
Abstract
The multilayer bucketing screener has proved to be effective to tune the sparse Speeded-Up Robust Features (SURF) flow. It not only reduces the influence of illumination changes but also makes the distribution of optical flow more uniform. Based on sparse SURF flow with multilayer bucketing screener, a complete scheme for the ego-motion estimation in monocular vision systems is proposed. Taking the advantage of two-view estimation to obtain the relative scale, we use the ground plane estimation to calculate the absolute scale. Random sample consensus-based outlier rejection schemes are applied to reduce the scale drift. Then experiments are implemented to evaluate our method in real environments. We tested four data sets, and the results show that our method gains smaller average errors than the other two.
Introduction
Autonomous navigation systems have been applied widely for military and civil usages such as unmanned aerial vehicles (UAVs), robots, and space explorations. With the help of navigating and positioning methods like GPS and Inertial Navigation Systems (INS), autonomous objects such as robots and UAVs are able to finish many advanced tasks like route planning, aerial surveillance, transportation, search, and rescue. However, GPS and INS do not have the ability of autonomous perception 1 , that is, they can only navigate on the basis of existing geographical information. In some environments where GPS signal declines or is denied (e.g. planetary exploration), the systems will performs poorly and even be invalid.
During the research about the vision and flight of insects and birds, biologists found that honeybees and dragonflies observe sphere images through their compound eyes, and then transform images to optical flow (OF) in the wide field of view. 2 In this way, they can finish landing, 3 flight distance estimation, 4 obstacle avoidance, flight speed regulation, 5 and so on. The points’ brightness on objects changes with their moving and thus generates OF. By analyzing the OF, agents’ motion information such as the translation and rotation can be obtained.
Research about OF launched since 1980s and OF has been an important field of machine vision. Many successful methods have been proposed such as traditional gradient-based Lucas–Kanade, 6 Horn–Shunck, 7 Proesmans, 8 and features-based Harris, Kanade–Lucas–Tomasi (KLT), 9 Scale-Invariant Feature Transform (SIFT), 10 and SURF. 11 Unfortunately, some preconditions, these methods need for model, are not satisfied adequately in many cases such as brightness or gradient constant in gradient-based methods. Other problems are also large challenges such as the complexity of calculation, the reliability and the edge of image, occlusion, and multi-objects motion. An evaluation of nine popular methods 12 with real image sequences showed that SIFT had the best accuracy but lower speed, therefore, it was not applicable in the situation with high real-time requirements.
Many different navigation applications have been developed, including ground odometry, 13 travel distance estimation, 14 velocity estimation, 15 path detection, 16 obstacle avoidance, 17,18 and vertical landing. 19 Stereo and wide-field vision systems require some specific hardware, but monocular systems that require only single vision sensor are cheaper relatively and applicable in many cases, therefore they are of high research value.
The term monocular means that the images captured can only store two-dimensional information. The lack of depth information leads to the unknown absolute scale (distance) in three-dimensional (3-D) space. Scale drift is one of the most important factors that affect the accuracy in monocular systems and poses new requirements: it requires not only the accurate OF but also the uniform distribution and controllable number of OF vectors. A large number of OF vectors will increase the time of iteration and affect the speed of estimation, whereas a small number will decrease the accuracy. In other words, as a supplement to the lack of depth information in monocular systems, the accuracy, uniform distribution, and controllable number of OF are required for the estimation.
Nister et al. developed the first real-time, large-scale visual odometry (VO) in his landmark work. 20 They calculated OF through features detecting and matching to avoid tracking drift in traditional methods. They added random sample consensus (RANSAC) 21 and five-point algorithm, 22 which is superior for lateral motion during initialization. Similar strategies are also applied in latter works. 23 –25 Then, three-point algorithm 26 was used in conjunction with RANSAC to solve perspective-n-point problem. Their research established a systemic framework for monocular vision systems. Kitt et al. gave another monocular VO libviso 27 in a completely different framework. They estimates a local ground plane to calculate the absolute scale. Their method is based on two-view estimation and libviso has superiority in robustness. However, two-view estimation will lead to high translational errors in the case of narrow baseline forward motion. 28 This results in larger errors when objects move slower.
Visual simultaneous localization and mapping (SLAM) 29 is also a field, developing rapidly. Although the early works were limited to small workspace, those working in large-scale regions have been designed later in the studies by Mei et al. and Strasdat et al.. 30,31 Similar to another implementation of SLAM, parallel tracking and mapping 32 runs the localization and mapping in two parallel threads, which highly accelerate the procedure. It is notable that in VO, we only care about local consistency of the trajectory, whereas SLAM is concerned with the global map consistency. SLAM is potentially precise but computation expensive.
In conclusion, it is still appealed for a solution to reduce the scale drift for a good accuracy. Mammarella et al. 12 revealed that SIFT had the best accuracy but lower speed, and SURF runs several times faster than SIFT and still remains similar accuracy. 10 Thereby, inspired by the ground plane estimation of libviso, a method based on sparse SURF flow was designed for ego-motion estimation.
First, with the help of feature detector SURF, a good quality of OF can be obtained. Then, SURF flow is adjusted by our multilayer bucketing screener (MBS) to be more accurate and uniformly distributed over the whole image. 33 Next, we use normalized eight-point algorithm with RANSAC, which is robust to the noise, to estimate the fundamental matrix. Then, through 3-D reconstruction techniques, the homogeneous coordinate of keypoints is recovered and we can further estimate the rotation and relative translation of camera. Finally, three-point algorithm with RANSAC is used to estimate ground plane and calculate the absolute scales of motion. Thus, we gain the ego-motion of the camera.
Note that libviso is originally designed to use stereo image sequences, in which the ground plane estimation is only a supplement for the absolute scale calculation. Whereas we are designing a monocular system here; therefore, the absolute scale calculation completely relies on the ground plane estimation and the uniform flow. Inherit from the monocular systems: one camera is less easily to degrade than two. For example, the agent’s vibration can lead to the relative motion of two cameras and change the fundamental matrix of stereo system, which will not happen in monocular systems. Additionally, there is no initialization stage in our method.
In this article, we will discuss the sparse SURF flow with MBS in section “Sparse SURF flow with MBS” and the method to estimate ego-motion is introduced in section “The Ego-motion Estimation.” In “Experiments” section, we use real image sequences to design experiments and analyze the results. A brief conclusion of this article is given in “Conclusion” section.
Sparse SURF flow with MBS
Here is a brief discuss about sparse SURF flow and MBS. For more information, please refer to our work. 33
Sparse SURF flow
The Hessian threshold has proved to be a significant parameter for the number and distribution of keypoints in SURF. A lower threshold will lead to more keypoints and less uniform distribution of flow on the whole image but more calculation time and mismatches, and vice versa. Here, we chose a variable threshold ε to tune the flow. A pair of keypoints will be discarded if the distance between them (dxy , defined as in SURF) is larger than the ε. When we set ε = 0.36 × average (max{dxy } + min{dxy }), tuned sparse SURF flow is shown in Figure 1 (the image is from 2011_09_26_drive_0001, KITTI).

