
Abstract
Common control systems for mobile robots include the use of some deterministic control law coupled with some pose estimation method, such as the extended Kalman filter, by considering the certainty equivalence principle. Recent approaches consider the use of partially observable Markov decision process strategies together with Bayesian estimators. These methods are well suited to handle the uncertainty in pose estimation but demand significant processing power. In order to reduce the required processing power and still allow for multimodal or non-Gaussian uncertain distributions, we propose a scheme based on a particle filter and a corresponding cloud of control signals. The approach avoids the use of the certainty equivalence principle by postponing the decision on the optimal estimate to the control stage. As the mapping between the pose space and the control action space is nonlinear and the best estimation of robot pose is uncertain, postponing the decision to the control space makes it possible to select a better control action in the presence of multimodal and non-Gaussian uncertainty models. Simulation results are presented.
Introduction
Mobile robots are known to be subject to uncertainty in both the robot behavior and the environment where the robot navigates. Additionally, the availability of sensors capable of characterizing the environment is, in general, an unsolved problem. These issues can be modeled by a stochastic system. The classic approach for state estimation and control of stochastic systems is to consider the expected value of the system state variables and the certainty equivalence principle. 1,2 Expected value approaches, however, cannot be used when multimodal (or even skewed) distributions are present. On the other hand, skewed or multimodal distributions can arise due to sensor fusion and other typical mobile robotics problems. 3 Also, nonlinear dynamics often generate multimodal or skewed distributions from normal or uniform distributions. The current state-of-the-art approach to cope with uncertainties, especially those with non-Gaussian probability distributions, is to use Bayesian filters to estimate the system state and then compute a control signal based on the result of the estimation procedure, which is a probability density, a histogram, or a set of particles or probabilities over a topological map. This signal can be obtained from a mode or through optimization, such as partially observable Markov decision processes (POMDP) approaches. 4,5 The use of POMDP for systems with continuous states demands approximations, or the problem becomes intractable. 3
This article proposes a control scheme for a differential-drive mobile robot that maps a set of possible states into a space of control signals. Both the state transition and observations are subject to uncertainty. Hence, a particle filter is proposed for state estimation. However, contrariwise to the usual approach, the resulting state estimate is not taken to be a single point in the state space, but the full cloud of particles which represents the probability of each estimated particle to be the true state. Then, a globally stable control law is considered for the mapping of the cloud of particles in state space into a cloud of particles in control space. Then, the control signal to be applied to the robot is chosen as one of those in the most populated regions in the control space.
In other words, the proposed method avoids to decide the robot pose and then compute the control signal to correct it, but instead, postpones the decision to the control stage. The traditional approach (at least for low-level control) is to use the particle filter to solve the localization problem which gives a best estimation of the robot pose and then use this pose to compute the control action. As the mapping between the pose space and the control action space is nonlinear and the best estimation of robot pose is uncertain, postponing the decision to the control space makes it possible to select a better control action as many not-so-good pose estimatives could be mapped to the same control action giving it a higher probability to be a better control action. This capability is important in the case of multimodal and non-Gaussian uncertainty models.
Furthermore, the sensor observations are restricted in sampling frequency, in the sense that an absolute pose measurement, which was assumed to be obtained from a GPS, is only available on same control cycles, while dead-reckoning information from encoder measurements is available in all control cycles.
A description of the robot is presented in section “Robot model.” The proposed control method is explained in sections “Pose estimation by particle filter” and “Control using a cloud of particles.” More specifically, section “Pose estimation by particle filter” explains the pose estimation based on a particle filter and section “Control using a cloud of particles” presents the control method based on the cloud of particles. Results are presented in section “Simulation results” and final remarks and suggestions for future development are presented in section “Conclusions.”
Robot model
Consider a differential-drive mobile robot, with the coordinate systems shown in Figure 1, where the

Differential-drive mobile robot coordinates.

