
Abstract
To improve the robustness of biped walking, a model parameters optimization method based on policy gradient decent learning is presented. For the linear inverted pendulum mode-based model parameters optimization, firstly, select the input parameters of the inverted pendulum model and the torso attitude parameters of the robot as the correction variables and establish the correction equation. Then, using the tracking errors of center of mass (CoM) of the robot and the errors of the robot posture relative to the upright state of the body to establish the fitness function. According to the fitness function, the gain coefficients in the model parameters correction equation are optimized by using the strategy gradient learning method, and the modified gain parameters are substituted into the model parameters correction equation to obtain the correction amount. By applying the model parameters optimization strategy, the robot can quickly and in real time adjust the body posture and walking patterns under unknown disturbances, hence, the walking robustness can be enhanced. Simulation and experiments on a full-body humanoid robot NAO validate the effectiveness of the proposed method. The experiments show that the optimized model yields a more controlled, robust walk on NAO robot and on various surfaces without additional manual parameters tuning.
Keywords
Introduction
For humanoid robots, stable and robust biped walking gait generation is very important. Many studies for dynamic biped walking are based on a simple humanoid robot as simplified dynamics models, 1 –6 like three-dimensional linear inverted pendulum mode (3D-LIPM), cart-table model, and so on. Using such an abstract model, there are various ways to generate appropriate gait patterns. Humanoid walking is commonly realized by planning the center of mass (CoM) trajectories, so that the resultant zero moment point (ZMP) trajectory follows a desired ZMP trajectory, which is normally determined by predefined foot positioning. These models based on control methods can realize biped walking under ideal environment. However, in complex condition, the balanced walking of a humanoid robot requires compensation in real time to guarantee the dynamic stability. To realize robust and dynamic walking, many strategies have been proposed to compensate for the nonzero variations in momentum 7,8 or regulate CoM through sensory feedback. 9 –11
Biped dynamic walking under disturbances is still an open question. To achieve external environment disturbance rebalancing, some well-known methods to stabilize walking using sensor feedback are proposed, 7 –9,12,13 including regulation of the states of CoM or by modification of the predefined foot positions online through sensory feedback. 10,11,14 –17 Considering humanoid momentum compensation, Englsberger and Ott 7 proposed a walking method based on a capture point, which integrates CoM vertical motion and angular momentum change. Ugurlu et al. 12 created a strategy to rotate a humanoid’s upper body to compensate for undesired yaw movement when the robot walks. Chang et al. 8 estimated the robot state and regulated the angular momentum of CoM and steps to recover from a push. Castano et al. 10 proposed an online walking control that replanned the gait pattern based on foot placement control using the actual CoM state feedback. Wieber 11,15 proposed an online walking gait generation approach, with both adjustable foot positioning and step duration based on the linear model predictive control scheme. Based on the preview control scheme, Nishiwaki and Kagami 16 proposed strategies to adjust future foot positioning and ZMP trajectory. Stephens 17 utilized an integral control method to maintain standing balance and viewed the disturbance as impulsive. Liu and Atkeson 18 studied the balance of a robot standing based on a trajectory library, which is time-consuming.
Open loop walk can easily be disturbed by external influences like hitting obstacles or more irregular terrains. Closed loop online modulation of the controller is the important strategy to solve the disturbance affect question during biped walking. Graf and Röfer 19 presented a closed loop 3D-LIPM-based gait generation method for the RoboCup standard platform. By adding the sensor feedback, robot can reach faster walking speeds and be robust to disturbances. On one hand, this allows reacting to unexpected disruptions such as unevenness of the ground or the forces exerted on the robot. On the other hand, it compensates the forces and hardware characteristics that were not considered within the model used. Using sensor feedback to observe the state of the robot and to adjust the inverted pendulum model to the observed state in order to improve the stability of the walk. Their approach not only allow compensating the inaccuracies in the model but also allows for reacting to external perturbations effectively, like with robustness against perturbations such as forces exerted on the robot. Urbann and Hofmann 5 presented a reactive stepping algorithm based on the generation of walking motions with sensor feedback. The closed form calculation of foot placement modifications, such as disturbances of the CoM position, could be balanced with negligible ZMP deviations.
In order to improve the robustness of the previous work on the biped dynamic walking based on the LIPM model, the main contribution of this article is presenting an improved closed loop dynamic gait generation method based on the previous work of Graf et al. for humanoid robots combining LIPM with parameter optimization. For the presented LIPM-based model parameters optimization, firstly, select the input parameters of the inverted pendulum model and the torso attitude parameters of the robot as the correction variables and establish the correction equation. Then, using the tracking errors of CoM of the robot and the errors of the robot posture relative to the upright state of the body as the fitness index of the robot to the current environment, and establish the fitness function. According to the fitness function, the gain coefficients in the model parameters correction equation are optimized by using the strategy gradient learning method, and the modified gain parameters are substituted into the model parameters correction equation to obtain the correction amount. By applying the model parameters optimization strategy, the robot can quickly and in real time adjust the body posture and walking pattern under unknown disturbance, hence, the walking robustness can be enhanced. Simulation and experiments on a full-body humanoid robot NAO validate the effectiveness of the proposed method. The experiments show that the optimized model yields a more controlled, robust walk from NAO robots and on various surfaces without additional manual parameters tuning.
The rest of this article is organized as follows. Second section presents the LIPM-based biped gait generation, including the LIPM model, the CoM trajectory and foot trajectory planning, and observation of the CoM by Kalman filter. Third section introduces the design method of model parameters corrector based on policy gradient decent learning method. Fourth section verifies the real-time performance and validity of the presented compensation algorithm by experiments. Fifth section provides the conclusions and discussion.
LIPM-based gait generation
The dynamics of a humanoid robot can be approximated as a linear inverted pendulum with its mass concentrated at CoM and supported at ZMP (Figure 1). In this model, the robot’s leg is assumed as a weightless scalable limb and its kinematics constraints are not considered. When not considering the constraint of the limited area of supporting polygon and neglecting the vertical moment of the CoM, the dynamics of LIPM in the x–z plane can be formulated as a strictly proper dynamic system as follows