Tuned sparse SURF flow by variable Hessian thresholds.
Tuned OF is more accurate and uniform. A possible limit of this method in practice is that ε is variable, that is, it must be calculated for every image. Besides, the OF is not uniform as expected. We introduce MBS for the latter problem.
Multilayer bucketing screener
Bucketing mechanism divides an image into several subregions, limits the number of keypoints, and then tunes the OF in every subregion to make overall OF distribution uniform. In the light of the main orientation of descriptor in SURF, we calculate the main range of orientation for every subregion to screen the wrong OF whose direction is large different from the main range. Then, the subregions grow larger, forming multilayer screeners, to ensure that the selection of main orientation in small regions is less easily wrong due to wrong OF, thus the accuracy and distribution of OF are improved and the number of keypoints can be controlled.
First of all, the image is divided into several nonoverlapping rectangles (buckets). In every bucket, we use histogram voting method as in SURF, to count the number of keypoints, respectively, in eight ranges of orientation, thus the potential main orientation of this bucket can be determined. Each orientation represents an angle range. If the number of OF vectors in the potential main orientation is larger than 60% of that in a subregion, then we define the orientation as the real main orientation. Keypoints that are not in the range of main orientation will be discarded. Next, a maximal number of OF vectors θ is set to control the number of keypoints in every subregion. If the vectors are more than θ, we sort them by the distance of descriptor dxy from small to large and remain the first θ vectors.
We increase the sizes of buckets in the upper layer to merge OF in a smaller subregion with its neighbors. The area of region in the upper layer is four times as that in the lower layer, which means all the OF four subregions will be merged and screened again, which guarantees that the wrong OF in local regions does not severely affect the global orientation of OF. An example that shows final tuned sparse SURF flow with MBS is given in Figure 2. Compared with Figure 1, the flow field tuned by MBS becomes more uniform.

