
Abstract
Robust extraction of consensus sets from noisy data is a fundamental problem in robot vision. Existing multimodel estimation algorithms have shown success on large consensus sets estimations. One remaining challenge is to extract small consensus sets in cluttered multimodel data set. In this article, we present an effective multimodel extraction method to solve this challenge. Our technique is based on smallest consensus set random sampling, which we prove can guarantee to extract all consensus sets larger than the smallest set from input data. We then develop an efficient model competition scheme that iteratively removes redundant and incorrect model samplings. Extensive experiments on both synthetic data and real data with high percentage of outliers and multimodel intersections demonstrate the superiority of our method.
Introduction
Robust extraction of consensus sets (CSs) from noisy data is a fundamental problem in computer vision. Applications are numerous, ranging from data parameterizations, to feature extraction and 3-D reconstruction, and to frame-to-frame motion segmentation. 1 –6 The problem is inherently challenging as multiple heterogenous models can coexist in the data. An ideal estimator should be able to robustly handle multiple challenges from both model and noise perspectives.
Figure 1 shows several typical data sets where reliable model extraction can be difficult: the number of models is generally unknown (Figure 1(a)), model size can exhibit large variations (Figure 1(b), large and small triangles CS), the data can contain a high percentage of outliers (Figure 1(c)), and multiple models can overlap (Figure 1(d)). Furthermore, many real-world problems can exhibit multiple challenges at the same time. In this article, we focus on extracting both large- and small-sized CS from the data. Here, the size refers to the inliers ratio, that is, the ratio between the number of inliers in CS over the total number of data points. Since the probability of a random sample being an inlier of a small CS would be much lower than it being an inlier of a large CS, small CS extraction is particularly challenging.

Examples of challenges for multiple model estimation.
Tremendous efforts have been made to resolve each or combinations of these challenges. 2 –14 For example, random sample consensus (RANSAC) 3 is probably the most widely used technique that applies straightforward optimization techniques to search for the best hypothesis. Although highly successful, RANSAC assumes that data contains only a single model and hence only extracts one model. To extend the RANSAC for multimodel estimation, sequential RANSAC sequentially estimates the parameters of one of the current best model and removes the inliers from the data. The method is highly efficient but its heuristic “fit-then-remove” procedure loses random sampling, the solid theoretical basis of RANSAC, 3 and the confidence of extraction degrades severely as more models get extracted.
It is also possible to apply RANSAC to simultaneously extract multiple models. For example, multi-RANSAC 7 asks the user to specify the model number which, in reality, is generally unknown. Other approaches, such as Hough transform (HT), 2 randomized HT (RHT), 4 mean shift (MS) 5,6 attempt to estimate the model number by finding the local maximums (peaks) in parameter space. However, if the data contains a high percentage of outliers, these methods can easily fail due to the large number of peaks caused by noise.
To address this challenge, J-Linkage 10 adopts agglomerative clustering to group points that potentially belong to the same model. Specifically, it attempts to construct the sample sets such that neighboring points would be selected with a higher probability. Such a sampling scheme, however, is biased and cannot guarantee that it can find small CS from the input data. In fact, our experiments show that this clustering procedure has a high risk of assigning outliers as clustered data. More recent solutions aim to robustly estimate inliers scales 15 –20 ; however, they still cannot guarantee that both big and small CS can be accurately extracted. In essence, existing multimodel estimation algorithms are highly successful on extracting large CS, but they cannot guarantee the robustness on extracting small CS when they coexist in the data sets.
Instead of customizing solutions to separately extract small and large CS, we present a novel framework with proved reliability to simultaneously extract both types of CS. Our technique is based on smallest CS random sampling, which we prove can guarantee to extract all CS larger than the smallest set from input data. We then develop an efficiently model competition scheme that iteratively removes redundant and incorrect model samplings. Extensive experiments on both synthetic data and real data demonstrate that our approach can handle unknown model number, a high percentage of outliers, large model size variations, and multimodel intersections.
Random sampling and model competition
Our approach consists of two major steps: smallest CS random sampling and global model competition.
Step one: Smallest CS random sampling
The objective of the sampling step is to guarantee all valid models will be successfully sampled at least once. Here, any model with higher inliers ratio above user specified will be considered as a valid model. Many recent approaches have modified the sampling strategy, for example, by including user interactions, adding heuristics or priors, and so on. For instance, J-Linkage 10 and multi-RANSAC 7 construct the minimal sample sets in a way that neighboring points are selected with higher probability. The main issue with these sampling schemes is that they destroy the randomness of sampling and hence no longer guarantee to find models with largely scattered data points. We believe that an unbiased random selection of individuals is very important for multimodel estimation. We therefore do not apply any strategy or prior information to change, speed up or simplify the random sampling. Instead, we apply the simple random sampling on the entire data.
Although standard RANSAC also adopt random sampling, it takes the inliers ratio of the largest CS dynamically to estimate the random sampling times. As a result, it can only be used for single model estimation. In contrast, we propose the following smallest CS sampling strategy to guarantee that even the smallest model meeting our requirement would be correctly sampled at least once.
Given input data
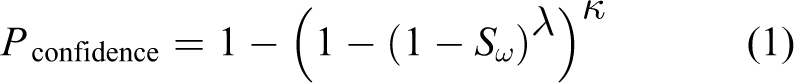
To extract the correct model with enough confidence, the value of probability Pconfidence is usually set as high value like 99%. A common scenario is that Sω is not known beforehand where some low value can be given according to different applications. Once we set a threshold Sω, we can solve for the required sampling times λ from equation (1) as

