
Abstract
Generating a group of category-independent proposals of objects in an image within a very short time is an effective approach to accelerate traditional sliding window search, which has been widely used in preprocessing step of object recognition. In this article, we propose a novel object proposals generation method to produce an order set of candidate windows covering most of object instances. With combination of gradient and local binary pattern, our approach achieves better performance than BING in finding occluded objects and objects in dim lighting conditions. In experiments on the challenging PASCAL VOC 2007 data set, we show that our approach is significantly more accurate than BING. In particular, using 2000 proposals, we achieve 97.6% object detection rate and 69.3% mean average best overlap. Moreover, our proposed method is very efficient and takes only about 0.006 s per image on a laptop central processing unit. The detection speed and high accuracy of proposed method mean that it can be applied to recognizing specific objects in robot visions.
Introduction
In recent years, object detection has made great strides and has been widely used in computer vision and robotic vision. Many vision tasks, such as pointing gestures for human–robot interaction, face recognition for robot vision, and route recognition for mobile robot, are closely tied to object recognition algorithm. There are already some effective methods improving the object detection performance through a variety of complex features 1,2 or classifiers. 3 However, most state-of-the-art detectors still determine the most possible object positions over the image by sliding windows, 4 –6 which are computationally expensive to evaluate all locations. For a successful detection system, it is quite an important problem to increase the computational efficiency without losing the detection accuracy. In order to accelerate object detection, objectness proposals generation has recently attracted much attention. 7 –9
Objectness proposals generation, which produces some category-independent candidate windows of objects in an image within a very short time, has been widely used in the preprocessing step of object recognition. We hope to generate a small number of bounding boxes, such that each object is well located by at least one box. Thereby, object recognition algorithms would be able to evaluate a complex classifier only at a small group of plausible regions rather than at all possible positions and scales in the whole image. Most state-of-the-art object detection frameworks 3,9 –12 proposed recently are composed of proposal generation procedure and object recognition procedure. Being different with time-consuming exhausted search, the proposal generation phase remarkably reduces computation cost by generating a group of candidate proposals that may contain objects. Thus, sophisticated classifiers can be used for window assessment in object recognition. Although there exist a variety of proposal generation approaches, they can be put into two categories roughly grouping methods and window scoring methods. 13
Grouping proposals methods normally employ superpixels grouping strategy to generate multiple (possibly overlapping) segmentations that are likely corresponding to complete objects. A typical approach is a selective search proposed by Uijlings et al. 1 It uses many randomly initialized seeds to start hierarchical superpixels merging based on diversified criteria to generate high-quality proposals.
In contrast, window scoring methods score to generate candidate windows with high ranks, such as objectness—first introduced by Alexe et al. 8 Objectness methods judge how likely it is for an image window to contain an entire object of any class and select windows which are scored based on multiple cues including color, boundary, and superpixel shape. BING 14 is a very fast objectness measure, which selects bounding boxes by training a simple linear classifier with gradient feature (a short review is given in “Overview of BING” section). EdgeBoxes 15 has no learned parameters (similar with selective search) and scores each window according to the number of complete contours in its edge map (obtained via structured forests 16,17 ). Zhang et al. 18 proposed a cascade ranking SVMs to generate proposals for object detection. The first stage learns several classifiers for each scale and aspect ratio in a sliding window manner; and the second stage ranks all proposals from the previous stage. Endres and Hoiem 19 coarsely extracted regions following multiple cues and proposed structure learning algorithm to produce object proposals.
Generally speaking, objectness tends to be faster than grouping proposal methods because objectness only returns bounding boxes. Therefore, objectness has been recently applied to various computer vision tasks for improving accuracy or speed, such as pedestrian detection, 20 visual object detection, 21,22 salient region segmentation 23 robot vision, and so on.
Keeping the computational cost feasible is very important 24,25 for efficient object detection. In this article, we propose a new approach to locate objects by producing a small bag of objectness proposals which cover almost all object instances. According to experiment results, our method reaches surprising detection performance using standard metrics while being very fast to compute.
The article’s main contributions are as follows: (a) Firstly, we study how BING method works to obtain suggested windows and analyze its problem in locating occluded instances. (b) Secondly, we improve BING by adding local binary pattern (LBP) as a new feature into our model. On VOC 2007 26 data set, the detection rate (DR) of our method is increased from 96% to 97.5%, and the mean average best overlap (MABO) is increased from 65% to 69.3% for 2000 proposals. Moreover, our method would achieve over 99% DR when using 4000 proposals. By this way, we preserve the speed advantage of BING while reaching more accurate detection results, so that we could be able to provide higher quality windows for various detection tasks.
Overview of BING
BING method, an acceleration framework of generic objectness measure, has made significant breakthroughs on calculation efficiency (300 fps on VOC 2007) compared with the current state of the art. The outputs of BING is a small set of proposals covering most of objects rather than their precise locations. Based on the fact that objects are stand-alone things with well-defined closed boundaries and centers 27,28 (different from amorphous background stuff like grass, sky), Cheng et al. 14 observed that when resizing their corresponding windows to a small fixed size, their norm of gradients becomes a discriminative feature (named NG feature), regardless of objects with different shapes and colors. It is because that little variation of closed boundaries could be presented in such an abstract view. 14 In order to realize the acceleration of proposals generation, BING firstly defines 36 different sizes for windows quantification and employs simple norm of gradients to train a two-stage cascaded model with linear SVM. The advantage of gradient maps is that they preserve boundaries information completely with efficient data representation. In the test stage, each window is scored with a linear model w ∈ R64. Window scoring formula is represented as