where
By supposing a zero-order holder on the control inputs, the trajectories of the discretized version of equation (1) are circumference arcs and the robot orientation is tangent to the arc as shown in Figure 1 and given by

where
However, imperfections due to the type of terrain, differences in wheel sizes, geometry of the robot, wheel slipping, and others affect the actual trajectory, which differs from the ones described by either equation (1) or (2). Furthermore, common assumptions such as that the velocity is known with absolute accuracy, instantaneous computation of control signals, and constant sampling period do not actually hold. Hence, the robot behavior can be better described by stochastic models, as proposed by Thrun et al. 5 and Rekleitis. 6 These models account for two types of errors, in fact: systematic errors and nonsystematic errors. Systematic errors can be compensated for by appropriately calibrating the parameters of the model. 6,7 However, nonsystematic errors are due to stochastic effects and cannot be compensated for by calibrating.
The stochastic effects can be observed in the robot motion by drifting robot with respect to the nominal trajectory in both traveled distance and orientation. By drifting, those errors increase with time, and therefore, they are modeled as uncertainty in linear and angular velocities of the robot. Furthermore, the stochastic effects are closely related to the linear velocity of the model. 6 Hence, the stochastic version of equation (1) is

with
It must be noted that while
An equivalent discrete model could be obtained by considering a discrete uncertainty

Discrete-time system transition. (a) Deterministic system and (b) stochastic system.
In order to obtain a discrete model that can properly represent the orientation uncertainty at k + 1, it can be assumed
6
that half of the effects of the uncertain angular velocity acts through the state transition, therefore affecting both position and orientation at k + 1, and the other half acts directly on the orientation at k + 1. Hence, the uncertainty wD(t) in the continuous model is represented by two uncertainties in the discrete model

where the state transition fd(⋅, ⋅) is given by equation (2) and

Since
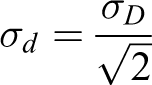
The state transition is illustrated in Figure 2(a), where both the arc distance and angle are affected by
As Figure 2(a) shows, the model (equation (4)) describes the state transition as circumference arcs with stochastic length and angle, with an added orientation uncertainty. This model will be used for estimating the state transitions for a set of possible values for the state vector, as explained in detail in section “Pose estimation by particle filter.” It is important to note that even though wt(k),
Pose estimation by particle filter
Mobile robots suffer from several sources of uncertainty. Their sense of awareness of the surrounding environment is limited not only by the sensors it is equipped with but also by its ability to process and act based on the information provided by the observations from these sensors. 5,7 These are also limited in the sense that not all sensors can return an observation at the same rate.
The state of a mobile robot is not readily available and must be estimated from sensor observations. In general, the observation vector,
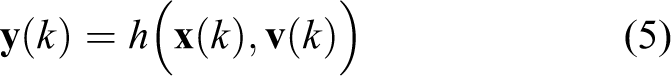
In this article, we consider digital incremental encoders on the wheels and a GPS sensor. The method, however, could be extended to consider more and other types of sensors, just by considering them in the definition of

with
Note that for other types of sensors, the mapping from
Data from sensors are integrated by a particle filter for a pose estimate represented by a set of particles. Particle filters belong to a family of estimation methods known as Bayesian estimators. Bayesian estimators aim to consider the uncertainty of both state transition and system observations in order to provide a realistic result. In accordance with the uncertainty approach in metrology, 8 the estimation result is extended so as to include information other than a single value, to be attributed to the quantity being measured. The most comprehensive result of an estimation is a (joint) probability distribution function of the state vector, considered at each sampling instant. These have either one of two disadvantages: requiring an analytic solution of the Bayes filter equations or requiring an infinite number of parameters to be fully described. Kalman filters are able to, under appropriate assumptions, generate an analytic solution in the form of a multivariate Gaussian distribution. This makes it possible to summarize the data as a mean vector and a covariance matrix. Therefore, the resulting probability density can be finitely parameterized. However, for nonlinear systems or uncertainties that cannot be expressed as a Gaussian parcel added to the state transition, such analytic solution cannot be obtained and the estimation result cannot be expressed using a finite set of parameters. General Bayesian estimators provide a density function or an approximation of it but require high processing power and memory. Particle filters are an efficient approximation which returns a set of particles as possible values for the state vector at each sampling instant, instead of an analytic function.
As is the case for many Bayesian filter techniques, particle filter algorithms can be viewed as composed of two stages called prediction and update. This last step is also called resampling or importance sampling.
The particle filter scheme is summarized below. A more detailed presentation is available in the work done by Thrun et al. 5
At each sampling instant, possible values for the state vector

