
Abstract
Self-localization in autonomous robots is one of the fundamental issues in the development of intelligent robots, and processing of raw sensory information into useful features is an integral part of this problem. In a typical scenario, there are several choices for the feature extraction algorithm, and each has its weaknesses and strengths depending on the characteristics of the environment. In this work, we introduce a localization algorithm that is capable of capturing the quality of a feature type based on the local environment and makes soft selection of feature types throughout different regions. A batch expectation–maximization algorithm is developed for both discrete and Monte Carlo localization models, exploiting the probabilistic pose estimations of the robot without requiring ground truth poses and also considering different observation types as blackbox algorithms. We tested our method in simulations, data collected from an indoor environment with a custom robot platform and a public data set. The results are compared with the individual feature types as well as naive fusion strategy.
Introduction
Robot navigation has an important place in the development of intelligent and autonomous robots. The robots need to recognize and model their surroundings and estimate their position within this model to accomplish complex tasks and make decisions. The localization problem is the estimation of robot pose within the known map of the environment based on sensory observations. The probabilistic approaches for solving this problem involve definition of an observation model, which compares observed data with the map and defines a similarity between them. In most of the applications, instead of using the raw sensory data directly in the observation model, a feature extraction process collects useful and more compact information to be used as observations. In this article, feature is used as a general term and refers to the compact information extracted from some raw sensory data. As an example, a color histogram may be extracted from an image or straight lines and corners may be extracted from the raw laser scans. When developing a localization algorithm, the designers usually decide on a feature extraction method, which aligns with the assumptions about the current environment. However, the same method may not perform well in a different environment, and another feature extraction method might have to be selected by the designers. Automating this feature type selection process for different environments would make the localization system easier to deploy into new places and increase robustness in heterogeneous environments.
In the context of localization, the desired attributes of a feature extraction method are to produce information which has a low systematic error against the dynamism in the environment (e.g. color histograms may be consistently wrong based on the known map with changing light conditions, hence has high systematic error) and to carry out this robustness into various types of places the robot operates. While there may be several types of sensors and feature extraction methods with strengths and weaknesses for a particular environment, as the diversity of the environment increases, it becomes challenging for a particular feature extraction method to perform well in all places. With this intuition, in this work, we propose a method for autonomous selection of feature types based on the environment without any supervised information in the localization setting. The framework treats feature types as independent blackbox methods, and instead of modifying or tuning the feature extraction method for a particular environment, it aims at improving the localization accuracy by fusing features from different sources in the observation model. We also assume that the map (and its quality) is tied to the feature extraction method and given to the framework (i.e. it is not estimated along with the robot pose).
