
Abstract
Future trends in robotics call for robots that can work, interact and collaborate with humans. Developing these kind of robots requires the development of intelligent behaviours. As a minimum standard for behaviours to be considered as intelligent, it is required at least to present the ability to learn skills, represent skill’s knowledge and adapt and generate new skills. In this work, a cognitive framework is proposed for learning and adapting models of robot skills knowledge. The proposed framework is meant to allow for an operator to teach and demonstrate the robot the motion of a task skill it must reproduce; to build a knowledge base of the learned skills knowledge allowing for its storage, classification and retrieval; to adapt and generate new models of a skill for compliance with the current task constraints. This framework has been implemented in the humanoid robot HOAP-3 and experimental results show the applicability of the approach.
Keywords
Introduction
This work is centred on the major idea of future robotic systems, more specifically humanoid robots, with the cognitive capabilities that allow them to interact with humans in their homes, workplaces and communities, providing support in several areas, and to collaborate with humans in the same unstructured working environments. Our focus is on topics concerning the learning, representation, generation and adaptation, and reproduction of robot skills knowledge. In this work, a framework is proposed for the learning, generation and adaptation of robot skill models for complying with task constraints.
The innovation of this work is in the real implementation and test of the proposed architecture. The efforts have been devoted to (1) the study of the state of the art on existing methods to achieve the functionality of every part of the architecture proposed; (2) the improvement of the corresponding methods in order to adapt them to the requirements of our particular architecture or framework; (3) the implementation of the complete architecture in a real humanoid robot for the performing and testing of the approach.
The rest of the article is organized as follows. A discussion on the state of the art is given in section ‘Review of cognitive systems approaches for intelligent robots’. Our proposed framework is introduced in section ‘Cognitive framework for generation and adaptation of humanoid robots skills’. Section ‘Learning robot skills models’ addresses the learning of the skill models. Section ‘Representation of robot skills knowledge’ discusses the representation and organization of knowledge. Section ‘Adaptation of robot skills’ discusses the adaptation of the robot skills. Section ‘Reproduction of robot skills’ deals with the reproduction of the robot skills. The experimental validation is described in section ‘Experimental evaluation’. Finally, section ‘Conclusions and future works’ presents the main conclusions from this article.
Review of cognitive systems approaches for intelligent robots
The development of robots exhibiting human-like cognitive abilities is within our reach. 1 These robots are expected to be capable of working autonomously and serving humans and are required to have advanced motor control skills, comprehensive perceptual systems and suitable intelligence. The challenge of developing cognitive architectures and systems for intelligent robots is one of the most important topics for the future development of humanoid robots. The function of a cognitive architecture is to provide a comprehensive initial framework for the modelling and understanding of cognitive phenomena, in a variety of task domains. 2 Research in cognitive architectures constitute a solid basis for building intelligent systems centred on the configuration and interaction of cognitive modules dealing with the various mechanisms and abilities that constitute the various processes of human intelligence.
Vernon et al. 3 discerns among two major classes of cognitive systems along their different stances on the nature of cognition, what a cognitive system does and how a cognitive system should be analysed and synthesized. So we can group approaches as whether they are cognitive approaches, emergent systems approaches and also efforts to combine the two in hybrid systems. For cognitive systems, cognition is representational; it involves computations of explicit symbolic representations about the world, abstracted by perception, to facilitate appropriate, adaptive, anticipatory and effective interaction to plan and act in the world. 3 For most cognitive approaches concerned with the creation of artificial cognitive systems, the symbolic representations are the descriptive product of a human designer. For emergent approaches, cognition is the process whereby an autonomous system becomes viable and effective in its environment; it involves a process of self-organization through which the system continually reconstitutes itself. 3 The emergent approaches assert that the primary model for cognitive learning is anticipative skill construction rather than knowledge acquisition; in emergent approaches, embodiment and the physical instantiation plays a pivotal role in cognition. Considerable effort has also gone into developing approaches that combine aspects of both systems. For hybrid approaches, perception–action behaviours, rather than the perceptual abstraction of representations, become the focus. The ability to interpret objects and the external world is dependent on its ability to flexibly interact with it. Hybrid systems are in many ways consistent with emergent systems, while still exploiting programmer-centred representations. 3
