
Abstract
Isometry has been widely used in corresponding problem with pose variation. However, most existing methods are causing wrong correspondences due to the ambiguity of geodesic distance. This article introduces the semantic isometry to three-dimensional shape correspondence and proposes a new framework called detection–recognition–correspondence. The idea of semantic isometry is to embed the semantic information and statistical learning through sparse correspondence for better performance. Feature point detection is first utilized to extract the salient feature point of the three-dimensional shapes. Then, instead of finding correspondence pairs directly by minimizing the isometric error of the detected feature points, the semantic labels of these feature points are recognized using the support vector machine. The semantic label is used to perform a priority-driven isometric correspondence.The highly reliable corresponding pairs are then obtained to serve as the further constraint in the following corresponding process. During the experiments, the robustness of the proposed algorithm is verified by different kinds of three-dimensional dynamic models, including some very challenging data with pose variation and missing parts. Moreover, the proposed framework can greatly improve the corresponding accuracy over the existing state-of-the-art algorithms.
Keywords
Introduction
Three-dimensional (3-D) shape correspondence is focusing on building a mapping between two given shapes. It is one of the fundamental problems of computer vision and computer graphics. It has a wide application in humanoid robot. 1 The point–point matching among different poses built by 3-D shape correspondence can be used for building marker-less motion capture. In this way, humanoid robot imitate without expensive full-body motion capture suit. 2 In addition, the human shapes with different poses are generally isometric (or nearly isometric). Therefore, the correspondence problem can be reduced to isometric mapping. This article addresses the problem of establishing correspondence between isometric (or nearly isometric) shapes, which are very popular for human motion capture.
If two shapes are completely isometric, we can find a distance-preserving mapping between two shapes using geodesic distance. 3 However, in real case, the two shapes with different poses cannot be perfectly isometric due to many factors, like topological noise, scanning accuracy, geometry discretization errors, and missing data. Currently, numerous optimizing methods have been proposed to minimize the amount of deviation from isometry. Most of these methods are defined in embedding space instead of original Euclidean space. However, these embedding methods require the input shapes to satisfy some strict conditions like watertight and no holes. Moreover, some embedding errors will also be carried in, affecting the shape of correspondence accuracy. Recently, Sahillioglu and Yemez 4 focus on using isometric model directly in 3-D Euclidean space, which can avoid distortion error of embedding process. Experimental results show that the optimizing method in 3-D Euclidean space can get better accuracy. However, the main problem of this method is how to roughly align two shapes before isometric mapping. Sahillioglu and Yemez developed two methods for initial alignments, including spectral embedding and geodesic distance–based feature point matching. However, the former method cannot work on partial correspondence since spectral embedding is highly affected by missing parts. While the latter method is also not stable due to the ambiguity of geodesic distance.
In this article, we introduce the notion of semantic isometry for 3-D shape correspondence. It can robustly obtain sparse correspondence. Our motivation comes from the following observation: the detected feature points are visually salient and distinguishable; if their semantic labels can be firstly recognized and served as a constraint through the following correspondence, the corresponding accuracy can be greatly improved. Therefore, we perform a sparse-to-dense correspondence with the constraint of semantic label and propose a new framework called detection–recognition–correspondence (DRC). The framework mainly consists of the following steps. Firstly, the salient feature points of the 3-D shapes are detected. Secondly, the semantic labels of these feature points are recognized using support vector machine (SVM). Thirdly, the sparse correspondences are obtained with the constraint of semantic labels. Finally, we minimize the isometric distortion directly in the 3-D Euclidean space by defining a bipartite graph with each edge weight representing the geodesic distance of two points. Apart from its robustness in the case of pose variation and deformation, the algorithm supports partial correspondence as well. Our experiments further verify that the proposed method can produce better performance over the similar method.
The rest of this article is organized as follows: “Related work” section provides a brief review of some related work; “semantic isometry for 3-D shape correspondence” section gives the proposed algorithm in details; “experiments” section presents the experimental analysis for shape correspondence; And finally a conclusion is drawn in the fifth section , followed by some future work.
Related work
Many existing methods have been proposed to find optimal correspondence by minimizing isometric error. 5 The optimizing methods can be mainly defined in embedding or Euclidean space.
The idea of embedding methods is to remove pose variance by transforming 3-D shape from Euclidean space into another space. Generally, this kind of method constructs a pose-invariant representation of 3-D shape. Spectral embedding 6 is one of the most classical methods, which approximates geodesic distances by Euclidean distances. Similarly, Bronstein et al. 7 performed correspondences by embedding one into another using geodesic distance. Their method is a generalization of the multidimensional scaling method. Conformal mapping was first proposed by Lipman and Funkhouser. 8 It iteratively samples a random triplet from each of the shape surfaces. Then, many improved methods followed. For example, high-order graph matching is used to combine geometry feature and appearance for better correspondence. 9 While Blended intrinsic maps method is to search for a continuous blend of multiple low-dimensional maps by Mobius transformations. 10 They combine many conformal maps with weights varying over the surface to obtain a space of maps. Other embedding methods include heat kernel. 11 Recently, Chen and Koltun cast isometric embedding as Markov random field optimization and apply efficient global optimization algorithms based on linear programming relaxations. 12
A common problem of embedding-based methods is that they only compute deviations from isometry since embedding space is actually an approximation. There are many rooms to improve the corresponding accuracy. One way is to incorporate local shape information. A point-based statistical descriptor incorporates an approximation of the geodesic shape distribution and other geometric information to define isometric mapping. 13 Recently, Sahillioglu and Yemez proposed to perform isometric optimization in original Euclidean space. Their results show that the corresponding results can be greatly improved over the embedding methods. Their most recent work called rank-and-vote-and-combine (RAVAC) 14 measures a correspondence pair based on only partial shape. The main advantage of RAVAC method is to support partial correspondence. However, RAVAC is not stable for any kinds of 3-D shapes since the method ranks the confidence only using geodesic distance through sparse correspondence. As we know, the ambiguity of geodesic distance will cause wrong correspondence. Another improvement is to define more robust distance measure, like geodesic field estimate (GFE). It calculates the probability of the geodesic between points x and y passing through the given point f. 15 Its scale-, rotation-, and isometry-invariant features are its main advantages. However, the authors did not give more details and experimental results to demonstrate the performance of GFE.
Semantic isometry for 3-D shape correspondence
Performing the shape correspondence from a sparse to dense manner is the most common and effective scheme. The proposed method in this section is also performed from sparse correspondence to dense correspondence. Our algorithm is deduced by the following observation shown in Figure 1. Due to the ambiguity of geodesic distance, isometry-based RAVAC algorithm wrongly maps the head point to the hand point (left figure). However, two points have very obvious difference in local shape feature. Therefore, we can build a recognition framework for feature points. For each feature point, its label can be recognized by a classifier via local features. Furthermore, the recognized labels are used for a constraint of isometry mapping. Based on this idea, we can obtain a better sparse correspondence over the RAVAC algorithm. Right figure shows our result of sparse correspondence with semantic isometry. To give an overview at first, a flowchart of our proposed framework is given in Figure 2. Firstly, some distinctive feature points are identified on both shapes. Secondly, the semantic label of each feature point is recognized by combining feature descriptors and SVM. Thirdly, the mapping confidence is ranked by semantic isometry to get an optimal sparse correspondence. And finally, the corresponding cost matrix is constructed with the constraint sparse correspondence to compute the best correspondence, which is obtained using the linear assignment.