Different from the single model RANSAC, the advantage of using the above sampling times λ is that we have a probability of 99% to correctly sample every CS with higher inlier ratio than Sω at least once. In other words, the proposed technique guarantees to extract every model with a simple inliers ratio threshold Sω.
Step two: Global model competition
The result of random sampling is a set of κ model hypotheses
Recall that algorithms such as J-Linkage 10 propose to merge models with small distance. However, these techniques have a number of drawbacks: (1) Merging different models means both optimal and suboptimal sampling of the same model are combined. This increases the risk of bringing outliers into the merged cluster. (2) Model merging will only assign one data to one model, and therefore, it cannot guarantee the correctness in the case of model intersection where a data point can be associated with multiple models. (3) The merge of multiple models loses the properties of model sampling, that is, the confidence probability of the merged model cannot be calculated. Rather than merging models, we select the top competitive models through the following global model competition scheme.
Given a set of κ model hypotheses
Definition 1. Maximal model hypotheses (MMH). The inliers of this hypotheses model only contain the largest CS from one real model.
Definition 2. Redundant model hypotheses (RMH). The inliers of this hypotheses only contain a part of CS from one real model.
Definition 3. Intersected model hypotheses (IMH). The inliers of this hypotheses contain the largest CS from one real model, which shares part of inliers with other models due to intersection.
Definition 4. Noise model hypotheses (NMH). The inliers of this hypotheses only contain gross outliers.
The objective of model competition is to extract the MMH and IMH models completely and efficiently from the entire model hypotheses

where
If the inliers ratio of the selected model

Proposition 1 Equation (4) significantly reduce the inliers of RMH model while maintaining the inliers of MMH, IMH, and NMH.
Proof
If
If
If
If
Through iteratively selecting the most competitive model and updating the rest of the model hypotheses, we can reformat equations (3) and (4) as the following recursive algorithm


where
The confidence of each output model can be calculated as
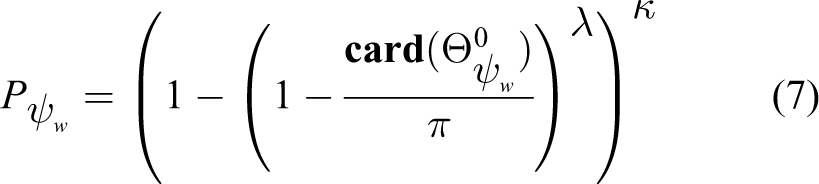
where
Our iterative model competition process is highly efficient. In our experiments, we find that over 95% of the total computation time is used for generating sufficient model hypotheses via random sampling and only 5% of the time is used for model competition. As we have mentioned in the previous section, random sampling can be easily speed up via parallel processing. Therefore, our scheme can be potentially used on applications that demand real-time performance. The complete random sampling and model competition algorithm is shown in Table 1. The parameters of the remaining models in each iteration step are recomputed after choosing the most prominent model.
The complete random sampling and model competition algorithm.

It is important to note that we do not impose any prior information about the model number. Instead, any model with higher inliers ratio above user specified Sω will be considered as an interest model, and will be extracted with a sufficient high confidence Pconfidence by our method.
Regarding other factors such as large size variations, a high percentage of outliers, and model intersection, recall that the small-scale model with a small number of liners and a high percentage of outliers may be easily lost in previous approaches. We believe an unbiased random sampling is the key to conquer these challenges. By applying simple random sampling on the entire data, our technique guarantees that every model that is larger than the smallest scale will be extracted.
Experiments
In this section, we first compare our random sampling and model competition (RSAMC) with sequential RANSAC, HT, 2 and J-Linkage, 10 and then, we test our approach in challenging real data, including point cloud 3-D plan fitting, and multiobject matching. We choose these techniques as bench as for a number of reasons: The sequential RANSAC is based on single model RANSAC, which has similar probability foundation like our approach. The HT 2 represents the kind of methods, such as RHT 4 and MS 5 in parameter space. The J-linkage 10 is one of the most popular approaches for the multiple model estimation. Notice that our technique does not aim to resolve the model finesse problem, we did not compare with approaches that address the model inliers scale estimations. 15 –19
Line fitting
The results on synthetic data with multiple models, increased outliers, and model intersection are reported in Figures 2 and 3. We observe that all four methods produce the correct results with gross outliers ratio less than 50%. However, both HT (Figures 2(b) and 3(b)) and J-Linkage (Figures 2(d) and 3(d)) fail when the outliers ratio reaches 90%. The sequential RANSAC can produce correct result with five lines (Figure 2(c)). However, when the number of lines increases to 11, the sequential RANSAC fails (Figure 3(c)) due to a high percentage of outliers.