In the field of artificial intelligence and cognitive systems, there are various works on the development of cognitive architectures to model cognitive processes and functionality of humans. We will summarize some of the better known architectures.
State operator and result (Soar) 4 cognitive architecture has been under continuous development since the early 1980s. The architecture is based on the theoretical framework of knowledge-based systems seen as an approximation to physical symbol systems. 5 Soar stores its knowledge in the form of production rules, which are in turn organized in terms of operators that act in the problem space.
Adaptive control of thought-rational (ACT-R) 6 architecture is primarily concerned with modelling human behaviour. The aim is to build systems that perform the whole space of humans’ cognitive tasks and describe mechanisms underlying perception, thinking and action. 5 The ACT-R architecture is organized into a set of modules, including sensory modules for visual processing, motor modules for action, an intentional module for goals and a declarative module for long-term declarative knowledge.
Executive process interactive control 7 aims at capturing human perceptual, cognitive and motor activities through several interconnected processors working in parallel, to build models of human–computer interaction for practical purposes. 5 The architecture encodes long-term knowledge as production rules and a set of perceptual (visual, auditory, tactile) and motor processors.
Real-time control system (RCS) 8 is a cognitive architecture, originally designed for the sensory-interactive goal-directed control of laboratory manipulators. It has evolved over three decades into real-time control architecture for intelligent machine tools, factory automation systems and intelligent autonomous vehicles. 8 The RCS architecture consists of a multilayered hierarchy of computational modules, operating in parallel, containing elements of sensory processing (SP), examining the current state, world modelling (WM), predicting future states, value judgement (VJ), selecting among alternatives, behaviour generation (BG), carrying out tasks and a knowledge database (KD).
Global workspace cognitive architecture 9 is a brain-inspired cognitive architecture that incorporates approximations to the concepts of consciousness, imagination and emotion. Cognitive functions are realized through internal simulation of interaction with the environment and action selection is mediated by affect.
Cog: Theory of Mind 10 focuses on social interaction as a key aspect of cognitive function. Cog is an upper-torso humanoid robot platform for research on developmental robotics. Cog has a pair of six degree-of-freedom arms, a three degree-of-freedom torso and a seven degree-of-freedom head and neck. The Theory of Mind focus is on the creation of the precursor perceptual and motor skills upon which more complex theory of mind capabilities can be built.
The different attempts at developing cognitive architectures differ in the assumptions they make and the design decisions they take about how to manage these aspects; however, every effort in cognitive architectures has produced important advances in cognition, reasoning and conceptual aspects of human thinking. Vernon et al. 3 offer a very complete survey of artificial cognitive systems and their implications for the development of computational agents, while Levesque and Lakemeyer 11 offer an overview of the challenges and efforts taken in the subject of cognitive robotics. A cognitive architecture can support several capabilities and can differ variedly in its set of abilities. The architecture design must specify the overall structures, essential divisions of modules and their interrelationships, basic representations, essential algorithms and a variety of other aspects.
Cognitive framework for generation and adaptation of humanoid robots skills
A cognitive framework for humanoid robots needs to provide a minimum degree of intelligent behaviour, that is, the ability to sense the environment, learn and adapt its actions to perform successfully under a set of circumstances. The reference model architecture 8 identifies five elemental systems contained in each layer, such as SP, WM, BG, VJ and knowledge, interconnected in a way that enables the different system elements to interact and communicate with each other in intimate and sophisticated ways. Research efforts must focus on building the necessary modules of cognition that would form the layers in this hierarchy and allow the assembly of the intelligence levels.
Figure 1 illustrates our proposed framework. The main purpose of the framework is to provide the humanoid robot with a basic level of intelligence, namely the ability to sense the environment, learn and adapt its actions to perform successfully under a set of circumstances. In the developed framework, a knowledge base of skills is built with the models of the skills learned through demonstrations. During execution, the constraints of a requested task are extracted from the perception of the working environment, and the models of an appropriate skill are retrieved from the skills knowledge base. With all available information, a new adapted task model is generated for reproduction.