The widely accepted solutions to the self-localization problem originates from probabilistic modeling and Bayesian filtering. The metric approaches estimate the robot pose in a continuous state space (CSS) and model the environment with spatial objects or quantized obstacle locations. The Extended Kalman Filter (EKF) 1,2 assumes a Gaussian distribution on all variables, and Monte Carlo Localization (MCL) 3,4 relaxes this assumption with a nonparametric distribution by utilizing Particle Filters. On the other hand, topological approaches represent the possible poses of the robot as a set of discrete places and the environment as the compact descriptions of these places. 5 –8 With the range sensors, the observation models include scan matching, 9,10 possibly with likelihood field representation 11 or line 12 and corner extraction. 13 The visual sensors are utilized in landmark extraction methods with features such as scale-invariant feature transform (SIFT) 14,15 and speeded up robust features (SURF), 16,17 which provide robust descriptors against changes in viewpoints. In the topological approaches, observation models based on place similarity have become more popular. With the visual sensors, image retrieval algorithms with color histograms 18 or Bag of Words (BoW) representations 19 –21 prove to be viable choices for comparing appearances. With these methods, topological navigation systems evolved toward utilizing more sparse and qualitative representations, and this allowed larger scale operations and longer term autonomy. These effects are more pronounced in more recent works. 22,23 As will be discussed later, our optimization algorithm assumes a finite and discrete set of poses as its input; therefore, we formulated our method on topological localization with discrete Bayes Filter and MCL with a set of particles. In the real-world implementation, we used image similarity with SIFT descriptors and BoW representation, and likelihood field based scan similarity for the range sensor, and compared the localization accuracy with the performance of individual feature types. We tested the MCL algorithm in a simulated landmark-based map environment.
Using more than one sensor type in robot navigation is extensively studied in sensor fusion literature for a variety of benefits such as improving accuracy, recovering from failures, and extended coverage. 24 From the perspective of localization and mapping, the works on sensor fusion can be grouped into feature level fusion and filter level filters. 24 In the feature level approaches, extracted features from different sensors are processed together to generate more informative features, and they usually exploit the domain and sensor specific properties. In Castellanos et al.’s study, 25 associations between different sets of landmarks are established by considering their Gaussian uncertainties. In Deelertpaiboon and Parnichkun’s work, 26 uncertainties are represented and fused with fuzzy membership functions. In the filter level approaches, different features directly contribute to the estimation of the target variables, hence uncertainties are augmented in the probabilistic model of the filter. 24 These approaches have the benefit of augmenting the filter with latent variables to increase accuracy of the assumptions in the model. In Zhu et al.’s work, 27 sensor biases are estimated with Variational Bayesian algorithm and in Caron et al.’s work, 28 the switching observation model is used to recover from changing sensor states. While our approach is also a filter level approach, it models the feature quality based on the environment and weighs them in a complementary way.
The expectation–maximization (EM) algorithm is an iterative batch algorithm for maximum likelihood estimations. 8,29 The method is particularly useful when there are unknown latent variables in the problem. The algorithm involves an expectation step (E-step) where the latent variables are estimated and then followed by a likelihood maximization step (M-step) based on the estimated latent variables. This factorization of variables is particularly convenient for the simultaneous localization and mapping (SLAM) problem, where the distribution of the robot trajectory is estimated in the E-step and the most likely map is estimated in the M-step. 8,30 Some other latent variable types are: the loop closure constraints in a topological mapping model in the study by Lee et al. 31 and landmarks being dynamic or not in the study by Rogers et al. 32 In our approach, the latent variables are the indicators of the best quality feature for current region.
The rest of the article is organized as follows. In second section, we introduce the problem statement, modified probabilistic model, formulation of the EM algorithm, and feature types used in the real world. In third section, we describe our experiment environment and report the results from the simulation environment, real-world, and public data set. In fourth section 4, we conclude the contributions of this work.
Proposed approach
Basic localization model
In this section, we start by stating the probabilistic model of the localization problem, which is an instance of the recursive state estimation problem.
33
Let the random variable