Isometry versus semantic isometry.

The flowchart of our proposed DRC algorithm. DRC: detection–recognition–correspondence.
In the following, we discuss the algorithm implementation in detail. To simplify the description in the following subsection, here we give some common definitions for both source and target shape. A 3-D shape is represented as a set of vertices denoted by V. For any two vertices vq, vw ∈ V, their geodesic distance is denoted by g(vq, vw).
Detection of feature points
To generate such a correspondence, we need to compute a few salient feature points on both shapes. Our algorithm is independent of the feature point detection methods. Many methods can be used in extracting the feature points. In this article, we focus on the correspondence of 3-D deformable shapes. This kind of 3-D shapes is usually composed of a main part (e.g. the torso of an animal) and several connected exterior parts (e.g. the head, limbs, and tail). Therefore, here we choose to use the feature point detection method in part-based 3-D decomposition. 16 Katz’s method detects some exterior feature points to represent the structures of a 3-D shape before decomposition. We take this idea to detect some exterior feature points for our feature matching task. The detecting method firstly obtains the core point f1 ∈ V by summing the geodesic distances to all other vertices. Obviously for a deformable shape, the core vertex lies on its main part. The feature points on the exterior parts must be far away from the core point. Therefore, the required feature points can be iteratively detected using the following equation

The second part of equation (1) maximizes their minimum distance to previously detected feature points. The iterative process exits if the following equation is satisfied

Notice that the right side of the equation is the average distance to the core feature point, f1, which can be considered as the minimum length of a single part. The parameter α is used to control the number of feature points. If the value is set to be small, more feature points can be extracted. In our implementation, the value is set to be 0.5. As a result, most important feature points can be extracted to represent the structures of a 3-D shape. Figure 3 shows the extracted feature points of some 3-D shapes. Notice that these feature points are mainly lying on the protrusion of 3-D deformable shapes. Definitely, if we can make a correct matching of these feature points, we can easily perform a dense correspondence between two shapes with the constraint of these matching.

