
Abstract
Due to its complexity and non-deterministic polynomial-time hard characteristic, multirobot task allocation problem remains a challenging issue in the field of cooperative robotics. Thanks to its easy implementation and promising convergence speed, the particle swarm optimization method has recently aroused increasing research interest in the area of multirobot task allocation problem. However, the efficiency of the standard particle swarm optimization is hindered by several deficiencies such as the inefficient capabilities in balancing exploration and exploitation, as well as the high likelihood of plunging into stagnation. Aiming at enhancing the performance of particle swarm optimization via remedying these two drawbacks, this paper proposes an improved particle swarm optimization method, which integrates standard particle swarm optimization 2011 with evolutionary game theory. To prevent particles being locked into stagnation, particles in the proposed particle swarm optimization first adopt the updating rules of standard particle swarm optimization 2011 to undertake their movements. Subsequently, attempting to well trade off the exploration and exploitation capabilities of particles, a novel self-adaptive strategy, which is determined by the evolutionary stable strategies of evolutionary game theory and the iteration number of particle swarm optimization, is presented to adaptively adjust the main control parameters of particles in the proposed particle swarm optimization. Since the convergence of particle swarm optimization remains paramount and dramatically affects the performance of particle swarm optimization, this paper also analytically investigates the convergence of the proposed particle swarm optimization and provides a convergence-guaranteed parameter selection principle for the proposed method. Finally, leveraging the development of the proposed particle swarm optimization, this paper completes the design of a new particle swarm optimization–based multirobot task allocation method. The performance of the new particle swarm optimization–based multirobot task allocation method is tested through three different allocation cases against four well-known evolutionary methods. Experimental results confirm that the proposed method generally outperforms its contenders in terms of the solution quality. Moreover, the proposed method performs slightly better than the majority of its peers as far as the computation time is concerned.
Keywords
Introduction
Since the cooperation of multiple robots can enhance the overall performance of the multirobot system, the application of teams of multiple robots to accomplish some important unmanned tasks has become increasingly common over the past few decades. 1,2 A crucial and fundamental issue of the cooperative robotics is the task allocation problem (TAP), which aims to determine robot-to-task assignments, while optimizing a set of predefined performance criteria. 3 In virtue of its importance in the multirobot system, TAP has persistently aroused great research interest in recent years. 3,4 However, the TAP has naturally been proven to be a non-deterministic polynomial-time hard (NP-hard) problem, and the NP-hard nature of TAP results in difficulties in solving this problem. 3,4 Therefore, far more effective optimization methods are always demanded in the field of TAP.
Based on the best knowledge of the authors, the market-based allocation approaches can be one of main streams in solving TAP. The most representative market-based allocation approach could be the contract network protocol (CNP) method which was proposed by Smith in 1980. 5 Since the initial development of CNP, many researchers have committed themselves to developing some other market-based allocation methods in order to further efficiently solve TAP. A market-based allocation method for the energy-efficient execution problem has been presented by Haghighi in the study by Mo. 6 The authors in the study by Gautham et al. 7 have developed a distributed task allocation method based on auction and consensus principles for the multirobot system in healthcare facilities. A distributed market-based method where each robot bids for each task has been established in the study by Sahar et al.. 8 Thanks to their formidable reliability and scalability, the market-based allocation methods are particularly suitable to find optimal solutions for the distributed multirobot system. 4 But, in order to determine optimal robot-to-task assignments, robots in the market-based allocation approach often need to cooperate with each other through explicit communication. Once the commutation network of the multirobot system is interrupted or encounters some other potential issues, the performance of the market-based allocation approach would significantly degrade, which may constraint the implementation of the market-based method on large-scale allocation problems. 4
Probably because of their population-based nature and promising parallel search power to find satisfied solutions to some complex NP-hard problems within tractable time, many different evolutionary algorithms (EAs) such as modified differential evolution (mDE), 3 genetic algorithm (GA), 9 harmony search algorithm (HSA), 10 and hybrid ant colony optimization (HACO) 11 have been proposed for solving the TAP within the last decade. Among the currently existing EAs, due to its simplicity and fast convergence speed, particle swarm optimization (PSO) algorithm has been widely used to solve TAP in recent years. A modified binary PSO (mbPSO) task allocation method has been proposed to handle the real-time task allocation in the study by Prescilla et al.. 12 Since the cognitive and social acceleration parameters are fixed to 2 in mbPSO, this method may have difficulties in adaptively adjust the global and local search abilities of particles. The authors in the literature 13 have developed a motivated guaranteed convergence PSO (M-GCPSO) to handle TAP under communication constraints. Because different models of motivations of robots are incorporated into M-GCPSO, this method may be problem-dependent, which may restrict its implementation on some other allocation problems. An intrinsically motivated PSO (IMPSO) method, in which an intrinsic motivation for the fitness function is integrated with PSO, has been presented to solve TAP in the study by Klyne and Merrick. 14 As values of the inertia weight of particles are either fixed to 0.729 or 0 by the noisy of the fitness function in IMPSO, this method may be unable to well strengthen the exploration capabilities of particles in the early stages of the evolution.
Proverbially, the optimization efficiency of the standard PSO is restricted by its some typical drawbacks such as the inefficient ability in adjusting exploration and exploration as well as the high possibility of trapping into stagnation. 15,16 In order to enhance of performance of PSO, these two typical flaws of the standard PSO need to be remedied or overcome. For this purpose, from the initial development of the standard PSO, 17 a considerable amount of research work has been devoted to developing different PSO methods. Aiming at avoiding particles being locked into stagnation, Clerc 18 has developed a modified PSO, called standard PSO 2011 (SPSO 2011). In order to guarantee the particle can search the solution space with a non-zero velocity, an additional random point is added to the velocity of the particle in SPSO 2011. Yet, since the three control parameters of particles are fixed, SPSO 2011 may still suffer from the difficulties in trade offing exploration and exploitation. 19
Because the exploration and exploitation capabilities of PSO heavily rely on its three control parameters that are the inertia weight and the cognitive and social acceleration parameters, developing PSO through different parameter settings has been extensively studied in recent years. In an attempt to well balance exploration and exploitation, Akbari and Ziarati 20 have proposed a rank-based PSO (RBPSO), in which the γ best particles are considered to contribute to the updating of the three control parameters of particles. In order to strike a good balance between exploration and exploitation, some other terrific research work focusing on improving PSO through different parameter setting principles can be also found in literatures. 21 –23 Reviewing the excellent work done in literatures, 20 –23 despite improving the exploration and exploitation abilities of PSO through some advanced parameter setting principles, the convergence of their proposed PSO methods remains unknown or uncertain. Since the three main control parameters of particles not only influence the exploration and exploitation capabilities of PSO but also determine the convergence of PSO, and the convergence property is of great importance in the field of PSO development, the issue of guaranteeing the convergence of PSO must be addressed when improving PSO through different parameter setting principles. 24 Unfortunately, as a stochastic method, like the most of the stochastic methods, the stochastic nature of PSO imposes on difficulties in the analytical investigation of the convergence of PSO. 24
Aiming at remedying the two aforementioned shortcomings of the standard PSO to enhance the performance of PSO, this paper proposes a new enhanced PSO method, called self-adaptive evolutionary game particle swarm optimization (SAEGPSO), which integrates SPSO 2011 with evolutionary game theory (EGT). In order to drag particles in SAEGPSO out of stagnation, SAEGPSO first borrows the moving rules defined in SPSO 2011 to update the velocities and positions of particles. Then, in an attempt to adaptively adjust the exploration and exploitation powers of SAEGPSO, a novel self-adaptive strategy determined by the evolutionary stable strategies of EGT and the iteration number of SAEGPSO is presented to fine-tune the three main control parameters of particles. Moreover, since the three control parameters have profound impacts on the convergence of PSO, this paper also analytically investigates the convergence of SAEGPSO and provides a convergence-guaranteed parameter selection principle for the proposed method.
Leveraging the development of SAEGPSO, this paper completes the design of a SAEGPSO-based task allocation method for the multirobot task allocation problem (MRTAP). In order to reduce the optimization burden and add more diversification to solutions, the feasibility-based rule presented by Kalyanmoy et al. 25 is adopted to handle constraints of the MRTAP in the SAEGPSO-based allocation method. Finally, the developed SAEGPSO-based task allocation method is verified through three different task allocation cases against mDE, 3 GA, 9 SPSO 2011, 18 and improved linearly decreasing weight particle swarm optimization (ILDWPSO). 26 The simulation results indicate that the proposed method performs superior to its competitors as far as the solution quality is considered. Moreover, the computation time of the proposed method is comparable with that of SPSO 2011 and slightly better than those of the other compared methods.
The rest of this paper is organized as follows. The second section states and formulates the studied MRTAP. After simply reviewing SPSO 2011 and EGT, SAEGPSO is presented in the third section. The fourth section mainly analytically investigates the convergence of SAEGPSO. The fifth section describes the SAEGPSO-based allocation method for the MRTAP. Simulations and comparisons are conducted in the sixth section. The seventh section ends this study by drawing conclusions and showing some potential future work.
Formulation of MRTAP
This study concentrates on the multitask single-robot (MT-SR) allocation instance,
27
in which each robot can execute multiple tasks and each task only needs a single robot to execute. Given a set of
In this paper, the global objective function of the multirobot system is the summation of objective functions of each robot. Similar to the study by Shin and Zhang, 28 three objective functions that are the traveling distance, denoted as Jdi, the paid cost, denoted as Jci, and the gained benefit, denoted as Jbi, are considered for each robot i in this article. The traveling distance Jdi denotes the total traveling distance that robot i needs to move after the robot accomplishing all assigned tasks. 28 The paid cost Jci stands for the cost that robot i needs to pay when it fails to execute the assigned tasks. 28 The gained benefit Jbi represents the benefit that robot i gains after the robot executing the assigned tasks. 28
In real-world applications, when each robot can successfully execute some tasks, the multirobot system can obtain a reward. Therefore, in the studied MRTAP, the gained benefit Jbi is designed to simulate the reward that the multirobot system can obtain when the robot successfully completes the assigned tasks. On the other hand, in real-world applications, since the robot may fail to accomplish some tasks, especially in some complex or hazard environments, the multirobot system needs to pay some costs in the case where some tasks are not assigned or executed. As a result, in the studied MRTAP, the paid cost Jci is designed to simulate the cost that the multirobot system needs to pay when some tasks are not assigned or executed. Obviously, the more tasks the team of robots execute, the more gained benefit the multirobot system may gain; however, the more risks the multiple-robot system has to take to accomplish the assigned tasks, that is, the more paid cost the multirobot system may need to pay. Therefore, there exist conflicts between the paid cost Jci and the gained benefit Jbi in the MRTAP. 28
Similar to the study by Shin and Zhang, 28 this study also focuses on the numerical value of each objective function. Using a binary decision variable xij to indicate whether task j is assigned to robot i or not, the three objective functions of each robot are calculated as follows 28

