
The requiring reward function R can be written by a linear combination of 540 kernel functions based on the kernel function with state vector, as shown in equation (7)

Next, the value of each component

Solving process of

where γ is the discount factor, which evaluates the discount rate of drivers. In this work, the value is selected as
Determine the weights of reward function
After calculating
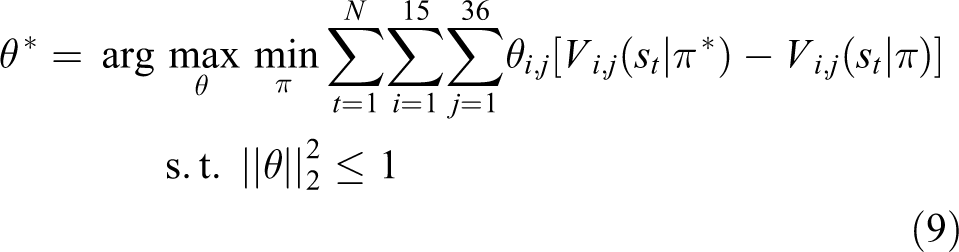
where θ is the vector expanded by

Relationship between variables of max-margin algorithm based on IRL. IRL: inverse reinforcement learning.
Equation (9) can be transformed into the optimization problem under the inequality constraint, as shown in equation (10)

Furthermore, equation (10) can be simplified to equation (11) if only one strategy for each state is present

The number of samples is sufficient (for each test, N ≈ 60000); therefore, equation (11) is taken into account in the calculation. For each optimal car-following state, one of the other car-following actions is randomly selected for the solution. The effect of traversing the other strategies for an average performance can be achieved. The selection of the other car-following action is based on the statistics of acceleration of the testing vehicle, which can provide the range of acceleration

Experiment and analysis
Experiment setup
Hardware and software