Proposed cognitive framework for the learning and adaptation of robot skills to task constraints. A knowledge base (2) is built with the models of the robot skills, which are learned through demonstrations (1). The constraints of a requested task are extracted from the perception of the world state. With the current task constraints and the models of a skill retrieved from the knowledge base, an adapted task model (3) is generated for reproduction (4).
The proposed framework is formed by four modules: Module for the learning of robot skills. Module for the management and representation of robot skill knowledge. Module for the generation and adaptation of robot skills. Module for the reproduction of robot skills.
The robot skill learning module collects the learning processes and algorithms used for learning and encoding the models of the skills. The robot skill knowledge module controls the developed knowledge base for the storing and retrieval of the learned models of the skills. The robot skill generation and adaptation module governs the process by which the learned model of a skill can be operated to reproduce a new task. The robot skill reproduction module produces the adequate control signals to the robot for the reproduction of those skills. Additionally, a perception and interaction module is in charge of processing the outside information of the robot’s working environment to be used by the other modules. First interactions of this framework have been presented in the research by Hernández et al., 12 but further steps towards the real integration and validation of the whole architecture are presented in this article.
Learning robot skills models
The robot skills models are learned by employing an autonomous dynamical systems (DS) approach. DS has been proposed representing movements as mixtures of non-linear differential equations with well-defined attractor dynamics. 13 Common approaches in learning from demonstration create a model of the skill based on sets of demonstrations performed in slightly different conditions generalizing over the inherent variability to extract the essential components of the skill. 14 Employing statistical learning techniques is a popular trend for dealing with the high variability inherent to the demonstrations. 15
Learning motion dynamics as multivariate Gaussian mixtures
The DS framework provides an effective mean to encode trajectories through time-independent functions that define the temporal evolution of the motions. A probabilistic framework is employed to build an estimate
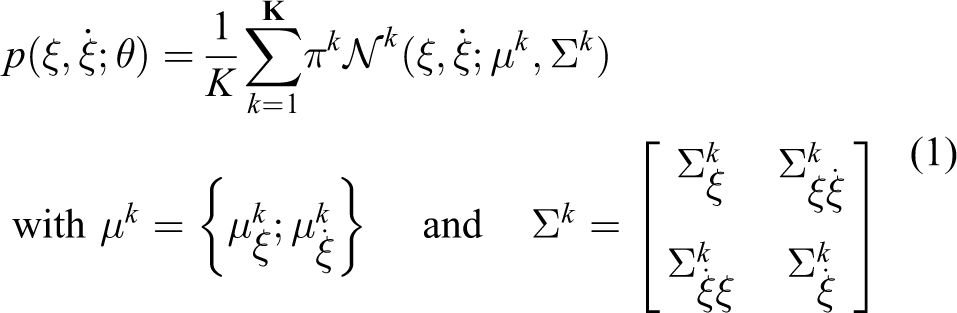
To recover the expected output variable