where sl and gl are the filter score and NG feature, respectively. In order to avoid heavy computing when scoring windows, BING realizes speeding up by translating equation (1) into fast bitwise and POPCNT SSE operators.
Such a two-stage cascaded model provides a framework for fast proposals generation. However, we observe that the behavior of BING is not satisfactory in some cases. An apparent drawback of BING is that boundaries are not always closed for occluded or truncated objects. Actually, results of BING show that considerable undetected objects are partially or totally occluded by obstacles around them. Besides, we observe that BING is also poor at finding objects in dim lighting conditions because it’s hard to captain complete contour in such illumination conditions. Figure 1 gives several instances to testify drawbacks of BING in detecting incomplete objects and objects in poor lighting conditions. The main reason is that the success of BING depends largely on simple gradient feature while boundaries are not always closed for all kinds of object instances. It’s difficult to captain complete contour when objects are partially or totally occluded by obstacles around them. Similarly, the gradient feature of objects under dark situation usually cannot be distinguished from amorphous backgrounds stuff.

Instances of BING’s detection result (pink proposals) on VOC 2007 test images. Proposals in yellow represent objects undetected with BING. Most of them are occluded or in dark lighting.
Motivated by this work, we could be able to improve detection performance by incorporating different kinds of features and classifiers into model training. We choose adding texture feature to increase robustness of new model for hard instances because that objects with incomplete boundaries would usually have distinguished texture from their backgrounds. Considering the balance of detection quality and computation efficiency, we employ LBP to describe image local texture.
Local binary patterns
Local binary pattern, a powerful description for image local texture, was first proposed by Harwoodet al.
29
The original LBP operator works with a 3 × 3 neighborhood by thresholding each pixel with the center value to obtain eight thresholded binary values (such as 00100011), which are saved as a BYTE value (0–255) to express the LBP code of center pixel. An instance of the LBP operator is shown in Figure 2. According to Harwood et al.,
29
the LBP code for a center pixel with coordinate (x, y) can be computed by

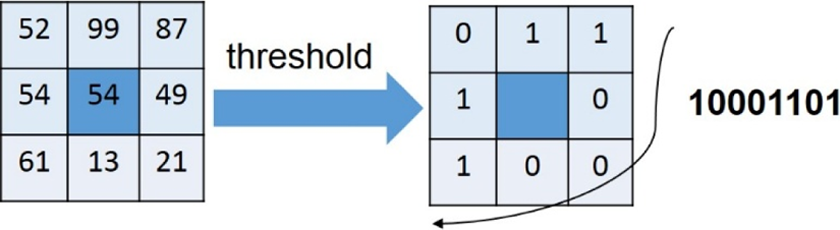
An instance of the LBP operator. The value of center pixel (x, y) is 54. LBP: local binary pattern.
where s(z) is the threshold function:
Apparently, the result is a LBP map after calculating LBP code during the whole image. In applications of LBP such as texture classification 30 and face recognition, 31 people usually use the statistical histogram of LBP code rather than LBP map as feature vectors. However, we are going to use LBP map as a 64-D feature in our proposed model because of the usage of INT64 similar to BING. Since the original LBP was introduced, several improved LBP operators are proposed, such as an extension of LBP using circular neighborhoods of different sizes, 32 rotation-invariant LBP, and uniform patterns LBP. LBP operator and its extensions have been applied in different areas because of their good rotation invariance, robustness to illumination, and calculating efficiency. People usually combine LBP with HOG as features for human recognition, 33,34 which remarkably increases detection rate.
In this article, we use a modified LBP operator, called MLBP, to compose a 64-D feature of our model in consideration of effectiveness. MLBP code of a center pixel is calculated by comparing the value of each pixel in its neighborhood with the mean value of them represented by