The state belief is an approximation of a probability density function in the following sense: State space regions with a relatively large number of particles have high probability density values, while regions with relatively few particles are supposed to have low density values. Figure 3 shows an example of a state belief given by particles for a second-order system, where the region
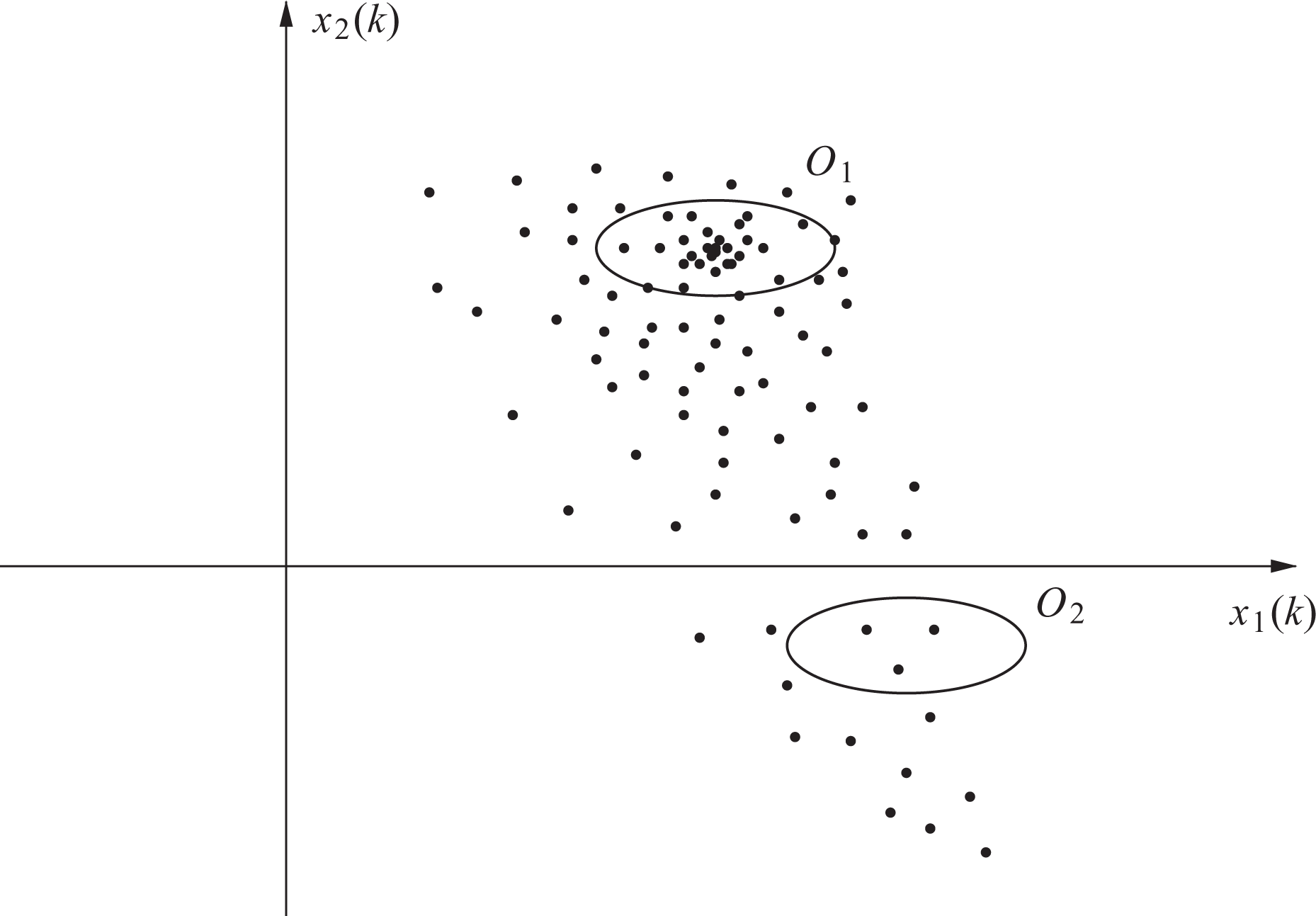
Example of state belief for a second-order system and two regions
The prediction step of the algorithm takes the state belief and the system input (control) vector as arguments to generate the prior state belief