Graphical representation of the classical localization problem. At each discrete time step, the observation
The state transition model
The state of the robot, based on the application, can be represented in different ways, and we developed our algorithm for two cases: a discrete state space (
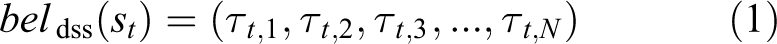
where

where first term is the state transition model (assumed to be known) and the second term is the previous belief state, and the summation is defined over all possible values of the previous state. The second step of the localization formulation is called the correction step, where the predicted belief state is corrected with the observation model. Using Baye’s rule on the belief state (inverting variables

where
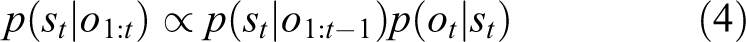
In the continuous state space case, in a 2-D map, the state is the tuple

where
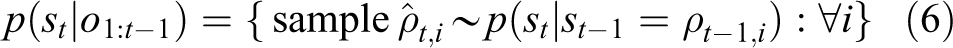
where for each particle, a new random particle is sampled from the distribution


Note that, for simplicity, the weights (
The DSS and CSS are illustrated in Figure 2. The navigation of the robot from start to finish is called an episode. We also assume, without loss of generality, that the environment has different characteristic at various regions. Each region is a subset of all possible states (places or poses), and the function
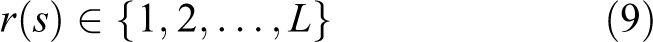

Illustration of DSS and CSS. Dashed line represents the actual path of the robot. The DSS is formed by N places, and the belief at time t is a list of probability values (
maps states to L possible regions (e.g. rooms). This function is considered available (e.g. “Region change detection” section) but not used for constraining the belief distribution, instead will be useful in “Multiple feature types” section.
Also note that we don’t provide a formal definition of map, instead assume the observation model
Multiple feature types
In the basic localization model, the observation
Let us also assume, without loss of generality, that in each region, one feature type is better suited to be used as opposed to others. To model this, we introduce a discrete variable

which basically states that the variable b is uniform inside the same region. The modified graphical model is given in Figure 3 in the case of two feature types.

Graphical representation of the modified model with
With the new model, the observation model is given as

The new observation model simply selects the best feature type, indicated by
Optimization with EM
In practical localization applications, the observation model is often implemented as a likelihood function instead of a probability distribution, the difference being likelihood function does not have to integrate to 1. Inspection of equation (11) reveals that the combined likelihood at any time is the weighted average of the individual likelihoods of the feature types. We can write the observation model in likelihood function form as

where

represents the likelihood function for feature type i,

represents the combined likelihood and

represents the weight of feature type i for robot position s, which also satisfies

Furthermore, with the assumption that the weights are uniform across a region with equation (10), the weight function becomes a table

with
In this form, the problem is to estimate
The weights are trained iteratively in two steps. For simplicity let α represent all the weights



The term
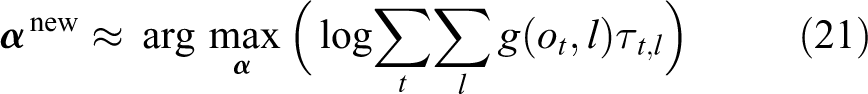
When we also substitute equations (12) and (17) into equation (21), we get

To maximize equation (22), we follow an approximate approach based on counting the strong feature type for the entire episode and maximize the term

The value of this function is 1 if the likelihood of a feature type at time t is the highest for that particular place, among other places (and it has the value of N if it has the lowest value). The rank function is useful in comparing different types of likelihood functions with possibly different scaling on the basis of current place. With the help of the rank function, let us also define an indicator function

The function

where

Equation (25) evaluates the number of times, in the course of an episode, a feature type is considered best for a particular place, weighted with the probabilities of that place. The numbers used in computation of

The values used in computation of

A sample image and the corresponding keypoints. The distribution of keypoints (histogram) over clusters forms the observation for that place.
The weight optimization algorithm is given in Algorithm 1. Note that we kept the function notation instead of defining redundant variables for simplicity. The EM iteration is repeated until change in weights is sufficiently low. Note that training is a batch algorithm and can be incrementally performed again with the new episodes. In Algorithm 5, the complexity of lines from 4 to 10 is
Weight optimization (DSS case).

Application to MCL
In MCL, the probability distribution over the continuous state space is represented with the set of finite particles instead of parameterization as a known distribution. This gives the ability to define an estimator over the state space using samples instead of complete analytical solution. Notice that in the equation (22), the operation is an accumulation over all possible places, weighted by their probabilities. With the particle set, the same operation can be defined using particles and their weights, over all possible poses. The term

and equation (25) can be replaced as

And finally the
Weight optimization (CSS case).