where AVi denotes the tactical value of robot i. VPj denotes the violated execute probability of task j to all robots. ATj is the tactical value of the j th task. EPi is the execution probability of robot i to all tasks. dij represents the Euclidean distance between the current position of robot i and the position of task j. Here, it is important to note that since the mission of the MRTAP is to determine a conflict-free task execution sequence for each robot i in the multirobot system, the current position of robot i is determined by the positions of tasks in the task execute sequence assigned to the robot. For example, the execution sequence of robot i is given as [Task A , Task B ], namely, robot i is first assigned to execute Task A , and then execute Task B . When robot i is first allocated to complete Task A , the current position of robot i is the initial position of this robot in the working environment. Next, after robot i completing Task A , the robot is then assigned to execute Task B from the position of Task A , that is, the current position of robot i is now changed into the position of Task A . Therefore, in the given example, the total traveling distance Jdi of robot i equals to the summation of the distance between the initial position of the robot to Task A and the distance between Task A and Task B .
Clearly, Jdi and Jci need to be minimized, while Jbi must be maximized in order to guarantee the multirobot system to gain maximum benefit with minimum traveling distance and paid cost. Therefore, the MRTAP can be formulated into a combinatorial optimization problem using the model described in equation (1) as follows
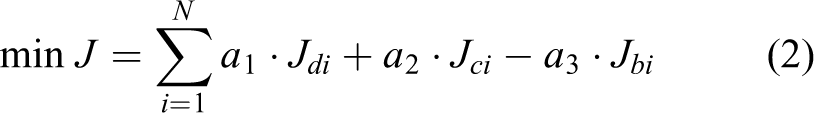

where a1, a2, and a3 are three weighting parameters indicating the relative importance of Jdi, Jci, and Jbi (
The proposed SAEGPSO method
Since SPSO 2011 and EGT are incorporated into the proposed SAEGPSO method, both these methods are first reviewed in this section. Afterwards, the proposed SAEGPSO is presented at the end of this section.
Review of SPSO 2011
Assume that the position and velocity of the i th particle at iteration t are denoted as

where c1 and c2 are two positive parameters denoting the cognitive and social acceleration parameters, respectively.
In SPSO 2011, a random point, denoted as

where ω is a real coefficient denoting the inertia weight of the particle.
Also, it was suggested in the literature 18 to fix the three control parameters of particles in SPSO 2011 as follows

As given in equation (7), because
Review of EGT
Suppose a population has a certain amount of players who are playing a game in competition with one another. The purpose of each player in the competition game is to maximum its fitness value by selecting different strategies both based on the experience of the player and those of its competitors. The basic idea of playing this kind of game is that the more fit a strategy is at the current moment, the more likely it will be employed by more players in the future. 32 In order to answer how strategies adopted by players change over time in this kind of game, modeling over different types of animal conflicts, EGT was originally proposed in the context of biology. 33 The requirement on modeling the evolution phenomena leads to the application of mathematical theory of games to interpret aspects of the evolutionary process. 34
Although EGT was originally developed in the context of the biologic science, it has increasingly aroused research interest of the other researchers from different fields such as the economists, sociologists, and the philosophers over the last few decades. Such an interpretation to the wide application of EGT on different fields may be explained by the following facts. Firstly, the notion of the evolution needs to be understood as the change of beliefs and norms over time. 34 Secondly, the modeling of the variations of strategies offers a social aspect which exactly matches the social system interactions. 34 Lastly, EGT can dynamically model the social interactions of different players within a population, which is one of missing elements of the classical game theory. 34 In EGT, the final output of a game is determined by the equilibrium point, called the evolutionary stable strategy (ESS). The principle of EGT is both based on the performances gained by a single strategy and the presence of other strategies. In addition to the ESS, the replicator dynamic equation (RDE) is another key concept in EGT, which is used to describe the adaptation of the population over time. Considering their importance in EGT, both ESS and RDE are described in the herein subsections.
Description of ESS
In EGT, a strategy can be considered as an ESS such that, when all players in a population play this strategy, no mutant strategy can invade the population under the influence of the natural selection.
32
Suppose a population has some players following the strategy p1 and a few players adopting strategy p2. Assume