Tuned sparse SURF flow with MBS. MBS: multilayer bucketing screener.
The ego-motion estimation
Fundamental matrix estimation
As a method of parameter estimation, RANSAC is often used in the model which contains outliers. Optimized by iteration, RANSAC is able to search for an
Let p be the probability that all selected points are inliers at least once during iteration, that is, the probability that finds the optimal estimation. For N points, let w be the probability that a selected randomly point is an inlier, then

In order to obtain a more reliable estimation, we add the standard deviation SD(k) of k to itself, and SD(k) is defined as
Ego-motion estimation
When camera’s calibration matrix
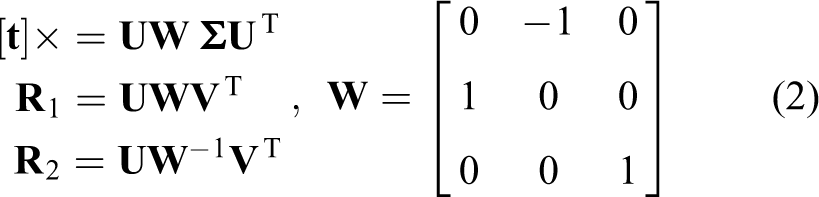
when
In Figure 3, the points A and B are the optical centers of two cameras, the horizontal axes of T-shaped symbols represent image planes and the vertical axes are parallel with optical axes. It is necessary to determine the optimal one among these four because the relatively fixed motion models rarely exist in practice. We transform the coordinate of homonymous points in two images to 3-D world coordinate system (WCS), and then the depths of them can be calculated. Only if the depths of keypoints in both of camera coordinate systems (CCS) are positive, the corresponding parameters (

Four possible position relations between two images.
The method to calculate the 3-D coordinate of keypoints in WCS is described as follows.
The project matrices of camera in two different positions are given as

A similar equation can be obtained from

Equations similar to equation (4) can be listed for every keypoint. Applying SVD to the coefficient matrix
The 3-D homogeneous coordinates of keypoints in WCS can be calculated through algorithm 3.1, and then their 3-D homogeneous coordinate in CCS can be obtained through camera imaging model. According to Figure 3, the depths of keypoint should be positive. We call the keypoints which under this constraint inliers in this model (
Ground plane estimation
We normalize keypoints’ 3-D coordinates

The geometry of ground plane {h,
In fact, if the pitch angle θ
c between the camera and the ground plane is a constant, then we can calculate the corresponding height h of every point in
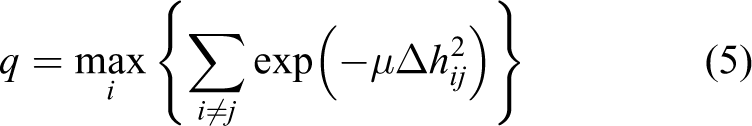
where μ is the weight coefficient and is chosen as μ = 50 here.
We can find out a keypoint i which maximize q from equation (5). Assuming its coordinate is (xi
, yi
, zi
)T, and the optimal height of ground is h
best, the unit of translation vector

where the Euler angles ψ, θ, and φ are, respectively, called roll, yaw, and pitch. In this article, we use intrinsic rotations sequence “z–y–x” in Tait–Bryan angles. As shown in Figure 5, The x–y–z (original) system is shown in blue, and the X–Y–Z (rotated) system is shown in red. Here z-axis is the forward direction of the object (a car in experiments below). Therefore, the rotation ψ, θ, and φ (round axes z, y, and x) are derived from equation (6)


Angles ψ, θ, and φ in Tait–Bryan angles.
Experiments
Real image sequences were used to evaluate the performance of motion estimation method proposed in this article. We tested four data sets respectively for short and long distance ego-motion estimation.
Short distance test
At first, we chose the first 400 frames in sequence 03 and 06 of the odometry dataset in KITTI, 34 to evaluate the performance in short distance estimation. These frames in two sequences are named benchmark 1 and benchmark 2 here for convenience. Both of them capture the road scenes on a car at the frame rate of 10 fps, and the image dimensions are 1226 × 370.
The trajectory of the car on the real road environment can be calculated using the algorithm stated in section “The Ego-motion Estimation.” In the experiment, the new method, ego-motion estimation based on sparse SURF flow (SURF with MBS below for short), is compared with other two methods, tuned SURF flow by Hessian threshold 33 (Tuned SURF below for short) and Harris-KLT feature tracker (Harris-KLT), 8 which is classical and designed for tracking and navigation.
Figure 6 shows the ground truth and estimated trajectories of benchmarks 1 and 2. The square at point (0, 0) indicates the starting point.