where
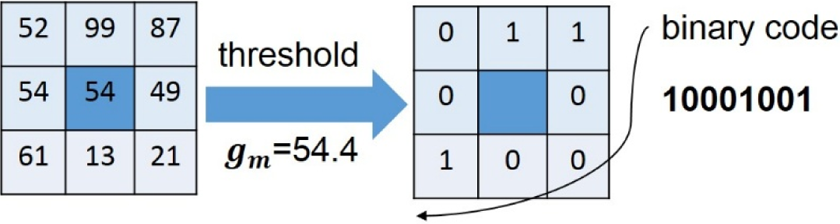
An instance of MLBP operator. The value of center pixel is 54. MLBP: modified local binary pattern.
Proposed approach
In this article, we propose an improved approach based on BING for efficient objectness estimation, which outputs an order set of windows containing object instances. A real-time object proposals generation method is very helpful in preprocessing step of object recognition, which can be widely applied in pattern recognition, artificial intelligence, and robot vision. Motivated by the observation that most undetected instances of BING method are occluded or in dim lighting, we learn a new model by combining NG feature and LBP feature, which enables to improve the robustness of model. By following clues of texture and contour, we can improve the detection rate as well as proposals quality. As shown in Figure 4, the framework of our approach consists of two analogous submodels: (1) the original model as in BING and (2) a model training with MLBP feature. Both of the two submodels are two-stage cascaded models sharing similar structure, and they are special for different types of object features. In the testing stage, each image window is scored with two learned models, respectively, and after a size-weighted step, our system would outputs a set of windows with top-ranking scores.

The framework of our method. It consists of two submodels training with NG feature and MLBP feature, respectively. The input of it is image data set and the output is a set of proposals with objectness score. MLBP: modified LBP.
Since the training process of submodel 1 (same as model of original BING) is already introduced in “Overview of BING” section, next we will flesh out the training paradigm of submodel 2. As illustrated in Figure 5, four components are needed for submodel 2, including window quantization, feature extraction, learning a linear filter w, and learning a learnt coefficient vi and a bias term ti for each quantized size i. Besides, speeding up step is also indispensable for our model.

Illustration of submodel 2 in training stage, including window quantization, feature extraction, learning a linear filter w, and learning a learnt coefficient vi and a bias term ti for each quantized size i.
Window quantization
Quantization is an important step in our method. In order to collect more positive samples with diversity and get a more robust linear model, we quantize a ground truth window to several (normally two or three) windows of base-2 sizes (For example, a 196 × 174 window will be quantized to a 256 × 128 window and a 256 × 256 window, and a 214 × 113 window will be quantized to a 256 × 64 window, a 128 × 128 window, and a 256 × 128 window.), guaranteeing no less than 50% overlap with the original ground truth. By this way, all training samples are divided into 36 kinds based on their sizes, and samples in size i will be discarded if their amount is less than 50. Two instances of window quantization are illustrated in Figure 6. If the quantized window is partly out of range of image, the outranged part will be cut to adjust to image. These quantized windows will then replace the original ground truth window becoming positive samples of linear SVM after resizing and feature extraction.

Two instances of window quantization on the PASCAL VOC 2007 training set. The ground truth windows are in red. (a) A toy car with two quantized windows (yellow and blue) and (b) a cat with three quantized windows (yellow, green, and pink).
Window quantization step not only reduces variation of sizes of samples but also largely simplifies the procedure of estimating windows in the sliding window manner over the image. Our model aims to generate a set of suggested windows in less than 36 kinds of sizes (our model generates suggested windows of
Feature extraction
In training stage, we resize all quantized windows of each size i and randomly sampled windows to a uniform 8 × 8 size and then extract MLBP feature over them to form 64-D features, which are used as inputted samples of linear SVM. MLBP is an extension of original LBP operator introduced in “Local binary patterns” section. Figure 7 shows two examples of extracting 64-D MLBP feature from quantized window.

Two examples of extracting 64-D MLBP feature from quantized window. Extracted features are used as positive samples in linear SVM. MLBP: modified LBP.
Learning a linear filter w
We train a linear filter w using linear SVM in the first learning stage. MLBP features of the ground truth object windows (after quantization) and randomly sampled background windows are used as positive and negative training samples, respectively. The learnt filter w is added to the first stage of cascaded model after normalization.
Learning vi and ti
Since some sizes are more likely to contain an object instance than others, the second stage of model is designed to obtain learnt coefficient vi and bias term ti for each quantized size i. Firstly, we estimate sliding windows (for each quantized size i) with learnt filter w and then perform non-maximum suppression to select a set of windows with high-filter scores. These selected windows are divided into positive and negative samples according to their overlap scores with the ground truth. Actually, given the selected window bounding box (rt
) and the ground truth bounding box (rg
), the overlap score
Speeding up
As we hope to generate proposals by scoring windows according to MLBP feature in a sliding window manner, we are following equation (1) to calculate filter score of a window. The convolution operation in equation (1) can be replaced with several bit operation after approximation, as much as possible reducing computation cost. Speeding up procedure includes approximation representation and INT64 data storage. The 64-D linear filter w is approximately represented as a linear combination of nw binary vectors

The approximation of extracted MLBP feature is represented by replacing each MLBP code using its top nf binary bits, which can be expressed as

where bk,i denotes the binary value of MLBP code at the i th bit. nf = 4 means replacing MLBP feature using its top four binary bits, within accepting error range while reducing following computation to 50%. Two examples of MLBP feature approximation are illustrated in Figure 8.