where μ denotes the frequency of p2 in the population.
Description of RDE
In order to discuss the stability of EGT, it is essential to define a dynamic for the EGT
32
to describe the impacts of the variations of strategies on the population.
32
For this purpose, Taylor and Jonker
32
have developed the replicator dynamic equation to model the adaptation of strategies in a population. From the work done by Taylor and Jonker,
32
it can be found that the matrix game is a most commonly used way to depict the strategy interactions among players, which can be described using the following notations: (1) ei represents the i th pure strategy, where
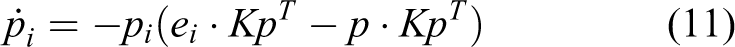
The RED defined by equation (11) is one of the most widely accepted evolutionary dynamics used to describe the evolution of the strategy frequency pi. 34 Thanks to its promising search stability and population-based nature, EGT has been widely studied in literatures. 24,34 –37 For more details about EGT, the reader is also suggested to refer to these excellent works done in literatures. 24,34 –37
Modeling of SAEGPSO
Universally, striking a good balance between the exploration and exploitation capabilities of PSO is of great importance in the design of a PSO-based optimizer in order to enhance the performance of PSO. Ideally, on one hand, the exploration ability of PSO must be strengthened in the early stages of the evolution in order to encourage particles to search through the whole search space, rather than converging toward the current population-best solution. 15,20,22,38 On the other hand, the exploitation capability of PSO needs to be promoted in the latter phases of the evolution, so that particles are more likely to be encouraged to search carefully in a local region to increase the likelihood of finding the global optimal solution. 15,20,22,38 As is known to all, such two abilities of PSO are dramatically affected by its three control parameters. The basic principles regarding how the three control parameters of PSO influence such two capabilities can be summarized as follows: (1) the exploration power of PSO benefits from a large inertia weight, while the exploitation power benefits from a small inertia weight 15,20,22,38 ; (2) comparing with the social component, a large cognitive acceleration parameter leads particles to global searches and, consequently, promotes the exploration ability of PSO 15,38,39 ; (3) comparing with the cognitive component, a large social acceleration parameter turns particles into local searches and thus facilitates the exploitation ability of PSO. 15,38,39
Based on the basic principles stated above, despite achieving the non-stagnation property in SPSO 2011, this method may still suffer from the potential difficulties in well trade offing the exploration and exploitation abilities, since the three control parameters of particles in SPSO 2011 are fixed and there does not exit any distinction between the cognitive and social acceleration parameters. This paper concentrates on improving PSO through remedying the two aforementioned shortcomings of the standard PSO and proposes an improved method, called SAEGPSO, which combines SPSO 2011 with EGT. The motivation of integrating SPSO 2011 with EGT is that since both these two approaches are population-based methods, combining them together can naturally leverage their advantages to improve the performance of the enhanced method. Motivated by this consideration, in order to avoid particles falling into stagnation, the moving rules defined by equations (6) to (8) in SPSO 2011 are applied to guide the movements of particles in SAEGPSO. In order to well trade off the exploration and exploitation powers of SAEGPSO, a newly developed self-adaptive strategy determined by the evolutionary stable strategies of EGT and the iteration number of SAEGSPO is proposed to fine-tune the three control parameters of particles in SAEGPSO.
Prior to presenting how to combine the EGT principle with the iteration number of SAEGPSO in the developed self-adaptive strategy, there is necessity to recall some important notations such as “player”, “strategy,” and “payoff matrix” of EGT, since these notations will be analogized in the newly developed self-adaptive strategy presented in SAEGPSO. Players in EGT denote candidate solutions to an optimization problem, which push the evolution process of EGT. Strategies in EGT denote the candidate principles that each player can select to maximize its playoff, that is, the fitness value. The payoff matrix is a matrix which is constructed by the payoffs, that is, the fitness values of all players in the population. After recalling these notations in EGT, before the introduction of the proposed self-adaptive strategy, we first present the analogy between SAEGPSO and EGT as follows: (1) each player in EGT analogizes each particle in SAEGPSO; (2) each particle in SAEGPSO has three candidate strategies, which are moving only based on its inertia weight, moving only based on its personal best solution, and moving only based on the global best solution of the swarm, respectively; (3) the average of performance gained by the particle in SAEGPSO playing a specific strategy among the three candidate strategies consists of the payoff matrix of EGT.
Let e1, e2, and e3, respectively, denote that the particle follows the strategy only based on its inertia weight, the strategy only based on its personal best solution, and the strategy only based on global best solution of the swarm. Then, the payoff matrix used in this article is defined as follows

where
At each iteration t, the ESS of EGT is used to weight the mean of the fitness obtained by each particle, which denotes the ratio of each strategy when the swarm of SAEGPSO reaches a stable equilibrium point. At each iteration t, the ESS applied in this study is given as follows

subject to (s.t.)

The value of

where t ∈ ℕ denotes the iteration number of SAEGPSO.
Once the payoff
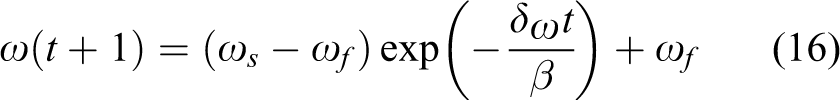


where




where the subscripts “s” and “f” in ω, c1, and c2 denote their initial and final values, respectively. tmax represents the maximum iteration number. Δ is a sufficiently small positive parameter and empirically set to be
The implementation of the three ratios
Parametric analysis for SAEGPSO
In order to intuitively interpret the rationalities of the developed self-adaptive strategy in SAEGPSO, this subsection conducts a parametric analysis for SAEGPSO. It is clear from equations (16) to (18) that the inertia weight ω and the cognitive acceleration parameter c1 decrease, while the social acceleration parameter c2 increases as the iteration number t increases. Thus, based on the basic principles noted above, the exploration ability of SAEGPSO is more likely to be maintained in the early phases of the evolutionary process, which would be reduced over time, so that the exploitation capability may take over the exploration ability quickly in the latter states of the evolution. It is noticeable that, adopting the updating rule of a constant β, trade-offs between these two abilities only vary with respect to the iteration number t.
In addition to the iteration number t, the balance of the search behavior in SAEGPSO is also adapted based on the parameter β. From equations (16)
to (18), one can easily observe that ω and c1 decrease, while the variation in c2 becomes larger as β increases. According to the basic principles stated above, this implies that the exploration tendency of SAEGPSO will be more preserved for a large β. From equation (22), a large β indicates a relatively large value of (
To summarize, through implementing the self-adaptive strategy defined by equations (16) to (22), the three main control parameters of particles in SAEGPSO are adaptively adjusted, complying with the basic principles of PSO development. Thus, particles may be promoted to search for high-quality solutions and the performance of SAEGPSO can be enhanced. The variation trends of these three parameters of particles in SAEGPSO under different values of β are illustrated in Figure 1.

Parameter changes with respect to different β in SAEGPSO. (a) Changes of inertia weight ω under different β. (b) Changes of cognitive acceleration parameter c1 under different β. (c) Changes of social acceleration parameter c2 under different β. SAEGPSO: self-adaptive evolutionary game particle swarm optimization.
Theoretical investigations of SAEGPSO
As stated in the third section, in order to enhance the performance of PSO via remedying the two typical flaws of the standard PSO, this paper proposes an enhanced PSO, called SAEGPSO. Aiming at dragging particles in SAEGPSO out of stagnation, the updating rules of SPSO 2011 defined by equations (7) and (8) are borrowed by SAEGPSO to update the velocities and positions of particles. On the other hand, focusing on well balancing the exploration and exploitation capabilities of SAEGPSO, a newly developed self-adaptive strategy determined by EGT and the iteration number of SAEGPSO is presented to tune the three control parameters of particles in SAEGPSO. Since one main modification of SAEGPSO lies on proposing a parameter setting principle to update the three control parameters of particles and the three control parameters influence the convergence of PSO, there is necessity to analytically investigate the convergence of SAEGPSO with respect to different values of the three control parameters. Therefore, we carry out a theoretical investigation, including the convergence analysis, the equilibrium point, and the convergence-guaranteed parameter selection principle, pertaining to SAEGPSO in following contents of this section.
Convergence analysis for SAEGPSO
The convergence analysis of PSO is used to determine the boundaries of the three control parameters which guarantee the convergence of PSO. In this subsection, we focus on investigating the convergence of SAEGPSO based on the deterministic model convergence analysis,
30
that is, in the case where

where

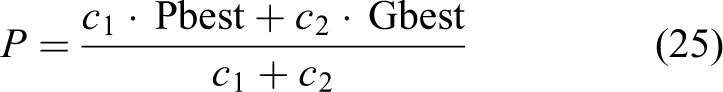
The characteristic equation of system (23) is easily obtained as follows