Khansari-Zadeh and Billard 16 proposed a learning method, called stable estimator of dynamical systems (SEDS), to learn the parameters of the DS ensuring asymptotically stable trajectories for all motions that closely follow the demonstrations dynamics.
It is desirable to validate the performance of the method; for this, the performance is evaluated over two error measurements: an accuracy error measurement

where r and q are positive scalars that weight the relative influence of each factor, and ∊ is a very small positive scalar. An estimate of the dynamics is considered accurate if
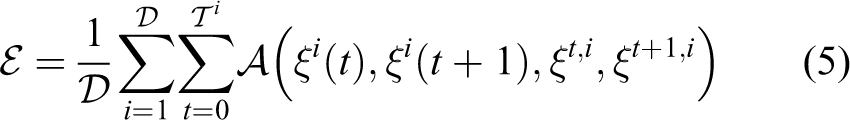
Representation of robot skills knowledge
An important challenge for robots acting on unstructured dynamic environments is dealing with internal representation and understanding of the world. The interrelation between objects and actions representation is fundamental when executing tasks upon the world. Thus, focussing only on objects and actions would not be enough for the knowledge representation needed by the humanoid robots. Representational attributes need to also take into account the state of the world, grounding the representations to the environment, the task at hand and present events.
Representations thus perform as functional abstractions of the perceived environment, encoding an agent’s knowledge about its world, objects, actions, events, into manageable internal structures. Here, we will organize our knowledge into manageable structures using object-oriented groups of procedures, which are called frames. Representations of events concentrate on two frames, one of the system tasks knowledge and the other representing the state of the world knowledge. Task and world frames would hold knowledge for the requested execution of a task and the agent’s environment.
Knowledge base structure
The knowledge base needs to hold all necessary information for reproduction of the skills in the environment. Knowledge of the task would be distributed among the representation of objects, actions and events of the goal and the state of the world. From a given scene, the system instantiates frames, generally governed by the precedence of visual evidence. From the perceived given input, the first step for extracting task constraints is the matching of the world to an instance of the world event frame and the instantiation of the task event. From information collected in the world and task event frames, which in turn are made up of object and action frames, the system would have information about its current goals and situation of the environment, yet this is not enough to ground the representation in order to effectively use them for supporting its performance. For an agent working in an unstructured environment, the focus of its perception must be directed towards its executing action. Knowledge of its environment and task would be collected into their appropriate frames, and a focused active view frame would be built taken from their global knowledge and breaking it down into a simpler framework from which computations and knowledge take place. Figure 2 presents the control data flow for the process of using the representations in the knowledge base, and Figure 3 presents the organization of the knowledge base.

Knowledge base control flow. World event frame and task event frame are instantiated, and an active view event frame is built from them. From object and action frames, the models of the skill are taken for building the task model.

Knowledge base structure and organization of the knowledge representations. World event frame and task event frame represent the knowledge of the state of the environment, with object and action frames representing the available objects and actions. From the knowledge of these frames, an active view event frame is built of the focused knowledge required to drive the agent execution.
Figure 4 shows the representation of the skills in the KD in a three-dimensional space defined by the 〈Object, Goal, World State 〉 triple, selecting from their intersection an adequate model of the skill for the reproduction of the task.

Representation of the skills in the knowledge base. The intersection of the triple 〈Object, Goal, World State 〉 allows the selection of the adequate model of the skill for reproduction.
Further development of the knowledge base representation and structure can be found in the research by Hernández García et al. 17 Different approaches on related topics focusing on the management of knowledge by robotic system exist, such as KnowRob 18 or RoboEarth. 19 However, these systems lie at a higher more abstract level of the cognitive hierarchy, while our framework lies at a lower level of action execution. Further research requires study and comparison of other systems, in particular, the ones that may be used to complement the framework developed in this work.
Adaptation of robot skills
The robot skills learned with the methodology described in section ‘Learning robot skills models’ would present stable trajectories that accurately reproduce the demonstrated motion dynamics. The robot skills models were learned by employing a DS approach. These learned models would form a set of primitives of action from which a knowledge base of skills was built as given in section ‘Representation of robot skills knowledge’. Evidences exist from human and animal experiments supporting the belief that sets of motor primitives are used to build a basis for voluntary motor control. 20 To generate complex motions from a learned set of basic primitive skills and be able to reproduce various complex task behaviours, methods for operating and manipulating upon the primitives are needed.
Ideally, robots would have a vast repertoire of learned skills or would be able to learn, in real time, any skill set they may be missing with minimal help from human agents, making them capable of performing in every needed task and for every foreseen situation. However, following this approach would be impractical because of the time and resources required for it. Robot skills learning approaches to develop humanoid robotic systems would have greater impact if the models of the skills can be operated upon to generate new behaviours of higher levels of complexity. We adopt this idea in our work and present simple modalities for the adaptation and generation of new skill models by taking advantage of useful properties of the SEDS 16 formulation chosen to learn the skills, which allows us to adapt, merge and combine the learned skill models without the need to use more complex algorithms like GMM, expectation-maximization (EM), SEDS and so on to relearn the complete set of parameters of a skill from the very beginning of the demonstrations.
The work done by Hernández et al. 21 contains more detailed information about generation and adaptation of robot skills models, and a short review is given next.
Update of robot skills
When an update is required with new given data, a process of GMR is performed over the learned model to stochastically generate a data set from the model. Therefore, a new data set is created composed of this generated demonstration and the new observed data set. The parameters of the updated model are then retrained. For this purpose, a learning rate α is defined.
For our method, the new updated demonstration data set
To illustrate this method, Figure 5 shows the result of updating a learned model of a skill.