where each particle

Figure 4 shows three prediction steps from a set of 50 particles with input

Predicted particles for three steps with null initial conditions and
The set of particles

where
In this article, it was assumed that the GPS observation noise

where n is the number of rows of
The observation
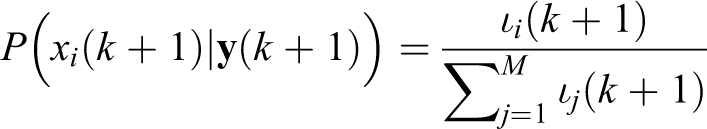
until M particles are selected. Each particle selection is independent of the previous one. Hence, some particles from the prior state belief are not included in the current belief, while others, usually those with higher importance factors, are included more than once.
The belief update demands an observation to take place. In this article, a GPS was considered to have a sampling period larger than that of the incremental encoders. As a result, the update step does not occur at every sampling instant, but only when the observation from the GPS is available.
Control using a cloud of particles
Differential-drive mobile robots are nonholonomic systems.
9
For this type of system, it is hard to steer the state to any fixed point in the space due to limited state manipulability from the inputs. This is easy to verify by inspecting equation (1), taking the inputs to be either u1 = 1 and u2 = 0 or u1 = 0 and u2 = 1. The first situation has the robot moving in the same direction of the wheels, which affects the first two state variables, while the second one results in a pure rotation around its axis, which affects the third one. These cannot be combined to obtain instant velocity that is not also along the direction of
Ways around Brockett’s conditions to obtain asymptotic stability are time-variant control, 12 –15 nonsmooth control, 10,16,17 and hybrid control laws. 18 These can be used for low-level control, which is the task of moving a robot either to a location or along a defined trajectory, with no consideration about why it should do so. In this article, we will obtain a set of possible control signals based on a nonsmooth control law. A general way of designing control laws for nonholonomic systems through nonsmooth coordinate transformations was presented by Astolfi. 10
The mappings from the system state to the control space which are used for point stabilization are such that the state space origin is made asymptotically stable. If we represent the mapping as

where f(⋅, ⋅) described by equation (1) is asymptotically stable at the origin. However, it is desired to stabilize the robot at any point

Robot coordinates with respect to the reference frame.
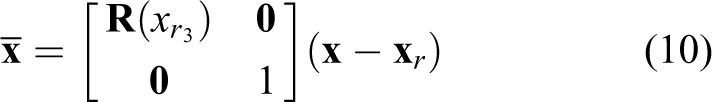
where

Hence, if the system
Low-level mobile robot control schemes usually take the state vector as input. However, here, the estimation result is a set of particles. This resulting estimation may have points grouped around different regions, as a result of multimodal beliefs. As a consequence, either a mean squared estimation or the expected value is not an appropriate estimation result, and the certainty equivalence principle cannot be applied. We present a way of generating a control signal from the current belief by considering the resulting signal from each of the belief particles and verifying their distribution in the space of the control inputs. This way, not only an appropriate action can be found, but it can be reasoned whether an action is appropriate at a given instant, depending on the resulting set of control particles.
At each sampling instant k, the current belief

with

where
For each particle, a coordinate change given by Barros and Lages 19,20 is considered