Assume two roots to equation (26) are denoted as η1 and η2. Then, it is easily obtained that
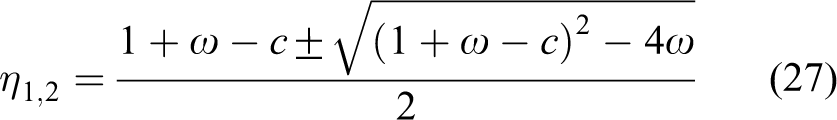
Based on the dynamic system theory, the system (23) converges iff the magnitudes of the two characteristic roots are less than 1 (“iff” means “if and only if” in this paper). 40 In another word, system (23) converges, iff

From equation (27), since η1 and η2 may be two real or complex roots, both these two cases are discussed separately so as to easily study the convergence of system (23). Case 1. η1 and η2 are two complex roots, presented as
Lemma 1
For system (23),

Proof
It is trivial from equation (26) that

The proof of lemma 1 is completed by solving equation (30) with classical mathematical method.
Then, we need to find the conditions on ω and c which guarantee the convergence of system (23) in the case where
Lemma 2
For

Proof
Notice that the magnitude of any imaginary number H can be calculated as
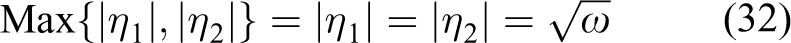
Therefore
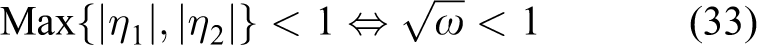
In the case where

This completes the proof of lemma 2.
Figure 2 displays the three-dimensional convergence domain of SAEGPSO and the corresponding projections of the convergence domain on different parameter planes in the case where

The convergence domain of SAEGPSO for
Case 2. η1 and η2 are two real roots, denoted as
Lemma 3
For equation (23),
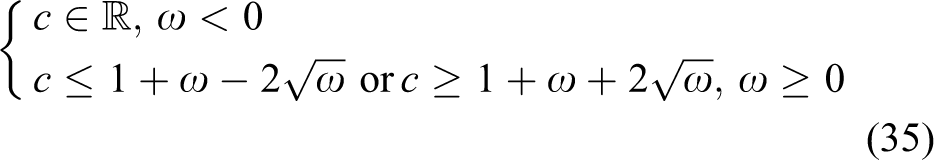
Proof
It is clear from equation (26) that

Solving equation (36) using classical mathematical method, the proof of lemma 3 is completed.
Then, let us discover conditions on ω and c which can guarantee the convergence of system (23) under the situation where
Lemma 4
System (23) converges in the case where

Proof
It is trivial from equations (27) and (28) that

Namely, iff
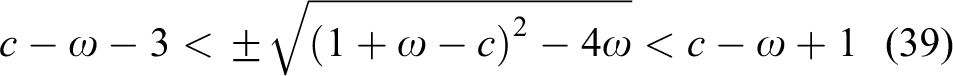
As

Simplifying the right-hand inequalities in equation (40) using classical mathematical method, generates
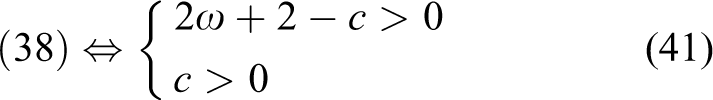
Based on lemma 3, equation (35) must hold when

For

The convergence domain of SAEGPSO in the case where
Then, let us combine the conclusions drawn in lemma 3 and lemma 4 together, we can conclude that the system (23), that is, SAEGPSO, converges, iff

Figure 4 shows the three-dimensional convergence domain of SAEGPSO and the corresponding projections of the convergence domain on different parameter planes. The convergence of SAEGPSO can be guaranteed as long as any parameter choice of ω and c locates within the triangle region shown in Figure 4(b).

The convergence domain of SAEGPSO. (a) 3-D presentation of the convergence domain. (b) Projection of convergence domain on plane (ω, c). (c) Projection of convergence domain on plane (ω, Max
The equilibrium point of SAEGPSO
The equilibrium point of PSO is a stable point that particles converge toward at the end of the evolution. After studying the convergence of SAEGPSO in ‘Convergence analysis for SAEGPSO’ section, we still need to find the equilibrium point of this method. Calculating limits on both sides of equation (23) yields
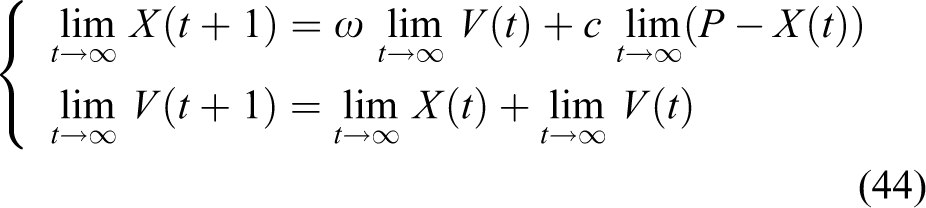
Obviously,

where c1 and c2, respectively, denote the cognitive and social acceleration parameters of the particle.
Convergence-guaranteed parameter selection principle for SAEGPSO
In ‘Convergence analysis for SAEGPSO’ section, it has been proven that SAEGPSO converges iff the condition given by equation (43) is satisfied. Here, the remaining task is to answer how to set the initial and final values of the three control parameters of particles in the newly developed self-adaptive strategy to satisfy the condition given by equation (43), so that the convergence of SAEGPSO can be sufficiently guaranteed. Thus, this subsection provides a convergence-guaranteed parameter selection principle for SAEGPSO.
Lemma 5
SAEGPSO converges, only if the initial and final values of the three control parameters meet the following conditions

Proof
Substituting

If
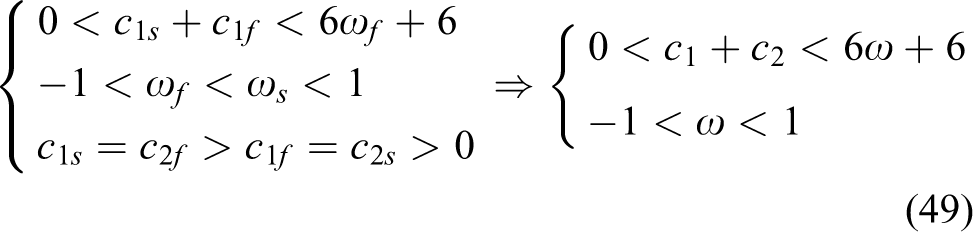
Because the right-hand side of equation (49) is the necessary and sufficient condition for the convergence of SAEGPSO, the proof of lemma 5 is completed based on the relationship given by equation (49).
It is important to note that values of ωs, ωf,

Convergent trajectory of the particle in SAEGPSO. (a) Convergent position trajectory. (b) Convergent velocity trajectory. SAEGPSO: self-adaptive evolutionary game particle swarm optimization.
The SAEGPSO-based allocation method for the MRTAP
When using the proposed SAEGPSO method to develop a SAEGPSO-based allocation method for the MRTAP, two issues need to be first addressed. The first one is to how to encode particles, that is, how to build a mapping between positions of particles and solutions to the MRTAP. The second issue is to answer how to handle constraints of the MRTAP in the SAEGPSO-based allocation method. The main mission of this section is to answer these two questions.
Encoding particles
As stated in the second section, the purpose of the studied MRTAP is to find a task execution sequence for each robot. To achieve this goal, as illustrated in Figure 6, the position of the particle in SAEGPSO is encoded as a