Update process of a robot skill. Model of the learned skill with new demonstrations (left). Updated model of the skill (right). The parameter αk is defined to govern the influence of new data on the update process. Appropriate selection of αk allows the updated model to reproduce the curve at the top of the trajectory.
Merger of robot skills models
Intuitively, one could consider an approach the fact of merging two or more models of a skill simply by adding and averaging together their learned parameters θ = (π, μ, Σ) in order to obtain a new skill model. While this approach may work for some cases, it is important to note that the direct superposition of the skills does not allow the system to control the manner in which the new model is generated and its stability.
In order to generate a new skill based on the merger of several robot skills previously learned, we first review a couple of useful mathematical properties from the SEDS 16 formulation chosen to learn the skills

The merger of the robot skills can be carried out with a model combination approach expressed as mixtures of expert models

The SEDS models encoded into a GMM are already a form of model combination approach. Here, recalling the expression of the non-linear weighting function hk(ξ), as in equation (3), it can be found that it shares a similar formulation with the expression of the weights for the gating function as from equation (7). The process for the merging of robot skills would first join the GMM of the robot skills into a single model. Then, a new weighting function
Figure 6 illustrates the results of merging two robot skills to generate a new skill model.
Merger of two learned GMM skill models to generate a new skill. Learned models of the robot skill (left). Merging process of the two models to generate a new one (centre). Merged skill model (right). GMM: Gaussian mixture models.
Combination of robot skills models
In order to generate a new skill made of the combination of several robot skills models previously learned, we have developed a method for skills combination. Two different SEDS models,
Figure 7 illustrates the results of combining three robot skills to generate a new skill model.
Combining the dynamics of three skills into a single task model.
Reproduction of robot skills
In this section, the development and operation of the robot skill reproduction module will be presented. The robot reproduction module is assigned with the task of providing suitable controllers that convert kinematic variables into appropriate motor commands. In order to test the proposed architecture, the HOAP-3 humanoid robot was used as a test platform. The HOAP-3 was designed to resemble the human shape, on a small scale, with a complete humanoid configuration with two legs and arms, a head with vision and sound capacities, and gripable hands.
The robot skill reproduction module works as follows. Once a command has been received, the robot distinguishes if it is a command for the walking generation or for the arms movement. The walking patterns of the robot have been designed based on the theory of the 3-D linear inverted pendulum mode presented in the work done by Kajita et al. 22 If the received command requires a movement of the arms, as in the case of a grasping task, the selection of the suitable arm is first considered. Finally, the trajectory of the arm is evaluated online through the algorithm of kinematic inversion, 23 once the command provides the distance and the orientation from the object. The orientation reference for the object is calculated with the support of the unit quaternion.
The HOAP-3 control system is in charge of computing the appropriate command to control the execution in real time. The physical implementation of the robot control system is made on three PCs: an on-board PC implements the robot control systems; an auxiliary PC implements the knowledge and learning systems; and a laptop computer implements the Human-Robot Interaction (HRI) and perception systems. A Yet Another Robot Platform (YARP) layer was implemented for the communications between processes.
Experimental evaluation
This section reports and discusses the results obtained during the evaluation of the proposed framework, both in a quantitative and a qualitative way. Several experiments were conducted to prove the validity of the system and to test the operation of the developed framework.
Knowledge base scenario
A first experiment involves an agent and a humanoid robot (here a HOAP-3 robot) interacting to complete a simple task. The task in this case requires the robot to pick up a cup and a spoon in each hand and then to put the spoon inside the cup; finally, it will put down the cup in front of it. The agent will provide the robot with the cup and spoon objects so it can pick them up; also, the agent will indicate the robot where to put the cup down.
The execution of the demonstration could vary depending on the actions of both the human agent and the HOAP-3 robot. At the start of the demonstration, the robot is given the task event frame knowledge for the desired behaviour containing the knowledge of the four action skills needed to complete the action: pick spoon, pick cup, place spoon in cup and place cup down. Extracting the adequate action will depend on the agent interaction and the content of the rest of the knowledge base. The purpose of this demonstration is to validate the performance of the developed knowledge base in a dynamic interaction with an agent. Depending on the agent interactions with the robot, there would exist two possible main paths for the demonstration: (1) action SpoonA, where the robot holds both the spoon and the cup to complete the task and (2) action SpoonB, where it is the user who holds the cup while the robot completes the operation of putting the spoon inside the cup. Figure 8 presents a storyboard of the performance of the system during the execution of the two different paths that the demonstrator experiments can take, with snapshots taken at various stages.