The working conditions of vehicle and the road environment must be precisely controlled to study the car-following behavior of drivers under given conditions. Therefore, this work is based on the dynamic driving simulation test bench of Tsinghua University. The dynamic driving simulation test bench is shown in Figure 4, and its system components are shown in Figure 5.

Dynamic driving simulation test bench.
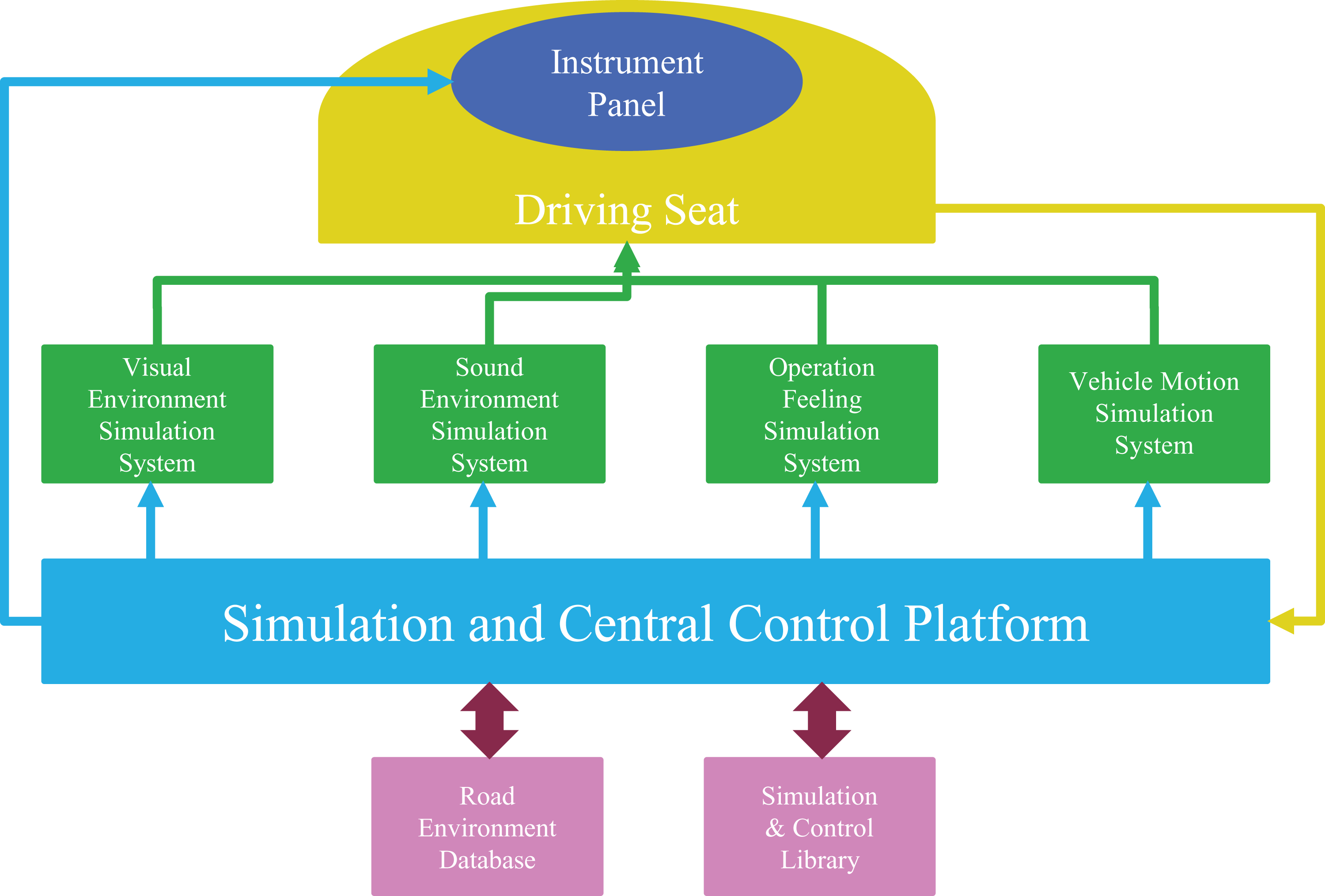
System components of the dynamic driving simulation test bench.
The hardware part of the simulator consists of five parts: simulation cockpit, external visual environment simulation system, vehicle motion simulation system, sound environment simulation system, and operation tactile sensation simulation system. 35 The software part of driving simulator consists of six parts: system control module, environment control and scene creation module, simulation calculation module, input and output module, graphics calculation and rendering module, and actuator control module. 36,37
Environment modeling
This work is about the car-following behavior of drivers under a single lane (no lane change, no overtaking, and no traffic light); therefore, the freeway is selected as a road scene. A two-lane road of 200 km in length is designed. The road includes a fast lane, a slow lane, and an emergency lane with widths of 3.75, 3.75, and 2.5 m, respectively. The road model is shown in Figure 6.