Representation of the particle in SAEGPSO. SAEGPSO: self-adaptive evolutionary game particle swarm optimization.
To concretely explain how to encode and decode particles based on the way described above, an illustrative MRTAP example in which three robots are assigned to execute seven tasks is given here. Assume the position vector of a particle is randomly given as [3.5211, 1.312, 2.23416, 1.45016, 1.01001, 2.36143, 3.25]. According to the way of decoding particles depicted above, the task execution sequences for robots 1, 2, and 3 are:
Handling constraints of the MRTAP
Because the MRTAP studied in this paper is a constrained optimization problem (COP), the task regarding how to handle constraints of the problem must be addressed in order to efficiently solve this problem. Among the currently existing constraint handling techniques, the penalty function approach 41 could be one of the most popular approaches. The penalty method can transform a COP into an unstrained optimization problem through introducing several penalty terms to the objective function of the COP. However, properly setting the penalty factors of the penalty function method is difficult and problem-dependent, which is the main drawback of this method. 42
In our SAEGPSO-based task allocation method, we adopt the feasibility-based rule 25 to tackle constraints of the MRTAP in order to release the burden of the optimizer, as well as increase diversification of solutions. As explained in ‘Encoding particles’ section, the constraints given by equations (3) and (5) of the MRTAP are trivially met using the way presented in this paper to encode particles. Therefore, only the constraint given by equation (4) of the MRTAP needs to be tackled. In order to handle the constraint given by equation (4), the constraint violation degree of each particle is first calculated as follows

where N is the total number of robots.
After calculating constraint violation degrees of particles based on equation (50), the feasibility-based rule presented by Kalyanmoy et al. 25 is then used to choose the dominated solution between any two candidate solutions in the SAEGPSO-based allocation method. For a minimization optimization problem, the feasibility-based rule is depicted as follows: (1) for any two candidate solutions having the same constraint violation degree, the solution with smaller fitness value dominates the solution with larger fitness value; (2) for any two candidate solutions having different constraint violation degrees, the solution with smaller constraint violation degree is preferred over the solution with larger constraint violation degree.
Because the objective function and the constraint violation degree of each particle are considered and compared separately in the feasibility-based rule, no additional penalty factor is required when implementing this rule to handle constraints. Therefore, this rule can reduce the burden of the optimizer. 25 In addition, although the non-feasible solutions violate some constraints, they may also contain some useful information for finding high-quality solutions. 42 Consequently, when these non-feasible solutions are considered in the feasibility-based rule, the diversification of solutions and the likelihood of finding better solutions may be increased.
In the proposed SAEGPSO-based task allocation method, in order to assure each task can assign a robot,
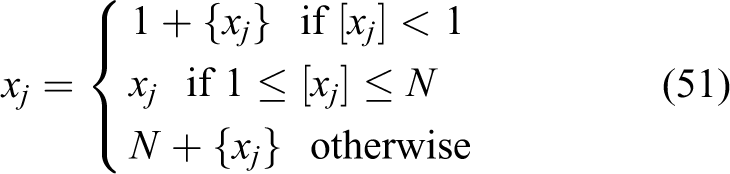
where
Application of SAEGPSO-based allocation method on the MRTAP
The pseudocode of SAEGPSO for solving the MRTAP is shown in Table 1, where
The SAEGPSO-based framework for MRTAP.

It is noticeable from Table 1 that, similar to ωs, ωf,
Simulations, comparisons, and analysis
In this subsection, SAEGPSO is evaluated through three different-sized task allocation cases against mDE,
3
GA,
9
SPSO 2011,
18
and ILDWPSO.
26
For each allocation case, after each method conducting a Monte Carlo experiment with 30 runs, this study reports and compares the statistical results with respect to the solution optimality and computation time of each method. In every single run of the Monte Carlo test, the best solution of each method is output after 40 particles evolve 2000 iterations. The simulation parameters for SAEGPSO are set as follows:
The simulation parameters for different compared methods.

Case study 1
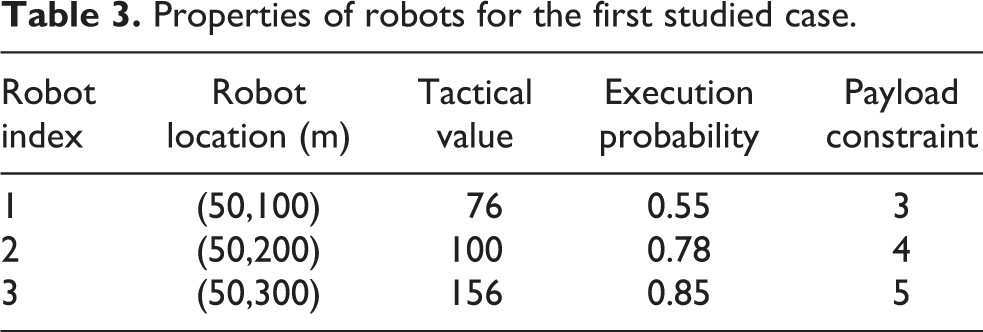
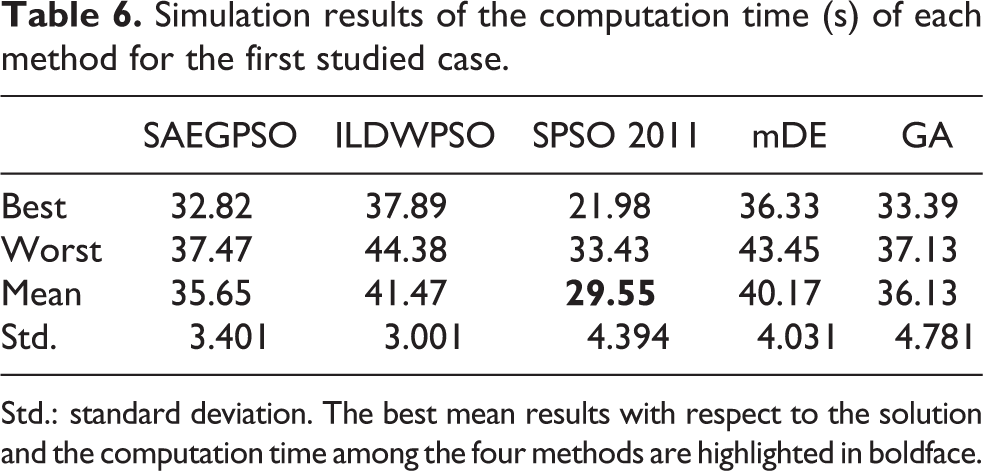
This subsection shows the simulation results of all methods in solving the first allocation instance which assigns three robots to 12 tasks. The properties of robots and tasks are given and shown in Tables 3 and 4, respectively. After conducting the Monte Carlo experiment, Tables 5 and 6 report the statistical results of the solution and the computation time of each method, respectively. In these two tables, the best mean results with respect to the solution and computation time are highlighted in boldface. For concretely showing the allocation results and better understanding the evolutionary processes of different methods, the allocation schemes and fitness curves of the best solutions obtained by different methods in the Monte Carlo test are exhibited in Table 7 and Figure 7, respectively. The robots’ trajectories of the best solutions of SAEGPSO and GA are illustrated in Figure 8, respectively. Note that because positions of robots and tasks are given in Tables 3 and 4, and the allocation schemes of the best solutions of all methods are shown in Table 7, the robots’ trajectories of the best solutions of the other methods (except SAEGPSO and GA) are not displayed in order not to enlarge the size of the paper.
Properties of robots for the first studied case.
Properties of tasks for the first studied case.

vio-execution probability: violated execution probability of the task to robots.
Simulation results of the allocated solutions obtained by each method for the first studied case.