Knowledge base scenario experiment: different snapshots during the execution of the demonstration. The top row represents the path corresponding to action SpoonA and the bottom row represents the path corresponding to action SpoonB.
The operation of the knowledge base system during the execution of the demonstrator experiments can be seen in Figure 9. The knowledge base presents information for the environment and the task execution. The task frame holds knowledge of the actions to carry out by the robot for the execution of the task. Actions highlighted in blue reflect the current invocation of that action’s knowledge for the robot reproduction of the skill. Actions that have been completed are deactivated and highlighted in grey. The selection and activation of which skill motion to carry out next is completely determined by the skill initial conditions being matched to the state of the environment. Therefore, the sequence of execution of the task is controlled by the human agent as it interacts with the robot and the environment and facilitates the objects and conditions needed for the robot to fulfil the task. Table 1 shows the average duration of the tasks during various runs and the rate of successful completions of the task. Success is defined as correct operation of the knowledge base system in selecting the expected skill during completion of the task. In total, 16 repetitions were conducted, 8 for each of the 2 possible main paths. When the agent’s interactions lead the completion of the task towards the path involving skill action SpoonA, it takes longer for the robot to complete the task, since the robot is in charge of holding both the cup and the spoon and the operation is more time-consuming in comparison with action SpoonB, as expected. However, the success ratio in this operation is higher than that with action SpoonB. Table 2 shows a matrix of matches between the action taken by the robot and the expected interaction from the agent. NA indicates that the robot failed to take any action from the presented agent interaction. The recognition of the right task to perform is quite high, thanks to the nature of the knowledge base and to the fact that actions that are not ready to be taken or have already been executed are deactivated and cannot be selected.

Knowledge base scenario experiment: different snapshots of the execution of the demonstration illustrating the operation of the perception system and the knowledge base system.
Knowledge base scenario experiment.

aSummary of results.
Knowledge base scenario experiment.