Linear inverted pendulum model.
where
Given a set of future foot positioning, a reference ZMP trajectory can be generated on fulfillment of the dynamic stability requirement, and the desired CoM trajectory can be generated online using preview control (or the build in PID control) based on the LIPM. Using the inverse kinematics to obtain joint commands from the CoM trajectory, an open-loop humanoid walking control method can be realized. However, this just can realize biped walking under ideal environment, like flat terrain walking without external disturbance.
The LIPM-based trajectory planning
The position and velocity of the CoM relative to the origin of the inverted pendulum are given by Graf and Röfer 19 as follows


where
The support leg is constantly switching during walking, so the origin of the pendulum
need to be constantly switching because the origin of the pendulum is on the support foot.
As shown in Figures 1(a) and 2, Q is the
coordinate system of the robot, and its origin is located between the feet. To eliminate
the double support phase, we need to calculate the switching time point of the support
leg. t = 0 is defined as a starting time point for altering the support
leg, when t = 0, the y-component of the velocity is 0
(


xy-cross section showing the step size
The inverted pendulum motion diagram in the y–z plane
is shown in Figure 3. The swing
foot should have crossed a distance of

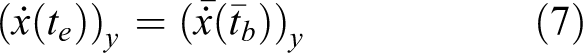

The inverted pendulum motion in y–z plane.
where
The support leg switching in x-direction have the same regularity with the y-direction as follows