Std.: standard deviation. The best mean results with respect to the solution and the computation time among the four methods are highlighted in boldface.
Simulation results of the computation time (s) of each method for the first studied case.
Std.: standard deviation. The best mean results with respect to the solution and the computation time among the four methods are highlighted in boldface.
Allocation schemes of the best solutions searched by different methods for the first studied case.a

aHere, Ri and Tj denote the i th robot and j th task, and “

The fitness curves of the best runs of different methods for the first studied case.
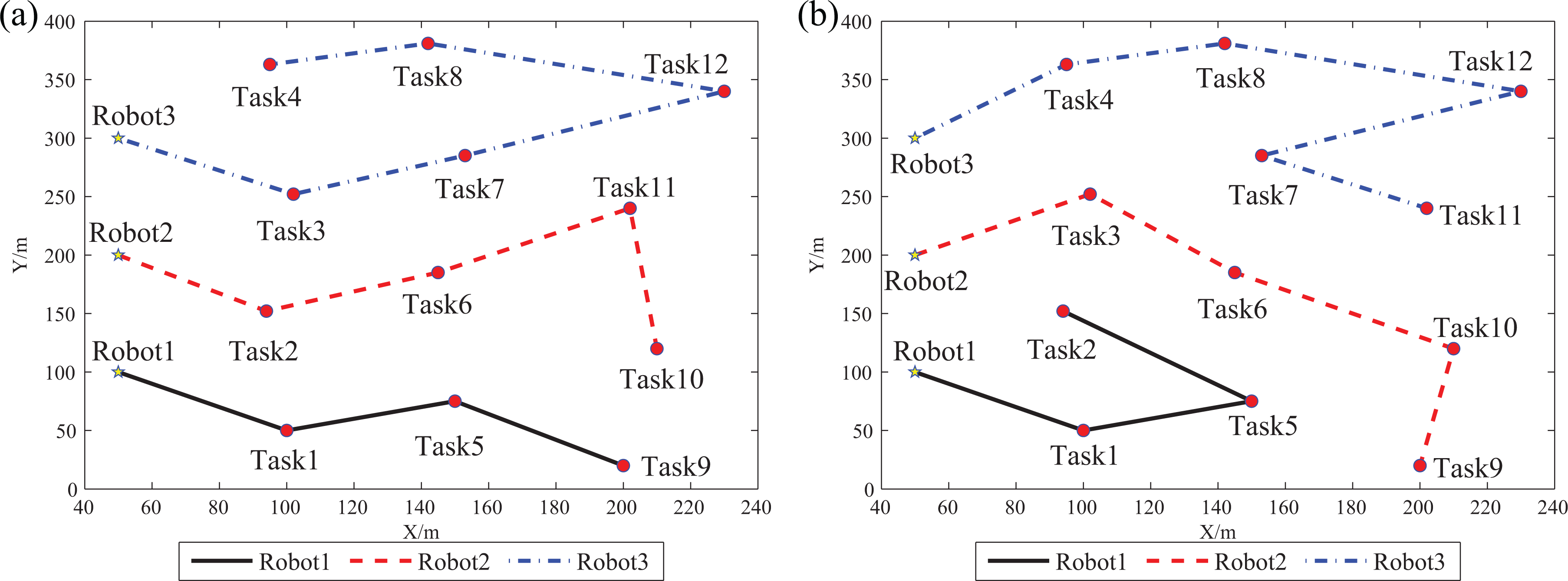
Robots’ trajectories of the best solutions searched by SAEGPSO and GA for the first studied case. (a) Robots’ trajectories of the best solution searched by SAEGPSO. (b) Robots’ trajectories of the best solution searched by GA. SAEGPSO: self-adaptive evolutionary game particle swarm optimization; GA: genetic algorithm.
From Table 5, the proposed SAEGPSO method is followed by ILDWPSO, mDE, GA, and SPSO 2011 in terms of the average solution optimality, which implies that SAEGPSO generally outperforms its contenders in terms of the solution optimality in solving the first test case. From Table 5, comparing with ILDWPSO, mDE, GA, and SPSO 2011, SAEGPSO averagely improves the solution optimality by 21.98%, 37.37%, 48.17%, and 59.63%, respectively. From Table 6, one can easily observe that SPSO 2011 is the most efficient method, while SAEGPSO method is ranked second in terms of the average computation time. Such observation is reasonable because the three control parameters of SPSO 2011 remain constant, no additional computation resource is needed to update these control parameters of SPSO 2011. Hence, in comparison with SAEGPSO, the computation time of SPSO 2011 is naturally reduced. However, it is important to note from Tables 5 and 6 that although SPSO 2011 is the most efficient method in the computation time, it obtains the worst performance in terms of the solution quality, and even if SAEGPSO is the second most efficient method as far as the computation time is concerned, it has the best performance in terms of solution quality. Since the studied MRTAP is completed off-line, the computation time may weigh less than the solution optimality in evaluating a task allocation optimizer. Thus, considering all of the concerns raised, it allows us to conclude that, comparing with the other four methods, SAEGPSO is highly competitive in solving the first test case. Moreover, from Table 7, it can be easily observed that the best solutions obtained by all methods are feasible since all the best solutions satisfy the constraints of the first studied allocation case, which, to some extent, can reveal the feasibility of these methods in solving the small-scale MRTAP.
Case study 2
The second task allocation instance is a medium-scale TAP, in which five robots are assigned to complete 22 tasks. The properties of robots and tasks are given and shown in Tables 8 and 9, respectively. The statistical results with respect to the solution and computation time of different methods for this allocation case are summarized in Tables 10 and 11, respectively. With the same reasons explained in ‘Case study 1’ section, the allocation schemes and fitness curves of the best solutions searched by all considered methods are displayed in Table 12 and Figure 9, respectively.
Properties of robots for the second studied case.

Properties of tasks for the second studied case.

vio-execution probability: violated execution probability of the task to robots.
Simulation results of the allocated solutions obtained by each method for the second studied case.

The best mean results with respect to the solution and the computation time among the four methods are highlighted in boldface.
Simulation results of the computation time (seconds) of each method for the second studied case.
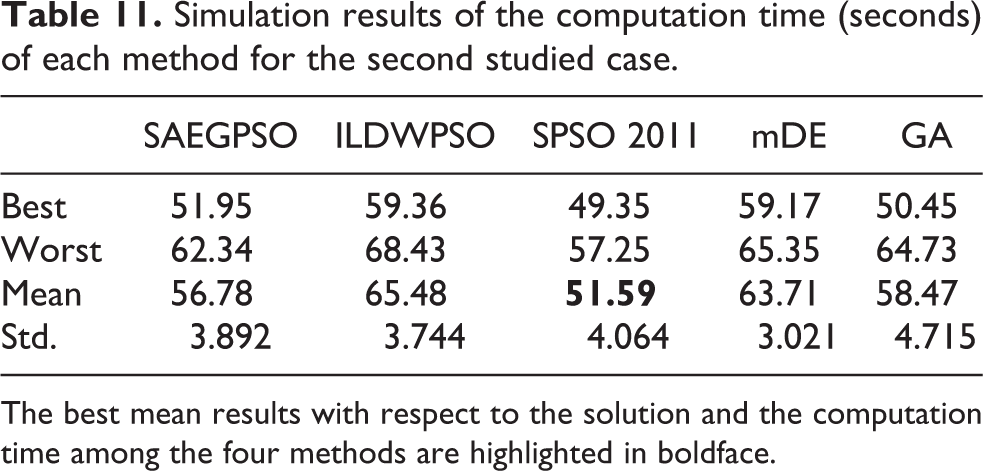
The best mean results with respect to the solution and the computation time among the four methods are highlighted in boldface.
Allocation schemes of the best solutions searched by different methods for the second studied case.