aSkill action match matrix.
A potential problem is determining which action has precedence when many of them can satisfy their conditions at the same time. The tasks considered in the demonstrator do not deal with this issue, since the robot’s limited workspace prevents the conditions for picking up the cup and placing the spoon to be satisfied at the same time. This issue has not been fully explored so far, and as a first simplification, the precedence is determined by the order of the actions in the task frame as determined by the programmer of the task; although not satisfactory for every scenario, this solution is probable enough for many common tasks. The use of some form of long time planner could be effective to solve this issue by assigning precedence by determining how the decision of performing one action over another could affect the execution of the task.
A knowledge base approach for robots working in unstructured environments, where the execution of the task cannot be scripted beforehand, is fundamental if they are to be able to work successfully. Without such a system, the robot would be unfit to respond to any unforeseen deviation from the plan, and largely ineffective to perform in all but the most ideal of situations. The knowledge base system allows the robot to keep track of the environment and the execution state of the task, which provides the system with flexibility to deal with different states at a particular point without losing focus on the global task objective.
A video of the performance of the system in this scenario is available at www.youtube.com/watch?v=3l7-KrMa84o.
Robot skill reproduction scenario
As a final experiment, we will visit a kitchen or dinner table scenario and expand the demonstrator presented in the previous section. In this scenario, the HOAP-3 robot is required to complete the task of setting up a dinner service in conjunction with a human agent. The purpose of the demonstrator is to test the overall operation of the developed framework, as well as to validate the performance of every individual module and interaction between themselves, involving the perception of objects and interaction with the agent, the learning of various robot skills, the representation of knowledge in the knowledge base, the generation and adaptation of the skill models and the adequate reproduction of the robot skills.
During the operation, the user will provide objects to the robot by placing them in its action field, both of vision and manipulation. The perception system will handle the interaction with the user and the detection of objects in the environment. The knowledge base system will receive this information from the perception system and will instantiate the frames and build the knowledge representation of the scene in the knowledge base. Through this interaction with the user and the environment, the knowledge base system will select the corresponding skills to activate. Once the necessary robot skills are selected, the generation and adaptation system will be in charge of building the appropriate task model satisfying the desired command and constraints of the environment for reproducing the appropriate skill action. Finally, the HOAP-3 robot controller will execute the robot commands required for skill reproduction.
This demonstrator scenario is meant to provide proof of concept of how the knowledge base operates to instantiate frames from the perception of the environment, and how the knowledge base maintains and upkeeps its knowledge representation over time in a changing environment, as well as how action execution is invoked by the state of the representation frames present in the knowledge base. Additionally, the demonstrator scenario provides validation for the generation and adaptation system and how it operates over learned robot skills for increasing the scope of available skills for the performance of the HOAP humanoid robot.
Figure 10 depicts a storyboard of the performance of the second demonstrator showing several snapshots captured from the execution experiment. The demonstrator scenario will develop as follows: first, the robot is given the task of setting up the dinner service at the table in front of it, and all necessary robot skill actions and task event frames are stored in the knowledge base. The task begins with the robot standing in front of the empty table. The final set-up of the table requires a plate to be placed at the centre, a cup placed on top of the plate, a spoon placed inside the cup and a fork and knife flanking the plate at its left and right sides, respectively. Completing the task requires the performance of several different skills. The sequence of execution of the task is governed by the human agent as it is him who chooses the order in which to provide the robot with the needed objects. Certain items, however, have precedence over others, that is, the plate must be placed on the table before the cup, since the cup goes on top of it.

Robot skill reproduction scenario experiment: different snapshots from the execution of the task in the demonstrator.
In total, 10 repetitions were conducted, 8 of which were conducted successfully, with an average task duration of 4 min and 38 s. Table 3 summarizes the results of the eight learned skill actions models required for the task completion. They are evaluated according to the accuracy error
Results of the eight learned skill actions models.