Feature points of some 3-D shapes. 3-D: three-dimensional.
Recognition of semantic labels
After feature point detection, we need to assign a semantic label L(fi) for each detected feature point fi by SVM and shape descriptor. Many shape descriptors can be used to work out the recognizing task, like shape diameter function, heat kernel signature (HKS), or wave kernel.
Here, we use HKS shape descriptor, which is based on the fundamental solutions of the heat equation. For each point in the shape, HKS defines its feature vector representing the point’s local and global geometric properties. The heat kernel is invariant under isometric transformations and stable under small perturbations to the isometry. Figure 4 shows HKS distributions of two shapes. The red indicates large HKS value and blue indicates small value. Notice that feature points on different parts are very distinguishable from each other.

HKS shape descriptor of different feature points. HKS: heat kernel signatures.
However, the HKS-based matching method is highly affected by capturing noise and variant position of feature points. To further improve the robustness of semantic label recognition, we build a learning-based method. The power of learning method has been verified by shape understanding problems, 17 such as the co-segmentation and shape retrieval. For each feature point fi, its geometry vector defined by HKS is represented by FEi. Notice that to minimize the scale effect, a normalization is required to be added to the geometry vector.
Then, the recognition task is to distinguish feature points into different classes using the corresponding geometry vectors. Therefore, it is a very typical multi-class problem. The multi-class problem can be efficiently solved by SVM. Notice that some feature geometry cannot be classified in linear manner. Therefore, we define a kernel trick to implicitly map the feature vectors into a high-dimensional feature space, as shown in the following equation

where αt is the lagrange multiplier and K(⋅) is the Gaussian kernel function, which is defined by the following equation
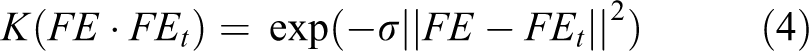
In equation (4), the value of kernel parameter σ has a great effect on the final recognition accuracy. Additionally, we need to decide a penalty factor (denoted by C) during the training stage. To make a best recognition rate, we use a grid search method to make a hyperparameter optimization. The gird search method measures the final performance by cross validation on the training set. The best combination is selected as the optimal parameters. Figure 5 shows the performance on the range [2−10, 210]. When parameters satisfy the following condition (log2(C), log2(σ)) = (−1,−5), SVM shows the best performance.

Optimal parameters searching for unique point recognition.
The above binary classifier can be easily extended to the multiple classier by the voting rule as defined in the following equation

where VT(yi) denotes the voting number belonging to the label yi. Finally, the final label of each feature point is decided by maximizing rule.
Figure 6 shows some results of the semantic label recognition. Different labels are described by different colors. It can be seen that the semantic labels are very distinctive for different parts of the deformable 3-D shapes. In addition, it remains locally stable in the process of motion variation since it is based on statistical learning method. Even for some low-quality 3-D scanning data under occlusion (see the first model in Figure 6), the SVM can reliably recognize the semantic label.

Some results of semantic label recognition.
Sparse correspondence with semantic label constraint
Let fs = s1, s2, … sn denotes the feature point set corresponding to the source shape S and ft = t1, t2, … tn denotes the feature point set corresponding to the target shape T. Notice that not every feature point in the source shape can find a corresponding point in the target shape. If the algorithm forces to find a corresponding point for each point of the source shape, the corresponding results might be wrong. To solve this problem, we choose to build a very sparse correspondence that only need to search three key points in the source shape. Figure 7 gives an example of finding the best correspondence in 2-D space. Suppose five feature points are detected in the source shape, while four feature points are detected in the destination shape. The dashed lines show the best triplet. For each pair in the mapped triplet, the two mapped points share the same semantic labels. Furthermore, it has similar geodesic distance to other mapped points due to isometric constraint. Therefore, the algorithm can select the best correspondence even if some feature points are wrongly detected or recognized.