Road model.
Vehicle model
The most common vehicle is chosen as the front car (BMW 3 Series as a template), and the dynamics model of the vehicle was generated by CarSim. In addition, the brake lights turn red when the vehicle is decelerating, which is consistent with the real situation. The road scene of the actual testing process is shown in Figure 7. Three computer screens correspond to three projection screens (middle, left, and right) of the external virtual environment system. These screens constitute the front view of the drivers.

Road scene of the actual test.
In order to intuitively demonstrate the effectiveness and generalization ability of the IRL algorithm, the experimental data are obtained by selecting two subjects who have been driving for more than 5 years as drivers A and B. According to two different operating conditions of the New European Driving Cycle (NEDC) and Japan’s 10–15, the following experiments are carried out on the driving simulator, the following data of drivers A and B are recorded, and the reward function r of drivers A and B is visualized, giving the NEDC and Japan’s 10–15. For each working condition, two randomly selected tests are performed to verify the reproducibility of the test results.
Experiment result
The entire space

Diagram of the reward function.
The 3-D graphics are transformed into a 2-D plan, as shown in Figures 9 to 12. Figure 9 shows the diagram of the reward function of driver A under NEDC conditions (two randomly selected trials), and Figure 10 shows the reward function of driver A under Japan 10–15 condition. Similarly, Figure 11 shows the diagram of the reward function of driver B under NEDC conditions (two randomly selected trials), and Figure 12 shows the reward function of driver B under Japan 10–15 condition.
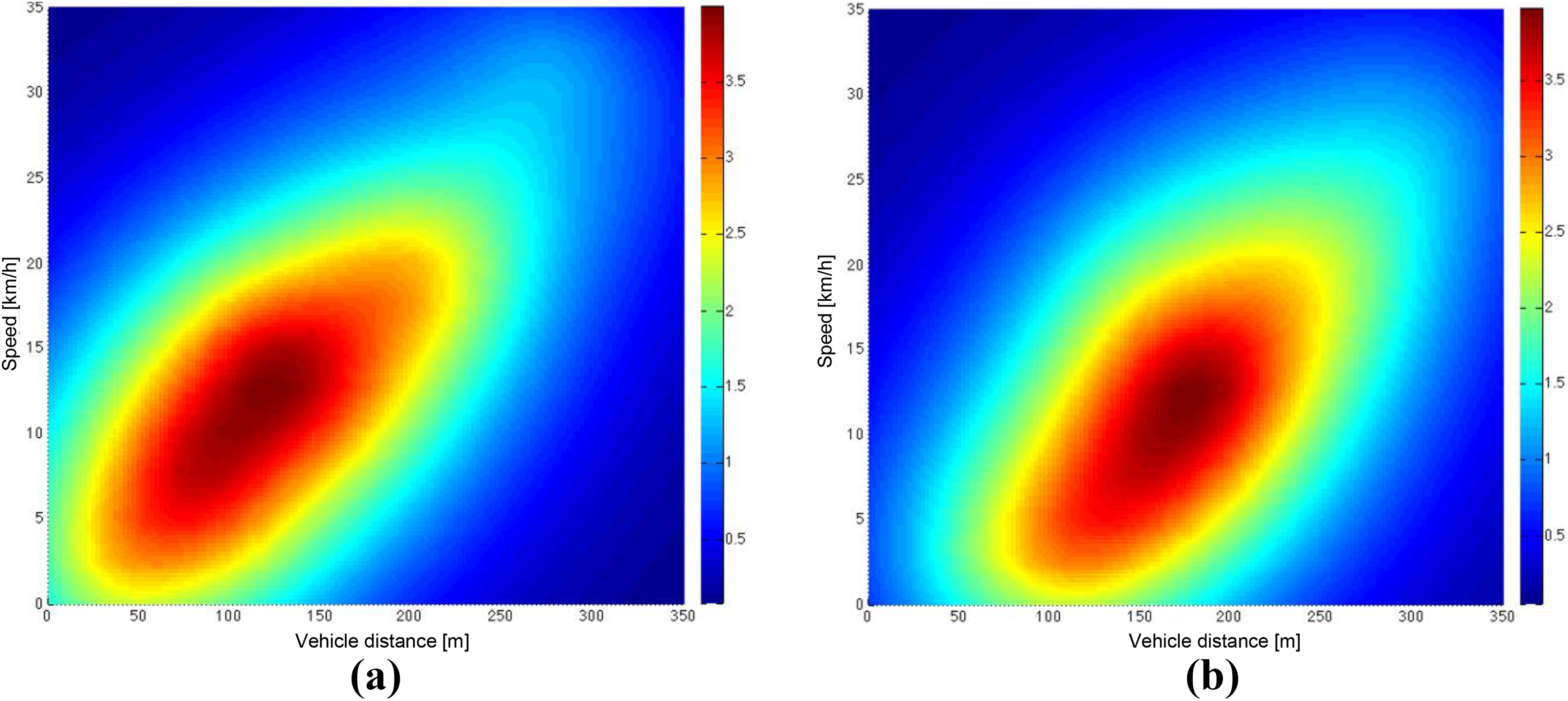
Driver A (female): diagram of the reward function under NEDC condition. (a) The result of randomly selected trial 1. (b) The result of randomly selected trial 2. NEDC: New European Driving Cycle.

Driver A (female): diagram of the reward function under Japan 10–15 condition. (a) The result of randomly selected trial 1. (b) The result of randomly selected trial 2.