Two examples of MLBP feature approximation using its top four binary bits. (a) The situation of maximum error is 15-pixel difference and (b) the minimum error is 0-pixel difference.
According to above algorithms, the filter score of an image window can be efficiently evaluated using

where

Illustration of translating data access into bit shift procedure when scoring window in a sliding window manner. Variable explanation: a MLBP window
Experimental evaluation
In order to facilitate comparing our algorithm with previous approaches, we train our model and perform quantitative evaluation on PASCAL VOC 2007 26 data set. PASCAL VOC 2007 26 is a standard data set of image and annotation, in which each image is annotated with ground truth bounding boxes of objects from 20 categories (bird, aeroplane, cow, etc.). Since we want to find all objects in the image irrespective of their categories, we train our model on official training set with 6 object categories and evaluate it on testing set with other 14 unseen categories. The results of experiment show that our method reaches a higher performance than original BING.
We follow the protocol in the studies by Uijlings et al., Desai et al., and Alexe et al.
1,6,10
for evaluation. One metric is the detection rate (DR) based on the overlapping area between predicted bounding box (rt
) and the ground truth annotation (rg
). An object is considered to be found out successfully if the overlap score
Performance comparison of different extensions of LBP combined with BING.a

DR: detection rate; MABO: mean average best overlap.
aThe values within parenthesis means (DR × 100, MABO × 100).

Comparison of our proposed method (curves in red) with the original BING (curves in blue) in DR metric and MABO metric. DR and MABO of proposed method achieve higher values than those of BING when more than 2000 windows are generated. DR: detection rate; MABO: mean average best overlap.
DR and MABO results for our method compared with the original BING.a

DR: detection rate; MABO: mean average best overlap.
aThe values within parenthesis means (DR × 100, MABO × 100).
Figure 11 gives several examples to explicitly illustrate that our proposed method is better than the original BING at detecting difficult instances, especially objects with partial truncation or occlusion and objects in poor lighting conditions. BING has difficulties in finding these kinds of objects because BING relies on simple gradient feature while it is uneasy to find complete contours in occlusion situations or poor lighting conditions. Instead, our proposed method combines gradient feature and texture feature complementally to learn our model, which therefore enhances the detection rate of these hard object instances.

Examples of comparing proposal quality between BING and proposed method on VOC 2007 26 test images. The first row shows objects covered by BING’s proposals (pink boxes), and the second row shows objects covered by proposed method’s proposals (green and red boxes). Clearly, our method is better at detecting incomplete objects and objects in poor lighting conditions (red boxes).
In addition, LBP is excellent in discriminating an object from its surroundings especially when their textures are entirely different. Thus, it is easier for our method to get accurate location of an object. Figure 12 illustrates comparison results of proposals quality between BING and our method. We can produce higher quality proposals than BING, locating objects with more compact coordinates and reaching a higher average score. Different with BING, proposals generated by our method cover most objects more accurately and thus can provide more reliable input for subsequent detectors. Besides evaluation metrics mentioned above, computation efficiency is also indispensable for an outstanding detection system. Our proposed method is very efficient and takes only about 0.006 s per image using a laptop with an Intel Core i7-3940XM CPU@4.00GHZ. Figure 13 shows more instances of our method’s detection result compared with BING on VOC 2007 26 data set.

Comparison of proposals generated by BING and our proposed method. The first row shows objects covered by BING’s proposals (pink boxes), and the second row shows objects covered by proposed method’s proposals (green boxes). Proposals in the second row cover objects more compactly and more accurately.

Conclusion and future work
In this article, we have proposed an effective objectness estimation framework, which outputs an order set of windows covering almost all object instances. The framework we presented is mainly based on the observation that incorporating texture feature into model training would be helpful for detecting incomplete objects and objects in dim lighting. Our framework consists of two analogous cascaded submodels—one original model as in BING and another training with MLBP feature. Each submodel generates a set of proposals separately, and then they are combined to produce final output—a series high-ranking windows. We evaluate our proposed method on official PASCAL VOC 2007 data set, and the results of experiment indicate that we achieve more accurate detection results while preserving the speed advantage of BING in the meantime. By this way, we could be able to provide input of higher quality in the following object recognition stage.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.