Then, the equation (1) can be rewritten as

Given a Lyapunov candidate function

it can be shown that the input signal


with h, γ1, and γ2 > 0, makes equation (15) asymptotically stable. 19,20 As a consequence, the input belief contains control signals related to point stabilization of the state particles under no state transition uncertainty, that is to say, assuming a deterministic system with known parameters. Note that even though equation (15) is discontinuous at the origin, due to e in the denominator, the closed loop system is not. The term in the denominator is canceled in closed loop because equation (16) contains e as a factor. For simplicity and easy of analysis, in this article, only the kinematic model of the robot was used. However, the control law equations (16) and (17) can be extended to include the dynamics of the mobile robots. See the work done by Barros and Lages 19,20 for details.
The input belief, obtained by computing equations (16) and (17) for each state particle, cannot be considered a result of the control scheme the way the state belief can for estimation, as it is obvious that the system takes a single two-dimensional vector as input. On the other hand, while an appropriate input vector could be any at a neighborhood of the input particles, we have the input belief as a discretization of an infinite set of possible inputs in a fashion similar to the state belief as a simplification for an infinite set of possible state vectors. As a result, it makes sense to restrict the search and decision regarding an input vector among the ones which belong to
The criterion for choosing an input vector among

where a1 and a2 are the ellipsoid radii.
The ellipsoid form is based on input limits for wheel velocities. As the input selection happens in the control input space, a particle is selected based on locally supported control signals in that space. That is, regardless of where the respective state particles are located in the state space.
The input restrictions are defined based on the limits for the speed of each of the wheels, as in Alves and Lages. 21 The set of possible input signals is illustrated in Figure 6.

Input restrictions. The hatched region is the set of possible input signals so as to satisfy wheel speed limits.
Simulation results
The simulated robot was modeled as the continuous-time stochastic system equation (3), with the state evolution obtained by a fourth-order Runge–Kutta with four steps at each sampling instant. For the particle filter prediction step, the robot was modeled as a discrete-time stochastic (nonlinear) system, described by equation (4). The values of the noise parameters σt and σD were set as 0.005 and 0.1745 rad/m, respectively. The observation covariance matrix is
At each sampling instant, the state belief is predicted. In the initial state belief, the particles are uniformly distributed in space.
The belief update is done when the observation from the GPS is available. Else, there is no further information and the prior belief is taken as the current belief. The first update takes place in k = 3. A plot of the prior belief