The best triple correspondence by semantic isometry.
In this way, we can robustly find those highly reliable corresponding points while ignoring some possible wrong-corresponding points. In consequence, the problem of our sparse corresponding is reduced to searching three matching feature point pairs between the source shape and the target shape. Since we use geodesic distance to extract feature points, the number of extracted points is usually less than 10. Therefore, we can perform a combinational searching for all possible matching. Finally, those matching pairs with the highest confidences are selected as the sparse corresponding pairs. We can rank all the possible triplets by combining their isometric errors and semantic labels. We can formulate the semantic isometry using the following function

where

The main difference with the traditional isometry lies on the factor, w1, which is defined by the semantic consistence. The triplet correspondence with the semantic label constraint is very stable under different poses. Furthermore, it can tolerate distortion and noise. To verify this point, we show some corresponding results of distorted 3-D shapes. Figure 8 shows some triplets obtained by our method. Notice that these 3-D shapes are distorted by a few noises. For these 3-D shapes, the geodesic distance and shape descriptors are not stable enough to build a correct correspondence. Fortunately, semantic labels can work very well under noise. As a result, the proposed algorithm can robustly output triplet correspondence.

Matching results under noise distortion.
Dense correspondence with linear assignment
After finding the three-point matching pairs, we can use isometric searching to build a dense correspondence. Here, we use a minimum cost perfect matching algorithm.
18
The algorithm performs isometric searching by computing the cost matrix. Firstly, the algorithm evenly samples some points both over two shapes. To make sampling points cover the whole surface, we set the sampling radius to be

where
Experiments
To demonstrate the performance of our proposed algorithm, we conducted experiments on two types of databases containing different poses. We mainly compare our method with RAVAC algorithm. 17 RAVAC algorithm improves mapping confidence by accumulating vote matrix with the constraint isometric mapping. We have used the same publicly available RAVAC code with the settings identical to the one used in the correspondence experiments. Firstly, we perform an experimental analysis to show the robustness of semantic label recognition. Secondly, we perform an experimental comparison on a public whole-to-whole correspondence database. Thirdly, we further verify our method by part-to-whole corresponding experiments, including some very challenging and complicated 3-D shapes.
Database and evaluation metrics
To evaluate our method, we used two kinds of database. Besides correspondence benchmark, we also collect some reconstructed data from real senses. The correspondence benchmark includes SCAPE 19 and TOSCA 20 Generally, 3-D shapes in this database are of high quality and very smooth, with no topological noise. In addition, these databases have ground truth. Therefore, we can evaluate correspondence error by standard curves. 10 The other database contains some very challenging data reconstructed from real scenes (denoted by SCANNING in the following), including Dancing Woman 21 and Kicker Man 22 Among them, Kicker Man is very difficult to be resolved since the scanner is not able to resolve the gap between the arms and the body. Moreover, the topology is ambiguous and the geometry shows systematic low-frequency artifacts. For this kind of data, the quantitative measures used in this article show isometric error. The main advantage of isometric error is that it is independent of ground truth data. That means, we can evaluate results on some challenging real-scan data without ground truth. To quantify the isometric distortion, we use the average distortion error defined in the following equation

where ξ denotes the set of correspondence pairs between two 3-D shapes S and T. For each pair, we can use the following equation to compute the isometric error