Star 5 data set with Gaussian noise (σn = 0.0075) and increased gross outliers (gross outliers ratio = 0%, 50%, 75%, 90%).

Star 11 data set with Gaussian noise (σn = 0.0075) and increased gross outliers (gross outliers ratio = 0, 50, 75, 90%).
Figure 4 shows the results on Kite data with large model size variations. Both big and small CS are included in these data (Figure 4(a)), that is, large triangle and small triangle. All method successfully find the large CS. However, HT fails to detect the small-scale model in parameter space, and both sequential RANSAC and J-Linkage lose one small CS (Figure 4(c), Figure 4(d), top line of the small triangle). RSAMC is the only one that works correctly in all the experiments (Figures 2(e), 3(e), and 4(e) and (f)). We believe that it is because RSAMC guarantees the confidence probability to extract even the smallest CS.

Kite 6 data set with large model scale changes and multiple model intersections.
Plane fitting for 3-D reconstruction
Range data acquired by Laser sensor or multiview reconstruction usually contain fewer gross outliers but a high percentage of pseudo outliers caused by multiple scene structures. Figure 5 shows the results of fitting planes to a couple of 3-D points. 21 The “Piazza Dante” data includes 2971 points constructed from 39 camera views, and the “Pozzoveggiani” data contains 11094 points captured by 48 cameras. Our approach can extract both large walls and small structures correctly. 3-D points that belong to the same plane are visualized by the same color, as shown in the right column of Figure 5.

3-D reconstruction data set. 3-D plane CSs by our RSAMC is displayed in different colors. CSs: consensus sets; RSAMC: random sampling and model competition.
Figure 6 displays a house data set from Google SketchUp 22 of urban scenes in the first column. Two views of our plane fitting results are shown in the second and third columns. Large model size variations and multiple model intersection appear frequently in this data set. Nevertheless, our approach can robustly extract the large walls as well as small ceilings and side walls.

“Google SketchUp Data” data set with houses in urban scenes. 3-D plane CSs by our RSAMC are displayed in different views and colors. RSAMC: random sampling and model competition.
Feature matching
In Figure 7, we apply our proposed approach to obtain homography of multiple objects through scale invariant feature transform (SIFT) feature correspondences. The building images in Figure 7(a) come from the visual geometry group at Oxford, and the books images in Figure 7(b) and (c) are captured by our group using the Cannon Marker III camera. Four books are captured at different poses and positions. Our approach successfully handles both gross and pseudo outliers in the initial local feature correspondences. It further extracts all CS correctly, as shown by different color points in Figure 7(c).

Homography estimation and segmentation of multiobject by RSAMC. RSAMC: random sampling and model competition.
Some further discussions
In this section, we discuss the difference between our approach and sequential RANSAC, since it also removes inliers assigned to estimated models. A sequential RANSAC method extracts multiple models by repeating two steps: RANSAC model extraction and removal of inliers from the point set. One major disadvantage of this method is that removal of incorrect inliers, which is caused by misclassification, may seriously impact the subsequent RANSAC process. In other words, the wrong model choice in the previous step will lead to failure of subsequent model extraction. Another disadvantage of the sequential RANSAC is that it may fail when a point set contains multiple intersecting models with limited sizes. For instance, in the case of 2-D point set with multiple intersecting lines, the sequential RANSAC will extract a plane with maximal inliers, and then remove all inliers even include those intersecting inliers of other planes. As a result, other plane with limited size may not be extracted, as shown in Figure 4(c).
We believe that the essential reason of the sequential RANSAC’s disadvantages arises from its greedy “fit-then-remove” strategy, which destroy the randomness of sampling, and hence no longer guarantee to find all models. In contrast, our smallest CS method is based on unbiased random sampling on the entire point set, even the smallest model with limited size would be correctly sampled at least once by our approach. In addition, we also develop an efficient model competition scheme, which can iteratively remove the redundant and incorrect model samplings. As a result, we can avoid the disadvantages of sequential RANSAC and guarantee to extract all model larger than the smallest model correctly.
Conclusions
We have presented a simple but effective method for multimodel estimation. At the core of our work is a smallest CS random sampling scheme and a global multimodel competition algorithm. We have proved that our techniques are guaranteed to extract both large and small CSs from data. Experimental results on challenging synthetic data and real data demonstrate the robustness of our method.
There are many future directions that we plan to explore. In our algorithm, the distance threshold for model inliers is uniform across all models. In reality, the threshold should adapt to model scales. As immediate future work, we will explore integrating our solution with robust inliers scale estimation 15 –20 to dynamically adjust the threshold. We also plan to valid our technique on several real-world problems, such as video surveillance. In particular, it will be highly useful to customize a robust model fitting framework to conduct scene motion flow segmentation and clustering in dynamic environment where our solution is effective.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Natural Science Foundation of China (No.61502364,No.61672429).