Real-world features
In the application of the discrete localization model to the real world, two feature extraction algorithms are selected for a color camera and a 2-D laser scanner. The feature types are selected based on their compatibility with the discrete state representation. The process has two steps. In the first step, called mapping episode, the robot is navigated through the environment with reasonable coverage of the environment and during navigation, a new place is created at regular displacements of the robot and associated with features collected at that place. The features collected in this step represent the map and used in the second step. In the second step, the robot is navigated through a similar path, the features are collected again for discrete places and used as observations to localize the robot in the generated map from the first step. The second step will be referred as the localization episode.
To measure the localization error, each place in the localization episode must be associated with a place in the mapping episode. To achieve this, in our experiments, we manually navigated the robot as close to the mapping trajectory as possible but that alone does not ensure unambiguous association. Therefore, we manually identified real-world correspondences between the two episodes and interpolated the rest of the trajectory to obtain ground truth for the localization episode.
In the rest of this section, the likelihood functions
Camera features
For the camera sensor, the BoW 19 representation is widely used in localization and SLAM applications. BoW allows compact representation of scenes and robust comparison with other scenes. The application of BoW requires a training step before forming the map and observations.
In the training step, for each place in the mapping episode, the corresponding image is processed and SIFT keypoints are collected along with their descriptors. Once all of the places are created and the mapping phase is finished, the keypoints collected from the entire episode are clustered with the K-Means algorithm into a certain number of groups. Once the clustering is finished, for each image, a histogram is calculated which represents the number of keypoints assigned to each cluster within that image. The calculated histogram is then associated with the place. A sample image and the corresponding keypoints are given in Figure 5. Note that the image is blurred to lower the noise caused by the robot motion.

A sample laser scan, extracted lines (right) and corresponding likelihood field (left). Darker points have higher probability.
In the localization episode, for each image from a place, the histogram is calculated with the cluster centers built in the training step. The histogram is then compared with all the histograms from the mapping episode and the comparison results are used as the observation model (probability distribution over all possible places).
There are two widely used methods for histogram comparison. Let


where C is the number of cluster centers. Another method for comparing histograms is the χ 2 method given as

While the χ
2 method assumes the histogram values are categorical variables drawn from a discrete probability distribution, the correlation method makes no such assumption and just measures how histogram bins change together. Therefore, χ
2 method is more suitable comparison of BoW histograms, where each bin represents number of keypoints at each category. The observation model for the camera sensor is defined as
Laser features
In structured indoor environments, extracting line and corner features from raw laser data is widely used in navigation algorithms to create a robust description of the local environment. The raw laser data is segmented into lines using the Random Sample Consensus (RANSAC) algorithm. 36 After each line segment is estimated, the RANSAC algorithm is reapplied iteratively to the remaining laser scans until no more line candidate is found. Very small, noisy line segments are pruned and as a result, a set of lines are collected.
A suitable method for comparing different laser scans is building a likelihood field.
33
A likelihood field, just like an occupancy grid, is a 2-D discrete grid G where each value
During the mapping episode, for each node, the likelihood field is calculated and added to the map. In the localization phase, the similarity of the line segments L extracted from the newly received laser scan is given as

where

The grid values are normalized during the mapping phase, so the similarity
Region change detection
In a structured indoor environment, a good heuristic for different feature qualities is assuming rooms as regions. In real-world experiments, we used a doorway detection algorithm, similar to the method in the study by ElKaissi et al., 37 to detect changes in the regions. The robot continuously checks the laser scans for a pattern resembling a real doorway and, whenever detects one, assumes it entered a new region and associates places to new regions. A snapshot of the running of the algorithm is given in Figure 7.

Detection of doorways. White circle is the robot and dots are the laser scans. From left-to-right; the robot is heading toward a new room, detects the doorway as blue line, and then enters the room.
Experiments and results
Simulation experiment with particle filters
We developed a 2-D simulation environment for testing the CSS case, based on MCL. In this setup, the robot state is a 3-D vector consisting of 2-D coordinates and bearing. There are several point-based landmarks in the environment, and the robot is assumed to observe all the landmarks within a limited range. Each observation of a landmark consists of a distance and bearing measurement, and a random Gaussian noise is added to sample the observations. To model different feature types, the landmarks are grouped into three groups, where observations from each group of landmark represent a different feature type. A snapshot of the simulation environment is given in Figure 8.