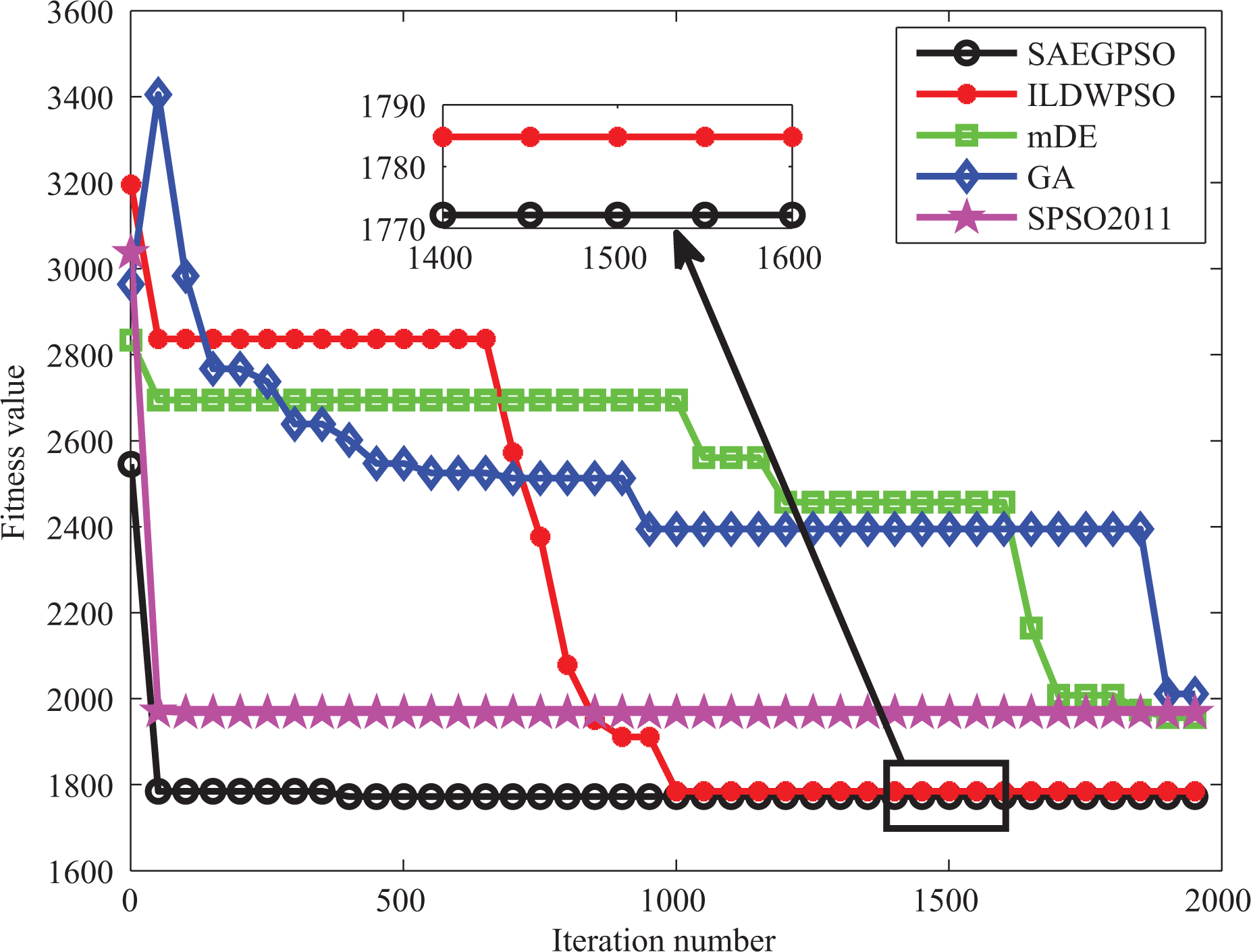
The fitness curves of the best runs of different methods for the second studied case.
From Table 10, it is clear that SAEGPSO and ILDWPSO are the most and second most efficient approaches, while SPSO 2011 obtains the worst performance in terms of the solution quality for the second simulation scenario. Based on the results shown in Table 10, comparing with ILDWPSO, mDE, GA, and SPSO 2011, SAEGPSO generally enhances the solution optimality by 6.07%, 9.28%, 11.83%, and 13.65%, respectively. From Table 11, SPSO 2011 and SAEGPSO are ranked the first and second in terms of the computation time, respectively. It is notable from Tables 10 and 11 that, despite having the best performance in the computation time, SPSO 2011 is the least efficient method in the solution optimality, and even if SAEGPSO is ranked second in terms of the computation time, it is the most efficient approach among the five methods in terms of the solution quality. Hence, we can still conclude that SAEGPSO is highly competitive in solving the second allocation instance. Moreover, it can easily seen from Table 12 that the best solutions found by the five methods are feasible because these best solutions can satisfy all the constraints of the second allocation case, which, to a certain degree, indicates the feasibility of these methods in the medium-scale MRTAP.
From Figure 9, it is interesting to observe that the best fitness curves of some methods such as GA first rise in the early of the evolution and then drop or remain stable in the later stages of the evolution. This observation is due to that we use the feasibility-based rule 25 to choose the dominated solution between any two candidate solutions in the SAEGPSO-based task allocation method. Because the initial population of each method is randomly produced for any simulation scenario, it may happen that all the initial individuals of a method violate some constraints of this scenario, which means that all individuals of the method are initially non-feasible. In this case, the initial global best solution of the method is thus also non-feasible. As the evolutionary process of the method carrying on, if any particle of the method can find a solution having a smaller constraint violation degree but a larger fitness value than the initial non-feasible global best solution, the newly produced solution will then replace the initial non-feasible global best solution according to the feasibility-based rule. Therefore, in such a case, the fitness curves of the method first rise in the early stages of the evolutionary process. However, this phenomenon will vanish in the later stages of the evolutionary process, namely the fitness curves of the method either keep dropping or stable in the latter stages of the evolutionary process. This is because, with the evolution of the method continuing, some individuals of the method can find some feasible solutions in the latter stages of the evolution. In this case, after these newly found feasible solutions replace the historically non-feasible global best solution of the method, the current global best solution of the method becomes feasible, which can be only replaced by the feasible solutions that have less fitness values than the current feasible global best solution based on the feasibility-based rule. Therefore, as shown in Figure 9, the fitness curves of the five methods keep dropping or stable in the latter phases of the evolution.
Note that, since the first test case studied in ‘Case study 1’ section is a small-scale TAP, in which only 12 tasks are involved, it has a high chance that each method can obtain a feasible initial global best solution after randomly initializing the swarm of each method. Because all the initial global best solutions of all methods are feasible in the first test case studied in ‘Case study 1’ section, all the initial global best solutions of these methods can be only replaced by newly produced feasible solutions with smaller fitness values according to the feasibility-based rule. Therefore, as shown in Figure 7, the best fitness curves of the five methods first keep going down in the early stages of the evolution and then remain unchanged in the latter stages of the evolution.
Case study 3
The third test case is a relatively large-sized allocation instance, in which six robots are assigned to 40 tasks. The properties of robots and tasks are shown in Tables 13 and 14, respectively. Tables 15 and 16 show the statistical results of the allocation solution and the computation time of different methods for this studied case, respectively. The allocation results and fitness curves of the best runs of different methods in the Monte Carlo experiments conducted for this scenario are illustrated in Table 17 and Figure 10, respectively.
Properties of robots for the third studied case.