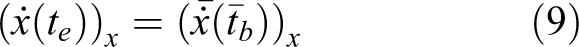
To ensure the optimum original of the inverted pendulum in the next single support phase,
and the CoM is located just above the origin, we design the conditions of
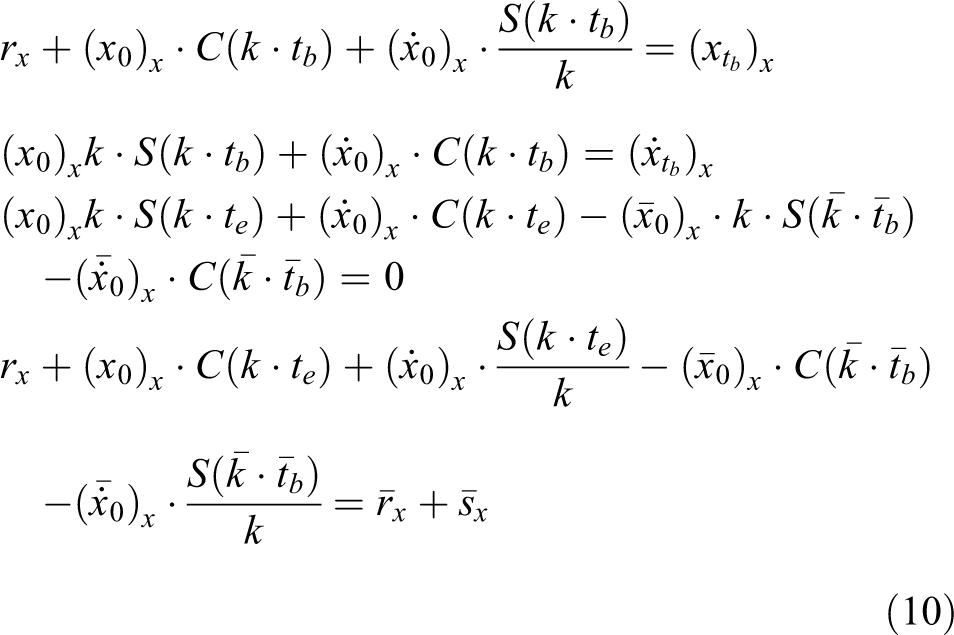
where C( ) and S( ) are the abbreviation of cosh( ) and sinh( ).
The



where lz is the lift height in z-direction
of CoM, φs and φD are the
proportional constant coefficients, which describe the beginning time and the duration of
movement with the relationship of
When the movement of the CoM trajectory relative to the origin of the pendulum motion is determined, the movement of the support leg with respect to the CoM will also be determined, which can be expressed as
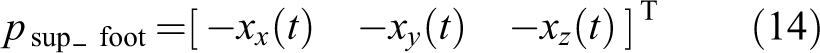
The movement of the swing foot with respect to the robot coordinate system Q can be divided into the xy-direction movement and the z-direction movement as follows


where sxy and
Meanwhile, we need to set the angular velocity of the support foot and the swing foot as follows
Finally, combining target foot positions relative to the CoM and CoM position relative to torso by computing current robot’s stance, the joint angles can be calculated by inverse kinematics.
Observing the CoM by Kalman filter
Based on Craf’s previous work, 19 for determining an observed position of the CoM, two Kalman filters are used for the x- and y-components of the position and the velocity of the CoM. The expected CoM position xei with respect to Q is computed using x(t) and the error with the measured position xmi is calculated to get update the Kalman as follows


The state quantities and covariance matrices of the Kalman prediction phase are as follows


where
The state quantity and covariance matrix of the Kalman update phase are as follows