The ground truth and estimated trajectories of benchmarks 1 and 2.
We can see that the OF combined with ego-motion method is able to estimate object’s ego-motion on the road more accurately. Intuitively SURF with MBS gains higher accuracy than the others. We define the average error rate as

Where
The distance of two benchmarks is 284.59 m and 416.42 m, respectively, and the average position errors of SURF with MBS, Tuned SURF and Harris-KLT are 9.14%, 13.62%, and 20.84% and 1.44%, 5.65%, and 20.31%, respectively. SURF with MBS gets smaller error than other two methods.
Long distance test
As for the long distance test, we ran sequence 09 and 02 (named benchmarks 3 and 4 below) of the odometry benchmark in database KITTI. They are also captured at the frame rate of 10 fps with dimensions of 1226 × 370.
There are 1590 frames in benchmark 3, which contains complex environment including pedestrians, automobiles, high- and low-level sunlight, lots of obstacles, and narrow roads. The ground truth and estimated trajectories are shown in Figure 7.

The ground truth and estimated trajectories of benchmark 3.
The total distance traveled by the car in benchmark 3 is around 1705 m, which is longer than that in benchmarks 1 and 2. Long distance travel is more challenging for navigation system’s performance and robustness due to the error accumulation in OF ego-motion estimation. Average error rates of three methods are 2.02%, 5.70% and 31.03% in this test. As can be seen from Figure 7, the performance of system established by us do not decline heavily when the car travels longer. The red estimated trajectory is close to the black ground truth, which indicates the higher accuracy in this test as well.
We suppose intuitively that errors are mainly occurred when the car turns according to Figure 7. Figure 8 (top) shows the accumulated translation error and error rate of benchmark 3 per 100 frames respectively as in KITTI. The error rate is calculated by dividing accumulated errors by the translation traveled up to current frame. We can see that the translation error rates are overall controlled within 5%. It is worth noting that the accumulated translation error in the direction of y-axis is the largest among the three. It is likely to result from the slight change of θ c (Figure 4) due to the car’s pitch. In addition, we calculate the car’s relative rotation with respect to the previous 100th frame and rotation error rates per 100 frames through equation (7). Rotation error rates are derived from dividing rotation errors by the distance the car traveled.
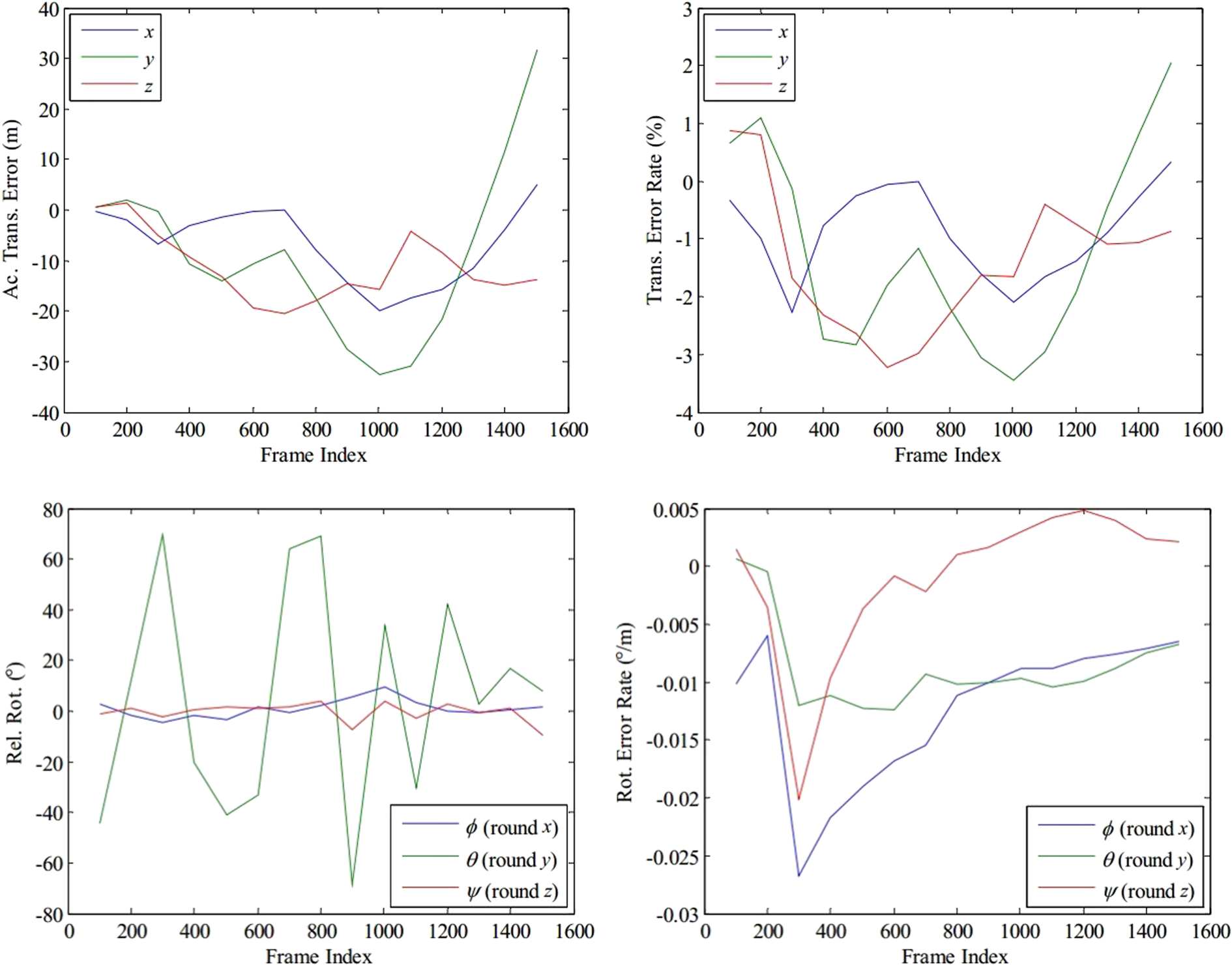
The results of benchmark 3. Top: accumulated translation errors and error rates; bottom: relative rotation and rotation error rates.
It can be seen from Figure 8 (bottom) that the relative translation error along z-axis (forward) is the largest; errors along x-axis (lateral) and y-axis (downward) are about smaller than 0.1 m (per frame). Besides, the extrema of errors along z-axis are coincident to the extrema of the relative rotation round y-axis, which is coincident to our intuition above: turns lead to large errors. Final rotation error rates are controlled within 0.02° m−1. In addition, it is notable that the problem of error resulting from turns exists in all the three methods, and relatively, ours obtains the smallest and acceptable errors.
Benchmark 4 contains 4660 frames. The estimation and ground truth are shown in Figure 9.