Driver B (male): diagram of the reward function under NEDC condition. (a) The result of randomly selected trial 1. (b) The result of randomly selected trial 2. NEDC: New European Driving Cycle.
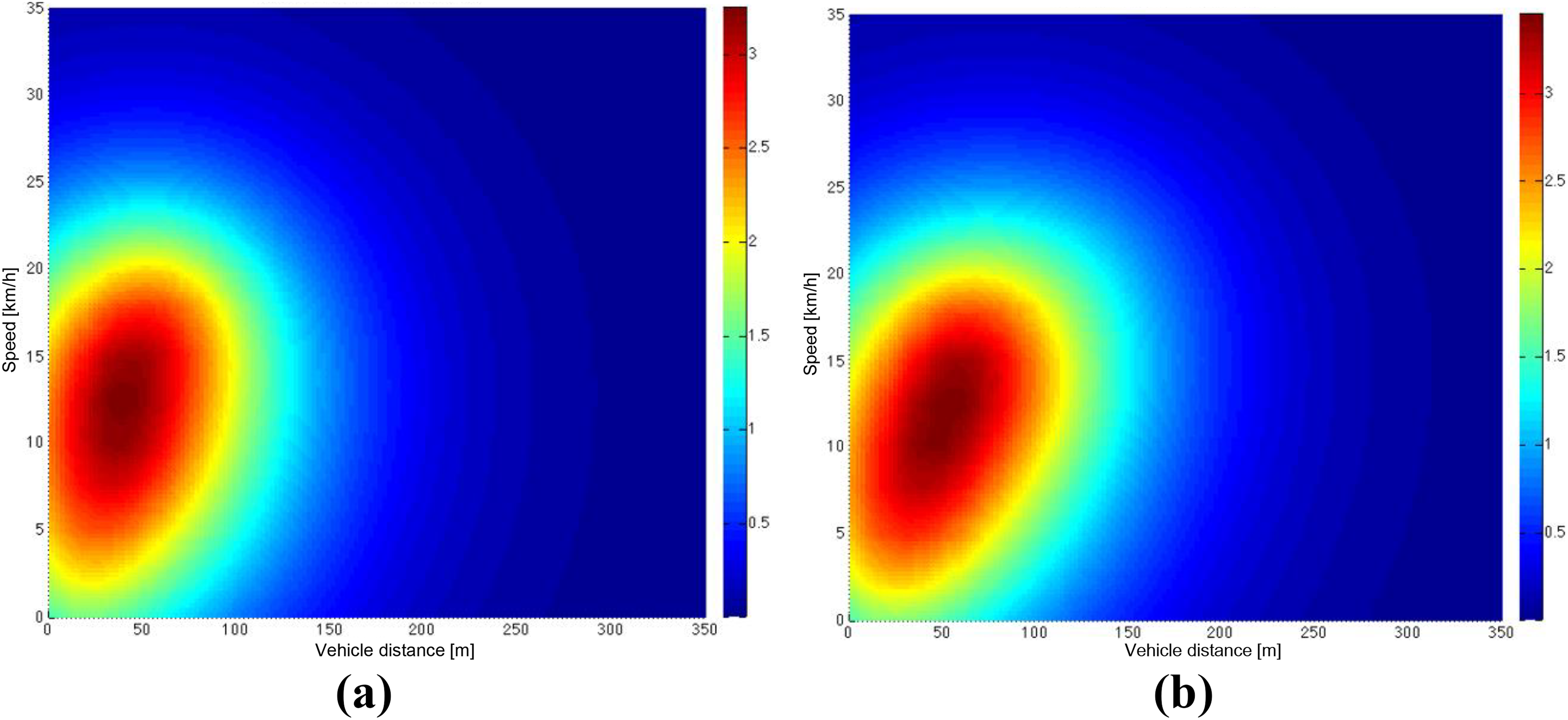
Driver B (male): diagram of the reward function under Japan 10–15 condition. (a) The result of randomly selected trial 1. (b) The result of randomly selected trial 2.
Experiment analysis
The comparison of the results presented in Figures 9
to 12 obtained the following conclusions: For the different tests of the same driver under the same condition, the shapes of reward functions are basically identical. This finding proves that the IRL algorithm has certain repeatability and can extract the characteristics of the car-following strategy of drivers. For the same driver, the shapes of reward functions under different working conditions are the same, mainly due to the inconsistent state space under different conditions. For different conditions, the main part and the trend of the reward function of the same driver are basically the same. This finding indicates that the IRL algorithm does not depend on the specific conditions and can effectively extract the car-following characteristics. The reward functions have completely different shapes for different drivers. The comparison of drivers A (Figures 9 and 10) and B (Figures 11 and 12) shows that as velocity increases, the distances corresponding to the peaks of two reward functions increase. For constant speed, the distance corresponding to the peak of the reward function of A is large, whereas the distance to the peak of the reward function of B is small. Therefore, the reward function of A is generally close to the coordinate axis of distance, and that of B is close to the axis of speed. This finding indicates that the car-following distance of the driving strategy of A is large, and that of B is small. In addition, the gradient of the reward function of A is small, and that of B is large. The reward function of driver A is shown in Figure 13, the reward function of driver B is shown in Figure 14, This finding indicates that A is less sensitive to changes in vehicle distance and speed, but B is more sensitive to the changing information.

Reward function of driver A.

Reward function of driver B.
Conclusions and future work
This work proposes the reward function R for drivers under different conditions by basing on the IRL algorithm and by combining the car-following data of two drivers. In addition, the visual verification and analysis of the reward functions are presented. First, preprocessing, analysis, and visualization of the car-following data are achieved. Second, the reward function is obtained in three steps: (1) The state space is determined, and the kernel function is transformed. (2) The reward function
In future works, using the obtained reward function R, RL method is carried out to verify the car-following experiment.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Junior Fellowships for Advanced Innovation Think-tank Program of China Association for Science and Technology under grant no. DXB-ZKQN-2017-035, Project funded by China Postdoctoral Science Foundation under grant no. 2017M620765, Project funded by China Postdoctoral Science Foundation Special Foundation under grant no. 2018T110095, the National Key Research and Development Program of China under grant no. 2017YFB0102603.