where Ki is the Kalman gain,
The filtered position xfi and the filtered velocity


The motion equation in the y-direction is corrected as follows


The values of

Learning-based model parameters correction
In this work, a model parameters optimization method based on policy gradient decent learning is proposed. Usually, there are two methods of using policy gradient learning in the inverted pendulum model. One approach is to update the input parameters of the inverted pendulum every time a policy set is generated during the process of parameter optimization. When a robot via the virtual linkage model takes one step using this policy set, the corresponding value of the objective function and the parameter set of the next iteration are obtained. Once the iteration number reaches the preset iteration number Niter, the parameter set is taken as the input parameters of the inverted pendulum, and the output parameters of the inverted pendulum are passed on to the robot. This method can directly adjust the gait of a robot. However, the computations of the robot model and the inverted pendulum model are involved in each iteration, which means Niter previews for each real step of the robot. The previews will take a long time, preventing the robot’s pace from being smooth, and therefore the approach is not suitable for real-time robot walking.
The other approach is that after a robot takes a step, the objective function is used to evaluate the state of this step, and then the input parameters for the inverted pendulum are compensated. At this time, the method of policy gradient learning does not directly optimize the input parameters of the inverted pendulum but optimizes the gain coefficient of the compensation amount, thereby indirectly adjusting the gait of the robot. The second approach separates the gradient descent method for policy search from the virtual linkage model for the robot, and the computation speed is greatly improved. It is thus suitable for the real-time gait adjustment of the robot. However, the relational function for the parameter compensation of the inverted pendulum and the gain coefficient need to be established to find the internal relationship between the compensation amount and the virtual linkage model for robots, with a certain degree of increase in difficulty.
The overall procedure of humanoid walking with learning-based parameters correction can be
summarized by the diagram of Figure
4. For determining an observed position of the CoM, a Kalman filter will be used
for the x- and y-components of the position and the
velocity of the CoM in the inner feedback loop. The filtered position
xf and the filtered velocity

The diagram of our humanoid walking control with model parameters correction.
Model parameters correction equation
There have been many parameters in the LIPM model which influence the biped walking, such
as, the step stride sx and sy, the
step height sz, and the height of the inverted pendulum
h. In addition, the robot is a multidimensional model with high degrees
of freedom (DOFs), it cannot be completely described by the inverted pendulum, such as the
trunk posture θB, and so on. Select the variables
sx, sy,

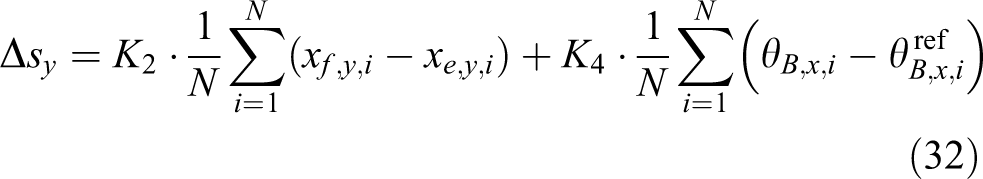


where
This parameter modification function is designed based on the correction of the foothold
of the robot in the x- and y-directions and the
correction of the straightness of the torso. The correction of the step length along the
x-direction,
The output of the compensator is used to correct the inverted pendulum model and the robot model as follows


where
Policy gradient reinforcement learning
Policy gradient learning method is a powerful machine learning algorithm to find the
local optimal policy when there is no analytic mapping from the performance index to the
pending parameters or when the gradient of the cost function cannot be directly
calculated. This method has already been adopted in many robotics applications, especially
for learning the walking of legged robot.
21
–23
In this work, the parameters of inverted pendulum is optimized by using the method
of gradient learning. As we know, when the robot is disturbed by unknown disturbance, if
after adjusting, it can maintain an high accuracy of CoM tracking and good body upright
posture, then the robot’s with high adaptability to the disturbance. In the correction
equation,
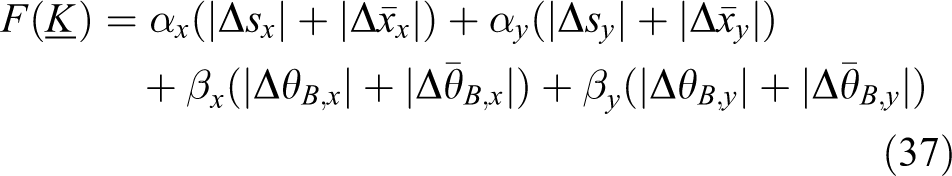
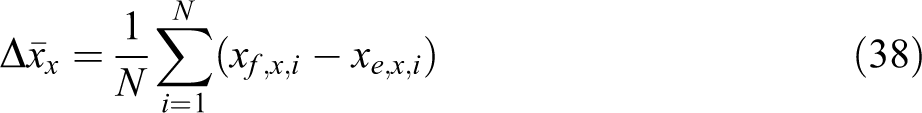