Robot skill reproduction scenario experiment.
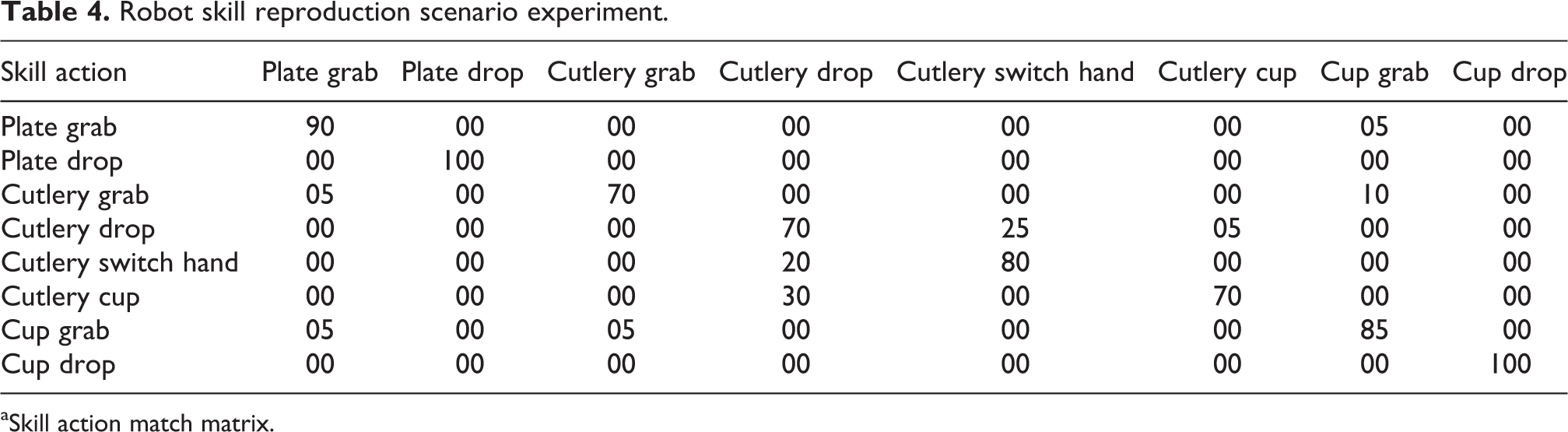
aSkill action match matrix.
A video of the performance of the system in this scenario is available at www.youtube.com/watch?v=BKXaZGV8xvM.
Conclusions and future works
This work is centred on the aspiration of building humanoid robots capable of interacting with humans in their homes, workplaces and communities, providing support in several areas and collaborating with humans in the same unstructured working environments. The aspiration is to have humanoid robots acting as robot companions and co-workers sharing the same space, tools and activities.
The main contribution of this work is the proposition and real implementation of a framework for the generation and management of adaptive skill models for complying with task constraints. The framework developed in this work was proposed as a cognitive model intended to provide the robot with an essential cognitive ability for learning and adaptation of skills. The goal of the developed framework is to provide a minimum degree of intelligence for the humanoid robot. We consider as a minimal desirable level of intelligence for our humanoid robots the ability to sense the environment, learn and adapt their actions to perform successfully under a set of circumstances.
The framework is formed by modules for the learning of robot skills, the perception and interaction with the environment, the representation and management of the skill knowledge, the generation and adaptation of skill models and the reproduction of robot skills. To learn the skills motion, a time-independent model of the motion dynamics was estimated through a set of first-order non-linear multivariate DS. A knowledge base of skills has been developed and implemented. The knowledge base holds all the necessary information for reproduction of the skills in the environment. The knowledge of the task is distributed among the representation of objects, actions and events of the task and the state of the world. A structure built on frames has been adopted in this work. The knowledge of the environment and goals is represented in terms of the world event frame and task event frames, with object and action frames representing the knowledge about available objects and actions, respectively. From the knowledge of these frames, an active view event frame is built of the focused knowledge required to drive the agent execution.
The proposed framework was demonstrated with a commercial humanoid robot HOAP-3, endowing it with the capacity to learn skill models from teacher demonstrations, to store them in a knowledge base and to adapt the learned models in order to reproduce the required skills in different contexts. Different evaluation scenarios were developed to test the performance of the modules implemented in our framework. Demonstrations were organized over two major scenarios to provide separate validation for the knowledge base system and the complete developed framework.
Our framework has been devised as a bottom-level module that could be part of a more complex system, with the goal of providing a minimum functional degree of intelligence which would be continuously increased as the system develops further. Future work will focus on augmenting the framework capacities to generate more intelligent behaviours.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The research leading to these results has received funding from the RoboCity2030-III-CM project (Robótica aplicada a la mejora de la calidad de vida de los ciudadanos. Fase III; S2013/MIT-2748), funded by Programas de Actividades I+D en la Comunidad de Madrid and cofunded by Structural Funds of the EU.