The metric diso take values in the interval [0; 1] since the function g is normalized with respect to the maximum geodesic distance over the shape. Obviously, the isometric error is expected to be very close to zero for natural deformations. Generally, the wrong correspondence will cause a big value of this metric. Therefore, the smaller the value, the better the corresponding accuracy.
Robustness of semantic label recognition
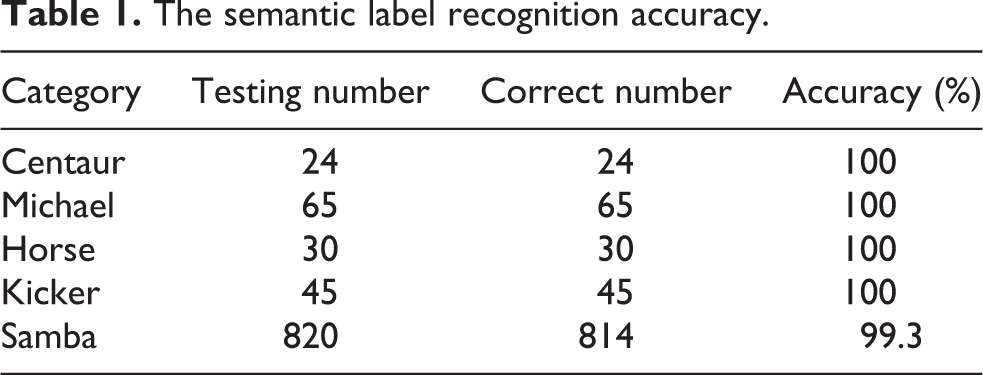
The algorithm’s accuracy mainly depends on the robustness of semantic label recognition. The training set of SVM is created on a collection of representative shapes and their feature points. Then, the recognition accuracy of shapes in the testing set is calculated to show how robust the algorithm is. The results of the recognition rate are shown in Table 1. Notice that the accuracy for synthesis models (shown in the top three rows of Table 1) is 100% for the testing data since these data are smooth and of high quality. Even for real-scanning data with high noise, our algorithm still obtains a very high recognition rate.
The semantic label recognition accuracy.
Quantitative comparing with similar algorithm
We have conducted quantitative evaluation on the three databases to compare our method with the RAVAC method. For RAVAC, we used the publicly available C++ code which uses combinational searching. Firstly, we give the performance comparison for benchmark SCAPE. This database only contains scanning results for one human with different poses. Figure 9 shows the results of two methods. For this database, RAVAC method also shows good accuracy. Our method has a slight improvement over RAVAC method. Next, we perform comparisons for TOSCA. Compared to SCAPE, TOSCA is more complicated since it contains different kinds of 3-D shapes. Figure 10 shows the results of the two methods. It can be found that the correspondence performance has improved greatly. Finally, we perform experiments on the SCANNING database. The isometric error is used for measuring since there are no benchmark for this kind of data. The quantitative results of the comparison tests are shown in Table 2. It can be seen that our DRC method still significantly outperforms RAVAC method. For the real-scan data Kicker with the lowest quality, our method makes a great improvement of almost three times on the corresponding accuracy. The reason is that RAVAC method builds sparse correspondence only by geodesic distance, which makes the method very unstable under distortions and noisy data. And the proposed DRC method has addressed this problem.
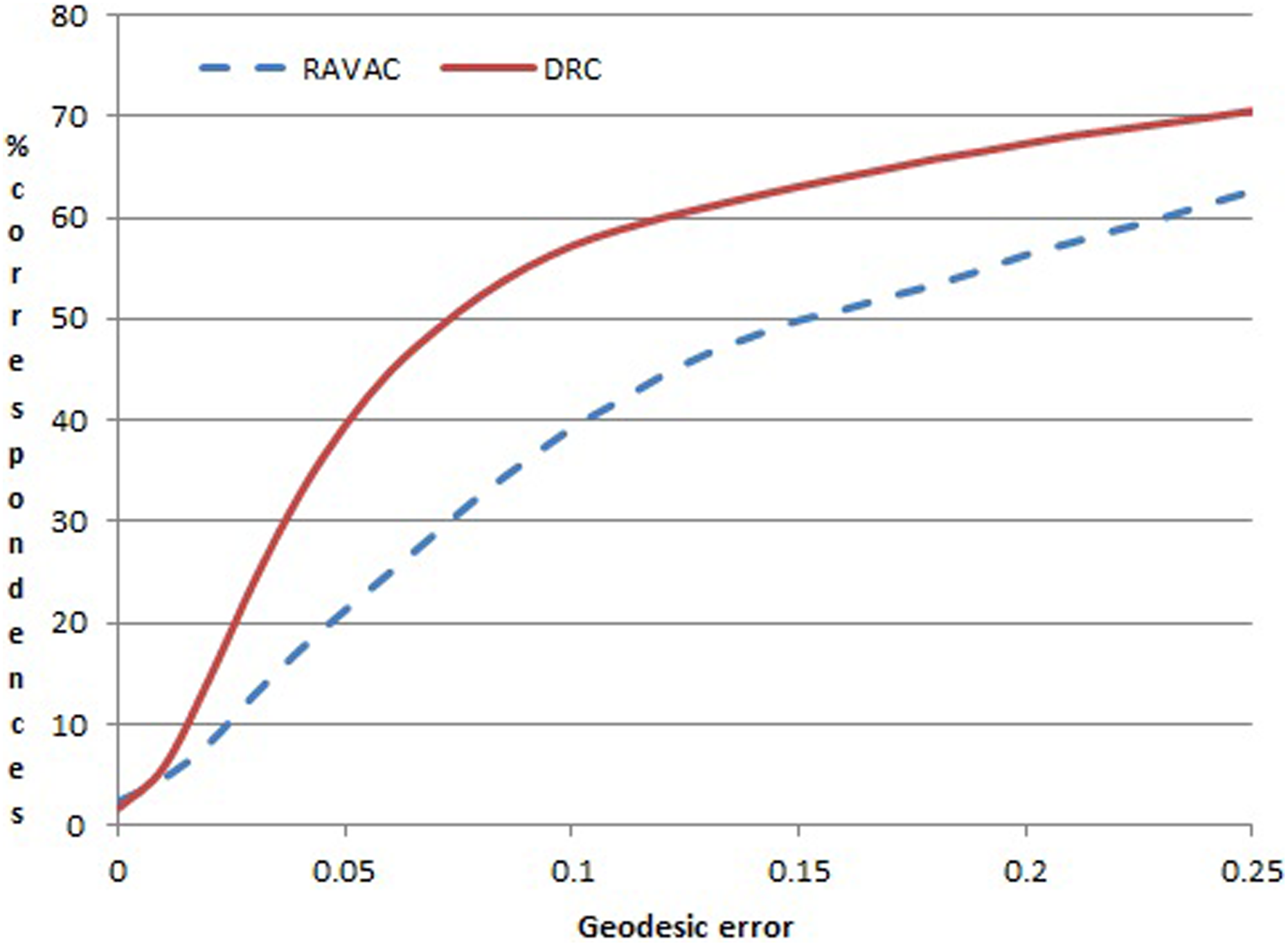
Comparison of two methods for SCAPE.