The ground truth and estimated trajectories of benchmark 4.
The car travels around 5067.2 m and the average errors of the three methods are, respectively,
According to the tests above, the following error analyses about the method proposed are concluded: The strategy proposed here can control translation error rate within 5% and average errors 2.02% and 2.16% when traveled distances rise to 1705.1 m and 5067.2 m. The results indicate the robustness of this method in practice. The estimation performance declines when objects move slowly. Although the OF algorithm based on SURF can detect keypoints at the lever of sub-pixel, the slow motion will lead to a narrow baseline, and the procedure of calculation is more sensitive to the low-amplitude OF. Thus, small existed errors of OF will have a great large influence on the accuracy of estimation. The estimation error rises rapidly while the car is turning, and this drawback exists in all three methods. The future research can detect the object’s velocity, and try to apply corresponding strategies to reduce the errors result from car’s turns.
Conclusion
A method based on sparse SURF flow with MBS is proposed to estimate the ego-motion in monocular systems. The MBS is able to tune the OF obtained by SURF detectors and make the distribution of flow fields more uniform, which is the key to reduce scale drift. Then, with the help of ground estimation and triangulation, an approach to calculating ego-motion is given, which makes the best of the accurate and uniformly distributed flow. RANSAC-based strategies are used to reduce noises in this article, including normalized eight-point algorithm for fundamental matrix estimation, the calculation of rotation and translation, and three-point algorithm for ground plane estimation. We experiment to verify the accuracy and robustness of our method in practice. We test four data sets in experiments and the results show that the proposed method gains a good accuracy of ego-motion.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the National Basic Research 973 Program of China [Grant number 2012CB720003], and the National Nature Science Foundation of China [Grant numbers 61320106010, 61573019, 61627810].