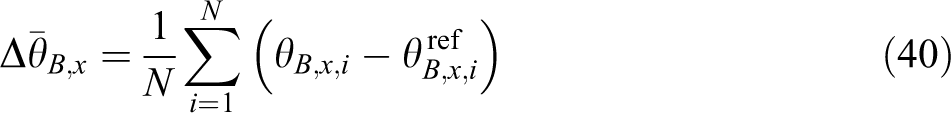

where
Each term of the fitness function contains an absolute value of the compensation amount with the mean error, which is obtained by the linear addition of the absolute value of the output of the compensator, the absolute value of the centroid error, and the absolute value of the body inclination angle error, with different weights. The first two terms represent the following effect of the centroid, and the latter two terms represent the erecting effect of the body. In the process of gradient learning, if the value of the fitness function decreases gradually, the errors in the centroid following and the body inclination are gradually reduced, and the adaptability of the robot under the current parameter set is gradually increased. The corrections of the input parameters and the body inclination of the inverted pendulum cannot be too large, to ensure a reasonable range for allocation of the robot joint space. At the same time, it should be noted that the objective function is not directly associated with the robot walking time but a better erecting effect of the body indicates a longer implementation of centroid following in the robot.
Optimization learning of the parameters in the model
Policy gradient learning is used to optimize the gain parameter set of
The specific procedures of the method of policy gradient learning are as follows.
Step 1
In the k th iteration, for the gain parameter set

where
Step 2
According to the values of −em, 0,
+em for the disturbance ρm,
the
Step 3
To calculate the approximate gradient value
Step 4
With the orthogonal processing for
Step 5
When the number of iterations reaches the preset value Niter, the iteration ends.
Experiments and results
Humanoid robot
To validate the proposed method, NAO robot produced by Aldebaran robotics is used for the experiments (Figure 5(a)). The robot has 25 DOFs, with 11 DOFs for the two legs. The height of this robot is about 54 cm during walking and its weight is 4.35 kg. The sensors data and the walking control module update at a rate of 50 frames per second. Besides, the robot is equipped with an ×86 AMD GEODE 500 MHz CPU. The difficulty to develop walking approaches on this robot is that each leg weighs almost the same with its body and the links of the robot are made of plastic, which makes the dynamics of the robot differs a lot from the simplified dynamics model, and the disturbances brought with the deformation of plastic links are significant.