Comparison of two methods for TOSCA.
Isometric error comparision for SCANNING.

DRC: detection–recognition–correspondence; RAVAC: rank-and-vote-and-combine.
To give a visual demonstration, some correspondence results are shown in Figure 11. For a better visualization, matching points are rendered in different colors. Each of the two matching points have the same color and are connected by a line. From the top row of Figure 11, it can be seen that the RAVAC method cannot correctly match all the shape extremities. It shows that RAVAC is not general for each case. For example, it can output good correspondence for the horse. However, it causes a very serious problem that leads the leg point to the head point for the kicker man. This is mainly due to the fact that RAVAC is a searching process without local shape descriptor and learning strategy. In our proposed DRC method, a matching priority is introduced to the problem. The matching priority is effectively obtained by learning shape descriptor of feature points. From the top row of Figure 11, it can be seen that the DRC method obtains better correspondence results in all the three cases with semantic recognition.

Comparison of correspondence results. Top: results of RAVAC; Bottom: results of DRC. RAVAC: rank-and-vote-and-combine; DRC: detection–recognition–correspondence.
The main limitation is the symmetrical flip problem, which is natural to isometric mapping. Our recognition framework is still suffering from this problem since it cannot distinguish the left and right side. It remains a future study.
Conclusions
The 3-D shape extremities-based correspondence directly builds a mapping in Euclidean space. Therefore, it can support partial correspondence. However, existing methods will cause wrong correspondence under non-isometric cases. This work addresses the problem and proposes a framework DRC of building 3-D correspondence by semantic isometry. Semantic label recognition is introduced to constrain the correspondence work. For two points on the source shape and their matching points on the destination shape, their isometries depend not only on their geodesic distance but also on their semantic labels. Semantic labels of the feature points are recognized by SVM and local shape descriptors. As a result, the dense correspondence between two shapes is obtained with the constraint of sematic labels. The approach is shown to obtain promising results on different kinds of 3-D shapes over the existing methods.
In the future, we plan to resolve the flip problem by space–time feature. The flip problem is very common in nonrigid correspondence. In addition, it is very difficult to distinguish flip parts by different kinds of local features. Most nonrigid correspondences are addressing 3-D dynamic model. For these 3-D shapes, the continuous space information can be incorporated into 3-D correspondence to remove the flip problem.
Footnotes
Author note
Ying Cui is also affiliated to Key Laboratory of Intelligent Perception and Systems for High-Dimensional Information of Ministry of Education, Nanjing University of Science and Technology, Nanjing, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work was supported by China Natural Science Foundation (grant no: 61403342). Part of work is supported by Natural Science Foundation of Zhejiang Province, China (grant no: LY 15F020024, LQ18F030014) and the Innovation Foundation from Key Laboratory of Intelligent Perception and Systems for High-Dimensional Information of Ministry of Education (grant no: JYB201706).