Predicted state belief at k = 3 in the X1 × X2 plane. Orientation is omitted.
The updated state belief at k = 3 is shown in Figure 8(a) and a plot of updated belief in the X1 × X2 plane is presented in Figure 8(b) for easier comparison with Figure 7.
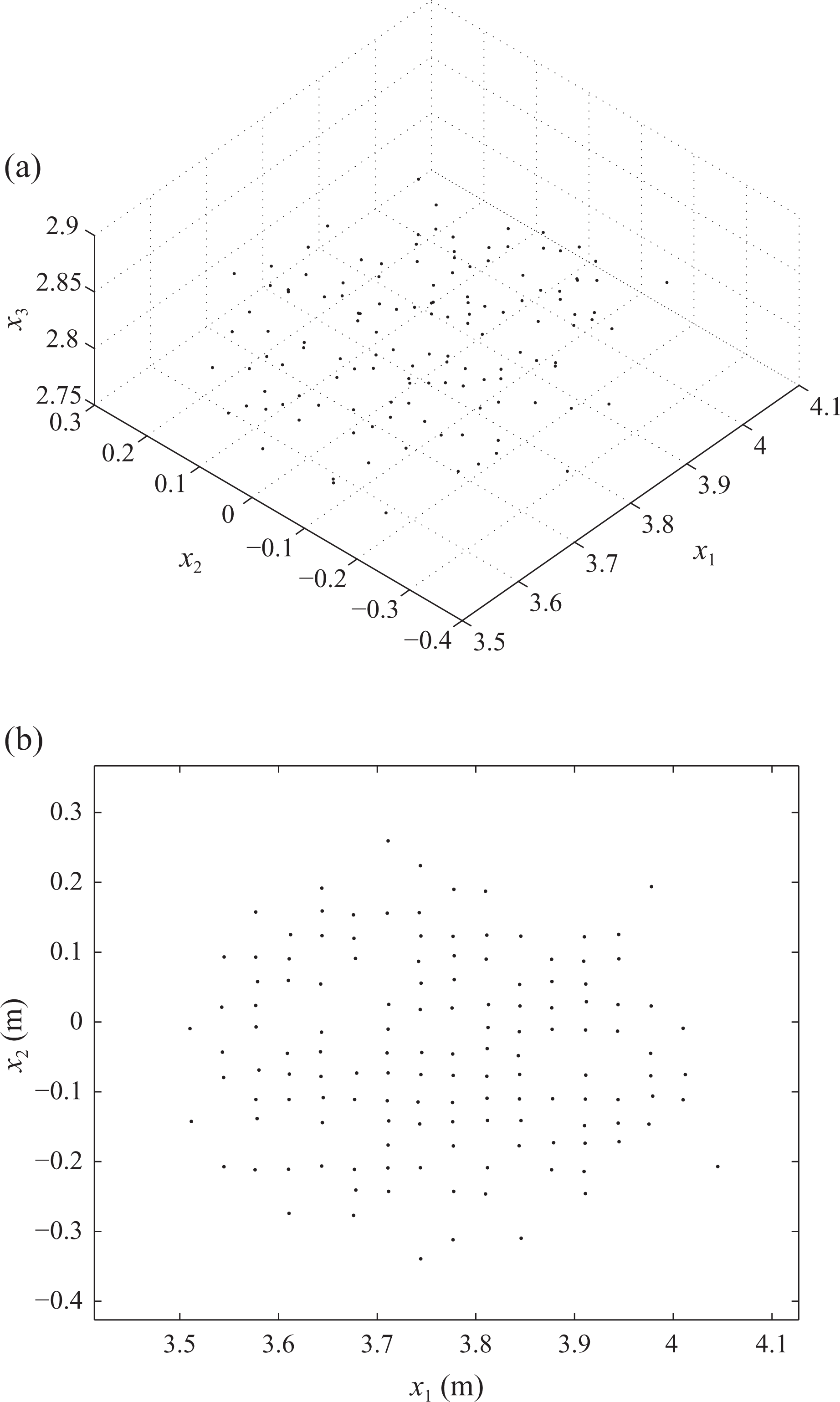
Updated state belief at k = 3. (a) 3-D view and (b) X1 × X2 plane. Orientation is omitted.
A number of particles present in
It has been observed that the update step demands significantly more time (see Table 1) than the prediction. This happens because the prediction model equation (4) is relatively simple, hence the prediction is a straightforward step: a single action is required for each particle. On the other hand, the update is done in two separate steps: the calculation of the importance factors, which has a computational complexity that is proportional to the number of particles, and a further resampling, which requires ordering a vector and finding the position index of values inside it. However, those timings were obtained in a Matlab implementation running in a single core computer. A proper implementation in C or C++ using a multicore machine would be much faster. The calculations have been carried out in Matlab release 2010bSP1 running on an AMD Athlon 64 machine at 3.0 GHz running the Linux operating system. Matlab has to interpret code before executing it and the implemented algorithm was not implemented with parallelization in mind.
Average computation time for each control method steps.

The set of control signal particles is obtained from the current belief. This has a much different shape than the state belief, as the mapping from states to control signals is done through a discontinuous coordinate transformation, which then is subject to a nonlinear control law.
The control belief at k = 0 is presented in Figure 9(a). As the particles from the initial state belief are uniformly distributed in space, the resulting control belief keeps part of that structure. At the next sampling instant (k = 1), the new state belief, which resulted from the stochastic model assumed for the state transition, is used to compute a new control belief, shown in Figure 9(b).