Properties of tasks for the third studied case.
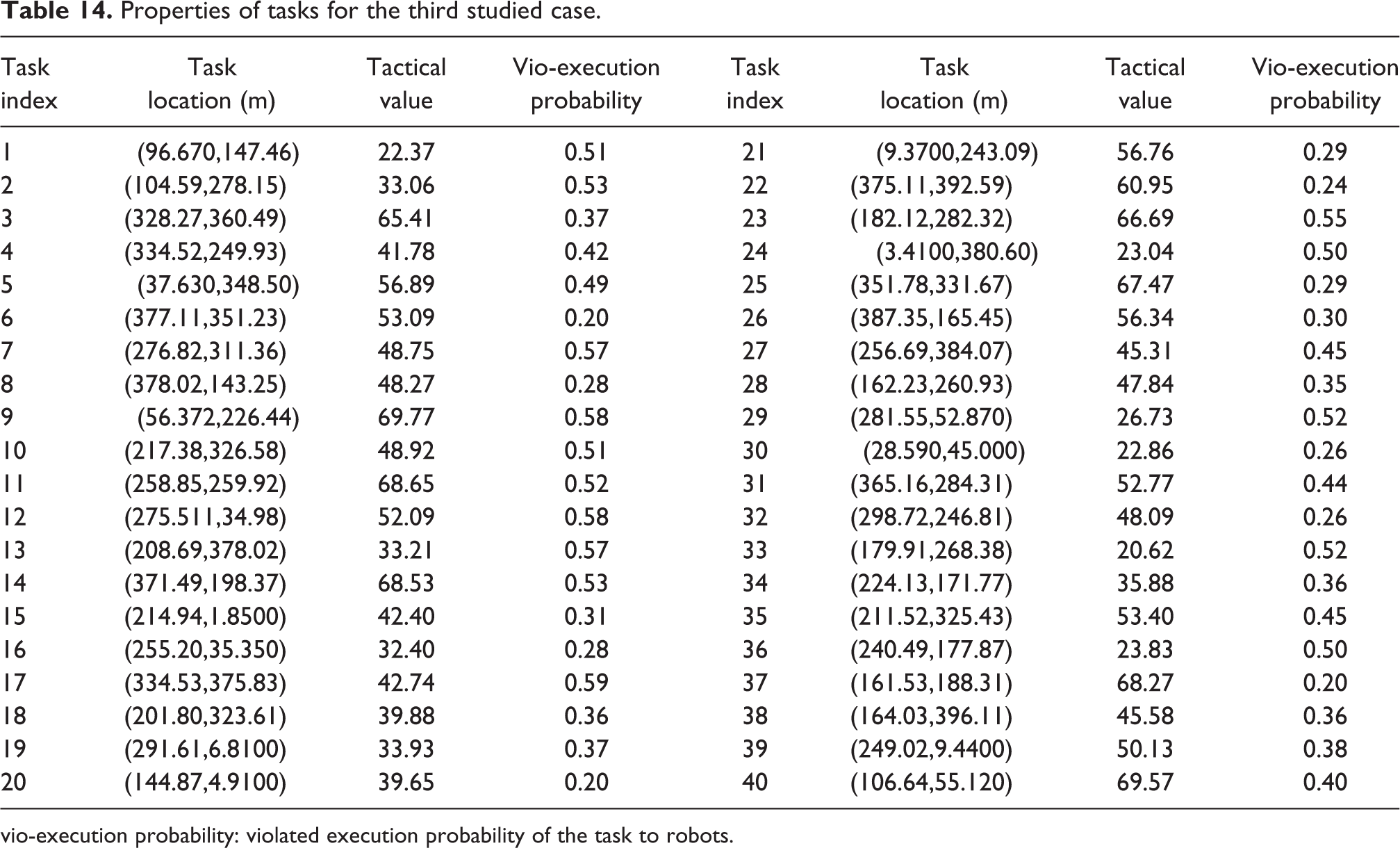
vio-execution probability: violated execution probability of the task to robots.
Simulation results of the allocated solutions obtained by each method for the third studied case.

The best mean results with respect to the solution and the computation time among the four methods are highlighted in boldface.
Simulation results of the computation time (s) of each method for the third studied case.
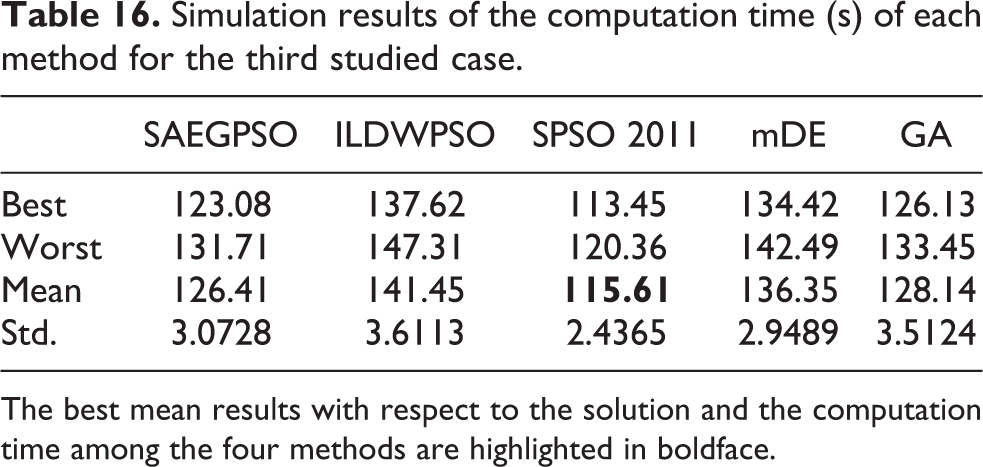
The best mean results with respect to the solution and the computation time among the four methods are highlighted in boldface.
Allocation schemes of the best solutions searched by different methods for the third studied case.


The fitness curves of the best runs of different methods for the third studied case.
From Tables 15 and 16, it is apparent that the proposed SAEGPSO is followed by ILDWPSO, mDE, GA, and SPSO 2011 in terms of the average solution quality, and SPSO 2011 is followed by SAEGPSO, GA, mDE, and ILDWPSO in the average computation time. Both considering the statistical results of the solution quality and the computation time shown in Tables 15 and 16, we can conclude that SAEGPSO is highly powerful in solving the large-size MRTAP. From Table 17, it can easily noted that the best solutions obtained by all methods are feasible since all the best solutions trivially meet the constraints of the third task allocation case, which, more or less, can reflect the feasibility of each considered method in solving the large-scale MRTAP. With the same reasons depicted in ‘Case study 2’ section, as shown in Figure 10, the best fitness curves of mDE and SPSO 2011 first rise in the early stages of the evolution and then keep going down in the latter stages of the evolution.
Conclusion and future work
Focusing on enhancing the performance of PSO via overcoming two typical drawbacks of the standard PSO, this study proposes a novel enhanced SAEGPSO. To this end, we first let particles update their movements based on the moving rules defined in SPSO 2011 to avoid stagnation in SAEGPSO. Afterwards, a self-adaptive strategy determined by the evolutionary stable strategies of EGT and the iteration number of SAEGPSO is proposed for fine-tuning the control parameters of particles in order to well trade off the exploration and exploitation capabilities of SAEGPSO. To properly set the self-adaptive strategy, this paper also theoretically investigates the convergence of SAEGPSO with respect to values of the three control parameters and provides a convergence-guaranteed parameter selection principle for SAEGPSO.
Leveraging the development of SAEGPSO, this paper also develops a SAEGPSO-based allocation method for solving the MRTAP. In order to efficiently solve the MRTAP and reduce the optimization difficulties, the feasibility-based rule is adopted in the developed SAEGPSO-based allocation method to handle constraints of the MRTAP. In addition, the performance of the proposed method is verified through three different-scaled task allocation cases against four well-established evolutionary methods. The simulation results confirm that SAEGPSO outperforms its contenders in terms of the solution quality. Moreover, SAEGPSO is also highly powerful in terms of the computation time. Therefore, it allows us to conclude that SAEGPSO is highly promising in solving the MRTAP and can be considered as vital alternative in the field of MRTAP.
There are a few potential issues that deserve some future study. Firstly, the performance of SAEGPSO can be further enhanced through improving the EGT. Secondly, since the three control parameters not only affect the convergence of PSO, but also affect the convergence speed of PSO, we will study the convergence speed of SAEGPSO with respect to different control parameter settings in the future. Moreover, despite investigating the convergence to an equilibrium point of SAEGPSO, the local or global optimality of the equilibrium point has not been investigated in this study, which will be addressed in the near future. Thirdly, in order to further evaluate SAEGPSO in the MRTAP, we are also considering the possibility of comparing SAEGPSO with some other non-evolutionary methods such as the auction-based methods in the near future. Last but not least, we are considering to use the proposed PSO method to solve some other COP such as environmental/economic dispatch problem 43 and TAP 44 in the near future.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflict of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.