Humanoid robot platform. (a) NAO robot. (b) The ODE-based simulation environment. (c) Coordinate systems of the humanoid robot.
Two coordinate systems are used (Figure 5(c), the first one is the world coordinate system ∑ w , with its origin on the ground and its x-, y-axis formed a plane parallel to the ground; the second one is called the supporting coordinate system ∑sup, which is attached on the supporting foot. Its origin is the origin point of the supporting foot with its x-axis pointing in the forward direction of the supporting foot, and y-axis to the outside. In this work, experiments on both the simulated and real full-body humanoid robot are developed to show the performance of proposed method. Due to the potential damages and time involved in PGL process on a real humanoid robot, the learning process is currently carried out in Webots simulator.
Simulated experiments
Two experimental setups are developed to test the robot performance and in both the experimental setups, the robot has no prior knowledge of the terrain. The first experimental setup is to let the robot disturbed by uncertain external force during walking. The impose point of the external force on the robot and the force moment, the size of the force and the duration of the force are all uncertain, which can verify the robustness of the robot to unknown disturbances during walking. The second experimental setup is to let the robot walk on different walking terrains to verify the walking robustness when the walking condition changes.
Experiements with only Kalman filter
Omnidirectional walking with only Kalman filter
Figure 6 shows an experiment that the robot turning counterclockwise during forward walk at a speed of 0.05 m/s and with only Kalman filter but no LIPM model parameters online correction. The robot can follow the specified pace size, and with good CoM trajectory tracking result, the ZMP always remain in the feet supporting polygons.
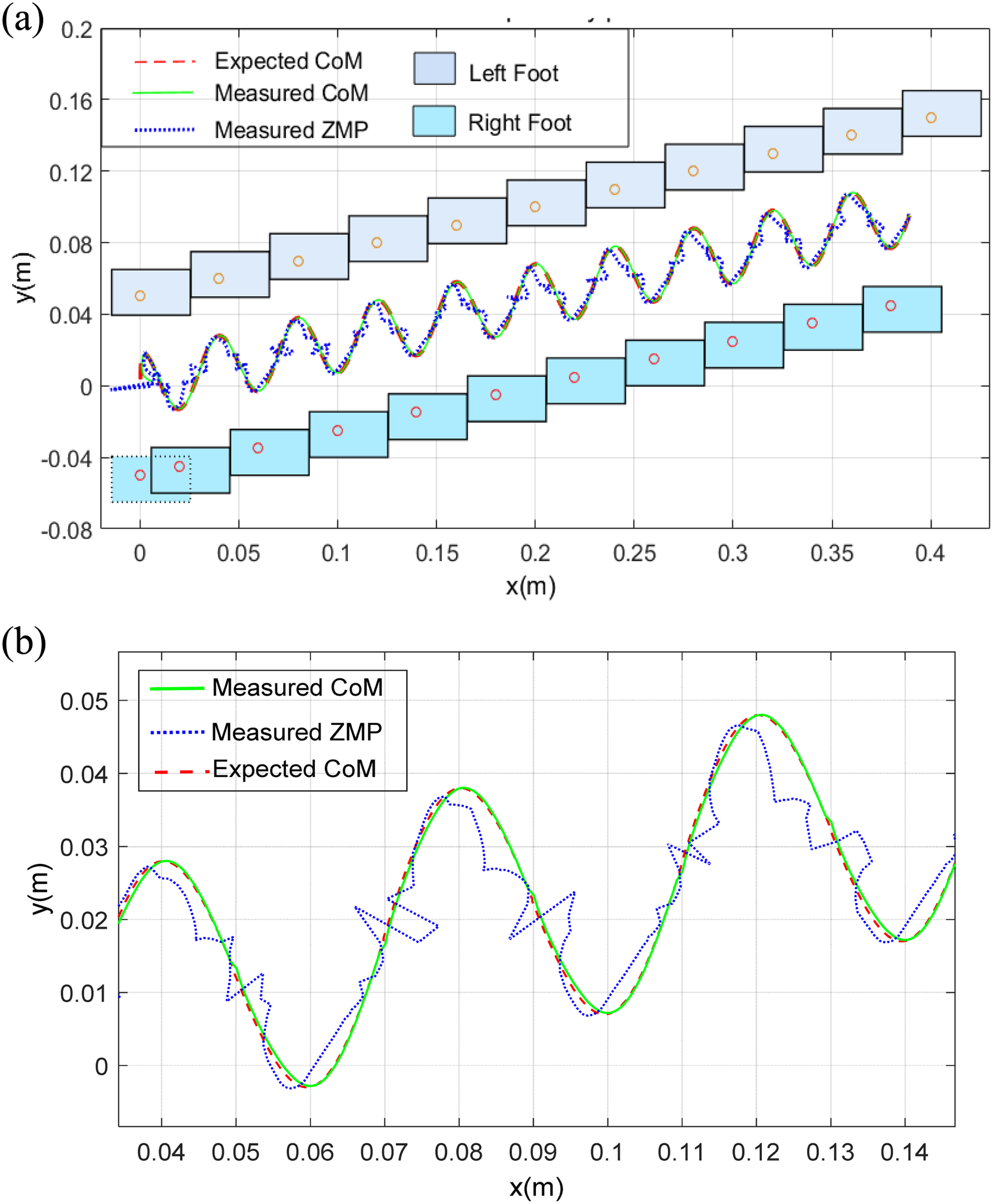
Plot recorded when the robot walks both forward and turning counterclockwise. The plot on the top is the x–y plane data and the plot on the bottom is the CoM and ZMP trajectories. CoM: Centre of mass; ZMP: Zero moment point.
Flat terrain walking with unknown disturbance
The external impulse about 6.5 N happens at about 9 s, the direction is mainly along the y-axis positive direction. Figure 7 shows an experiment that the robot walk straight forward and with only Graf’s method of correcting the inverted pendulum parameters but no model parameters optimization method based policy learning. The robot swings and falls down after being hit by the disturbance. Since there is no online compensation to modify the state of the robot, the robot still follows the predefined footsteps and thus results in the same reference ZMP trajectory. Although with the Kalman filter, the robot can generate the appropriate CoM trajectory to track the reference ZMP, the CoM tracking requirement is however unable to be fulfilled with large external disturbance. The robot manages to swing for several steps and finally falls down.