Input belief. (a) k = 0 and (b) k = 1.
The state belief at k = 50 is presented in Figure 10(a). Figure 10(b) shows its plot in the X1 × X2 plane with orientation omitted. The corresponding input belief is shown in Figure 11. Note that the particles are concentrated in smaller regions.

(a) State belief at k = 50 and (b) its projection in the X1 × X2 plane. Orientation is omitted.

Input belief at k = 50.
A control signal is selected as the particle that maximizes the number of other particles in its neighborhood, as explained in section “Control using a cloud of particles.” While most of them are related to state particles inside a neighborhood of each other, this is not always true as

Control signals with respect to time.
The trajectory of the robot on the plane is presented in Figure 13(a). The state-input mapping is such that the robot approaches the reference with small angle error and negative linear speed (see Figure 12). This happens due to equations (12) and (13), which forces e > 0 and given that the Lyapunov function has a quadratic term in φ. The final position of the robot in Figure 13(a) is
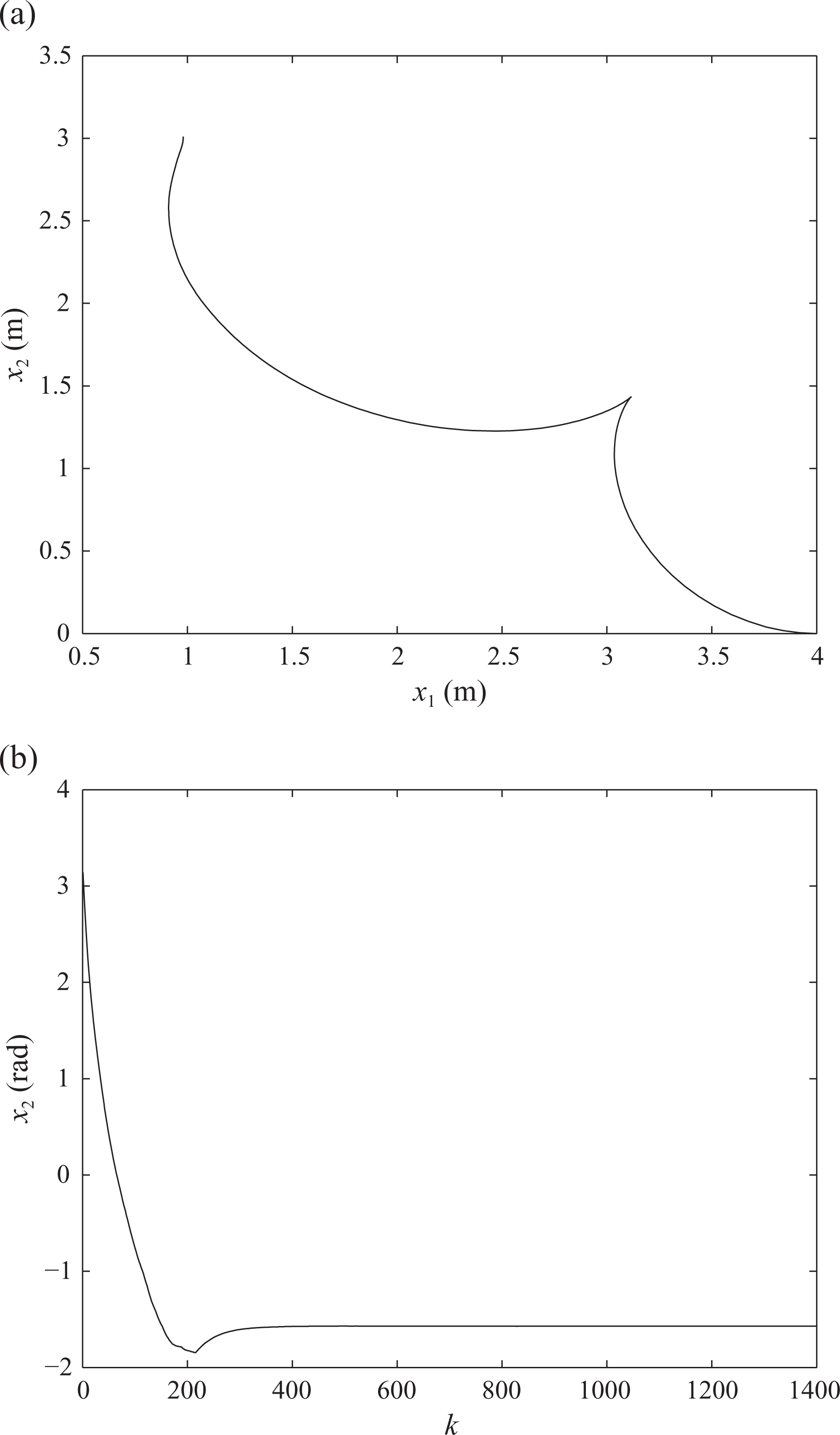
(a) Robot trajectory on the horizontal plane and (b) orientation angle with respect to time.
The experiment has been repeated in order to verify the stochastic effects in steady state. Particularly, the experiment has been reproduced 50 times and the final state position has been recorded. The mean and standard deviation of the state at the last sampling instant are presented in Table 2.
Final position mean and standard deviation for