The simulation setup. Observations (distance and bearing) generated from each landmark type, illustrated with different shapes, represent a different feature type.
The observation for a feature type is a set of distance v and an bearing ϕ as

where
Different feature qualities is achieved by separating true landmarks from the robot map (i.e. expected locations) and displacing them arbitrarily by short distances. These modifications to true locations can be considered as dynamism in the environment, and lowers the localization performance, because they are not captured by a naive observation model. The test environment is given in Figure 9. There are three regions (rooms) and each region contains all three types of landmarks. However, the second landmark type is disrupted in the second region, while first and third types are disrupted in the third region.

The simulation environment. The robot thinks landmarks are at small symbols but true landmarks are large symbols. Type 2 is disrupted in
We performed episodes for each feature type, where only one feature type is active and others are not available. Another episode when all the feature types are active and have equal weights. And finally another episode with weight optimization algorithm (in Algorithm 2) is enabled. The trajectory errors for each episode are given in Figure 10 and all 5 cases are compared. The region boundaries within the episode are illustrated. For each region, for each case, the mean error within that region is also illustrated as a bar for easier comparison. Notice that the mean trajectory error in

Position estimation errors throughout episode. The five bars within each region show the mean error within that region for easier comparison.
The optimized weights are given in Table 1. Note that the second feature type has the lowest weight in the second region and highest weight in the third region, as the other values are close to each other. The mean position errors over the entire episodes are compared in Table 2.
Optimized weights for the regions in the simulation.

Mean trajectory errors over the episodes in the simulation.

Real-world experiments
We tested the feature selection algorithm in an indoor environment. The experiments was conducted with a Festo Robotino (Festo Didactic GmbH & Co.KG, Denkendorf) 38 equipped with a laser range finder and a color camera given in Figure 11. We collected data from two large labs and a corridor which spans an entire floor in the Bogazici University Department of Computer Engineering building. We collected two episodes of data in different days and with moderate amount of dynamism between episodes. The purpose of having these dynamisms between the mapping and localization episodes is to introduce possibly different types of errors into the feature types used in localization and obtain an uneven observation quality to demonstrate the effects of our approach. Each episode took 7 min. In Figure 12, some snapshots which summarize the dynamisms in the environment are given. The dynamism between episodes include

Robot platform used in experiments.