Plot recorded when the robot walks forward with only Graf’s method but no learning-based model parameters correction.
Experiments with parameters online correction
Flat terrain walking with unknown disturbance
The parameters correction is added outside loop of PGL compensator as shown in Figure 4 in the same experiment. By using the input parameters of the inverted pendulum model and the torso attitude parameters of the robot as the correction variables and establish the compensator, and optimizing the parameters of inverted pendulum by using the method of gradient learning. Figure 8 shows the snapshots of the motions performed in disturbance resistance. The external impulse about 6.5 N happens at about 5 s in the y-direction, the duration of force of about 0.5 s. The initial values and the weight factors are set as shown in Table 1. The robot begins to walk along the x-direction, after disturbance by the external force in the left direction, and with the online compensation, the robot immediately adjust the next few steps to adjust the pace, steps to the left, and through the trunk angle compensation, the robot gradually restores upright state.

Snapshots of the motions performed in disturbance resistance.
FPC parameters.

The curve of the torso of the robot is shown in Figure 9. It can be seen from the plot that the robot is tilted to the right after being subjected to external force. After about 7s′ adjustment, the x-axis torso curve returns to the periodic fluctuation during normal walking. Since the robot inertial unit sensor cannot measure the z-axis torso angle, the z-axis torso angle compensation is not added to the parametric compensator design, so the z-axis torso angle is always zero. The expected and measured CoM trajectories and the measured ZMP trajectory are shown in Figure 10. When the robot is subjected to the right external force, the ZMP is shifted to the right and has a large fluctuation but always remains in the support area. The centroid has a good tracking effect, and the external disturbance has little effect on the centroid tracking. The recorded footstep of the robot in the world coordinate system is shown in Figure 11. After using the compensator, the pace of the robot changes due to external disturbances, and when the robot is subjected to right external forces, it will move to the right and the travel distance in the x-direction is slightly reduced. The value of the objective function of the strategy gradient learning method is shown in Figure 12 when the parameter compensator is called in the process of robot walking. The objective function curve shows a decreasing trend as a whole, indicating that the error of the centroid tracking and the error of the torso angle are gradually reduced, which verify the effectiveness of the presented model compensation.

Body attitude of robot under external disturbance.

The ideal CoM, measured CoM and measured ZMP trajectory under external disturbance. CoM: Centre of mass; ZMP: Zero moment point.

The footstep of the robot in x–y plane under external disturbance.