Finally, a number of initial conditions have been considered. The trajectories for eight different initial conditions, given by

are shown in Figure 14(a), and a detail around the reference position is shown in Figure 14(b). The × denotes the final point of the trajectory at k = 1400. It can be observed that the asymptotic convergence which exists in the deterministic and observable case is downgraded to convergence to points in a neighborhood of the reference in the presence of noise and with limited observations. Note, however, that the standard deviation of the final point is consistent with those of the uncertainties, given by σt and σD.

Trajectories for eight different initial conditions. (a) Trajectory and (b) detail around the final reference point.
The control signals with respect to time for the eight cases are shown in Figure 15. It can be seen that there are a few peaks. These occur due to the state belief update, which sometimes selects particles from some other region, depending on the last observation.

Input signals with respect to time.
Again, the experiment has been repeated many times to verify the consistence of the results despite the stochastic effects. The experiment for each initial condition was repeated five times for a total of 40 different trajectories. The final poses have been recorded, and their mean and standard deviation at the last sampling instant are presented in Table 3.
Final position mean and standard deviation for different initial conditions and

Conclusions
A method for controlling a differential-drive mobile robot through output feedback has been proposed. While only simulation results have been presented, a realistic model for the robot has been used. The system behavior and the information that can be obtained from sensors are subject to uncertainties which are present in mobile robot applications. Furthermore, there are the natural difficulty of controlling nonholonomic systems. In order to overcome these problems, a pose estimation scheme that uses a particle filter was employed, and the full cloud of state particles was used combined with a nonsmooth state feedback law to generate a cloud of possible control signals. A single control signal was chosen and an appropriate way of dealing with control saturation was employed to preserve the expected behavior of the system.
The calculations have been carried out in Matlab which has to interpret code before executing it and the implemented algorithm was not implemented with parallelization in mind. However, most algorithms which have been used in this work can be adapted to multicore machines. Particularly, particle filters are well suited for parallelization. The control signals can also be computed at different cores, and the input selection algorithm can also be broken into parallelized code. In addition to this, the Matlab code can be ported to another programming language to obtain a compiled code, which of course, means that it will demand much less time to run. Therefore, the scheme which was presented can be readily employed in real time.
Footnotes
Acknowledgements
The authors would like to thank Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) and Fundação de Apoio à Pesquisa do Estado do Rio Grande do Sul (FAPERGS), edital PqG 2013, process 002119-2251/13-5, for the financial support.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) and Fundação de Apoio à Pesquisa do Estado do Rio Grande do Sul (FAPERGS), edital PqG 2013, process 002119-2251/13-5.