Some examples from the dynamism in the environment between mapping and localization episodes.
different hours of day, some curtains are closed, some chairs are displaced, occasional unexpected human obstruction, and some tabletop objects.
The observations extracted with the methods described in “Camera feature” and “Laser feature” sections are compatible with the discrete models, for that reason, we tested our optimization method in a discrete localization setting. The robot is navigated manually with constant speed and each time the robot makes a displacement of 30 cm, a new place, representing the current position and observations is added to the list of places. Figure 13 illustrates the place creation process and shows the layout of the environment. The localization is performed among the places collected in the mapping episode. The first episode is used for training BoW clusters and associating to the places. The BoW algorithm is trained with 700 clusters, chosen empirically, and histograms are compared with the correlation method. The second episode is used for localization in the generated map. Each episode contains around 700 places. To gather the ground truth information, some control points are selected in both episodes that correspond to the same point in the real world. Given the constant speed of the robot, time span between the control points is interpolated to match the places in both episodes. The ground truth data are used in the calculation of the average position error of the localization algorithm. For each time step, the position index error is given by
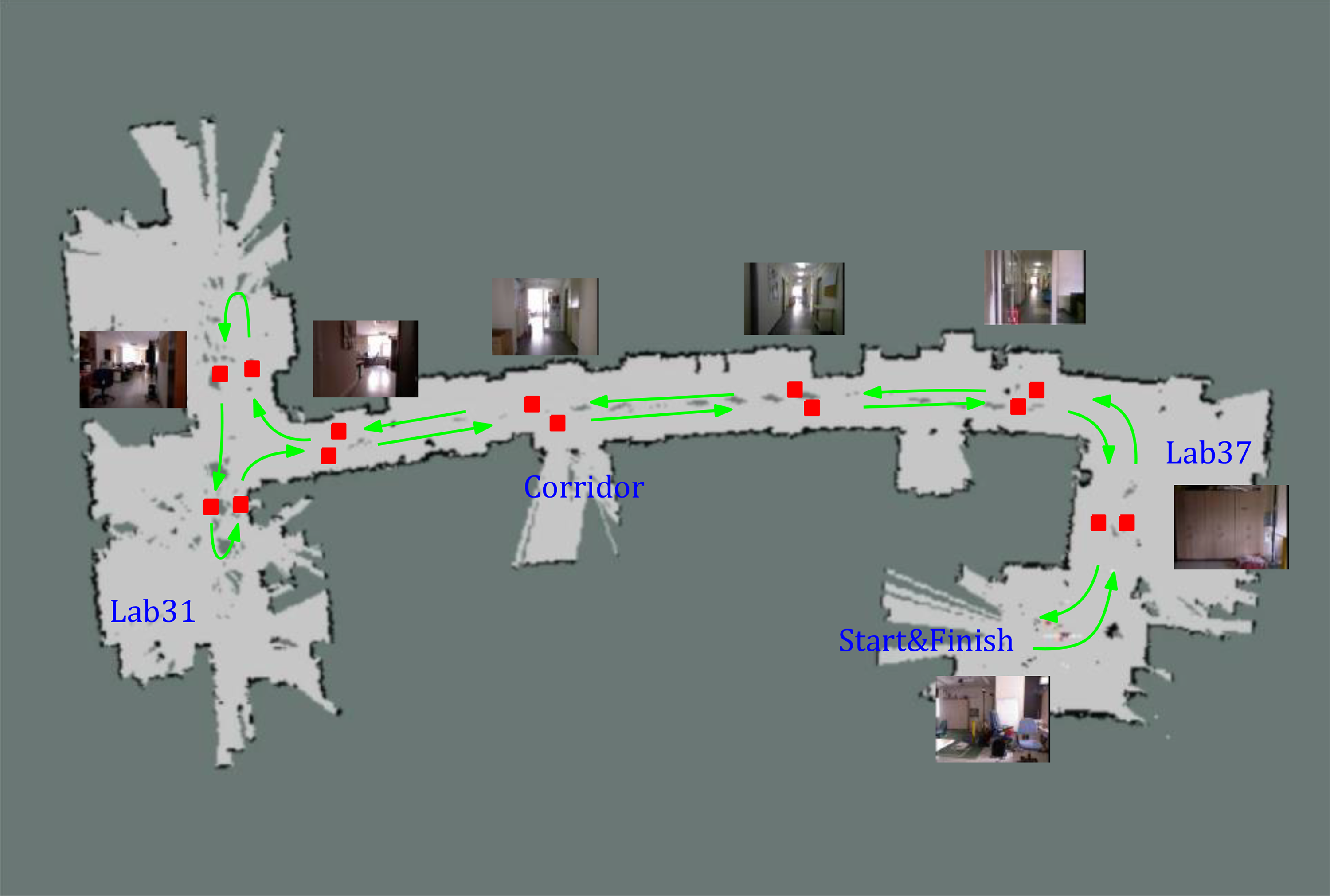
Illustration of map creation. Robot is navigated manually, new places (illustrated as red rectangles) are created at every 30 cm and associated with image (and laser) features. Note that the occupancy map is for illustration purposes and does not have an effect on the algorithm or results.
where
There are two large labs and a corridor in the episodes. The regions are defined with the doorways being region boundaries. The robot passed two different doors four times, so there are five regions with transitions near time steps 80, 220, 460, and 600. The robot visited Lab 37, corridor, Lab 31, corridor, and finally Lab 37 again. To show that a single observation type may not be robust in all regions, we also excluded the effects of the localization algorithm and tested the observation model through regression with the K-NN algorithm. For each place in the localization episode, the average index of the most similar K places from the mapping episodes is illustrated in Figure 14(a) for image features and Figure 14(b) for laser features. While it is more pronounced for the image features, the distribution of the most likely place varies in different regions for both feature types.