Fitness function curve of the policy gradient learning.
Irregular terrain adaptive walking
The second experiment setup is to test the ability of the presented method’s walking
on irregular terrain. In the simulated experiment, a flat plate with size 0.5 × 0.5 ×
0.016 m3 is laid in walking ground. During walking on the plate, the robot
will be affected by the reaction of the plate. The parameter set initial value of the
strategy gradient learning method is set as:

Snapshots of the walking up and down the plate. (a) Without online parameters correction and (b) with online parameters correction.
Figure 14 shows the body attitude in pitch plane and roll plane during walking. The robot slides backward with shaking when walking up the plate. When walking on the plate, the robot’s x-axis torso curve returns to normal waveform, while the y-axis torso curve remains negative and fluctuates slightly, with fluctuations and slides in the forward direction when the robot walking down the plate. The ideal CoM of the robot, the measured CoM and the measured ZMP trajectory are shown in Figure 15. When the robot walks up and down the plate, the x-direction centroid tracking appears as a more obvious error, the actual CoM position lags behind the ideal CoM position. The ZMP trajectory has a large fluctuation while walking up and down the plate but always remain in the supporting polygon. In the world coordinate system, the foothold diagram of the robot with the compensator is shown in Figure 16. The yellow area is the walking on plate. When the robot moves up and down the plate, the pace of the robot changes with the change in the ground conditions.

Body attitude angles.

The ideal CoM, measured CoM, and measured ZMP trajectory during adaptive walking. CoM: Centre of mass; ZMP: Zero moment point.

Footsteps in x–y plane during walking through the plate.
Real robot experiments
Two experimental setups are developed to test the real robot performance and in both the experimental steups the robot has no prior knowledge of the disturbance and the walking terrain. The video clips of the experiments can be found in the video attachment. The first experiment setup is to let the robot disturbed by the unknown external force as on Figure 17. The result of the experiment is shown in Figure 18. The robot is disturbed by an external force from the back with about 5 N during the robot walking at a speed of 0.12 m/s. After the disturbance, by applying the model parameter compensator, the robot can adjust the pace and body posture according to the target equation in real time, thus reducing the error of the CoM tracking and the inclination of the body. Several experiments show that the robot can withstand the external force of about 10 N in the y-direction in the simulation environment, and can withstand the force of about 6 N in the x-direction. The real experiment can resist about 5 N force in the x-direction.

Real experiment setup of external disturbance during biped walking.

Real experiment setup of external disturbance during biped walking
Conclusions and discussion
For the control problem of humanoid walking, many recent researchers focus on generating reference CoM trajectories according to the constraints, predefined ZMP or other dynamics. To resist with small disturbances, online adaptation of those trajectories are also added in some recent approaches, with heuristics that the robot can exactly track these trajectories. However, due to the nature of the robot’s contact with the environment, the ability of the robot to track these trajectories is unavoidably limited, which consequently leads to the out of control and correspondingly the fall of the robot. Although this problem has been noticed in some recent propositions and some approaches are also presented, an applicable and efficient method is yet to be explored. In this article, a novel solution is proposed to the problem raised above. By the online model parameters optimization strategy, the robot can quickly and in real time adjust the body posture and walking patterns under unknown disturbances, hence, the walking robustness can be enhanced. The robot can successfully retrieve its balance even after being pushed by external forces significantly. The gains of the model parameters corrector are learnt through the policy gradient reinforcement learning method, and it shows satisfactory results when applied on both the physical simulated and real full-body humanoid robots.
Footnotes
Acknowledgements
The authors would like to thank the technicians in the Laboratory of Robotics and Intelligent Systems of Tongji University for their assistance during experiments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China (grant nos. U1713211, 61673300), and the Fundamental Research Funds for the Central Universities, Basic Research Project of Shanghai Science and Technology Commission (grant nos. 16JC1401200, 16DZ1200903).
Supplemental material
Supplementary material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.