Observation qualities throughout the environment. Each point represents the most likely place association with the observation model. Diagonal layout is the true association. The regions are also illustrated.
The final weights obtained from the EM algorithm are reported in Table 3. Note that the weights agree with the results from Figure 14(a) that image features perform comparatively well in corridor, but poorly in the labs.
Weights for regions.

The comparison of trajectory errors of optimized weights with single feature types as well as equally weighted features is given in Table 4. The effect of using optimized weights in the localization episode can be seen more clearly in Figure 15. The boundaries of regions are also overlaid onto the position error plots. Note that the laser and image features perform poorly in different regions, but the weighted observation model keeps the error low.

Trajectory error comparison for the localization episode. The unit of error is the mean position index difference.
Trajectory error comparison.

EM: expectation maximization.
Experiments on the COsy Localization Database data set
We also tested our method on the COsy Localization Database (COLD).
39
The data set includes raw sensory data from three different environments under various illumination conditions. Each environment includes data taken during cloudy weather, sunny weather, and at night. We chose two COLD-Freiburg subsets with cloudy and night conditions, because we want to introduce dynamism between the mapping and localization episodes. The episode with cloudy conditions is used as the mapping episode, and the night recording is used as the localization episode. Some of the properties of the data sets used are as follows: robotic platform: ActivMedia Pioneer-3; both omnidirectional and regular images; laser range scans; and Nine regions labeled with six different environment types.
The data are collected from the robot that is manually driven on a specific path in both episodes. Each episode took about 8 min with frequent stops. Our displacement-based place creation algorithm created 578 place in the mapping set and 562 place in the localization set. The data set includes about five frames per second camera images, each labeled with the current room type and the pose taken.
We extracted two feature types as discussed in “Camera feature” and “Laser feature” sections. The BoW algorithm is trained with 300 clusters, chosen empirically, and histograms are compared with the χ 2 method. The maximum range of the laser range finder in the data set is clamped to 20 m.
The optimized weights for the regions is given in Table 5, and the comparison of trajectory errors for the localization episode is given in Table 6. Even though the optimized weights outperformed others, the decrease in trajectory error provided by the optimized weights is lower compared to the previous experiment in Table 4. This can be explained with the domination of image features in most of the regions, which is also reflected in the region weights in Table 5.
Weights for regions in COLD data set.

Reg: region; COLD: COsy Localization Database.
Regression errors in COLD database.

EM: expectation maximization; COLD: COsy Localization Database.
Conclusions
In this work, a feature type selection algorithm based on the local environment is developed for self-localization. The main contribution of this method is using more than one feature in a complementary way to increase overall robustness and localization accuracy. A latent variable about the quality of feature types is introduced to the observation model of the probabilistic localization problem, which is then estimated with a batch EM algorithm. The method is tested in the real world, simulations, and public COLD data set. The localization accuracy is compared with individual feature types and a naive fusion strategy. The data show that the optimized weights of feature types align with the changing qualities of the observations and making soft selections with those weights resulted with the best localization accuracy.
In this work, the feature qualities are estimated per local region, and regions in the environment are formed independently of features. As a future work, having a place classification strategy, such as in the work of Pronobis and Jensfelt, 40 would make the regions more aligned with the feature performance. Such change would also enable carrying of estimated weights to a new environment by associating new regions to the already experienced ones.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of following financial support for the research, authorship, and/or publication of this article: This work has been jointly supported by Bogazici University Scientific Research Fund project BAP13162 and Turkish State Planning Organization (DPT) under grant DPT 2007K120610.